From 24f8991e817879a19801fcbc172ed4552202a024 Mon Sep 17 00:00:00 2001
From: LeiGong-USTC <gleisa19@mail.ustc.edu.cn>
Date: Sun, 15 Aug 2021 15:47:20 +0800
Subject: [PATCH] init
---
.gitignore | 21 +
LICENSE.txt | 13 +
docs/faqs.md | 29 +
docs/installation.md | 136 +
docs/instructions_lidarseg.md | 149 ++
docs/instructions_nuimages.md | 160 ++
docs/instructions_nuscenes.md | 373 +++
docs/schema_nuimages.md | 162 ++
docs/schema_nuscenes.md | 211 ++
python-sdk/nuimages/__init__.py | 1 +
python-sdk/nuimages/export/export_release.py | 66 +
python-sdk/nuimages/nuimages.py | 769 ++++++
python-sdk/nuimages/scripts/render_images.py | 227 ++
.../nuimages/scripts/render_rare_classes.py | 86 +
python-sdk/nuimages/tests/__init__.py | 0
python-sdk/nuimages/tests/assert_download.py | 46 +
python-sdk/nuimages/tests/test_attributes.py | 115 +
.../nuimages/tests/test_foreign_keys.py | 147 ++
python-sdk/nuimages/utils/__init__.py | 0
python-sdk/nuimages/utils/test_nuimages.py | 26 +
python-sdk/nuimages/utils/utils.py | 106 +
python-sdk/nuscenes/__init__.py | 1 +
python-sdk/nuscenes/can_bus/README.md | 144 ++
python-sdk/nuscenes/can_bus/can_bus_api.py | 263 ++
python-sdk/nuscenes/eval/__init__.py | 0
python-sdk/nuscenes/eval/common/__init__.py | 0
python-sdk/nuscenes/eval/common/config.py | 37 +
.../nuscenes/eval/common/data_classes.py | 149 ++
python-sdk/nuscenes/eval/common/loaders.py | 284 ++
python-sdk/nuscenes/eval/common/render.py | 68 +
python-sdk/nuscenes/eval/common/utils.py | 169 ++
python-sdk/nuscenes/eval/detection/README.md | 269 ++
.../nuscenes/eval/detection/__init__.py | 0
python-sdk/nuscenes/eval/detection/algo.py | 189 ++
python-sdk/nuscenes/eval/detection/config.py | 29 +
.../configs/detection_cvpr_2019.json | 21 +
.../nuscenes/eval/detection/constants.py | 50 +
.../nuscenes/eval/detection/data_classes.py | 425 +++
.../nuscenes/eval/detection/evaluate.py | 302 +++
python-sdk/nuscenes/eval/detection/render.py | 338 +++
.../nuscenes/eval/detection/tests/__init__.py | 0
.../eval/detection/tests/test_algo.py | 428 +++
.../eval/detection/tests/test_data_classes.py | 117 +
.../eval/detection/tests/test_evaluate.py | 134 +
.../eval/detection/tests/test_loader.py | 194 ++
.../eval/detection/tests/test_utils.py | 225 ++
python-sdk/nuscenes/eval/detection/utils.py | 56 +
python-sdk/nuscenes/eval/lidarseg/README.md | 217 ++
python-sdk/nuscenes/eval/lidarseg/__init__.py | 0
python-sdk/nuscenes/eval/lidarseg/evaluate.py | 158 ++
.../nuscenes/eval/lidarseg/tests/__init__.py | 0
python-sdk/nuscenes/eval/lidarseg/utils.py | 331 +++
.../eval/lidarseg/validate_submission.py | 137 +
python-sdk/nuscenes/eval/prediction/README.md | 91 +
.../nuscenes/eval/prediction/__init__.py | 0
.../prediction/baseline_model_inference.py | 55 +
.../eval/prediction/compute_metrics.py | 67 +
python-sdk/nuscenes/eval/prediction/config.py | 58 +
.../prediction/configs/predict_2020_icra.json | 53 +
.../nuscenes/eval/prediction/data_classes.py | 75 +
.../prediction/docker_container/README.md | 74 +
.../docker_container/docker/Dockerfile | 40 +
.../docker/docker-compose.yml | 17 +
.../nuscenes/eval/prediction/metrics.py | 468 ++++
python-sdk/nuscenes/eval/prediction/splits.py | 41 +
.../eval/prediction/submission/__init__.py | 0
.../prediction/submission/do_inference.py | 81 +
.../prediction/submission/extra_packages.txt | 0
.../eval/prediction/tests/__init__.py | 0
.../eval/prediction/tests/test_dataclasses.py | 18 +
.../eval/prediction/tests/test_metrics.py | 331 +++
python-sdk/nuscenes/eval/tracking/README.md | 351 +++
python-sdk/nuscenes/eval/tracking/__init__.py | 0
python-sdk/nuscenes/eval/tracking/algo.py | 333 +++
.../tracking/configs/tracking_nips_2019.json | 35 +
.../nuscenes/eval/tracking/constants.py | 56 +
.../nuscenes/eval/tracking/data_classes.py | 350 +++
python-sdk/nuscenes/eval/tracking/evaluate.py | 272 ++
python-sdk/nuscenes/eval/tracking/loaders.py | 170 ++
python-sdk/nuscenes/eval/tracking/metrics.py | 202 ++
python-sdk/nuscenes/eval/tracking/mot.py | 131 +
python-sdk/nuscenes/eval/tracking/render.py | 165 ++
.../nuscenes/eval/tracking/tests/__init__.py | 0
.../nuscenes/eval/tracking/tests/scenarios.py | 93 +
.../nuscenes/eval/tracking/tests/test_algo.py | 297 +++
.../eval/tracking/tests/test_evaluate.py | 234 ++
python-sdk/nuscenes/eval/tracking/utils.py | 172 ++
python-sdk/nuscenes/lidarseg/__init__.py | 0
.../nuscenes/lidarseg/class_histogram.py | 199 ++
.../nuscenes/lidarseg/lidarseg_utils.py | 218 ++
python-sdk/nuscenes/map_expansion/__init__.py | 0
.../map_expansion/arcline_path_utils.py | 283 ++
python-sdk/nuscenes/map_expansion/bitmap.py | 75 +
python-sdk/nuscenes/map_expansion/map_api.py | 2296 +++++++++++++++++
.../nuscenes/map_expansion/tests/__init__.py | 0
.../map_expansion/tests/test_all_maps.py | 88 +
.../tests/test_arcline_path_utils.py | 133 +
python-sdk/nuscenes/map_expansion/utils.py | 142 +
python-sdk/nuscenes/nuscenes.py | 2152 +++++++++++++++
python-sdk/nuscenes/prediction/__init__.py | 1 +
python-sdk/nuscenes/prediction/helper.py | 424 +++
.../input_representation/__init__.py | 0
.../prediction/input_representation/agents.py | 276 ++
.../input_representation/combinators.py | 53 +
.../input_representation/interface.py | 54 +
.../input_representation/static_layers.py | 290 +++
.../input_representation/tests/__init__.py | 0
.../input_representation/tests/test_agents.py | 161 ++
.../tests/test_combinators.py | 32 +
.../tests/test_static_layers.py | 88 +
.../input_representation/tests/test_utils.py | 80 +
.../prediction/input_representation/utils.py | 73 +
.../nuscenes/prediction/models/__init__.py | 0
.../nuscenes/prediction/models/backbone.py | 91 +
.../nuscenes/prediction/models/covernet.py | 120 +
python-sdk/nuscenes/prediction/models/mtp.py | 264 ++
.../nuscenes/prediction/models/physics.py | 199 ++
.../nuscenes/prediction/tests/__init__.py | 0
.../nuscenes/prediction/tests/run_covernet.py | 92 +
.../prediction/tests/run_image_generation.py | 117 +
.../nuscenes/prediction/tests/run_mtp.py | 109 +
.../prediction/tests/test_backbone.py | 52 +
.../prediction/tests/test_covernet.py | 81 +
.../nuscenes/prediction/tests/test_mtp.py | 59 +
.../prediction/tests/test_mtp_loss.py | 183 ++
.../prediction/tests/test_physics_models.py | 78 +
.../prediction/tests/test_predict_helper.py | 496 ++++
python-sdk/nuscenes/scripts/README.md | 1 +
python-sdk/nuscenes/scripts/__init__.py | 0
.../scripts/export_2d_annotations_as_json.py | 207 ++
.../scripts/export_egoposes_on_map.py | 57 +
python-sdk/nuscenes/scripts/export_kitti.py | 362 +++
.../scripts/export_pointclouds_as_obj.py | 208 ++
python-sdk/nuscenes/scripts/export_poses.py | 208 ++
.../nuscenes/scripts/export_scene_videos.py | 55 +
python-sdk/nuscenes/tests/__init__.py | 0
python-sdk/nuscenes/tests/assert_download.py | 51 +
python-sdk/nuscenes/tests/test_lidarseg.py | 41 +
python-sdk/nuscenes/tests/test_nuscenes.py | 26 +
.../nuscenes/tests/test_predict_helper.py | 669 +++++
python-sdk/nuscenes/utils/__init__.py | 0
python-sdk/nuscenes/utils/color_map.py | 45 +
python-sdk/nuscenes/utils/data_classes.py | 686 +++++
python-sdk/nuscenes/utils/geometry_utils.py | 145 ++
python-sdk/nuscenes/utils/kitti.py | 554 ++++
python-sdk/nuscenes/utils/map_mask.py | 114 +
python-sdk/nuscenes/utils/splits.py | 218 ++
python-sdk/nuscenes/utils/tests/__init__.py | 0
.../utils/tests/test_geometry_utils.py | 115 +
.../nuscenes/utils/tests/test_map_mask.py | 126 +
python-sdk/tutorials/README.md | 4 +
python-sdk/tutorials/can_bus_tutorial.ipynb | 225 ++
.../tutorials/map_expansion_tutorial.ipynb | 1137 ++++++++
python-sdk/tutorials/nuimages_tutorial.ipynb | 526 ++++
.../nuscenes_lidarseg_tutorial.ipynb | 506 ++++
python-sdk/tutorials/nuscenes_tutorial.ipynb | 1337 ++++++++++
.../tutorials/prediction_tutorial.ipynb | 698 +++++
python-sdk/tutorials/trajectory.gif | Bin 0 -> 365639 bytes
setup/Dockerfile | 30 +
setup/Jenkinsfile | 189 ++
setup/requirements.txt | 4 +
setup/requirements/requirements_base.txt | 13 +
setup/requirements/requirements_nuimages.txt | 1 +
.../requirements/requirements_prediction.txt | 2 +
setup/requirements/requirements_tracking.txt | 2 +
setup/setup.py | 60 +
setup/test_tutorial.sh | 29 +
167 files changed, 29618 insertions(+)
create mode 100644 .gitignore
create mode 100644 LICENSE.txt
create mode 100644 docs/faqs.md
create mode 100644 docs/installation.md
create mode 100644 docs/instructions_lidarseg.md
create mode 100644 docs/instructions_nuimages.md
create mode 100644 docs/instructions_nuscenes.md
create mode 100644 docs/schema_nuimages.md
create mode 100644 docs/schema_nuscenes.md
create mode 100644 python-sdk/nuimages/__init__.py
create mode 100644 python-sdk/nuimages/export/export_release.py
create mode 100644 python-sdk/nuimages/nuimages.py
create mode 100644 python-sdk/nuimages/scripts/render_images.py
create mode 100644 python-sdk/nuimages/scripts/render_rare_classes.py
create mode 100644 python-sdk/nuimages/tests/__init__.py
create mode 100644 python-sdk/nuimages/tests/assert_download.py
create mode 100644 python-sdk/nuimages/tests/test_attributes.py
create mode 100644 python-sdk/nuimages/tests/test_foreign_keys.py
create mode 100644 python-sdk/nuimages/utils/__init__.py
create mode 100644 python-sdk/nuimages/utils/test_nuimages.py
create mode 100644 python-sdk/nuimages/utils/utils.py
create mode 100644 python-sdk/nuscenes/__init__.py
create mode 100644 python-sdk/nuscenes/can_bus/README.md
create mode 100644 python-sdk/nuscenes/can_bus/can_bus_api.py
create mode 100644 python-sdk/nuscenes/eval/__init__.py
create mode 100644 python-sdk/nuscenes/eval/common/__init__.py
create mode 100644 python-sdk/nuscenes/eval/common/config.py
create mode 100644 python-sdk/nuscenes/eval/common/data_classes.py
create mode 100644 python-sdk/nuscenes/eval/common/loaders.py
create mode 100644 python-sdk/nuscenes/eval/common/render.py
create mode 100644 python-sdk/nuscenes/eval/common/utils.py
create mode 100644 python-sdk/nuscenes/eval/detection/README.md
create mode 100644 python-sdk/nuscenes/eval/detection/__init__.py
create mode 100644 python-sdk/nuscenes/eval/detection/algo.py
create mode 100644 python-sdk/nuscenes/eval/detection/config.py
create mode 100644 python-sdk/nuscenes/eval/detection/configs/detection_cvpr_2019.json
create mode 100644 python-sdk/nuscenes/eval/detection/constants.py
create mode 100644 python-sdk/nuscenes/eval/detection/data_classes.py
create mode 100644 python-sdk/nuscenes/eval/detection/evaluate.py
create mode 100644 python-sdk/nuscenes/eval/detection/render.py
create mode 100644 python-sdk/nuscenes/eval/detection/tests/__init__.py
create mode 100644 python-sdk/nuscenes/eval/detection/tests/test_algo.py
create mode 100644 python-sdk/nuscenes/eval/detection/tests/test_data_classes.py
create mode 100644 python-sdk/nuscenes/eval/detection/tests/test_evaluate.py
create mode 100644 python-sdk/nuscenes/eval/detection/tests/test_loader.py
create mode 100644 python-sdk/nuscenes/eval/detection/tests/test_utils.py
create mode 100644 python-sdk/nuscenes/eval/detection/utils.py
create mode 100644 python-sdk/nuscenes/eval/lidarseg/README.md
create mode 100644 python-sdk/nuscenes/eval/lidarseg/__init__.py
create mode 100644 python-sdk/nuscenes/eval/lidarseg/evaluate.py
create mode 100644 python-sdk/nuscenes/eval/lidarseg/tests/__init__.py
create mode 100644 python-sdk/nuscenes/eval/lidarseg/utils.py
create mode 100644 python-sdk/nuscenes/eval/lidarseg/validate_submission.py
create mode 100644 python-sdk/nuscenes/eval/prediction/README.md
create mode 100644 python-sdk/nuscenes/eval/prediction/__init__.py
create mode 100644 python-sdk/nuscenes/eval/prediction/baseline_model_inference.py
create mode 100644 python-sdk/nuscenes/eval/prediction/compute_metrics.py
create mode 100644 python-sdk/nuscenes/eval/prediction/config.py
create mode 100644 python-sdk/nuscenes/eval/prediction/configs/predict_2020_icra.json
create mode 100644 python-sdk/nuscenes/eval/prediction/data_classes.py
create mode 100644 python-sdk/nuscenes/eval/prediction/docker_container/README.md
create mode 100644 python-sdk/nuscenes/eval/prediction/docker_container/docker/Dockerfile
create mode 100644 python-sdk/nuscenes/eval/prediction/docker_container/docker/docker-compose.yml
create mode 100644 python-sdk/nuscenes/eval/prediction/metrics.py
create mode 100644 python-sdk/nuscenes/eval/prediction/splits.py
create mode 100644 python-sdk/nuscenes/eval/prediction/submission/__init__.py
create mode 100644 python-sdk/nuscenes/eval/prediction/submission/do_inference.py
create mode 100644 python-sdk/nuscenes/eval/prediction/submission/extra_packages.txt
create mode 100644 python-sdk/nuscenes/eval/prediction/tests/__init__.py
create mode 100644 python-sdk/nuscenes/eval/prediction/tests/test_dataclasses.py
create mode 100644 python-sdk/nuscenes/eval/prediction/tests/test_metrics.py
create mode 100644 python-sdk/nuscenes/eval/tracking/README.md
create mode 100644 python-sdk/nuscenes/eval/tracking/__init__.py
create mode 100644 python-sdk/nuscenes/eval/tracking/algo.py
create mode 100644 python-sdk/nuscenes/eval/tracking/configs/tracking_nips_2019.json
create mode 100644 python-sdk/nuscenes/eval/tracking/constants.py
create mode 100644 python-sdk/nuscenes/eval/tracking/data_classes.py
create mode 100644 python-sdk/nuscenes/eval/tracking/evaluate.py
create mode 100644 python-sdk/nuscenes/eval/tracking/loaders.py
create mode 100644 python-sdk/nuscenes/eval/tracking/metrics.py
create mode 100644 python-sdk/nuscenes/eval/tracking/mot.py
create mode 100644 python-sdk/nuscenes/eval/tracking/render.py
create mode 100644 python-sdk/nuscenes/eval/tracking/tests/__init__.py
create mode 100644 python-sdk/nuscenes/eval/tracking/tests/scenarios.py
create mode 100644 python-sdk/nuscenes/eval/tracking/tests/test_algo.py
create mode 100644 python-sdk/nuscenes/eval/tracking/tests/test_evaluate.py
create mode 100644 python-sdk/nuscenes/eval/tracking/utils.py
create mode 100644 python-sdk/nuscenes/lidarseg/__init__.py
create mode 100644 python-sdk/nuscenes/lidarseg/class_histogram.py
create mode 100644 python-sdk/nuscenes/lidarseg/lidarseg_utils.py
create mode 100644 python-sdk/nuscenes/map_expansion/__init__.py
create mode 100644 python-sdk/nuscenes/map_expansion/arcline_path_utils.py
create mode 100644 python-sdk/nuscenes/map_expansion/bitmap.py
create mode 100644 python-sdk/nuscenes/map_expansion/map_api.py
create mode 100644 python-sdk/nuscenes/map_expansion/tests/__init__.py
create mode 100644 python-sdk/nuscenes/map_expansion/tests/test_all_maps.py
create mode 100644 python-sdk/nuscenes/map_expansion/tests/test_arcline_path_utils.py
create mode 100644 python-sdk/nuscenes/map_expansion/utils.py
create mode 100644 python-sdk/nuscenes/nuscenes.py
create mode 100644 python-sdk/nuscenes/prediction/__init__.py
create mode 100644 python-sdk/nuscenes/prediction/helper.py
create mode 100644 python-sdk/nuscenes/prediction/input_representation/__init__.py
create mode 100644 python-sdk/nuscenes/prediction/input_representation/agents.py
create mode 100644 python-sdk/nuscenes/prediction/input_representation/combinators.py
create mode 100644 python-sdk/nuscenes/prediction/input_representation/interface.py
create mode 100644 python-sdk/nuscenes/prediction/input_representation/static_layers.py
create mode 100644 python-sdk/nuscenes/prediction/input_representation/tests/__init__.py
create mode 100644 python-sdk/nuscenes/prediction/input_representation/tests/test_agents.py
create mode 100644 python-sdk/nuscenes/prediction/input_representation/tests/test_combinators.py
create mode 100644 python-sdk/nuscenes/prediction/input_representation/tests/test_static_layers.py
create mode 100644 python-sdk/nuscenes/prediction/input_representation/tests/test_utils.py
create mode 100644 python-sdk/nuscenes/prediction/input_representation/utils.py
create mode 100644 python-sdk/nuscenes/prediction/models/__init__.py
create mode 100644 python-sdk/nuscenes/prediction/models/backbone.py
create mode 100644 python-sdk/nuscenes/prediction/models/covernet.py
create mode 100644 python-sdk/nuscenes/prediction/models/mtp.py
create mode 100644 python-sdk/nuscenes/prediction/models/physics.py
create mode 100644 python-sdk/nuscenes/prediction/tests/__init__.py
create mode 100644 python-sdk/nuscenes/prediction/tests/run_covernet.py
create mode 100644 python-sdk/nuscenes/prediction/tests/run_image_generation.py
create mode 100644 python-sdk/nuscenes/prediction/tests/run_mtp.py
create mode 100644 python-sdk/nuscenes/prediction/tests/test_backbone.py
create mode 100644 python-sdk/nuscenes/prediction/tests/test_covernet.py
create mode 100644 python-sdk/nuscenes/prediction/tests/test_mtp.py
create mode 100644 python-sdk/nuscenes/prediction/tests/test_mtp_loss.py
create mode 100644 python-sdk/nuscenes/prediction/tests/test_physics_models.py
create mode 100644 python-sdk/nuscenes/prediction/tests/test_predict_helper.py
create mode 100644 python-sdk/nuscenes/scripts/README.md
create mode 100644 python-sdk/nuscenes/scripts/__init__.py
create mode 100644 python-sdk/nuscenes/scripts/export_2d_annotations_as_json.py
create mode 100644 python-sdk/nuscenes/scripts/export_egoposes_on_map.py
create mode 100644 python-sdk/nuscenes/scripts/export_kitti.py
create mode 100644 python-sdk/nuscenes/scripts/export_pointclouds_as_obj.py
create mode 100644 python-sdk/nuscenes/scripts/export_poses.py
create mode 100644 python-sdk/nuscenes/scripts/export_scene_videos.py
create mode 100644 python-sdk/nuscenes/tests/__init__.py
create mode 100644 python-sdk/nuscenes/tests/assert_download.py
create mode 100644 python-sdk/nuscenes/tests/test_lidarseg.py
create mode 100644 python-sdk/nuscenes/tests/test_nuscenes.py
create mode 100644 python-sdk/nuscenes/tests/test_predict_helper.py
create mode 100644 python-sdk/nuscenes/utils/__init__.py
create mode 100644 python-sdk/nuscenes/utils/color_map.py
create mode 100644 python-sdk/nuscenes/utils/data_classes.py
create mode 100644 python-sdk/nuscenes/utils/geometry_utils.py
create mode 100644 python-sdk/nuscenes/utils/kitti.py
create mode 100644 python-sdk/nuscenes/utils/map_mask.py
create mode 100644 python-sdk/nuscenes/utils/splits.py
create mode 100644 python-sdk/nuscenes/utils/tests/__init__.py
create mode 100644 python-sdk/nuscenes/utils/tests/test_geometry_utils.py
create mode 100644 python-sdk/nuscenes/utils/tests/test_map_mask.py
create mode 100644 python-sdk/tutorials/README.md
create mode 100644 python-sdk/tutorials/can_bus_tutorial.ipynb
create mode 100644 python-sdk/tutorials/map_expansion_tutorial.ipynb
create mode 100644 python-sdk/tutorials/nuimages_tutorial.ipynb
create mode 100644 python-sdk/tutorials/nuscenes_lidarseg_tutorial.ipynb
create mode 100644 python-sdk/tutorials/nuscenes_tutorial.ipynb
create mode 100644 python-sdk/tutorials/prediction_tutorial.ipynb
create mode 100644 python-sdk/tutorials/trajectory.gif
create mode 100644 setup/Dockerfile
create mode 100644 setup/Jenkinsfile
create mode 100644 setup/requirements.txt
create mode 100644 setup/requirements/requirements_base.txt
create mode 100644 setup/requirements/requirements_nuimages.txt
create mode 100644 setup/requirements/requirements_prediction.txt
create mode 100644 setup/requirements/requirements_tracking.txt
create mode 100644 setup/setup.py
create mode 100755 setup/test_tutorial.sh
diff --git a/.gitignore b/.gitignore
new file mode 100644
index 0000000..97addba
--- /dev/null
+++ b/.gitignore
@@ -0,0 +1,21 @@
+*.brf
+*.gz
+*.log
+*.aux
+*.pdf
+*.pyc
+*.png
+*.jpg
+*ipynb_*
+*._*
+*.so
+*.o
+*.pth.tar
+bbox.c
+doc
+.DS_STORE
+.DS_Store
+.idea
+.project
+.pydevproject
+_ext
diff --git a/LICENSE.txt b/LICENSE.txt
new file mode 100644
index 0000000..9d987e9
--- /dev/null
+++ b/LICENSE.txt
@@ -0,0 +1,13 @@
+Copyright 2019 Aptiv
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
diff --git a/docs/faqs.md b/docs/faqs.md
new file mode 100644
index 0000000..539aeed
--- /dev/null
+++ b/docs/faqs.md
@@ -0,0 +1,29 @@
+# Frequently asked questions
+On this page we try to answer questions frequently asked by our users.
+
+- How can I get in contact?
+ - For questions about commercialization, collaboration and marketing, please contact [nuScenes@nuTonomy.com](mailto:nuScenes@nuTonomy.com).
+ - For issues and bugs *with the devkit*, file an issue on [Github](https://github.com/nutonomy/nuscenes-devkit/issues).
+ - For any other questions, please post in the [nuScenes user forum](https://forum.nuscenes.org/).
+
+- Can I use nuScenes and nuImages for free?
+ - For non-commercial use [nuScenes and nuImages are free](https://www.nuscenes.org/terms-of-use), e.g. for educational use and some research use.
+ - For commercial use please contact [nuScenes@nuTonomy.com](mailto:nuScenes@nuTonomy.com). To allow startups to use our dataset, we adjust the pricing terms to the use case and company size.
+
+- How can I participate in the nuScenes challenges?
+ - See the overview site for the [object detection challenge](https://www.nuscenes.org/object-detection).
+ - See the overview site for the [tracking challenge](https://www.nuscenes.org/tracking).
+ - See the overview site for the [prediction challenge](https://www.nuscenes.org/prediction).
+
+- How can I get more information on the sensors used?
+ - Read the [Data collection](https://www.nuscenes.org/data-collection) page.
+ - Note that we do not *publicly* reveal the vendor name and model to avoid endorsing a particular vendor. All sensors are publicly available from third-party vendors.
+ - For more information, please contact [nuScenes@nuTonomy.com](mailto:nuScenes@nuTonomy.com).
+
+- Can I use nuScenes for 2d object detection?
+ - Objects in nuScenes are annotated in 3d.
+ - You can use [this script](https://github.com/nutonomy/nuscenes-devkit/blob/master/python-sdk/nuscenes/scripts/export_2d_annotations_as_json.py) to project them to 2d, but note that such 2d boxes are not generally tight.
+
+- How can I share my new dataset / paper for Autonomous Driving?
+ - Please contact [nuScenes@nuTonomy.com](mailto:nuScenes@nuTonomy.com) to discuss possible collaborations and listing your work on the [Publications](https://www.nuscenes.org/publications) page.
+ - To discuss it with the community, please post in the [nuScenes user forum](https://forum.nuscenes.org/).
\ No newline at end of file
diff --git a/docs/installation.md b/docs/installation.md
new file mode 100644
index 0000000..645317c
--- /dev/null
+++ b/docs/installation.md
@@ -0,0 +1,136 @@
+# Advanced Installation
+We provide step-by-step instructions to install our devkit. These instructions apply to both nuScenes and nuImages.
+- [Download](#download)
+- [Install Python](#install-python)
+- [Setup a Conda environment](#setup-a-conda-environment)
+- [Setup a virtualenvwrapper environment](#setup-a-virtualenvwrapper-environment)
+- [Setup PYTHONPATH](#setup-pythonpath)
+- [Install required packages](#install-required-packages)
+- [Setup environment variable](#setup-environment-variable)
+- [Setup Matplotlib backend](#setup-matplotlib-backend)
+- [Verify install](#verify-install)
+
+## Download
+
+Download the devkit to your home directory using:
+```
+cd && git clone https://github.com/nutonomy/nuscenes-devkit.git
+```
+## Install Python
+
+The devkit is tested for Python 3.6 onwards, but we recommend to use Python 3.7.
+For Ubuntu: If the right Python version is not already installed on your system, install it by running:
+```
+sudo apt install python-pip
+sudo add-apt-repository ppa:deadsnakes/ppa
+sudo apt-get update
+sudo apt-get install python3.7
+sudo apt-get install python3.7-dev
+```
+For Mac OS download and install from `https://www.python.org/downloads/mac-osx/`.
+
+## Setup a Conda environment
+Next we setup a Conda environment.
+An alternative to Conda is to use virtualenvwrapper, as described [below](#setup-a-virtualenvwrapper-environment).
+
+#### Install miniconda
+See the [official Miniconda page](https://conda.io/en/latest/miniconda.html).
+
+#### Setup a Conda environment
+We create a new Conda environment named `nuscenes`. We will use this environment for both nuScenes and nuImages.
+```
+conda create --name nuscenes python=3.7
+```
+
+#### Activate the environment
+If you are inside the virtual environment, your shell prompt should look like: `(nuscenes) user@computer:~$`
+If that is not the case, you can enable the virtual environment using:
+```
+conda activate nuscenes
+```
+To deactivate the virtual environment, use:
+```
+source deactivate
+```
+
+-----
+## Setup a virtualenvwrapper environment
+Another option for setting up a new virtual environment is to use virtualenvwrapper.
+**Skip these steps if you have already setup a Conda environment**.
+Follow these instructions to setup your environment.
+
+#### Install virtualenvwrapper
+To install virtualenvwrapper, run:
+```
+pip install virtualenvwrapper
+```
+Add the following two lines to `~/.bashrc` (`~/.bash_profile` on MAC OS) to set the location where the virtual environments should live and the location of the script installed with this package:
+```
+export WORKON_HOME=$HOME/.virtualenvs
+source [VIRTUAL_ENV_LOCATION]
+```
+Replace `[VIRTUAL_ENV_LOCATION]` with either `/usr/local/bin/virtualenvwrapper.sh` or `~/.local/bin/virtualenvwrapper.sh` depending on where it is installed on your system.
+After editing it, reload the shell startup file by running e.g. `source ~/.bashrc`.
+
+Note: If you are facing dependency issues with the PIP package, you can also install the devkit as a Conda package.
+For more details, see [this issue](https://github.com/nutonomy/nuscenes-devkit/issues/155).
+
+#### Create the virtual environment
+We create a new virtual environment named `nuscenes`.
+```
+mkvirtualenv nuscenes --python=python3.7
+```
+
+#### Activate the virtual environment
+If you are inside the virtual environment, your shell prompt should look like: `(nuscenes) user@computer:~$`
+If that is not the case, you can enable the virtual environment using:
+```
+workon nuscenes
+```
+To deactivate the virtual environment, use:
+```
+deactivate
+```
+
+## Setup PYTHONPATH
+Add the `python-sdk` directory to your `PYTHONPATH` environmental variable, by adding the following to your `~/.bashrc` (for virtualenvwrapper, you could alternatively add it in `~/.virtualenvs/nuscenes/bin/postactivate`):
+```
+export PYTHONPATH="${PYTHONPATH}:$HOME/nuscenes-devkit/python-sdk"
+```
+
+## Install required packages
+
+To install the required packages, run the following command in your favourite virtual environment:
+```
+pip install -r setup/requirements.txt
+```
+**Note:** The requirements file is internally divided into base requirements (`base`) and requirements specific to certain products or challenges (`nuimages`, `prediction` and `tracking`). If you only plan to use a subset of the codebase, feel free to comment out the lines that you do not need.
+
+## Setup environment variable
+Finally, if you want to run the unit tests you need to point the devkit to the `nuscenes` folder on your disk.
+Set the NUSCENES environment variable to point to your data folder:
+```
+export NUSCENES="/data/sets/nuscenes"
+```
+or for NUIMAGES:
+```
+export NUIMAGES="/data/sets/nuimages"
+```
+
+## Setup Matplotlib backend
+When using Matplotlib, it is generally recommended to define the backend used for rendering:
+1) Under Ubuntu the default backend `Agg` results in any plot not being rendered by default. This does not apply inside Jupyter notebooks.
+2) Under MacOSX a call to `plt.plot()` may fail with the following error (see [here](https://github.com/matplotlib/matplotlib/issues/13414) for more details):
+ ```
+ libc++abi.dylib: terminating with uncaught exception of type NSException
+ ```
+To set the backend, add the following to your `~/.matplotlib/matplotlibrc` file, which needs to be created if it does not exist yet:
+```
+backend: TKAgg
+```
+
+## Verify install
+To verify your environment run `python -m unittest` in the `python-sdk` folder.
+You can also run `assert_download.py` in the `python-sdk/nuscenes/tests` and `python-sdk/nuimages/tests` folders to verify that all files are in the right place.
+
+That's it you should be good to go!
diff --git a/docs/instructions_lidarseg.md b/docs/instructions_lidarseg.md
new file mode 100644
index 0000000..e4dd949
--- /dev/null
+++ b/docs/instructions_lidarseg.md
@@ -0,0 +1,149 @@
+# nuScenes-lidarseg Annotator Instructions
+
+# Overview
+- [Introduction](#introduction)
+- [General Instructions](#general-instructions)
+- [Detailed Instructions](#detailed-instructions)
+- [Classes](#classes)
+
+# Introduction
+In nuScenes-lidarseg, we annotate every point in the lidar pointcloud with a semantic label.
+All the labels from nuScenes are carried over into nuScenes-lidarseg; in addition, more ["stuff" (background) classes](#classes) have been included.
+Thus, nuScenes-lidarseg contains both foreground classes (pedestrians, vehicles, cyclists, etc.) and background classes (driveable surface, nature, buildings, etc.).
+
+
+# General Instructions
+ - Label each point with a class.
+ - Use the camera images to facilitate, check and validate the labels.
+ - Each point belongs to only one class, i.e., one class per point.
+
+
+# Detailed Instructions
++ **Extremities** such as vehicle doors, car mirrors and human limbs should be assigned the same label as the object.
+Note that in contrast to the nuScenes 3d cuboids, the lidarseg labels include car mirrors and antennas.
++ **Minimum number of points**
+ + An object can have as little as **one** point.
+ In such cases, that point should only be labeled if it is certain that the point belongs to a class
+ (with additional verification by looking at the corresponding camera frame).
+ Otherwise, the point should be labeled as `static.other`.
++ **Other static object vs noise.**
+ + **Other static object:** Points that belong to some physical object, but are not defined in our taxonomy.
+ + **Noise:** Points that do not correspond to physical objects or surfaces in the environment
+ (e.g. noise, reflections, dust, fog, raindrops or smoke).
++ **Terrain vs other flat.**
+ + **Terrain:** Grass, all kinds of horizontal vegetation, soil or sand. These areas are not meant to be driven on.
+ This label includes a possibly delimiting curb.
+ Single grass stalks do not need to be annotated and get the label of the region they are growing on.
+ + Short bushes / grass with **heights of less than 20cm**, should be labeled as terrain.
+ Similarly, tall bushes / grass which are higher than 20cm should be labeled as vegetation.
+ + **Other flat:** Horizontal surfaces which cannot be classified as ground plane / sidewalk / terrain, e.g., water.
++ **Terrain vs sidewalk**
+ + **Terrain:** See above.
+ + **Sidewalk:** A sidewalk is a walkway designed for pedestrians and / or cyclists. Sidewalks are always paved.
+
+
+# Classes
+The following classes are in **addition** to the existing ones in nuScenes:
+
+| Label ID | Label | Short Description |
+| --- | --- | --- |
+| 0 | [`noise`](#1-noise-class-0) | Any lidar return that does not correspond to a physical object, such as dust, vapor, noise, fog, raindrops, smoke and reflections. |
+| 24 | [`flat.driveable_surface`](#2-flatdriveable_surface-class-24) | All paved or unpaved surfaces that a car can drive on with no concern of traffic rules. |
+| 25 | [`flat.sidewalk`](#3-flatsidewalk-class-25) | Sidewalk, pedestrian walkways, bike paths, etc. Part of the ground designated for pedestrians or cyclists. Sidewalks do **not** have to be next to a road. |
+| 26 | [`flat.terrain`](#4-flatterrain-class-26) | Natural horizontal surfaces such as ground level horizontal vegetation (< 20 cm tall), grass, rolling hills, soil, sand and gravel. |
+| 27 | [`flat.other`](#5-flatother-class-27) | All other forms of horizontal ground-level structures that do not belong to any of driveable_surface, curb, sidewalk and terrain. Includes elevated parts of traffic islands, delimiters, rail tracks, stairs with at most 3 steps and larger bodies of water (lakes, rivers). |
+| 28 | [`static.manmade`](#6-staticmanmade-class-28) | Includes man-made structures but not limited to: buildings, walls, guard rails, fences, poles, drainages, hydrants, flags, banners, street signs, electric circuit boxes, traffic lights, parking meters and stairs with more than 3 steps. |
+| 29 | [`static.vegetation`](#7-staticvegetation-class-29) | Any vegetation in the frame that is higher than the ground, including bushes, plants, potted plants, trees, etc. Only tall grass (> 20cm) is part of this, ground level grass is part of `flat.terrain`.|
+| 30 | [`static.other`](#8-staticother-class-30) | Points in the background that are not distinguishable. Or objects that do not match any of the above labels. |
+| 31 | [`vehicle.ego`](#9-vehicleego-class-31) | The vehicle on which the cameras, radar and lidar are mounted, that is sometimes visible at the bottom of the image. |
+
+## Examples of classes
+Below are examples of the classes added in nuScenes-lidarseg.
+For simplicity, we only show lidar points which are relevant to the class being discussed.
+
+
+### 1. noise (class 0)
+
+
+
+
+
+[Top](#classes)
+
+
+### 2. flat.driveable_surface (class 24)
+
+
+
+
+
+[Top](#classes)
+
+
+### 3. flat.sidewalk (class 25)
+
+
+
+
+
+[Top](#classes)
+
+
+### 4. flat.terrain (class 26)
+
+
+
+
+
+[Top](#classes)
+
+
+### 5. flat.other (class 27)
+
+
+
+
+
+[Top](#classes)
+
+
+### 6. static.manmade (class 28)
+
+
+
+
+
+[Top](#classes)
+
+
+### 7. static.vegetation (class 29)
+
+
+
+
+
+[Top](#classes)
+
+
+### 8. static.other (class 30)
+
+
+
+
+
+[Top](#classes)
+
+
+### 9. vehicle.ego (class 31)
+Points on the ego vehicle generally arise due to self-occlusion, in which some lidar beams hit the ego vehicle.
+When the pointcloud is projected into a chosen camera image, the devkit removes points which are less than
+1m in front of the camera to prevent such points from cluttering the image. Thus, users will not see points
+belonging to `vehicle.ego` projected onto the camera images when using the devkit. To give examples, of the
+`vehicle.ego` class, the bird's eye view (BEV) is used instead:
+
+
+
+
+
+
+[Top](#classes)
diff --git a/docs/instructions_nuimages.md b/docs/instructions_nuimages.md
new file mode 100644
index 0000000..ba45bbf
--- /dev/null
+++ b/docs/instructions_nuimages.md
@@ -0,0 +1,160 @@
+# nuImages Annotator Instructions
+
+# Overview
+- [Introduction](#introduction)
+- [Objects](#objects)
+ - [Bounding Boxes](#bounding-boxes)
+ - [Instance Segmentation](#instance-segmentation)
+ - [Attributes](#attributes)
+- [Surfaces](#surfaces)
+ - [Semantic Segmentation](#semantic-segmentation)
+
+# Introduction
+In nuImages, we annotate objects with 2d boxes, instance masks and 2d segmentation masks. All the labels and attributes from nuScenes are carried over into nuImages.
+We have also [added more attributes](#attributes) in nuImages. For segmentation, we have included ["stuff" (background) classes](#surfaces).
+
+# Objects
+nuImages contains the [same object classes as nuScenes](https://github.com/nutonomy/nuscenes-devkit/tree/master/docs/instructions_nuscenes.md#labels),
+while the [attributes](#attributes) are a superset of the [attributes in nuScenes](https://github.com/nutonomy/nuscenes-devkit/tree/master/docs/instructions_nuscenes.md#attributes).
+
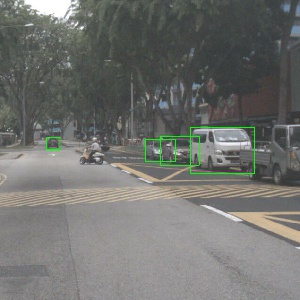
+## Bounding Boxes
+### General Instructions
+ - Draw bounding boxes around all objects that are in the list of [object classes](https://github.com/nutonomy/nuscenes-devkit/tree/master/docs/instructions_nuscenes.md#labels).
+ - Do not apply more than one box to a single object.
+ - If an object is occluded, then draw the bounding box to include the occluded part of the object according to your best guess.
+
+
+
+ - If an object is cut off at the edge of the image, then the bounding box should stop at the image boundary.
+ - If an object is reflected clearly in a glass window, then the reflection should be annotated.
+
+
+ - If an object has extremities, the bounding box should include **all** the extremities (exceptions are the side view mirrors and antennas of vehicles).
+ Note that this differs [from how the instance masks are annotated](#instance-segmentation), in which the extremities are included in the masks.
+
+
+
+ - Only label objects if the object is clear enough to be certain of what it is. If an object is so blurry it cannot be known, do not label the object.
+ - Do not label an object if its height is less than 10 pixels.
+ - Do not label an object if its less than 20% visible, unless you can confidently tell what the object is.
+ An object can have low visibility when it is occluded or cut off by the image.
+ The clarity and orientation of the object does not influence its visibility.
+
+### Detailed Instructions
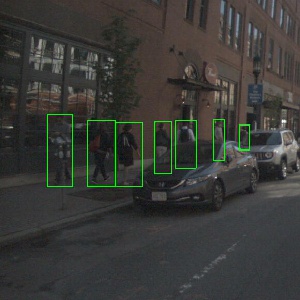
+ - `human.pedestrian.*`
+ - In nighttime images, annotate the pedestrian only when either the body part(s) of a person is clearly visible (leg, arm, head etc.), or the person is clearly in motion.
+
+
+
+ - `vehicle.*`
+ - In nighttime images, annotate a vehicle only when a pair of lights is clearly visible (break or head or hazard lights), and it is clearly on the road surface.
+
+
+
+
+
+[Top](#overview)
+
+## Instance Segmentation
+### General Instructions
+ - Given a bounding box, outline the **visible** parts of the object enclosed within the bounding box using a polygon.
+ - Each pixel on the image should be assigned to at most one object instance (i.e. the polygons should not overlap).
+ - There should not be a discrepancy of more than 2 pixels between the edge of the object instance and the polygon.
+ - If an object is occluded by another object whose width is less than 5 pixels (e.g. a thin fence), then the external object can be included in the polygon.
+
+
+ - If an object is loosely covered by another object (e.g. branches, bushes), do not create several polygons for visible areas that are less than 15 pixels in diameter.
+
+
+ - If an object enclosed by the bounding box is occluded by another foreground object but has a visible area through a glass window (like for cars / vans / trucks),
+ do not create a polygon on that visible area.
+
+
+ - If an object has a visible area through a hole of another foreground object, create a polygon on the visible area.
+ Exemptions would be holes from bicycle / motorcycles / bike racks and holes that are less than 15 pixels diameter.
+
+
+ - If a static / moveable object has another object attached to it (signboard, rope), include it in the annotation.
+
+
+ - If parts of an object are not visible due to lighting and / or shadow, it is best to have an educated guess on the non-visible areas of the object.
+
+
+ - If an object is reflected clearly in a glass window, then the reflection should be annotated.
+
+
+
+### Detailed Instructions
+ - `vehicle.*`
+ - Include extremities (e.g. side view mirrors, taxi heads, police sirens, etc.); exceptions are the crane arms on construction vehicles.
+
+
+
+ - `static_object.bicycle_rack`
+ - All bicycles in a bicycle rack should be annotated collectively as bicycle rack.
+ - **Note:** A previous version of this taxonomy did not include bicycle racks and therefore some images are missing bicycle rack annotations. We leave this class in the dataset, as it is merely an ignore label. The ignore label is used to avoid punishing false positives or false negatives on bicycle racks, where individual bicycles are difficult to identify.
+
+[Top](#overview)
+
+## Attributes
+In nuImages, each object comes with a box, a mask and a set of attributes.
+The following attributes are in **addition** to the [existing ones in nuScenes]((https://github.com/nutonomy/nuscenes-devkit/tree/master/docs/instructions_nuscenes.md#attributes)):
+
+| Attribute | Short Description |
+| --- | --- |
+| vehicle_light.emergency.flashing | The emergency lights on the vehicle are flashing. |
+| vehicle_light.emergency.not_flashing | The emergency lights on the vehicle are not flashing. |
+| vertical_position.off_ground | The object is not in the ground (e.g. it is flying, falling, jumping or positioned in a tree or on a vehicle). |
+| vertical_position.on_ground | The object is on the ground plane. |
+
+[Top](#overview)
+
+
+# Surfaces
+nuImages includes surface classes as well:
+
+| Label | Short Description |
+| --- | --- |
+| [`flat.driveable_surface`](#1-flatdriveable_surface) | All paved or unpaved surfaces that a car can drive on with no concern of traffic rules. |
+| [`vehicle.ego`](#2-vehicleego) | The vehicle on which the sensors are mounted, that are sometimes visible at the bottom of the image. |
+
+### 1. flat.driveable_surface
+
+
+
+
+
+### 2. vehicle.ego
+
+
+
+
+
+## Semantic Segmentation
+### General Instructions
+ - Only annotate a surface if its length and width are **both** greater than 20 pixels.
+ - Annotations should tightly bound the edges of the area(s) of interest.
+
+
+ - If two areas/objects of interest are adjacent to each other, there should be no gap between the two annotations.
+
+
+ - Annotate a surface only as far as it is clearly visible.
+
+
+ - If a surface is occluded (e.g. by branches, trees, fence poles), only annotate the visible areas (which are more than 20 pixels in length and width).
+
+
+ - If a surface is covered by dirt or snow of less than 20 cm in height, include the dirt or snow in the annotation (since it can be safely driven over).
+
+
+ - If a surface has puddles in it, always include them in the annotation.
+ - Do not annotate reflections of surfaces.
+
+### Detailed Instructions
+ - `flat.driveable_surface`
+ - Include surfaces blocked by road blockers or pillars as long as they are the same surface as the driveable surface.
+
+
+
+[Top](#overview)
diff --git a/docs/instructions_nuscenes.md b/docs/instructions_nuscenes.md
new file mode 100644
index 0000000..96b8287
--- /dev/null
+++ b/docs/instructions_nuscenes.md
@@ -0,0 +1,373 @@
+# nuScenes Annotator Instructions
+
+# Overview
+- [Instructions](#instructions)
+- [Special Rules](#special-rules)
+- [Labels](#labels)
+- [Attributes](#attributes)
+- [Detailed Instructions and Examples](#detailed-instructions-and-examples)
+
+# Instructions
++ Draw 3D bounding boxes around all objects from the [labels](#labels) list, and label them according to the instructions below.
++ **Do not** apply more than one box to a single object.
++ Check every cuboid in every frame, to make sure all points are inside the cuboid and **look reasonable in the image view**.
++ For nighttime or rainy scenes, annotate objects as if these are daytime or normal weather scenes.
+
+# Special Rules
++ **Minimum number of points** :
+ + Label any target object containing **at least 1 LIDAR or RADAR point**, as long as you can be reasonably sure you know the location and shape of the object. Use your best judgment on correct cuboid position, sizing, and heading.
++ **Cuboid Sizing** :
+ + **Cuboids must be very tight.** Draw the cuboid as close as possible to the edge of the object without excluding any LIDAR points. There should be almost no visible space between the cuboid border and the closest point on the object.
++ **Extremities** :
+ + **If** an object has extremities (eg. arms and legs of pedestrians), **then** the bounding box should include the extremities.
+ + **Exception**: Do not include vehicle side view mirrors. Also, do not include other vehicle extremities (crane arms etc.) that are above 1.5 meters high.
++ **Carried Object** :
+ + If a pedestrian is carrying an object (bags, umbrellas, tools etc.), such object will be included in the bounding box for the pedestrian. If two or more pedestrians are carrying the same object, the bounding box of only one of them will include the object.
++ **Stationary Objects** :
+ + Sometimes stationary objects move over time due to errors in the localization. If a stationary object’s points shift over time, please create a separate cuboid for every frame.
++ **Use Pictures**:
+ + For objects with few LIDAR or RADAR points, use the images to make sure boxes are correctly sized. If you see that a cuboid is too short in the image view, adjust it to cover the entire object based on the image view.
++ **Visibility Attribute** :
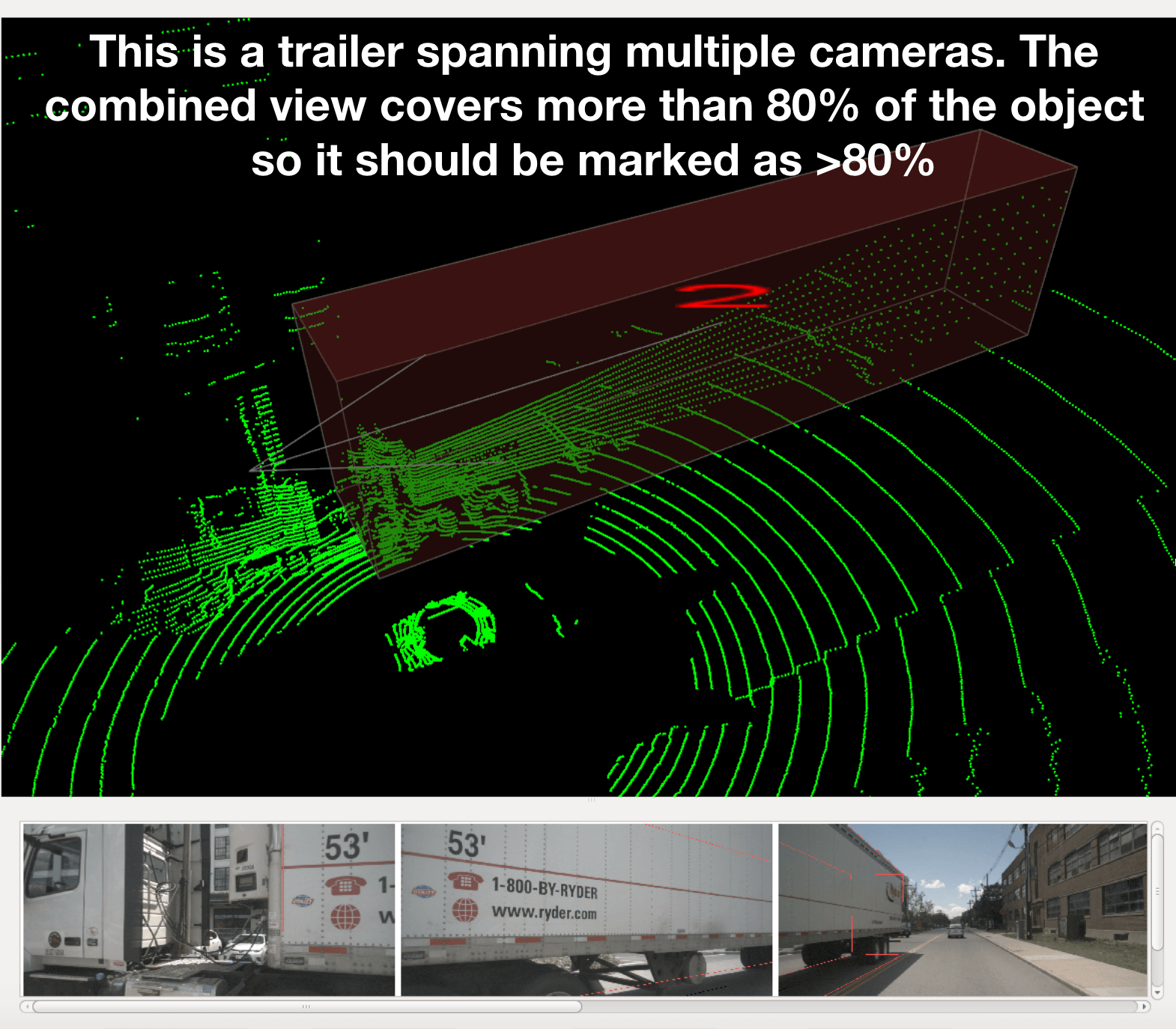
+ + The visibility attribute specifies the percentage of object pixels visible in the panoramic view of all cameras.
+ + 
+
+# Labels
+**For every bounding box, include one of the following labels:**
+1. **[Car or Van or SUV](#car-or-van-or-suv)**: Vehicle designed primarily for personal use, e.g. sedans, hatch-backs, wagons, vans, mini-vans, SUVs and jeeps.
+
+2. **[Truck](#truck)**: Vehicles primarily designed to haul cargo including pick-ups, lorrys, trucks and semi-tractors. Trailers hauled after a semi-tractor should be labeled as "Trailer".
+
+ - **[Pickup Truck](#pickup-truck)**: A pickup truck is a light duty truck with an enclosed cab and an open or closed cargo area. A pickup truck can be intended primarily for hauling cargo or for personal use.
+
+ - **[Front Of Semi Truck](#front-of-semi-truck)**: Tractor part of a semi trailer truck. Trailers hauled after a semi-tractor should be labeled as a trailer.
+
+5. **[Bendy Bus](#bendy-bus)**: Buses and shuttles designed to carry more than 10 people and comprises two or more rigid sections linked by a pivoting joint. Annotate each section of the bendy bus individually.
+
+6. **[Rigid Bus](#rigid-bus)**: Rigid buses and shuttles designed to carry more than 10 people.
+
+7. **[Construction Vehicle](#construction-vehicle)**: Vehicles primarily designed for construction. Typically very slow moving or stationary. Cranes and extremities of construction vehicles are only included in annotations if they interfere with traffic. Trucks used to hauling rocks or building materials are considered trucks rather than construction vehicles.
+
+8. **[Motorcycle](#motorcycle)**: Gasoline or electric powered 2-wheeled vehicle designed to move rapidly (at the speed of standard cars) on the road surface. This category includes all motorcycles, vespas and scooters. It also includes light 3-wheel vehicles, often with a light plastic roof and open on the sides, that tend to be common in Asia. If there is a rider and/or passenger, include them in the box.
+
+9. **[Bicycle](#bicycle)**: Human or electric powered 2-wheeled vehicle designed to travel at lower speeds either on road surface, sidewalks or bicycle paths. If there is a rider and/or passenger, include them in the box.
+
+10. **[Bicycle Rack](#bicycle-rack)**: Area or device intended to park or secure the bicycles in a row. It includes all the bicycles parked in it and any empty slots that are intended for parking bicycles. Bicycles that are not part of the rack should not be included. Instead they should be annotated as bicycles separately.
+
+11. **[Trailer](#trailer)**: Any vehicle trailer, both for trucks, cars and motorcycles (regardless of whether currently being towed or not). For semi-trailers (containers) label the truck itself as "Truck".
+
+12. **[Police Vehicle](#police-vehicle)**: All types of police vehicles including police bicycles and motorcycles.
+
+13. **[Ambulance](#ambulance)**: All types of ambulances.
+
+14. **[Adult Pedestrian](#adult-pedestrian)**: An adult pedestrian moving around the cityscape. Mannequins should also be annotated as Adult Pedestrian.
+
+15. **[Child Pedestrian](#child-pedestrian)**: A child pedestrian moving around the cityscape.
+
+16. **[Construction Worker](#construction-worker)**: A human in the scene whose main purpose is construction work.
+
+17. **[Stroller](#stroller)**: Any stroller. If a person is in the stroller, include in the annotation. If a pedestrian pushing the stroller, then they should be labeled separately.
+
+18. **[Wheelchair](#wheelchair)**: Any type of wheelchair. If a pedestrian is pushing the wheelchair then they should be labeled separately.
+
+19. **[Portable Personal Mobility Vehicle](#portable-personal-mobility-vehicle)**: A small electric or self-propelled vehicle, e.g. skateboard, segway, or scooters, on which the person typically travels in a upright position. Driver and (if applicable) rider should be included in the bounding box along with the vehicle.
+
+20. **[Police Officer](#police-officer)**: Any type of police officer, regardless whether directing the traffic or not.
+
+21. **[Animal](#animal)**: All animals, e.g. cats, rats, dogs, deer, birds.
+
+22. **[Traffic Cone](#traffic-cone)**: All types of traffic cones.
+
+23. **[Temporary Traffic Barrier](#temporary-traffic-barrier)**: Any metal, concrete or water barrier temporarily placed in the scene in order to re-direct vehicle or pedestrian traffic. In particular, includes barriers used at construction zones. If there are multiple barriers either connected or just placed next to each other, they should be annotated separately.
+
+24. **[Pushable Pullable Object](#pushable-pullable-object)**: Objects that a pedestrian may push or pull. For example dolleys, wheel barrows, garbage-bins with wheels, or shopping carts. Typically not designed to carry humans.
+
+25. **[Debris](#debris)**: Debris or movable object that is too large to be driven over safely. Includes misc. things like trash bags, temporary road-signs, objects around construction zones, and trash cans.
+
+# Attributes
+1. **For every object, include the attribute:**
+ + **Visibility**:
+ + **0%-40%**: The object is 0% to 40% visible in panoramic view of all cameras.
+ + **41%-60%**: The object is 41% to 60% visible in panoramic view of all cameras.
+ + **61%-80%**: The object is 61% to 80% visible in panoramic view of all cameras.
+ + **81%-100%**: The object is 81% to 100% visible in panoramic view of all cameras.
+ + This attribute specifies the percentage of an object visible through the cameras. For this estimation to be carried out, all the different camera views should be considered as one and the visible portion would be gauged in the resulting **panoramic view**
+ + 
+2. **For each vehicle with four or more wheels, select the status:**
+ + **Vehicle Activity**:
+ + **Parked**: Vehicle is stationary (usually for longer duration) with no immediate intent to move.
+ + **Stopped**: Vehicle, with a driver/rider in/on it, is currently stationary but has an intent to move.
+ + **Moving**: Vehicle is moving.
+3. **For each bicycle, motorcycle and portable personal mobility vehicle, select the rider status.**
+ + **Has Rider**:
+ + **Yes**: There is a rider on the bicycle or motorcycle.
+ + **No**: There is NO rider on the bicycle or motorcycle.
+4. **For each human in the scene, select the status**
+ + **Human Activity**:
+ + **Sitting or Lying Down**: The human is sitting or lying down.
+ + **Standing**: The human is standing.
+ + **Moving**: The human is moving.
+
+<br><br><br>
+ # Detailed Instructions and Examples
+
+Bounding Box color convention in example images:
+ + **Green**: Objects like this should be annotated
+ + **Red**: Objects like this should not be annotated
+
+
+## Car or Van or SUV
++ Vehicle designed primarily for personal use, e.g. sedans, hatch-backs, wagons, vans, mini-vans, SUVs and jeeps.
+ + If the vehicle is designed to carry more than 10 people label it is a bus.
+ + If it is primarily designed to haul cargo it is a truck.
+
+ 
+ 
+
+ [Top](#overview)
+## Truck
++ Vehicles primarily designed to haul cargo including pick-ups, lorrys, trucks and semi-tractors. Trailers hauled after a semi-tractor should be labeled as vehicle.trailer.
+
+ 
+ 
+ 
+ 
+
+**Pickup Truck**
++ A pickup truck is a light duty truck with an enclosed cab and an open or closed cargo area. A pickup truck can be intended primarily for hauling cargo or for personal use.
+
+ 
+ 
+ 
+ 
+
+**Front Of Semi Truck**
++ Tractor part of a semi trailer truck. Trailers hauled after a semi-tractor should be labeled as a trailer.
+
+ 
+ 
+ 
+ 
+ 
+ 
+
+ [Top](#overview)
+## Bendy Bus
++ Buses and shuttles designed to carry more than 10 people and comprises two or more rigid sections linked by a pivoting joint.
+ + Annotate each section of the bendy bus individually.
+ + If you cannot see the pivoting joint of the bus, annotate it as **rigid bus**.
+
+ 
+ 
+ 
+ 
+
+ [Top](#overview)
+## Rigid Bus
++ Rigid buses and shuttles designed to carry more than 10 people.
+
+ 
+ 
+ 
+ 
+
+ [Top](#overview)
+## Construction Vehicle
++ Vehicles primarily designed for construction. Typically very slow moving or stationary.
+ + Trucks used to hauling rocks or building materials are considered as truck rather than construction vehicles.
+ + Cranes and extremities of construction vehicles are only included in annotations if they interferes with traffic.
+
+ 
+ 
+ 
+ 
+ 
+
+ [Top](#overview)
+## Motorcycle
++ Gasoline or electric powered 2-wheeled vehicle designed to move rapidly (at the speed of standard cars) on the road surface. This category includes all motorcycles, vespas and scooters. It also includes light 3-wheel vehicles, often with a light plastic roof and open on the sides, that tend to be common in Asia.
+ + If there is a rider, include the rider in the box.
+ + If there is a passenger, include the passenger in the box.
+ + If there is a pedestrian standing next to the motorcycle, do NOT include in the annotation.
+
+ 
+ 
+ 
+ 
+ 
+ 
+ 
+ 
+
+ [Top](#overview)
+## Bicycle
++ Human or electric powered 2-wheeled vehicle designed to travel at lower speeds either on road surface, sidewalks or bicycle paths.
+ + If there is a rider, include the rider in the box
+ + If there is a passenger, include the passenger in the box
+ + If there is a pedestrian standing next to the bicycle, do NOT include in the annotation
+
+ 
+ 
+ 
+ 
+
+ [Top](#overview)
+## Bicycle Rack
++ Area or device intended to park or secure the bicycles in a row. It includes all the bicycles parked in it and any empty slots that are intended for parking bicycles.
+ + Bicycles that are not part of the rack should not be included. Instead they should be annotated as bicycles separately.
+
+ 
+ 
+ 
+ 
+ 
+ 
+
+ [Top](#overview)
+## Trailer
++ Any vehicle trailer, both for trucks, cars and motorcycles (regardless of whether currently being towed or not). For semi-trailers (containers) label the truck itself as "front of semi truck".
+ + A vehicle towed by another vehicle should be labeled as vehicle (not as trailer).
+
+ 
+ 
+ 
+ 
+ 
+ 
+ 
+ 
+ 
+ 
+
+ [Top](#overview)
+## Police Vehicle
++ All types of police vehicles including police bicycles and motorcycles.
+
+ 
+ 
+ 
+ 
+ 
+
+ [Top](#overview)
+## Ambulance
++ All types of ambulances.
+
+ 
+ 
+
+ [Top](#overview)
+## Adult Pedestrian
++ An adult pedestrian moving around the cityscape.
+ + Mannequins should also be treated as adult pedestrian.
+
+ 
+ 
+ 
+ 
+ 
+
+ [Top](#overview)
+## Child Pedestrian
++ A child pedestrian moving around the cityscape.
+
+ 
+ 
+ 
+ 
+
+ [Top](#overview)
+## Construction Worker
++ A human in the scene whose main purpose is construction work.
+
+ 
+ 
+ 
+ 
+
+ [Top](#overview)
+## Stroller
++ Any stroller
+ + If a person is in the stroller, include in the annotation.
+ + Pedestrians pushing strollers should be labeled separately.
+
+ 
+ 
+ 
+ 
+
+ [Top](#overview)
+## Wheelchair
++ Any type of wheelchair
+ + If a person is in the wheelchair, include in the annotation.
+ + Pedestrians pushing wheelchairs should be labeled separately.
+
+ 
+ 
+ 
+
+ [Top](#overview)
+## Portable Personal Mobility Vehicle
++ A small electric or self-propelled vehicle, e.g. skateboard, segway, or scooters, on which the person typically travels in a upright position. Driver and (if applicable) rider should be included in the bounding box along with the vehicle.
+
+ 
+ 
+
+ [Top](#overview)
+## Police Officer
++ Any type of police officer, regardless whether directing the traffic or not.
+
+ 
+ 
+ 
+ 
+
+ [Top](#overview)
+## Animal
++ All animals, e.g. cats, rats, dogs, deer, birds.
+
+ 
+ 
+ 
+ 
+ 
+
+ [Top](#overview)
+## Traffic Cone
++ All types of traffic cones.
+
+ 
+ 
+ 
+ 
+ 
+
+ [Top](#overview)
+## Temporary Traffic Barrier
++ Any metal, concrete or water barrier temporarily placed in the scene in order to re-direct vehicle or pedestrian traffic. In particular, includes barriers used at construction zones.
+ + If there are multiple barriers either connected or just placed next to each other, they should be annotated separately.
+ + If barriers are installed permanently, then do NOT include them.
+
+ 
+ 
+ 
+ 
+ 
+ 
+
+ [Top](#overview)
+## Pushable Pullable Object
++ Objects that a pedestrian may push or pull. For example dolleys, wheel barrows, garbage-bins with wheels, or shopping carts. Typically not designed to carry humans.
+
+ 
+ 
+ 
+ 
+
+ [Top](#overview)
+## Debris
++ Debris or movable object that is left **on the driveable surface** that is too large to be driven over safely, e.g tree branch, full trash bag etc.
+
+ 
+ 
+
+ [Top](#overview)
diff --git a/docs/schema_nuimages.md b/docs/schema_nuimages.md
new file mode 100644
index 0000000..172196f
--- /dev/null
+++ b/docs/schema_nuimages.md
@@ -0,0 +1,162 @@
+nuImages schema
+==========
+This document describes the database schema used in nuImages.
+All annotations and meta data (including calibration, maps, vehicle coordinates etc.) are covered in a relational database.
+The database tables are listed below.
+Every row can be identified by its unique primary key `token`.
+Foreign keys such as `sample_token` may be used to link to the `token` of the table `sample`.
+Please refer to the [tutorial](https://www.nuscenes.org/nuimages#tutorials) for an introduction to the most important database tables.
+
+
+
+attribute
+---------
+An attribute is a property of an instance that can change while the category remains the same.
+Example: a vehicle being parked/stopped/moving, and whether or not a bicycle has a rider.
+The attributes in nuImages are a superset of those in nuScenes.
+```
+attribute {
+ "token": <str> -- Unique record identifier.
+ "name": <str> -- Attribute name.
+ "description": <str> -- Attribute description.
+}
+```
+
+calibrated_sensor
+---------
+Definition of a particular camera as calibrated on a particular vehicle.
+All extrinsic parameters are given with respect to the ego vehicle body frame.
+Contrary to nuScenes, all camera images come distorted and unrectified.
+```
+calibrated_sensor {
+ "token": <str> -- Unique record identifier.
+ "sensor_token": <str> -- Foreign key pointing to the sensor type.
+ "translation": <float> [3] -- Coordinate system origin in meters: x, y, z.
+ "rotation": <float> [4] -- Coordinate system orientation as quaternion: w, x, y, z.
+ "camera_intrinsic": <float> [3, 3] -- Intrinsic camera calibration. Empty for sensors that are not cameras.
+ "camera_distortion": <float> [5 or 6] -- Camera calibration parameters [k1, k2, p1, p2, k3, k4]. We use the 5 parameter camera convention of the CalTech camera calibration toolbox, that is also used in OpenCV. Only for fish-eye lenses in CAM_BACK do we use the 6th parameter (k4).
+}
+```
+
+category
+---------
+Taxonomy of object categories (e.g. vehicle, human).
+Subcategories are delineated by a period (e.g. `human.pedestrian.adult`).
+The categories in nuImages are the same as in nuScenes (w/o lidarseg), plus `flat.driveable_surface`.
+```
+category {
+ "token": <str> -- Unique record identifier.
+ "name": <str> -- Category name. Subcategories indicated by period.
+ "description": <str> -- Category description.
+}
+```
+
+ego_pose
+---------
+Ego vehicle pose at a particular timestamp. Given with respect to global coordinate system of the log's map.
+The ego_pose is the output of a lidar map-based localization algorithm described in our paper.
+The localization is 2-dimensional in the x-y plane.
+Warning: nuImages is collected from almost 500 logs with different maps versions.
+Therefore the coordinates **should not be compared across logs** or rendered on the semantic maps of nuScenes.
+```
+ego_pose {
+ "token": <str> -- Unique record identifier.
+ "translation": <float> [3] -- Coordinate system origin in meters: x, y, z. Note that z is always 0.
+ "rotation": <float> [4] -- Coordinate system orientation as quaternion: w, x, y, z.
+ "timestamp": <int> -- Unix time stamp.
+ "rotation_rate": <float> [3] -- The angular velocity vector (x, y, z) of the vehicle in rad/s. This is expressed in the ego vehicle frame.
+ "acceleration": <float> [3] -- Acceleration vector (x, y, z) in the ego vehicle frame in m/s/s. The z value is close to the gravitational acceleration `g = 9.81 m/s/s`.
+ "speed": <float> -- The speed of the ego vehicle in the driving direction in m/s.
+}
+```
+
+log
+---------
+Information about the log from which the data was extracted.
+```
+log {
+ "token": <str> -- Unique record identifier.
+ "logfile": <str> -- Log file name.
+ "vehicle": <str> -- Vehicle name.
+ "date_captured": <str> -- Date (YYYY-MM-DD).
+ "location": <str> -- Area where log was captured, e.g. singapore-onenorth.
+}
+```
+
+object_ann
+---------
+The annotation of a foreground object (car, bike, pedestrian) in an image.
+Each foreground object is annotated with a 2d box, a 2d instance mask and category-specific attributes.
+```
+object_ann {
+ "token": <str> -- Unique record identifier.
+ "sample_data_token": <str> -- Foreign key pointing to the sample data, which must be a keyframe image.
+ "category_token": <str> -- Foreign key pointing to the object category.
+ "attribute_tokens": <str> [n] -- Foreign keys. List of attributes for this annotation.
+ "bbox": <int> [4] -- Annotated amodal bounding box. Given as [xmin, ymin, xmax, ymax].
+ "mask": <RLE> -- Run length encoding of instance mask using the pycocotools package.
+}
+```
+
+sample_data
+---------
+Sample_data contains the images and information about when they were captured.
+Sample_data covers all images, regardless of whether they are a keyframe or not.
+Only keyframes are annotated.
+For every keyframe, we also include up to 6 past and 6 future sweeps at 2 Hz.
+We can navigate between consecutive images using the `prev` and `next` pointers.
+The sample timestamp is inherited from the keyframe camera sample_data timestamp.
+```
+sample_data {
+ "token": <str> -- Unique record identifier.
+ "sample_token": <str> -- Foreign key. Sample to which this sample_data is associated.
+ "ego_pose_token": <str> -- Foreign key.
+ "calibrated_sensor_token": <str> -- Foreign key.
+ "filename": <str> -- Relative path to data-blob on disk.
+ "fileformat": <str> -- Data file format.
+ "width": <int> -- If the sample data is an image, this is the image width in pixels.
+ "height": <int> -- If the sample data is an image, this is the image height in pixels.
+ "timestamp": <int> -- Unix time stamp.
+ "is_key_frame": <bool> -- True if sample_data is part of key_frame, else False.
+ "next": <str> -- Foreign key. Sample data from the same sensor that follows this in time. Empty if end of scene.
+ "prev": <str> -- Foreign key. Sample data from the same sensor that precedes this in time. Empty if start of scene.
+}
+```
+
+sample
+---------
+A sample is an annotated keyframe selected from a large pool of images in a log.
+Every sample has up to 13 camera sample_datas corresponding to it.
+These include the keyframe, which can be accessed via `key_camera_token`.
+```
+sample {
+ "token": <str> -- Unique record identifier.
+ "timestamp": <int> -- Unix time stamp.
+ "log_token": <str> -- Foreign key pointing to the log.
+ "key_camera_token": <str> -- Foreign key of the sample_data corresponding to the camera keyframe.
+}
+```
+
+sensor
+---------
+A specific sensor type.
+```
+sensor {
+ "token": <str> -- Unique record identifier.
+ "channel": <str> -- Sensor channel name.
+ "modality": <str> -- Sensor modality. Always "camera" in nuImages.
+}
+```
+
+surface_ann
+---------
+The annotation of a background object (driveable surface) in an image.
+Each background object is annotated with a 2d semantic segmentation mask.
+```
+surface_ann {
+ "token": <str> -- Unique record identifier.
+ "sample_data_token": <str> -- Foreign key pointing to the sample data, which must be a keyframe image.
+ "category_token": <str> -- Foreign key pointing to the surface category.
+ "mask": <RLE> -- Run length encoding of segmentation mask using the pycocotools package.
+}
+```
diff --git a/docs/schema_nuscenes.md b/docs/schema_nuscenes.md
new file mode 100644
index 0000000..e69415c
--- /dev/null
+++ b/docs/schema_nuscenes.md
@@ -0,0 +1,211 @@
+nuScenes schema
+==========
+This document describes the database schema used in nuScenes.
+All annotations and meta data (including calibration, maps, vehicle coordinates etc.) are covered in a relational database.
+The database tables are listed below.
+Every row can be identified by its unique primary key `token`.
+Foreign keys such as `sample_token` may be used to link to the `token` of the table `sample`.
+Please refer to the [tutorial](https://www.nuscenes.org/nuimages#tutorial) for an introduction to the most important database tables.
+
+
+
+attribute
+---------
+An attribute is a property of an instance that can change while the category remains the same.
+Example: a vehicle being parked/stopped/moving, and whether or not a bicycle has a rider.
+```
+attribute {
+ "token": <str> -- Unique record identifier.
+ "name": <str> -- Attribute name.
+ "description": <str> -- Attribute description.
+}
+```
+
+calibrated_sensor
+---------
+Definition of a particular sensor (lidar/radar/camera) as calibrated on a particular vehicle.
+All extrinsic parameters are given with respect to the ego vehicle body frame.
+All camera images come undistorted and rectified.
+```
+calibrated_sensor {
+ "token": <str> -- Unique record identifier.
+ "sensor_token": <str> -- Foreign key pointing to the sensor type.
+ "translation": <float> [3] -- Coordinate system origin in meters: x, y, z.
+ "rotation": <float> [4] -- Coordinate system orientation as quaternion: w, x, y, z.
+ "camera_intrinsic": <float> [3, 3] -- Intrinsic camera calibration. Empty for sensors that are not cameras.
+}
+```
+
+category
+---------
+Taxonomy of object categories (e.g. vehicle, human).
+Subcategories are delineated by a period (e.g. `human.pedestrian.adult`).
+```
+category {
+ "token": <str> -- Unique record identifier.
+ "name": <str> -- Category name. Subcategories indicated by period.
+ "description": <str> -- Category description.
+ "index": <int> -- The index of the label used for efficiency reasons in the .bin label files of nuScenes-lidarseg. This field did not exist previously.
+}
+```
+
+ego_pose
+---------
+Ego vehicle pose at a particular timestamp. Given with respect to global coordinate system of the log's map.
+The ego_pose is the output of a lidar map-based localization algorithm described in our paper.
+The localization is 2-dimensional in the x-y plane.
+```
+ego_pose {
+ "token": <str> -- Unique record identifier.
+ "translation": <float> [3] -- Coordinate system origin in meters: x, y, z. Note that z is always 0.
+ "rotation": <float> [4] -- Coordinate system orientation as quaternion: w, x, y, z.
+ "timestamp": <int> -- Unix time stamp.
+}
+```
+
+instance
+---------
+An object instance, e.g. particular vehicle.
+This table is an enumeration of all object instances we observed.
+Note that instances are not tracked across scenes.
+```
+instance {
+ "token": <str> -- Unique record identifier.
+ "category_token": <str> -- Foreign key pointing to the object category.
+ "nbr_annotations": <int> -- Number of annotations of this instance.
+ "first_annotation_token": <str> -- Foreign key. Points to the first annotation of this instance.
+ "last_annotation_token": <str> -- Foreign key. Points to the last annotation of this instance.
+}
+```
+
+lidarseg
+---------
+Mapping between nuScenes-lidarseg annotations and sample_datas corresponding to the lidar pointcloud associated with a keyframe.
+```
+lidarseg {
+ "token": <str> -- Unique record identifier.
+ "filename": <str> -- The name of the .bin files containing the nuScenes-lidarseg labels. These are numpy arrays of uint8 stored in binary format using numpy.
+ "sample_data_token": <str> -- Foreign key. Sample_data corresponding to the annotated lidar pointcloud with is_key_frame=True.
+}
+```
+
+log
+---------
+Information about the log from which the data was extracted.
+```
+log {
+ "token": <str> -- Unique record identifier.
+ "logfile": <str> -- Log file name.
+ "vehicle": <str> -- Vehicle name.
+ "date_captured": <str> -- Date (YYYY-MM-DD).
+ "location": <str> -- Area where log was captured, e.g. singapore-onenorth.
+}
+```
+
+map
+---------
+Map data that is stored as binary semantic masks from a top-down view.
+```
+map {
+ "token": <str> -- Unique record identifier.
+ "log_tokens": <str> [n] -- Foreign keys.
+ "category": <str> -- Map category, currently only semantic_prior for drivable surface and sidewalk.
+ "filename": <str> -- Relative path to the file with the map mask.
+}
+```
+
+sample
+---------
+A sample is an annotated keyframe at 2 Hz.
+The data is collected at (approximately) the same timestamp as part of a single LIDAR sweep.
+```
+sample {
+ "token": <str> -- Unique record identifier.
+ "timestamp": <int> -- Unix time stamp.
+ "scene_token": <str> -- Foreign key pointing to the scene.
+ "next": <str> -- Foreign key. Sample that follows this in time. Empty if end of scene.
+ "prev": <str> -- Foreign key. Sample that precedes this in time. Empty if start of scene.
+}
+```
+
+sample_annotation
+---------
+A bounding box defining the position of an object seen in a sample.
+All location data is given with respect to the global coordinate system.
+```
+sample_annotation {
+ "token": <str> -- Unique record identifier.
+ "sample_token": <str> -- Foreign key. NOTE: this points to a sample NOT a sample_data since annotations are done on the sample level taking all relevant sample_data into account.
+ "instance_token": <str> -- Foreign key. Which object instance is this annotating. An instance can have multiple annotations over time.
+ "attribute_tokens": <str> [n] -- Foreign keys. List of attributes for this annotation. Attributes can change over time, so they belong here, not in the instance table.
+ "visibility_token": <str> -- Foreign key. Visibility may also change over time. If no visibility is annotated, the token is an empty string.
+ "translation": <float> [3] -- Bounding box location in meters as center_x, center_y, center_z.
+ "size": <float> [3] -- Bounding box size in meters as width, length, height.
+ "rotation": <float> [4] -- Bounding box orientation as quaternion: w, x, y, z.
+ "num_lidar_pts": <int> -- Number of lidar points in this box. Points are counted during the lidar sweep identified with this sample.
+ "num_radar_pts": <int> -- Number of radar points in this box. Points are counted during the radar sweep identified with this sample. This number is summed across all radar sensors without any invalid point filtering.
+ "next": <str> -- Foreign key. Sample annotation from the same object instance that follows this in time. Empty if this is the last annotation for this object.
+ "prev": <str> -- Foreign key. Sample annotation from the same object instance that precedes this in time. Empty if this is the first annotation for this object.
+}
+```
+
+sample_data
+---------
+A sensor data e.g. image, point cloud or radar return.
+For sample_data with is_key_frame=True, the time-stamps should be very close to the sample it points to.
+For non key-frames the sample_data points to the sample that follows closest in time.
+```
+sample_data {
+ "token": <str> -- Unique record identifier.
+ "sample_token": <str> -- Foreign key. Sample to which this sample_data is associated.
+ "ego_pose_token": <str> -- Foreign key.
+ "calibrated_sensor_token": <str> -- Foreign key.
+ "filename": <str> -- Relative path to data-blob on disk.
+ "fileformat": <str> -- Data file format.
+ "width": <int> -- If the sample data is an image, this is the image width in pixels.
+ "height": <int> -- If the sample data is an image, this is the image height in pixels.
+ "timestamp": <int> -- Unix time stamp.
+ "is_key_frame": <bool> -- True if sample_data is part of key_frame, else False.
+ "next": <str> -- Foreign key. Sample data from the same sensor that follows this in time. Empty if end of scene.
+ "prev": <str> -- Foreign key. Sample data from the same sensor that precedes this in time. Empty if start of scene.
+}
+```
+
+scene
+---------
+A scene is a 20s long sequence of consecutive frames extracted from a log.
+Multiple scenes can come from the same log.
+Note that object identities (instance tokens) are not preserved across scenes.
+```
+scene {
+ "token": <str> -- Unique record identifier.
+ "name": <str> -- Short string identifier.
+ "description": <str> -- Longer description of the scene.
+ "log_token": <str> -- Foreign key. Points to log from where the data was extracted.
+ "nbr_samples": <int> -- Number of samples in this scene.
+ "first_sample_token": <str> -- Foreign key. Points to the first sample in scene.
+ "last_sample_token": <str> -- Foreign key. Points to the last sample in scene.
+}
+```
+
+sensor
+---------
+A specific sensor type.
+```
+sensor {
+ "token": <str> -- Unique record identifier.
+ "channel": <str> -- Sensor channel name.
+ "modality": <str> {camera, lidar, radar} -- Sensor modality. Supports category(ies) in brackets.
+}
+```
+
+visibility
+---------
+The visibility of an instance is the fraction of annotation visible in all 6 images. Binned into 4 bins 0-40%, 40-60%, 60-80% and 80-100%.
+```
+visibility {
+ "token": <str> -- Unique record identifier.
+ "level": <str> -- Visibility level.
+ "description": <str> -- Description of visibility level.
+}
+```
diff --git a/python-sdk/nuimages/__init__.py b/python-sdk/nuimages/__init__.py
new file mode 100644
index 0000000..0010d97
--- /dev/null
+++ b/python-sdk/nuimages/__init__.py
@@ -0,0 +1 @@
+from .nuimages import NuImages
diff --git a/python-sdk/nuimages/export/export_release.py b/python-sdk/nuimages/export/export_release.py
new file mode 100644
index 0000000..c246ada
--- /dev/null
+++ b/python-sdk/nuimages/export/export_release.py
@@ -0,0 +1,66 @@
+# nuScenes dev-kit.
+# Code written by Holger Caesar, 2020.
+
+import fire
+import os
+import json
+import tarfile
+from typing import List
+
+
+def export_release(dataroot='/data/sets/nuimages', version: str = 'v1.0') -> None:
+ """
+ This script tars the image and metadata files for release on https://www.nuscenes.org/download.
+ :param dataroot: The nuImages folder.
+ :param version: The nuImages dataset version.
+ """
+ # Create export folder.
+ export_dir = os.path.join(dataroot, 'export')
+ if not os.path.isdir(export_dir):
+ os.makedirs(export_dir)
+
+ # Determine the images from the mini split.
+ mini_src = os.path.join(dataroot, version + '-mini')
+ with open(os.path.join(mini_src, 'sample_data.json'), 'r') as f:
+ sample_data = json.load(f)
+ file_names = [sd['filename'] for sd in sample_data]
+
+ # Hard-code the mapping from archive names to their relative folder paths.
+ archives = {
+ 'all-metadata': [version + '-train', version + '-val', version + '-test', version + '-mini'],
+ 'all-samples': ['samples'],
+ 'all-sweeps-cam-back': ['sweeps/CAM_BACK'],
+ 'all-sweeps-cam-back-left': ['sweeps/CAM_BACK_LEFT'],
+ 'all-sweeps-cam-back-right': ['sweeps/CAM_BACK_RIGHT'],
+ 'all-sweeps-cam-front': ['sweeps/CAM_FRONT'],
+ 'all-sweeps-cam-front-left': ['sweeps/CAM_FRONT_LEFT'],
+ 'all-sweeps-cam-front-right': ['sweeps/CAM_FRONT_RIGHT'],
+ 'mini': [version + '-mini'] + file_names
+ }
+
+ # Pack each folder.
+ for key, folder_list in archives.items():
+ out_path = os.path.join(export_dir, 'nuimages-%s-%s.tgz' % (version, key))
+ if os.path.exists(out_path):
+ print('Warning: Skipping export for file as it already exists: %s' % out_path)
+ continue
+ print('Compressing archive %s...' % out_path)
+ pack_folder(out_path, dataroot, folder_list)
+
+
+def pack_folder(out_path: str, dataroot: str, folder_list: List[str], tar_format: str = 'w:gz') -> None:
+ """
+ :param out_path: The output path where we write the tar file.
+ :param dataroot: The nuImages folder.
+ :param folder_list: List of files or folders to include in the archive.
+ :param tar_format: The compression format to use. See tarfile package for more options.
+ """
+ tar = tarfile.open(out_path, tar_format)
+ for name in folder_list:
+ folder_path = os.path.join(dataroot, name)
+ tar.add(folder_path, arcname=name)
+ tar.close()
+
+
+if __name__ == '__main__':
+ fire.Fire(export_release)
diff --git a/python-sdk/nuimages/nuimages.py b/python-sdk/nuimages/nuimages.py
new file mode 100644
index 0000000..66198cf
--- /dev/null
+++ b/python-sdk/nuimages/nuimages.py
@@ -0,0 +1,769 @@
+# nuScenes dev-kit.
+# Code written by Asha Asvathaman & Holger Caesar, 2020.
+
+import json
+import os.path as osp
+import sys
+import time
+from collections import defaultdict
+from typing import Any, List, Dict, Optional, Tuple, Callable
+
+import matplotlib.pyplot as plt
+import numpy as np
+from PIL import Image, ImageDraw
+from pyquaternion import Quaternion
+
+from nuimages.utils.utils import annotation_name, mask_decode, get_font, name_to_index_mapping
+from nuscenes.utils.color_map import get_colormap
+
+PYTHON_VERSION = sys.version_info[0]
+
+if not PYTHON_VERSION == 3:
+ raise ValueError("nuScenes dev-kit only supports Python version 3.")
+
+
+class NuImages:
+ """
+ Database class for nuImages to help query and retrieve information from the database.
+ """
+
+ def __init__(self,
+ version: str = 'v1.0-mini',
+ dataroot: str = '/data/sets/nuimages',
+ lazy: bool = True,
+ verbose: bool = False):
+ """
+ Loads database and creates reverse indexes and shortcuts.
+ :param version: Version to load (e.g. "v1.0-train", "v1.0-val", "v1.0-test", "v1.0-mini").
+ :param dataroot: Path to the tables and data.
+ :param lazy: Whether to use lazy loading for the database tables.
+ :param verbose: Whether to print status messages during load.
+ """
+ self.version = version
+ self.dataroot = dataroot
+ self.lazy = lazy
+ self.verbose = verbose
+
+ self.table_names = ['attribute', 'calibrated_sensor', 'category', 'ego_pose', 'log', 'object_ann', 'sample',
+ 'sample_data', 'sensor', 'surface_ann']
+
+ assert osp.exists(self.table_root), 'Database version not found: {}'.format(self.table_root)
+
+ start_time = time.time()
+ if verbose:
+ print("======\nLoading nuImages tables for version {}...".format(self.version))
+
+ # Init reverse indexing.
+ self._token2ind: Dict[str, Optional[dict]] = dict()
+ for table in self.table_names:
+ self._token2ind[table] = None
+
+ # Load tables directly if requested.
+ if not self.lazy:
+ # Explicitly init tables to help the IDE determine valid class members.
+ self.attribute = self.__load_table__('attribute')
+ self.calibrated_sensor = self.__load_table__('calibrated_sensor')
+ self.category = self.__load_table__('category')
+ self.ego_pose = self.__load_table__('ego_pose')
+ self.log = self.__load_table__('log')
+ self.object_ann = self.__load_table__('object_ann')
+ self.sample = self.__load_table__('sample')
+ self.sample_data = self.__load_table__('sample_data')
+ self.sensor = self.__load_table__('sensor')
+ self.surface_ann = self.__load_table__('surface_ann')
+
+ self.color_map = get_colormap()
+
+ if verbose:
+ print("Done loading in {:.3f} seconds (lazy={}).\n======".format(time.time() - start_time, self.lazy))
+
+ # ### Internal methods. ###
+
+ def __getattr__(self, attr_name: str) -> Any:
+ """
+ Implement lazy loading for the database tables. Otherwise throw the default error.
+ :param attr_name: The name of the variable to look for.
+ :return: The dictionary that represents that table.
+ """
+ if attr_name in self.table_names:
+ return self._load_lazy(attr_name, lambda tab_name: self.__load_table__(tab_name))
+ else:
+ raise AttributeError("Error: %r object has no attribute %r" % (self.__class__.__name__, attr_name))
+
+ def get(self, table_name: str, token: str) -> dict:
+ """
+ Returns a record from table in constant runtime.
+ :param table_name: Table name.
+ :param token: Token of the record.
+ :return: Table record. See README.md for record details for each table.
+ """
+ assert table_name in self.table_names, "Table {} not found".format(table_name)
+
+ return getattr(self, table_name)[self.getind(table_name, token)]
+
+ def getind(self, table_name: str, token: str) -> int:
+ """
+ This returns the index of the record in a table in constant runtime.
+ :param table_name: Table name.
+ :param token: Token of the record.
+ :return: The index of the record in table, table is an array.
+ """
+ # Lazy loading: Compute reverse indices.
+ if self._token2ind[table_name] is None:
+ self._token2ind[table_name] = dict()
+ for ind, member in enumerate(getattr(self, table_name)):
+ self._token2ind[table_name][member['token']] = ind
+
+ return self._token2ind[table_name][token]
+
+ @property
+ def table_root(self) -> str:
+ """
+ Returns the folder where the tables are stored for the relevant version.
+ """
+ return osp.join(self.dataroot, self.version)
+
+ def load_tables(self, table_names: List[str]) -> None:
+ """
+ Load tables and add them to self, if not already loaded.
+ :param table_names: The names of the nuImages tables to be loaded.
+ """
+ for table_name in table_names:
+ self._load_lazy(table_name, lambda tab_name: self.__load_table__(tab_name))
+
+ def _load_lazy(self, attr_name: str, loading_func: Callable) -> Any:
+ """
+ Load an attribute and add it to self, if it isn't already loaded.
+ :param attr_name: The name of the attribute to be loaded.
+ :param loading_func: The function used to load it if necessary.
+ :return: The loaded attribute.
+ """
+ if attr_name in self.__dict__.keys():
+ return self.__getattribute__(attr_name)
+ else:
+ attr = loading_func(attr_name)
+ self.__setattr__(attr_name, attr)
+ return attr
+
+ def __load_table__(self, table_name) -> List[dict]:
+ """
+ Load a table and return it.
+ :param table_name: The name of the table to load.
+ :return: The table dictionary.
+ """
+ start_time = time.time()
+ table_path = osp.join(self.table_root, '{}.json'.format(table_name))
+ assert osp.exists(table_path), 'Error: Table %s does not exist!' % table_name
+ with open(table_path) as f:
+ table = json.load(f)
+ end_time = time.time()
+
+ # Print a message to stdout.
+ if self.verbose:
+ print("Loaded {} {}(s) in {:.3f}s,".format(len(table), table_name, end_time - start_time))
+
+ return table
+
+ def shortcut(self, src_table: str, tgt_table: str, src_token: str) -> Dict[str, Any]:
+ """
+ Convenience function to navigate between different tables that have one-to-one relations.
+ E.g. we can use this function to conveniently retrieve the sensor for a sample_data.
+ :param src_table: The name of the source table.
+ :param tgt_table: The name of the target table.
+ :param src_token: The source token.
+ :return: The entry of the destination table corresponding to the source token.
+ """
+ if src_table == 'sample_data' and tgt_table == 'sensor':
+ sample_data = self.get('sample_data', src_token)
+ calibrated_sensor = self.get('calibrated_sensor', sample_data['calibrated_sensor_token'])
+ sensor = self.get('sensor', calibrated_sensor['sensor_token'])
+
+ return sensor
+ elif (src_table == 'object_ann' or src_table == 'surface_ann') and tgt_table == 'sample':
+ src = self.get(src_table, src_token)
+ sample_data = self.get('sample_data', src['sample_data_token'])
+ sample = self.get('sample', sample_data['sample_token'])
+
+ return sample
+ else:
+ raise Exception('Error: Shortcut from %s to %s not implemented!' % (src_table, tgt_table))
+
+ def check_sweeps(self, filename: str) -> None:
+ """
+ Check that the sweeps folder was downloaded if required.
+ :param filename: The filename of the sample_data.
+ """
+ assert filename.startswith('samples') or filename.startswith('sweeps'), \
+ 'Error: You passed an incorrect filename to check_sweeps(). Please use sample_data[''filename''].'
+
+ if 'sweeps' in filename:
+ sweeps_dir = osp.join(self.dataroot, 'sweeps')
+ if not osp.isdir(sweeps_dir):
+ raise Exception('Error: You are missing the "%s" directory! The devkit generally works without this '
+ 'directory, but you cannot call methods that use non-keyframe sample_datas.'
+ % sweeps_dir)
+
+ # ### List methods. ###
+
+ def list_attributes(self, sort_by: str = 'freq') -> None:
+ """
+ List all attributes and the number of annotations with each attribute.
+ :param sort_by: Sorting criteria, e.g. "name", "freq".
+ """
+ # Preload data if in lazy load to avoid confusing outputs.
+ if self.lazy:
+ self.load_tables(['attribute', 'object_ann'])
+
+ # Count attributes.
+ attribute_freqs = defaultdict(lambda: 0)
+ for object_ann in self.object_ann:
+ for attribute_token in object_ann['attribute_tokens']:
+ attribute_freqs[attribute_token] += 1
+
+ # Sort entries.
+ if sort_by == 'name':
+ sort_order = [i for (i, _) in sorted(enumerate(self.attribute), key=lambda x: x[1]['name'])]
+ elif sort_by == 'freq':
+ attribute_freqs_order = [attribute_freqs[c['token']] for c in self.attribute]
+ sort_order = [i for (i, _) in
+ sorted(enumerate(attribute_freqs_order), key=lambda x: x[1], reverse=True)]
+ else:
+ raise Exception('Error: Invalid sorting criterion %s!' % sort_by)
+
+ # Print to stdout.
+ format_str = '{:11} {:24.24} {:48.48}'
+ print()
+ print(format_str.format('Annotations', 'Name', 'Description'))
+ for s in sort_order:
+ attribute = self.attribute[s]
+ print(format_str.format(
+ attribute_freqs[attribute['token']], attribute['name'], attribute['description']))
+
+ def list_cameras(self) -> None:
+ """
+ List all cameras and the number of samples for each.
+ """
+ # Preload data if in lazy load to avoid confusing outputs.
+ if self.lazy:
+ self.load_tables(['sample', 'sample_data', 'calibrated_sensor', 'sensor'])
+
+ # Count cameras.
+ cs_freqs = defaultdict(lambda: 0)
+ channel_freqs = defaultdict(lambda: 0)
+ for calibrated_sensor in self.calibrated_sensor:
+ sensor = self.get('sensor', calibrated_sensor['sensor_token'])
+ cs_freqs[sensor['channel']] += 1
+ for sample_data in self.sample_data:
+ if sample_data['is_key_frame']: # Only use keyframes (samples).
+ sensor = self.shortcut('sample_data', 'sensor', sample_data['token'])
+ channel_freqs[sensor['channel']] += 1
+
+ # Print to stdout.
+ format_str = '{:15} {:7} {:25}'
+ print()
+ print(format_str.format('Calibr. sensors', 'Samples', 'Channel'))
+ for channel in cs_freqs.keys():
+ cs_freq = cs_freqs[channel]
+ channel_freq = channel_freqs[channel]
+ print(format_str.format(
+ cs_freq, channel_freq, channel))
+
+ def list_categories(self, sample_tokens: List[str] = None, sort_by: str = 'object_freq') -> None:
+ """
+ List all categories and the number of object_anns and surface_anns for them.
+ :param sample_tokens: A list of sample tokens for which category stats will be shown.
+ :param sort_by: Sorting criteria, e.g. "name", "object_freq", "surface_freq".
+ """
+ # Preload data if in lazy load to avoid confusing outputs.
+ if self.lazy:
+ self.load_tables(['sample', 'object_ann', 'surface_ann', 'category'])
+
+ # Count object_anns and surface_anns.
+ object_freqs = defaultdict(lambda: 0)
+ surface_freqs = defaultdict(lambda: 0)
+ if sample_tokens is not None:
+ sample_tokens = set(sample_tokens)
+
+ for object_ann in self.object_ann:
+ sample = self.shortcut('object_ann', 'sample', object_ann['token'])
+ if sample_tokens is None or sample['token'] in sample_tokens:
+ object_freqs[object_ann['category_token']] += 1
+
+ for surface_ann in self.surface_ann:
+ sample = self.shortcut('surface_ann', 'sample', surface_ann['token'])
+ if sample_tokens is None or sample['token'] in sample_tokens:
+ surface_freqs[surface_ann['category_token']] += 1
+
+ # Sort entries.
+ if sort_by == 'name':
+ sort_order = [i for (i, _) in sorted(enumerate(self.category), key=lambda x: x[1]['name'])]
+ elif sort_by == 'object_freq':
+ object_freqs_order = [object_freqs[c['token']] for c in self.category]
+ sort_order = [i for (i, _) in sorted(enumerate(object_freqs_order), key=lambda x: x[1], reverse=True)]
+ elif sort_by == 'surface_freq':
+ surface_freqs_order = [surface_freqs[c['token']] for c in self.category]
+ sort_order = [i for (i, _) in sorted(enumerate(surface_freqs_order), key=lambda x: x[1], reverse=True)]
+ else:
+ raise Exception('Error: Invalid sorting criterion %s!' % sort_by)
+
+ # Print to stdout.
+ format_str = '{:11} {:12} {:24.24} {:48.48}'
+ print()
+ print(format_str.format('Object_anns', 'Surface_anns', 'Name', 'Description'))
+ for s in sort_order:
+ category = self.category[s]
+ category_token = category['token']
+ object_freq = object_freqs[category_token]
+ surface_freq = surface_freqs[category_token]
+
+ # Skip empty categories.
+ if object_freq == 0 and surface_freq == 0:
+ continue
+
+ name = category['name']
+ description = category['description']
+ print(format_str.format(
+ object_freq, surface_freq, name, description))
+
+ def list_anns(self, sample_token: str, verbose: bool = True) -> Tuple[List[str], List[str]]:
+ """
+ List all the annotations of a sample.
+ :param sample_token: Sample token.
+ :param verbose: Whether to print to stdout.
+ :return: The object and surface annotation tokens in this sample.
+ """
+ # Preload data if in lazy load to avoid confusing outputs.
+ if self.lazy:
+ self.load_tables(['sample', 'object_ann', 'surface_ann', 'category'])
+
+ sample = self.get('sample', sample_token)
+ key_camera_token = sample['key_camera_token']
+ object_anns = [o for o in self.object_ann if o['sample_data_token'] == key_camera_token]
+ surface_anns = [o for o in self.surface_ann if o['sample_data_token'] == key_camera_token]
+
+ if verbose:
+ print('Printing object annotations:')
+ for object_ann in object_anns:
+ category = self.get('category', object_ann['category_token'])
+ attribute_names = [self.get('attribute', at)['name'] for at in object_ann['attribute_tokens']]
+ print('{} {} {}'.format(object_ann['token'], category['name'], attribute_names))
+
+ print('\nPrinting surface annotations:')
+ for surface_ann in surface_anns:
+ category = self.get('category', surface_ann['category_token'])
+ print(surface_ann['token'], category['name'])
+
+ object_tokens = [o['token'] for o in object_anns]
+ surface_tokens = [s['token'] for s in surface_anns]
+ return object_tokens, surface_tokens
+
+ def list_logs(self) -> None:
+ """
+ List all logs and the number of samples per log.
+ """
+ # Preload data if in lazy load to avoid confusing outputs.
+ if self.lazy:
+ self.load_tables(['sample', 'log'])
+
+ # Count samples.
+ sample_freqs = defaultdict(lambda: 0)
+ for sample in self.sample:
+ sample_freqs[sample['log_token']] += 1
+
+ # Print to stdout.
+ format_str = '{:6} {:29} {:24}'
+ print()
+ print(format_str.format('Samples', 'Log', 'Location'))
+ for log in self.log:
+ sample_freq = sample_freqs[log['token']]
+ logfile = log['logfile']
+ location = log['location']
+ print(format_str.format(
+ sample_freq, logfile, location))
+
+ def list_sample_content(self, sample_token: str) -> None:
+ """
+ List the sample_datas for a given sample.
+ :param sample_token: Sample token.
+ """
+ # Preload data if in lazy load to avoid confusing outputs.
+ if self.lazy:
+ self.load_tables(['sample', 'sample_data'])
+
+ # Print content for each modality.
+ sample = self.get('sample', sample_token)
+ sample_data_tokens = self.get_sample_content(sample_token)
+ timestamps = np.array([self.get('sample_data', sd_token)['timestamp'] for sd_token in sample_data_tokens])
+ rel_times = (timestamps - sample['timestamp']) / 1e6
+
+ print('\nListing sample content...')
+ print('Rel. time\tSample_data token')
+ for rel_time, sample_data_token in zip(rel_times, sample_data_tokens):
+ print('{:>9.1f}\t{}'.format(rel_time, sample_data_token))
+
+ def list_sample_data_histogram(self) -> None:
+ """
+ Show a histogram of the number of sample_datas per sample.
+ """
+ # Preload data if in lazy load to avoid confusing outputs.
+ if self.lazy:
+ self.load_tables(['sample_data'])
+
+ # Count sample_datas for each sample.
+ sample_counts = defaultdict(lambda: 0)
+ for sample_data in self.sample_data:
+ sample_counts[sample_data['sample_token']] += 1
+
+ # Compute histogram.
+ sample_counts_list = np.array(list(sample_counts.values()))
+ bin_range = np.max(sample_counts_list) - np.min(sample_counts_list)
+ if bin_range == 0:
+ values = [len(sample_counts_list)]
+ freqs = [sample_counts_list[0]]
+ else:
+ values, bins = np.histogram(sample_counts_list, bin_range)
+ freqs = bins[1:] # To get the frequency we need to use the right side of the bin.
+
+ # Print statistics.
+ print('\nListing sample_data frequencies..')
+ print('# images\t# samples')
+ for freq, val in zip(freqs, values):
+ print('{:>8d}\t{:d}'.format(int(freq), int(val)))
+
+ # ### Getter methods. ###
+
+ def get_sample_content(self,
+ sample_token: str) -> List[str]:
+ """
+ For a given sample, return all the sample_datas in chronological order.
+ :param sample_token: Sample token.
+ :return: A list of sample_data tokens sorted by their timestamp.
+ """
+ sample = self.get('sample', sample_token)
+ key_sd = self.get('sample_data', sample['key_camera_token'])
+
+ # Go forward.
+ cur_sd = key_sd
+ forward = []
+ while cur_sd['next'] != '':
+ cur_sd = self.get('sample_data', cur_sd['next'])
+ forward.append(cur_sd['token'])
+
+ # Go backward.
+ cur_sd = key_sd
+ backward = []
+ while cur_sd['prev'] != '':
+ cur_sd = self.get('sample_data', cur_sd['prev'])
+ backward.append(cur_sd['token'])
+
+ # Combine.
+ result = backward[::-1] + [key_sd['token']] + forward
+
+ return result
+
+ def get_ego_pose_data(self,
+ sample_token: str,
+ attribute_name: str = 'translation') -> Tuple[np.ndarray, np.ndarray]:
+ """
+ Return the ego pose data of the <= 13 sample_datas associated with this sample.
+ The method return translation, rotation, rotation_rate, acceleration and speed.
+ :param sample_token: Sample token.
+ :param attribute_name: The ego_pose field to extract, e.g. "translation", "acceleration" or "speed".
+ :return: (
+ timestamps: The timestamp of each ego_pose.
+ attributes: A matrix with sample_datas x len(attribute) number of fields.
+ )
+ """
+ assert attribute_name in ['translation', 'rotation', 'rotation_rate', 'acceleration', 'speed'], \
+ 'Error: The attribute_name %s is not a valid option!' % attribute_name
+
+ if attribute_name == 'speed':
+ attribute_len = 1
+ elif attribute_name == 'rotation':
+ attribute_len = 4
+ else:
+ attribute_len = 3
+
+ sd_tokens = self.get_sample_content(sample_token)
+ attributes = np.zeros((len(sd_tokens), attribute_len))
+ timestamps = np.zeros((len(sd_tokens)))
+ for i, sd_token in enumerate(sd_tokens):
+ # Get attribute.
+ sample_data = self.get('sample_data', sd_token)
+ ego_pose = self.get('ego_pose', sample_data['ego_pose_token'])
+ attribute = ego_pose[attribute_name]
+
+ # Store results.
+ attributes[i, :] = attribute
+ timestamps[i] = ego_pose['timestamp']
+
+ return timestamps, attributes
+
+ def get_trajectory(self,
+ sample_token: str,
+ rotation_yaw: float = 0.0,
+ center_key_pose: bool = True) -> Tuple[np.ndarray, int]:
+ """
+ Get the trajectory of the ego vehicle and optionally rotate and center it.
+ :param sample_token: Sample token.
+ :param rotation_yaw: Rotation of the ego vehicle in the plot.
+ Set to None to use lat/lon coordinates.
+ Set to 0 to point in the driving direction at the time of the keyframe.
+ Set to any other value to rotate relative to the driving direction (in radians).
+ :param center_key_pose: Whether to center the trajectory on the key pose.
+ :return: (
+ translations: A matrix with sample_datas x 3 values of the translations at each timestamp.
+ key_index: The index of the translations corresponding to the keyframe (usually 6).
+ )
+ """
+ # Get trajectory data.
+ timestamps, translations = self.get_ego_pose_data(sample_token)
+
+ # Find keyframe translation and rotation.
+ sample = self.get('sample', sample_token)
+ sample_data = self.get('sample_data', sample['key_camera_token'])
+ ego_pose = self.get('ego_pose', sample_data['ego_pose_token'])
+ key_rotation = Quaternion(ego_pose['rotation'])
+ key_timestamp = ego_pose['timestamp']
+ key_index = [i for i, t in enumerate(timestamps) if t == key_timestamp][0]
+
+ # Rotate points such that the initial driving direction points upwards.
+ if rotation_yaw is not None:
+ rotation = key_rotation.inverse * Quaternion(axis=[0, 0, 1], angle=np.pi / 2 - rotation_yaw)
+ translations = np.dot(rotation.rotation_matrix, translations.T).T
+
+ # Subtract origin to have lower numbers on the axes.
+ if center_key_pose:
+ translations -= translations[key_index, :]
+
+ return translations, key_index
+
+ def get_segmentation(self,
+ sd_token: str) -> Tuple[np.ndarray, np.ndarray]:
+ """
+ Produces two segmentation masks as numpy arrays of size H x W each, where H and W are the height and width
+ of the camera image respectively:
+ - semantic mask: A mask in which each pixel is an integer value between 0 to C (inclusive),
+ where C is the number of categories in nuImages. Each integer corresponds to
+ the index of the class in the category.json.
+ - instance mask: A mask in which each pixel is an integer value between 0 to N, where N is the
+ number of objects in a given camera sample_data. Each integer corresponds to
+ the order in which the object was drawn into the mask.
+ :param sd_token: The token of the sample_data to be rendered.
+ :return: Two 2D numpy arrays (one semantic mask <int32: H, W>, and one instance mask <int32: H, W>).
+ """
+ # Validate inputs.
+ sample_data = self.get('sample_data', sd_token)
+ assert sample_data['is_key_frame'], 'Error: Cannot render annotations for non keyframes!'
+
+ name_to_index = name_to_index_mapping(self.category)
+
+ # Get image data.
+ self.check_sweeps(sample_data['filename'])
+ im_path = osp.join(self.dataroot, sample_data['filename'])
+ im = Image.open(im_path)
+
+ (width, height) = im.size
+ semseg_mask = np.zeros((height, width)).astype('int32')
+ instanceseg_mask = np.zeros((height, width)).astype('int32')
+
+ # Load stuff / surface regions.
+ surface_anns = [o for o in self.surface_ann if o['sample_data_token'] == sd_token]
+
+ # Draw stuff / surface regions.
+ for ann in surface_anns:
+ # Get color and mask.
+ category_token = ann['category_token']
+ category_name = self.get('category', category_token)['name']
+ if ann['mask'] is None:
+ continue
+ mask = mask_decode(ann['mask'])
+
+ # Draw mask for semantic segmentation.
+ semseg_mask[mask == 1] = name_to_index[category_name]
+
+ # Load object instances.
+ object_anns = [o for o in self.object_ann if o['sample_data_token'] == sd_token]
+
+ # Sort by token to ensure that objects always appear in the instance mask in the same order.
+ object_anns = sorted(object_anns, key=lambda k: k['token'])
+
+ # Draw object instances.
+ # The 0 index is reserved for background; thus, the instances should start from index 1.
+ for i, ann in enumerate(object_anns, start=1):
+ # Get color, box, mask and name.
+ category_token = ann['category_token']
+ category_name = self.get('category', category_token)['name']
+ if ann['mask'] is None:
+ continue
+ mask = mask_decode(ann['mask'])
+
+ # Draw masks for semantic segmentation and instance segmentation.
+ semseg_mask[mask == 1] = name_to_index[category_name]
+ instanceseg_mask[mask == 1] = i
+
+ return semseg_mask, instanceseg_mask
+
+ # ### Rendering methods. ###
+
+ def render_image(self,
+ sd_token: str,
+ annotation_type: str = 'all',
+ with_category: bool = False,
+ with_attributes: bool = False,
+ object_tokens: List[str] = None,
+ surface_tokens: List[str] = None,
+ render_scale: float = 1.0,
+ box_line_width: int = -1,
+ font_size: int = None,
+ out_path: str = None) -> None:
+ """
+ Renders an image (sample_data), optionally with annotations overlaid.
+ :param sd_token: The token of the sample_data to be rendered.
+ :param annotation_type: The types of annotations to draw on the image; there are four options:
+ 'all': Draw surfaces and objects, subject to any filtering done by object_tokens and surface_tokens.
+ 'surfaces': Draw only surfaces, subject to any filtering done by surface_tokens.
+ 'objects': Draw objects, subject to any filtering done by object_tokens.
+ 'none': Neither surfaces nor objects will be drawn.
+ :param with_category: Whether to include the category name at the top of a box.
+ :param with_attributes: Whether to include attributes in the label tags. Note that with_attributes=True
+ will only work if with_category=True.
+ :param object_tokens: List of object annotation tokens. If given, only these annotations are drawn.
+ :param surface_tokens: List of surface annotation tokens. If given, only these annotations are drawn.
+ :param render_scale: The scale at which the image will be rendered. Use 1.0 for the original image size.
+ :param box_line_width: The box line width in pixels. The default is -1.
+ If set to -1, box_line_width equals render_scale (rounded) to be larger in larger images.
+ :param font_size: Size of the text in the rendered image. Use None for the default size.
+ :param out_path: The path where we save the rendered image, or otherwise None.
+ If a path is provided, the plot is not shown to the user.
+ """
+ # Validate inputs.
+ sample_data = self.get('sample_data', sd_token)
+ if not sample_data['is_key_frame']:
+ assert annotation_type != 'none', 'Error: Cannot render annotations for non keyframes!'
+ assert not with_attributes, 'Error: Cannot render attributes for non keyframes!'
+ if with_attributes:
+ assert with_category, 'In order to set with_attributes=True, with_category must be True.'
+ assert type(box_line_width) == int, 'Error: box_line_width must be an integer!'
+ if box_line_width == -1:
+ box_line_width = int(round(render_scale))
+
+ # Get image data.
+ self.check_sweeps(sample_data['filename'])
+ im_path = osp.join(self.dataroot, sample_data['filename'])
+ im = Image.open(im_path)
+
+ # Initialize drawing.
+ if with_category and font_size is not None:
+ font = get_font(font_size=font_size)
+ else:
+ font = None
+ im = im.convert('RGBA')
+ draw = ImageDraw.Draw(im, 'RGBA')
+
+ annotations_types = ['all', 'surfaces', 'objects', 'none']
+ assert annotation_type in annotations_types, \
+ 'Error: {} is not a valid option for annotation_type. ' \
+ 'Only {} are allowed.'.format(annotation_type, annotations_types)
+ if annotation_type is not 'none':
+ if annotation_type == 'all' or annotation_type == 'surfaces':
+ # Load stuff / surface regions.
+ surface_anns = [o for o in self.surface_ann if o['sample_data_token'] == sd_token]
+ if surface_tokens is not None:
+ sd_surface_tokens = set([s['token'] for s in surface_anns if s['token']])
+ assert set(surface_tokens).issubset(sd_surface_tokens), \
+ 'Error: The provided surface_tokens do not belong to the sd_token!'
+ surface_anns = [o for o in surface_anns if o['token'] in surface_tokens]
+
+ # Draw stuff / surface regions.
+ for ann in surface_anns:
+ # Get color and mask.
+ category_token = ann['category_token']
+ category_name = self.get('category', category_token)['name']
+ color = self.color_map[category_name]
+ if ann['mask'] is None:
+ continue
+ mask = mask_decode(ann['mask'])
+
+ # Draw mask. The label is obvious from the color.
+ draw.bitmap((0, 0), Image.fromarray(mask * 128), fill=tuple(color + (128,)))
+
+ if annotation_type == 'all' or annotation_type == 'objects':
+ # Load object instances.
+ object_anns = [o for o in self.object_ann if o['sample_data_token'] == sd_token]
+ if object_tokens is not None:
+ sd_object_tokens = set([o['token'] for o in object_anns if o['token']])
+ assert set(object_tokens).issubset(sd_object_tokens), \
+ 'Error: The provided object_tokens do not belong to the sd_token!'
+ object_anns = [o for o in object_anns if o['token'] in object_tokens]
+
+ # Draw object instances.
+ for ann in object_anns:
+ # Get color, box, mask and name.
+ category_token = ann['category_token']
+ category_name = self.get('category', category_token)['name']
+ color = self.color_map[category_name]
+ bbox = ann['bbox']
+ attr_tokens = ann['attribute_tokens']
+ attributes = [self.get('attribute', at) for at in attr_tokens]
+ name = annotation_name(attributes, category_name, with_attributes=with_attributes)
+ if ann['mask'] is not None:
+ mask = mask_decode(ann['mask'])
+
+ # Draw mask, rectangle and text.
+ draw.bitmap((0, 0), Image.fromarray(mask * 128), fill=tuple(color + (128,)))
+ draw.rectangle(bbox, outline=color, width=box_line_width)
+ if with_category:
+ draw.text((bbox[0], bbox[1]), name, font=font)
+
+ # Plot the image.
+ (width, height) = im.size
+ pix_to_inch = 100 / render_scale
+ figsize = (height / pix_to_inch, width / pix_to_inch)
+ plt.figure(figsize=figsize)
+ plt.axis('off')
+ plt.imshow(im)
+
+ # Save to disk.
+ if out_path is not None:
+ plt.savefig(out_path, bbox_inches='tight', dpi=2.295 * pix_to_inch, pad_inches=0)
+ plt.close()
+
+ def render_trajectory(self,
+ sample_token: str,
+ rotation_yaw: float = 0.0,
+ center_key_pose: bool = True,
+ out_path: str = None) -> None:
+ """
+ Render a plot of the trajectory for the clip surrounding the annotated keyframe.
+ A red cross indicates the starting point, a green dot the ego pose of the annotated keyframe.
+ :param sample_token: Sample token.
+ :param rotation_yaw: Rotation of the ego vehicle in the plot.
+ Set to None to use lat/lon coordinates.
+ Set to 0 to point in the driving direction at the time of the keyframe.
+ Set to any other value to rotate relative to the driving direction (in radians).
+ :param center_key_pose: Whether to center the trajectory on the key pose.
+ :param out_path: Optional path to save the rendered figure to disk.
+ If a path is provided, the plot is not shown to the user.
+ """
+ # Get the translations or poses.
+ translations, key_index = self.get_trajectory(sample_token, rotation_yaw=rotation_yaw,
+ center_key_pose=center_key_pose)
+
+ # Render translations.
+ plt.figure()
+ plt.plot(translations[:, 0], translations[:, 1])
+ plt.plot(translations[key_index, 0], translations[key_index, 1], 'go', markersize=10) # Key image.
+ plt.plot(translations[0, 0], translations[0, 1], 'rx', markersize=10) # Start point.
+ max_dist = translations - translations[key_index, :]
+ max_dist = np.ceil(np.max(np.abs(max_dist)) * 1.05) # Leave some margin.
+ max_dist = np.maximum(10, max_dist)
+ plt.xlim([translations[key_index, 0] - max_dist, translations[key_index, 0] + max_dist])
+ plt.ylim([translations[key_index, 1] - max_dist, translations[key_index, 1] + max_dist])
+ plt.xlabel('x in meters')
+ plt.ylabel('y in meters')
+
+ # Save to disk.
+ if out_path is not None:
+ plt.savefig(out_path, bbox_inches='tight', dpi=150, pad_inches=0)
+ plt.close()
diff --git a/python-sdk/nuimages/scripts/render_images.py b/python-sdk/nuimages/scripts/render_images.py
new file mode 100644
index 0000000..3f22913
--- /dev/null
+++ b/python-sdk/nuimages/scripts/render_images.py
@@ -0,0 +1,227 @@
+# nuScenes dev-kit.
+# Code written by Holger Caesar, 2020.
+
+import argparse
+import gc
+import os
+import random
+from typing import List
+from collections import defaultdict
+
+import cv2
+import tqdm
+
+from nuimages.nuimages import NuImages
+
+
+def render_images(nuim: NuImages,
+ mode: str = 'all',
+ cam_name: str = None,
+ log_name: str = None,
+ sample_limit: int = 50,
+ filter_categories: List[str] = None,
+ out_type: str = 'image',
+ out_dir: str = '~/Downloads/nuImages',
+ cleanup: bool = True) -> None:
+ """
+ Render a random selection of images and save them to disk.
+ Note: The images rendered here are keyframes only.
+ :param nuim: NuImages instance.
+ :param mode: What to render:
+ "image" for the image without annotations,
+ "annotated" for the image with annotations,
+ "trajectory" for a rendering of the trajectory of the vehice,
+ "all" to render all of the above separately.
+ :param cam_name: Only render images from a particular camera, e.g. "CAM_BACK'.
+ :param log_name: Only render images from a particular log, e.g. "n013-2018-09-04-13-30-50+0800".
+ :param sample_limit: Maximum number of samples (images) to render. Note that the mini split only includes 50 images.
+ :param filter_categories: Specify a list of object_ann category names. Every sample that is rendered must
+ contain annotations of any of those categories.
+ :param out_type: The output type as one of the following:
+ 'image': Renders a single image for the image keyframe of each sample.
+ 'video': Renders a video for all images/pcls in the clip associated with each sample.
+ :param out_dir: Folder to render the images to.
+ :param cleanup: Whether to delete images after rendering the video. Not relevant for out_type == 'image'.
+ """
+ # Check and convert inputs.
+ assert out_type in ['image', 'video'], ' Error: Unknown out_type %s!' % out_type
+ all_modes = ['image', 'annotated', 'trajectory']
+ assert mode in all_modes + ['all'], 'Error: Unknown mode %s!' % mode
+ assert not (out_type == 'video' and mode == 'trajectory'), 'Error: Cannot render "trajectory" for videos!'
+
+ if mode == 'all':
+ if out_type == 'image':
+ modes = all_modes
+ elif out_type == 'video':
+ modes = [m for m in all_modes if m not in ['annotated', 'trajectory']]
+ else:
+ raise Exception('Error" Unknown mode %s!' % mode)
+ else:
+ modes = [mode]
+
+ if filter_categories is not None:
+ category_names = [c['name'] for c in nuim.category]
+ for category_name in filter_categories:
+ assert category_name in category_names, 'Error: Invalid object_ann category %s!' % category_name
+
+ # Create output folder.
+ out_dir = os.path.expanduser(out_dir)
+ if not os.path.isdir(out_dir):
+ os.makedirs(out_dir)
+
+ # Filter by camera.
+ sample_tokens = [s['token'] for s in nuim.sample]
+ if cam_name is not None:
+ sample_tokens_cam = []
+ for sample_token in sample_tokens:
+ sample = nuim.get('sample', sample_token)
+ key_camera_token = sample['key_camera_token']
+ sensor = nuim.shortcut('sample_data', 'sensor', key_camera_token)
+ if sensor['channel'] == cam_name:
+ sample_tokens_cam.append(sample_token)
+ sample_tokens = sample_tokens_cam
+
+ # Filter by log.
+ if log_name is not None:
+ sample_tokens_cleaned = []
+ for sample_token in sample_tokens:
+ sample = nuim.get('sample', sample_token)
+ log = nuim.get('log', sample['log_token'])
+ if log['logfile'] == log_name:
+ sample_tokens_cleaned.append(sample_token)
+ sample_tokens = sample_tokens_cleaned
+
+ # Filter samples by category.
+ if filter_categories is not None:
+ # Get categories in each sample.
+ sd_to_object_cat_names = defaultdict(lambda: set())
+ for object_ann in nuim.object_ann:
+ category = nuim.get('category', object_ann['category_token'])
+ sd_to_object_cat_names[object_ann['sample_data_token']].add(category['name'])
+
+ # Filter samples.
+ sample_tokens_cleaned = []
+ for sample_token in sample_tokens:
+ sample = nuim.get('sample', sample_token)
+ key_camera_token = sample['key_camera_token']
+ category_names = sd_to_object_cat_names[key_camera_token]
+ if any([c in category_names for c in filter_categories]):
+ sample_tokens_cleaned.append(sample_token)
+ sample_tokens = sample_tokens_cleaned
+
+ # Get a random selection of samples.
+ random.shuffle(sample_tokens)
+
+ # Limit number of samples.
+ sample_tokens = sample_tokens[:sample_limit]
+
+ print('Rendering %s for mode %s to folder %s...' % (out_type, mode, out_dir))
+ for sample_token in tqdm.tqdm(sample_tokens):
+ sample = nuim.get('sample', sample_token)
+ log = nuim.get('log', sample['log_token'])
+ log_name = log['logfile']
+ key_camera_token = sample['key_camera_token']
+ sensor = nuim.shortcut('sample_data', 'sensor', key_camera_token)
+ sample_cam_name = sensor['channel']
+ sd_tokens = nuim.get_sample_content(sample_token)
+
+ # We cannot render a video if there are missing camera sample_datas.
+ if len(sd_tokens) < 13 and out_type == 'video':
+ print('Warning: Skipping video for sample token %s, as not all 13 frames exist!' % sample_token)
+ continue
+
+ for mode in modes:
+ out_path_prefix = os.path.join(out_dir, '%s_%s_%s_%s' % (log_name, sample_token, sample_cam_name, mode))
+ if out_type == 'image':
+ write_image(nuim, key_camera_token, mode, '%s.jpg' % out_path_prefix)
+ elif out_type == 'video':
+ write_video(nuim, sd_tokens, mode, out_path_prefix, cleanup=cleanup)
+
+
+def write_video(nuim: NuImages,
+ sd_tokens: List[str],
+ mode: str,
+ out_path_prefix: str,
+ cleanup: bool = True) -> None:
+ """
+ Render a video by combining all the images of type mode for each sample_data.
+ :param nuim: NuImages instance.
+ :param sd_tokens: All sample_data tokens in chronological order.
+ :param mode: The mode - see render_images().
+ :param out_path_prefix: The file prefix used for the images and video.
+ :param cleanup: Whether to delete images after rendering the video.
+ """
+ # Loop through each frame to create the video.
+ out_paths = []
+ for i, sd_token in enumerate(sd_tokens):
+ out_path = '%s_%d.jpg' % (out_path_prefix, i)
+ out_paths.append(out_path)
+ write_image(nuim, sd_token, mode, out_path)
+
+ # Create video.
+ first_im = cv2.imread(out_paths[0])
+ freq = 2 # Display frequency (Hz).
+ fourcc = cv2.VideoWriter_fourcc(*'MJPG')
+ video_path = '%s.avi' % out_path_prefix
+ out = cv2.VideoWriter(video_path, fourcc, freq, first_im.shape[1::-1])
+
+ # Load each image and add to the video.
+ for out_path in out_paths:
+ im = cv2.imread(out_path)
+ out.write(im)
+
+ # Delete temporary image if requested.
+ if cleanup:
+ os.remove(out_path)
+
+ # Finalize video.
+ out.release()
+
+
+def write_image(nuim: NuImages, sd_token: str, mode: str, out_path: str) -> None:
+ """
+ Render a single image of type mode for the given sample_data.
+ :param nuim: NuImages instance.
+ :param sd_token: The sample_data token.
+ :param mode: The mode - see render_images().
+ :param out_path: The file to write the image to.
+ """
+ if mode == 'annotated':
+ nuim.render_image(sd_token, annotation_type='all', out_path=out_path)
+ elif mode == 'image':
+ nuim.render_image(sd_token, annotation_type='none', out_path=out_path)
+ elif mode == 'trajectory':
+ sample_data = nuim.get('sample_data', sd_token)
+ nuim.render_trajectory(sample_data['sample_token'], out_path=out_path)
+ else:
+ raise Exception('Error: Unknown mode %s!' % mode)
+
+ # Trigger garbage collection to avoid memory overflow from the render functions.
+ gc.collect()
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser(description='Render a random selection of images and save them to disk.')
+ parser.add_argument('--seed', type=int, default=42) # Set to 0 to disable.
+ parser.add_argument('--version', type=str, default='v1.0-mini')
+ parser.add_argument('--dataroot', type=str, default='/data/sets/nuimages')
+ parser.add_argument('--verbose', type=int, default=1)
+ parser.add_argument('--mode', type=str, default='all')
+ parser.add_argument('--cam_name', type=str, default=None)
+ parser.add_argument('--log_name', type=str, default=None)
+ parser.add_argument('--sample_limit', type=int, default=50)
+ parser.add_argument('--filter_categories', action='append')
+ parser.add_argument('--out_type', type=str, default='image')
+ parser.add_argument('--out_dir', type=str, default='~/Downloads/nuImages')
+ args = parser.parse_args()
+
+ # Set random seed for reproducible image selection.
+ if args.seed != 0:
+ random.seed(args.seed)
+
+ # Initialize NuImages class.
+ nuim_ = NuImages(version=args.version, dataroot=args.dataroot, verbose=bool(args.verbose), lazy=False)
+
+ # Render images.
+ render_images(nuim_, mode=args.mode, cam_name=args.cam_name, log_name=args.log_name, sample_limit=args.sample_limit,
+ filter_categories=args.filter_categories, out_type=args.out_type, out_dir=args.out_dir)
diff --git a/python-sdk/nuimages/scripts/render_rare_classes.py b/python-sdk/nuimages/scripts/render_rare_classes.py
new file mode 100644
index 0000000..c09dcf1
--- /dev/null
+++ b/python-sdk/nuimages/scripts/render_rare_classes.py
@@ -0,0 +1,86 @@
+# nuScenes dev-kit.
+# Code written by Holger Caesar, 2020.
+
+import argparse
+import random
+from collections import defaultdict
+from typing import Dict, Any, List
+
+from nuimages.nuimages import NuImages
+from nuimages.scripts.render_images import render_images
+
+
+def render_rare_classes(nuim: NuImages,
+ render_args: Dict[str, Any],
+ filter_categories: List[str] = None,
+ max_frequency: float = 0.1) -> None:
+ """
+ Wrapper around render_images() that renders images with rare classes.
+ :param nuim: NuImages instance.
+ :param render_args: The render arguments passed on to the render function. See render_images().
+ :param filter_categories: Specify a list of object_ann category names.
+ Every sample that is rendered must contain annotations of any of those categories.
+ Filter_categories are a applied on top of the frequency filering.
+ :param max_frequency: The maximum relative frequency of the categories, at least one of which is required to be
+ present in the image. E.g. 0.1 indicates that one of the classes that account for at most 10% of the annotations
+ is present.
+ """
+ # Checks.
+ assert 'filter_categories' not in render_args.keys(), \
+ 'Error: filter_categories is a separate argument and should not be part of render_args!'
+ assert 0 <= max_frequency <= 1, 'Error: max_frequency must be a ratio between 0 and 1!'
+
+ # Compute object class frequencies.
+ object_freqs = defaultdict(lambda: 0)
+ for object_ann in nuim.object_ann:
+ category = nuim.get('category', object_ann['category_token'])
+ object_freqs[category['name']] += 1
+
+ # Find rare classes.
+ total_freqs = len(nuim.object_ann)
+ filter_categories_freq = sorted([k for (k, v) in object_freqs.items() if v / total_freqs <= max_frequency])
+ assert len(filter_categories_freq) > 0, 'Error: No classes found with the specified max_frequency!'
+ print('The rare classes are: %s' % filter_categories_freq)
+
+ # If specified, additionally filter these categories by what was requested.
+ if filter_categories is None:
+ filter_categories = filter_categories_freq
+ else:
+ filter_categories = list(set(filter_categories_freq).intersection(set(filter_categories)))
+ assert len(filter_categories) > 0, 'Error: No categories left after applying filter_categories!'
+
+ # Call render function.
+ render_images(nuim, filter_categories=filter_categories, **render_args)
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser(description='Render a random selection of images and save them to disk.')
+ parser.add_argument('--seed', type=int, default=42) # Set to 0 to disable.
+ parser.add_argument('--version', type=str, default='v1.0-mini')
+ parser.add_argument('--dataroot', type=str, default='/data/sets/nuimages')
+ parser.add_argument('--verbose', type=int, default=1)
+ parser.add_argument('--mode', type=str, default='all')
+ parser.add_argument('--cam_name', type=str, default=None)
+ parser.add_argument('--sample_limit', type=int, default=100)
+ parser.add_argument('--max_frequency', type=float, default=0.1)
+ parser.add_argument('--filter_categories', action='append')
+ parser.add_argument('--out_type', type=str, default='image')
+ parser.add_argument('--out_dir', type=str, default='~/Downloads/nuImages')
+ args = parser.parse_args()
+
+ # Set random seed for reproducible image selection.
+ if args.seed != 0:
+ random.seed(args.seed)
+
+ # Initialize NuImages class.
+ nuim_ = NuImages(version=args.version, dataroot=args.dataroot, verbose=bool(args.verbose), lazy=False)
+
+ # Render images.
+ _render_args = {
+ 'mode': args.mode,
+ 'cam_name': args.cam_name,
+ 'sample_limit': args.sample_limit,
+ 'out_type': args.out_type,
+ 'out_dir': args.out_dir
+ }
+ render_rare_classes(nuim_, _render_args, filter_categories=args.filter_categories, max_frequency=args.max_frequency)
diff --git a/python-sdk/nuimages/tests/__init__.py b/python-sdk/nuimages/tests/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/python-sdk/nuimages/tests/assert_download.py b/python-sdk/nuimages/tests/assert_download.py
new file mode 100644
index 0000000..7dbb3d8
--- /dev/null
+++ b/python-sdk/nuimages/tests/assert_download.py
@@ -0,0 +1,46 @@
+# nuScenes dev-kit.
+# Code written by Holger Caesar, 2020.
+
+import argparse
+import os
+
+from tqdm import tqdm
+
+from nuimages import NuImages
+
+
+def verify_setup(nuim: NuImages):
+ """
+ Script to verify that the nuImages installation is complete.
+ Note that this may take several minutes or hours.
+ """
+
+ # Check that each sample_data file exists.
+ print('Checking that sample_data files are complete...')
+ for sd in tqdm(nuim.sample_data):
+ file_path = os.path.join(nuim.dataroot, sd['filename'])
+ assert os.path.exists(file_path), 'Error: Missing sample_data at: %s' % file_path
+
+
+if __name__ == "__main__":
+
+ # Settings.
+ parser = argparse.ArgumentParser(description='Test that the installed dataset is complete.',
+ formatter_class=argparse.ArgumentDefaultsHelpFormatter)
+ parser.add_argument('--dataroot', type=str, default='/data/sets/nuimages',
+ help='Default nuImages data directory.')
+ parser.add_argument('--version', type=str, default='v1.0-train',
+ help='Which version of the nuImages dataset to evaluate on, e.g. v1.0-train.')
+ parser.add_argument('--verbose', type=int, default=1,
+ help='Whether to print to stdout.')
+
+ args = parser.parse_args()
+ dataroot = args.dataroot
+ version = args.version
+ verbose = bool(args.verbose)
+
+ # Init.
+ nuim_ = NuImages(version=version, verbose=verbose, dataroot=dataroot)
+
+ # Verify data blobs.
+ verify_setup(nuim_)
diff --git a/python-sdk/nuimages/tests/test_attributes.py b/python-sdk/nuimages/tests/test_attributes.py
new file mode 100644
index 0000000..264c933
--- /dev/null
+++ b/python-sdk/nuimages/tests/test_attributes.py
@@ -0,0 +1,115 @@
+# nuScenes dev-kit.
+# Code written by Holger Caesar, 2020.
+
+import os
+import unittest
+from typing import Any
+
+from nuimages.nuimages import NuImages
+
+
+class TestAttributes(unittest.TestCase):
+
+ def __init__(self, _: Any = None, version: str = 'v1.0-mini', dataroot: str = None):
+ """
+ Initialize TestAttributes.
+ Note: The second parameter is a dummy parameter required by the TestCase class.
+ :param version: The NuImages version.
+ :param dataroot: The root folder where the dataset is installed.
+ """
+ super().__init__()
+
+ self.version = version
+ if dataroot is None:
+ self.dataroot = os.environ['NUIMAGES']
+ else:
+ self.dataroot = dataroot
+ self.nuim = NuImages(version=self.version, dataroot=self.dataroot, verbose=False)
+ self.valid_attributes = {
+ 'animal': ['pedestrian', 'vertical_position'],
+ 'human.pedestrian.adult': ['pedestrian'],
+ 'human.pedestrian.child': ['pedestrian'],
+ 'human.pedestrian.construction_worker': ['pedestrian'],
+ 'human.pedestrian.personal_mobility': ['cycle'],
+ 'human.pedestrian.police_officer': ['pedestrian'],
+ 'human.pedestrian.stroller': [],
+ 'human.pedestrian.wheelchair': [],
+ 'movable_object.barrier': [],
+ 'movable_object.debris': [],
+ 'movable_object.pushable_pullable': [],
+ 'movable_object.trafficcone': [],
+ 'static_object.bicycle_rack': [],
+ 'vehicle.bicycle': ['cycle'],
+ 'vehicle.bus.bendy': ['vehicle'],
+ 'vehicle.bus.rigid': ['vehicle'],
+ 'vehicle.car': ['vehicle'],
+ 'vehicle.construction': ['vehicle'],
+ 'vehicle.ego': [],
+ 'vehicle.emergency.ambulance': ['vehicle', 'vehicle_light.emergency'],
+ 'vehicle.emergency.police': ['vehicle', 'vehicle_light.emergency'],
+ 'vehicle.motorcycle': ['cycle'],
+ 'vehicle.trailer': ['vehicle'],
+ 'vehicle.truck': ['vehicle']
+ }
+
+ def runTest(self) -> None:
+ """
+ Dummy function required by the TestCase class.
+ """
+ pass
+
+ def test_object_anns(self, print_only: bool = False) -> None:
+ """
+ For every object_ann, check that all the required attributes for that class are present.
+ :param print_only: Whether to throw assertion errors or just print a warning message.
+ """
+ att_token_to_name = {att['token']: att['name'] for att in self.nuim.attribute}
+ cat_token_to_name = {cat['token']: cat['name'] for cat in self.nuim.category}
+ for object_ann in self.nuim.object_ann:
+ # Collect the attribute names used here.
+ category_name = cat_token_to_name[object_ann['category_token']]
+ sample_token = self.nuim.get('sample_data', object_ann['sample_data_token'])['sample_token']
+
+ cur_att_names = []
+ for attribute_token in object_ann['attribute_tokens']:
+ attribute_name = att_token_to_name[attribute_token]
+ cur_att_names.append(attribute_name)
+
+ # Compare to the required attribute name prefixes.
+ # Check that the length is correct.
+ required_att_names = self.valid_attributes[category_name]
+ condition = len(cur_att_names) == len(required_att_names)
+ if not condition:
+ debug_output = {
+ 'sample_token': sample_token,
+ 'category_name': category_name,
+ 'cur_att_names': cur_att_names,
+ 'required_att_names': required_att_names
+ }
+ error_msg = 'Error: ' + str(debug_output)
+ if print_only:
+ print(error_msg)
+ else:
+ self.assertTrue(condition, error_msg)
+
+ # Skip next check if we already saw an error.
+ continue
+
+ # Check that they are really the same.
+ for required in required_att_names:
+ condition = any([cur.startswith(required + '.') for cur in cur_att_names])
+ if not condition:
+ error_msg = 'Errors: Required attribute ''%s'' not in %s for class %s! (sample %s)' \
+ % (required, cur_att_names, category_name, sample_token)
+ if print_only:
+ print(error_msg)
+ else:
+ self.assertTrue(condition, error_msg)
+
+
+if __name__ == '__main__':
+ # Runs the tests without aborting on error.
+ for nuim_version in ['v1.0-train', 'v1.0-val', 'v1.0-test', 'v1.0-mini']:
+ print('Running TestAttributes for version %s...' % nuim_version)
+ test = TestAttributes(version=nuim_version)
+ test.test_object_anns(print_only=True)
diff --git a/python-sdk/nuimages/tests/test_foreign_keys.py b/python-sdk/nuimages/tests/test_foreign_keys.py
new file mode 100644
index 0000000..df9729a
--- /dev/null
+++ b/python-sdk/nuimages/tests/test_foreign_keys.py
@@ -0,0 +1,147 @@
+# nuScenes dev-kit.
+# Code written by Holger Caesar, 2020.
+
+import itertools
+import os
+import unittest
+from collections import defaultdict
+from typing import List, Dict, Any
+
+from nuimages.nuimages import NuImages
+
+
+class TestForeignKeys(unittest.TestCase):
+ def __init__(self, _: Any = None, version: str = 'v1.0-mini', dataroot: str = None):
+ """
+ Initialize TestForeignKeys.
+ Note: The second parameter is a dummy parameter required by the TestCase class.
+ :param version: The NuImages version.
+ :param dataroot: The root folder where the dataset is installed.
+ """
+ super().__init__()
+
+ self.version = version
+ if dataroot is None:
+ self.dataroot = os.environ['NUIMAGES']
+ else:
+ self.dataroot = dataroot
+ self.nuim = NuImages(version=self.version, dataroot=self.dataroot, verbose=False)
+
+ def runTest(self) -> None:
+ """
+ Dummy function required by the TestCase class.
+ """
+ pass
+
+ def test_foreign_keys(self) -> None:
+ """
+ Test that every foreign key points to a valid token.
+ """
+ # Index the tokens of all tables.
+ index = dict()
+ for table_name in self.nuim.table_names:
+ print('Indexing table %s...' % table_name)
+ table: list = self.nuim.__getattr__(table_name)
+ tokens = [row['token'] for row in table]
+ index[table_name] = set(tokens)
+
+ # Go through each table and check the foreign_keys.
+ for table_name in self.nuim.table_names:
+ table: List[Dict[str, Any]] = self.nuim.__getattr__(table_name)
+ if self.version.endswith('-test') and len(table) == 0: # Skip test annotations.
+ continue
+ keys = table[0].keys()
+
+ # Check 1-to-1 link.
+ one_to_one_names = [k for k in keys if k.endswith('_token') and not k.startswith('key_')]
+ for foreign_key_name in one_to_one_names:
+ print('Checking one-to-one key %s in table %s...' % (foreign_key_name, table_name))
+ foreign_table_name = foreign_key_name.replace('_token', '')
+ foreign_tokens = set([row[foreign_key_name] for row in table])
+
+ # Check all tokens are valid.
+ if self.version.endswith('-mini') and foreign_table_name == 'category':
+ continue # Mini does not cover all categories.
+ foreign_index = index[foreign_table_name]
+ self.assertTrue(foreign_tokens.issubset(foreign_index))
+
+ # Check all tokens are covered.
+ # By default we check that all tokens are covered. Exceptions are listed below.
+ if table_name == 'object_ann':
+ if foreign_table_name == 'category':
+ remove = set([cat['token'] for cat in self.nuim.category if cat['name']
+ in ['vehicle.ego', 'flat.driveable_surface']])
+ foreign_index = foreign_index.difference(remove)
+ elif foreign_table_name == 'sample_data':
+ foreign_index = None # Skip as sample_datas may have no object_ann.
+ elif table_name == 'surface_ann':
+ if foreign_table_name == 'category':
+ remove = set([cat['token'] for cat in self.nuim.category if cat['name']
+ not in ['vehicle.ego', 'flat.driveable_surface']])
+ foreign_index = foreign_index.difference(remove)
+ elif foreign_table_name == 'sample_data':
+ foreign_index = None # Skip as sample_datas may have no surface_ann.
+ if foreign_index is not None:
+ self.assertEqual(foreign_tokens, foreign_index)
+
+ # Check 1-to-many link.
+ one_to_many_names = [k for k in keys if k.endswith('_tokens')]
+ for foreign_key_name in one_to_many_names:
+ print('Checking one-to-many key %s in table %s...' % (foreign_key_name, table_name))
+ foreign_table_name = foreign_key_name.replace('_tokens', '')
+ foreign_tokens_nested = [row[foreign_key_name] for row in table]
+ foreign_tokens = set(itertools.chain(*foreign_tokens_nested))
+
+ # Check that all tokens are valid.
+ foreign_index = index[foreign_table_name]
+ self.assertTrue(foreign_tokens.issubset(foreign_index))
+
+ # Check all tokens are covered.
+ if self.version.endswith('-mini') and foreign_table_name == 'attribute':
+ continue # Mini does not cover all categories.
+ if foreign_index is not None:
+ self.assertEqual(foreign_tokens, foreign_index)
+
+ # Check prev and next.
+ prev_next_names = [k for k in keys if k in ['previous', 'next']]
+ for foreign_key_name in prev_next_names:
+ print('Checking prev-next key %s in table %s...' % (foreign_key_name, table_name))
+ foreign_table_name = table_name
+ foreign_tokens = set([row[foreign_key_name] for row in table if len(row[foreign_key_name]) > 0])
+
+ # Check that all tokens are valid.
+ foreign_index = index[foreign_table_name]
+ self.assertTrue(foreign_tokens.issubset(foreign_index))
+
+ def test_prev_next(self) -> None:
+ """
+ Test that the prev and next points in sample_data cover all entries and have the correct ordering.
+ """
+ # Register all sample_datas.
+ sample_to_sample_datas = defaultdict(lambda: [])
+ for sample_data in self.nuim.sample_data:
+ sample_to_sample_datas[sample_data['sample_token']].append(sample_data['token'])
+
+ print('Checking prev-next pointers for completeness and correct ordering...')
+ for sample in self.nuim.sample:
+ # Compare the above sample_datas against those retrieved by using prev and next pointers.
+ sd_tokens_pointers = self.nuim.get_sample_content(sample['token'])
+ sd_tokens_all = sample_to_sample_datas[sample['token']]
+ self.assertTrue(set(sd_tokens_pointers) == set(sd_tokens_all),
+ 'Error: Inconsistency in prev/next pointers!')
+
+ timestamps = []
+ for sd_token in sd_tokens_pointers:
+ sample_data = self.nuim.get('sample_data', sd_token)
+ timestamps.append(sample_data['timestamp'])
+ self.assertTrue(sorted(timestamps) == timestamps, 'Error: Timestamps not properly sorted!')
+
+
+if __name__ == '__main__':
+ # Runs the tests without aborting on error.
+ for nuim_version in ['v1.0-train', 'v1.0-val', 'v1.0-test', 'v1.0-mini']:
+ print('Running TestForeignKeys for version %s...' % nuim_version)
+ test = TestForeignKeys(version=nuim_version)
+ test.test_foreign_keys()
+ test.test_prev_next()
+ print()
diff --git a/python-sdk/nuimages/utils/__init__.py b/python-sdk/nuimages/utils/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/python-sdk/nuimages/utils/test_nuimages.py b/python-sdk/nuimages/utils/test_nuimages.py
new file mode 100644
index 0000000..7e5e2de
--- /dev/null
+++ b/python-sdk/nuimages/utils/test_nuimages.py
@@ -0,0 +1,26 @@
+# nuScenes dev-kit.
+# Code written by Holger Caesar, 2020.
+
+import os
+import unittest
+
+from nuimages import NuImages
+
+
+class TestNuImages(unittest.TestCase):
+
+ def test_load(self):
+ """
+ Loads up NuImages.
+ This is intended to simply run the NuImages class to check for import errors, typos, etc.
+ """
+
+ assert 'NUIMAGES' in os.environ, 'Set NUIMAGES env. variable to enable tests.'
+ nuim = NuImages(version='v1.0-mini', dataroot=os.environ['NUIMAGES'], verbose=False)
+
+ # Trivial assert statement
+ self.assertEqual(nuim.table_root, os.path.join(os.environ['NUIMAGES'], 'v1.0-mini'))
+
+
+if __name__ == '__main__':
+ unittest.main()
diff --git a/python-sdk/nuimages/utils/utils.py b/python-sdk/nuimages/utils/utils.py
new file mode 100644
index 0000000..6ce3135
--- /dev/null
+++ b/python-sdk/nuimages/utils/utils.py
@@ -0,0 +1,106 @@
+# nuScenes dev-kit.
+# Code written by Asha Asvathaman & Holger Caesar, 2020.
+
+import base64
+import os
+from typing import List, Dict
+import warnings
+
+import matplotlib.font_manager
+from PIL import ImageFont
+import numpy as np
+from pycocotools import mask as cocomask
+
+
+def annotation_name(attributes: List[dict],
+ category_name: str,
+ with_attributes: bool = False) -> str:
+ """
+ Returns the "name" of an annotation, optionally including the attributes.
+ :param attributes: The attribute dictionary.
+ :param category_name: Name of the object category.
+ :param with_attributes: Whether to print the attributes alongside the category name.
+ :return: A human readable string describing the annotation.
+ """
+ outstr = category_name
+
+ if with_attributes:
+ atts = [attribute['name'] for attribute in attributes]
+ if len(atts) > 0:
+ outstr = outstr + "--" + '.'.join(atts)
+
+ return outstr
+
+
+def mask_decode(mask: dict) -> np.ndarray:
+ """
+ Decode the mask from base64 string to binary string, then feed it to the external pycocotools library to get a mask.
+ :param mask: The mask dictionary with fields `size` and `counts`.
+ :return: A numpy array representing the binary mask for this class.
+ """
+ # Note that it is essential to copy the mask here. If we use the same variable we will overwrite the NuImage class
+ # and cause the Jupyter Notebook to crash on some systems.
+ new_mask = mask.copy()
+ new_mask['counts'] = base64.b64decode(mask['counts'])
+ return cocomask.decode(new_mask)
+
+
+def get_font(fonts_valid: List[str] = None, font_size: int = 15) -> ImageFont:
+ """
+ Check if there is a desired font present in the user's system. If there is, use that font; otherwise, use a default
+ font.
+ :param fonts_valid: A list of fonts which are desirable.
+ :param font_size: The size of the font to set. Note that if the default font is used, then the font size
+ cannot be set.
+ :return: An ImageFont object to use as the font in a PIL image.
+ """
+ # If there are no desired fonts supplied, use a hardcoded list of fonts which are desirable.
+ if fonts_valid is None:
+ fonts_valid = ['FreeSerif.ttf', 'FreeSans.ttf', 'Century.ttf', 'Calibri.ttf', 'arial.ttf']
+
+ # Find a list of fonts within the user's system.
+ fonts_in_sys = matplotlib.font_manager.findSystemFonts(fontpaths=None, fontext='ttf')
+ # Sort the list of fonts to ensure that the desired fonts are always found in the same order.
+ fonts_in_sys = sorted(fonts_in_sys)
+ # Of all the fonts found in the user's system, check if any of them are desired.
+ for font_in_sys in fonts_in_sys:
+ if any(os.path.basename(font_in_sys) in s for s in fonts_valid):
+ return ImageFont.truetype(font_in_sys, font_size)
+
+ # If none of the fonts in the user's system are desirable, then use the default font.
+ warnings.warn('No suitable fonts were found in your system. '
+ 'A default font will be used instead (the font size will not be adjustable).')
+ return ImageFont.load_default()
+
+
+def name_to_index_mapping(category: List[dict]) -> Dict[str, int]:
+ """
+ Build a mapping from name to index to look up index in O(1) time.
+ :param category: The nuImages category table.
+ :return: The mapping from category name to category index.
+ """
+ # The 0 index is reserved for non-labelled background; thus, the categories should start from index 1.
+ # Also, sort the categories before looping so that the order is always the same (alphabetical).
+ name_to_index = dict()
+ i = 1
+ sorted_category: List = sorted(category.copy(), key=lambda k: k['name'])
+ for c in sorted_category:
+ # Ignore the vehicle.ego and flat.driveable_surface classes first; they will be mapped later.
+ if c['name'] != 'vehicle.ego' and c['name'] != 'flat.driveable_surface':
+ name_to_index[c['name']] = i
+ i += 1
+
+ assert max(name_to_index.values()) < 24, \
+ 'Error: There are {} classes (excluding vehicle.ego and flat.driveable_surface), ' \
+ 'but there should be 23. Please check your category.json'.format(max(name_to_index.values()))
+
+ # Now map the vehicle.ego and flat.driveable_surface classes.
+ name_to_index['flat.driveable_surface'] = 24
+ name_to_index['vehicle.ego'] = 31
+
+ # Ensure that each class name is uniquely paired with a class index, and vice versa.
+ assert len(name_to_index) == len(set(name_to_index.values())), \
+ 'Error: There are {} class names but {} class indices'.format(len(name_to_index),
+ len(set(name_to_index.values())))
+
+ return name_to_index
diff --git a/python-sdk/nuscenes/__init__.py b/python-sdk/nuscenes/__init__.py
new file mode 100644
index 0000000..dd528e8
--- /dev/null
+++ b/python-sdk/nuscenes/__init__.py
@@ -0,0 +1 @@
+from .nuscenes import NuScenes, NuScenesExplorer
diff --git a/python-sdk/nuscenes/can_bus/README.md b/python-sdk/nuscenes/can_bus/README.md
new file mode 100644
index 0000000..a3fe106
--- /dev/null
+++ b/python-sdk/nuscenes/can_bus/README.md
@@ -0,0 +1,144 @@
+# nuScenes CAN bus expansion
+This page describes the Controller Area Network (CAN) bus expansion for the nuScenes dataset.
+This is additional information that was published in January 2020 after the initial nuScenes release in March 2019.
+The data can be used for tasks such as trajectory estimation, object detection and tracking.
+
+# Overview
+- [Introduction](#introduction)
+ - [Notation](#notation)
+- [Derived messages](#derived-messages)
+ - [Meta](#meta)
+ - [Route](#route)
+- [CAN bus messages](#can-bus-messages)
+ - [IMU](#imu)
+ - [Pose](#pose)
+ - [Steer Angle Feedback](#steer-angle-feedback)
+ - [Vehicle Monitor](#vehicle-monitor)
+ - [Zoe Sensors](#zoe-sensors)
+ - [Zoe Vehicle Info](#zoe-vehicle-info)
+
+## Introduction
+The nuScenes dataset provides sensor data and annotations for 1000 scenes.
+The CAN bus expansion includes additional information for these scenes.
+The [CAN bus](https://copperhilltech.com/a-brief-introduction-to-controller-area-network/) is used for communication in automobiles and includes low-level messages regarding position, velocity, acceleration, steering, lights, battery and many more.
+In addition to this raw data we also provide some meta data, such as statistics of the different message types.
+Note that the CAN bus data is highly experimental.
+Some data may be redundant across different messages.
+Finally we extract a snippet of the route that the vehicle is currently travelling on.
+
+### Notation
+All messages of a particular type are captured in a file of the format `scene_0001_message.json`, where `0001` indicates the scene id and `message` the message name.
+The messages (except *route*) contain different keys and values.
+Below we notate the dimensionality as \[d\] to indicate that a value has d dimensions.
+
+## Derived messages
+Here we store additional information that is derived from various [CAN bus messages](#can-bus-messages) below.
+These messages are timeless and therefore do not provide the `utime` timestamp common to the CAN bus messages.
+
+### Meta
+Format: `scene_0001_meta.json`
+
+This meta file summarizes all CAN bus messages (except *route*) and provides some statistics that may be helpful to understand the data.
+- message_count: \[1\] How many messages of this type were logged.
+- message_freq: \[1\] The message frequency computed from timestamp and message_count.
+- timespan: \[1\] How many seconds passed from first to last message in a scene. Usually around 20s.
+- var_stats: (dict) Contains the maximum, mean, minimum and standard deviation for both the raw values and the differences of two consecutive values.
+
+### Route
+Format: `scene_0001_route.json`
+
+Our vehicles follow predefined routes through the city.
+The baseline route is the recommended navigation path for the vehicle to follow.
+This is an ideal route that does not take into account any blocking objects or road closures.
+The route contains the relevant section of the current scene and around 50m before and after it.
+The route is stored as a list of 2-tuples (x, y) in meters on the current nuScenes map.
+The data is recorded at approximately 50Hz.
+For 3% of the scenes this data is not available as the drivers were not following any route.
+
+## CAN bus messages
+Here we list the raw CAN bus messages.
+We store each type of message in a separate file for each scene (e.g. `scene-0001_ms_imu.json`).
+Messages are stored in chronological order in the above file.
+Each message has the following field:
+- utime: \[1\] The integer timestamp in microseconds that the actual measurement took place (e.g. 1531883549954657).
+For the *Zoe Sensors* and *Zoe Vehicle Info* messages this info is not directly available and is therefore replaced by the timestamp when the CAN bus message was received.
+
+### IMU
+Frequency: 100Hz
+
+Format: `scene_0001_imu.json`
+
+- linear_accel: \[3\] Acceleration vector (x, y, z) in the IMU frame in m/s/s.
+- q: \[4\] Quaternion that transforms from IMU coordinates to a fixed reference frame. The yaw of this reference frame is arbitrary, determined by the IMU. However, the x-y plane of the reference frame is perpendicular to gravity, and z points up.
+- rotation_rate: \[3\] Angular velocity in rad/s around the x, y, and z axes, respectively, in the IMU coordinate frame.
+
+### Pose
+Frequency: 50Hz
+
+Format: `scene_0001_pose.json`
+
+The current pose of the ego vehicle, sampled at 50Hz.
+- accel: \[3\] Acceleration vector in the ego vehicle frame in m/s/s.
+- orientation: \[4\] The rotation vector in the ego vehicle frame.
+- pos: \[3\] The position (x, y, z) in meters in the global frame. This is identical to the [nuScenes ego pose](https://github.com/nutonomy/nuscenes-devkit/blob/master/docs/schema_nuscenes.md#ego_pose), but sampled at a higher frequency.
+- rotation_rate: \[3\] The angular velocity vector of the vehicle in rad/s. This is expressed in the ego vehicle frame.
+- vel: \[3\] The velocity in m/s, expressed in the ego vehicle frame.
+
+### Steer Angle Feedback
+Frequency: 100Hz
+
+Format: `scene_0001_steeranglefeedback.json`
+
+- value: \[1\] Steering angle feedback in radians in range \[-7.7, 6.3\]. 0 indicates no steering, positive values indicate left turns, negative values right turns.
+
+### Vehicle Monitor
+Frequency: 2Hz
+
+Format: `scene_0001_vehicle_monitor.json`
+
+- available_distance: \[1\] Available vehicle range given the current battery level in kilometers.
+- battery_level: \[1\] Current battery level in range \[0, 100\].
+- brake: \[1\] Braking pressure in bar. An integer in range \[0, 126\].
+- brake_switch: \[1\] Brake switch as an integer, 1 (pedal not pressed), 2 (pedal pressed) or 3 (pedal confirmed pressed).
+- gear_position: \[1\] The gear position as an integer, typically 0 (parked) or 7 (driving).
+- left_signal: \[1\] Left turning signal as an integer, 0 (inactive) or 1 (active).
+- rear_left_rpm: \[1\] Rear left brake speed in revolutions per minute.
+- rear_right_rpm: \[1\] Rear right brake speed in revolutions per minute.
+- right_signal: \[1\] Right turning signal as an integer, 0 (inactive) or 1 (active).
+- steering: \[1\] Steering angle in degrees at a resolution of 0.1 in range \[-780, 779.9\].
+- steering_speed: \[1\] Steering speed in degrees per second in range \[-465, 393\].
+- throttle: \[1\] Throttle pedal position as an integer in range \[0, 1000\].
+- vehicle_speed: \[1\] Vehicle speed in km/h at a resolution of 0.01.
+- yaw_rate: \[1\] Yaw turning rate in degrees per second at a resolution of 0.1.
+
+### Zoe Sensors
+Frequency: 794-973Hz
+
+Format: `scene_0001_zoesensors.json`
+
+- brake_sensor: \[1\] Vehicle break sensor in range \[0.375,0.411\]. High values indicate breaking.
+- steering_sensor: \[1\] Vehicle steering sensor. Same as vehicle_monitor.steering.
+- throttle_sensor: \[1\] Vehicle throttle sensor. Same as vehicle_monitor.throttle.
+
+### Zoe Vehicle Info
+Frequency: 100Hz
+
+Format: `scene_0001_zoe_veh_info.json`
+
+- FL_wheel_speed: \[1\] Front left wheel speed. The unit is rounds per minute with a resolution of 0.0417rpm.
+- FR_wheel_speed: \[1\] Front right wheel speed. The unit is rounds per minute with a resolution of 0.0417rpm.
+- RL_wheel_speed: \[1\] Rear left wheel speed. The unit is rounds per minute with a resolution of 0.0417rpm.
+- RR_wheel_speed: \[1\] Rear right wheel speed. The unit is rounds per minute with a resolution of 0.0417rpm.
+- left_solar: \[1\] Zoe vehicle left solar sensor value as an integer.
+- longitudinal_accel: \[1\] Longitudinal acceleration in meters per second squared at a resolution of 0.05.
+- meanEffTorque: \[1\] Actual torque delivered by the engine in Newton meters at a resolution of 0.5. Values in range \[-400, 1647\], offset by -400.
+- odom: \[1\] Odometry distance travelled modulo vehicle circumference. Values are in centimeters in range \[0, 124\]. Note that due to the low sampling frequency these values are only useful at low speeds.
+- odom_speed: \[1\] Vehicle speed in km/h. Values in range \[0, 60\]. For a higher sampling rate refer to the pose.vel message.
+- pedal_cc: \[1\] Throttle value. Values in range \[0, 1000\].
+- regen: \[1\] Coasting throttle. Values in range \[0, 100\].
+- requestedTorqueAfterProc: \[1\] Input torque requested in Newton meters at a resolution of 0.5. Values in range \[-400, 1647\], offset by -400.
+- right_solar: \[1\] Zoe vehicle right solar sensor value as an integer.
+- steer_corrected: \[1\] Steering angle (steer_raw) corrected by an offset (steer_offset_can).
+- steer_offset_can: \[1\] Steering angle offset in degrees, typically -12.6.
+- steer_raw: \[1\] Raw steering angle in degrees.
+- transversal_accel: \[1\] Transversal acceleration in g at a resolution of 0.004.
\ No newline at end of file
diff --git a/python-sdk/nuscenes/can_bus/can_bus_api.py b/python-sdk/nuscenes/can_bus/can_bus_api.py
new file mode 100644
index 0000000..8b13e5a
--- /dev/null
+++ b/python-sdk/nuscenes/can_bus/can_bus_api.py
@@ -0,0 +1,263 @@
+# nuScenes dev-kit.
+# Code written by Holger Caesar, 2020.
+
+import argparse
+import json
+import os
+import re
+import warnings
+from typing import Dict, List, Tuple, Union
+
+import matplotlib.pyplot as plt
+import numpy as np
+import scipy.spatial.distance as scipy_dist
+
+
+class NuScenesCanBus:
+ """
+ This class encapsulates the files of the nuScenes CAN bus expansion set.
+ It can be used to access the baseline navigation route as well as the various CAN bus messages.
+ """
+
+ def __init__(self,
+ dataroot: str = '/data/sets/nuscenes',
+ max_misalignment: float = 5.0):
+ """
+ Initialize the nuScenes CAN bus API.
+ :param dataroot: The nuScenes directory where the "can" folder is located.
+ :param max_misalignment: Maximum distance in m that any pose is allowed to be away from the route.
+ """
+ # Check that folder exists.
+ self.can_dir = os.path.join(dataroot, 'can_bus')
+ if not os.path.isdir(self.can_dir):
+ raise Exception('Error: CAN bus directory not found: %s. Please download it from '
+ 'https://www.nuscenes.org/download' % self.can_dir)
+
+ # Define blacklist for scenes where route and ego pose are not aligned.
+ if max_misalignment == 5.0:
+ # Default settings are hard-coded for performance reasons.
+ self.route_blacklist = [
+ 71, 73, 74, 75, 76, 85, 100, 101, 106, 107, 108, 109, 110, 112, 113, 114, 115, 116, 117, 118, 119,
+ 261, 262, 263, 264, 276, 302, 303, 304, 305, 306, 334, 388, 389, 390, 436, 499, 500, 501, 502, 504,
+ 505, 506, 507, 508, 509, 510, 511, 512, 513, 514, 515, 517, 518, 547, 548, 549, 550, 551, 556, 557,
+ 558, 559, 560, 561, 562, 563, 564, 565, 730, 731, 733, 734, 735, 736, 737, 738, 778, 780, 781, 782,
+ 783, 784, 904, 905, 1073, 1074
+ ]
+ else:
+ misaligned = self.list_misaligned_routes()
+ self.route_blacklist = [int(s[-4:]) for s in misaligned]
+
+ # Define blacklist for scenes without CAN bus data.
+ self.can_blacklist = [
+ 161, 162, 163, 164, 165, 166, 167, 168, 170, 171, 172, 173, 174, 175, 176, 309, 310, 311, 312, 313, 314
+ ]
+
+ # Define all messages.
+ self.can_messages = [
+ 'ms_imu', 'pose', 'steeranglefeedback', 'vehicle_monitor', 'zoesensors', 'zoe_veh_info'
+ ]
+ self.derived_messages = [
+ 'meta', 'route'
+ ]
+ self.all_messages = self.can_messages + self.derived_messages
+
+ def print_all_message_stats(self,
+ scene_name: str,
+ print_full: bool = False) -> None:
+ """
+ Prints the meta stats for each CAN message type of a particular scene.
+ :param scene_name: The name of the scene, e.g. scene-0001.
+ :param print_full: Whether to show all stats for all message types in the scene.
+ """
+ all_messages = {}
+ for message_name in self.can_messages:
+ messages = self.get_messages(scene_name, 'meta')
+ all_messages[message_name] = messages
+
+ if print_full:
+ print(json.dumps(all_messages, indent=2))
+ else:
+ partial_messages = {message: list(stats.keys()) for message, stats in all_messages.items()}
+ print(json.dumps(partial_messages, indent=2))
+
+ def print_message_stats(self,
+ scene_name: str,
+ message_name: str) -> None:
+ """
+ Prints the meta stats for a particular scene and message name.
+ :param scene_name: The name of the scene, e.g. scene-0001.
+ :param message_name: The name of the CAN bus message type, e.g. ms_imu.
+ """
+ assert message_name != 'meta', 'Error: Cannot print stats for meta '
+ messages = self.get_messages(scene_name, 'meta')
+ print(json.dumps(messages[message_name], indent=2))
+
+ def plot_baseline_route(self,
+ scene_name: str,
+ out_path: str = None) -> None:
+ """
+ Plot the baseline route and the closest ego poses for a scene.
+ Note that the plot is not closed and should be closed by the caller.
+ :param scene_name: The name of the scene, e.g. scene-0001.
+ :param out_path: Output path to dump the plot to. Ignored if None.
+ """
+ # Get data.
+ route, pose = self.get_pose_and_route(scene_name)
+
+ # Visualize.
+ plt.figure()
+ plt.plot(route[:, 0], route[:, 1])
+ plt.plot(pose[:, 0], pose[:, 1])
+ plt.plot(pose[0, 0], pose[0, 1], 'rx', markersize=10)
+ plt.legend(('Route', 'Pose', 'Start'))
+ plt.xlabel('Map coordinate x in m')
+ plt.ylabel('Map coordinate y in m')
+ if out_path is not None:
+ plt.savefig(out_path)
+ plt.show()
+
+ def plot_message_data(self,
+ scene_name: str,
+ message_name: str,
+ key_name: str,
+ dimension: int = 0,
+ out_path: str = None,
+ plot_format: str = 'b-') -> None:
+ """
+ Plot the data for a particular message.
+ :param scene_name: The name of the scene, e.g. scene-0001.
+ :param message_name: The name of the CAN bus message type, e.g. ms_imu.
+ :param key_name: The name of the key in the message, e.g. linear_accel.
+ :param dimension: Which dimension to render (default is 0). If -1, we render the norm of the values.
+ :param out_path: Output path to dump the plot to. Ignored if None.
+ :param plot_format: A string that describes a matplotlib format, by default 'b-' for a blue dashed line.
+ """
+ # Get data.
+ messages = self.get_messages(scene_name, message_name)
+ data = np.array([m[key_name] for m in messages])
+ utimes = np.array([m['utime'] for m in messages])
+
+ # Convert utimes to seconds and subtract the minimum.
+ utimes = (utimes - min(utimes)) / 1e6
+
+ # Take selected column.
+ if dimension == -1:
+ data = np.linalg.norm(data, axis=1)
+ elif dimension == 0:
+ pass
+ elif data.ndim > 1 and data.shape[1] >= dimension + 1:
+ data = data[:, dimension]
+ else:
+ raise Exception('Error: Invalid dimension %d for key "%s"!' % (dimension, key_name))
+
+ # Render.
+ plt.figure()
+ plt.plot(utimes, data, plot_format, markersize=1)
+ plt.title(scene_name)
+ plt.xlabel('Scene time in s')
+ plt.ylabel('%s - %s' % (message_name, key_name))
+ if out_path is not None:
+ plt.savefig(out_path)
+ plt.show()
+
+ def list_misaligned_routes(self,
+ max_misalignment: float = 5.0) -> List[str]:
+ """
+ Print all scenes where ego poses and baseline route are misaligned.
+ We use the Hausdorff distance to decide on the misalignment.
+ :param max_misalignment: Maximum distance in m that any pose is allowed to be away from the route.
+ :return: A list of all the names of misaligned scenes.
+ """
+ # Get all scenes.
+ all_files = os.listdir(self.can_dir)
+ scene_list = list(np.unique([f[:10] for f in all_files])) # Get the scene name from e.g. scene-0123_meta.json.
+
+ # Init.
+ misaligned = []
+
+ for scene_name in scene_list:
+ # Get data.
+ route, pose = self.get_pose_and_route(scene_name, print_warnings=False)
+
+ # Filter by Hausdorff distance.
+ dists = scipy_dist.cdist(pose, route)
+ max_dist = np.max(np.min(dists, axis=1))
+ if max_dist > max_misalignment:
+ misaligned.append(scene_name)
+
+ return misaligned
+
+ def get_pose_and_route(self,
+ scene_name: str,
+ print_warnings: bool = True) -> Tuple[np.ndarray, np.ndarray]:
+ """
+ Return the route and pose for a scene as numpy arrays.
+ :param scene_name: The name of the scene, e.g. scene-0001.
+ :param print_warnings: Whether to print out warnings if the requested data is not available or not reliable.
+ :return: A tuple of route and pose arrays (each point is 2d).
+ """
+ # Load baseline route and poses.
+ route = self.get_messages(scene_name, 'route', print_warnings=print_warnings)
+ pose = self.get_messages(scene_name, 'pose', print_warnings=print_warnings)
+
+ # Convert to numpy format.
+ route = np.asarray(route)
+ pose = np.asarray([p['pos'][:2] for p in pose])
+
+ return route, pose
+
+ def get_messages(self,
+ scene_name: str,
+ message_name: str,
+ print_warnings: bool = True) -> Union[List[Dict], Dict]:
+ """
+ Retrieve the messages for a particular scene and message type.
+ :param scene_name: The name of the scene, e.g. scene-0001.
+ :param message_name: The name of the CAN bus message type, e.g. ms_imu.
+ :param print_warnings: Whether to print out warnings if the requested data is not available or not reliable.
+ :return: The raw contents of the message type, either a dict (for `meta`) or a list of messages.
+ """
+ # Check inputs. Scene names must be in the format scene-0123.
+ assert re.match('^scene-\\d\\d\\d\\d$', scene_name)
+ assert message_name in self.all_messages, 'Error: Invalid CAN bus message name: %s' % message_name
+
+ # Check for data issues.
+ scene_id = int(scene_name[-4:])
+ if scene_id in self.can_blacklist:
+ # Check for logs that have no CAN bus data.
+ raise Exception('Error: %s does not have any CAN bus data!' % scene_name)
+ elif print_warnings:
+ # Print warnings for scenes that are known to have bad data.
+ if message_name == 'route':
+ if scene_id in self.route_blacklist:
+ warnings.warn('Warning: %s is not well aligned with the baseline route!' % scene_name)
+ elif message_name == 'vehicle_monitor':
+ if scene_id in [419]:
+ warnings.warn('Warning: %s does not have any vehicle_monitor messages!')
+
+ # Load messages.
+ message_path = os.path.join(self.can_dir, '%s_%s.json' % (scene_name, message_name))
+ with open(message_path, 'r') as f:
+ messages = json.load(f)
+ assert type(messages) in [list, dict]
+
+ # Rename all dict keys to lower-case.
+ if isinstance(messages, dict):
+ messages = {k.lower(): v for (k, v) in messages.items()}
+
+ return messages
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser(description='Plot stats for the CAN bus API.')
+ parser.add_argument('--dataroot', type=str, default='/data/sets/nuscenes')
+ parser.add_argument('--scene_name', type=str, default='scene-0028')
+ parser.add_argument('--message_name', type=str, default='steeranglefeedback')
+ parser.add_argument('--key_name', type=str, default='value')
+ args = parser.parse_args()
+
+ nusc_can = NuScenesCanBus(dataroot=args.dataroot)
+ if args.message_name == 'route+pose':
+ nusc_can.plot_baseline_route(args.scene_name)
+ else:
+ nusc_can.plot_message_data(args.scene_name, args.message_name, args.key_name)
diff --git a/python-sdk/nuscenes/eval/__init__.py b/python-sdk/nuscenes/eval/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/python-sdk/nuscenes/eval/common/__init__.py b/python-sdk/nuscenes/eval/common/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/python-sdk/nuscenes/eval/common/config.py b/python-sdk/nuscenes/eval/common/config.py
new file mode 100644
index 0000000..13ff104
--- /dev/null
+++ b/python-sdk/nuscenes/eval/common/config.py
@@ -0,0 +1,37 @@
+# nuScenes dev-kit.
+# Code written by Holger Caesar, 2019.
+
+import json
+import os
+from typing import Union
+
+from nuscenes.eval.detection.data_classes import DetectionConfig
+from nuscenes.eval.tracking.data_classes import TrackingConfig
+
+
+def config_factory(configuration_name: str) -> Union[DetectionConfig, TrackingConfig]:
+ """
+ Creates a *Config instance that can be used to initialize a *Eval instance, where * stands for Detection/Tracking.
+ Note that this only works if the config file is located in the nuscenes/eval/common/configs folder.
+ :param configuration_name: Name of desired configuration in eval_detection_configs.
+ :return: *Config instance.
+ """
+ # Check if config exists.
+ tokens = configuration_name.split('_')
+ assert len(tokens) > 1, 'Error: Configuration name must be have prefix "detection_" or "tracking_"!'
+ task = tokens[0]
+ this_dir = os.path.dirname(os.path.abspath(__file__))
+ cfg_path = os.path.join(this_dir, '..', task, 'configs', '%s.json' % configuration_name)
+ assert os.path.exists(cfg_path), 'Requested unknown configuration {}'.format(configuration_name)
+
+ # Load config file and deserialize it.
+ with open(cfg_path, 'r') as f:
+ data = json.load(f)
+ if task == 'detection':
+ cfg = DetectionConfig.deserialize(data)
+ elif task == 'tracking':
+ cfg = TrackingConfig.deserialize(data)
+ else:
+ raise Exception('Error: Invalid config file name: %s' % configuration_name)
+
+ return cfg
diff --git a/python-sdk/nuscenes/eval/common/data_classes.py b/python-sdk/nuscenes/eval/common/data_classes.py
new file mode 100644
index 0000000..6b2f212
--- /dev/null
+++ b/python-sdk/nuscenes/eval/common/data_classes.py
@@ -0,0 +1,149 @@
+# nuScenes dev-kit.
+# Code written by Holger Caesar & Oscar Beijbom, 2019.
+
+import abc
+from collections import defaultdict
+from typing import List, Tuple, Union
+
+import numpy as np
+
+
+class EvalBox(abc.ABC):
+ """ Abstract base class for data classes used during detection evaluation. Can be a prediction or ground truth."""
+
+ def __init__(self,
+ sample_token: str = "",
+ translation: Tuple[float, float, float] = (0, 0, 0),
+ size: Tuple[float, float, float] = (0, 0, 0),
+ rotation: Tuple[float, float, float, float] = (0, 0, 0, 0),
+ velocity: Tuple[float, float] = (0, 0),
+ ego_translation: Tuple[float, float, float] = (0, 0, 0), # Translation to ego vehicle in meters.
+ num_pts: int = -1): # Nbr. LIDAR or RADAR inside the box. Only for gt boxes.
+
+ # Assert data for shape and NaNs.
+ assert type(sample_token) == str, 'Error: sample_token must be a string!'
+
+ assert len(translation) == 3, 'Error: Translation must have 3 elements!'
+ assert not np.any(np.isnan(translation)), 'Error: Translation may not be NaN!'
+
+ assert len(size) == 3, 'Error: Size must have 3 elements!'
+ assert not np.any(np.isnan(size)), 'Error: Size may not be NaN!'
+
+ assert len(rotation) == 4, 'Error: Rotation must have 4 elements!'
+ assert not np.any(np.isnan(rotation)), 'Error: Rotation may not be NaN!'
+
+ # Velocity can be NaN from our database for certain annotations.
+ assert len(velocity) == 2, 'Error: Velocity must have 2 elements!'
+
+ assert len(ego_translation) == 3, 'Error: Translation must have 3 elements!'
+ assert not np.any(np.isnan(ego_translation)), 'Error: Translation may not be NaN!'
+
+ assert type(num_pts) == int, 'Error: num_pts must be int!'
+ assert not np.any(np.isnan(num_pts)), 'Error: num_pts may not be NaN!'
+
+ # Assign.
+ self.sample_token = sample_token
+ self.translation = translation
+ self.size = size
+ self.rotation = rotation
+ self.velocity = velocity
+ self.ego_translation = ego_translation
+ self.num_pts = num_pts
+
+ @property
+ def ego_dist(self) -> float:
+ """ Compute the distance from this box to the ego vehicle in 2D. """
+ return np.sqrt(np.sum(np.array(self.ego_translation[:2]) ** 2))
+
+ def __repr__(self):
+ return str(self.serialize())
+
+ @abc.abstractmethod
+ def serialize(self) -> dict:
+ pass
+
+ @classmethod
+ @abc.abstractmethod
+ def deserialize(cls, content: dict):
+ pass
+
+
+EvalBoxType = Union['DetectionBox', 'TrackingBox']
+
+
+class EvalBoxes:
+ """ Data class that groups EvalBox instances by sample. """
+
+ def __init__(self):
+ """
+ Initializes the EvalBoxes for GT or predictions.
+ """
+ self.boxes = defaultdict(list)
+
+ def __repr__(self):
+ return "EvalBoxes with {} boxes across {} samples".format(len(self.all), len(self.sample_tokens))
+
+ def __getitem__(self, item) -> List[EvalBoxType]:
+ return self.boxes[item]
+
+ def __eq__(self, other):
+ if not set(self.sample_tokens) == set(other.sample_tokens):
+ return False
+ for token in self.sample_tokens:
+ if not len(self[token]) == len(other[token]):
+ return False
+ for box1, box2 in zip(self[token], other[token]):
+ if box1 != box2:
+ return False
+ return True
+
+ def __len__(self):
+ return len(self.boxes)
+
+ @property
+ def all(self) -> List[EvalBoxType]:
+ """ Returns all EvalBoxes in a list. """
+ ab = []
+ for sample_token in self.sample_tokens:
+ ab.extend(self[sample_token])
+ return ab
+
+ @property
+ def sample_tokens(self) -> List[str]:
+ """ Returns a list of all keys. """
+ return list(self.boxes.keys())
+
+ def add_boxes(self, sample_token: str, boxes: List[EvalBoxType]) -> None:
+ """ Adds a list of boxes. """
+ self.boxes[sample_token].extend(boxes)
+
+ def serialize(self) -> dict:
+ """ Serialize instance into json-friendly format. """
+ return {key: [box.serialize() for box in boxes] for key, boxes in self.boxes.items()}
+
+ @classmethod
+ def deserialize(cls, content: dict, box_cls):
+ """
+ Initialize from serialized content.
+ :param content: A dictionary with the serialized content of the box.
+ :param box_cls: The class of the boxes, DetectionBox or TrackingBox.
+ """
+ eb = cls()
+ for sample_token, boxes in content.items():
+ eb.add_boxes(sample_token, [box_cls.deserialize(box) for box in boxes])
+ return eb
+
+
+class MetricData(abc.ABC):
+ """ Abstract base class for the *MetricData classes specific to each task. """
+
+ @abc.abstractmethod
+ def serialize(self):
+ """ Serialize instance into json-friendly format. """
+ pass
+
+ @classmethod
+ @abc.abstractmethod
+ def deserialize(cls, content: dict):
+ """ Initialize from serialized content. """
+ pass
diff --git a/python-sdk/nuscenes/eval/common/loaders.py b/python-sdk/nuscenes/eval/common/loaders.py
new file mode 100644
index 0000000..8e70bee
--- /dev/null
+++ b/python-sdk/nuscenes/eval/common/loaders.py
@@ -0,0 +1,284 @@
+# nuScenes dev-kit.
+# Code written by Oscar Beijbom, 2019.
+
+import json
+from typing import Dict, Tuple
+
+import numpy as np
+import tqdm
+from pyquaternion import Quaternion
+
+from nuscenes import NuScenes
+from nuscenes.eval.common.data_classes import EvalBoxes
+from nuscenes.eval.detection.data_classes import DetectionBox
+from nuscenes.eval.detection.utils import category_to_detection_name
+from nuscenes.eval.tracking.data_classes import TrackingBox
+from nuscenes.eval.tracking.utils import category_to_tracking_name
+from nuscenes.utils.data_classes import Box
+from nuscenes.utils.geometry_utils import points_in_box
+from nuscenes.utils.splits import create_splits_scenes
+
+
+def load_prediction(result_path: str, max_boxes_per_sample: int, box_cls, verbose: bool = False) \
+ -> Tuple[EvalBoxes, Dict]:
+ """
+ Loads object predictions from file.
+ :param result_path: Path to the .json result file provided by the user.
+ :param max_boxes_per_sample: Maximim number of boxes allowed per sample.
+ :param box_cls: Type of box to load, e.g. DetectionBox or TrackingBox.
+ :param verbose: Whether to print messages to stdout.
+ :return: The deserialized results and meta data.
+ """
+
+ # Load from file and check that the format is correct.
+ with open(result_path) as f:
+ data = json.load(f)
+ assert 'results' in data, 'Error: No field `results` in result file. Please note that the result format changed.' \
+ 'See https://www.nuscenes.org/object-detection for more information.'
+
+ # Deserialize results and get meta data.
+ all_results = EvalBoxes.deserialize(data['results'], box_cls)
+ meta = data['meta']
+ if verbose:
+ print("Loaded results from {}. Found detections for {} samples."
+ .format(result_path, len(all_results.sample_tokens)))
+
+ # Check that each sample has no more than x predicted boxes.
+ for sample_token in all_results.sample_tokens:
+ assert len(all_results.boxes[sample_token]) <= max_boxes_per_sample, \
+ "Error: Only <= %d boxes per sample allowed!" % max_boxes_per_sample
+
+ return all_results, meta
+
+
+def load_gt(nusc: NuScenes, eval_split: str, box_cls, verbose: bool = False) -> EvalBoxes:
+ """
+ Loads ground truth boxes from DB.
+ :param nusc: A NuScenes instance.
+ :param eval_split: The evaluation split for which we load GT boxes.
+ :param box_cls: Type of box to load, e.g. DetectionBox or TrackingBox.
+ :param verbose: Whether to print messages to stdout.
+ :return: The GT boxes.
+ """
+ # Init.
+ if box_cls == DetectionBox:
+ attribute_map = {a['token']: a['name'] for a in nusc.attribute}
+
+ if verbose:
+ print('Loading annotations for {} split from nuScenes version: {}'.format(eval_split, nusc.version))
+ # Read out all sample_tokens in DB.
+ sample_tokens_all = [s['token'] for s in nusc.sample]
+ assert len(sample_tokens_all) > 0, "Error: Database has no samples!"
+
+ # Only keep samples from this split.
+ splits = create_splits_scenes()
+
+ # Check compatibility of split with nusc_version.
+ version = nusc.version
+ if eval_split in {'train', 'val', 'train_detect', 'train_track'}:
+ assert version.endswith('trainval'), \
+ 'Error: Requested split {} which is not compatible with NuScenes version {}'.format(eval_split, version)
+ elif eval_split in {'mini_train', 'mini_val'}:
+ assert version.endswith('mini'), \
+ 'Error: Requested split {} which is not compatible with NuScenes version {}'.format(eval_split, version)
+ elif eval_split == 'test':
+ assert version.endswith('test'), \
+ 'Error: Requested split {} which is not compatible with NuScenes version {}'.format(eval_split, version)
+ else:
+ raise ValueError('Error: Requested split {} which this function cannot map to the correct NuScenes version.'
+ .format(eval_split))
+
+ if eval_split == 'test':
+ # Check that you aren't trying to cheat :).
+ assert len(nusc.sample_annotation) > 0, \
+ 'Error: You are trying to evaluate on the test set but you do not have the annotations!'
+
+ sample_tokens = []
+ for sample_token in sample_tokens_all:
+ scene_token = nusc.get('sample', sample_token)['scene_token']
+ scene_record = nusc.get('scene', scene_token)
+ if scene_record['name'] in splits[eval_split]:
+ sample_tokens.append(sample_token)
+
+ all_annotations = EvalBoxes()
+
+ # Load annotations and filter predictions and annotations.
+ tracking_id_set = set()
+ for sample_token in tqdm.tqdm(sample_tokens, leave=verbose):
+
+ sample = nusc.get('sample', sample_token)
+ sample_annotation_tokens = sample['anns']
+
+ sample_boxes = []
+ for sample_annotation_token in sample_annotation_tokens:
+
+ sample_annotation = nusc.get('sample_annotation', sample_annotation_token)
+ if box_cls == DetectionBox:
+ # Get label name in detection task and filter unused labels.
+ detection_name = category_to_detection_name(sample_annotation['category_name'])
+ if detection_name is None:
+ continue
+
+ # Get attribute_name.
+ attr_tokens = sample_annotation['attribute_tokens']
+ attr_count = len(attr_tokens)
+ if attr_count == 0:
+ attribute_name = ''
+ elif attr_count == 1:
+ attribute_name = attribute_map[attr_tokens[0]]
+ else:
+ raise Exception('Error: GT annotations must not have more than one attribute!')
+
+ sample_boxes.append(
+ box_cls(
+ sample_token=sample_token,
+ translation=sample_annotation['translation'],
+ size=sample_annotation['size'],
+ rotation=sample_annotation['rotation'],
+ velocity=nusc.box_velocity(sample_annotation['token'])[:2],
+ num_pts=sample_annotation['num_lidar_pts'] + sample_annotation['num_radar_pts'],
+ detection_name=detection_name,
+ detection_score=-1.0, # GT samples do not have a score.
+ attribute_name=attribute_name
+ )
+ )
+ elif box_cls == TrackingBox:
+ # Use nuScenes token as tracking id.
+ tracking_id = sample_annotation['instance_token']
+ tracking_id_set.add(tracking_id)
+
+ # Get label name in detection task and filter unused labels.
+ tracking_name = category_to_tracking_name(sample_annotation['category_name'])
+ if tracking_name is None:
+ continue
+
+ sample_boxes.append(
+ box_cls(
+ sample_token=sample_token,
+ translation=sample_annotation['translation'],
+ size=sample_annotation['size'],
+ rotation=sample_annotation['rotation'],
+ velocity=nusc.box_velocity(sample_annotation['token'])[:2],
+ num_pts=sample_annotation['num_lidar_pts'] + sample_annotation['num_radar_pts'],
+ tracking_id=tracking_id,
+ tracking_name=tracking_name,
+ tracking_score=-1.0 # GT samples do not have a score.
+ )
+ )
+ else:
+ raise NotImplementedError('Error: Invalid box_cls %s!' % box_cls)
+
+ all_annotations.add_boxes(sample_token, sample_boxes)
+
+ if verbose:
+ print("Loaded ground truth annotations for {} samples.".format(len(all_annotations.sample_tokens)))
+
+ return all_annotations
+
+
+def add_center_dist(nusc: NuScenes,
+ eval_boxes: EvalBoxes):
+ """
+ Adds the cylindrical (xy) center distance from ego vehicle to each box.
+ :param nusc: The NuScenes instance.
+ :param eval_boxes: A set of boxes, either GT or predictions.
+ :return: eval_boxes augmented with center distances.
+ """
+ for sample_token in eval_boxes.sample_tokens:
+ sample_rec = nusc.get('sample', sample_token)
+ sd_record = nusc.get('sample_data', sample_rec['data']['LIDAR_TOP'])
+ pose_record = nusc.get('ego_pose', sd_record['ego_pose_token'])
+
+ for box in eval_boxes[sample_token]:
+ # Both boxes and ego pose are given in global coord system, so distance can be calculated directly.
+ # Note that the z component of the ego pose is 0.
+ ego_translation = (box.translation[0] - pose_record['translation'][0],
+ box.translation[1] - pose_record['translation'][1],
+ box.translation[2] - pose_record['translation'][2])
+ if isinstance(box, DetectionBox) or isinstance(box, TrackingBox):
+ box.ego_translation = ego_translation
+ else:
+ raise NotImplementedError
+
+ return eval_boxes
+
+
+def filter_eval_boxes(nusc: NuScenes,
+ eval_boxes: EvalBoxes,
+ max_dist: Dict[str, float],
+ verbose: bool = False) -> EvalBoxes:
+ """
+ Applies filtering to boxes. Distance, bike-racks and points per box.
+ :param nusc: An instance of the NuScenes class.
+ :param eval_boxes: An instance of the EvalBoxes class.
+ :param max_dist: Maps the detection name to the eval distance threshold for that class.
+ :param verbose: Whether to print to stdout.
+ """
+ # Retrieve box type for detectipn/tracking boxes.
+ class_field = _get_box_class_field(eval_boxes)
+
+ # Accumulators for number of filtered boxes.
+ total, dist_filter, point_filter, bike_rack_filter = 0, 0, 0, 0
+ for ind, sample_token in enumerate(eval_boxes.sample_tokens):
+
+ # Filter on distance first.
+ total += len(eval_boxes[sample_token])
+ eval_boxes.boxes[sample_token] = [box for box in eval_boxes[sample_token] if
+ box.ego_dist < max_dist[box.__getattribute__(class_field)]]
+ dist_filter += len(eval_boxes[sample_token])
+
+ # Then remove boxes with zero points in them. Eval boxes have -1 points by default.
+ eval_boxes.boxes[sample_token] = [box for box in eval_boxes[sample_token] if not box.num_pts == 0]
+ point_filter += len(eval_boxes[sample_token])
+
+ # Perform bike-rack filtering.
+ sample_anns = nusc.get('sample', sample_token)['anns']
+ bikerack_recs = [nusc.get('sample_annotation', ann) for ann in sample_anns if
+ nusc.get('sample_annotation', ann)['category_name'] == 'static_object.bicycle_rack']
+ bikerack_boxes = [Box(rec['translation'], rec['size'], Quaternion(rec['rotation'])) for rec in bikerack_recs]
+ filtered_boxes = []
+ for box in eval_boxes[sample_token]:
+ if box.__getattribute__(class_field) in ['bicycle', 'motorcycle']:
+ in_a_bikerack = False
+ for bikerack_box in bikerack_boxes:
+ if np.sum(points_in_box(bikerack_box, np.expand_dims(np.array(box.translation), axis=1))) > 0:
+ in_a_bikerack = True
+ if not in_a_bikerack:
+ filtered_boxes.append(box)
+ else:
+ filtered_boxes.append(box)
+
+ eval_boxes.boxes[sample_token] = filtered_boxes
+ bike_rack_filter += len(eval_boxes.boxes[sample_token])
+
+ if verbose:
+ print("=> Original number of boxes: %d" % total)
+ print("=> After distance based filtering: %d" % dist_filter)
+ print("=> After LIDAR points based filtering: %d" % point_filter)
+ print("=> After bike rack filtering: %d" % bike_rack_filter)
+
+ return eval_boxes
+
+
+def _get_box_class_field(eval_boxes: EvalBoxes) -> str:
+ """
+ Retrieve the name of the class field in the boxes.
+ This parses through all boxes until it finds a valid box.
+ If there are no valid boxes, this function throws an exception.
+ :param eval_boxes: The EvalBoxes used for evaluation.
+ :return: The name of the class field in the boxes, e.g. detection_name or tracking_name.
+ """
+ assert len(eval_boxes.boxes) > 0
+ box = None
+ for val in eval_boxes.boxes.values():
+ if len(val) > 0:
+ box = val[0]
+ break
+ if isinstance(box, DetectionBox):
+ class_field = 'detection_name'
+ elif isinstance(box, TrackingBox):
+ class_field = 'tracking_name'
+ else:
+ raise Exception('Error: Invalid box type: %s' % box)
+
+ return class_field
diff --git a/python-sdk/nuscenes/eval/common/render.py b/python-sdk/nuscenes/eval/common/render.py
new file mode 100644
index 0000000..b6bb99b
--- /dev/null
+++ b/python-sdk/nuscenes/eval/common/render.py
@@ -0,0 +1,68 @@
+# nuScenes dev-kit.
+# Code written by Holger Caesar, Varun Bankiti, and Alex Lang, 2019.
+
+from typing import Any
+
+import matplotlib.pyplot as plt
+
+Axis = Any
+
+
+def setup_axis(xlabel: str = None,
+ ylabel: str = None,
+ xlim: int = None,
+ ylim: int = None,
+ title: str = None,
+ min_precision: float = None,
+ min_recall: float = None,
+ ax: Axis = None,
+ show_spines: str = 'none'):
+ """
+ Helper method that sets up the axis for a plot.
+ :param xlabel: x label text.
+ :param ylabel: y label text.
+ :param xlim: Upper limit for x axis.
+ :param ylim: Upper limit for y axis.
+ :param title: Axis title.
+ :param min_precision: Visualize minimum precision as horizontal line.
+ :param min_recall: Visualize minimum recall as vertical line.
+ :param ax: (optional) an existing axis to be modified.
+ :param show_spines: Whether to show axes spines, set to 'none' by default.
+ :return: The axes object.
+ """
+ if ax is None:
+ ax = plt.subplot()
+
+ ax.get_xaxis().tick_bottom()
+ ax.tick_params(labelsize=16)
+ ax.get_yaxis().tick_left()
+
+ # Hide the selected axes spines.
+ if show_spines in ['bottomleft', 'none']:
+ ax.spines['top'].set_visible(False)
+ ax.spines['right'].set_visible(False)
+
+ if show_spines == 'none':
+ ax.spines['bottom'].set_visible(False)
+ ax.spines['left'].set_visible(False)
+ elif show_spines in ['all']:
+ pass
+ else:
+ raise NotImplementedError
+
+ if title is not None:
+ ax.set_title(title, size=24)
+ if xlabel is not None:
+ ax.set_xlabel(xlabel, size=16)
+ if ylabel is not None:
+ ax.set_ylabel(ylabel, size=16)
+ if xlim is not None:
+ ax.set_xlim(0, xlim)
+ if ylim is not None:
+ ax.set_ylim(0, ylim)
+ if min_recall is not None:
+ ax.axvline(x=min_recall, linestyle='--', color=(0, 0, 0, 0.3))
+ if min_precision is not None:
+ ax.axhline(y=min_precision, linestyle='--', color=(0, 0, 0, 0.3))
+
+ return ax
diff --git a/python-sdk/nuscenes/eval/common/utils.py b/python-sdk/nuscenes/eval/common/utils.py
new file mode 100644
index 0000000..248ec77
--- /dev/null
+++ b/python-sdk/nuscenes/eval/common/utils.py
@@ -0,0 +1,169 @@
+# nuScenes dev-kit.
+# Code written by Holger Caesar, 2018.
+
+from typing import List, Dict, Any
+
+import numpy as np
+from pyquaternion import Quaternion
+
+from nuscenes.eval.common.data_classes import EvalBox
+from nuscenes.utils.data_classes import Box
+
+DetectionBox = Any # Workaround as direct imports lead to cyclic dependencies.
+
+
+def center_distance(gt_box: EvalBox, pred_box: EvalBox) -> float:
+ """
+ L2 distance between the box centers (xy only).
+ :param gt_box: GT annotation sample.
+ :param pred_box: Predicted sample.
+ :return: L2 distance.
+ """
+ return np.linalg.norm(np.array(pred_box.translation[:2]) - np.array(gt_box.translation[:2]))
+
+
+def velocity_l2(gt_box: EvalBox, pred_box: EvalBox) -> float:
+ """
+ L2 distance between the velocity vectors (xy only).
+ If the predicted velocities are nan, we return inf, which is subsequently clipped to 1.
+ :param gt_box: GT annotation sample.
+ :param pred_box: Predicted sample.
+ :return: L2 distance.
+ """
+ return np.linalg.norm(np.array(pred_box.velocity) - np.array(gt_box.velocity))
+
+
+def yaw_diff(gt_box: EvalBox, eval_box: EvalBox, period: float = 2*np.pi) -> float:
+ """
+ Returns the yaw angle difference between the orientation of two boxes.
+ :param gt_box: Ground truth box.
+ :param eval_box: Predicted box.
+ :param period: Periodicity in radians for assessing angle difference.
+ :return: Yaw angle difference in radians in [0, pi].
+ """
+ yaw_gt = quaternion_yaw(Quaternion(gt_box.rotation))
+ yaw_est = quaternion_yaw(Quaternion(eval_box.rotation))
+
+ return abs(angle_diff(yaw_gt, yaw_est, period))
+
+
+def angle_diff(x: float, y: float, period: float) -> float:
+ """
+ Get the smallest angle difference between 2 angles: the angle from y to x.
+ :param x: To angle.
+ :param y: From angle.
+ :param period: Periodicity in radians for assessing angle difference.
+ :return: <float>. Signed smallest between-angle difference in range (-pi, pi).
+ """
+
+ # calculate angle difference, modulo to [0, 2*pi]
+ diff = (x - y + period / 2) % period - period / 2
+ if diff > np.pi:
+ diff = diff - (2 * np.pi) # shift (pi, 2*pi] to (-pi, 0]
+
+ return diff
+
+
+def attr_acc(gt_box: DetectionBox, pred_box: DetectionBox) -> float:
+ """
+ Computes the classification accuracy for the attribute of this class (if any).
+ If the GT class has no attributes or the annotation is missing attributes, we assign an accuracy of nan, which is
+ ignored later on.
+ :param gt_box: GT annotation sample.
+ :param pred_box: Predicted sample.
+ :return: Attribute classification accuracy (0 or 1) or nan if GT annotation does not have any attributes.
+ """
+ if gt_box.attribute_name == '':
+ # If the class does not have attributes or this particular sample is missing attributes, return nan, which is
+ # ignored later. Note that about 0.4% of the sample_annotations have no attributes, although they should.
+ acc = np.nan
+ else:
+ # Check that label is correct.
+ acc = float(gt_box.attribute_name == pred_box.attribute_name)
+ return acc
+
+
+def scale_iou(sample_annotation: EvalBox, sample_result: EvalBox) -> float:
+ """
+ This method compares predictions to the ground truth in terms of scale.
+ It is equivalent to intersection over union (IOU) between the two boxes in 3D,
+ if we assume that the boxes are aligned, i.e. translation and rotation are considered identical.
+ :param sample_annotation: GT annotation sample.
+ :param sample_result: Predicted sample.
+ :return: Scale IOU.
+ """
+ # Validate inputs.
+ sa_size = np.array(sample_annotation.size)
+ sr_size = np.array(sample_result.size)
+ assert all(sa_size > 0), 'Error: sample_annotation sizes must be >0.'
+ assert all(sr_size > 0), 'Error: sample_result sizes must be >0.'
+
+ # Compute IOU.
+ min_wlh = np.minimum(sa_size, sr_size)
+ volume_annotation = np.prod(sa_size)
+ volume_result = np.prod(sr_size)
+ intersection = np.prod(min_wlh) # type: float
+ union = volume_annotation + volume_result - intersection # type: float
+ iou = intersection / union
+
+ return iou
+
+
+def quaternion_yaw(q: Quaternion) -> float:
+ """
+ Calculate the yaw angle from a quaternion.
+ Note that this only works for a quaternion that represents a box in lidar or global coordinate frame.
+ It does not work for a box in the camera frame.
+ :param q: Quaternion of interest.
+ :return: Yaw angle in radians.
+ """
+
+ # Project into xy plane.
+ v = np.dot(q.rotation_matrix, np.array([1, 0, 0]))
+
+ # Measure yaw using arctan.
+ yaw = np.arctan2(v[1], v[0])
+
+ return yaw
+
+
+def boxes_to_sensor(boxes: List[EvalBox], pose_record: Dict, cs_record: Dict):
+ """
+ Map boxes from global coordinates to the vehicle's sensor coordinate system.
+ :param boxes: The boxes in global coordinates.
+ :param pose_record: The pose record of the vehicle at the current timestamp.
+ :param cs_record: The calibrated sensor record of the sensor.
+ :return: The transformed boxes.
+ """
+ boxes_out = []
+ for box in boxes:
+ # Create Box instance.
+ box = Box(box.translation, box.size, Quaternion(box.rotation))
+
+ # Move box to ego vehicle coord system.
+ box.translate(-np.array(pose_record['translation']))
+ box.rotate(Quaternion(pose_record['rotation']).inverse)
+
+ # Move box to sensor coord system.
+ box.translate(-np.array(cs_record['translation']))
+ box.rotate(Quaternion(cs_record['rotation']).inverse)
+
+ boxes_out.append(box)
+
+ return boxes_out
+
+
+def cummean(x: np.array) -> np.array:
+ """
+ Computes the cumulative mean up to each position in a NaN sensitive way
+ - If all values are NaN return an array of ones.
+ - If some values are NaN, accumulate arrays discording those entries.
+ """
+ if sum(np.isnan(x)) == len(x):
+ # Is all numbers in array are NaN's.
+ return np.ones(len(x)) # If all errors are NaN set to error to 1 for all operating points.
+ else:
+ # Accumulate in a nan-aware manner.
+ sum_vals = np.nancumsum(x.astype(float)) # Cumulative sum ignoring nans.
+ count_vals = np.cumsum(~np.isnan(x)) # Number of non-nans up to each position.
+ return np.divide(sum_vals, count_vals, out=np.zeros_like(sum_vals), where=count_vals != 0)
diff --git a/python-sdk/nuscenes/eval/detection/README.md b/python-sdk/nuscenes/eval/detection/README.md
new file mode 100644
index 0000000..5ee1b74
--- /dev/null
+++ b/python-sdk/nuscenes/eval/detection/README.md
@@ -0,0 +1,269 @@
+# nuScenes detection task
+
+
+## Overview
+- [Introduction](#introduction)
+- [Participation](#participation)
+- [Challenges](#challenges)
+- [Submission rules](#submission-rules)
+- [Results format](#results-format)
+- [Classes and attributes](#classes-attributes-and-detection-ranges)
+- [Evaluation metrics](#evaluation-metrics)
+- [Leaderboard](#leaderboard)
+
+## Introduction
+Here we define the 3D object detection task on nuScenes.
+The goal of this task is to place a 3D bounding box around 10 different object categories,
+as well as estimating a set of attributes and the current velocity vector.
+
+## Participation
+The nuScenes detection [evaluation server](https://eval.ai/web/challenges/challenge-page/356/overview) is open all year round for submission.
+To participate in the challenge, please create an account at [EvalAI](https://eval.ai/web/challenges/challenge-page/356/overview).
+Then upload your zipped result file including all of the required [meta data](#results-format).
+After each challenge, the results will be exported to the nuScenes [leaderboard](https://www.nuscenes.org/object-detection) shown above.
+This is the only way to benchmark your method against the test dataset.
+We require that all participants send the following information to nuScenes@motional.com after submitting their results on EvalAI:
+- Team name
+- Method name
+- Authors
+- Affiliations
+- Method description (5+ sentences)
+- Project URL
+- Paper URL
+- FPS in Hz (and the hardware used to measure it)
+
+## Challenges
+To allow users to benchmark the performance of their method against the community, we host a single [leaderboard](https://www.nuscenes.org/object-detection) all-year round.
+Additionally we organize a number of challenges at leading Computer Vision conference workshops.
+Users that submit their results during the challenge period are eligible for awards.
+Any user that cannot attend the workshop (direct or via a representative) will be excluded from the challenge, but will still be listed on the leaderboard.
+
+Click [here](https://eval.ai/web/challenges/challenge-page/356/overview) for the **EvalAI detection evaluation server**.
+
+### 5th AI Driving Olympics, NeurIPS 2020
+The third nuScenes detection challenge will be held at [NeurIPS 2020](https://nips.cc/Conferences/2020/).
+Submission will open on Nov 15, 2020 and close in early Dec, 2020.
+Results and winners will be announced at the [5th AI Driving Olympics](https://driving-olympics.ai/) at NeurIPS 2020.
+Note that this challenge uses the same [evaluation server](https://eval.ai/web/challenges/challenge-page/356/overview) as previous detection challenges.
+
+### Workshop on Benchmarking Progress in Autonomous Driving, ICRA 2020
+The second nuScenes detection challenge will be held at [ICRA 2020](https://www.icra2020.org/).
+The submission period will open April 1 and continue until May 28th, 2020.
+Results and winners will be announced at the [Workshop on Benchmarking Progress in Autonomous Driving](http://montrealrobotics.ca/driving-benchmarks/).
+Note that the previous [evaluation server](https://eval.ai/web/challenges/challenge-page/356/overview) can still be used to benchmark your results after the challenge period.
+
+### Workshop on Autonomous Driving, CVPR 2019
+The first nuScenes detection challenge was held at CVPR 2019.
+Submission opened May 6 and closed June 12, 2019.
+Results and winners were announced at the Workshop on Autonomous Driving ([WAD](https://sites.google.com/view/wad2019)) at [CVPR 2019](http://cvpr2019.thecvf.com/).
+For more information see the [leaderboard](https://www.nuscenes.org/object-detection).
+Note that the [evaluation server](https://eval.ai/web/challenges/challenge-page/356/overview) can still be used to benchmark your results.
+
+## Submission rules
+### Detection-specific rules
+* The maximum time window of past sensor data and ego poses that may be used at inference time is approximately 0.5s (at most 6 *past* camera images, 6 *past* radar sweeps and 10 *past* lidar sweeps). At training time there are no restrictions.
+
+### General rules
+* We release annotations for the train and val set, but not for the test set.
+* We release sensor data for train, val and test set.
+* Users make predictions on the test set and submit the results to our evaluation server, which returns the metrics listed below.
+* We do not use strata. Instead, we filter annotations and predictions beyond class specific distances.
+* Users must limit the number of submitted boxes per sample to 500.
+* Every submission provides method information. We encourage publishing code, but do not make it a requirement.
+* Top leaderboard entries and their papers will be manually reviewed.
+* Each user or team can have at most one one account on the evaluation server.
+* Each user or team can submit at most 3 results. These results must come from different models, rather than submitting results from the same model at different training epochs or with slightly different parameters.
+* Any attempt to circumvent these rules will result in a permanent ban of the team or company from all nuScenes challenges.
+
+## Results format
+We define a standardized detection result format that serves as an input to the evaluation code.
+Results are evaluated for each 2Hz keyframe, also known as `sample`.
+The detection results for a particular evaluation set (train/val/test) are stored in a single JSON file.
+For the train and val sets the evaluation can be performed by the user on their local machine.
+For the test set the user needs to zip the single JSON result file and submit it to the official evaluation server.
+The JSON file includes meta data `meta` on the type of inputs used for this method.
+Furthermore it includes a dictionary `results` that maps each sample_token to a list of `sample_result` entries.
+Each `sample_token` from the current evaluation set must be included in `results`, although the list of predictions may be empty if no object is detected.
+```
+submission {
+ "meta": {
+ "use_camera": <bool> -- Whether this submission uses camera data as an input.
+ "use_lidar": <bool> -- Whether this submission uses lidar data as an input.
+ "use_radar": <bool> -- Whether this submission uses radar data as an input.
+ "use_map": <bool> -- Whether this submission uses map data as an input.
+ "use_external": <bool> -- Whether this submission uses external data as an input.
+ },
+ "results": {
+ sample_token <str>: List[sample_result] -- Maps each sample_token to a list of sample_results.
+ }
+}
+```
+For the predictions we create a new database table called `sample_result`.
+The `sample_result` table is designed to mirror the `sample_annotation` table.
+This allows for processing of results and annotations using the same tools.
+A `sample_result` is a dictionary defined as follows:
+```
+sample_result {
+ "sample_token": <str> -- Foreign key. Identifies the sample/keyframe for which objects are detected.
+ "translation": <float> [3] -- Estimated bounding box location in m in the global frame: center_x, center_y, center_z.
+ "size": <float> [3] -- Estimated bounding box size in m: width, length, height.
+ "rotation": <float> [4] -- Estimated bounding box orientation as quaternion in the global frame: w, x, y, z.
+ "velocity": <float> [2] -- Estimated bounding box velocity in m/s in the global frame: vx, vy.
+ "detection_name": <str> -- The predicted class for this sample_result, e.g. car, pedestrian.
+ "detection_score": <float> -- Object prediction score between 0 and 1 for the class identified by detection_name.
+ "attribute_name": <str> -- Name of the predicted attribute or empty string for classes without attributes.
+ See table below for valid attributes for each class, e.g. cycle.with_rider.
+ Attributes are ignored for classes without attributes.
+ There are a few cases (0.4%) where attributes are missing also for classes
+ that should have them. We ignore the predicted attributes for these cases.
+}
+```
+Note that the detection classes may differ from the general nuScenes classes, as detailed below.
+
+## Classes, attributes, and detection ranges
+The nuScenes dataset comes with annotations for 23 classes ([details](https://www.nuscenes.org/data-annotation)).
+Some of these only have a handful of samples.
+Hence we merge similar classes and remove rare classes.
+This results in 10 classes for the detection challenge.
+Below we show the table of detection classes and their counterparts in the nuScenes dataset.
+For more information on the classes and their frequencies, see [this page](https://www.nuscenes.org/nuscenes#data-annotation).
+
+| nuScenes detection class| nuScenes general class |
+| --- | --- |
+| void / ignore | animal |
+| void / ignore | human.pedestrian.personal_mobility |
+| void / ignore | human.pedestrian.stroller |
+| void / ignore | human.pedestrian.wheelchair |
+| void / ignore | movable_object.debris |
+| void / ignore | movable_object.pushable_pullable |
+| void / ignore | static_object.bicycle_rack |
+| void / ignore | vehicle.emergency.ambulance |
+| void / ignore | vehicle.emergency.police |
+| barrier | movable_object.barrier |
+| bicycle | vehicle.bicycle |
+| bus | vehicle.bus.bendy |
+| bus | vehicle.bus.rigid |
+| car | vehicle.car |
+| construction_vehicle | vehicle.construction |
+| motorcycle | vehicle.motorcycle |
+| pedestrian | human.pedestrian.adult |
+| pedestrian | human.pedestrian.child |
+| pedestrian | human.pedestrian.construction_worker |
+| pedestrian | human.pedestrian.police_officer |
+| traffic_cone | movable_object.trafficcone |
+| trailer | vehicle.trailer |
+| truck | vehicle.truck |
+
+Below we list which nuScenes classes can have which attributes.
+Note that some annotations are missing attributes (0.4% of all sample_annotations).
+
+For each nuScenes detection class, the number of annotations decreases with increasing range from the ego vehicle,
+but the number of annotations per range varies by class. Therefore, each class has its own upper bound on evaluated
+detection range, as shown below:
+
+| nuScenes detection class | Attributes | Detection range (meters) |
+| --- | --- | --- |
+| barrier | void | 30 |
+| traffic_cone | void | 30 |
+| bicycle | cycle.{with_rider, without_rider} | 40 |
+| motorcycle | cycle.{with_rider, without_rider} | 40 |
+| pedestrian | pedestrian.{moving, standing, sitting_lying_down} | 40 |
+| car | vehicle.{moving, parked, stopped} | 50 |
+| bus | vehicle.{moving, parked, stopped} | 50 |
+| construction_vehicle | vehicle.{moving, parked, stopped} | 50 |
+| trailer | vehicle.{moving, parked, stopped} | 50 |
+| truck | vehicle.{moving, parked, stopped} | 50 |
+
+## Evaluation metrics
+Below we define the metrics for the nuScenes detection task.
+Our final score is a weighted sum of mean Average Precision (mAP) and several True Positive (TP) metrics.
+
+### Preprocessing
+Before running the evaluation code the following pre-processing is done on the data
+* All boxes (GT and prediction) are removed if they exceed the class-specific detection range.
+* All bikes and motorcycle boxes (GT and prediction) that fall inside a bike-rack are removed. The reason is that we do not annotate bikes inside bike-racks.
+* All boxes (GT) without lidar or radar points in them are removed. The reason is that we can not guarantee that they are actually visible in the frame. We do not filter the predicted boxes based on number of points.
+
+### Average Precision metric
+* **mean Average Precision (mAP)**:
+We use the well-known Average Precision metric,
+but define a match by considering the 2D center distance on the ground plane rather than intersection over union based affinities.
+Specifically, we match predictions with the ground truth objects that have the smallest center-distance up to a certain threshold.
+For a given match threshold we calculate average precision (AP) by integrating the recall vs precision curve for recalls and precisions > 0.1.
+We finally average over match thresholds of {0.5, 1, 2, 4} meters and compute the mean across classes.
+
+### True Positive metrics
+Here we define metrics for a set of true positives (TP) that measure translation / scale / orientation / velocity and attribute errors.
+All TP metrics are calculated using a threshold of 2m center distance during matching, and they are all designed to be positive scalars.
+
+Matching and scoring happen independently per class and each metric is the average of the cumulative mean at each achieved recall level above 10%.
+If 10% recall is not achieved for a particular class, all TP errors for that class are set to 1.
+We define the following TP errors:
+* **Average Translation Error (ATE)**: Euclidean center distance in 2D in meters.
+* **Average Scale Error (ASE)**: Calculated as *1 - IOU* after aligning centers and orientation.
+* **Average Orientation Error (AOE)**: Smallest yaw angle difference between prediction and ground-truth in radians. Orientation error is evaluated at 360 degree for all classes except barriers where it is only evaluated at 180 degrees. Orientation errors for cones are ignored.
+* **Average Velocity Error (AVE)**: Absolute velocity error in m/s. Velocity error for barriers and cones are ignored.
+* **Average Attribute Error (AAE)**: Calculated as *1 - acc*, where acc is the attribute classification accuracy. Attribute error for barriers and cones are ignored.
+
+All errors are >= 0, but note that for translation and velocity errors the errors are unbounded, and can be any positive value.
+
+The TP metrics are defined per class, and we then take a mean over classes to calculate mATE, mASE, mAOE, mAVE and mAAE.
+
+### nuScenes detection score
+* **nuScenes detection score (NDS)**:
+We consolidate the above metrics by computing a weighted sum: mAP, mATE, mASE, mAOE, mAVE and mAAE.
+As a first step we convert the TP errors to TP scores as *TP_score = max(1 - TP_error, 0.0)*.
+We then assign a weight of *5* to mAP and *1* to each of the 5 TP scores and calculate the normalized sum.
+
+### Configuration
+The default evaluation metrics configurations can be found in `nuscenes/eval/detection/configs/detection_cvpr_2019.json`.
+
+## Leaderboard
+nuScenes will maintain a single leaderboard for the detection task.
+For each submission the leaderboard will list method aspects and evaluation metrics.
+Method aspects include input modalities (lidar, radar, vision), use of map data and use of external data.
+To enable a fair comparison between methods, the user will be able to filter the methods by method aspects.
+
+We define three such filters here which correspond to the tracks in the nuScenes detection challenge.
+Methods will be compared within these tracks and the winners will be decided for each track separately.
+Furthermore, there will also be an award for novel ideas, as well as the best student submission.
+
+**Lidar track**:
+* Only lidar input allowed.
+* External data or map data <u>not allowed</u>.
+* May use pre-training.
+
+**Vision track**:
+* Only camera input allowed.
+* External data or map data <u>not allowed</u>.
+* May use pre-training.
+
+**Open track**:
+* Any sensor input allowed.
+* External data and map data allowed.
+* May use pre-training.
+
+**Details**:
+* *Sensor input:*
+For the lidar and vision tracks we restrict the type of sensor input that may be used.
+Note that this restriction applies only at test time.
+At training time any sensor input may be used.
+In particular this also means that at training time you are allowed to filter the GT boxes using `num_lidar_pts` and `num_radar_pts`, regardless of the track.
+However, during testing the predicted boxes may *not* be filtered based on input from other sensor modalities.
+
+* *Map data:*
+By `map data` we mean using the *semantic* map provided in nuScenes.
+
+* *Meta data:*
+Other meta data included in the dataset may be used without restrictions.
+E.g. calibration parameters, ego poses, `location`, `timestamp`, `num_lidar_pts`, `num_radar_pts`, `translation`, `rotation` and `size`.
+Note that `instance`, `sample_annotation` and `scene` description are not provided for the test set.
+
+* *Pre-training:*
+By pre-training we mean training a network for the task of image classification using only image-level labels,
+as done in [[Krizhevsky NIPS 2012]](http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networ).
+The pre-training may not involve bounding box, mask or other localized annotations.
+
+* *Reporting:*
+Users are required to report detailed information on their method regarding sensor input, map data, meta data and pre-training.
+Users that fail to adequately report this information may be excluded from the challenge.
diff --git a/python-sdk/nuscenes/eval/detection/__init__.py b/python-sdk/nuscenes/eval/detection/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/python-sdk/nuscenes/eval/detection/algo.py b/python-sdk/nuscenes/eval/detection/algo.py
new file mode 100644
index 0000000..7e6f38b
--- /dev/null
+++ b/python-sdk/nuscenes/eval/detection/algo.py
@@ -0,0 +1,189 @@
+# nuScenes dev-kit.
+# Code written by Oscar Beijbom, 2019.
+
+from typing import Callable
+
+import numpy as np
+
+from nuscenes.eval.common.data_classes import EvalBoxes
+from nuscenes.eval.common.utils import center_distance, scale_iou, yaw_diff, velocity_l2, attr_acc, cummean
+from nuscenes.eval.detection.data_classes import DetectionMetricData
+
+
+def accumulate(gt_boxes: EvalBoxes,
+ pred_boxes: EvalBoxes,
+ class_name: str,
+ dist_fcn: Callable,
+ dist_th: float,
+ verbose: bool = False) -> DetectionMetricData:
+ """
+ Average Precision over predefined different recall thresholds for a single distance threshold.
+ The recall/conf thresholds and other raw metrics will be used in secondary metrics.
+ :param gt_boxes: Maps every sample_token to a list of its sample_annotations.
+ :param pred_boxes: Maps every sample_token to a list of its sample_results.
+ :param class_name: Class to compute AP on.
+ :param dist_fcn: Distance function used to match detections and ground truths.
+ :param dist_th: Distance threshold for a match.
+ :param verbose: If true, print debug messages.
+ :return: (average_prec, metrics). The average precision value and raw data for a number of metrics.
+ """
+ # ---------------------------------------------
+ # Organize input and initialize accumulators.
+ # ---------------------------------------------
+
+ # Count the positives.
+ npos = len([1 for gt_box in gt_boxes.all if gt_box.detection_name == class_name])
+ if verbose:
+ print("Found {} GT of class {} out of {} total across {} samples.".
+ format(npos, class_name, len(gt_boxes.all), len(gt_boxes.sample_tokens)))
+
+ # For missing classes in the GT, return a data structure corresponding to no predictions.
+ if npos == 0:
+ return DetectionMetricData.no_predictions()
+
+ # Organize the predictions in a single list.
+ pred_boxes_list = [box for box in pred_boxes.all if box.detection_name == class_name]
+ pred_confs = [box.detection_score for box in pred_boxes_list]
+
+ if verbose:
+ print("Found {} PRED of class {} out of {} total across {} samples.".
+ format(len(pred_confs), class_name, len(pred_boxes.all), len(pred_boxes.sample_tokens)))
+
+ # Sort by confidence.
+ sortind = [i for (v, i) in sorted((v, i) for (i, v) in enumerate(pred_confs))][::-1]
+
+ # Do the actual matching.
+ tp = [] # Accumulator of true positives.
+ fp = [] # Accumulator of false positives.
+ conf = [] # Accumulator of confidences.
+
+ # match_data holds the extra metrics we calculate for each match.
+ match_data = {'trans_err': [],
+ 'vel_err': [],
+ 'scale_err': [],
+ 'orient_err': [],
+ 'attr_err': [],
+ 'conf': []}
+
+ # ---------------------------------------------
+ # Match and accumulate match data.
+ # ---------------------------------------------
+
+ taken = set() # Initially no gt bounding box is matched.
+ for ind in sortind:
+ pred_box = pred_boxes_list[ind]
+ min_dist = np.inf
+ match_gt_idx = None
+
+ for gt_idx, gt_box in enumerate(gt_boxes[pred_box.sample_token]):
+
+ # Find closest match among ground truth boxes
+ if gt_box.detection_name == class_name and not (pred_box.sample_token, gt_idx) in taken:
+ this_distance = dist_fcn(gt_box, pred_box)
+ if this_distance < min_dist:
+ min_dist = this_distance
+ match_gt_idx = gt_idx
+
+ # If the closest match is close enough according to threshold we have a match!
+ is_match = min_dist < dist_th
+
+ if is_match:
+ taken.add((pred_box.sample_token, match_gt_idx))
+
+ # Update tp, fp and confs.
+ tp.append(1)
+ fp.append(0)
+ conf.append(pred_box.detection_score)
+
+ # Since it is a match, update match data also.
+ gt_box_match = gt_boxes[pred_box.sample_token][match_gt_idx]
+
+ match_data['trans_err'].append(center_distance(gt_box_match, pred_box))
+ match_data['vel_err'].append(velocity_l2(gt_box_match, pred_box))
+ match_data['scale_err'].append(1 - scale_iou(gt_box_match, pred_box))
+
+ # Barrier orientation is only determined up to 180 degree. (For cones orientation is discarded later)
+ period = np.pi if class_name == 'barrier' else 2 * np.pi
+ match_data['orient_err'].append(yaw_diff(gt_box_match, pred_box, period=period))
+
+ match_data['attr_err'].append(1 - attr_acc(gt_box_match, pred_box))
+ match_data['conf'].append(pred_box.detection_score)
+
+ else:
+ # No match. Mark this as a false positive.
+ tp.append(0)
+ fp.append(1)
+ conf.append(pred_box.detection_score)
+
+ # Check if we have any matches. If not, just return a "no predictions" array.
+ if len(match_data['trans_err']) == 0:
+ return DetectionMetricData.no_predictions()
+
+ # ---------------------------------------------
+ # Calculate and interpolate precision and recall
+ # ---------------------------------------------
+
+ # Accumulate.
+ tp = np.cumsum(tp).astype(np.float)
+ fp = np.cumsum(fp).astype(np.float)
+ conf = np.array(conf)
+
+ # Calculate precision and recall.
+ prec = tp / (fp + tp)
+ rec = tp / float(npos)
+
+ rec_interp = np.linspace(0, 1, DetectionMetricData.nelem) # 101 steps, from 0% to 100% recall.
+ prec = np.interp(rec_interp, rec, prec, right=0)
+ conf = np.interp(rec_interp, rec, conf, right=0)
+ rec = rec_interp
+
+ # ---------------------------------------------
+ # Re-sample the match-data to match, prec, recall and conf.
+ # ---------------------------------------------
+
+ for key in match_data.keys():
+ if key == "conf":
+ continue # Confidence is used as reference to align with fp and tp. So skip in this step.
+
+ else:
+ # For each match_data, we first calculate the accumulated mean.
+ tmp = cummean(np.array(match_data[key]))
+
+ # Then interpolate based on the confidences. (Note reversing since np.interp needs increasing arrays)
+ match_data[key] = np.interp(conf[::-1], match_data['conf'][::-1], tmp[::-1])[::-1]
+
+ # ---------------------------------------------
+ # Done. Instantiate MetricData and return
+ # ---------------------------------------------
+ return DetectionMetricData(recall=rec,
+ precision=prec,
+ confidence=conf,
+ trans_err=match_data['trans_err'],
+ vel_err=match_data['vel_err'],
+ scale_err=match_data['scale_err'],
+ orient_err=match_data['orient_err'],
+ attr_err=match_data['attr_err'])
+
+
+def calc_ap(md: DetectionMetricData, min_recall: float, min_precision: float) -> float:
+ """ Calculated average precision. """
+
+ assert 0 <= min_precision < 1
+ assert 0 <= min_recall <= 1
+
+ prec = np.copy(md.precision)
+ prec = prec[round(100 * min_recall) + 1:] # Clip low recalls. +1 to exclude the min recall bin.
+ prec -= min_precision # Clip low precision
+ prec[prec < 0] = 0
+ return float(np.mean(prec)) / (1.0 - min_precision)
+
+
+def calc_tp(md: DetectionMetricData, min_recall: float, metric_name: str) -> float:
+ """ Calculates true positive errors. """
+
+ first_ind = round(100 * min_recall) + 1 # +1 to exclude the error at min recall.
+ last_ind = md.max_recall_ind # First instance of confidence = 0 is index of max achieved recall.
+ if last_ind < first_ind:
+ return 1.0 # Assign 1 here. If this happens for all classes, the score for that TP metric will be 0.
+ else:
+ return float(np.mean(getattr(md, metric_name)[first_ind: last_ind + 1])) # +1 to include error at max recall.
diff --git a/python-sdk/nuscenes/eval/detection/config.py b/python-sdk/nuscenes/eval/detection/config.py
new file mode 100644
index 0000000..34d7f02
--- /dev/null
+++ b/python-sdk/nuscenes/eval/detection/config.py
@@ -0,0 +1,29 @@
+# nuScenes dev-kit.
+# Code written by Holger Caesar, 2019.
+
+import json
+import os
+
+from nuscenes.eval.detection.data_classes import DetectionConfig
+
+
+def config_factory(configuration_name: str) -> DetectionConfig:
+ """
+ Creates a DetectionConfig instance that can be used to initialize a NuScenesEval instance.
+ Note that this only works if the config file is located in the nuscenes/eval/detection/configs folder.
+ :param configuration_name: Name of desired configuration in eval_detection_configs.
+ :return: DetectionConfig instance.
+ """
+
+ # Check if config exists.
+ this_dir = os.path.dirname(os.path.abspath(__file__))
+ cfg_path = os.path.join(this_dir, 'configs', '%s.json' % configuration_name)
+ assert os.path.exists(cfg_path), \
+ 'Requested unknown configuration {}'.format(configuration_name)
+
+ # Load config file and deserialize it.
+ with open(cfg_path, 'r') as f:
+ data = json.load(f)
+ cfg = DetectionConfig.deserialize(data)
+
+ return cfg
diff --git a/python-sdk/nuscenes/eval/detection/configs/detection_cvpr_2019.json b/python-sdk/nuscenes/eval/detection/configs/detection_cvpr_2019.json
new file mode 100644
index 0000000..809ba46
--- /dev/null
+++ b/python-sdk/nuscenes/eval/detection/configs/detection_cvpr_2019.json
@@ -0,0 +1,21 @@
+{
+ "class_range": {
+ "car": 50,
+ "truck": 50,
+ "bus": 50,
+ "trailer": 50,
+ "construction_vehicle": 50,
+ "pedestrian": 40,
+ "motorcycle": 40,
+ "bicycle": 40,
+ "traffic_cone": 30,
+ "barrier": 30
+ },
+ "dist_fcn": "center_distance",
+ "dist_ths": [0.5, 1.0, 2.0, 4.0],
+ "dist_th_tp": 2.0,
+ "min_recall": 0.1,
+ "min_precision": 0.1,
+ "max_boxes_per_sample": 500,
+ "mean_ap_weight": 5
+}
diff --git a/python-sdk/nuscenes/eval/detection/constants.py b/python-sdk/nuscenes/eval/detection/constants.py
new file mode 100644
index 0000000..e3ee158
--- /dev/null
+++ b/python-sdk/nuscenes/eval/detection/constants.py
@@ -0,0 +1,50 @@
+# nuScenes dev-kit.
+# Code written by Oscar Beijbom and Varun Bankiti, 2019.
+
+DETECTION_NAMES = ['car', 'truck', 'bus', 'trailer', 'construction_vehicle', 'pedestrian', 'motorcycle', 'bicycle',
+ 'traffic_cone', 'barrier']
+
+PRETTY_DETECTION_NAMES = {'car': 'Car',
+ 'truck': 'Truck',
+ 'bus': 'Bus',
+ 'trailer': 'Trailer',
+ 'construction_vehicle': 'Constr. Veh.',
+ 'pedestrian': 'Pedestrian',
+ 'motorcycle': 'Motorcycle',
+ 'bicycle': 'Bicycle',
+ 'traffic_cone': 'Traffic Cone',
+ 'barrier': 'Barrier'}
+
+DETECTION_COLORS = {'car': 'C0',
+ 'truck': 'C1',
+ 'bus': 'C2',
+ 'trailer': 'C3',
+ 'construction_vehicle': 'C4',
+ 'pedestrian': 'C5',
+ 'motorcycle': 'C6',
+ 'bicycle': 'C7',
+ 'traffic_cone': 'C8',
+ 'barrier': 'C9'}
+
+ATTRIBUTE_NAMES = ['pedestrian.moving', 'pedestrian.sitting_lying_down', 'pedestrian.standing', 'cycle.with_rider',
+ 'cycle.without_rider', 'vehicle.moving', 'vehicle.parked', 'vehicle.stopped']
+
+PRETTY_ATTRIBUTE_NAMES = {'pedestrian.moving': 'Ped. Moving',
+ 'pedestrian.sitting_lying_down': 'Ped. Sitting',
+ 'pedestrian.standing': 'Ped. Standing',
+ 'cycle.with_rider': 'Cycle w/ Rider',
+ 'cycle.without_rider': 'Cycle w/o Rider',
+ 'vehicle.moving': 'Veh. Moving',
+ 'vehicle.parked': 'Veh. Parked',
+ 'vehicle.stopped': 'Veh. Stopped'}
+
+TP_METRICS = ['trans_err', 'scale_err', 'orient_err', 'vel_err', 'attr_err']
+
+PRETTY_TP_METRICS = {'trans_err': 'Trans.', 'scale_err': 'Scale', 'orient_err': 'Orient.', 'vel_err': 'Vel.',
+ 'attr_err': 'Attr.'}
+
+TP_METRICS_UNITS = {'trans_err': 'm',
+ 'scale_err': '1-IOU',
+ 'orient_err': 'rad.',
+ 'vel_err': 'm/s',
+ 'attr_err': '1-acc.'}
diff --git a/python-sdk/nuscenes/eval/detection/data_classes.py b/python-sdk/nuscenes/eval/detection/data_classes.py
new file mode 100644
index 0000000..8e0a7fc
--- /dev/null
+++ b/python-sdk/nuscenes/eval/detection/data_classes.py
@@ -0,0 +1,425 @@
+# nuScenes dev-kit.
+# Code written by Oscar Beijbom, 2019.
+
+from collections import defaultdict
+from typing import List, Dict, Tuple
+
+import numpy as np
+
+from nuscenes.eval.common.data_classes import MetricData, EvalBox
+from nuscenes.eval.common.utils import center_distance
+from nuscenes.eval.detection.constants import DETECTION_NAMES, ATTRIBUTE_NAMES, TP_METRICS
+
+
+class DetectionConfig:
+ """ Data class that specifies the detection evaluation settings. """
+
+ def __init__(self,
+ class_range: Dict[str, int],
+ dist_fcn: str,
+ dist_ths: List[float],
+ dist_th_tp: float,
+ min_recall: float,
+ min_precision: float,
+ max_boxes_per_sample: int,
+ mean_ap_weight: int):
+
+ assert set(class_range.keys()) == set(DETECTION_NAMES), "Class count mismatch."
+ assert dist_th_tp in dist_ths, "dist_th_tp must be in set of dist_ths."
+
+ self.class_range = class_range
+ self.dist_fcn = dist_fcn
+ self.dist_ths = dist_ths
+ self.dist_th_tp = dist_th_tp
+ self.min_recall = min_recall
+ self.min_precision = min_precision
+ self.max_boxes_per_sample = max_boxes_per_sample
+ self.mean_ap_weight = mean_ap_weight
+
+ self.class_names = self.class_range.keys()
+
+ def __eq__(self, other):
+ eq = True
+ for key in self.serialize().keys():
+ eq = eq and np.array_equal(getattr(self, key), getattr(other, key))
+ return eq
+
+ def serialize(self) -> dict:
+ """ Serialize instance into json-friendly format. """
+ return {
+ 'class_range': self.class_range,
+ 'dist_fcn': self.dist_fcn,
+ 'dist_ths': self.dist_ths,
+ 'dist_th_tp': self.dist_th_tp,
+ 'min_recall': self.min_recall,
+ 'min_precision': self.min_precision,
+ 'max_boxes_per_sample': self.max_boxes_per_sample,
+ 'mean_ap_weight': self.mean_ap_weight
+ }
+
+ @classmethod
+ def deserialize(cls, content: dict):
+ """ Initialize from serialized dictionary. """
+ return cls(content['class_range'],
+ content['dist_fcn'],
+ content['dist_ths'],
+ content['dist_th_tp'],
+ content['min_recall'],
+ content['min_precision'],
+ content['max_boxes_per_sample'],
+ content['mean_ap_weight'])
+
+ @property
+ def dist_fcn_callable(self):
+ """ Return the distance function corresponding to the dist_fcn string. """
+ if self.dist_fcn == 'center_distance':
+ return center_distance
+ else:
+ raise Exception('Error: Unknown distance function %s!' % self.dist_fcn)
+
+
+class DetectionMetricData(MetricData):
+ """ This class holds accumulated and interpolated data required to calculate the detection metrics. """
+
+ nelem = 101
+
+ def __init__(self,
+ recall: np.array,
+ precision: np.array,
+ confidence: np.array,
+ trans_err: np.array,
+ vel_err: np.array,
+ scale_err: np.array,
+ orient_err: np.array,
+ attr_err: np.array):
+
+ # Assert lengths.
+ assert len(recall) == self.nelem
+ assert len(precision) == self.nelem
+ assert len(confidence) == self.nelem
+ assert len(trans_err) == self.nelem
+ assert len(vel_err) == self.nelem
+ assert len(scale_err) == self.nelem
+ assert len(orient_err) == self.nelem
+ assert len(attr_err) == self.nelem
+
+ # Assert ordering.
+ assert all(confidence == sorted(confidence, reverse=True)) # Confidences should be descending.
+ assert all(recall == sorted(recall)) # Recalls should be ascending.
+
+ # Set attributes explicitly to help IDEs figure out what is going on.
+ self.recall = recall
+ self.precision = precision
+ self.confidence = confidence
+ self.trans_err = trans_err
+ self.vel_err = vel_err
+ self.scale_err = scale_err
+ self.orient_err = orient_err
+ self.attr_err = attr_err
+
+ def __eq__(self, other):
+ eq = True
+ for key in self.serialize().keys():
+ eq = eq and np.array_equal(getattr(self, key), getattr(other, key))
+ return eq
+
+ @property
+ def max_recall_ind(self):
+ """ Returns index of max recall achieved. """
+
+ # Last instance of confidence > 0 is index of max achieved recall.
+ non_zero = np.nonzero(self.confidence)[0]
+ if len(non_zero) == 0: # If there are no matches, all the confidence values will be zero.
+ max_recall_ind = 0
+ else:
+ max_recall_ind = non_zero[-1]
+
+ return max_recall_ind
+
+ @property
+ def max_recall(self):
+ """ Returns max recall achieved. """
+
+ return self.recall[self.max_recall_ind]
+
+ def serialize(self):
+ """ Serialize instance into json-friendly format. """
+ return {
+ 'recall': self.recall.tolist(),
+ 'precision': self.precision.tolist(),
+ 'confidence': self.confidence.tolist(),
+ 'trans_err': self.trans_err.tolist(),
+ 'vel_err': self.vel_err.tolist(),
+ 'scale_err': self.scale_err.tolist(),
+ 'orient_err': self.orient_err.tolist(),
+ 'attr_err': self.attr_err.tolist(),
+ }
+
+ @classmethod
+ def deserialize(cls, content: dict):
+ """ Initialize from serialized content. """
+ return cls(recall=np.array(content['recall']),
+ precision=np.array(content['precision']),
+ confidence=np.array(content['confidence']),
+ trans_err=np.array(content['trans_err']),
+ vel_err=np.array(content['vel_err']),
+ scale_err=np.array(content['scale_err']),
+ orient_err=np.array(content['orient_err']),
+ attr_err=np.array(content['attr_err']))
+
+ @classmethod
+ def no_predictions(cls):
+ """ Returns a md instance corresponding to having no predictions. """
+ return cls(recall=np.linspace(0, 1, cls.nelem),
+ precision=np.zeros(cls.nelem),
+ confidence=np.zeros(cls.nelem),
+ trans_err=np.ones(cls.nelem),
+ vel_err=np.ones(cls.nelem),
+ scale_err=np.ones(cls.nelem),
+ orient_err=np.ones(cls.nelem),
+ attr_err=np.ones(cls.nelem))
+
+ @classmethod
+ def random_md(cls):
+ """ Returns an md instance corresponding to a random results. """
+ return cls(recall=np.linspace(0, 1, cls.nelem),
+ precision=np.random.random(cls.nelem),
+ confidence=np.linspace(0, 1, cls.nelem)[::-1],
+ trans_err=np.random.random(cls.nelem),
+ vel_err=np.random.random(cls.nelem),
+ scale_err=np.random.random(cls.nelem),
+ orient_err=np.random.random(cls.nelem),
+ attr_err=np.random.random(cls.nelem))
+
+
+class DetectionMetrics:
+ """ Stores average precision and true positive metric results. Provides properties to summarize. """
+
+ def __init__(self, cfg: DetectionConfig):
+
+ self.cfg = cfg
+ self._label_aps = defaultdict(lambda: defaultdict(float))
+ self._label_tp_errors = defaultdict(lambda: defaultdict(float))
+ self.eval_time = None
+
+ def add_label_ap(self, detection_name: str, dist_th: float, ap: float) -> None:
+ self._label_aps[detection_name][dist_th] = ap
+
+ def get_label_ap(self, detection_name: str, dist_th: float) -> float:
+ return self._label_aps[detection_name][dist_th]
+
+ def add_label_tp(self, detection_name: str, metric_name: str, tp: float):
+ self._label_tp_errors[detection_name][metric_name] = tp
+
+ def get_label_tp(self, detection_name: str, metric_name: str) -> float:
+ return self._label_tp_errors[detection_name][metric_name]
+
+ def add_runtime(self, eval_time: float) -> None:
+ self.eval_time = eval_time
+
+ @property
+ def mean_dist_aps(self) -> Dict[str, float]:
+ """ Calculates the mean over distance thresholds for each label. """
+ return {class_name: np.mean(list(d.values())) for class_name, d in self._label_aps.items()}
+
+ @property
+ def mean_ap(self) -> float:
+ """ Calculates the mean AP by averaging over distance thresholds and classes. """
+ return float(np.mean(list(self.mean_dist_aps.values())))
+
+ @property
+ def tp_errors(self) -> Dict[str, float]:
+ """ Calculates the mean true positive error across all classes for each metric. """
+ errors = {}
+ for metric_name in TP_METRICS:
+ class_errors = []
+ for detection_name in self.cfg.class_names:
+ class_errors.append(self.get_label_tp(detection_name, metric_name))
+
+ errors[metric_name] = float(np.nanmean(class_errors))
+
+ return errors
+
+ @property
+ def tp_scores(self) -> Dict[str, float]:
+ scores = {}
+ tp_errors = self.tp_errors
+ for metric_name in TP_METRICS:
+
+ # We convert the true positive errors to "scores" by 1-error.
+ score = 1.0 - tp_errors[metric_name]
+
+ # Some of the true positive errors are unbounded, so we bound the scores to min 0.
+ score = max(0.0, score)
+
+ scores[metric_name] = score
+
+ return scores
+
+ @property
+ def nd_score(self) -> float:
+ """
+ Compute the nuScenes detection score (NDS, weighted sum of the individual scores).
+ :return: The NDS.
+ """
+ # Summarize.
+ total = float(self.cfg.mean_ap_weight * self.mean_ap + np.sum(list(self.tp_scores.values())))
+
+ # Normalize.
+ total = total / float(self.cfg.mean_ap_weight + len(self.tp_scores.keys()))
+
+ return total
+
+ def serialize(self):
+ return {
+ 'label_aps': self._label_aps,
+ 'mean_dist_aps': self.mean_dist_aps,
+ 'mean_ap': self.mean_ap,
+ 'label_tp_errors': self._label_tp_errors,
+ 'tp_errors': self.tp_errors,
+ 'tp_scores': self.tp_scores,
+ 'nd_score': self.nd_score,
+ 'eval_time': self.eval_time,
+ 'cfg': self.cfg.serialize()
+ }
+
+ @classmethod
+ def deserialize(cls, content: dict):
+ """ Initialize from serialized dictionary. """
+
+ cfg = DetectionConfig.deserialize(content['cfg'])
+
+ metrics = cls(cfg=cfg)
+ metrics.add_runtime(content['eval_time'])
+
+ for detection_name, label_aps in content['label_aps'].items():
+ for dist_th, ap in label_aps.items():
+ metrics.add_label_ap(detection_name=detection_name, dist_th=float(dist_th), ap=float(ap))
+
+ for detection_name, label_tps in content['label_tp_errors'].items():
+ for metric_name, tp in label_tps.items():
+ metrics.add_label_tp(detection_name=detection_name, metric_name=metric_name, tp=float(tp))
+
+ return metrics
+
+ def __eq__(self, other):
+ eq = True
+ eq = eq and self._label_aps == other._label_aps
+ eq = eq and self._label_tp_errors == other._label_tp_errors
+ eq = eq and self.eval_time == other.eval_time
+ eq = eq and self.cfg == other.cfg
+
+ return eq
+
+
+class DetectionBox(EvalBox):
+ """ Data class used during detection evaluation. Can be a prediction or ground truth."""
+
+ def __init__(self,
+ sample_token: str = "",
+ translation: Tuple[float, float, float] = (0, 0, 0),
+ size: Tuple[float, float, float] = (0, 0, 0),
+ rotation: Tuple[float, float, float, float] = (0, 0, 0, 0),
+ velocity: Tuple[float, float] = (0, 0),
+ ego_translation: [float, float, float] = (0, 0, 0), # Translation to ego vehicle in meters.
+ num_pts: int = -1, # Nbr. LIDAR or RADAR inside the box. Only for gt boxes.
+ detection_name: str = 'car', # The class name used in the detection challenge.
+ detection_score: float = -1.0, # GT samples do not have a score.
+ attribute_name: str = ''): # Box attribute. Each box can have at most 1 attribute.
+
+ super().__init__(sample_token, translation, size, rotation, velocity, ego_translation, num_pts)
+
+ assert detection_name is not None, 'Error: detection_name cannot be empty!'
+ assert detection_name in DETECTION_NAMES, 'Error: Unknown detection_name %s' % detection_name
+
+ assert attribute_name in ATTRIBUTE_NAMES or attribute_name == '', \
+ 'Error: Unknown attribute_name %s' % attribute_name
+
+ assert type(detection_score) == float, 'Error: detection_score must be a float!'
+ assert not np.any(np.isnan(detection_score)), 'Error: detection_score may not be NaN!'
+
+ # Assign.
+ self.detection_name = detection_name
+ self.detection_score = detection_score
+ self.attribute_name = attribute_name
+
+ def __eq__(self, other):
+ return (self.sample_token == other.sample_token and
+ self.translation == other.translation and
+ self.size == other.size and
+ self.rotation == other.rotation and
+ self.velocity == other.velocity and
+ self.ego_translation == other.ego_translation and
+ self.num_pts == other.num_pts and
+ self.detection_name == other.detection_name and
+ self.detection_score == other.detection_score and
+ self.attribute_name == other.attribute_name)
+
+ def serialize(self) -> dict:
+ """ Serialize instance into json-friendly format. """
+ return {
+ 'sample_token': self.sample_token,
+ 'translation': self.translation,
+ 'size': self.size,
+ 'rotation': self.rotation,
+ 'velocity': self.velocity,
+ 'ego_translation': self.ego_translation,
+ 'num_pts': self.num_pts,
+ 'detection_name': self.detection_name,
+ 'detection_score': self.detection_score,
+ 'attribute_name': self.attribute_name
+ }
+
+ @classmethod
+ def deserialize(cls, content: dict):
+ """ Initialize from serialized content. """
+ return cls(sample_token=content['sample_token'],
+ translation=tuple(content['translation']),
+ size=tuple(content['size']),
+ rotation=tuple(content['rotation']),
+ velocity=tuple(content['velocity']),
+ ego_translation=(0.0, 0.0, 0.0) if 'ego_translation' not in content
+ else tuple(content['ego_translation']),
+ num_pts=-1 if 'num_pts' not in content else int(content['num_pts']),
+ detection_name=content['detection_name'],
+ detection_score=-1.0 if 'detection_score' not in content else float(content['detection_score']),
+ attribute_name=content['attribute_name'])
+
+
+class DetectionMetricDataList:
+ """ This stores a set of MetricData in a dict indexed by (name, match-distance). """
+
+ def __init__(self):
+ self.md = {}
+
+ def __getitem__(self, key):
+ return self.md[key]
+
+ def __eq__(self, other):
+ eq = True
+ for key in self.md.keys():
+ eq = eq and self[key] == other[key]
+ return eq
+
+ def get_class_data(self, detection_name: str) -> List[Tuple[DetectionMetricData, float]]:
+ """ Get all the MetricData entries for a certain detection_name. """
+ return [(md, dist_th) for (name, dist_th), md in self.md.items() if name == detection_name]
+
+ def get_dist_data(self, dist_th: float) -> List[Tuple[DetectionMetricData, str]]:
+ """ Get all the MetricData entries for a certain match_distance. """
+ return [(md, detection_name) for (detection_name, dist), md in self.md.items() if dist == dist_th]
+
+ def set(self, detection_name: str, match_distance: float, data: DetectionMetricData):
+ """ Sets the MetricData entry for a certain detection_name and match_distance. """
+ self.md[(detection_name, match_distance)] = data
+
+ def serialize(self) -> dict:
+ return {key[0] + ':' + str(key[1]): value.serialize() for key, value in self.md.items()}
+
+ @classmethod
+ def deserialize(cls, content: dict):
+ mdl = cls()
+ for key, md in content.items():
+ name, distance = key.split(':')
+ mdl.set(name, float(distance), DetectionMetricData.deserialize(md))
+ return mdl
diff --git a/python-sdk/nuscenes/eval/detection/evaluate.py b/python-sdk/nuscenes/eval/detection/evaluate.py
new file mode 100644
index 0000000..dc30725
--- /dev/null
+++ b/python-sdk/nuscenes/eval/detection/evaluate.py
@@ -0,0 +1,302 @@
+# nuScenes dev-kit.
+# Code written by Holger Caesar & Oscar Beijbom, 2018.
+
+import argparse
+import json
+import os
+import random
+import time
+from typing import Tuple, Dict, Any
+
+import numpy as np
+
+from nuscenes import NuScenes
+from nuscenes.eval.common.config import config_factory
+from nuscenes.eval.common.data_classes import EvalBoxes
+from nuscenes.eval.common.loaders import load_prediction, load_gt, add_center_dist, filter_eval_boxes
+from nuscenes.eval.detection.algo import accumulate, calc_ap, calc_tp
+from nuscenes.eval.detection.constants import TP_METRICS
+from nuscenes.eval.detection.data_classes import DetectionConfig, DetectionMetrics, DetectionBox, \
+ DetectionMetricDataList
+from nuscenes.eval.detection.render import summary_plot, class_pr_curve, class_tp_curve, dist_pr_curve, visualize_sample
+
+
+class DetectionEval:
+ """
+ This is the official nuScenes detection evaluation code.
+ Results are written to the provided output_dir.
+
+ nuScenes uses the following detection metrics:
+ - Mean Average Precision (mAP): Uses center-distance as matching criterion; averaged over distance thresholds.
+ - True Positive (TP) metrics: Average of translation, velocity, scale, orientation and attribute errors.
+ - nuScenes Detection Score (NDS): The weighted sum of the above.
+
+ Here is an overview of the functions in this method:
+ - init: Loads GT annotations and predictions stored in JSON format and filters the boxes.
+ - run: Performs evaluation and dumps the metric data to disk.
+ - render: Renders various plots and dumps to disk.
+
+ We assume that:
+ - Every sample_token is given in the results, although there may be not predictions for that sample.
+
+ Please see https://www.nuscenes.org/object-detection for more details.
+ """
+ def __init__(self,
+ nusc: NuScenes,
+ config: DetectionConfig,
+ result_path: str,
+ eval_set: str,
+ output_dir: str = None,
+ verbose: bool = True):
+ """
+ Initialize a DetectionEval object.
+ :param nusc: A NuScenes object.
+ :param config: A DetectionConfig object.
+ :param result_path: Path of the nuScenes JSON result file.
+ :param eval_set: The dataset split to evaluate on, e.g. train, val or test.
+ :param output_dir: Folder to save plots and results to.
+ :param verbose: Whether to print to stdout.
+ """
+ self.nusc = nusc
+ self.result_path = result_path
+ self.eval_set = eval_set
+ self.output_dir = output_dir
+ self.verbose = verbose
+ self.cfg = config
+
+ # Check result file exists.
+ assert os.path.exists(result_path), 'Error: The result file does not exist!'
+
+ # Make dirs.
+ self.plot_dir = os.path.join(self.output_dir, 'plots')
+ if not os.path.isdir(self.output_dir):
+ os.makedirs(self.output_dir)
+ if not os.path.isdir(self.plot_dir):
+ os.makedirs(self.plot_dir)
+
+ # Load data.
+ if verbose:
+ print('Initializing nuScenes detection evaluation')
+ self.pred_boxes, self.meta = load_prediction(self.result_path, self.cfg.max_boxes_per_sample, DetectionBox,
+ verbose=verbose)
+ self.gt_boxes = load_gt(self.nusc, self.eval_set, DetectionBox, verbose=verbose)
+
+ assert set(self.pred_boxes.sample_tokens) == set(self.gt_boxes.sample_tokens), \
+ "Samples in split doesn't match samples in predictions."
+
+ # Add center distances.
+ self.pred_boxes = add_center_dist(nusc, self.pred_boxes)
+ self.gt_boxes = add_center_dist(nusc, self.gt_boxes)
+
+ # Filter boxes (distance, points per box, etc.).
+ if verbose:
+ print('Filtering predictions')
+ self.pred_boxes = filter_eval_boxes(nusc, self.pred_boxes, self.cfg.class_range, verbose=verbose)
+ if verbose:
+ print('Filtering ground truth annotations')
+ self.gt_boxes = filter_eval_boxes(nusc, self.gt_boxes, self.cfg.class_range, verbose=verbose)
+
+ self.sample_tokens = self.gt_boxes.sample_tokens
+
+ def evaluate(self) -> Tuple[DetectionMetrics, DetectionMetricDataList]:
+ """
+ Performs the actual evaluation.
+ :return: A tuple of high-level and the raw metric data.
+ """
+ start_time = time.time()
+
+ # -----------------------------------
+ # Step 1: Accumulate metric data for all classes and distance thresholds.
+ # -----------------------------------
+ if self.verbose:
+ print('Accumulating metric data...')
+ metric_data_list = DetectionMetricDataList()
+ for class_name in self.cfg.class_names:
+ for dist_th in self.cfg.dist_ths:
+ md = accumulate(self.gt_boxes, self.pred_boxes, class_name, self.cfg.dist_fcn_callable, dist_th)
+ metric_data_list.set(class_name, dist_th, md)
+
+ # -----------------------------------
+ # Step 2: Calculate metrics from the data.
+ # -----------------------------------
+ if self.verbose:
+ print('Calculating metrics...')
+ metrics = DetectionMetrics(self.cfg)
+ for class_name in self.cfg.class_names:
+ # Compute APs.
+ for dist_th in self.cfg.dist_ths:
+ metric_data = metric_data_list[(class_name, dist_th)]
+ ap = calc_ap(metric_data, self.cfg.min_recall, self.cfg.min_precision)
+ metrics.add_label_ap(class_name, dist_th, ap)
+
+ # Compute TP metrics.
+ for metric_name in TP_METRICS:
+ metric_data = metric_data_list[(class_name, self.cfg.dist_th_tp)]
+ if class_name in ['traffic_cone'] and metric_name in ['attr_err', 'vel_err', 'orient_err']:
+ tp = np.nan
+ elif class_name in ['barrier'] and metric_name in ['attr_err', 'vel_err']:
+ tp = np.nan
+ else:
+ tp = calc_tp(metric_data, self.cfg.min_recall, metric_name)
+ metrics.add_label_tp(class_name, metric_name, tp)
+
+ # Compute evaluation time.
+ metrics.add_runtime(time.time() - start_time)
+
+ return metrics, metric_data_list
+
+ def render(self, metrics: DetectionMetrics, md_list: DetectionMetricDataList) -> None:
+ """
+ Renders various PR and TP curves.
+ :param metrics: DetectionMetrics instance.
+ :param md_list: DetectionMetricDataList instance.
+ """
+ if self.verbose:
+ print('Rendering PR and TP curves')
+
+ def savepath(name):
+ return os.path.join(self.plot_dir, name + '.pdf')
+
+ summary_plot(md_list, metrics, min_precision=self.cfg.min_precision, min_recall=self.cfg.min_recall,
+ dist_th_tp=self.cfg.dist_th_tp, savepath=savepath('summary'))
+
+ for detection_name in self.cfg.class_names:
+ class_pr_curve(md_list, metrics, detection_name, self.cfg.min_precision, self.cfg.min_recall,
+ savepath=savepath(detection_name + '_pr'))
+
+ class_tp_curve(md_list, metrics, detection_name, self.cfg.min_recall, self.cfg.dist_th_tp,
+ savepath=savepath(detection_name + '_tp'))
+
+ for dist_th in self.cfg.dist_ths:
+ dist_pr_curve(md_list, metrics, dist_th, self.cfg.min_precision, self.cfg.min_recall,
+ savepath=savepath('dist_pr_' + str(dist_th)))
+
+ def main(self,
+ plot_examples: int = 0,
+ render_curves: bool = True) -> Dict[str, Any]:
+ """
+ Main function that loads the evaluation code, visualizes samples, runs the evaluation and renders stat plots.
+ :param plot_examples: How many example visualizations to write to disk.
+ :param render_curves: Whether to render PR and TP curves to disk.
+ :return: A dict that stores the high-level metrics and meta data.
+ """
+ if plot_examples > 0:
+ # Select a random but fixed subset to plot.
+ random.seed(42)
+ sample_tokens = list(self.sample_tokens)
+ random.shuffle(sample_tokens)
+ sample_tokens = sample_tokens[:plot_examples]
+
+ # Visualize samples.
+ example_dir = os.path.join(self.output_dir, 'examples')
+ if not os.path.isdir(example_dir):
+ os.mkdir(example_dir)
+ for sample_token in sample_tokens:
+ visualize_sample(self.nusc,
+ sample_token,
+ self.gt_boxes if self.eval_set != 'test' else EvalBoxes(),
+ # Don't render test GT.
+ self.pred_boxes,
+ eval_range=max(self.cfg.class_range.values()),
+ savepath=os.path.join(example_dir, '{}.png'.format(sample_token)))
+
+ # Run evaluation.
+ metrics, metric_data_list = self.evaluate()
+
+ # Render PR and TP curves.
+ if render_curves:
+ self.render(metrics, metric_data_list)
+
+ # Dump the metric data, meta and metrics to disk.
+ if self.verbose:
+ print('Saving metrics to: %s' % self.output_dir)
+ metrics_summary = metrics.serialize()
+ metrics_summary['meta'] = self.meta.copy()
+ with open(os.path.join(self.output_dir, 'metrics_summary.json'), 'w') as f:
+ json.dump(metrics_summary, f, indent=2)
+ with open(os.path.join(self.output_dir, 'metrics_details.json'), 'w') as f:
+ json.dump(metric_data_list.serialize(), f, indent=2)
+
+ # Print high-level metrics.
+ print('mAP: %.4f' % (metrics_summary['mean_ap']))
+ err_name_mapping = {
+ 'trans_err': 'mATE',
+ 'scale_err': 'mASE',
+ 'orient_err': 'mAOE',
+ 'vel_err': 'mAVE',
+ 'attr_err': 'mAAE'
+ }
+ for tp_name, tp_val in metrics_summary['tp_errors'].items():
+ print('%s: %.4f' % (err_name_mapping[tp_name], tp_val))
+ print('NDS: %.4f' % (metrics_summary['nd_score']))
+ print('Eval time: %.1fs' % metrics_summary['eval_time'])
+
+ # Print per-class metrics.
+ print()
+ print('Per-class results:')
+ print('Object Class\tAP\tATE\tASE\tAOE\tAVE\tAAE')
+ class_aps = metrics_summary['mean_dist_aps']
+ class_tps = metrics_summary['label_tp_errors']
+ for class_name in class_aps.keys():
+ print('%s\t%.3f\t%.3f\t%.3f\t%.3f\t%.3f\t%.3f'
+ % (class_name, class_aps[class_name],
+ class_tps[class_name]['trans_err'],
+ class_tps[class_name]['scale_err'],
+ class_tps[class_name]['orient_err'],
+ class_tps[class_name]['vel_err'],
+ class_tps[class_name]['attr_err']))
+
+ return metrics_summary
+
+
+class NuScenesEval(DetectionEval):
+ """
+ Dummy class for backward-compatibility. Same as DetectionEval.
+ """
+
+
+if __name__ == "__main__":
+
+ # Settings.
+ parser = argparse.ArgumentParser(description='Evaluate nuScenes detection results.',
+ formatter_class=argparse.ArgumentDefaultsHelpFormatter)
+ parser.add_argument('result_path', type=str, help='The submission as a JSON file.')
+ parser.add_argument('--output_dir', type=str, default='~/nuscenes-metrics',
+ help='Folder to store result metrics, graphs and example visualizations.')
+ parser.add_argument('--eval_set', type=str, default='val',
+ help='Which dataset split to evaluate on, train, val or test.')
+ parser.add_argument('--dataroot', type=str, default='/data/sets/nuscenes',
+ help='Default nuScenes data directory.')
+ parser.add_argument('--version', type=str, default='v1.0-trainval',
+ help='Which version of the nuScenes dataset to evaluate on, e.g. v1.0-trainval.')
+ parser.add_argument('--config_path', type=str, default='',
+ help='Path to the configuration file.'
+ 'If no path given, the CVPR 2019 configuration will be used.')
+ parser.add_argument('--plot_examples', type=int, default=10,
+ help='How many example visualizations to write to disk.')
+ parser.add_argument('--render_curves', type=int, default=1,
+ help='Whether to render PR and TP curves to disk.')
+ parser.add_argument('--verbose', type=int, default=1,
+ help='Whether to print to stdout.')
+ args = parser.parse_args()
+
+ result_path_ = os.path.expanduser(args.result_path)
+ output_dir_ = os.path.expanduser(args.output_dir)
+ eval_set_ = args.eval_set
+ dataroot_ = args.dataroot
+ version_ = args.version
+ config_path = args.config_path
+ plot_examples_ = args.plot_examples
+ render_curves_ = bool(args.render_curves)
+ verbose_ = bool(args.verbose)
+
+ if config_path == '':
+ cfg_ = config_factory('detection_cvpr_2019')
+ else:
+ with open(config_path, 'r') as _f:
+ cfg_ = DetectionConfig.deserialize(json.load(_f))
+
+ nusc_ = NuScenes(version=version_, verbose=verbose_, dataroot=dataroot_)
+ nusc_eval = DetectionEval(nusc_, config=cfg_, result_path=result_path_, eval_set=eval_set_,
+ output_dir=output_dir_, verbose=verbose_)
+ nusc_eval.main(plot_examples=plot_examples_, render_curves=render_curves_)
diff --git a/python-sdk/nuscenes/eval/detection/render.py b/python-sdk/nuscenes/eval/detection/render.py
new file mode 100644
index 0000000..68c56af
--- /dev/null
+++ b/python-sdk/nuscenes/eval/detection/render.py
@@ -0,0 +1,338 @@
+# nuScenes dev-kit.
+# Code written by Holger Caesar, Varun Bankiti, and Alex Lang, 2019.
+
+import json
+from typing import Any
+
+import numpy as np
+from matplotlib import pyplot as plt
+
+from nuscenes import NuScenes
+from nuscenes.eval.common.data_classes import EvalBoxes
+from nuscenes.eval.common.render import setup_axis
+from nuscenes.eval.common.utils import boxes_to_sensor
+from nuscenes.eval.detection.constants import TP_METRICS, DETECTION_NAMES, DETECTION_COLORS, TP_METRICS_UNITS, \
+ PRETTY_DETECTION_NAMES, PRETTY_TP_METRICS
+from nuscenes.eval.detection.data_classes import DetectionMetrics, DetectionMetricData, DetectionMetricDataList
+from nuscenes.utils.data_classes import LidarPointCloud
+from nuscenes.utils.geometry_utils import view_points
+
+Axis = Any
+
+
+def visualize_sample(nusc: NuScenes,
+ sample_token: str,
+ gt_boxes: EvalBoxes,
+ pred_boxes: EvalBoxes,
+ nsweeps: int = 1,
+ conf_th: float = 0.15,
+ eval_range: float = 50,
+ verbose: bool = True,
+ savepath: str = None) -> None:
+ """
+ Visualizes a sample from BEV with annotations and detection results.
+ :param nusc: NuScenes object.
+ :param sample_token: The nuScenes sample token.
+ :param gt_boxes: Ground truth boxes grouped by sample.
+ :param pred_boxes: Prediction grouped by sample.
+ :param nsweeps: Number of sweeps used for lidar visualization.
+ :param conf_th: The confidence threshold used to filter negatives.
+ :param eval_range: Range in meters beyond which boxes are ignored.
+ :param verbose: Whether to print to stdout.
+ :param savepath: If given, saves the the rendering here instead of displaying.
+ """
+ # Retrieve sensor & pose records.
+ sample_rec = nusc.get('sample', sample_token)
+ sd_record = nusc.get('sample_data', sample_rec['data']['LIDAR_TOP'])
+ cs_record = nusc.get('calibrated_sensor', sd_record['calibrated_sensor_token'])
+ pose_record = nusc.get('ego_pose', sd_record['ego_pose_token'])
+
+ # Get boxes.
+ boxes_gt_global = gt_boxes[sample_token]
+ boxes_est_global = pred_boxes[sample_token]
+
+ # Map GT boxes to lidar.
+ boxes_gt = boxes_to_sensor(boxes_gt_global, pose_record, cs_record)
+
+ # Map EST boxes to lidar.
+ boxes_est = boxes_to_sensor(boxes_est_global, pose_record, cs_record)
+
+ # Add scores to EST boxes.
+ for box_est, box_est_global in zip(boxes_est, boxes_est_global):
+ box_est.score = box_est_global.detection_score
+
+ # Get point cloud in lidar frame.
+ pc, _ = LidarPointCloud.from_file_multisweep(nusc, sample_rec, 'LIDAR_TOP', 'LIDAR_TOP', nsweeps=nsweeps)
+
+ # Init axes.
+ _, ax = plt.subplots(1, 1, figsize=(9, 9))
+
+ # Show point cloud.
+ points = view_points(pc.points[:3, :], np.eye(4), normalize=False)
+ dists = np.sqrt(np.sum(pc.points[:2, :] ** 2, axis=0))
+ colors = np.minimum(1, dists / eval_range)
+ ax.scatter(points[0, :], points[1, :], c=colors, s=0.2)
+
+ # Show ego vehicle.
+ ax.plot(0, 0, 'x', color='black')
+
+ # Show GT boxes.
+ for box in boxes_gt:
+ box.render(ax, view=np.eye(4), colors=('g', 'g', 'g'), linewidth=2)
+
+ # Show EST boxes.
+ for box in boxes_est:
+ # Show only predictions with a high score.
+ assert not np.isnan(box.score), 'Error: Box score cannot be NaN!'
+ if box.score >= conf_th:
+ box.render(ax, view=np.eye(4), colors=('b', 'b', 'b'), linewidth=1)
+
+ # Limit visible range.
+ axes_limit = eval_range + 3 # Slightly bigger to include boxes that extend beyond the range.
+ ax.set_xlim(-axes_limit, axes_limit)
+ ax.set_ylim(-axes_limit, axes_limit)
+
+ # Show / save plot.
+ if verbose:
+ print('Rendering sample token %s' % sample_token)
+ plt.title(sample_token)
+ if savepath is not None:
+ plt.savefig(savepath)
+ plt.close()
+ else:
+ plt.show()
+
+
+def class_pr_curve(md_list: DetectionMetricDataList,
+ metrics: DetectionMetrics,
+ detection_name: str,
+ min_precision: float,
+ min_recall: float,
+ savepath: str = None,
+ ax: Axis = None) -> None:
+ """
+ Plot a precision recall curve for the specified class.
+ :param md_list: DetectionMetricDataList instance.
+ :param metrics: DetectionMetrics instance.
+ :param detection_name: The detection class.
+ :param min_precision:
+ :param min_recall: Minimum recall value.
+ :param savepath: If given, saves the the rendering here instead of displaying.
+ :param ax: Axes onto which to render.
+ """
+ # Prepare axis.
+ if ax is None:
+ ax = setup_axis(title=PRETTY_DETECTION_NAMES[detection_name], xlabel='Recall', ylabel='Precision', xlim=1,
+ ylim=1, min_precision=min_precision, min_recall=min_recall)
+
+ # Get recall vs precision values of given class for each distance threshold.
+ data = md_list.get_class_data(detection_name)
+
+ # Plot the recall vs. precision curve for each distance threshold.
+ for md, dist_th in data:
+ md: DetectionMetricData
+ ap = metrics.get_label_ap(detection_name, dist_th)
+ ax.plot(md.recall, md.precision, label='Dist. : {}, AP: {:.1f}'.format(dist_th, ap * 100))
+
+ ax.legend(loc='best')
+ if savepath is not None:
+ plt.savefig(savepath)
+ plt.close()
+
+
+def class_tp_curve(md_list: DetectionMetricDataList,
+ metrics: DetectionMetrics,
+ detection_name: str,
+ min_recall: float,
+ dist_th_tp: float,
+ savepath: str = None,
+ ax: Axis = None) -> None:
+ """
+ Plot the true positive curve for the specified class.
+ :param md_list: DetectionMetricDataList instance.
+ :param metrics: DetectionMetrics instance.
+ :param detection_name:
+ :param min_recall: Minimum recall value.
+ :param dist_th_tp: The distance threshold used to determine matches.
+ :param savepath: If given, saves the the rendering here instead of displaying.
+ :param ax: Axes onto which to render.
+ """
+ # Get metric data for given detection class with tp distance threshold.
+ md = md_list[(detection_name, dist_th_tp)]
+ min_recall_ind = round(100 * min_recall)
+ if min_recall_ind <= md.max_recall_ind:
+ # For traffic_cone and barrier only a subset of the metrics are plotted.
+ rel_metrics = [m for m in TP_METRICS if not np.isnan(metrics.get_label_tp(detection_name, m))]
+ ylimit = max([max(getattr(md, metric)[min_recall_ind:md.max_recall_ind + 1]) for metric in rel_metrics]) * 1.1
+ else:
+ ylimit = 1.0
+
+ # Prepare axis.
+ if ax is None:
+ ax = setup_axis(title=PRETTY_DETECTION_NAMES[detection_name], xlabel='Recall', ylabel='Error', xlim=1,
+ min_recall=min_recall)
+ ax.set_ylim(0, ylimit)
+
+ # Plot the recall vs. error curve for each tp metric.
+ for metric in TP_METRICS:
+ tp = metrics.get_label_tp(detection_name, metric)
+
+ # Plot only if we have valid data.
+ if tp is not np.nan and min_recall_ind <= md.max_recall_ind:
+ recall, error = md.recall[:md.max_recall_ind + 1], getattr(md, metric)[:md.max_recall_ind + 1]
+ else:
+ recall, error = [], []
+
+ # Change legend based on tp value
+ if tp is np.nan:
+ label = '{}: n/a'.format(PRETTY_TP_METRICS[metric])
+ elif min_recall_ind > md.max_recall_ind:
+ label = '{}: nan'.format(PRETTY_TP_METRICS[metric])
+ else:
+ label = '{}: {:.2f} ({})'.format(PRETTY_TP_METRICS[metric], tp, TP_METRICS_UNITS[metric])
+ ax.plot(recall, error, label=label)
+ ax.axvline(x=md.max_recall, linestyle='-.', color=(0, 0, 0, 0.3))
+ ax.legend(loc='best')
+
+ if savepath is not None:
+ plt.savefig(savepath)
+ plt.close()
+
+
+def dist_pr_curve(md_list: DetectionMetricDataList,
+ metrics: DetectionMetrics,
+ dist_th: float,
+ min_precision: float,
+ min_recall: float,
+ savepath: str = None) -> None:
+ """
+ Plot the PR curves for different distance thresholds.
+ :param md_list: DetectionMetricDataList instance.
+ :param metrics: DetectionMetrics instance.
+ :param dist_th: Distance threshold for matching.
+ :param min_precision: Minimum precision value.
+ :param min_recall: Minimum recall value.
+ :param savepath: If given, saves the the rendering here instead of displaying.
+ """
+ # Prepare axis.
+ fig, (ax, lax) = plt.subplots(ncols=2, gridspec_kw={"width_ratios": [4, 1]},
+ figsize=(7.5, 5))
+ ax = setup_axis(xlabel='Recall', ylabel='Precision',
+ xlim=1, ylim=1, min_precision=min_precision, min_recall=min_recall, ax=ax)
+
+ # Plot the recall vs. precision curve for each detection class.
+ data = md_list.get_dist_data(dist_th)
+ for md, detection_name in data:
+ md = md_list[(detection_name, dist_th)]
+ ap = metrics.get_label_ap(detection_name, dist_th)
+ ax.plot(md.recall, md.precision, label='{}: {:.1f}%'.format(PRETTY_DETECTION_NAMES[detection_name], ap * 100),
+ color=DETECTION_COLORS[detection_name])
+ hx, lx = ax.get_legend_handles_labels()
+ lax.legend(hx, lx, borderaxespad=0)
+ lax.axis("off")
+ plt.tight_layout()
+ if savepath is not None:
+ plt.savefig(savepath)
+ plt.close()
+
+
+def summary_plot(md_list: DetectionMetricDataList,
+ metrics: DetectionMetrics,
+ min_precision: float,
+ min_recall: float,
+ dist_th_tp: float,
+ savepath: str = None) -> None:
+ """
+ Creates a summary plot with PR and TP curves for each class.
+ :param md_list: DetectionMetricDataList instance.
+ :param metrics: DetectionMetrics instance.
+ :param min_precision: Minimum precision value.
+ :param min_recall: Minimum recall value.
+ :param dist_th_tp: The distance threshold used to determine matches.
+ :param savepath: If given, saves the the rendering here instead of displaying.
+ """
+ n_classes = len(DETECTION_NAMES)
+ _, axes = plt.subplots(nrows=n_classes, ncols=2, figsize=(15, 5 * n_classes))
+ for ind, detection_name in enumerate(DETECTION_NAMES):
+ title1, title2 = ('Recall vs Precision', 'Recall vs Error') if ind == 0 else (None, None)
+
+ ax1 = setup_axis(xlim=1, ylim=1, title=title1, min_precision=min_precision,
+ min_recall=min_recall, ax=axes[ind, 0])
+ ax1.set_ylabel('{} \n \n Precision'.format(PRETTY_DETECTION_NAMES[detection_name]), size=20)
+
+ ax2 = setup_axis(xlim=1, title=title2, min_recall=min_recall, ax=axes[ind, 1])
+ if ind == n_classes - 1:
+ ax1.set_xlabel('Recall', size=20)
+ ax2.set_xlabel('Recall', size=20)
+
+ class_pr_curve(md_list, metrics, detection_name, min_precision, min_recall, ax=ax1)
+ class_tp_curve(md_list, metrics, detection_name, min_recall, dist_th_tp=dist_th_tp, ax=ax2)
+
+ plt.tight_layout()
+
+ if savepath is not None:
+ plt.savefig(savepath)
+ plt.close()
+
+
+def detailed_results_table_tex(metrics_path: str, output_path: str) -> None:
+ """
+ Renders a detailed results table in tex.
+ :param metrics_path: path to a serialized DetectionMetrics file.
+ :param output_path: path to the output file.
+ """
+ with open(metrics_path, 'r') as f:
+ metrics = json.load(f)
+
+ tex = ''
+ tex += '\\begin{table}[]\n'
+ tex += '\\small\n'
+ tex += '\\begin{tabular}{| c | c | c | c | c | c | c |} \\hline\n'
+ tex += '\\textbf{Class} & \\textbf{AP} & \\textbf{ATE} & \\textbf{ASE} & \\textbf{AOE} & ' \
+ '\\textbf{AVE} & ' \
+ '\\textbf{AAE} \\\\ \\hline ' \
+ '\\hline\n'
+ for name in DETECTION_NAMES:
+ ap = np.mean(metrics['label_aps'][name].values()) * 100
+ ate = metrics['label_tp_errors'][name]['trans_err']
+ ase = metrics['label_tp_errors'][name]['scale_err']
+ aoe = metrics['label_tp_errors'][name]['orient_err']
+ ave = metrics['label_tp_errors'][name]['vel_err']
+ aae = metrics['label_tp_errors'][name]['attr_err']
+ tex_name = PRETTY_DETECTION_NAMES[name]
+ if name == 'traffic_cone':
+ tex += '{} & {:.1f} & {:.2f} & {:.2f} & N/A & N/A & N/A \\\\ \\hline\n'.format(
+ tex_name, ap, ate, ase)
+ elif name == 'barrier':
+ tex += '{} & {:.1f} & {:.2f} & {:.2f} & {:.2f} & N/A & N/A \\\\ \\hline\n'.format(
+ tex_name, ap, ate, ase, aoe)
+ else:
+ tex += '{} & {:.1f} & {:.2f} & {:.2f} & {:.2f} & {:.2f} & {:.2f} \\\\ ' \
+ '\\hline\n'.format(tex_name, ap, ate, ase, aoe, ave, aae)
+
+ map_ = metrics['mean_ap']
+ mate = metrics['tp_errors']['trans_err']
+ mase = metrics['tp_errors']['scale_err']
+ maoe = metrics['tp_errors']['orient_err']
+ mave = metrics['tp_errors']['vel_err']
+ maae = metrics['tp_errors']['attr_err']
+ tex += '\\hline {} & {:.1f} & {:.2f} & {:.2f} & {:.2f} & {:.2f} & {:.2f} \\\\ ' \
+ '\\hline\n'.format('\\textbf{Mean}', map_, mate, mase, maoe, mave, maae)
+
+ tex += '\\end{tabular}\n'
+
+ # All one line
+ tex += '\\caption{Detailed detection performance on the val set. \n'
+ tex += 'AP: average precision averaged over distance thresholds (%), \n'
+ tex += 'ATE: average translation error (${}$), \n'.format(TP_METRICS_UNITS['trans_err'])
+ tex += 'ASE: average scale error (${}$), \n'.format(TP_METRICS_UNITS['scale_err'])
+ tex += 'AOE: average orientation error (${}$), \n'.format(TP_METRICS_UNITS['orient_err'])
+ tex += 'AVE: average velocity error (${}$), \n'.format(TP_METRICS_UNITS['vel_err'])
+ tex += 'AAE: average attribute error (${}$). \n'.format(TP_METRICS_UNITS['attr_err'])
+ tex += 'nuScenes Detection Score (NDS) = {:.1f} \n'.format(metrics['nd_score'] * 100)
+ tex += '}\n'
+
+ tex += '\\end{table}\n'
+
+ with open(output_path, 'w') as f:
+ f.write(tex)
diff --git a/python-sdk/nuscenes/eval/detection/tests/__init__.py b/python-sdk/nuscenes/eval/detection/tests/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/python-sdk/nuscenes/eval/detection/tests/test_algo.py b/python-sdk/nuscenes/eval/detection/tests/test_algo.py
new file mode 100644
index 0000000..35fa9ca
--- /dev/null
+++ b/python-sdk/nuscenes/eval/detection/tests/test_algo.py
@@ -0,0 +1,428 @@
+# nuScenes dev-kit.
+# Code written by Oscar Beijbom and Varun Bankiti, 2019.
+
+import random
+import unittest
+from typing import Dict, List
+
+import numpy as np
+from pyquaternion import Quaternion
+
+from nuscenes.eval.common.config import config_factory
+from nuscenes.eval.common.data_classes import EvalBoxes
+from nuscenes.eval.common.utils import center_distance
+from nuscenes.eval.detection.algo import accumulate, calc_ap, calc_tp
+from nuscenes.eval.detection.constants import TP_METRICS
+from nuscenes.eval.detection.data_classes import DetectionMetrics, DetectionMetricData, DetectionBox, \
+ DetectionMetricDataList
+from nuscenes.eval.detection.utils import detection_name_to_rel_attributes
+
+
+class TestAlgo(unittest.TestCase):
+
+ cfg = config_factory('detection_cvpr_2019')
+
+ @staticmethod
+ def _mock_results(nsamples, ngt, npred, detection_name):
+
+ def random_attr():
+ """
+ This is the most straight-forward way to generate a random attribute.
+ Not currently used b/c we want the test fixture to be back-wards compatible.
+ """
+ # Get relevant attributes.
+ rel_attributes = detection_name_to_rel_attributes(detection_name)
+
+ if len(rel_attributes) == 0:
+ # Empty string for classes without attributes.
+ return ''
+ else:
+ # Pick a random attribute otherwise.
+ return rel_attributes[np.random.randint(0, len(rel_attributes))]
+
+ pred = EvalBoxes()
+ gt = EvalBoxes()
+
+ for sample_itt in range(nsamples):
+
+ this_gt = []
+
+ for box_itt in range(ngt):
+ translation_xy = tuple(np.random.rand(2) * 15)
+ this_gt.append(DetectionBox(
+ sample_token=str(sample_itt),
+ translation=(translation_xy[0], translation_xy[1], 0.0),
+ size=tuple(np.random.rand(3)*4),
+ rotation=tuple(np.random.rand(4)),
+ velocity=tuple(np.random.rand(3)[:2]*4),
+ detection_name=detection_name,
+ detection_score=random.random(),
+ attribute_name=random_attr(),
+ ego_translation=(random.random() * 10, 0, 0),
+ ))
+ gt.add_boxes(str(sample_itt), this_gt)
+
+ for sample_itt in range(nsamples):
+ this_pred = []
+
+ for box_itt in range(npred):
+ translation_xy = tuple(np.random.rand(2) * 10)
+ this_pred.append(DetectionBox(
+ sample_token=str(sample_itt),
+ translation=(translation_xy[0], translation_xy[1], 0.0),
+ size=tuple(np.random.rand(3) * 4),
+ rotation=tuple(np.random.rand(4)),
+ velocity=tuple(np.random.rand(3)[:2] * 4),
+ detection_name=detection_name,
+ detection_score=random.random(),
+ attribute_name=random_attr(),
+ ego_translation=(random.random() * 10, 0, 0),
+ ))
+
+ pred.add_boxes(str(sample_itt), this_pred)
+
+ return gt, pred
+
+ def test_nd_score(self):
+ """
+ This tests runs the full evaluation for an arbitrary random set of predictions.
+ """
+
+ random.seed(42)
+ np.random.seed(42)
+
+ mdl = DetectionMetricDataList()
+ for class_name in self.cfg.class_names:
+ gt, pred = self._mock_results(30, 3, 25, class_name)
+ for dist_th in self.cfg.dist_ths:
+ mdl.set(class_name, dist_th, accumulate(gt, pred, class_name, center_distance, 2))
+
+ metrics = DetectionMetrics(self.cfg)
+ for class_name in self.cfg.class_names:
+ for dist_th in self.cfg.dist_ths:
+ ap = calc_ap(mdl[(class_name, dist_th)], self.cfg.min_recall, self.cfg.min_precision)
+ metrics.add_label_ap(class_name, dist_th, ap)
+
+ for metric_name in TP_METRICS:
+ metric_data = mdl[(class_name, self.cfg.dist_th_tp)]
+ if class_name in ['traffic_cone'] and metric_name in ['attr_err', 'vel_err', 'orient_err']:
+ tp = np.nan
+ elif class_name in ['barrier'] and metric_name in ['attr_err', 'vel_err']:
+ tp = np.nan
+ else:
+ tp = calc_tp(metric_data, self.cfg.min_recall, metric_name)
+ metrics.add_label_tp(class_name, metric_name, tp)
+
+ self.assertEqual(0.08606662159639042, metrics.nd_score)
+
+ def test_calc_tp(self):
+ """Test for calc_tp()."""
+
+ random.seed(42)
+ np.random.seed(42)
+
+ md = DetectionMetricData.random_md()
+
+ # min_recall greater than 1.
+ self.assertEqual(1.0, calc_tp(md, min_recall=1, metric_name='trans_err'))
+
+ def test_calc_ap(self):
+ """Test for calc_ap()."""
+
+ random.seed(42)
+ np.random.seed(42)
+
+ md = DetectionMetricData.random_md()
+
+ # Negative min_recall and min_precision
+ self.assertRaises(AssertionError, calc_ap, md, -0.5, 0.4)
+ self.assertRaises(AssertionError, calc_ap, md, 0.5, -0.8)
+
+ # More than 1 min_precision/min_recall
+ self.assertRaises(AssertionError, calc_ap, md, 0.7, 1)
+ self.assertRaises(AssertionError, calc_ap, md, 1.2, 0)
+
+
+def get_metric_data(gts: Dict[str, List[Dict]],
+ preds: Dict[str, List[Dict]],
+ detection_name: str,
+ dist_th: float) -> DetectionMetricData:
+ """
+ Calculate and check the AP value.
+ :param gts: Ground truth data.
+ :param preds: Predictions.
+ :param detection_name: Name of the class we are interested in.
+ :param dist_th: Distance threshold for matching.
+ """
+
+ # Some or all of the defaults will be replaced by if given.
+ defaults = {'trans': (0, 0, 0), 'size': (1, 1, 1), 'rot': (0, 0, 0, 0),
+ 'vel': (0, 0), 'attr': 'vehicle.parked', 'score': -1.0, 'name': 'car'}
+ # Create GT EvalBoxes instance.
+ gt_eval_boxes = EvalBoxes()
+ for sample_token, data in gts.items():
+ gt_boxes = []
+ for gt in data:
+ gt = {**defaults, **gt} # The defaults will be replaced by gt if given.
+ eb = DetectionBox(sample_token=sample_token, translation=gt['trans'], size=gt['size'],
+ rotation=gt['rot'], detection_name=gt['name'], attribute_name=gt['attr'],
+ velocity=gt['vel'])
+ gt_boxes.append(eb)
+
+ gt_eval_boxes.add_boxes(sample_token, gt_boxes)
+
+ # Create Predictions EvalBoxes instance.
+ pred_eval_boxes = EvalBoxes()
+ for sample_token, data in preds.items():
+ pred_boxes = []
+ for pred in data:
+ pred = {**defaults, **pred}
+ eb = DetectionBox(sample_token=sample_token, translation=pred['trans'], size=pred['size'],
+ rotation=pred['rot'], detection_name=pred['name'], detection_score=pred['score'],
+ velocity=pred['vel'], attribute_name=pred['attr'])
+ pred_boxes.append(eb)
+ pred_eval_boxes.add_boxes(sample_token, pred_boxes)
+
+ metric_data = accumulate(gt_eval_boxes, pred_eval_boxes, class_name=detection_name,
+ dist_fcn=center_distance, dist_th=dist_th)
+
+ return metric_data
+
+
+class TestAPSimple(unittest.TestCase):
+ """ Tests the correctness of AP calculation for simple cases. """
+
+ def setUp(self):
+ self.car1 = {'trans': (1, 1, 1), 'name': 'car', 'score': 1.0, }
+ self.car2 = {'trans': (3, 3, 1), 'name': 'car', 'score': 0.7}
+ self.bicycle1 = {'trans': (5, 5, 1), 'name': 'bicycle', 'score': 1.0}
+ self.bicycle2 = {'trans': (7, 7, 1), 'name': 'bicycle', 'score': 0.7}
+
+ def check_ap(self, gts: Dict[str, List[Dict]],
+ preds: Dict[str, List[Dict]],
+ target_ap: float,
+ detection_name: str = 'car',
+ dist_th: float = 2.0,
+ min_precision: float = 0.1,
+ min_recall: float = 0.1) -> None:
+ """
+ Calculate and check the AP value.
+ :param gts: Ground truth data.
+ :param preds: Predictions.
+ :param target_ap: Expected Average Precision value.
+ :param detection_name: Name of the class we are interested in.
+ :param dist_th: Distance threshold for matching.
+ :param min_precision: Minimum precision value.
+ :param min_recall: Minimum recall value.
+ """
+ metric_data = get_metric_data(gts, preds, detection_name, dist_th)
+ ap = calc_ap(metric_data, min_precision=min_precision, min_recall=min_recall)
+
+ # We quantize the curve into 100 bins to calculate integral so the AP is accurate up to 1%.
+ self.assertGreaterEqual(0.01, abs(ap - target_ap), msg='Incorrect AP')
+
+ def test_no_data(self):
+ """ Test empty ground truth and/or predictions. """
+
+ gts = {'sample1': [self.car1]}
+ preds = {'sample1': [self.car1]}
+ empty = {'sample1': []}
+
+ # No ground truth objects (all False positives)
+ self.check_ap(empty, preds, target_ap=0.0)
+
+ # No predictions (all False negatives)
+ self.check_ap(gts, empty, target_ap=0.0)
+
+ # No predictions and no ground truth objects.
+ self.check_ap(empty, empty, target_ap=0.0)
+
+ def test_one_sample(self):
+ """ Test the single sample case. """
+ # Perfect detection.
+ self.check_ap({'sample1': [self.car1]},
+ {'sample1': [self.car1]},
+ target_ap=1.0, detection_name='car')
+
+ # Detect one of the two objects
+ self.check_ap({'sample1': [self.car1, self.car2]},
+ {'sample1': [self.car1]},
+ target_ap=0.4/0.9, detection_name='car')
+
+ # One detection and one FP. FP score is less than TP score.
+ self.check_ap({'sample1': [self.car1]},
+ {'sample1': [self.car1, self.car2]},
+ target_ap=1.0, detection_name='car')
+
+ # One detection and one FP. FP score is more than TP score.
+ self.check_ap({'sample1': [self.car2]},
+ {'sample1': [self.car1, self.car2]},
+ target_ap=((0.8*0.4)/2)/(0.9*0.9), detection_name='car')
+
+ # FP but different class.
+ self.check_ap({'sample1': [self.car1]},
+ {'sample1': [self.car1, self.bicycle1]},
+ target_ap=1.0, detection_name='car')
+
+ def test_two_samples(self):
+ """ Test more than one sample case. """
+ # Objects in both samples are detected.
+ self.check_ap({'sample1': [self.car1], 'sample2': [self.car2]},
+ {'sample1': [self.car1], 'sample2': [self.car2]},
+ target_ap=1.0, detection_name='car')
+
+ # Object in first sample is detected, second sample is empty.
+ self.check_ap({'sample1': [self.car1], 'sample2': []},
+ {'sample1': [self.car1], 'sample2': []},
+ target_ap=1.0, detection_name='car')
+
+ # Perfect detection in one image, FN in other.
+ self.check_ap({'sample1': [self.car1], 'sample2': [self.car2]},
+ {'sample1': [self.car1], 'sample2': []},
+ target_ap=0.4/0.9, detection_name='car')
+
+
+class TestTPSimple(unittest.TestCase):
+ """ Tests the correctness of true positives metrics calculation for simple cases. """
+
+ def setUp(self):
+
+ self.car3 = {'trans': (3, 3, 1), 'size': (2, 4, 2), 'rot': Quaternion(axis=(0, 0, 1), angle=0), 'score': 1.0}
+ self.car4 = {'trans': (3, 3, 1), 'size': (2, 4, 2), 'rot': Quaternion(axis=(0, 0, 1), angle=0), 'score': 1.0}
+
+ def check_tp(self, gts: Dict[str, List[Dict]],
+ preds: Dict[str, List[Dict]],
+ target_error: float,
+ metric_name: str,
+ detection_name: str = 'car',
+ min_recall: float = 0.1):
+ """
+ Calculate and check the AP value.
+ :param gts: Ground truth data.
+ :param preds: Predictions.
+ :param target_error: Expected error value.
+ :param metric_name: Name of the TP metric.
+ :param detection_name: Name of the class we are interested in.
+ :param min_recall: Minimum recall value.
+ """
+
+ metric_data = get_metric_data(gts, preds, detection_name, 2.0) # Distance threshold for TP metrics is 2.0
+ tp_error = calc_tp(metric_data, min_recall=min_recall, metric_name=metric_name)
+ # We quantize the error curve into 100 bins to calculate the metric so it is only accurate up to 1%.
+ self.assertGreaterEqual(0.01, abs(tp_error - target_error), msg='Incorrect {} value'.format(metric_name))
+
+ def test_no_positives(self):
+ """ Tests the error if there are no matches. The expected behaviour is to return error of 1.0. """
+
+ # Same type of objects but are more than 2m away.
+ car1 = {'trans': (1, 1, 1), 'score': 1.0}
+ car2 = {'trans': (3, 3, 1), 'score': 1.0}
+ bike1 = {'trans': (1, 1, 1), 'score': 1.0, 'name': 'bicycle', 'attr': 'cycle.with_rider'}
+ for metric_name in TP_METRICS:
+ self.check_tp({'sample1': [car1]}, {'sample1': [car2]}, target_error=1.0, metric_name=metric_name)
+
+ # Within distance threshold away but different classes.
+ for metric_name in TP_METRICS:
+ self.check_tp({'sample1': [car1]}, {'sample1': [bike1]}, target_error=1.0, metric_name=metric_name)
+
+ def test_perfect(self):
+ """ Tests when everything is estimated perfectly. """
+
+ car1 = {'trans': (1, 1, 1), 'score': 1.0}
+ car2 = {'trans': (1, 1, 1), 'score': 0.3}
+ for metric_name in TP_METRICS:
+ # Detected with perfect score.
+ self.check_tp({'sample1': [car1]}, {'sample1': [car1]}, target_error=0.0, metric_name=metric_name)
+
+ # Detected with low score.
+ self.check_tp({'sample1': [car1]}, {'sample1': [car2]}, target_error=0.0, metric_name=metric_name)
+
+ def test_one_img(self):
+ """ Test single sample case. """
+
+ # Note all the following unit tests can be repeated to other metrics, but they are not needed.
+ # The intention of these tests is to measure the calc_tp function which is common for all metrics.
+
+ gt1 = {'trans': (1, 1, 1)}
+ gt2 = {'trans': (10, 10, 1), 'size': (2, 2, 2)}
+ gt3 = {'trans': (20, 20, 1), 'size': (2, 4, 2)}
+
+ pred1 = {'trans': (1, 1, 1), 'score': 1.0}
+ pred2 = {'trans': (11, 10, 1), 'size': (2, 2, 2), 'score': 0.9}
+ pred3 = {'trans': (100, 10, 1), 'size': (2, 2, 2), 'score': 0.8}
+ pred4 = {'trans': (20, 20, 1), 'size': (2, 4, 2), 'score': 0.7}
+ pred5 = {'trans': (21, 20, 1), 'size': (2, 4, 2), 'score': 0.7}
+
+ # one GT and one matching prediction. Object location is off by 1 meter, so error 1.
+ self.check_tp({'sample1': [gt2]}, {'sample1': [pred2]}, target_error=1, metric_name='trans_err')
+
+ # Two GT's and two detections.
+ # The target is the average value of the recall vs. Error curve.
+ # In this case there will three points on the curve. (0.1, 0), (0.5, 0), (1.0, 0.5).
+ # (0.1, 0): Minimum recall we start from.
+ # (0.5, 0): Detection with highest score has no translation error, and one of out of two objects recalled.
+ # (1.0, 0.5): The last object is recalled but with 1m translation error, the cumulative mean gets to 0.5m error.
+ # Error value of first segment of curve starts at 0 and ends at 0, so the average of this segment is 0.
+ # Next segment of the curve starts at 0 and ends at 0.5, so the average is 0.25.
+ # Then we take average of all segments and normalize it with the recall values we averaged over.
+ target_error = ((0 + 0) / 2 + (0 + 0.5) / 2) / (2 * 0.9)
+ self.check_tp({'sample1': [gt1, gt2]}, {'sample1': [pred1, pred2]}, target_error=target_error,
+ metric_name='trans_err')
+
+ # Adding a false positive with smaller detection score should not affect the true positive metric.
+ self.check_tp({'sample1': [gt1, gt2]}, {'sample1': [pred1, pred2, pred3]}, target_error=target_error,
+ metric_name='trans_err')
+
+ # In this case there will four points on the curve. (0.1, 0), (0.33, 0), (0.66, 0.5) (1.0, 0.33).
+ # (0.1, 0): Minimum recall we start from.
+ # (0.33, 0): One of out of three objects recalled with no error.
+ # (0.66, 0.5): Second object is recalled but with 1m error. Cumulative error becomes 0.5m.
+ # (1.0, 0.33): Third object recalled with no error. Cumulative error becomes 0.33m.
+ # First segment starts at 0 and ends at 0: average error 0.
+ # Next segment starts at 0 and ends at 0.5: average error is 0.25.
+ # Next segment starts at 0.5 and ends at 0.33: average error is 0.416
+ # Then we take average of all segments and normalize it with the recall values we averaged over.
+ target_error = ((0+0)/2 + (0+0.5)/2 + (0.5 + 0.33)/2) / (3 * 0.9) # It is a piecewise linear with 3 segments
+ self.check_tp({'sample1': [gt1, gt2, gt3]}, {'sample1': [pred1, pred2, pred4]}, target_error=target_error,
+ metric_name='trans_err')
+
+ # Both matches have same translational error (1 meter), so the overall error is also 1 meter
+ self.check_tp({'sample1': [gt2, gt3]}, {'sample1': [pred2, pred5]}, target_error=1.0,
+ metric_name='trans_err')
+
+ def test_two_imgs(self):
+ """ Test the more than one sample case. """
+
+ # Note all the following unit tests can be repeated to other metrics, but they are not needed.
+ # The intention of these tests is to measure the calc_tp function which is common for all metrics.
+
+ gt1 = {'trans': (1, 1, 1)}
+ gt2 = {'trans': (10, 10, 1), 'size': (2, 2, 2)}
+ gt3 = {'trans': (20, 20, 1), 'size': (2, 4, 2)}
+
+ pred1 = {'trans': (1, 1, 1), 'score': 1.0}
+ pred2 = {'trans': (11, 10, 1), 'size': (2, 2, 2), 'score': 0.9}
+ pred3 = {'trans': (100, 10, 1), 'size': (2, 2, 2), 'score': 0.8}
+ pred4 = {'trans': (21, 20, 1), 'size': (2, 4, 2), 'score': 0.7}
+
+ # One GT and one detection
+ self.check_tp({'sample1': [gt2]}, {'sample1': [pred2]}, target_error=1, metric_name='trans_err')
+
+ # Two GT's and two detections.
+ # The target is the average value of the recall vs. Error curve.
+ target_error = ((0 + 0) / 2 + (0 + 0.5) / 2) / (2 * 0.9) # It is a piecewise linear with 2 segments.
+ self.check_tp({'sample1': [gt1], 'sample2': [gt2]}, {'sample1': [pred1], 'sample2': [pred2]},
+ target_error=target_error, metric_name='trans_err')
+
+ # Adding a false positive and/or an empty sample should not affect the score
+ self.check_tp({'sample1': [gt1], 'sample2': [gt2], 'sample3': []},
+ {'sample1': [pred1], 'sample2': [pred2, pred3], 'sample3': []},
+ target_error=target_error, metric_name='trans_err')
+
+ # All the detections does have same error, so the overall error is also same.
+ self.check_tp({'sample1': [gt2, gt3], 'sample2': [gt3]}, {'sample1': [pred2], 'sample2': [pred4]},
+ target_error=1.0, metric_name='trans_err')
+
+
+if __name__ == '__main__':
+ unittest.main()
diff --git a/python-sdk/nuscenes/eval/detection/tests/test_data_classes.py b/python-sdk/nuscenes/eval/detection/tests/test_data_classes.py
new file mode 100644
index 0000000..5a8db9f
--- /dev/null
+++ b/python-sdk/nuscenes/eval/detection/tests/test_data_classes.py
@@ -0,0 +1,117 @@
+# nuScenes dev-kit.
+# Code written by Oscar Beijbom and Alex Lang, 2019.
+
+import json
+import os
+import unittest
+
+from nuscenes.eval.common.data_classes import EvalBoxes
+from nuscenes.eval.detection.constants import TP_METRICS
+from nuscenes.eval.detection.data_classes import DetectionMetricData, DetectionConfig, DetectionMetrics, DetectionBox, \
+ DetectionMetricDataList
+
+
+class TestDetectionConfig(unittest.TestCase):
+
+ def test_serialization(self):
+ """ test that instance serialization protocol works with json encoding """
+
+ this_dir = os.path.dirname(os.path.abspath(__file__))
+ cfg_name = 'detection_cvpr_2019'
+ config_path = os.path.join(this_dir, '..', 'configs', cfg_name + '.json')
+
+ with open(config_path) as f:
+ cfg = json.load(f)
+
+ detect_cfg = DetectionConfig.deserialize(cfg)
+
+ self.assertEqual(cfg, detect_cfg.serialize())
+
+ recovered = DetectionConfig.deserialize(json.loads(json.dumps(detect_cfg.serialize())))
+ self.assertEqual(detect_cfg, recovered)
+
+
+class TestDetectionBox(unittest.TestCase):
+
+ def test_serialization(self):
+ """ Test that instance serialization protocol works with json encoding. """
+ box = DetectionBox()
+ recovered = DetectionBox.deserialize(json.loads(json.dumps(box.serialize())))
+ self.assertEqual(box, recovered)
+
+
+class TestEvalBoxes(unittest.TestCase):
+
+ def test_serialization(self):
+ """ Test that instance serialization protocol works with json encoding. """
+ boxes = EvalBoxes()
+ for i in range(10):
+ boxes.add_boxes(str(i), [DetectionBox(), DetectionBox(), DetectionBox()])
+
+ recovered = EvalBoxes.deserialize(json.loads(json.dumps(boxes.serialize())), DetectionBox)
+ self.assertEqual(boxes, recovered)
+
+
+class TestMetricData(unittest.TestCase):
+
+ def test_serialization(self):
+ """ Test that instance serialization protocol works with json encoding. """
+ md = DetectionMetricData.random_md()
+ recovered = DetectionMetricData.deserialize(json.loads(json.dumps(md.serialize())))
+ self.assertEqual(md, recovered)
+
+
+class TestDetectionMetricDataList(unittest.TestCase):
+
+ def test_serialization(self):
+ """ Test that instance serialization protocol works with json encoding. """
+ mdl = DetectionMetricDataList()
+ for i in range(10):
+ mdl.set('name', 0.1, DetectionMetricData.random_md())
+ recovered = DetectionMetricDataList.deserialize(json.loads(json.dumps(mdl.serialize())))
+ self.assertEqual(mdl, recovered)
+
+
+class TestDetectionMetrics(unittest.TestCase):
+
+ def test_serialization(self):
+ """ Test that instance serialization protocol works with json encoding. """
+
+ cfg = {
+ 'class_range': {
+ 'car': 1.0,
+ 'truck': 1.0,
+ 'bus': 1.0,
+ 'trailer': 1.0,
+ 'construction_vehicle': 1.0,
+ 'pedestrian': 1.0,
+ 'motorcycle': 1.0,
+ 'bicycle': 1.0,
+ 'traffic_cone': 1.0,
+ 'barrier': 1.0
+ },
+ 'dist_fcn': 'distance',
+ 'dist_ths': [0.0, 1.0],
+ 'dist_th_tp': 1.0,
+ 'min_recall': 0.0,
+ 'min_precision': 0.0,
+ 'max_boxes_per_sample': 1,
+ 'mean_ap_weight': 1.0
+ }
+ detect_config = DetectionConfig.deserialize(cfg)
+
+ metrics = DetectionMetrics(cfg=detect_config)
+
+ for i, name in enumerate(cfg['class_range'].keys()):
+ metrics.add_label_ap(name, 1.0, float(i))
+ for j, tp_name in enumerate(TP_METRICS):
+ metrics.add_label_tp(name, tp_name, float(j))
+
+ serialized = json.dumps(metrics.serialize())
+ deserialized = DetectionMetrics.deserialize(json.loads(serialized))
+
+ self.assertEqual(metrics, deserialized)
+
+
+if __name__ == '__main__':
+ unittest.main()
diff --git a/python-sdk/nuscenes/eval/detection/tests/test_evaluate.py b/python-sdk/nuscenes/eval/detection/tests/test_evaluate.py
new file mode 100644
index 0000000..0808b03
--- /dev/null
+++ b/python-sdk/nuscenes/eval/detection/tests/test_evaluate.py
@@ -0,0 +1,134 @@
+# nuScenes dev-kit.
+# Code written by Oscar Beijbom, 2019.
+
+import json
+import os
+import random
+import shutil
+import unittest
+from typing import Dict
+
+import numpy as np
+from tqdm import tqdm
+
+from nuscenes import NuScenes
+from nuscenes.eval.common.config import config_factory
+from nuscenes.eval.detection.constants import DETECTION_NAMES
+from nuscenes.eval.detection.evaluate import DetectionEval
+from nuscenes.eval.detection.utils import category_to_detection_name, detection_name_to_rel_attributes
+from nuscenes.utils.splits import create_splits_scenes
+
+
+class TestMain(unittest.TestCase):
+ res_mockup = 'nusc_eval.json'
+ res_eval_folder = 'tmp'
+
+ def tearDown(self):
+ if os.path.exists(self.res_mockup):
+ os.remove(self.res_mockup)
+ if os.path.exists(self.res_eval_folder):
+ shutil.rmtree(self.res_eval_folder)
+
+ @staticmethod
+ def _mock_submission(nusc: NuScenes, split: str) -> Dict[str, dict]:
+ """
+ Creates "reasonable" submission (results and metadata) by looping through the mini-val set, adding 1 GT
+ prediction per sample. Predictions will be permuted randomly along all axes.
+ """
+
+ def random_class(category_name: str) -> str:
+ # Alter 10% of the valid labels.
+ class_names = sorted(DETECTION_NAMES)
+ tmp = category_to_detection_name(category_name)
+ if tmp is not None and np.random.rand() < .9:
+ return tmp
+ else:
+ return class_names[np.random.randint(0, len(class_names) - 1)]
+
+ def random_attr(name: str) -> str:
+ """
+ This is the most straight-forward way to generate a random attribute.
+ Not currently used b/c we want the test fixture to be back-wards compatible.
+ """
+ # Get relevant attributes.
+ rel_attributes = detection_name_to_rel_attributes(name)
+
+ if len(rel_attributes) == 0:
+ # Empty string for classes without attributes.
+ return ''
+ else:
+ # Pick a random attribute otherwise.
+ return rel_attributes[np.random.randint(0, len(rel_attributes))]
+
+ mock_meta = {
+ 'use_camera': False,
+ 'use_lidar': True,
+ 'use_radar': False,
+ 'use_map': False,
+ 'use_external': False,
+ }
+ mock_results = {}
+ splits = create_splits_scenes()
+ val_samples = []
+ for sample in nusc.sample:
+ if nusc.get('scene', sample['scene_token'])['name'] in splits[split]:
+ val_samples.append(sample)
+
+ for sample in tqdm(val_samples, leave=False):
+ sample_res = []
+ for ann_token in sample['anns']:
+ ann = nusc.get('sample_annotation', ann_token)
+ detection_name = random_class(ann['category_name'])
+ sample_res.append(
+ {
+ 'sample_token': sample['token'],
+ 'translation': list(np.array(ann['translation']) + 5 * (np.random.rand(3) - 0.5)),
+ 'size': list(np.array(ann['size']) * 2 * (np.random.rand(3) + 0.5)),
+ 'rotation': list(np.array(ann['rotation']) + ((np.random.rand(4) - 0.5) * .1)),
+ 'velocity': list(nusc.box_velocity(ann_token)[:2] * (np.random.rand(3)[:2] + 0.5)),
+ 'detection_name': detection_name,
+ 'detection_score': random.random(),
+ 'attribute_name': random_attr(detection_name)
+ })
+ mock_results[sample['token']] = sample_res
+ mock_submission = {
+ 'meta': mock_meta,
+ 'results': mock_results
+ }
+ return mock_submission
+
+ def test_delta(self):
+ """
+ This tests runs the evaluation for an arbitrary random set of predictions.
+ This score is then captured in this very test such that if we change the eval code,
+ this test will trigger if the results changed.
+ """
+ random.seed(42)
+ np.random.seed(42)
+ assert 'NUSCENES' in os.environ, 'Set NUSCENES env. variable to enable tests.'
+
+ nusc = NuScenes(version='v1.0-mini', dataroot=os.environ['NUSCENES'], verbose=False)
+
+ with open(self.res_mockup, 'w') as f:
+ json.dump(self._mock_submission(nusc, 'mini_val'), f, indent=2)
+
+ cfg = config_factory('detection_cvpr_2019')
+ nusc_eval = DetectionEval(nusc, cfg, self.res_mockup, eval_set='mini_val', output_dir=self.res_eval_folder,
+ verbose=False)
+ metrics, md_list = nusc_eval.evaluate()
+
+ # 1. Score = 0.22082865720221012. Measured on the branch "release_v0.2" on March 7 2019.
+ # 2. Score = 0.2199307290627096. Changed to measure center distance from the ego-vehicle.
+ # 3. Score = 0.24954451673961747. Changed to 1.0-mini and cleaned up build script.
+ # 4. Score = 0.20478832626986893. Updated treatment of cones, barriers, and other algo tunings.
+ # 5. Score = 0.2043569666105005. AP calculation area is changed from >=min_recall to >min_recall.
+ # 6. Score = 0.20636954644294506. After bike-rack filtering.
+ # 7. Score = 0.20237925145690996. After TP reversion bug.
+ # 8. Score = 0.24047129251302665. After bike racks bug.
+ # 9. Score = 0.24104572227466886. After bug fix in calc_tp. Include the max recall and exclude the min recall.
+ # 10. Score = 0.19449091580477748. Changed to use v1.0 mini_val split.
+ self.assertAlmostEqual(metrics.nd_score, 0.19449091580477748)
+
+
+if __name__ == '__main__':
+ unittest.main()
diff --git a/python-sdk/nuscenes/eval/detection/tests/test_loader.py b/python-sdk/nuscenes/eval/detection/tests/test_loader.py
new file mode 100644
index 0000000..83ab18d
--- /dev/null
+++ b/python-sdk/nuscenes/eval/detection/tests/test_loader.py
@@ -0,0 +1,194 @@
+# nuScenes dev-kit.
+# Code written by Sourabh Vora, 2019.
+
+import os
+import unittest
+
+from nuscenes import NuScenes
+from nuscenes.eval.common.config import config_factory
+from nuscenes.eval.common.data_classes import EvalBoxes
+from nuscenes.eval.common.loaders import filter_eval_boxes
+from nuscenes.eval.detection.data_classes import DetectionBox
+from nuscenes.eval.common.loaders import _get_box_class_field
+
+
+class TestLoader(unittest.TestCase):
+ def test_filter_eval_boxes(self):
+ """
+ This tests runs the evaluation for an arbitrary random set of predictions.
+ This score is then captured in this very test such that if we change the eval code,
+ this test will trigger if the results changed.
+ """
+ # Get the maximum distance from the config
+ cfg = config_factory('detection_cvpr_2019')
+ max_dist = cfg.class_range
+
+ assert 'NUSCENES' in os.environ, 'Set NUSCENES env. variable to enable tests.'
+
+ nusc = NuScenes(version='v1.0-mini', dataroot=os.environ['NUSCENES'], verbose=False)
+
+ sample_token = '0af0feb5b1394b928dd13d648de898f5'
+ # This sample has a bike rack instance 'bfe685042aa34ab7b2b2f24ee0f1645f' with these parameters
+ # 'translation': [683.681, 1592.002, 0.809],
+ # 'size': [1.641, 14.465, 1.4],
+ # 'rotation': [0.3473693995546558, 0.0, 0.0, 0.9377283723195315]
+
+ # Test bicycle filtering by creating a box at the same position as the bike rack.
+ box1 = DetectionBox(sample_token=sample_token,
+ translation=(683.681, 1592.002, 0.809),
+ size=(1, 1, 1),
+ detection_name='bicycle')
+
+ eval_boxes = EvalBoxes()
+ eval_boxes.add_boxes(sample_token, [box1])
+
+ filtered_boxes = filter_eval_boxes(nusc, eval_boxes, max_dist)
+
+ self.assertEqual(len(filtered_boxes.boxes[sample_token]), 0) # box1 should be filtered.
+
+ # Test motorcycle filtering by creating a box at the same position as the bike rack.
+ box2 = DetectionBox(sample_token=sample_token,
+ translation=(683.681, 1592.002, 0.809),
+ size=(1, 1, 1),
+ detection_name='motorcycle')
+
+ eval_boxes = EvalBoxes()
+ eval_boxes.add_boxes(sample_token, [box1, box2])
+
+ filtered_boxes = filter_eval_boxes(nusc, eval_boxes, max_dist)
+
+ self.assertEqual(len(filtered_boxes.boxes[sample_token]), 0) # both box1 and box2 should be filtered.
+
+ # Now create a car at the same position as the bike rack.
+ box3 = DetectionBox(sample_token=sample_token,
+ translation=(683.681, 1592.002, 0.809),
+ size=(1, 1, 1),
+ detection_name='car')
+
+ eval_boxes = EvalBoxes()
+ eval_boxes.add_boxes(sample_token, [box1, box2, box3])
+
+ filtered_boxes = filter_eval_boxes(nusc, eval_boxes, max_dist)
+
+ self.assertEqual(len(filtered_boxes.boxes[sample_token]), 1) # box1 and box2 to be filtered. box3 to stay.
+ self.assertEqual(filtered_boxes.boxes[sample_token][0].detection_name, 'car')
+
+ # Now add a bike outside the bike rack.
+ box4 = DetectionBox(sample_token=sample_token,
+ translation=(68.681, 1592.002, 0.809),
+ size=(1, 1, 1),
+ detection_name='bicycle')
+
+ eval_boxes = EvalBoxes()
+ eval_boxes.add_boxes(sample_token, [box1, box2, box3, box4])
+
+ filtered_boxes = filter_eval_boxes(nusc, eval_boxes, max_dist)
+
+ self.assertEqual(len(filtered_boxes.boxes[sample_token]), 2) # box1, box2 to be filtered. box3, box4 to stay.
+ self.assertEqual(filtered_boxes.boxes[sample_token][0].detection_name, 'car')
+ self.assertEqual(filtered_boxes.boxes[sample_token][1].detection_name, 'bicycle')
+ self.assertEqual(filtered_boxes.boxes[sample_token][1].translation[0], 68.681)
+
+ # Add another bike on the bike rack center,
+ # but set the ego_dist (derived from ego_translation) higher than what's defined in max_dist
+ box5 = DetectionBox(sample_token=sample_token,
+ translation=(683.681, 1592.002, 0.809),
+ size=(1, 1, 1),
+ detection_name='bicycle',
+ ego_translation=(100.0, 0.0, 0.0))
+
+ eval_boxes = EvalBoxes()
+ eval_boxes.add_boxes(sample_token, [box1, box2, box3, box4, box5])
+
+ filtered_boxes = filter_eval_boxes(nusc, eval_boxes, max_dist)
+ self.assertEqual(len(filtered_boxes.boxes[sample_token]), 2) # box1, box2, box5 filtered. box3, box4 to stay.
+ self.assertEqual(filtered_boxes.boxes[sample_token][0].detection_name, 'car')
+ self.assertEqual(filtered_boxes.boxes[sample_token][1].detection_name, 'bicycle')
+ self.assertEqual(filtered_boxes.boxes[sample_token][1].translation[0], 68.681)
+
+ # Add another bike on the bike rack center but set the num_pts to be zero so that it gets filtered.
+ box6 = DetectionBox(sample_token=sample_token,
+ translation=(683.681, 1592.002, 0.809),
+ size=(1, 1, 1),
+ detection_name='bicycle',
+ num_pts=0)
+
+ eval_boxes = EvalBoxes()
+ eval_boxes.add_boxes(sample_token, [box1, box2, box3, box4, box5, box6])
+
+ filtered_boxes = filter_eval_boxes(nusc, eval_boxes, max_dist)
+ self.assertEqual(len(filtered_boxes.boxes[sample_token]), 2) # box1, box2, box5, box6 filtered. box3, box4 stay
+ self.assertEqual(filtered_boxes.boxes[sample_token][0].detection_name, 'car')
+ self.assertEqual(filtered_boxes.boxes[sample_token][1].detection_name, 'bicycle')
+ self.assertEqual(filtered_boxes.boxes[sample_token][1].translation[0], 68.681)
+
+ # Check for a sample where there are no bike racks. Everything should be filtered correctly.
+ sample_token = 'ca9a282c9e77460f8360f564131a8af5' # This sample has no bike-racks.
+
+ box1 = DetectionBox(sample_token=sample_token,
+ translation=(683.681, 1592.002, 0.809),
+ size=(1, 1, 1),
+ detection_name='bicycle',
+ ego_translation=(25.0, 0.0, 0.0))
+
+ box2 = DetectionBox(sample_token=sample_token,
+ translation=(683.681, 1592.002, 0.809),
+ size=(1, 1, 1),
+ detection_name='motorcycle',
+ ego_translation=(45.0, 0.0, 0.0))
+
+ box3 = DetectionBox(sample_token=sample_token,
+ translation=(683.681, 1592.002, 0.809),
+ size=(1, 1, 1),
+ detection_name='car',
+ ego_translation=(45.0, 0.0, 0.0))
+
+ box4 = DetectionBox(sample_token=sample_token,
+ translation=(683.681, 1592.002, 0.809),
+ size=(1, 1, 1),
+ detection_name='car',
+ ego_translation=(55.0, 0.0, 0.0))
+
+ box5 = DetectionBox(sample_token=sample_token,
+ translation=(683.681, 1592.002, 0.809),
+ size=(1, 1, 1),
+ detection_name='bicycle',
+ num_pts=1)
+
+ box6 = DetectionBox(sample_token=sample_token,
+ translation=(683.681, 1592.002, 0.809),
+ size=(1, 1, 1),
+ detection_name='bicycle',
+ num_pts=0)
+
+ eval_boxes = EvalBoxes()
+ eval_boxes.add_boxes(sample_token, [box1, box2, box3, box4, box5, box6])
+
+ filtered_boxes = filter_eval_boxes(nusc, eval_boxes, max_dist)
+ self.assertEqual(len(filtered_boxes.boxes[sample_token]), 3) # box2, box4, box6 filtered. box1, box3, box5 stay
+ self.assertEqual(filtered_boxes.boxes[sample_token][0].ego_dist, 25.0)
+ self.assertEqual(filtered_boxes.boxes[sample_token][1].ego_dist, 45.0)
+ self.assertEqual(filtered_boxes.boxes[sample_token][2].num_pts, 1)
+
+ def test_get_box_class_field(self):
+ eval_boxes = EvalBoxes()
+ box1 = DetectionBox(sample_token='box1',
+ translation=(683.681, 1592.002, 0.809),
+ size=(1, 1, 1),
+ detection_name='bicycle',
+ ego_translation=(25.0, 0.0, 0.0))
+
+ box2 = DetectionBox(sample_token='box2',
+ translation=(683.681, 1592.002, 0.809),
+ size=(1, 1, 1),
+ detection_name='motorcycle',
+ ego_translation=(45.0, 0.0, 0.0))
+ eval_boxes.add_boxes('sample1', [])
+ eval_boxes.add_boxes('sample2', [box1, box2])
+
+ class_field = _get_box_class_field(eval_boxes)
+ self.assertEqual(class_field, 'detection_name')
+
+
+if __name__ == '__main__':
+ unittest.main()
diff --git a/python-sdk/nuscenes/eval/detection/tests/test_utils.py b/python-sdk/nuscenes/eval/detection/tests/test_utils.py
new file mode 100644
index 0000000..2f2d9a2
--- /dev/null
+++ b/python-sdk/nuscenes/eval/detection/tests/test_utils.py
@@ -0,0 +1,225 @@
+# nuScenes dev-kit.
+# Code written by Holger Caesar, 2018.
+
+import unittest
+
+import numpy as np
+from numpy.testing import assert_array_almost_equal
+from pyquaternion import Quaternion
+
+from nuscenes.eval.common.utils import attr_acc, scale_iou, yaw_diff, angle_diff, center_distance, velocity_l2, \
+ cummean
+from nuscenes.eval.detection.data_classes import DetectionBox
+
+
+class TestEval(unittest.TestCase):
+ def test_scale_iou(self):
+ """Test valid and invalid inputs for scale_iou()."""
+
+ # Identical boxes.
+ sa = DetectionBox(size=(4, 4, 4))
+ sr = DetectionBox(size=(4, 4, 4))
+ res = scale_iou(sa, sr)
+ self.assertEqual(res, 1)
+
+ # SA is bigger.
+ sa = DetectionBox(size=(2, 2, 2))
+ sr = DetectionBox(size=(1, 1, 1))
+ res = scale_iou(sa, sr)
+ self.assertEqual(res, 1/8)
+
+ # SR is bigger.
+ sa = DetectionBox(size=(1, 1, 1))
+ sr = DetectionBox(size=(2, 2, 2))
+ res = scale_iou(sa, sr)
+ self.assertEqual(res, 1/8)
+
+ # Arbitrary values.
+ sa = DetectionBox(size=(0.96, 0.37, 0.69))
+ sr = DetectionBox(size=(0.32, 0.01, 0.39))
+ res = scale_iou(sa, sr)
+ self.assertAlmostEqual(res, 0.00509204)
+
+ # One empty box.
+ sa = DetectionBox(size=(0, 4, 4))
+ sr = DetectionBox(size=(4, 4, 4))
+ self.assertRaises(AssertionError, scale_iou, sa, sr)
+
+ # Two empty boxes.
+ sa = DetectionBox(size=(0, 4, 4))
+ sr = DetectionBox(size=(4, 0, 4))
+ self.assertRaises(AssertionError, scale_iou, sa, sr)
+
+ # Negative sizes.
+ sa = DetectionBox(size=(4, 4, 4))
+ sr = DetectionBox(size=(4, -5, 4))
+ self.assertRaises(AssertionError, scale_iou, sa, sr)
+
+ def test_yaw_diff(self):
+ """Test valid and invalid inputs for yaw_diff()."""
+
+ # Identical rotation.
+ sa = DetectionBox(rotation=Quaternion(axis=(0, 0, 1), angle=np.pi/8).elements)
+ sr = DetectionBox(rotation=Quaternion(axis=(0, 0, 1), angle=np.pi/8).elements)
+ diff = yaw_diff(sa, sr)
+ self.assertAlmostEqual(diff, 0)
+
+ # Rotation around another axis.
+ sa = DetectionBox(rotation=Quaternion(axis=(0, 0, 1), angle=np.pi/8).elements)
+ sr = DetectionBox(rotation=Quaternion(axis=(0, 1, 0), angle=np.pi/8).elements)
+ diff = yaw_diff(sa, sr)
+ self.assertAlmostEqual(diff, np.pi/8)
+
+ # Misc sr yaws for fixed sa yaw.
+ q0 = Quaternion(axis=(0, 0, 1), angle=0)
+ sa = DetectionBox(rotation=q0.elements)
+ for yaw_in in np.linspace(-10, 10, 100):
+ q1 = Quaternion(axis=(0, 0, 1), angle=yaw_in)
+ sr = DetectionBox(rotation=q1.elements)
+ diff = yaw_diff(sa, sr)
+ yaw_true = yaw_in % (2 * np.pi)
+ if yaw_true > np.pi:
+ yaw_true = 2 * np.pi - yaw_true
+ self.assertAlmostEqual(diff, yaw_true)
+
+ # Rotation beyond pi.
+ sa = DetectionBox(rotation=Quaternion(axis=(0, 0, 1), angle=1.1 * np.pi).elements)
+ sr = DetectionBox(rotation=Quaternion(axis=(0, 0, 1), angle=0.9 * np.pi).elements)
+ diff = yaw_diff(sa, sr)
+ self.assertAlmostEqual(diff, 0.2 * np.pi)
+
+ def test_angle_diff(self):
+ """Test valid and invalid inputs for angle_diff()."""
+ def rad(x):
+ return x/180*np.pi
+
+ a = 90.0
+ b = 0.0
+ period = 360
+ self.assertAlmostEqual(rad(90), abs(angle_diff(rad(a), rad(b), rad(period))))
+
+ a = 90.0
+ b = 0.0
+ period = 180
+ self.assertAlmostEqual(rad(90), abs(angle_diff(rad(a), rad(b), rad(period))))
+
+ a = 90.0
+ b = 0.0
+ period = 90
+ self.assertAlmostEqual(rad(0), abs(angle_diff(rad(a), rad(b), rad(period))))
+
+ a = 0.0
+ b = 90.0
+ period = 90
+ self.assertAlmostEqual(rad(0), abs(angle_diff(rad(a), rad(b), rad(period))))
+
+ a = 0.0
+ b = 180.0
+ period = 180
+ self.assertAlmostEqual(rad(0), abs(angle_diff(rad(a), rad(b), rad(period))))
+
+ a = 0.0
+ b = 180.0
+ period = 360
+ self.assertAlmostEqual(rad(180), abs(angle_diff(rad(a), rad(b), rad(period))))
+
+ a = 0.0
+ b = 180.0 + 360*200
+ period = 360
+ self.assertAlmostEqual(rad(180), abs(angle_diff(rad(a), rad(b), rad(period))))
+
+ def test_center_distance(self):
+ """Test for center_distance()."""
+
+ # Same boxes.
+ sa = DetectionBox(translation=(4, 4, 5))
+ sr = DetectionBox(translation=(4, 4, 5))
+ self.assertAlmostEqual(center_distance(sa, sr), 0)
+
+ # When no translation given
+ sa = DetectionBox(size=(4, 4, 4))
+ sr = DetectionBox(size=(3, 3, 3))
+ self.assertAlmostEqual(center_distance(sa, sr), 0)
+
+ # Different z translation (z should be ignored).
+ sa = DetectionBox(translation=(4, 4, 4))
+ sr = DetectionBox(translation=(3, 3, 3))
+ self.assertAlmostEqual(center_distance(sa, sr), np.sqrt((3 - 4) ** 2 + (3 - 4) ** 2))
+
+ # Negative values.
+ sa = DetectionBox(translation=(-1, -1, -1))
+ sr = DetectionBox(translation=(1, 1, 1))
+ self.assertAlmostEqual(center_distance(sa, sr), np.sqrt((1 + 1) ** 2 + (1 + 1) ** 2))
+
+ # Arbitrary values.
+ sa = DetectionBox(translation=(4.2, 2.8, 4.2))
+ sr = DetectionBox(translation=(-1.45, 3.5, 3.9))
+ self.assertAlmostEqual(center_distance(sa, sr), np.sqrt((-1.45 - 4.2) ** 2 + (3.5 - 2.8) ** 2))
+
+ def test_velocity_l2(self):
+ """Test for velocity_l2()."""
+
+ # Same velocity.
+ sa = DetectionBox(velocity=(4, 4))
+ sr = DetectionBox(velocity=(4, 4))
+ self.assertAlmostEqual(velocity_l2(sa, sr), 0)
+
+ # Negative values.
+ sa = DetectionBox(velocity=(-1, -1))
+ sr = DetectionBox(velocity=(1, 1))
+ self.assertAlmostEqual(velocity_l2(sa, sr), np.sqrt((1 + 1) ** 2 + (1 + 1) ** 2))
+
+ # Arbitrary values.
+ sa = DetectionBox(velocity=(8.2, 1.4))
+ sr = DetectionBox(velocity=(6.4, -9.4))
+ self.assertAlmostEqual(velocity_l2(sa, sr), np.sqrt((6.4 - 8.2) ** 2 + (-9.4 - 1.4) ** 2))
+
+ def test_cummean(self):
+ """Test for cummean()."""
+
+ # Single NaN.
+ x = np.array((np.nan, 5))
+ assert_array_almost_equal(cummean(x), np.array((0, 5)))
+
+ x = np.array((5, 2, np.nan))
+ assert_array_almost_equal(cummean(x), np.array((5, 3.5, 3.5)))
+
+ # Two NaN values.
+ x = np.array((np.nan, 4.5, np.nan))
+ assert_array_almost_equal(cummean(x), np.array((0, 4.5, 4.5)))
+
+ # All NaN values.
+ x = np.array((np.nan, np.nan, np.nan, np.nan))
+ assert_array_almost_equal(cummean(x), np.array((1, 1, 1, 1)))
+
+ # Single value array.
+ x = np.array([np.nan])
+ assert_array_almost_equal(cummean(x), np.array([1]))
+ x = np.array([4])
+ assert_array_almost_equal(cummean(x), np.array([4.0]))
+
+ # Arbitrary values.
+ x = np.array((np.nan, 3.58, 2.14, np.nan, 9, 1.48, np.nan))
+ assert_array_almost_equal(cummean(x), np.array((0, 3.58, 2.86, 2.86, 4.906666, 4.05, 4.05)))
+
+ def test_attr_acc(self):
+ """Test for attr_acc()."""
+
+ # Same attributes.
+ sa = DetectionBox(attribute_name='vehicle.parked')
+ sr = DetectionBox(attribute_name='vehicle.parked')
+ self.assertAlmostEqual(attr_acc(sa, sr), 1.0)
+
+ # Different attributes.
+ sa = DetectionBox(attribute_name='vehicle.parked')
+ sr = DetectionBox(attribute_name='vehicle.moving')
+ self.assertAlmostEqual(attr_acc(sa, sr), 0.0)
+
+ # No attribute in one.
+ sa = DetectionBox(attribute_name='')
+ sr = DetectionBox(attribute_name='vehicle.parked')
+ self.assertIs(attr_acc(sa, sr), np.nan)
+
+
+if __name__ == '__main__':
+ unittest.main()
diff --git a/python-sdk/nuscenes/eval/detection/utils.py b/python-sdk/nuscenes/eval/detection/utils.py
new file mode 100644
index 0000000..51a542b
--- /dev/null
+++ b/python-sdk/nuscenes/eval/detection/utils.py
@@ -0,0 +1,56 @@
+# nuScenes dev-kit.
+# Code written by Holger Caesar, 2018.
+
+from typing import List, Optional
+
+
+def category_to_detection_name(category_name: str) -> Optional[str]:
+ """
+ Default label mapping from nuScenes to nuScenes detection classes.
+ Note that pedestrian does not include personal_mobility, stroller and wheelchair.
+ :param category_name: Generic nuScenes class.
+ :return: nuScenes detection class.
+ """
+ detection_mapping = {
+ 'movable_object.barrier': 'barrier',
+ 'vehicle.bicycle': 'bicycle',
+ 'vehicle.bus.bendy': 'bus',
+ 'vehicle.bus.rigid': 'bus',
+ 'vehicle.car': 'car',
+ 'vehicle.construction': 'construction_vehicle',
+ 'vehicle.motorcycle': 'motorcycle',
+ 'human.pedestrian.adult': 'pedestrian',
+ 'human.pedestrian.child': 'pedestrian',
+ 'human.pedestrian.construction_worker': 'pedestrian',
+ 'human.pedestrian.police_officer': 'pedestrian',
+ 'movable_object.trafficcone': 'traffic_cone',
+ 'vehicle.trailer': 'trailer',
+ 'vehicle.truck': 'truck'
+ }
+
+ if category_name in detection_mapping:
+ return detection_mapping[category_name]
+ else:
+ return None
+
+
+def detection_name_to_rel_attributes(detection_name: str) -> List[str]:
+ """
+ Returns a list of relevant attributes for a given detection class.
+ :param detection_name: The detection class.
+ :return: List of relevant attributes.
+ """
+ if detection_name in ['pedestrian']:
+ rel_attributes = ['pedestrian.moving', 'pedestrian.sitting_lying_down', 'pedestrian.standing']
+ elif detection_name in ['bicycle', 'motorcycle']:
+ rel_attributes = ['cycle.with_rider', 'cycle.without_rider']
+ elif detection_name in ['car', 'bus', 'construction_vehicle', 'trailer', 'truck']:
+ rel_attributes = ['vehicle.moving', 'vehicle.parked', 'vehicle.stopped']
+ elif detection_name in ['barrier', 'traffic_cone']:
+ # Classes without attributes: barrier, traffic_cone.
+ rel_attributes = []
+ else:
+ raise ValueError('Error: %s is not a valid detection class.' % detection_name)
+
+ return rel_attributes
+
diff --git a/python-sdk/nuscenes/eval/lidarseg/README.md b/python-sdk/nuscenes/eval/lidarseg/README.md
new file mode 100644
index 0000000..7151665
--- /dev/null
+++ b/python-sdk/nuscenes/eval/lidarseg/README.md
@@ -0,0 +1,217 @@
+# nuScenes lidar segmentation task
+
+
+## Overview
+- [Introduction](#introduction)
+- [Participation](#participation)
+- [Challenges](#challenges)
+- [Submission rules](#submission-rules)
+- [Results format](#results-format)
+- [Classes](#classes)
+- [Evaluation metrics](#evaluation-metrics)
+- [Leaderboard](#leaderboard)
+
+## Introduction
+Here we define the lidar segmentation task on nuScenes.
+The goal of this task is to predict the category of every point in a set of point clouds. There are 16 categories (10 foreground classes and 6 background classes).
+
+## Participation
+The nuScenes lidarseg segmentation [evaluation server](https://eval.ai/web/challenges/challenge-page/720/overview) is open all year round for submission.
+To participate in the challenge, please create an account at [EvalAI](https://eval.ai).
+Then upload your zipped result folder with the required [content](#results-format).
+After each challenge, the results will be exported to the nuScenes [leaderboard](https://www.nuscenes.org/lidar-segmentation).
+This is the only way to benchmark your method against the test dataset.
+We require that all participants send the following information to nuScenes@motional.com after submitting their results on EvalAI:
+- Team name
+- Method name
+- Authors
+- Affiliations
+- Method description (5+ sentences)
+- Project URL
+- Paper URL
+- FPS in Hz (and the hardware used to measure it)
+
+## Challenges
+To allow users to benchmark the performance of their method against the community, we host a single [leaderboard](https://www.nuscenes.org/lidar-segmentation) all-year round.
+Additionally we organize a number of challenges at leading Computer Vision conference workshops.
+Users that submit their results during the challenge period are eligible for awards.
+Any user that cannot attend the workshop (direct or via a representative) will be excluded from the challenge, but will still be listed on the leaderboard.
+
+Click [here](https://eval.ai/web/challenges/challenge-page/720/overview) for the **EvalAI lidar segmentation evaluation server**.
+
+### 5th AI Driving Olympics, NeurIPS 2020
+The first nuScenes lidar segmentation challenge will be held at [NeurIPS 2020](https://nips.cc/Conferences/2020/).
+Submission will open on Nov 15, 2020 and close on 8 Dec, 2020.
+Results and winners will be announced at the [5th AI Driving Olympics](https://driving-olympics.ai/) at NeurIPS 2020.
+For more information see the [leaderboard](https://www.nuscenes.org/lidar-segmentation).
+Note that the [evaluation server](https://eval.ai/web/challenges/challenge-page/720/overview) can still be used to benchmark your results.
+
+## Submission rules
+### Lidar segmentation-specific rules
+* The maximum time window of past sensor data and ego poses that may be used at inference time is approximately 0.5s (at most 6 past camera images, 6 past radar sweeps and 10 past lidar sweeps). At training time there are no restrictions.
+
+### General rules
+* We release annotations for the train and val set, but not for the test set.
+* We release sensor data for train, val and test set.
+* Users make predictions on the test set and submit the results to our evaluation server, which returns the metrics listed below.
+* Every submission provides method information. We encourage publishing code, but do not make it a requirement.
+* Top leaderboard entries and their papers will be manually reviewed.
+* Each user or team can have at most one one account on the evaluation server.
+* Each user or team can submit at most 3 results. These results must come from different models, rather than submitting results from the same model at different training epochs or with slightly different parameters.
+* Any attempt to circumvent these rules will result in a permanent ban of the team or company from all nuScenes challenges.
+
+## Results format
+We define a standardized lidar segmentation result format that serves as an input to the evaluation code.
+Results are evaluated for each 2Hz keyframe, also known as a `sample`.
+The lidar segmentation results for a particular evaluation set (train/val/test) are stored in a folder.
+
+The folder structure of the results should be as follows:
+```
+└── results_folder
+ ├── lidarseg
+ │ └── {test, train, val} <- Contains the .bin files; a .bin file
+ │ contains the labels of the points in a
+ │ point cloud
+ └── {test, train, val}
+ └── submission.json <- contains certain information about
+ the submission
+```
+
+The contents of the `submision.json` file and `test` folder are defined below:
+* The `submission.json` file includes meta data `meta` on the type of inputs used for this method.
+ ```
+ "meta": {
+ "use_camera": <bool> -- Whether this submission uses camera data as an input.
+ "use_lidar": <bool> -- Whether this submission uses lidar data as an input.
+ "use_radar": <bool> -- Whether this submission uses radar data as an input.
+ "use_map": <bool> -- Whether this submission uses map data as an input.
+ "use_external": <bool> -- Whether this submission uses external data as an input.
+ },
+ ```
+* The `test` folder contains .bin files, where each .bin file contains the labels of the points for the point cloud.
+ Pay special attention that each set of predictions in the folder must be a .bin file and named as **<lidar_sample_data_token>_lidarseg.bin**.
+ A .bin file contains an array of `uint8` values in which each value is the predicted [class index](#classes) of the corresponding point in the point cloud, e.g.:
+ ```
+ [1, 5, 4, 1, ...]
+ ```
+ Below is an example of how to save the predictions for a single point cloud:
+ ```
+ bin_file_path = lidar_sample_data_token + '_lidarseg.bin"
+ np.array(predicted_labels).astype(np.uint8).tofile(bin_file_path)
+ ```
+ Note that the arrays should **not** contain the `ignore` class (i.e. class index 0).
+ Each `lidar_sample_data_token` from the current evaluation set must be included in the `test` folder.
+
+For the train and val sets, the evaluation can be performed by the user on their local machine.
+For the test set, the user needs to zip the results folder and submit it to the official evaluation server.
+
+For convenience, a `validate_submission.py` [script](https://github.com/nutonomy/nuscenes-devkit/blob/master/python-sdk/nuscenes/eval/lidarseg/validate_submission.py) has been provided to check that a given results folder is of the correct format.
+
+Note that the lidar segmentation classes differ from the general nuScenes classes, as detailed below.
+
+## Classes
+The nuScenes-lidarseg dataset comes with annotations for 32 classes ([details](https://www.nuscenes.org/data-annotation)).
+Some of these only have a handful of samples.
+Hence we merge similar classes and remove rare classes.
+This results in 16 classes for the lidar segmentation challenge.
+Below we show the table of lidar segmentation classes and their counterparts in the nuScenes-lidarseg dataset.
+For more information on the classes and their frequencies, see [this page](https://www.nuscenes.org/nuscenes#data-annotation).
+
+| lidar segmentation index | lidar segmentation class | nuScenes-lidarseg general class |
+| --- | --- | --- |
+| 0 | void / ignore | animal |
+| 0 | void / ignore | human.pedestrian.personal_mobility |
+| 0 | void / ignore | human.pedestrian.stroller |
+| 0 | void / ignore | human.pedestrian.wheelchair |
+| 0 | void / ignore | movable_object.debris |
+| 0 | void / ignore | movable_object.pushable_pullable |
+| 0 | void / ignore | static_object.bicycle_rack |
+| 0 | void / ignore | vehicle.emergency.ambulance |
+| 0 | void / ignore | vehicle.emergency.police |
+| 0 | void / ignore | noise |
+| 0 | void / ignore | static.other |
+| 0 | void / ignore | vehicle.ego |
+| 1 | barrier | movable_object.barrier |
+| 2 | bicycle | vehicle.bicycle |
+| 3 | bus | vehicle.bus.bendy |
+| 3 | bus | vehicle.bus.rigid |
+| 4 | car | vehicle.car |
+| 5 | construction_vehicle | vehicle.construction |
+| 6 | motorcycle | vehicle.motorcycle |
+| 7 | pedestrian | human.pedestrian.adult |
+| 7 | pedestrian | human.pedestrian.child |
+| 7 | pedestrian | human.pedestrian.construction_worker |
+| 7 | pedestrian | human.pedestrian.police_officer |
+| 8 | traffic_cone | movable_object.trafficcone |
+| 9 | trailer | vehicle.trailer |
+| 10 | truck | vehicle.truck |
+| 11 | driveable_surface | flat.driveable_surface |
+| 12 | other_flat | flat.other |
+| 13 | sidewalk | flat.sidewalk |
+| 14 | terrain | flat.terrain |
+| 15 | manmade | static.manmade |
+| 16 | vegetation | static.vegetation |
+
+
+## Evaluation metrics
+Below we define the metrics for the nuScenes lidar segmentation task.
+The challenge winners and leaderboard ranking will be determined by the mean intersection-over-union (mIOU) score.
+
+### Preprocessing
+Contrary to the [nuScenes detection task](https://github.com/nutonomy/nuscenes-devkit/blob/master/python-sdk/nuscenes/eval/detection/README.md),
+we do not perform any preprocessing, such as removing GT / predictions if they exceed the class-specific detection range
+or if they fall inside a bike-rack.
+
+### Mean IOU (mIOU)
+We use the well-known IOU metric, which is defined as TP / (TP + FP + FN).
+The IOU score is calculated separately for each class, and then the mean is computed across classes.
+Note that lidar segmentation index 0 is ignored in the calculation.
+
+### Frequency-weighted IOU (fwIOU)
+Instead of taking the mean of the IOUs across all the classes, each IOU is weighted by the point-level frequency of its class.
+Note that lidar segmentation index 0 is ignored in the calculation.
+FWIOU is not used for the challenge.
+
+## Leaderboard
+nuScenes will maintain a single leaderboard for the lidar segmentation task.
+For each submission the leaderboard will list method aspects and evaluation metrics.
+Method aspects include input modalities (lidar, radar, vision), use of map data and use of external data.
+To enable a fair comparison between methods, the user will be able to filter the methods by method aspects.
+
+Methods will be compared within these tracks and the winners will be decided for each track separately.
+Furthermore, there will also be an award for novel ideas, as well as the best student submission.
+
+**Lidar track**:
+* Only lidar input allowed.
+* Only lidar segmentation annotations from nuScenes-lidarseg are allowed.
+* External data or map data <u>not allowed</u>.
+* May use pre-training.
+
+**Open track**:
+* Any sensor input allowed.
+* All nuScenes, nuScenes-lidarseg and nuImages annotations are allowed.
+* External data and map data allowed.
+* May use pre-training.
+
+**Details**:
+* *Sensor input:*
+For the lidar track we restrict the type of sensor input that may be used.
+Note that this restriction applies only at test time.
+At training time any sensor input may be used.
+
+* *Map data:*
+By `map data` we mean using the *semantic* map provided in nuScenes.
+
+* *Meta data:*
+Other meta data included in the dataset may be used without restrictions.
+E.g. bounding box annotations provided in nuScenes, calibration parameters, ego poses, `location`, `timestamp`, `num_lidar_pts`, `num_radar_pts`, `translation`, `rotation` and `size`.
+Note that .bin files, `instance`, `sample_annotation` and `scene` description are not provided for the test set.
+
+* *Pre-training:*
+By pre-training we mean training a network for the task of image classification using only image-level labels,
+as done in [[Krizhevsky NIPS 2012]](http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networ).
+The pre-training may not involve bounding boxes, masks or other localized annotations.
+
+* *Reporting:*
+Users are required to report detailed information on their method regarding sensor input, map data, meta data and pre-training.
+Users that fail to adequately report this information may be excluded from the challenge.
diff --git a/python-sdk/nuscenes/eval/lidarseg/__init__.py b/python-sdk/nuscenes/eval/lidarseg/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/python-sdk/nuscenes/eval/lidarseg/evaluate.py b/python-sdk/nuscenes/eval/lidarseg/evaluate.py
new file mode 100644
index 0000000..03ed7bb
--- /dev/null
+++ b/python-sdk/nuscenes/eval/lidarseg/evaluate.py
@@ -0,0 +1,158 @@
+import argparse
+import json
+import os
+from typing import Dict
+
+import numpy as np
+from tqdm import tqdm
+
+from nuscenes import NuScenes
+from nuscenes.eval.lidarseg.utils import LidarsegClassMapper, ConfusionMatrix, get_samples_in_eval_set
+
+
+class LidarSegEval:
+ """
+ This is the official nuScenes-lidarseg evaluation code.
+ Results are written to the provided output_dir.
+
+ nuScenes-lidarseg uses the following metrics:
+ - Mean Intersection-over-Union (mIOU): We use the well-known IOU metric, which is defined as TP / (TP + FP + FN).
+ The IOU score is calculated separately for each class, and then the mean is
+ computed across classes. Note that in the challenge, index 0 is ignored in
+ the calculation.
+ - Frequency-weighted IOU (FWIOU): Instead of taking the mean of the IOUs across all the classes, each IOU is
+ weighted by the point-level frequency of its class. Note that in the challenge,
+ index 0 is ignored in the calculation. FWIOU is not used for the challenge.
+
+ We assume that:
+ - For each pointcloud, the prediction for every point is present in a .bin file, in the same order as that of the
+ points stored in the corresponding .bin file.
+ - The naming convention of the .bin files containing the predictions for a single point cloud is:
+ <lidar_sample_data_token>_lidarseg.bin
+ - The predictions are between 1 and 16 (inclusive); 0 is the index of the ignored class.
+
+ Please see https://www.nuscenes.org/lidar-segmentation for more details.
+ """
+ def __init__(self,
+ nusc: NuScenes,
+ results_folder: str,
+ eval_set: str,
+ verbose: bool = False):
+ """
+ Initialize a LidarSegEval object.
+ :param nusc: A NuScenes object.
+ :param results_folder: Path to the folder.
+ :param eval_set: The dataset split to evaluate on, e.g. train, val or test.
+ :param verbose: Whether to print messages during the evaluation.
+ """
+ # Check there are ground truth annotations.
+ assert len(nusc.lidarseg) > 0, 'Error: No ground truth annotations found in {}.'.format(nusc.version)
+
+ # Check results folder exists.
+ self.results_folder = results_folder
+ self.results_bin_folder = os.path.join(results_folder, 'lidarseg', eval_set)
+ assert os.path.exists(self.results_bin_folder), \
+ 'Error: The folder containing the .bin files ({}) does not exist.'.format(self.results_bin_folder)
+
+ self.nusc = nusc
+ self.results_folder = results_folder
+ self.eval_set = eval_set
+ self.verbose = verbose
+
+ self.mapper = LidarsegClassMapper(self.nusc)
+ self.ignore_idx = self.mapper.ignore_class['index']
+ self.id2name = {idx: name for name, idx in self.mapper.coarse_name_2_coarse_idx_mapping.items()}
+ self.num_classes = len(self.mapper.coarse_name_2_coarse_idx_mapping)
+
+ if self.verbose:
+ print('There are {} classes.'.format(self.num_classes))
+
+ self.global_cm = ConfusionMatrix(self.num_classes, self.ignore_idx)
+
+ self.sample_tokens = get_samples_in_eval_set(self.nusc, self.eval_set)
+ if self.verbose:
+ print('There are {} samples.'.format(len(self.sample_tokens)))
+
+ def evaluate(self) -> Dict:
+ """
+ Performs the actual evaluation.
+ :return: A dictionary containing the evaluated metrics.
+ """
+ for sample_token in tqdm(self.sample_tokens, disable=not self.verbose):
+ sample = self.nusc.get('sample', sample_token)
+
+ # Get the sample data token of the point cloud.
+ sd_token = sample['data']['LIDAR_TOP']
+
+ # Load the ground truth labels for the point cloud.
+ lidarseg_label_filename = os.path.join(self.nusc.dataroot,
+ self.nusc.get('lidarseg', sd_token)['filename'])
+ lidarseg_label = self.load_bin_file(lidarseg_label_filename)
+
+ lidarseg_label = self.mapper.convert_label(lidarseg_label)
+
+ # Load the predictions for the point cloud.
+ lidarseg_pred_filename = os.path.join(self.results_folder, 'lidarseg',
+ self.eval_set, sd_token + '_lidarseg.bin')
+ lidarseg_pred = self.load_bin_file(lidarseg_pred_filename)
+
+ # Get the confusion matrix between the ground truth and predictions.
+ # Update the confusion matrix for the sample data into the confusion matrix for the eval set.
+ self.global_cm.update(lidarseg_label, lidarseg_pred)
+
+ iou_per_class = self.global_cm.get_per_class_iou()
+ miou = self.global_cm.get_mean_iou()
+ freqweighted_iou = self.global_cm.get_freqweighted_iou()
+
+ # Put everything nicely into a dict.
+ results = {'iou_per_class': {self.id2name[i]: class_iou for i, class_iou in enumerate(iou_per_class)},
+ 'miou': miou,
+ 'freq_weighted_iou': freqweighted_iou}
+
+ # Print the results if desired.
+ if self.verbose:
+ print("======\nnuScenes-lidarseg evaluation for {}".format(self.eval_set))
+ print(json.dumps(results, indent=4, sort_keys=False))
+ print("======")
+
+ return results
+
+ @staticmethod
+ def load_bin_file(bin_path: str) -> np.ndarray:
+ """
+ Loads a .bin file containing the labels.
+ :param bin_path: Path to the .bin file.
+ :return: An array containing the labels.
+ """
+ assert os.path.exists(bin_path), 'Error: Unable to find {}.'.format(bin_path)
+ bin_content = np.fromfile(bin_path, dtype=np.uint8)
+ assert len(bin_content) > 0, 'Error: {} is empty.'.format(bin_path)
+
+ return bin_content
+
+
+if __name__ == '__main__':
+ # Settings.
+ parser = argparse.ArgumentParser(description='Evaluate nuScenes-lidarseg results.')
+ parser.add_argument('--result_path', type=str,
+ help='The path to the results folder.')
+ parser.add_argument('--eval_set', type=str, default='val',
+ help='Which dataset split to evaluate on, train, val or test.')
+ parser.add_argument('--dataroot', type=str, default='/data/sets/nuscenes',
+ help='Default nuScenes data directory.')
+ parser.add_argument('--version', type=str, default='v1.0-trainval',
+ help='Which version of the nuScenes dataset to evaluate on, e.g. v1.0-trainval.')
+ parser.add_argument('--verbose', type=bool, default=False,
+ help='Whether to print to stdout.')
+ args = parser.parse_args()
+
+ result_path_ = args.result_path
+ eval_set_ = args.eval_set
+ dataroot_ = args.dataroot
+ version_ = args.version
+ verbose_ = args.verbose
+
+ nusc_ = NuScenes(version=version_, dataroot=dataroot_, verbose=verbose_)
+
+ evaluator = LidarSegEval(nusc_, result_path_, eval_set=eval_set_, verbose=verbose_)
+ evaluator.evaluate()
diff --git a/python-sdk/nuscenes/eval/lidarseg/tests/__init__.py b/python-sdk/nuscenes/eval/lidarseg/tests/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/python-sdk/nuscenes/eval/lidarseg/utils.py b/python-sdk/nuscenes/eval/lidarseg/utils.py
new file mode 100644
index 0000000..38a4af7
--- /dev/null
+++ b/python-sdk/nuscenes/eval/lidarseg/utils.py
@@ -0,0 +1,331 @@
+from typing import Dict, List
+
+import numpy as np
+
+from nuscenes import NuScenes
+from nuscenes.utils.splits import create_splits_scenes
+
+
+class ConfusionMatrix:
+ """
+ Class for confusion matrix with various convenient methods.
+ """
+ def __init__(self, num_classes: int, ignore_idx: int = None):
+ """
+ Initialize a ConfusionMatrix object.
+ :param num_classes: Number of classes in the confusion matrix.
+ :param ignore_idx: Index of the class to be ignored in the confusion matrix.
+ """
+ self.num_classes = num_classes
+ self.ignore_idx = ignore_idx
+
+ self.global_cm = None
+
+ def update(self, gt_array: np.ndarray, pred_array: np.ndarray) -> None:
+ """
+ Updates the global confusion matrix.
+ :param gt_array: An array containing the ground truth labels.
+ :param pred_array: An array containing the predicted labels.
+ """
+ cm = self._get_confusion_matrix(gt_array, pred_array)
+
+ if self.global_cm is None:
+ self.global_cm = cm
+ else:
+ self.global_cm += cm
+
+ def _get_confusion_matrix(self, gt_array: np.ndarray, pred_array: np.ndarray) -> np.ndarray:
+ """
+ Obtains the confusion matrix for the segmentation of a single point cloud.
+ :param gt_array: An array containing the ground truth labels.
+ :param pred_array: An array containing the predicted labels.
+ :return: N x N array where N is the number of classes.
+ """
+ assert all((gt_array >= 0) & (gt_array < self.num_classes)), \
+ "Error: Array for ground truth must be between 0 and {} (inclusive).".format(self.num_classes - 1)
+ assert all((pred_array > 0) & (pred_array < self.num_classes)), \
+ "Error: Array for predictions must be between 1 and {} (inclusive).".format(self.num_classes - 1)
+
+ label = self.num_classes * gt_array.astype('int') + pred_array
+ count = np.bincount(label, minlength=self.num_classes ** 2)
+
+ # Make confusion matrix (rows = gt, cols = preds).
+ confusion_matrix = count.reshape(self.num_classes, self.num_classes)
+
+ # For the class to be ignored, set both the row and column to 0 (adapted from
+ # https://github.com/davidtvs/PyTorch-ENet/blob/master/metric/iou.py).
+ if self.ignore_idx is not None:
+ confusion_matrix[self.ignore_idx, :] = 0
+ confusion_matrix[:, self.ignore_idx] = 0
+
+ return confusion_matrix
+
+ def get_per_class_iou(self) -> List[float]:
+ """
+ Gets the IOU of each class in a confusion matrix.
+ :return: An array in which the IOU of a particular class sits at the array index corresponding to the
+ class index.
+ """
+ conf = self.global_cm.copy()
+
+ # Get the intersection for each class.
+ intersection = np.diagonal(conf)
+
+ # Get the union for each class.
+ ground_truth_set = conf.sum(axis=1)
+ predicted_set = conf.sum(axis=0)
+ union = ground_truth_set + predicted_set - intersection
+
+ # Get the IOU for each class.
+ # In case we get a division by 0, ignore / hide the error(adapted from
+ # https://github.com/davidtvs/PyTorch-ENet/blob/master/metric/iou.py).
+ with np.errstate(divide='ignore', invalid='ignore'):
+ iou_per_class = intersection / (union.astype(np.float32))
+
+ return iou_per_class
+
+ def get_mean_iou(self) -> float:
+ """
+ Gets the mean IOU (mIOU) over the classes.
+ :return: mIOU over the classes.
+ """
+ iou_per_class = self.get_per_class_iou()
+ miou = float(np.nanmean(iou_per_class))
+ return miou
+
+ def get_freqweighted_iou(self) -> float:
+ """
+ Gets the frequency-weighted IOU over the classes.
+ :return: Frequency-weighted IOU over the classes.
+ """
+ conf = self.global_cm.copy()
+
+ # Get the number of points per class (based on ground truth).
+ num_points_per_class = conf.sum(axis=1)
+
+ # Get the total number of points in the eval set.
+ num_points_total = conf.sum()
+
+ # Get the IOU per class.
+ iou_per_class = self.get_per_class_iou()
+
+ # Weight the IOU by frequency and sum across the classes.
+ freqweighted_iou = float(np.nansum(num_points_per_class * iou_per_class) / num_points_total)
+
+ return freqweighted_iou
+
+
+class LidarsegClassMapper:
+ """
+ Maps the (fine) classes in nuScenes-lidarseg to the (coarse) classes for the nuScenes-lidarseg challenge.
+
+ Example usage::
+ nusc_ = NuScenes(version='v1.0-mini', dataroot='/data/sets/nuscenes', verbose=True)
+ mapper_ = LidarsegClassMapper(nusc_)
+ """
+ def __init__(self, nusc: NuScenes):
+ """
+ Initialize a LidarsegClassMapper object.
+ :param nusc: A NuScenes object.
+ """
+ self.nusc = nusc
+
+ self.ignore_class = self.get_ignore_class()
+
+ self.fine_name_2_coarse_name_mapping = self.get_fine2coarse()
+ self.coarse_name_2_coarse_idx_mapping = self.get_coarse2idx()
+
+ self.check_mapping()
+
+ self.fine_idx_2_coarse_idx_mapping = self.get_fine_idx_2_coarse_idx()
+
+ @staticmethod
+ def get_ignore_class() -> Dict[str, int]:
+ """
+ Defines the name and index of the ignore class.
+ :return: A dictionary containing the name and index of the ignore class.
+ """
+ return {'name': 'ignore', 'index': 0}
+
+ def get_fine2coarse(self) -> Dict:
+ """
+ Returns the mapping from the fine classes to the coarse classes.
+ :return: A dictionary containing the mapping from the fine classes to the coarse classes.
+ """
+ return {'noise': self.ignore_class['name'],
+ 'human.pedestrian.adult': 'pedestrian',
+ 'human.pedestrian.child': 'pedestrian',
+ 'human.pedestrian.wheelchair': self.ignore_class['name'],
+ 'human.pedestrian.stroller': self.ignore_class['name'],
+ 'human.pedestrian.personal_mobility': self.ignore_class['name'],
+ 'human.pedestrian.police_officer': 'pedestrian',
+ 'human.pedestrian.construction_worker': 'pedestrian',
+ 'animal': self.ignore_class['name'],
+ 'vehicle.car': 'car',
+ 'vehicle.motorcycle': 'motorcycle',
+ 'vehicle.bicycle': 'bicycle',
+ 'vehicle.bus.bendy': 'bus',
+ 'vehicle.bus.rigid': 'bus',
+ 'vehicle.truck': 'truck',
+ 'vehicle.construction': 'construction_vehicle',
+ 'vehicle.emergency.ambulance': self.ignore_class['name'],
+ 'vehicle.emergency.police': self.ignore_class['name'],
+ 'vehicle.trailer': 'trailer',
+ 'movable_object.barrier': 'barrier',
+ 'movable_object.trafficcone': 'traffic_cone',
+ 'movable_object.pushable_pullable': self.ignore_class['name'],
+ 'movable_object.debris': self.ignore_class['name'],
+ 'static_object.bicycle_rack': self.ignore_class['name'],
+ 'flat.driveable_surface': 'driveable_surface',
+ 'flat.sidewalk': 'sidewalk',
+ 'flat.terrain': 'terrain',
+ 'flat.other': 'other_flat',
+ 'static.manmade': 'manmade',
+ 'static.vegetation': 'vegetation',
+ 'static.other': self.ignore_class['name'],
+ 'vehicle.ego': self.ignore_class['name']}
+
+ def get_coarse2idx(self) -> Dict[str, int]:
+ """
+ Returns the mapping from the coarse class names to the coarse class indices.
+ :return: A dictionary containing the mapping from the coarse class names to the coarse class indices.
+ """
+ return {self.ignore_class['name']: self.ignore_class['index'],
+ 'barrier': 1,
+ 'bicycle': 2,
+ 'bus': 3,
+ 'car': 4,
+ 'construction_vehicle': 5,
+ 'motorcycle': 6,
+ 'pedestrian': 7,
+ 'traffic_cone': 8,
+ 'trailer': 9,
+ 'truck': 10,
+ 'driveable_surface': 11,
+ 'other_flat': 12,
+ 'sidewalk': 13,
+ 'terrain': 14,
+ 'manmade': 15,
+ 'vegetation': 16}
+
+ def get_fine_idx_2_coarse_idx(self) -> Dict[int, int]:
+ """
+ Returns the mapping from the the indices of the coarse classes to that of the coarse classes.
+ :return: A dictionary containing the mapping from the the indices of the coarse classes to that of the
+ coarse classes.
+ """
+ fine_idx_2_coarse_idx_mapping = dict()
+ for fine_name, fine_idx in self.nusc.lidarseg_name2idx_mapping.items():
+ fine_idx_2_coarse_idx_mapping[fine_idx] = self.coarse_name_2_coarse_idx_mapping[
+ self.fine_name_2_coarse_name_mapping[fine_name]]
+ return fine_idx_2_coarse_idx_mapping
+
+ def check_mapping(self) -> None:
+ """
+ Convenient method to check that the mappings for fine2coarse and coarse2idx are synced.
+ """
+ coarse_set = set()
+ for fine_name, coarse_name in self.fine_name_2_coarse_name_mapping.items():
+ coarse_set.add(coarse_name)
+
+ assert coarse_set == set(self.coarse_name_2_coarse_idx_mapping.keys()), \
+ 'Error: Number of coarse classes is not the same as the number of coarse indices.'
+
+ def convert_label(self, points_label: np.ndarray) -> np.ndarray:
+ """
+ Convert the labels in a single .bin file according to the provided mapping.
+ :param points_label: The .bin to be converted (e.g. './i_contain_the_labels_for_a_pointcloud.bin')
+ """
+ counter_before = self.get_stats(points_label) # get stats before conversion
+
+ # Map the labels accordingly; if there are labels present in points_label but not in the map,
+ # an error will be thrown
+ points_label = np.vectorize(self.fine_idx_2_coarse_idx_mapping.__getitem__)(points_label)
+
+ counter_after = self.get_stats(points_label) # Get stats after conversion.
+
+ assert self.compare_stats(counter_before, counter_after), 'Error: Statistics of labels have changed ' \
+ 'after conversion. Pls check.'
+
+ return points_label
+
+ def compare_stats(self, counter_before: List[int], counter_after: List[int]) -> bool:
+ """
+ Compare stats for a single .bin file before and after conversion.
+ :param counter_before: A numpy array which contains the counts of each class (the index of the array corresponds
+ to the class label), before conversion; e.g. np.array([0, 1, 34, ...]) --> class 0 has
+ no points, class 1 has 1 point, class 2 has 34 points, etc.
+ :param counter_after: A numpy array which contains the counts of each class (the index of the array corresponds
+ to the class label) after conversion
+ :return: True or False; True if the stats before and after conversion are the same, and False if otherwise.
+ """
+ counter_check = [0] * len(counter_after)
+ for i, count in enumerate(counter_before): # Note that the class labels are 0-indexed.
+ counter_check[self.fine_idx_2_coarse_idx_mapping[i]] += count
+
+ comparison = counter_check == counter_after
+
+ return comparison
+
+ def get_stats(self, points_label: np.array) -> List[int]:
+ """
+ Get frequency of each label in a point cloud.
+ :param points_label: A numpy array which contains the labels of the point cloud;
+ e.g. np.array([2, 1, 34, ..., 38])
+ :return: An array which contains the counts of each label in the point cloud. The index of the point cloud
+ corresponds to the index of the class label. E.g. [0, 2345, 12, 451] means that there are no points
+ in class 0, there are 2345 points in class 1, there are 12 points in class 2 etc.
+ """
+ # Create "buckets" to store the counts for each label; the number of "buckets" is the larger of the number
+ # of classes in nuScenes-lidarseg and lidarseg challenge.
+ lidarseg_counts = [0] * (max(max(self.fine_idx_2_coarse_idx_mapping.keys()),
+ max(self.fine_idx_2_coarse_idx_mapping.values())) + 1)
+
+ indices: np.ndarray = np.bincount(points_label)
+ ii = np.nonzero(indices)[0]
+
+ for class_idx, class_count in zip(ii, indices[ii]):
+ lidarseg_counts[class_idx] += class_count # Increment the count for the particular class name.
+
+ return lidarseg_counts
+
+
+def get_samples_in_eval_set(nusc: NuScenes, eval_set: str) -> List[str]:
+ """
+ Gets all the sample tokens from the split that are relevant to the eval set.
+ :param nusc: A NuScenes object.
+ :param eval_set: The dataset split to evaluate on, e.g. train, val or test.
+ :return: A list of sample tokens.
+ """
+ # Create a dict to map from scene name to scene token for quick lookup later on.
+ scene_name2tok = dict()
+ for rec in nusc.scene:
+ scene_name2tok[rec['name']] = rec['token']
+
+ # Get scenes splits from nuScenes.
+ scenes_splits = create_splits_scenes(verbose=False)
+
+ # Collect sample tokens for each scene.
+ samples = []
+ for scene in scenes_splits[eval_set]:
+ scene_record = nusc.get('scene', scene_name2tok[scene])
+ total_num_samples = scene_record['nbr_samples']
+ first_sample_token = scene_record['first_sample_token']
+ last_sample_token = scene_record['last_sample_token']
+
+ sample_token = first_sample_token
+ i = 0
+ while sample_token != '':
+ sample_record = nusc.get('sample', sample_token)
+ samples.append(sample_record['token'])
+
+ if sample_token == last_sample_token:
+ sample_token = ''
+ else:
+ sample_token = sample_record['next']
+ i += 1
+
+ assert total_num_samples == i, 'Error: There were supposed to be {} keyframes, ' \
+ 'but only {} keyframes were processed'.format(total_num_samples, i)
+
+ return samples
diff --git a/python-sdk/nuscenes/eval/lidarseg/validate_submission.py b/python-sdk/nuscenes/eval/lidarseg/validate_submission.py
new file mode 100644
index 0000000..cb8763a
--- /dev/null
+++ b/python-sdk/nuscenes/eval/lidarseg/validate_submission.py
@@ -0,0 +1,137 @@
+import argparse
+import json
+import os
+
+import numpy as np
+from tqdm import tqdm
+
+from nuscenes import NuScenes
+from nuscenes.eval.lidarseg.utils import LidarsegClassMapper, get_samples_in_eval_set
+from nuscenes.utils.data_classes import LidarPointCloud
+
+
+def validate_submission(nusc: NuScenes, results_folder: str, eval_set: str, verbose: bool = False) -> None:
+ """
+ Checks if a results folder is valid. The following checks are performed:
+ - Check that the submission folder is according to that described in
+ https://github.com/nutonomy/nuscenes-devkit/blob/master/python-sdk/nuscenes/eval/lidarseg/README.md
+ - Check that the submission.json is of the following structure:
+ {"meta": {"use_camera": false,
+ "use_lidar": true,
+ "use_radar": false,
+ "use_map": false,
+ "use_external": false}}
+ - Check that each each lidar sample data in the evaluation set is present and valid.
+
+ :param nusc: A NuScenes object.
+ :param results_folder: Path to the folder.
+ :param eval_set: The dataset split to evaluate on, e.g. train, val or test.
+ :param verbose: Whether to print messages during the evaluation.
+ """
+ mapper = LidarsegClassMapper(nusc)
+ num_classes = len(mapper.coarse_name_2_coarse_idx_mapping)
+
+ if verbose:
+ print('Checking if folder structure of {} is correct...'.format(results_folder))
+
+ # Check that {results_folder}/{eval_set} exists.
+ results_meta_folder = os.path.join(results_folder, eval_set)
+ assert os.path.exists(results_meta_folder), \
+ 'Error: The folder containing the submission.json ({}) does not exist.'.format(results_meta_folder)
+
+ # Check that {results_folder}/{eval_set}/submission.json exists.
+ submisson_json_path = os.path.join(results_meta_folder, 'submission.json')
+ assert os.path.exists(submisson_json_path), \
+ 'Error: submission.json ({}) does not exist.'.format(submisson_json_path)
+
+ # Check that {results_folder}/lidarseg/{eval_set} exists.
+ results_bin_folder = os.path.join(results_folder, 'lidarseg', eval_set)
+ assert os.path.exists(results_bin_folder), \
+ 'Error: The folder containing the .bin files ({}) does not exist.'.format(results_bin_folder)
+
+ if verbose:
+ print('\tPassed.')
+
+ if verbose:
+ print('Checking contents of {}...'.format(submisson_json_path))
+
+ with open(submisson_json_path) as f:
+ submission_meta = json.load(f)
+ valid_meta = {"use_camera", "use_lidar", "use_radar", "use_map", "use_external"}
+ assert valid_meta == set(submission_meta['meta'].keys()), \
+ '{} must contain {}.'.format(submisson_json_path, valid_meta)
+ for meta_key in valid_meta:
+ meta_key_type = type(submission_meta['meta'][meta_key])
+ assert meta_key_type == bool, 'Error: Value for {} should be bool, not {}.'.format(meta_key, meta_key_type)
+
+ if verbose:
+ print('\tPassed.')
+
+ if verbose:
+ print('Checking if all .bin files for {} exist and are valid...'.format(eval_set))
+ sample_tokens = get_samples_in_eval_set(nusc, eval_set)
+ for sample_token in tqdm(sample_tokens, disable=not verbose):
+ sample = nusc.get('sample', sample_token)
+
+ # Get the sample data token of the point cloud.
+ sd_token = sample['data']['LIDAR_TOP']
+
+ # Load the predictions for the point cloud.
+ lidarseg_pred_filename = os.path.join(results_bin_folder, sd_token + '_lidarseg.bin')
+ assert os.path.exists(lidarseg_pred_filename), \
+ 'Error: The prediction .bin file {} does not exist.'.format(lidarseg_pred_filename)
+ lidarseg_pred = np.fromfile(lidarseg_pred_filename, dtype=np.uint8)
+
+ # Check number of predictions for the point cloud.
+ if len(nusc.lidarseg) > 0: # If ground truth exists, compare the no. of predictions with that of ground truth.
+ lidarseg_label_filename = os.path.join(nusc.dataroot, nusc.get('lidarseg', sd_token)['filename'])
+ assert os.path.exists(lidarseg_label_filename), \
+ 'Error: The ground truth .bin file {} does not exist.'.format(lidarseg_label_filename)
+ lidarseg_label = np.fromfile(lidarseg_label_filename, dtype=np.uint8)
+ num_points = len(lidarseg_label)
+ else: # If no ground truth is available, compare the no. of predictions with that of points in a point cloud.
+ pointsensor = nusc.get('sample_data', sd_token)
+ pcl_path = os.path.join(nusc.dataroot, pointsensor['filename'])
+ pc = LidarPointCloud.from_file(pcl_path)
+ points = pc.points
+ num_points = points.shape[1]
+
+ assert num_points == len(lidarseg_pred), \
+ 'Error: There are {} predictions for lidar sample data token {} ' \
+ 'but there are only {} points in the point cloud.'\
+ .format(len(lidarseg_pred), sd_token, num_points)
+
+ assert all((lidarseg_pred > 0) & (lidarseg_pred < num_classes)), \
+ "Error: Array for predictions in {} must be between 1 and {} (inclusive)."\
+ .format(lidarseg_pred_filename, num_classes - 1)
+
+ if verbose:
+ print('\tPassed.')
+
+ if verbose:
+ print('Results folder {} successfully validated!'.format(results_folder))
+
+
+if __name__ == '__main__':
+ # Settings.
+ parser = argparse.ArgumentParser(description='Check if a results folder is valid.')
+ parser.add_argument('--result_path', type=str,
+ help='The path to the results folder.')
+ parser.add_argument('--eval_set', type=str, default='val',
+ help='Which dataset split to evaluate on, train, val or test.')
+ parser.add_argument('--dataroot', type=str, default='/data/sets/nuscenes',
+ help='Default nuScenes data directory.')
+ parser.add_argument('--version', type=str, default='v1.0-trainval',
+ help='Which version of the nuScenes dataset to evaluate on, e.g. v1.0-trainval.')
+ parser.add_argument('--verbose', type=bool, default=False,
+ help='Whether to print to stdout.')
+ args = parser.parse_args()
+
+ result_path_ = args.result_path
+ eval_set_ = args.eval_set
+ dataroot_ = args.dataroot
+ version_ = args.version
+ verbose_ = args.verbose
+
+ nusc_ = NuScenes(version=version_, dataroot=dataroot_, verbose=verbose_)
+ validate_submission(nusc=nusc_, results_folder=result_path_, eval_set=eval_set_, verbose=verbose_)
diff --git a/python-sdk/nuscenes/eval/prediction/README.md b/python-sdk/nuscenes/eval/prediction/README.md
new file mode 100644
index 0000000..1f3d1a8
--- /dev/null
+++ b/python-sdk/nuscenes/eval/prediction/README.md
@@ -0,0 +1,91 @@
+# nuScenes prediction task
+
+
+## Overview
+- [Introduction](#introduction)
+- [Challenges](#challenges)
+- [Submission rules](#submission-rules)
+- [Results format](#results-format)
+- [Evaluation metrics](#evaluation-metrics)
+
+## Introduction
+The goal of the nuScenes prediction task is to predict the future trajectories of objects in the nuScenes dataset.
+A trajectory is a sequence of x-y locations. For this challenge, the predictions are 6-seconds long and sampled at
+2 hertz.
+
+## Participation
+The nuScenes prediction [evaluation server](https://eval.ai/web/challenges/challenge-page/591/overview) is open all year round for submission.
+To participate in the challenge, please create an account at [EvalAI](https://eval.ai/web/challenges/challenge-page/591/overview).
+Then upload your zipped result file including all of the required [meta data](#results-format).
+After each challenge, the results will be exported to the nuScenes [leaderboard](https://www.nuscenes.org/prediction) shown above.
+This is the only way to benchmark your method against the test dataset.
+We require that all participants send the following information to nuScenes@motional.com after submitting their results on EvalAI:
+- Team name
+- Method name
+- Authors
+- Affiliations
+- Method description (5+ sentences)
+- Project URL
+- Paper URL
+- FPS in Hz (and the hardware used to measure it)
+
+## Challenges
+To allow users to benchmark the performance of their method against the community, we will host a single leaderboard all year round.
+Additionally, we intend to organize a number of challenges at leading Computer Vision and Machine Learning conference workshops.
+Users that submit their results during the challenge period are eligible for awards. These awards may be different for each challenge.
+
+Click [here](https://eval.ai/web/challenges/challenge-page/591/overview) for the **EvalAI prediction evaluation server**.
+
+### Workshop on Benchmarking Progress in Autonomous Driving, ICRA 2020
+The first nuScenes prediction challenge will be held at [ICRA 2020](https://www.icra2020.org/).
+This challenge will be focused on predicting trajectories for vehicles. The submission period will open April 1 and continue until May 28th, 2020.
+Results and winners will be announced at the [Workshop on Benchmarking Progress in Autonomous Driving](http://montrealrobotics.ca/driving-benchmarks/).
+Note that the evaluation server can still be used to benchmark your results after the challenge period.
+
+*Update:* Due to the COVID-19 situation, participants are **not** required to attend in person
+to be eligible for the prizes.
+
+## Submission rules
+### Prediction-specific rules
+* The user can submit up to 25 proposed future trajectories, called `modes`, for each agent along with a probability the agent follows that proposal. Our metrics (explained below) will measure how well this proposed set of trajectories matches the ground truth.
+* Up to two seconds of past history can be used to predict the future trajectory for each agent.
+* Unlike previous challenges, the leaderboard will be ranked according to performance on the nuScenes val set. This is because we cannot release the annotations on the test set, so users would not be able to run their models on the test set and then submit their predictions to the server. To prevent overfitting on the val set, the top 5 submissions on the leaderboard will be asked to send us their code and we will run their model on the test set. The winners will be chosen based on their performance on the test set, not the val set.
+* Every submission to the challenge must be accompanied by a brief technical report (no more than 1-2 pages) describing the method in sufficient detail to allow for independent verification.
+
+### General rules
+* We release annotations for the train and val set, but not for the test set. We have created a hold out set for validation
+from the training set called the `train_val` set.
+* We release sensor data for train, val and test set.
+* Top leaderboard entries and their papers will be manually reviewed to ensure no cheating was done.
+* Each user or team can have at most one one account on the evaluation server.
+* Each user or team can submit at most 3 results. These results must come from different models, rather than submitting results from the same model at different training epochs or with slightly weights or hyperparameter values.
+* Any attempt to make more submissions than allowed will result in a permanent ban of the team or company from all nuScenes challenges.
+
+## Results format
+Users must submit a json file with a list of [`Predictions`](https://github.com/nutonomy/nuscenes-devkit/blob/master/python-sdk/nuscenes/eval/prediction/data_classes.py) for each agent. A `Prediction` has the following components:
+
+```
+instance: Instance token for agent.
+sample: Sample token for agent.
+prediction: Numpy array of shape [num_modes, n_timesteps, state_dim]
+probabilities: Numpy array of shape [num_modes]
+```
+
+Each agent in nuScenes is indexed by an instance token and a sample token. As mentioned previously, `num_modes` can be up to 25. Since we are making 6 second predictions at 2 Hz, `n_timesteps` is 12. We are concerned only with x-y coordinates, so `state_dim` is 2. Note that the prediction must be reported in **the global coordinate frame**.
+Consult the [`baseline_model_inference`](https://github.com/nutonomy/nuscenes-devkit/blob/master/python-sdk/nuscenes/eval/prediction/baseline_model_inference.py) script for an example on how to make a submission for two physics-based baseline models.
+
+## Evaluation metrics
+Below we define the metrics for the nuScenes prediction task.
+
+### Minimum Average Displacement Error over k (minADE_k)
+The average of pointwise L2 distances between the predicted trajectory and ground truth over the `k` most likely predictions.
+
+### Minimum Final Displacement Error over k (minFDE_k)
+The final displacement error (FDE) is the L2 distance between the final points of the prediction and ground truth. We take the minimum FDE over the k most likely predictions and average over all agents.
+
+### Miss Rate At 2 meters over k (MissRate_2_k)
+If the maximum pointwise L2 distance between the prediction and ground truth is greater than 2 meters, we define the prediction as a miss.
+For each agent, we take the k most likely predictions and evaluate if any are misses. The MissRate_2_k is the proportion of misses over all agents.
+
+### Configuration
+The metrics configuration file for the ICRA 2020 challenge can be found in this [file](https://github.com/nutonomy/nuscenes-devkit/blob/master/python-sdk/nuscenes/eval/prediction/configs/predict_2020_icra.json).
diff --git a/python-sdk/nuscenes/eval/prediction/__init__.py b/python-sdk/nuscenes/eval/prediction/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/python-sdk/nuscenes/eval/prediction/baseline_model_inference.py b/python-sdk/nuscenes/eval/prediction/baseline_model_inference.py
new file mode 100644
index 0000000..cd881ac
--- /dev/null
+++ b/python-sdk/nuscenes/eval/prediction/baseline_model_inference.py
@@ -0,0 +1,55 @@
+# nuScenes dev-kit.
+# Code written by Freddy Boulton, 2020.
+
+""" Script for running baseline models on a given nuscenes-split. """
+
+import argparse
+import json
+import os
+
+from nuscenes import NuScenes
+from nuscenes.eval.prediction.config import load_prediction_config
+from nuscenes.eval.prediction.splits import get_prediction_challenge_split
+from nuscenes.prediction import PredictHelper
+from nuscenes.prediction.models.physics import ConstantVelocityHeading, PhysicsOracle
+
+
+def main(version: str, data_root: str,
+ split_name: str, output_dir: str, config_name: str = 'predict_2020_icra.json') -> None:
+ """
+ Performs inference for all of the baseline models defined in the physics model module.
+ :param version: nuScenes dataset version.
+ :param data_root: Directory where the NuScenes data is stored.
+ :param split_name: nuScenes data split name, e.g. train, val, mini_train, etc.
+ :param output_dir: Directory where predictions should be stored.
+ :param config_name: Name of config file.
+ """
+
+ nusc = NuScenes(version=version, dataroot=data_root)
+ helper = PredictHelper(nusc)
+ dataset = get_prediction_challenge_split(split_name)
+ config = load_prediction_config(helper, config_name)
+ oracle = PhysicsOracle(config.seconds, helper)
+ cv_heading = ConstantVelocityHeading(config.seconds, helper)
+
+ cv_preds = []
+ oracle_preds = []
+ for token in dataset:
+ cv_preds.append(cv_heading(token).serialize())
+ oracle_preds.append(oracle(token).serialize())
+
+ json.dump(cv_preds, open(os.path.join(output_dir, "cv_preds.json"), "w"))
+ json.dump(oracle_preds, open(os.path.join(output_dir, "oracle_preds.json"), "w"))
+
+
+if __name__ == "__main__":
+
+ parser = argparse.ArgumentParser(description='Perform Inference with baseline models.')
+ parser.add_argument('--version', help='nuScenes version number.')
+ parser.add_argument('--data_root', help='Directory storing NuScenes data.', default='/data/sets/nuscenes')
+ parser.add_argument('--split_name', help='Data split to run inference on.')
+ parser.add_argument('--output_dir', help='Directory to store output files.')
+ parser.add_argument('--config_name', help='Config file to use.', default='predict_2020_icra.json')
+
+ args = parser.parse_args()
+ main(args.version, args.data_root, args.split_name, args.output_dir, args.config_name)
diff --git a/python-sdk/nuscenes/eval/prediction/compute_metrics.py b/python-sdk/nuscenes/eval/prediction/compute_metrics.py
new file mode 100644
index 0000000..f3d201a
--- /dev/null
+++ b/python-sdk/nuscenes/eval/prediction/compute_metrics.py
@@ -0,0 +1,67 @@
+# nuScenes dev-kit.
+# Code written by Freddy Boulton, 2020.
+""" Script for computing metrics for a submission to the nuscenes prediction challenge. """
+import argparse
+import json
+from collections import defaultdict
+from typing import List, Dict, Any
+
+import numpy as np
+
+from nuscenes import NuScenes
+from nuscenes.eval.prediction.config import PredictionConfig, load_prediction_config
+from nuscenes.eval.prediction.data_classes import Prediction
+from nuscenes.prediction import PredictHelper
+
+
+def compute_metrics(predictions: List[Dict[str, Any]],
+ helper: PredictHelper, config: PredictionConfig) -> Dict[str, Any]:
+ """
+ Computes metrics from a set of predictions.
+ :param predictions: List of prediction JSON objects.
+ :param helper: Instance of PredictHelper that wraps the nuScenes val set.
+ :param config: Config file.
+ :return: Metrics. Nested dictionary where keys are metric names and value is a dictionary
+ mapping the Aggregator name to the results.
+ """
+ n_preds = len(predictions)
+ containers = {metric.name: np.zeros((n_preds, metric.shape)) for metric in config.metrics}
+ for i, prediction_str in enumerate(predictions):
+ prediction = Prediction.deserialize(prediction_str)
+ ground_truth = helper.get_future_for_agent(prediction.instance, prediction.sample,
+ config.seconds, in_agent_frame=False)
+ for metric in config.metrics:
+ containers[metric.name][i] = metric(ground_truth, prediction)
+ aggregations: Dict[str, Dict[str, List[float]]] = defaultdict(dict)
+ for metric in config.metrics:
+ for agg in metric.aggregators:
+ aggregations[metric.name][agg.name] = agg(containers[metric.name])
+ return aggregations
+
+
+def main(version: str, data_root: str, submission_path: str,
+ config_name: str = 'predict_2020_icra.json') -> None:
+ """
+ Computes metrics for a submission stored in submission_path with a given submission_name with the metrics
+ specified by the config_name.
+ :param version: nuScenes dataset version.
+ :param data_root: Directory storing NuScenes data.
+ :param submission_path: Directory storing submission.
+ :param config_name: Name of config file.
+ """
+ predictions = json.load(open(submission_path, "r"))
+ nusc = NuScenes(version=version, dataroot=data_root)
+ helper = PredictHelper(nusc)
+ config = load_prediction_config(helper, config_name)
+ results = compute_metrics(predictions, helper, config)
+ json.dump(results, open(submission_path.replace('.json', '_metrics.json'), "w"), indent=2)
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser(description='Perform Inference with baseline models.')
+ parser.add_argument('--version', help='nuScenes version number.')
+ parser.add_argument('--data_root', help='Directory storing NuScenes data.', default='/data/sets/nuscenes')
+ parser.add_argument('--submission_path', help='Path storing the submission file.')
+ parser.add_argument('--config_name', help='Config file to use.', default='predict_2020_icra.json')
+ args = parser.parse_args()
+ main(args.version, args.data_root, args.submission_path, args.config_name)
diff --git a/python-sdk/nuscenes/eval/prediction/config.py b/python-sdk/nuscenes/eval/prediction/config.py
new file mode 100644
index 0000000..22f8c57
--- /dev/null
+++ b/python-sdk/nuscenes/eval/prediction/config.py
@@ -0,0 +1,58 @@
+# nuScenes dev-kit.
+# Code written by Freddy Boulton, Eric Wolff, 2020.
+import json
+import os
+from typing import List, Dict, Any
+
+from nuscenes.eval.prediction.metrics import Metric, deserialize_metric
+from nuscenes.prediction import PredictHelper
+
+
+class PredictionConfig:
+
+ def __init__(self,
+ metrics: List[Metric],
+ seconds: int = 6,
+ frequency: int = 2):
+ """
+ Data class that specifies the prediction evaluation settings.
+ Initialized with:
+ metrics: List of nuscenes.eval.prediction.metric.Metric objects.
+ seconds: Number of seconds to predict for each agent.
+ frequency: Rate at which prediction is made, in Hz.
+ """
+ self.metrics = metrics
+ self.seconds = seconds
+ self.frequency = frequency # Hz
+
+ def serialize(self) -> Dict[str, Any]:
+ """ Serialize instance into json-friendly format. """
+
+ return {'metrics': [metric.serialize() for metric in self.metrics],
+ 'seconds': self.seconds}
+
+ @classmethod
+ def deserialize(cls, content: Dict[str, Any], helper: PredictHelper):
+ """ Initialize from serialized dictionary. """
+ return cls([deserialize_metric(metric, helper) for metric in content['metrics']],
+ seconds=content['seconds'])
+
+
+def load_prediction_config(helper: PredictHelper, config_name: str = 'predict_2020_icra.json') -> PredictionConfig:
+ """
+ Loads a PredictionConfig from json file stored in eval/prediction/configs.
+ :param helper: Instance of PredictHelper. Needed for OffRoadRate metric.
+ :param config_name: Name of json config file.
+ :return: PredictionConfig.
+ """
+ this_dir = os.path.dirname(os.path.abspath(__file__))
+ cfg_path = os.path.join(this_dir, "configs", config_name)
+ assert os.path.exists(cfg_path), f'Requested unknown configuration {cfg_path}'
+
+ # Load config file and deserialize it.
+ with open(cfg_path, 'r') as f:
+ config = json.load(f)
+
+ return PredictionConfig.deserialize(config, helper)
+
+
diff --git a/python-sdk/nuscenes/eval/prediction/configs/predict_2020_icra.json b/python-sdk/nuscenes/eval/prediction/configs/predict_2020_icra.json
new file mode 100644
index 0000000..ea856da
--- /dev/null
+++ b/python-sdk/nuscenes/eval/prediction/configs/predict_2020_icra.json
@@ -0,0 +1,53 @@
+{
+ "seconds": 6,
+ "metrics": [
+ {
+ "k_to_report": [
+ 1,
+ 5,
+ 10
+ ],
+ "name": "MinFDEK",
+ "aggregators": [
+ {
+ "name": "RowMean"
+ }
+ ]
+ },
+ {
+ "k_to_report": [
+ 1,
+ 5,
+ 10
+ ],
+ "name": "MinADEK",
+ "aggregators": [
+ {
+ "name": "RowMean"
+ }
+ ]
+ },
+ {
+ "k_to_report": [
+ 1,
+ 5,
+ 10
+ ],
+ "name": "MissRateTopK",
+ "aggregators": [
+ {
+ "name": "RowMean"
+ }
+ ],
+ "tolerance": 2
+ },
+ {
+ "name": "OffRoadRate",
+ "aggregators": [
+ {
+ "name": "RowMean"
+ }
+ ]
+ }
+ ]
+}
\ No newline at end of file
diff --git a/python-sdk/nuscenes/eval/prediction/data_classes.py b/python-sdk/nuscenes/eval/prediction/data_classes.py
new file mode 100644
index 0000000..a9ee6bb
--- /dev/null
+++ b/python-sdk/nuscenes/eval/prediction/data_classes.py
@@ -0,0 +1,75 @@
+# nuScenes dev-kit.
+# Code written by Freddy Boulton 2020.
+from typing import Dict, Any
+
+import numpy as np
+
+from nuscenes.eval.common.data_classes import MetricData
+
+MAX_NUMBER_OF_MODES = 25
+
+
+class Prediction(MetricData):
+ """
+ Stores predictions of Models.
+ Metrics are calculated from Predictions.
+
+ Attributes:
+ instance: Instance token for prediction.
+ sample: Sample token for prediction.
+ prediction: Prediction of model [num_modes, n_timesteps, state_dim].
+ probabilities: Probabilities of each mode [num_modes].
+ """
+ def __init__(self, instance: str, sample: str, prediction: np.ndarray,
+ probabilities: np.ndarray):
+ self.is_valid(instance, sample, prediction, probabilities)
+
+ self.instance = instance
+ self.sample = sample
+ self.prediction = prediction
+ self.probabilities = probabilities
+
+ @property
+ def number_of_modes(self) -> int:
+ return self.prediction.shape[0]
+
+ def serialize(self):
+ """ Serialize to json. """
+ return {'instance': self.instance,
+ 'sample': self.sample,
+ 'prediction': self.prediction.tolist(),
+ 'probabilities': self.probabilities.tolist()}
+
+ @classmethod
+ def deserialize(cls, content: Dict[str, Any]):
+ """ Initialize from serialized content. """
+ return cls(instance=content['instance'],
+ sample=content['sample'],
+ prediction=np.array(content['prediction']),
+ probabilities=np.array(content['probabilities']))
+
+ @staticmethod
+ def is_valid(instance, sample, prediction, probabilities):
+ if not isinstance(prediction, np.ndarray):
+ raise ValueError(f"Error: prediction must be of type np.ndarray. Received {str(type(prediction))}.")
+ if not isinstance(probabilities, np.ndarray):
+ raise ValueError(f"Error: probabilities must be of type np.ndarray. Received {type(probabilities)}.")
+ if not isinstance(instance, str):
+ raise ValueError(f"Error: instance token must be of type string. Received {type(instance)}")
+ if not isinstance(sample, str):
+ raise ValueError(f"Error: sample token must be of type string. Received {type(sample)}.")
+ if prediction.ndim != 3:
+ raise ValueError("Error: prediction must have three dimensions (number of modes, number of timesteps, 2).\n"
+ f"Received {prediction.ndim}")
+ if probabilities.ndim != 1:
+ raise ValueError(f"Error: probabilities must be a single dimension. Received {probabilities.ndim}.")
+ if len(probabilities) != prediction.shape[0]:
+ raise ValueError("Error: there must be the same number of probabilities as predicted modes.\n"
+ f"Received {len(probabilities)} probabilities and {prediction.shape[0]} modes.")
+ if prediction.shape[0] > MAX_NUMBER_OF_MODES:
+ raise ValueError(f"Error: prediction contains more than {MAX_NUMBER_OF_MODES} modes.")
+
+ def __repr__(self):
+ return f"Prediction(instance={self.instance}, sample={self.sample},"\
+ f" prediction={self.prediction}, probabilities={self.probabilities})"
+
diff --git a/python-sdk/nuscenes/eval/prediction/docker_container/README.md b/python-sdk/nuscenes/eval/prediction/docker_container/README.md
new file mode 100644
index 0000000..57650ce
--- /dev/null
+++ b/python-sdk/nuscenes/eval/prediction/docker_container/README.md
@@ -0,0 +1,74 @@
+# nuScenes Prediction Challenge Docker Submission Process
+
+We will ask at least the top five teams ranked on the leader board to submit their code to us so we can
+evaluate their model on the private test set. To ensure reproducibility, we will run their code
+in a Docker container. This document explains how you can run your model inside the Docker container we
+will use. If you follow these steps, then if it runs on your machine, it will run on ours.
+
+## Requirements
+
+- Docker version >= 19 (We tested with 19.03.7)
+- machine with GPU card, nvidia drivers and CUDA 10.1 (for GPU support)
+- nvidia-docker https://github.com/NVIDIA/nvidia-docker. You can use generic docker image if you don't need GPU support
+- nuScenes dataset
+- cloned nuScenes-devkit repo https://github.com/nutonomy/nuscenes-devkit
+
+## Usage
+- Pull docker image. For CUDA 10.1 use:
+```
+docker pull nuscenes/dev-challenge:10.1
+```
+- Pull docker image. For CUDA 9.2 use:
+```
+docker pull nuscenes/dev-challenge:9.2
+```
+
+
+- Create directory for output data
+```
+mkdir -p ~/Documents/submissions
+```
+
+- Create home directory for the image (needed if you need to install extra packages).
+```
+mkdir -p ~/Desktop/home_directory
+```
+
+- Modify `do_inference.py` in `nuscenes/eval/prediction/submission` to
+run your model. Place your model weights in
+`nuscenes/eval/prediction/submission` as well. If you need to install any
+extra packages, add them (along with the **exact** version number) to
+`nuscenes/eval/prediction/submission/extra_packages.txt`.
+
+- Run docker container
+```
+cd <NUSCENES ROOT DIR>
+docker run [ --gpus all ] -ti --rm \
+ -v <PATH TO NUSCENES DATASET>:/data/sets/nuscenes \
+ -v <PATH TO nuScenes-devkit ROOT DIR>/python-sdk:/nuscenes-dev/python-sdk \
+ -v <PATH TO nuscenes/eval/prediction/submission>:/nuscenes-dev/prediction \
+ -v ~/Documents/:/nuscenes-dev/Documents \
+ -v ~/Desktop/home_directory:/home/<username>
+ <name of image>
+```
+
+NOTE: The docker image uses 1000:1000 uid:gid
+If this is different from your local setup, you may want to add this options into `docker run` command
+```
+--user `id -u`:`id -g` -v /etc/passwd:/etc/passwd -v /etc/group:/etc/group
+```
+
+- Execute your script inside docker container
+```
+source activate /home/nuscenes/.conda/envs/nuscenes
+
+pip install -r submission/extra_packages.txt
+
+# Use v1.0-trainval and split_name val to run on the entire val set
+
+python do_inference.py --version v1.0-mini \
+ --data_root /data/sets/nuscenes \
+ --split_name mini_val \
+ --output_dir /nuscenes-dev/Documents/submissions \
+ --submission_name <submission-name>
+```
diff --git a/python-sdk/nuscenes/eval/prediction/docker_container/docker/Dockerfile b/python-sdk/nuscenes/eval/prediction/docker_container/docker/Dockerfile
new file mode 100644
index 0000000..087b5ed
--- /dev/null
+++ b/python-sdk/nuscenes/eval/prediction/docker_container/docker/Dockerfile
@@ -0,0 +1,40 @@
+ARG FROM
+FROM ${FROM}
+
+MAINTAINER nutonomy.com
+
+RUN apt-get update && apt-get install -y --no-install-recommends \
+ curl \
+ libsm6 \
+ libxext6 \
+ libxrender-dev \
+ libgl1-mesa-glx \
+ libglib2.0-0 \
+ xvfb \
+ && rm -rf /var/lib/apt/lists/*
+
+RUN curl -OL https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh \
+ && bash ./Miniconda3-latest-Linux-x86_64.sh -b -p /opt/miniconda3 \
+ && rm -f Miniconda3-latest-Linux-x86_64.sh
+
+ENV PATH /opt/miniconda3/bin:$PATH
+
+RUN conda update -n base -c defaults conda
+
+RUN groupadd -g 1000 dev \
+ && useradd -d /home/nuscenes -u 1000 -g 1000 -m -s /bin/bash dev
+
+USER dev
+
+WORKDIR /nuscenes-dev/prediction
+
+ENV PYTHONPATH=/nuscenes-dev/python-sdk
+
+COPY setup/requirements.txt .
+
+RUN bash -c "conda create -y -n nuscenes python=3.7 \
+ && source activate nuscenes \
+ && pip install --no-cache-dir -r /nuscenes-dev/prediction/requirements.txt \
+ && conda clean --yes --all"
+
+VOLUME [ '/nuscenes-dev/python-sdk', '/nuscenes-dev/prediction', '/data/sets/nuscenes', '/nuscenes-dev/Documents' ]
diff --git a/python-sdk/nuscenes/eval/prediction/docker_container/docker/docker-compose.yml b/python-sdk/nuscenes/eval/prediction/docker_container/docker/docker-compose.yml
new file mode 100644
index 0000000..3bd7a20
--- /dev/null
+++ b/python-sdk/nuscenes/eval/prediction/docker_container/docker/docker-compose.yml
@@ -0,0 +1,17 @@
+version: '3.7'
+
+services:
+ dev-10.1:
+ image: nuscenes/dev-challenge:10.1
+ build:
+ context: ../../../../../../
+ dockerfile: python-sdk/nuscenes/eval/prediction/docker_container/docker/Dockerfile
+ args:
+ FROM: nvidia/cuda:10.1-base-ubuntu18.04
+ dev-9.2:
+ image: nuscenes/dev-challenge:9.2
+ build:
+ context: ../../../../../../
+ dockerfile: python-sdk/nuscenes/eval/prediction/docker_container/docker/Dockerfile
+ args:
+ FROM: nvidia/cuda:9.2-base-ubuntu18.04
diff --git a/python-sdk/nuscenes/eval/prediction/metrics.py b/python-sdk/nuscenes/eval/prediction/metrics.py
new file mode 100644
index 0000000..aac4ffa
--- /dev/null
+++ b/python-sdk/nuscenes/eval/prediction/metrics.py
@@ -0,0 +1,468 @@
+# nuScenes dev-kit.
+# Code written by Freddy Boulton, Eric Wolff 2020.
+""" Implementation of metrics used in the nuScenes prediction challenge. """
+import abc
+from typing import List, Dict, Any, Tuple
+
+import numpy as np
+from scipy import interpolate
+
+from nuscenes.eval.prediction.data_classes import Prediction
+from nuscenes.map_expansion.map_api import NuScenesMap
+from nuscenes.prediction import PredictHelper
+from nuscenes.prediction.input_representation.static_layers import load_all_maps
+
+
+def returns_2d_array(function):
+ """ Makes sure that the metric returns an array of shape [batch_size, num_modes]. """
+
+ def _returns_array(*args, **kwargs):
+ result = function(*args, **kwargs)
+
+ if isinstance(result, (int, float)):
+ result = np.array([[result]])
+
+ elif result.ndim == 1:
+ result = np.expand_dims(result, 0)
+
+ return result
+
+ return _returns_array
+
+
+@returns_2d_array
+def mean_distances(stacked_trajs: np.ndarray,
+ stacked_ground_truth: np.ndarray) -> np.ndarray:
+ """
+ Efficiently compute mean L2 norm between trajectories and ground truths (pairwise over states).
+ :param stacked_trajs: Array of [batch_size, num_modes, horizon_length, state_dim].
+ :param stacked_ground_truth: Array of [batch_size, num_modes, horizon_length, state_dim].
+ :return: Array of mean L2 norms as [batch_size, num_modes].
+ """
+ return np.mean(np.linalg.norm(stacked_trajs - stacked_ground_truth, axis=-1), axis=-1)
+
+
+@returns_2d_array
+def max_distances(stacked_trajs: np.ndarray, stacked_ground_truth: np.ndarray) -> np.ndarray:
+ """
+ Efficiently compute max L2 norm between trajectories and ground truths (pairwise over states).
+ :pram stacked_trajs: Array of shape [num_modes, horizon_length, state_dim].
+ :pram stacked_ground_truth: Array of [num_modes, horizon_length, state_dim].
+ :return: Array of max L2 norms as [num_modes].
+ """
+ return np.max(np.linalg.norm(stacked_trajs - stacked_ground_truth, axis=-1), axis=-1)
+
+
+@returns_2d_array
+def final_distances(stacked_trajs: np.ndarray, stacked_ground_truth: np.ndarray) -> np.ndarray:
+ """
+ Efficiently compute the L2 norm between the last points in the trajectory.
+ :param stacked_trajs: Array of shape [num_modes, horizon_length, state_dim].
+ :param stacked_ground_truth: Array of shape [num_modes, horizon_length, state_dim].
+ :return: mean L2 norms between final points. Array of shape [num_modes].
+ """
+ # We use take to index the elements in the last dimension so that we can also
+ # apply this function for a batch
+ diff_of_last = np.take(stacked_trajs, [-1], -2).squeeze() - np.take(stacked_ground_truth, [-1], -2).squeeze()
+ return np.linalg.norm(diff_of_last, axis=-1)
+
+
+@returns_2d_array
+def miss_max_distances(stacked_trajs: np.ndarray, stacked_ground_truth: np.ndarray,
+ tolerance: float) -> np.array:
+ """
+ Efficiently compute 'miss' metric between trajectories and ground truths.
+ :param stacked_trajs: Array of shape [num_modes, horizon_length, state_dim].
+ :param stacked_ground_truth: Array of shape [num_modes, horizon_length, state_dim].
+ :param tolerance: max distance (m) for a 'miss' to be True.
+ :return: True iff there was a 'miss.' Size [num_modes].
+ """
+ return max_distances(stacked_trajs, stacked_ground_truth) >= tolerance
+
+
+@returns_2d_array
+def rank_metric_over_top_k_modes(metric_results: np.ndarray,
+ mode_probabilities: np.ndarray,
+ ranking_func: str) -> np.ndarray:
+ """
+ Compute a metric over all trajectories ranked by probability of each trajectory.
+ :param metric_results: 1-dimensional array of shape [batch_size, num_modes].
+ :param mode_probabilities: 1-dimensional array of shape [batch_size, num_modes].
+ :param ranking_func: Either 'min' or 'max'. How you want to metrics ranked over the top
+ k modes.
+ :return: Array of shape [num_modes].
+ """
+
+ if ranking_func == "min":
+ func = np.minimum.accumulate
+ elif ranking_func == "max":
+ func = np.maximum.accumulate
+ else:
+ raise ValueError(f"Parameter ranking_func must be one of min or max. Received {ranking_func}")
+
+ p_sorted = np.flip(mode_probabilities.argsort(axis=-1), axis=-1)
+ indices = np.indices(metric_results.shape)
+
+ sorted_metrics = metric_results[indices[0], p_sorted]
+
+ return func(sorted_metrics, axis=-1)
+
+
+def miss_rate_top_k(stacked_trajs: np.ndarray, stacked_ground_truth: np.ndarray,
+ mode_probabilities: np.ndarray,
+ tolerance: float) -> np.ndarray:
+ """ Compute the miss rate over the top k modes. """
+
+ miss_rate = miss_max_distances(stacked_trajs, stacked_ground_truth, tolerance)
+ return rank_metric_over_top_k_modes(miss_rate, mode_probabilities, "min")
+
+
+def min_ade_k(stacked_trajs: np.ndarray, stacked_ground_truth: np.ndarray,
+ mode_probabilities: np.ndarray) -> np.ndarray:
+ """ Compute the min ade over the top k modes. """
+
+ ade = mean_distances(stacked_trajs, stacked_ground_truth)
+ return rank_metric_over_top_k_modes(ade, mode_probabilities, "min")
+
+
+def min_fde_k(stacked_trajs: np.ndarray, stacked_ground_truth: np.ndarray,
+ mode_probabilities: np.ndarray) -> np.ndarray:
+ """ Compute the min fde over the top k modes. """
+
+ fde = final_distances(stacked_trajs, stacked_ground_truth)
+ return rank_metric_over_top_k_modes(fde, mode_probabilities, "min")
+
+
+def stack_ground_truth(ground_truth: np.ndarray, num_modes: int) -> np.ndarray:
+ """
+ Make k identical copies of the ground truth to make computing the metrics across modes
+ easier.
+ :param ground_truth: Array of shape [horizon_length, state_dim].
+ :param num_modes: number of modes in prediction.
+ :return: Array of shape [num_modes, horizon_length, state_dim].
+ """
+ return np.repeat(np.expand_dims(ground_truth, 0), num_modes, axis=0)
+
+
+class SerializableFunction(abc.ABC):
+ """ Function that can be serialized/deserialized to/from json. """
+
+ @abc.abstractmethod
+ def serialize(self) -> Dict[str, Any]:
+ pass
+
+ @property
+ @abc.abstractmethod
+ def name(self,) -> str:
+ pass
+
+
+class Aggregator(SerializableFunction):
+ """ Function that can aggregate many metrics across predictions. """
+
+ @abc.abstractmethod
+ def __call__(self, array: np.ndarray, **kwargs) -> List[float]:
+ pass
+
+
+class RowMean(Aggregator):
+
+ def __call__(self, array: np.ndarray, **kwargs) -> np.ndarray:
+ return array.mean(axis=0).tolist()
+
+ def serialize(self) -> Dict[str, Any]:
+ return {'name': self.name}
+
+ @property
+ def name(self,) -> str:
+ return 'RowMean'
+
+
+class Metric(SerializableFunction):
+
+ @abc.abstractmethod
+ def __call__(self, ground_truth: np.ndarray, prediction: Prediction) -> np.ndarray:
+ pass
+
+ @property
+ @abc.abstractmethod
+ def aggregators(self,) -> List[Aggregator]:
+ pass
+
+ @property
+ @abc.abstractmethod
+ def shape(self,) -> str:
+ pass
+
+
+def desired_number_of_modes(results: np.ndarray,
+ k_to_report: List[int]) -> np.ndarray:
+ """ Ensures we return len(k_to_report) values even when results has less modes than what we want. """
+ return results[:, [min(k, results.shape[1]) - 1 for k in k_to_report]]
+
+
+class MinADEK(Metric):
+
+ def __init__(self, k_to_report: List[int], aggregators: List[Aggregator]):
+ """
+ Computes the minimum average displacement error over the top k predictions.
+ :param k_to_report: Will report the top k result for the k in this list.
+ :param aggregators: How to aggregate the results across the dataset.
+ """
+ super().__init__()
+ self.k_to_report = k_to_report
+ self._aggregators = aggregators
+
+ def __call__(self, ground_truth: np.ndarray, prediction: Prediction) -> np.ndarray:
+ ground_truth = stack_ground_truth(ground_truth, prediction.number_of_modes)
+ results = min_ade_k(prediction.prediction, ground_truth, prediction.probabilities)
+ return desired_number_of_modes(results, self.k_to_report)
+
+ def serialize(self) -> Dict[str, Any]:
+ return {'k_to_report': self.k_to_report,
+ 'name': self.name,
+ 'aggregators': [agg.serialize() for agg in self.aggregators]}
+
+ @property
+ def aggregators(self,) -> List[Aggregator]:
+ return self._aggregators
+
+ @property
+ def name(self):
+ return 'MinADEK'
+
+ @property
+ def shape(self):
+ return len(self.k_to_report)
+
+
+class MinFDEK(Metric):
+
+ def __init__(self, k_to_report, aggregators: List[Aggregator]):
+ """
+ Computes the minimum final displacement error over the top k predictions.
+ :param k_to_report: Will report the top k result for the k in this list.
+ :param aggregators: How to aggregate the results across the dataset.
+ """
+ super().__init__()
+ self.k_to_report = k_to_report
+ self._aggregators = aggregators
+
+ def __call__(self, ground_truth: np.ndarray, prediction: Prediction) -> np.ndarray:
+ ground_truth = stack_ground_truth(ground_truth, prediction.number_of_modes)
+ results = min_fde_k(prediction.prediction, ground_truth, prediction.probabilities)
+ return desired_number_of_modes(results, self.k_to_report)
+
+ def serialize(self) -> Dict[str, Any]:
+ return {'k_to_report': self.k_to_report,
+ 'name': self.name,
+ 'aggregators': [agg.serialize() for agg in self.aggregators]}
+
+ @property
+ def aggregators(self,) -> List[Aggregator]:
+ return self._aggregators
+
+ @property
+ def name(self):
+ return "MinFDEK"
+
+ @property
+ def shape(self):
+ return len(self.k_to_report)
+
+
+class MissRateTopK(Metric):
+
+ def __init__(self, k_to_report: List[int], aggregators: List[Aggregator],
+ tolerance: float = 2.):
+ """
+ If any point in the prediction is more than tolerance meters from the ground truth, it is a miss.
+ This metric computes the fraction of predictions that are misses over the top k most likely predictions.
+ :param k_to_report: Will report the top k result for the k in this list.
+ :param aggregators: How to aggregate the results across the dataset.
+ :param tolerance: Threshold to consider if a prediction is a hit or not.
+ """
+ self.k_to_report = k_to_report
+ self._aggregators = aggregators
+ self.tolerance = tolerance
+
+ def __call__(self, ground_truth: np.ndarray, prediction: Prediction) -> np.ndarray:
+ ground_truth = stack_ground_truth(ground_truth, prediction.number_of_modes)
+ results = miss_rate_top_k(prediction.prediction, ground_truth,
+ prediction.probabilities, self.tolerance)
+ return desired_number_of_modes(results, self.k_to_report)
+
+ def serialize(self) -> Dict[str, Any]:
+ return {'k_to_report': self.k_to_report,
+ 'name': 'MissRateTopK',
+ 'aggregators': [agg.serialize() for agg in self.aggregators],
+ 'tolerance': self.tolerance}
+
+ @property
+ def aggregators(self,) -> List[Aggregator]:
+ return self._aggregators
+
+ @property
+ def name(self):
+ return f"MissRateTopK_{self.tolerance}"
+
+ @property
+ def shape(self):
+ return len(self.k_to_report)
+
+
+class OffRoadRate(Metric):
+
+ def __init__(self, helper: PredictHelper, aggregators: List[Aggregator]):
+ """
+ The OffRoadRate is defined as the fraction of trajectories that are not entirely contained
+ in the drivable area of the map.
+ :param helper: Instance of PredictHelper. Used to determine the map version for each prediction.
+ :param aggregators: How to aggregate the results across the dataset.
+ """
+ self._aggregators = aggregators
+ self.helper = helper
+ self.drivable_area_polygons = self.load_drivable_area_masks(helper)
+ self.pixels_per_meter = 10
+ self.number_of_points = 200
+
+ @staticmethod
+ def load_drivable_area_masks(helper: PredictHelper) -> Dict[str, np.ndarray]:
+ """
+ Loads the polygon representation of the drivable area for each map.
+ :param helper: Instance of PredictHelper.
+ :return: Mapping from map_name to drivable area polygon.
+ """
+
+ maps: Dict[str, NuScenesMap] = load_all_maps(helper)
+
+ masks = {}
+ for map_name, map_api in maps.items():
+
+ masks[map_name] = map_api.get_map_mask(patch_box=None, patch_angle=0, layer_names=['drivable_area'],
+ canvas_size=None)[0]
+
+ return masks
+
+ @staticmethod
+ def interpolate_path(mode: np.ndarray, number_of_points: int) -> Tuple[np.ndarray, np.ndarray]:
+ """ Interpolate trajectory with a cubic spline if there are enough points. """
+
+ # interpolate.splprep needs unique points.
+ # We use a loop as opposed to np.unique because
+ # the order of the points must be the same
+ seen = set()
+ ordered_array = []
+ for row in mode:
+ row_tuple = tuple(row)
+ if row_tuple not in seen:
+ seen.add(row_tuple)
+ ordered_array.append(row_tuple)
+
+ new_array = np.array(ordered_array)
+
+ unique_points = np.atleast_2d(new_array)
+
+ if unique_points.shape[0] <= 3:
+ return unique_points[:, 0], unique_points[:, 1]
+ else:
+ knots, _ = interpolate.splprep([unique_points[:, 0], unique_points[:, 1]], k=3, s=0.1)
+ x_interpolated, y_interpolated = interpolate.splev(np.linspace(0, 1, number_of_points), knots)
+ return x_interpolated, y_interpolated
+
+ def __call__(self, ground_truth: np.ndarray, prediction: Prediction) -> np.ndarray:
+ """
+ Computes the fraction of modes in prediction that are not entirely contained in the drivable area.
+ :param ground_truth: Not used. Included signature to adhere to Metric API.
+ :param prediction: Model prediction.
+ :return: Array of shape (1, ) containing the fraction of modes that are not entirely contained in the
+ drivable area.
+ """
+ map_name = self.helper.get_map_name_from_sample_token(prediction.sample)
+ drivable_area = self.drivable_area_polygons[map_name]
+ max_row, max_col = drivable_area.shape
+
+ n_violations = 0
+ for mode in prediction.prediction:
+
+ # Fit a cubic spline to the trajectory and interpolate with 200 points
+ x_interpolated, y_interpolated = self.interpolate_path(mode, self.number_of_points)
+
+ # x coordinate -> col, y coordinate -> row
+ # Mask has already been flipped over y-axis
+ index_row = (y_interpolated * self.pixels_per_meter).astype("int")
+ index_col = (x_interpolated * self.pixels_per_meter).astype("int")
+
+ row_out_of_bounds = np.any(index_row >= max_row) or np.any(index_row < 0)
+ col_out_of_bounds = np.any(index_col >= max_col) or np.any(index_col < 0)
+ out_of_bounds = row_out_of_bounds or col_out_of_bounds
+
+ if out_of_bounds or not np.all(drivable_area[index_row, index_col]):
+ n_violations += 1
+
+ return np.array([n_violations / prediction.prediction.shape[0]])
+
+ def serialize(self) -> Dict[str, Any]:
+ return {'name': self.name,
+ 'aggregators': [agg.serialize() for agg in self.aggregators]}
+
+ @property
+ def aggregators(self,) -> List[Aggregator]:
+ return self._aggregators
+
+ @property
+ def name(self):
+ return 'OffRoadRate'
+
+ @property
+ def shape(self):
+ return 1
+
+
+def deserialize_aggregator(config: Dict[str, Any]) -> Aggregator:
+ """ Helper for deserializing Aggregators. """
+ if config['name'] == 'RowMean':
+ return RowMean()
+ else:
+ raise ValueError(f"Cannot deserialize Aggregator {config['name']}.")
+
+
+def deserialize_metric(config: Dict[str, Any], helper: PredictHelper) -> Metric:
+ """ Helper for deserializing Metrics. """
+ if config['name'] == 'MinADEK':
+ return MinADEK(config['k_to_report'], [deserialize_aggregator(agg) for agg in config['aggregators']])
+ elif config['name'] == 'MinFDEK':
+ return MinFDEK(config['k_to_report'], [deserialize_aggregator(agg) for agg in config['aggregators']])
+ elif config['name'] == 'MissRateTopK':
+ return MissRateTopK(config['k_to_report'], [deserialize_aggregator(agg) for agg in config['aggregators']],
+ tolerance=config['tolerance'])
+ elif config['name'] == 'OffRoadRate':
+ return OffRoadRate(helper, [deserialize_aggregator(agg) for agg in config['aggregators']])
+ else:
+ raise ValueError(f"Cannot deserialize function {config['name']}.")
+
+
+def flatten_metrics(results: Dict[str, Any], metrics: List[Metric]) -> Dict[str, List[float]]:
+ """
+ Collapses results into a 2D table represented by a dictionary mapping the metric name to
+ the metric values.
+ :param results: Mapping from metric function name to result of aggregators.
+ :param metrics: List of metrics in the results.
+ :return: Dictionary mapping metric name to the metric value.
+ """
+
+ metric_names = {metric.name: metric for metric in metrics}
+
+ flattened_metrics = {}
+
+ for metric_name, values in results.items():
+
+ metric_class = metric_names[metric_name]
+
+ if hasattr(metric_class, 'k_to_report'):
+ for value, k in zip(values['RowMean'], metric_class.k_to_report):
+ flattened_metrics[f"{metric_name}_{k}"] = value
+ else:
+ flattened_metrics[metric_name] = values['RowMean']
+
+ return flattened_metrics
diff --git a/python-sdk/nuscenes/eval/prediction/splits.py b/python-sdk/nuscenes/eval/prediction/splits.py
new file mode 100644
index 0000000..08a8008
--- /dev/null
+++ b/python-sdk/nuscenes/eval/prediction/splits.py
@@ -0,0 +1,41 @@
+# nuScenes dev-kit.
+# Code written by Freddy Boulton.
+
+import json
+import os
+from itertools import chain
+from typing import List
+
+from nuscenes.utils.splits import create_splits_scenes
+
+NUM_IN_TRAIN_VAL = 200
+
+
+def get_prediction_challenge_split(split: str, dataroot: str = '/data/sets/nuscenes') -> List[str]:
+ """
+ Gets a list of {instance_token}_{sample_token} strings for each split.
+ :param split: One of 'mini_train', 'mini_val', 'train', 'val'.
+ :param dataroot: Path to the nuScenes dataset.
+ :return: List of tokens belonging to the split. Format {instance_token}_{sample_token}.
+ """
+ if split not in {'mini_train', 'mini_val', 'train', 'train_val', 'val'}:
+ raise ValueError("split must be one of (mini_train, mini_val, train, train_val, val)")
+
+ if split == 'train_val':
+ split_name = 'train'
+ else:
+ split_name = split
+
+ path_to_file = os.path.join(dataroot, "maps", "prediction", "prediction_scenes.json")
+ prediction_scenes = json.load(open(path_to_file, "r"))
+ scenes = create_splits_scenes()
+ scenes_for_split = scenes[split_name]
+
+ if split == 'train':
+ scenes_for_split = scenes_for_split[NUM_IN_TRAIN_VAL:]
+ if split == 'train_val':
+ scenes_for_split = scenes_for_split[:NUM_IN_TRAIN_VAL]
+
+ token_list_for_scenes = map(lambda scene: prediction_scenes.get(scene, []), scenes_for_split)
+
+ return list(chain.from_iterable(token_list_for_scenes))
diff --git a/python-sdk/nuscenes/eval/prediction/submission/__init__.py b/python-sdk/nuscenes/eval/prediction/submission/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/python-sdk/nuscenes/eval/prediction/submission/do_inference.py b/python-sdk/nuscenes/eval/prediction/submission/do_inference.py
new file mode 100644
index 0000000..83f6b01
--- /dev/null
+++ b/python-sdk/nuscenes/eval/prediction/submission/do_inference.py
@@ -0,0 +1,81 @@
+# nuScenes dev-kit.
+# Code written by Freddy Boulton, 2020.
+""" Script for generating a submission to the nuScenes prediction challenge. """
+import argparse
+import json
+import os
+from typing import List, Any
+
+from nuscenes import NuScenes
+from nuscenes.eval.prediction.config import PredictionConfig
+from nuscenes.eval.prediction.config import load_prediction_config
+from nuscenes.eval.prediction.data_classes import Prediction
+from nuscenes.eval.prediction.splits import get_prediction_challenge_split
+from nuscenes.prediction import PredictHelper
+from nuscenes.prediction.models.physics import ConstantVelocityHeading
+
+
+def load_model(helper: PredictHelper, config: PredictionConfig, path_to_model_weights: str) -> Any:
+ """ Loads model with desired weights. """
+ return ConstantVelocityHeading(config.seconds, helper)
+
+
+def do_inference_for_submission(helper: PredictHelper,
+ config: PredictionConfig,
+ dataset_tokens: List[str]) -> List[Prediction]:
+ """
+ Currently, this will make a submission with a constant velocity and heading model.
+ Fill in all the code needed to run your model on the test set here. You do not need to worry
+ about providing any of the parameters to this function since they are provided by the main function below.
+ You can test if your script works by evaluating on the val set.
+ :param helper: Instance of PredictHelper that wraps the nuScenes test set.
+ :param config: Instance of PredictionConfig.
+ :param dataset_tokens: Tokens of instance_sample pairs in the test set.
+ :returns: List of predictions.
+ """
+
+ # User: Fill in the path to the model weights here.
+ path_to_model_weights = ""
+
+ cv_heading = load_model(helper, config, path_to_model_weights)
+
+ cv_preds = []
+ for token in dataset_tokens:
+ cv_preds.append(cv_heading(token))
+
+ return cv_preds
+
+
+def main(version: str, data_root: str, split_name: str, output_dir: str, submission_name: str, config_name: str) \
+ -> None:
+ """
+ Makes predictions for a submission to the nuScenes prediction challenge.
+ :param version: NuScenes version.
+ :param data_root: Directory storing NuScenes data.
+ :param split_name: Data split to run inference on.
+ :param output_dir: Directory to store the output file.
+ :param submission_name: Name of the submission to use for the results file.
+ :param config_name: Name of config file to use.
+ """
+ nusc = NuScenes(version=version, dataroot=data_root)
+ helper = PredictHelper(nusc)
+ dataset = get_prediction_challenge_split(split_name)
+ config = load_prediction_config(helper, config_name)
+
+ predictions = do_inference_for_submission(helper, config, dataset)
+ predictions = [prediction.serialize() for prediction in predictions]
+ json.dump(predictions, open(os.path.join(output_dir, f"{submission_name}_inference.json"), "w"))
+
+
+if __name__ == "__main__":
+
+ parser = argparse.ArgumentParser(description='Perform Inference with baseline models.')
+ parser.add_argument('--version', help='NuScenes version number.')
+ parser.add_argument('--data_root', help='Root directory for NuScenes json files.')
+ parser.add_argument('--split_name', help='Data split to run inference on.')
+ parser.add_argument('--output_dir', help='Directory to store output file.')
+ parser.add_argument('--submission_name', help='Name of the submission to use for the results file.')
+ parser.add_argument('--config_name', help='Name of the config file to use', default='predict_2020_icra.json')
+
+ args = parser.parse_args()
+ main(args.version, args.data_root, args.split_name, args.output_dir, args.submission_name, args.config_name)
diff --git a/python-sdk/nuscenes/eval/prediction/submission/extra_packages.txt b/python-sdk/nuscenes/eval/prediction/submission/extra_packages.txt
new file mode 100644
index 0000000..e69de29
diff --git a/python-sdk/nuscenes/eval/prediction/tests/__init__.py b/python-sdk/nuscenes/eval/prediction/tests/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/python-sdk/nuscenes/eval/prediction/tests/test_dataclasses.py b/python-sdk/nuscenes/eval/prediction/tests/test_dataclasses.py
new file mode 100644
index 0000000..51065e8
--- /dev/null
+++ b/python-sdk/nuscenes/eval/prediction/tests/test_dataclasses.py
@@ -0,0 +1,18 @@
+import unittest
+
+import numpy as np
+
+from nuscenes.eval.prediction.data_classes import Prediction
+
+
+class TestPrediction(unittest.TestCase):
+
+ def test(self):
+ prediction = Prediction('instance', 'sample', np.ones((2, 2, 2)), np.zeros(2))
+
+ self.assertEqual(prediction.number_of_modes, 2)
+ self.assertDictEqual(prediction.serialize(), {'instance': 'instance',
+ 'sample': 'sample',
+ 'prediction': [[[1, 1], [1, 1]],
+ [[1, 1], [1, 1]]],
+ 'probabilities': [0, 0]})
diff --git a/python-sdk/nuscenes/eval/prediction/tests/test_metrics.py b/python-sdk/nuscenes/eval/prediction/tests/test_metrics.py
new file mode 100644
index 0000000..26e37b9
--- /dev/null
+++ b/python-sdk/nuscenes/eval/prediction/tests/test_metrics.py
@@ -0,0 +1,331 @@
+import os
+import unittest
+from unittest.mock import MagicMock, patch
+
+import numpy as np
+
+from nuscenes import NuScenes
+from nuscenes.eval.prediction import metrics
+from nuscenes.eval.prediction.data_classes import Prediction
+from nuscenes.prediction import PredictHelper
+
+
+class TestFunctions(unittest.TestCase):
+
+ def setUp(self):
+ self.x_one_mode = np.ones((1, 5, 2))
+ self.y_one_mode = np.expand_dims(np.arange(10).reshape(5, 2), 0)
+ self.p_one_mode = np.array([[1.]])
+
+ x_many_modes = np.repeat(self.x_one_mode, 3, axis=0)
+ x_many_modes[0, :] = 0
+ x_many_modes[2, :] = 2
+ self.x_many_modes = x_many_modes
+ self.y_many_modes = np.repeat(self.y_one_mode, 3, axis=0)
+ self.p_many_modes = np.array([[0.2, 0.5, 0.3]])
+
+ self.x_many_batches_and_modes = np.repeat(np.expand_dims(self.x_many_modes, 0), 5, axis=0)
+ self.y_many_batches_and_modes = np.repeat(np.expand_dims(self.y_many_modes, 0), 5, axis=0)
+ self.p_many_batches_and_modes = np.array([[0.2, 0.5, 0.3],
+ [0.5, 0.3, 0.2],
+ [0.2, 0.3, 0.5],
+ [0.3, 0.2, 0.5],
+ [0.3, 0.5, 0.2]])
+
+ def test_returns_2d_array_float(self):
+
+ func = lambda x: 2
+ value = metrics.returns_2d_array(func)(2)
+ np.testing.assert_equal(value, np.array([[2]]))
+
+ func = lambda x: 3.
+ value = metrics.returns_2d_array(func)(np.ones((10, 1)))
+ np.testing.assert_equal(value, np.array([[3]]))
+
+ def test_returns_2d_array_one_dim(self):
+
+ func = lambda x: np.ones(10)
+ value = metrics.returns_2d_array(func)(1)
+ np.testing.assert_equal(value, np.ones((1, 10)))
+
+ def test_mean_distances_one_mode(self):
+
+ value = metrics.mean_distances(self.x_one_mode, self.y_one_mode)
+ np.testing.assert_allclose(value, np.array([[5.33529]]), atol=1e-4, rtol=1e-4)
+
+ def test_mean_distances_many_modes(self):
+ value = metrics.mean_distances(self.x_many_modes, self.y_many_modes)
+ np.testing.assert_allclose(value, np.array([[6.45396, 5.33529, 4.49286]]), atol=1e-4, rtol=1e-4)
+
+ def test_mean_distances_many_batches_and_modes(self):
+ value = metrics.mean_distances(self.x_many_batches_and_modes, self.y_many_batches_and_modes)
+ np.testing.assert_allclose(value, np.array(5*[[6.45396, 5.33529, 4.49286]]), atol=1e-4, rtol=1e-4)
+
+ def test_max_distances_one_mode(self):
+ value = metrics.max_distances(self.x_one_mode, self.y_one_mode)
+ np.testing.assert_allclose(value, np.array([[10.63014]]), atol=1e-4, rtol=1e-4)
+
+ def test_max_distances_many_modes(self):
+ value = metrics.max_distances(self.x_many_modes, self.y_many_modes)
+ np.testing.assert_allclose(value, np.array([[12.04159, 10.63014, 9.21954]]), atol=1e-4, rtol=1e-4)
+
+ def test_max_distances_many_batches_and_modes(self):
+ value = metrics.max_distances(self.x_many_batches_and_modes, self.y_many_batches_and_modes)
+ np.testing.assert_allclose(value, np.array(5*[[12.04159, 10.63014, 9.21954]]), atol=1e-4, rtol=1e-4)
+
+ def test_final_distances_one_mode(self):
+ value = metrics.max_distances(self.x_one_mode, self.y_one_mode)
+ np.testing.assert_allclose(value, np.array([[10.63014]]), atol=1e-4, rtol=1e-4)
+
+ def test_final_distances_many_modes(self):
+ value = metrics.max_distances(self.x_many_modes, self.y_many_modes)
+ np.testing.assert_allclose(value, np.array([[12.04159, 10.63014, 9.21954]]), atol=1e-4, rtol=1e-4)
+
+ def test_final_distances_many_batches_and_modes(self):
+ value = metrics.max_distances(self.x_many_batches_and_modes, self.y_many_batches_and_modes)
+ np.testing.assert_allclose(value, np.array(5*[[12.04159, 10.63014, 9.21954]]), atol=1e-4, rtol=1e-4)
+
+ def test_miss_max_distance_one_mode(self):
+ value = metrics.miss_max_distances(self.x_one_mode, self.y_one_mode, 1)
+ np.testing.assert_equal(value, np.array([[True]]))
+
+ value = metrics.miss_max_distances(self.x_one_mode, self.y_one_mode, 15)
+ np.testing.assert_equal(value, np.array([[False]]))
+
+ def test_miss_max_distances_many_modes(self):
+ value = metrics.miss_max_distances(self.x_many_modes, self.y_many_modes, 10)
+ np.testing.assert_equal(value, np.array([[True, True, False]]))
+
+ def test_miss_max_distances_many_batches_and_modes(self):
+ value = metrics.miss_max_distances(self.x_many_batches_and_modes, self.y_many_batches_and_modes, 10)
+ np.testing.assert_equal(value, np.array(5*[[True, True, False]]))
+
+ def test_miss_rate_top_k_one_mode(self):
+ value = metrics.miss_rate_top_k(self.x_one_mode, self.y_one_mode, self.p_one_mode, 2)
+ np.testing.assert_equal(value, np.array([[True]]))
+
+ def test_miss_rate_top_k_many_modes(self):
+ value = metrics.miss_rate_top_k(self.x_many_modes, self.y_many_modes, self.p_many_modes, 10)
+ np.testing.assert_equal(value, np.array([[True, False, False]]))
+
+ def test_miss_rate_top_k_many_batches_and_modes(self):
+ value = metrics.miss_rate_top_k(self.x_many_batches_and_modes,
+ self.y_many_batches_and_modes, self.p_many_batches_and_modes, 10)
+ np.testing.assert_equal(value, np.array([[True, False, False],
+ [True, True, False],
+ [False, False, False],
+ [False, False, False],
+ [True, True, False]]))
+
+ def test_min_ade_k_one_mode(self):
+ value = metrics.min_ade_k(self.x_one_mode, self.y_one_mode, self.p_one_mode)
+ np.testing.assert_allclose(value, np.array([[5.33529]]), atol=1e-4, rtol=1e-4)
+
+ def test_min_ade_k_many_modes(self):
+ value = metrics.min_ade_k(self.x_many_modes, self.y_many_modes, self.p_many_modes)
+ np.testing.assert_allclose(value, np.array([[5.33529, 4.49286, 4.49286]]), atol=1e-4, rtol=1e-4)
+
+ def test_min_ade_k_many_batches_and_modes(self):
+ value = metrics.min_ade_k(self.x_many_batches_and_modes, self.y_many_batches_and_modes,
+ self.p_many_batches_and_modes)
+ np.testing.assert_allclose(value, np.array([[5.33529, 4.49286, 4.49286],
+ [6.45396, 5.33529, 4.49286],
+ [4.49286, 4.49286, 4.49286],
+ [4.49286, 4.49286, 4.49286],
+ [5.33529, 5.33529, 4.49286]
+ ]), atol=1e-4, rtol=1e-4)
+
+ def test_min_fde_k_one_mode(self):
+ value = metrics.min_fde_k(self.x_one_mode, self.y_one_mode, self.p_one_mode)
+ np.testing.assert_allclose(value, np.array([[10.63014]]), atol=1e-4, rtol=1e-4)
+
+ def test_min_fde_k_many_modes(self):
+ value = metrics.min_fde_k(self.x_many_modes, self.y_many_modes, self.p_many_modes)
+ np.testing.assert_allclose(value, np.array([[10.63014, 9.21954, 9.21954]]), atol=1e-4, rtol=1e-4)
+
+ def test_min_fde_k_many_batches_and_modes(self):
+ value = metrics.min_fde_k(self.x_many_batches_and_modes, self.y_many_batches_and_modes,
+ self.p_many_batches_and_modes)
+ np.testing.assert_allclose(value, np.array([[10.63014, 9.21954, 9.21954],
+ [12.04159, 10.63014, 9.21954],
+ [9.21954, 9.21954, 9.21954],
+ [9.21954, 9.21954, 9.21954],
+ [10.63014, 10.64014, 9.21954]]), atol=1e-3, rtol=1e-3)
+
+ def test_stack_ground_truth(self):
+ value = metrics.stack_ground_truth(np.ones((5, 2)), 10)
+ np.testing.assert_equal(value, np.ones((10, 5, 2)))
+
+ def test_desired_number_of_modes_one_mode(self):
+ results = np.ones((10, 1))
+ value = metrics.desired_number_of_modes(results, [1, 5, 15, 25])
+ np.testing.assert_equal(value, np.ones((10, 4)))
+
+ def test_desired_number_of_modes_enough_data(self):
+ results = np.arange(75).reshape(3, 25)
+ value = metrics.desired_number_of_modes(results, [1, 5, 15, 25])
+ np.testing.assert_equal(value, np.array([[0, 4, 14, 24],
+ [25, 29, 39, 49],
+ [50, 54, 64, 74]]))
+
+ def test_desired_number_of_modes_not_enough(self):
+ results = np.arange(30).reshape(2, 15)
+ value = metrics.desired_number_of_modes(results, [1, 5, 15, 25])
+ np.testing.assert_equal(value, np.array([[0, 4, 14, 14],
+ [15, 19, 29, 29]]))
+
+
+class TestAggregators(unittest.TestCase):
+
+ def test_RowMean(self):
+ rm = metrics.RowMean()
+ value = rm(np.arange(20).reshape(2, 10))
+ self.assertListEqual(list(value), [5, 6, 7, 8, 9, 10, 11, 12, 13, 14])
+
+ self.assertDictEqual(rm.serialize(), {'name': 'RowMean'})
+
+
+class TestMetrics(unittest.TestCase):
+
+ def test_MinADEK(self):
+ min_ade = metrics.MinADEK([1, 5, 10], [metrics.RowMean()])
+ self.assertDictEqual(min_ade.serialize(), {'name': 'MinADEK',
+ 'k_to_report': [1, 5, 10],
+ 'aggregators': [{'name': 'RowMean'}]})
+
+ def test_MinFDEK(self):
+ min_fde = metrics.MinFDEK([1, 5, 10], [metrics.RowMean()])
+ self.assertDictEqual(min_fde.serialize(), {'name': 'MinFDEK',
+ 'k_to_report': [1, 5, 10],
+ 'aggregators': [{'name': 'RowMean'}]})
+
+ def test_MissRateTopK(self):
+ hit_rate = metrics.MissRateTopK([1, 5, 10], [metrics.RowMean()], 2)
+ self.assertDictEqual(hit_rate.serialize(), {'k_to_report': [1, 5, 10],
+ 'name': 'MissRateTopK',
+ 'aggregators': [{'name': 'RowMean'}],
+ 'tolerance': 2})
+
+ def test_OffRoadRate(self):
+ with patch.object(metrics.OffRoadRate, 'load_drivable_area_masks'):
+ helper = MagicMock(spec=PredictHelper)
+ off_road_rate = metrics.OffRoadRate(helper, [metrics.RowMean()])
+ self.assertDictEqual(off_road_rate.serialize(), {'name': 'OffRoadRate',
+ 'aggregators': [{'name': 'RowMean'}]})
+
+ def test_deserialize_metric(self):
+
+ config = {'name': 'MinADEK',
+ 'k_to_report': [1, 5, 10],
+ 'aggregators': [{'name': 'RowMean'}]}
+
+ helper = MagicMock(spec=PredictHelper)
+ m = metrics.deserialize_metric(config, helper)
+ self.assertEqual(m.name, 'MinADEK')
+ self.assertListEqual(m.k_to_report, [1, 5, 10])
+ self.assertEqual(m.aggregators[0].name, 'RowMean')
+
+ config = {'name': 'MinFDEK',
+ 'k_to_report': [1, 5, 10],
+ 'aggregators': [{'name': 'RowMean'}]}
+
+ m = metrics.deserialize_metric(config, helper)
+ self.assertEqual(m.name, 'MinFDEK')
+ self.assertListEqual(m.k_to_report, [1, 5, 10])
+ self.assertEqual(m.aggregators[0].name, 'RowMean')
+
+ config = {'name': 'MissRateTopK',
+ 'k_to_report': [1, 5, 10],
+ 'tolerance': 2,
+ 'aggregators': [{'name': 'RowMean'}]}
+
+ m = metrics.deserialize_metric(config, helper)
+ self.assertEqual(m.name, 'MissRateTopK_2')
+ self.assertListEqual(m.k_to_report, [1, 5, 10])
+ self.assertEqual(m.aggregators[0].name, 'RowMean')
+
+ with patch.object(metrics.OffRoadRate, 'load_drivable_area_masks'):
+ config = {'name': 'OffRoadRate',
+ 'aggregators': [{'name': 'RowMean'}]}
+
+ m = metrics.deserialize_metric(config, helper)
+ self.assertEqual(m.name, 'OffRoadRate')
+ self.assertEqual(m.aggregators[0].name, 'RowMean')
+
+ def test_flatten_metrics(self):
+ results = {"MinFDEK": {"RowMean": [5.92, 6.1, 7.2]},
+ "MinADEK": {"RowMean": [2.48, 3.29, 3.79]},
+ "MissRateTopK_2": {"RowMean": [0.37, 0.45, 0.55]}}
+
+ metric_functions = [metrics.MinFDEK([1, 5, 10], aggregators=[metrics.RowMean()]),
+ metrics.MinADEK([1, 5, 10], aggregators=[metrics.RowMean()]),
+ metrics.MissRateTopK([1, 5, 10], tolerance=2, aggregators=[metrics.RowMean()])]
+
+ flattened = metrics.flatten_metrics(results, metric_functions)
+
+ answer = {'MinFDEK_1': 5.92, 'MinFDEK_5': 6.1, 'MinFDEK_10': 7.2,
+ 'MinADEK_1': 2.48, 'MinADEK_5': 3.29, 'MinADEK_10': 3.79,
+ 'MissRateTopK_2_1': 0.37, 'MissRateTopK_2_5': 0.45, 'MissRateTopK_2_10': 0.55}
+
+ self.assertDictEqual(flattened, answer)
+
+
+class TestOffRoadRate(unittest.TestCase):
+
+ def _do_test(self, map_name, predictions, answer):
+ with patch.object(PredictHelper, 'get_map_name_from_sample_token') as get_map_name:
+ get_map_name.return_value = map_name
+ nusc = NuScenes('v1.0-mini', dataroot=os.environ['NUSCENES'], verbose=False)
+ helper = PredictHelper(nusc)
+
+ off_road_rate = metrics.OffRoadRate(helper, [metrics.RowMean()])
+
+ probabilities = np.array([1/3] * predictions.shape[0])
+ prediction = Prediction('foo-instance', 'foo-sample', predictions, probabilities)
+
+ # Two violations out of three trajectories
+ np.testing.assert_allclose(off_road_rate(np.array([]), prediction), np.array([answer]))
+
+ def test_boston(self):
+ predictions = np.array([[(486.91778944573264, 812.8782745377198),
+ (487.3648565923963, 813.7269620253566),
+ (487.811923719944, 814.5756495230632),
+ (488.2589908474917, 815.4243370207698)],
+ [(486.91778944573264, 812.8782745377198),
+ (487.3648565923963, 813.7269620253566),
+ (487.811923719944, 814.5756495230632),
+ (0, 0)],
+ [(0, 0), (0, 1), (0, 2), (0, 3)]])
+ self._do_test('boston-seaport', predictions, 2/3)
+
+
+ def test_one_north(self):
+ predictions = np.array([[[965.8515334916171, 535.711518726687],
+ [963.6475430050381, 532.9713854167148],
+ [961.4435525191437, 530.231252106192],
+ [959.239560587773, 527.4911199583674]],
+ [[508.8742570078554, 875.3458194583762],
+ [505.2029816111618, 877.7929160023881],
+ [501.5317062144682, 880.2400125464],
+ [497.86043081777467, 882.6871090904118]],
+ [[0, 0], [0, 1], [0, 2], [0, 3]]])
+ self._do_test('singapore-onenorth', predictions, 1/3)
+
+ def test_queenstown(self):
+ predictions = np.array([[[744.8769428947988, 2508.398411382534],
+ [747.7808552527478, 2507.131371270205],
+ [750.7893530020073, 2506.1385301483474],
+ [751, 2506]],
+ [[-100, 0], [-10, 100], [0, 2], [-20, 70]]])
+ self._do_test('singapore-queenstown', predictions, 1/2)
+
+ def test_hollandvillage(self):
+ predictions = np.array([[(1150.811356677105, 1598.0397224872172),
+ (1158.783061670897, 1595.5210995059333),
+ (1166.7543904812692, 1593.0012894706226),
+ (1174.6895821186222, 1590.3704726754975)],
+ [(1263.841977478558, 943.4546342496925),
+ (1262.3235250519404, 944.6782247770625),
+ (1260.8163412684773, 945.9156425437817),
+ (1259.3272449205788, 947.1747683330505)]])
+ self._do_test('singapore-hollandvillage', predictions, 0)
diff --git a/python-sdk/nuscenes/eval/tracking/README.md b/python-sdk/nuscenes/eval/tracking/README.md
new file mode 100644
index 0000000..c3bf764
--- /dev/null
+++ b/python-sdk/nuscenes/eval/tracking/README.md
@@ -0,0 +1,351 @@
+# nuScenes tracking task
+
+
+## Overview
+- [Introduction](#introduction)
+- [Authors](#authors)
+- [Getting started](#getting-started)
+- [Participation](#participation)
+- [Challenges](#challenges)
+- [Submission rules](#submission-rules)
+- [Results format](#results-format)
+- [Classes](#classes)
+- [Evaluation metrics](#evaluation-metrics)
+- [Baselines](#baselines)
+- [Leaderboard](#leaderboard)
+- [Yonohub](#yonohub)
+
+## Introduction
+The [nuScenes dataset](http://www.nuScenes.org) \[1\] has achieved widespread acceptance in academia and industry as a standard dataset for AV perception problems.
+To advance the state-of-the-art on the problems of interest we propose benchmark challenges to measure the performance on our dataset.
+At CVPR 2019 we organized the [nuScenes detection challenge](https://www.nuscenes.org/object-detection).
+The nuScenes tracking challenge is a natural progression to the detection challenge, building on the best known detection algorithms and tracking these across time.
+Here we describe the challenge, the rules, the classes, evaluation metrics and general infrastructure.
+
+## Authors
+The tracking task and challenge are a joint work between **Aptiv** (Holger Caesar, Caglayan Dicle, Oscar Beijbom) and **Carnegie Mellon University** (Xinshuo Weng, Kris Kitani).
+They are based upon the [nuScenes dataset](http://www.nuScenes.org) \[1\] and the [3D MOT baseline and benchmark](https://github.com/xinshuoweng/AB3DMOT) defined in \[2\].
+
+# Getting started
+To participate in the tracking challenge you should first [get familiar with the nuScenes dataset and install it](https://github.com/nutonomy/nuscenes-devkit/blob/master/README.md).
+In particular, the [tutorial](https://www.nuscenes.org/nuscenes#tutorials) explains how to use the various database tables.
+The tutorial also shows how to retrieve the images, lidar pointclouds and annotations for each sample (timestamp).
+To retrieve the instance/track of an object, take a look at the [instance table](https://github.com/nutonomy/nuscenes-devkit/blob/master/docs/schema_nuscenes.md#instance).
+Now you are ready to train your tracking algorithm on the dataset.
+If you are only interested in tracking (as opposed to detection), you can use the provided detections for several state-of-the-art methods [below](#baselines).
+To evaluate the tracking results, use `evaluate.py` in the [eval folder](https://github.com/nutonomy/nuscenes-devkit/tree/master/python-sdk/nuscenes/eval/tracking).
+In `loaders.py` we provide some methods to organize the raw box data into tracks that may be helpful.
+
+## Participation
+The nuScenes tracking evaluation server is open all year round for submission.
+To participate in the challenge, please create an account at [EvalAI](https://eval.ai/web/challenges/challenge-page/476/overview).
+Then upload your zipped result file including all of the required [meta data](#results-format).
+The results will be exported to the nuScenes leaderboard shown above (coming soon).
+This is the only way to benchmark your method against the test dataset.
+We require that all participants send the following information to nuScenes@motional.com after submitting their results on EvalAI:
+- Team name
+- Method name
+- Authors
+- Affiliations
+- Method description (5+ sentences)
+- Project URL
+- Paper URL
+- FPS in Hz (and the hardware used to measure it)
+
+## Challenges
+To allow users to benchmark the performance of their method against the community, we host a single [leaderboard](#leaderboard) all-year round.
+Additionally we organize a number of challenges at leading Computer Vision conference workshops.
+Users that submit their results during the challenge period are eligible for awards.
+Any user that cannot attend the workshop (direct or via a representative) will be excluded from the challenge, but will still be listed on the leaderboard.
+
+Click [here](https://eval.ai/web/challenges/challenge-page/476/overview) for the **EvalAI tracking evaluation server**.
+
+### AI Driving Olympics (AIDO), NIPS 2019
+The first nuScenes tracking challenge will be held at NIPS 2019.
+Submission will open October 1 and close December 9.
+The leaderboard will remain private until the end of the challenge.
+Results and winners will be announced at the [AI Driving Olympics](http://www.driving-olympics.ai/) Workshop (AIDO) at NIPS 2019.
+
+## Submission rules
+### Tracking-specific rules
+* We perform 3D Multi Object Tracking (MOT) as in \[2\], rather than 2D MOT as in KITTI \[4\].
+* Possible input modalities are camera, lidar and radar.
+* We perform online tracking \[2\]. This means that the tracker may only use past and current, but not future sensor data.
+* Noisy object detections are provided below (including for the test split), but do not have to be used.
+* At inference time users may use all past sensor data and ego poses from the current scene, but not from a previous scene. At training time there are no restrictions.
+
+### General rules
+* We release annotations for the train and val set, but not for the test set.
+* We release sensor data for train, val and test set.
+* Users make predictions on the test set and submit the results to our evaluation server, which returns the metrics listed below.
+* We do not use strata. Instead, we filter annotations and predictions beyond class specific distances.
+* Users must limit the number of submitted boxes per sample to 500.
+* Every submission provides method information. We encourage publishing code, but do not make it a requirement.
+* Top leaderboard entries and their papers will be manually reviewed.
+* Each user or team can have at most one account on the evaluation server.
+* Each user or team can submit at most 3 results. These results must come from different models, rather than submitting results from the same model at different training epochs or with slightly different parameters.
+* Any attempt to circumvent these rules will result in a permanent ban of the team or company from all nuScenes challenges.
+
+## Results format
+We define a standardized tracking result format that serves as an input to the evaluation code.
+Results are evaluated for each 2Hz keyframe, also known as `sample`.
+The tracking results for a particular evaluation set (train/val/test) are stored in a single JSON file.
+For the train and val sets the evaluation can be performed by the user on their local machine.
+For the test set the user needs to zip the single JSON result file and submit it to the official evaluation server (see above).
+The JSON file includes meta data `meta` on the type of inputs used for this method.
+Furthermore it includes a dictionary `results` that maps each sample_token to a list of `sample_result` entries.
+Each `sample_token` from the current evaluation set must be included in `results`, although the list of predictions may be empty if no object is tracked.
+```
+submission {
+ "meta": {
+ "use_camera": <bool> -- Whether this submission uses camera data as an input.
+ "use_lidar": <bool> -- Whether this submission uses lidar data as an input.
+ "use_radar": <bool> -- Whether this submission uses radar data as an input.
+ "use_map": <bool> -- Whether this submission uses map data as an input.
+ "use_external": <bool> -- Whether this submission uses external data as an input.
+ },
+ "results": {
+ sample_token <str>: List[sample_result] -- Maps each sample_token to a list of sample_results.
+ }
+}
+```
+For the predictions we create a new database table called `sample_result`.
+The `sample_result` table is designed to mirror the [`sample_annotation`](https://github.com/nutonomy/nuscenes-devkit/blob/master/docs/schema_nuscenes.md#sample_annotation) table.
+This allows for processing of results and annotations using the same tools.
+A `sample_result` is a dictionary defined as follows:
+```
+sample_result {
+ "sample_token": <str> -- Foreign key. Identifies the sample/keyframe for which objects are detected.
+ "translation": <float> [3] -- Estimated bounding box location in meters in the global frame: center_x, center_y, center_z.
+ "size": <float> [3] -- Estimated bounding box size in meters: width, length, height.
+ "rotation": <float> [4] -- Estimated bounding box orientation as quaternion in the global frame: w, x, y, z.
+ "velocity": <float> [2] -- Estimated bounding box velocity in m/s in the global frame: vx, vy.
+ "tracking_id": <str> -- Unique object id that is used to identify an object track across samples.
+ "tracking_name": <str> -- The predicted class for this sample_result, e.g. car, pedestrian.
+ Note that the tracking_name cannot change throughout a track.
+ "tracking_score": <float> -- Object prediction score between 0 and 1 for the class identified by tracking_name.
+ We average over frame level scores to compute the track level score.
+ The score is used to determine positive and negative tracks via thresholding.
+}
+```
+Note that except for the `tracking_*` fields the result format is identical to the [detection challenge](https://www.nuscenes.org/object-detection).
+
+## Classes
+The nuScenes dataset comes with annotations for 23 classes ([details](https://www.nuscenes.org/nuscenes#data-annotation)).
+Some of these only have a handful of samples.
+Hence we merge similar classes and remove rare classes.
+From these *detection challenge classes* we further remove the classes *barrier*, *trafficcone* and *construction_vehicle*, as these are typically static.
+Below we show the table of the 7 tracking classes and their counterparts in the nuScenes dataset.
+For more information on the classes and their frequencies, see [this page](https://www.nuscenes.org/nuscenes#data-annotation).
+
+| nuScenes general class | nuScenes tracking class |
+| --- | --- |
+| animal | void / ignore |
+| human.pedestrian.personal_mobility | void / ignore |
+| human.pedestrian.stroller | void / ignore |
+| human.pedestrian.wheelchair | void / ignore |
+| movable_object.barrier | void / ignore |
+| movable_object.debris | void / ignore |
+| movable_object.pushable_pullable | void / ignore |
+| movable_object.trafficcone | void / ignore |
+| static_object.bicycle_rack | void / ignore |
+| vehicle.emergency.ambulance | void / ignore |
+| vehicle.emergency.police | void / ignore |
+| vehicle.construction | void / ignore |
+| vehicle.bicycle | bicycle |
+| vehicle.bus.bendy | bus |
+| vehicle.bus.rigid | bus |
+| vehicle.car | car |
+| vehicle.motorcycle | motorcycle |
+| human.pedestrian.adult | pedestrian |
+| human.pedestrian.child | pedestrian |
+| human.pedestrian.construction_worker | pedestrian |
+| human.pedestrian.police_officer | pedestrian |
+| vehicle.trailer | trailer |
+| vehicle.truck | truck |
+
+For each nuScenes class, the number of annotations decreases with increasing radius from the ego vehicle,
+but the number of annotations per radius varies by class. Therefore, each class has its own upper bound on evaluated
+detection radius, as shown below:
+
+| nuScenes tracking class | KITTI class | Tracking range (meters) |
+| --- | --- | --- |
+| bicycle | cyclist | 40 |
+| motorcycle | cyclist | 40 |
+| pedestrian | pedestrian / person (sitting) | 40 |
+| bus | - | 50 |
+| car | car / van | 50 |
+| trailer | - | 50 |
+| truck | truck | 50 |
+
+In the above table we also provide the mapping from nuScenes tracking class to KITTI \[4\] class.
+While KITTI defines 8 classes in total, only `car` and `pedestrian` are used for the tracking benchmark, as the other classes do not have enough samples.
+Our goal is to perform tracking of all moving objects in a traffic scene.
+
+## Evaluation metrics
+Below we define the metrics for the nuScenes tracking task.
+Note that all metrics below (except FPS) are computed per class and then averaged over all classes.
+The challenge winner will be determined based on AMOTA.
+Additionally a number of secondary metrics are computed and shown on the leaderboard.
+
+### Preprocessing
+Before running the evaluation code the following pre-processing is done on the data
+* All boxes (GT and prediction) are removed if they exceed the class-specific detection range.
+
+### Preprocessing
+Before running the evaluation code the following pre-processing is done on the data:
+* All boxes (GT and prediction) are removed if they exceed the class-specific tracking range.
+* All bikes and motorcycle boxes (GT and prediction) that fall inside a bike-rack are removed. The reason is that we do not annotate bikes inside bike-racks.
+* All boxes (GT) without lidar or radar points in them are removed. The reason is that we can not guarantee that they are actually visible in the frame. We do not filter the predicted boxes based on number of points.
+* To avoid excessive track fragmentation from lidar/radar point filtering, we linearly interpolate GT and predicted tracks.
+
+### Matching criterion
+For all metrics, we define a match by thresholding the 2D center distance on the ground plane rather than Intersection Over Union (IOU) based affinities.
+We find that this measure is more forgiving for far-away objects than IOU which is often 0, particularly for monocular image-based approaches.
+The matching threshold (center distance) is 2m.
+
+### AMOTA and AMOTP metrics
+Our main metrics are the AMOTA and AMOTP metrics developed in \[2\].
+These are integrals over the MOTA/MOTP curves using `n`-point interpolation (`n = 40`).
+Similar to the detection challenge, we do not include points with `recall < 0.1` (not shown in the equation), as these are typically noisy.
+
+- **AMOTA** (average multi object tracking accuracy):
+Average over the MOTA \[3\] metric (see below) at different recall thresholds.
+For the traditional MOTA formulation at recall 10% there are at least 90% false negatives, which may lead to negative MOTAs.
+Therefore the contribution of identity switches and false positives becomes negligible at low recall values.
+In `MOTAR` we include recall-normalization term `- (1-r) * P` in the nominator, the factor `r` in the denominator and the maximum.
+These guarantee that the values span the entire `[0, 1]` range and brings the three error types into a similar value range.
+`P` refers to the number of ground-truth positives for the current class.
+<br />
+<a href="https://www.codecogs.com/eqnedit.php?latex=\dpi{300}&space;\dpi{400}&space;\tiny&space;\mathit{AMOTA}&space;=&space;\small&space;\frac{1}{n-1}&space;\sum_{r&space;\in&space;\{\frac{1}{n-1},&space;\frac{2}{n-1}&space;\,&space;...&space;\,&space;\,&space;1\}}&space;\mathit{MOTAR}" target="_blank">
+<img width="400" src="https://latex.codecogs.com/gif.latex?\dpi{300}&space;\dpi{400}&space;\tiny&space;\mathit{AMOTA}&space;=&space;\small&space;\frac{1}{n-1}&space;\sum_{r&space;\in&space;\{\frac{1}{n-1},&space;\frac{2}{n-1}&space;\,&space;...&space;\,&space;\,&space;1\}}&space;\mathit{MOTAR}" title="\dpi{400} \tiny \mathit{AMOTA} = \small \frac{1}{n-1} \sum_{r \in \{\frac{1}{n-1}, \frac{2}{n-1} \, ... \, \, 1\}} \mathit{MOTAR}" /></a>
+<br />
+<a href="https://www.codecogs.com/eqnedit.php?latex=\dpi{300}&space;\mathit{MOTAR}&space;=&space;\max&space;(0,\;&space;1&space;\,&space;-&space;\,&space;\frac{\mathit{IDS}_r&space;+&space;\mathit{FP}_r&space;+&space;\mathit{FN}_r&space;-&space;(1-r)&space;*&space;\mathit{P}}{r&space;*&space;\mathit{P}})" target="_blank">
+<img width="450" src="https://latex.codecogs.com/gif.latex?\dpi{300}&space;\mathit{MOTAR}&space;=&space;\max&space;(0,\;&space;1&space;\,&space;-&space;\,&space;\frac{\mathit{IDS}_r&space;+&space;\mathit{FP}_r&space;+&space;\mathit{FN}_r&space;-&space;(1-r)&space;*&space;\mathit{P}}{r&space;*&space;\mathit{P}})" title="\mathit{MOTAR} = \max (0,\; 1 \, - \, \frac{\mathit{IDS}_r + \mathit{FP}_r + \mathit{FN}_r + (1-r) * \mathit{P}}{r * \mathit{P}})" /></a>
+
+- **AMOTP** (average multi object tracking precision):
+Average over the MOTP metric defined below.
+Here `d_{i,t}` indicates the position error of track `i` at time `t` and `TP_t` indicates the number of matches at time `t`. See \[3\].
+<br />
+<a href="https://www.codecogs.com/eqnedit.php?latex=\dpi{300}&space;\mathit{AMOTP}&space;=&space;\small&space;\frac{1}{n-1}&space;\sum_{r&space;\in&space;\{\frac{1}{n-1},&space;\frac{2}{n-1},&space;..,&space;1\}}&space;\frac{\sum_{i,t}&space;d_{i,t}}{\sum_t&space;\mathit{TP}_t}" target="_blank">
+<img width="300" src="https://latex.codecogs.com/png.latex?\dpi{300}&space;\mathit{AMOTP}&space;=&space;\small&space;\frac{1}{n-1}&space;\sum_{r&space;\in&space;\{\frac{1}{n-1},&space;\frac{2}{n-1},&space;..,&space;1\}}&space;\frac{\sum_{i,t}&space;d_{i,t}}{\sum_t&space;\mathit{TP}_t}" title="\mathit{AMOTP} = \small \frac{1}{n-1} \sum_{r \in \{\frac{1}{n-1}, \frac{2}{n-1}, .., 1\}} \frac{\sum_{i,t} d_{i,t}}{\sum_t \mathit{TP}_t}" />
+</a>
+
+### Secondary metrics
+We use a number of standard MOT metrics including CLEAR MOT \[3\] and ML/MT as listed on [motchallenge.net](https://motchallenge.net).
+Contrary to the above AMOTA and AMOTP metrics, these metrics use a confidence threshold to determine positive and negative tracks.
+The confidence threshold is selected for every class independently by picking the threshold that achieves the highest MOTA.
+The track level scores are determined by averaging the frame level scores.
+Tracks with a score below the confidence threshold are discarded.
+* **MOTA** (multi object tracking accuracy) \[3\]: This measure combines three error sources: false positives, missed targets and identity switches.
+* **MOTP** (multi object tracking precision) \[3\]: The misalignment between the annotated and the predicted bounding boxes.
+* **FAF**: The average number of false alarms per frame.
+* **MT** (number of mostly tracked trajectories): The number of ground-truth trajectories that are covered by a track hypothesis for at least 80% of their respective life span.
+* **ML** (number of mostly lost trajectories): The number of ground-truth trajectories that are covered by a track hypothesis for at most 20% of their respective life span.
+* **FP** (number of false positives): The total number of false positives.
+* **FN** (number of false negatives): The total number of false negatives (missed targets).
+* **IDS** (number of identity switches): The total number of identity switches.
+* **Frag** (number of track fragmentations): The total number of times a trajectory is fragmented (i.e. interrupted during tracking).
+
+Users are asked to provide the runtime of their method:
+* **FPS** (tracker speed in frames per second): Processing speed in frames per second excluding the detector on the benchmark. Users report both the detector and tracking FPS separately as well as cumulative. This metric is self-reported and therefore not directly comparable.
+
+Furthermore we propose a number of additional metrics:
+* **TID** (average track initialization duration in seconds): Some trackers require a fixed window of past sensor readings. Trackers may also perform poorly without a good initialization. The purpose of this metric is to measure for each track the initialization duration until the first object was successfully detected. If an object is not tracked, we assign the entire track duration as initialization duration. Then we compute the average over all tracks.
+* **LGD** (average longest gap duration in seconds): *Frag* measures the number of fragmentations. For the application of Autonomous Driving it is crucial to know how long an object has been missed. We compute this duration for each track. If an object is not tracked, we assign the entire track duration as initialization duration.
+
+### Configuration
+The default evaluation metrics configurations can be found in `nuscenes/eval/tracking/configs/tracking_nips_2019.json`.
+
+### Baselines
+To allow the user focus on the tracking problem, we release object detections from state-of-the-art methods as listed on the [detection leaderboard](https://www.nuscenes.org/object-detection).
+We thank Alex Lang (Aptiv), Benjin Zhu (Megvii) and Andrea Simonelli (Mapillary) for providing these.
+The use of these detections is entirely optional.
+The detections on the train, val and test splits can be downloaded from the table below.
+Our tracking baseline is taken from *"A Baseline for 3D Multi-Object Tracking"* \[2\] and uses each of the provided detections.
+The results for object detection and tracking can be seen below.
+These numbers are measured on the val split and therefore not identical to the test set numbers on the leaderboard.
+Note that we no longer use the weighted version of AMOTA (*Updated 10 December 2019*).
+
+| Method | NDS | mAP | AMOTA | AMOTP | Modality | Detections download | Tracking download |
+| --- | --- | --- | --- | --- | --- | --- | --- |
+| Megvii \[6\] | 62.8 | 51.9 | 17.9 | 1.50 | Lidar | [link](https://www.nuscenes.org/data/detection-megvii.zip) | [link](https://www.nuscenes.org/data/tracking-megvii.zip) |
+| PointPillars \[5\] | 44.8 | 29.5 | 3.5 | 1.69 | Lidar | [link](https://www.nuscenes.org/data/detection-pointpillars.zip) | [link](https://www.nuscenes.org/data/tracking-pointpillars.zip) |
+| Mapillary \[7\] | 36.9 | 29.8 | 4.5 | 1.79 | Camera | [link](https://www.nuscenes.org/data/detection-mapillary.zip) | [link](https://www.nuscenes.org/data/tracking-mapillary.zip) |
+
+#### Overfitting
+Some object detection methods overfit to the training data.
+E.g. for the PointPillars method we see a drop in mAP of 6.2% from train to val split (35.7% vs. 29.5%).
+This may affect (learning-based) tracking algorithms, when the training split has more accurate detections than the validation split.
+To remedy this problem we have split the existing `train` set into `train_detect` and `train_track` (350 scenes each).
+Both splits have the same distribution of Singapore, Boston, night and rain data.
+You can use these splits to train your own detection and tracking algorithms.
+The use of these splits is entirely optional.
+The object detection baselines provided in the table above are trained on the *entire* training set, as our tracking baseline \[2\] is not learning-based and therefore not prone to overfitting.
+
+## Leaderboard
+nuScenes will maintain a single leaderboard for the tracking task.
+For each submission the leaderboard will list method aspects and evaluation metrics.
+Method aspects include input modalities (lidar, radar, vision), use of map data and use of external data.
+To enable a fair comparison between methods, the user will be able to filter the methods by method aspects.
+
+We define three such filters here which correspond to the tracks in the nuScenes tracking challenge.
+Methods will be compared within these tracks and the winners will be decided for each track separately.
+Note that the tracks are identical to the [nuScenes detection challenge](https://www.nuscenes.org/object-detection) tracks.
+
+**Lidar track**:
+* Only lidar input allowed.
+* External data or map data <u>not allowed</u>.
+* May use pre-training.
+
+**Vision track**:
+* Only camera input allowed.
+* External data or map data <u>not allowed</u>.
+* May use pre-training.
+
+**Open track**:
+* Any sensor input allowed (radar, lidar, camera, ego pose).
+* External data and map data allowed.
+* May use pre-training.
+
+**Details**:
+* *Sensor input:*
+For the lidar and vision tracks we restrict the type of sensor input that may be used.
+Note that this restriction applies only at test time.
+At training time any sensor input may be used.
+In particular this also means that at training time you are allowed to filter the GT boxes using `num_lidar_pts` and `num_radar_pts`, regardless of the track.
+However, during testing the predicted boxes may *not* be filtered based on input from other sensor modalities.
+
+* *Map data:*
+By `map data` we mean using the *semantic* map provided in nuScenes.
+
+* *Meta data:*
+Other meta data included in the dataset may be used without restrictions.
+E.g. calibration parameters, ego poses, `location`, `timestamp`, `num_lidar_pts`, `num_radar_pts`, `translation`, `rotation` and `size`.
+Note that `instance`, `sample_annotation` and `scene` description are not provided for the test set.
+
+* *Pre-training:*
+By pre-training we mean training a network for the task of image classification using only image-level labels,
+as done in [[Krizhevsky NIPS 2012]](http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networ).
+The pre-training may not involve bounding box, mask or other localized annotations.
+
+* *Reporting:*
+Users are required to report detailed information on their method regarding sensor input, map data, meta data and pre-training.
+Users that fail to adequately report this information may be excluded from the challenge.
+
+## Yonohub
+[Yonohub](https://yonohub.com/) is a web-based system for building, sharing, and evaluating complex systems, such as autonomous vehicles, using drag-and-drop tools.
+It supports general blocks for nuScenes, as well as the detection and tracking baselines and evaluation code.
+For more information read the [medium article](https://medium.com/@ahmedmagdyattia1996/using-yonohub-to-participate-in-the-nuscenes-tracking-challenge-338a3e338db9) and the [tutorial](https://docs.yonohub.com/docs/yonohub/nuscenes-package/).
+Yonohub also provides [free credits](https://yonohub.com/nuscenes-package-and-sponsorship/) of up to $1000 for students to get started with Yonohub on nuScenes.
+Note that these are available even after the end of the official challenge.
+
+## References
+- \[1\] *"nuScenes: A multimodal dataset for autonomous driving"*, H. Caesar, V. Bankiti, A. H. Lang, S. Vora, V. E. Liong, Q. Xu, A. Krishnan, Y. Pan, G. Baldan and O. Beijbom, In arXiv 2019.
+- \[2\] *"A Baseline for 3D Multi-Object Tracking"*, X. Weng and K. Kitani, In arXiv 2019.
+- \[3\] *"Multiple object tracking performance metrics and evaluation in a smart room environment"*, K. Bernardin, A. Elbs, R. Stiefelhagen, In Sixth IEEE International Workshop on Visual Surveillance, in conjunction with ECCV, 2006.
+- \[4\] *"Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite"*, A. Geiger, P. Lenz, R. Urtasun, In CVPR 2012.
+- \[5\] *"PointPillars: Fast Encoders for Object Detection from Point Clouds"*, A. H. Lang, S. Vora, H. Caesar, L. Zhou, J. Yang and O. Beijbom, In CVPR 2019.
+- \[6\] *"Class-balanced Grouping and Sampling for Point Cloud 3D Object Detection"*, B. Zhu, Z. Jiang, X. Zhou, Z. Li, G. Yu, In arXiv 2019.
+- \[7\] *"Disentangling Monocular 3D Object Detection"*, A. Simonelli, S. R. Bulo, L. Porzi, M. Lopez-Antequera, P. Kontschieder, In arXiv 2019.
+- \[8\] *"PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud"*, S. Shi, X. Wang, H. Li, In CVPR 2019.
diff --git a/python-sdk/nuscenes/eval/tracking/__init__.py b/python-sdk/nuscenes/eval/tracking/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/python-sdk/nuscenes/eval/tracking/algo.py b/python-sdk/nuscenes/eval/tracking/algo.py
new file mode 100644
index 0000000..03235b3
--- /dev/null
+++ b/python-sdk/nuscenes/eval/tracking/algo.py
@@ -0,0 +1,333 @@
+"""
+nuScenes dev-kit.
+Code written by Holger Caesar, Caglayan Dicle and Oscar Beijbom, 2019.
+
+This code is based on two repositories:
+
+Xinshuo Weng's AB3DMOT code at:
+https://github.com/xinshuoweng/AB3DMOT/blob/master/evaluation/evaluate_kitti3dmot.py
+
+py-motmetrics at:
+https://github.com/cheind/py-motmetrics
+"""
+import os
+from typing import List, Dict, Callable, Tuple
+
+import numpy as np
+import pandas
+import sklearn
+import tqdm
+
+from nuscenes.eval.tracking.constants import MOT_METRIC_MAP, TRACKING_METRICS
+from nuscenes.eval.tracking.data_classes import TrackingBox, TrackingMetricData
+from nuscenes.eval.tracking.mot import MOTAccumulatorCustom
+from nuscenes.eval.tracking.render import TrackingRenderer
+from nuscenes.eval.tracking.utils import print_threshold_metrics, create_motmetrics
+
+
+class TrackingEvaluation(object):
+ def __init__(self,
+ tracks_gt: Dict[str, Dict[int, List[TrackingBox]]],
+ tracks_pred: Dict[str, Dict[int, List[TrackingBox]]],
+ class_name: str,
+ dist_fcn: Callable,
+ dist_th_tp: float,
+ min_recall: float,
+ num_thresholds: int,
+ metric_worst: Dict[str, float],
+ verbose: bool = True,
+ output_dir: str = None,
+ render_classes: List[str] = None):
+ """
+ Create a TrackingEvaluation object which computes all metrics for a given class.
+ :param tracks_gt: The ground-truth tracks.
+ :param tracks_pred: The predicted tracks.
+ :param class_name: The current class we are evaluating on.
+ :param dist_fcn: The distance function used for evaluation.
+ :param dist_th_tp: The distance threshold used to determine matches.
+ :param min_recall: The minimum recall value below which we drop thresholds due to too much noise.
+ :param num_thresholds: The number of recall thresholds from 0 to 1. Note that some of these may be dropped.
+ :param metric_worst: Mapping from metric name to the fallback value assigned if a recall threshold
+ is not achieved.
+ :param verbose: Whether to print to stdout.
+ :param output_dir: Output directory to save renders.
+ :param render_classes: Classes to render to disk or None.
+
+ Computes the metrics defined in:
+ - Stiefelhagen 2008: Evaluating Multiple Object Tracking Performance: The CLEAR MOT Metrics.
+ MOTA, MOTP
+ - Nevatia 2008: Global Data Association for Multi-Object Tracking Using Network Flows.
+ MT/PT/ML
+ - Weng 2019: "A Baseline for 3D Multi-Object Tracking".
+ AMOTA/AMOTP
+ """
+ self.tracks_gt = tracks_gt
+ self.tracks_pred = tracks_pred
+ self.class_name = class_name
+ self.dist_fcn = dist_fcn
+ self.dist_th_tp = dist_th_tp
+ self.min_recall = min_recall
+ self.num_thresholds = num_thresholds
+ self.metric_worst = metric_worst
+ self.verbose = verbose
+ self.output_dir = output_dir
+ self.render_classes = [] if render_classes is None else render_classes
+
+ self.n_scenes = len(self.tracks_gt)
+
+ # Specify threshold naming pattern. Note that no two thresholds may have the same name.
+ def name_gen(_threshold):
+ return 'thr_%.4f' % _threshold
+ self.name_gen = name_gen
+
+ # Check that metric definitions are consistent.
+ for metric_name in MOT_METRIC_MAP.values():
+ assert metric_name == '' or metric_name in TRACKING_METRICS
+
+ def accumulate(self) -> TrackingMetricData:
+ """
+ Compute metrics for all recall thresholds of the current class.
+ :returns: TrackingMetricData instance which holds the metrics for each threshold.
+ """
+ # Init.
+ if self.verbose:
+ print('Computing metrics for class %s...\n' % self.class_name)
+ accumulators = []
+ thresh_metrics = []
+ md = TrackingMetricData()
+
+ # Skip missing classes.
+ gt_box_count = 0
+ gt_track_ids = set()
+ for scene_tracks_gt in self.tracks_gt.values():
+ for frame_gt in scene_tracks_gt.values():
+ for box in frame_gt:
+ if box.tracking_name == self.class_name:
+ gt_box_count += 1
+ gt_track_ids.add(box.tracking_id)
+ if gt_box_count == 0:
+ # Do not add any metric. The average metrics will then be nan.
+ return md
+
+ # Register mot metrics.
+ mh = create_motmetrics()
+
+ # Get thresholds.
+ # Note: The recall values are the hypothetical recall (10%, 20%, ..).
+ # The actual recall may vary as there is no way to compute it without trying all thresholds.
+ thresholds, recalls = self.compute_thresholds(gt_box_count)
+ md.confidence = thresholds
+ md.recall_hypo = recalls
+ if self.verbose:
+ print('Computed thresholds\n')
+
+ for t, threshold in enumerate(thresholds):
+ # If recall threshold is not achieved, we assign the worst possible value in AMOTA and AMOTP.
+ if np.isnan(threshold):
+ continue
+
+ # Do not compute the same threshold twice.
+ # This becomes relevant when a user submits many boxes with the exact same score.
+ if threshold in thresholds[:t]:
+ continue
+
+ # Accumulate track data.
+ acc, _ = self.accumulate_threshold(threshold)
+ accumulators.append(acc)
+
+ # Compute metrics for current threshold.
+ thresh_name = self.name_gen(threshold)
+ thresh_summary = mh.compute(acc, metrics=MOT_METRIC_MAP.keys(), name=thresh_name)
+ thresh_metrics.append(thresh_summary)
+
+ # Print metrics to stdout.
+ if self.verbose:
+ print_threshold_metrics(thresh_summary.to_dict())
+
+ # Concatenate all metrics. We only do this for more convenient access.
+ if len(thresh_metrics) == 0:
+ summary = []
+ else:
+ summary = pandas.concat(thresh_metrics)
+
+ # Sanity checks.
+ unachieved_thresholds = np.sum(np.isnan(thresholds))
+ duplicate_thresholds = len(thresholds) - len(np.unique(thresholds))
+ assert unachieved_thresholds + duplicate_thresholds + len(thresh_metrics) == self.num_thresholds
+
+ # Figure out how many times each threshold should be repeated.
+ valid_thresholds = [t for t in thresholds if not np.isnan(t)]
+ assert valid_thresholds == sorted(valid_thresholds)
+ rep_counts = [np.sum(thresholds == t) for t in np.unique(valid_thresholds)]
+
+ # Store all traditional metrics.
+ for (mot_name, metric_name) in MOT_METRIC_MAP.items():
+ # Skip metrics which we don't output.
+ if metric_name == '':
+ continue
+
+ # Retrieve and store values for current metric.
+ if len(thresh_metrics) == 0:
+ # Set all the worst possible value if no recall threshold is achieved.
+ worst = self.metric_worst[metric_name]
+ if worst == -1:
+ if metric_name == 'ml':
+ worst = len(gt_track_ids)
+ elif metric_name in ['gt', 'fn']:
+ worst = gt_box_count
+ elif metric_name in ['fp', 'ids', 'frag']:
+ worst = np.nan # We can't know how these error types are distributed.
+ else:
+ raise NotImplementedError
+
+ all_values = [worst] * TrackingMetricData.nelem
+ else:
+ values = summary.get(mot_name).values
+ assert np.all(values[np.logical_not(np.isnan(values))] >= 0)
+
+ # If a threshold occurred more than once, duplicate the metric values.
+ assert len(rep_counts) == len(values)
+ values = np.concatenate([([v] * r) for (v, r) in zip(values, rep_counts)])
+
+ # Pad values with nans for unachieved recall thresholds.
+ all_values = [np.nan] * unachieved_thresholds
+ all_values.extend(values)
+
+ assert len(all_values) == TrackingMetricData.nelem
+ md.set_metric(metric_name, all_values)
+
+ return md
+
+ def accumulate_threshold(self, threshold: float = None) -> Tuple[pandas.DataFrame, List[float]]:
+ """
+ Accumulate metrics for a particular recall threshold of the current class.
+ The scores are only computed if threshold is set to None. This is used to infer the recall thresholds.
+ :param threshold: score threshold used to determine positives and negatives.
+ :returns: (The MOTAccumulator that stores all the hits/misses/etc, Scores for each TP).
+ """
+ accs = []
+ scores = [] # The scores of the TPs. These are used to determine the recall thresholds initially.
+
+ # Go through all frames and associate ground truth and tracker results.
+ # Groundtruth and tracker contain lists for every single frame containing lists detections.
+ for scene_id in tqdm.tqdm(self.tracks_gt.keys(), disable=not self.verbose, leave=False):
+
+ # Initialize accumulator and frame_id for this scene
+ acc = MOTAccumulatorCustom()
+ frame_id = 0 # Frame ids must be unique across all scenes
+
+ # Retrieve GT and preds.
+ scene_tracks_gt = self.tracks_gt[scene_id]
+ scene_tracks_pred = self.tracks_pred[scene_id]
+
+ # Visualize the boxes in this frame.
+ if self.class_name in self.render_classes and threshold is None:
+ save_path = os.path.join(self.output_dir, 'render', str(scene_id), self.class_name)
+ os.makedirs(save_path, exist_ok=True)
+ renderer = TrackingRenderer(save_path)
+ else:
+ renderer = None
+
+ for timestamp in scene_tracks_gt.keys():
+ # Select only the current class.
+ frame_gt = scene_tracks_gt[timestamp]
+ frame_pred = scene_tracks_pred[timestamp]
+ frame_gt = [f for f in frame_gt if f.tracking_name == self.class_name]
+ frame_pred = [f for f in frame_pred if f.tracking_name == self.class_name]
+
+ # Threshold boxes by score. Note that the scores were previously averaged over the whole track.
+ if threshold is not None:
+ frame_pred = [f for f in frame_pred if f.tracking_score >= threshold]
+
+ # Abort if there are neither GT nor pred boxes.
+ gt_ids = [gg.tracking_id for gg in frame_gt]
+ pred_ids = [tt.tracking_id for tt in frame_pred]
+ if len(gt_ids) == 0 and len(pred_ids) == 0:
+ continue
+
+ # Calculate distances.
+ # Note that the distance function is hard-coded to achieve significant speedups via vectorization.
+ assert self.dist_fcn.__name__ == 'center_distance'
+ if len(frame_gt) == 0 or len(frame_pred) == 0:
+ distances = np.ones((0, 0))
+ else:
+ gt_boxes = np.array([b.translation[:2] for b in frame_gt])
+ pred_boxes = np.array([b.translation[:2] for b in frame_pred])
+ distances = sklearn.metrics.pairwise.euclidean_distances(gt_boxes, pred_boxes)
+
+ # Distances that are larger than the threshold won't be associated.
+ assert len(distances) == 0 or not np.all(np.isnan(distances))
+ distances[distances >= self.dist_th_tp] = np.nan
+
+ # Accumulate results.
+ # Note that we cannot use timestamp as frameid as motmetrics assumes it's an integer.
+ acc.update(gt_ids, pred_ids, distances, frameid=frame_id)
+
+ # Store scores of matches, which are used to determine recall thresholds.
+ if threshold is None:
+ events = acc.events.loc[frame_id]
+ matches = events[events.Type == 'MATCH']
+ match_ids = matches.HId.values
+ match_scores = [tt.tracking_score for tt in frame_pred if tt.tracking_id in match_ids]
+ scores.extend(match_scores)
+ else:
+ events = None
+
+ # Render the boxes in this frame.
+ if self.class_name in self.render_classes and threshold is None:
+ renderer.render(events, timestamp, frame_gt, frame_pred)
+
+ # Increment the frame_id, unless there are no boxes (equivalent to what motmetrics does).
+ frame_id += 1
+
+ accs.append(acc)
+
+ # Merge accumulators
+ acc_merged = MOTAccumulatorCustom.merge_event_dataframes(accs)
+
+ return acc_merged, scores
+
+ def compute_thresholds(self, gt_box_count: int) -> Tuple[List[float], List[float]]:
+ """
+ Compute the score thresholds for predefined recall values.
+ AMOTA/AMOTP average over all thresholds, whereas MOTA/MOTP/.. pick the threshold with the highest MOTA.
+ :param gt_box_count: The number of GT boxes for this class.
+ :return: The lists of thresholds and their recall values.
+ """
+ # Run accumulate to get the scores of TPs.
+ _, scores = self.accumulate_threshold(threshold=None)
+
+ # Abort if no predictions exist.
+ if len(scores) == 0:
+ return [np.nan] * self.num_thresholds, [np.nan] * self.num_thresholds
+
+ # Sort scores.
+ scores = np.array(scores)
+ scores.sort()
+ scores = scores[::-1]
+
+ # Compute recall levels.
+ tps = np.array(range(1, len(scores) + 1))
+ rec = tps / gt_box_count
+ assert len(scores) / gt_box_count <= 1
+
+ # Determine thresholds.
+ max_recall_achieved = np.max(rec)
+ rec_interp = np.linspace(self.min_recall, 1, self.num_thresholds).round(12)
+ thresholds = np.interp(rec_interp, rec, scores, right=0)
+
+ # Set thresholds for unachieved recall values to nan to penalize AMOTA/AMOTP later.
+ thresholds[rec_interp > max_recall_achieved] = np.nan
+
+ # Cast to list.
+ thresholds = list(thresholds.tolist())
+ rec_interp = list(rec_interp.tolist())
+
+ # Reverse order for more convenient presentation.
+ thresholds.reverse()
+ rec_interp.reverse()
+
+ # Check that we return the correct number of thresholds.
+ assert len(thresholds) == len(rec_interp) == self.num_thresholds
+
+ return thresholds, rec_interp
diff --git a/python-sdk/nuscenes/eval/tracking/configs/tracking_nips_2019.json b/python-sdk/nuscenes/eval/tracking/configs/tracking_nips_2019.json
new file mode 100644
index 0000000..587a86a
--- /dev/null
+++ b/python-sdk/nuscenes/eval/tracking/configs/tracking_nips_2019.json
@@ -0,0 +1,35 @@
+{
+ "class_range": {
+ "car": 50,
+ "truck": 50,
+ "bus": 50,
+ "trailer": 50,
+ "pedestrian": 40,
+ "motorcycle": 40,
+ "bicycle": 40
+ },
+ "dist_fcn": "center_distance",
+ "dist_th_tp": 2.0,
+ "min_recall": 0.1,
+ "max_boxes_per_sample": 500,
+ "metric_worst": {
+ "amota": 0.0,
+ "amotp": 2.0,
+ "recall": 0.0,
+ "motar": 0.0,
+ "mota": 0.0,
+ "motp": 2.0,
+ "mt": 0.0,
+ "ml": -1.0,
+ "faf": 500,
+ "gt": -1,
+ "tp": 0.0,
+ "fp": -1.0,
+ "fn": -1.0,
+ "ids": -1.0,
+ "frag": -1.0,
+ "tid": 20,
+ "lgd": 20
+ },
+ "num_thresholds": 40
+}
diff --git a/python-sdk/nuscenes/eval/tracking/constants.py b/python-sdk/nuscenes/eval/tracking/constants.py
new file mode 100644
index 0000000..ea7e8ef
--- /dev/null
+++ b/python-sdk/nuscenes/eval/tracking/constants.py
@@ -0,0 +1,56 @@
+# nuScenes dev-kit.
+# Code written by Holger Caesar, Caglayan Dicle and Oscar Beijbom, 2019.
+
+TRACKING_NAMES = ['bicycle', 'bus', 'car', 'motorcycle', 'pedestrian', 'trailer', 'truck']
+
+AMOT_METRICS = ['amota', 'amotp']
+INTERNAL_METRICS = ['recall', 'motar', 'gt']
+LEGACY_METRICS = ['mota', 'motp', 'mt', 'ml', 'faf', 'tp', 'fp', 'fn', 'ids', 'frag', 'tid', 'lgd']
+TRACKING_METRICS = [*AMOT_METRICS, *INTERNAL_METRICS, *LEGACY_METRICS]
+
+PRETTY_TRACKING_NAMES = {
+ 'bicycle': 'Bicycle',
+ 'bus': 'Bus',
+ 'car': 'Car',
+ 'motorcycle': 'Motorcycle',
+ 'pedestrian': 'Pedestrian',
+ 'trailer': 'Trailer',
+ 'truck': 'Truck'
+}
+
+TRACKING_COLORS = {
+ 'bicycle': 'C9', # Differs from detection.
+ 'bus': 'C2',
+ 'car': 'C0',
+ 'motorcycle': 'C6',
+ 'pedestrian': 'C5',
+ 'trailer': 'C3',
+ 'truck': 'C1'
+}
+
+# Define mapping for metrics averaged over classes.
+AVG_METRIC_MAP = { # Mapping from average metric name to individual per-threshold metric name.
+ 'amota': 'motar',
+ 'amotp': 'motp'
+}
+
+# Define mapping for metrics that use motmetrics library.
+MOT_METRIC_MAP = { # Mapping from motmetrics names to metric names used here.
+ 'num_frames': '', # Used in FAF.
+ 'num_objects': 'gt', # Used in MOTAR computation.
+ 'num_predictions': '', # Only printed out.
+ 'num_matches': 'tp', # Used in MOTAR computation and printed out.
+ 'motar': 'motar', # Only used in AMOTA.
+ 'mota_custom': 'mota', # Traditional MOTA, but clipped below 0.
+ 'motp_custom': 'motp', # Traditional MOTP.
+ 'faf': 'faf',
+ 'mostly_tracked': 'mt',
+ 'mostly_lost': 'ml',
+ 'num_false_positives': 'fp',
+ 'num_misses': 'fn',
+ 'num_switches': 'ids',
+ 'num_fragmentations_custom': 'frag',
+ 'recall': 'recall',
+ 'tid': 'tid',
+ 'lgd': 'lgd'
+}
diff --git a/python-sdk/nuscenes/eval/tracking/data_classes.py b/python-sdk/nuscenes/eval/tracking/data_classes.py
new file mode 100644
index 0000000..3d17536
--- /dev/null
+++ b/python-sdk/nuscenes/eval/tracking/data_classes.py
@@ -0,0 +1,350 @@
+# nuScenes dev-kit.
+# Code written by Holger Caesar, Caglayan Dicle and Oscar Beijbom, 2019.
+
+from typing import Dict, Tuple, Any
+
+import numpy as np
+
+from nuscenes.eval.common.data_classes import MetricData, EvalBox
+from nuscenes.eval.common.utils import center_distance
+from nuscenes.eval.tracking.constants import TRACKING_NAMES, TRACKING_METRICS, AMOT_METRICS
+
+
+class TrackingConfig:
+ """ Data class that specifies the tracking evaluation settings. """
+
+ def __init__(self,
+ class_range: Dict[str, int],
+ dist_fcn: str,
+ dist_th_tp: float,
+ min_recall: float,
+ max_boxes_per_sample: float,
+ metric_worst: Dict[str, float],
+ num_thresholds: int):
+
+ assert set(class_range.keys()) == set(TRACKING_NAMES), "Class count mismatch."
+
+ self.class_range = class_range
+ self.dist_fcn = dist_fcn
+ self.dist_th_tp = dist_th_tp
+ self.min_recall = min_recall
+ self.max_boxes_per_sample = max_boxes_per_sample
+ self.metric_worst = metric_worst
+ self.num_thresholds = num_thresholds
+
+ TrackingMetricData.set_nelem(num_thresholds)
+
+ self.class_names = sorted(self.class_range.keys())
+
+ def __eq__(self, other):
+ eq = True
+ for key in self.serialize().keys():
+ eq = eq and np.array_equal(getattr(self, key), getattr(other, key))
+ return eq
+
+ def serialize(self) -> dict:
+ """ Serialize instance into json-friendly format. """
+ return {
+ 'class_range': self.class_range,
+ 'dist_fcn': self.dist_fcn,
+ 'dist_th_tp': self.dist_th_tp,
+ 'min_recall': self.min_recall,
+ 'max_boxes_per_sample': self.max_boxes_per_sample,
+ 'metric_worst': self.metric_worst,
+ 'num_thresholds': self.num_thresholds
+ }
+
+ @classmethod
+ def deserialize(cls, content: dict):
+ """ Initialize from serialized dictionary. """
+ return cls(content['class_range'],
+ content['dist_fcn'],
+ content['dist_th_tp'],
+ content['min_recall'],
+ content['max_boxes_per_sample'],
+ content['metric_worst'],
+ content['num_thresholds'])
+
+ @property
+ def dist_fcn_callable(self):
+ """ Return the distance function corresponding to the dist_fcn string. """
+ if self.dist_fcn == 'center_distance':
+ return center_distance
+ else:
+ raise Exception('Error: Unknown distance function %s!' % self.dist_fcn)
+
+
+class TrackingMetricData(MetricData):
+ """ This class holds accumulated and interpolated data required to calculate the tracking metrics. """
+
+ nelem = None
+ metrics = [m for m in list(set(TRACKING_METRICS) - set(AMOT_METRICS))]
+
+ def __init__(self):
+ # Set attributes explicitly to help IDEs figure out what is going on.
+ assert TrackingMetricData.nelem is not None
+ init = np.full(TrackingMetricData.nelem, np.nan)
+ self.confidence = init
+ self.recall_hypo = init
+ self.recall = init
+ self.motar = init
+ self.mota = init
+ self.motp = init
+ self.faf = init
+ self.gt = init
+ self.tp = init
+ self.mt = init
+ self.ml = init
+ self.fp = init
+ self.fn = init
+ self.ids = init
+ self.frag = init
+ self.tid = init
+ self.lgd = init
+
+ def __eq__(self, other):
+ eq = True
+ for key in self.serialize().keys():
+ eq = eq and np.array_equal(getattr(self, key), getattr(other, key))
+ return eq
+
+ def __setattr__(self, *args, **kwargs):
+ assert len(args) == 2
+ name = args[0]
+ values = np.array(args[1])
+ assert values is None or len(values) == TrackingMetricData.nelem
+ super(TrackingMetricData, self).__setattr__(name, values)
+
+ def set_metric(self, metric_name: str, values: np.ndarray) -> None:
+ """ Sets the specified metric. """
+ self.__setattr__(metric_name, values)
+
+ def get_metric(self, metric_name: str) -> np.ndarray:
+ """ Returns the specified metric. """
+ return self.__getattribute__(metric_name)
+
+ @property
+ def max_recall_ind(self):
+ """ Returns index of max recall achieved. """
+
+ # Last instance of confidence > 0 is index of max achieved recall.
+ non_zero = np.nonzero(self.confidence)[0]
+ if len(non_zero) == 0: # If there are no matches, all the confidence values will be zero.
+ max_recall_ind = 0
+ else:
+ max_recall_ind = non_zero[-1]
+
+ return max_recall_ind
+
+ @property
+ def max_recall(self):
+ """ Returns max recall achieved. """
+ return self.recall[self.max_recall_ind]
+
+ def serialize(self):
+ """ Serialize instance into json-friendly format. """
+ ret_dict = dict()
+ for metric_name in ['confidence', 'recall_hypo'] + TrackingMetricData.metrics:
+ ret_dict[metric_name] = self.get_metric(metric_name).tolist()
+ return ret_dict
+
+ @classmethod
+ def set_nelem(cls, nelem: int) -> None:
+ cls.nelem = nelem
+
+ @classmethod
+ def deserialize(cls, content: dict):
+ """ Initialize from serialized content. """
+ md = cls()
+ for metric in ['confidence', 'recall_hypo'] + TrackingMetricData.metrics:
+ md.set_metric(metric, content[metric])
+ return md
+
+ @classmethod
+ def no_predictions(cls):
+ """ Returns an md instance corresponding to having no predictions. """
+ md = cls()
+ md.confidence = np.zeros(cls.nelem)
+ for metric in TrackingMetricData.metrics:
+ md.set_metric(metric, np.zeros(cls.nelem))
+ md.recall = np.linspace(0, 1, cls.nelem)
+ return md
+
+ @classmethod
+ def random_md(cls):
+ """ Returns an md instance corresponding to a random results. """
+ md = cls()
+ md.confidence = np.linspace(0, 1, cls.nelem)[::-1]
+ for metric in TrackingMetricData.metrics:
+ md.set_metric(metric, np.random.random(cls.nelem))
+ md.recall = np.linspace(0, 1, cls.nelem)
+ return md
+
+
+class TrackingMetrics:
+ """ Stores tracking metric results. Provides properties to summarize. """
+
+ def __init__(self, cfg: TrackingConfig):
+
+ self.cfg = cfg
+ self.eval_time = None
+ self.label_metrics: Dict[str, Dict[str, float]] = {}
+ self.class_names = self.cfg.class_names
+ self.metric_names = [l for l in TRACKING_METRICS]
+
+ # Init every class.
+ for metric_name in self.metric_names:
+ self.label_metrics[metric_name] = {}
+ for class_name in self.class_names:
+ self.label_metrics[metric_name][class_name] = np.nan
+
+ def add_label_metric(self, metric_name: str, tracking_name: str, value: float) -> None:
+ assert metric_name in self.label_metrics
+ self.label_metrics[metric_name][tracking_name] = float(value)
+
+ def add_runtime(self, eval_time: float) -> None:
+ self.eval_time = eval_time
+
+ def compute_metric(self, metric_name: str, class_name: str = 'all') -> float:
+ if class_name == 'all':
+ data = list(self.label_metrics[metric_name].values())
+ if len(data) > 0:
+ # Some metrics need to be summed, not averaged.
+ # Nan entries are ignored.
+ if metric_name in ['mt', 'ml', 'tp', 'fp', 'fn', 'ids', 'frag']:
+ return float(np.nansum(data))
+ else:
+ return float(np.nanmean(data))
+ else:
+ return np.nan
+ else:
+ return float(self.label_metrics[metric_name][class_name])
+
+ def serialize(self) -> Dict[str, Any]:
+ metrics = dict()
+ metrics['label_metrics'] = self.label_metrics
+ metrics['eval_time'] = self.eval_time
+ metrics['cfg'] = self.cfg.serialize()
+ for metric_name in self.label_metrics.keys():
+ metrics[metric_name] = self.compute_metric(metric_name)
+
+ return metrics
+
+ @classmethod
+ def deserialize(cls, content: dict) -> 'TrackingMetrics':
+ """ Initialize from serialized dictionary. """
+ cfg = TrackingConfig.deserialize(content['cfg'])
+ tm = cls(cfg=cfg)
+ tm.add_runtime(content['eval_time'])
+ tm.label_metrics = content['label_metrics']
+
+ return tm
+
+ def __eq__(self, other):
+ eq = True
+ eq = eq and self.label_metrics == other.label_metrics
+ eq = eq and self.eval_time == other.eval_time
+ eq = eq and self.cfg == other.cfg
+
+ return eq
+
+
+class TrackingBox(EvalBox):
+ """ Data class used during tracking evaluation. Can be a prediction or ground truth."""
+
+ def __init__(self,
+ sample_token: str = "",
+ translation: Tuple[float, float, float] = (0, 0, 0),
+ size: Tuple[float, float, float] = (0, 0, 0),
+ rotation: Tuple[float, float, float, float] = (0, 0, 0, 0),
+ velocity: Tuple[float, float] = (0, 0),
+ ego_translation: Tuple[float, float, float] = (0, 0, 0), # Translation to ego vehicle in meters.
+ num_pts: int = -1, # Nbr. LIDAR or RADAR inside the box. Only for gt boxes.
+ tracking_id: str = '', # Instance id of this object.
+ tracking_name: str = '', # The class name used in the tracking challenge.
+ tracking_score: float = -1.0): # Does not apply to GT.
+
+ super().__init__(sample_token, translation, size, rotation, velocity, ego_translation, num_pts)
+
+ assert tracking_name is not None, 'Error: tracking_name cannot be empty!'
+ assert tracking_name in TRACKING_NAMES, 'Error: Unknown tracking_name %s' % tracking_name
+
+ assert type(tracking_score) == float, 'Error: tracking_score must be a float!'
+ assert not np.any(np.isnan(tracking_score)), 'Error: tracking_score may not be NaN!'
+
+ # Assign.
+ self.tracking_id = tracking_id
+ self.tracking_name = tracking_name
+ self.tracking_score = tracking_score
+
+ def __eq__(self, other):
+ return (self.sample_token == other.sample_token and
+ self.translation == other.translation and
+ self.size == other.size and
+ self.rotation == other.rotation and
+ self.velocity == other.velocity and
+ self.ego_translation == other.ego_translation and
+ self.num_pts == other.num_pts and
+ self.tracking_id == other.tracking_id and
+ self.tracking_name == other.tracking_name and
+ self.tracking_score == other.tracking_score)
+
+ def serialize(self) -> dict:
+ """ Serialize instance into json-friendly format. """
+ return {
+ 'sample_token': self.sample_token,
+ 'translation': self.translation,
+ 'size': self.size,
+ 'rotation': self.rotation,
+ 'velocity': self.velocity,
+ 'ego_translation': self.ego_translation,
+ 'num_pts': self.num_pts,
+ 'tracking_id': self.tracking_id,
+ 'tracking_name': self.tracking_name,
+ 'tracking_score': self.tracking_score
+ }
+
+ @classmethod
+ def deserialize(cls, content: dict):
+ """ Initialize from serialized content. """
+ return cls(sample_token=content['sample_token'],
+ translation=tuple(content['translation']),
+ size=tuple(content['size']),
+ rotation=tuple(content['rotation']),
+ velocity=tuple(content['velocity']),
+ ego_translation=(0.0, 0.0, 0.0) if 'ego_translation' not in content
+ else tuple(content['ego_translation']),
+ num_pts=-1 if 'num_pts' not in content else int(content['num_pts']),
+ tracking_id=content['tracking_id'],
+ tracking_name=content['tracking_name'],
+ tracking_score=-1.0 if 'tracking_score' not in content else float(content['tracking_score']))
+
+
+class TrackingMetricDataList:
+ """ This stores a set of MetricData in a dict indexed by name. """
+
+ def __init__(self):
+ self.md: Dict[str, TrackingMetricData] = {}
+
+ def __getitem__(self, key) -> TrackingMetricData:
+ return self.md[key]
+
+ def __eq__(self, other):
+ eq = True
+ for key in self.md.keys():
+ eq = eq and self[key] == other[key]
+ return eq
+
+ def set(self, tracking_name: str, data: TrackingMetricData):
+ """ Sets the MetricData entry for a certain tracking_name. """
+ self.md[tracking_name] = data
+
+ def serialize(self) -> dict:
+ return {key: value.serialize() for key, value in self.md.items()}
+
+ @classmethod
+ def deserialize(cls, content: dict, metric_data_cls):
+ mdl = cls()
+ for name, md in content.items():
+ mdl.set(name, metric_data_cls.deserialize(md))
+ return mdl
diff --git a/python-sdk/nuscenes/eval/tracking/evaluate.py b/python-sdk/nuscenes/eval/tracking/evaluate.py
new file mode 100644
index 0000000..c9579b7
--- /dev/null
+++ b/python-sdk/nuscenes/eval/tracking/evaluate.py
@@ -0,0 +1,272 @@
+# nuScenes dev-kit.
+# Code written by Holger Caesar, Caglayan Dicle and Oscar Beijbom, 2019.
+
+import argparse
+import json
+import os
+import time
+from typing import Tuple, List, Dict, Any
+
+import numpy as np
+
+from nuscenes import NuScenes
+from nuscenes.eval.common.config import config_factory
+from nuscenes.eval.common.loaders import load_prediction, load_gt, add_center_dist, filter_eval_boxes
+from nuscenes.eval.tracking.algo import TrackingEvaluation
+from nuscenes.eval.tracking.constants import AVG_METRIC_MAP, MOT_METRIC_MAP, LEGACY_METRICS
+from nuscenes.eval.tracking.data_classes import TrackingMetrics, TrackingMetricDataList, TrackingConfig, TrackingBox, \
+ TrackingMetricData
+from nuscenes.eval.tracking.loaders import create_tracks
+from nuscenes.eval.tracking.render import recall_metric_curve, summary_plot
+from nuscenes.eval.tracking.utils import print_final_metrics
+
+
+class TrackingEval:
+ """
+ This is the official nuScenes tracking evaluation code.
+ Results are written to the provided output_dir.
+
+ Here is an overview of the functions in this method:
+ - init: Loads GT annotations and predictions stored in JSON format and filters the boxes.
+ - run: Performs evaluation and dumps the metric data to disk.
+ - render: Renders various plots and dumps to disk.
+
+ We assume that:
+ - Every sample_token is given in the results, although there may be not predictions for that sample.
+
+ Please see https://www.nuscenes.org/tracking for more details.
+ """
+ def __init__(self,
+ config: TrackingConfig,
+ result_path: str,
+ eval_set: str,
+ output_dir: str,
+ nusc_version: str,
+ nusc_dataroot: str,
+ verbose: bool = True,
+ render_classes: List[str] = None):
+ """
+ Initialize a TrackingEval object.
+ :param config: A TrackingConfig object.
+ :param result_path: Path of the nuScenes JSON result file.
+ :param eval_set: The dataset split to evaluate on, e.g. train, val or test.
+ :param output_dir: Folder to save plots and results to.
+ :param nusc_version: The version of the NuScenes dataset.
+ :param nusc_dataroot: Path of the nuScenes dataset on disk.
+ :param verbose: Whether to print to stdout.
+ :param render_classes: Classes to render to disk or None.
+ """
+ self.cfg = config
+ self.result_path = result_path
+ self.eval_set = eval_set
+ self.output_dir = output_dir
+ self.verbose = verbose
+ self.render_classes = render_classes
+
+ # Check result file exists.
+ assert os.path.exists(result_path), 'Error: The result file does not exist!'
+
+ # Make dirs.
+ self.plot_dir = os.path.join(self.output_dir, 'plots')
+ if not os.path.isdir(self.output_dir):
+ os.makedirs(self.output_dir)
+ if not os.path.isdir(self.plot_dir):
+ os.makedirs(self.plot_dir)
+
+ # Initialize NuScenes object.
+ # We do not store it in self to let garbage collection take care of it and save memory.
+ nusc = NuScenes(version=nusc_version, verbose=verbose, dataroot=nusc_dataroot)
+
+ # Load data.
+ if verbose:
+ print('Initializing nuScenes tracking evaluation')
+ pred_boxes, self.meta = load_prediction(self.result_path, self.cfg.max_boxes_per_sample, TrackingBox,
+ verbose=verbose)
+ gt_boxes = load_gt(nusc, self.eval_set, TrackingBox, verbose=verbose)
+
+ assert set(pred_boxes.sample_tokens) == set(gt_boxes.sample_tokens), \
+ "Samples in split don't match samples in predicted tracks."
+
+ # Add center distances.
+ pred_boxes = add_center_dist(nusc, pred_boxes)
+ gt_boxes = add_center_dist(nusc, gt_boxes)
+
+ # Filter boxes (distance, points per box, etc.).
+ if verbose:
+ print('Filtering tracks')
+ pred_boxes = filter_eval_boxes(nusc, pred_boxes, self.cfg.class_range, verbose=verbose)
+ if verbose:
+ print('Filtering ground truth tracks')
+ gt_boxes = filter_eval_boxes(nusc, gt_boxes, self.cfg.class_range, verbose=verbose)
+
+ self.sample_tokens = gt_boxes.sample_tokens
+
+ # Convert boxes to tracks format.
+ self.tracks_gt = create_tracks(gt_boxes, nusc, self.eval_set, gt=True)
+ self.tracks_pred = create_tracks(pred_boxes, nusc, self.eval_set, gt=False)
+
+ def evaluate(self) -> Tuple[TrackingMetrics, TrackingMetricDataList]:
+ """
+ Performs the actual evaluation.
+ :return: A tuple of high-level and the raw metric data.
+ """
+ start_time = time.time()
+ metrics = TrackingMetrics(self.cfg)
+
+ # -----------------------------------
+ # Step 1: Accumulate metric data for all classes and distance thresholds.
+ # -----------------------------------
+ if self.verbose:
+ print('Accumulating metric data...')
+ metric_data_list = TrackingMetricDataList()
+
+ def accumulate_class(curr_class_name):
+ curr_ev = TrackingEvaluation(self.tracks_gt, self.tracks_pred, curr_class_name, self.cfg.dist_fcn_callable,
+ self.cfg.dist_th_tp, self.cfg.min_recall,
+ num_thresholds=TrackingMetricData.nelem,
+ metric_worst=self.cfg.metric_worst,
+ verbose=self.verbose,
+ output_dir=self.output_dir,
+ render_classes=self.render_classes)
+ curr_md = curr_ev.accumulate()
+ metric_data_list.set(curr_class_name, curr_md)
+
+ for class_name in self.cfg.class_names:
+ accumulate_class(class_name)
+
+ # -----------------------------------
+ # Step 2: Aggregate metrics from the metric data.
+ # -----------------------------------
+ if self.verbose:
+ print('Calculating metrics...')
+ for class_name in self.cfg.class_names:
+ # Find best MOTA to determine threshold to pick for traditional metrics.
+ # If multiple thresholds have the same value, pick the one with the highest recall.
+ md = metric_data_list[class_name]
+ if np.all(np.isnan(md.mota)):
+ best_thresh_idx = None
+ else:
+ best_thresh_idx = np.nanargmax(md.mota)
+
+ # Pick best value for traditional metrics.
+ if best_thresh_idx is not None:
+ for metric_name in MOT_METRIC_MAP.values():
+ if metric_name == '':
+ continue
+ value = md.get_metric(metric_name)[best_thresh_idx]
+ metrics.add_label_metric(metric_name, class_name, value)
+
+ # Compute AMOTA / AMOTP.
+ for metric_name in AVG_METRIC_MAP.keys():
+ values = np.array(md.get_metric(AVG_METRIC_MAP[metric_name]))
+ assert len(values) == TrackingMetricData.nelem
+
+ if np.all(np.isnan(values)):
+ # If no GT exists, set to nan.
+ value = np.nan
+ else:
+ # Overwrite any nan value with the worst possible value.
+ np.all(values[np.logical_not(np.isnan(values))] >= 0)
+ values[np.isnan(values)] = self.cfg.metric_worst[metric_name]
+ value = float(np.nanmean(values))
+ metrics.add_label_metric(metric_name, class_name, value)
+
+ # Compute evaluation time.
+ metrics.add_runtime(time.time() - start_time)
+
+ return metrics, metric_data_list
+
+ def render(self, md_list: TrackingMetricDataList) -> None:
+ """
+ Renders a plot for each class and each metric.
+ :param md_list: TrackingMetricDataList instance.
+ """
+ if self.verbose:
+ print('Rendering curves')
+
+ def savepath(name):
+ return os.path.join(self.plot_dir, name + '.pdf')
+
+ # Plot a summary.
+ summary_plot(md_list, min_recall=self.cfg.min_recall, savepath=savepath('summary'))
+
+ # For each metric, plot all the classes in one diagram.
+ for metric_name in LEGACY_METRICS:
+ recall_metric_curve(md_list, metric_name,
+ self.cfg.min_recall, savepath=savepath('%s' % metric_name))
+
+ def main(self, render_curves: bool = True) -> Dict[str, Any]:
+ """
+ Main function that loads the evaluation code, visualizes samples, runs the evaluation and renders stat plots.
+ :param render_curves: Whether to render PR and TP curves to disk.
+ :return: The serialized TrackingMetrics computed during evaluation.
+ """
+ # Run evaluation.
+ metrics, metric_data_list = self.evaluate()
+
+ # Dump the metric data, meta and metrics to disk.
+ if self.verbose:
+ print('Saving metrics to: %s' % self.output_dir)
+ metrics_summary = metrics.serialize()
+ metrics_summary['meta'] = self.meta.copy()
+ with open(os.path.join(self.output_dir, 'metrics_summary.json'), 'w') as f:
+ json.dump(metrics_summary, f, indent=2)
+ with open(os.path.join(self.output_dir, 'metrics_details.json'), 'w') as f:
+ json.dump(metric_data_list.serialize(), f, indent=2)
+
+ # Print metrics to stdout.
+ if self.verbose:
+ print_final_metrics(metrics)
+
+ # Render curves.
+ if render_curves:
+ self.render(metric_data_list)
+
+ return metrics_summary
+
+
+if __name__ == "__main__":
+
+ # Settings.
+ parser = argparse.ArgumentParser(description='Evaluate nuScenes tracking results.',
+ formatter_class=argparse.ArgumentDefaultsHelpFormatter)
+ parser.add_argument('result_path', type=str, help='The submission as a JSON file.')
+ parser.add_argument('--output_dir', type=str, default='~/nuscenes-metrics',
+ help='Folder to store result metrics, graphs and example visualizations.')
+ parser.add_argument('--eval_set', type=str, default='val',
+ help='Which dataset split to evaluate on, train, val or test.')
+ parser.add_argument('--dataroot', type=str, default='/data/sets/nuscenes',
+ help='Default nuScenes data directory.')
+ parser.add_argument('--version', type=str, default='v1.0-trainval',
+ help='Which version of the nuScenes dataset to evaluate on, e.g. v1.0-trainval.')
+ parser.add_argument('--config_path', type=str, default='',
+ help='Path to the configuration file.'
+ 'If no path given, the NIPS 2019 configuration will be used.')
+ parser.add_argument('--render_curves', type=int, default=1,
+ help='Whether to render statistic curves to disk.')
+ parser.add_argument('--verbose', type=int, default=1,
+ help='Whether to print to stdout.')
+ parser.add_argument('--render_classes', type=str, default='', nargs='+',
+ help='For which classes we render tracking results to disk.')
+ args = parser.parse_args()
+
+ result_path_ = os.path.expanduser(args.result_path)
+ output_dir_ = os.path.expanduser(args.output_dir)
+ eval_set_ = args.eval_set
+ dataroot_ = args.dataroot
+ version_ = args.version
+ config_path = args.config_path
+ render_curves_ = bool(args.render_curves)
+ verbose_ = bool(args.verbose)
+ render_classes_ = args.render_classes
+
+ if config_path == '':
+ cfg_ = config_factory('tracking_nips_2019')
+ else:
+ with open(config_path, 'r') as _f:
+ cfg_ = TrackingConfig.deserialize(json.load(_f))
+
+ nusc_eval = TrackingEval(config=cfg_, result_path=result_path_, eval_set=eval_set_, output_dir=output_dir_,
+ nusc_version=version_, nusc_dataroot=dataroot_, verbose=verbose_,
+ render_classes=render_classes_)
+ nusc_eval.main(render_curves=render_curves_)
diff --git a/python-sdk/nuscenes/eval/tracking/loaders.py b/python-sdk/nuscenes/eval/tracking/loaders.py
new file mode 100644
index 0000000..02430d4
--- /dev/null
+++ b/python-sdk/nuscenes/eval/tracking/loaders.py
@@ -0,0 +1,170 @@
+# nuScenes dev-kit.
+# Code written by Holger Caesar, Caglayan Dicle and Oscar Beijbom, 2019.
+
+from bisect import bisect
+from collections import defaultdict
+from typing import List, Dict, DefaultDict
+
+import numpy as np
+from pyquaternion import Quaternion
+
+from nuscenes.eval.common.data_classes import EvalBoxes
+from nuscenes.eval.tracking.data_classes import TrackingBox
+from nuscenes.nuscenes import NuScenes
+from nuscenes.utils.splits import create_splits_scenes
+
+
+def interpolate_tracking_boxes(left_box: TrackingBox, right_box: TrackingBox, right_ratio: float) -> TrackingBox:
+ """
+ Linearly interpolate box parameters between two boxes.
+ :param left_box: A Trackingbox.
+ :param right_box: Another TrackingBox
+ :param right_ratio: Weight given to the right box.
+ :return: The interpolated TrackingBox.
+ """
+ def interp_list(left, right, rratio):
+ return tuple(
+ (1.0 - rratio) * np.array(left, dtype=float)
+ + rratio * np.array(right, dtype=float)
+ )
+
+ def interp_float(left, right, rratio):
+ return (1.0 - rratio) * float(left) + rratio * float(right)
+
+ # Interpolate quaternion.
+ rotation = Quaternion.slerp(
+ q0=Quaternion(left_box.rotation),
+ q1=Quaternion(right_box.rotation),
+ amount=right_ratio
+ ).elements
+
+ # Score will remain -1 for GT.
+ tracking_score = interp_float(left_box.tracking_score, right_box.tracking_score, right_ratio)
+
+ return TrackingBox(sample_token=right_box.sample_token,
+ translation=interp_list(left_box.translation, right_box.translation, right_ratio),
+ size=interp_list(left_box.size, right_box.size, right_ratio),
+ rotation=rotation,
+ velocity=interp_list(left_box.velocity, right_box.velocity, right_ratio),
+ ego_translation=interp_list(left_box.ego_translation, right_box.ego_translation,
+ right_ratio), # May be inaccurate.
+ tracking_id=right_box.tracking_id,
+ tracking_name=right_box.tracking_name,
+ tracking_score=tracking_score)
+
+
+def interpolate_tracks(tracks_by_timestamp: DefaultDict[int, List[TrackingBox]]) -> DefaultDict[int, List[TrackingBox]]:
+ """
+ Interpolate the tracks to fill in holes, especially since GT boxes with 0 lidar points are removed.
+ This interpolation does not take into account visibility. It interpolates despite occlusion.
+ :param tracks_by_timestamp: The tracks.
+ :return: The interpolated tracks.
+ """
+ # Group tracks by id.
+ tracks_by_id = defaultdict(list)
+ track_timestamps_by_id = defaultdict(list)
+ for timestamp, tracking_boxes in tracks_by_timestamp.items():
+ for tracking_box in tracking_boxes:
+ tracks_by_id[tracking_box.tracking_id].append(tracking_box)
+ track_timestamps_by_id[tracking_box.tracking_id].append(timestamp)
+
+ # Interpolate missing timestamps for each track.
+ timestamps = tracks_by_timestamp.keys()
+ interpolate_count = 0
+ for timestamp in timestamps:
+ for tracking_id, track in tracks_by_id.items():
+ if track_timestamps_by_id[tracking_id][0] <= timestamp <= track_timestamps_by_id[tracking_id][-1] and \
+ timestamp not in track_timestamps_by_id[tracking_id]:
+
+ # Find the closest boxes before and after this timestamp.
+ right_ind = bisect(track_timestamps_by_id[tracking_id], timestamp)
+ left_ind = right_ind - 1
+ right_timestamp = track_timestamps_by_id[tracking_id][right_ind]
+ left_timestamp = track_timestamps_by_id[tracking_id][left_ind]
+ right_tracking_box = tracks_by_id[tracking_id][right_ind]
+ left_tracking_box = tracks_by_id[tracking_id][left_ind]
+ right_ratio = float(right_timestamp - timestamp) / (right_timestamp - left_timestamp)
+
+ # Interpolate.
+ tracking_box = interpolate_tracking_boxes(left_tracking_box, right_tracking_box, right_ratio)
+ interpolate_count += 1
+ tracks_by_timestamp[timestamp].append(tracking_box)
+
+ return tracks_by_timestamp
+
+
+def create_tracks(all_boxes: EvalBoxes, nusc: NuScenes, eval_split: str, gt: bool) \
+ -> Dict[str, Dict[int, List[TrackingBox]]]:
+ """
+ Returns all tracks for all scenes. Samples within a track are sorted in chronological order.
+ This can be applied either to GT or predictions.
+ :param all_boxes: Holds all GT or predicted boxes.
+ :param nusc: The NuScenes instance to load the sample information from.
+ :param eval_split: The evaluation split for which we create tracks.
+ :param gt: Whether we are creating tracks for GT or predictions
+ :return: The tracks.
+ """
+ # Only keep samples from this split.
+ splits = create_splits_scenes()
+ scene_tokens = set()
+ for sample_token in all_boxes.sample_tokens:
+ scene_token = nusc.get('sample', sample_token)['scene_token']
+ scene = nusc.get('scene', scene_token)
+ if scene['name'] in splits[eval_split]:
+ scene_tokens.add(scene_token)
+
+ # Tracks are stored as dict {scene_token: {timestamp: List[TrackingBox]}}.
+ tracks = defaultdict(lambda: defaultdict(list))
+
+ # Init all scenes and timestamps to guarantee completeness.
+ for scene_token in scene_tokens:
+ # Init all timestamps in this scene.
+ scene = nusc.get('scene', scene_token)
+ cur_sample_token = scene['first_sample_token']
+ while True:
+ # Initialize array for current timestamp.
+ cur_sample = nusc.get('sample', cur_sample_token)
+ tracks[scene_token][cur_sample['timestamp']] = []
+
+ # Abort after the last sample.
+ if cur_sample_token == scene['last_sample_token']:
+ break
+
+ # Move to next sample.
+ cur_sample_token = cur_sample['next']
+
+ # Group annotations wrt scene and timestamp.
+ for sample_token in all_boxes.sample_tokens:
+ sample_record = nusc.get('sample', sample_token)
+ scene_token = sample_record['scene_token']
+ tracks[scene_token][sample_record['timestamp']] = all_boxes.boxes[sample_token]
+
+ # Replace box scores with track score (average box score). This only affects the compute_thresholds method and
+ # should be done before interpolation to avoid diluting the original scores with interpolated boxes.
+ if not gt:
+ for scene_id, scene_tracks in tracks.items():
+ # For each track_id, collect the scores.
+ track_id_scores = defaultdict(list)
+ for timestamp, boxes in scene_tracks.items():
+ for box in boxes:
+ track_id_scores[box.tracking_id].append(box.tracking_score)
+
+ # Compute average scores for each track.
+ track_id_avg_scores = {}
+ for tracking_id, scores in track_id_scores.items():
+ track_id_avg_scores[tracking_id] = np.mean(scores)
+
+ # Apply average score to each box.
+ for timestamp, boxes in scene_tracks.items():
+ for box in boxes:
+ box.tracking_score = track_id_avg_scores[box.tracking_id]
+
+ # Interpolate GT and predicted tracks.
+ for scene_token in tracks.keys():
+ tracks[scene_token] = interpolate_tracks(tracks[scene_token])
+
+ if not gt:
+ # Make sure predictions are sorted in in time. (Always true for GT).
+ tracks[scene_token] = defaultdict(list, sorted(tracks[scene_token].items(), key=lambda kv: kv[0]))
+
+ return tracks
diff --git a/python-sdk/nuscenes/eval/tracking/metrics.py b/python-sdk/nuscenes/eval/tracking/metrics.py
new file mode 100644
index 0000000..fad9330
--- /dev/null
+++ b/python-sdk/nuscenes/eval/tracking/metrics.py
@@ -0,0 +1,202 @@
+"""
+nuScenes dev-kit.
+Code written by Holger Caesar, Caglayan Dicle and Oscar Beijbom, 2019.
+
+This code is based on:
+
+py-motmetrics at:
+https://github.com/cheind/py-motmetrics
+"""
+from typing import Any
+
+import numpy as np
+
+DataFrame = Any
+
+
+def track_initialization_duration(df: DataFrame, obj_frequencies: DataFrame) -> float:
+ """
+ Computes the track initialization duration, which is the duration from the first occurrence of an object to
+ it's first correct detection (TP).
+ Note that this True Positive metric is undefined if there are no matched tracks.
+ :param df: Motmetrics dataframe that is required, but not used here.
+ :param obj_frequencies: Stores the GT tracking_ids and their frequencies.
+ :return: The track initialization time.
+ """
+ tid = 0
+ missed_tracks = 0
+ for gt_tracking_id in obj_frequencies.index:
+ # Get matches.
+ dfo = df.noraw[df.noraw.OId == gt_tracking_id]
+ notmiss = dfo[dfo.Type != 'MISS']
+
+ if len(notmiss) == 0:
+ # Consider only tracked objects.
+ diff = 0
+ missed_tracks += 1
+ else:
+ # Find the first time the object was detected and compute the difference to first time the object
+ # entered the scene.
+ diff = notmiss.index[0][0] - dfo.index[0][0]
+
+ # Multiply number of sample differences with approx. sample period (0.5 sec).
+ assert diff >= 0, 'Time difference should be larger than or equal to zero: %.2f'
+ tid += diff * 0.5
+
+ matched_tracks = len(obj_frequencies) - missed_tracks
+ if matched_tracks == 0:
+ # Return nan if there are no matches.
+ return np.nan
+ else:
+ return tid / matched_tracks
+
+
+def longest_gap_duration(df: DataFrame, obj_frequencies: DataFrame) -> float:
+ """
+ Computes the longest gap duration, which is the longest duration of any gaps in the detection of an object.
+ Note that this True Positive metric is undefined if there are no matched tracks.
+ :param df: Motmetrics dataframe that is required, but not used here.
+ :param obj_frequencies: Dataframe with all object frequencies.
+ :return: The longest gap duration.
+ """
+ # Return nan if the class is not in the GT.
+ if len(obj_frequencies.index) == 0:
+ return np.nan
+
+ lgd = 0
+ missed_tracks = 0
+ for gt_tracking_id in obj_frequencies.index:
+ # Find the frame_ids object is tracked and compute the gaps between those. Take the maximum one for longest gap.
+ dfo = df.noraw[df.noraw.OId == gt_tracking_id]
+ matched = set(dfo[dfo.Type != 'MISS'].index.get_level_values(0).values)
+
+ if len(matched) == 0:
+ # Ignore untracked objects.
+ gap = 0
+ missed_tracks += 1
+ else:
+ # Find the biggest gap.
+ # Note that we don't need to deal with FPs within the track as the GT is interpolated.
+ gap = 0 # The biggest gap found.
+ cur_gap = 0 # Current gap.
+ first_index = dfo.index[0][0]
+ last_index = dfo.index[-1][0]
+
+ for i in range(first_index, last_index + 1):
+ if i in matched:
+ # Reset when matched.
+ gap = np.maximum(gap, cur_gap)
+ cur_gap = 0
+ else: # Grow gap when missed.
+ # Gap grows.
+ cur_gap += 1
+
+ gap = np.maximum(gap, cur_gap)
+
+ # Multiply number of sample differences with approx. sample period (0.5 sec).
+ assert gap >= 0, 'Time difference should be larger than or equal to zero: %.2f'
+ lgd += gap * 0.5
+
+ # Average LGD over the number of tracks.
+ matched_tracks = len(obj_frequencies) - missed_tracks
+ if matched_tracks == 0:
+ # Return nan if there are no matches.
+ lgd = np.nan
+ else:
+ lgd = lgd / matched_tracks
+
+ return lgd
+
+
+def motar(df: DataFrame, num_matches: int, num_misses: int, num_switches: int, num_false_positives: int,
+ num_objects: int, alpha: float = 1.0) -> float:
+ """
+ Initializes a MOTAR class which refers to the modified MOTA metric at https://www.nuscenes.org/tracking.
+ Note that we use the measured recall, which is not identical to the hypothetical recall of the
+ AMOTA/AMOTP thresholds.
+ :param df: Motmetrics dataframe that is required, but not used here.
+ :param num_matches: The number of matches, aka. false positives.
+ :param num_misses: The number of misses, aka. false negatives.
+ :param num_switches: The number of identity switches.
+ :param num_false_positives: The number of false positives.
+ :param num_objects: The total number of objects of this class in the GT.
+ :param alpha: MOTAR weighting factor (previously 0.2).
+ :return: The MOTAR or nan if there are no GT objects.
+ """
+ recall = num_matches / num_objects
+ nominator = (num_misses + num_switches + num_false_positives) - (1 - recall) * num_objects
+ denominator = recall * num_objects
+ if denominator == 0:
+ motar_val = np.nan
+ else:
+ motar_val = 1 - alpha * nominator / denominator
+ motar_val = np.maximum(0, motar_val)
+
+ return motar_val
+
+
+def mota_custom(df: DataFrame, num_misses: int, num_switches: int, num_false_positives: int, num_objects: int) -> float:
+ """
+ Multiple object tracker accuracy.
+ Based on py-motmetric's mota function.
+ Compared to the original MOTA definition, we clip values below 0.
+ :param df: Motmetrics dataframe that is required, but not used here.
+ :param num_misses: The number of misses, aka. false negatives.
+ :param num_switches: The number of identity switches.
+ :param num_false_positives: The number of false positives.
+ :param num_objects: The total number of objects of this class in the GT.
+ :return: The MOTA or 0 if below 0.
+ """
+ mota = 1. - (num_misses + num_switches + num_false_positives) / num_objects
+ mota = np.maximum(0, mota)
+ return mota
+
+
+def motp_custom(df: DataFrame, num_detections: float) -> float:
+ """
+ Multiple object tracker precision.
+ Based on py-motmetric's motp function.
+ Additionally we check whether there are any detections.
+ :param df: Motmetrics dataframe that is required, but not used here.
+ :param num_detections: The number of detections.
+ :return: The MOTP or 0 if there are no detections.
+ """
+ # Note that the default motmetrics function throws a warning when num_detections == 0.
+ if num_detections == 0:
+ return np.nan
+ return df.noraw['D'].sum() / num_detections
+
+
+def faf(df: DataFrame, num_false_positives: float, num_frames: float) -> float:
+ """
+ The average number of false alarms per frame.
+ :param df: Motmetrics dataframe that is required, but not used here.
+ :param num_false_positives: The number of false positives.
+ :param num_frames: The number of frames.
+ :return: Average FAF.
+ """
+ return num_false_positives / num_frames * 100
+
+
+def num_fragmentations_custom(df: DataFrame, obj_frequencies: DataFrame) -> float:
+ """
+ Total number of switches from tracked to not tracked.
+ Based on py-motmetric's num_fragmentations function.
+ :param df: Motmetrics dataframe that is required, but not used here.
+ :param obj_frequencies: Stores the GT tracking_ids and their frequencies.
+ :return: The number of fragmentations.
+ """
+ fra = 0
+ for o in obj_frequencies.index:
+ # Find first and last time object was not missed (track span). Then count
+ # the number switches from NOT MISS to MISS state.
+ dfo = df.noraw[df.noraw.OId == o]
+ notmiss = dfo[dfo.Type != 'MISS']
+ if len(notmiss) == 0:
+ continue
+ first = notmiss.index[0]
+ last = notmiss.index[-1]
+ diffs = dfo.loc[first:last].Type.apply(lambda x: 1 if x == 'MISS' else 0).diff()
+ fra += diffs[diffs == 1].count()
+
+ return fra
diff --git a/python-sdk/nuscenes/eval/tracking/mot.py b/python-sdk/nuscenes/eval/tracking/mot.py
new file mode 100644
index 0000000..d176610
--- /dev/null
+++ b/python-sdk/nuscenes/eval/tracking/mot.py
@@ -0,0 +1,131 @@
+"""
+nuScenes dev-kit.
+Code written by Holger Caesar, Caglayan Dicle and Oscar Beijbom, 2019.
+
+This code is based on:
+
+py-motmetrics at:
+https://github.com/cheind/py-motmetrics
+"""
+from collections import OrderedDict
+from itertools import count
+
+import motmetrics
+import numpy as np
+import pandas as pd
+
+
+class MOTAccumulatorCustom(motmetrics.mot.MOTAccumulator):
+ def __init__(self):
+ super().__init__()
+
+ @staticmethod
+ def new_event_dataframe_with_data(indices, events):
+ """
+ Create a new DataFrame filled with data.
+ This version overwrites the original in MOTAccumulator achieves about 2x speedups.
+
+ Params
+ ------
+ indices: list
+ list of tuples (frameid, eventid)
+ events: list
+ list of events where each event is a list containing
+ 'Type', 'OId', HId', 'D'
+ """
+ idx = pd.MultiIndex.from_tuples(indices, names=['FrameId', 'Event'])
+ df = pd.DataFrame(events, index=idx, columns=['Type', 'OId', 'HId', 'D'])
+ return df
+
+ @staticmethod
+ def new_event_dataframe():
+ """ Create a new DataFrame for event tracking. """
+ idx = pd.MultiIndex(levels=[[], []], codes=[[], []], names=['FrameId', 'Event'])
+ cats = pd.Categorical([], categories=['RAW', 'FP', 'MISS', 'SWITCH', 'MATCH'])
+ df = pd.DataFrame(
+ OrderedDict([
+ ('Type', pd.Series(cats)), # Type of event. One of FP (false positive), MISS, SWITCH, MATCH
+ ('OId', pd.Series(dtype=object)),
+ # Object ID or -1 if FP. Using float as missing values will be converted to NaN anyways.
+ ('HId', pd.Series(dtype=object)),
+ # Hypothesis ID or NaN if MISS. Using float as missing values will be converted to NaN anyways.
+ ('D', pd.Series(dtype=float)), # Distance or NaN when FP or MISS
+ ]),
+ index=idx
+ )
+ return df
+
+ @property
+ def events(self):
+ if self.dirty_events:
+ self.cached_events_df = MOTAccumulatorCustom.new_event_dataframe_with_data(self._indices, self._events)
+ self.dirty_events = False
+ return self.cached_events_df
+
+ @staticmethod
+ def merge_event_dataframes(dfs, update_frame_indices=True, update_oids=True, update_hids=True,
+ return_mappings=False):
+ """Merge dataframes.
+
+ Params
+ ------
+ dfs : list of pandas.DataFrame or MotAccumulator
+ A list of event containers to merge
+
+ Kwargs
+ ------
+ update_frame_indices : boolean, optional
+ Ensure that frame indices are unique in the merged container
+ update_oids : boolean, unique
+ Ensure that object ids are unique in the merged container
+ update_hids : boolean, unique
+ Ensure that hypothesis ids are unique in the merged container
+ return_mappings : boolean, unique
+ Whether or not to return mapping information
+
+ Returns
+ -------
+ df : pandas.DataFrame
+ Merged event data frame
+ """
+
+ mapping_infos = []
+ new_oid = count()
+ new_hid = count()
+
+ r = MOTAccumulatorCustom.new_event_dataframe()
+ for df in dfs:
+
+ if isinstance(df, MOTAccumulatorCustom):
+ df = df.events
+
+ copy = df.copy()
+ infos = {}
+
+ # Update index
+ if update_frame_indices:
+ next_frame_id = max(r.index.get_level_values(0).max() + 1,
+ r.index.get_level_values(0).unique().shape[0])
+ if np.isnan(next_frame_id):
+ next_frame_id = 0
+ copy.index = copy.index.map(lambda x: (x[0] + next_frame_id, x[1]))
+ infos['frame_offset'] = next_frame_id
+
+ # Update object / hypothesis ids
+ if update_oids:
+ oid_map = dict([oid, str(next(new_oid))] for oid in copy['OId'].dropna().unique())
+ copy['OId'] = copy['OId'].map(lambda x: oid_map[x], na_action='ignore')
+ infos['oid_map'] = oid_map
+
+ if update_hids:
+ hid_map = dict([hid, str(next(new_hid))] for hid in copy['HId'].dropna().unique())
+ copy['HId'] = copy['HId'].map(lambda x: hid_map[x], na_action='ignore')
+ infos['hid_map'] = hid_map
+
+ r = r.append(copy)
+ mapping_infos.append(infos)
+
+ if return_mappings:
+ return r, mapping_infos
+ else:
+ return r
diff --git a/python-sdk/nuscenes/eval/tracking/render.py b/python-sdk/nuscenes/eval/tracking/render.py
new file mode 100644
index 0000000..c305753
--- /dev/null
+++ b/python-sdk/nuscenes/eval/tracking/render.py
@@ -0,0 +1,165 @@
+# nuScenes dev-kit.
+# Code written by Holger Caesar, Caglayan Dicle, Varun Bankiti, and Alex Lang, 2019.
+
+import os
+from typing import Any, List
+
+import matplotlib.pyplot as plt
+import numpy as np
+from pandas import DataFrame
+from pyquaternion import Quaternion
+
+from nuscenes.eval.common.render import setup_axis
+from nuscenes.eval.tracking.constants import TRACKING_COLORS, PRETTY_TRACKING_NAMES
+from nuscenes.eval.tracking.data_classes import TrackingBox, TrackingMetricDataList
+from nuscenes.utils.data_classes import Box
+
+Axis = Any
+
+
+def summary_plot(md_list: TrackingMetricDataList,
+ min_recall: float,
+ ncols: int = 2,
+ savepath: str = None) -> None:
+ """
+ Creates a summary plot with which includes all traditional metrics for each class.
+ :param md_list: TrackingMetricDataList instance.
+ :param min_recall: Minimum recall value.
+ :param ncols: How many columns the resulting plot should have.
+ :param savepath: If given, saves the the rendering here instead of displaying.
+ """
+ # Select metrics and setup plot.
+ rel_metrics = ['motar', 'motp', 'mota', 'recall', 'mt', 'ml', 'faf', 'tp', 'fp', 'fn', 'ids', 'frag', 'tid', 'lgd']
+ n_metrics = len(rel_metrics)
+ nrows = int(np.ceil(n_metrics / ncols))
+ _, axes = plt.subplots(nrows=nrows, ncols=ncols, figsize=(7.5 * ncols, 5 * nrows))
+
+ # For each metric, plot all the classes in one diagram.
+ for ind, metric_name in enumerate(rel_metrics):
+ row = ind // ncols
+ col = np.mod(ind, ncols)
+ recall_metric_curve(md_list, metric_name, min_recall, ax=axes[row, col])
+
+ # Set layout with little white space and save to disk.
+ plt.tight_layout()
+ if savepath is not None:
+ plt.savefig(savepath)
+ plt.close()
+
+
+def recall_metric_curve(md_list: TrackingMetricDataList,
+ metric_name: str,
+ min_recall: float,
+ savepath: str = None,
+ ax: Axis = None) -> None:
+ """
+ Plot the recall versus metric curve for the given metric.
+ :param md_list: TrackingMetricDataList instance.
+ :param metric_name: The name of the metric to plot.
+ :param min_recall: Minimum recall value.
+ :param savepath: If given, saves the the rendering here instead of displaying.
+ :param ax: Axes onto which to render or None to create a new axis.
+ """
+ # Setup plot.
+ if ax is None:
+ _, ax = plt.subplots(1, 1, figsize=(7.5, 5))
+ ax = setup_axis(xlabel='Recall', ylabel=metric_name.upper(),
+ xlim=1, ylim=None, min_recall=min_recall, ax=ax, show_spines='bottomleft')
+
+ # Plot the recall vs. precision curve for each detection class.
+ for tracking_name, md in md_list.md.items():
+ # Get values.
+ confidence = md.confidence
+ recalls = md.recall_hypo
+ values = md.get_metric(metric_name)
+
+ # Filter unachieved recall thresholds.
+ valid = np.where(np.logical_not(np.isnan(confidence)))[0]
+ if len(valid) == 0:
+ continue
+ first_valid = valid[0]
+ assert not np.isnan(confidence[-1])
+ recalls = recalls[first_valid:]
+ values = values[first_valid:]
+
+ ax.plot(recalls,
+ values,
+ label='%s' % PRETTY_TRACKING_NAMES[tracking_name],
+ color=TRACKING_COLORS[tracking_name])
+
+ # Scale count statistics and FAF logarithmically.
+ if metric_name in ['mt', 'ml', 'faf', 'tp', 'fp', 'fn', 'ids', 'frag']:
+ ax.set_yscale('symlog')
+
+ if metric_name in ['amota', 'motar', 'recall', 'mota']:
+ # Some metrics have an upper bound of 1.
+ ax.set_ylim(0, 1)
+ elif metric_name != 'motp':
+ # For all other metrics except MOTP we set a lower bound of 0.
+ ax.set_ylim(bottom=0)
+
+ ax.legend(loc='upper right', borderaxespad=0)
+ plt.tight_layout()
+ if savepath is not None:
+ plt.savefig(savepath)
+ plt.close()
+
+
+class TrackingRenderer:
+ """
+ Class that renders the tracking results in BEV and saves them to a folder.
+ """
+ def __init__(self, save_path):
+ """
+ :param save_path: Output path to save the renderings.
+ """
+ self.save_path = save_path
+ self.id2color = {} # The color of each track.
+
+ def render(self, events: DataFrame, timestamp: int, frame_gt: List[TrackingBox], frame_pred: List[TrackingBox]) \
+ -> None:
+ """
+ Render function for a given scene timestamp
+ :param events: motmetrics events for that particular
+ :param timestamp: timestamp for the rendering
+ :param frame_gt: list of ground truth boxes
+ :param frame_pred: list of prediction boxes
+ """
+ # Init.
+ print('Rendering {}'.format(timestamp))
+ switches = events[events.Type == 'SWITCH']
+ switch_ids = switches.HId.values
+ fig, ax = plt.subplots()
+
+ # Plot GT boxes.
+ for b in frame_gt:
+ color = 'k'
+ box = Box(b.ego_translation, b.size, Quaternion(b.rotation), name=b.tracking_name, token=b.tracking_id)
+ box.render(ax, view=np.eye(4), colors=(color, color, color), linewidth=1)
+
+ # Plot predicted boxes.
+ for b in frame_pred:
+ box = Box(b.ego_translation, b.size, Quaternion(b.rotation), name=b.tracking_name, token=b.tracking_id)
+
+ # Determine color for this tracking id.
+ if b.tracking_id not in self.id2color.keys():
+ self.id2color[b.tracking_id] = (float(hash(b.tracking_id + 'r') % 256) / 255,
+ float(hash(b.tracking_id + 'g') % 256) / 255,
+ float(hash(b.tracking_id + 'b') % 256) / 255)
+
+ # Render box. Highlight identity switches in red.
+ if b.tracking_id in switch_ids:
+ color = self.id2color[b.tracking_id]
+ box.render(ax, view=np.eye(4), colors=('r', 'r', color))
+ else:
+ color = self.id2color[b.tracking_id]
+ box.render(ax, view=np.eye(4), colors=(color, color, color))
+
+ # Plot ego pose.
+ plt.scatter(0, 0, s=96, facecolors='none', edgecolors='k', marker='o')
+ plt.xlim(-50, 50)
+ plt.ylim(-50, 50)
+
+ # Save to disk and close figure.
+ fig.savefig(os.path.join(self.save_path, '{}.png'.format(timestamp)))
+ plt.close(fig)
diff --git a/python-sdk/nuscenes/eval/tracking/tests/__init__.py b/python-sdk/nuscenes/eval/tracking/tests/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/python-sdk/nuscenes/eval/tracking/tests/scenarios.py b/python-sdk/nuscenes/eval/tracking/tests/scenarios.py
new file mode 100644
index 0000000..21514e6
--- /dev/null
+++ b/python-sdk/nuscenes/eval/tracking/tests/scenarios.py
@@ -0,0 +1,93 @@
+from typing import List, Dict
+
+import numpy as np
+
+
+def get_scenarios() -> List[Dict[str, dict]]:
+ """ """
+
+ scenarios = []
+
+ # Scenario 1.
+ # Parallel motion 1 meter distance.
+ pos_gt = np.array([[(1, -3), (1, -2), (1, -1), (1, -0)],
+ [(0, -3), (0, -2), (0, -1), (0, -0)], ]).astype(float)
+ pos_pred = pos_gt
+ sigma = 0.1
+ pos_pred += sigma * np.random.randn(*pos_pred.shape)
+
+ input_data = {'pos_gt': pos_gt,
+ 'pos_pred': pos_pred}
+ output_data = {'ids': 0.0}
+
+ scenarios.append({'input': input_data, 'output': output_data})
+
+ # Scenario 2.
+ # Parallel motion bring closer predictions.
+ pos_gt = np.array([[(1, -3), (1, -2), (1, -1), (1, -0)],
+ [(0, -3), (0, -2), (0, -1), (0, -0)], ]).astype(float)
+ pos_pred = pos_gt
+
+ pos_pred[0, :, 0] -= 0.3
+ pos_pred[1, :, 0] += 0.3
+ sigma = 0.1
+ pos_pred += sigma * np.random.randn(*pos_pred.shape)
+
+ input_data = {'pos_gt': pos_gt,
+ 'pos_pred': pos_pred}
+ output_data = {'ids': 0.0}
+
+ scenarios.append({'input': input_data, 'output': output_data})
+
+ # Scenario 3.
+ # Parallel motion bring closer both ground truth and predictions.
+ pos_gt = np.array([[(1, -3), (1, -2), (1, -1), (1, -0)],
+ [(0, -3), (0, -2), (0, -1), (0, -0)], ]).astype(float)
+ pos_pred = pos_gt
+
+ pos_gt[0, :, 0] -= 0.3
+ pos_gt[1, :, 0] += 0.3
+ pos_pred[0, :, 0] -= 0.3
+ pos_pred[1, :, 0] += 0.3
+ sigma = 0.1
+ pos_pred += sigma * np.random.randn(*pos_pred.shape)
+
+ input_data = {'pos_gt': pos_gt,
+ 'pos_pred': pos_pred}
+ output_data = {'ids': 0.0}
+
+ scenarios.append({'input': input_data, 'output': output_data})
+
+ # Scenario 4.
+ # Crossing motion.
+ pos_gt = np.array([[(2, -3), (1, -2), (0, -1), (-1, -0)],
+ [(-2, -3), (-1, -2), (0, -1), (1, -0)], ]).astype(float)
+ pos_pred = pos_gt
+ sigma = 0.1
+ pos_pred += sigma * np.random.randn(*pos_pred.shape)
+
+ input_data = {'pos_gt': pos_gt,
+ 'pos_pred': pos_pred}
+ output_data = {'ids': 0.0}
+
+ scenarios.append({'input': input_data, 'output': output_data})
+
+ # Scenario 5.
+ # Identity switch due to a single misdetection (3rd timestamp).
+ pos_pred = np.array([
+ [(0, -2), (0, -1), (0, 0), (0, 1), (0, 2)],
+ [(-2, 0), (-1, 0), (3, 0), (1, 0), (2, 0)],
+ ]).astype(float)
+ pos_gt = np.array([
+ [(-2, 0), (-1, 0), (0, 0), (1, 0), (2, 0)],
+ ]).astype(float)
+ sigma = 0.1
+ pos_pred += sigma * np.random.randn(*pos_pred.shape)
+
+ input_data = {'pos_gt': pos_gt,
+ 'pos_pred': pos_pred}
+ output_data = {'ids': 2}
+
+ scenarios.append({'input': input_data, 'output': output_data})
+
+ return scenarios
diff --git a/python-sdk/nuscenes/eval/tracking/tests/test_algo.py b/python-sdk/nuscenes/eval/tracking/tests/test_algo.py
new file mode 100644
index 0000000..44d6b67
--- /dev/null
+++ b/python-sdk/nuscenes/eval/tracking/tests/test_algo.py
@@ -0,0 +1,297 @@
+import copy
+import unittest
+from collections import defaultdict
+from typing import Tuple, Dict, List
+
+import numpy as np
+
+from nuscenes.eval.common.config import config_factory
+from nuscenes.eval.tracking.algo import TrackingEvaluation
+from nuscenes.eval.tracking.data_classes import TrackingMetricData, TrackingBox
+from nuscenes.eval.tracking.loaders import interpolate_tracks
+from nuscenes.eval.tracking.tests.scenarios import get_scenarios
+
+
+class TestAlgo(unittest.TestCase):
+
+ @staticmethod
+ def single_scene() -> Tuple[str, Dict[str, Dict[int, List[TrackingBox]]]]:
+ class_name = 'car'
+ box = TrackingBox(translation=(0, 0, 0), tracking_id='ta', tracking_name=class_name,
+ tracking_score=0.5)
+ timestamp_boxes_gt = {
+ 0: [copy.deepcopy(box)],
+ 1: [copy.deepcopy(box)],
+ 2: [copy.deepcopy(box)],
+ 3: [copy.deepcopy(box)]
+ }
+ timestamp_boxes_gt[0][0].sample_token = 'a'
+ timestamp_boxes_gt[1][0].sample_token = 'b'
+ timestamp_boxes_gt[2][0].sample_token = 'c'
+ timestamp_boxes_gt[3][0].sample_token = 'd'
+ tracks_gt = {'scene-1': timestamp_boxes_gt}
+
+ return class_name, tracks_gt
+
+ def test_gt_submission(self):
+ """ Test with GT submission. """
+
+ # Get config.
+ cfg = config_factory('tracking_nips_2019')
+
+ # Define inputs.
+ class_name, tracks_gt = TestAlgo.single_scene()
+ verbose = False
+
+ # Remove one prediction.
+ timestamp_boxes_pred = copy.deepcopy(tracks_gt['scene-1'])
+ tracks_pred = {'scene-1': timestamp_boxes_pred}
+
+ # Accumulate metrics.
+ ev = TrackingEvaluation(tracks_gt, tracks_pred, class_name, cfg.dist_fcn_callable,
+ cfg.dist_th_tp, cfg.min_recall, num_thresholds=TrackingMetricData.nelem,
+ metric_worst=cfg.metric_worst, verbose=verbose)
+ md = ev.accumulate()
+
+ # Check outputs.
+ assert np.all(md.tp == 4)
+ assert np.all(md.fn == 0)
+ assert np.all(md.fp == 0)
+ assert np.all(md.lgd == 0)
+ assert np.all(md.tid == 0)
+ assert np.all(md.frag == 0)
+ assert np.all(md.ids == 0)
+
+ def test_empty_submission(self):
+ """ Test a submission with no predictions. """
+
+ # Get config.
+ cfg = config_factory('tracking_nips_2019')
+
+ # Define inputs.
+ class_name, tracks_gt = TestAlgo.single_scene()
+ verbose = False
+
+ # Remove all predictions.
+ timestamp_boxes_pred = copy.deepcopy(tracks_gt['scene-1'])
+ for timestamp, box in timestamp_boxes_pred.items():
+ timestamp_boxes_pred[timestamp] = []
+ tracks_pred = {'scene-1': timestamp_boxes_pred}
+
+ # Accumulate metrics.
+ ev = TrackingEvaluation(tracks_gt, tracks_pred, class_name, cfg.dist_fcn_callable,
+ cfg.dist_th_tp, cfg.min_recall, num_thresholds=TrackingMetricData.nelem,
+ metric_worst=cfg.metric_worst, verbose=verbose)
+ md = ev.accumulate()
+
+ # Check outputs.
+ assert np.all(md.mota == 0)
+ assert np.all(md.motar == 0)
+ assert np.all(np.isnan(md.recall_hypo))
+ assert np.all(md.tp == 0)
+ assert np.all(md.fn == 4)
+ assert np.all(np.isnan(md.fp)) # FP/Frag/IDS are nan as we there were no predictions.
+ assert np.all(md.lgd == 20)
+ assert np.all(md.tid == 20)
+ assert np.all(np.isnan(md.frag))
+ assert np.all(np.isnan(md.ids))
+
+ def test_drop_prediction(self):
+ """ Drop one prediction from the GT submission. """
+
+ # Get config.
+ cfg = config_factory('tracking_nips_2019')
+
+ # Define inputs.
+ class_name, tracks_gt = TestAlgo.single_scene()
+ verbose = False
+
+ # Remove one predicted box.
+ timestamp_boxes_pred = copy.deepcopy(tracks_gt['scene-1'])
+ timestamp_boxes_pred[1] = []
+ tracks_pred = {'scene-1': timestamp_boxes_pred}
+
+ # Accumulate metrics.
+ ev = TrackingEvaluation(tracks_gt, tracks_pred, class_name, cfg.dist_fcn_callable,
+ cfg.dist_th_tp, cfg.min_recall, num_thresholds=TrackingMetricData.nelem,
+ metric_worst=cfg.metric_worst, verbose=verbose)
+ md = ev.accumulate()
+
+ # Check outputs.
+ # Recall values above 0.75 (3/4 correct) are not achieved and therefore nan.
+ first_achieved = np.where(md.recall_hypo <= 0.75)[0][0]
+ assert np.all(np.isnan(md.confidence[:first_achieved]))
+ assert md.tp[first_achieved] == 3
+ assert md.fp[first_achieved] == 0
+ assert md.fn[first_achieved] == 1
+ assert md.lgd[first_achieved] == 0.5
+ assert md.tid[first_achieved] == 0
+ assert md.frag[first_achieved] == 1
+ assert md.ids[first_achieved] == 0
+
+ def test_drop_prediction_multiple(self):
+ """ Drop the first three predictions from the GT submission. """
+
+ # Get config.
+ cfg = config_factory('tracking_nips_2019')
+
+ # Define inputs.
+ class_name, tracks_gt = TestAlgo.single_scene()
+ verbose = False
+
+ # Remove one predicted box.
+ timestamp_boxes_pred = copy.deepcopy(tracks_gt['scene-1'])
+ timestamp_boxes_pred[0] = []
+ timestamp_boxes_pred[1] = []
+ timestamp_boxes_pred[2] = []
+ tracks_pred = {'scene-1': timestamp_boxes_pred}
+
+ # Accumulate metrics.
+ ev = TrackingEvaluation(tracks_gt, tracks_pred, class_name, cfg.dist_fcn_callable,
+ cfg.dist_th_tp, cfg.min_recall, num_thresholds=TrackingMetricData.nelem,
+ metric_worst=cfg.metric_worst, verbose=verbose)
+ md = ev.accumulate()
+
+ # Check outputs.
+ # Recall values above 0.75 (3/4 correct) are not achieved and therefore nan.
+ first_achieved = np.where(md.recall_hypo <= 0.25)[0][0]
+ assert np.all(np.isnan(md.confidence[:first_achieved]))
+ assert md.tp[first_achieved] == 1
+ assert md.fp[first_achieved] == 0
+ assert md.fn[first_achieved] == 3
+ assert md.lgd[first_achieved] == 3 * 0.5
+ assert md.tid[first_achieved] == 3 * 0.5
+ assert md.frag[first_achieved] == 0
+ assert md.ids[first_achieved] == 0
+
+ def test_identity_switch(self):
+ """ Change the tracking_id of one frame from the GT submission. """
+
+ # Get config.
+ cfg = config_factory('tracking_nips_2019')
+
+ # Define inputs.
+ class_name, tracks_gt = TestAlgo.single_scene()
+ verbose = False
+
+ # Remove one predicted box.
+ timestamp_boxes_pred = copy.deepcopy(tracks_gt['scene-1'])
+ timestamp_boxes_pred[2][0].tracking_id = 'tb'
+ tracks_pred = {'scene-1': timestamp_boxes_pred}
+
+ # Accumulate metrics.
+ ev = TrackingEvaluation(tracks_gt, tracks_pred, class_name, cfg.dist_fcn_callable,
+ cfg.dist_th_tp, cfg.min_recall, num_thresholds=TrackingMetricData.nelem,
+ metric_worst=cfg.metric_worst, verbose=verbose)
+ md = ev.accumulate()
+
+ # Check outputs.
+ first_achieved = np.where(md.recall_hypo <= 0.5)[0][0]
+ assert md.tp[first_achieved] == 2
+ assert md.fp[first_achieved] == 0
+ assert md.fn[first_achieved] == 0
+ assert md.lgd[first_achieved] == 0
+ assert md.tid[first_achieved] == 0
+ assert md.frag[first_achieved] == 0
+ assert md.ids[first_achieved] == 2 # One wrong id leads to 2 identity switches.
+
+ def test_drop_gt(self):
+ """ Drop one box from the GT. """
+
+ # Get config.
+ cfg = config_factory('tracking_nips_2019')
+
+ # Define inputs.
+ class_name, tracks_gt = TestAlgo.single_scene()
+ verbose = False
+
+ # Remove one GT box.
+ timestamp_boxes_pred = copy.deepcopy(tracks_gt['scene-1'])
+ tracks_gt['scene-1'][1] = []
+ tracks_pred = {'scene-1': timestamp_boxes_pred}
+
+ # Accumulate metrics.
+ ev = TrackingEvaluation(tracks_gt, tracks_pred, class_name, cfg.dist_fcn_callable,
+ cfg.dist_th_tp, cfg.min_recall, num_thresholds=TrackingMetricData.nelem,
+ metric_worst=cfg.metric_worst, verbose=verbose)
+ md = ev.accumulate()
+
+ # Check outputs.
+ assert np.all(md.tp == 3)
+ assert np.all(md.fp == 1)
+ assert np.all(md.fn == 0)
+ assert np.all(md.lgd == 0.5)
+ assert np.all(md.tid == 0)
+ assert np.all(md.frag == 0)
+ assert np.all(md.ids == 0)
+
+ def test_drop_gt_interpolate(self):
+ """ Drop one box from the GT and interpolate the results to fill in that box. """
+
+ # Get config.
+ cfg = config_factory('tracking_nips_2019')
+
+ # Define inputs.
+ class_name, tracks_gt = TestAlgo.single_scene()
+ verbose = False
+
+ # Remove one GT box.
+ timestamp_boxes_pred = copy.deepcopy(tracks_gt['scene-1'])
+ tracks_gt['scene-1'][1] = []
+ tracks_pred = {'scene-1': timestamp_boxes_pred}
+
+ # Interpolate to "restore" dropped GT.
+ tracks_gt['scene-1'] = interpolate_tracks(defaultdict(list, tracks_gt['scene-1']))
+
+ # Accumulate metrics.
+ ev = TrackingEvaluation(tracks_gt, tracks_pred, class_name, cfg.dist_fcn_callable,
+ cfg.dist_th_tp, cfg.min_recall, num_thresholds=TrackingMetricData.nelem,
+ metric_worst=cfg.metric_worst, verbose=verbose)
+ md = ev.accumulate()
+
+ # Check outputs.
+ assert np.all(md.tp == 4)
+ assert np.all(md.fp == 0)
+ assert np.all(md.fn == 0)
+ assert np.all(md.lgd == 0)
+ assert np.all(md.tid == 0)
+ assert np.all(md.frag == 0)
+ assert np.all(md.ids == 0)
+
+ def test_scenarios(self):
+ """ More flexible scenario test structure. """
+
+ def create_tracks(_scenario, tag=None):
+ tracks = {}
+ for entry_id, entry in enumerate(_scenario['input']['pos_'+tag]):
+ tracking_id = 'tag_{}'.format(entry_id)
+ for timestamp, pos in enumerate(entry):
+ if timestamp not in tracks.keys():
+ tracks[timestamp] = []
+ box = TrackingBox(translation=(pos[0], pos[1], 0.0), tracking_id=tracking_id, tracking_name='car',
+ tracking_score=0.5)
+ tracks[timestamp].append(box)
+
+ return tracks
+
+ # Get config.
+ cfg = config_factory('tracking_nips_2019')
+
+ for scenario in get_scenarios():
+ tracks_gt = {'scene-1': create_tracks(scenario, tag='gt')}
+ tracks_pred = {'scene-1': create_tracks(scenario, tag='pred')}
+
+ # Accumulate metrics.
+ ev = TrackingEvaluation(tracks_gt, tracks_pred, 'car', cfg.dist_fcn_callable,
+ cfg.dist_th_tp, cfg.min_recall, num_thresholds=TrackingMetricData.nelem,
+ metric_worst=cfg.metric_worst, verbose=False)
+ md = ev.accumulate()
+
+ for key, value in scenario['output'].items():
+ metric_values = getattr(md, key)
+ metric_values = metric_values[np.logical_not(np.isnan(metric_values))]
+ assert np.all(metric_values == value)
+
+
+if __name__ == '__main__':
+ unittest.main()
diff --git a/python-sdk/nuscenes/eval/tracking/tests/test_evaluate.py b/python-sdk/nuscenes/eval/tracking/tests/test_evaluate.py
new file mode 100644
index 0000000..2d2b025
--- /dev/null
+++ b/python-sdk/nuscenes/eval/tracking/tests/test_evaluate.py
@@ -0,0 +1,234 @@
+# nuScenes dev-kit.
+# Code written by Holger Caesar, 2019.
+
+import json
+import os
+import random
+import shutil
+import sys
+import unittest
+from typing import Dict, Optional, Any
+
+import numpy as np
+from tqdm import tqdm
+
+from nuscenes import NuScenes
+from nuscenes.eval.common.config import config_factory
+from nuscenes.eval.tracking.constants import TRACKING_NAMES
+from nuscenes.eval.tracking.evaluate import TrackingEval
+from nuscenes.eval.tracking.utils import category_to_tracking_name
+from nuscenes.utils.splits import create_splits_scenes
+
+
+class TestMain(unittest.TestCase):
+ res_mockup = 'nusc_eval.json'
+ res_eval_folder = 'tmp'
+
+ def tearDown(self):
+ if os.path.exists(self.res_mockup):
+ os.remove(self.res_mockup)
+ if os.path.exists(self.res_eval_folder):
+ shutil.rmtree(self.res_eval_folder)
+
+ @staticmethod
+ def _mock_submission(nusc: NuScenes,
+ split: str,
+ add_errors: bool = False) -> Dict[str, dict]:
+ """
+ Creates "reasonable" submission (results and metadata) by looping through the mini-val set, adding 1 GT
+ prediction per sample. Predictions will be permuted randomly along all axes.
+ :param nusc: NuScenes instance.
+ :param split: Dataset split to use.
+ :param add_errors: Whether to use GT or add errors to it.
+ """
+
+ def random_class(category_name: str, _add_errors: bool = False) -> Optional[str]:
+ # Alter 10% of the valid labels.
+ class_names = sorted(TRACKING_NAMES)
+ tmp = category_to_tracking_name(category_name)
+
+ if tmp is None:
+ return None
+ else:
+ if not _add_errors or np.random.rand() < .9:
+ return tmp
+ else:
+ return class_names[np.random.randint(0, len(class_names) - 1)]
+
+ def random_id(instance_token: str, _add_errors: bool = False) -> str:
+ # Alter 10% of the valid ids to be a random string, which hopefully corresponds to a new track.
+ if not _add_errors or np.random.rand() < .9:
+ _tracking_id = instance_token + '_pred'
+ else:
+ _tracking_id = str(np.random.randint(0, sys.maxsize))
+
+ return _tracking_id
+
+ mock_meta = {
+ 'use_camera': False,
+ 'use_lidar': True,
+ 'use_radar': False,
+ 'use_map': False,
+ 'use_external': False,
+ }
+ mock_results = {}
+
+ # Get all samples in the current evaluation split.
+ splits = create_splits_scenes()
+ val_samples = []
+ for sample in nusc.sample:
+ if nusc.get('scene', sample['scene_token'])['name'] in splits[split]:
+ val_samples.append(sample)
+
+ # Prepare results.
+ instance_to_score = dict()
+ for sample in tqdm(val_samples, leave=False):
+ sample_res = []
+ for ann_token in sample['anns']:
+ ann = nusc.get('sample_annotation', ann_token)
+ translation = np.array(ann['translation'])
+ size = np.array(ann['size'])
+ rotation = np.array(ann['rotation'])
+ velocity = nusc.box_velocity(ann_token)[:2]
+ tracking_id = random_id(ann['instance_token'], _add_errors=add_errors)
+ tracking_name = random_class(ann['category_name'], _add_errors=add_errors)
+
+ # Skip annotations for classes not part of the detection challenge.
+ if tracking_name is None:
+ continue
+
+ # Skip annotations with 0 lidar/radar points.
+ num_pts = ann['num_lidar_pts'] + ann['num_radar_pts']
+ if num_pts == 0:
+ continue
+
+ # If we randomly assign a score in [0, 1] to each box and later average over the boxes in the track,
+ # the average score will be around 0.5 and we will have 0 predictions above that.
+ # Therefore we assign the same scores to each box in a track.
+ if ann['instance_token'] not in instance_to_score:
+ instance_to_score[ann['instance_token']] = random.random()
+ tracking_score = instance_to_score[ann['instance_token']]
+ tracking_score = np.clip(tracking_score + random.random() * 0.3, 0, 1)
+
+ if add_errors:
+ translation += 4 * (np.random.rand(3) - 0.5)
+ size *= (np.random.rand(3) + 0.5)
+ rotation += (np.random.rand(4) - 0.5) * .1
+ velocity *= np.random.rand(3)[:2] + 0.5
+
+ sample_res.append({
+ 'sample_token': sample['token'],
+ 'translation': list(translation),
+ 'size': list(size),
+ 'rotation': list(rotation),
+ 'velocity': list(velocity),
+ 'tracking_id': tracking_id,
+ 'tracking_name': tracking_name,
+ 'tracking_score': tracking_score
+ })
+ mock_results[sample['token']] = sample_res
+ mock_submission = {
+ 'meta': mock_meta,
+ 'results': mock_results
+ }
+ return mock_submission
+
+ @unittest.skip
+ def basic_test(self,
+ eval_set: str = 'mini_val',
+ add_errors: bool = False,
+ render_curves: bool = False) -> Dict[str, Any]:
+ """
+ Run the evaluation with fixed randomness on the specified subset, with or without introducing errors in the
+ submission.
+ :param eval_set: Which split to evaluate on.
+ :param add_errors: Whether to use GT as submission or introduce additional errors.
+ :param render_curves: Whether to render stats curves to disk.
+ :return: The metrics returned by the evaluation.
+ """
+ random.seed(42)
+ np.random.seed(42)
+ assert 'NUSCENES' in os.environ, 'Set NUSCENES env. variable to enable tests.'
+
+ if eval_set.startswith('mini'):
+ version = 'v1.0-mini'
+ elif eval_set == 'test':
+ version = 'v1.0-test'
+ else:
+ version = 'v1.0-trainval'
+ nusc = NuScenes(version=version, dataroot=os.environ['NUSCENES'], verbose=False)
+
+ with open(self.res_mockup, 'w') as f:
+ mock = self._mock_submission(nusc, eval_set, add_errors=add_errors)
+ json.dump(mock, f, indent=2)
+
+ cfg = config_factory('tracking_nips_2019')
+ nusc_eval = TrackingEval(cfg, self.res_mockup, eval_set=eval_set, output_dir=self.res_eval_folder,
+ nusc_version=version, nusc_dataroot=os.environ['NUSCENES'], verbose=False)
+ metrics = nusc_eval.main(render_curves=render_curves)
+
+ return metrics
+
+ @unittest.skip
+ def test_delta_mock(self,
+ eval_set: str = 'mini_val',
+ render_curves: bool = False):
+ """
+ This tests runs the evaluation for an arbitrary random set of predictions.
+ This score is then captured in this very test such that if we change the eval code,
+ this test will trigger if the results changed.
+ :param eval_set: Which set to evaluate on.
+ :param render_curves: Whether to render stats curves to disk.
+ """
+ # Run the evaluation with errors.
+ metrics = self.basic_test(eval_set, add_errors=True, render_curves=render_curves)
+
+ # Compare metrics to known solution.
+ if eval_set == 'mini_val':
+ self.assertAlmostEqual(metrics['amota'], 0.23766771095785147)
+ self.assertAlmostEqual(metrics['amotp'], 1.5275400961369252)
+ self.assertAlmostEqual(metrics['motar'], 0.3726570200013319)
+ self.assertAlmostEqual(metrics['mota'], 0.25003943918566174)
+ self.assertAlmostEqual(metrics['motp'], 1.2976508610883917)
+ else:
+ print('Skipping checks due to choice of custom eval_set: %s' % eval_set)
+
+ @unittest.skip
+ def test_delta_gt(self,
+ eval_set: str = 'mini_val',
+ render_curves: bool = False):
+ """
+ This tests runs the evaluation with the ground truth used as predictions.
+ This should result in a perfect score for every metric.
+ This score is then captured in this very test such that if we change the eval code,
+ this test will trigger if the results changed.
+ :param eval_set: Which set to evaluate on.
+ :param render_curves: Whether to render stats curves to disk.
+ """
+ # Run the evaluation without errors.
+ metrics = self.basic_test(eval_set, add_errors=False, render_curves=render_curves)
+
+ # Compare metrics to known solution. Do not check:
+ # - MT/TP (hard to figure out here).
+ # - AMOTA/AMOTP (unachieved recall values lead to hard unintuitive results).
+ if eval_set == 'mini_val':
+ self.assertAlmostEqual(metrics['amota'], 1.0)
+ self.assertAlmostEqual(metrics['amotp'], 0.0, delta=1e-5)
+ self.assertAlmostEqual(metrics['motar'], 1.0)
+ self.assertAlmostEqual(metrics['recall'], 1.0)
+ self.assertAlmostEqual(metrics['mota'], 1.0)
+ self.assertAlmostEqual(metrics['motp'], 0.0, delta=1e-5)
+ self.assertAlmostEqual(metrics['faf'], 0.0)
+ self.assertAlmostEqual(metrics['ml'], 0.0)
+ self.assertAlmostEqual(metrics['fp'], 0.0)
+ self.assertAlmostEqual(metrics['fn'], 0.0)
+ self.assertAlmostEqual(metrics['ids'], 0.0)
+ self.assertAlmostEqual(metrics['frag'], 0.0)
+ self.assertAlmostEqual(metrics['tid'], 0.0)
+ self.assertAlmostEqual(metrics['lgd'], 0.0)
+ else:
+ print('Skipping checks due to choice of custom eval_set: %s' % eval_set)
+
+
+if __name__ == '__main__':
+ unittest.main()
diff --git a/python-sdk/nuscenes/eval/tracking/utils.py b/python-sdk/nuscenes/eval/tracking/utils.py
new file mode 100644
index 0000000..f07c0e6
--- /dev/null
+++ b/python-sdk/nuscenes/eval/tracking/utils.py
@@ -0,0 +1,172 @@
+# nuScenes dev-kit.
+# Code written by Holger Caesar, 2019.
+
+import warnings
+from typing import Optional, Dict
+
+import motmetrics
+import numpy as np
+from motmetrics.metrics import MetricsHost
+
+from nuscenes.eval.tracking.data_classes import TrackingMetrics
+from nuscenes.eval.tracking.metrics import motar, mota_custom, motp_custom, faf, track_initialization_duration, \
+ longest_gap_duration, num_fragmentations_custom
+
+
+def category_to_tracking_name(category_name: str) -> Optional[str]:
+ """
+ Default label mapping from nuScenes to nuScenes tracking classes.
+ :param category_name: Generic nuScenes class.
+ :return: nuScenes tracking class.
+ """
+ tracking_mapping = {
+ 'vehicle.bicycle': 'bicycle',
+ 'vehicle.bus.bendy': 'bus',
+ 'vehicle.bus.rigid': 'bus',
+ 'vehicle.car': 'car',
+ 'vehicle.motorcycle': 'motorcycle',
+ 'human.pedestrian.adult': 'pedestrian',
+ 'human.pedestrian.child': 'pedestrian',
+ 'human.pedestrian.construction_worker': 'pedestrian',
+ 'human.pedestrian.police_officer': 'pedestrian',
+ 'vehicle.trailer': 'trailer',
+ 'vehicle.truck': 'truck'
+ }
+
+ if category_name in tracking_mapping:
+ return tracking_mapping[category_name]
+ else:
+ return None
+
+
+def metric_name_to_print_format(metric_name) -> str:
+ """
+ Get the standard print format (numerical precision) for each metric.
+ :param metric_name: The lowercase metric name.
+ :return: The print format.
+ """
+ if metric_name in ['amota', 'amotp', 'motar', 'recall', 'mota', 'motp']:
+ print_format = '%.3f'
+ elif metric_name in ['tid', 'lgd']:
+ print_format = '%.2f'
+ elif metric_name in ['faf']:
+ print_format = '%.1f'
+ else:
+ print_format = '%d'
+ return print_format
+
+
+def print_final_metrics(metrics: TrackingMetrics) -> None:
+ """
+ Print metrics to stdout.
+ :param metrics: The output of evaluate().
+ """
+ print('\n### Final results ###')
+
+ # Print per-class metrics.
+ metric_names = metrics.label_metrics.keys()
+ print('\nPer-class results:')
+ print('\t\t', end='')
+ print('\t'.join([m.upper() for m in metric_names]))
+
+ class_names = metrics.class_names
+ max_name_length = 7
+ for class_name in class_names:
+ print_class_name = class_name[:max_name_length].ljust(max_name_length + 1)
+ print('%s' % print_class_name, end='')
+
+ for metric_name in metric_names:
+ val = metrics.label_metrics[metric_name][class_name]
+ print_format = '%f' if np.isnan(val) else metric_name_to_print_format(metric_name)
+ print('\t%s' % (print_format % val), end='')
+
+ print()
+
+ # Print high-level metrics.
+ print('\nAggregated results:')
+ for metric_name in metric_names:
+ val = metrics.compute_metric(metric_name, 'all')
+ print_format = metric_name_to_print_format(metric_name)
+ print('%s\t%s' % (metric_name.upper(), print_format % val))
+
+ print('Eval time: %.1fs' % metrics.eval_time)
+ print()
+
+
+def print_threshold_metrics(metrics: Dict[str, Dict[str, float]]) -> None:
+ """
+ Print only a subset of the metrics for the current class and threshold.
+ :param metrics: A dictionary representation of the metrics.
+ """
+ # Specify threshold name and metrics.
+ assert len(metrics['mota_custom'].keys()) == 1
+ threshold_str = list(metrics['mota_custom'].keys())[0]
+ motar_val = metrics['motar'][threshold_str]
+ motp = metrics['motp_custom'][threshold_str]
+ recall = metrics['recall'][threshold_str]
+ num_frames = metrics['num_frames'][threshold_str]
+ num_objects = metrics['num_objects'][threshold_str]
+ num_predictions = metrics['num_predictions'][threshold_str]
+ num_false_positives = metrics['num_false_positives'][threshold_str]
+ num_misses = metrics['num_misses'][threshold_str]
+ num_switches = metrics['num_switches'][threshold_str]
+ num_matches = metrics['num_matches'][threshold_str]
+
+ # Print.
+ print('%s\t%s\t%s\t%s\t%s\t%s\t%s\t%s\t%s\t%s\t%s\t%s\t%s'
+ % ('\t', 'MOTAR', 'MOTP', 'Recall', 'Frames',
+ 'GT', 'GT-Mtch', 'GT-Miss', 'GT-IDS',
+ 'Pred', 'Pred-TP', 'Pred-FP', 'Pred-IDS',))
+ print('%s\t%.3f\t%.3f\t%.3f\t%d\t%d\t%d\t%d\t%d\t%d\t%d\t%d\t%d'
+ % (threshold_str, motar_val, motp, recall, num_frames,
+ num_objects, num_matches, num_misses, num_switches,
+ num_predictions, num_matches, num_false_positives, num_switches))
+ print()
+
+ # Check metrics for consistency.
+ assert num_objects == num_matches + num_misses + num_switches
+ assert num_predictions == num_matches + num_false_positives + num_switches
+
+
+def create_motmetrics() -> MetricsHost:
+ """
+ Creates a MetricsHost and populates it with default and custom metrics.
+ It does not populate the global metrics which are more time consuming.
+ :return The initialized MetricsHost object with default MOT metrics.
+ """
+ # Create new metrics host object.
+ mh = MetricsHost()
+
+ # Suppress deprecation warning from py-motmetrics.
+ warnings.filterwarnings('ignore', category=DeprecationWarning)
+
+ # Register standard metrics.
+ fields = [
+ 'num_frames', 'obj_frequencies', 'num_matches', 'num_switches', 'num_false_positives', 'num_misses',
+ 'num_detections', 'num_objects', 'num_predictions', 'mostly_tracked', 'mostly_lost', 'num_fragmentations',
+ 'motp', 'mota', 'precision', 'recall', 'track_ratios'
+ ]
+ for field in fields:
+ mh.register(getattr(motmetrics.metrics, field), formatter='{:d}'.format)
+
+ # Reenable deprecation warning.
+ warnings.filterwarnings('default', category=DeprecationWarning)
+
+ # Register custom metrics.
+ # Specify all inputs to avoid errors incompatibility between type hints and py-motmetric's introspection.
+ mh.register(motar, ['num_matches', 'num_misses', 'num_switches', 'num_false_positives', 'num_objects'],
+ formatter='{:.2%}'.format, name='motar')
+ mh.register(mota_custom, ['num_misses', 'num_switches', 'num_false_positives', 'num_objects'],
+ formatter='{:.2%}'.format, name='mota_custom')
+ mh.register(motp_custom, ['num_detections'],
+ formatter='{:.2%}'.format, name='motp_custom')
+ mh.register(num_fragmentations_custom, ['obj_frequencies'],
+ formatter='{:.2%}'.format, name='num_fragmentations_custom')
+ mh.register(faf, ['num_false_positives', 'num_frames'],
+ formatter='{:.2%}'.format, name='faf')
+ mh.register(track_initialization_duration, ['obj_frequencies'],
+ formatter='{:.2%}'.format, name='tid')
+ mh.register(longest_gap_duration, ['obj_frequencies'],
+ formatter='{:.2%}'.format, name='lgd')
+
+ return mh
diff --git a/python-sdk/nuscenes/lidarseg/__init__.py b/python-sdk/nuscenes/lidarseg/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/python-sdk/nuscenes/lidarseg/class_histogram.py b/python-sdk/nuscenes/lidarseg/class_histogram.py
new file mode 100644
index 0000000..d513fa6
--- /dev/null
+++ b/python-sdk/nuscenes/lidarseg/class_histogram.py
@@ -0,0 +1,199 @@
+import os
+import time
+from typing import List, Tuple
+
+import matplotlib.pyplot as plt
+from matplotlib.ticker import FuncFormatter, ScalarFormatter
+import matplotlib.transforms as mtrans
+import numpy as np
+
+from nuscenes import NuScenes
+from nuscenes.utils.color_map import get_colormap
+
+
+def truncate_class_name(class_name: str) -> str:
+ """
+ Truncate a given class name according to a pre-defined map.
+ :param class_name: The long form (i.e. original form) of the class name.
+ :return: The truncated form of the class name.
+ """
+
+ string_mapper = {
+ "noise": 'noise',
+ "human.pedestrian.adult": 'adult',
+ "human.pedestrian.child": 'child',
+ "human.pedestrian.wheelchair": 'wheelchair',
+ "human.pedestrian.stroller": 'stroller',
+ "human.pedestrian.personal_mobility": 'p.mobility',
+ "human.pedestrian.police_officer": 'police',
+ "human.pedestrian.construction_worker": 'worker',
+ "animal": 'animal',
+ "vehicle.car": 'car',
+ "vehicle.motorcycle": 'motorcycle',
+ "vehicle.bicycle": 'bicycle',
+ "vehicle.bus.bendy": 'bus.bendy',
+ "vehicle.bus.rigid": 'bus.rigid',
+ "vehicle.truck": 'truck',
+ "vehicle.construction": 'constr. veh',
+ "vehicle.emergency.ambulance": 'ambulance',
+ "vehicle.emergency.police": 'police car',
+ "vehicle.trailer": 'trailer',
+ "movable_object.barrier": 'barrier',
+ "movable_object.trafficcone": 'trafficcone',
+ "movable_object.pushable_pullable": 'push/pullable',
+ "movable_object.debris": 'debris',
+ "static_object.bicycle_rack": 'bicycle racks',
+ "flat.driveable_surface": 'driveable',
+ "flat.sidewalk": 'sidewalk',
+ "flat.terrain": 'terrain',
+ "flat.other": 'flat.other',
+ "static.manmade": 'manmade',
+ "static.vegetation": 'vegetation',
+ "static.other": 'static.other',
+ "vehicle.ego": "ego"
+ }
+
+ return string_mapper[class_name]
+
+
+def render_lidarseg_histogram(nusc: NuScenes,
+ sort_by: str = 'count_desc',
+ chart_title: str = None,
+ x_label: str = None,
+ y_label: str = "Lidar points (logarithmic)",
+ y_log_scale: bool = True,
+ verbose: bool = True,
+ font_size: int = 20,
+ save_as_img_name: str = None) -> None:
+ """
+ Render a histogram for the given nuScenes split.
+ :param nusc: A nuScenes object.
+ :param sort_by: How to sort the classes:
+ - count_desc: Sort the classes by the number of points belonging to each class, in descending order.
+ - count_asc: Sort the classes by the number of points belonging to each class, in ascending order.
+ - name: Sort the classes by alphabetical order.
+ - index: Sort the classes by their indices.
+ :param chart_title: Title to display on the histogram.
+ :param x_label: Title to display on the x-axis of the histogram.
+ :param y_label: Title to display on the y-axis of the histogram.
+ :param y_log_scale: Whether to use log scale on the y-axis.
+ :param verbose: Whether to display plot in a window after rendering.
+ :param font_size: Size of the font to use for the histogram.
+ :param save_as_img_name: Path (including image name and extension) to save the histogram as.
+ """
+
+ print('Calculating stats for nuScenes-lidarseg...')
+ start_time = time.time()
+
+ # Get the statistics for the given nuScenes split.
+ class_names, counts = get_lidarseg_stats(nusc, sort_by=sort_by)
+
+ print('Calculated stats for {} point clouds in {:.1f} seconds.\n====='.format(
+ len(nusc.lidarseg), time.time() - start_time))
+
+ # Create an array with the colors to use.
+ cmap = get_colormap()
+ colors = ['#%02x%02x%02x' % tuple(cmap[cn]) for cn in class_names] # Convert from RGB to hex.
+
+ # Make the class names shorter so that they do not take up much space in the plot.
+ class_names = [truncate_class_name(cn) for cn in class_names]
+
+ # Start a plot.
+ fig, ax = plt.subplots(figsize=(16, 9))
+ plt.margins(x=0.005) # Add some padding to the left and right limits of the x-axis for aesthetics.
+ ax.set_axisbelow(True) # Ensure that axis ticks and gridlines will be below all other ploy elements.
+ ax.yaxis.grid(color='white', linewidth=2) # Show horizontal gridlines.
+ ax.set_facecolor('#eaeaf2') # Set background of plot.
+ ax.spines['top'].set_visible(False) # Remove top border of plot.
+ ax.spines['right'].set_visible(False) # Remove right border of plot.
+ ax.spines['bottom'].set_visible(False) # Remove bottom border of plot.
+ ax.spines['left'].set_visible(False) # Remove left border of plot.
+
+ # Plot the histogram.
+ ax.bar(class_names, counts, color=colors)
+ assert len(class_names) == len(ax.get_xticks()), \
+ 'There are {} classes, but {} are shown on the x-axis'.format(len(class_names), len(ax.get_xticks()))
+
+ # Format the x-axis.
+ ax.set_xlabel(x_label, fontsize=font_size)
+ ax.set_xticklabels(class_names, rotation=45, horizontalalignment='right',
+ fontweight='light', fontsize=font_size)
+
+ # Shift the class names on the x-axis slightly to the right for aesthetics.
+ trans = mtrans.Affine2D().translate(10, 0)
+ for t in ax.get_xticklabels():
+ t.set_transform(t.get_transform() + trans)
+
+ # Format the y-axis.
+ ax.set_ylabel(y_label, fontsize=font_size)
+ ax.set_yticklabels(counts, size=font_size)
+
+ # Transform the y-axis to log scale.
+ if y_log_scale:
+ ax.set_yscale("log")
+
+ # Display the y-axis using nice scientific notation.
+ formatter = ScalarFormatter(useOffset=False, useMathText=True)
+ ax.yaxis.set_major_formatter(
+ FuncFormatter(lambda x, pos: "${}$".format(formatter._formatSciNotation('%1.10e' % x))))
+
+ if chart_title:
+ ax.set_title(chart_title, fontsize=font_size)
+
+ if save_as_img_name:
+ fig = ax.get_figure()
+ plt.tight_layout()
+ fig.savefig(save_as_img_name)
+
+ if verbose:
+ plt.show()
+
+
+def get_lidarseg_stats(nusc: NuScenes, sort_by: str = 'count_desc') -> Tuple[List[str], List[int]]:
+ """
+ Get the number of points belonging to each class for the given nuScenes split.
+ :param nusc: A NuScenes object.
+ :param sort_by: How to sort the classes:
+ - count_desc: Sort the classes by the number of points belonging to each class, in descending order.
+ - count_asc: Sort the classes by the number of points belonging to each class, in ascending order.
+ - name: Sort the classes by alphabetical order.
+ - index: Sort the classes by their indices.
+ :return: A list of class names and a list of the corresponding number of points for each class.
+ """
+
+ # Initialize an array of zeroes, one for each class name.
+ lidarseg_counts = [0] * len(nusc.lidarseg_idx2name_mapping)
+
+ for record_lidarseg in nusc.lidarseg:
+ lidarseg_labels_filename = os.path.join(nusc.dataroot, record_lidarseg['filename'])
+
+ points_label = np.fromfile(lidarseg_labels_filename, dtype=np.uint8)
+ indices = np.bincount(points_label)
+ ii = np.nonzero(indices)[0]
+ for class_idx, class_count in zip(ii, indices[ii]):
+ lidarseg_counts[class_idx] += class_count
+
+ lidarseg_counts_dict = dict()
+ for i in range(len(lidarseg_counts)):
+ lidarseg_counts_dict[nusc.lidarseg_idx2name_mapping[i]] = lidarseg_counts[i]
+
+ if sort_by == 'count_desc':
+ out = sorted(lidarseg_counts_dict.items(), key=lambda item: item[1], reverse=True)
+ elif sort_by == 'count_asc':
+ out = sorted(lidarseg_counts_dict.items(), key=lambda item: item[1])
+ elif sort_by == 'name':
+ out = sorted(lidarseg_counts_dict.items())
+ elif sort_by == 'index':
+ out = lidarseg_counts_dict.items()
+ else:
+ raise Exception('Error: Invalid sorting mode {}. '
+ 'Only `count_desc`, `count_asc`, `name` or `index` are valid.'.format(sort_by))
+
+ # Get frequency counts of each class in the lidarseg dataset.
+ class_names = []
+ counts = []
+ for class_name, count in out:
+ class_names.append(class_name)
+ counts.append(count)
+
+ return class_names, counts
diff --git a/python-sdk/nuscenes/lidarseg/lidarseg_utils.py b/python-sdk/nuscenes/lidarseg/lidarseg_utils.py
new file mode 100644
index 0000000..8452049
--- /dev/null
+++ b/python-sdk/nuscenes/lidarseg/lidarseg_utils.py
@@ -0,0 +1,218 @@
+# nuScenes dev-kit.
+# Code written by Fong Whye Kit, 2020.
+
+from typing import Dict, Iterable, List, Tuple
+
+import cv2
+import matplotlib.patches as mpatches
+import matplotlib.pyplot as plt
+import numpy as np
+from matplotlib.backends.backend_agg import FigureCanvasAgg as FigureCanvas
+
+
+def get_stats(points_label: np.array, num_classes: int) -> List[int]:
+ """
+ Get frequency of each label in a point cloud.
+ :param num_classes: The number of classes.
+ :param points_label: A numPy array which contains the labels of the point cloud; e.g. np.array([2, 1, 34, ..., 38])
+ :return: An array which contains the counts of each label in the point cloud. The index of the point cloud
+ corresponds to the index of the class label. E.g. [0, 2345, 12, 451] means that there are no points in
+ class 0, there are 2345 points in class 1, there are 12 points in class 2 etc.
+ """
+
+ lidarseg_counts = [0] * num_classes # Create as many bins as there are classes, and initialize all bins as 0.
+
+ indices: np.ndarray = np.bincount(points_label)
+ ii = np.nonzero(indices)[0]
+
+ for class_idx, class_count in zip(ii, indices[ii]):
+ lidarseg_counts[class_idx] += class_count # Increment the count for the particular class name.
+
+ return lidarseg_counts
+
+
+def plt_to_cv2(points: np.array, coloring: np.array, im, imsize: Tuple[int, int] = (640, 360), dpi: int = 100):
+ """
+ Converts a scatter plot in matplotlib to an image in cv2. This is useful as cv2 is unable to do
+ scatter plots.
+ :param points: A numPy array (of size [2 x num_points] and type float) representing the pointcloud.
+ :param coloring: A numPy array (of size [num_points] containing the color (in RGB, normalized
+ between 0 and 1) for each point.
+ :param im: An image (e.g. a camera view) to put the scatter plot on.
+ :param imsize: Size of image to render. The larger the slower this will run.
+ :param dpi: Resolution of the output figure.
+ :return: cv2 image with the scatter plot.
+ """
+ # Render lidarseg labels in image.
+ fig = plt.figure(figsize=(imsize[0] / dpi, imsize[1] / dpi), dpi=dpi)
+ ax = plt.Axes(fig, [0., 0., 1., 1.])
+ fig.add_axes(ax)
+
+ ax.axis('off')
+ ax.margins(0, 0)
+
+ ax.imshow(im)
+ ax.scatter(points[0, :], points[1, :], c=coloring, s=5)
+
+ # Convert from pyplot to cv2.
+ canvas = FigureCanvas(fig)
+ canvas.draw()
+ mat = np.array(canvas.renderer.buffer_rgba()).astype('uint8') # Put pixel buffer in numpy array.
+ mat = cv2.cvtColor(mat, cv2.COLOR_RGB2BGR)
+ mat = cv2.resize(mat, imsize)
+
+ # Clear off the current figure to prevent an accumulation of figures in memory.
+ plt.close('all')
+
+ return mat
+
+
+def colormap_to_colors(colormap: Dict[str, Iterable[int]], name2idx: Dict[str, int]) -> np.ndarray:
+ """
+ Create an array of RGB values from a colormap. Note that the RGB values are normalized
+ between 0 and 1, not 0 and 255.
+ :param colormap: A dictionary containing the mapping from class names to RGB values.
+ :param name2idx: A dictionary containing the mapping form class names to class index.
+ :return: An array of colors.
+ """
+ colors = []
+ for i, (k, v) in enumerate(colormap.items()):
+ # Ensure that the indices from the colormap is same as the class indices.
+ assert i == name2idx[k], 'Error: {} is of index {}, ' \
+ 'but it is of index {} in the colormap.'.format(k, name2idx[k], i)
+ colors.append(v)
+
+ colors = np.array(colors) / 255 # Normalize RGB values to be between 0 and 1 for each channel.
+
+ return colors
+
+
+def filter_colors(colors: np.array, classes_to_display: np.array) -> np.ndarray:
+ """
+ Given an array of RGB colors and a list of classes to display, return a colormap (in RGBA) with the opacity
+ of the labels to be display set to 1.0 and those to be hidden set to 0.0
+ :param colors: [n x 3] array where each row consist of the RGB values for the corresponding class index
+ :param classes_to_display: An array of classes to display (e.g. [1, 8, 32]). The array need not be ordered.
+ :return: (colormap <np.float: n, 4)>).
+
+ colormap = np.array([[R1, G1, B1], colormap = np.array([[1.0, 1.0, 1.0, 0.0],
+ [R2, G2, B2], ------> [R2, G2, B2, 1.0],
+ ..., ...,
+ Rn, Gn, Bn]]) [1.0, 1.0, 1.0, 0.0]])
+ """
+ for i in range(len(colors)):
+ if i not in classes_to_display:
+ colors[i] = [1.0, 1.0, 1.0] # Mask labels to be hidden with 1.0 in all channels.
+
+ # Convert the RGB colormap to an RGBA array, with the alpha channel set to zero whenever the R, G and B channels
+ # are all equal to 1.0.
+ alpha = np.array([~np.all(colors == 1.0, axis=1) * 1.0])
+ colors = np.concatenate((colors, alpha.T), axis=1)
+
+ return colors
+
+
+def get_labels_in_coloring(color_legend: np.ndarray, coloring: np.ndarray) -> List[int]:
+ """
+ Find the class labels which are present in a pointcloud which has been projected onto an image.
+ :param color_legend: A list of arrays in which each array corresponds to the RGB values of a class.
+ :param coloring: A list of arrays in which each array corresponds to the RGB values of a point in the portion of
+ the pointcloud projected onto the image.
+ :return: List of class indices which are present in the image.
+ """
+
+ def _array_in_list(arr: List, list_arrays: List) -> bool:
+ """
+ Check if an array is in a list of arrays.
+ :param: arr: An array.
+ :param: list_arrays: A list of arrays.
+ :return: Whether the given array is in the list of arrays.
+ """
+ # Credits: https://stackoverflow.com/questions/23979146/check-if-numpy-array-is-in-list-of-numpy-arrays
+ return next((True for elem in list_arrays if np.array_equal(elem, arr)), False)
+
+ filter_lidarseg_labels = []
+
+ # Get only the distinct colors present in the pointcloud so that we will not need to compare each color in
+ # the color legend with every single point in the pointcloud later.
+ distinct_colors = list(set(tuple(c) for c in coloring))
+
+ for i, color in enumerate(color_legend):
+ if _array_in_list(color, distinct_colors):
+ filter_lidarseg_labels.append(i)
+
+ return filter_lidarseg_labels
+
+
+def create_lidarseg_legend(labels_to_include_in_legend: List[int],
+ idx2name: Dict[int, str], name2color: Dict[str, Tuple[int, int, int]],
+ loc: str = 'upper center', ncol: int = 3, bbox_to_anchor: Tuple = None):
+ """
+ Given a list of class indices, the mapping from class index to class name, and the mapping from class name
+ to class color, produce a legend which shows the color and the corresponding class name.
+ :param labels_to_include_in_legend: Labels to show in the legend.
+ :param idx2name: The mapping from class index to class name.
+ :param name2color: The mapping from class name to class color.
+ :param loc: The location of the legend.
+ :param ncol: The number of columns that the legend has.
+ :param bbox_to_anchor: A 2-tuple (x, y) which places the top-left corner of the legend specified by loc
+ at x, y. The origin is at the bottom-left corner and x and y are normalized between
+ 0 and 1 (i.e. x > 1 and / or y > 1 will place the legend outside the plot.
+ """
+
+ recs = []
+ classes_final = []
+ classes = [name for idx, name in sorted(idx2name.items())]
+
+ for i in range(len(classes)):
+ if labels_to_include_in_legend is None or i in labels_to_include_in_legend:
+ name = classes[i]
+ recs.append(mpatches.Rectangle((0, 0), 1, 1, fc=np.array(name2color[name]) / 255))
+
+ # Truncate class names to only first 25 chars so that legend is not excessively long.
+ classes_final.append(classes[i][:25])
+
+ plt.legend(recs, classes_final, loc=loc, ncol=ncol, bbox_to_anchor=bbox_to_anchor)
+
+
+def paint_points_label(lidarseg_labels_filename: str, filter_lidarseg_labels: List[int],
+ name2idx: Dict[str, int], colormap: Dict[str, Tuple[int, int, int]]) -> np.ndarray:
+ """
+ Paint each label in a pointcloud with the corresponding RGB value, and set the opacity of the labels to
+ be shown to 1 (the opacity of the rest will be set to 0); e.g.:
+ [30, 5, 12, 34, ...] ------> [[R30, G30, B30, 0], [R5, G5, B5, 1], [R34, G34, B34, 1], ...]
+ :param lidarseg_labels_filename: Path to the .bin file containing the labels.
+ :param filter_lidarseg_labels: The labels for which to set opacity to zero; this is to hide those points
+ thereby preventing them from being displayed.
+ :param name2idx: A dictionary containing the mapping from class names to class indices.
+ :param colormap: A dictionary containing the mapping from class names to RGB values.
+ :return: A numpy array which has length equal to the number of points in the pointcloud, and each value is
+ a RGBA array.
+ """
+
+ # Load labels from .bin file.
+ points_label = np.fromfile(lidarseg_labels_filename, dtype=np.uint8) # [num_points]
+
+ # Given a colormap (class name -> RGB color) and a mapping from class name to class index,
+ # get an array of RGB values where each color sits at the index in the array corresponding
+ # to the class index.
+ colors = colormap_to_colors(colormap, name2idx) # Shape: [num_class, 3]
+
+ if filter_lidarseg_labels is not None:
+ # Ensure that filter_lidarseg_labels is an iterable.
+ assert isinstance(filter_lidarseg_labels, (list, np.ndarray)), \
+ 'Error: filter_lidarseg_labels should be a list of class indices, eg. [9], [10, 21].'
+
+ # Check that class indices in filter_lidarseg_labels are valid.
+ assert all([0 <= x < len(name2idx) for x in filter_lidarseg_labels]), \
+ 'All class indices in filter_lidarseg_labels should ' \
+ 'be between 0 and {}'.format(len(name2idx) - 1)
+
+ # Filter to get only the colors of the desired classes; this is done by setting the
+ # alpha channel of the classes to be viewed to 1, and the rest to 0.
+ colors = filter_colors(colors, filter_lidarseg_labels) # Shape: [num_class, 4]
+
+ # Paint each label with its respective RGBA value.
+ coloring = colors[points_label] # Shape: [num_points, 4]
+
+ return coloring
diff --git a/python-sdk/nuscenes/map_expansion/__init__.py b/python-sdk/nuscenes/map_expansion/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/python-sdk/nuscenes/map_expansion/arcline_path_utils.py b/python-sdk/nuscenes/map_expansion/arcline_path_utils.py
new file mode 100644
index 0000000..f7d7805
--- /dev/null
+++ b/python-sdk/nuscenes/map_expansion/arcline_path_utils.py
@@ -0,0 +1,283 @@
+# nuScenes dev-kit.
+# Code written by Freddy Boulton, 2020.
+
+import math
+from typing import Dict, Any, Tuple, List
+
+import numpy as np
+
+# (x, y, yaw) in global frame
+Pose = Tuple[float, float, float]
+
+ArcLinePath = Dict[str, Any]
+
+
+def principal_value(angle_in_radians: float) -> float:
+ """
+ Ensures the angle is within [-pi, pi).
+ :param angle_in_radians: Angle in radians.
+ :return: Scaled angle in radians.
+ """
+
+ interval_min = -math.pi
+ two_pi = 2 * math.pi
+ scaled_angle = (angle_in_radians - interval_min) % two_pi + interval_min
+ return scaled_angle
+
+
+def compute_segment_sign(arcline_path: ArcLinePath) -> Tuple[int, int, int]:
+ """
+ Compute the sign of an arcline path based on its shape.
+ :param arcline_path: arcline path record.
+ :return: Tuple of signs for all three parts of the path. 0 if straight, -1 if right,
+ 1 if left.
+ """
+ shape = arcline_path['shape']
+ segment_sign = [0, 0, 0]
+
+ if shape in ("LRL", "LSL", "LSR"):
+ segment_sign[0] = 1
+ else:
+ segment_sign[0] = -1
+
+ if shape == "RLR":
+ segment_sign[1] = 1
+ elif shape == "LRL":
+ segment_sign[1] = -1
+ else:
+ segment_sign[1] = 0
+
+ if shape in ("LRL", "LSL", "RSL"):
+ segment_sign[2] = 1
+ else:
+ segment_sign[2] = -1
+
+ return segment_sign[0], segment_sign[1], segment_sign[2]
+
+
+def get_transformation_at_step(pose: Pose,
+ step: float) -> Pose:
+ """
+ Get the affine transformation at s meters along the path.
+ :param pose: Pose represented as tuple (x, y, yaw).
+ :param step: Length along the arcline path in range (0, length_of_arcline_path].
+ :return: Transformation represented as pose tuple.
+ """
+
+ theta = pose[2] * step # The equation of arc length calculation : theta * r = l ,theta = l * 1/r
+ ctheta = math.cos(theta)
+ stheta = math.sin(theta)
+
+ if abs(pose[2]) < 1e-6:
+ return pose[0] * step, pose[1] * step, theta
+ else:
+ new_x = (pose[1] * (ctheta - 1.0) + pose[0] * stheta) / pose[2]
+ new_y = (pose[0] * (1.0 - ctheta) + pose[1] * stheta) / pose[2]
+ return new_x, new_y, theta
+
+
+def apply_affine_transformation(pose: Pose,
+ transformation: Pose) -> Pose:
+ """
+ Apply affine transformation to pose.
+ :param pose: Starting pose.
+ :param transformation: Affine transformation represented as a pose tuple.
+ :return: Pose tuple - the result of applying the transformation to the starting pose.
+ """
+
+ new_x = math.cos(pose[2]) * transformation[0] - math.sin(pose[2]) * transformation[1] + pose[0]
+ new_y = math.sin(pose[2]) * transformation[0] + math.cos(pose[2]) * transformation[1] + pose[1]
+ new_yaw = principal_value(pose[2] + transformation[2])
+
+ return new_x, new_y, new_yaw
+
+
+def _get_lie_algebra(segment_sign: Tuple[int, int, int],
+ radius: float) -> List[Tuple[float, float, float]]:
+ """
+ Gets the Lie algebra for an arcline path.
+ :param segment_sign: Tuple of signs for each segment in the arcline path.
+ :param radius: Radius of curvature of the arcline path.
+ :return: List of lie algebra poses.
+ """
+
+ return [(1.0, 0.0, segment_sign[0] / radius),
+ (1.0, 0.0, segment_sign[1] / radius),
+ (1.0, 0.0, segment_sign[2] / radius)]
+
+
+def pose_at_length(arcline_path: ArcLinePath,
+ pos: float) -> Tuple[float, float, float]:
+ """
+ Retrieves pose at l meters along the arcline path.
+ :param arcline_path: Arcline path object.
+ :param pos: Get the pose this many meters along the path.
+ :return: Pose tuple.
+ """
+
+ path_length = sum(arcline_path['segment_length'])
+
+ assert 1e-6 <= pos
+
+ pos = max(0.0, min(pos, path_length))
+
+ result = arcline_path['start_pose']
+ segment_sign = compute_segment_sign(arcline_path)
+
+ break_points = _get_lie_algebra(segment_sign, arcline_path['radius'])
+
+ for i in range(len(break_points)):
+
+ length = arcline_path['segment_length'][i]
+
+ if pos <= length:
+ transformation = get_transformation_at_step(break_points[i], pos)
+ result = apply_affine_transformation(result, transformation)
+ break
+
+ transformation = get_transformation_at_step(break_points[i], length)
+ result = apply_affine_transformation(result, transformation)
+ pos -= length
+
+ return result
+
+
+def discretize(arcline_path: ArcLinePath,
+ resolution_meters: float) -> List[Pose]:
+ """
+ Discretize an arcline path.
+ :param arcline_path: Arcline path record.
+ :param resolution_meters: How finely to discretize the path.
+ :return: List of pose tuples.
+ """
+
+ path_length = sum(arcline_path['segment_length'])
+ radius = arcline_path['radius']
+
+ n_points = int(max(math.ceil(path_length / resolution_meters) + 1.5, 2))
+
+ resolution_meters = path_length / (n_points - 1)
+
+ discretization = []
+
+ cumulative_length = [arcline_path['segment_length'][0],
+ arcline_path['segment_length'][0] + arcline_path['segment_length'][1],
+ path_length + resolution_meters]
+
+ segment_sign = compute_segment_sign(arcline_path)
+
+ poses = _get_lie_algebra(segment_sign, radius)
+
+ temp_pose = arcline_path['start_pose']
+
+ g_i = 0 #goal_index
+ g_s = 0.0 # goal_start
+
+ for step in range(n_points):
+
+ step_along_path = step * resolution_meters
+
+ if step_along_path > cumulative_length[g_i]:
+ temp_pose = pose_at_length(arcline_path, step_along_path)
+ g_s = step_along_path
+ g_i += 1
+
+ transformation = get_transformation_at_step(poses[g_i], step_along_path - g_s)
+ new_pose = apply_affine_transformation(temp_pose, transformation)
+ discretization.append(new_pose)
+
+ return discretization
+
+
+def discretize_lane(lane: List[ArcLinePath],
+ resolution_meters: float) -> List[Pose]:
+ """
+ Discretizes a lane and returns list of all the poses alone the lane.
+ :param lane: Lanes are represented as a list of arcline paths.
+ :param resolution_meters: How finely to discretize the lane. Smaller values ensure curved
+ lanes are properly represented.
+ :return: List of pose tuples along the lane.
+ """
+
+ pose_list = []
+ for path in lane:
+ poses = discretize(path, resolution_meters)
+ for pose in poses:
+ pose_list.append(pose)
+ return pose_list
+
+
+def length_of_lane(lane: List[ArcLinePath]) -> float:
+ """
+ Calculates the length of a lane in meters.
+ :param lane: Lane.
+ :return: Length of lane in meters.
+ """
+
+ # Meters
+ return sum(sum(path['segment_length']) for path in lane)
+
+
+def project_pose_to_lane(pose: Pose, lane: List[ArcLinePath], resolution_meters: float = 0.5) -> Tuple[Pose, float]:
+ """
+ Find the closest pose on a lane to a query pose and additionally return the
+ distance along the lane for this pose. Note that this function does
+ not take the heading of the query pose into account.
+ :param pose: Query pose.
+ :param lane: Will find the closest pose on this lane.
+ :param resolution_meters: How finely to discretize the lane.
+ :return: Tuple of the closest pose and the distance along the lane
+ """
+
+ discretized_lane = discretize_lane(lane, resolution_meters=resolution_meters)
+
+ xy_points = np.array(discretized_lane)[:, :2]
+ closest_pose_index = np.linalg.norm(xy_points - pose[:2], axis=1).argmin()
+
+ closest_pose = discretized_lane[closest_pose_index]
+ distance_along_lane = closest_pose_index * 0.5
+ return closest_pose, distance_along_lane
+
+
+def _find_index(distance_along_lane: float, lengths: List[float]) -> int:
+ """
+ Helper function for finding of path along lane corresponding to the distance_along_lane.
+ :param distance_along_lane: Distance along the lane (in meters).
+ :param lengths: Cumulative distance at each end point along the paths in the lane.
+ :return: Index of path.
+ """
+
+ if len(lengths) == 1:
+ return 0
+ else:
+ return min(index for index, length in enumerate(lengths) if distance_along_lane <= length)
+
+
+def get_curvature_at_distance_along_lane(distance_along_lane: float, lane: List[ArcLinePath]) -> float:
+ """
+ Computes the unsigned curvature (1 / meters) at a distance along a lane.
+ :param distance_along_lane: Distance along the lane to calculate the curvature at.
+ :param lane: Lane to query.
+ :return: Curvature, always non negative.
+ """
+
+ total_length_at_segments = np.cumsum([sum(path['segment_length']) for path in lane])
+ segment_index = _find_index(distance_along_lane, total_length_at_segments)
+
+ path = lane[segment_index]
+ path_length = path['segment_length']
+
+ if segment_index > 0:
+ distance_along_path = distance_along_lane - total_length_at_segments[segment_index - 1]
+ else:
+ distance_along_path = distance_along_lane
+
+ segment_index = _find_index(distance_along_path, np.cumsum(path_length))
+
+ segment_shape = path['shape'][segment_index]
+
+ # Straight lanes have no curvature
+ if segment_shape == 'S':
+ return 0
+ else:
+ return 1 / path['radius']
diff --git a/python-sdk/nuscenes/map_expansion/bitmap.py b/python-sdk/nuscenes/map_expansion/bitmap.py
new file mode 100644
index 0000000..7e9f228
--- /dev/null
+++ b/python-sdk/nuscenes/map_expansion/bitmap.py
@@ -0,0 +1,75 @@
+import os
+from typing import Tuple, Any
+
+import numpy as np
+from PIL import Image
+import matplotlib.pyplot as plt
+
+Axis = Any
+
+
+class BitMap:
+
+ def __init__(self, dataroot: str, map_name: str, layer_name: str):
+ """
+ This class is used to render bitmap map layers. Currently these are:
+ - semantic_prior: The semantic prior (driveable surface and sidewalks) mask from nuScenes 1.0.
+ - basemap: The HD lidar basemap used for localization and as general context.
+
+ :param dataroot: Path of the nuScenes dataset.
+ :param map_name: Which map out of `singapore-onenorth`, `singepore-hollandvillage`, `singapore-queenstown` and
+ 'boston-seaport'.
+ :param layer_name: The type of bitmap map, `semanitc_prior` or `basemap.
+ """
+ self.dataroot = dataroot
+ self.map_name = map_name
+ self.layer_name = layer_name
+
+ self.image = self.load_bitmap()
+
+ def load_bitmap(self) -> np.ndarray:
+ """
+ Load the specified bitmap.
+ """
+ # Load bitmap.
+ if self.layer_name == 'basemap':
+ map_path = os.path.join(self.dataroot, 'maps', 'basemap', self.map_name + '.png')
+ elif self.layer_name == 'semantic_prior':
+ map_hashes = {
+ 'singapore-onenorth': '53992ee3023e5494b90c316c183be829',
+ 'singapore-hollandvillage': '37819e65e09e5547b8a3ceaefba56bb2',
+ 'singapore-queenstown': '93406b464a165eaba6d9de76ca09f5da',
+ 'boston-seaport': '36092f0b03a857c6a3403e25b4b7aab3'
+ }
+ map_hash = map_hashes[self.map_name]
+ map_path = os.path.join(self.dataroot, 'maps', map_hash + '.png')
+ else:
+ raise Exception('Error: Invalid bitmap layer: %s' % self.layer_name)
+
+ # Convert to numpy.
+ if os.path.exists(map_path):
+ image = np.array(Image.open(map_path))
+ else:
+ raise Exception('Error: Cannot find %s %s! Please make sure that the map is correctly installed.'
+ % (self.layer_name, map_path))
+
+ # Invert semantic prior colors.
+ if self.layer_name == 'semantic_prior':
+ image = image.max() - image
+
+ return image
+
+ def render(self, canvas_edge: Tuple[float, float], ax: Axis = None):
+ """
+ Render the bitmap.
+ Note: Regardless of the image dimensions, the image will be rendered to occupy the entire map.
+ :param canvas_edge: The dimension of the current map in meters (width, height).
+ :param ax: Optional axis to render to.
+ """
+ if ax is None:
+ ax = plt.subplot()
+ x, y = canvas_edge
+ if len(self.image.shape) == 2:
+ ax.imshow(self.image, extent=[0, x, 0, y], cmap='gray')
+ else:
+ ax.imshow(self.image, extent=[0, x, 0, y])
diff --git a/python-sdk/nuscenes/map_expansion/map_api.py b/python-sdk/nuscenes/map_expansion/map_api.py
new file mode 100644
index 0000000..186fcfd
--- /dev/null
+++ b/python-sdk/nuscenes/map_expansion/map_api.py
@@ -0,0 +1,2296 @@
+# nuScenes dev-kit.
+# Code written by Sergi Adipraja Widjaja, 2019.
+# + Map mask by Kiwoo Shin, 2019.
+# + Methods operating on NuScenesMap and NuScenes by Holger Caesar, 2019.
+
+import json
+import os
+import random
+from typing import Dict, List, Tuple, Optional, Union
+
+import cv2
+import descartes
+import matplotlib.gridspec as gridspec
+import matplotlib.pyplot as plt
+import numpy as np
+from PIL import Image
+from matplotlib.axes import Axes
+from matplotlib.figure import Figure
+from matplotlib.patches import Rectangle, Arrow
+from mpl_toolkits.axes_grid1.inset_locator import mark_inset
+from pyquaternion import Quaternion
+from shapely import affinity
+from shapely.geometry import Polygon, MultiPolygon, LineString, Point, box
+from tqdm import tqdm
+
+from nuscenes.map_expansion.arcline_path_utils import discretize_lane, ArcLinePath
+from nuscenes.map_expansion.bitmap import BitMap
+from nuscenes.nuscenes import NuScenes
+from nuscenes.utils.geometry_utils import view_points
+
+# Recommended style to use as the plots will show grids.
+plt.style.use('seaborn-whitegrid')
+
+# Define a map geometry type for polygons and lines.
+Geometry = Union[Polygon, LineString]
+
+locations = ['singapore-onenorth', 'singapore-hollandvillage', 'singapore-queenstown', 'boston-seaport']
+
+
+class NuScenesMap:
+ """
+ NuScenesMap database class for querying and retrieving information from the semantic maps.
+ Before using this class please use the provided tutorial `map_expansion_tutorial.ipynb`.
+
+ Below you can find the map origins (south western corner, in [lat, lon]) for each of the 4 maps in nuScenes:
+ boston-seaport: [42.336849169438615, -71.05785369873047]
+ singapore-onenorth: [1.2882100868743724, 103.78475189208984]
+ singapore-hollandvillage: [1.2993652317780957, 103.78217697143555]
+ singapore-queenstown: [1.2782562240223188, 103.76741409301758]
+
+ The dimensions of the maps are as follows ([width, height] in meters):
+ singapore-onenorth: [1585.6, 2025.0]
+ singapore-hollandvillage: [2808.3, 2922.9]
+ singapore-queenstown: [3228.6, 3687.1]
+ boston-seaport: [2979.5, 2118.1]
+ The rasterized semantic maps (e.g. singapore-onenorth.png) published with nuScenes v1.0 have a scale of 10px/m,
+ hence the above numbers are the image dimensions divided by 10.
+
+ We use the same WGS 84 Web Mercator (EPSG:3857) projection as Google Maps/Earth.
+ """
+ def __init__(self,
+ dataroot: str = '/data/sets/nuscenes',
+ map_name: str = 'singapore-onenorth'):
+ """
+ Loads the layers, create reverse indices and shortcuts, initializes the explorer class.
+ :param dataroot: Path to the layers in the form of a .json file.
+ :param map_name: Which map out of `singapore-onenorth`, `singepore-hollandvillage`, `singapore-queenstown`,
+ `boston-seaport` that we want to load.
+ """
+ assert map_name in locations, 'Error: Unknown map name %s!' % map_name
+
+ self.dataroot = dataroot
+ self.map_name = map_name
+
+ self.geometric_layers = ['polygon', 'line', 'node']
+
+ # These are the non-geometric layers which have polygons as the geometric descriptors.
+ self.non_geometric_polygon_layers = ['drivable_area', 'road_segment', 'road_block', 'lane', 'ped_crossing',
+ 'walkway', 'stop_line', 'carpark_area']
+
+ # We want to be able to search for lane connectors, but not render them.
+ self.lookup_polygon_layers = self.non_geometric_polygon_layers + ['lane_connector']
+
+ # These are the non-geometric layers which have line strings as the geometric descriptors.
+ self.non_geometric_line_layers = ['road_divider', 'lane_divider', 'traffic_light']
+ self.non_geometric_layers = self.non_geometric_polygon_layers + self.non_geometric_line_layers
+ self.layer_names = self.geometric_layers + self.lookup_polygon_layers + self.non_geometric_line_layers
+
+ # Load the selected map.
+ self.json_fname = os.path.join(self.dataroot, 'maps', 'expansion', '{}.json'.format(self.map_name))
+ with open(self.json_fname, 'r') as fh:
+ self.json_obj = json.load(fh)
+
+ # Parse the map version and print an error for deprecated maps.
+ if 'version' in self.json_obj:
+ self.version = self.json_obj['version']
+ else:
+ self.version = '1.0'
+ if self.version < '1.3':
+ raise Exception('Error: You are using an outdated map version (%s)! '
+ 'Please go to https://www.nuscenes.org/download to download the latest map!')
+
+ self.canvas_edge = self.json_obj['canvas_edge']
+ self._load_layers()
+ self._make_token2ind()
+ self._make_shortcuts()
+
+ self.explorer = NuScenesMapExplorer(self)
+
+ def _load_layer(self, layer_name: str) -> List[dict]:
+ """
+ Returns a list of records corresponding to the layer name.
+ :param layer_name: Name of the layer that will be loaded.
+ :return: A list of records corresponding to a layer.
+ """
+ return self.json_obj[layer_name]
+
+ def _load_layer_dict(self, layer_name: str) -> Dict[str, Union[dict, list]]:
+ """
+ Returns a dict of records corresponding to the layer name.
+ :param layer_name: Name of the layer that will be loaded.
+ :return: A dict of records corresponding to a layer.
+ """
+ return self.json_obj[layer_name]
+
+ def _load_layers(self) -> None:
+ """ Loads each available layer. """
+
+ # Explicit assignment of layers are necessary to help the IDE determine valid class members.
+ self.polygon = self._load_layer('polygon')
+ self.line = self._load_layer('line')
+ self.node = self._load_layer('node')
+ self.drivable_area = self._load_layer('drivable_area')
+ self.road_segment = self._load_layer('road_segment')
+ self.road_block = self._load_layer('road_block')
+ self.lane = self._load_layer('lane')
+ self.ped_crossing = self._load_layer('ped_crossing')
+ self.walkway = self._load_layer('walkway')
+ self.stop_line = self._load_layer('stop_line')
+ self.carpark_area = self._load_layer('carpark_area')
+ self.road_divider = self._load_layer('road_divider')
+ self.lane_divider = self._load_layer('lane_divider')
+ self.traffic_light = self._load_layer('traffic_light')
+
+ self.arcline_path_3: Dict[str, List[dict]] = self._load_layer_dict('arcline_path_3')
+ self.connectivity: Dict[str, dict] = self._load_layer_dict('connectivity')
+ self.lane_connector = self._load_layer('lane_connector')
+
+ def _make_token2ind(self) -> None:
+ """ Store the mapping from token to layer index for each layer. """
+ self._token2ind = dict()
+ for layer_name in self.layer_names:
+ self._token2ind[layer_name] = dict()
+
+ for ind, member in enumerate(getattr(self, layer_name)):
+ self._token2ind[layer_name][member['token']] = ind
+
+ def _make_shortcuts(self) -> None:
+ """ Makes the record shortcuts. """
+
+ # Makes a shortcut between non geometric records to their nodes.
+ for layer_name in self.non_geometric_polygon_layers:
+ if layer_name == 'drivable_area': # Drivable area has more than one geometric representation.
+ pass
+ else:
+ for record in self.__dict__[layer_name]:
+ polygon_obj = self.get('polygon', record['polygon_token'])
+ record['exterior_node_tokens'] = polygon_obj['exterior_node_tokens']
+ record['holes'] = polygon_obj['holes']
+
+ for layer_name in self.non_geometric_line_layers:
+ for record in self.__dict__[layer_name]:
+ record['node_tokens'] = self.get('line', record['line_token'])['node_tokens']
+
+ # Makes a shortcut between stop lines to their cues, there's different cues for different types of stop line.
+ # Refer to `_get_stop_line_cue()` for details.
+ for record in self.stop_line:
+ cue = self._get_stop_line_cue(record)
+ record['cue'] = cue
+
+ # Makes a shortcut between lanes to their lane divider segment nodes.
+ for record in self.lane:
+ record['left_lane_divider_segment_nodes'] = [self.get('node', segment['node_token']) for segment in
+ record['left_lane_divider_segments']]
+ record['right_lane_divider_segment_nodes'] = [self.get('node', segment['node_token']) for segment in
+ record['right_lane_divider_segments']]
+
+ def _get_stop_line_cue(self, stop_line_record: dict) -> List[dict]:
+ """
+ Get the different cues for different types of stop lines.
+ :param stop_line_record: A single stop line record.
+ :return: The cue for that stop line.
+ """
+ if stop_line_record['stop_line_type'] in ['PED_CROSSING', 'TURN_STOP']:
+ return [self.get('ped_crossing', token) for token in stop_line_record['ped_crossing_tokens']]
+ elif stop_line_record['stop_line_type'] in ['STOP_SIGN', 'YIELD']:
+ return []
+ elif stop_line_record['stop_line_type'] == 'TRAFFIC_LIGHT':
+ return [self.get('traffic_light', token) for token in stop_line_record['traffic_light_tokens']]
+
+ def get(self, layer_name: str, token: str) -> dict:
+ """
+ Returns a record from the layer in constant runtime.
+ :param layer_name: Name of the layer that we are interested in.
+ :param token: Token of the record.
+ :return: A single layer record.
+ """
+ assert layer_name in self.layer_names, "Layer {} not found".format(layer_name)
+
+ return getattr(self, layer_name)[self.getind(layer_name, token)]
+
+ def getind(self, layer_name: str, token: str) -> int:
+ """
+ This returns the index of the record in a layer in constant runtime.
+ :param layer_name: Name of the layer we are interested in.
+ :param token: Token of the record.
+ :return: The index of the record in the layer, layer is an array.
+ """
+ return self._token2ind[layer_name][token]
+ def my_render_record(self,
+ layer_name: str,
+ token: str,
+ alpha: float = 0.5,
+ figsize: Tuple[float, float] = None,
+ other_layers: List[str] = None,
+ bitmap: Optional[BitMap] = None) -> Tuple[Figure, Tuple[Axes, Axes]]:
+ """
+ Render a single map record. By default will also render 3 layers which are `drivable_area`, `lane`,
+ and `walkway` unless specified by `other_layers`.
+ :param layer_name: Name of the layer that we are interested in.
+ :param token: Token of the record that you want to render.
+ :param alpha: The opacity of each layer that gets rendered.
+ :param figsize: Size of the whole figure.
+ :param other_layers: What other layers to render aside from the one specified in `layer_name`.
+ :param bitmap: Optional BitMap object to render below the other map layers.
+ :return: The matplotlib figure and axes of the rendered layers.
+ """
+ return self.explorer.my_render_record(layer_name, token, alpha,
+ figsize=figsize, other_layers=other_layers, bitmap=bitmap)
+ def render_record(self,
+ layer_name: str,
+ token: str,
+ alpha: float = 0.5,
+ figsize: Tuple[float, float] = None,
+ other_layers: List[str] = None,
+ bitmap: Optional[BitMap] = None) -> Tuple[Figure, Tuple[Axes, Axes]]:
+ """
+ Render a single map record. By default will also render 3 layers which are `drivable_area`, `lane`,
+ and `walkway` unless specified by `other_layers`.
+ :param layer_name: Name of the layer that we are interested in.
+ :param token: Token of the record that you want to render.
+ :param alpha: The opacity of each layer that gets rendered.
+ :param figsize: Size of the whole figure.
+ :param other_layers: What other layers to render aside from the one specified in `layer_name`.
+ :param bitmap: Optional BitMap object to render below the other map layers.
+ :return: The matplotlib figure and axes of the rendered layers.
+ """
+ return self.explorer.render_record(layer_name, token, alpha,
+ figsize=figsize, other_layers=other_layers, bitmap=bitmap)
+ def my_render_layers(self,
+ layer_names: List[str],
+ alpha: float = 0.5,
+ figsize: Union[None, float, Tuple[float, float]] = None,
+ tokens: List[List[str]] = None,
+ bitmap: Optional[BitMap] = None) -> Tuple[Figure, Axes]:
+ """
+ Render a list of layer names.
+ :param layer_names: A list of layer names.
+ :param alpha: The opacity of each layer that gets rendered.
+ :param figsize: Size of the whole figure.
+ :param tokens: Optional list of tokens to render. None means all tokens are rendered.
+ :param bitmap: Optional BitMap object to render below the other map layers.
+ :return: The matplotlib figure and axes of the rendered layers.
+ """
+ return self.explorer.my_render_layers(layer_names, alpha,
+ figsize=figsize, tokens=tokens, bitmap=bitmap)
+ def render_layers(self,
+ layer_names: List[str],
+ alpha: float = 0.5,
+ figsize: Union[None, float, Tuple[float, float]] = None,
+ tokens: List[str] = None,
+ bitmap: Optional[BitMap] = None) -> Tuple[Figure, Axes]:
+ """
+ Render a list of layer names.
+ :param layer_names: A list of layer names.
+ :param alpha: The opacity of each layer that gets rendered.
+ :param figsize: Size of the whole figure.
+ :param tokens: Optional list of tokens to render. None means all tokens are rendered.
+ :param bitmap: Optional BitMap object to render below the other map layers.
+ :return: The matplotlib figure and axes of the rendered layers.
+ """
+ return self.explorer.render_layers(layer_names, alpha,
+ figsize=figsize, tokens=tokens, bitmap=bitmap)
+ def my_render_map_patch(self,
+ box_coords: Tuple[float, float, float, float],
+ layer_names: List[str] = None,
+ alpha: float = 0.5,
+ figsize: Tuple[int, int] = (15, 15),
+ render_egoposes_range: bool = True,
+ render_legend: bool = True,
+ tokens: List[List[str]] = None,
+ bitmap: Optional[BitMap] = None) -> Tuple[Figure, Axes]:
+ """
+ Renders a rectangular patch specified by `box_coords`. By default renders all layers.
+ :param box_coords: The rectangular patch coordinates (x_min, y_min, x_max, y_max).
+ :param layer_names: All the non geometric layers that we want to render.
+ :param alpha: The opacity of each layer.
+ :param figsize: Size of the whole figure.
+ :param render_egoposes_range: Whether to render a rectangle around all ego poses.
+ :param render_legend: Whether to render the legend of map layers.
+ :param bitmap: Optional BitMap object to render below the other map layers.
+ :return: The matplotlib figure and axes of the rendered layers.
+ """
+ return self.explorer.my_render_map_patch(box_coords, layer_names=layer_names, alpha=alpha, figsize=figsize,
+ render_egoposes_range=render_egoposes_range,
+ render_legend=render_legend, tokens=tokens,bitmap=bitmap)
+ def render_map_patch(self,
+ box_coords: Tuple[float, float, float, float],
+ layer_names: List[str] = None,
+ alpha: float = 0.5,
+ figsize: Tuple[int, int] = (15, 15),
+ render_egoposes_range: bool = True,
+ render_legend: bool = True,
+ bitmap: Optional[BitMap] = None) -> Tuple[Figure, Axes]:
+ """
+ Renders a rectangular patch specified by `box_coords`. By default renders all layers.
+ :param box_coords: The rectangular patch coordinates (x_min, y_min, x_max, y_max).
+ :param layer_names: All the non geometric layers that we want to render.
+ :param alpha: The opacity of each layer.
+ :param figsize: Size of the whole figure.
+ :param render_egoposes_range: Whether to render a rectangle around all ego poses.
+ :param render_legend: Whether to render the legend of map layers.
+ :param bitmap: Optional BitMap object to render below the other map layers.
+ :return: The matplotlib figure and axes of the rendered layers.
+ """
+ return self.explorer.render_map_patch(box_coords, layer_names=layer_names, alpha=alpha, figsize=figsize,
+ render_egoposes_range=render_egoposes_range,
+ render_legend=render_legend, bitmap=bitmap)
+
+ def render_map_in_image(self,
+ nusc: NuScenes,
+ sample_token: str,
+ camera_channel: str = 'CAM_FRONT',
+ alpha: float = 0.3,
+ patch_radius: float = 10000,
+ min_polygon_area: float = 1000,
+ render_behind_cam: bool = True,
+ render_outside_im: bool = True,
+ layer_names: List[str] = None,
+ verbose: bool = True,
+ out_path: str = None) -> Tuple[Figure, Axes]:
+ """
+ Render a nuScenes camera image and overlay the polygons for the specified map layers.
+ Note that the projections are not always accurate as the localization is in 2d.
+ :param nusc: The NuScenes instance to load the image from.
+ :param sample_token: The image's corresponding sample_token.
+ :param camera_channel: Camera channel name, e.g. 'CAM_FRONT'.
+ :param alpha: The transparency value of the layers to render in [0, 1].
+ :param patch_radius: The radius in meters around the ego car in which to select map records.
+ :param min_polygon_area: Minimum area a polygon needs to have to be rendered.
+ :param render_behind_cam: Whether to render polygons where any point is behind the camera.
+ :param render_outside_im: Whether to render polygons where any point is outside the image.
+ :param layer_names: The names of the layers to render, e.g. ['lane'].
+ If set to None, the recommended setting will be used.
+ :param verbose: Whether to print to stdout.
+ :param out_path: Optional path to save the rendered figure to disk.
+ """
+ return self.explorer.render_map_in_image(
+ nusc, sample_token, camera_channel=camera_channel, alpha=alpha,
+ patch_radius=patch_radius, min_polygon_area=min_polygon_area,
+ render_behind_cam=render_behind_cam, render_outside_im=render_outside_im,
+ layer_names=layer_names, verbose=verbose, out_path=out_path)
+
+ def render_egoposes_on_fancy_map(self,
+ nusc: NuScenes,
+ scene_tokens: List = None,
+ verbose: bool = True,
+ out_path: str = None,
+ render_egoposes: bool = True,
+ render_egoposes_range: bool = True,
+ render_legend: bool = True,
+ bitmap: Optional[BitMap] = None) -> Tuple[np.ndarray, Figure, Axes]:
+ """
+ Renders each ego pose of a list of scenes on the map (around 40 poses per scene).
+ This method is heavily inspired by NuScenes.render_egoposes_on_map(), but uses the map expansion pack maps.
+ :param nusc: The NuScenes instance to load the ego poses from.
+ :param scene_tokens: Optional list of scene tokens corresponding to the current map location.
+ :param verbose: Whether to show status messages and progress bar.
+ :param out_path: Optional path to save the rendered figure to disk.
+ :param render_egoposes: Whether to render ego poses.
+ :param render_egoposes_range: Whether to render a rectangle around all ego poses.
+ :param render_legend: Whether to render the legend of map layers.
+ :param bitmap: Optional BitMap object to render below the other map layers.
+ :return: <np.float32: n, 2>. Returns a matrix with n ego poses in global map coordinates.
+ """
+ return self.explorer.render_egoposes_on_fancy_map(nusc, scene_tokens=scene_tokens,
+ verbose=verbose, out_path=out_path,
+ render_egoposes=render_egoposes,
+ render_egoposes_range=render_egoposes_range,
+ render_legend=render_legend, bitmap=bitmap)
+
+ def render_centerlines(self,
+ resolution_meters: float = 0.5,
+ figsize: Union[None, float, Tuple[float, float]] = None,
+ bitmap: Optional[BitMap] = None) -> Tuple[Figure, Axes]:
+ """
+ Render the centerlines of all lanes and lane connectors.
+ :param resolution_meters: How finely to discretize the lane. Smaller values ensure curved
+ lanes are properly represented.
+ :param figsize: Size of the figure.
+ :param bitmap: Optional BitMap object to render below the other map layers.
+ """
+ return self.explorer.render_centerlines(resolution_meters=resolution_meters, figsize=figsize, bitmap=bitmap)
+
+ def render_map_mask(self,
+ patch_box: Tuple[float, float, float, float],
+ patch_angle: float,
+ layer_names: List[str] = None,
+ canvas_size: Tuple[int, int] = (100, 100),
+ figsize: Tuple[int, int] = (15, 15),
+ n_row: int = 2) -> Tuple[Figure, List[Axes]]:
+ """
+ Render map mask of the patch specified by patch_box and patch_angle.
+ :param patch_box: Patch box defined as [x_center, y_center, height, width].
+ :param patch_angle: Patch orientation in degrees.
+ :param layer_names: A list of layer names to be returned.
+ :param canvas_size: Size of the output mask (h, w).
+ :param figsize: Size of the figure.
+ :param n_row: Number of rows with plots.
+ :return: The matplotlib figure and a list of axes of the rendered layers.
+ """
+ return self.explorer.render_map_mask(patch_box, patch_angle,
+ layer_names=layer_names, canvas_size=canvas_size,
+ figsize=figsize, n_row=n_row)
+
+ def get_map_mask(self,
+ patch_box: Optional[Tuple[float, float, float, float]],
+ patch_angle: float,
+ layer_names: List[str] = None,
+ canvas_size: Optional[Tuple[int, int]] = (100, 100)) -> np.ndarray:
+ """
+ Return list of map mask layers of the specified patch.
+ :param patch_box: Patch box defined as [x_center, y_center, height, width]. If None, this plots the entire map.
+ :param patch_angle: Patch orientation in degrees. North-facing corresponds to 0.
+ :param layer_names: A list of layer names to be extracted, or None for all non-geometric layers.
+ :param canvas_size: Size of the output mask (h, w). If None, we use the default resolution of 10px/m.
+ :return: Stacked numpy array of size [c x h x w] with c channels and the same width/height as the canvas.
+ """
+ return self.explorer.get_map_mask(patch_box, patch_angle, layer_names=layer_names, canvas_size=canvas_size)
+
+ def get_map_geom(self,
+ patch_box: Tuple[float, float, float, float],
+ patch_angle: float,
+ layer_names: List[str]) -> List[Tuple[str, List[Geometry]]]:
+ """
+ Returns a list of geometries in the specified patch_box.
+ These are unscaled, but aligned with the patch angle.
+ :param patch_box: Patch box defined as [x_center, y_center, height, width].
+ :param patch_angle: Patch orientation in degrees.
+ North-facing corresponds to 0.
+ :param layer_names: A list of layer names to be extracted, or None for all non-geometric layers.
+ :return: List of layer names and their corresponding geometries.
+ """
+ return self.explorer.get_map_geom(patch_box, patch_angle, layer_names)
+
+ def get_records_in_patch(self,
+ box_coords: Tuple[float, float, float, float],
+ layer_names: List[str] = None,
+ mode: str = 'intersect') -> Dict[str, List[str]]:
+ """
+ Get all the record token that intersects or is within a particular rectangular patch.
+ :param box_coords: The rectangular patch coordinates (x_min, y_min, x_max, y_max).
+ :param layer_names: Names of the layers that we want to retrieve in a particular patch. By default will always
+ look at the all non geometric layers.
+ :param mode: "intersect" will return all non geometric records that intersects the patch, "within" will return
+ all non geometric records that are within the patch.
+ :return: Dictionary of layer_name - tokens pairs.
+ """
+ return self.explorer.get_records_in_patch(box_coords, layer_names=layer_names, mode=mode)
+
+ def is_record_in_patch(self,
+ layer_name: str,
+ token: str,
+ box_coords: Tuple[float, float, float, float],
+ mode: str = 'intersect') -> bool:
+ """
+ Query whether a particular record is in a rectangular patch
+ :param layer_name: The layer name of the record.
+ :param token: The record token.
+ :param box_coords: The rectangular patch coordinates (x_min, y_min, x_max, y_max).
+ :param mode: "intersect" means it will return True if the geometric object intersects the patch, "within" will
+ return True if the geometric object is within the patch.
+ :return: Boolean value on whether a particular record intersects or within a particular patch.
+ """
+ return self.explorer.is_record_in_patch(layer_name, token, box_coords, mode=mode)
+
+ def layers_on_point(self, x: float, y: float, layer_names: List[str] = None) -> Dict[str, str]:
+ """
+ Returns all the polygonal layers that a particular point is on.
+ :param x: x coordinate of the point of interest.
+ :param y: y coordinate of the point of interest.
+ :param layer_names: The names of the layers to search for.
+ :return: All the polygonal layers that a particular point is on. {<layer name>: <list of tokens>}
+ """
+ return self.explorer.layers_on_point(x, y, layer_names=layer_names)
+
+ def record_on_point(self, x: float, y: float, layer_name: str) -> str:
+ """
+ Query what record of a layer a particular point is on.
+ :param x: x coordinate of the point of interest.
+ :param y: y coordinate of the point of interest.
+ :param layer_name: The non geometric polygonal layer name that we are interested in.
+ :return: The first token of a layer a particular point is on or '' if no layer is found.
+ """
+ return self.explorer.record_on_point(x, y, layer_name)
+
+ def extract_polygon(self, polygon_token: str) -> Polygon:
+ """
+ Construct a shapely Polygon object out of a polygon token.
+ :param polygon_token: The token of the polygon record.
+ :return: The polygon wrapped in a shapely Polygon object.
+ """
+ return self.explorer.extract_polygon(polygon_token)
+
+ def extract_line(self, line_token: str) -> LineString:
+ """
+ Construct a shapely LineString object out of a line token.
+ :param line_token: The token of the line record.
+ :return: The line wrapped in a LineString object.
+ """
+ return self.explorer.extract_line(line_token)
+
+ def get_bounds(self, layer_name: str, token: str) -> Tuple[float, float, float, float]:
+ """
+ Get the bounds of the geometric object that corresponds to a non geometric record.
+ :param layer_name: Name of the layer that we are interested in.
+ :param token: Token of the record.
+ :return: min_x, min_y, max_x, max_y of of the line representation.
+ """
+ return self.explorer.get_bounds(layer_name, token)
+
+ def get_records_in_radius(self, x: float, y: float, radius: float,
+ layer_names: List[str], mode: str = 'intersect') -> Dict[str, List[str]]:
+ """
+ Get all the record tokens that intersect a square patch of side length 2*radius centered on (x,y).
+ :param x: X-coordinate in global frame.
+ :param y: y-coordinate in global frame.
+ :param radius: All records within radius meters of point (x, y) will be returned.
+ :param layer_names: Names of the layers that we want to retrieve. By default will always
+ look at the all non geometric layers.
+ :param mode: "intersect" will return all non geometric records that intersects the patch, "within" will return
+ all non geometric records that are within the patch.
+ :return: Dictionary of layer_name - tokens pairs.
+ """
+
+ patch = (x - radius, y - radius, x + radius, y + radius)
+ return self.explorer.get_records_in_patch(patch, layer_names, mode=mode)
+
+ def discretize_centerlines(self, resolution_meters: float) -> List[np.array]:
+ """
+ Discretize the centerlines of lanes and lane connectors.
+ :param resolution_meters: How finely to discretize the lane. Smaller values ensure curved
+ lanes are properly represented.
+ :return: A list of np.arrays with x, y and z values for each point.
+ """
+ pose_lists = []
+ for lane in self.lane + self.lane_connector:
+ my_lane = self.arcline_path_3.get(lane['token'], [])
+ discretized = np.array(discretize_lane(my_lane, resolution_meters))
+ pose_lists.append(discretized)
+
+ return pose_lists
+
+ def discretize_lanes(self, tokens: List[str],
+ resolution_meters: float) -> Dict[str, List[Tuple[float, float, float]]]:
+ """
+ Discretizes a list of lane/lane connector tokens.
+ :param tokens: List of lane and/or lane connector record tokens. Can be retrieved with
+ get_records_in_radius or get_records_in_patch.
+ :param resolution_meters: How finely to discretize the splines.
+ :return: Mapping from lane/lane connector token to sequence of poses along the lane.
+ """
+
+ return {ID: discretize_lane(self.arcline_path_3.get(ID, []), resolution_meters) for ID in tokens}
+
+ def _get_connected_lanes(self, lane_token: str, incoming_outgoing: str) -> List[str]:
+ """
+ Helper for getting the lanes connected to a given lane
+ :param lane_token: Token for the lane.
+ :param incoming_outgoing: Whether to get incoming or outgoing lanes
+ :return: List of lane tokens this lane is connected to.
+ """
+
+ if lane_token not in self.connectivity:
+ raise ValueError(f"{lane_token} is not a valid lane.")
+
+ return self.connectivity[lane_token][incoming_outgoing]
+
+ def get_outgoing_lane_ids(self, lane_token: str) -> List[str]:
+ """
+ Get the out-going lanes.
+ :param lane_token: Token for the lane.
+ :return: List of lane tokens that start at the end of this lane.
+ """
+
+ return self._get_connected_lanes(lane_token, 'outgoing')
+
+ def get_incoming_lane_ids(self, lane_token: str) -> List[str]:
+ """
+ Get the incoming lanes.
+ :param lane_token: Token for the lane.
+ :return: List of lane tokens that end at the start of this lane.
+ """
+
+ return self._get_connected_lanes(lane_token, 'incoming')
+
+ def get_arcline_path(self, lane_token: str) -> List[ArcLinePath]:
+ """
+ Get the arcline path representation for a lane.
+ Note: This function was previously called `get_lane()`, but renamed to avoid confusion between lanes and
+ arcline paths.
+ :param lane_token: Token for the lane.
+ :return: Arc line path representation of the lane.
+ """
+
+ arcline_path = self.arcline_path_3.get(lane_token)
+ if not arcline_path:
+ raise ValueError(f'Error: Lane with token {lane_token} does not have a valid arcline path!')
+
+ return arcline_path
+
+ def get_closest_lane(self, x: float, y: float, radius: float = 5) -> str:
+ """
+ Get closest lane id within a radius of query point. The distance from a point (x, y) to a lane is
+ the minimum l2 distance from (x, y) to a point on the lane.
+ :param x: X coordinate in global coordinate frame.
+ :param y: Y Coordinate in global coordinate frame.
+ :param radius: Radius around point to consider.
+ :return: Lane id of closest lane within radius.
+ """
+
+ lanes = self.get_records_in_radius(x, y, radius, ['lane', 'lane_connector'])
+ lanes = lanes['lane'] + lanes['lane_connector']
+
+ discrete_points = self.discretize_lanes(lanes, 0.5)
+
+ current_min = np.inf
+
+ min_id = ""
+ for lane_id, points in discrete_points.items():
+
+ distance = np.linalg.norm(np.array(points)[:, :2] - [x, y], axis=1).min()
+ if distance <= current_min:
+ current_min = distance
+ min_id = lane_id
+
+ return min_id
+
+ def render_next_roads(self,
+ x: float,
+ y: float,
+ alpha: float = 0.5,
+ figsize: Union[None, float, Tuple[float, float]] = None,
+ bitmap: Optional[BitMap] = None) -> Tuple[Figure, Axes]:
+ """
+ Renders the possible next roads from a point of interest.
+ :param x: x coordinate of the point of interest.
+ :param y: y coordinate of the point of interest.
+ :param alpha: The opacity of each layer that gets rendered.
+ :param figsize: Size of the whole figure.
+ :param bitmap: Optional BitMap object to render below the other map layers.
+ """
+ return self.explorer.render_next_roads(x, y, alpha, figsize=figsize, bitmap=bitmap)
+
+ def get_next_roads(self, x: float, y: float) -> Dict[str, List[str]]:
+ """
+ Get the possible next roads from a point of interest.
+ Returns road_segment, road_block and lane.
+ :param x: x coordinate of the point of interest.
+ :param y: y coordinate of the point of interest.
+ :return: Dictionary of layer_name - tokens pairs.
+ """
+ # Filter out irrelevant layers.
+ road_layers = ['road_segment', 'road_block', 'lane']
+ layers = self.explorer.layers_on_point(x, y)
+ rel_layers = {layer: layers[layer] for layer in road_layers}
+
+ # Pick most fine-grained road layer (lane, road_block, road_segment) object that contains the point.
+ rel_layer = None
+ rel_token = None
+ for layer in road_layers[::-1]:
+ if rel_layers[layer] != '':
+ rel_layer = layer
+ rel_token = rel_layers[layer]
+ break
+ assert rel_layer is not None, 'Error: No suitable layer in the specified point location!'
+
+ # Get all records that overlap with the bounding box of the selected road.
+ box_coords = self.explorer.get_bounds(rel_layer, rel_token)
+ intersect = self.explorer.get_records_in_patch(box_coords, road_layers, mode='intersect')
+
+ # Go through all objects within the bounding box.
+ result = {layer: [] for layer in road_layers}
+ if rel_layer == 'road_segment':
+ # For road segments, we do not have a direction.
+ # Return objects that have ANY exterior points in common with the relevant layer.
+ rel_exterior_nodes = self.get(rel_layer, rel_token)['exterior_node_tokens']
+ for layer in road_layers:
+ for token in intersect[layer]:
+ exterior_nodes = self.get(layer, token)['exterior_node_tokens']
+ if any(n in exterior_nodes for n in rel_exterior_nodes) \
+ and token != rel_layers[layer]:
+ result[layer].append(token)
+ else:
+ # For lanes and road blocks, the next road is indicated by the edge line.
+ # Return objects where ALL edge line nodes are included in the exterior nodes.
+ to_edge_line = self.get(rel_layer, rel_token)['to_edge_line_token']
+ to_edge_nodes = self.get('line', to_edge_line)['node_tokens']
+ for layer in road_layers:
+ for token in intersect[layer]:
+ exterior_nodes = self.get(layer, token)['exterior_node_tokens']
+ if all(n in exterior_nodes for n in to_edge_nodes) \
+ and token != rel_layers[layer]:
+ result[layer].append(token)
+ return result
+
+
+class NuScenesMapExplorer:
+ """ Helper class to explore the nuScenes map data. """
+ def __init__(self,
+ map_api: NuScenesMap,
+ representative_layers: Tuple[str] = ('drivable_area', 'lane', 'walkway'),
+ color_map: dict = None):
+ """
+ :param map_api: NuScenesMap database class.
+ :param representative_layers: These are the layers that we feel are representative of the whole mapping data.
+ :param color_map: Color map.
+ """
+ # Mutable default argument.
+ if color_map is None:
+ color_map = dict(drivable_area='#a6cee3',
+ road_segment='#1f78b4',
+ road_block='#b2df8a',
+ lane='#33a02c',
+ ped_crossing='#fb9a99',
+ walkway='#e31a1c',
+ stop_line='#fdbf6f',
+ carpark_area='#ff7f00',
+ road_divider='#cab2d6',
+ lane_divider='#6a3d9a',
+ traffic_light='#7e772e')
+
+ self.map_api = map_api
+ self.representative_layers = representative_layers
+ self.color_map = color_map
+
+ self.canvas_max_x = self.map_api.canvas_edge[0]
+ self.canvas_min_x = 0
+ self.canvas_max_y = self.map_api.canvas_edge[1]
+ self.canvas_min_y = 0
+ self.canvas_aspect_ratio = (self.canvas_max_x - self.canvas_min_x) / (self.canvas_max_y - self.canvas_min_y)
+
+ def render_centerlines(self,
+ resolution_meters: float,
+ figsize: Union[None, float, Tuple[float, float]] = None,
+ bitmap: Optional[BitMap] = None) -> Tuple[Figure, Axes]:
+ """
+ Render the centerlines of all lanes and lane connectors.
+ :param resolution_meters: How finely to discretize the lane. Smaller values ensure curved
+ lanes are properly represented.
+ :param figsize: Size of the figure.
+ :param bitmap: Optional BitMap object to render below the other map layers.
+ """
+ # Discretize all lanes and lane connectors.
+ pose_lists = self.map_api.discretize_centerlines(resolution_meters)
+
+ # Render connectivity lines.
+ fig = plt.figure(figsize=self._get_figsize(figsize))
+ ax = fig.add_axes([0, 0, 1, 1 / self.canvas_aspect_ratio])
+
+ if bitmap is not None:
+ bitmap.render(self.map_api.canvas_edge, ax)
+
+ for pose_list in pose_lists:
+ if len(pose_list) > 0:
+ plt.plot(pose_list[:, 0], pose_list[:, 1])
+
+ return fig, ax
+
+ def render_map_mask(self,
+ patch_box: Tuple[float, float, float, float],
+ patch_angle: float,
+ layer_names: List[str],
+ canvas_size: Tuple[int, int],
+ figsize: Tuple[int, int],
+ n_row: int = 2) -> Tuple[Figure, List[Axes]]:
+ """
+ Render map mask of the patch specified by patch_box and patch_angle.
+ :param patch_box: Patch box defined as [x_center, y_center, height, width].
+ :param patch_angle: Patch orientation in degrees.
+ :param layer_names: A list of layer names to be extracted.
+ :param canvas_size: Size of the output mask (h, w).
+ :param figsize: Size of the figure.
+ :param n_row: Number of rows with plots.
+ :return: The matplotlib figure and a list of axes of the rendered layers.
+ """
+ if layer_names is None:
+ layer_names = self.map_api.non_geometric_layers
+
+ map_mask = self.get_map_mask(patch_box, patch_angle, layer_names, canvas_size)
+
+ # If no canvas_size is specified, retrieve the default from the output of get_map_mask.
+ if canvas_size is None:
+ canvas_size = map_mask.shape[1:]
+
+ fig = plt.figure(figsize=figsize)
+ ax = fig.add_axes([0, 0, 1, 1])
+ ax.set_xlim(0, canvas_size[1])
+ ax.set_ylim(0, canvas_size[0])
+
+ n_col = len(map_mask) // n_row
+ gs = gridspec.GridSpec(n_row, n_col)
+ gs.update(wspace=0.025, hspace=0.05)
+ for i in range(len(map_mask)):
+ r = i // n_col
+ c = i - r * n_col
+ subax = plt.subplot(gs[r, c])
+ subax.imshow(map_mask[i], origin='lower')
+ subax.text(canvas_size[0] * 0.5, canvas_size[1] * 1.1, layer_names[i])
+ subax.grid(False)
+
+ return fig, fig.axes
+
+ def get_map_geom(self,
+ patch_box: Tuple[float, float, float, float],
+ patch_angle: float,
+ layer_names: List[str]) -> List[Tuple[str, List[Geometry]]]:
+ """
+ Returns a list of geometries in the specified patch_box.
+ These are unscaled, but aligned with the patch angle.
+ :param patch_box: Patch box defined as [x_center, y_center, height, width].
+ :param patch_angle: Patch orientation in degrees.
+ North-facing corresponds to 0.
+ :param layer_names: A list of layer names to be extracted, or None for all non-geometric layers.
+ :return: List of layer names and their corresponding geometries.
+ """
+ # If None, return all geometric layers.
+ if layer_names is None:
+ layer_names = self.map_api.non_geometric_layers
+
+ # Get each layer name and geometry and store them in a list.
+ map_geom = []
+ for layer_name in layer_names:
+ layer_geom = self._get_layer_geom(patch_box, patch_angle, layer_name)
+ if layer_geom is None:
+ continue
+ map_geom.append((layer_name, layer_geom))
+
+ return map_geom
+
+ def map_geom_to_mask(self,
+ map_geom: List[Tuple[str, List[Geometry]]],
+ local_box: Tuple[float, float, float, float],
+ canvas_size: Tuple[int, int]) -> np.ndarray:
+ """
+ Return list of map mask layers of the specified patch.
+ :param map_geom: List of layer names and their corresponding geometries.
+ :param local_box: The local patch box defined as (x_center, y_center, height, width), where typically
+ x_center = y_center = 0.
+ :param canvas_size: Size of the output mask (h, w).
+ :return: Stacked numpy array of size [c x h x w] with c channels and the same height/width as the canvas.
+ """
+ # Get each layer mask and stack them into a numpy tensor.
+ map_mask = []
+ for layer_name, layer_geom in map_geom:
+ layer_mask = self._layer_geom_to_mask(layer_name, layer_geom, local_box, canvas_size)
+ if layer_mask is not None:
+ map_mask.append(layer_mask)
+
+ return np.array(map_mask)
+
+ def get_map_mask(self,
+ patch_box: Optional[Tuple[float, float, float, float]],
+ patch_angle: float,
+ layer_names: List[str] = None,
+ canvas_size: Tuple[int, int] = (100, 100)) -> np.ndarray:
+ """
+ Return list of map mask layers of the specified patch.
+ :param patch_box: Patch box defined as [x_center, y_center, height, width]. If None, this plots the entire map.
+ :param patch_angle: Patch orientation in degrees. North-facing corresponds to 0.
+ :param layer_names: A list of layer names to be extracted, or None for all non-geometric layers.
+ :param canvas_size: Size of the output mask (h, w). If None, we use the default resolution of 10px/m.
+ :return: Stacked numpy array of size [c x h x w] with c channels and the same width/height as the canvas.
+ """
+ # For some combination of parameters, we need to know the size of the current map.
+ if self.map_api.map_name == 'singapore-onenorth':
+ map_dims = [1585.6, 2025.0]
+ elif self.map_api.map_name == 'singapore-hollandvillage':
+ map_dims = [2808.3, 2922.9]
+ elif self.map_api.map_name == 'singapore-queenstown':
+ map_dims = [3228.6, 3687.1]
+ elif self.map_api.map_name == 'boston-seaport':
+ map_dims = [2979.5, 2118.1]
+ else:
+ raise Exception('Error: Invalid map!')
+
+ # If None, return the entire map.
+ if patch_box is None:
+ patch_box = [map_dims[0] / 2, map_dims[1] / 2, map_dims[1], map_dims[0]]
+
+ # If None, return all geometric layers.
+ if layer_names is None:
+ layer_names = self.map_api.non_geometric_layers
+
+ # If None, return the specified patch in the original scale of 10px/m.
+ if canvas_size is None:
+ map_scale = 10
+ canvas_size = np.array((patch_box[2], patch_box[3])) * map_scale
+ canvas_size = tuple(np.round(canvas_size).astype(np.int32))
+
+ # Get geometry of each layer.
+ map_geom = self.get_map_geom(patch_box, patch_angle, layer_names)
+
+ # Convert geometry of each layer into mask and stack them into a numpy tensor.
+ # Convert the patch box from global coordinates to local coordinates by setting the center to (0, 0).
+ local_box = (0.0, 0.0, patch_box[2], patch_box[3])
+ map_mask = self.map_geom_to_mask(map_geom, local_box, canvas_size)
+ assert np.all(map_mask.shape[1:] == canvas_size)
+
+ return map_mask
+ def my_render_record(self,
+ layer_name: str,
+ token: str,
+ alpha: float = 0.5,
+ figsize: Union[None, float, Tuple[float, float]] = None,
+ other_layers: List[str] = None,
+ bitmap: Optional[BitMap] = None) -> Tuple[Figure, Tuple[Axes, Axes]]:
+ """
+ Render a single map record.
+ By default will also render 3 layers which are `drivable_area`, `lane`, and `walkway` unless specified by
+ `other_layers`.
+ :param layer_name: Name of the layer that we are interested in.
+ :param token: Token of the record that you want to render.
+ :param alpha: The opacity of each layer that gets rendered.
+ :param figsize: Size of the whole figure.
+ :param other_layers: What other layers to render aside from the one specified in `layer_name`.
+ :param bitmap: Optional BitMap object to render below the other map layers.
+ :return: The matplotlib figure and axes of the rendered layers.
+ """
+ if other_layers is None:
+ other_layers = [] #list(self.representative_layers)
+
+ # for other_layer in other_layers:
+ # if other_layer not in self.map_api.non_geometric_layers:
+ # raise ValueError("{} is not a non geometric layer".format(layer_name))
+
+ x1, y1, x2, y2 = self.map_api.get_bounds(layer_name, token)
+
+ local_width = x2 - x1
+ local_height = y2 - y1
+ assert local_height > 0, 'Error: Map has 0 height!'
+ local_aspect_ratio = local_width / local_height
+
+ # We obtained the values 0.65 and 0.66 by trials.
+ fig = plt.figure(figsize=self._get_figsize(figsize))
+ global_ax = fig.add_axes([0, 0, 0.65, 0.65 / self.canvas_aspect_ratio])
+ local_ax = fig.add_axes([0.66, 0.66 / self.canvas_aspect_ratio, 0.34, 0.34 / local_aspect_ratio])
+
+ # To make sure the sequence of the layer overlays is always consistent after typesetting set().
+ random.seed('nutonomy')
+
+ if bitmap is not None:
+ bitmap.render(self.map_api.canvas_edge, global_ax)
+ bitmap.render(self.map_api.canvas_edge, local_ax)
+
+ layer_names = other_layers + [layer_name]
+ layer_names = list(set(layer_names))
+
+ for layer in layer_names:
+ self._render_layer(global_ax, layer, alpha)
+
+ for layer in layer_names:
+ self._render_layer(local_ax, layer, alpha)
+
+ if layer_name == 'drivable_area':
+ # Bad output aesthetically if we add spacing between the objects and the axes for drivable area.
+ local_ax_xlim = (x1, x2)
+ local_ax_ylim = (y1, y2)
+ else:
+ # Add some spacing between the object and the axes.
+ local_ax_xlim = (x1 - local_width / 3, x2 + local_width / 3)
+ local_ax_ylim = (y1 - local_height / 3, y2 + local_height / 3)
+
+ # Draws the rectangular patch on the local_ax.
+ local_ax.add_patch(Rectangle((x1, y1), local_width, local_height, linestyle='-.', color='red', fill=False,
+ lw=2))
+
+ local_ax.set_xlim(*local_ax_xlim)
+ local_ax.set_ylim(*local_ax_ylim)
+ local_ax.set_title('Local View')
+
+ global_ax.set_xlim(self.canvas_min_x, self.canvas_max_x)
+ global_ax.set_ylim(self.canvas_min_y, self.canvas_max_y)
+ global_ax.set_title('Global View')
+ global_ax.legend()
+
+ # Adds the zoomed in effect to the plot.
+ mark_inset(global_ax, local_ax, loc1=2, loc2=4)
+
+ return fig, (global_ax, local_ax)
+ def render_record(self,
+ layer_name: str,
+ token: str,
+ alpha: float = 0.5,
+ figsize: Union[None, float, Tuple[float, float]] = None,
+ other_layers: List[str] = None,
+ bitmap: Optional[BitMap] = None) -> Tuple[Figure, Tuple[Axes, Axes]]:
+ """
+ Render a single map record.
+ By default will also render 3 layers which are `drivable_area`, `lane`, and `walkway` unless specified by
+ `other_layers`.
+ :param layer_name: Name of the layer that we are interested in.
+ :param token: Token of the record that you want to render.
+ :param alpha: The opacity of each layer that gets rendered.
+ :param figsize: Size of the whole figure.
+ :param other_layers: What other layers to render aside from the one specified in `layer_name`.
+ :param bitmap: Optional BitMap object to render below the other map layers.
+ :return: The matplotlib figure and axes of the rendered layers.
+ """
+ if other_layers is None:
+ other_layers = list(self.representative_layers)
+
+ for other_layer in other_layers:
+ if other_layer not in self.map_api.non_geometric_layers:
+ raise ValueError("{} is not a non geometric layer".format(layer_name))
+
+ x1, y1, x2, y2 = self.map_api.get_bounds(layer_name, token)
+
+ local_width = x2 - x1
+ local_height = y2 - y1
+ assert local_height > 0, 'Error: Map has 0 height!'
+ local_aspect_ratio = local_width / local_height
+
+ # We obtained the values 0.65 and 0.66 by trials.
+ fig = plt.figure(figsize=self._get_figsize(figsize))
+ global_ax = fig.add_axes([0, 0, 0.65, 0.65 / self.canvas_aspect_ratio])
+ local_ax = fig.add_axes([0.66, 0.66 / self.canvas_aspect_ratio, 0.34, 0.34 / local_aspect_ratio])
+
+ # To make sure the sequence of the layer overlays is always consistent after typesetting set().
+ random.seed('nutonomy')
+
+ if bitmap is not None:
+ bitmap.render(self.map_api.canvas_edge, global_ax)
+ bitmap.render(self.map_api.canvas_edge, local_ax)
+
+ layer_names = other_layers + [layer_name]
+ layer_names = list(set(layer_names))
+
+ for layer in layer_names:
+ self._render_layer(global_ax, layer, alpha)
+
+ for layer in layer_names:
+ self._render_layer(local_ax, layer, alpha)
+
+ if layer_name == 'drivable_area':
+ # Bad output aesthetically if we add spacing between the objects and the axes for drivable area.
+ local_ax_xlim = (x1, x2)
+ local_ax_ylim = (y1, y2)
+ else:
+ # Add some spacing between the object and the axes.
+ local_ax_xlim = (x1 - local_width / 3, x2 + local_width / 3)
+ local_ax_ylim = (y1 - local_height / 3, y2 + local_height / 3)
+
+ # Draws the rectangular patch on the local_ax.
+ local_ax.add_patch(Rectangle((x1, y1), local_width, local_height, linestyle='-.', color='red', fill=False,
+ lw=2))
+
+ local_ax.set_xlim(*local_ax_xlim)
+ local_ax.set_ylim(*local_ax_ylim)
+ local_ax.set_title('Local View')
+
+ global_ax.set_xlim(self.canvas_min_x, self.canvas_max_x)
+ global_ax.set_ylim(self.canvas_min_y, self.canvas_max_y)
+ global_ax.set_title('Global View')
+ global_ax.legend()
+
+ # Adds the zoomed in effect to the plot.
+ mark_inset(global_ax, local_ax, loc1=2, loc2=4)
+
+ return fig, (global_ax, local_ax)
+
+ def my_render_layers(self,
+ layer_names: List[str],
+ alpha: float,
+ figsize: Union[None, float, Tuple[float, float]],
+ tokens: List[List[str]] = None,
+ bitmap: Optional[BitMap] = None) -> Tuple[Figure, Axes]:
+ """
+ Render a list of layers.
+ :param layer_names: A list of layer names.
+ :param alpha: The opacity of each layer.
+ :param figsize: Size of the whole figure.
+ :param tokens: Optional list of tokens to render. None means all tokens are rendered.
+ :param bitmap: Optional BitMap object to render below the other map layers.
+ :return: The matplotlib figure and axes of the rendered layers.
+ """
+ fig = plt.figure(figsize=self._get_figsize(figsize))
+ ax = fig.add_axes([0, 0, 1, 1 / self.canvas_aspect_ratio])
+
+ ax.set_xlim(self.canvas_min_x, self.canvas_max_x)
+ ax.set_ylim(self.canvas_min_y, self.canvas_max_y)
+
+ if bitmap is not None:
+ bitmap.render(self.map_api.canvas_edge, ax)
+
+ # layer_names = list(set(layer_names))
+ for layer_name ,token_list in zip(layer_names, tokens):
+ self._render_layer(ax, layer_name, alpha, token_list)
+
+ ax.legend()
+
+ return fig, ax
+ def render_layers(self,
+ layer_names: List[str],
+ alpha: float,
+ figsize: Union[None, float, Tuple[float, float]],
+ tokens: List[str] = None,
+ bitmap: Optional[BitMap] = None) -> Tuple[Figure, Axes]:
+ """
+ Render a list of layers.
+ :param layer_names: A list of layer names.
+ :param alpha: The opacity of each layer.
+ :param figsize: Size of the whole figure.
+ :param tokens: Optional list of tokens to render. None means all tokens are rendered.
+ :param bitmap: Optional BitMap object to render below the other map layers.
+ :return: The matplotlib figure and axes of the rendered layers.
+ """
+ fig = plt.figure(figsize=self._get_figsize(figsize))
+ ax = fig.add_axes([0, 0, 1, 1 / self.canvas_aspect_ratio])
+
+ ax.set_xlim(self.canvas_min_x, self.canvas_max_x)
+ ax.set_ylim(self.canvas_min_y, self.canvas_max_y)
+
+ if bitmap is not None:
+ bitmap.render(self.map_api.canvas_edge, ax)
+
+ layer_names = list(set(layer_names))
+ for layer_name in layer_names:
+ self._render_layer(ax, layer_name, alpha, tokens)
+
+ ax.legend()
+
+ return fig, ax
+
+ def my_render_map_patch(self,
+ box_coords: Tuple[float, float, float, float],
+ layer_names: List[str] = None,
+ alpha: float = 0.5,
+ figsize: Tuple[float, float] = (15, 15),
+ render_egoposes_range: bool = True,
+ render_legend: bool = True,
+ tokens: List[List[str]] = None,
+ bitmap: Optional[BitMap] = None) -> Tuple[Figure, Axes]:
+ """
+ Renders a rectangular patch specified by `box_coords`. By default renders all layers.
+ :param box_coords: The rectangular patch coordinates (x_min, y_min, x_max, y_max).
+ :param layer_names: All the non geometric layers that we want to render.
+ :param alpha: The opacity of each layer.
+ :param figsize: Size of the whole figure.
+ :param render_egoposes_range: Whether to render a rectangle around all ego poses.
+ :param render_legend: Whether to render the legend of map layers.
+ :param bitmap: Optional BitMap object to render below the other map layers.
+ :return: The matplotlib figure and axes of the rendered layers.
+ """
+ x_min, y_min, x_max, y_max = box_coords
+
+ if layer_names is None:
+ layer_names = self.map_api.non_geometric_layers
+
+ fig = plt.figure(figsize=figsize)
+
+ local_width = x_max - x_min
+ local_height = y_max - y_min
+ assert local_height > 0, 'Error: Map patch has 0 height!'
+ local_aspect_ratio = local_width / local_height
+
+ ax = fig.add_axes([0, 0, 1, 1 / local_aspect_ratio])
+
+ if bitmap is not None:
+ bitmap.render(self.map_api.canvas_edge, ax)
+
+ for (token_list,layer_name) in zip(tokens,layer_names):
+ self._render_layer(ax, layer_name, alpha,tokens=token_list)
+
+ x_margin = np.minimum(local_width / 4, 50)
+ y_margin = np.minimum(local_height / 4, 10)
+ ax.set_xlim(x_min - x_margin, x_max + x_margin)
+ ax.set_ylim(y_min - y_margin, y_max + y_margin)
+
+ if render_egoposes_range:
+ ax.add_patch(Rectangle((x_min, y_min), local_width, local_height, fill=False, linestyle='-.', color='red',
+ lw=2))
+ ax.text(x_min + local_width / 100, y_min + local_height / 2, "%g m" % local_height,
+ fontsize=14, weight='bold')
+ ax.text(x_min + local_width / 2, y_min + local_height / 100, "%g m" % local_width,
+ fontsize=14, weight='bold')
+
+ if render_legend:
+ ax.legend(frameon=True, loc='upper right')
+
+ return fig, ax
+
+ def render_map_patch(self,
+ box_coords: Tuple[float, float, float, float],
+ layer_names: List[str] = None,
+ alpha: float = 0.5,
+ figsize: Tuple[float, float] = (15, 15),
+ render_egoposes_range: bool = True,
+ render_legend: bool = True,
+ bitmap: Optional[BitMap] = None) -> Tuple[Figure, Axes]:
+ """
+ Renders a rectangular patch specified by `box_coords`. By default renders all layers.
+ :param box_coords: The rectangular patch coordinates (x_min, y_min, x_max, y_max).
+ :param layer_names: All the non geometric layers that we want to render.
+ :param alpha: The opacity of each layer.
+ :param figsize: Size of the whole figure.
+ :param render_egoposes_range: Whether to render a rectangle around all ego poses.
+ :param render_legend: Whether to render the legend of map layers.
+ :param bitmap: Optional BitMap object to render below the other map layers.
+ :return: The matplotlib figure and axes of the rendered layers.
+ """
+ x_min, y_min, x_max, y_max = box_coords
+
+ if layer_names is None:
+ layer_names = self.map_api.non_geometric_layers
+
+ fig = plt.figure(figsize=figsize)
+
+ local_width = x_max - x_min
+ local_height = y_max - y_min
+ assert local_height > 0, 'Error: Map patch has 0 height!'
+ local_aspect_ratio = local_width / local_height
+
+ ax = fig.add_axes([0, 0, 1, 1 / local_aspect_ratio])
+
+ if bitmap is not None:
+ bitmap.render(self.map_api.canvas_edge, ax)
+
+ for layer_name in layer_names:
+ self._render_layer(ax, layer_name, alpha)
+
+ x_margin = np.minimum(local_width / 4, 50)
+ y_margin = np.minimum(local_height / 4, 10)
+ ax.set_xlim(x_min - x_margin, x_max + x_margin)
+ ax.set_ylim(y_min - y_margin, y_max + y_margin)
+
+ if render_egoposes_range:
+ ax.add_patch(Rectangle((x_min, y_min), local_width, local_height, fill=False, linestyle='-.', color='red',
+ lw=2))
+ ax.text(x_min + local_width / 100, y_min + local_height / 2, "%g m" % local_height,
+ fontsize=14, weight='bold')
+ ax.text(x_min + local_width / 2, y_min + local_height / 100, "%g m" % local_width,
+ fontsize=14, weight='bold')
+
+ if render_legend:
+ ax.legend(frameon=True, loc='upper right')
+
+ return fig, ax
+
+ def render_map_in_image(self,
+ nusc: NuScenes,
+ sample_token: str,
+ camera_channel: str = 'CAM_FRONT',
+ alpha: float = 0.3,
+ patch_radius: float = 10000,
+ min_polygon_area: float = 1000,
+ render_behind_cam: bool = True,
+ render_outside_im: bool = True,
+ layer_names: List[str] = None,
+ verbose: bool = True,
+ out_path: str = None) -> Tuple[Figure, Axes]:
+ """
+ Render a nuScenes camera image and overlay the polygons for the specified map layers.
+ Note that the projections are not always accurate as the localization is in 2d.
+ :param nusc: The NuScenes instance to load the image from.
+ :param sample_token: The image's corresponding sample_token.
+ :param camera_channel: Camera channel name, e.g. 'CAM_FRONT'.
+ :param alpha: The transparency value of the layers to render in [0, 1].
+ :param patch_radius: The radius in meters around the ego car in which to select map records.
+ :param min_polygon_area: Minimum area a polygon needs to have to be rendered.
+ :param render_behind_cam: Whether to render polygons where any point is behind the camera.
+ :param render_outside_im: Whether to render polygons where any point is outside the image.
+ :param layer_names: The names of the layers to render, e.g. ['lane'].
+ If set to None, the recommended setting will be used.
+ :param verbose: Whether to print to stdout.
+ :param out_path: Optional path to save the rendered figure to disk.
+ """
+ near_plane = 1e-8
+
+ if verbose:
+ print('Warning: Note that the projections are not always accurate as the localization is in 2d.')
+
+ # Default layers.
+ if layer_names is None:
+ layer_names = ['road_segment', 'lane', 'ped_crossing', 'walkway', 'stop_line', 'carpark_area']
+
+ # Check layers whether we can render them.
+ for layer_name in layer_names:
+ assert layer_name in self.map_api.non_geometric_polygon_layers, \
+ 'Error: Can only render non-geometry polygons: %s' % layer_names
+
+ # Check that NuScenesMap was loaded for the correct location.
+ sample_record = nusc.get('sample', sample_token)
+ scene_record = nusc.get('scene', sample_record['scene_token'])
+ log_record = nusc.get('log', scene_record['log_token'])
+ log_location = log_record['location']
+ assert self.map_api.map_name == log_location, \
+ 'Error: NuScenesMap loaded for location %s, should be %s!' % (self.map_api.map_name, log_location)
+
+ # Grab the front camera image and intrinsics.
+ cam_token = sample_record['data'][camera_channel]
+ cam_record = nusc.get('sample_data', cam_token)
+ cam_path = nusc.get_sample_data_path(cam_token)
+ im = Image.open(cam_path)
+ im_size = im.size
+ cs_record = nusc.get('calibrated_sensor', cam_record['calibrated_sensor_token'])
+ cam_intrinsic = np.array(cs_record['camera_intrinsic'])
+
+ # Retrieve the current map.
+ poserecord = nusc.get('ego_pose', cam_record['ego_pose_token'])
+ ego_pose = poserecord['translation']
+ box_coords = (
+ ego_pose[0] - patch_radius,
+ ego_pose[1] - patch_radius,
+ ego_pose[0] + patch_radius,
+ ego_pose[1] + patch_radius,
+ )
+ records_in_patch = self.get_records_in_patch(box_coords, layer_names, 'intersect')
+
+ # Init axes.
+ fig = plt.figure(figsize=(9, 16))
+ ax = fig.add_axes([0, 0, 1, 1])
+ ax.set_xlim(0, im_size[0])
+ ax.set_ylim(0, im_size[1])
+ ax.imshow(im)
+
+ # Retrieve and render each record.
+ for layer_name in layer_names:
+ for token in records_in_patch[layer_name]:
+ record = self.map_api.get(layer_name, token)
+ if layer_name == 'drivable_area':
+ polygon_tokens = record['polygon_tokens']
+ else:
+ polygon_tokens = [record['polygon_token']]
+
+ for polygon_token in polygon_tokens:
+ polygon = self.map_api.extract_polygon(polygon_token)
+
+ # Convert polygon nodes to pointcloud with 0 height.
+ points = np.array(polygon.exterior.xy)
+ points = np.vstack((points, np.zeros((1, points.shape[1]))))
+
+ # Transform into the ego vehicle frame for the timestamp of the image.
+ points = points - np.array(poserecord['translation']).reshape((-1, 1))
+ points = np.dot(Quaternion(poserecord['rotation']).rotation_matrix.T, points)
+
+ # Transform into the camera.
+ points = points - np.array(cs_record['translation']).reshape((-1, 1))
+ points = np.dot(Quaternion(cs_record['rotation']).rotation_matrix.T, points)
+
+ # Remove points that are partially behind the camera.
+ depths = points[2, :]
+ behind = depths < near_plane
+ if np.all(behind):
+ continue
+
+ if render_behind_cam:
+ # Perform clipping on polygons that are partially behind the camera.
+ points = NuScenesMapExplorer._clip_points_behind_camera(points, near_plane)
+ elif np.any(behind):
+ # Otherwise ignore any polygon that is partially behind the camera.
+ continue
+
+ # Ignore polygons with less than 3 points after clipping.
+ if len(points) == 0 or points.shape[1] < 3:
+ continue
+
+ # Take the actual picture (matrix multiplication with camera-matrix + renormalization).
+ points = view_points(points, cam_intrinsic, normalize=True)
+
+ # Skip polygons where all points are outside the image.
+ # Leave a margin of 1 pixel for aesthetic reasons.
+ inside = np.ones(points.shape[1], dtype=bool)
+ inside = np.logical_and(inside, points[0, :] > 1)
+ inside = np.logical_and(inside, points[0, :] < im.size[0] - 1)
+ inside = np.logical_and(inside, points[1, :] > 1)
+ inside = np.logical_and(inside, points[1, :] < im.size[1] - 1)
+ if render_outside_im:
+ if np.all(np.logical_not(inside)):
+ continue
+ else:
+ if np.any(np.logical_not(inside)):
+ continue
+
+ points = points[:2, :]
+ points = [(p0, p1) for (p0, p1) in zip(points[0], points[1])]
+ polygon_proj = Polygon(points)
+
+ # Filter small polygons
+ if polygon_proj.area < min_polygon_area:
+ continue
+
+ label = layer_name
+ ax.add_patch(descartes.PolygonPatch(polygon_proj, fc=self.color_map[layer_name], alpha=alpha,
+ label=label))
+
+ # Display the image.
+ plt.axis('off')
+ ax.invert_yaxis()
+
+ if out_path is not None:
+ plt.tight_layout()
+ plt.savefig(out_path, bbox_inches='tight', pad_inches=0)
+
+ return fig, ax
+
+ def render_egoposes_on_fancy_map(self,
+ nusc: NuScenes,
+ scene_tokens: List = None,
+ verbose: bool = True,
+ out_path: str = None,
+ render_egoposes: bool = True,
+ render_egoposes_range: bool = True,
+ render_legend: bool = True,
+ bitmap: Optional[BitMap] = None) -> Tuple[np.ndarray, Figure, Axes]:
+ """
+ Renders each ego pose of a list of scenes on the map (around 40 poses per scene).
+ This method is heavily inspired by NuScenes.render_egoposes_on_map(), but uses the map expansion pack maps.
+ Note that the maps are constantly evolving, whereas we only released a single snapshot of the data.
+ Therefore for some scenes there is a bad fit between ego poses and maps.
+ :param nusc: The NuScenes instance to load the ego poses from.
+ :param scene_tokens: Optional list of scene tokens corresponding to the current map location.
+ :param verbose: Whether to show status messages and progress bar.
+ :param out_path: Optional path to save the rendered figure to disk.
+ :param render_egoposes: Whether to render ego poses.
+ :param render_egoposes_range: Whether to render a rectangle around all ego poses.
+ :param render_legend: Whether to render the legend of map layers.
+ :param bitmap: Optional BitMap object to render below the other map layers.
+ :return: <np.float32: n, 2>. Returns a matrix with n ego poses in global map coordinates.
+ """
+ # Settings
+ patch_margin = 2
+ min_diff_patch = 30
+
+ # Ids of scenes with a bad match between localization and map.
+ scene_blacklist = [499, 515, 517]
+
+ # Get logs by location.
+ log_location = self.map_api.map_name
+ log_tokens = [log['token'] for log in nusc.log if log['location'] == log_location]
+ assert len(log_tokens) > 0, 'Error: This split has 0 scenes for location %s!' % log_location
+
+ # Filter scenes.
+ scene_tokens_location = [e['token'] for e in nusc.scene if e['log_token'] in log_tokens]
+ if scene_tokens is not None:
+ scene_tokens_location = [t for t in scene_tokens_location if t in scene_tokens]
+ assert len(scene_tokens_location) > 0, 'Error: Found 0 valid scenes for location %s!' % log_location
+
+ map_poses = []
+ if verbose:
+ print('Adding ego poses to map...')
+ for scene_token in tqdm(scene_tokens_location, disable=not verbose):
+ # Check that the scene is from the correct location.
+ scene_record = nusc.get('scene', scene_token)
+ scene_name = scene_record['name']
+ scene_id = int(scene_name.replace('scene-', ''))
+ log_record = nusc.get('log', scene_record['log_token'])
+ assert log_record['location'] == log_location, \
+ 'Error: The provided scene_tokens do not correspond to the provided map location!'
+
+ # Print a warning if the localization is known to be bad.
+ if verbose and scene_id in scene_blacklist:
+ print('Warning: %s is known to have a bad fit between ego pose and map.' % scene_name)
+
+ # For each sample in the scene, store the ego pose.
+ sample_tokens = nusc.field2token('sample', 'scene_token', scene_token)
+ for sample_token in sample_tokens:
+ sample_record = nusc.get('sample', sample_token)
+
+ # Poses are associated with the sample_data. Here we use the lidar sample_data.
+ sample_data_record = nusc.get('sample_data', sample_record['data']['LIDAR_TOP'])
+ pose_record = nusc.get('ego_pose', sample_data_record['ego_pose_token'])
+
+ # Calculate the pose on the map and append.
+ map_poses.append(pose_record['translation'])
+
+ # Check that ego poses aren't empty.
+ assert len(map_poses) > 0, 'Error: Found 0 ego poses. Please check the inputs.'
+
+ # Compute number of close ego poses.
+ if verbose:
+ print('Creating plot...')
+ map_poses = np.vstack(map_poses)[:, :2]
+
+ # Render the map patch with the current ego poses.
+ min_patch = np.floor(map_poses.min(axis=0) - patch_margin)
+ max_patch = np.ceil(map_poses.max(axis=0) + patch_margin)
+ diff_patch = max_patch - min_patch
+ if any(diff_patch < min_diff_patch):
+ center_patch = (min_patch + max_patch) / 2
+ diff_patch = np.maximum(diff_patch, min_diff_patch)
+ min_patch = center_patch - diff_patch / 2
+ max_patch = center_patch + diff_patch / 2
+ my_patch = (min_patch[0], min_patch[1], max_patch[0], max_patch[1])
+ fig, ax = self.render_map_patch(my_patch, self.map_api.non_geometric_layers, figsize=(10, 10),
+ render_egoposes_range=render_egoposes_range,
+ render_legend=render_legend, bitmap=bitmap)
+
+ # Plot in the same axis as the map.
+ # Make sure these are plotted "on top".
+ if render_egoposes:
+ ax.scatter(map_poses[:, 0], map_poses[:, 1], s=20, c='k', alpha=1.0, zorder=2)
+ plt.axis('off')
+
+ if out_path is not None:
+ plt.savefig(out_path, bbox_inches='tight', pad_inches=0)
+
+ return map_poses, fig, ax
+
+ def render_next_roads(self,
+ x: float,
+ y: float,
+ alpha: float = 0.5,
+ figsize: Union[None, float, Tuple[float, float]] = None,
+ bitmap: Optional[BitMap] = None) -> Tuple[Figure, Axes]:
+ """
+ Renders the possible next roads from a point of interest.
+ :param x: x coordinate of the point of interest.
+ :param y: y coordinate of the point of interest.
+ :param alpha: The opacity of each layer that gets rendered.
+ :param figsize: Size of the whole figure.
+ :param bitmap: Optional BitMap object to render below the other map layers.
+ """
+ # Get next roads.
+ next_roads = self.map_api.get_next_roads(x, y)
+ layer_names = []
+ tokens = []
+ for layer_name, layer_tokens in next_roads.items():
+ if len(layer_tokens) > 0:
+ layer_names.append(layer_name)
+ tokens.extend(layer_tokens)
+
+ # Render them.
+ fig, ax = self.render_layers(layer_names, alpha, figsize, tokens=tokens, bitmap=bitmap)
+
+ # Render current location with an x.
+ ax.plot(x, y, 'x', markersize=12, color='red')
+
+ return fig, ax
+
+ @staticmethod
+ def _clip_points_behind_camera(points, near_plane: float):
+ """
+ Perform clipping on polygons that are partially behind the camera.
+ This method is necessary as the projection does not work for points behind the camera.
+ Hence we compute the line between the point and the camera and follow that line until we hit the near plane of
+ the camera. Then we use that point.
+ :param points: <np.float32: 3, n> Matrix of points, where each point (x, y, z) is along each column.
+ :param near_plane: If we set the near_plane distance of the camera to 0 then some points will project to
+ infinity. Therefore we need to clip these points at the near plane.
+ :return: The clipped version of the polygon. This may have fewer points than the original polygon if some lines
+ were entirely behind the polygon.
+ """
+ points_clipped = []
+ # Loop through each line on the polygon.
+ # For each line where exactly 1 endpoints is behind the camera, move the point along the line until
+ # it hits the near plane of the camera (clipping).
+ assert points.shape[0] == 3
+ point_count = points.shape[1]
+ for line_1 in range(point_count):
+ line_2 = (line_1 + 1) % point_count
+ point_1 = points[:, line_1]
+ point_2 = points[:, line_2]
+ z_1 = point_1[2]
+ z_2 = point_2[2]
+
+ if z_1 >= near_plane and z_2 >= near_plane:
+ # Both points are in front.
+ # Add both points unless the first is already added.
+ if len(points_clipped) == 0 or all(points_clipped[-1] != point_1):
+ points_clipped.append(point_1)
+ points_clipped.append(point_2)
+ elif z_1 < near_plane and z_2 < near_plane:
+ # Both points are in behind.
+ # Don't add anything.
+ continue
+ else:
+ # One point is in front, one behind.
+ # By convention pointA is behind the camera and pointB in front.
+ if z_1 <= z_2:
+ point_a = points[:, line_1]
+ point_b = points[:, line_2]
+ else:
+ point_a = points[:, line_2]
+ point_b = points[:, line_1]
+ z_a = point_a[2]
+ z_b = point_b[2]
+
+ # Clip line along near plane.
+ pointdiff = point_b - point_a
+ alpha = (near_plane - z_b) / (z_a - z_b)
+ clipped = point_a + (1 - alpha) * pointdiff
+ assert np.abs(clipped[2] - near_plane) < 1e-6
+
+ # Add the first point (if valid and not duplicate), the clipped point and the second point (if valid).
+ if z_1 >= near_plane and (len(points_clipped) == 0 or all(points_clipped[-1] != point_1)):
+ points_clipped.append(point_1)
+ points_clipped.append(clipped)
+ if z_2 >= near_plane:
+ points_clipped.append(point_2)
+
+ points_clipped = np.array(points_clipped).transpose()
+ return points_clipped
+
+ def get_records_in_patch(self,
+ box_coords: Tuple[float, float, float, float],
+ layer_names: List[str] = None,
+ mode: str = 'intersect') -> Dict[str, List[str]]:
+ """
+ Get all the record token that intersects or within a particular rectangular patch.
+ :param box_coords: The rectangular patch coordinates (x_min, y_min, x_max, y_max).
+ :param layer_names: Names of the layers that we want to retrieve in a particular patch.
+ By default will always look for all non geometric layers.
+ :param mode: "intersect" will return all non geometric records that intersects the patch,
+ "within" will return all non geometric records that are within the patch.
+ :return: Dictionary of layer_name - tokens pairs.
+ """
+ if mode not in ['intersect', 'within']:
+ raise ValueError("Mode {} is not valid, choice=('intersect', 'within')".format(mode))
+
+ if layer_names is None:
+ layer_names = self.map_api.non_geometric_layers
+
+ records_in_patch = dict()
+ for layer_name in layer_names:
+ layer_records = []
+ for record in getattr(self.map_api, layer_name):
+ token = record['token']
+ if self.is_record_in_patch(layer_name, token, box_coords, mode):
+ layer_records.append(token)
+
+ records_in_patch.update({layer_name: layer_records})
+
+ return records_in_patch
+
+ def is_record_in_patch(self,
+ layer_name: str,
+ token: str,
+ box_coords: Tuple[float, float, float, float],
+ mode: str = 'intersect') -> bool:
+ """
+ Query whether a particular record is in a rectangular patch.
+ :param layer_name: The layer name of the record.
+ :param token: The record token.
+ :param box_coords: The rectangular patch coordinates (x_min, y_min, x_max, y_max).
+ :param mode: "intersect" means it will return True if the geometric object intersects the patch and False
+ otherwise, "within" will return True if the geometric object is within the patch and False otherwise.
+ :return: Boolean value on whether a particular record intersects or is within a particular patch.
+ """
+ if mode not in ['intersect', 'within']:
+ raise ValueError("Mode {} is not valid, choice=('intersect', 'within')".format(mode))
+
+ if layer_name in self.map_api.lookup_polygon_layers:
+ return self._is_polygon_record_in_patch(token, layer_name, box_coords, mode)
+ elif layer_name in self.map_api.non_geometric_line_layers:
+ return self._is_line_record_in_patch(token, layer_name, box_coords, mode)
+ else:
+ raise ValueError("{} is not a valid layer".format(layer_name))
+
+ def layers_on_point(self, x: float, y: float, layer_names: List[str] = None) -> Dict[str, str]:
+ """
+ Returns all the polygonal layers that a particular point is on.
+ :param x: x coordinate of the point of interest.
+ :param y: y coordinate of the point of interest.
+ :param layer_names: The names of the layers to search for.
+ :return: All the polygonal layers that a particular point is on.
+ """
+ # Default option.
+ if layer_names is None:
+ layer_names = self.map_api.non_geometric_polygon_layers
+
+ layers_on_point = dict()
+ for layer_name in layer_names:
+ layers_on_point.update({layer_name: self.record_on_point(x, y, layer_name)})
+
+ return layers_on_point
+
+ def record_on_point(self, x: float, y: float, layer_name: str) -> str:
+ """
+ Query what record of a layer a particular point is on.
+ :param x: x coordinate of the point of interest.
+ :param y: y coordinate of the point of interest.
+ :param layer_name: The non geometric polygonal layer name that we are interested in.
+ :return: The first token of a layer a particular point is on or '' if no layer is found.
+ """
+ if layer_name not in self.map_api.non_geometric_polygon_layers:
+ raise ValueError("{} is not a polygon layer".format(layer_name))
+
+ point = Point(x, y)
+ records = getattr(self.map_api, layer_name)
+
+ if layer_name == 'drivable_area':
+ for record in records:
+ polygons = [self.map_api.extract_polygon(polygon_token) for polygon_token in record['polygon_tokens']]
+ for polygon in polygons:
+ if point.within(polygon):
+ return record['token']
+ else:
+ pass
+ else:
+ for record in records:
+ polygon = self.map_api.extract_polygon(record['polygon_token'])
+ if point.within(polygon):
+ return record['token']
+ else:
+ pass
+
+ # If nothing is found, return an empty string.
+ return ''
+
+ def extract_polygon(self, polygon_token: str) -> Polygon:
+ """
+ Construct a shapely Polygon object out of a polygon token.
+ :param polygon_token: The token of the polygon record.
+ :return: The polygon wrapped in a shapely Polygon object.
+ """
+ polygon_record = self.map_api.get('polygon', polygon_token)
+
+ exterior_coords = [(self.map_api.get('node', token)['x'], self.map_api.get('node', token)['y'])
+ for token in polygon_record['exterior_node_tokens']]
+
+ interiors = []
+ for hole in polygon_record['holes']:
+ interior_coords = [(self.map_api.get('node', token)['x'], self.map_api.get('node', token)['y'])
+ for token in hole['node_tokens']]
+ if len(interior_coords) > 0: # Add only non-empty holes.
+ interiors.append(interior_coords)
+
+ return Polygon(exterior_coords, interiors)
+
+ def extract_line(self, line_token: str) -> LineString:
+ """
+ Construct a shapely LineString object out of a line token.
+ :param line_token: The token of the line record.
+ :return: The line wrapped in a LineString object.
+ """
+ line_record = self.map_api.get('line', line_token)
+ line_nodes = [(self.map_api.get('node', token)['x'], self.map_api.get('node', token)['y'])
+ for token in line_record['node_tokens']]
+
+ return LineString(line_nodes)
+
+ def get_bounds(self, layer_name: str, token: str) -> Tuple[float, float, float, float]:
+ """
+ Get the bounds of the geometric object that corresponds to a non geometric record.
+ :param layer_name: Name of the layer that we are interested in.
+ :param token: Token of the record.
+ :return: min_x, min_y, max_x, max_y of the line representation.
+ """
+ if layer_name in self.map_api.non_geometric_polygon_layers:
+ return self._get_polygon_bounds(layer_name, token)
+ elif layer_name in self.map_api.non_geometric_line_layers:
+ return self._get_line_bounds(layer_name, token)
+ else:
+ raise ValueError("{} is not a valid layer".format(layer_name))
+
+ def _get_polygon_bounds(self, layer_name: str, token: str) -> Tuple[float, float, float, float]:
+ """
+ Get the extremities of the polygon object that corresponds to a non geometric record.
+ :param layer_name: Name of the layer that we are interested in.
+ :param token: Token of the record.
+ :return: min_x, min_y, max_x, max_y of of the polygon or polygons (for drivable_area) representation.
+ """
+ if layer_name not in self.map_api.non_geometric_polygon_layers:
+ raise ValueError("{} is not a record with polygon representation".format(token))
+
+ record = self.map_api.get(layer_name, token)
+
+ if layer_name == 'drivable_area':
+ polygons = [self.map_api.get('polygon', polygon_token) for polygon_token in record['polygon_tokens']]
+ exterior_node_coords = []
+
+ for polygon in polygons:
+ nodes = [self.map_api.get('node', node_token) for node_token in polygon['exterior_node_tokens']]
+ node_coords = [(node['x'], node['y']) for node in nodes]
+ exterior_node_coords.extend(node_coords)
+
+ exterior_node_coords = np.array(exterior_node_coords)
+ else:
+ exterior_nodes = [self.map_api.get('node', token) for token in record['exterior_node_tokens']]
+ exterior_node_coords = np.array([(node['x'], node['y']) for node in exterior_nodes])
+
+ xs = exterior_node_coords[:, 0]
+ ys = exterior_node_coords[:, 1]
+
+ x2 = xs.max()
+ x1 = xs.min()
+ y2 = ys.max()
+ y1 = ys.min()
+
+ return x1, y1, x2, y2
+
+ def _get_line_bounds(self, layer_name: str, token: str) -> Tuple[float, float, float, float]:
+ """
+ Get the bounds of the line object that corresponds to a non geometric record.
+ :param layer_name: Name of the layer that we are interested in.
+ :param token: Token of the record.
+ :return: min_x, min_y, max_x, max_y of of the line representation.
+ """
+ if layer_name not in self.map_api.non_geometric_line_layers:
+ raise ValueError("{} is not a record with line representation".format(token))
+
+ record = self.map_api.get(layer_name, token)
+ nodes = [self.map_api.get('node', node_token) for node_token in record['node_tokens']]
+ node_coords = [(node['x'], node['y']) for node in nodes]
+ node_coords = np.array(node_coords)
+
+ xs = node_coords[:, 0]
+ ys = node_coords[:, 1]
+
+ x2 = xs.max()
+ x1 = xs.min()
+ y2 = ys.max()
+ y1 = ys.min()
+
+ return x1, y1, x2, y2
+
+ def _is_polygon_record_in_patch(self,
+ token: str,
+ layer_name: str,
+ box_coords: Tuple[float, float, float, float],
+ mode: str = 'intersect') -> bool:
+ """
+ Query whether a particular polygon record is in a rectangular patch.
+ :param layer_name: The layer name of the record.
+ :param token: The record token.
+ :param box_coords: The rectangular patch coordinates (x_min, y_min, x_max, y_max).
+ :param mode: "intersect" means it will return True if the geometric object intersects the patch and False
+ otherwise, "within" will return True if the geometric object is within the patch and False otherwise.
+ :return: Boolean value on whether a particular polygon record intersects or is within a particular patch.
+ """
+ if layer_name not in self.map_api.lookup_polygon_layers:
+ raise ValueError('{} is not a polygonal layer'.format(layer_name))
+
+ x_min, y_min, x_max, y_max = box_coords
+ record = self.map_api.get(layer_name, token)
+ rectangular_patch = box(x_min, y_min, x_max, y_max)
+
+ if layer_name == 'drivable_area':
+ polygons = [self.map_api.extract_polygon(polygon_token) for polygon_token in record['polygon_tokens']]
+ geom = MultiPolygon(polygons)
+ else:
+ geom = self.map_api.extract_polygon(record['polygon_token'])
+
+ if mode == 'intersect':
+ return geom.intersects(rectangular_patch)
+ elif mode == 'within':
+ return geom.within(rectangular_patch)
+
+ def _is_line_record_in_patch(self,
+ token: str,
+ layer_name: str,
+ box_coords: Tuple[float, float, float, float],
+ mode: str = 'intersect') -> bool:
+ """
+ Query whether a particular line record is in a rectangular patch.
+ :param layer_name: The layer name of the record.
+ :param token: The record token.
+ :param box_coords: The rectangular patch coordinates (x_min, y_min, x_max, y_max).
+ :param mode: "intersect" means it will return True if the geometric object intersects the patch and False
+ otherwise, "within" will return True if the geometric object is within the patch and False otherwise.
+ :return: Boolean value on whether a particular line record intersects or is within a particular patch.
+ """
+ if layer_name not in self.map_api.non_geometric_line_layers:
+ raise ValueError("{} is not a line layer".format(layer_name))
+
+ # Retrieve nodes of this line.
+ record = self.map_api.get(layer_name, token)
+ node_recs = [self.map_api.get('node', node_token) for node_token in record['node_tokens']]
+ node_coords = [[node['x'], node['y']] for node in node_recs]
+ node_coords = np.array(node_coords)
+
+ # A few lines in Queenstown have zero nodes. In this case we return False.
+ if len(node_coords) == 0:
+ return False
+
+ # Check that nodes fall inside the path.
+ x_min, y_min, x_max, y_max = box_coords
+ cond_x = np.logical_and(node_coords[:, 0] < x_max, node_coords[:, 0] > x_min)
+ cond_y = np.logical_and(node_coords[:, 1] < y_max, node_coords[:, 1] > y_min)
+ cond = np.logical_and(cond_x, cond_y)
+ if mode == 'intersect':
+ return np.any(cond)
+ elif mode == 'within':
+ return np.all(cond)
+
+ def _render_layer(self, ax: Axes, layer_name: str, alpha: float, tokens: List[str] = None) -> None:
+ """
+ Wrapper method that renders individual layers on an axis.
+ :param ax: The matplotlib axes where the layer will get rendered.
+ :param layer_name: Name of the layer that we are interested in.
+ :param alpha: The opacity of the layer to be rendered.
+ :param tokens: Optional list of tokens to render. None means all tokens are rendered.
+ """
+ if layer_name in self.map_api.non_geometric_polygon_layers:
+ self._render_polygon_layer(ax, layer_name, alpha, tokens)
+ elif layer_name in self.map_api.non_geometric_line_layers:
+ self._render_line_layer(ax, layer_name, alpha, tokens)
+ else:
+ raise ValueError("{} is not a valid layer".format(layer_name))
+
+ def _render_polygon_layer(self, ax: Axes, layer_name: str, alpha: float, tokens: List[str] = None) -> None:
+ """
+ Renders an individual non-geometric polygon layer on an axis.
+ :param ax: The matplotlib axes where the layer will get rendered.
+ :param layer_name: Name of the layer that we are interested in.
+ :param alpha: The opacity of the layer to be rendered.
+ :param tokens: Optional list of tokens to render. None means all tokens are rendered.
+ """
+ if layer_name not in self.map_api.non_geometric_polygon_layers:
+ raise ValueError('{} is not a polygonal layer'.format(layer_name))
+
+ first_time = True
+ records = getattr(self.map_api, layer_name)
+ if tokens is not None:
+ records = [r for r in records if r['token'] in tokens]
+ if layer_name == 'drivable_area':
+ for record in records:
+ polygons = [self.map_api.extract_polygon(polygon_token) for polygon_token in record['polygon_tokens']]
+
+ for polygon in polygons:
+ if first_time:
+ label = layer_name
+ first_time = False
+ else:
+ label = None
+ ax.add_patch(descartes.PolygonPatch(polygon, fc=self.color_map[layer_name], alpha=alpha,
+ label=label))
+ else:
+ for record in records:
+ polygon = self.map_api.extract_polygon(record['polygon_token'])
+
+ if first_time:
+ label = layer_name
+ first_time = False
+ else:
+ label = None
+
+ ax.add_patch(descartes.PolygonPatch(polygon, fc=self.color_map[layer_name], alpha=alpha,
+ label=label))
+
+ def _render_line_layer(self, ax: Axes, layer_name: str, alpha: float, tokens: List[str] = None) -> None:
+ """
+ Renders an individual non-geometric line layer on an axis.
+ :param ax: The matplotlib axes where the layer will get rendered.
+ :param layer_name: Name of the layer that we are interested in.
+ :param alpha: The opacity of the layer to be rendered.
+ :param tokens: Optional list of tokens to render. None means all tokens are rendered.
+ """
+ if layer_name not in self.map_api.non_geometric_line_layers:
+ raise ValueError("{} is not a line layer".format(layer_name))
+
+ first_time = True
+ records = getattr(self.map_api, layer_name)
+ if tokens is not None:
+ records = [r for r in records if r['token'] in tokens]
+ for record in records:
+ if first_time:
+ label = layer_name
+ first_time = False
+ else:
+ label = None
+ line = self.map_api.extract_line(record['line_token'])
+ if line.is_empty: # Skip lines without nodes
+ continue
+ xs, ys = line.xy
+
+ if layer_name == 'traffic_light':
+ # Draws an arrow with the physical traffic light as the starting point, pointing to the direction on
+ # where the traffic light points.
+ ax.add_patch(Arrow(xs[0], ys[0], xs[1]-xs[0], ys[1]-ys[0], color=self.color_map[layer_name],
+ label=label))
+ else:
+ ax.plot(xs, ys, color=self.color_map[layer_name], alpha=alpha, label=label)
+
+ def _get_layer_geom(self,
+ patch_box: Tuple[float, float, float, float],
+ patch_angle: float,
+ layer_name: str) -> List[Geometry]:
+ """
+ Wrapper method that gets the geometries for each layer.
+ :param patch_box: Patch box defined as [x_center, y_center, height, width].
+ :param patch_angle: Patch orientation in degrees.
+ :param layer_name: Name of map layer to be converted to binary map mask patch.
+ :return: List of geometries for the given layer.
+ """
+ if layer_name in self.map_api.non_geometric_polygon_layers:
+ return self._get_layer_polygon(patch_box, patch_angle, layer_name)
+ elif layer_name in self.map_api.non_geometric_line_layers:
+ return self._get_layer_line(patch_box, patch_angle, layer_name)
+ else:
+ raise ValueError("{} is not a valid layer".format(layer_name))
+
+ def _layer_geom_to_mask(self,
+ layer_name: str,
+ layer_geom: List[Geometry],
+ local_box: Tuple[float, float, float, float],
+ canvas_size: Tuple[int, int]) -> np.ndarray:
+ """
+ Wrapper method that gets the mask for each layer's geometries.
+ :param layer_name: The name of the layer for which we get the masks.
+ :param layer_geom: List of the geometries of the layer specified in layer_name.
+ :param local_box: The local patch box defined as (x_center, y_center, height, width), where typically
+ x_center = y_center = 0.
+ :param canvas_size: Size of the output mask (h, w).
+ """
+ if layer_name in self.map_api.non_geometric_polygon_layers:
+ return self._polygon_geom_to_mask(layer_geom, local_box, layer_name, canvas_size)
+ elif layer_name in self.map_api.non_geometric_line_layers:
+ return self._line_geom_to_mask(layer_geom, local_box, layer_name, canvas_size)
+ else:
+ raise ValueError("{} is not a valid layer".format(layer_name))
+
+ @staticmethod
+ def mask_for_polygons(polygons: MultiPolygon, mask: np.ndarray) -> np.ndarray:
+ """
+ Convert a polygon or multipolygon list to an image mask ndarray.
+ :param polygons: List of Shapely polygons to be converted to numpy array.
+ :param mask: Canvas where mask will be generated.
+ :return: Numpy ndarray polygon mask.
+ """
+ if not polygons:
+ return mask
+
+ def int_coords(x):
+ # function to round and convert to int
+ return np.array(x).round().astype(np.int32)
+ exteriors = [int_coords(poly.exterior.coords) for poly in polygons]
+ interiors = [int_coords(pi.coords) for poly in polygons for pi in poly.interiors]
+ cv2.fillPoly(mask, exteriors, 1)
+ cv2.fillPoly(mask, interiors, 0)
+ return mask
+
+ @staticmethod
+ def mask_for_lines(lines: LineString, mask: np.ndarray) -> np.ndarray:
+ """
+ Convert a Shapely LineString back to an image mask ndarray.
+ :param lines: List of shapely LineStrings to be converted to a numpy array.
+ :param mask: Canvas where mask will be generated.
+ :return: Numpy ndarray line mask.
+ """
+ if lines.geom_type == 'MultiLineString':
+ for line in lines:
+ coords = np.asarray(list(line.coords), np.int32)
+ coords = coords.reshape((-1, 2))
+ cv2.polylines(mask, [coords], False, 1, 2)
+ else:
+ coords = np.asarray(list(lines.coords), np.int32)
+ coords = coords.reshape((-1, 2))
+ cv2.polylines(mask, [coords], False, 1, 2)
+
+ return mask
+
+ def _polygon_geom_to_mask(self,
+ layer_geom: List[Polygon],
+ local_box: Tuple[float, float, float, float],
+ layer_name: str,
+ canvas_size: Tuple[int, int]) -> np.ndarray:
+ """
+ Convert polygon inside patch to binary mask and return the map patch.
+ :param layer_geom: list of polygons for each map layer
+ :param local_box: The local patch box defined as (x_center, y_center, height, width), where typically
+ x_center = y_center = 0.
+ :param layer_name: name of map layer to be converted to binary map mask patch.
+ :param canvas_size: Size of the output mask (h, w).
+ :return: Binary map mask patch with the size canvas_size.
+ """
+ if layer_name not in self.map_api.non_geometric_polygon_layers:
+ raise ValueError('{} is not a polygonal layer'.format(layer_name))
+
+ patch_x, patch_y, patch_h, patch_w = local_box
+
+ patch = self.get_patch_coord(local_box)
+
+ canvas_h = canvas_size[0]
+ canvas_w = canvas_size[1]
+
+ scale_height = canvas_h / patch_h
+ scale_width = canvas_w / patch_w
+
+ trans_x = -patch_x + patch_w / 2.0
+ trans_y = -patch_y + patch_h / 2.0
+
+ map_mask = np.zeros(canvas_size, np.uint8)
+
+ for polygon in layer_geom:
+ new_polygon = polygon.intersection(patch)
+ if not new_polygon.is_empty:
+ new_polygon = affinity.affine_transform(new_polygon,
+ [1.0, 0.0, 0.0, 1.0, trans_x, trans_y])
+ new_polygon = affinity.scale(new_polygon, xfact=scale_width, yfact=scale_height, origin=(0, 0))
+
+ if new_polygon.geom_type is 'Polygon':
+ new_polygon = MultiPolygon([new_polygon])
+ map_mask = self.mask_for_polygons(new_polygon, map_mask)
+
+ return map_mask
+
+ def _line_geom_to_mask(self,
+ layer_geom: List[LineString],
+ local_box: Tuple[float, float, float, float],
+ layer_name: str,
+ canvas_size: Tuple[int, int]) -> Optional[np.ndarray]:
+ """
+ Convert line inside patch to binary mask and return the map patch.
+ :param layer_geom: list of LineStrings for each map layer
+ :param local_box: The local patch box defined as (x_center, y_center, height, width), where typically
+ x_center = y_center = 0.
+ :param layer_name: name of map layer to be converted to binary map mask patch.
+ :param canvas_size: Size of the output mask (h, w).
+ :return: Binary map mask patch in a canvas size.
+ """
+ if layer_name not in self.map_api.non_geometric_line_layers:
+ raise ValueError("{} is not a line layer".format(layer_name))
+
+ patch_x, patch_y, patch_h, patch_w = local_box
+
+ patch = self.get_patch_coord(local_box)
+
+ canvas_h = canvas_size[0]
+ canvas_w = canvas_size[1]
+ scale_height = canvas_h/patch_h
+ scale_width = canvas_w/patch_w
+
+ trans_x = -patch_x + patch_w / 2.0
+ trans_y = -patch_y + patch_h / 2.0
+
+ map_mask = np.zeros(canvas_size, np.uint8)
+
+ if layer_name is 'traffic_light':
+ return None
+
+ for line in layer_geom:
+ new_line = line.intersection(patch)
+ if not new_line.is_empty:
+ new_line = affinity.affine_transform(new_line,
+ [1.0, 0.0, 0.0, 1.0, trans_x, trans_y])
+ new_line = affinity.scale(new_line, xfact=scale_width, yfact=scale_height, origin=(0, 0))
+
+ map_mask = self.mask_for_lines(new_line, map_mask)
+ return map_mask
+
+ def _get_layer_polygon(self,
+ patch_box: Tuple[float, float, float, float],
+ patch_angle: float,
+ layer_name: str) -> List[Polygon]:
+ """
+ Retrieve the polygons of a particular layer within the specified patch.
+ :param patch_box: Patch box defined as [x_center, y_center, height, width].
+ :param patch_angle: Patch orientation in degrees.
+ :param layer_name: name of map layer to be extracted.
+ :return: List of Polygon in a patch box.
+ """
+ if layer_name not in self.map_api.non_geometric_polygon_layers:
+ raise ValueError('{} is not a polygonal layer'.format(layer_name))
+
+ patch_x = patch_box[0]
+ patch_y = patch_box[1]
+
+ patch = self.get_patch_coord(patch_box, patch_angle)
+
+ records = getattr(self.map_api, layer_name)
+
+ polygon_list = []
+ if layer_name == 'drivable_area':
+ for record in records:
+ polygons = [self.map_api.extract_polygon(polygon_token) for polygon_token in record['polygon_tokens']]
+
+ for polygon in polygons:
+ new_polygon = polygon.intersection(patch)
+ if not new_polygon.is_empty:
+ new_polygon = affinity.rotate(new_polygon, -patch_angle,
+ origin=(patch_x, patch_y), use_radians=False)
+ new_polygon = affinity.affine_transform(new_polygon,
+ [1.0, 0.0, 0.0, 1.0, -patch_x, -patch_y])
+ if new_polygon.geom_type is 'Polygon':
+ new_polygon = MultiPolygon([new_polygon])
+ polygon_list.append(new_polygon)
+
+ else:
+ for record in records:
+ polygon = self.map_api.extract_polygon(record['polygon_token'])
+
+ if polygon.is_valid:
+ new_polygon = polygon.intersection(patch)
+ if not new_polygon.is_empty:
+ new_polygon = affinity.rotate(new_polygon, -patch_angle,
+ origin=(patch_x, patch_y), use_radians=False)
+ new_polygon = affinity.affine_transform(new_polygon,
+ [1.0, 0.0, 0.0, 1.0, -patch_x, -patch_y])
+ if new_polygon.geom_type is 'Polygon':
+ new_polygon = MultiPolygon([new_polygon])
+ polygon_list.append(new_polygon)
+
+ return polygon_list
+
+ def _get_layer_line(self,
+ patch_box: Tuple[float, float, float, float],
+ patch_angle: float,
+ layer_name: str) -> Optional[List[LineString]]:
+ """
+ Retrieve the lines of a particular layer within the specified patch.
+ :param patch_box: Patch box defined as [x_center, y_center, height, width].
+ :param patch_angle: Patch orientation in degrees.
+ :param layer_name: name of map layer to be converted to binary map mask patch.
+ :return: List of LineString in a patch box.
+ """
+ if layer_name not in self.map_api.non_geometric_line_layers:
+ raise ValueError("{} is not a line layer".format(layer_name))
+
+ if layer_name is 'traffic_light':
+ return None
+
+ patch_x = patch_box[0]
+ patch_y = patch_box[1]
+
+ patch = self.get_patch_coord(patch_box, patch_angle)
+
+ line_list = []
+ records = getattr(self.map_api, layer_name)
+ for record in records:
+ line = self.map_api.extract_line(record['line_token'])
+ if line.is_empty: # Skip lines without nodes.
+ continue
+
+ new_line = line.intersection(patch)
+ if not new_line.is_empty:
+ new_line = affinity.rotate(new_line, -patch_angle, origin=(patch_x, patch_y), use_radians=False)
+ new_line = affinity.affine_transform(new_line,
+ [1.0, 0.0, 0.0, 1.0, -patch_x, -patch_y])
+ line_list.append(new_line)
+
+ return line_list
+
+ @staticmethod
+ def get_patch_coord(patch_box: Tuple[float, float, float, float],
+ patch_angle: float = 0.0) -> Polygon:
+ """
+ Convert patch_box to shapely Polygon coordinates.
+ :param patch_box: Patch box defined as [x_center, y_center, height, width].
+ :param patch_angle: Patch orientation in degrees.
+ :return: Box Polygon for patch_box.
+ """
+ patch_x, patch_y, patch_h, patch_w = patch_box
+
+ x_min = patch_x - patch_w / 2.0
+ y_min = patch_y - patch_h / 2.0
+ x_max = patch_x + patch_w / 2.0
+ y_max = patch_y + patch_h / 2.0
+
+ patch = box(x_min, y_min, x_max, y_max)
+ patch = affinity.rotate(patch, patch_angle, origin=(patch_x, patch_y), use_radians=False)
+
+ return patch
+
+ def _get_figsize(self, figsize: Union[None, float, Tuple[float, float]]) -> Tuple[float, float]:
+ """
+ Utility function that scales the figure size by the map canvas size.
+ If figsize is:
+ - None => Return default scale.
+ - Scalar => Scale canvas size.
+ - Two-tuple => Use the specified figure size.
+ :param figsize: The input figure size.
+ :return: The output figure size.
+ """
+ # Divide canvas size by arbitrary scalar to get into cm range.
+ canvas_size = np.array(self.map_api.canvas_edge)[::-1] / 200
+
+ if figsize is None:
+ return tuple(canvas_size)
+ elif type(figsize) in [int, float]:
+ return tuple(canvas_size * figsize)
+ elif type(figsize) == tuple and len(figsize) == 2:
+ return figsize
+ else:
+ raise Exception('Error: Invalid figsize: %s' % figsize)
diff --git a/python-sdk/nuscenes/map_expansion/tests/__init__.py b/python-sdk/nuscenes/map_expansion/tests/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/python-sdk/nuscenes/map_expansion/tests/test_all_maps.py b/python-sdk/nuscenes/map_expansion/tests/test_all_maps.py
new file mode 100644
index 0000000..3da14cd
--- /dev/null
+++ b/python-sdk/nuscenes/map_expansion/tests/test_all_maps.py
@@ -0,0 +1,88 @@
+import os
+import unittest
+from collections import defaultdict
+
+import matplotlib.pyplot as plt
+import tqdm
+
+from nuscenes.map_expansion.map_api import NuScenesMap, locations
+from nuscenes.map_expansion.utils import get_egoposes_on_drivable_ratio, get_disconnected_lanes
+from nuscenes.nuscenes import NuScenes
+
+
+class TestAllMaps(unittest.TestCase):
+ version = 'v1.0-mini'
+ render = False
+
+ def setUp(self):
+ """ Initialize the map for each location. """
+
+ self.nusc_maps = dict()
+ for map_name in locations:
+ # Load map.
+ nusc_map = NuScenesMap(map_name=map_name, dataroot=os.environ['NUSCENES'])
+
+ # Render for debugging.
+ if self.render:
+ nusc_map.render_layers(['lane'], figsize=1)
+ plt.show()
+
+ self.nusc_maps[map_name] = nusc_map
+
+ def test_layer_stats(self):
+ """ Test if each layer has the right number of instances. This is useful to compare between map versions. """
+ layer_counts = defaultdict(lambda: [])
+ ref_counts = {
+ 'singapore-onenorth': [1, 783, 645, 936, 120, 838, 451, 39, 152, 357, 127],
+ 'singapore-hollandvillage': [426, 167, 387, 601, 28, 498, 300, 0, 107, 220, 119],
+ 'singapore-queenstown': [219, 260, 676, 910, 75, 457, 437, 40, 172, 257, 81],
+ 'boston-seaport': [2, 928, 969, 1215, 340, 301, 775, 275, 377, 671, 307]
+ }
+
+ for map_name in locations:
+ nusc_map = self.nusc_maps[map_name]
+ for layer_name in nusc_map.non_geometric_layers:
+ layer_objs = nusc_map.json_obj[layer_name]
+ layer_counts[map_name].append(len(layer_objs))
+
+ assert ref_counts[map_name] == layer_counts[map_name], \
+ 'Error: Map %s has a different number of layers: \n%s vs. \n%s' % \
+ (map_name, ref_counts[map_name], layer_counts[map_name])
+
+ @unittest.skip # This test is known to fail on dozens of disconnected lanes.
+ def test_disconnected_lanes(self):
+ """ Check if any lanes are disconnected. """
+ found_error = False
+ for map_name in locations:
+ nusc_map = self.nusc_maps[map_name]
+ disconnected = get_disconnected_lanes(nusc_map)
+ if len(disconnected) > 0:
+ print('Error: Missing connectivity in map %s for %d lanes: \n%s'
+ % (map_name, len(disconnected), disconnected))
+ found_error = True
+ self.assertFalse(found_error, 'Error: Found missing connectivity. See messages above!')
+
+ def test_egoposes_on_map(self):
+ """ Test that all ego poses land on """
+ nusc = NuScenes(version=self.version, dataroot=os.environ['NUSCENES'], verbose=False)
+ whitelist = ['scene-0499', 'scene-0501', 'scene-0502', 'scene-0515', 'scene-0517']
+
+ invalid_scenes = []
+ for scene in tqdm.tqdm(nusc.scene):
+ if scene['name'] in whitelist:
+ continue
+
+ log = nusc.get('log', scene['log_token'])
+ map_name = log['location']
+ nusc_map = self.nusc_maps[map_name]
+ ratio_valid = get_egoposes_on_drivable_ratio(nusc, nusc_map, scene['token'])
+ if ratio_valid != 1.0:
+ print('Error: Scene %s has a ratio of %f ego poses on the driveable area!'
+ % (scene['name'], ratio_valid))
+ invalid_scenes.append(scene['name'])
+
+ self.assertEqual(len(invalid_scenes), 0)
+
+
+if __name__ == '__main__':
+ unittest.main()
diff --git a/python-sdk/nuscenes/map_expansion/tests/test_arcline_path_utils.py b/python-sdk/nuscenes/map_expansion/tests/test_arcline_path_utils.py
new file mode 100644
index 0000000..0344425
--- /dev/null
+++ b/python-sdk/nuscenes/map_expansion/tests/test_arcline_path_utils.py
@@ -0,0 +1,133 @@
+import unittest
+
+import math
+import numpy as np
+
+from nuscenes.map_expansion import arcline_path_utils
+
+
+class TestUtils(unittest.TestCase):
+
+ def setUp(self) -> None:
+ self.straight_path = {'start_pose': [421.2419602954602, 1087.9127960414617, 2.739593514975998],
+ 'end_pose': [391.7142849867393, 1100.464077182952, 2.7365754617298705],
+ 'shape': 'LSR',
+ 'radius': 999.999,
+ 'segment_length': [0.23651121617864976, 28.593481378991886, 3.254561444252876]}
+ self.left_path = {'start_pose': [391.7142849867393, 1100.464077182952, 2.7365754617298705],
+ 'end_pose': [372.7733659833846, 1093.0160135871615, -2.000208580915862],
+ 'shape': 'LSL',
+ 'radius': 14.473414516079979,
+ 'segment_length': [22.380622583127813, 0.18854612175175053, 0.0010839266609007578]}
+ self.right_path = {'start_pose': [367.53376358458553, 1097.5300417399676, 1.1738120532326812],
+ 'end_pose': [392.24904359636037, 1112.5206834496375, -0.4033046016493182],
+ 'shape': 'RSR',
+ 'radius': 16.890467008945414,
+ 'segment_length': [4.423187697943063e-05, 6.490596454713637, 26.63819259666578]}
+
+ self.straight_lane = [self.straight_path]
+ self.curved_lane = [self.straight_path, self.left_path]
+ self.right_lane = [self.right_path]
+
+ def test_discretize_straight_path(self):
+
+ discrete_path = arcline_path_utils.discretize(self.straight_path, 10)
+ answer = np.array([(421.2419602954602, 1087.9127960414617, 2.739593514975998),
+ (413.85953060356087, 1091.049417600379, 2.739830026428688),
+ (406.4770899726762, 1094.1860134184205, 2.739830026428688),
+ (399.0946493417915, 1097.322609236462, 2.739830026428688),
+ (391.71428498673856, 1100.4640771829522, 2.7365754617298705)])
+
+ np.testing.assert_allclose(answer, discrete_path)
+
+ def test_discretize_curved_path(self):
+
+ discrete_path = arcline_path_utils.discretize(self.left_path, 2)
+ answer = np.array([(391.7142849867393, 1100.464077182952, 2.7365754617298705),
+ (389.94237388555354, 1101.0909492468568, 2.8665278225823894),
+ (388.10416900705434, 1101.4829190922167, 2.996480183434908),
+ (386.23066958739906, 1101.633376593063, 3.126432544287426),
+ (384.3534700650694, 1101.539784454639, -3.026800402039642),
+ (382.50422727657343, 1101.2037210019917, -2.8968480411871234),
+ (380.714126599876, 1100.630853563314, -2.7668956803346045),
+ (379.01335604844144, 1099.830842896896, -2.6369433194820857),
+ (377.4305971846951, 1098.8171802734153, -2.506990958629568),
+ (375.99254143806974, 1097.6069599609898, -2.377038597777049),
+ (374.7234399843828, 1096.220590949774, -2.24708623692453),
+ (373.64469477731785, 1094.6814527775348, -2.117133876072012),
+ (372.7733659833847, 1093.0160135871613, -2.0002085809158623)])
+
+ np.testing.assert_allclose(answer, discrete_path)
+
+ def test_discretize_curved_lane(self):
+
+ discrete_path = arcline_path_utils.discretize_lane(self.curved_lane, 5)
+ answer = np.array([(421.2419602954602, 1087.9127960414617, 2.739593514975998),
+ (417.0234337310829, 1089.7051622497897, 2.739830026428688),
+ (412.80489622772023, 1091.497502717242, 2.739830026428688),
+ (408.5863587243576, 1093.2898431846943, 2.739830026428688),
+ (404.3678212209949, 1095.0821836521468, 2.739830026428688),
+ (400.1492837176322, 1096.874524119599, 2.739830026428688),
+ (395.93074621426956, 1098.6668645870514, 2.739830026428688),
+ (391.71428498673856, 1100.4640771829522, 2.7365754617298705),
+ (391.7142849867393, 1100.464077182952, 2.7365754617298705),
+ (387.35724292592613, 1101.5723176767192, 3.048461127775915),
+ (382.87033132963325, 1101.2901176788932, -2.922838513357627),
+ (378.6864775951582, 1099.6447057425564, -2.610952847311582),
+ (375.20936805976606, 1096.7948422737907, -2.2990671812655377),
+ (372.7733659833847, 1093.0160135871613, -2.0002085809158623)])
+ np.testing.assert_allclose(answer, discrete_path)
+
+ def test_length_of_lane(self):
+
+ self.assertEqual(arcline_path_utils.length_of_lane(self.straight_lane),
+ sum(self.straight_path['segment_length']))
+
+ self.assertEqual(arcline_path_utils.length_of_lane(self.right_lane),
+ sum(self.right_path['segment_length']))
+
+ self.assertEqual(arcline_path_utils.length_of_lane(self.curved_lane),
+ sum(self.straight_path['segment_length']) + sum(self.left_path['segment_length']))
+
+ def test_project_pose_to_straight_lane(self):
+
+ theta = 2.739593514975998
+ end_pose = 421.2419602954602 + 10 * math.cos(theta), 1087.9127960414617 + 10 * math.sin(theta), theta
+
+ pose, s = arcline_path_utils.project_pose_to_lane(end_pose, self.straight_lane)
+
+ np.testing.assert_allclose(np.array(pose).astype('int'), np.array(end_pose).astype('int'))
+ self.assertTrue(abs(s - 10) <= 0.5)
+
+ def test_project_pose_not_close_to_lane(self):
+
+ pose = 362, 1092, 1.15
+
+ pose_on_lane, s = arcline_path_utils.project_pose_to_lane(pose, self.right_lane)
+ self.assertListEqual(list(pose_on_lane), self.right_path['start_pose'])
+ self.assertEqual(s, 0)
+
+ def test_project_pose_to_curved_lane(self):
+
+ theta = 2.739593514975998
+ end_pose_1 = 421.2419602954602 + 10 * math.cos(theta), 1087.9127960414617 + 10 * math.sin(theta), theta
+
+ end_pose_2 = 381, 1100, -2.76
+
+ pose, s = arcline_path_utils.project_pose_to_lane(end_pose_1, self.curved_lane)
+ np.testing.assert_allclose(np.array(pose).astype('int'), np.array(end_pose_1).astype('int'))
+ self.assertTrue(abs(s - 10) <= 0.5)
+
+ pose_2, s_2 = arcline_path_utils.project_pose_to_lane(end_pose_2, self.curved_lane)
+ np.testing.assert_allclose(np.array(pose_2[:2]).astype('int'), np.array([380, 1100]))
+ self.assertTrue(abs(s_2 - 44) <= 0.5)
+
+ def test_get_curvature_straight_lane(self):
+
+ curvature = arcline_path_utils.get_curvature_at_distance_along_lane(15, self.straight_lane)
+ self.assertEqual(curvature, 0)
+
+ def test_curvature_curved_lane(self):
+
+ curvature = arcline_path_utils.get_curvature_at_distance_along_lane(53, self.curved_lane)
+ self.assertEqual(curvature, 1 / self.left_path['radius'])
diff --git a/python-sdk/nuscenes/map_expansion/utils.py b/python-sdk/nuscenes/map_expansion/utils.py
new file mode 100644
index 0000000..1d5f501
--- /dev/null
+++ b/python-sdk/nuscenes/map_expansion/utils.py
@@ -0,0 +1,142 @@
+from typing import List, Dict, Set
+
+from nuscenes.map_expansion.map_api import NuScenesMap
+from nuscenes.nuscenes import NuScenes
+
+
+def get_egoposes_on_drivable_ratio(nusc: NuScenes, nusc_map: NuScenesMap, scene_token: str) -> float:
+ """
+ Get the ratio of ego poses on the drivable area.
+ :param nusc: A NuScenes instance.
+ :param nusc_map: The NuScenesMap instance of a particular map location.
+ :param scene_token: The token of the current scene.
+ :return: The ratio of poses that fall on the driveable area.
+ """
+
+ # Go through each sample in the scene.
+ sample_tokens = nusc.field2token('sample', 'scene_token', scene_token)
+ poses_all = 0
+ poses_valid = 0
+ for sample_token in sample_tokens:
+
+ # Poses are associated with the sample_data. Here we use the lidar sample_data.
+ sample_record = nusc.get('sample', sample_token)
+ sample_data_record = nusc.get('sample_data', sample_record['data']['LIDAR_TOP'])
+ pose_record = nusc.get('ego_pose', sample_data_record['ego_pose_token'])
+
+ # Check if the ego pose is on the driveable area.
+ ego_pose = pose_record['translation'][:2]
+ record = nusc_map.record_on_point(ego_pose[0], ego_pose[1], 'drivable_area')
+ if len(record) > 0:
+ poses_valid += 1
+ poses_all += 1
+ ratio_valid = poses_valid / poses_all
+
+ return ratio_valid
+
+
+def get_disconnected_subtrees(connectivity: Dict[str, dict]) -> Set[str]:
+ """
+ Compute lanes or lane_connectors that are part of disconnected subtrees.
+ :param connectivity: The connectivity of the current NuScenesMap.
+ :return: The lane_tokens for lanes that are part of a disconnected subtree.
+ """
+ # Init.
+ connected = set()
+ pending = set()
+
+ # Add first lane.
+ all_keys = list(connectivity.keys())
+ first_key = all_keys[0]
+ all_keys = set(all_keys)
+ pending.add(first_key)
+
+ while len(pending) > 0:
+ # Get next lane.
+ lane_token = pending.pop()
+ connected.add(lane_token)
+
+ # Add lanes connected to this lane.
+ if lane_token in connectivity:
+ incoming = connectivity[lane_token]['incoming']
+ outgoing = connectivity[lane_token]['outgoing']
+ inout_lanes = set(incoming + outgoing)
+ for other_lane_token in inout_lanes:
+ if other_lane_token not in connected:
+ pending.add(other_lane_token)
+
+ disconnected = all_keys - connected
+ assert len(disconnected) < len(connected), 'Error: Bad initialization chosen!'
+ return disconnected
+
+
+def drop_disconnected_lanes(nusc_map: NuScenesMap) -> NuScenesMap:
+ """
+ Remove any disconnected lanes.
+ Note: This function is currently not used and we do not recommend using it. Some lanes that we do not drive on are
+ disconnected from the other lanes. Removing them would create a single connected graph. It also removes
+ meaningful information, which is why we do not drop these.
+ :param nusc_map: The NuScenesMap instance of a particular map location.
+ :return: The cleaned NuScenesMap instance.
+ """
+
+ # Get disconnected lanes.
+ disconnected = get_disconnected_lanes(nusc_map)
+
+ # Remove lane.
+ nusc_map.lane = [lane for lane in nusc_map.lane if lane['token'] not in disconnected]
+
+ # Remove lane_connector.
+ nusc_map.lane_connector = [lane for lane in nusc_map.lane_connector if lane['token'] not in disconnected]
+
+ # Remove connectivity entries.
+ for lane_token in disconnected:
+ if lane_token in nusc_map.connectivity:
+ del nusc_map.connectivity[lane_token]
+
+ # Remove arcline_path_3.
+ for lane_token in disconnected:
+ if lane_token in nusc_map.arcline_path_3:
+ del nusc_map.arcline_path_3[lane_token]
+
+ # Remove connectivity references.
+ empty_connectivity = []
+ for lane_token, connectivity in nusc_map.connectivity.items():
+ connectivity['incoming'] = [i for i in connectivity['incoming'] if i not in disconnected]
+ connectivity['outgoing'] = [o for o in connectivity['outgoing'] if o not in disconnected]
+ if len(connectivity['incoming']) + len(connectivity['outgoing']) == 0:
+ empty_connectivity.append(lane_token)
+ for lane_token in empty_connectivity:
+ del nusc_map.connectivity[lane_token]
+
+ # To fix the map class, we need to update some indices.
+ nusc_map._make_token2ind()
+
+ return nusc_map
+
+
+def get_disconnected_lanes(nusc_map: NuScenesMap) -> List[str]:
+ """
+ Get a list of all disconnected lanes and lane_connectors.
+ :param nusc_map: The NuScenesMap instance of a particular map location.
+ :return: A list of lane or lane_connector tokens.
+ """
+ disconnected = set()
+ for lane_token, connectivity in nusc_map.connectivity.items():
+ # Lanes which are disconnected.
+ inout_lanes = connectivity['incoming'] + connectivity['outgoing']
+ if len(inout_lanes) == 0:
+ disconnected.add(lane_token)
+ continue
+
+ # Lanes that only exist in connectivity (not currently an issue).
+ for inout_lane_token in inout_lanes:
+ if inout_lane_token not in nusc_map._token2ind['lane'] and \
+ inout_lane_token not in nusc_map._token2ind['lane_connector']:
+ disconnected.add(inout_lane_token)
+
+ # Lanes that are part of disconnected subtrees.
+ subtrees = get_disconnected_subtrees(nusc_map.connectivity)
+ disconnected = disconnected.union(subtrees)
+
+ return sorted(list(disconnected))
diff --git a/python-sdk/nuscenes/nuscenes.py b/python-sdk/nuscenes/nuscenes.py
new file mode 100644
index 0000000..7139f82
--- /dev/null
+++ b/python-sdk/nuscenes/nuscenes.py
@@ -0,0 +1,2152 @@
+# nuScenes dev-kit.
+# Code written by Oscar Beijbom, Holger Caesar & Fong Whye Kit, 2020.
+
+import json
+import math
+import os
+import os.path as osp
+import sys
+import time
+from datetime import datetime
+from typing import Tuple, List, Iterable
+
+import cv2
+import matplotlib.pyplot as plt
+import numpy as np
+import sklearn.metrics
+from PIL import Image
+from matplotlib import rcParams
+from matplotlib.axes import Axes
+from pyquaternion import Quaternion
+from tqdm import tqdm
+
+from nuscenes.lidarseg.lidarseg_utils import colormap_to_colors, plt_to_cv2, get_stats, \
+ get_labels_in_coloring, create_lidarseg_legend, paint_points_label
+from nuscenes.utils.data_classes import LidarPointCloud, RadarPointCloud, Box, MyBox
+from nuscenes.utils.geometry_utils import view_points, box_in_image, BoxVisibility, transform_matrix
+from nuscenes.utils.map_mask import MapMask
+from nuscenes.utils.color_map import get_colormap
+
+PYTHON_VERSION = sys.version_info[0]
+
+if not PYTHON_VERSION == 3:
+ raise ValueError("nuScenes dev-kit only supports Python version 3.")
+
+
+class NuScenes:
+ """
+ Database class for nuScenes to help query and retrieve information from the database.
+ """
+
+ def __init__(self,
+ version: str = 'v1.0-mini',
+ dataroot: str = '/data/sets/nuscenes',
+ verbose: bool = True,
+ map_resolution: float = 0.1):
+ """
+ Loads database and creates reverse indexes and shortcuts.
+ :param version: Version to load (e.g. "v1.0", ...).
+ :param dataroot: Path to the tables and data.
+ :param verbose: Whether to print status messages during load.
+ :param map_resolution: Resolution of maps (meters).
+ """
+ self.version = version
+ self.dataroot = dataroot
+ self.verbose = verbose
+ self.table_names = ['category', 'attribute', 'visibility', 'instance', 'sensor', 'calibrated_sensor',
+ 'ego_pose', 'log', 'scene', 'sample', 'sample_data', 'sample_annotation', 'map']
+
+ assert osp.exists(self.table_root), 'Database version not found: {}'.format(self.table_root)
+
+ start_time = time.time()
+ if verbose:
+ print("======\nLoading NuScenes tables for version {}...".format(self.version))
+
+ # Explicitly assign tables to help the IDE determine valid class members.
+ self.category = self.__load_table__('category')
+ self.attribute = self.__load_table__('attribute')
+ self.visibility = self.__load_table__('visibility')
+ self.instance = self.__load_table__('instance')
+ self.sensor = self.__load_table__('sensor')
+ self.calibrated_sensor = self.__load_table__('calibrated_sensor')
+ self.ego_pose = self.__load_table__('ego_pose')
+ self.log = self.__load_table__('log')
+ self.scene = self.__load_table__('scene')
+ self.sample = self.__load_table__('sample')
+ self.sample_data = self.__load_table__('sample_data')
+ self.sample_annotation = self.__load_table__('sample_annotation')
+ self.map = self.__load_table__('map')
+
+ # Initialize the colormap which maps from class names to RGB values.
+ self.colormap = get_colormap()
+
+ # If available, also load the lidarseg annotations.
+ if osp.exists(osp.join(self.table_root, 'lidarseg.json')):
+ if self.verbose:
+ print('Loading nuScenes-lidarseg...')
+
+ self.lidarseg = self.__load_table__('lidarseg')
+ num_lidarseg_recs = len(self.lidarseg)
+ num_bin_files = len([name for name in os.listdir(os.path.join(self.dataroot, 'lidarseg', self.version))
+ if name.endswith('.bin')])
+ assert num_lidarseg_recs == num_bin_files, \
+ 'Error: There are {} .bin files but {} lidarseg records.'.format(num_bin_files, num_lidarseg_recs)
+ self.table_names.append('lidarseg')
+
+ # Create mapping from class index to class name, and vice versa, for easy lookup later on.
+ self.lidarseg_idx2name_mapping = dict()
+ self.lidarseg_name2idx_mapping = dict()
+ for lidarseg_category in self.category:
+ # Check that the category records contain both the keys 'name' and 'index'.
+ assert 'index' in lidarseg_category.keys(), \
+ 'Please use the category.json that comes with nuScenes-lidarseg, and not the old category.json.'
+
+ self.lidarseg_idx2name_mapping[lidarseg_category['index']] = lidarseg_category['name']
+ self.lidarseg_name2idx_mapping[lidarseg_category['name']] = lidarseg_category['index']
+
+ # Sort the colormap to ensure that it is ordered according to the indices in self.category.
+ self.colormap = dict({c['name']: self.colormap[c['name']]
+ for c in sorted(self.category, key=lambda k: k['index'])})
+
+ # If available, also load the image_annotations table created by export_2d_annotations_as_json().
+ if osp.exists(osp.join(self.table_root, 'image_annotations.json')):
+ self.image_annotations = self.__load_table__('image_annotations')
+
+ # Initialize map mask for each map record.
+ for map_record in self.map:
+ map_record['mask'] = MapMask(osp.join(self.dataroot, map_record['filename']), resolution=map_resolution)
+
+ if verbose:
+ for table in self.table_names:
+ print("{} {},".format(len(getattr(self, table)), table))
+ print("Done loading in {:.3f} seconds.\n======".format(time.time() - start_time))
+
+ # Make reverse indexes for common lookups.
+ self.__make_reverse_index__(verbose)
+
+ # Initialize NuScenesExplorer class.
+ self.explorer = NuScenesExplorer(self)
+
+ @property
+ def table_root(self) -> str:
+ """ Returns the folder where the tables are stored for the relevant version. """
+ return osp.join(self.dataroot, self.version)
+
+ def __load_table__(self, table_name) -> dict:
+ """ Loads a table. """
+ with open(osp.join(self.table_root, '{}.json'.format(table_name))) as f:
+ table = json.load(f)
+ return table
+
+ def __make_reverse_index__(self, verbose: bool) -> None:
+ """
+ De-normalizes database to create reverse indices for common cases.
+ :param verbose: Whether to print outputs.
+ """
+
+ start_time = time.time()
+ if verbose:
+ print("Reverse indexing ...")
+
+ # Store the mapping from token to table index for each table.
+ self._token2ind = dict()
+ for table in self.table_names:
+ self._token2ind[table] = dict()
+
+ for ind, member in enumerate(getattr(self, table)):
+ self._token2ind[table][member['token']] = ind
+
+ # Decorate (adds short-cut) sample_annotation table with for category name.
+ for record in self.sample_annotation:
+ inst = self.get('instance', record['instance_token'])
+ record['category_name'] = self.get('category', inst['category_token'])['name']
+
+ # Decorate (adds short-cut) sample_data with sensor information.
+ for record in self.sample_data:
+ cs_record = self.get('calibrated_sensor', record['calibrated_sensor_token'])
+ sensor_record = self.get('sensor', cs_record['sensor_token'])
+ record['sensor_modality'] = sensor_record['modality']
+ record['channel'] = sensor_record['channel']
+
+ # Reverse-index samples with sample_data and annotations.
+ for record in self.sample:
+ record['data'] = {}
+ record['anns'] = []
+
+ for record in self.sample_data:
+ if record['is_key_frame']:
+ sample_record = self.get('sample', record['sample_token'])
+ sample_record['data'][record['channel']] = record['token']
+
+ for ann_record in self.sample_annotation:
+ sample_record = self.get('sample', ann_record['sample_token'])
+ sample_record['anns'].append(ann_record['token'])
+
+ # Add reverse indices from log records to map records.
+ if 'log_tokens' not in self.map[0].keys():
+ raise Exception('Error: log_tokens not in map table. This code is not compatible with the teaser dataset.')
+ log_to_map = dict()
+ for map_record in self.map:
+ for log_token in map_record['log_tokens']:
+ log_to_map[log_token] = map_record['token']
+ for log_record in self.log:
+ log_record['map_token'] = log_to_map[log_record['token']]
+
+ if verbose:
+ print("Done reverse indexing in {:.1f} seconds.\n======".format(time.time() - start_time))
+
+ def get(self, table_name: str, token: str) -> dict:
+ """
+ Returns a record from table in constant runtime.
+ :param table_name: Table name.
+ :param token: Token of the record.
+ :return: Table record. See README.md for record details for each table.
+ """
+ assert table_name in self.table_names, "Table {} not found".format(table_name)
+
+ return getattr(self, table_name)[self.getind(table_name, token)]
+
+ def getind(self, table_name: str, token: str) -> int:
+ """
+ This returns the index of the record in a table in constant runtime.
+ :param table_name: Table name.
+ :param token: Token of the record.
+ :return: The index of the record in table, table is an array.
+ """
+ return self._token2ind[table_name][token]
+
+ def field2token(self, table_name: str, field: str, query) -> List[str]:
+ """
+ This function queries all records for a certain field value, and returns the tokens for the matching records.
+ Warning: this runs in linear time.
+ :param table_name: Table name.
+ :param field: Field name. See README.md for details.
+ :param query: Query to match against. Needs to type match the content of the query field.
+ :return: List of tokens for the matching records.
+ """
+ matches = []
+ for member in getattr(self, table_name):
+ if member[field] == query:
+ matches.append(member['token'])
+ return matches
+
+ def get_sample_data_path(self, sample_data_token: str) -> str:
+ """ Returns the path to a sample_data. """
+
+ sd_record = self.get('sample_data', sample_data_token)
+ return osp.join(self.dataroot, sd_record['filename'])
+
+ def get_sample_data(self, sample_data_token: str,
+ box_vis_level: BoxVisibility = BoxVisibility.ANY,
+ selected_anntokens: List[str] = None,
+ use_flat_vehicle_coordinates: bool = False) -> \
+ Tuple[str, List[Box], np.array]:
+ """
+ Returns the data path as well as all annotations related to that sample_data.
+ Note that the boxes are transformed into the current sensor's coordinate frame.
+ :param sample_data_token: Sample_data token.
+ :param box_vis_level: If sample_data is an image, this sets required visibility for boxes.
+ :param selected_anntokens: If provided only return the selected annotation.
+ :param use_flat_vehicle_coordinates: Instead of the current sensor's coordinate frame, use ego frame which is
+ aligned to z-plane in the world.
+ :return: (data_path, boxes, camera_intrinsic <np.array: 3, 3>)
+ """
+
+ # Retrieve sensor & pose records
+ sd_record = self.get('sample_data', sample_data_token)
+ cs_record = self.get('calibrated_sensor', sd_record['calibrated_sensor_token'])
+ sensor_record = self.get('sensor', cs_record['sensor_token'])
+ pose_record = self.get('ego_pose', sd_record['ego_pose_token'])
+
+ data_path = self.get_sample_data_path(sample_data_token)
+
+ if sensor_record['modality'] == 'camera':
+ cam_intrinsic = np.array(cs_record['camera_intrinsic'])
+ imsize = (sd_record['width'], sd_record['height'])
+ else:
+ cam_intrinsic = None
+ imsize = None
+
+ # Retrieve all sample annotations and map to sensor coordinate system.
+ if selected_anntokens is not None:
+ boxes = list(map(self.get_box, selected_anntokens))
+ else:
+ boxes = self.get_boxes(sample_data_token)
+
+ # Make list of Box objects including coord system transforms.
+ box_list = []
+ for box in boxes:
+ if use_flat_vehicle_coordinates:
+ # Move box to ego vehicle coord system parallel to world z plane.
+ yaw = Quaternion(pose_record['rotation']).yaw_pitch_roll[0]
+ box.translate(-np.array(pose_record['translation']))
+ box.rotate(Quaternion(scalar=np.cos(yaw / 2), vector=[0, 0, np.sin(yaw / 2)]).inverse)
+ else:
+ # Move box to ego vehicle coord system.
+ box.translate(-np.array(pose_record['translation']))
+ box.rotate(Quaternion(pose_record['rotation']).inverse)
+
+ # Move box to sensor coord system.
+ box.translate(-np.array(cs_record['translation']))
+ box.rotate(Quaternion(cs_record['rotation']).inverse)
+
+ if sensor_record['modality'] == 'camera' and not \
+ box_in_image(box, cam_intrinsic, imsize, vis_level=box_vis_level):
+ continue
+
+ box_list.append(box)
+
+ return data_path, box_list, cam_intrinsic
+
+ def get_box(self, sample_annotation_token: str) -> Box:
+ """
+ Instantiates a Box class from a sample annotation record.
+ :param sample_annotation_token: Unique sample_annotation identifier.
+ """
+ record = self.get('sample_annotation', sample_annotation_token)
+ return Box(record['translation'], record['size'], Quaternion(record['rotation']),
+ name=record['category_name'], token=record['token'])
+
+ def get_my_own_box(self, sample_annotation_token: str,sample_data_token:str) -> Box:
+ record = self.get('sample_annotation', sample_annotation_token)
+ return MyBox(record['translation'], record['size'], Quaternion(record['rotation']),
+ name=record['category_name'], anno_token=record['token'],sample_data_token=sample_data_token)
+ def get_my_own_boxes(self, sample_data_token: str) -> List[Box]:
+ """
+ gl: get my own boxes ,because the default box is not suit
+ """
+ # Retrieve sensor & pose records
+ sd_record = self.get('sample_data', sample_data_token)
+ curr_sample_record = self.get('sample', sd_record['sample_token'])
+
+ if curr_sample_record['prev'] == "" or sd_record['is_key_frame']:
+ # If no previous annotations available, or if sample_data is keyframe just return the current ones.
+ boxes=[]
+ for anno in curr_sample_record['anns']:
+ box = self.get_my_own_box(anno,sample_data_token)
+ boxes.append(box)
+ # boxes = list(map(self.get_my_own_box, curr_sample_record['anns']))
+
+ else:
+ prev_sample_record = self.get('sample', curr_sample_record['prev'])
+
+ curr_ann_recs = [self.get('sample_annotation', token) for token in curr_sample_record['anns']]
+ prev_ann_recs = [self.get('sample_annotation', token) for token in prev_sample_record['anns']]
+
+ # Maps instance tokens to prev_ann records
+ prev_inst_map = {entry['instance_token']: entry for entry in prev_ann_recs}
+
+ t0 = prev_sample_record['timestamp']
+ t1 = curr_sample_record['timestamp']
+ t = sd_record['timestamp']
+
+ # There are rare situations where the timestamps in the DB are off so ensure that t0 < t < t1.
+ t = max(t0, min(t1, t))
+
+ boxes = []
+ for curr_ann_rec in curr_ann_recs:
+
+ if curr_ann_rec['instance_token'] in prev_inst_map:
+ # If the annotated instance existed in the previous frame, interpolate center & orientation.
+ prev_ann_rec = prev_inst_map[curr_ann_rec['instance_token']]
+
+ # Interpolate center.
+ center = [np.interp(t, [t0, t1], [c0, c1]) for c0, c1 in zip(prev_ann_rec['translation'],
+ curr_ann_rec['translation'])]
+
+ # Interpolate orientation.
+ rotation = Quaternion.slerp(q0=Quaternion(prev_ann_rec['rotation']),
+ q1=Quaternion(curr_ann_rec['rotation']),
+ amount=(t - t0) / (t1 - t0))
+
+ box = MyBox(center, curr_ann_rec['size'], rotation, name=curr_ann_rec['category_name'],
+ anno_token=curr_ann_rec['token'],sample_data_token = sample_data_token)
+
+ boxes.append(box)
+ else:
+ # do nothing, this mean that the instance dispaired
+ pass
+ # box = ""
+
+ # boxes.append(box)
+ return boxes
+ def get_boxes(self, sample_data_token: str) -> List[Box]:
+ """
+ Instantiates Boxes for all annotation for a particular sample_data record. If the sample_data is a
+ keyframe, this returns the annotations for that sample. But if the sample_data is an intermediate
+ sample_data, a linear interpolation is applied to estimate the location of the boxes at the time the
+ sample_data was captured.
+ :param sample_data_token: Unique sample_data identifier.
+ """
+
+ # Retrieve sensor & pose records
+ sd_record = self.get('sample_data', sample_data_token)
+ curr_sample_record = self.get('sample', sd_record['sample_token'])
+
+ if curr_sample_record['prev'] == "" or sd_record['is_key_frame']:
+ # If no previous annotations available, or if sample_data is keyframe just return the current ones.
+ boxes = list(map(self.get_box, curr_sample_record['anns']))
+
+ else:
+ prev_sample_record = self.get('sample', curr_sample_record['prev'])
+
+ curr_ann_recs = [self.get('sample_annotation', token) for token in curr_sample_record['anns']]
+ prev_ann_recs = [self.get('sample_annotation', token) for token in prev_sample_record['anns']]
+
+ # Maps instance tokens to prev_ann records
+ prev_inst_map = {entry['instance_token']: entry for entry in prev_ann_recs}
+
+ t0 = prev_sample_record['timestamp']
+ t1 = curr_sample_record['timestamp']
+ t = sd_record['timestamp']
+
+ # There are rare situations where the timestamps in the DB are off so ensure that t0 < t < t1.
+ t = max(t0, min(t1, t))
+
+ boxes = []
+ for curr_ann_rec in curr_ann_recs:
+
+ if curr_ann_rec['instance_token'] in prev_inst_map:
+ # If the annotated instance existed in the previous frame, interpolate center & orientation.
+ prev_ann_rec = prev_inst_map[curr_ann_rec['instance_token']]
+
+ # Interpolate center.
+ center = [np.interp(t, [t0, t1], [c0, c1]) for c0, c1 in zip(prev_ann_rec['translation'],
+ curr_ann_rec['translation'])]
+
+ # Interpolate orientation.
+ rotation = Quaternion.slerp(q0=Quaternion(prev_ann_rec['rotation']),
+ q1=Quaternion(curr_ann_rec['rotation']),
+ amount=(t - t0) / (t1 - t0))
+
+ box = Box(center, curr_ann_rec['size'], rotation, name=curr_ann_rec['category_name'],
+ token=curr_ann_rec['token'])
+ else:
+ # If not, simply grab the current annotation.
+ box = self.get_box(curr_ann_rec['token'])
+
+ boxes.append(box)
+ return boxes
+
+ def box_velocity(self, sample_annotation_token: str, max_time_diff: float = 1.5) -> np.ndarray:
+ """
+ Estimate the velocity for an annotation.
+ If possible, we compute the centered difference between the previous and next frame.
+ Otherwise we use the difference between the current and previous/next frame.
+ If the velocity cannot be estimated, values are set to np.nan.
+ :param sample_annotation_token: Unique sample_annotation identifier.
+ :param max_time_diff: Max allowed time diff between consecutive samples that are used to estimate velocities.
+ :return: <np.float: 3>. Velocity in x/y/z direction in m/s.
+ """
+
+ current = self.get('sample_annotation', sample_annotation_token)
+ has_prev = current['prev'] != ''
+ has_next = current['next'] != ''
+
+ # Cannot estimate velocity for a single annotation.
+ if not has_prev and not has_next:
+ return np.array([np.nan, np.nan, np.nan])
+
+ if has_prev:
+ first = self.get('sample_annotation', current['prev'])
+ else:
+ first = current
+
+ if has_next:
+ last = self.get('sample_annotation', current['next'])
+ else:
+ last = current
+
+ pos_last = np.array(last['translation'])
+ pos_first = np.array(first['translation'])
+ pos_diff = pos_last - pos_first
+
+ time_last = 1e-6 * self.get('sample', last['sample_token'])['timestamp']
+ time_first = 1e-6 * self.get('sample', first['sample_token'])['timestamp']
+ time_diff = time_last - time_first
+
+ if has_next and has_prev:
+ # If doing centered difference, allow for up to double the max_time_diff.
+ max_time_diff *= 2
+
+ if time_diff > max_time_diff:
+ # If time_diff is too big, don't return an estimate.
+ return np.array([np.nan, np.nan, np.nan])
+ else:
+ return pos_diff / time_diff
+
+ def get_sample_lidarseg_stats(self, sample_token: str, sort_by: str = 'count',
+ lidarseg_preds_bin_path: str = None) -> None:
+ """
+ Print the number of points for each class in the lidar pointcloud of a sample. Classes with have no
+ points in the pointcloud will not be printed.
+ :param sample_token: Sample token.
+ :param sort_by: One of three options: count / name / index. If 'count`, the stats will be printed in
+ ascending order of frequency; if `name`, the stats will be printed alphabetically
+ according to class name; if `index`, the stats will be printed in ascending order of
+ class index.
+ :param lidarseg_preds_bin_path: A path to the .bin file which contains the user's lidar segmentation
+ predictions for the sample.
+ """
+ assert hasattr(self, 'lidarseg'), 'Error: You have no lidarseg data; unable to get ' \
+ 'statistics for segmentation of the point cloud.'
+ assert sort_by in ['count', 'name', 'index'], 'Error: sort_by can only be one of the following: ' \
+ 'count / name / index.'
+
+ sample_rec = self.get('sample', sample_token)
+ ref_sd_token = sample_rec['data']['LIDAR_TOP']
+ ref_sd_record = self.get('sample_data', ref_sd_token)
+
+ # Ensure that lidar pointcloud is from a keyframe.
+ assert ref_sd_record['is_key_frame'], 'Error: Only pointclouds which are keyframes have ' \
+ 'lidar segmentation labels. Rendering aborted.'
+
+ if lidarseg_preds_bin_path:
+ lidarseg_labels_filename = lidarseg_preds_bin_path
+ assert os.path.exists(lidarseg_labels_filename), \
+ 'Error: Unable to find {} to load the predictions for sample token {} ' \
+ '(lidar sample data token {}) from.'.format(lidarseg_labels_filename, sample_token, ref_sd_token)
+
+ header = '===== Statistics for ' + sample_token + ' (predictions) ====='
+ else:
+ assert len(self.lidarseg) > 0, 'Error: There are no ground truth labels found for nuScenes-lidarseg ' \
+ 'for {}. Are you loading the test set? \nIf you want to see the sample ' \
+ 'statistics for your predictions, pass a path to the appropriate .bin ' \
+ 'file using the lidarseg_preds_bin_path argument.'.format(self.version)
+ lidar_sd_token = self.get('sample', sample_token)['data']['LIDAR_TOP']
+ lidarseg_labels_filename = os.path.join(self.dataroot,
+ self.get('lidarseg', lidar_sd_token)['filename'])
+
+ header = '===== Statistics for ' + sample_token + ' ====='
+ print(header)
+
+ points_label = np.fromfile(lidarseg_labels_filename, dtype=np.uint8)
+ lidarseg_counts = get_stats(points_label, len(self.lidarseg_idx2name_mapping))
+
+ lidarseg_counts_dict = dict()
+ for i in range(len(lidarseg_counts)):
+ lidarseg_counts_dict[self.lidarseg_idx2name_mapping[i]] = lidarseg_counts[i]
+
+ if sort_by == 'count':
+ out = sorted(lidarseg_counts_dict.items(), key=lambda item: item[1])
+ elif sort_by == 'name':
+ out = sorted(lidarseg_counts_dict.items())
+ else:
+ out = lidarseg_counts_dict.items()
+
+ for class_name, count in out:
+ if count > 0:
+ idx = self.lidarseg_name2idx_mapping[class_name]
+ print('{:3} {:40} n={:12,}'.format(idx, class_name, count))
+
+ print('=' * len(header))
+
+ def list_categories(self) -> None:
+ self.explorer.list_categories()
+
+ def list_lidarseg_categories(self, sort_by: str = 'count') -> None:
+ self.explorer.list_lidarseg_categories(sort_by=sort_by)
+
+ def list_attributes(self) -> None:
+ self.explorer.list_attributes()
+
+ def list_scenes(self) -> None:
+ self.explorer.list_scenes()
+
+ def list_sample(self, sample_token: str) -> None:
+ self.explorer.list_sample(sample_token)
+
+ def render_pointcloud_in_image(self, sample_token: str, dot_size: int = 5, pointsensor_channel: str = 'LIDAR_TOP',
+ camera_channel: str = 'CAM_FRONT', out_path: str = None,
+ render_intensity: bool = False,
+ show_lidarseg: bool = False,
+ filter_lidarseg_labels: List = None,
+ show_lidarseg_legend: bool = False,
+ verbose: bool = True,
+ lidarseg_preds_bin_path: str = None) -> None:
+ self.explorer.render_pointcloud_in_image(sample_token, dot_size, pointsensor_channel=pointsensor_channel,
+ camera_channel=camera_channel, out_path=out_path,
+ render_intensity=render_intensity,
+ show_lidarseg=show_lidarseg,
+ filter_lidarseg_labels=filter_lidarseg_labels,
+ show_lidarseg_legend=show_lidarseg_legend,
+ verbose=verbose,
+ lidarseg_preds_bin_path=lidarseg_preds_bin_path)
+
+ def render_sample(self, sample_token: str, box_vis_level: BoxVisibility = BoxVisibility.ANY, nsweeps: int = 1,
+ out_path: str = None, show_lidarseg: bool = False,
+ filter_lidarseg_labels: List = None,
+ lidarseg_preds_bin_path: str = None, verbose: bool = True) -> None:
+ self.explorer.render_sample(sample_token, box_vis_level, nsweeps=nsweeps,
+ out_path=out_path, show_lidarseg=show_lidarseg,
+ filter_lidarseg_labels=filter_lidarseg_labels,
+ lidarseg_preds_bin_path=lidarseg_preds_bin_path, verbose=verbose)
+
+ def render_sample_data(self, sample_data_token: str, with_anns: bool = True,
+ box_vis_level: BoxVisibility = BoxVisibility.ANY, axes_limit: float = 40, ax: Axes = None,
+ nsweeps: int = 1, out_path: str = None, underlay_map: bool = True,
+ use_flat_vehicle_coordinates: bool = True,
+ show_lidarseg: bool = False,
+ show_lidarseg_legend: bool = False,
+ filter_lidarseg_labels: List = None,
+ lidarseg_preds_bin_path: str = None, verbose: bool = True) -> None:
+ self.explorer.render_sample_data(sample_data_token, with_anns, box_vis_level, axes_limit, ax, nsweeps=nsweeps,
+ out_path=out_path, underlay_map=underlay_map,
+ use_flat_vehicle_coordinates=use_flat_vehicle_coordinates,
+ show_lidarseg=show_lidarseg,
+ show_lidarseg_legend=show_lidarseg_legend,
+ filter_lidarseg_labels=filter_lidarseg_labels,
+ lidarseg_preds_bin_path=lidarseg_preds_bin_path, verbose=verbose)
+
+ def render_annotation(self, sample_annotation_token: str, margin: float = 10, view: np.ndarray = np.eye(4),
+ box_vis_level: BoxVisibility = BoxVisibility.ANY, out_path: str = None,
+ extra_info: bool = False) -> None:
+ self.explorer.render_annotation(sample_annotation_token, margin, view, box_vis_level, out_path, extra_info)
+
+ def render_instance(self, instance_token: str, margin: float = 10, view: np.ndarray = np.eye(4),
+ box_vis_level: BoxVisibility = BoxVisibility.ANY, out_path: str = None,
+ extra_info: bool = False) -> None:
+ self.explorer.render_instance(instance_token, margin, view, box_vis_level, out_path, extra_info)
+
+ def render_scene(self, scene_token: str, freq: float = 10, imsize: Tuple[float, float] = (640, 360),
+ out_path: str = None) -> None:
+ self.explorer.render_scene(scene_token, freq, imsize, out_path)
+
+ def render_scene_channel(self, scene_token: str, channel: str = 'CAM_FRONT', freq: float = 10,
+ imsize: Tuple[float, float] = (640, 360), out_path: str = None) -> None:
+ self.explorer.render_scene_channel(scene_token, channel=channel, freq=freq, imsize=imsize, out_path=out_path)
+
+ def render_egoposes_on_map(self, log_location: str, scene_tokens: List = None, out_path: str = None) -> None:
+ self.explorer.render_egoposes_on_map(log_location, scene_tokens, out_path=out_path)
+
+ def render_scene_channel_lidarseg(self, scene_token: str,
+ channel: str,
+ out_folder: str = None,
+ filter_lidarseg_labels: Iterable[int] = None,
+ with_anns: bool = False,
+ render_mode: str = None,
+ verbose: bool = True,
+ imsize: Tuple[int, int] = (640, 360),
+ freq: float = 2,
+ dpi: int = 150,
+ lidarseg_preds_folder: str = None) -> None:
+ self.explorer.render_scene_channel_lidarseg(scene_token,
+ channel,
+ out_folder=out_folder,
+ filter_lidarseg_labels=filter_lidarseg_labels,
+ with_anns=with_anns,
+ render_mode=render_mode,
+ verbose=verbose,
+ imsize=imsize,
+ freq=freq,
+ dpi=dpi,
+ lidarseg_preds_folder=lidarseg_preds_folder)
+
+ def render_scene_lidarseg(self, scene_token: str,
+ out_path: str = None,
+ filter_lidarseg_labels: Iterable[int] = None,
+ with_anns: bool = False,
+ imsize: Tuple[int, int] = (640, 360),
+ freq: float = 2,
+ verbose: bool = True,
+ dpi: int = 200,
+ lidarseg_preds_folder: str = None) -> None:
+ self.explorer.render_scene_lidarseg(scene_token,
+ out_path=out_path,
+ filter_lidarseg_labels=filter_lidarseg_labels,
+ with_anns=with_anns,
+ imsize=imsize,
+ freq=freq,
+ verbose=verbose,
+ dpi=dpi,
+ lidarseg_preds_folder=lidarseg_preds_folder)
+
+
+class NuScenesExplorer:
+ """ Helper class to list and visualize NuScenes data. These are meant to serve as tutorials and templates for
+ working with the data. """
+
+ def __init__(self, nusc: NuScenes):
+ self.nusc = nusc
+
+ def get_color(self, category_name: str) -> Tuple[int, int, int]:
+ """
+ Provides the default colors based on the category names.
+ This method works for the general nuScenes categories, as well as the nuScenes detection categories.
+ """
+
+ return self.nusc.colormap[category_name]
+
+ def list_categories(self) -> None:
+ """ Print categories, counts and stats. These stats only cover the split specified in nusc.version. """
+ print('Category stats for split %s:' % self.nusc.version)
+
+ # Add all annotations.
+ categories = dict()
+ for record in self.nusc.sample_annotation:
+ if record['category_name'] not in categories:
+ categories[record['category_name']] = []
+ categories[record['category_name']].append(record['size'] + [record['size'][1] / record['size'][0]])
+
+ # Print stats.
+ for name, stats in sorted(categories.items()):
+ stats = np.array(stats)
+ print('{:27} n={:5}, width={:5.2f}\u00B1{:.2f}, len={:5.2f}\u00B1{:.2f}, height={:5.2f}\u00B1{:.2f}, '
+ 'lw_aspect={:5.2f}\u00B1{:.2f}'.format(name[:27], stats.shape[0],
+ np.mean(stats[:, 0]), np.std(stats[:, 0]),
+ np.mean(stats[:, 1]), np.std(stats[:, 1]),
+ np.mean(stats[:, 2]), np.std(stats[:, 2]),
+ np.mean(stats[:, 3]), np.std(stats[:, 3])))
+
+ def list_lidarseg_categories(self, sort_by: str = 'count') -> None:
+ """
+ Print categories and counts of the lidarseg data. These stats only cover
+ the split specified in nusc.version.
+ :param sort_by: One of three options: count / name / index. If 'count`, the stats will be printed in
+ ascending order of frequency; if `name`, the stats will be printed alphabetically
+ according to class name; if `index`, the stats will be printed in ascending order of
+ class index.
+ """
+ assert hasattr(self.nusc, 'lidarseg'), 'Error: nuScenes-lidarseg not installed!'
+ assert sort_by in ['count', 'name', 'index'], 'Error: sort_by can only be one of the following: ' \
+ 'count / name / index.'
+
+ print('Calculating stats for nuScenes-lidarseg...')
+ start_time = time.time()
+
+ # Initialize an array of zeroes, one for each class name.
+ lidarseg_counts = [0] * len(self.nusc.lidarseg_idx2name_mapping)
+
+ for record_lidarseg in self.nusc.lidarseg:
+ lidarseg_labels_filename = osp.join(self.nusc.dataroot, record_lidarseg['filename'])
+
+ points_label = np.fromfile(lidarseg_labels_filename, dtype=np.uint8)
+ indices = np.bincount(points_label)
+ ii = np.nonzero(indices)[0]
+ for class_idx, class_count in zip(ii, indices[ii]):
+ lidarseg_counts[class_idx] += class_count
+
+ lidarseg_counts_dict = dict()
+ for i in range(len(lidarseg_counts)):
+ lidarseg_counts_dict[self.nusc.lidarseg_idx2name_mapping[i]] = lidarseg_counts[i]
+
+ if sort_by == 'count':
+ out = sorted(lidarseg_counts_dict.items(), key=lambda item: item[1])
+ elif sort_by == 'name':
+ out = sorted(lidarseg_counts_dict.items())
+ else:
+ out = lidarseg_counts_dict.items()
+
+ # Print frequency counts of each class in the lidarseg dataset.
+ for class_name, count in out:
+ idx = self.nusc.lidarseg_name2idx_mapping[class_name]
+ print('{:3} {:40} nbr_points={:12,}'.format(idx, class_name, count))
+
+ print('Calculated stats for {} point clouds in {:.1f} seconds.\n====='.format(
+ len(self.nusc.lidarseg), time.time() - start_time))
+
+ def list_attributes(self) -> None:
+ """ Prints attributes and counts. """
+ attribute_counts = dict()
+ for record in self.nusc.sample_annotation:
+ for attribute_token in record['attribute_tokens']:
+ att_name = self.nusc.get('attribute', attribute_token)['name']
+ if att_name not in attribute_counts:
+ attribute_counts[att_name] = 0
+ attribute_counts[att_name] += 1
+
+ for name, count in sorted(attribute_counts.items()):
+ print('{}: {}'.format(name, count))
+
+ def list_scenes(self) -> None:
+ """ Lists all scenes with some meta data. """
+
+ def ann_count(record):
+ count = 0
+ sample = self.nusc.get('sample', record['first_sample_token'])
+ while not sample['next'] == "":
+ count += len(sample['anns'])
+ sample = self.nusc.get('sample', sample['next'])
+ return count
+
+ recs = [(self.nusc.get('sample', record['first_sample_token'])['timestamp'], record) for record in
+ self.nusc.scene]
+
+ for start_time, record in sorted(recs):
+ start_time = self.nusc.get('sample', record['first_sample_token'])['timestamp'] / 1000000
+ length_time = self.nusc.get('sample', record['last_sample_token'])['timestamp'] / 1000000 - start_time
+ location = self.nusc.get('log', record['log_token'])['location']
+ desc = record['name'] + ', ' + record['description']
+ if len(desc) > 55:
+ desc = desc[:51] + "..."
+ if len(location) > 18:
+ location = location[:18]
+
+ print('{:16} [{}] {:4.0f}s, {}, #anns:{}'.format(
+ desc, datetime.utcfromtimestamp(start_time).strftime('%y-%m-%d %H:%M:%S'),
+ length_time, location, ann_count(record)))
+
+ def list_sample(self, sample_token: str) -> None:
+ """ Prints sample_data tokens and sample_annotation tokens related to the sample_token. """
+
+ sample_record = self.nusc.get('sample', sample_token)
+ print('Sample: {}\n'.format(sample_record['token']))
+ for sd_token in sample_record['data'].values():
+ sd_record = self.nusc.get('sample_data', sd_token)
+ print('sample_data_token: {}, mod: {}, channel: {}'.format(sd_token, sd_record['sensor_modality'],
+ sd_record['channel']))
+ print('')
+ for ann_token in sample_record['anns']:
+ ann_record = self.nusc.get('sample_annotation', ann_token)
+ print('sample_annotation_token: {}, category: {}'.format(ann_record['token'], ann_record['category_name']))
+
+ def map_pointcloud_to_image(self,
+ pointsensor_token: str,
+ camera_token: str,
+ min_dist: float = 1.0,
+ render_intensity: bool = False,
+ show_lidarseg: bool = False,
+ filter_lidarseg_labels: List = None,
+ lidarseg_preds_bin_path: str = None) -> Tuple:
+ """
+ Given a point sensor (lidar/radar) token and camera sample_data token, load pointcloud and map it to the image
+ plane.
+ :param pointsensor_token: Lidar/radar sample_data token.
+ :param camera_token: Camera sample_data token.
+ :param min_dist: Distance from the camera below which points are discarded.
+ :param render_intensity: Whether to render lidar intensity instead of point depth.
+ :param show_lidarseg: Whether to render lidar intensity instead of point depth.
+ :param filter_lidarseg_labels: Only show lidar points which belong to the given list of classes. If None
+ or the list is empty, all classes will be displayed.
+ :param lidarseg_preds_bin_path: A path to the .bin file which contains the user's lidar segmentation
+ predictions for the sample.
+ :return (pointcloud <np.float: 2, n)>, coloring <np.float: n>, image <Image>).
+ """
+
+ cam = self.nusc.get('sample_data', camera_token)
+ pointsensor = self.nusc.get('sample_data', pointsensor_token)
+ pcl_path = osp.join(self.nusc.dataroot, pointsensor['filename'])
+ if pointsensor['sensor_modality'] == 'lidar':
+ if show_lidarseg:
+ assert hasattr(self.nusc, 'lidarseg'), 'Error: nuScenes-lidarseg not installed!'
+
+ # Ensure that lidar pointcloud is from a keyframe.
+ assert pointsensor['is_key_frame'], \
+ 'Error: Only pointclouds which are keyframes have lidar segmentation labels. Rendering aborted.'
+
+ assert not render_intensity, 'Error: Invalid options selected. You can only select either ' \
+ 'render_intensity or show_lidarseg, not both.'
+
+ pc = LidarPointCloud.from_file(pcl_path)
+ else:
+ pc = RadarPointCloud.from_file(pcl_path)
+ im = Image.open(osp.join(self.nusc.dataroot, cam['filename']))
+
+ # Points live in the point sensor frame. So they need to be transformed via global to the image plane.
+ # First step: transform the pointcloud to the ego vehicle frame for the timestamp of the sweep.
+ cs_record = self.nusc.get('calibrated_sensor', pointsensor['calibrated_sensor_token'])
+ pc.rotate(Quaternion(cs_record['rotation']).rotation_matrix)
+ pc.translate(np.array(cs_record['translation']))
+
+ # Second step: transform from ego to the global frame.
+ poserecord = self.nusc.get('ego_pose', pointsensor['ego_pose_token'])
+ pc.rotate(Quaternion(poserecord['rotation']).rotation_matrix)
+ pc.translate(np.array(poserecord['translation']))
+
+ # Third step: transform from global into the ego vehicle frame for the timestamp of the image.
+ poserecord = self.nusc.get('ego_pose', cam['ego_pose_token'])
+ pc.translate(-np.array(poserecord['translation']))
+ pc.rotate(Quaternion(poserecord['rotation']).rotation_matrix.T)
+
+ # Fourth step: transform from ego into the camera.
+ cs_record = self.nusc.get('calibrated_sensor', cam['calibrated_sensor_token'])
+ pc.translate(-np.array(cs_record['translation']))
+ pc.rotate(Quaternion(cs_record['rotation']).rotation_matrix.T)
+
+ # Fifth step: actually take a "picture" of the point cloud.
+ # Grab the depths (camera frame z axis points away from the camera).
+ depths = pc.points[2, :]
+
+ if render_intensity:
+ assert pointsensor['sensor_modality'] == 'lidar', 'Error: Can only render intensity for lidar, ' \
+ 'not %s!' % pointsensor['sensor_modality']
+ # Retrieve the color from the intensities.
+ # Performs arbitary scaling to achieve more visually pleasing results.
+ intensities = pc.points[3, :]
+ intensities = (intensities - np.min(intensities)) / (np.max(intensities) - np.min(intensities))
+ intensities = intensities ** 0.1
+ intensities = np.maximum(0, intensities - 0.5)
+ coloring = intensities
+ elif show_lidarseg:
+ assert pointsensor['sensor_modality'] == 'lidar', 'Error: Can only render lidarseg labels for lidar, ' \
+ 'not %s!' % pointsensor['sensor_modality']
+
+ if lidarseg_preds_bin_path:
+ sample_token = self.nusc.get('sample_data', pointsensor_token)['sample_token']
+ lidarseg_labels_filename = lidarseg_preds_bin_path
+ assert os.path.exists(lidarseg_labels_filename), \
+ 'Error: Unable to find {} to load the predictions for sample token {} (lidar ' \
+ 'sample data token {}) from.'.format(lidarseg_labels_filename, sample_token, pointsensor_token)
+ else:
+ if len(self.nusc.lidarseg) > 0: # Ensure lidarseg.json is not empty (e.g. in case of v1.0-test).
+ lidarseg_labels_filename = osp.join(self.nusc.dataroot,
+ self.nusc.get('lidarseg', pointsensor_token)['filename'])
+ else:
+ lidarseg_labels_filename = None
+
+ if lidarseg_labels_filename:
+ # Paint each label in the pointcloud with a RGBA value.
+ coloring = paint_points_label(lidarseg_labels_filename, filter_lidarseg_labels,
+ self.nusc.lidarseg_name2idx_mapping, self.nusc.colormap)
+ else:
+ coloring = depths
+ print('Warning: There are no lidarseg labels in {}. Points will be colored according to distance '
+ 'from the ego vehicle instead.'.format(self.nusc.version))
+ else:
+ # Retrieve the color from the depth.
+ coloring = depths
+
+ # Take the actual picture (matrix multiplication with camera-matrix + renormalization).
+ points = view_points(pc.points[:3, :], np.array(cs_record['camera_intrinsic']), normalize=True)
+
+ # Remove points that are either outside or behind the camera. Leave a margin of 1 pixel for aesthetic reasons.
+ # Also make sure points are at least 1m in front of the camera to avoid seeing the lidar points on the camera
+ # casing for non-keyframes which are slightly out of sync.
+ mask = np.ones(depths.shape[0], dtype=bool)
+ mask = np.logical_and(mask, depths > min_dist)
+ mask = np.logical_and(mask, points[0, :] > 1)
+ mask = np.logical_and(mask, points[0, :] < im.size[0] - 1)
+ mask = np.logical_and(mask, points[1, :] > 1)
+ mask = np.logical_and(mask, points[1, :] < im.size[1] - 1)
+ points = points[:, mask]
+ coloring = coloring[mask]
+
+ return points, coloring, im
+
+ def render_pointcloud_in_image(self,
+ sample_token: str,
+ dot_size: int = 5,
+ pointsensor_channel: str = 'LIDAR_TOP',
+ camera_channel: str = 'CAM_FRONT',
+ out_path: str = None,
+ render_intensity: bool = False,
+ show_lidarseg: bool = False,
+ filter_lidarseg_labels: List = None,
+ ax: Axes = None,
+ show_lidarseg_legend: bool = False,
+ verbose: bool = True,
+ lidarseg_preds_bin_path: str = None):
+ """
+ Scatter-plots a pointcloud on top of image.
+ :param sample_token: Sample token.
+ :param dot_size: Scatter plot dot size.
+ :param pointsensor_channel: RADAR or LIDAR channel name, e.g. 'LIDAR_TOP'.
+ :param camera_channel: Camera channel name, e.g. 'CAM_FRONT'.
+ :param out_path: Optional path to save the rendered figure to disk.
+ :param render_intensity: Whether to render lidar intensity instead of point depth.
+ :param show_lidarseg: Whether to render lidarseg labels instead of point depth.
+ :param filter_lidarseg_labels: Only show lidar points which belong to the given list of classes.
+ :param ax: Axes onto which to render.
+ :param show_lidarseg_legend: Whether to display the legend for the lidarseg labels in the frame.
+ :param verbose: Whether to display the image in a window.
+ :param lidarseg_preds_bin_path: A path to the .bin file which contains the user's lidar segmentation
+ predictions for the sample.
+
+ """
+ sample_record = self.nusc.get('sample', sample_token)
+
+ # Here we just grab the front camera and the point sensor.
+ pointsensor_token = sample_record['data'][pointsensor_channel]
+ camera_token = sample_record['data'][camera_channel]
+
+ points, coloring, im = self.map_pointcloud_to_image(pointsensor_token, camera_token,
+ render_intensity=render_intensity,
+ show_lidarseg=show_lidarseg,
+ filter_lidarseg_labels=filter_lidarseg_labels,
+ lidarseg_preds_bin_path=lidarseg_preds_bin_path)
+
+ # Init axes.
+ if ax is None:
+ fig, ax = plt.subplots(1, 1, figsize=(9, 16))
+ if lidarseg_preds_bin_path:
+ fig.canvas.set_window_title(sample_token + '(predictions)')
+ else:
+ fig.canvas.set_window_title(sample_token)
+ else: # Set title on if rendering as part of render_sample.
+ ax.set_title(camera_channel)
+ ax.imshow(im)
+ ax.scatter(points[0, :], points[1, :], c=coloring, s=dot_size)
+ ax.axis('off')
+
+ # Produce a legend with the unique colors from the scatter.
+ if pointsensor_channel == 'LIDAR_TOP' and show_lidarseg and show_lidarseg_legend:
+ # Since the labels are stored as class indices, we get the RGB colors from the colormap in an array where
+ # the position of the RGB color corresponds to the index of the class it represents.
+ color_legend = colormap_to_colors(self.nusc.colormap, self.nusc.lidarseg_name2idx_mapping)
+
+ # If user does not specify a filter, then set the filter to contain the classes present in the pointcloud
+ # after it has been projected onto the image; this will allow displaying the legend only for classes which
+ # are present in the image (instead of all the classes).
+ if filter_lidarseg_labels is None:
+ filter_lidarseg_labels = get_labels_in_coloring(color_legend, coloring)
+
+ create_lidarseg_legend(filter_lidarseg_labels,
+ self.nusc.lidarseg_idx2name_mapping, self.nusc.colormap)
+
+ if out_path is not None:
+ plt.savefig(out_path, bbox_inches='tight', pad_inches=0, dpi=200)
+ if verbose:
+ plt.show()
+
+ def render_sample(self,
+ token: str,
+ box_vis_level: BoxVisibility = BoxVisibility.ANY,
+ nsweeps: int = 1,
+ out_path: str = None,
+ show_lidarseg: bool = False,
+ filter_lidarseg_labels: List = None,
+ lidarseg_preds_bin_path: str = None,
+ verbose: bool = True) -> None:
+ """
+ Render all LIDAR and camera sample_data in sample along with annotations.
+ :param token: Sample token.
+ :param box_vis_level: If sample_data is an image, this sets required visibility for boxes.
+ :param nsweeps: Number of sweeps for lidar and radar.
+ :param out_path: Optional path to save the rendered figure to disk.
+ :param show_lidarseg: Whether to show lidar segmentations labels or not.
+ :param filter_lidarseg_labels: Only show lidar points which belong to the given list of classes.
+ :param lidarseg_preds_bin_path: A path to the .bin file which contains the user's lidar segmentation
+ predictions for the sample.
+ :param verbose: Whether to show the rendered sample in a window or not.
+ """
+ record = self.nusc.get('sample', token)
+
+ # Separate RADAR from LIDAR and vision.
+ radar_data = {}
+ camera_data = {}
+ lidar_data = {}
+ for channel, token in record['data'].items():
+ sd_record = self.nusc.get('sample_data', token)
+ sensor_modality = sd_record['sensor_modality']
+
+ if sensor_modality == 'camera':
+ camera_data[channel] = token
+ elif sensor_modality == 'lidar':
+ lidar_data[channel] = token
+ else:
+ radar_data[channel] = token
+
+ # Create plots.
+ num_radar_plots = 1 if len(radar_data) > 0 else 0
+ num_lidar_plots = 1 if len(lidar_data) > 0 else 0
+ n = num_radar_plots + len(camera_data) + num_lidar_plots
+ cols = 2
+ fig, axes = plt.subplots(int(np.ceil(n / cols)), cols, figsize=(16, 24))
+
+ # Plot radars into a single subplot.
+ if len(radar_data) > 0:
+ ax = axes[0, 0]
+ for i, (_, sd_token) in enumerate(radar_data.items()):
+ self.render_sample_data(sd_token, with_anns=i == 0, box_vis_level=box_vis_level, ax=ax, nsweeps=nsweeps,
+ verbose=False)
+ ax.set_title('Fused RADARs')
+
+ # Plot lidar into a single subplot.
+ if len(lidar_data) > 0:
+ for (_, sd_token), ax in zip(lidar_data.items(), axes.flatten()[num_radar_plots:]):
+ self.render_sample_data(sd_token, box_vis_level=box_vis_level, ax=ax, nsweeps=nsweeps,
+ show_lidarseg=show_lidarseg,
+ filter_lidarseg_labels=filter_lidarseg_labels,
+ lidarseg_preds_bin_path=lidarseg_preds_bin_path,
+ verbose=False)
+
+ # Plot cameras in separate subplots.
+ for (_, sd_token), ax in zip(camera_data.items(), axes.flatten()[num_radar_plots + num_lidar_plots:]):
+ if not show_lidarseg:
+ self.render_sample_data(sd_token, box_vis_level=box_vis_level, ax=ax, nsweeps=nsweeps,
+ show_lidarseg=False, verbose=False)
+ else:
+ sd_record = self.nusc.get('sample_data', sd_token)
+ sensor_channel = sd_record['channel']
+ valid_channels = ['CAM_FRONT_LEFT', 'CAM_FRONT', 'CAM_FRONT_RIGHT',
+ 'CAM_BACK_LEFT', 'CAM_BACK', 'CAM_BACK_RIGHT']
+ assert sensor_channel in valid_channels, 'Input camera channel {} not valid.'.format(sensor_channel)
+
+ self.render_pointcloud_in_image(record['token'],
+ pointsensor_channel='LIDAR_TOP',
+ camera_channel=sensor_channel,
+ show_lidarseg=show_lidarseg,
+ filter_lidarseg_labels=filter_lidarseg_labels,
+ ax=ax, verbose=False,
+ lidarseg_preds_bin_path=lidarseg_preds_bin_path)
+
+ # Change plot settings and write to disk.
+ axes.flatten()[-1].axis('off')
+ plt.tight_layout()
+ fig.subplots_adjust(wspace=0, hspace=0)
+
+ if out_path is not None:
+ plt.savefig(out_path)
+
+ if verbose:
+ plt.show()
+
+ def render_ego_centric_map(self,
+ sample_data_token: str,
+ axes_limit: float = 40,
+ ax: Axes = None) -> None:
+ """
+ Render map centered around the associated ego pose.
+ :param sample_data_token: Sample_data token.
+ :param axes_limit: Axes limit measured in meters.
+ :param ax: Axes onto which to render.
+ """
+
+ def crop_image(image: np.array,
+ x_px: int,
+ y_px: int,
+ axes_limit_px: int) -> np.array:
+ x_min = int(x_px - axes_limit_px)
+ x_max = int(x_px + axes_limit_px)
+ y_min = int(y_px - axes_limit_px)
+ y_max = int(y_px + axes_limit_px)
+
+ cropped_image = image[y_min:y_max, x_min:x_max]
+
+ return cropped_image
+
+ # Get data.
+ sd_record = self.nusc.get('sample_data', sample_data_token)
+ sample = self.nusc.get('sample', sd_record['sample_token'])
+ scene = self.nusc.get('scene', sample['scene_token'])
+ log = self.nusc.get('log', scene['log_token'])
+ map_ = self.nusc.get('map', log['map_token'])
+ map_mask = map_['mask']
+ pose = self.nusc.get('ego_pose', sd_record['ego_pose_token'])
+
+ # Retrieve and crop mask.
+ pixel_coords = map_mask.to_pixel_coords(pose['translation'][0], pose['translation'][1])
+ scaled_limit_px = int(axes_limit * (1.0 / map_mask.resolution))
+ mask_raster = map_mask.mask()
+ cropped = crop_image(mask_raster, pixel_coords[0], pixel_coords[1], int(scaled_limit_px * math.sqrt(2)))
+
+ # Rotate image.
+ ypr_rad = Quaternion(pose['rotation']).yaw_pitch_roll
+ yaw_deg = -math.degrees(ypr_rad[0])
+ rotated_cropped = np.array(Image.fromarray(cropped).rotate(yaw_deg))
+
+ # Crop image.
+ ego_centric_map = crop_image(rotated_cropped, rotated_cropped.shape[1] / 2,
+ rotated_cropped.shape[0] / 2,
+ scaled_limit_px)
+
+ # Init axes and show image.
+ # Set background to white and foreground (semantic prior) to gray.
+ if ax is None:
+ _, ax = plt.subplots(1, 1, figsize=(9, 9))
+ ego_centric_map[ego_centric_map == map_mask.foreground] = 125
+ ego_centric_map[ego_centric_map == map_mask.background] = 255
+ ax.imshow(ego_centric_map, extent=[-axes_limit, axes_limit, -axes_limit, axes_limit],
+ cmap='gray', vmin=0, vmax=255)
+
+ def render_sample_data(self,
+ sample_data_token: str,
+ with_anns: bool = True,
+ box_vis_level: BoxVisibility = BoxVisibility.ANY,
+ axes_limit: float = 40,
+ ax: Axes = None,
+ nsweeps: int = 1,
+ out_path: str = None,
+ underlay_map: bool = True,
+ use_flat_vehicle_coordinates: bool = True,
+ show_lidarseg: bool = False,
+ show_lidarseg_legend: bool = False,
+ filter_lidarseg_labels: List = None,
+ lidarseg_preds_bin_path: str = None,
+ verbose: bool = True) -> None:
+ """
+ Render sample data onto axis.
+ :param sample_data_token: Sample_data token.
+ :param with_anns: Whether to draw box annotations.
+ :param box_vis_level: If sample_data is an image, this sets required visibility for boxes.
+ :param axes_limit: Axes limit for lidar and radar (measured in meters).
+ :param ax: Axes onto which to render.
+ :param nsweeps: Number of sweeps for lidar and radar.
+ :param out_path: Optional path to save the rendered figure to disk.
+ :param underlay_map: When set to true, lidar data is plotted onto the map. This can be slow.
+ :param use_flat_vehicle_coordinates: Instead of the current sensor's coordinate frame, use ego frame which is
+ aligned to z-plane in the world. Note: Previously this method did not use flat vehicle coordinates, which
+ can lead to small errors when the vertical axis of the global frame and lidar are not aligned. The new
+ setting is more correct and rotates the plot by ~90 degrees.
+ :param show_lidarseg: When set to True, the lidar data is colored with the segmentation labels. When set
+ to False, the colors of the lidar data represent the distance from the center of the ego vehicle.
+ :param show_lidarseg_legend: Whether to display the legend for the lidarseg labels in the frame.
+ :param filter_lidarseg_labels: Only show lidar points which belong to the given list of classes. If None
+ or the list is empty, all classes will be displayed.
+ :param lidarseg_preds_bin_path: A path to the .bin file which contains the user's lidar segmentation
+ predictions for the sample.
+ :param verbose: Whether to display the image after it is rendered.
+ """
+ # Get sensor modality.
+ sd_record = self.nusc.get('sample_data', sample_data_token)
+ sensor_modality = sd_record['sensor_modality']
+
+ if sensor_modality in ['lidar', 'radar']:
+ sample_rec = self.nusc.get('sample', sd_record['sample_token'])
+ chan = sd_record['channel']
+ ref_chan = 'LIDAR_TOP'
+ ref_sd_token = sample_rec['data'][ref_chan]
+ ref_sd_record = self.nusc.get('sample_data', ref_sd_token)
+
+ if sensor_modality == 'lidar':
+ if show_lidarseg:
+ assert hasattr(self.nusc, 'lidarseg'), 'Error: nuScenes-lidarseg not installed!'
+
+ # Ensure that lidar pointcloud is from a keyframe.
+ assert sd_record['is_key_frame'], \
+ 'Error: Only pointclouds which are keyframes have lidar segmentation labels. Rendering aborted.'
+
+ assert nsweeps == 1, \
+ 'Error: Only pointclouds which are keyframes have lidar segmentation labels; nsweeps should ' \
+ 'be set to 1.'
+
+ # Load a single lidar point cloud.
+ pcl_path = osp.join(self.nusc.dataroot, ref_sd_record['filename'])
+ pc = LidarPointCloud.from_file(pcl_path)
+ else:
+ # Get aggregated lidar point cloud in lidar frame.
+ '''
+ problem : can only get the key frame data
+ '''
+ ## [gl:fix bug test]
+ if sd_record['is_key_frame'] != True:
+ pcl_path = osp.join(self.nusc.dataroot, sd_record['filename'])
+ pc = LidarPointCloud.from_file(pcl_path)
+ else:
+ pc, times = LidarPointCloud.from_file_multisweep(self.nusc, sample_rec, chan, ref_chan,
+ nsweeps=nsweeps)
+ # [gl:above is original code ,but have bug ,i fixed it]
+ velocities = None
+ else:
+ # Get aggregated radar point cloud in reference frame.
+ # The point cloud is transformed to the reference frame for visualization purposes.
+ pc, times = RadarPointCloud.from_file_multisweep(self.nusc, sample_rec, chan, ref_chan, nsweeps=nsweeps)
+
+ # Transform radar velocities (x is front, y is left), as these are not transformed when loading the
+ # point cloud.
+ radar_cs_record = self.nusc.get('calibrated_sensor', sd_record['calibrated_sensor_token'])
+ ref_cs_record = self.nusc.get('calibrated_sensor', ref_sd_record['calibrated_sensor_token'])
+ velocities = pc.points[8:10, :] # Compensated velocity
+ velocities = np.vstack((velocities, np.zeros(pc.points.shape[1])))
+ velocities = np.dot(Quaternion(radar_cs_record['rotation']).rotation_matrix, velocities)
+ velocities = np.dot(Quaternion(ref_cs_record['rotation']).rotation_matrix.T, velocities)
+ velocities[2, :] = np.zeros(pc.points.shape[1])
+
+ # By default we render the sample_data top down in the sensor frame.
+ # This is slightly inaccurate when rendering the map as the sensor frame may not be perfectly upright.
+ # Using use_flat_vehicle_coordinates we can render the map in the ego frame instead.
+ if use_flat_vehicle_coordinates:
+ # Retrieve transformation matrices for reference point cloud.
+ cs_record = self.nusc.get('calibrated_sensor', ref_sd_record['calibrated_sensor_token'])
+
+ # [gl:bug fix]
+ # pose_record = self.nusc.get('ego_pose', ref_sd_record['ego_pose_token'])
+ pose_record = self.nusc.get('ego_pose', sd_record['ego_pose_token'])
+ #
+ ref_to_ego = transform_matrix(translation=cs_record['translation'],
+ rotation=Quaternion(cs_record["rotation"]))
+
+ # Compute rotation between 3D vehicle pose and "flat" vehicle pose (parallel to global z plane).
+ ego_yaw = Quaternion(pose_record['rotation']).yaw_pitch_roll[0]
+ # [gl: first turn inverse then turn back , so we can make it more flat ,because the x,y rotation is discarded]
+ rotation_vehicle_flat_from_vehicle = np.dot(
+ Quaternion(scalar=np.cos(ego_yaw / 2), vector=[0, 0, np.sin(ego_yaw / 2)]).rotation_matrix,
+ Quaternion(pose_record['rotation']).inverse.rotation_matrix)
+ vehicle_flat_from_vehicle = np.eye(4)
+ vehicle_flat_from_vehicle[:3, :3] = rotation_vehicle_flat_from_vehicle
+ viewpoint = np.dot(vehicle_flat_from_vehicle, ref_to_ego)
+ else:
+ viewpoint = np.eye(4)
+
+ # Init axes.
+ if ax is None:
+ _, ax = plt.subplots(1, 1, figsize=(9, 9))
+
+ # Render map if requested.
+ if underlay_map:
+ assert use_flat_vehicle_coordinates, 'Error: underlay_map requires use_flat_vehicle_coordinates, as ' \
+ 'otherwise the location does not correspond to the map!'
+ self.render_ego_centric_map(sample_data_token=sample_data_token, axes_limit=axes_limit, ax=ax)
+
+ # Show point cloud.
+ points = view_points(pc.points[:3, :], viewpoint, normalize=False)
+ dists = np.sqrt(np.sum(pc.points[:2, :] ** 2, axis=0))
+ if sensor_modality == 'lidar' and show_lidarseg:
+ # Load labels for pointcloud.
+ if lidarseg_preds_bin_path:
+ sample_token = self.nusc.get('sample_data', sample_data_token)['sample_token']
+ lidarseg_labels_filename = lidarseg_preds_bin_path
+ assert os.path.exists(lidarseg_labels_filename), \
+ 'Error: Unable to find {} to load the predictions for sample token {} (lidar ' \
+ 'sample data token {}) from.'.format(lidarseg_labels_filename, sample_token, sample_data_token)
+ else:
+ if len(self.nusc.lidarseg) > 0: # Ensure lidarseg.json is not empty (e.g. in case of v1.0-test).
+ lidarseg_labels_filename = osp.join(self.nusc.dataroot,
+ self.nusc.get('lidarseg', sample_data_token)['filename'])
+ else:
+ lidarseg_labels_filename = None
+
+ if lidarseg_labels_filename:
+ # Paint each label in the pointcloud with a RGBA value.
+ colors = paint_points_label(lidarseg_labels_filename, filter_lidarseg_labels,
+ self.nusc.lidarseg_name2idx_mapping, self.nusc.colormap)
+
+ if show_lidarseg_legend:
+ # Since the labels are stored as class indices, we get the RGB colors from the colormap
+ # in an array where the position of the RGB color corresponds to the index of the class
+ # it represents.
+ color_legend = colormap_to_colors(self.nusc.colormap, self.nusc.lidarseg_name2idx_mapping)
+
+ # If user does not specify a filter, then set the filter to contain the classes present in
+ # the pointcloud after it has been projected onto the image; this will allow displaying the
+ # legend only for classes which are present in the image (instead of all the classes).
+ if filter_lidarseg_labels is None:
+ filter_lidarseg_labels = get_labels_in_coloring(color_legend, colors)
+
+ create_lidarseg_legend(filter_lidarseg_labels,
+ self.nusc.lidarseg_idx2name_mapping, self.nusc.colormap,
+ loc='upper left', ncol=1, bbox_to_anchor=(1.05, 1.0))
+ else:
+ colors = np.minimum(1, dists / axes_limit / np.sqrt(2))
+ print('Warning: There are no lidarseg labels in {}. Points will be colored according to distance '
+ 'from the ego vehicle instead.'.format(self.nusc.version))
+ else:
+ colors = np.minimum(1, dists / axes_limit / np.sqrt(2))
+ point_scale = 0.2 if sensor_modality == 'lidar' else 3.0
+
+ scatter = ax.scatter(points[0, :], points[1, :], c=colors, s=point_scale,) # fix bug cmap lost
+ # Show velocities.
+ if sensor_modality == 'radar':
+ points_vel = view_points(pc.points[:3, :] + velocities, viewpoint, normalize=False)
+ deltas_vel = points_vel - points
+ deltas_vel = 6 * deltas_vel # Arbitrary scaling
+ max_delta = 20
+ deltas_vel = np.clip(deltas_vel, -max_delta, max_delta) # Arbitrary clipping
+ colors_rgba = scatter.to_rgba(colors)
+ for i in range(points.shape[1]):
+ ax.arrow(points[0, i], points[1, i], deltas_vel[0, i], deltas_vel[1, i], color=colors_rgba[i])
+
+ # Show ego vehicle.
+ # [gl:picture left x ,up y ]
+ ax.plot(0, 0, 'x', color='red')
+
+ # Get boxes in lidar frame.[gl:this function have bug ,can't get none key frame lidar data]
+ if sd_record['is_key_frame'] != True:
+ _, boxes, _ = self.nusc.get_sample_data(sample_data_token, box_vis_level=box_vis_level,
+ use_flat_vehicle_coordinates=use_flat_vehicle_coordinates)
+ else:
+ _, boxes, _ = self.nusc.get_sample_data(ref_sd_token, box_vis_level=box_vis_level,
+ use_flat_vehicle_coordinates=use_flat_vehicle_coordinates)
+
+ # Show boxes.
+ if with_anns:
+ for box in boxes:
+ c = np.array(self.get_color(box.name)) / 255.0
+ box.render(ax, view=np.eye(4), colors=(c, c, c))
+
+ # Limit visible range.
+ ax.set_xlim(-axes_limit, axes_limit)
+ ax.set_ylim(-axes_limit, axes_limit)
+ elif sensor_modality == 'camera':
+ # Load boxes and image.
+ data_path, boxes, camera_intrinsic = self.nusc.get_sample_data(sample_data_token,
+ box_vis_level=box_vis_level)
+ data = Image.open(data_path)
+
+ # Init axes.
+ if ax is None:
+ _, ax = plt.subplots(1, 1, figsize=(9, 16))
+
+ # Show image.
+ ax.imshow(data)
+
+ # Show boxes.
+ if with_anns:
+ for box in boxes:
+ c = np.array(self.get_color(box.name)) / 255.0
+ box.render(ax, view=camera_intrinsic, normalize=True, colors=(c, c, c))
+
+ # Limit visible range.
+ ax.set_xlim(0, data.size[0])
+ ax.set_ylim(data.size[1], 0)
+
+ else:
+ raise ValueError("Error: Unknown sensor modality!")
+
+ ax.axis('off')
+ ax.set_title('{} {labels_type}'.format(
+ sd_record['channel'], labels_type='(predictions)' if lidarseg_preds_bin_path else ''))
+ ax.set_aspect('equal')
+
+ if out_path is not None:
+ plt.savefig(out_path, bbox_inches='tight', pad_inches=0, dpi=200)
+
+ if verbose:
+ plt.show()
+
+ def render_annotation(self,
+ anntoken: str,
+ margin: float = 10,
+ view: np.ndarray = np.eye(4),
+ box_vis_level: BoxVisibility = BoxVisibility.ANY,
+ out_path: str = None,
+ extra_info: bool = False) -> None:
+ """
+ Render selected annotation.
+ :param anntoken: Sample_annotation token.
+ :param margin: How many meters in each direction to include in LIDAR view.
+ :param view: LIDAR view point.
+ :param box_vis_level: If sample_data is an image, this sets required visibility for boxes.
+ :param out_path: Optional path to save the rendered figure to disk.
+ :param extra_info: Whether to render extra information below camera view.
+ """
+ ann_record = self.nusc.get('sample_annotation', anntoken)
+ sample_record = self.nusc.get('sample', ann_record['sample_token'])
+ assert 'LIDAR_TOP' in sample_record['data'].keys(), 'Error: No LIDAR_TOP in data, unable to render.'
+
+ fig, axes = plt.subplots(1, 2, figsize=(18, 9))
+
+ # Figure out which camera the object is fully visible in (this may return nothing).
+ boxes, cam = [], []
+ cams = [key for key in sample_record['data'].keys() if 'CAM' in key]
+ for cam in cams:
+ _, boxes, _ = self.nusc.get_sample_data(sample_record['data'][cam], box_vis_level=box_vis_level,
+ selected_anntokens=[anntoken])
+ if len(boxes) > 0:
+ break # We found an image that matches. Let's abort.
+ assert len(boxes) > 0, 'Error: Could not find image where annotation is visible. ' \
+ 'Try using e.g. BoxVisibility.ANY.'
+ assert len(boxes) < 2, 'Error: Found multiple annotations. Something is wrong!'
+
+ cam = sample_record['data'][cam]
+
+ # Plot LIDAR view.
+ lidar = sample_record['data']['LIDAR_TOP']
+ data_path, boxes, camera_intrinsic = self.nusc.get_sample_data(lidar, selected_anntokens=[anntoken])
+ LidarPointCloud.from_file(data_path).render_height(axes[0], view=view)
+ for box in boxes:
+ c = np.array(self.get_color(box.name)) / 255.0
+ box.render(axes[0], view=view, colors=(c, c, c))
+ corners = view_points(boxes[0].corners(), view, False)[:2, :]
+ axes[0].set_xlim([np.min(corners[0, :]) - margin, np.max(corners[0, :]) + margin])
+ axes[0].set_ylim([np.min(corners[1, :]) - margin, np.max(corners[1, :]) + margin])
+ axes[0].axis('off')
+ axes[0].set_aspect('equal')
+
+ # Plot CAMERA view.
+ data_path, boxes, camera_intrinsic = self.nusc.get_sample_data(cam, selected_anntokens=[anntoken])
+ im = Image.open(data_path)
+ axes[1].imshow(im)
+ axes[1].set_title(self.nusc.get('sample_data', cam)['channel'])
+ axes[1].axis('off')
+ axes[1].set_aspect('equal')
+ for box in boxes:
+ c = np.array(self.get_color(box.name)) / 255.0
+ box.render(axes[1], view=camera_intrinsic, normalize=True, colors=(c, c, c))
+
+ # Print extra information about the annotation below the camera view.
+ if extra_info:
+ rcParams['font.family'] = 'monospace'
+
+ w, l, h = ann_record['size']
+ category = ann_record['category_name']
+ lidar_points = ann_record['num_lidar_pts']
+ radar_points = ann_record['num_radar_pts']
+
+ sample_data_record = self.nusc.get('sample_data', sample_record['data']['LIDAR_TOP'])
+ pose_record = self.nusc.get('ego_pose', sample_data_record['ego_pose_token'])
+ dist = np.linalg.norm(np.array(pose_record['translation']) - np.array(ann_record['translation']))
+
+ information = ' \n'.join(['category: {}'.format(category),
+ '',
+ '# lidar points: {0:>4}'.format(lidar_points),
+ '# radar points: {0:>4}'.format(radar_points),
+ '',
+ 'distance: {:>7.3f}m'.format(dist),
+ '',
+ 'width: {:>7.3f}m'.format(w),
+ 'length: {:>7.3f}m'.format(l),
+ 'height: {:>7.3f}m'.format(h)])
+
+ plt.annotate(information, (0, 0), (0, -20), xycoords='axes fraction', textcoords='offset points', va='top')
+
+ if out_path is not None:
+ plt.savefig(out_path)
+
+ def render_instance(self,
+ instance_token: str,
+ margin: float = 10,
+ view: np.ndarray = np.eye(4),
+ box_vis_level: BoxVisibility = BoxVisibility.ANY,
+ out_path: str = None,
+ extra_info: bool = False) -> None:
+ """
+ Finds the annotation of the given instance that is closest to the vehicle, and then renders it.
+ :param instance_token: The instance token.
+ :param margin: How many meters in each direction to include in LIDAR view.
+ :param view: LIDAR view point.
+ :param box_vis_level: If sample_data is an image, this sets required visibility for boxes.
+ :param out_path: Optional path to save the rendered figure to disk.
+ :param extra_info: Whether to render extra information below camera view.
+ """
+ ann_tokens = self.nusc.field2token('sample_annotation', 'instance_token', instance_token)
+ closest = [np.inf, None]
+ for ann_token in ann_tokens:
+ ann_record = self.nusc.get('sample_annotation', ann_token)
+ sample_record = self.nusc.get('sample', ann_record['sample_token'])
+ sample_data_record = self.nusc.get('sample_data', sample_record['data']['LIDAR_TOP'])
+ pose_record = self.nusc.get('ego_pose', sample_data_record['ego_pose_token'])
+ dist = np.linalg.norm(np.array(pose_record['translation']) - np.array(ann_record['translation']))
+ if dist < closest[0]:
+ closest[0] = dist
+ closest[1] = ann_token
+
+ self.render_annotation(closest[1], margin, view, box_vis_level, out_path, extra_info)
+
+ def render_scene(self,
+ scene_token: str,
+ freq: float = 10,
+ imsize: Tuple[float, float] = (640, 360),
+ out_path: str = None) -> None:
+ """
+ Renders a full scene with all camera channels.
+ :param scene_token: Unique identifier of scene to render.
+ :param freq: Display frequency (Hz).
+ :param imsize: Size of image to render. The larger the slower this will run.
+ :param out_path: Optional path to write a video file of the rendered frames.
+ """
+
+ assert imsize[0] / imsize[1] == 16 / 9, "Aspect ratio should be 16/9."
+
+ if out_path is not None:
+ assert osp.splitext(out_path)[-1] == '.avi'
+
+ # Get records from DB.
+ scene_rec = self.nusc.get('scene', scene_token)
+ first_sample_rec = self.nusc.get('sample', scene_rec['first_sample_token'])
+ last_sample_rec = self.nusc.get('sample', scene_rec['last_sample_token'])
+
+ # Set some display parameters.
+ layout = {
+ 'CAM_FRONT_LEFT': (0, 0),
+ 'CAM_FRONT': (imsize[0], 0),
+ 'CAM_FRONT_RIGHT': (2 * imsize[0], 0),
+ 'CAM_BACK_LEFT': (0, imsize[1]),
+ 'CAM_BACK': (imsize[0], imsize[1]),
+ 'CAM_BACK_RIGHT': (2 * imsize[0], imsize[1]),
+ }
+
+ horizontal_flip = ['CAM_BACK_LEFT', 'CAM_BACK', 'CAM_BACK_RIGHT'] # Flip these for aesthetic reasons.
+
+ time_step = 1 / freq * 1e6 # Time-stamps are measured in micro-seconds.
+
+ window_name = '{}'.format(scene_rec['name'])
+ cv2.namedWindow(window_name)
+ cv2.moveWindow(window_name, 0, 0)
+
+ canvas = np.ones((2 * imsize[1], 3 * imsize[0], 3), np.uint8)
+ if out_path is not None:
+ fourcc = cv2.VideoWriter_fourcc(*'MJPG')
+ out = cv2.VideoWriter(out_path, fourcc, freq, canvas.shape[1::-1])
+ else:
+ out = None
+
+ # Load first sample_data record for each channel.
+ current_recs = {} # Holds the current record to be displayed by channel.
+ prev_recs = {} # Hold the previous displayed record by channel.
+ for channel in layout:
+ current_recs[channel] = self.nusc.get('sample_data', first_sample_rec['data'][channel])
+ prev_recs[channel] = None
+
+ current_time = first_sample_rec['timestamp']
+
+ while current_time < last_sample_rec['timestamp']:
+
+ current_time += time_step
+
+ # For each channel, find first sample that has time > current_time.
+ for channel, sd_rec in current_recs.items():
+ while sd_rec['timestamp'] < current_time and sd_rec['next'] != '':
+ sd_rec = self.nusc.get('sample_data', sd_rec['next'])
+ current_recs[channel] = sd_rec
+
+ # Now add to canvas
+ for channel, sd_rec in current_recs.items():
+
+ # Only update canvas if we have not already rendered this one.
+ if not sd_rec == prev_recs[channel]:
+
+ # Get annotations and params from DB.
+ impath, boxes, camera_intrinsic = self.nusc.get_sample_data(sd_rec['token'],
+ box_vis_level=BoxVisibility.ANY)
+
+ # Load and render.
+ if not osp.exists(impath):
+ raise Exception('Error: Missing image %s' % impath)
+ im = cv2.imread(impath)
+ for box in boxes:
+ c = self.get_color(box.name)
+ box.render_cv2(im, view=camera_intrinsic, normalize=True, colors=(c, c, c))
+
+ im = cv2.resize(im, imsize)
+ if channel in horizontal_flip:
+ im = im[:, ::-1, :]
+
+ canvas[
+ layout[channel][1]: layout[channel][1] + imsize[1],
+ layout[channel][0]:layout[channel][0] + imsize[0], :
+ ] = im
+
+ prev_recs[channel] = sd_rec # Store here so we don't render the same image twice.
+
+ # Show updated canvas.
+ cv2.imshow(window_name, canvas)
+ if out_path is not None:
+ out.write(canvas)
+
+ key = cv2.waitKey(1) # Wait a very short time (1 ms).
+
+ if key == 32: # if space is pressed, pause.
+ key = cv2.waitKey()
+
+ if key == 27: # if ESC is pressed, exit.
+ cv2.destroyAllWindows()
+ break
+
+ cv2.destroyAllWindows()
+ if out_path is not None:
+ out.release()
+
+ def render_scene_channel(self,
+ scene_token: str,
+ channel: str = 'CAM_FRONT',
+ freq: float = 10,
+ imsize: Tuple[float, float] = (640, 360),
+ out_path: str = None) -> None:
+ """
+ Renders a full scene for a particular camera channel.
+ :param scene_token: Unique identifier of scene to render.
+ :param channel: Channel to render.
+ :param freq: Display frequency (Hz).
+ :param imsize: Size of image to render. The larger the slower this will run.
+ :param out_path: Optional path to write a video file of the rendered frames.
+ """
+ valid_channels = ['CAM_FRONT_LEFT', 'CAM_FRONT', 'CAM_FRONT_RIGHT',
+ 'CAM_BACK_LEFT', 'CAM_BACK', 'CAM_BACK_RIGHT']
+
+ assert imsize[0] / imsize[1] == 16 / 9, "Error: Aspect ratio should be 16/9."
+ assert channel in valid_channels, 'Error: Input channel {} not valid.'.format(channel)
+
+ if out_path is not None:
+ assert osp.splitext(out_path)[-1] == '.avi'
+
+ # Get records from DB.
+ scene_rec = self.nusc.get('scene', scene_token)
+ sample_rec = self.nusc.get('sample', scene_rec['first_sample_token'])
+ sd_rec = self.nusc.get('sample_data', sample_rec['data'][channel])
+
+ # Open CV init.
+ name = '{}: {} (Space to pause, ESC to exit)'.format(scene_rec['name'], channel)
+ cv2.namedWindow(name)
+ cv2.moveWindow(name, 0, 0)
+
+ if out_path is not None:
+ fourcc = cv2.VideoWriter_fourcc(*'MJPG')
+ out = cv2.VideoWriter(out_path, fourcc, freq, imsize)
+ else:
+ out = None
+
+ has_more_frames = True
+ while has_more_frames:
+
+ # Get data from DB.
+ impath, boxes, camera_intrinsic = self.nusc.get_sample_data(sd_rec['token'],
+ box_vis_level=BoxVisibility.ANY)
+
+ # Load and render.
+ if not osp.exists(impath):
+ raise Exception('Error: Missing image %s' % impath)
+ im = cv2.imread(impath)
+ for box in boxes:
+ c = self.get_color(box.name)
+ box.render_cv2(im, view=camera_intrinsic, normalize=True, colors=(c, c, c))
+
+ # Render.
+ im = cv2.resize(im, imsize)
+ cv2.imshow(name, im)
+ if out_path is not None:
+ out.write(im)
+
+ key = cv2.waitKey(10) # Images stored at approx 10 Hz, so wait 10 ms.
+ if key == 32: # If space is pressed, pause.
+ key = cv2.waitKey()
+
+ if key == 27: # If ESC is pressed, exit.
+ cv2.destroyAllWindows()
+ break
+
+ if not sd_rec['next'] == "":
+ sd_rec = self.nusc.get('sample_data', sd_rec['next'])
+ else:
+ has_more_frames = False
+
+ cv2.destroyAllWindows()
+ if out_path is not None:
+ out.release()
+
+ def render_egoposes_on_map(self,
+ log_location: str,
+ scene_tokens: List = None,
+ close_dist: float = 100,
+ color_fg: Tuple[int, int, int] = (167, 174, 186),
+ color_bg: Tuple[int, int, int] = (255, 255, 255),
+ out_path: str = None) -> None:
+ """
+ Renders ego poses a the map. These can be filtered by location or scene.
+ :param log_location: Name of the location, e.g. "singapore-onenorth", "singapore-hollandvillage",
+ "singapore-queenstown' and "boston-seaport".
+ :param scene_tokens: Optional list of scene tokens.
+ :param close_dist: Distance in meters for an ego pose to be considered within range of another ego pose.
+ :param color_fg: Color of the semantic prior in RGB format (ignored if map is RGB).
+ :param color_bg: Color of the non-semantic prior in RGB format (ignored if map is RGB).
+ :param out_path: Optional path to save the rendered figure to disk.
+ """
+ # Get logs by location.
+ log_tokens = [log['token'] for log in self.nusc.log if log['location'] == log_location]
+ assert len(log_tokens) > 0, 'Error: This split has 0 scenes for location %s!' % log_location
+
+ # Filter scenes.
+ scene_tokens_location = [e['token'] for e in self.nusc.scene if e['log_token'] in log_tokens]
+ if scene_tokens is not None:
+ scene_tokens_location = [t for t in scene_tokens_location if t in scene_tokens]
+ if len(scene_tokens_location) == 0:
+ print('Warning: Found 0 valid scenes for location %s!' % log_location)
+
+ map_poses = []
+ map_mask = None
+
+ print('Adding ego poses to map...')
+ for scene_token in tqdm(scene_tokens_location):
+
+ # Get records from the database.
+ scene_record = self.nusc.get('scene', scene_token)
+ log_record = self.nusc.get('log', scene_record['log_token'])
+ map_record = self.nusc.get('map', log_record['map_token'])
+ map_mask = map_record['mask']
+
+ # For each sample in the scene, store the ego pose.
+ sample_tokens = self.nusc.field2token('sample', 'scene_token', scene_token)
+ for sample_token in sample_tokens:
+ sample_record = self.nusc.get('sample', sample_token)
+
+ # Poses are associated with the sample_data. Here we use the lidar sample_data.
+ sample_data_record = self.nusc.get('sample_data', sample_record['data']['LIDAR_TOP'])
+ pose_record = self.nusc.get('ego_pose', sample_data_record['ego_pose_token'])
+
+ # Calculate the pose on the map and append.
+ map_poses.append(np.concatenate(
+ map_mask.to_pixel_coords(pose_record['translation'][0], pose_record['translation'][1])))
+
+ # Compute number of close ego poses.
+ print('Creating plot...')
+ map_poses = np.vstack(map_poses)
+ dists = sklearn.metrics.pairwise.euclidean_distances(map_poses * map_mask.resolution)
+ close_poses = np.sum(dists < close_dist, axis=0)
+
+ if len(np.array(map_mask.mask()).shape) == 3 and np.array(map_mask.mask()).shape[2] == 3:
+ # RGB Colour maps.
+ mask = map_mask.mask()
+ else:
+ # Monochrome maps.
+ # Set the colors for the mask.
+ mask = Image.fromarray(map_mask.mask())
+ mask = np.array(mask)
+
+ maskr = color_fg[0] * np.ones(np.shape(mask), dtype=np.uint8)
+ maskr[mask == 0] = color_bg[0]
+ maskg = color_fg[1] * np.ones(np.shape(mask), dtype=np.uint8)
+ maskg[mask == 0] = color_bg[1]
+ maskb = color_fg[2] * np.ones(np.shape(mask), dtype=np.uint8)
+ maskb[mask == 0] = color_bg[2]
+ mask = np.concatenate((np.expand_dims(maskr, axis=2),
+ np.expand_dims(maskg, axis=2),
+ np.expand_dims(maskb, axis=2)), axis=2)
+
+ # Plot.
+ _, ax = plt.subplots(1, 1, figsize=(10, 10))
+ ax.imshow(mask)
+ title = 'Number of ego poses within {}m in {}'.format(close_dist, log_location)
+ ax.set_title(title, color='k')
+ sc = ax.scatter(map_poses[:, 0], map_poses[:, 1], s=10, c=close_poses)
+ color_bar = plt.colorbar(sc, fraction=0.025, pad=0.04)
+ plt.rcParams['figure.facecolor'] = 'black'
+ color_bar_ticklabels = plt.getp(color_bar.ax.axes, 'yticklabels')
+ plt.setp(color_bar_ticklabels, color='k')
+ plt.rcParams['figure.facecolor'] = 'white' # Reset for future plots.
+
+ if out_path is not None:
+ plt.savefig(out_path)
+
+ def _plot_points_and_bboxes(self,
+ pointsensor_token: str,
+ camera_token: str,
+ filter_lidarseg_labels: Iterable[int] = None,
+ lidarseg_preds_bin_path: str = None,
+ with_anns: bool = False,
+ imsize: Tuple[int, int] = (640, 360),
+ dpi: int = 100,
+ line_width: int = 5) -> Tuple[np.ndarray, bool]:
+ """
+ Projects a pointcloud into a camera image along with the lidarseg labels. There is an option to plot the
+ bounding boxes as well.
+ :param pointsensor_token: Token of lidar sensor to render points from and lidarseg labels.
+ :param camera_token: Token of camera to render image from.
+ :param filter_lidarseg_labels: Only show lidar points which belong to the given list of classes. If None
+ or the list is empty, all classes will be displayed.
+ :param lidarseg_preds_bin_path: A path to the .bin file which contains the user's lidar segmentation
+ predictions for the sample.
+ :param with_anns: Whether to draw box annotations.
+ :param imsize: Size of image to render. The larger the slower this will run.
+ :param dpi: Resolution of the output figure.
+ :param line_width: Line width of bounding boxes.
+ :return: An image with the projected pointcloud, lidarseg labels and (if applicable) the bounding boxes. Also,
+ whether there are any lidarseg points (after the filter has been applied) in the image.
+ """
+ points, coloring, im = self.map_pointcloud_to_image(pointsensor_token, camera_token,
+ render_intensity=False,
+ show_lidarseg=True,
+ filter_lidarseg_labels=filter_lidarseg_labels,
+ lidarseg_preds_bin_path=lidarseg_preds_bin_path)
+
+ # Prevent rendering images which have no lidarseg labels in them (e.g. the classes in the filter chosen by
+ # the users do not appear within the image). To check if there are no lidarseg labels belonging to the desired
+ # classes in an image, we check if any column in the coloring is all zeros (the alpha column will be all
+ # zeroes if so).
+ if (~coloring.any(axis=0)).any():
+ no_points_in_im = True
+ else:
+ no_points_in_im = False
+
+ if with_anns:
+ # Get annotations and params from DB.
+ impath, boxes, camera_intrinsic = self.nusc.get_sample_data(camera_token, box_vis_level=BoxVisibility.ANY)
+
+ # We need to get the image's original height and width as the boxes returned by get_sample_data
+ # are scaled wrt to that.
+ h, w, c = cv2.imread(impath).shape
+
+ # Place the projected pointcloud and lidarseg labels onto the image.
+ mat = plt_to_cv2(points, coloring, im, (w, h), dpi=dpi)
+
+ # Plot each box onto the image.
+ for box in boxes:
+ # If a filter is set, and the class of the box is not among the classes that the user wants to see,
+ # then we skip plotting the box.
+ if filter_lidarseg_labels is not None and \
+ self.nusc.lidarseg_name2idx_mapping[box.name] not in filter_lidarseg_labels:
+ continue
+ c = self.get_color(box.name)
+ box.render_cv2(mat, view=camera_intrinsic, normalize=True, colors=(c, c, c), linewidth=line_width)
+
+ # Only after points and boxes have been placed in the image, then we resize (this is to prevent
+ # weird scaling issues where the dots and boxes are not of the same scale).
+ mat = cv2.resize(mat, imsize)
+ else:
+ mat = plt_to_cv2(points, coloring, im, imsize, dpi=dpi)
+
+ return mat, no_points_in_im
+
+ def render_scene_channel_lidarseg(self,
+ scene_token: str,
+ channel: str,
+ out_folder: str = None,
+ filter_lidarseg_labels: Iterable[int] = None,
+ render_mode: str = None,
+ verbose: bool = True,
+ imsize: Tuple[int, int] = (640, 360),
+ with_anns: bool = False,
+ freq: float = 2,
+ dpi: int = 150,
+ lidarseg_preds_folder: str = None) -> None:
+ """
+ Renders a full scene with labelled lidar pointclouds for a particular camera channel.
+ The scene can be rendered either to a video or to a set of images.
+ :param scene_token: Unique identifier of scene to render.
+ :param channel: Camera channel to render.
+ :param out_folder: Optional path to save the rendered frames to disk, either as a video or as individual images.
+ :param filter_lidarseg_labels: Only show lidar points which belong to the given list of classes. If None
+ or the list is empty, all classes will be displayed.
+ :param render_mode: Either 'video' or 'image'. 'video' will render the frames into a video (the name of the
+ video will follow this format: <scene_number>_<camera_channel>.avi) while 'image' will
+ render the frames into individual images (each image name wil follow this format:
+ <scene_name>_<camera_channel>_<original_file_name>.jpg). 'out_folder' must be specified
+ to save the video / images.
+ :param verbose: Whether to show the frames as they are being rendered.
+ :param imsize: Size of image to render. The larger the slower this will run.
+ :param with_anns: Whether to draw box annotations.
+ :param freq: Display frequency (Hz).
+ :param dpi: Resolution of the output dots.
+ :param lidarseg_preds_folder: A path to the folder which contains the user's lidar segmentation predictions for
+ the scene. The naming convention of each .bin file in the folder should be
+ named in this format: <lidar_sample_data_token>_lidarseg.bin.
+ """
+
+ assert hasattr(self.nusc, 'lidarseg'), 'Error: nuScenes-lidarseg not installed!'
+
+ valid_channels = ['CAM_FRONT_LEFT', 'CAM_FRONT', 'CAM_FRONT_RIGHT',
+ 'CAM_BACK_LEFT', 'CAM_BACK', 'CAM_BACK_RIGHT']
+ assert channel in valid_channels, 'Error: Input camera channel {} not valid.'.format(channel)
+ assert imsize[0] / imsize[1] == 16 / 9, 'Error: Aspect ratio should be 16/9.'
+
+ if lidarseg_preds_folder:
+ assert(os.path.isdir(lidarseg_preds_folder)), \
+ 'Error: The lidarseg predictions folder ({}) does not exist.'.format(lidarseg_preds_folder)
+
+ save_as_vid = False
+ if out_folder:
+ assert render_mode in ['video', 'image'], 'Error: For the renderings to be saved to {}, either `video` ' \
+ 'or `image` must be specified for render_mode. {} is ' \
+ 'not a valid mode.'.format(out_folder, render_mode)
+ assert os.path.isdir(out_folder), 'Error: {} does not exist.'.format(out_folder)
+ if render_mode == 'video':
+ save_as_vid = True
+
+ scene_record = self.nusc.get('scene', scene_token)
+
+ total_num_samples = scene_record['nbr_samples']
+ first_sample_token = scene_record['first_sample_token']
+ last_sample_token = scene_record['last_sample_token']
+
+ current_token = first_sample_token
+ keep_looping = True
+ i = 0
+
+ # Open CV init.
+ if verbose:
+ name = '{}: {} {labels_type} (Space to pause, ESC to exit)'.format(
+ scene_record['name'], channel, labels_type="(predictions)" if lidarseg_preds_folder else "")
+ cv2.namedWindow(name)
+ cv2.moveWindow(name, 0, 0)
+ else:
+ name = None
+
+ if save_as_vid:
+ out_path = os.path.join(out_folder, scene_record['name'] + '_' + channel + '.avi')
+ fourcc = cv2.VideoWriter_fourcc(*'MJPG')
+ out = cv2.VideoWriter(out_path, fourcc, freq, imsize)
+ else:
+ out = None
+
+ while keep_looping:
+ if current_token == last_sample_token:
+ keep_looping = False
+
+ sample_record = self.nusc.get('sample', current_token)
+
+ # Set filename of the image.
+ camera_token = sample_record['data'][channel]
+ cam = self.nusc.get('sample_data', camera_token)
+ filename = scene_record['name'] + '_' + channel + '_' + os.path.basename(cam['filename'])
+
+ # Determine whether to render lidarseg points from ground truth or predictions.
+ pointsensor_token = sample_record['data']['LIDAR_TOP']
+ if lidarseg_preds_folder:
+ lidarseg_preds_bin_path = osp.join(lidarseg_preds_folder, pointsensor_token + '_lidarseg.bin')
+ else:
+ lidarseg_preds_bin_path = None
+
+ mat, no_points_in_mat = self._plot_points_and_bboxes(pointsensor_token, camera_token,
+ filter_lidarseg_labels=filter_lidarseg_labels,
+ lidarseg_preds_bin_path=lidarseg_preds_bin_path,
+ with_anns=with_anns, imsize=imsize,
+ dpi=dpi, line_width=2)
+
+ if verbose:
+ cv2.imshow(name, mat)
+
+ key = cv2.waitKey(1)
+ if key == 32: # If space is pressed, pause.
+ key = cv2.waitKey()
+
+ if key == 27: # if ESC is pressed, exit.
+ plt.close('all') # To prevent figures from accumulating in memory.
+ # If rendering is stopped halfway, save whatever has been rendered so far into a video
+ # (if save_as_vid = True).
+ if save_as_vid:
+ out.write(mat)
+ out.release()
+ cv2.destroyAllWindows()
+ break
+
+ plt.close('all') # To prevent figures from accumulating in memory.
+
+ if save_as_vid:
+ out.write(mat)
+ elif not no_points_in_mat and out_folder:
+ cv2.imwrite(os.path.join(out_folder, filename), mat)
+ else:
+ pass
+
+ next_token = sample_record['next']
+ current_token = next_token
+ i += 1
+
+ cv2.destroyAllWindows()
+
+ if save_as_vid:
+ assert total_num_samples == i, 'Error: There were supposed to be {} keyframes, ' \
+ 'but only {} keyframes were processed'.format(total_num_samples, i)
+ out.release()
+
+ def render_scene_lidarseg(self,
+ scene_token: str,
+ out_path: str = None,
+ filter_lidarseg_labels: Iterable[int] = None,
+ with_anns: bool = False,
+ imsize: Tuple[int, int] = (640, 360),
+ freq: float = 2,
+ verbose: bool = True,
+ dpi: int = 200,
+ lidarseg_preds_folder: str = None) -> None:
+ """
+ Renders a full scene with all camera channels and the lidar segmentation labels for each camera.
+ The scene can be rendered either to a video or to a set of images.
+ :param scene_token: Unique identifier of scene to render.
+ :param out_path: Optional path to write a video file (must be .avi) of the rendered frames
+ (e.g. '~/Desktop/my_rendered_scene.avi),
+ :param filter_lidarseg_labels: Only show lidar points which belong to the given list of classes. If None
+ or the list is empty, all classes will be displayed.
+ :param with_anns: Whether to draw box annotations.
+ :param freq: Display frequency (Hz).
+ :param imsize: Size of image to render. The larger the slower this will run.
+ :param verbose: Whether to show the frames as they are being rendered.
+ :param dpi: Resolution of the output dots.
+ :param lidarseg_preds_folder: A path to the folder which contains the user's lidar segmentation predictions for
+ the scene. The naming convention of each .bin file in the folder should be
+ named in this format: <lidar_sample_data_token>_lidarseg.bin.
+ """
+ assert hasattr(self.nusc, 'lidarseg'), 'Error: nuScenes-lidarseg not installed!'
+
+ assert imsize[0] / imsize[1] == 16 / 9, "Aspect ratio should be 16/9."
+
+ if lidarseg_preds_folder:
+ assert(os.path.isdir(lidarseg_preds_folder)), \
+ 'Error: The lidarseg predictions folder ({}) does not exist.'.format(lidarseg_preds_folder)
+
+ # Get records from DB.
+ scene_record = self.nusc.get('scene', scene_token)
+
+ total_num_samples = scene_record['nbr_samples']
+ first_sample_token = scene_record['first_sample_token']
+ last_sample_token = scene_record['last_sample_token']
+
+ current_token = first_sample_token
+
+ # Set some display parameters.
+ layout = {
+ 'CAM_FRONT_LEFT': (0, 0),
+ 'CAM_FRONT': (imsize[0], 0),
+ 'CAM_FRONT_RIGHT': (2 * imsize[0], 0),
+ 'CAM_BACK_LEFT': (0, imsize[1]),
+ 'CAM_BACK': (imsize[0], imsize[1]),
+ 'CAM_BACK_RIGHT': (2 * imsize[0], imsize[1]),
+ }
+
+ horizontal_flip = ['CAM_BACK_LEFT', 'CAM_BACK', 'CAM_BACK_RIGHT'] # Flip these for aesthetic reasons.
+
+ if verbose:
+ window_name = '{} {labels_type} (Space to pause, ESC to exit)'.format(
+ scene_record['name'], labels_type="(predictions)" if lidarseg_preds_folder else "")
+ cv2.namedWindow(window_name)
+ cv2.moveWindow(window_name, 0, 0)
+ else:
+ window_name = None
+
+ slate = np.ones((2 * imsize[1], 3 * imsize[0], 3), np.uint8)
+
+ if out_path:
+ path_to_file, filename = os.path.split(out_path)
+ assert os.path.isdir(path_to_file), 'Error: {} does not exist.'.format(path_to_file)
+ assert os.path.splitext(filename)[-1] == '.avi', 'Error: Video can only be saved in .avi format.'
+ fourcc = cv2.VideoWriter_fourcc(*'MJPG')
+ out = cv2.VideoWriter(out_path, fourcc, freq, slate.shape[1::-1])
+ else:
+ out = None
+
+ keep_looping = True
+ i = 0
+ while keep_looping:
+ if current_token == last_sample_token:
+ keep_looping = False
+
+ sample_record = self.nusc.get('sample', current_token)
+
+ for camera_channel in layout:
+ pointsensor_token = sample_record['data']['LIDAR_TOP']
+ camera_token = sample_record['data'][camera_channel]
+
+ # Determine whether to render lidarseg points from ground truth or predictions.
+ if lidarseg_preds_folder:
+ lidarseg_preds_bin_path = osp.join(lidarseg_preds_folder, pointsensor_token + '_lidarseg.bin')
+ else:
+ lidarseg_preds_bin_path = None
+
+ mat, _ = self._plot_points_and_bboxes(pointsensor_token, camera_token,
+ filter_lidarseg_labels=filter_lidarseg_labels,
+ lidarseg_preds_bin_path=lidarseg_preds_bin_path,
+ with_anns=with_anns, imsize=imsize, dpi=dpi, line_width=3)
+
+ if camera_channel in horizontal_flip:
+ # Flip image horizontally.
+ mat = cv2.flip(mat, 1)
+
+ slate[
+ layout[camera_channel][1]: layout[camera_channel][1] + imsize[1],
+ layout[camera_channel][0]:layout[camera_channel][0] + imsize[0], :
+ ] = mat
+
+ if verbose:
+ cv2.imshow(window_name, slate)
+
+ key = cv2.waitKey(1)
+ if key == 32: # If space is pressed, pause.
+ key = cv2.waitKey()
+
+ if key == 27: # if ESC is pressed, exit.
+ plt.close('all') # To prevent figures from accumulating in memory.
+ # If rendering is stopped halfway, save whatever has been rendered so far into a video
+ # (if save_as_vid = True).
+ if out_path:
+ out.write(slate)
+ out.release()
+ cv2.destroyAllWindows()
+ break
+
+ plt.close('all') # To prevent figures from accumulating in memory.
+
+ if out_path:
+ out.write(slate)
+ else:
+ pass
+
+ next_token = sample_record['next']
+ current_token = next_token
+
+ i += 1
+
+ cv2.destroyAllWindows()
+
+ if out_path:
+ assert total_num_samples == i, 'Error: There were supposed to be {} keyframes, ' \
+ 'but only {} keyframes were processed'.format(total_num_samples, i)
+ out.release()
diff --git a/python-sdk/nuscenes/prediction/__init__.py b/python-sdk/nuscenes/prediction/__init__.py
new file mode 100644
index 0000000..c043e71
--- /dev/null
+++ b/python-sdk/nuscenes/prediction/__init__.py
@@ -0,0 +1 @@
+from .helper import PredictHelper, convert_global_coords_to_local, convert_local_coords_to_global
\ No newline at end of file
diff --git a/python-sdk/nuscenes/prediction/helper.py b/python-sdk/nuscenes/prediction/helper.py
new file mode 100644
index 0000000..e2e98e6
--- /dev/null
+++ b/python-sdk/nuscenes/prediction/helper.py
@@ -0,0 +1,424 @@
+# nuScenes dev-kit.
+# Code written by Freddy Boulton, 2020.
+from typing import Dict, Tuple, Any, List, Callable, Union
+
+import numpy as np
+from pyquaternion import Quaternion
+
+from nuscenes import NuScenes
+from nuscenes.eval.common.utils import quaternion_yaw, angle_diff
+
+MICROSECONDS_PER_SECOND = 1e6
+BUFFER = 0.15 # seconds
+
+Record = Dict[str, Any]
+
+
+def angle_of_rotation(yaw: float) -> float:
+ """
+ Given a yaw angle (measured from x axis), find the angle needed to rotate by so that
+ the yaw is aligned with the y axis (pi / 2).
+ :param yaw: Radians. Output of quaternion_yaw function.
+ :return: Angle in radians.
+ """
+ return (np.pi / 2) + np.sign(-yaw) * np.abs(yaw)
+
+
+def make_2d_rotation_matrix(angle_in_radians: float) -> np.ndarray:
+ """
+ Makes rotation matrix to rotate point in x-y plane counterclockwise
+ by angle_in_radians.
+ """
+
+ return np.array([[np.cos(angle_in_radians), -np.sin(angle_in_radians)],
+ [np.sin(angle_in_radians), np.cos(angle_in_radians)]])
+
+
+def convert_global_coords_to_local(coordinates: np.ndarray,
+ translation: Tuple[float, float, float],
+ rotation: Tuple[float, float, float, float]) -> np.ndarray:
+ """
+ Converts global coordinates to coordinates in the frame given by the rotation quaternion and
+ centered at the translation vector. The rotation is meant to be a z-axis rotation.
+ :param coordinates: x,y locations. array of shape [n_steps, 2].
+ :param translation: Tuple of (x, y, z) location that is the center of the new frame.
+ :param rotation: Tuple representation of quaternion of new frame.
+ Representation - cos(theta / 2) + (xi + yi + zi)sin(theta / 2).
+ :return: x,y locations in frame stored in array of share [n_times, 2].
+ """
+ yaw = angle_of_rotation(quaternion_yaw(Quaternion(rotation)))
+
+ transform = make_2d_rotation_matrix(angle_in_radians=yaw)
+
+ coords = (coordinates - np.atleast_2d(np.array(translation)[:2])).T
+
+ return np.dot(transform, coords).T[:, :2]
+
+
+def convert_local_coords_to_global(coordinates: np.ndarray,
+ translation: Tuple[float, float, float],
+ rotation: Tuple[float, float, float, float]) -> np.ndarray:
+ """
+ Converts local coordinates to global coordinates.
+ :param coordinates: x,y locations. array of shape [n_steps, 2]
+ :param translation: Tuple of (x, y, z) location that is the center of the new frame
+ :param rotation: Tuple representation of quaternion of new frame.
+ Representation - cos(theta / 2) + (xi + yi + zi)sin(theta / 2).
+ :return: x,y locations stored in array of share [n_times, 2].
+ """
+ yaw = angle_of_rotation(quaternion_yaw(Quaternion(rotation)))
+
+ transform = make_2d_rotation_matrix(angle_in_radians=-yaw)
+
+ return np.dot(transform, coordinates.T).T[:, :2] + np.atleast_2d(np.array(translation)[:2])
+
+
+class PredictHelper:
+ """ Wrapper class around NuScenes to help retrieve data for the prediction task. """
+
+ def __init__(self, nusc: NuScenes):
+ """
+ Inits PredictHelper
+ :param nusc: Instance of NuScenes class.
+ """
+ self.data = nusc
+ self.inst_sample_to_ann = self._map_sample_and_instance_to_annotation()
+
+ def _map_sample_and_instance_to_annotation(self) -> Dict[Tuple[str, str], str]:
+ """
+ Creates mapping to look up an annotation given a sample and instance in constant time.
+ :return: Mapping from (sample_token, instance_token) -> sample_annotation_token.
+ """
+ mapping = {}
+
+ for record in self.data.sample_annotation:
+ mapping[(record['sample_token'], record['instance_token'])] = record['token']
+
+ return mapping
+
+ def _timestamp_for_sample(self, sample_token: str) -> float:
+ """
+ Gets timestamp from sample token.
+ :param sample_token: Get the timestamp for this sample.
+ :return: Timestamp (microseconds).
+ """
+ return self.data.get('sample', sample_token)['timestamp']
+
+ def _absolute_time_diff(self, time1: float, time2: float) -> float:
+ """
+ Helper to compute how much time has elapsed in _iterate method.
+ :param time1: First timestamp (microseconds since unix epoch).
+ :param time2: Second timestamp (microseconds since unix epoch).
+ :return: Absolute Time difference in floats.
+ """
+ return abs(time1 - time2) / MICROSECONDS_PER_SECOND
+
+ def _iterate(self, starting_annotation: Dict[str, Any], seconds: float, direction: str) -> List[Dict[str, Any]]:
+ """
+ Iterates forwards or backwards in time through the annotations for a given amount of seconds.
+ :param starting_annotation: Sample annotation record to start from.
+ :param seconds: Number of seconds to iterate.
+ :param direction: 'prev' for past and 'next' for future.
+ :return: List of annotations ordered by time.
+ """
+ if seconds < 0:
+ raise ValueError(f"Parameter seconds must be non-negative. Received {seconds}.")
+
+ # Need to exit early because we technically _could_ return data in this case if
+ # the first observation is within the BUFFER.
+ if seconds == 0:
+ return []
+
+ seconds_with_buffer = seconds + BUFFER
+ starting_time = self._timestamp_for_sample(starting_annotation['sample_token'])
+
+ next_annotation = starting_annotation
+
+ time_elapsed = 0.
+
+ annotations = []
+
+ expected_samples_per_sec = 2
+ max_annotations = int(expected_samples_per_sec * seconds)
+ while time_elapsed <= seconds_with_buffer and len(annotations) < max_annotations:
+
+ if next_annotation[direction] == '':
+ break
+
+ next_annotation = self.data.get('sample_annotation', next_annotation[direction])
+ current_time = self._timestamp_for_sample(next_annotation['sample_token'])
+
+ time_elapsed = self._absolute_time_diff(current_time, starting_time)
+
+ if time_elapsed < seconds_with_buffer:
+ annotations.append(next_annotation)
+
+ return annotations
+
+ def get_sample_annotation(self, instance_token: str, sample_token: str) -> Record:
+ """
+ Retrieves an annotation given an instance token and its sample.
+ :param instance_token: Instance token.
+ :param sample_token: Sample token for instance.
+ :return: Sample annotation record.
+ """
+ return self.data.get('sample_annotation', self.inst_sample_to_ann[(sample_token, instance_token)])
+
+ def get_annotations_for_sample(self, sample_token: str) -> List[Record]:
+ """
+ Gets a list of sample annotation records for a sample.
+ :param sample_token: Sample token.
+ """
+
+ sample_record = self.data.get('sample', sample_token)
+ annotations = []
+
+ for annotation_token in sample_record['anns']:
+ annotation_record = self.data.get('sample_annotation', annotation_token)
+ annotations.append(annotation_record)
+
+ return annotations
+
+ def _get_past_or_future_for_agent(self, instance_token: str, sample_token: str,
+ seconds: float, in_agent_frame: bool,
+ direction: str,
+ just_xy: bool = True) -> Union[List[Record], np.ndarray]:
+ """
+ Helper function to reduce code duplication between get_future and get_past for agent.
+ :param instance_token: Instance of token.
+ :param sample_token: Sample token for instance.
+ :param seconds: How many seconds of data to retrieve.
+ :param in_agent_frame: Whether to rotate the coordinates so the
+ heading is aligned with the y-axis.
+ :param direction: 'next' for future or 'prev' for past.
+ :return: array of shape [n_timesteps, 2].
+ """
+ starting_annotation = self.get_sample_annotation(instance_token, sample_token)
+ sequence = self._iterate(starting_annotation, seconds, direction)
+
+ if not just_xy:
+ return sequence
+
+ coords = np.array([r['translation'][:2] for r in sequence])
+
+ if coords.size == 0:
+ return coords
+
+ if in_agent_frame:
+ coords = convert_global_coords_to_local(coords,
+ starting_annotation['translation'],
+ starting_annotation['rotation'])
+
+ return coords
+
+ def get_future_for_agent(self, instance_token: str, sample_token: str,
+ seconds: float, in_agent_frame: bool,
+ just_xy: bool = True) -> Union[List[Record], np.ndarray]:
+ """
+ Retrieves the agent's future x,y locations.
+ :param instance_token: Instance token.
+ :param sample_token: Sample token.
+ :param seconds: How much future data to retrieve.
+ :param in_agent_frame: If true, locations are rotated to the agent frame.
+ :param just_xy: If true, returns an np.array of x,y locations as opposed to the
+ entire record.
+ :return: If just_xy, np.ndarray. Else, List of records.
+ The rows increate with time, i.e the last row occurs the farthest in the future.
+ """
+ return self._get_past_or_future_for_agent(instance_token, sample_token, seconds,
+ in_agent_frame, direction='next', just_xy=just_xy)
+
+ def get_past_for_agent(self, instance_token: str, sample_token: str,
+ seconds: float, in_agent_frame: bool,
+ just_xy: bool = True) -> Union[List[Record], np.ndarray]:
+ """
+ Retrieves the agent's past sample annotation records.
+ :param instance_token: Instance token.
+ :param sample_token: Sample token.
+ :param seconds: How much past data to retrieve.
+ :param in_agent_frame: If true, locations are rotated to the agent frame.
+ Only relevant if just_xy = True.
+ :param just_xy: If true, returns an np.array of x,y locations as opposed to the
+ entire record.
+ :return: If just_xy, np.ndarray. Else, List of records.
+ The rows decrease with time, i.e the last row occurs the farthest in the past.
+ """
+ return self._get_past_or_future_for_agent(instance_token, sample_token, seconds,
+ in_agent_frame, direction='prev', just_xy=just_xy)
+
+ def _get_past_or_future_for_sample(self, sample_token: str, seconds: float, in_agent_frame: bool,
+ direction: str, just_xy: bool,
+ function: Callable[[str, str, float, bool, str, bool], np.ndarray]) -> Union[Dict[str, np.ndarray], Dict[str, List[Record]]]:
+ """
+ Helper function to reduce code duplication between get_future and get_past for sample.
+ :param sample_token: Sample token.
+ :param seconds: How much past or future data to retrieve.
+ :param in_agent_frame: Whether to rotate each agent future.
+ Only relevant if just_xy = True.
+ :param just_xy: If true, returns an np.array of x,y locations as opposed to the
+ entire record.
+ :param function: _get_past_or_future_for_agent.
+ :return: Dictionary mapping instance token to np.array or list of records.
+ """
+ sample_record = self.data.get('sample', sample_token)
+ sequences = {}
+ for annotation in sample_record['anns']:
+ annotation_record = self.data.get('sample_annotation', annotation)
+ sequence = function(annotation_record['instance_token'],
+ annotation_record['sample_token'],
+ seconds, in_agent_frame, direction, just_xy=just_xy)
+
+ sequences[annotation_record['instance_token']] = sequence
+
+ return sequences
+
+ def get_future_for_sample(self, sample_token: str, seconds: float, in_agent_frame: bool,
+ just_xy: bool = True) -> Union[Dict[str, np.ndarray], Dict[str, List[Record]]]:
+ """
+ Retrieves the the future x,y locations of all agents in the sample.
+ :param sample_token: Sample token.
+ :param seconds: How much future data to retrieve.
+ :param in_agent_frame: If true, locations are rotated to the agent frame.
+ Only relevant if just_xy = True.
+ :param just_xy: If true, returns an np.array of x,y locations as opposed to the
+ entire record.
+ :return: If just_xy, Mapping of instance token to np.ndarray.
+ Else, the mapping is from instance token to list of records.
+ The rows increase with time, i.e the last row occurs the farthest in the future.
+ """
+ return self._get_past_or_future_for_sample(sample_token, seconds, in_agent_frame, 'next',
+ just_xy,
+ function=self._get_past_or_future_for_agent)
+
+ def get_past_for_sample(self, sample_token: str, seconds: float, in_agent_frame: bool,
+ just_xy: bool = True) -> Dict[str, np.ndarray]:
+ """
+ Retrieves the the past x,y locations of all agents in the sample.
+ :param sample_token: Sample token.
+ :param seconds: How much past data to retrieve.
+ :param in_agent_frame: If true, locations are rotated to the agent frame.
+ Only relevant if just_xy = True.
+ :param just_xy: If true, returns an np.array of x,y locations as opposed to the
+ entire record.
+ :return: If just_xy, Mapping of instance token to np.ndarray.
+ Else, the mapping is from instance token to list of records.
+ The rows decrease with time, i.e the last row occurs the farthest in the past.
+ """
+ return self._get_past_or_future_for_sample(sample_token, seconds, in_agent_frame, 'prev',
+ just_xy,
+ function=self._get_past_or_future_for_agent)
+
+ def _compute_diff_between_sample_annotations(self, instance_token: str,
+ sample_token: str, max_time_diff: float,
+ with_function, **kwargs) -> float:
+ """
+ Grabs current and previous annotation and computes a float from them.
+ :param instance_token: Instance token.
+ :param sample_token: Sample token.
+ :param max_time_diff: If the time difference between now and the most recent annotation is larger
+ than this param, function will return np.nan.
+ :param with_function: Function to apply to the annotations.
+ :param **kwargs: Keyword arguments to give to with_function.
+
+ """
+ annotation = self.get_sample_annotation(instance_token, sample_token)
+
+ if annotation['prev'] == '':
+ return np.nan
+
+ prev = self.data.get('sample_annotation', annotation['prev'])
+
+ current_time = 1e-6 * self.data.get('sample', sample_token)['timestamp']
+ prev_time = 1e-6 * self.data.get('sample', prev['sample_token'])['timestamp']
+ time_diff = current_time - prev_time
+
+ if time_diff <= max_time_diff:
+
+ return with_function(annotation, prev, time_diff, **kwargs)
+
+ else:
+ return np.nan
+
+ def get_velocity_for_agent(self, instance_token: str, sample_token: str, max_time_diff: float = 1.5) -> float:
+ """
+ Computes velocity based on the difference between the current and previous annotation.
+ :param instance_token: Instance token.
+ :param sample_token: Sample token.
+ :param max_time_diff: If the time difference between now and the most recent annotation is larger
+ than this param, function will return np.nan.
+ """
+ return self._compute_diff_between_sample_annotations(instance_token, sample_token, max_time_diff,
+ with_function=velocity)
+
+ def get_heading_change_rate_for_agent(self, instance_token: str, sample_token: str,
+ max_time_diff: float = 1.5) -> float:
+ """
+ Computes heading change rate based on the difference between the current and previous annotation.
+ :param instance_token: Instance token.
+ :param sample_token: Sample token.
+ :param max_time_diff: If the time difference between now and the most recent annotation is larger
+ than this param, function will return np.nan.
+ """
+ return self._compute_diff_between_sample_annotations(instance_token, sample_token, max_time_diff,
+ with_function=heading_change_rate)
+
+ def get_acceleration_for_agent(self, instance_token: str, sample_token: str, max_time_diff: float = 1.5) -> float:
+ """
+ Computes heading change rate based on the difference between the current and previous annotation.
+ :param instance_token: Instance token.
+ :param sample_token: Sample token.
+ :param max_time_diff: If the time difference between now and the most recent annotation is larger
+ than this param, function will return np.nan.
+ """
+ return self._compute_diff_between_sample_annotations(instance_token, sample_token,
+ max_time_diff,
+ with_function=acceleration,
+ instance_token_for_velocity=instance_token,
+ helper=self)
+
+ def get_map_name_from_sample_token(self, sample_token: str) -> str:
+
+ sample = self.data.get('sample', sample_token)
+ scene = self.data.get('scene', sample['scene_token'])
+ log = self.data.get('log', scene['log_token'])
+ return log['location']
+
+
+def velocity(current: Dict[str, Any], prev: Dict[str, Any], time_diff: float) -> float:
+ """
+ Helper function to compute velocity between sample annotations.
+ :param current: Sample annotation record for the current timestamp.
+ :param prev: Sample annotation record for the previous time stamp.
+ :param time_diff: How much time has elapsed between the records.
+ """
+ diff = (np.array(current['translation']) - np.array(prev['translation'])) / time_diff
+ return np.linalg.norm(diff[:2])
+
+
+def heading_change_rate(current: Dict[str, Any], prev: Dict[str, Any], time_diff: float) -> float:
+ """
+ Helper function to compute heading change rate between sample annotations.
+ :param current: Sample annotation record for the current timestamp.
+ :param prev: Sample annotation record for the previous time stamp.
+ :param time_diff: How much time has elapsed between the records.
+ """
+ current_yaw = quaternion_yaw(Quaternion(current['rotation']))
+ prev_yaw = quaternion_yaw(Quaternion(prev['rotation']))
+
+ return angle_diff(current_yaw, prev_yaw, period=2*np.pi) / time_diff
+
+
+def acceleration(current: Dict[str, Any], prev: Dict[str, Any],
+ time_diff: float, instance_token_for_velocity: str, helper: PredictHelper) -> float:
+ """
+ Helper function to compute acceleration between sample annotations.
+ :param current: Sample annotation record for the current timestamp.
+ :param prev: Sample annotation record for the previous time stamp.
+ :param time_diff: How much time has elapsed between the records.
+ :param instance_token_for_velocity: Instance token to compute velocity.
+ :param helper: Instance of PredictHelper.
+ """
+ current_velocity = helper.get_velocity_for_agent(instance_token_for_velocity, current['sample_token'])
+ prev_velocity = helper.get_velocity_for_agent(instance_token_for_velocity, prev['sample_token'])
+
+ return (current_velocity - prev_velocity) / time_diff
diff --git a/python-sdk/nuscenes/prediction/input_representation/__init__.py b/python-sdk/nuscenes/prediction/input_representation/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/python-sdk/nuscenes/prediction/input_representation/agents.py b/python-sdk/nuscenes/prediction/input_representation/agents.py
new file mode 100644
index 0000000..a19894c
--- /dev/null
+++ b/python-sdk/nuscenes/prediction/input_representation/agents.py
@@ -0,0 +1,276 @@
+# nuScenes dev-kit.
+# Code written by Freddy Boulton, 2020.
+import colorsys
+from typing import Any, Dict, List, Tuple, Callable
+
+import cv2
+import numpy as np
+from pyquaternion import Quaternion
+
+from nuscenes.prediction import PredictHelper
+from nuscenes.prediction.helper import quaternion_yaw
+from nuscenes.prediction.input_representation.interface import AgentRepresentation
+from nuscenes.prediction.input_representation.utils import convert_to_pixel_coords, get_crops, get_rotation_matrix
+
+History = Dict[str, List[Dict[str, Any]]]
+
+
+def pixels_to_box_corners(row_pixel: int,
+ column_pixel: int,
+ length_in_pixels: float,
+ width_in_pixels: float,
+ yaw_in_radians: float) -> np.ndarray:
+ """
+ Computes four corners of 2d bounding box for agent.
+ The coordinates of the box are in pixels.
+ :param row_pixel: Row pixel of the agent.
+ :param column_pixel: Column pixel of the agent.
+ :param length_in_pixels: Length of the agent.
+ :param width_in_pixels: Width of the agent.
+ :param yaw_in_radians: Yaw of the agent (global coordinates).
+ :return: numpy array representing the four corners of the agent.
+ """
+
+ # cv2 has the convention where they flip rows and columns so it matches
+ # the convention of x and y on a coordinate plane
+ # Also, a positive angle is a clockwise rotation as opposed to counterclockwise
+ # so that is why we negate the rotation angle
+ coord_tuple = ((column_pixel, row_pixel), (length_in_pixels, width_in_pixels), -yaw_in_radians * 180 / np.pi)
+
+ box = cv2.boxPoints(coord_tuple)
+
+ return box
+
+
+def get_track_box(annotation: Dict[str, Any],
+ center_coordinates: Tuple[float, float],
+ center_pixels: Tuple[float, float],
+ resolution: float = 0.1) -> np.ndarray:
+ """
+ Get four corners of bounding box for agent in pixels.
+ :param annotation: The annotation record of the agent.
+ :param center_coordinates: (x, y) coordinates in global frame
+ of the center of the image.
+ :param center_pixels: (row_index, column_index) location of the center
+ of the image in pixel coordinates.
+ :param resolution: Resolution pixels/meter of the image.
+ """
+
+ assert resolution > 0
+
+ location = annotation['translation'][:2]
+ yaw_in_radians = quaternion_yaw(Quaternion(annotation['rotation']))
+
+ row_pixel, column_pixel = convert_to_pixel_coords(location,
+ center_coordinates,
+ center_pixels, resolution)
+
+ width = annotation['size'][0] / resolution
+ length = annotation['size'][1] / resolution
+
+ # Width and length are switched here so that we can draw them along the x-axis as
+ # opposed to the y. This makes rotation easier.
+ return pixels_to_box_corners(row_pixel, column_pixel, length, width, yaw_in_radians)
+
+
+def reverse_history(history: History) -> History:
+ """
+ Reverse history so that most distant observations are first.
+ We do this because we want to draw more recent bounding boxes on top of older ones.
+ :param history: result of get_past_for_sample PredictHelper method.
+ :return: History with the values reversed.
+ """
+ return {token: anns[::-1] for token, anns in history.items()}
+
+
+def add_present_time_to_history(current_time: List[Dict[str, Any]],
+ history: History) -> History:
+ """
+ Adds the sample annotation records from the current time to the
+ history object.
+ :param current_time: List of sample annotation records from the
+ current time. Result of get_annotations_for_sample method of
+ PredictHelper.
+ :param history: Result of get_past_for_sample method of PredictHelper.
+ :return: History with values from current_time appended.
+ """
+
+ for annotation in current_time:
+ token = annotation['instance_token']
+
+ if token in history:
+
+ # We append because we've reversed the history
+ history[token].append(annotation)
+
+ else:
+ history[token] = [annotation]
+
+ return history
+
+
+def fade_color(color: Tuple[int, int, int],
+ step: int,
+ total_number_of_steps: int) -> Tuple[int, int, int]:
+ """
+ Fades a color so that past observations are darker in the image.
+ :param color: Tuple of ints describing an RGB color.
+ :param step: The current time step.
+ :param total_number_of_steps: The total number of time steps
+ the agent has in the image.
+ :return: Tuple representing faded rgb color.
+ """
+
+ LOWEST_VALUE = 0.4
+
+ if step == total_number_of_steps:
+ return color
+
+ hsv_color = colorsys.rgb_to_hsv(*color)
+
+ increment = (float(hsv_color[2])/255. - LOWEST_VALUE) / total_number_of_steps
+
+ new_value = LOWEST_VALUE + step * increment
+
+ new_rgb = colorsys.hsv_to_rgb(float(hsv_color[0]),
+ float(hsv_color[1]),
+ new_value * 255.)
+ return new_rgb
+
+
+def default_colors(category_name: str) -> Tuple[int, int, int]:
+ """
+ Maps a category name to an rgb color (without fading).
+ :param category_name: Name of object category for the annotation.
+ :return: Tuple representing rgb color.
+ """
+
+ if 'vehicle' in category_name:
+ return 255, 255, 0 # yellow
+ elif 'object' in category_name:
+ return 204, 0, 204 # violet
+ elif 'human' in category_name or 'animal' in category_name:
+ return 255, 153, 51 # orange
+ else:
+ raise ValueError(f"Cannot map {category_name} to a color.")
+
+
+def draw_agent_boxes(center_agent_annotation: Dict[str, Any],
+ center_agent_pixels: Tuple[float, float],
+ agent_history: History,
+ base_image: np.ndarray,
+ get_color: Callable[[str], Tuple[int, int, int]],
+ resolution: float = 0.1) -> None:
+ """
+ Draws past sequence of agent boxes on the image.
+ :param center_agent_annotation: Annotation record for the agent
+ that is in the center of the image.
+ :param center_agent_pixels: Pixel location of the agent in the
+ center of the image.
+ :param agent_history: History for all agents in the scene.
+ :param base_image: Image to draw the agents in.
+ :param get_color: Mapping from category_name to RGB tuple.
+ :param resolution: Size of the image in pixels / meter.
+ :return: None.
+ """
+
+ agent_x, agent_y = center_agent_annotation['translation'][:2]
+
+ for instance_token, annotations in agent_history.items():
+
+ num_points = len(annotations)
+
+ for i, annotation in enumerate(annotations):
+
+ box = get_track_box(annotation, (agent_x, agent_y), center_agent_pixels, resolution)
+
+ if instance_token == center_agent_annotation['instance_token']:
+ color = (255, 0, 0)
+ else:
+ color = get_color(annotation['category_name'])
+
+ # Don't fade the colors if there is no history
+ if num_points > 1:
+ color = fade_color(color, i, num_points - 1)
+
+ cv2.fillPoly(base_image, pts=[np.int0(box)], color=color)
+
+
+class AgentBoxesWithFadedHistory(AgentRepresentation):
+ """
+ Represents the past sequence of agent states as a three-channel
+ image with faded 2d boxes.
+ """
+
+ def __init__(self, helper: PredictHelper,
+ seconds_of_history: float = 2,
+ frequency_in_hz: float = 2,
+ resolution: float = 0.1, # meters / pixel
+ meters_ahead: float = 40, meters_behind: float = 10,
+ meters_left: float = 25, meters_right: float = 25,
+ color_mapping: Callable[[str], Tuple[int, int, int]] = None):
+
+ self.helper = helper
+ self.seconds_of_history = seconds_of_history
+ self.frequency_in_hz = frequency_in_hz
+
+ if not resolution > 0:
+ raise ValueError(f"Resolution must be positive. Received {resolution}.")
+
+ self.resolution = resolution
+
+ self.meters_ahead = meters_ahead
+ self.meters_behind = meters_behind
+ self.meters_left = meters_left
+ self.meters_right = meters_right
+
+ if not color_mapping:
+ color_mapping = default_colors
+
+ self.color_mapping = color_mapping
+
+ def make_representation(self, instance_token: str, sample_token: str) -> np.ndarray:
+ """
+ Draws agent boxes with faded history into a black background.
+ :param instance_token: Instance token.
+ :param sample_token: Sample token.
+ :return: np.ndarray representing a 3 channel image.
+ """
+
+ # Taking radius around track before to ensure all actors are in image
+ buffer = max([self.meters_ahead, self.meters_behind,
+ self.meters_left, self.meters_right]) * 2
+
+ image_side_length = int(buffer/self.resolution)
+
+ # We will center the track in the image
+ central_track_pixels = (image_side_length / 2, image_side_length / 2)
+
+ base_image = np.zeros((image_side_length, image_side_length, 3))
+
+ history = self.helper.get_past_for_sample(sample_token,
+ self.seconds_of_history,
+ in_agent_frame=False,
+ just_xy=False)
+ history = reverse_history(history)
+
+ present_time = self.helper.get_annotations_for_sample(sample_token)
+
+ history = add_present_time_to_history(present_time, history)
+
+ center_agent_annotation = self.helper.get_sample_annotation(instance_token, sample_token)
+
+ draw_agent_boxes(center_agent_annotation, central_track_pixels,
+ history, base_image, resolution=self.resolution, get_color=self.color_mapping)
+
+ center_agent_yaw = quaternion_yaw(Quaternion(center_agent_annotation['rotation']))
+ rotation_mat = get_rotation_matrix(base_image.shape, center_agent_yaw)
+
+ rotated_image = cv2.warpAffine(base_image, rotation_mat, (base_image.shape[1],
+ base_image.shape[0]))
+
+ row_crop, col_crop = get_crops(self.meters_ahead, self.meters_behind,
+ self.meters_left, self.meters_right, self.resolution,
+ image_side_length)
+
+ return rotated_image[row_crop, col_crop].astype('uint8')
diff --git a/python-sdk/nuscenes/prediction/input_representation/combinators.py b/python-sdk/nuscenes/prediction/input_representation/combinators.py
new file mode 100644
index 0000000..43eb0f8
--- /dev/null
+++ b/python-sdk/nuscenes/prediction/input_representation/combinators.py
@@ -0,0 +1,53 @@
+# nuScenes dev-kit.
+# Code written by Freddy Boulton, 2020.
+from functools import reduce
+from typing import List
+
+import cv2
+import numpy as np
+
+from nuscenes.prediction.input_representation.interface import Combinator
+
+
+def add_foreground_to_image(base_image: np.ndarray,
+ foreground_image: np.ndarray) -> np.ndarray:
+ """
+ Overlays a foreground image on top of a base image without mixing colors. Type uint8.
+ :param base_image: Image that will be the background. Type uint8.
+ :param foreground_image: Image that will be the foreground.
+ :return: Image Numpy array of type uint8.
+ """
+
+ if not base_image.shape == foreground_image.shape:
+ raise ValueError("base_image and foreground image must have the same shape."
+ " Received {} and {}".format(base_image.shape, foreground_image.shape))
+
+ if not (base_image.dtype == "uint8" and foreground_image.dtype == "uint8"):
+ raise ValueError("base_image and foreground image must be of type 'uint8'."
+ " Received {} and {}".format(base_image.dtype, foreground_image.dtype))
+
+ img2gray = cv2.cvtColor(foreground_image, cv2.COLOR_BGR2GRAY)
+ _, mask = cv2.threshold(img2gray, 0, 255, cv2.THRESH_BINARY)
+ mask_inv = cv2.bitwise_not(mask)
+ img1_bg = cv2.bitwise_and(base_image, base_image, mask=mask_inv)
+ img2_fg = cv2.bitwise_and(foreground_image, foreground_image, mask=mask)
+ combined_image = cv2.add(img1_bg, img2_fg)
+ return combined_image
+
+
+class Rasterizer(Combinator):
+ """
+ Combines images into a three channel image.
+ """
+
+ def combine(self, data: List[np.ndarray]) -> np.ndarray:
+ """
+ Combine three channel images into a single image.
+ :param data: List of images to combine.
+ :return: Numpy array representing image (type 'uint8')
+ """
+ # All images in the dict are the same shape
+ image_shape = data[0].shape
+
+ base_image = np.zeros(image_shape).astype("uint8")
+ return reduce(add_foreground_to_image, [base_image] + data)
diff --git a/python-sdk/nuscenes/prediction/input_representation/interface.py b/python-sdk/nuscenes/prediction/input_representation/interface.py
new file mode 100644
index 0000000..df4db9c
--- /dev/null
+++ b/python-sdk/nuscenes/prediction/input_representation/interface.py
@@ -0,0 +1,54 @@
+# nuScenes dev-kit.
+# Code written by Freddy Boulton 2020.
+import abc
+from typing import List
+
+import numpy as np
+
+
+class StaticLayerRepresentation(abc.ABC):
+ """ Represents static map information as a numpy array. """
+
+ @abc.abstractmethod
+ def make_representation(self, instance_token: str, sample_token: str) -> np.ndarray:
+ raise NotImplementedError()
+
+
+class AgentRepresentation(abc.ABC):
+ """ Represents information of agents in scene as numpy array. """
+
+ @abc.abstractmethod
+ def make_representation(self, instance_token: str, sample_token: str) -> np.ndarray:
+ raise NotImplementedError()
+
+
+class Combinator(abc.ABC):
+ """ Combines the StaticLayer and Agent representations into a single one. """
+
+ @abc.abstractmethod
+ def combine(self, data: List[np.ndarray]) -> np.ndarray:
+ raise NotImplementedError()
+
+
+class InputRepresentation:
+ """
+ Specifies how to represent the input for a prediction model.
+ Need to provide a StaticLayerRepresentation - how the map is represented,
+ an AgentRepresentation - how agents in the scene are represented,
+ and a Combinator, how the StaticLayerRepresentation and AgentRepresentation should be combined.
+ """
+
+ def __init__(self, static_layer: StaticLayerRepresentation, agent: AgentRepresentation,
+ combinator: Combinator):
+
+ self.static_layer_rasterizer = static_layer
+ self.agent_rasterizer = agent
+ self.combinator = combinator
+
+ def make_input_representation(self, instance_token: str, sample_token: str) -> np.ndarray:
+
+ static_layers = self.static_layer_rasterizer.make_representation(instance_token, sample_token)
+ agents = self.agent_rasterizer.make_representation(instance_token, sample_token)
+
+ return self.combinator.combine([static_layers, agents])
+
diff --git a/python-sdk/nuscenes/prediction/input_representation/static_layers.py b/python-sdk/nuscenes/prediction/input_representation/static_layers.py
new file mode 100644
index 0000000..181f22d
--- /dev/null
+++ b/python-sdk/nuscenes/prediction/input_representation/static_layers.py
@@ -0,0 +1,290 @@
+# nuScenes dev-kit.
+# Code written by Freddy Boulton, 2020.
+import colorsys
+import os
+from typing import Dict, List, Tuple, Callable
+
+import cv2
+import numpy as np
+from pyquaternion import Quaternion
+
+from nuscenes.eval.common.utils import quaternion_yaw
+from nuscenes.map_expansion.map_api import NuScenesMap, locations
+from nuscenes.prediction import PredictHelper
+from nuscenes.prediction.helper import angle_of_rotation, angle_diff
+from nuscenes.prediction.input_representation.combinators import Rasterizer
+from nuscenes.prediction.input_representation.interface import \
+ StaticLayerRepresentation
+from nuscenes.prediction.input_representation.utils import get_crops, get_rotation_matrix, convert_to_pixel_coords
+
+Color = Tuple[float, float, float]
+
+
+def load_all_maps(helper: PredictHelper, verbose: bool = False) -> Dict[str, NuScenesMap]:
+ """
+ Loads all NuScenesMap instances for all available maps.
+ :param helper: Instance of PredictHelper.
+ :param verbose: Whether to print to stdout.
+ :return: Mapping from map-name to the NuScenesMap api instance.
+ """
+ dataroot = helper.data.dataroot
+ maps = {}
+
+ for map_name in locations:
+ if verbose:
+ print(f'static_layers.py - Loading Map: {map_name}')
+
+ maps[map_name] = NuScenesMap(dataroot, map_name=map_name)
+
+ return maps
+
+
+def get_patchbox(x_in_meters: float, y_in_meters: float,
+ image_side_length: float) -> Tuple[float, float, float, float]:
+ """
+ Gets the patchbox representing the area to crop the base image.
+ :param x_in_meters: X coordinate.
+ :param y_in_meters: Y coordiante.
+ :param image_side_length: Length of the image.
+ :return: Patch box tuple.
+ """
+
+ patch_box = (x_in_meters, y_in_meters, image_side_length, image_side_length)
+
+ return patch_box
+
+
+def change_color_of_binary_mask(image: np.ndarray, color: Color) -> np.ndarray:
+ """
+ Changes color of binary mask. The image has values 0 or 1 but has three channels.
+ :param image: Image with either 0 or 1 values and three channels.
+ :param color: RGB color tuple.
+ :return: Image with color changed (type uint8).
+ """
+
+ image = image * color
+
+ # Return as type int so cv2 can manipulate it later.
+ image = image.astype("uint8")
+
+ return image
+
+
+def correct_yaw(yaw: float) -> float:
+ """
+ nuScenes maps were flipped over the y-axis, so we need to
+ add pi to the angle needed to rotate the heading.
+ :param yaw: Yaw angle to rotate the image.
+ :return: Yaw after correction.
+ """
+ if yaw <= 0:
+ yaw = -np.pi - yaw
+ else:
+ yaw = np.pi - yaw
+
+ return yaw
+
+
+def get_lanes_in_radius(x: float, y: float, radius: float,
+ discretization_meters: float,
+ map_api: NuScenesMap) -> Dict[str, List[Tuple[float, float, float]]]:
+ """
+ Retrieves all the lanes and lane connectors in a radius of the query point.
+ :param x: x-coordinate of point in global coordinates.
+ :param y: y-coordinate of point in global coordinates.
+ :param radius: Any lanes within radius meters of the (x, y) point will be returned.
+ :param discretization_meters: How finely to discretize the lane. If 1 is given, for example,
+ the lane will be discretized into a list of points such that the distances between points
+ is approximately 1 meter.
+ :param map_api: The NuScenesMap instance to query.
+ :return: Mapping from lane id to list of coordinate tuples in global coordinate system.
+ """
+
+ lanes = map_api.get_records_in_radius(x, y, radius, ['lane', 'lane_connector'])
+ lanes = lanes['lane'] + lanes['lane_connector']
+ lanes = map_api.discretize_lanes(lanes, discretization_meters)
+
+ return lanes
+
+
+def color_by_yaw(agent_yaw_in_radians: float,
+ lane_yaw_in_radians: float) -> Color:
+ """
+ Color the pose one the lane based on its yaw difference to the agent yaw.
+ :param agent_yaw_in_radians: Yaw of the agent with respect to the global frame.
+ :param lane_yaw_in_radians: Yaw of the pose on the lane with respect to the global frame.
+ """
+
+ # By adding pi, lanes in the same direction as the agent are colored blue.
+ angle = angle_diff(agent_yaw_in_radians, lane_yaw_in_radians, 2*np.pi) + np.pi
+
+ # Convert to degrees per colorsys requirement
+ angle = angle * 180/np.pi
+
+ normalized_rgb_color = colorsys.hsv_to_rgb(angle/360, 1., 1.)
+
+ color = [color*255 for color in normalized_rgb_color]
+
+ # To make the return type consistent with Color definition
+ return color[0], color[1], color[2]
+
+
+def draw_lanes_on_image(image: np.ndarray,
+ lanes: Dict[str, List[Tuple[float, float, float]]],
+ agent_global_coords: Tuple[float, float],
+ agent_yaw_in_radians: float,
+ agent_pixels: Tuple[int, int],
+ resolution: float,
+ color_function: Callable[[float, float], Color] = color_by_yaw) -> np.ndarray:
+ """
+ Draws lanes on image.
+ :param image: Image to draw lanes on. Preferably all-black or all-white image.
+ :param lanes: Mapping from lane id to list of coordinate tuples in global coordinate system.
+ :param agent_global_coords: Location of the agent in the global coordinate frame.
+ :param agent_yaw_in_radians: Yaw of agent in radians.
+ :param agent_pixels: Location of the agent in the image as (row_pixel, column_pixel).
+ :param resolution: Resolution in meters/pixel.
+ :param color_function: By default, lanes are colored by the yaw difference between the pose
+ on the lane and the agent yaw. However, you can supply your own function to color the lanes.
+ :return: Image (represented as np.ndarray) with lanes drawn.
+ """
+
+ for poses_along_lane in lanes.values():
+
+ for start_pose, end_pose in zip(poses_along_lane[:-1], poses_along_lane[1:]):
+
+ start_pixels = convert_to_pixel_coords(start_pose[:2], agent_global_coords,
+ agent_pixels, resolution)
+ end_pixels = convert_to_pixel_coords(end_pose[:2], agent_global_coords,
+ agent_pixels, resolution)
+
+ start_pixels = (start_pixels[1], start_pixels[0])
+ end_pixels = (end_pixels[1], end_pixels[0])
+
+ color = color_function(agent_yaw_in_radians, start_pose[2])
+
+ # Need to flip the row coordinate and the column coordinate
+ # because of cv2 convention
+ cv2.line(image, start_pixels, end_pixels, color,
+ thickness=5)
+
+ return image
+
+
+def draw_lanes_in_agent_frame(image_side_length: int,
+ agent_x: float, agent_y: float,
+ agent_yaw: float,
+ radius: float,
+ image_resolution: float,
+ discretization_resolution_meters: float,
+ map_api: NuScenesMap,
+ color_function: Callable[[float, float], Color] = color_by_yaw) -> np.ndarray:
+ """
+ Queries the map api for the nearest lanes, discretizes them, draws them on an image
+ and rotates the image so the agent heading is aligned with the postive y axis.
+ :param image_side_length: Length of the image.
+ :param agent_x: Agent X-coordinate in global frame.
+ :param agent_y: Agent Y-coordinate in global frame.
+ :param agent_yaw: Agent yaw, in radians.
+ :param radius: Draws the lanes that are within radius meters of the agent.
+ :param image_resolution: Image resolution in pixels / meter.
+ :param discretization_resolution_meters: How finely to discretize the lanes.
+ :param map_api: Instance of NuScenesMap.
+ :param color_function: By default, lanes are colored by the yaw difference between the pose
+ on the lane and the agent yaw. However, you can supply your own function to color the lanes.
+ :return: np array with lanes drawn.
+ """
+
+ agent_pixels = int(image_side_length / 2), int(image_side_length / 2)
+ base_image = np.zeros((image_side_length, image_side_length, 3))
+
+ lanes = get_lanes_in_radius(agent_x, agent_y, radius, discretization_resolution_meters, map_api)
+
+ image_with_lanes = draw_lanes_on_image(base_image, lanes, (agent_x, agent_y), agent_yaw,
+ agent_pixels, image_resolution, color_function)
+
+ rotation_mat = get_rotation_matrix(image_with_lanes.shape, agent_yaw)
+
+ rotated_image = cv2.warpAffine(image_with_lanes, rotation_mat, image_with_lanes.shape[:2])
+
+ return rotated_image.astype("uint8")
+
+
+class StaticLayerRasterizer(StaticLayerRepresentation):
+ """
+ Creates a representation of the static map layers where
+ the map layers are given a color and rasterized onto a
+ three channel image.
+ """
+
+ def __init__(self, helper: PredictHelper,
+ layer_names: List[str] = None,
+ colors: List[Color] = None,
+ resolution: float = 0.1, # meters / pixel
+ meters_ahead: float = 40, meters_behind: float = 10,
+ meters_left: float = 25, meters_right: float = 25):
+
+ self.helper = helper
+ self.maps = load_all_maps(helper)
+
+ if not layer_names:
+ layer_names = ['drivable_area', 'ped_crossing', 'walkway']
+ self.layer_names = layer_names
+
+ if not colors:
+ colors = [(255, 255, 255), (119, 136, 153), (0, 0, 255)]
+ self.colors = colors
+
+ self.resolution = resolution
+ self.meters_ahead = meters_ahead
+ self.meters_behind = meters_behind
+ self.meters_left = meters_left
+ self.meters_right = meters_right
+ self.combinator = Rasterizer()
+
+ def make_representation(self, instance_token: str, sample_token: str) -> np.ndarray:
+ """
+ Makes rasterized representation of static map layers.
+ :param instance_token: Token for instance.
+ :param sample_token: Token for sample.
+ :return: Three channel image.
+ """
+
+ sample_annotation = self.helper.get_sample_annotation(instance_token, sample_token)
+ map_name = self.helper.get_map_name_from_sample_token(sample_token)
+
+ x, y = sample_annotation['translation'][:2]
+
+ yaw = quaternion_yaw(Quaternion(sample_annotation['rotation']))
+
+ yaw_corrected = correct_yaw(yaw)
+
+ image_side_length = 2 * max(self.meters_ahead, self.meters_behind,
+ self.meters_left, self.meters_right)
+ image_side_length_pixels = int(image_side_length / self.resolution)
+
+ patchbox = get_patchbox(x, y, image_side_length)
+
+ angle_in_degrees = angle_of_rotation(yaw_corrected) * 180 / np.pi
+
+ canvas_size = (image_side_length_pixels, image_side_length_pixels)
+
+ masks = self.maps[map_name].get_map_mask(patchbox, angle_in_degrees, self.layer_names, canvas_size=canvas_size)
+
+ images = []
+ for mask, color in zip(masks, self.colors):
+ images.append(change_color_of_binary_mask(np.repeat(mask[::-1, :, np.newaxis], 3, 2), color))
+
+ lanes = draw_lanes_in_agent_frame(image_side_length_pixels, x, y, yaw, radius=50,
+ image_resolution=self.resolution, discretization_resolution_meters=1,
+ map_api=self.maps[map_name])
+
+ images.append(lanes)
+
+ image = self.combinator.combine(images)
+
+ row_crop, col_crop = get_crops(self.meters_ahead, self.meters_behind, self.meters_left,
+ self.meters_right, self.resolution,
+ int(image_side_length / self.resolution))
+
+ return image[row_crop, col_crop, :]
diff --git a/python-sdk/nuscenes/prediction/input_representation/tests/__init__.py b/python-sdk/nuscenes/prediction/input_representation/tests/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/python-sdk/nuscenes/prediction/input_representation/tests/test_agents.py b/python-sdk/nuscenes/prediction/input_representation/tests/test_agents.py
new file mode 100644
index 0000000..7bd17dc
--- /dev/null
+++ b/python-sdk/nuscenes/prediction/input_representation/tests/test_agents.py
@@ -0,0 +1,161 @@
+# nuScenes dev-kit.
+# Code written by Freddy Boulton, 2020.
+
+import unittest
+from unittest.mock import MagicMock
+
+import cv2
+import numpy as np
+
+from nuscenes.prediction import PredictHelper
+from nuscenes.prediction.helper import make_2d_rotation_matrix
+from nuscenes.prediction.input_representation import agents
+
+
+class Test_get_track_box(unittest.TestCase):
+
+
+ def test_heading_positive_30(self):
+
+ annotation = {'translation': [0, 0, 0],
+ 'rotation': [np.cos(np.pi / 12), 0, 0, np.sin(np.pi / 12)],
+ 'size': [4, 2]}
+
+ ego_center = (0, 0)
+ ego_pixels = (50, 50)
+
+ pi_over_six = np.pi / 6
+
+ box = agents.get_track_box(annotation, ego_center, ego_pixels, resolution=1.)
+
+ mat = make_2d_rotation_matrix(pi_over_six)
+ coordinates = np.array([[-2, 1], [-2, -1], [2, -1], [2, 1]])
+ answer = mat.dot(coordinates.T).T + ego_pixels
+ answer = answer[:, [1, 0]]
+
+ np.testing.assert_allclose(np.sort(answer, axis=0), np.sort(box, axis=0))
+
+
+ def test_heading_neg_30(self):
+
+ annotation = {'translation': [0, 0, 0],
+ 'rotation': [np.cos(-np.pi / 12), 0, 0, np.sin(-np.pi / 12)],
+ 'size': [4, 2]}
+
+ ego_center = (0, 0)
+ ego_pixels = (50, 50)
+
+ pi_over_six = -np.pi / 6
+
+ box = agents.get_track_box(annotation, ego_center, ego_pixels, resolution=1.)
+
+ mat = make_2d_rotation_matrix(pi_over_six)
+ coordinates = np.array([[-2, 1], [-2, -1], [2, -1], [2, 1]])
+ answer = mat.dot(coordinates.T).T + ego_pixels
+ answer = answer[:, [1, 0]]
+
+ np.testing.assert_allclose(np.sort(answer, axis=0), np.sort(box, axis=0))
+
+
+class Test_reverse_history(unittest.TestCase):
+
+ def test(self):
+
+ history = {'instance_1': [{'time': 0}, {'time': -1}, {'time': -2}],
+ 'instance_2': [{'time': -1}, {'time': -2}],
+ 'instance_3': [{'time': 0}]}
+
+ agent_history = agents.reverse_history(history)
+
+ answer = {'instance_1': [{'time': -2}, {'time': -1}, {'time': 0}],
+ 'instance_2': [{'time': -2}, {'time': -1}],
+ 'instance_3': [{'time': 0}]}
+
+ self.assertDictEqual(answer, agent_history)
+
+
+class Test_add_present_time_to_history(unittest.TestCase):
+
+ def test(self):
+
+ current_time = [{'instance_token': 0, 'time': 3},
+ {'instance_token': 1, 'time': 3},
+ {'instance_token': 2, 'time': 3}]
+
+ history = {0: [{'instance_token': 0, 'time': 1},
+ {'instance_token': 0, 'time': 2}],
+ 1: [{'instance_token': 1, 'time': 2}]}
+
+ history = agents.add_present_time_to_history(current_time, history)
+
+ answer = {0: [{'instance_token': 0, 'time': 1},
+ {'instance_token': 0, 'time': 2},
+ {'instance_token': 0, 'time': 3}],
+ 1: [{'instance_token': 1, 'time': 2},
+ {'instance_token': 1, 'time': 3}],
+ 2: [{'instance_token': 2, 'time': 3}]}
+
+ self.assertDictEqual(answer, history)
+
+
+class Test_fade_color(unittest.TestCase):
+
+ def test_dont_fade_last(self):
+
+ color = agents.fade_color((200, 0, 0), 10, 10)
+ self.assertTupleEqual(color, (200, 0, 0))
+
+ def test_first_is_darkest(self):
+
+ color = agents.fade_color((200, 200, 0), 0, 10)
+ self.assertTupleEqual(color, (102, 102, 0))
+
+
+class TestAgentBoxesWithFadedHistory(unittest.TestCase):
+
+ def test_make_representation(self):
+
+ mock_helper = MagicMock(spec=PredictHelper)
+
+ mock_helper.get_past_for_sample.return_value = {0: [{'rotation': [1, 0, 0, 0], 'translation': [-5, 0, 0],
+ 'size': [2, 4, 0], 'instance_token': 0,
+ 'category_name': 'vehicle'}],
+ 1: [{'rotation': [1, 0, 0, 0], 'translation': [5, -5, 0],
+ 'size': [3, 3, 0], 'instance_token': 1,
+ 'category_name': 'human'}]}
+ mock_helper.get_annotations_for_sample.return_value = [{'rotation': [1, 0, 0, 0], 'translation': [0, 0, 0],
+ 'size': [2, 4, 0], 'instance_token': 0,
+ 'category_name': 'vehicle'},
+ {'rotation': [1, 0, 0, 0], 'translation': [10, -5, 0],
+ 'size': [3, 3, 0], 'instance_token': 1,
+ 'category_name': 'human'}]
+
+ mock_helper.get_sample_annotation.return_value = {'rotation': [1, 0, 0, 0], 'translation': [0, 0, 0],
+ 'size': [2, 4, 0], 'instance_token': 0,
+ 'category_name': 'vehicle'}
+
+ def get_colors(name):
+ if 'vehicle' in name:
+ return (255, 0, 0)
+ else:
+ return (255, 255, 0)
+
+ agent_rasterizer = agents.AgentBoxesWithFadedHistory(mock_helper,
+ color_mapping=get_colors)
+
+ img = agent_rasterizer.make_representation(0, 'foo_sample')
+
+ answer = np.zeros((500, 500, 3))
+
+ agent_0_ts_0 = cv2.boxPoints(((250, 450), (40, 20), -90))
+ angent_0_ts_1 = cv2.boxPoints(((250, 400), (40, 20), -90))
+
+ agent_1_ts_0 = cv2.boxPoints(((300, 350), (30, 30), -90))
+ agent_1_ts_1 = cv2.boxPoints(((300, 300), (30, 30), -90))
+
+ answer = cv2.fillPoly(answer, pts=[np.int0(agent_0_ts_0)], color=(102, 0, 0))
+ answer = cv2.fillPoly(answer, pts=[np.int0(angent_0_ts_1)], color=(255, 0, 0))
+ answer = cv2.fillPoly(answer, pts=[np.int0(agent_1_ts_0)], color=(102, 102, 0))
+ answer = cv2.fillPoly(answer, pts=[np.int0(agent_1_ts_1)], color=(255, 255, 0))
+
+ np.testing.assert_allclose(answer, img)
diff --git a/python-sdk/nuscenes/prediction/input_representation/tests/test_combinators.py b/python-sdk/nuscenes/prediction/input_representation/tests/test_combinators.py
new file mode 100644
index 0000000..bc81be4
--- /dev/null
+++ b/python-sdk/nuscenes/prediction/input_representation/tests/test_combinators.py
@@ -0,0 +1,32 @@
+# nuScenes dev-kit.
+# Code written by Freddy Boulton, 2020.
+
+import unittest
+
+import cv2
+import numpy as np
+
+from nuscenes.prediction.input_representation.combinators import Rasterizer
+
+
+class TestRasterizer(unittest.TestCase):
+
+ def test(self):
+
+ layer_1 = np.zeros((100, 100, 3))
+ box_1 = cv2.boxPoints(((50, 50), (20, 20), 0))
+ layer_1 = cv2.fillPoly(layer_1, pts=[np.int0(box_1)], color=(255, 255, 255))
+
+ layer_2 = np.zeros((100, 100, 3))
+ box_2 = cv2.boxPoints(((70, 30), (10, 10), 0))
+ layer_2 = cv2.fillPoly(layer_2, pts=[np.int0(box_2)], color=(0, 0, 255))
+
+ rasterizer = Rasterizer()
+ image = rasterizer.combine([layer_1.astype('uint8'), layer_2.astype('uint8')])
+
+ answer = np.zeros((100, 100, 3))
+ answer = cv2.fillPoly(answer, pts=[np.int0(box_1)], color=(255, 255, 255))
+ answer = cv2.fillPoly(answer, pts=[np.int0(box_2)], color=(0, 0, 255))
+ answer = answer.astype('uint8')
+
+ np.testing.assert_allclose(answer, image)
diff --git a/python-sdk/nuscenes/prediction/input_representation/tests/test_static_layers.py b/python-sdk/nuscenes/prediction/input_representation/tests/test_static_layers.py
new file mode 100644
index 0000000..1ef17ad
--- /dev/null
+++ b/python-sdk/nuscenes/prediction/input_representation/tests/test_static_layers.py
@@ -0,0 +1,88 @@
+# nuScenes dev-kit.
+# Code written by Freddy Boulton, 2020.
+
+import unittest
+from unittest.mock import MagicMock, patch
+
+import cv2
+import numpy as np
+
+from nuscenes.prediction import PredictHelper
+from nuscenes.prediction.input_representation.static_layers import StaticLayerRasterizer, draw_lanes_on_image
+
+
+class TestStaticLayerRasterizer(unittest.TestCase):
+
+ PATH = 'nuscenes.prediction.input_representation.static_layers.{}'
+
+ @staticmethod
+ def get_layer_mocks():
+
+ layer_1 = np.zeros((100, 100, 3))
+ box = cv2.boxPoints(((50, 50), (20, 10), -90))
+ layer_1 = cv2.fillPoly(layer_1, pts=[np.int0(box)], color=(1, 1, 1))
+ layer_1 = layer_1[::-1, :, 0]
+
+ layer_2 = np.zeros((100, 100, 3))
+ layer_2 = cv2.line(layer_2, (50, 50), (50, 40), color=(1, 0, 0), thickness=2)
+ layer_2 = layer_2[::-1, :, 0]
+
+ return [layer_1, layer_2]
+
+ def test_draw_lanes_on_image(self):
+
+ image = np.zeros((200, 200, 3))
+ lanes = {'lane_1': [(15, 0, 0), (15, 10, 0), (15, 20, 0)],
+ 'lane_2': [(0, 15, 0), (10, 15, 0), (20, 15, 0)]}
+
+ def color_function(heading_1, heading_2):
+ return 0, 200, 200
+
+ img = draw_lanes_on_image(image, lanes, (10, 10), 0, (100, 100), 0.1, color_function)
+
+ answer = np.zeros((200, 200, 3))
+ cv2.line(answer, (150, 0), (150, 200), [0, 200, 200], thickness=5)
+ cv2.line(answer, (0, 50), (200, 50), [0, 200, 200], thickness=5)
+
+ np.testing.assert_allclose(answer, img)
+
+ @patch(PATH.format('load_all_maps'))
+ @patch(PATH.format('draw_lanes_in_agent_frame'))
+ def test_make_rasterization(self, mock_draw_lanes, mock_load_maps):
+ """
+ Mainly a smoke test since most of the logic is handled under-the-hood
+ by get_map_mask method of nuScenes map API.
+ """
+
+ lanes = np.zeros((100, 100, 3)).astype('uint8')
+ lane_box = cv2.boxPoints(((25, 75), (5, 5), -90))
+ lanes = cv2.fillPoly(lanes, pts=[np.int0(lane_box)], color=(255, 0, 0))
+ mock_draw_lanes.return_value = lanes
+
+ layers = self.get_layer_mocks()
+ mock_map_api = MagicMock()
+ mock_map_api.get_map_mask.return_value = layers
+
+ mock_maps = {'mock_map_version': mock_map_api}
+
+ mock_load_maps.return_value = mock_maps
+
+ mock_helper = MagicMock(spec=PredictHelper)
+ mock_helper.get_map_name_from_sample_token.return_value = 'mock_map_version'
+ mock_helper.get_sample_annotation.return_value = {'translation': [0, 0, 0],
+ 'rotation': [-np.pi/8, 0, 0, -np.pi/8]}
+
+ static_layers = StaticLayerRasterizer(mock_helper, ['layer_1', 'layer_2'],
+ [(255, 255, 255), (255, 0, 0)],
+ resolution=0.1, meters_ahead=5, meters_behind=5,
+ meters_left=5, meters_right=5)
+
+ image = static_layers.make_representation('foo_instance', 'foo_sample')
+
+ answer = np.zeros((100, 100, 3))
+ box = cv2.boxPoints(((50, 50), (20, 10), -90))
+ answer = cv2.fillPoly(answer, pts=[np.int0(box)], color=(255, 255, 255))
+ answer = cv2.line(answer, (50, 50), (50, 40), color=(255, 0, 0), thickness=2)
+ answer = cv2.fillPoly(answer, pts=[np.int0(lane_box)], color=(255, 0, 0))
+
+ np.testing.assert_allclose(answer, image)
diff --git a/python-sdk/nuscenes/prediction/input_representation/tests/test_utils.py b/python-sdk/nuscenes/prediction/input_representation/tests/test_utils.py
new file mode 100644
index 0000000..efbf2e7
--- /dev/null
+++ b/python-sdk/nuscenes/prediction/input_representation/tests/test_utils.py
@@ -0,0 +1,80 @@
+import unittest
+
+from nuscenes.prediction.input_representation import utils
+
+
+class Test_convert_to_pixel_coords(unittest.TestCase):
+
+ def test_above_and_to_the_right(self):
+
+ location = (55, 60)
+ center_of_image_in_global = (50, 50)
+ center_of_image_in_pixels = (400, 250)
+
+ pixels = utils.convert_to_pixel_coords(location,
+ center_of_image_in_global,
+ center_of_image_in_pixels)
+
+ answer = (300, 300)
+ self.assertTupleEqual(pixels, answer)
+
+ pixels = utils.convert_to_pixel_coords(location,
+ center_of_image_in_global,
+ center_of_image_in_pixels,
+ resolution=0.2)
+ answer = (350, 275)
+ self.assertTupleEqual(pixels, answer)
+
+ def test_above_and_to_the_left(self):
+
+ location = (40, 70)
+ center_of_image_in_global = (50, 50)
+ center_of_image_in_pixels = (300, 300)
+
+ pixels = utils.convert_to_pixel_coords(location, center_of_image_in_global,
+ center_of_image_in_pixels)
+ answer = (100, 200)
+ self.assertTupleEqual(pixels, answer)
+
+ pixels = utils.convert_to_pixel_coords(location, center_of_image_in_global,
+ center_of_image_in_pixels, resolution=0.2)
+ answer = (200, 250)
+ self.assertTupleEqual(answer, pixels)
+
+ def test_below_and_to_the_right(self):
+
+ location = (60, 45)
+ center_of_image_in_global = (50, 50)
+ center_of_image_in_pixels = (400, 250)
+
+ pixels = utils.convert_to_pixel_coords(location, center_of_image_in_global, center_of_image_in_pixels)
+ answer = (450, 350)
+ self.assertTupleEqual(pixels, answer)
+
+ def test_below_and_to_the_left(self):
+
+ location = (30, 40)
+ center_of_image_in_global = (50, 50)
+ center_of_image_in_pixels = (400, 250)
+
+ pixels = utils.convert_to_pixel_coords(location, center_of_image_in_global, center_of_image_in_pixels)
+ answer = (500, 50)
+ self.assertTupleEqual(pixels, answer)
+
+ def test_same_location(self):
+
+ location = (50, 50)
+ center_of_image_in_global = (50, 50)
+ center_of_image_in_pixels = (400, 250)
+
+ pixels = utils.convert_to_pixel_coords(location, center_of_image_in_global, center_of_image_in_pixels)
+ self.assertTupleEqual(pixels, (400, 250))
+
+class Test_get_crops(unittest.TestCase):
+
+ def test(self):
+
+ row_crop, col_crop = utils.get_crops(40, 10, 25, 25, 0.1, 800)
+
+ self.assertEqual(row_crop, slice(0, 500))
+ self.assertEqual(col_crop, slice(150, 650))
diff --git a/python-sdk/nuscenes/prediction/input_representation/utils.py b/python-sdk/nuscenes/prediction/input_representation/utils.py
new file mode 100644
index 0000000..6cafc00
--- /dev/null
+++ b/python-sdk/nuscenes/prediction/input_representation/utils.py
@@ -0,0 +1,73 @@
+# nuScenes dev-kit.
+# Code written by Freddy Boulton, 2020.
+from typing import Tuple
+
+import cv2
+import numpy as np
+
+from nuscenes.prediction.helper import angle_of_rotation
+
+
+def convert_to_pixel_coords(location: Tuple[float, float],
+ center_of_image_in_global: Tuple[float, float],
+ center_of_image_in_pixels: Tuple[float, float],
+ resolution: float = 0.1) -> Tuple[int, int]:
+ """
+ Convert from global coordinates to pixel coordinates.
+ :param location: Location in global coordinates as (x, y) tuple.
+ :param center_of_image_in_global: Center of the image in global coordinates (x, y) tuple.
+ :param center_of_image_in_pixels: Center of the image in pixel coordinates (row_pixel, column pixel).
+ :param resolution: Resolution of image in pixels / meters.
+ """
+
+ x, y = location
+ x_offset = (x - center_of_image_in_global[0])
+ y_offset = (y - center_of_image_in_global[1])
+
+ x_pixel = x_offset / resolution
+
+ # Negate the y coordinate because (0, 0) is ABOVE and to the LEFT
+ y_pixel = -y_offset / resolution
+
+ row_pixel = int(center_of_image_in_pixels[0] + y_pixel)
+ column_pixel = int(center_of_image_in_pixels[1] + x_pixel)
+
+ return row_pixel, column_pixel
+
+
+def get_crops(meters_ahead: float, meters_behind: float,
+ meters_left: float, meters_right: float,
+ resolution: float,
+ image_side_length_pixels: int) -> Tuple[slice, slice]:
+ """
+ Crop the excess pixels and centers the agent at the (meters_ahead, meters_left)
+ coordinate in the image.
+ :param meters_ahead: Meters ahead of the agent.
+ :param meters_behind: Meters behind of the agent.
+ :param meters_left: Meters to the left of the agent.
+ :param meters_right: Meters to the right of the agent.
+ :param resolution: Resolution of image in pixels / meters.
+ :param image_side_length_pixels: Length of the image in pixels.
+ :return: Tuple of row and column slices to crop image.
+ """
+
+ row_crop = slice(0, int((meters_ahead + meters_behind) / resolution))
+ col_crop = slice(int(image_side_length_pixels / 2 - (meters_left / resolution)),
+ int(image_side_length_pixels / 2 + (meters_right / resolution)))
+
+ return row_crop, col_crop
+
+
+def get_rotation_matrix(image_shape: Tuple[int, int, int], yaw_in_radians: float) -> np.ndarray:
+ """
+ Gets a rotation matrix to rotate a three channel image so that
+ yaw_in_radians points along the positive y-axis.
+ :param image_shape: (Length, width, n_channels).
+ :param yaw_in_radians: Angle to rotate the image by.
+ :return: rotation matrix represented as np.ndarray.
+ :return: The rotation matrix.
+ """
+
+ rotation_in_degrees = angle_of_rotation(yaw_in_radians) * 180 / np.pi
+
+ return cv2.getRotationMatrix2D((image_shape[1] / 2, image_shape[0] / 2), rotation_in_degrees, 1)
diff --git a/python-sdk/nuscenes/prediction/models/__init__.py b/python-sdk/nuscenes/prediction/models/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/python-sdk/nuscenes/prediction/models/backbone.py b/python-sdk/nuscenes/prediction/models/backbone.py
new file mode 100644
index 0000000..0112ff2
--- /dev/null
+++ b/python-sdk/nuscenes/prediction/models/backbone.py
@@ -0,0 +1,91 @@
+# nuScenes dev-kit.
+# Code written by Freddy Boulton 2020.
+from typing import Tuple
+
+import torch
+from torch import nn
+from torchvision.models import (mobilenet_v2, resnet18, resnet34, resnet50,
+ resnet101, resnet152)
+
+
+def trim_network_at_index(network: nn.Module, index: int = -1) -> nn.Module:
+ """
+ Returns a new network with all layers up to index from the back.
+ :param network: Module to trim.
+ :param index: Where to trim the network. Counted from the last layer.
+ """
+ assert index < 0, f"Param index must be negative. Received {index}."
+ return nn.Sequential(*list(network.children())[:index])
+
+
+def calculate_backbone_feature_dim(backbone, input_shape: Tuple[int, int, int]) -> int:
+ """ Helper to calculate the shape of the fully-connected regression layer. """
+ tensor = torch.ones(1, *input_shape)
+ output_feat = backbone.forward(tensor)
+ return output_feat.shape[-1]
+
+
+RESNET_VERSION_TO_MODEL = {'resnet18': resnet18, 'resnet34': resnet34,
+ 'resnet50': resnet50, 'resnet101': resnet101,
+ 'resnet152': resnet152}
+
+
+class ResNetBackbone(nn.Module):
+ """
+ Outputs tensor after last convolution before the fully connected layer.
+
+ Allowed versions: resnet18, resnet34, resnet50, resnet101, resnet152.
+ """
+
+ def __init__(self, version: str):
+ """
+ Inits ResNetBackbone
+ :param version: resnet version to use.
+ """
+ super().__init__()
+
+ if version not in RESNET_VERSION_TO_MODEL:
+ raise ValueError(f'Parameter version must be one of {list(RESNET_VERSION_TO_MODEL.keys())}'
+ f'. Received {version}.')
+
+ self.backbone = trim_network_at_index(RESNET_VERSION_TO_MODEL[version](), -1)
+
+ def forward(self, input_tensor: torch.Tensor) -> torch.Tensor:
+ """
+ Outputs features after last convolution.
+ :param input_tensor: Shape [batch_size, n_channels, length, width].
+ :return: Tensor of shape [batch_size, n_convolution_filters]. For resnet50,
+ the shape is [batch_size, 2048].
+ """
+ backbone_features = self.backbone(input_tensor)
+ return torch.flatten(backbone_features, start_dim=1)
+
+
+class MobileNetBackbone(nn.Module):
+ """
+ Outputs tensor after last convolution before the fully connected layer.
+
+ Allowed versions: mobilenet_v2.
+ """
+
+ def __init__(self, version: str):
+ """
+ Inits MobileNetBackbone.
+ :param version: mobilenet version to use.
+ """
+ super().__init__()
+
+ if version != 'mobilenet_v2':
+ raise NotImplementedError(f'Only mobilenet_v2 has been implemented. Received {version}.')
+
+ self.backbone = trim_network_at_index(mobilenet_v2(), -1)
+
+ def forward(self, input_tensor: torch.Tensor) -> torch.Tensor:
+ """
+ Outputs features after last convolution.
+ :param input_tensor: Shape [batch_size, n_channels, length, width].
+ :return: Tensor of shape [batch_size, n_convolution_filters]. For mobilenet_v2,
+ the shape is [batch_size, 1280].
+ """
+ backbone_features = self.backbone(input_tensor)
+ return backbone_features.mean([2, 3])
diff --git a/python-sdk/nuscenes/prediction/models/covernet.py b/python-sdk/nuscenes/prediction/models/covernet.py
new file mode 100644
index 0000000..05cf3c8
--- /dev/null
+++ b/python-sdk/nuscenes/prediction/models/covernet.py
@@ -0,0 +1,120 @@
+# nuScenes dev-kit.
+# Code written by Freddy Boulton, Tung Phan 2020.
+from typing import List, Tuple, Callable, Union
+
+import numpy as np
+import torch
+from torch import nn
+from torch.nn import functional as f
+
+from nuscenes.prediction.models.backbone import calculate_backbone_feature_dim
+
+# Number of entries in Agent State Vector
+ASV_DIM = 3
+
+
+class CoverNet(nn.Module):
+ """ Implementation of CoverNet https://arxiv.org/pdf/1911.10298.pdf """
+
+ def __init__(self, backbone: nn.Module, num_modes: int,
+ n_hidden_layers: List[int] = None,
+ input_shape: Tuple[int, int, int] = (3, 500, 500)):
+ """
+ Inits Covernet.
+ :param backbone: Backbone model. Typically ResNetBackBone or MobileNetBackbone
+ :param num_modes: Number of modes in the lattice
+ :param n_hidden_layers: List of dimensions in the fully connected layers after the backbones.
+ If None, set to [4096]
+ :param input_shape: Shape of image input. Used to determine the dimensionality of the feature
+ vector after the CNN backbone.
+ """
+
+ if n_hidden_layers and not isinstance(n_hidden_layers, list):
+ raise ValueError(f"Param n_hidden_layers must be a list. Received {type(n_hidden_layers)}")
+
+ super().__init__()
+
+ if not n_hidden_layers:
+ n_hidden_layers = [4096]
+
+ self.backbone = backbone
+
+ backbone_feature_dim = calculate_backbone_feature_dim(backbone, input_shape)
+ n_hidden_layers = [backbone_feature_dim + ASV_DIM] + n_hidden_layers + [num_modes]
+
+ linear_layers = [nn.Linear(in_dim, out_dim)
+ for in_dim, out_dim in zip(n_hidden_layers[:-1], n_hidden_layers[1:])]
+
+ self.head = nn.ModuleList(linear_layers)
+
+ def forward(self, image_tensor: torch.Tensor,
+ agent_state_vector: torch.Tensor) -> torch.Tensor:
+ """
+ :param image_tensor: Tensor of images in the batch.
+ :param agent_state_vector: Tensor of agent state vectors in the batch
+ :return: Logits for the batch.
+ """
+
+ backbone_features = self.backbone(image_tensor)
+
+ logits = torch.cat([backbone_features, agent_state_vector], dim=1)
+
+ for linear in self.head:
+ logits = linear(logits)
+
+ return logits
+
+
+def mean_pointwise_l2_distance(lattice: torch.Tensor, ground_truth: torch.Tensor) -> torch.Tensor:
+ """
+ Computes the index of the closest trajectory in the lattice as measured by l1 distance.
+ :param lattice: Lattice of pre-generated trajectories. Shape [num_modes, n_timesteps, state_dim]
+ :param ground_truth: Ground truth trajectory of agent. Shape [1, n_timesteps, state_dim].
+ :return: Index of closest mode in the lattice.
+ """
+ stacked_ground_truth = ground_truth.repeat(lattice.shape[0], 1, 1)
+ return torch.pow(lattice - stacked_ground_truth, 2).sum(dim=2).sqrt().mean(dim=1).argmin()
+
+
+class ConstantLatticeLoss:
+ """
+ Computes the loss for a constant lattice CoverNet model.
+ """
+
+ def __init__(self, lattice: Union[np.ndarray, torch.Tensor],
+ similarity_function: Callable[[torch.Tensor, torch.Tensor], int] = mean_pointwise_l2_distance):
+ """
+ Inits the loss.
+ :param lattice: numpy array of shape [n_modes, n_timesteps, state_dim]
+ :param similarity_function: Function that computes the index of the closest trajectory in the lattice
+ to the actual ground truth trajectory of the agent.
+ """
+
+ self.lattice = torch.Tensor(lattice)
+ self.similarity_func = similarity_function
+
+ def __call__(self, batch_logits: torch.Tensor, batch_ground_truth_trajectory: torch.Tensor) -> torch.Tensor:
+ """
+ Computes the loss on a batch.
+ :param batch_logits: Tensor of shape [batch_size, n_modes]. Output of a linear layer since this class
+ uses nn.functional.cross_entropy.
+ :param batch_ground_truth_trajectory: Tensor of shape [batch_size, 1, n_timesteps, state_dim]
+ :return: Average element-wise loss on the batch.
+ """
+
+ # If using GPU, need to copy the lattice to the GPU if haven't done so already
+ # This ensures we only copy it once
+ if self.lattice.device != batch_logits.device:
+ self.lattice = self.lattice.to(batch_logits.device)
+
+ batch_losses = torch.Tensor().requires_grad_(True).to(batch_logits.device)
+
+ for logit, ground_truth in zip(batch_logits, batch_ground_truth_trajectory):
+
+ closest_lattice_trajectory = self.similarity_func(self.lattice, ground_truth)
+ label = torch.LongTensor([closest_lattice_trajectory]).to(batch_logits.device)
+ classification_loss = f.cross_entropy(logit.unsqueeze(0), label)
+
+ batch_losses = torch.cat((batch_losses, classification_loss.unsqueeze(0)), 0)
+
+ return batch_losses.mean()
diff --git a/python-sdk/nuscenes/prediction/models/mtp.py b/python-sdk/nuscenes/prediction/models/mtp.py
new file mode 100644
index 0000000..a2e0ed1
--- /dev/null
+++ b/python-sdk/nuscenes/prediction/models/mtp.py
@@ -0,0 +1,264 @@
+# nuScenes dev-kit.
+# Code written by Freddy Boulton, Elena Corina Grigore 2020.
+
+import math
+import random
+from typing import List, Tuple
+
+import torch
+from torch import nn
+from torch.nn import functional as f
+
+from nuscenes.prediction.models.backbone import calculate_backbone_feature_dim
+
+# Number of entries in Agent State Vector
+ASV_DIM = 3
+
+
+class MTP(nn.Module):
+ """
+ Implementation of Multiple-Trajectory Prediction (MTP) model
+ based on https://arxiv.org/pdf/1809.10732.pdf
+ """
+
+ def __init__(self, backbone: nn.Module, num_modes: int,
+ seconds: float = 6, frequency_in_hz: float = 2,
+ n_hidden_layers: int = 4096, input_shape: Tuple[int, int, int] = (3, 500, 500)):
+ """
+ Inits the MTP network.
+ :param backbone: CNN Backbone to use.
+ :param num_modes: Number of predicted paths to estimate for each agent.
+ :param seconds: Number of seconds into the future to predict.
+ Default for the challenge is 6.
+ :param frequency_in_hz: Frequency between timesteps in the prediction (in Hz).
+ Highest frequency is nuScenes is 2 Hz.
+ :param n_hidden_layers: Size of fully connected layer after the CNN
+ backbone processes the image.
+ :param input_shape: Shape of the input expected by the network.
+ This is needed because the size of the fully connected layer after
+ the backbone depends on the backbone and its version.
+
+ Note:
+ Although seconds and frequency_in_hz are typed as floats, their
+ product should be an int.
+ """
+
+ super().__init__()
+
+ self.backbone = backbone
+ self.num_modes = num_modes
+ backbone_feature_dim = calculate_backbone_feature_dim(backbone, input_shape)
+ self.fc1 = nn.Linear(backbone_feature_dim + ASV_DIM, n_hidden_layers)
+ predictions_per_mode = int(seconds * frequency_in_hz) * 2
+
+ self.fc2 = nn.Linear(n_hidden_layers, int(num_modes * predictions_per_mode + num_modes))
+
+ def forward(self, image_tensor: torch.Tensor,
+ agent_state_vector: torch.Tensor) -> torch.Tensor:
+ """
+ Forward pass of the model.
+ :param image_tensor: Tensor of images shape [batch_size, n_channels, length, width].
+ :param agent_state_vector: Tensor of floats representing the agent state.
+ [batch_size, 3].
+ :returns: Tensor of dimension [batch_size, number_of_modes * number_of_predictions_per_mode + number_of_modes]
+ storing the predicted trajectory and mode probabilities. Mode probabilities are normalized to sum
+ to 1 during inference.
+ """
+
+ backbone_features = self.backbone(image_tensor)
+
+ features = torch.cat([backbone_features, agent_state_vector], dim=1)
+
+ predictions = self.fc2(self.fc1(features))
+
+ # Normalize the probabilities to sum to 1 for inference.
+ mode_probabilities = predictions[:, -self.num_modes:].clone()
+ if not self.training:
+ mode_probabilities = f.softmax(mode_probabilities, dim=-1)
+
+ predictions = predictions[:, :-self.num_modes]
+
+ return torch.cat((predictions, mode_probabilities), 1)
+
+
+class MTPLoss:
+ """ Computes the loss for the MTP model. """
+
+ def __init__(self,
+ num_modes: int,
+ regression_loss_weight: float = 1.,
+ angle_threshold_degrees: float = 5.):
+ """
+ Inits MTP loss.
+ :param num_modes: How many modes are being predicted for each agent.
+ :param regression_loss_weight: Coefficient applied to the regression loss to
+ balance classification and regression performance.
+ :param angle_threshold_degrees: Minimum angle needed between a predicted trajectory
+ and the ground to consider it a match.
+ """
+ self.num_modes = num_modes
+ self.num_location_coordinates_predicted = 2 # We predict x, y coordinates at each timestep.
+ self.regression_loss_weight = regression_loss_weight
+ self.angle_threshold = angle_threshold_degrees
+
+ def _get_trajectory_and_modes(self,
+ model_prediction: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
+ """
+ Splits the predictions from the model into mode probabilities and trajectory.
+ :param model_prediction: Tensor of shape [batch_size, n_timesteps * n_modes * 2 + n_modes].
+ :return: Tuple of tensors. First item is the trajectories of shape [batch_size, n_modes, n_timesteps, 2].
+ Second item are the mode probabilities of shape [batch_size, num_modes].
+ """
+ mode_probabilities = model_prediction[:, -self.num_modes:].clone()
+
+ desired_shape = (model_prediction.shape[0], self.num_modes, -1, self.num_location_coordinates_predicted)
+ trajectories_no_modes = model_prediction[:, :-self.num_modes].clone().reshape(desired_shape)
+
+ return trajectories_no_modes, mode_probabilities
+
+ @staticmethod
+ def _angle_between(ref_traj: torch.Tensor,
+ traj_to_compare: torch.Tensor) -> float:
+ """
+ Computes the angle between the last points of the two trajectories.
+ The resulting angle is in degrees and is an angle in the [0; 180) interval.
+ :param ref_traj: Tensor of shape [n_timesteps, 2].
+ :param traj_to_compare: Tensor of shape [n_timesteps, 2].
+ :return: Angle between the trajectories.
+ """
+
+ EPSILON = 1e-5
+
+ if (ref_traj.ndim != 2 or traj_to_compare.ndim != 2 or
+ ref_traj.shape[1] != 2 or traj_to_compare.shape[1] != 2):
+ raise ValueError('Both tensors should have shapes (-1, 2).')
+
+ if torch.isnan(traj_to_compare[-1]).any() or torch.isnan(ref_traj[-1]).any():
+ return 180. - EPSILON
+
+ traj_norms_product = float(torch.norm(ref_traj[-1]) * torch.norm(traj_to_compare[-1]))
+
+ # If either of the vectors described in the docstring has norm 0, return 0 as the angle.
+ if math.isclose(traj_norms_product, 0):
+ return 0.
+
+ # We apply the max and min operations below to ensure there is no value
+ # returned for cos_angle that is greater than 1 or less than -1.
+ # This should never be the case, but the check is in place for cases where
+ # we might encounter numerical instability.
+ dot_product = float(ref_traj[-1].dot(traj_to_compare[-1]))
+ angle = math.degrees(math.acos(max(min(dot_product / traj_norms_product, 1), -1)))
+
+ if angle >= 180:
+ return angle - EPSILON
+
+ return angle
+
+ @staticmethod
+ def _compute_ave_l2_norms(tensor: torch.Tensor) -> float:
+ """
+ Compute the average of l2 norms of each row in the tensor.
+ :param tensor: Shape [1, n_timesteps, 2].
+ :return: Average l2 norm. Float.
+ """
+ l2_norms = torch.norm(tensor, p=2, dim=2)
+ avg_distance = torch.mean(l2_norms)
+ return avg_distance.item()
+
+ def _compute_angles_from_ground_truth(self, target: torch.Tensor,
+ trajectories: torch.Tensor) -> List[Tuple[float, int]]:
+ """
+ Compute angle between the target trajectory (ground truth) and the predicted trajectories.
+ :param target: Shape [1, n_timesteps, 2].
+ :param trajectories: Shape [n_modes, n_timesteps, 2].
+ :return: List of angle, index tuples.
+ """
+ angles_from_ground_truth = []
+ for mode, mode_trajectory in enumerate(trajectories):
+ # For each mode, we compute the angle between the last point of the predicted trajectory for that
+ # mode and the last point of the ground truth trajectory.
+ angle = self._angle_between(target[0], mode_trajectory)
+
+ angles_from_ground_truth.append((angle, mode))
+ return angles_from_ground_truth
+
+ def _compute_best_mode(self,
+ angles_from_ground_truth: List[Tuple[float, int]],
+ target: torch.Tensor, trajectories: torch.Tensor) -> int:
+ """
+ Finds the index of the best mode given the angles from the ground truth.
+ :param angles_from_ground_truth: List of (angle, mode index) tuples.
+ :param target: Shape [1, n_timesteps, 2]
+ :param trajectories: Shape [n_modes, n_timesteps, 2]
+ :return: Integer index of best mode.
+ """
+
+ # We first sort the modes based on the angle to the ground truth (ascending order), and keep track of
+ # the index corresponding to the biggest angle that is still smaller than a threshold value.
+ angles_from_ground_truth = sorted(angles_from_ground_truth)
+ max_angle_below_thresh_idx = -1
+ for angle_idx, (angle, mode) in enumerate(angles_from_ground_truth):
+ if angle <= self.angle_threshold:
+ max_angle_below_thresh_idx = angle_idx
+ else:
+ break
+
+ # We choose the best mode at random IF there are no modes with an angle less than the threshold.
+ if max_angle_below_thresh_idx == -1:
+ best_mode = random.randint(0, self.num_modes - 1)
+
+ # We choose the best mode to be the one that provides the lowest ave of l2 norms between the
+ # predicted trajectory and the ground truth, taking into account only the modes with an angle
+ # less than the threshold IF there is at least one mode with an angle less than the threshold.
+ else:
+ # Out of the selected modes above, we choose the final best mode as that which returns the
+ # smallest ave of l2 norms between the predicted and ground truth trajectories.
+ distances_from_ground_truth = []
+
+ for angle, mode in angles_from_ground_truth[:max_angle_below_thresh_idx + 1]:
+ norm = self._compute_ave_l2_norms(target - trajectories[mode, :, :])
+
+ distances_from_ground_truth.append((norm, mode))
+
+ distances_from_ground_truth = sorted(distances_from_ground_truth)
+ best_mode = distances_from_ground_truth[0][1]
+
+ return best_mode
+
+ def __call__(self, predictions: torch.Tensor, targets: torch.Tensor) -> torch.Tensor:
+ """
+ Computes the MTP loss on a batch.
+ The predictions are of shape [batch_size, n_ouput_neurons of last linear layer]
+ and the targets are of shape [batch_size, 1, n_timesteps, 2]
+ :param predictions: Model predictions for batch.
+ :param targets: Targets for batch.
+ :return: zero-dim tensor representing the loss on the batch.
+ """
+
+ batch_losses = torch.Tensor().requires_grad_(True).to(predictions.device)
+ trajectories, modes = self._get_trajectory_and_modes(predictions)
+
+ for batch_idx in range(predictions.shape[0]):
+
+ angles = self._compute_angles_from_ground_truth(target=targets[batch_idx],
+ trajectories=trajectories[batch_idx])
+
+ best_mode = self._compute_best_mode(angles,
+ target=targets[batch_idx],
+ trajectories=trajectories[batch_idx])
+
+ best_mode_trajectory = trajectories[batch_idx, best_mode, :].unsqueeze(0)
+
+ regression_loss = f.smooth_l1_loss(best_mode_trajectory, targets[batch_idx])
+
+ mode_probabilities = modes[batch_idx].unsqueeze(0)
+ best_mode_target = torch.tensor([best_mode], device=predictions.device)
+ classification_loss = f.cross_entropy(mode_probabilities, best_mode_target)
+
+ loss = classification_loss + self.regression_loss_weight * regression_loss
+
+ batch_losses = torch.cat((batch_losses, loss.unsqueeze(0)), 0)
+
+ avg_loss = torch.mean(batch_losses)
+
+ return avg_loss
diff --git a/python-sdk/nuscenes/prediction/models/physics.py b/python-sdk/nuscenes/prediction/models/physics.py
new file mode 100644
index 0000000..42b0049
--- /dev/null
+++ b/python-sdk/nuscenes/prediction/models/physics.py
@@ -0,0 +1,199 @@
+# nuScenes dev-kit.
+# Code written by Freddy Boulton, Robert Beaudoin 2020.
+import abc
+from typing import Tuple
+
+import numpy as np
+from pyquaternion import Quaternion
+
+from nuscenes.eval.common.utils import quaternion_yaw
+from nuscenes.eval.prediction.data_classes import Prediction
+from nuscenes.prediction import PredictHelper
+
+KinematicsData = Tuple[float, float, float, float, float, float, float, float, float, float]
+
+
+def _kinematics_from_tokens(helper: PredictHelper, instance: str, sample: str) -> KinematicsData:
+ """
+ Returns the 2D position, velocity and acceleration vectors from the given track records,
+ along with the speed, yaw rate, (scalar) acceleration (magnitude), and heading.
+ :param helper: Instance of PredictHelper.
+ :instance: Token of instance.
+ :sample: Token of sample.
+ :return: KinematicsData.
+ """
+
+ annotation = helper.get_sample_annotation(instance, sample)
+ x, y, _ = annotation['translation']
+ yaw = quaternion_yaw(Quaternion(annotation['rotation']))
+
+ velocity = helper.get_velocity_for_agent(instance, sample)
+ acceleration = helper.get_acceleration_for_agent(instance, sample)
+ yaw_rate = helper.get_heading_change_rate_for_agent(instance, sample)
+
+ if np.isnan(velocity):
+ velocity = 0.0
+ if np.isnan(acceleration):
+ acceleration = 0.0
+ if np.isnan(yaw_rate):
+ yaw_rate = 0.0
+
+ hx, hy = np.cos(yaw), np.sin(yaw)
+ vx, vy = velocity * hx, velocity * hy
+ ax, ay = acceleration * hx, acceleration * hy
+
+ return x, y, vx, vy, ax, ay, velocity, yaw_rate, acceleration, yaw
+
+
+def _constant_velocity_heading_from_kinematics(kinematics_data: KinematicsData,
+ sec_from_now: float,
+ sampled_at: int) -> np.ndarray:
+ """
+ Computes a constant velocity baseline for given kinematics data, time window
+ and frequency.
+ :param kinematics_data: KinematicsData for agent.
+ :param sec_from_now: How many future seconds to use.
+ :param sampled_at: Number of predictions to make per second.
+ """
+ x, y, vx, vy, _, _, _, _, _, _ = kinematics_data
+ preds = []
+ time_step = 1.0 / sampled_at
+ for time in np.arange(time_step, sec_from_now + time_step, time_step):
+ preds.append((x + time * vx, y + time * vy))
+ return np.array(preds)
+
+
+def _constant_acceleration_and_heading(kinematics_data: KinematicsData,
+ sec_from_now: float, sampled_at: int) -> np.ndarray:
+ """
+ Computes a baseline prediction for the given time window and frequency, under
+ the assumption that the acceleration and heading are constant.
+ :param kinematics_data: KinematicsData for agent.
+ :param sec_from_now: How many future seconds to use.
+ :param sampled_at: Number of predictions to make per second.
+ """
+ x, y, vx, vy, ax, ay, _, _, _, _ = kinematics_data
+
+ preds = []
+ time_step = 1.0 / sampled_at
+ for time in np.arange(time_step, sec_from_now + time_step, time_step):
+ half_time_squared = 0.5 * time * time
+ preds.append((x + time * vx + half_time_squared * ax,
+ y + time * vy + half_time_squared * ay))
+ return np.array(preds)
+
+
+def _constant_speed_and_yaw_rate(kinematics_data: KinematicsData,
+ sec_from_now: float, sampled_at: int) -> np.ndarray:
+ """
+ Computes a baseline prediction for the given time window and frequency, under
+ the assumption that the (scalar) speed and yaw rate are constant.
+ :param kinematics_data: KinematicsData for agent.
+ :param sec_from_now: How many future seconds to use.
+ :param sampled_at: Number of predictions to make per second.
+ """
+ x, y, vx, vy, _, _, speed, yaw_rate, _, yaw = kinematics_data
+
+ preds = []
+ time_step = 1.0 / sampled_at
+ distance_step = time_step * speed
+ yaw_step = time_step * yaw_rate
+ for _ in np.arange(time_step, sec_from_now + time_step, time_step):
+ x += distance_step * np.cos(yaw)
+ y += distance_step * np.sin(yaw)
+ preds.append((x, y))
+ yaw += yaw_step
+ return np.array(preds)
+
+
+def _constant_magnitude_accel_and_yaw_rate(kinematics_data: KinematicsData,
+ sec_from_now: float, sampled_at: int) -> np.ndarray:
+ """
+ Computes a baseline prediction for the given time window and frequency, under
+ the assumption that the rates of change of speed and yaw are constant.
+ :param kinematics_data: KinematicsData for agent.
+ :param sec_from_now: How many future seconds to use.
+ :param sampled_at: Number of predictions to make per second.
+ """
+ x, y, vx, vy, _, _, speed, yaw_rate, accel, yaw = kinematics_data
+
+ preds = []
+ time_step = 1.0 / sampled_at
+ speed_step = time_step * accel
+ yaw_step = time_step * yaw_rate
+ for _ in np.arange(time_step, sec_from_now + time_step, time_step):
+ distance_step = time_step * speed
+ x += distance_step * np.cos(yaw)
+ y += distance_step * np.sin(yaw)
+ preds.append((x, y))
+ speed += speed_step
+ yaw += yaw_step
+ return np.array(preds)
+
+
+class Baseline(abc.ABC):
+
+ def __init__(self, sec_from_now: float, helper: PredictHelper):
+ """
+ Inits Baseline.
+ :param sec_from_now: How many seconds into the future to make the prediction.
+ :param helper: Instance of PredictHelper.
+ """
+ assert sec_from_now % 0.5 == 0, f"Parameter sec from now must be divisible by 0.5. Received {sec_from_now}."
+ self.helper = helper
+ self.sec_from_now = sec_from_now
+ self.sampled_at = 2 # 2 Hz between annotations.
+
+ @abc.abstractmethod
+ def __call__(self, token: str) -> Prediction:
+ pass
+
+
+class ConstantVelocityHeading(Baseline):
+ """ Makes predictions according to constant velocity and heading model. """
+
+ def __call__(self, token: str) -> Prediction:
+ """
+ Makes prediction.
+ :param token: string of format {instance_token}_{sample_token}.
+ """
+ instance, sample = token.split("_")
+ kinematics = _kinematics_from_tokens(self.helper, instance, sample)
+ cv_heading = _constant_velocity_heading_from_kinematics(kinematics, self.sec_from_now, self.sampled_at)
+
+ # Need the prediction to have 2d.
+ return Prediction(instance, sample, np.expand_dims(cv_heading, 0), np.array([1]))
+
+
+class PhysicsOracle(Baseline):
+ """ Makes several physics-based predictions and picks the one closest to the ground truth. """
+
+ def __call__(self, token) -> Prediction:
+ """
+ Makes prediction.
+ :param token: string of format {instance_token}_{sample_token}.
+ """
+ instance, sample = token.split("_")
+ kinematics = _kinematics_from_tokens(self.helper, instance, sample)
+ ground_truth = self.helper.get_future_for_agent(instance, sample, self.sec_from_now, in_agent_frame=False)
+
+ assert ground_truth.shape[0] == int(self.sec_from_now * self.sampled_at), ("Ground truth does not correspond "
+ f"to {self.sec_from_now} seconds.")
+
+ path_funs = [
+ _constant_acceleration_and_heading,
+ _constant_magnitude_accel_and_yaw_rate,
+ _constant_speed_and_yaw_rate,
+ _constant_velocity_heading_from_kinematics
+ ]
+
+ paths = [path_fun(kinematics, self.sec_from_now, self.sampled_at) for path_fun in path_funs]
+
+ # Select the one with the least l2 error, averaged (or equivalently, summed) over all
+ # points of the path. This is (proportional to) the Frobenius norm of the difference
+ # between the path (as an n x 2 matrix) and the ground truth.
+ oracle = sorted(paths,
+ key=lambda path: np.linalg.norm(np.array(path) - ground_truth, ord="fro"))[0]
+
+ # Need the prediction to have 2d.
+ return Prediction(instance, sample, np.expand_dims(oracle, 0), np.array([1]))
diff --git a/python-sdk/nuscenes/prediction/tests/__init__.py b/python-sdk/nuscenes/prediction/tests/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/python-sdk/nuscenes/prediction/tests/run_covernet.py b/python-sdk/nuscenes/prediction/tests/run_covernet.py
new file mode 100644
index 0000000..b5be26f
--- /dev/null
+++ b/python-sdk/nuscenes/prediction/tests/run_covernet.py
@@ -0,0 +1,92 @@
+# nuScenes dev-kit.
+# Code written by Freddy Boulton, 2020.
+
+"""
+Regression test to see if CoverNet implementation can overfit on a single example.
+"""
+
+import argparse
+import math
+
+import numpy as np
+import torch
+import torch.optim as optim
+from torch.utils.data import DataLoader, IterableDataset
+
+from nuscenes.prediction.models.backbone import MobileNetBackbone
+from nuscenes.prediction.models.covernet import CoverNet, ConstantLatticeLoss
+
+
+def generate_trajectory(theta: float) -> torch.Tensor:
+ trajectory = torch.zeros(6, 2)
+ trajectory[:, 0] = torch.arange(6) * math.cos(theta)
+ trajectory[:, 1] = torch.arange(6) * math.sin(theta)
+ return trajectory
+
+
+class Dataset(IterableDataset):
+ """ Implements an infinite dataset of the same input image, agent state vector and ground truth label. """
+
+ def __iter__(self,):
+
+ while True:
+ image = torch.zeros((3, 100, 100))
+ agent_state_vector = torch.ones(3)
+ ground_truth = generate_trajectory(math.pi / 2)
+
+ yield image, agent_state_vector, ground_truth.unsqueeze(0)
+
+
+if __name__ == "__main__":
+
+ parser = argparse.ArgumentParser(description='Run CoverNet to make sure it overfits on a single test case.')
+ parser.add_argument('--use_gpu', type=int, help='Whether to use gpu', default=0)
+ args = parser.parse_args()
+
+ if args.use_gpu:
+ device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
+ else:
+ device = torch.device('cpu')
+
+ dataset = Dataset()
+ dataloader = DataLoader(dataset, batch_size=16, num_workers=0)
+
+ backbone = MobileNetBackbone('mobilenet_v2')
+ model = CoverNet(backbone, num_modes=3, input_shape=(3, 100, 100))
+ model = model.to(device)
+
+ lattice = torch.zeros(3, 6, 2)
+ lattice[0] = generate_trajectory(math.pi / 2)
+ lattice[1] = generate_trajectory(math.pi / 4)
+ lattice[2] = generate_trajectory(3 * math.pi / 4)
+
+ loss_function = ConstantLatticeLoss(lattice)
+
+ optimizer = optim.SGD(model.parameters(), lr=0.1)
+
+ n_iter = 0
+
+ minimum_loss = 0
+
+ for img, agent_state_vector, ground_truth in dataloader:
+
+ img = img.to(device)
+ agent_state_vector = agent_state_vector.to(device)
+ ground_truth = ground_truth.to(device)
+
+ optimizer.zero_grad()
+
+ logits = model(img, agent_state_vector)
+ loss = loss_function(logits, ground_truth)
+ loss.backward()
+ optimizer.step()
+
+ current_loss = loss.cpu().detach().numpy()
+
+ print(f"Current loss is {current_loss:.2f}")
+ if np.allclose(current_loss, minimum_loss, atol=1e-2):
+ print(f"Achieved near-zero loss after {n_iter} iterations.")
+ break
+
+ n_iter += 1
+
diff --git a/python-sdk/nuscenes/prediction/tests/run_image_generation.py b/python-sdk/nuscenes/prediction/tests/run_image_generation.py
new file mode 100644
index 0000000..140f09c
--- /dev/null
+++ b/python-sdk/nuscenes/prediction/tests/run_image_generation.py
@@ -0,0 +1,117 @@
+import argparse
+from typing import List
+
+import torch
+import torch.optim as optim
+from torch.utils.data import DataLoader, Dataset
+
+from nuscenes import NuScenes
+from nuscenes.prediction import PredictHelper
+from nuscenes.prediction.input_representation.static_layers import StaticLayerRasterizer
+from nuscenes.prediction.models.backbone import ResNetBackbone
+from nuscenes.prediction.models.mtp import MTP, MTPLoss
+
+
+class TestDataset(Dataset):
+
+ def __init__(self, tokens: List[str], helper: PredictHelper):
+ self.tokens = tokens
+ self.static_layer_representation = StaticLayerRasterizer(helper)
+
+ def __len__(self):
+ return len(self.tokens)
+
+ def __getitem__(self, index: int):
+
+ token = self.tokens[index]
+ instance_token, sample_token = token.split("_")
+
+ image = self.static_layer_representation.make_representation(instance_token, sample_token)
+ image = torch.Tensor(image).permute(2, 0, 1)
+ agent_state_vector = torch.ones((3))
+ ground_truth = torch.ones((1, 12, 2))
+
+ ground_truth[:, :, 1] = torch.arange(0, 6, step=0.5)
+
+ return image, agent_state_vector, ground_truth
+
+
+if __name__ == "__main__":
+
+ parser = argparse.ArgumentParser(description="Makes sure image generation code can run on gpu "
+ "with multiple workers")
+ parser.add_argument('--data_root', type=str)
+ parser.add_argument('--use_gpu', type=bool, help='Whether to use gpu', default=False)
+ args = parser.parse_args()
+
+ NUM_MODES = 1
+
+ if args.use_gpu:
+ device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
+ else:
+ device = torch.device('cpu')
+
+ tokens = ['bd26c2cdb22d4bb1834e808c89128898_ca9a282c9e77460f8360f564131a8af5',
+ '085fb7c411914888907f7198e998a951_ca9a282c9e77460f8360f564131a8af5',
+ 'bc38961ca0ac4b14ab90e547ba79fbb6_ca9a282c9e77460f8360f564131a8af5',
+ '56a71c208ac6472f90b6a82529a6ce61_ca9a282c9e77460f8360f564131a8af5',
+ '85246a44cc6340509e3882e2ff088391_ca9a282c9e77460f8360f564131a8af5',
+ '42641eb6adcb4f8f8def8ef129d9e843_ca9a282c9e77460f8360f564131a8af5',
+ '4080c30aa7104d91ad005a50b18f6108_ca9a282c9e77460f8360f564131a8af5',
+ 'c1958768d48640948f6053d04cffd35b_ca9a282c9e77460f8360f564131a8af5',
+ '4005437c730645c2b628dc1da999e06a_39586f9d59004284a7114a68825e8eec',
+ 'a017fe4e9c3d445784aae034b1322006_356d81f38dd9473ba590f39e266f54e5',
+ 'a0049f95375044b8987fbcca8fda1e2b_c923fe08b2ff4e27975d2bf30934383b',
+ '61dd7d03d7ad466d89f901ed64e2c0dd_e0845f5322254dafadbbed75aaa07969',
+ '86ed8530809d4b1b8fbc53808f599339_39586f9d59004284a7114a68825e8eec',
+ '2a80b29c0281435ca4893e158a281ce0_2afb9d32310e4546a71cbe432911eca2',
+ '8ce4fe54af77467d90c840465f69677f_de7593d76648450e947ba0c203dee1b0',
+ 'f4af7fd215ee47aa8b64bac0443d7be8_9ee4020153674b9e9943d395ff8cfdf3']
+
+ tokens = tokens * 32
+
+ nusc = NuScenes('v1.0-trainval', dataroot=args.data_root)
+ helper = PredictHelper(nusc)
+
+ dataset = TestDataset(tokens, helper)
+ dataloader = DataLoader(dataset, batch_size=16, num_workers=16)
+
+ backbone = ResNetBackbone('resnet18')
+ model = MTP(backbone, NUM_MODES)
+ model = model.to(device)
+
+ loss_function = MTPLoss(NUM_MODES, 1, 5)
+
+ current_loss = 10000
+
+ optimizer = optim.SGD(model.parameters(), lr=0.1)
+
+ n_iter = 0
+
+ minimum_loss = 0
+
+ while True:
+
+ for img, agent_state_vector, ground_truth in dataloader:
+
+ img = img.to(device)
+ agent_state_vector = agent_state_vector.to(device)
+ ground_truth = ground_truth.to(device)
+
+ optimizer.zero_grad()
+
+ prediction = model(img, agent_state_vector)
+ loss = loss_function(prediction, ground_truth)
+ loss.backward()
+ optimizer.step()
+
+ current_loss = loss.cpu().detach().numpy()
+
+ print(f"Current loss is {current_loss:.4f}")
+
+ if n_iter % 32 == 0:
+ print(f"Number of iterations: {n_iter}.")
+
+ n_iter += 1
+
+
diff --git a/python-sdk/nuscenes/prediction/tests/run_mtp.py b/python-sdk/nuscenes/prediction/tests/run_mtp.py
new file mode 100644
index 0000000..7d09de4
--- /dev/null
+++ b/python-sdk/nuscenes/prediction/tests/run_mtp.py
@@ -0,0 +1,109 @@
+# nuScenes dev-kit.
+# Code written by Freddy Boulton, 2020.
+
+"""
+Regression test to see if MTP can overfit on a single example.
+"""
+
+import argparse
+
+import numpy as np
+import torch
+import torch.optim as optim
+from torch.utils.data import DataLoader, IterableDataset
+
+from nuscenes.prediction.models.backbone import ResNetBackbone
+from nuscenes.prediction.models.mtp import MTP, MTPLoss
+
+
+class Dataset(IterableDataset):
+ """
+ Implements an infinite dataset where the input data
+ is always the same and the target is a path going
+ forward with 75% probability, and going backward
+ with 25% probability.
+ """
+
+ def __init__(self, num_modes: int = 1):
+ self.num_modes = num_modes
+
+ def __iter__(self,):
+
+ while True:
+ image = torch.zeros((3, 100, 100))
+ agent_state_vector = torch.ones(3)
+ ground_truth = torch.ones((1, 12, 2))
+
+ if self.num_modes == 1:
+ going_forward = True
+ else:
+ going_forward = np.random.rand() > 0.25
+
+ if going_forward:
+ ground_truth[:, :, 1] = torch.arange(0, 6, step=0.5)
+ else:
+ ground_truth[:, :, 1] = -torch.arange(0, 6, step=0.5)
+
+ yield image, agent_state_vector, ground_truth
+
+
+if __name__ == "__main__":
+
+ parser = argparse.ArgumentParser(description='Run MTP to make sure it overfits on a single test case.')
+ parser.add_argument('--num_modes', type=int, help='How many modes to learn.', default=1)
+ parser.add_argument('--use_gpu', type=bool, help='Whether to use gpu', default=False)
+ args = parser.parse_args()
+
+ if args.use_gpu:
+ device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
+ else:
+ device = torch.device('cpu')
+
+ dataset = Dataset(args.num_modes)
+ dataloader = DataLoader(dataset, batch_size=16, num_workers=0)
+
+ backbone = ResNetBackbone('resnet18')
+ model = MTP(backbone, args.num_modes)
+ model = model.to(device)
+
+ loss_function = MTPLoss(args.num_modes, 1, 5)
+
+ current_loss = 10000
+
+ optimizer = optim.SGD(model.parameters(), lr=0.1)
+
+ n_iter = 0
+
+ minimum_loss = 0
+
+ if args.num_modes == 2:
+
+ # We expect to see 75% going_forward and
+ # 25% going backward. So the minimum
+ # classification loss is expected to be
+ # 0.56234
+
+ minimum_loss += 0.56234
+
+ for img, agent_state_vector, ground_truth in dataloader:
+
+ img = img.to(device)
+ agent_state_vector = agent_state_vector.to(device)
+ ground_truth = ground_truth.to(device)
+
+ optimizer.zero_grad()
+
+ prediction = model(img, agent_state_vector)
+ loss = loss_function(prediction, ground_truth)
+ loss.backward()
+ optimizer.step()
+
+ current_loss = loss.cpu().detach().numpy()
+
+ print(f"Current loss is {current_loss:.4f}")
+ if np.allclose(current_loss, minimum_loss, atol=1e-4):
+ print(f"Achieved near-zero loss after {n_iter} iterations.")
+ break
+
+ n_iter += 1
+
diff --git a/python-sdk/nuscenes/prediction/tests/test_backbone.py b/python-sdk/nuscenes/prediction/tests/test_backbone.py
new file mode 100644
index 0000000..697d498
--- /dev/null
+++ b/python-sdk/nuscenes/prediction/tests/test_backbone.py
@@ -0,0 +1,52 @@
+import unittest
+
+import torch
+from torchvision.models.resnet import BasicBlock, Bottleneck
+
+from nuscenes.prediction.models.backbone import ResNetBackbone, MobileNetBackbone
+
+
+class TestBackBones(unittest.TestCase):
+
+ def count_layers(self, model):
+ if isinstance(model[4][0], BasicBlock):
+ n_convs = 2
+ elif isinstance(model[4][0], Bottleneck):
+ n_convs = 3
+ else:
+ raise ValueError("Backbone layer block not supported!")
+
+ return sum([len(model[i]) for i in range(4, 8)]) * n_convs + 2
+
+ def test_resnet(self):
+
+ rn_18 = ResNetBackbone('resnet18')
+ rn_34 = ResNetBackbone('resnet34')
+ rn_50 = ResNetBackbone('resnet50')
+ rn_101 = ResNetBackbone('resnet101')
+ rn_152 = ResNetBackbone('resnet152')
+
+ tensor = torch.ones((1, 3, 100, 100))
+
+ self.assertEqual(rn_18(tensor).shape[1], 512)
+ self.assertEqual(rn_34(tensor).shape[1], 512)
+ self.assertEqual(rn_50(tensor).shape[1], 2048)
+ self.assertEqual(rn_101(tensor).shape[1], 2048)
+ self.assertAlmostEqual(rn_152(tensor).shape[1], 2048)
+
+ self.assertEqual(self.count_layers(list(rn_18.backbone.children())), 18)
+ self.assertEqual(self.count_layers(list(rn_34.backbone.children())), 34)
+ self.assertEqual(self.count_layers(list(rn_50.backbone.children())), 50)
+ self.assertEqual(self.count_layers(list(rn_101.backbone.children())), 101)
+ self.assertEqual(self.count_layers(list(rn_152.backbone.children())), 152)
+
+ with self.assertRaises(ValueError):
+ ResNetBackbone('resnet51')
+
+ def test_mobilenet(self):
+
+ mobilenet = MobileNetBackbone('mobilenet_v2')
+
+ tensor = torch.ones((1, 3, 100, 100))
+
+ self.assertEqual(mobilenet(tensor).shape[1], 1280)
\ No newline at end of file
diff --git a/python-sdk/nuscenes/prediction/tests/test_covernet.py b/python-sdk/nuscenes/prediction/tests/test_covernet.py
new file mode 100644
index 0000000..19b5674
--- /dev/null
+++ b/python-sdk/nuscenes/prediction/tests/test_covernet.py
@@ -0,0 +1,81 @@
+# nuScenes dev-kit.
+# Code written by Freddy Boulton, 2020.
+
+import math
+import unittest
+
+import torch
+from torch.nn.functional import cross_entropy
+
+from nuscenes.prediction.models.backbone import ResNetBackbone
+from nuscenes.prediction.models.covernet import mean_pointwise_l2_distance, ConstantLatticeLoss, CoverNet
+
+
+class TestCoverNet(unittest.TestCase):
+
+ def test_shapes_in_forward_pass_correct(self):
+ resnet = ResNetBackbone('resnet50')
+
+ covernet = CoverNet(resnet, 5, n_hidden_layers=[4096], input_shape=(3, 100, 100))
+
+ image = torch.zeros(4, 3, 100, 100)
+ asv = torch.empty(4, 3).random_(12)
+
+ logits = covernet(image, asv)
+ self.assertTupleEqual(logits.shape, (4, 5))
+
+
+class TestConstantLatticeLoss(unittest.TestCase):
+
+ def test_l1_distance(self):
+
+ lattice = torch.zeros(3, 6, 2)
+ lattice[0] = torch.arange(1, 13).reshape(6, 2)
+ lattice[1] = torch.arange(1, 13).reshape(6, 2) * 3
+ lattice[2] = torch.arange(1, 13).reshape(6, 2) * 6
+
+ # Should select the first mode
+ ground_truth = torch.arange(1, 13, dtype=torch.float).reshape(6, 2).unsqueeze(0) + 2
+ self.assertEqual(mean_pointwise_l2_distance(lattice, ground_truth), 0)
+
+ # Should select the second mode
+ ground_truth = torch.arange(1, 13, dtype=torch.float).reshape(6, 2).unsqueeze(0) * 3 + 4
+ self.assertEqual(mean_pointwise_l2_distance(lattice, ground_truth), 1)
+
+ # Should select the third mode
+ ground_truth = torch.arange(1, 13, dtype=torch.float).reshape(6, 2).unsqueeze(0) * 6 + 10
+ self.assertEqual(mean_pointwise_l2_distance(lattice, ground_truth), 2)
+
+ def test_constant_lattice_loss(self):
+
+
+ def generate_trajectory(theta: float) -> torch.Tensor:
+ trajectory = torch.zeros(6, 2)
+ trajectory[:, 0] = torch.arange(6, dtype=torch.float) * math.cos(theta)
+ trajectory[:, 1] = torch.arange(6, dtype=torch.float) * math.sin(theta)
+ return trajectory
+
+ lattice = torch.zeros(3, 6, 2)
+ lattice[0] = generate_trajectory(math.pi / 2)
+ lattice[1] = generate_trajectory(math.pi / 4)
+ lattice[2] = generate_trajectory(3 * math.pi / 4)
+
+ ground_truth = torch.zeros(5, 1, 6, 2)
+ ground_truth[0, 0] = generate_trajectory(0.2)
+ ground_truth[1, 0] = generate_trajectory(math.pi / 3)
+ ground_truth[2, 0] = generate_trajectory(5 * math.pi / 6)
+ ground_truth[3, 0] = generate_trajectory(6 * math.pi / 11)
+ ground_truth[4, 0] = generate_trajectory(4 * math.pi / 9)
+
+ logits = torch.Tensor([[2, 10, 5],
+ [-3, 4, 5],
+ [-4, 2, 7],
+ [8, -2, 3],
+ [10, 3, 6]])
+
+ answer = cross_entropy(logits, torch.LongTensor([1, 1, 2, 0, 0]))
+
+ loss = ConstantLatticeLoss(lattice, mean_pointwise_l2_distance)
+ loss_value = loss(logits, ground_truth)
+
+ self.assertAlmostEqual(float(loss_value.detach().numpy()), float(answer.detach().numpy()))
diff --git a/python-sdk/nuscenes/prediction/tests/test_mtp.py b/python-sdk/nuscenes/prediction/tests/test_mtp.py
new file mode 100644
index 0000000..071e38c
--- /dev/null
+++ b/python-sdk/nuscenes/prediction/tests/test_mtp.py
@@ -0,0 +1,59 @@
+import unittest
+
+import torch
+
+from nuscenes.prediction.models import backbone
+from nuscenes.prediction.models import mtp
+
+
+class TestMTP(unittest.TestCase):
+
+ def setUp(self):
+ self.image = torch.ones((1, 3, 100, 100))
+ self.agent_state_vector = torch.ones((1, 3))
+ self.image_5 = torch.ones((5, 3, 100, 100))
+ self.agent_state_vector_5 = torch.ones((5, 3))
+
+ def _run(self, model):
+ pred = model(self.image, self.agent_state_vector)
+ pred_5 = model(self.image_5, self.agent_state_vector_5)
+
+ self.assertTupleEqual(pred.shape, (1, 75))
+ self.assertTupleEqual(pred_5.shape, (5, 75))
+
+ model.training = False
+ pred = model(self.image, self.agent_state_vector)
+ self.assertTrue(torch.allclose(pred[:, -3:].sum(axis=1), torch.ones(pred.shape[0])))
+
+ def test_works_with_resnet_18(self,):
+ rn_18 = backbone.ResNetBackbone('resnet18')
+ model = mtp.MTP(rn_18, 3, 6, 2, input_shape=(3, 100, 100))
+ self._run(model)
+
+ def test_works_with_resnet_34(self,):
+ rn_34 = backbone.ResNetBackbone('resnet34')
+ model = mtp.MTP(rn_34, 3, 6, 2, input_shape=(3, 100, 100))
+ self._run(model)
+
+ def test_works_with_resnet_50(self,):
+ rn_50 = backbone.ResNetBackbone('resnet50')
+ model = mtp.MTP(rn_50, 3, 6, 2, input_shape=(3, 100, 100))
+ self._run(model)
+
+ def test_works_with_resnet_101(self,):
+ rn_101 = backbone.ResNetBackbone('resnet101')
+ model = mtp.MTP(rn_101, 3, 6, 2, input_shape=(3, 100, 100))
+ self._run(model)
+
+ def test_works_with_resnet_152(self,):
+ rn_152 = backbone.ResNetBackbone('resnet152')
+ model = mtp.MTP(rn_152, 3, 6, 2, input_shape=(3, 100, 100))
+ self._run(model)
+
+ def test_works_with_mobilenet_v2(self,):
+ mobilenet = backbone.MobileNetBackbone('mobilenet_v2')
+ model = mtp.MTP(mobilenet, 3, 6, 2, input_shape=(3, 100, 100))
+ self._run(model)
+
+
+
diff --git a/python-sdk/nuscenes/prediction/tests/test_mtp_loss.py b/python-sdk/nuscenes/prediction/tests/test_mtp_loss.py
new file mode 100644
index 0000000..49ee2e2
--- /dev/null
+++ b/python-sdk/nuscenes/prediction/tests/test_mtp_loss.py
@@ -0,0 +1,183 @@
+
+import math
+import unittest
+
+import torch
+
+from nuscenes.prediction.models import mtp
+
+
+class TestMTPLoss(unittest.TestCase):
+ """
+ Test each component of MTPLoss as well as the
+ __call__ method.
+ """
+
+ def test_get_trajectories_and_modes(self):
+
+ loss_n_modes_5 = mtp.MTPLoss(5, 0, 0)
+ loss_n_modes_1 = mtp.MTPLoss(1, 0, 0)
+
+ xy_pred = torch.arange(60).view(1, -1).repeat(1, 5).view(-1, 60)
+ mode_pred = torch.arange(5).view(1, -1)
+
+ prediction_bs_1 = torch.cat([xy_pred.reshape(1, -1), mode_pred], dim=1)
+ prediction_bs_2 = prediction_bs_1.repeat(2, 1)
+
+ # Testing many modes with batch size 1.
+ traj, modes = loss_n_modes_5._get_trajectory_and_modes(prediction_bs_1)
+ self.assertTrue(torch.allclose(traj, xy_pred.unsqueeze(0).reshape(1, 5, 30, 2)))
+ self.assertTrue(torch.allclose(modes, mode_pred))
+
+ # Testing many modes with batch size > 1.
+ traj, modes = loss_n_modes_5._get_trajectory_and_modes(prediction_bs_2)
+ self.assertTrue(torch.allclose(traj, xy_pred.repeat(1, 2).unsqueeze(0).reshape(2, 5, 30, 2)))
+ self.assertTrue(torch.allclose(modes, mode_pred.repeat(2, 1)))
+
+ xy_pred = torch.arange(60).view(1, -1).repeat(1, 1).view(-1, 60)
+ mode_pred = torch.arange(1).view(1, -1)
+
+ prediction_bs_1 = torch.cat([xy_pred.reshape(1, -1), mode_pred], dim=1)
+ prediction_bs_2 = prediction_bs_1.repeat(2, 1)
+
+ # Testing one mode with batch size 1.
+ traj, modes = loss_n_modes_1._get_trajectory_and_modes(prediction_bs_1)
+ self.assertTrue(torch.allclose(traj, xy_pred.unsqueeze(0).reshape(1, 1, 30, 2)))
+ self.assertTrue(torch.allclose(modes, mode_pred))
+
+ # Testing one mode with batch size > 1.
+ traj, modes = loss_n_modes_1._get_trajectory_and_modes(prediction_bs_2)
+ self.assertTrue(torch.allclose(traj, xy_pred.repeat(1, 2).unsqueeze(0).reshape(2, 1, 30, 2)))
+ self.assertTrue(torch.allclose(modes, mode_pred.repeat(2, 1)))
+
+ def test_angle_between_trajectories(self):
+
+ def make_trajectory(last_point):
+ traj = torch.zeros((12, 2))
+ traj[-1] = torch.Tensor(last_point)
+ return traj
+
+ loss = mtp.MTPLoss(0, 0, 0)
+
+ # test angle is 0.
+ self.assertEqual(loss._angle_between(make_trajectory([0, 0]), make_trajectory([0, 0])), 0.)
+ self.assertEqual(loss._angle_between(make_trajectory([15, 15]), make_trajectory([15, 15])), 0.)
+
+ # test angle is 15.
+ self.assertAlmostEqual(loss._angle_between(make_trajectory([1, 1]),
+ make_trajectory([math.sqrt(3)/2, 0.5])), 15., places=4)
+
+ # test angle is 30.
+ self.assertAlmostEqual(loss._angle_between(make_trajectory([1, 0]),
+ make_trajectory([math.sqrt(3)/2, 0.5])), 30., places=4)
+
+ # test angle is 45.
+ self.assertAlmostEqual(loss._angle_between(make_trajectory([1, 1]),
+ make_trajectory([0, 1])), 45., places=4)
+
+ # test angle is 90.
+ self.assertAlmostEqual(loss._angle_between(make_trajectory([1, 1]),
+ make_trajectory([-1, 1])), 90., places=4)
+ self.assertAlmostEqual(loss._angle_between(make_trajectory([1, 0]),
+ make_trajectory([0, 1])), 90., places=4)
+
+ # test angle is 180.
+ self.assertAlmostEqual(loss._angle_between(make_trajectory([1, 0]),
+ make_trajectory([-1, 0])), 180., places=4)
+ self.assertAlmostEqual(loss._angle_between(make_trajectory([0, 1]),
+ make_trajectory([0, -1])), 180., places=4)
+ self.assertAlmostEqual(loss._angle_between(make_trajectory([3, 1]),
+ make_trajectory([-3, -1])), 180., places=4)
+
+ def test_compute_best_mode_nothing_below_threshold(self):
+ angles = [(90, 0), (80, 1), (70, 2)]
+ target = None
+ traj = None
+
+ loss = mtp.MTPLoss(3, 0, 5)
+ self.assertTrue(loss._compute_best_mode(angles, target, traj) in {0, 1, 2})
+
+ loss = mtp.MTPLoss(3, 0, 65)
+ self.assertTrue(loss._compute_best_mode(angles, target, traj) in {0, 1, 2})
+
+ def test_compute_best_mode_only_one_below_threshold(self):
+ angles = [(30, 1), (3, 0), (25, 2)]
+
+ target = torch.ones((1, 6, 2))
+ trajectory = torch.zeros((3, 6, 2))
+
+ loss = mtp.MTPLoss(3, 0, 5)
+ self.assertEqual(loss._compute_best_mode(angles, target, trajectory), 0)
+
+ def test_compute_best_mode_multiple_below_threshold(self):
+ angles = [(2, 2), (4, 1), (10, 0)]
+ target = torch.ones((1, 6, 2))
+ trajectory = torch.zeros((3, 6, 2))
+ trajectory[1] = 1
+
+ loss = mtp.MTPLoss(3, 0, 5)
+ self.assertEqual(loss._compute_best_mode(angles, target, trajectory), 1)
+
+ def test_compute_best_mode_only_one_mode(self):
+ angles = [(25, 0)]
+ target = torch.ones((1, 6, 2))
+ trajectory = torch.zeros((1, 6, 2))
+
+ loss = mtp.MTPLoss(1, 0, 5)
+ self.assertEqual(loss._compute_best_mode(angles, target, trajectory), 0)
+
+ trajectory[0] = 1
+ self.assertEqual(loss._compute_best_mode(angles, target, trajectory), 0)
+
+ def test_loss_single_mode(self):
+ targets = torch.zeros((16, 1, 30, 2))
+ targets[:, :, :, 1] = torch.arange(start=0, end=3, step=0.1)
+
+ predictions = torch.ones((16, 61))
+ predictions[:, :60] = targets[0, 0, :, :].reshape(-1, 60)
+ predictions[:, 60] = 1/10
+
+ loss = mtp.MTPLoss(1, 1, angle_threshold_degrees=20)
+
+ # Only regression loss in single mode case.
+ self.assertAlmostEqual(float(loss(predictions, targets).detach().numpy()),
+ 0, places=4)
+
+ # Now the best mode differs by 1 from the ground truth.
+ # Smooth l1 loss subtracts 0.5 from l1 norm if diff >= 1.
+ predictions[:, :60] += 1
+ self.assertAlmostEqual(float(loss(predictions, targets).detach().numpy()), 0.5,
+ places=4)
+
+ # In this case, one element has perfect regression, the others are off by 1.
+ predictions[1, :60] -= 1
+ self.assertAlmostEqual(float(loss(predictions, targets).detach().numpy()),
+ (15/16)*0.5,
+ places=4)
+
+ def test_loss_many_modes(self):
+ targets = torch.zeros((16, 1, 30, 2))
+ targets[:, :, :, 1] = torch.arange(start=0, end=3, step=0.1)
+
+ predictions = torch.ones((16, 610))
+ predictions[:, 540:600] = targets[0, 0, :, :].reshape(-1, 60)
+ predictions[:, -10:] = 1/10
+
+ loss = mtp.MTPLoss(10, 1, angle_threshold_degrees=20)
+
+ # Since one mode exactly matches gt, loss should only be classification error.
+ self.assertAlmostEqual(float(loss(predictions, targets).detach().numpy()),
+ -math.log(1/10), places=4)
+
+ # Now the best mode differs by 1 from the ground truth.
+ # Smooth l1 loss subtracts 0.5 from l1 norm if diff >= 1.
+ predictions[:, 540:600] += 1
+ self.assertAlmostEqual(float(loss(predictions, targets).detach().numpy()),
+ -math.log(1/10) + 0.5,
+ places=4)
+
+ # In this case, one element has perfect regression, the others are off by 1.
+ predictions[1, 540:600] -= 1
+ self.assertAlmostEqual(float(loss(predictions, targets).detach().numpy()),
+ -math.log(1/10) + (15/16)*0.5,
+ places=4)
diff --git a/python-sdk/nuscenes/prediction/tests/test_physics_models.py b/python-sdk/nuscenes/prediction/tests/test_physics_models.py
new file mode 100644
index 0000000..9430789
--- /dev/null
+++ b/python-sdk/nuscenes/prediction/tests/test_physics_models.py
@@ -0,0 +1,78 @@
+import unittest
+from unittest.mock import MagicMock, patch
+
+import numpy as np
+
+from nuscenes.prediction import PredictHelper
+from nuscenes.prediction.models.physics import ConstantVelocityHeading, PhysicsOracle
+
+
+class TestPhysicsBaselines(unittest.TestCase):
+
+ def test_Baselines_raise_error_when_sec_from_now_bad(self):
+
+ with self.assertRaises(AssertionError):
+ ConstantVelocityHeading(2.23, None)
+
+ with self.assertRaises(AssertionError):
+ PhysicsOracle(2.25, None)
+
+ PhysicsOracle(5.5, None)
+ ConstantVelocityHeading(3, None)
+
+ @patch('nuscenes.prediction.models.physics._kinematics_from_tokens')
+ def test_ConstantVelocityHeading(self, mock_kinematics):
+
+ mock_helper = MagicMock(spec=PredictHelper)
+ mock_helper.get_sample_annotation.return_value = {'translation': [0, 0, 0], 'rotation': [1, 0, 0, 0]}
+
+ # x, y, vx, vy, ax, ay, velocity, yaw_rate, acceleration, yaw
+ mock_kinematics.return_value = 0, 0, 1, 0, 2, 0, 1, 0, 2, 0
+
+ cv_model = ConstantVelocityHeading(6, mock_helper)
+ prediction = cv_model('foo-instance_bar-sample')
+
+ answer = np.array([[[0.5, 0], [1, 0], [1.5, 0], [2.0, 0], [2.5, 0], [3.0, 0],
+ [3.5, 0.0], [4.0, 0], [4.5, 0], [5.0, 0], [5.5, 0], [6.0, 0]]])
+
+ np.testing.assert_allclose(answer, np.round(prediction.prediction, 3))
+
+ @patch('nuscenes.prediction.models.physics._kinematics_from_tokens')
+ def test_PhysicsOracle(self, mock_kinematics):
+
+ mock_helper = MagicMock(spec=PredictHelper)
+ mock_helper.get_sample_annotation.return_value = {'translation': [0, 0, 0], 'rotation': [1, 0, 0, 0]}
+
+ # Made to look like constant acceleration and heading
+ mock_helper.get_future_for_agent.return_value = np.array([[0, 1.3], [0, 2.9], [0, 5.2], [0, 8.3], [0, 11.3],
+ [0, 14.6], [0, 19.29], [0, 23.7], [0, 29.19],
+ [0, 33.], [0, 41.3], [0, 48.2]])
+
+ # x, y, vx, vy, ax, ay, velocity, yaw_rate, acceleration, yaw
+ mock_kinematics.return_value = 0, 0, 0, 2, 0, 2, 2, 0.05, 2, 0
+
+ oracle = PhysicsOracle(6, mock_helper)
+ prediction = oracle('foo-instance_bar-sample')
+
+ answer = np.array([[[0., 1.25], [0., 3.], [0., 5.25], [0., 8.], [0., 11.25], [0., 15.],
+ [0., 19.25], [0., 24.], [0., 29.25], [0., 35.], [0., 41.25], [0., 48.]]])
+
+ np.testing.assert_allclose(answer, np.round(prediction.prediction, 3))
+
+ @patch('nuscenes.prediction.models.physics._kinematics_from_tokens')
+ def test_PhysicsOracle_raises_error_when_not_enough_gt(self, mock_kinematics):
+
+ mock_helper = MagicMock(spec=PredictHelper)
+ mock_helper.get_sample_annotation.return_value = {'translation': [0, 0, 0], 'rotation': [1, 0, 0, 0]}
+
+ # Made to look like constant acceleration and heading
+ mock_helper.get_future_for_agent.return_value = np.array([[0, 1.3], [0, 2.9], [0, 5.2], [0, 8.3], [0, 11.3],
+ [0, 14.6], [0, 19.29], [0, 23.7], [0, 29.19],
+ [0, 33.]])
+
+ # x, y, vx, vy, ax, ay, velocity, yaw_rate, acceleration, yaw
+ mock_kinematics.return_value = 0, 0, 0, 2, 0, 2, 2, 0.05, 2, 0
+
+ oracle = PhysicsOracle(6, mock_helper)
+ with self.assertRaises(AssertionError):
+ oracle('foo-instance_bar-sample')
diff --git a/python-sdk/nuscenes/prediction/tests/test_predict_helper.py b/python-sdk/nuscenes/prediction/tests/test_predict_helper.py
new file mode 100644
index 0000000..d151be2
--- /dev/null
+++ b/python-sdk/nuscenes/prediction/tests/test_predict_helper.py
@@ -0,0 +1,496 @@
+# nuScenes dev-kit.
+# Code written by Freddy Boulton, 2020.
+
+import copy
+import unittest
+from typing import Any, Dict, List, Tuple
+
+import numpy as np
+
+from nuscenes.nuscenes import NuScenes
+from nuscenes.prediction import PredictHelper, convert_global_coords_to_local
+
+
+class MockNuScenes(NuScenes):
+
+ def __init__(self,
+ sample_annotations: List[Dict[str, Any]],
+ samples: List[Dict[str, Any]]):
+ """
+ Mocks the NuScenes API needed to test PredictHelper.
+ Note that we are skipping the call to the super class constructor on purpose to avoid loading the tables.
+ :param sample_annotations: The sample_annotations table used in this fake version of nuScenes.
+ :param samples: The sample table used in this fake version of nuScenes.
+ """
+ self._sample_annotation = {r['token']: r for r in sample_annotations}
+ self._sample = {r['token']: r for r in samples}
+
+ @property
+ def sample_annotation(self) -> List[Dict[str, Any]]:
+ return list(self._sample_annotation.values())
+
+ def get(self, table_name: str, token: str) -> Dict[str, Any]:
+ assert table_name in {'sample_annotation', 'sample'}
+ return getattr(self, "_" + table_name)[token]
+
+
+class TestConvertGlobalCoordsToLocal(unittest.TestCase):
+
+ def setUp(self) -> None:
+ # Creating 5 different trajectories to be shared by
+ # coordinate frame rotation unit tests.
+ # These trajectories go along each of the axes in
+ # the x-y plane as well as the line y=x
+ along_pos_x = np.zeros((5, 2))
+ along_pos_y = np.zeros((5, 2))
+ along_neg_x = np.zeros((5, 2))
+ along_neg_y = np.zeros((5, 2))
+
+ along_pos_x[:, 0] = np.arange(1, 6)
+ along_pos_y[:, 1] = np.arange(1, 6)
+ along_neg_x[:, 0] = -np.arange(1, 6)
+ along_neg_y[:, 1] = -np.arange(1, 6)
+ self.along_pos_x, self.along_pos_y = along_pos_x, along_pos_y
+ self.along_neg_x, self.along_neg_y = along_neg_x, along_neg_y
+
+ y_equals_x = np.zeros((5, 2))
+ y_equals_x[:, 0] = np.arange(1, 6)
+ y_equals_x[:, 1] = np.arange(1, 6)
+ self.y_equals_x = y_equals_x
+
+ def _run(self,
+ rotation: Tuple[float, float, float, float],
+ origin: Tuple[float, float, float],
+ offset: Tuple[float, float, float],
+ along_pos_x_answer: np.ndarray,
+ along_pos_y_answer: np.ndarray,
+ along_neg_x_answer: np.ndarray,
+ along_neg_y_answer: np.ndarray,
+ ) -> None:
+
+ offset_as_list = [[offset[0], offset[1]]]
+
+ # Testing path along pos x direction
+ answer = convert_global_coords_to_local(self.along_pos_x, origin, rotation)
+ np.testing.assert_allclose(answer, along_pos_x_answer, atol=1e-4)
+
+ answer = convert_global_coords_to_local(self.along_pos_x + offset_as_list, offset, rotation)
+ np.testing.assert_allclose(answer, along_pos_x_answer, atol=1e-4)
+
+ # Testing path along pos y direction
+ answer = convert_global_coords_to_local(self.along_pos_y, origin, rotation)
+ np.testing.assert_allclose(answer, along_pos_y_answer, atol=1e-4)
+
+ answer = convert_global_coords_to_local(self.along_pos_y + offset_as_list, offset, rotation)
+ np.testing.assert_allclose(answer, along_pos_y_answer, atol=1e-4)
+
+ # Testing path along neg x direction
+ answer = convert_global_coords_to_local(self.along_neg_x, origin, rotation)
+ np.testing.assert_allclose(answer, along_neg_x_answer, atol=1e-4)
+
+ answer = convert_global_coords_to_local(self.along_neg_x + offset_as_list, offset, rotation)
+ np.testing.assert_allclose(answer, along_neg_x_answer, atol=1e-4)
+
+ # Testing path along neg y direction
+ answer = convert_global_coords_to_local(self.along_neg_y, origin, rotation)
+ np.testing.assert_allclose(answer, along_neg_y_answer, atol=1e-4)
+
+ answer = convert_global_coords_to_local(self.along_neg_y + offset_as_list, offset, rotation)
+ np.testing.assert_allclose(answer, along_neg_y_answer, atol=1e-4)
+
+ def test_heading_0(self) -> None:
+ self._run(rotation=(1, 0, 0, 0),
+ origin=(0, 0, 0),
+ offset=(50, 25, 0),
+ along_pos_x_answer=self.along_pos_y,
+ along_pos_y_answer=self.along_neg_x,
+ along_neg_x_answer=self.along_neg_y,
+ along_neg_y_answer=self.along_pos_x)
+
+ def test_heading_pi_over_4(self) -> None:
+ self._run(rotation=(np.cos(np.pi / 8), 0, 0, np.sin(np.pi / 8)),
+ origin=(0, 0, 0),
+ offset=(50, 25, 0),
+ along_pos_x_answer=self.y_equals_x * np.sqrt(2) / 2,
+ along_pos_y_answer=self.y_equals_x * [[-np.sqrt(2) / 2, np.sqrt(2) / 2]],
+ along_neg_x_answer=self.y_equals_x * [[-np.sqrt(2) / 2, -np.sqrt(2) / 2]],
+ along_neg_y_answer=self.y_equals_x * [[np.sqrt(2) / 2, -np.sqrt(2) / 2]])
+
+ def test_heading_pi_over_2(self) -> None:
+ self._run(rotation=(np.cos(np.pi / 4), 0, 0, np.sin(np.pi / 4)),
+ origin=(0, 0, 0),
+ offset=(50, 25, 0),
+ along_pos_x_answer=self.along_pos_x,
+ along_pos_y_answer=self.along_pos_y,
+ along_neg_x_answer=self.along_neg_x,
+ along_neg_y_answer=self.along_neg_y)
+
+ def test_heading_3pi_over_4(self) -> None:
+ self._run(rotation=(np.cos(3 * np.pi / 8), 0, 0, np.sin(3 * np.pi / 8)),
+ origin=(0, 0, 0),
+ offset=(50, 25, 0),
+ along_pos_x_answer=self.y_equals_x * [[np.sqrt(2) / 2, -np.sqrt(2) / 2]],
+ along_pos_y_answer=self.y_equals_x * [[np.sqrt(2) / 2, np.sqrt(2) / 2]],
+ along_neg_x_answer=self.y_equals_x * [[-np.sqrt(2) / 2, np.sqrt(2) / 2]],
+ along_neg_y_answer=self.y_equals_x * [[-np.sqrt(2) / 2, -np.sqrt(2) / 2]])
+
+ def test_heading_pi(self) -> None:
+ self._run(rotation=(np.cos(np.pi / 2), 0, 0, np.sin(np.pi / 2)),
+ origin=(0, 0, 0),
+ offset=(50, 25, 0),
+ along_pos_x_answer=self.along_neg_y,
+ along_pos_y_answer=self.along_pos_x,
+ along_neg_x_answer=self.along_pos_y,
+ along_neg_y_answer=self.along_neg_x)
+
+ def test_heading_neg_pi_over_4(self) -> None:
+ self._run(rotation=(np.cos(-np.pi / 8), 0, 0, np.sin(-np.pi / 8)),
+ origin=(0, 0, 0),
+ offset=(50, 25, 0),
+ along_pos_x_answer=self.y_equals_x * [[-np.sqrt(2) / 2, np.sqrt(2) / 2]],
+ along_pos_y_answer=self.y_equals_x * [[-np.sqrt(2) / 2, -np.sqrt(2) / 2]],
+ along_neg_x_answer=self.y_equals_x * [[np.sqrt(2) / 2, -np.sqrt(2) / 2]],
+ along_neg_y_answer=self.y_equals_x * [[np.sqrt(2) / 2, np.sqrt(2) / 2]])
+
+
+class TestPredictHelper(unittest.TestCase):
+
+ def setUp(self) -> None:
+
+ self.mock_annotations = [{'token': '1', 'instance_token': '1', 'sample_token': '1', 'translation': [0, 0, 0], 'rotation': [1, 0, 0, 0],
+ 'prev': '', 'next': '2'},
+ {'token': '2', 'instance_token': '1', 'sample_token': '2', 'translation': [1, 1, 1], 'rotation': [np.sqrt(2) / 2, 0, 0, np.sqrt(2) / 2],
+ 'prev': '1', 'next': '3'},
+ {'token': '3', 'instance_token': '1', 'sample_token': '3', 'translation': [2, 2, 2], 'prev': '2', 'next': '4'},
+ {'token': '4', 'instance_token': '1', 'sample_token': '4', 'translation': [3, 3, 3], 'prev': '3', 'next': '5'},
+ {'token': '5', 'instance_token': '1', 'sample_token': '5', 'translation': [4, 4, 4], 'rotation': [1, 0, 0, 0],
+ 'prev': '4', 'next': '6'},
+ {'token': '6', 'instance_token': '1', 'sample_token': '6', 'translation': [5, 5, 5], 'prev': '5', 'next': ''}]
+
+ self.multiagent_mock_annotations = [{'token': '1', 'instance_token': '1', 'sample_token': '1', 'translation': [0, 0, 0], 'rotation': [1, 0, 0, 0],
+ 'prev': '', 'next': '2'},
+ {'token': '2', 'instance_token': '1', 'sample_token': '2', 'translation': [1, 1, 1], 'prev': '1', 'next': '3'},
+ {'token': '3', 'instance_token': '1', 'sample_token': '3', 'translation': [2, 2, 2], 'prev': '2', 'next': '4'},
+ {'token': '4', 'instance_token': '1', 'sample_token': '4', 'translation': [3, 3, 3], 'prev': '3', 'next': '5'},
+ {'token': '5', 'instance_token': '1', 'sample_token': '5', 'translation': [4, 4, 4], 'rotation': [1, 0, 0, 0],
+ 'prev': '4', 'next': '6'},
+ {'token': '6', 'instance_token': '1', 'sample_token': '6', 'translation': [5, 5, 5], 'prev': '5', 'next': ''},
+ {'token': '1b', 'instance_token': '2', 'sample_token': '1', 'translation': [6, 6, 6], 'rotation': [1, 0, 0, 0],
+ 'prev': '', 'next': '2b'},
+ {'token': '2b', 'instance_token': '2', 'sample_token': '2', 'translation': [7, 7, 7], 'prev': '1b', 'next': '3b'},
+ {'token': '3b', 'instance_token': '2', 'sample_token': '3', 'translation': [8, 8, 8], 'prev': '2b', 'next': '4b'},
+ {'token': '4b', 'instance_token': '2', 'sample_token': '4', 'translation': [9, 9, 9], 'prev': '3b', 'next': '5b'},
+ {'token': '5b', 'instance_token': '2', 'sample_token': '5', 'translation': [10, 10, 10], 'rotation': [1, 0, 0, 0],
+ 'prev': '4b', 'next': '6b'},
+ {'token': '6b', 'instance_token': '2', 'sample_token': '6', 'translation': [11, 11, 11], 'prev': '5b', 'next': ''}]
+
+ def test_get_sample_annotation(self) -> None:
+
+ mock_annotation = {'token': '1', 'instance_token': 'instance_1', 'sample_token': 'sample_1'}
+ mock_sample = {'token': 'sample_1', 'timestamp': 0}
+
+ nusc = MockNuScenes([mock_annotation], [mock_sample])
+
+ helper = PredictHelper(nusc)
+ self.assertDictEqual(mock_annotation, helper.get_sample_annotation('instance_1', 'sample_1'))
+
+ def test_get_future_for_agent_exact_amount(self) -> None:
+
+ mock_samples = [{'token': '1', 'timestamp': 0},
+ {'token': '2', 'timestamp': 1e6},
+ {'token': '3', 'timestamp': 2e6},
+ {'token': '4', 'timestamp': 3e6},
+ {'token': '5', 'timestamp': 4e6}]
+
+ # Testing we can get the exact amount of future seconds available
+ nusc = MockNuScenes(self.mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ future = helper.get_future_for_agent('1', '1', 3, False)
+ np.testing.assert_equal(future, np.array([[1, 1], [2, 2], [3, 3]]))
+
+ def test_get_future_for_agent_in_agent_frame(self) -> None:
+ mock_samples = [{'token': '1', 'timestamp': 0},
+ {'token': '2', 'timestamp': 1e6},
+ {'token': '3', 'timestamp': 2e6},
+ {'token': '4', 'timestamp': 3e6},
+ {'token': '5', 'timestamp': 4e6}]
+
+ nusc = MockNuScenes(self.mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ future = helper.get_future_for_agent('1', '1', 3, True)
+ np.testing.assert_allclose(future, np.array([[-1, 1], [-2, 2], [-3, 3]]))
+
+ def test_get_future_for_agent_less_amount(self) -> None:
+
+ mock_samples = [{'token': '1', 'timestamp': 0},
+ {'token': '2', 'timestamp': 1e6},
+ {'token': '3', 'timestamp': 2.6e6},
+ {'token': '4', 'timestamp': 4e6},
+ {'token': '5', 'timestamp': 5.5e6}]
+
+ # Testing we do not include data after the future seconds
+ nusc = MockNuScenes(self.mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ future = helper.get_future_for_agent('1', '1', 3, False)
+ np.testing.assert_equal(future, np.array([[1, 1], [2, 2]]))
+
+ def test_get_future_for_agent_within_buffer(self) -> None:
+
+ mock_samples = [{'token': '1', 'timestamp': 0},
+ {'token': '2', 'timestamp': 1e6},
+ {'token': '3', 'timestamp': 2.6e6},
+ {'token': '4', 'timestamp': 3.05e6},
+ {'token': '5', 'timestamp': 3.5e6}]
+
+ # Testing we get data if it is after future seconds but within buffer
+ nusc = MockNuScenes(self.mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ future = helper.get_future_for_agent('1', '1', 3, False)
+ np.testing.assert_equal(future, np.array([[1, 1], [2, 2], [3, 3]]))
+
+ def test_get_future_for_agent_no_data_to_get(self) -> None:
+ mock_samples = [{'token': '1', 'timestamp': 0},
+ {'token': '2', 'timestamp': 3.5e6}]
+
+ # Testing we get nothing if the first sample annotation is past our threshold
+ nusc = MockNuScenes(self.mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ future = helper.get_future_for_agent('1', '1', 3, False)
+ np.testing.assert_equal(future, np.array([]))
+
+ def test_get_future_for_last_returns_nothing(self) -> None:
+ mock_samples = [{'token': '6', 'timestamp': 0}]
+
+ # Testing we get nothing if we're at the last annotation
+ nusc = MockNuScenes(self.mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ future = helper.get_future_for_agent('1', '6', 3, False)
+ np.testing.assert_equal(future, np.array([]))
+
+ def test_get_past_for_agent_exact_amount(self) -> None:
+
+ mock_samples = [{'token': '5', 'timestamp': 0},
+ {'token': '4', 'timestamp': -1e6},
+ {'token': '3', 'timestamp': -2e6},
+ {'token': '2', 'timestamp': -3e6},
+ {'token': '1', 'timestamp': -4e6}]
+
+ # Testing we can get the exact amount of past seconds available
+ nusc = MockNuScenes(self.mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ past = helper.get_past_for_agent('1', '5', 3, False)
+ np.testing.assert_equal(past, np.array([[3, 3], [2, 2], [1, 1]]))
+
+ def test_get_past_for_agent_in_frame(self) -> None:
+
+ mock_samples = [{'token': '5', 'timestamp': 0},
+ {'token': '4', 'timestamp': -1e6},
+ {'token': '3', 'timestamp': -2e6},
+ {'token': '2', 'timestamp': -3e6},
+ {'token': '1', 'timestamp': -4e6}]
+
+ # Testing we can get the exact amount of past seconds available
+ nusc = MockNuScenes(self.mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ past = helper.get_past_for_agent('1', '5', 3, True)
+ np.testing.assert_allclose(past, np.array([[1., -1.], [2., -2.], [3., -3.]]))
+
+ def test_get_past_for_agent_less_amount(self) -> None:
+
+ mock_samples = [{'token': '5', 'timestamp': 0},
+ {'token': '4', 'timestamp': -1e6},
+ {'token': '3', 'timestamp': -2.6e6},
+ {'token': '2', 'timestamp': -4e6},
+ {'token': '1', 'timestamp': -5.5e6}]
+
+ # Testing we do not include data after the past seconds
+ nusc = MockNuScenes(self.mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ past = helper.get_past_for_agent('1', '5', 3, False)
+ np.testing.assert_equal(past, np.array([[3, 3], [2, 2]]))
+
+ def test_get_past_for_agent_within_buffer(self) -> None:
+
+ mock_samples = [{'token': '5', 'timestamp': 0},
+ {'token': '4', 'timestamp': -1e6},
+ {'token': '3', 'timestamp': -3.05e6},
+ {'token': '2', 'timestamp': -3.2e6}]
+
+ # Testing we get data if it is after future seconds but within buffer
+ nusc = MockNuScenes(self.mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ past = helper.get_past_for_agent('1', '5', 3, False)
+ np.testing.assert_equal(past, np.array([[3, 3], [2, 2]]))
+
+ def test_get_past_for_agent_no_data_to_get(self) -> None:
+ mock_samples = [{'token': '5', 'timestamp': 0},
+ {'token': '4', 'timestamp': -3.5e6}]
+
+ # Testing we get nothing if the first sample annotation is past our threshold
+ nusc = MockNuScenes(self.mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ past = helper.get_past_for_agent('1', '5', 3, False)
+ np.testing.assert_equal(past, np.array([]))
+
+ def test_get_past_for_last_returns_nothing(self) -> None:
+ mock_samples = [{'token': '1', 'timestamp': 0}]
+
+ # Testing we get nothing if we're at the last annotation
+ nusc = MockNuScenes(self.mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ past = helper.get_past_for_agent('1', '1', 3, False)
+ np.testing.assert_equal(past, np.array([]))
+
+ def test_get_future_for_sample(self) -> None:
+
+ mock_samples = [{'token': '1', 'timestamp': 0, 'anns': ['1', '1b']},
+ {'token': '2', 'timestamp': 1e6},
+ {'token': '3', 'timestamp': 2e6},
+ {'token': '4', 'timestamp': 3e6},
+ {'token': '5', 'timestamp': 4e6}]
+
+ nusc = MockNuScenes(self.multiagent_mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ future = helper.get_future_for_sample('1', 3, False)
+
+ answer = {'1': np.array([[1, 1], [2, 2], [3, 3]]),
+ '2': np.array([[7, 7], [8, 8], [9, 9]])}
+
+ for k in answer:
+ np.testing.assert_equal(answer[k], future[k])
+
+ future_in_sample = helper.get_future_for_sample('1', 3, True)
+
+ answer_in_sample = {'1': np.array([[-1, 1], [-2, 2], [-3, 3]]),
+ '2': np.array([[-1, 1], [-2, 2], [-3, 3]])}
+
+ for k in answer_in_sample:
+ np.testing.assert_allclose(answer_in_sample[k], future_in_sample[k])
+
+ def test_get_past_for_sample(self) -> None:
+
+ mock_samples = [{'token': '5', 'timestamp': 0, 'anns': ['5', '5b']},
+ {'token': '4', 'timestamp': -1e6},
+ {'token': '3', 'timestamp': -2e6},
+ {'token': '2', 'timestamp': -3e6},
+ {'token': '1', 'timestamp': -4e6}]
+
+ nusc = MockNuScenes(self.multiagent_mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ past = helper.get_past_for_sample('5', 3, True)
+
+ answer = {'1': np.array([[1, -1], [2, -2], [3, -3]]),
+ '2': np.array([[1, -1], [2, -2], [3, -3]])}
+
+ for k in answer:
+ np.testing.assert_allclose(past[k], answer[k])
+
+
+ def test_velocity(self) -> None:
+
+ mock_samples = [{'token': '1', 'timestamp': 0},
+ {'token': '2', 'timestamp': 0.5e6}]
+
+ nusc = MockNuScenes(self.mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+
+ self.assertEqual(helper.get_velocity_for_agent("1", "2"), np.sqrt(8))
+
+ def test_velocity_return_nan_one_obs(self) -> None:
+
+ mock_samples = [{'token': '1', 'timestamp': 0}]
+ nusc = MockNuScenes(self.mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+
+ self.assertTrue(np.isnan(helper.get_velocity_for_agent('1', '1')))
+
+ def test_velocity_return_nan_big_diff(self) -> None:
+ mock_samples = [{'token': '1', 'timestamp': 0},
+ {'token': '2', 'timestamp': 2.5e6}]
+ nusc = MockNuScenes(self.mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ self.assertTrue(np.isnan(helper.get_velocity_for_agent('1', '2')))
+
+ def test_heading_change_rate(self) -> None:
+ mock_samples = [{'token': '1', 'timestamp': 0}, {'token': '2', 'timestamp': 0.5e6}]
+ nusc = MockNuScenes(self.mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ self.assertEqual(helper.get_heading_change_rate_for_agent('1', '2'), np.pi)
+
+ def test_heading_change_rate_near_pi(self) -> None:
+ mock_samples = [{'token': '1', 'timestamp': 0}, {'token': '2', 'timestamp': 0.5e6}]
+ mock_annotations = copy.copy(self.mock_annotations)
+ mock_annotations[0]['rotation'] = [np.cos((np.pi - 0.05)/2), 0, 0, np.sin((np.pi - 0.05) / 2)]
+ mock_annotations[1]['rotation'] = [np.cos((-np.pi + 0.05)/2), 0, 0, np.sin((-np.pi + 0.05) / 2)]
+ nusc = MockNuScenes(mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ self.assertAlmostEqual(helper.get_heading_change_rate_for_agent('1', '2'), 0.2)
+
+ def test_acceleration_zero(self) -> None:
+ mock_samples = [{'token': '1', 'timestamp': 0},
+ {'token': '2', 'timestamp': 0.5e6},
+ {'token': '3', 'timestamp': 1e6}]
+ nusc = MockNuScenes(self.mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ self.assertEqual(helper.get_acceleration_for_agent('1', '3'), 0)
+
+ def test_acceleration_nonzero(self) -> None:
+ mock_samples = [{'token': '1', 'timestamp': 0},
+ {'token': '2', 'timestamp': 0.5e6},
+ {'token': '3', 'timestamp': 1e6}]
+ mock_annotations = copy.copy(self.mock_annotations)
+ mock_annotations[2]['translation'] = [3, 3, 3]
+ nusc = MockNuScenes(mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ self.assertAlmostEqual(helper.get_acceleration_for_agent('1', '3'), 2 * (np.sqrt(32) - np.sqrt(8)))
+
+ def test_acceleration_nan_not_enough_data(self) -> None:
+ mock_samples = [{'token': '1', 'timestamp': 0},
+ {'token': '2', 'timestamp': 0.5e6},
+ {'token': '3', 'timestamp': 1e6}]
+ nusc = MockNuScenes(self.mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ self.assertTrue(np.isnan(helper.get_acceleration_for_agent('1', '2')))
+
+ def test_get_no_data_when_seconds_0(self) -> None:
+ mock_samples = [{'token': '1', 'timestamp': 0, 'anns': ['1']}]
+ nusc = MockNuScenes(self.mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+
+ np.testing.assert_equal(helper.get_future_for_agent('1', '1', 0, False), np.array([]))
+ np.testing.assert_equal(helper.get_past_for_agent('1', '1', 0, False), np.array([]))
+ np.testing.assert_equal(helper.get_future_for_sample('1', 0, False), np.array([]))
+ np.testing.assert_equal(helper.get_past_for_sample('1', 0, False), np.array([]))
+
+ def test_raises_error_when_seconds_negative(self) -> None:
+ mock_samples = [{'token': '1', 'timestamp': 0, 'anns': ['1', '1b']}]
+ nusc = MockNuScenes(self.mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ with self.assertRaises(ValueError):
+ helper.get_future_for_agent('1', '1', -1, False)
+
+ with self.assertRaises(ValueError):
+ helper.get_past_for_agent('1', '1', -1, False)
+
+ with self.assertRaises(ValueError):
+ helper.get_past_for_sample('1', -1, False)
+
+ with self.assertRaises(ValueError):
+ helper.get_future_for_sample('1', -1, False)
+
+ def test_get_annotations_for_sample(self) -> None:
+
+ mock_samples = [{'token': '1', 'timestamp': -4e6, 'anns': ['1', '1b']}]
+
+ nusc = MockNuScenes(self.multiagent_mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ annotations = helper.get_annotations_for_sample('1')
+
+ answer = [{'token': '1', 'instance_token': '1', 'sample_token': '1',
+ 'translation': [0, 0, 0], 'rotation': [1, 0, 0, 0],
+ 'prev': '', 'next': '2'},
+ {'token': '1b', 'instance_token': '2', 'sample_token': '1',
+ 'translation': [6, 6, 6], 'rotation': [1, 0, 0, 0],
+ 'prev': '', 'next': '2b'}]
+
+ self.assertListEqual(annotations, answer)
\ No newline at end of file
diff --git a/python-sdk/nuscenes/scripts/README.md b/python-sdk/nuscenes/scripts/README.md
new file mode 100644
index 0000000..9f7bd00
--- /dev/null
+++ b/python-sdk/nuscenes/scripts/README.md
@@ -0,0 +1 @@
+Misc scripts not part of the core code-base.
\ No newline at end of file
diff --git a/python-sdk/nuscenes/scripts/__init__.py b/python-sdk/nuscenes/scripts/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/python-sdk/nuscenes/scripts/export_2d_annotations_as_json.py b/python-sdk/nuscenes/scripts/export_2d_annotations_as_json.py
new file mode 100644
index 0000000..b69d0d5
--- /dev/null
+++ b/python-sdk/nuscenes/scripts/export_2d_annotations_as_json.py
@@ -0,0 +1,207 @@
+# nuScenes dev-kit.
+# Code written by Sergi Adipraja Widjaja, 2019.
+
+"""
+Export 2D annotations (xmin, ymin, xmax, ymax) from re-projections of our annotated 3D bounding boxes to a .json file.
+
+Note: Projecting tight 3d boxes to 2d generally leads to non-tight boxes.
+ Furthermore it is non-trivial to determine whether a box falls into the image, rather than behind or around it.
+ Finally some of the objects may be occluded by other objects, in particular when the lidar can see them, but the
+ cameras cannot.
+"""
+
+import argparse
+import json
+import os
+from collections import OrderedDict
+from typing import List, Tuple, Union
+
+import numpy as np
+from pyquaternion.quaternion import Quaternion
+from shapely.geometry import MultiPoint, box
+from tqdm import tqdm
+
+from nuscenes.nuscenes import NuScenes
+from nuscenes.utils.geometry_utils import view_points
+
+
+def post_process_coords(corner_coords: List,
+ imsize: Tuple[int, int] = (1600, 900)) -> Union[Tuple[float, float, float, float], None]:
+ """
+ Get the intersection of the convex hull of the reprojected bbox corners and the image canvas, return None if no
+ intersection.
+ :param corner_coords: Corner coordinates of reprojected bounding box.
+ :param imsize: Size of the image canvas.
+ :return: Intersection of the convex hull of the 2D box corners and the image canvas.
+ """
+ polygon_from_2d_box = MultiPoint(corner_coords).convex_hull
+ img_canvas = box(0, 0, imsize[0], imsize[1])
+
+ if polygon_from_2d_box.intersects(img_canvas):
+ img_intersection = polygon_from_2d_box.intersection(img_canvas)
+ intersection_coords = np.array([coord for coord in img_intersection.exterior.coords])
+
+ min_x = min(intersection_coords[:, 0])
+ min_y = min(intersection_coords[:, 1])
+ max_x = max(intersection_coords[:, 0])
+ max_y = max(intersection_coords[:, 1])
+
+ return min_x, min_y, max_x, max_y
+ else:
+ return None
+
+
+def generate_record(ann_rec: dict,
+ x1: float,
+ y1: float,
+ x2: float,
+ y2: float,
+ sample_data_token: str,
+ filename: str) -> OrderedDict:
+ """
+ Generate one 2D annotation record given various informations on top of the 2D bounding box coordinates.
+ :param ann_rec: Original 3d annotation record.
+ :param x1: Minimum value of the x coordinate.
+ :param y1: Minimum value of the y coordinate.
+ :param x2: Maximum value of the x coordinate.
+ :param y2: Maximum value of the y coordinate.
+ :param sample_data_token: Sample data token.
+ :param filename:The corresponding image file where the annotation is present.
+ :return: A sample 2D annotation record.
+ """
+ repro_rec = OrderedDict()
+ repro_rec['sample_data_token'] = sample_data_token
+
+ relevant_keys = [
+ 'attribute_tokens',
+ 'category_name',
+ 'instance_token',
+ 'next',
+ 'num_lidar_pts',
+ 'num_radar_pts',
+ 'prev',
+ 'sample_annotation_token',
+ 'sample_data_token',
+ 'visibility_token',
+ ]
+
+ for key, value in ann_rec.items():
+ if key in relevant_keys:
+ repro_rec[key] = value
+
+ repro_rec['bbox_corners'] = [x1, y1, x2, y2]
+ repro_rec['filename'] = filename
+
+ return repro_rec
+
+
+def get_2d_boxes(sample_data_token: str, visibilities: List[str]) -> List[OrderedDict]:
+ """
+ Get the 2D annotation records for a given `sample_data_token`.
+ :param sample_data_token: Sample data token belonging to a camera keyframe.
+ :param visibilities: Visibility filter.
+ :return: List of 2D annotation record that belongs to the input `sample_data_token`
+ """
+
+ # Get the sample data and the sample corresponding to that sample data.
+ sd_rec = nusc.get('sample_data', sample_data_token)
+
+ assert sd_rec['sensor_modality'] == 'camera', 'Error: get_2d_boxes only works for camera sample_data!'
+ if not sd_rec['is_key_frame']:
+ raise ValueError('The 2D re-projections are available only for keyframes.')
+
+ s_rec = nusc.get('sample', sd_rec['sample_token'])
+
+ # Get the calibrated sensor and ego pose record to get the transformation matrices.
+ cs_rec = nusc.get('calibrated_sensor', sd_rec['calibrated_sensor_token'])
+ pose_rec = nusc.get('ego_pose', sd_rec['ego_pose_token'])
+ camera_intrinsic = np.array(cs_rec['camera_intrinsic'])
+
+ # Get all the annotation with the specified visibilties.
+ ann_recs = [nusc.get('sample_annotation', token) for token in s_rec['anns']]
+ ann_recs = [ann_rec for ann_rec in ann_recs if (ann_rec['visibility_token'] in visibilities)]
+
+ repro_recs = []
+
+ for ann_rec in ann_recs:
+ # Augment sample_annotation with token information.
+ ann_rec['sample_annotation_token'] = ann_rec['token']
+ ann_rec['sample_data_token'] = sample_data_token
+
+ # Get the box in global coordinates.
+ box = nusc.get_box(ann_rec['token'])
+
+ # Move them to the ego-pose frame.
+ box.translate(-np.array(pose_rec['translation']))
+ box.rotate(Quaternion(pose_rec['rotation']).inverse)
+
+ # Move them to the calibrated sensor frame.
+ box.translate(-np.array(cs_rec['translation']))
+ box.rotate(Quaternion(cs_rec['rotation']).inverse)
+
+ # Filter out the corners that are not in front of the calibrated sensor.
+ corners_3d = box.corners()
+ in_front = np.argwhere(corners_3d[2, :] > 0).flatten()
+ corners_3d = corners_3d[:, in_front]
+
+ # Project 3d box to 2d.
+ corner_coords = view_points(corners_3d, camera_intrinsic, True).T[:, :2].tolist()
+
+ # Keep only corners that fall within the image.
+ final_coords = post_process_coords(corner_coords)
+
+ # Skip if the convex hull of the re-projected corners does not intersect the image canvas.
+ if final_coords is None:
+ continue
+ else:
+ min_x, min_y, max_x, max_y = final_coords
+
+ # Generate dictionary record to be included in the .json file.
+ repro_rec = generate_record(ann_rec, min_x, min_y, max_x, max_y, sample_data_token, sd_rec['filename'])
+ repro_recs.append(repro_rec)
+
+ return repro_recs
+
+
+def main(args):
+ """Generates 2D re-projections of the 3D bounding boxes present in the dataset."""
+
+ print("Generating 2D reprojections of the nuScenes dataset")
+
+ # Get tokens for all camera images.
+ sample_data_camera_tokens = [s['token'] for s in nusc.sample_data if (s['sensor_modality'] == 'camera') and
+ s['is_key_frame']]
+
+ # For debugging purposes: Only produce the first n images.
+ if args.image_limit != -1:
+ sample_data_camera_tokens = sample_data_camera_tokens[:args.image_limit]
+
+ # Loop through the records and apply the re-projection algorithm.
+ reprojections = []
+ for token in tqdm(sample_data_camera_tokens):
+ reprojection_records = get_2d_boxes(token, args.visibilities)
+ reprojections.extend(reprojection_records)
+
+ # Save to a .json file.
+ dest_path = os.path.join(args.dataroot, args.version)
+ if not os.path.exists(dest_path):
+ os.makedirs(dest_path)
+ with open(os.path.join(args.dataroot, args.version, args.filename), 'w') as fh:
+ json.dump(reprojections, fh, sort_keys=True, indent=4)
+
+ print("Saved the 2D re-projections under {}".format(os.path.join(args.dataroot, args.version, args.filename)))
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser(description='Export 2D annotations from reprojections to a .json file.',
+ formatter_class=argparse.ArgumentDefaultsHelpFormatter)
+ parser.add_argument('--dataroot', type=str, default='/data/sets/nuscenes', help="Path where nuScenes is saved.")
+ parser.add_argument('--version', type=str, default='v1.0-trainval', help='Dataset version.')
+ parser.add_argument('--filename', type=str, default='image_annotations.json', help='Output filename.')
+ parser.add_argument('--visibilities', type=str, default=['', '1', '2', '3', '4'],
+ help='Visibility bins, the higher the number the higher the visibility.', nargs='+')
+ parser.add_argument('--image_limit', type=int, default=-1, help='Number of images to process or -1 to process all.')
+ args = parser.parse_args()
+
+ nusc = NuScenes(dataroot=args.dataroot, version=args.version)
+ main(args)
diff --git a/python-sdk/nuscenes/scripts/export_egoposes_on_map.py b/python-sdk/nuscenes/scripts/export_egoposes_on_map.py
new file mode 100644
index 0000000..756e17c
--- /dev/null
+++ b/python-sdk/nuscenes/scripts/export_egoposes_on_map.py
@@ -0,0 +1,57 @@
+# nuScenes dev-kit.
+# Code written by Holger Caesar, 2018.
+
+"""
+Exports an image for each map location with all the ego poses drawn on the map.
+"""
+
+import argparse
+import os
+
+import matplotlib.pyplot as plt
+import numpy as np
+
+from nuscenes import NuScenes
+
+
+def export_ego_poses(nusc: NuScenes, out_dir: str):
+ """ Script to render where ego vehicle drives on the maps """
+
+ # Load NuScenes locations
+ locations = np.unique([log['location'] for log in nusc.log])
+
+ # Create output directory
+ if not os.path.isdir(out_dir):
+ os.makedirs(out_dir)
+
+ for location in locations:
+ print('Rendering map {}...'.format(location))
+ nusc.render_egoposes_on_map(location)
+ out_path = os.path.join(out_dir, 'egoposes-{}.png'.format(location))
+ plt.tight_layout()
+ plt.savefig(out_path)
+
+
+if __name__ == '__main__':
+
+ # Settings.
+ parser = argparse.ArgumentParser(description='Export all ego poses to an image.',
+ formatter_class=argparse.ArgumentDefaultsHelpFormatter)
+ parser.add_argument('--out_dir', type=str, help='Directory where to save maps with ego poses.')
+ parser.add_argument('--dataroot', type=str, default='/data/sets/nuscenes',
+ help='Default nuScenes data directory.')
+ parser.add_argument('--version', type=str, default='v1.0-trainval',
+ help='Which version of the nuScenes dataset to evaluate on, e.g. v1.0-trainval.')
+ parser.add_argument('--verbose', type=int, default=1,
+ help='Whether to print to stdout.')
+
+ args = parser.parse_args()
+ dataroot = args.dataroot
+ version = args.version
+ verbose = bool(args.verbose)
+
+ # Init.
+ nusc_ = NuScenes(version=version, verbose=verbose, dataroot=dataroot)
+
+ # Export ego poses
+ export_ego_poses(nusc_, args.out_dir)
diff --git a/python-sdk/nuscenes/scripts/export_kitti.py b/python-sdk/nuscenes/scripts/export_kitti.py
new file mode 100644
index 0000000..36b08b1
--- /dev/null
+++ b/python-sdk/nuscenes/scripts/export_kitti.py
@@ -0,0 +1,362 @@
+# nuScenes dev-kit.
+# Code written by Holger Caesar, 2019.
+
+"""
+This script converts nuScenes data to KITTI format and KITTI results to nuScenes.
+It is used for compatibility with software that uses KITTI-style annotations.
+
+We do not encourage this, as:
+- KITTI has only front-facing cameras, whereas nuScenes has a 360 degree horizontal fov.
+- KITTI has no radar data.
+- The nuScenes database format is more modular.
+- KITTI fields like occluded and truncated cannot be exactly reproduced from nuScenes data.
+- KITTI has different categories.
+
+Limitations:
+- We don't specify the KITTI imu_to_velo_kitti projection in this code base.
+- We map nuScenes categories to nuScenes detection categories, rather than KITTI categories.
+- Attributes are not part of KITTI and therefore set to '' in the nuScenes result format.
+- Velocities are not part of KITTI and therefore set to 0 in the nuScenes result format.
+- This script uses the `train` and `val` splits of nuScenes, whereas standard KITTI has `training` and `testing` splits.
+
+This script includes three main functions:
+- nuscenes_gt_to_kitti(): Converts nuScenes GT annotations to KITTI format.
+- render_kitti(): Render the annotations of the (generated or real) KITTI dataset.
+- kitti_res_to_nuscenes(): Converts a KITTI detection result to the nuScenes detection results format.
+
+To launch these scripts run:
+- python export_kitti.py nuscenes_gt_to_kitti --nusc_kitti_dir ~/nusc_kitti
+- python export_kitti.py render_kitti --nusc_kitti_dir ~/nusc_kitti --render_2d False
+- python export_kitti.py kitti_res_to_nuscenes --nusc_kitti_dir ~/nusc_kitti
+Note: The parameter --render_2d specifies whether to draw 2d or 3d boxes.
+
+To work with the original KITTI dataset, use these parameters:
+ --nusc_kitti_dir /data/sets/kitti --split training
+
+See https://www.nuscenes.org/object-detection for more information on the nuScenes result format.
+"""
+import json
+import os
+from typing import List, Dict, Any
+
+import fire
+import matplotlib.pyplot as plt
+import numpy as np
+from PIL import Image
+from pyquaternion import Quaternion
+
+from nuscenes.eval.detection.utils import category_to_detection_name
+from nuscenes.nuscenes import NuScenes
+from nuscenes.utils.data_classes import LidarPointCloud, Box
+from nuscenes.utils.geometry_utils import BoxVisibility, transform_matrix
+from nuscenes.utils.kitti import KittiDB
+from nuscenes.utils.splits import create_splits_logs
+
+
+class KittiConverter:
+ def __init__(self,
+ nusc_kitti_dir: str = '~/nusc_kitti',
+ cam_name: str = 'CAM_FRONT',
+ lidar_name: str = 'LIDAR_TOP',
+ image_count: int = 10,
+ nusc_version: str = 'v1.0-mini',
+ split: str = 'mini_train'):
+ """
+ :param nusc_kitti_dir: Where to write the KITTI-style annotations.
+ :param cam_name: Name of the camera to export. Note that only one camera is allowed in KITTI.
+ :param lidar_name: Name of the lidar sensor.
+ :param image_count: Number of images to convert.
+ :param nusc_version: nuScenes version to use.
+ :param split: Dataset split to use.
+ """
+ self.nusc_kitti_dir = os.path.expanduser(nusc_kitti_dir)
+ self.cam_name = cam_name
+ self.lidar_name = lidar_name
+ self.image_count = image_count
+ self.nusc_version = nusc_version
+ self.split = split
+
+ # Create nusc_kitti_dir.
+ if not os.path.isdir(self.nusc_kitti_dir):
+ os.makedirs(self.nusc_kitti_dir)
+
+ # Select subset of the data to look at.
+ self.nusc = NuScenes(version=nusc_version)
+
+ def nuscenes_gt_to_kitti(self) -> None:
+ """
+ Converts nuScenes GT annotations to KITTI format.
+ """
+ kitti_to_nu_lidar = Quaternion(axis=(0, 0, 1), angle=np.pi / 2)
+ kitti_to_nu_lidar_inv = kitti_to_nu_lidar.inverse
+ imsize = (1600, 900)
+
+ token_idx = 0 # Start tokens from 0.
+
+ # Get assignment of scenes to splits.
+ split_logs = create_splits_logs(self.split, self.nusc)
+
+ # Create output folders.
+ label_folder = os.path.join(self.nusc_kitti_dir, self.split, 'label_2')
+ calib_folder = os.path.join(self.nusc_kitti_dir, self.split, 'calib')
+ image_folder = os.path.join(self.nusc_kitti_dir, self.split, 'image_2')
+ lidar_folder = os.path.join(self.nusc_kitti_dir, self.split, 'velodyne')
+ for folder in [label_folder, calib_folder, image_folder, lidar_folder]:
+ if not os.path.isdir(folder):
+ os.makedirs(folder)
+
+ # Use only the samples from the current split.
+ sample_tokens = self._split_to_samples(split_logs)
+ sample_tokens = sample_tokens[:self.image_count]
+
+ tokens = []
+ for sample_token in sample_tokens:
+
+ # Get sample data.
+ sample = self.nusc.get('sample', sample_token)
+ sample_annotation_tokens = sample['anns']
+ cam_front_token = sample['data'][self.cam_name]
+ lidar_token = sample['data'][self.lidar_name]
+
+ # Retrieve sensor records.
+ sd_record_cam = self.nusc.get('sample_data', cam_front_token)
+ sd_record_lid = self.nusc.get('sample_data', lidar_token)
+ cs_record_cam = self.nusc.get('calibrated_sensor', sd_record_cam['calibrated_sensor_token'])
+ cs_record_lid = self.nusc.get('calibrated_sensor', sd_record_lid['calibrated_sensor_token'])
+
+ # Combine transformations and convert to KITTI format.
+ # Note: cam uses same conventions in KITTI and nuScenes.
+ lid_to_ego = transform_matrix(cs_record_lid['translation'], Quaternion(cs_record_lid['rotation']),
+ inverse=False)
+ ego_to_cam = transform_matrix(cs_record_cam['translation'], Quaternion(cs_record_cam['rotation']),
+ inverse=True)
+ velo_to_cam = np.dot(ego_to_cam, lid_to_ego)
+
+ # Convert from KITTI to nuScenes LIDAR coordinates, where we apply velo_to_cam.
+ velo_to_cam_kitti = np.dot(velo_to_cam, kitti_to_nu_lidar.transformation_matrix)
+
+ # Currently not used.
+ imu_to_velo_kitti = np.zeros((3, 4)) # Dummy values.
+ r0_rect = Quaternion(axis=[1, 0, 0], angle=0) # Dummy values.
+
+ # Projection matrix.
+ p_left_kitti = np.zeros((3, 4))
+ p_left_kitti[:3, :3] = cs_record_cam['camera_intrinsic'] # Cameras are always rectified.
+
+ # Create KITTI style transforms.
+ velo_to_cam_rot = velo_to_cam_kitti[:3, :3]
+ velo_to_cam_trans = velo_to_cam_kitti[:3, 3]
+
+ # Check that the rotation has the same format as in KITTI.
+ assert (velo_to_cam_rot.round(0) == np.array([[0, -1, 0], [0, 0, -1], [1, 0, 0]])).all()
+ assert (velo_to_cam_trans[1:3] < 0).all()
+
+ # Retrieve the token from the lidar.
+ # Note that this may be confusing as the filename of the camera will include the timestamp of the lidar,
+ # not the camera.
+ filename_cam_full = sd_record_cam['filename']
+ filename_lid_full = sd_record_lid['filename']
+ # token = '%06d' % token_idx # Alternative to use KITTI names.
+ token_idx += 1
+
+ # Convert image (jpg to png).
+ src_im_path = os.path.join(self.nusc.dataroot, filename_cam_full)
+ dst_im_path = os.path.join(image_folder, sample_token + '.png')
+ if not os.path.exists(dst_im_path):
+ im = Image.open(src_im_path)
+ im.save(dst_im_path, "PNG")
+
+ # Convert lidar.
+ # Note that we are only using a single sweep, instead of the commonly used n sweeps.
+ src_lid_path = os.path.join(self.nusc.dataroot, filename_lid_full)
+ dst_lid_path = os.path.join(lidar_folder, sample_token + '.bin')
+ assert not dst_lid_path.endswith('.pcd.bin')
+ pcl = LidarPointCloud.from_file(src_lid_path)
+ pcl.rotate(kitti_to_nu_lidar_inv.rotation_matrix) # In KITTI lidar frame.
+ with open(dst_lid_path, "w") as lid_file:
+ pcl.points.T.tofile(lid_file)
+
+ # Add to tokens.
+ tokens.append(sample_token)
+
+ # Create calibration file.
+ kitti_transforms = dict()
+ kitti_transforms['P0'] = np.zeros((3, 4)) # Dummy values.
+ kitti_transforms['P1'] = np.zeros((3, 4)) # Dummy values.
+ kitti_transforms['P2'] = p_left_kitti # Left camera transform.
+ kitti_transforms['P3'] = np.zeros((3, 4)) # Dummy values.
+ kitti_transforms['R0_rect'] = r0_rect.rotation_matrix # Cameras are already rectified.
+ kitti_transforms['Tr_velo_to_cam'] = np.hstack((velo_to_cam_rot, velo_to_cam_trans.reshape(3, 1)))
+ kitti_transforms['Tr_imu_to_velo'] = imu_to_velo_kitti
+ calib_path = os.path.join(calib_folder, sample_token + '.txt')
+ with open(calib_path, "w") as calib_file:
+ for (key, val) in kitti_transforms.items():
+ val = val.flatten()
+ val_str = '%.12e' % val[0]
+ for v in val[1:]:
+ val_str += ' %.12e' % v
+ calib_file.write('%s: %s\n' % (key, val_str))
+
+ # Write label file.
+ label_path = os.path.join(label_folder, sample_token + '.txt')
+ if os.path.exists(label_path):
+ print('Skipping existing file: %s' % label_path)
+ continue
+ else:
+ print('Writing file: %s' % label_path)
+ with open(label_path, "w") as label_file:
+ for sample_annotation_token in sample_annotation_tokens:
+ sample_annotation = self.nusc.get('sample_annotation', sample_annotation_token)
+
+ # Get box in LIDAR frame.
+ _, box_lidar_nusc, _ = self.nusc.get_sample_data(lidar_token, box_vis_level=BoxVisibility.NONE,
+ selected_anntokens=[sample_annotation_token])
+ box_lidar_nusc = box_lidar_nusc[0]
+
+ # Truncated: Set all objects to 0 which means untruncated.
+ truncated = 0.0
+
+ # Occluded: Set all objects to full visibility as this information is not available in nuScenes.
+ occluded = 0
+
+ # Convert nuScenes category to nuScenes detection challenge category.
+ detection_name = category_to_detection_name(sample_annotation['category_name'])
+
+ # Skip categories that are not part of the nuScenes detection challenge.
+ if detection_name is None:
+ continue
+
+ # Convert from nuScenes to KITTI box format.
+ box_cam_kitti = KittiDB.box_nuscenes_to_kitti(
+ box_lidar_nusc, Quaternion(matrix=velo_to_cam_rot), velo_to_cam_trans, r0_rect)
+
+ # Project 3d box to 2d box in image, ignore box if it does not fall inside.
+ bbox_2d = KittiDB.project_kitti_box_to_image(box_cam_kitti, p_left_kitti, imsize=imsize)
+ if bbox_2d is None:
+ continue
+
+ # Set dummy score so we can use this file as result.
+ box_cam_kitti.score = 0
+
+ # Convert box to output string format.
+ output = KittiDB.box_to_string(name=detection_name, box=box_cam_kitti, bbox_2d=bbox_2d,
+ truncation=truncated, occlusion=occluded)
+
+ # Write to disk.
+ label_file.write(output + '\n')
+
+ def render_kitti(self, render_2d: bool) -> None:
+ """
+ Renders the annotations in the KITTI dataset from a lidar and a camera view.
+ :param render_2d: Whether to render 2d boxes (only works for camera data).
+ """
+ if render_2d:
+ print('Rendering 2d boxes from KITTI format')
+ else:
+ print('Rendering 3d boxes projected from 3d KITTI format')
+
+ # Load the KITTI dataset.
+ kitti = KittiDB(root=self.nusc_kitti_dir, splits=(self.split,))
+
+ # Create output folder.
+ render_dir = os.path.join(self.nusc_kitti_dir, 'render')
+ if not os.path.isdir(render_dir):
+ os.mkdir(render_dir)
+
+ # Render each image.
+ for token in kitti.tokens[:self.image_count]:
+ for sensor in ['lidar', 'camera']:
+ out_path = os.path.join(render_dir, '%s_%s.png' % (token, sensor))
+ print('Rendering file to disk: %s' % out_path)
+ kitti.render_sample_data(token, sensor_modality=sensor, out_path=out_path, render_2d=render_2d)
+ plt.close() # Close the windows to avoid a warning of too many open windows.
+
+ def kitti_res_to_nuscenes(self, meta: Dict[str, bool] = None) -> None:
+ """
+ Converts a KITTI detection result to the nuScenes detection results format.
+ :param meta: Meta data describing the method used to generate the result. See nuscenes.org/object-detection.
+ """
+ # Dummy meta data, please adjust accordingly.
+ if meta is None:
+ meta = {
+ 'use_camera': False,
+ 'use_lidar': True,
+ 'use_radar': False,
+ 'use_map': False,
+ 'use_external': False,
+ }
+
+ # Init.
+ results = {}
+
+ # Load the KITTI dataset.
+ kitti = KittiDB(root=self.nusc_kitti_dir, splits=(self.split, ))
+
+ # Get assignment of scenes to splits.
+ split_logs = create_splits_logs(self.split, self.nusc)
+
+ # Use only the samples from the current split.
+ sample_tokens = self._split_to_samples(split_logs)
+ sample_tokens = sample_tokens[:self.image_count]
+
+ for sample_token in sample_tokens:
+ # Get the KITTI boxes we just generated in LIDAR frame.
+ kitti_token = '%s_%s' % (self.split, sample_token)
+ boxes = kitti.get_boxes(token=kitti_token)
+
+ # Convert KITTI boxes to nuScenes detection challenge result format.
+ sample_results = [self._box_to_sample_result(sample_token, box) for box in boxes]
+
+ # Store all results for this image.
+ results[sample_token] = sample_results
+
+ # Store submission file to disk.
+ submission = {
+ 'meta': meta,
+ 'results': results
+ }
+ submission_path = os.path.join(self.nusc_kitti_dir, 'submission.json')
+ print('Writing submission to: %s' % submission_path)
+ with open(submission_path, 'w') as f:
+ json.dump(submission, f, indent=2)
+
+ def _box_to_sample_result(self, sample_token: str, box: Box, attribute_name: str = '') -> Dict[str, Any]:
+ # Prepare data
+ translation = box.center
+ size = box.wlh
+ rotation = box.orientation.q
+ velocity = box.velocity
+ detection_name = box.name
+ detection_score = box.score
+
+ # Create result dict
+ sample_result = dict()
+ sample_result['sample_token'] = sample_token
+ sample_result['translation'] = translation.tolist()
+ sample_result['size'] = size.tolist()
+ sample_result['rotation'] = rotation.tolist()
+ sample_result['velocity'] = velocity.tolist()[:2] # Only need vx, vy.
+ sample_result['detection_name'] = detection_name
+ sample_result['detection_score'] = detection_score
+ sample_result['attribute_name'] = attribute_name
+
+ return sample_result
+
+ def _split_to_samples(self, split_logs: List[str]) -> List[str]:
+ """
+ Convenience function to get the samples in a particular split.
+ :param split_logs: A list of the log names in this split.
+ :return: The list of samples.
+ """
+ samples = []
+ for sample in self.nusc.sample:
+ scene = self.nusc.get('scene', sample['scene_token'])
+ log = self.nusc.get('log', scene['log_token'])
+ logfile = log['logfile']
+ if logfile in split_logs:
+ samples.append(sample['token'])
+ return samples
+
+
+if __name__ == '__main__':
+ fire.Fire(KittiConverter)
diff --git a/python-sdk/nuscenes/scripts/export_pointclouds_as_obj.py b/python-sdk/nuscenes/scripts/export_pointclouds_as_obj.py
new file mode 100644
index 0000000..ef85697
--- /dev/null
+++ b/python-sdk/nuscenes/scripts/export_pointclouds_as_obj.py
@@ -0,0 +1,208 @@
+# nuScenes dev-kit.
+# Code written by Holger Caesar, 2018.
+
+"""
+Export fused pointclouds of a scene to a Wavefront OBJ file.
+This pointcloud can be viewed in your favorite 3D rendering tool, e.g. Meshlab or Maya.
+"""
+
+import argparse
+import os
+import os.path as osp
+from typing import Tuple
+
+import numpy as np
+from PIL import Image
+from pyquaternion import Quaternion
+from tqdm import tqdm
+
+from nuscenes import NuScenes
+from nuscenes.utils.data_classes import LidarPointCloud
+from nuscenes.utils.geometry_utils import view_points
+
+
+def export_scene_pointcloud(nusc: NuScenes,
+ out_path: str,
+ scene_token: str,
+ channel: str = 'LIDAR_TOP',
+ min_dist: float = 3.0,
+ max_dist: float = 30.0,
+ verbose: bool = True) -> None:
+ """
+ Export fused point clouds of a scene to a Wavefront OBJ file.
+ This pointcloud can be viewed in your favorite 3D rendering tool, e.g. Meshlab or Maya.
+ :param nusc: NuScenes instance.
+ :param out_path: Output path to write the pointcloud to.
+ :param scene_token: Unique identifier of scene to render.
+ :param channel: Channel to render.
+ :param min_dist: Minimum distance to ego vehicle below which points are dropped.
+ :param max_dist: Maximum distance to ego vehicle above which points are dropped.
+ :param verbose: Whether to print messages to stdout.
+ """
+
+ # Check inputs.
+ valid_channels = ['LIDAR_TOP', 'RADAR_FRONT', 'RADAR_FRONT_RIGHT', 'RADAR_FRONT_LEFT', 'RADAR_BACK_LEFT',
+ 'RADAR_BACK_RIGHT']
+ camera_channels = ['CAM_FRONT_LEFT', 'CAM_FRONT', 'CAM_FRONT_RIGHT', 'CAM_BACK_LEFT', 'CAM_BACK', 'CAM_BACK_RIGHT']
+ assert channel in valid_channels, 'Input channel {} not valid.'.format(channel)
+
+ # Get records from DB.
+ scene_rec = nusc.get('scene', scene_token)
+ start_sample_rec = nusc.get('sample', scene_rec['first_sample_token'])
+ sd_rec = nusc.get('sample_data', start_sample_rec['data'][channel])
+
+ # Make list of frames
+ cur_sd_rec = sd_rec
+ sd_tokens = []
+ while cur_sd_rec['next'] != '':
+ cur_sd_rec = nusc.get('sample_data', cur_sd_rec['next'])
+ sd_tokens.append(cur_sd_rec['token'])
+
+ # Write pointcloud.
+ with open(out_path, 'w') as f:
+ f.write("OBJ File:\n")
+
+ for sd_token in tqdm(sd_tokens):
+ if verbose:
+ print('Processing {}'.format(sd_rec['filename']))
+ sc_rec = nusc.get('sample_data', sd_token)
+ sample_rec = nusc.get('sample', sc_rec['sample_token'])
+ lidar_token = sd_rec['token']
+ lidar_rec = nusc.get('sample_data', lidar_token)
+ pc = LidarPointCloud.from_file(osp.join(nusc.dataroot, lidar_rec['filename']))
+
+ # Get point cloud colors.
+ coloring = np.ones((3, pc.points.shape[1])) * -1
+ for channel in camera_channels:
+ camera_token = sample_rec['data'][channel]
+ cam_coloring, cam_mask = pointcloud_color_from_image(nusc, lidar_token, camera_token)
+ coloring[:, cam_mask] = cam_coloring
+
+ # Points live in their own reference frame. So they need to be transformed via global to the image plane.
+ # First step: transform the point cloud to the ego vehicle frame for the timestamp of the sweep.
+ cs_record = nusc.get('calibrated_sensor', lidar_rec['calibrated_sensor_token'])
+ pc.rotate(Quaternion(cs_record['rotation']).rotation_matrix)
+ pc.translate(np.array(cs_record['translation']))
+
+ # Optional Filter by distance to remove the ego vehicle.
+ dists_origin = np.sqrt(np.sum(pc.points[:3, :] ** 2, axis=0))
+ keep = np.logical_and(min_dist <= dists_origin, dists_origin <= max_dist)
+ pc.points = pc.points[:, keep]
+ coloring = coloring[:, keep]
+ if verbose:
+ print('Distance filter: Keeping %d of %d points...' % (keep.sum(), len(keep)))
+
+ # Second step: transform to the global frame.
+ poserecord = nusc.get('ego_pose', lidar_rec['ego_pose_token'])
+ pc.rotate(Quaternion(poserecord['rotation']).rotation_matrix)
+ pc.translate(np.array(poserecord['translation']))
+
+ # Write points to file
+ for (v, c) in zip(pc.points.transpose(), coloring.transpose()):
+ if (c == -1).any():
+ # Ignore points without a color.
+ pass
+ else:
+ f.write("v {v[0]:.8f} {v[1]:.8f} {v[2]:.8f} {c[0]:.4f} {c[1]:.4f} {c[2]:.4f}\n"
+ .format(v=v, c=c/255.0))
+
+ if not sd_rec['next'] == "":
+ sd_rec = nusc.get('sample_data', sd_rec['next'])
+
+
+def pointcloud_color_from_image(nusc: NuScenes,
+ pointsensor_token: str,
+ camera_token: str) -> Tuple[np.array, np.array]:
+ """
+ Given a point sensor (lidar/radar) token and camera sample_data token, load pointcloud and map it to the image
+ plane, then retrieve the colors of the closest image pixels.
+ :param nusc: NuScenes instance.
+ :param pointsensor_token: Lidar/radar sample_data token.
+ :param camera_token: Camera sample data token.
+ :return (coloring <np.float: 3, n>, mask <np.bool: m>). Returns the colors for n points that reproject into the
+ image out of m total points. The mask indicates which points are selected.
+ """
+
+ cam = nusc.get('sample_data', camera_token)
+ pointsensor = nusc.get('sample_data', pointsensor_token)
+
+ pc = LidarPointCloud.from_file(osp.join(nusc.dataroot, pointsensor['filename']))
+ im = Image.open(osp.join(nusc.dataroot, cam['filename']))
+
+ # Points live in the point sensor frame. So they need to be transformed via global to the image plane.
+ # First step: transform the pointcloud to the ego vehicle frame for the timestamp of the sweep.
+ cs_record = nusc.get('calibrated_sensor', pointsensor['calibrated_sensor_token'])
+ pc.rotate(Quaternion(cs_record['rotation']).rotation_matrix)
+ pc.translate(np.array(cs_record['translation']))
+
+ # Second step: transform to the global frame.
+ poserecord = nusc.get('ego_pose', pointsensor['ego_pose_token'])
+ pc.rotate(Quaternion(poserecord['rotation']).rotation_matrix)
+ pc.translate(np.array(poserecord['translation']))
+
+ # Third step: transform into the ego vehicle frame for the timestamp of the image.
+ poserecord = nusc.get('ego_pose', cam['ego_pose_token'])
+ pc.translate(-np.array(poserecord['translation']))
+ pc.rotate(Quaternion(poserecord['rotation']).rotation_matrix.T)
+
+ # Fourth step: transform into the camera.
+ cs_record = nusc.get('calibrated_sensor', cam['calibrated_sensor_token'])
+ pc.translate(-np.array(cs_record['translation']))
+ pc.rotate(Quaternion(cs_record['rotation']).rotation_matrix.T)
+
+ # Fifth step: actually take a "picture" of the point cloud.
+ # Grab the depths (camera frame z axis points away from the camera).
+ depths = pc.points[2, :]
+
+ # Take the actual picture (matrix multiplication with camera-matrix + renormalization).
+ points = view_points(pc.points[:3, :], np.array(cs_record['camera_intrinsic']), normalize=True)
+
+ # Remove points that are either outside or behind the camera. Leave a margin of 1 pixel for aesthetic reasons.
+ mask = np.ones(depths.shape[0], dtype=bool)
+ mask = np.logical_and(mask, depths > 0)
+ mask = np.logical_and(mask, points[0, :] > 1)
+ mask = np.logical_and(mask, points[0, :] < im.size[0] - 1)
+ mask = np.logical_and(mask, points[1, :] > 1)
+ mask = np.logical_and(mask, points[1, :] < im.size[1] - 1)
+ points = points[:, mask]
+
+ # Pick the colors of the points
+ im_data = np.array(im)
+ coloring = np.zeros(points.shape)
+ for i, p in enumerate(points.transpose()):
+ point = p[:2].round().astype(np.int32)
+ coloring[:, i] = im_data[point[1], point[0], :]
+
+ return coloring, mask
+
+
+if __name__ == '__main__':
+ # Read input parameters
+ parser = argparse.ArgumentParser(description='Export a scene in Wavefront point cloud format.',
+ formatter_class=argparse.ArgumentDefaultsHelpFormatter)
+ parser.add_argument('--scene', default='scene-0061', type=str, help='Name of a scene, e.g. scene-0061')
+ parser.add_argument('--out_dir', default='~/nuscenes-visualization/pointclouds', type=str, help='Output folder')
+ parser.add_argument('--verbose', default=0, type=int, help='Whether to print outputs to stdout')
+
+ args = parser.parse_args()
+ out_dir = os.path.expanduser(args.out_dir)
+ scene_name = args.scene
+ verbose = bool(args.verbose)
+
+ out_path = osp.join(out_dir, '%s.obj' % scene_name)
+ if osp.exists(out_path):
+ print('=> File {} already exists. Aborting.'.format(out_path))
+ exit()
+ else:
+ print('=> Extracting scene {} to {}'.format(scene_name, out_path))
+
+ # Create output folder
+ if not out_dir == '' and not osp.isdir(out_dir):
+ os.makedirs(out_dir)
+
+ # Extract pointcloud for the specified scene
+ nusc = NuScenes()
+ scene_tokens = [s['token'] for s in nusc.scene if s['name'] == scene_name]
+ assert len(scene_tokens) == 1, 'Error: Invalid scene %s' % scene_name
+
+ export_scene_pointcloud(nusc, out_path, scene_tokens[0], channel='LIDAR_TOP', verbose=verbose)
diff --git a/python-sdk/nuscenes/scripts/export_poses.py b/python-sdk/nuscenes/scripts/export_poses.py
new file mode 100644
index 0000000..b517144
--- /dev/null
+++ b/python-sdk/nuscenes/scripts/export_poses.py
@@ -0,0 +1,208 @@
+# nuScenes dev-kit.
+# Code contributed by jean-lucas, 2020.
+
+"""
+Exports the nuScenes ego poses as "GPS" coordinates (lat/lon) for each scene into JSON or KML formatted files.
+"""
+
+
+import argparse
+import json
+import math
+import os
+from typing import List, Tuple, Dict
+
+from tqdm import tqdm
+
+from nuscenes.nuscenes import NuScenes
+
+
+EARTH_RADIUS_METERS = 6.378137e6
+REFERENCE_COORDINATES = {
+ "boston-seaport": [42.336849169438615, -71.05785369873047],
+ "singapore-onenorth": [1.2882100868743724, 103.78475189208984],
+ "singapore-hollandvillage": [1.2993652317780957, 103.78217697143555],
+ "singapore-queenstown": [1.2782562240223188, 103.76741409301758],
+}
+
+
+def get_poses(nusc: NuScenes, scene_token: str) -> List[dict]:
+ """
+ Return all ego poses for the current scene.
+ :param nusc: The NuScenes instance to load the ego poses from.
+ :param scene_token: The token of the scene.
+ :return: A list of the ego pose dicts.
+ """
+ pose_list = []
+ scene_rec = nusc.get('scene', scene_token)
+ sample_rec = nusc.get('sample', scene_rec['first_sample_token'])
+ sd_rec = nusc.get('sample_data', sample_rec['data']['LIDAR_TOP'])
+
+ ego_pose = nusc.get('ego_pose', sd_rec['token'])
+ pose_list.append(ego_pose)
+
+ while sd_rec['next'] != '':
+ sd_rec = nusc.get('sample_data', sd_rec['next'])
+ ego_pose = nusc.get('ego_pose', sd_rec['token'])
+ pose_list.append(ego_pose)
+
+ return pose_list
+
+
+def get_coordinate(ref_lat: float, ref_lon: float, bearing: float, dist: float) -> Tuple[float, float]:
+ """
+ Using a reference coordinate, extract the coordinates of another point in space given its distance and bearing
+ to the reference coordinate. For reference, please see: https://www.movable-type.co.uk/scripts/latlong.html.
+ :param ref_lat: Latitude of the reference coordinate in degrees, ie: 42.3368.
+ :param ref_lon: Longitude of the reference coordinate in degrees, ie: 71.0578.
+ :param bearing: The clockwise angle in radians between target point, reference point and the axis pointing north.
+ :param dist: The distance in meters from the reference point to the target point.
+ :return: A tuple of lat and lon.
+ """
+ lat, lon = math.radians(ref_lat), math.radians(ref_lon)
+ angular_distance = dist / EARTH_RADIUS_METERS
+
+ target_lat = math.asin(
+ math.sin(lat) * math.cos(angular_distance) +
+ math.cos(lat) * math.sin(angular_distance) * math.cos(bearing)
+ )
+ target_lon = lon + math.atan2(
+ math.sin(bearing) * math.sin(angular_distance) * math.cos(lat),
+ math.cos(angular_distance) - math.sin(lat) * math.sin(target_lat)
+ )
+ return math.degrees(target_lat), math.degrees(target_lon)
+
+
+def derive_latlon(location: str, poses: List[Dict[str, float]]) -> List[Dict[str, float]]:
+ """
+ For each pose value, extract its respective lat/lon coordinate and timestamp.
+
+ This makes the following two assumptions in order to work:
+ 1. The reference coordinate for each map is in the south-western corner.
+ 2. The origin of the global poses is also in the south-western corner (and identical to 1).
+
+ :param location: The name of the map the poses correspond to, ie: 'boston-seaport'.
+ :param poses: All nuScenes egopose dictionaries of a scene.
+ :return: A list of dicts (lat/lon coordinates and timestamps) for each pose.
+ """
+ assert location in REFERENCE_COORDINATES.keys(), \
+ f'Error: The given location: {location}, has no available reference.'
+
+ coordinates = []
+ reference_lat, reference_lon = REFERENCE_COORDINATES[location]
+ for p in poses:
+ ts = p['timestamp']
+ x, y = p['translation'][:2]
+ bearing = math.atan(x / y)
+ distance = math.sqrt(x**2 + y**2)
+ lat, lon = get_coordinate(reference_lat, reference_lon, bearing, distance)
+ coordinates.append({'timestamp': ts, 'latitude': lat, 'longitude': lon})
+ return coordinates
+
+
+def export_kml(coordinates_per_location: Dict[str, Dict[str, List[Dict[str, float]]]], output_path: str) -> None:
+ """
+ Export the coordinates of a scene to .kml file.
+ :param coordinates_per_location: A dict of lat/lon coordinate dicts for each scene.
+ :param output_path: Path of the kml file to write to disk.
+ """
+ # Opening lines.
+ result = \
+ f'<?xml version="1.0" encoding="UTF-8"?>\n' \
+ f'<kml xmlns="http://www.opengis.net/kml/2.2">\n' \
+ f' <Document>\n' \
+ f' <name>nuScenes ego poses</name>\n'
+
+ # Export each scene as a separate placemark to be able to view them independently.
+ for location, coordinates_per_scene in coordinates_per_location.items():
+ result += \
+ f' <Folder>\n' \
+ f' <name>{location}</name>\n'
+
+ for scene_name, coordinates in coordinates_per_scene.items():
+ result += \
+ f' <Placemark>\n' \
+ f' <name>{scene_name}</name>\n' \
+ f' <LineString>\n' \
+ f' <tessellate>1</tessellate>\n' \
+ f' <coordinates>\n'
+
+ for coordinate in coordinates:
+ coordinates_str = '%.10f,%.10f,%d' % (coordinate['longitude'], coordinate['latitude'], 0)
+ result += f' {coordinates_str}\n'
+
+ result += \
+ f' </coordinates>\n' \
+ f' </LineString>\n' \
+ f' </Placemark>\n'
+
+ result += \
+ f' </Folder>\n'
+
+ # Closing lines.
+ result += \
+ f' </Document>\n' \
+ f'</kml>'
+
+ # Write to disk.
+ with open(output_path, 'w') as f:
+ f.write(result)
+
+
+def main(dataroot: str, version: str, output_prefix: str, output_format: str = 'kml') -> None:
+ """
+ Extract the latlon coordinates for each available pose and write the results to a file.
+ The file is organized by location and scene_name.
+ :param dataroot: Path of the nuScenes dataset.
+ :param version: NuScenes version.
+ :param output_format: The output file format, kml or json.
+ :param output_prefix: Where to save the output file (without the file extension).
+ """
+ # Init nuScenes.
+ nusc = NuScenes(dataroot=dataroot, version=version, verbose=False)
+
+ coordinates_per_location = {}
+ print(f'Extracting coordinates...')
+ for scene in tqdm(nusc.scene):
+ # Retrieve nuScenes poses.
+ scene_name = scene['name']
+ scene_token = scene['token']
+ location = nusc.get('log', scene['log_token'])['location'] # Needed to extract the reference coordinate.
+ poses = get_poses(nusc, scene_token) # For each pose, we will extract the corresponding coordinate.
+
+ # Compute and store coordinates.
+ coordinates = derive_latlon(location, poses)
+ if location not in coordinates_per_location:
+ coordinates_per_location[location] = {}
+ coordinates_per_location[location][scene_name] = coordinates
+
+ # Create output directory if necessary.
+ dest_dir = os.path.dirname(output_prefix)
+ if dest_dir != '' and not os.path.exists(dest_dir):
+ os.makedirs(dest_dir)
+
+ # Write to json.
+ output_path = f'{output_prefix}_{version}.{output_format}'
+ if output_format == 'json':
+ with open(output_path, 'w') as fh:
+ json.dump(coordinates_per_location, fh, sort_keys=True, indent=4)
+ elif output_format == 'kml':
+ # Write to kml.
+ export_kml(coordinates_per_location, output_path)
+ else:
+ raise Exception('Error: Invalid output format: %s' % output_format)
+
+ print(f"Saved the coordinates in {output_path}")
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser(description='Export ego pose coordinates from a scene to a .json file.',
+ formatter_class=argparse.ArgumentDefaultsHelpFormatter)
+ parser.add_argument('--dataroot', type=str, default='/data/sets/nuscenes', help="Path where nuScenes is saved.")
+ parser.add_argument('--version', type=str, default='v1.0-mini', help='Dataset version.')
+ parser.add_argument('--output_prefix', type=str, default='latlon',
+ help='Output file path without file extension.')
+ parser.add_argument('--output_format', type=str, default='kml', help='Output format (kml or json).')
+ args = parser.parse_args()
+
+ main(args.dataroot, args.version, args.output_prefix, args.output_format)
diff --git a/python-sdk/nuscenes/scripts/export_scene_videos.py b/python-sdk/nuscenes/scripts/export_scene_videos.py
new file mode 100644
index 0000000..f65cf22
--- /dev/null
+++ b/python-sdk/nuscenes/scripts/export_scene_videos.py
@@ -0,0 +1,55 @@
+# nuScenes dev-kit.
+# Code written by Holger Caesar, 2018.
+
+"""
+Exports a video of each scene (with annotations) to disk.
+"""
+
+import argparse
+import os
+
+from nuscenes import NuScenes
+
+
+def export_videos(nusc: NuScenes, out_dir: str):
+ """ Export videos of the images displayed in the images. """
+
+ # Load NuScenes class
+ scene_tokens = [s['token'] for s in nusc.scene]
+
+ # Create output directory
+ if not os.path.isdir(out_dir):
+ os.makedirs(out_dir)
+
+ # Write videos to disk
+ for scene_token in scene_tokens:
+ scene = nusc.get('scene', scene_token)
+ print('Writing scene %s' % scene['name'])
+ out_path = os.path.join(out_dir, scene['name']) + '.avi'
+ if not os.path.exists(out_path):
+ nusc.render_scene(scene['token'], out_path=out_path)
+
+
+if __name__ == '__main__':
+
+ # Settings.
+ parser = argparse.ArgumentParser(description='Export all videos of annotations.',
+ formatter_class=argparse.ArgumentDefaultsHelpFormatter)
+ parser.add_argument('--out_dir', type=str, help='Directory where to save videos.')
+ parser.add_argument('--dataroot', type=str, default='/data/sets/nuscenes',
+ help='Default nuScenes data directory.')
+ parser.add_argument('--version', type=str, default='v1.0-trainval',
+ help='Which version of the nuScenes dataset to evaluate on, e.g. v1.0-trainval.')
+ parser.add_argument('--verbose', type=int, default=1,
+ help='Whether to print to stdout.')
+
+ args = parser.parse_args()
+ dataroot = args.dataroot
+ version = args.version
+ verbose = bool(args.verbose)
+
+ # Init.
+ nusc_ = NuScenes(version=version, verbose=verbose, dataroot=dataroot)
+
+ # Export videos of annotations
+ export_videos(nusc_, args.out_dir)
diff --git a/python-sdk/nuscenes/tests/__init__.py b/python-sdk/nuscenes/tests/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/python-sdk/nuscenes/tests/assert_download.py b/python-sdk/nuscenes/tests/assert_download.py
new file mode 100644
index 0000000..343d20f
--- /dev/null
+++ b/python-sdk/nuscenes/tests/assert_download.py
@@ -0,0 +1,51 @@
+# nuScenes dev-kit.
+# Code written by Holger Caesar, 2018.
+
+import argparse
+import os
+
+from tqdm import tqdm
+
+from nuscenes import NuScenes
+
+
+def verify_setup(nusc: NuScenes):
+ """
+ Script to verify that the nuScenes installation is complete.
+ """
+
+ # Check that each sample_data file exists.
+ print('Checking that sample_data files are complete...')
+ for sd in tqdm(nusc.sample_data):
+ file_path = os.path.join(nusc.dataroot, sd['filename'])
+ assert os.path.exists(file_path), 'Error: Missing sample_data at: %s' % file_path
+
+ # Check that each map file exists.
+ print('Checking that map files are complete...')
+ for map in tqdm(nusc.map):
+ file_path = os.path.join(nusc.dataroot, map['filename'])
+ assert os.path.exists(file_path), 'Error: Missing map at: %s' % file_path
+
+
+if __name__ == "__main__":
+
+ # Settings.
+ parser = argparse.ArgumentParser(description='Test that the installed dataset is complete.',
+ formatter_class=argparse.ArgumentDefaultsHelpFormatter)
+ parser.add_argument('--dataroot', type=str, default='/data/sets/nuscenes',
+ help='Default nuScenes data directory.')
+ parser.add_argument('--version', type=str, default='v1.0-trainval',
+ help='Which version of the nuScenes dataset to evaluate on, e.g. v1.0-trainval.')
+ parser.add_argument('--verbose', type=int, default=1,
+ help='Whether to print to stdout.')
+
+ args = parser.parse_args()
+ dataroot = args.dataroot
+ version = args.version
+ verbose = bool(args.verbose)
+
+ # Init.
+ nusc_ = NuScenes(version=version, verbose=verbose, dataroot=dataroot)
+
+ # Verify data blobs.
+ verify_setup(nusc_)
diff --git a/python-sdk/nuscenes/tests/test_lidarseg.py b/python-sdk/nuscenes/tests/test_lidarseg.py
new file mode 100644
index 0000000..8b636d7
--- /dev/null
+++ b/python-sdk/nuscenes/tests/test_lidarseg.py
@@ -0,0 +1,41 @@
+import unittest
+import os
+
+from nuscenes import NuScenes
+
+
+class TestNuScenesLidarseg(unittest.TestCase):
+ def setUp(self):
+ assert 'NUSCENES' in os.environ, 'Set NUSCENES env. variable to enable tests.'
+ self.nusc = NuScenes(version='v1.0-mini', dataroot=os.environ['NUSCENES'], verbose=False)
+
+ def test_num_classes(self) -> None:
+ """
+ Check that the correct number of classes (32 classes) are loaded.
+ """
+ self.assertEqual(len(self.nusc.lidarseg_idx2name_mapping), 32)
+
+ def test_num_colors(self) -> None:
+ """
+ Check that the number of colors in the colormap matches the number of classes.
+ """
+ num_classes = len(self.nusc.lidarseg_idx2name_mapping)
+ num_colors = len(self.nusc.colormap)
+ self.assertEqual(num_colors, num_classes)
+
+ def test_classes(self) -> None:
+ """
+ Check that the class names match the ones in the colormap, and are in the same order.
+ """
+ classes_in_colormap = list(self.nusc.colormap.keys())
+ for name, idx in self.nusc.lidarseg_name2idx_mapping.items():
+ self.assertEqual(name, classes_in_colormap[idx])
+
+
+if __name__ == '__main__':
+ # Runs the tests without throwing errors.
+ test = TestNuScenesLidarseg()
+ test.setUp()
+ test.test_num_classes()
+ test.test_num_colors()
+ test.test_classes()
diff --git a/python-sdk/nuscenes/tests/test_nuscenes.py b/python-sdk/nuscenes/tests/test_nuscenes.py
new file mode 100644
index 0000000..fc180a6
--- /dev/null
+++ b/python-sdk/nuscenes/tests/test_nuscenes.py
@@ -0,0 +1,26 @@
+# nuScenes dev-kit.
+# Code written by Oscar Beijbom, 2019.
+
+import os
+import unittest
+
+from nuscenes import NuScenes
+
+
+class TestNuScenes(unittest.TestCase):
+
+ def test_load(self):
+ """
+ Loads up NuScenes.
+ This is intended to simply run the NuScenes class to check for import errors, typos, etc.
+ """
+
+ assert 'NUSCENES' in os.environ, 'Set NUSCENES env. variable to enable tests.'
+ nusc = NuScenes(version='v1.0-mini', dataroot=os.environ['NUSCENES'], verbose=False)
+
+ # Trivial assert statement
+ self.assertEqual(nusc.table_root, os.path.join(os.environ['NUSCENES'], 'v1.0-mini'))
+
+
+if __name__ == '__main__':
+ unittest.main()
diff --git a/python-sdk/nuscenes/tests/test_predict_helper.py b/python-sdk/nuscenes/tests/test_predict_helper.py
new file mode 100644
index 0000000..ddc67af
--- /dev/null
+++ b/python-sdk/nuscenes/tests/test_predict_helper.py
@@ -0,0 +1,669 @@
+# nuScenes dev-kit.
+# Code written by Freddy Boulton, 2020.
+
+import copy
+import unittest
+from typing import Dict, List, Any
+
+import numpy as np
+
+from nuscenes.prediction import PredictHelper, convert_global_coords_to_local, convert_local_coords_to_global
+
+
+class MockNuScenes:
+ """Mocks the NuScenes API needed to test PredictHelper"""
+
+ def __init__(self, sample_annotations: List[Dict[str, Any]],
+ samples: List[Dict[str, Any]]):
+
+ self._sample_annotation = {r['token']: r for r in sample_annotations}
+ self._sample = {r['token']: r for r in samples}
+
+ @property
+ def sample_annotation(self,) -> List[Dict[str, Any]]:
+ return list(self._sample_annotation.values())
+
+ def get(self, table_name: str, token: str) -> Dict[str, Any]:
+ assert table_name in {'sample_annotation', 'sample'}
+ return getattr(self, "_" + table_name)[token]
+
+
+class TestConvertCoords(unittest.TestCase):
+
+ def setUp(self):
+ along_pos_x = np.zeros((5, 2))
+ along_pos_y = np.zeros((5, 2))
+ along_neg_x = np.zeros((5, 2))
+ along_neg_y = np.zeros((5, 2))
+
+ along_pos_x[:, 0] = np.arange(1, 6)
+ along_pos_y[:, 1] = np.arange(1, 6)
+ along_neg_x[:, 0] = -np.arange(1, 6)
+ along_neg_y[:, 1] = -np.arange(1, 6)
+ self.along_pos_x, self.along_pos_y = along_pos_x, along_pos_y
+ self.along_neg_x, self.along_neg_y = along_neg_x, along_neg_y
+
+ y_equals_x = np.zeros((5, 2))
+ y_equals_x[:, 0] = np.arange(1, 6)
+ y_equals_x[:, 1] = np.arange(1, 6)
+ self.y_equals_x = y_equals_x
+
+ def test_heading_0(self):
+ rotation = (1, 0, 0, 0)
+ origin = (0, 0, 0)
+ offset = (50, 25, 0)
+
+ # Testing path along pos x direction
+ answer = convert_global_coords_to_local(self.along_pos_x, origin, rotation)
+ np.testing.assert_allclose(answer, self.along_pos_y, atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, origin, rotation),
+ self.along_pos_x, atol=1e-4)
+
+ answer = convert_global_coords_to_local(self.along_pos_x + [[50, 25]], offset, rotation)
+ np.testing.assert_allclose(answer, self.along_pos_y, atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, offset, rotation),
+ self.along_pos_x + [[50, 25]], atol=1e-4)
+
+ # Testing path along pos y direction
+ answer = convert_global_coords_to_local(self.along_pos_y, origin, rotation)
+ np.testing.assert_allclose(answer, self.along_neg_x, atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, origin, rotation),
+ self.along_pos_y, atol=1e-4)
+
+ answer = convert_global_coords_to_local(self.along_pos_y + [[50, 25]], offset, rotation)
+ np.testing.assert_allclose(answer, self.along_neg_x, atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, offset, rotation),
+ self.along_pos_y + [[50, 25]], atol=1e-4)
+
+ # Testing path along neg x direction
+ answer = convert_global_coords_to_local(self.along_neg_x, origin, rotation)
+ np.testing.assert_allclose(answer, self.along_neg_y, atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, origin, rotation),
+ self.along_neg_x, atol=1e-4)
+
+ answer = convert_global_coords_to_local(self.along_neg_x + [[50, 25]], offset, rotation)
+ np.testing.assert_allclose(answer, self.along_neg_y, atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, offset, rotation),
+ self.along_neg_x + [[50, 25]], atol=1e-4)
+
+ # Testing path along neg y direction
+ answer = convert_global_coords_to_local(self.along_neg_y, origin, rotation)
+ np.testing.assert_allclose(answer, self.along_pos_x, atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, origin, rotation),
+ self.along_neg_y, atol=1e-4)
+
+ answer = convert_global_coords_to_local(self.along_neg_y + [[50, 25]], offset, rotation)
+ np.testing.assert_allclose(answer, self.along_pos_x, atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, offset, rotation),
+ self.along_neg_y + [[50, 25]], atol=1e-4)
+
+ def test_heading_pi_over_4(self):
+ rotation = (np.cos(np.pi / 8), 0, 0, np.sin(np.pi / 8))
+ origin = (0, 0, 0)
+ offset = (50, 25, 0)
+
+ # Testing path along pos x direction
+ answer = convert_global_coords_to_local(self.along_pos_x, origin, rotation)
+ np.testing.assert_allclose(answer, self.y_equals_x * np.sqrt(2) / 2, atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, origin, rotation),
+ self.along_pos_x, atol=1e-4)
+
+ answer = convert_global_coords_to_local(self.along_pos_x + [[50, 25]], offset, rotation)
+ np.testing.assert_allclose(answer, self.y_equals_x * np.sqrt(2) / 2, atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, offset, rotation),
+ self.along_pos_x + [[50, 25]], atol=1e-4)
+
+ # Testing path along pos y direction
+ answer = convert_global_coords_to_local(self.along_pos_y, origin, rotation)
+ np.testing.assert_allclose(answer, self.y_equals_x * [[-np.sqrt(2) / 2, np.sqrt(2) / 2]], atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, origin, rotation),
+ self.along_pos_y, atol=1e-4)
+
+ answer = convert_global_coords_to_local(self.along_pos_y + [[50, 25]], offset, rotation)
+ np.testing.assert_allclose(answer, self.y_equals_x * [[-np.sqrt(2) / 2, np.sqrt(2) / 2]], atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, offset, rotation),
+ self.along_pos_y + [[50, 25]], atol=1e-4)
+
+ # Testing path along neg x direction
+ answer = convert_global_coords_to_local(self.along_neg_x, origin, rotation)
+ np.testing.assert_allclose(answer, self.y_equals_x * [[-np.sqrt(2) / 2, -np.sqrt(2) / 2]], atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, origin, rotation),
+ self.along_neg_x, atol=1e-4)
+
+ answer = convert_global_coords_to_local(self.along_neg_x + [[50, 25]], offset, rotation)
+ np.testing.assert_allclose(answer, self.y_equals_x * [[-np.sqrt(2) / 2, -np.sqrt(2) / 2]], atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, offset, rotation),
+ self.along_neg_x + [[50, 25]], atol=1e-4)
+
+ # Testing path along neg y direction
+ answer = convert_global_coords_to_local(self.along_neg_y, origin, rotation)
+ np.testing.assert_allclose(answer, self.y_equals_x * [[np.sqrt(2) / 2, -np.sqrt(2) / 2]], atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, origin, rotation),
+ self.along_neg_y, atol=1e-4)
+
+ answer = convert_global_coords_to_local(self.along_neg_y + [[50, 25]], offset, rotation)
+ np.testing.assert_allclose(answer, self.y_equals_x * [[np.sqrt(2) / 2, -np.sqrt(2) / 2]], atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, offset, rotation),
+ self.along_neg_y + [[50, 25]], atol=1e-4)
+
+ def test_heading_pi_over_2(self):
+ rotation = (np.cos(np.pi / 4), 0, 0, np.sin(np.pi / 4))
+ origin = (0, 0, 0)
+ offset = (50, 25, 0)
+
+ # Testing path along pos x direction
+ answer = convert_global_coords_to_local(self.along_pos_x, origin, rotation)
+ np.testing.assert_allclose(answer, self.along_pos_x, atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, origin, rotation),
+ self.along_pos_x, atol=1e-4)
+
+ answer = convert_global_coords_to_local(self.along_pos_x + [[50, 25]], offset, rotation)
+ np.testing.assert_allclose(answer, self.along_pos_x, atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, offset, rotation),
+ self.along_pos_x + [[50, 25]], atol=1e-4)
+
+ # Testing path along pos y direction
+ answer = convert_global_coords_to_local(self.along_pos_y, origin, rotation)
+ np.testing.assert_allclose(answer, self.along_pos_y, atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, origin, rotation),
+ self.along_pos_y, atol=1e-4)
+
+ answer = convert_global_coords_to_local(self.along_pos_y + [[50, 25]], offset, rotation)
+ np.testing.assert_allclose(answer, self.along_pos_y, atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, offset, rotation),
+ self.along_pos_y + [[50, 25]], atol=1e-4)
+
+ # Testing path along neg x direction
+ answer = convert_global_coords_to_local(self.along_neg_x, origin, rotation)
+ np.testing.assert_allclose(answer, self.along_neg_x, atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, origin, rotation),
+ self.along_neg_x, atol=1e-4)
+
+ answer = convert_global_coords_to_local(self.along_neg_x + [[50, 25]], offset, rotation)
+ np.testing.assert_allclose(answer, self.along_neg_x, atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, offset, rotation),
+ self.along_neg_x + [[50, 25]], atol=1e-4)
+
+ # Testing path along neg y direction
+ answer = convert_global_coords_to_local(self.along_neg_y, origin, rotation)
+ np.testing.assert_allclose(answer, self.along_neg_y, atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, origin, rotation),
+ self.along_neg_y, atol=1e-4)
+
+ answer = convert_global_coords_to_local(self.along_neg_y + [[50, 25]], offset, rotation)
+ np.testing.assert_allclose(answer, self.along_neg_y, atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, offset, rotation),
+ self.along_neg_y + [[50, 25]], atol=1e-4)
+
+ def test_heading_3pi_over_4(self):
+ rotation = (np.cos(3 * np.pi / 8), 0, 0, np.sin(3 * np.pi / 8))
+ origin = (0, 0, 0)
+ offset = (50, 25, 0)
+
+ # Testing path along pos x direction
+ answer = convert_global_coords_to_local(self.along_pos_x, origin, rotation)
+ np.testing.assert_allclose(answer, self.y_equals_x * [[np.sqrt(2) / 2, -np.sqrt(2) / 2]], atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, origin, rotation),
+ self.along_pos_x, atol=1e-4)
+
+ answer = convert_global_coords_to_local(self.along_pos_x + [[50, 25]], offset, rotation)
+ np.testing.assert_allclose(answer, self.y_equals_x * [[np.sqrt(2) / 2, -np.sqrt(2) / 2]], atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, offset, rotation),
+ self.along_pos_x + [[50, 25]], atol=1e-4)
+
+ # Testing path along pos y direction
+ answer = convert_global_coords_to_local(self.along_pos_y, origin, rotation)
+ np.testing.assert_allclose(answer, self.y_equals_x * [[np.sqrt(2) / 2, np.sqrt(2) / 2]], atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, origin, rotation),
+ self.along_pos_y, atol=1e-4)
+
+ answer = convert_global_coords_to_local(self.along_pos_y + [[50, 25]], offset, rotation)
+ np.testing.assert_allclose(answer, self.y_equals_x * [[np.sqrt(2) / 2, np.sqrt(2) / 2]], atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, offset, rotation),
+ self.along_pos_y + [[50, 25]], atol=1e-4)
+
+ # Testing path along neg x direction
+ answer = convert_global_coords_to_local(self.along_neg_x, origin, rotation)
+ np.testing.assert_allclose(answer, self.y_equals_x * [[-np.sqrt(2) / 2, np.sqrt(2) / 2]], atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, origin, rotation),
+ self.along_neg_x, atol=1e-4)
+
+ answer = convert_global_coords_to_local(self.along_neg_x + [[50, 25]], offset, rotation)
+ np.testing.assert_allclose(answer, self.y_equals_x * [[-np.sqrt(2) / 2, np.sqrt(2) / 2]], atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, offset, rotation),
+ self.along_neg_x + [[50, 25]], atol=1e-4)
+
+ # Testing path along neg y direction
+ answer = convert_global_coords_to_local(self.along_neg_y, origin, rotation)
+ np.testing.assert_allclose(answer, self.y_equals_x * [[-np.sqrt(2) / 2, -np.sqrt(2) / 2]], atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, origin, rotation),
+ self.along_neg_y, atol=1e-4)
+
+ answer = convert_global_coords_to_local(self.along_neg_y + [[50, 25]], offset, rotation)
+ np.testing.assert_allclose(answer, self.y_equals_x * [[-np.sqrt(2) / 2, -np.sqrt(2) / 2]], atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, offset, rotation),
+ self.along_neg_y + [[50, 25]], atol=1e-4)
+
+ def test_heading_pi(self):
+ rotation = (np.cos(np.pi / 2), 0, 0, np.sin(np.pi / 2))
+ origin = (0, 0, 0)
+ offset = (50, 25, 0)
+
+ # Testing path along pos x direction
+ answer = convert_global_coords_to_local(self.along_pos_x, origin, rotation)
+ np.testing.assert_allclose(answer, self.along_neg_y, atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, origin, rotation),
+ self.along_pos_x, atol=1e-4)
+
+ answer = convert_global_coords_to_local(self.along_pos_x + [[50, 25]], offset, rotation)
+ np.testing.assert_allclose(answer, self.along_neg_y, atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, offset, rotation),
+ self.along_pos_x + [[50, 25]], atol=1e-4)
+
+ # Testing path along pos y direction
+ answer = convert_global_coords_to_local(self.along_pos_y, origin, rotation)
+ np.testing.assert_allclose(answer, self.along_pos_x, atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, origin, rotation),
+ self.along_pos_y, atol=1e-4)
+
+ answer = convert_global_coords_to_local(self.along_pos_y + [[50, 25]], offset, rotation)
+ np.testing.assert_allclose(answer, self.along_pos_x, atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, offset, rotation),
+ self.along_pos_y + [[50, 25]], atol=1e-4)
+
+ # Testing path along neg x direction
+ answer = convert_global_coords_to_local(self.along_neg_x, origin, rotation)
+ np.testing.assert_allclose(answer, self.along_pos_y, atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, origin, rotation),
+ self.along_neg_x, atol=1e-4)
+
+ answer = convert_global_coords_to_local(self.along_neg_x + [[50, 25]], offset, rotation)
+ np.testing.assert_allclose(answer, self.along_pos_y, atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, offset, rotation),
+ self.along_neg_x + [[50, 25]], atol=1e-4)
+
+ # Testing path along neg y direction
+ answer = convert_global_coords_to_local(self.along_neg_y, origin, rotation)
+ np.testing.assert_allclose(answer, self.along_neg_x, atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, origin, rotation),
+ self.along_neg_y, atol=1e-4)
+
+ answer = convert_global_coords_to_local(self.along_neg_y + [[50, 25]], offset, rotation)
+ np.testing.assert_allclose(answer, self.along_neg_x, atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, offset, rotation),
+ self.along_neg_y + [[50, 25]], atol=1e-4)
+
+ def test_heading_neg_pi_over_4(self):
+ rotation = (np.cos(-np.pi / 8), 0, 0, np.sin(-np.pi / 8))
+ origin = (0, 0, 0)
+ offset = (50, 25, 0)
+
+ # Testing path along pos x direction
+ answer = convert_global_coords_to_local(self.along_pos_x, origin, rotation)
+ np.testing.assert_allclose(answer, self.y_equals_x * [[-np.sqrt(2) / 2, np.sqrt(2) / 2]], atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, origin, rotation),
+ self.along_pos_x, atol=1e-4)
+
+ answer = convert_global_coords_to_local(self.along_pos_x + [[50, 25]], offset, rotation)
+ np.testing.assert_allclose(answer, self.y_equals_x * [[-np.sqrt(2) / 2, np.sqrt(2) / 2]], atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, offset, rotation),
+ self.along_pos_x + [[50, 25]], atol=1e-4)
+
+ # Testing path along pos y direction
+ answer = convert_global_coords_to_local(self.along_pos_y, origin, rotation)
+ np.testing.assert_allclose(answer, self.y_equals_x * [[-np.sqrt(2) / 2, -np.sqrt(2) / 2]], atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, origin, rotation),
+ self.along_pos_y, atol=1e-4)
+
+ answer = convert_global_coords_to_local(self.along_pos_y + [[50, 25]], offset, rotation)
+ np.testing.assert_allclose(answer, self.y_equals_x * [[-np.sqrt(2) / 2, -np.sqrt(2) / 2]], atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, offset, rotation),
+ self.along_pos_y + [[50, 25]], atol=1e-4)
+
+ # Testing path along neg x direction
+ answer = convert_global_coords_to_local(self.along_neg_x, origin, rotation)
+ np.testing.assert_allclose(answer, self.y_equals_x * [[np.sqrt(2) / 2, -np.sqrt(2) / 2]], atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, origin, rotation),
+ self.along_neg_x, atol=1e-4)
+
+ answer = convert_global_coords_to_local(self.along_neg_x + [[50, 25]], offset, rotation)
+ np.testing.assert_allclose(answer, self.y_equals_x * [[np.sqrt(2) / 2, -np.sqrt(2) / 2]], atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, offset, rotation),
+ self.along_neg_x + [[50, 25]], atol=1e-4)
+
+ # Testing path along neg y direction
+ answer = convert_global_coords_to_local(self.along_neg_y, origin, rotation)
+ np.testing.assert_allclose(answer, self.y_equals_x * [[np.sqrt(2) / 2, np.sqrt(2) / 2]], atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, origin, rotation),
+ self.along_neg_y, atol=1e-4)
+
+ answer = convert_global_coords_to_local(self.along_neg_y + [[50, 25]], offset, rotation)
+ np.testing.assert_allclose(answer, self.y_equals_x * [[np.sqrt(2) / 2, np.sqrt(2) / 2]], atol=1e-4)
+ np.testing.assert_allclose(convert_local_coords_to_global(answer, offset, rotation),
+ self.along_neg_y + [[50, 25]], atol=1e-4)
+
+
+class TestPredictHelper(unittest.TestCase):
+
+ def setUp(self):
+
+ self.mock_annotations = [{'token': '1', 'instance_token': '1', 'sample_token': '1', 'translation': [0, 0, 0], 'rotation': [1, 0, 0, 0],
+ 'prev': '', 'next': '2'},
+ {'token': '2', 'instance_token': '1', 'sample_token': '2', 'translation': [1, 1, 1], 'rotation': [np.sqrt(2) / 2, 0, 0, np.sqrt(2) / 2],
+ 'prev': '1', 'next': '3'},
+ {'token': '3', 'instance_token': '1', 'sample_token': '3', 'translation': [2, 2, 2], 'prev': '2', 'next': '4'},
+ {'token': '4', 'instance_token': '1', 'sample_token': '4', 'translation': [3, 3, 3], 'prev': '3', 'next': '5'},
+ {'token': '5', 'instance_token': '1', 'sample_token': '5', 'translation': [4, 4, 4], 'rotation': [1, 0, 0, 0],
+ 'prev': '4', 'next': '6'},
+ {'token': '6', 'instance_token': '1', 'sample_token': '6', 'translation': [5, 5, 5], 'prev': '5', 'next': ''}]
+
+ self.multiagent_mock_annotations = [{'token': '1', 'instance_token': '1', 'sample_token': '1', 'translation': [0, 0, 0], 'rotation': [1, 0, 0, 0],
+ 'prev': '', 'next': '2'},
+ {'token': '2', 'instance_token': '1', 'sample_token': '2', 'translation': [1, 1, 1], 'prev': '1', 'next': '3'},
+ {'token': '3', 'instance_token': '1', 'sample_token': '3', 'translation': [2, 2, 2], 'prev': '2', 'next': '4'},
+ {'token': '4', 'instance_token': '1', 'sample_token': '4', 'translation': [3, 3, 3], 'prev': '3', 'next': '5'},
+ {'token': '5', 'instance_token': '1', 'sample_token': '5', 'translation': [4, 4, 4], 'rotation': [1, 0, 0, 0],
+ 'prev': '4', 'next': '6'},
+ {'token': '6', 'instance_token': '1', 'sample_token': '6', 'translation': [5, 5, 5], 'prev': '5', 'next': ''},
+ {'token': '1b', 'instance_token': '2', 'sample_token': '1', 'translation': [6, 6, 6], 'rotation': [1, 0, 0, 0],
+ 'prev': '', 'next': '2b'},
+ {'token': '2b', 'instance_token': '2', 'sample_token': '2', 'translation': [7, 7, 7], 'prev': '1b', 'next': '3b'},
+ {'token': '3b', 'instance_token': '2', 'sample_token': '3', 'translation': [8, 8, 8], 'prev': '2b', 'next': '4b'},
+ {'token': '4b', 'instance_token': '2', 'sample_token': '4', 'translation': [9, 9, 9], 'prev': '3b', 'next': '5b'},
+ {'token': '5b', 'instance_token': '2', 'sample_token': '5', 'translation': [10, 10, 10], 'rotation': [1, 0, 0, 0],
+ 'prev': '4b', 'next': '6b'},
+ {'token': '6b', 'instance_token': '2', 'sample_token': '6', 'translation': [11, 11, 11], 'prev': '5b', 'next': ''}]
+
+ def test_get_sample_annotation(self,):
+
+ mock_annotation = {'token': '1', 'instance_token': 'instance_1',
+ 'sample_token': 'sample_1'}
+ mock_sample = {'token': 'sample_1', 'timestamp': 0}
+
+ nusc = MockNuScenes([mock_annotation], [mock_sample])
+
+ helper = PredictHelper(nusc)
+ self.assertDictEqual(mock_annotation, helper.get_sample_annotation('instance_1', 'sample_1'))
+
+ def test_get_future_for_agent_exact_amount(self,):
+
+ mock_samples = [{'token': '1', 'timestamp': 0},
+ {'token': '2', 'timestamp': 1e6},
+ {'token': '3', 'timestamp': 2e6},
+ {'token': '4', 'timestamp': 3e6},
+ {'token': '5', 'timestamp': 4e6}]
+
+ # Testing we can get the exact amount of future seconds available
+ nusc = MockNuScenes(self.mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ future = helper.get_future_for_agent('1', '1', 3, False)
+ np.testing.assert_equal(future, np.array([[1, 1], [2, 2], [3, 3]]))
+
+ def test_get_future_for_agent_in_agent_frame(self):
+ mock_samples = [{'token': '1', 'timestamp': 0},
+ {'token': '2', 'timestamp': 1e6},
+ {'token': '3', 'timestamp': 2e6},
+ {'token': '4', 'timestamp': 3e6},
+ {'token': '5', 'timestamp': 4e6}]
+
+ nusc = MockNuScenes(self.mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ future = helper.get_future_for_agent('1', '1', 3, True)
+ np.testing.assert_allclose(future, np.array([[-1, 1], [-2, 2], [-3, 3]]))
+
+ def test_get_future_for_agent_less_amount(self,):
+
+ mock_samples = [{'token': '1', 'timestamp': 0},
+ {'token': '2', 'timestamp': 1e6},
+ {'token': '3', 'timestamp': 2.6e6},
+ {'token': '4', 'timestamp': 4e6},
+ {'token': '5', 'timestamp': 5.5e6}]
+
+ # Testing we do not include data after the future seconds
+ nusc = MockNuScenes(self.mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ future = helper.get_future_for_agent('1', '1', 3, False)
+ np.testing.assert_equal(future, np.array([[1, 1], [2, 2]]))
+
+ def test_get_future_for_agent_within_buffer(self,):
+
+ mock_samples = [{'token': '1', 'timestamp': 0},
+ {'token': '2', 'timestamp': 1e6},
+ {'token': '3', 'timestamp': 2.6e6},
+ {'token': '4', 'timestamp': 3.05e6},
+ {'token': '5', 'timestamp': 3.5e6}]
+
+ # Testing we get data if it is after future seconds but within buffer
+ nusc = MockNuScenes(self.mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ future = helper.get_future_for_agent('1', '1', 3, False)
+ np.testing.assert_equal(future, np.array([[1, 1], [2, 2], [3, 3]]))
+
+ def test_get_future_for_agent_no_data_to_get(self,):
+ mock_samples = [{'token': '1', 'timestamp': 0},
+ {'token': '2', 'timestamp': 3.5e6}]
+
+ # Testing we get nothing if the first sample annotation is past our threshold
+ nusc = MockNuScenes(self.mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ future = helper.get_future_for_agent('1', '1', 3, False)
+ np.testing.assert_equal(future, np.array([]))
+
+ def test_get_future_for_last_returns_nothing(self):
+ mock_samples = [{'token': '6', 'timestamp': 0}]
+
+ # Testing we get nothing if we're at the last annotation
+ nusc = MockNuScenes(self.mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ future = helper.get_future_for_agent('1', '6', 3, False)
+ np.testing.assert_equal(future, np.array([]))
+
+ def test_get_past_for_agent_exact_amount(self,):
+
+ mock_samples = [{'token': '5', 'timestamp': 0},
+ {'token': '4', 'timestamp': -1e6},
+ {'token': '3', 'timestamp': -2e6},
+ {'token': '2', 'timestamp': -3e6},
+ {'token': '1', 'timestamp': -4e6}]
+
+ # Testing we can get the exact amount of past seconds available
+ nusc = MockNuScenes(self.mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ past = helper.get_past_for_agent('1', '5', 3, False)
+ np.testing.assert_equal(past, np.array([[3, 3], [2, 2], [1, 1]]))
+
+ def test_get_past_for_agent_in_frame(self,):
+
+ mock_samples = [{'token': '5', 'timestamp': 0},
+ {'token': '4', 'timestamp': -1e6},
+ {'token': '3', 'timestamp': -2e6},
+ {'token': '2', 'timestamp': -3e6},
+ {'token': '1', 'timestamp': -4e6}]
+
+ # Testing we can get the exact amount of past seconds available
+ nusc = MockNuScenes(self.mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ past = helper.get_past_for_agent('1', '5', 3, True)
+ np.testing.assert_allclose(past, np.array([[1., -1.], [2., -2.], [3., -3.]]))
+
+ def test_get_past_for_agent_less_amount(self,):
+
+ mock_samples = [{'token': '5', 'timestamp': 0},
+ {'token': '4', 'timestamp': -1e6},
+ {'token': '3', 'timestamp': -2.6e6},
+ {'token': '2', 'timestamp': -4e6},
+ {'token': '1', 'timestamp': -5.5e6}]
+
+ # Testing we do not include data after the past seconds
+ nusc = MockNuScenes(self.mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ past = helper.get_past_for_agent('1', '5', 3, False)
+ np.testing.assert_equal(past, np.array([[3, 3], [2, 2]]))
+
+ def test_get_past_for_agent_within_buffer(self,):
+
+ mock_samples = [{'token': '5', 'timestamp': 0},
+ {'token': '4', 'timestamp': -1e6},
+ {'token': '3', 'timestamp': -3.05e6},
+ {'token': '2', 'timestamp': -3.2e6}]
+
+ # Testing we get data if it is after future seconds but within buffer
+ nusc = MockNuScenes(self.mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ past = helper.get_past_for_agent('1', '5', 3, False)
+ np.testing.assert_equal(past, np.array([[3, 3], [2, 2]]))
+
+ def test_get_past_for_agent_no_data_to_get(self,):
+ mock_samples = [{'token': '5', 'timestamp': 0},
+ {'token': '4', 'timestamp': -3.5e6}]
+
+ # Testing we get nothing if the first sample annotation is past our threshold
+ nusc = MockNuScenes(self.mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ past = helper.get_past_for_agent('1', '5', 3, False)
+ np.testing.assert_equal(past, np.array([]))
+
+ def test_get_past_for_last_returns_nothing(self):
+ mock_samples = [{'token': '1', 'timestamp': 0}]
+
+ # Testing we get nothing if we're at the last annotation
+ nusc = MockNuScenes(self.mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ past = helper.get_past_for_agent('1', '1', 3, False)
+ np.testing.assert_equal(past, np.array([]))
+
+ def test_get_future_for_sample(self):
+
+ mock_samples = [{'token': '1', 'timestamp': 0, 'anns': ['1', '1b']},
+ {'token': '2', 'timestamp': 1e6},
+ {'token': '3', 'timestamp': 2e6},
+ {'token': '4', 'timestamp': 3e6},
+ {'token': '5', 'timestamp': 4e6}]
+
+ nusc = MockNuScenes(self.multiagent_mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ future = helper.get_future_for_sample("1", 3, False)
+
+ answer = {'1': np.array([[1, 1], [2, 2], [3, 3]]),
+ '2': np.array([[7, 7], [8, 8], [9, 9]])}
+
+ for k in answer:
+ np.testing.assert_equal(answer[k], future[k])
+
+ future_in_sample = helper.get_future_for_sample("1", 3, True)
+
+ answer_in_sample = {'1': np.array([[-1, 1], [-2, 2], [-3, 3]]),
+ '2': np.array([[-1, 1], [-2, 2], [-3, 3]])}
+
+ for k in answer_in_sample:
+ np.testing.assert_allclose(answer_in_sample[k], future_in_sample[k])
+
+ def test_get_past_for_sample(self):
+
+ mock_samples = [{'token': '5', 'timestamp': 0, 'anns': ['5', '5b']},
+ {'token': '4', 'timestamp': -1e6},
+ {'token': '3', 'timestamp': -2e6},
+ {'token': '2', 'timestamp': -3e6},
+ {'token': '1', 'timestamp': -4e6}]
+
+ nusc = MockNuScenes(self.multiagent_mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ past = helper.get_past_for_sample('5', 3, True)
+
+ answer = {'1': np.array([[-1, -1], [-2, -2], [-3, -3]]),
+ '2': np.array([[-1, -1], [-2, -2], [-3, -3]])}
+
+ for k in answer:
+ np.testing.assert_equal(answer[k], answer[k])
+
+ def test_velocity(self):
+
+ mock_samples = [{'token': '1', 'timestamp': 0},
+ {'token': '2', 'timestamp': 0.5e6}]
+
+ nusc = MockNuScenes(self.mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+
+ self.assertEqual(helper.get_velocity_for_agent("1", "2"), np.sqrt(8))
+
+ def test_velocity_return_nan_one_obs(self):
+
+ mock_samples = [{'token': '1', 'timestamp': 0}]
+ nusc = MockNuScenes(self.mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+
+ self.assertTrue(np.isnan(helper.get_velocity_for_agent('1', '1')))
+
+ def test_velocity_return_nan_big_diff(self):
+ mock_samples = [{'token': '1', 'timestamp': 0},
+ {'token': '2', 'timestamp': 2.5e6}]
+ nusc = MockNuScenes(self.mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ self.assertTrue(np.isnan(helper.get_velocity_for_agent('1', '2')))
+
+ def test_heading_change_rate(self):
+ mock_samples = [{'token': '1', 'timestamp': 0}, {'token': '2', 'timestamp': 0.5e6}]
+ nusc = MockNuScenes(self.mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ self.assertEqual(helper.get_heading_change_rate_for_agent('1', '2'), np.pi)
+
+ def test_heading_change_rate_near_pi(self):
+ mock_samples = [{'token': '1', 'timestamp': 0}, {'token': '2', 'timestamp': 0.5e6}]
+ mock_annotations = copy.copy(self.mock_annotations)
+ mock_annotations[0]['rotation'] = [np.cos((np.pi - 0.05)/2), 0, 0, np.sin((np.pi - 0.05) / 2)]
+ mock_annotations[1]['rotation'] = [np.cos((-np.pi + 0.05)/2), 0, 0, np.sin((-np.pi + 0.05) / 2)]
+ nusc = MockNuScenes(mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ self.assertAlmostEqual(helper.get_heading_change_rate_for_agent('1', '2'), 0.2)
+
+ def test_acceleration_zero(self):
+ mock_samples = [{'token': '1', 'timestamp': 0},
+ {'token': '2', 'timestamp': 0.5e6},
+ {'token': '3', 'timestamp': 1e6}]
+ nusc = MockNuScenes(self.mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ self.assertEqual(helper.get_acceleration_for_agent('1', '3'), 0)
+
+ def test_acceleration_nonzero(self):
+ mock_samples = [{'token': '1', 'timestamp': 0},
+ {'token': '2', 'timestamp': 0.5e6},
+ {'token': '3', 'timestamp': 1e6}]
+ mock_annotations = copy.copy(self.mock_annotations)
+ mock_annotations[2]['translation'] = [3, 3, 3]
+ nusc = MockNuScenes(mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ self.assertAlmostEqual(helper.get_acceleration_for_agent('1', '3'), 2 * (np.sqrt(32) - np.sqrt(8)))
+
+ def test_acceleration_nan_not_enough_data(self):
+ mock_samples = [{'token': '1', 'timestamp': 0},
+ {'token': '2', 'timestamp': 0.5e6},
+ {'token': '3', 'timestamp': 1e6}]
+ nusc = MockNuScenes(self.mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ self.assertTrue(np.isnan(helper.get_acceleration_for_agent('1', '2')))
+
+ def test_get_no_data_when_seconds_0(self):
+ mock_samples = [{'token': '1', 'timestamp': 0, 'anns': ['1']}]
+ nusc = MockNuScenes(self.mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+
+ np.testing.assert_equal(helper.get_future_for_agent('1', '1', 0, False), np.array([]))
+ np.testing.assert_equal(helper.get_past_for_agent('1', '1', 0, False), np.array([]))
+ np.testing.assert_equal(helper.get_future_for_sample('1', 0, False), np.array([]))
+ np.testing.assert_equal(helper.get_past_for_sample('1', 0, False), np.array([]))
+
+ def test_raises_error_when_seconds_negative(self):
+ mock_samples = [{'token': '1', 'timestamp': 0, 'anns': ['1', '1b']}]
+ nusc = MockNuScenes(self.mock_annotations, mock_samples)
+ helper = PredictHelper(nusc)
+ with self.assertRaises(ValueError):
+ helper.get_future_for_agent('1', '1', -1, False)
+
+ with self.assertRaises(ValueError):
+ helper.get_past_for_agent('1', '1', -1, False)
+
+ with self.assertRaises(ValueError):
+ helper.get_past_for_sample('1', -1, False)
+
+ with self.assertRaises(ValueError):
+ helper.get_future_for_sample('1', -1, False)
\ No newline at end of file
diff --git a/python-sdk/nuscenes/utils/__init__.py b/python-sdk/nuscenes/utils/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/python-sdk/nuscenes/utils/color_map.py b/python-sdk/nuscenes/utils/color_map.py
new file mode 100644
index 0000000..ce4f261
--- /dev/null
+++ b/python-sdk/nuscenes/utils/color_map.py
@@ -0,0 +1,45 @@
+from typing import Dict, Tuple
+
+
+def get_colormap() -> Dict[str, Tuple[int, int, int]]:
+ """
+ Get the defined colormap.
+ :return: A mapping from the class names to the respective RGB values.
+ """
+
+ classname_to_color = { # RGB.
+ "noise": (0, 0, 0), # Black.
+ "animal": (70, 130, 180), # Steelblue
+ "human.pedestrian.adult": (0, 0, 230), # Blue
+ "human.pedestrian.child": (135, 206, 235), # Skyblue,
+ "human.pedestrian.construction_worker": (100, 149, 237), # Cornflowerblue
+ "human.pedestrian.personal_mobility": (219, 112, 147), # Palevioletred
+ "human.pedestrian.police_officer": (0, 0, 128), # Navy,
+ "human.pedestrian.stroller": (240, 128, 128), # Lightcoral
+ "human.pedestrian.wheelchair": (138, 43, 226), # Blueviolet
+ "movable_object.barrier": (112, 128, 144), # Slategrey
+ "movable_object.debris": (210, 105, 30), # Chocolate
+ "movable_object.pushable_pullable": (105, 105, 105), # Dimgrey
+ "movable_object.trafficcone": (47, 79, 79), # Darkslategrey
+ "static_object.bicycle_rack": (188, 143, 143), # Rosybrown
+ "vehicle.bicycle": (220, 20, 60), # Crimson
+ "vehicle.bus.bendy": (255, 127, 80), # Coral
+ "vehicle.bus.rigid": (255, 69, 0), # Orangered
+ "vehicle.car": (255, 158, 0), # Orange
+ "vehicle.construction": (233, 150, 70), # Darksalmon
+ "vehicle.emergency.ambulance": (255, 83, 0),
+ "vehicle.emergency.police": (255, 215, 0), # Gold
+ "vehicle.motorcycle": (255, 61, 99), # Red
+ "vehicle.trailer": (255, 140, 0), # Darkorange
+ "vehicle.truck": (255, 99, 71), # Tomato
+ "flat.driveable_surface": (0, 207, 191), # nuTonomy green
+ "flat.other": (175, 0, 75),
+ "flat.sidewalk": (75, 0, 75),
+ "flat.terrain": (112, 180, 60),
+ "static.manmade": (222, 184, 135), # Burlywood
+ "static.other": (255, 228, 196), # Bisque
+ "static.vegetation": (0, 175, 0), # Green
+ "vehicle.ego": (255, 240, 245)
+ }
+
+ return classname_to_color
diff --git a/python-sdk/nuscenes/utils/data_classes.py b/python-sdk/nuscenes/utils/data_classes.py
new file mode 100644
index 0000000..92013d1
--- /dev/null
+++ b/python-sdk/nuscenes/utils/data_classes.py
@@ -0,0 +1,686 @@
+# nuScenes dev-kit.
+# Code written by Oscar Beijbom, 2018.
+
+import copy
+import os.path as osp
+import struct
+from abc import ABC, abstractmethod
+from functools import reduce
+from typing import Tuple, List, Dict
+
+import cv2
+import numpy as np
+from matplotlib.axes import Axes
+from pyquaternion import Quaternion
+
+from nuscenes.utils.geometry_utils import view_points, transform_matrix
+
+
+class PointCloud(ABC):
+ """
+ Abstract class for manipulating and viewing point clouds.
+ Every point cloud (lidar and radar) consists of points where:
+ - Dimensions 0, 1, 2 represent x, y, z coordinates.
+ These are modified when the point cloud is rotated or translated.
+ - All other dimensions are optional. Hence these have to be manually modified if the reference frame changes.
+ """
+
+ def __init__(self, points: np.ndarray):
+ """
+ Initialize a point cloud and check it has the correct dimensions.
+ :param points: <np.float: d, n>. d-dimensional input point cloud matrix.
+ """
+ assert points.shape[0] == self.nbr_dims(), 'Error: Pointcloud points must have format: %d x n' % self.nbr_dims()
+ self.points = points
+
+ @staticmethod
+ @abstractmethod
+ def nbr_dims() -> int:
+ """
+ Returns the number of dimensions.
+ :return: Number of dimensions.
+ """
+ pass
+
+ @classmethod
+ @abstractmethod
+ def from_file(cls, file_name: str) -> 'PointCloud':
+ """
+ Loads point cloud from disk.
+ :param file_name: Path of the pointcloud file on disk.
+ :return: PointCloud instance.
+ """
+ pass
+
+ @classmethod
+ def from_file_multisweep(cls,
+ nusc: 'NuScenes',
+ sample_rec: Dict,
+ chan: str,
+ ref_chan: str,
+ nsweeps: int = 5,
+ min_distance: float = 1.0) -> Tuple['PointCloud', np.ndarray]:
+ """
+ Return a point cloud that aggregates multiple sweeps.
+ As every sweep is in a different coordinate frame, we need to map the coordinates to a single reference frame.
+ As every sweep has a different timestamp, we need to account for that in the transformations and timestamps.
+ :param nusc: A NuScenes instance.
+ :param sample_rec: The current sample.
+ :param chan: The lidar/radar channel from which we track back n sweeps to aggregate the point cloud.
+ :param ref_chan: The reference channel of the current sample_rec that the point clouds are mapped to.
+ :param nsweeps: Number of sweeps to aggregated.
+ :param min_distance: Distance below which points are discarded.
+ :return: (all_pc, all_times). The aggregated point cloud and timestamps.
+ """
+ # Init.
+ points = np.zeros((cls.nbr_dims(), 0))
+ all_pc = cls(points)
+ all_times = np.zeros((1, 0))
+
+ # Get reference pose and timestamp.
+ ref_sd_token = sample_rec['data'][ref_chan]
+ ref_sd_rec = nusc.get('sample_data', ref_sd_token)
+ ref_pose_rec = nusc.get('ego_pose', ref_sd_rec['ego_pose_token'])
+ ref_cs_rec = nusc.get('calibrated_sensor', ref_sd_rec['calibrated_sensor_token'])
+ ref_time = 1e-6 * ref_sd_rec['timestamp']
+
+ # Homogeneous transform from ego car frame to reference frame.
+ ref_from_car = transform_matrix(ref_cs_rec['translation'], Quaternion(ref_cs_rec['rotation']), inverse=True)
+
+ # Homogeneous transformation matrix from global to _current_ ego car frame.
+ car_from_global = transform_matrix(ref_pose_rec['translation'], Quaternion(ref_pose_rec['rotation']),
+ inverse=True)
+
+ # Aggregate current and previous sweeps.
+ sample_data_token = sample_rec['data'][chan]
+ current_sd_rec = nusc.get('sample_data', sample_data_token)
+ for _ in range(nsweeps):
+ # Load up the pointcloud and remove points close to the sensor.
+ current_pc = cls.from_file(osp.join(nusc.dataroot, current_sd_rec['filename']))
+ current_pc.remove_close(min_distance)
+
+ # Get past pose.
+ current_pose_rec = nusc.get('ego_pose', current_sd_rec['ego_pose_token'])
+ global_from_car = transform_matrix(current_pose_rec['translation'],
+ Quaternion(current_pose_rec['rotation']), inverse=False)
+
+ # Homogeneous transformation matrix from sensor coordinate frame to ego car frame.
+ current_cs_rec = nusc.get('calibrated_sensor', current_sd_rec['calibrated_sensor_token'])
+ car_from_current = transform_matrix(current_cs_rec['translation'], Quaternion(current_cs_rec['rotation']),
+ inverse=False)
+
+ # Fuse four transformation matrices into one and perform transform.
+ trans_matrix = reduce(np.dot, [ref_from_car, car_from_global, global_from_car, car_from_current])
+ current_pc.transform(trans_matrix)
+
+ # Add time vector which can be used as a temporal feature.
+ time_lag = ref_time - 1e-6 * current_sd_rec['timestamp'] # Positive difference.
+ times = time_lag * np.ones((1, current_pc.nbr_points()))
+ all_times = np.hstack((all_times, times))
+
+ # Merge with key pc.
+ all_pc.points = np.hstack((all_pc.points, current_pc.points))
+
+ # Abort if there are no previous sweeps.
+ if current_sd_rec['prev'] == '':
+ break
+ else:
+ current_sd_rec = nusc.get('sample_data', current_sd_rec['prev'])
+
+ return all_pc, all_times
+
+ def nbr_points(self) -> int:
+ """
+ Returns the number of points.
+ :return: Number of points.
+ """
+ return self.points.shape[1]
+
+ def subsample(self, ratio: float) -> None:
+ """
+ Sub-samples the pointcloud.
+ :param ratio: Fraction to keep.
+ """
+ selected_ind = np.random.choice(np.arange(0, self.nbr_points()), size=int(self.nbr_points() * ratio))
+ self.points = self.points[:, selected_ind]
+
+ def remove_close(self, radius: float) -> None:
+ """
+ Removes point too close within a certain radius from origin.
+ :param radius: Radius below which points are removed.
+ """
+
+ x_filt = np.abs(self.points[0, :]) < radius
+ y_filt = np.abs(self.points[1, :]) < radius
+ not_close = np.logical_not(np.logical_and(x_filt, y_filt))
+ self.points = self.points[:, not_close]
+
+ def translate(self, x: np.ndarray) -> None:
+ """
+ Applies a translation to the point cloud.
+ :param x: <np.float: 3, 1>. Translation in x, y, z.
+ """
+ for i in range(3):
+ self.points[i, :] = self.points[i, :] + x[i]
+
+ def rotate(self, rot_matrix: np.ndarray) -> None:
+ """
+ Applies a rotation.
+ :param rot_matrix: <np.float: 3, 3>. Rotation matrix.
+ """
+ self.points[:3, :] = np.dot(rot_matrix, self.points[:3, :])
+
+ def transform(self, transf_matrix: np.ndarray) -> None:
+ """
+ Applies a homogeneous transform.
+ :param transf_matrix: <np.float: 4, 4>. Homogenous transformation matrix.
+ """
+ self.points[:3, :] = transf_matrix.dot(np.vstack((self.points[:3, :], np.ones(self.nbr_points()))))[:3, :]
+
+ def render_height(self,
+ ax: Axes,
+ view: np.ndarray = np.eye(4),
+ x_lim: Tuple[float, float] = (-20, 20),
+ y_lim: Tuple[float, float] = (-20, 20),
+ marker_size: float = 1) -> None:
+ """
+ Very simple method that applies a transformation and then scatter plots the points colored by height (z-value).
+ :param ax: Axes on which to render the points.
+ :param view: <np.float: n, n>. Defines an arbitrary projection (n <= 4).
+ :param x_lim: (min, max). x range for plotting.
+ :param y_lim: (min, max). y range for plotting.
+ :param marker_size: Marker size.
+ """
+ self._render_helper(2, ax, view, x_lim, y_lim, marker_size)
+
+ def render_intensity(self,
+ ax: Axes,
+ view: np.ndarray = np.eye(4),
+ x_lim: Tuple[float, float] = (-20, 20),
+ y_lim: Tuple[float, float] = (-20, 20),
+ marker_size: float = 1) -> None:
+ """
+ Very simple method that applies a transformation and then scatter plots the points colored by intensity.
+ :param ax: Axes on which to render the points.
+ :param view: <np.float: n, n>. Defines an arbitrary projection (n <= 4).
+ :param x_lim: (min, max).
+ :param y_lim: (min, max).
+ :param marker_size: Marker size.
+ """
+ self._render_helper(3, ax, view, x_lim, y_lim, marker_size)
+
+ def _render_helper(self,
+ color_channel: int,
+ ax: Axes,
+ view: np.ndarray,
+ x_lim: Tuple[float, float],
+ y_lim: Tuple[float, float],
+ marker_size: float) -> None:
+ """
+ Helper function for rendering.
+ :param color_channel: Point channel to use as color.
+ :param ax: Axes on which to render the points.
+ :param view: <np.float: n, n>. Defines an arbitrary projection (n <= 4).
+ :param x_lim: (min, max).
+ :param y_lim: (min, max).
+ :param marker_size: Marker size.
+ """
+ points = view_points(self.points[:3, :], view, normalize=False)
+ ax.scatter(points[0, :], points[1, :], c=self.points[color_channel, :], s=marker_size)
+ ax.set_xlim(x_lim[0], x_lim[1])
+ ax.set_ylim(y_lim[0], y_lim[1])
+
+
+class LidarPointCloud(PointCloud):
+
+ @staticmethod
+ def nbr_dims() -> int:
+ """
+ Returns the number of dimensions.
+ :return: Number of dimensions.
+ """
+ return 4
+
+ @classmethod
+ def from_file(cls, file_name: str) -> 'LidarPointCloud':
+ """
+ Loads LIDAR data from binary numpy format. Data is stored as (x, y, z, intensity, ring index).
+ :param file_name: Path of the pointcloud file on disk.
+ :return: LidarPointCloud instance (x, y, z, intensity).
+ """
+
+ assert file_name.endswith('.bin'), 'Unsupported filetype {}'.format(file_name)
+
+ scan = np.fromfile(file_name, dtype=np.float32)
+ points = scan.reshape((-1, 5))[:, :cls.nbr_dims()]
+ return cls(points.T)
+
+
+class RadarPointCloud(PointCloud):
+
+ # Class-level settings for radar pointclouds, see from_file().
+ invalid_states = [0] # type: List[int]
+ dynprop_states = range(7) # type: List[int] # Use [0, 2, 6] for moving objects only.
+ ambig_states = [3] # type: List[int]
+
+ @classmethod
+ def disable_filters(cls) -> None:
+ """
+ Disable all radar filter settings.
+ Use this method to plot all radar returns.
+ Note that this method affects the global settings.
+ """
+ cls.invalid_states = list(range(18))
+ cls.dynprop_states = list(range(8))
+ cls.ambig_states = list(range(5))
+
+ @classmethod
+ def default_filters(cls) -> None:
+ """
+ Set the defaults for all radar filter settings.
+ Note that this method affects the global settings.
+ """
+ cls.invalid_states = [0]
+ cls.dynprop_states = range(7)
+ cls.ambig_states = [3]
+
+ @staticmethod
+ def nbr_dims() -> int:
+ """
+ Returns the number of dimensions.
+ :return: Number of dimensions.
+ """
+ return 18
+
+ @classmethod
+ def from_file(cls,
+ file_name: str,
+ invalid_states: List[int] = None,
+ dynprop_states: List[int] = None,
+ ambig_states: List[int] = None) -> 'RadarPointCloud':
+ """
+ Loads RADAR data from a Point Cloud Data file. See details below.
+ :param file_name: The path of the pointcloud file.
+ :param invalid_states: Radar states to be kept. See details below.
+ :param dynprop_states: Radar states to be kept. Use [0, 2, 6] for moving objects only. See details below.
+ :param ambig_states: Radar states to be kept. See details below.
+ To keep all radar returns, set each state filter to range(18).
+ :return: <np.float: d, n>. Point cloud matrix with d dimensions and n points.
+
+ Example of the header fields:
+ # .PCD v0.7 - Point Cloud Data file format
+ VERSION 0.7
+ FIELDS x y z dyn_prop id rcs vx vy vx_comp vy_comp is_quality_valid ambig_state x_rms y_rms invalid_state pdh0 vx_rms vy_rms
+ SIZE 4 4 4 1 2 4 4 4 4 4 1 1 1 1 1 1 1 1
+ TYPE F F F I I F F F F F I I I I I I I I
+ COUNT 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
+ WIDTH 125
+ HEIGHT 1
+ VIEWPOINT 0 0 0 1 0 0 0
+ POINTS 125
+ DATA binary
+
+ Below some of the fields are explained in more detail:
+
+ x is front, y is left
+
+ vx, vy are the velocities in m/s.
+ vx_comp, vy_comp are the velocities in m/s compensated by the ego motion.
+ We recommend using the compensated velocities.
+
+ invalid_state: state of Cluster validity state.
+ (Invalid states)
+ 0x01 invalid due to low RCS
+ 0x02 invalid due to near-field artefact
+ 0x03 invalid far range cluster because not confirmed in near range
+ 0x05 reserved
+ 0x06 invalid cluster due to high mirror probability
+ 0x07 Invalid cluster because outside sensor field of view
+ 0x0d reserved
+ 0x0e invalid cluster because it is a harmonics
+ (Valid states)
+ 0x00 valid
+ 0x04 valid cluster with low RCS
+ 0x08 valid cluster with azimuth correction due to elevation
+ 0x09 valid cluster with high child probability
+ 0x0a valid cluster with high probability of being a 50 deg artefact
+ 0x0b valid cluster but no local maximum
+ 0x0c valid cluster with high artefact probability
+ 0x0f valid cluster with above 95m in near range
+ 0x10 valid cluster with high multi-target probability
+ 0x11 valid cluster with suspicious angle
+
+ dynProp: Dynamic property of cluster to indicate if is moving or not.
+ 0: moving
+ 1: stationary
+ 2: oncoming
+ 3: stationary candidate
+ 4: unknown
+ 5: crossing stationary
+ 6: crossing moving
+ 7: stopped
+
+ ambig_state: State of Doppler (radial velocity) ambiguity solution.
+ 0: invalid
+ 1: ambiguous
+ 2: staggered ramp
+ 3: unambiguous
+ 4: stationary candidates
+
+ pdh0: False alarm probability of cluster (i.e. probability of being an artefact caused by multipath or similar).
+ 0: invalid
+ 1: <25%
+ 2: 50%
+ 3: 75%
+ 4: 90%
+ 5: 99%
+ 6: 99.9%
+ 7: <=100%
+ """
+
+ assert file_name.endswith('.pcd'), 'Unsupported filetype {}'.format(file_name)
+
+ meta = []
+ with open(file_name, 'rb') as f:
+ for line in f:
+ line = line.strip().decode('utf-8')
+ meta.append(line)
+ if line.startswith('DATA'):
+ break
+
+ data_binary = f.read()
+
+ # Get the header rows and check if they appear as expected.
+ assert meta[0].startswith('#'), 'First line must be comment'
+ assert meta[1].startswith('VERSION'), 'Second line must be VERSION'
+ sizes = meta[3].split(' ')[1:]
+ types = meta[4].split(' ')[1:]
+ counts = meta[5].split(' ')[1:]
+ width = int(meta[6].split(' ')[1])
+ height = int(meta[7].split(' ')[1])
+ data = meta[10].split(' ')[1]
+ feature_count = len(types)
+ assert width > 0
+ assert len([c for c in counts if c != c]) == 0, 'Error: COUNT not supported!'
+ assert height == 1, 'Error: height != 0 not supported!'
+ assert data == 'binary'
+
+ # Lookup table for how to decode the binaries.
+ unpacking_lut = {'F': {2: 'e', 4: 'f', 8: 'd'},
+ 'I': {1: 'b', 2: 'h', 4: 'i', 8: 'q'},
+ 'U': {1: 'B', 2: 'H', 4: 'I', 8: 'Q'}}
+ types_str = ''.join([unpacking_lut[t][int(s)] for t, s in zip(types, sizes)])
+
+ # Decode each point.
+ offset = 0
+ point_count = width
+ points = []
+ for i in range(point_count):
+ point = []
+ for p in range(feature_count):
+ start_p = offset
+ end_p = start_p + int(sizes[p])
+ assert end_p < len(data_binary)
+ point_p = struct.unpack(types_str[p], data_binary[start_p:end_p])[0]
+ point.append(point_p)
+ offset = end_p
+ points.append(point)
+
+ # A NaN in the first point indicates an empty pointcloud.
+ point = np.array(points[0])
+ if np.any(np.isnan(point)):
+ return cls(np.zeros((feature_count, 0)))
+
+ # Convert to numpy matrix.
+ points = np.array(points).transpose()
+
+ # If no parameters are provided, use default settings.
+ invalid_states = cls.invalid_states if invalid_states is None else invalid_states
+ dynprop_states = cls.dynprop_states if dynprop_states is None else dynprop_states
+ ambig_states = cls.ambig_states if ambig_states is None else ambig_states
+
+ # Filter points with an invalid state.
+ valid = [p in invalid_states for p in points[-4, :]]
+ points = points[:, valid]
+
+ # Filter by dynProp.
+ valid = [p in dynprop_states for p in points[3, :]]
+ points = points[:, valid]
+
+ # Filter by ambig_state.
+ valid = [p in ambig_states for p in points[11, :]]
+ points = points[:, valid]
+
+ return cls(points)
+
+
+class Box:
+ """ Simple data class representing a 3d box including, label, score and velocity. """
+
+ def __init__(self,
+ center: List[float],
+ size: List[float],
+ orientation: Quaternion,
+ label: int = np.nan,
+ score: float = np.nan,
+ velocity: Tuple = (np.nan, np.nan, np.nan),
+ name: str = None,
+ token: str = None):
+ """
+ :param center: Center of box given as x, y, z.
+ :param size: Size of box in width, length, height.
+ :param orientation: Box orientation.
+ :param label: Integer label, optional.
+ :param score: Classification score, optional.
+ :param velocity: Box velocity in x, y, z direction.
+ :param name: Box name, optional. Can be used e.g. for denote category name.
+ :param token: Unique string identifier from DB.
+ """
+ assert not np.any(np.isnan(center))
+ assert not np.any(np.isnan(size))
+ assert len(center) == 3
+ assert len(size) == 3
+ assert type(orientation) == Quaternion
+
+ self.center = np.array(center)
+ self.wlh = np.array(size)
+ self.orientation = orientation
+ self.label = int(label) if not np.isnan(label) else label
+ self.score = float(score) if not np.isnan(score) else score
+ self.velocity = np.array(velocity)
+ self.name = name
+ self.token = token
+
+ def __eq__(self, other):
+ center = np.allclose(self.center, other.center)
+ wlh = np.allclose(self.wlh, other.wlh)
+ orientation = np.allclose(self.orientation.elements, other.orientation.elements)
+ label = (self.label == other.label) or (np.isnan(self.label) and np.isnan(other.label))
+ score = (self.score == other.score) or (np.isnan(self.score) and np.isnan(other.score))
+ vel = (np.allclose(self.velocity, other.velocity) or
+ (np.all(np.isnan(self.velocity)) and np.all(np.isnan(other.velocity))))
+
+ return center and wlh and orientation and label and score and vel
+
+ def __repr__(self):
+ repr_str = 'label: {}, score: {:.2f}, xyz: [{:.2f}, {:.2f}, {:.2f}], wlh: [{:.2f}, {:.2f}, {:.2f}], ' \
+ 'rot axis: [{:.2f}, {:.2f}, {:.2f}], ang(degrees): {:.2f}, ang(rad): {:.2f}, ' \
+ 'vel: {:.2f}, {:.2f}, {:.2f}, name: {}, token: {}'
+
+ return repr_str.format(self.label, self.score, self.center[0], self.center[1], self.center[2], self.wlh[0],
+ self.wlh[1], self.wlh[2], self.orientation.axis[0], self.orientation.axis[1],
+ self.orientation.axis[2], self.orientation.degrees, self.orientation.radians,
+ self.velocity[0], self.velocity[1], self.velocity[2], self.name, self.token)
+
+ @property
+ def rotation_matrix(self) -> np.ndarray:
+ """
+ Return a rotation matrix.
+ :return: <np.float: 3, 3>. The box's rotation matrix.
+ """
+ return self.orientation.rotation_matrix
+
+ def translate(self, x: np.ndarray) -> None:
+ """
+ Applies a translation.
+ :param x: <np.float: 3, 1>. Translation in x, y, z direction.
+ """
+ self.center += x
+
+ def rotate(self, quaternion: Quaternion) -> None:
+ """
+ Rotates box.
+ :param quaternion: Rotation to apply.
+ """
+ self.center = np.dot(quaternion.rotation_matrix, self.center)
+ self.orientation = quaternion * self.orientation
+ self.velocity = np.dot(quaternion.rotation_matrix, self.velocity)
+
+ def corners(self, wlh_factor: float = 1.0) -> np.ndarray:
+ """
+ Returns the bounding box corners.
+ :param wlh_factor: Multiply w, l, h by a factor to scale the box.
+ :return: <np.float: 3, 8>. First four corners are the ones facing forward.
+ The last four are the ones facing backwards.
+ """
+ w, l, h = self.wlh * wlh_factor
+
+ # 3D bounding box corners. (Convention: x points forward, y to the left, z up.)
+ x_corners = l / 2 * np.array([1, 1, 1, 1, -1, -1, -1, -1])
+ y_corners = w / 2 * np.array([1, -1, -1, 1, 1, -1, -1, 1])
+ z_corners = h / 2 * np.array([1, 1, -1, -1, 1, 1, -1, -1])
+ corners = np.vstack((x_corners, y_corners, z_corners))
+
+ # Rotate
+ corners = np.dot(self.orientation.rotation_matrix, corners)
+
+ # Translate
+ x, y, z = self.center
+ corners[0, :] = corners[0, :] + x
+ corners[1, :] = corners[1, :] + y
+ corners[2, :] = corners[2, :] + z
+
+ return corners
+
+ def bottom_corners(self) -> np.ndarray:
+ """
+ Returns the four bottom corners.
+ :return: <np.float: 3, 4>. Bottom corners. First two face forward, last two face backwards.
+ """
+ return self.corners()[:, [2, 3, 7, 6]]
+
+ def render(self,
+ axis: Axes,
+ view: np.ndarray = np.eye(3),
+ normalize: bool = False,
+ colors: Tuple = ('b', 'r', 'k'),
+ linewidth: float = 2) -> None:
+ """
+ Renders the box in the provided Matplotlib axis.
+ :param axis: Axis onto which the box should be drawn.
+ :param view: <np.array: 3, 3>. Define a projection in needed (e.g. for drawing projection in an image).
+ :param normalize: Whether to normalize the remaining coordinate.
+ :param colors: (<Matplotlib.colors>: 3). Valid Matplotlib colors (<str> or normalized RGB tuple) for front,
+ back and sides.
+ :param linewidth: Width in pixel of the box sides.
+ """
+ corners = view_points(self.corners(), view, normalize=normalize)[:2, :]
+
+ def draw_rect(selected_corners, color):
+ prev = selected_corners[-1]
+ for corner in selected_corners:
+ axis.plot([prev[0], corner[0]], [prev[1], corner[1]], color=color, linewidth=linewidth)
+ prev = corner
+
+ # Draw the sides
+ for i in range(4):
+ axis.plot([corners.T[i][0], corners.T[i + 4][0]],
+ [corners.T[i][1], corners.T[i + 4][1]],
+ color=colors[2], linewidth=linewidth)
+
+ # Draw front (first 4 corners) and rear (last 4 corners) rectangles(3d)/lines(2d)
+ draw_rect(corners.T[:4], colors[0])
+ draw_rect(corners.T[4:], colors[1])
+
+ # Draw line indicating the front
+ center_bottom_forward = np.mean(corners.T[2:4], axis=0)
+ center_bottom = np.mean(corners.T[[2, 3, 7, 6]], axis=0)
+ axis.plot([center_bottom[0], center_bottom_forward[0]],
+ [center_bottom[1], center_bottom_forward[1]],
+ color=colors[0], linewidth=linewidth)
+
+ def render_cv2(self,
+ im: np.ndarray,
+ view: np.ndarray = np.eye(3),
+ normalize: bool = False,
+ colors: Tuple = ((0, 0, 255), (255, 0, 0), (155, 155, 155)),
+ linewidth: int = 2) -> None:
+ """
+ Renders box using OpenCV2.
+ :param im: <np.array: width, height, 3>. Image array. Channels are in BGR order.
+ :param view: <np.array: 3, 3>. Define a projection if needed (e.g. for drawing projection in an image).
+ :param normalize: Whether to normalize the remaining coordinate.
+ :param colors: ((R, G, B), (R, G, B), (R, G, B)). Colors for front, side & rear.
+ :param linewidth: Linewidth for plot.
+ """
+ corners = view_points(self.corners(), view, normalize=normalize)[:2, :]
+
+ def draw_rect(selected_corners, color):
+ prev = selected_corners[-1]
+ for corner in selected_corners:
+ cv2.line(im,
+ (int(prev[0]), int(prev[1])),
+ (int(corner[0]), int(corner[1])),
+ color, linewidth)
+ prev = corner
+
+ # Draw the sides
+ for i in range(4):
+ cv2.line(im,
+ (int(corners.T[i][0]), int(corners.T[i][1])),
+ (int(corners.T[i + 4][0]), int(corners.T[i + 4][1])),
+ colors[2][::-1], linewidth)
+
+ # Draw front (first 4 corners) and rear (last 4 corners) rectangles(3d)/lines(2d)
+ draw_rect(corners.T[:4], colors[0][::-1])
+ draw_rect(corners.T[4:], colors[1][::-1])
+
+ # Draw line indicating the front
+ center_bottom_forward = np.mean(corners.T[2:4], axis=0)
+ center_bottom = np.mean(corners.T[[2, 3, 7, 6]], axis=0)
+ cv2.line(im,
+ (int(center_bottom[0]), int(center_bottom[1])),
+ (int(center_bottom_forward[0]), int(center_bottom_forward[1])),
+ colors[0][::-1], linewidth)
+
+ def copy(self) -> 'Box':
+ """
+ Create a copy of self.
+ :return: A copy.
+ """
+ return copy.deepcopy(self)
+
+class MyBox(Box):
+ def __init__(self,
+ center: List[float],
+ size: List[float],
+ orientation: Quaternion,
+ label: int = np.nan,
+ score: float = np.nan,
+ velocity: Tuple = (np.nan, np.nan, np.nan),
+ name: str = None,
+ anno_token: str = None,
+ sample_data_token: str = None # sample data token
+ ):
+
+ super(MyBox,self).__init__(
+ center,
+ size,
+ orientation,
+ label,
+ score,
+ velocity,
+ name,
+ anno_token)
+ self.sample_data_token = sample_data_token
+
\ No newline at end of file
diff --git a/python-sdk/nuscenes/utils/geometry_utils.py b/python-sdk/nuscenes/utils/geometry_utils.py
new file mode 100644
index 0000000..4a54cd9
--- /dev/null
+++ b/python-sdk/nuscenes/utils/geometry_utils.py
@@ -0,0 +1,145 @@
+# nuScenes dev-kit.
+# Code written by Oscar Beijbom and Alex Lang, 2018.
+
+from enum import IntEnum
+from typing import Tuple
+
+import numpy as np
+from pyquaternion import Quaternion
+
+
+class BoxVisibility(IntEnum):
+ """ Enumerates the various level of box visibility in an image """
+ ALL = 0 # Requires all corners are inside the image.
+ ANY = 1 # Requires at least one corner visible in the image.
+ NONE = 2 # Requires no corners to be inside, i.e. box can be fully outside the image.
+
+
+def view_points(points: np.ndarray, view: np.ndarray, normalize: bool) -> np.ndarray:
+ """
+ This is a helper class that maps 3d points to a 2d plane. It can be used to implement both perspective and
+ orthographic projections. It first applies the dot product between the points and the view. By convention,
+ the view should be such that the data is projected onto the first 2 axis. It then optionally applies a
+ normalization along the third dimension.
+
+ For a perspective projection the view should be a 3x3 camera matrix, and normalize=True
+ For an orthographic projection with translation the view is a 3x4 matrix and normalize=False
+ For an orthographic projection without translation the view is a 3x3 matrix (optionally 3x4 with last columns
+ all zeros) and normalize=False
+
+ :param points: <np.float32: 3, n> Matrix of points, where each point (x, y, z) is along each column.
+ :param view: <np.float32: n, n>. Defines an arbitrary projection (n <= 4).
+ The projection should be such that the corners are projected onto the first 2 axis.
+ :param normalize: Whether to normalize the remaining coordinate (along the third axis).
+ :return: <np.float32: 3, n>. Mapped point. If normalize=False, the third coordinate is the height.
+ """
+
+ assert view.shape[0] <= 4
+ assert view.shape[1] <= 4
+ assert points.shape[0] == 3
+
+ viewpad = np.eye(4)
+ viewpad[:view.shape[0], :view.shape[1]] = view
+
+ nbr_points = points.shape[1]
+
+ # Do operation in homogenous coordinates.
+ points = np.concatenate((points, np.ones((1, nbr_points))))
+ points = np.dot(viewpad, points)
+ points = points[:3, :]
+
+ if normalize:
+ points = points / points[2:3, :].repeat(3, 0).reshape(3, nbr_points)
+
+ return points
+
+
+def box_in_image(box, intrinsic: np.ndarray, imsize: Tuple[int, int], vis_level: int = BoxVisibility.ANY) -> bool:
+ """
+ Check if a box is visible inside an image without accounting for occlusions.
+ :param box: The box to be checked.
+ :param intrinsic: <float: 3, 3>. Intrinsic camera matrix.
+ :param imsize: (width, height).
+ :param vis_level: One of the enumerations of <BoxVisibility>.
+ :return True if visibility condition is satisfied.
+ """
+
+ corners_3d = box.corners()
+ corners_img = view_points(corners_3d, intrinsic, normalize=True)[:2, :]
+
+ visible = np.logical_and(corners_img[0, :] > 0, corners_img[0, :] < imsize[0])
+ visible = np.logical_and(visible, corners_img[1, :] < imsize[1])
+ visible = np.logical_and(visible, corners_img[1, :] > 0)
+ visible = np.logical_and(visible, corners_3d[2, :] > 1)
+
+ in_front = corners_3d[2, :] > 0.1 # True if a corner is at least 0.1 meter in front of the camera.
+
+ if vis_level == BoxVisibility.ALL:
+ return all(visible) and all(in_front)
+ elif vis_level == BoxVisibility.ANY:
+ return any(visible) and all(in_front)
+ elif vis_level == BoxVisibility.NONE:
+ return True
+ else:
+ raise ValueError("vis_level: {} not valid".format(vis_level))
+
+
+def transform_matrix(translation: np.ndarray = np.array([0, 0, 0]),
+ rotation: Quaternion = Quaternion([1, 0, 0, 0]),
+ inverse: bool = False) -> np.ndarray:
+ """
+ Convert pose to transformation matrix.
+ :param translation: <np.float32: 3>. Translation in x, y, z.
+ :param rotation: Rotation in quaternions (w ri rj rk).
+ :param inverse: Whether to compute inverse transform matrix.
+ :return: <np.float32: 4, 4>. Transformation matrix.
+ """
+ tm = np.eye(4)
+
+ if inverse:
+ rot_inv = rotation.rotation_matrix.T
+ trans = np.transpose(-np.array(translation))
+ tm[:3, :3] = rot_inv
+ tm[:3, 3] = rot_inv.dot(trans)
+ else:
+ tm[:3, :3] = rotation.rotation_matrix
+ tm[:3, 3] = np.transpose(np.array(translation))
+
+ return tm
+
+
+def points_in_box(box: 'Box', points: np.ndarray, wlh_factor: float = 1.0):
+ """
+ Checks whether points are inside the box.
+
+ Picks one corner as reference (p1) and computes the vector to a target point (v).
+ Then for each of the 3 axes, project v onto the axis and compare the length.
+ Inspired by: https://math.stackexchange.com/a/1552579
+ :param box: <Box>.
+ :param points: <np.float: 3, n>.
+ :param wlh_factor: Inflates or deflates the box.
+ :return: <np.bool: n, >.
+ """
+ corners = box.corners(wlh_factor=wlh_factor)
+
+ p1 = corners[:, 0]
+ p_x = corners[:, 4]
+ p_y = corners[:, 1]
+ p_z = corners[:, 3]
+
+ i = p_x - p1
+ j = p_y - p1
+ k = p_z - p1
+
+ v = points - p1.reshape((-1, 1))
+
+ iv = np.dot(i, v)
+ jv = np.dot(j, v)
+ kv = np.dot(k, v)
+
+ mask_x = np.logical_and(0 <= iv, iv <= np.dot(i, i))
+ mask_y = np.logical_and(0 <= jv, jv <= np.dot(j, j))
+ mask_z = np.logical_and(0 <= kv, kv <= np.dot(k, k))
+ mask = np.logical_and(np.logical_and(mask_x, mask_y), mask_z)
+
+ return mask
diff --git a/python-sdk/nuscenes/utils/kitti.py b/python-sdk/nuscenes/utils/kitti.py
new file mode 100644
index 0000000..8fb9b1b
--- /dev/null
+++ b/python-sdk/nuscenes/utils/kitti.py
@@ -0,0 +1,554 @@
+# nuScenes dev-kit.
+# Code written by Alex Lang and Holger Caesar, 2019.
+
+import os
+from os import path as osp
+from typing import List, Tuple, Any, Union
+
+import matplotlib.pyplot as plt
+import numpy as np
+from PIL import Image
+from matplotlib.axes import Axes
+from pyquaternion import Quaternion
+
+from nuscenes.nuscenes import NuScenesExplorer
+from nuscenes.utils.data_classes import Box, LidarPointCloud
+from nuscenes.utils.geometry_utils import box_in_image, BoxVisibility, view_points
+
+
+class KittiDB:
+ """
+ KITTI database that abstracts away interactions with KITTI files and handles all required transformations.
+ This file exists as a utility class for `export_kitti.py`. It may not support more general use cases.
+
+ NOTES about KITTI:
+ - Setup is defined here: http://www.cvlibs.net/datasets/kitti/setup.php
+ - Box annotations live in CamRect frame
+ - KITTI lidar frame is 90 degrees rotated from nuScenes lidar frame
+ - To export to KITTI format from nuScenes lidar requires:
+ - Rotate to KITTI lidar
+ - Transform lidar to camera
+ - Transform camera to camera rectified
+ - To transform from box annotations to nuScenes lidar requires:
+ - Inverse of camera rectification
+ - Inverse transform of lidar to camera
+ - Rotate to nuScenes lidar
+ - KITTI 2D boxes cannot always be obtained from the 3D box. The size of a 3D box was fixed for a tracklet
+ so it can be large for walking pedestrians that stop moving. Those loose 2D boxes were then corrected
+ using Mechanical Turk.
+
+ NOTES about KittiDB:
+ - The samples tokens are expected to have the format of SPLIT_INT where split is a data folder
+ {train, val, test} while INT is the integer label of the sample within that data folder.
+ - The KITTI dataset should be downloaded from http://www.cvlibs.net/datasets/kitti/.
+ - We use the MV3D splits, not the official KITTI splits (which doesn't have any val).
+ """
+
+ def __init__(self,
+ root: str = '/data/sets/kitti',
+ splits: Tuple[str, ...] = ('train',)):
+ """
+ :param root: Base folder for all KITTI data.
+ :param splits: Which splits to load.
+ """
+ self.root = root
+ self.tables = ('calib', 'image_2', 'label_2', 'velodyne')
+ self._kitti_fileext = {'calib': 'txt', 'image_2': 'png', 'label_2': 'txt', 'velodyne': 'bin'}
+
+ # Grab all the expected tokens.
+ self._kitti_tokens = {}
+ for split in splits:
+ split_dir = osp.join(self.root, split, 'image_2')
+ _tokens = os.listdir(split_dir)
+ _tokens = [t.replace('.png', '') for t in _tokens]
+ _tokens.sort()
+ self._kitti_tokens[split] = _tokens
+
+ # Creating the tokens.
+ self.tokens = []
+ for split, tokens in self._kitti_tokens.items():
+ self.tokens += ['{}_{}'.format(split, token) for token in tokens]
+
+ # KITTI LIDAR has the x-axis pointing forward, but our LIDAR points to the right. So we need to apply a
+ # 90 degree rotation around to yaw (z-axis) in order to align.
+ # The quaternions will be used a lot of time. We store them as instance variables so that we don't have
+ # to create a new one every single time.
+ self.kitti_to_nu_lidar = Quaternion(axis=(0, 0, 1), angle=np.pi / 2)
+ self.kitti_to_nu_lidar_inv = Quaternion(axis=(0, 0, 1), angle=np.pi / 2).inverse
+
+ @staticmethod
+ def standardize_sample_token(token: str) -> Tuple[str, str]:
+ """
+ Convert sample token into standard KITTI folder and local filename format.
+ :param token: KittiDB unique id.
+ :return: folder (ex. train, val, test), filename (ex. 000001)
+ """
+ splits = token.split('_')
+ folder = '_'.join(splits[:-1])
+ filename = splits[-1]
+ return folder, filename
+
+ @staticmethod
+ def parse_label_line(label_line) -> dict:
+ """
+ Parses single line from label file into a dict. Boxes are in camera frame. See KITTI devkit for details and
+ http://www.cvlibs.net/datasets/kitti/setup.php for visualizations of the setup.
+ :param label_line: Single line from KittiDB label file.
+ :return: Dictionary with all the line details.
+ """
+
+ parts = label_line.split(' ')
+ output = {
+ 'name': parts[0].strip(),
+ 'xyz_camera': (float(parts[11]), float(parts[12]), float(parts[13])),
+ 'wlh': (float(parts[9]), float(parts[10]), float(parts[8])),
+ 'yaw_camera': float(parts[14]),
+ 'bbox_camera': (float(parts[4]), float(parts[5]), float(parts[6]), float(parts[7])),
+ 'truncation': float(parts[1]),
+ 'occlusion': float(parts[2]),
+ 'alpha': float(parts[3])
+ }
+
+ # Add score if specified
+ if len(parts) > 15:
+ output['score'] = float(parts[15])
+ else:
+ output['score'] = np.nan
+
+ return output
+
+ @staticmethod
+ def box_nuscenes_to_kitti(box: Box, velo_to_cam_rot: Quaternion,
+ velo_to_cam_trans: np.ndarray,
+ r0_rect: Quaternion,
+ kitti_to_nu_lidar_inv: Quaternion = Quaternion(axis=(0, 0, 1), angle=np.pi / 2).inverse) \
+ -> Box:
+ """
+ Transform from nuScenes lidar frame to KITTI reference frame.
+ :param box: Instance in nuScenes lidar frame.
+ :param velo_to_cam_rot: Quaternion to rotate from lidar to camera frame.
+ :param velo_to_cam_trans: <np.float: 3>. Translate from lidar to camera frame.
+ :param r0_rect: Quaternion to rectify camera frame.
+ :param kitti_to_nu_lidar_inv: Quaternion to rotate nuScenes to KITTI LIDAR.
+ :return: Box instance in KITTI reference frame.
+ """
+ # Copy box to avoid side-effects.
+ box = box.copy()
+
+ # Rotate to KITTI lidar.
+ box.rotate(kitti_to_nu_lidar_inv)
+
+ # Transform to KITTI camera.
+ box.rotate(velo_to_cam_rot)
+ box.translate(velo_to_cam_trans)
+
+ # Rotate to KITTI rectified camera.
+ box.rotate(r0_rect)
+
+ # KITTI defines the box center as the bottom center of the object.
+ # We use the true center, so we need to adjust half height in y direction.
+ box.translate(np.array([0, box.wlh[2] / 2, 0]))
+
+ return box
+
+ @staticmethod
+ def project_kitti_box_to_image(box: Box, p_left: np.ndarray, imsize: Tuple[int, int]) \
+ -> Union[None, Tuple[int, int, int, int]]:
+ """
+ Projects 3D box into KITTI image FOV.
+ :param box: 3D box in KITTI reference frame.
+ :param p_left: <np.float: 3, 4>. Projection matrix.
+ :param imsize: (width, height). Image size.
+ :return: (xmin, ymin, xmax, ymax). Bounding box in image plane or None if box is not in the image.
+ """
+
+ # Create a new box.
+ box = box.copy()
+
+ # KITTI defines the box center as the bottom center of the object.
+ # We use the true center, so we need to adjust half height in negative y direction.
+ box.translate(np.array([0, -box.wlh[2] / 2, 0]))
+
+ # Check that some corners are inside the image.
+ corners = np.array([corner for corner in box.corners().T if corner[2] > 0]).T
+ if len(corners) == 0:
+ return None
+
+ # Project corners that are in front of the camera to 2d to get bbox in pixel coords.
+ imcorners = view_points(corners, p_left, normalize=True)[:2]
+ bbox = (np.min(imcorners[0]), np.min(imcorners[1]), np.max(imcorners[0]), np.max(imcorners[1]))
+
+ # Crop bbox to prevent it extending outside image.
+ bbox_crop = tuple(max(0, b) for b in bbox)
+ bbox_crop = (min(imsize[0], bbox_crop[0]),
+ min(imsize[0], bbox_crop[1]),
+ min(imsize[0], bbox_crop[2]),
+ min(imsize[1], bbox_crop[3]))
+
+ # Detect if a cropped box is empty.
+ if bbox_crop[0] >= bbox_crop[2] or bbox_crop[1] >= bbox_crop[3]:
+ return None
+
+ return bbox_crop
+
+ @staticmethod
+ def get_filepath(token: str, table: str, root: str='/data/sets/kitti') -> str:
+ """
+ For a token and table, get the filepath to the associated data.
+ :param token: KittiDB unique id.
+ :param table: Type of table, for example image or velodyne.
+ :param root: Base folder for all KITTI data.
+ :return: Full get_filepath to desired data.
+ """
+ folder, filename = KittiDB.standardize_sample_token(token)
+ kitti_fileext = {'calib': 'txt', 'image_2': 'png', 'label_2': 'txt', 'velodyne': 'bin'}
+
+ ending = kitti_fileext[table]
+
+ if token.startswith('test_') and table == 'label_2':
+ filepath = None
+ print('No cheating! The test set has no labels.')
+ else:
+ filepath = osp.join(root, folder, table, '{}.{}'.format(filename, ending))
+
+ return filepath
+
+ @staticmethod
+ def get_transforms(token: str, root: str='/data/sets/kitti') -> dict:
+ """
+ Returns transforms for the input token.
+ :param token: KittiDB unique id.
+ :param root: Base folder for all KITTI data.
+ :return: {
+ 'velo_to_cam': {'R': <np.float: 3, 3>, 'T': <np.float: 3, 1>}. Lidar to camera transformation matrix.
+ 'r0_rect': <np.float: 3, 3>. Rectification matrix.
+ 'p_left': <np.float: 3, 4>. Projection matrix.
+ 'p_combined': <np.float: 4, 4>. Combined rectification and projection matrix.
+ }. Returns the transformation matrices. For details refer to the KITTI devkit.
+ """
+ calib_filename = KittiDB.get_filepath(token, 'calib', root=root)
+
+ lines = [line.rstrip() for line in open(calib_filename)]
+ velo_to_cam = np.array(lines[5].strip().split(' ')[1:], dtype=np.float32)
+ velo_to_cam.resize((3, 4))
+
+ r0_rect = np.array(lines[4].strip().split(' ')[1:], dtype=np.float32)
+ r0_rect.resize((3, 3))
+ p_left = np.array(lines[2].strip().split(' ')[1:], dtype=np.float32)
+ p_left.resize((3, 4))
+
+ # Merge rectification and projection into one matrix.
+ p_combined = np.eye(4)
+ p_combined[:3, :3] = r0_rect
+ p_combined = np.dot(p_left, p_combined)
+ return {
+ 'velo_to_cam': {
+ 'R': velo_to_cam[:, :3],
+ 'T': velo_to_cam[:, 3]
+ },
+ 'r0_rect': r0_rect,
+ 'p_left': p_left,
+ 'p_combined': p_combined,
+ }
+
+ @staticmethod
+ def get_pointcloud(token: str, root: str = '/data/sets/kitti') -> LidarPointCloud:
+ """
+ Load up the pointcloud for a sample.
+ :param token: KittiDB unique id.
+ :param root: Base folder for all KITTI data.
+ :return: LidarPointCloud for the sample in the KITTI Lidar frame.
+ """
+ pc_filename = KittiDB.get_filepath(token, 'velodyne', root=root)
+
+ # The lidar PC is stored in the KITTI LIDAR coord system.
+ pc = LidarPointCloud(np.fromfile(pc_filename, dtype=np.float32).reshape(-1, 4).T)
+
+ return pc
+
+ def get_boxes(self,
+ token: str,
+ filter_classes: List[str] = None,
+ max_dist: float = None) -> List[Box]:
+ """
+ Load up all the boxes associated with a sample.
+ Boxes are in nuScenes lidar frame.
+ :param token: KittiDB unique id.
+ :param filter_classes: List of Kitti classes to use or None to use all.
+ :param max_dist: Maximum distance in m to still draw a box.
+ :return: Boxes in nuScenes lidar reference frame.
+ """
+ # Get transforms for this sample
+ transforms = self.get_transforms(token, root=self.root)
+
+ boxes = []
+ if token.startswith('test_'):
+ # No boxes to return for the test set.
+ return boxes
+
+ with open(KittiDB.get_filepath(token, 'label_2', root=self.root), 'r') as f:
+ for line in f:
+ # Parse this line into box information.
+ parsed_line = self.parse_label_line(line)
+
+ if parsed_line['name'] in {'DontCare', 'Misc'}:
+ continue
+
+ center = parsed_line['xyz_camera']
+ wlh = parsed_line['wlh']
+ yaw_camera = parsed_line['yaw_camera']
+ name = parsed_line['name']
+ score = parsed_line['score']
+
+ # Optional: Filter classes.
+ if filter_classes is not None and name not in filter_classes:
+ continue
+
+ # The Box class coord system is oriented the same way as as KITTI LIDAR: x forward, y left, z up.
+ # For orientation confer: http://www.cvlibs.net/datasets/kitti/setup.php.
+
+ # 1: Create box in Box coordinate system with center at origin.
+ # The second quaternion in yaw_box transforms the coordinate frame from the object frame
+ # to KITTI camera frame. The equivalent cannot be naively done afterwards, as it's a rotation
+ # around the local object coordinate frame, rather than the camera frame.
+ quat_box = Quaternion(axis=(0, 1, 0), angle=yaw_camera) * Quaternion(axis=(1, 0, 0), angle=np.pi/2)
+ box = Box([0.0, 0.0, 0.0], wlh, quat_box, name=name)
+
+ # 2: Translate: KITTI defines the box center as the bottom center of the vehicle. We use true center,
+ # so we need to add half height in negative y direction, (since y points downwards), to adjust. The
+ # center is already given in camera coord system.
+ box.translate(center + np.array([0, -wlh[2] / 2, 0]))
+
+ # 3: Transform to KITTI LIDAR coord system. First transform from rectified camera to camera, then
+ # camera to KITTI lidar.
+ box.rotate(Quaternion(matrix=transforms['r0_rect']).inverse)
+ box.translate(-transforms['velo_to_cam']['T'])
+ box.rotate(Quaternion(matrix=transforms['velo_to_cam']['R']).inverse)
+
+ # 4: Transform to nuScenes LIDAR coord system.
+ box.rotate(self.kitti_to_nu_lidar)
+
+ # Set score or NaN.
+ box.score = score
+
+ # Set dummy velocity.
+ box.velocity = np.array((0.0, 0.0, 0.0))
+
+ # Optional: Filter by max_dist
+ if max_dist is not None:
+ dist = np.sqrt(np.sum(box.center[:2] ** 2))
+ if dist > max_dist:
+ continue
+
+ boxes.append(box)
+
+ return boxes
+
+ def get_boxes_2d(self,
+ token: str,
+ filter_classes: List[str] = None) -> Tuple[
+ List[Tuple[float, float, float, float]],
+ List[str]
+ ]:
+ """
+ Get the 2d boxes associated with a sample.
+ :return: A list of boxes in KITTI format (xmin, ymin, xmax, ymax) and a list of the class names.
+ """
+ boxes = []
+ names = []
+ with open(KittiDB.get_filepath(token, 'label_2', root=self.root), 'r') as f:
+ for line in f:
+ # Parse this line into box information.
+ parsed_line = self.parse_label_line(line)
+
+ if parsed_line['name'] in {'DontCare', 'Misc'}:
+ continue
+
+ bbox_2d = parsed_line['bbox_camera']
+ name = parsed_line['name']
+
+ # Optional: Filter classes.
+ if filter_classes is not None and name not in filter_classes:
+ continue
+
+ boxes.append(bbox_2d)
+ names.append(name)
+ return boxes, names
+
+
+ @staticmethod
+ def box_to_string(name: str,
+ box: Box,
+ bbox_2d: Tuple[float, float, float, float] = (-1.0, -1.0, -1.0, -1.0),
+ truncation: float = -1.0,
+ occlusion: int = -1,
+ alpha: float = -10.0) -> str:
+ """
+ Convert box in KITTI image frame to official label string fromat.
+ :param name: KITTI name of the box.
+ :param box: Box class in KITTI image frame.
+ :param bbox_2d: Optional, 2D bounding box obtained by projected Box into image (xmin, ymin, xmax, ymax).
+ Otherwise set to KITTI default.
+ :param truncation: Optional truncation, otherwise set to KITTI default.
+ :param occlusion: Optional occlusion, otherwise set to KITTI default.
+ :param alpha: Optional alpha, otherwise set to KITTI default.
+ :return: KITTI string representation of box.
+ """
+ # Convert quaternion to yaw angle.
+ v = np.dot(box.rotation_matrix, np.array([1, 0, 0]))
+ yaw = -np.arctan2(v[2], v[0])
+
+ # Prepare output.
+ name += ' '
+ trunc = '{:.2f} '.format(truncation)
+ occ = '{:d} '.format(occlusion)
+ a = '{:.2f} '.format(alpha)
+ bb = '{:.2f} {:.2f} {:.2f} {:.2f} '.format(bbox_2d[0], bbox_2d[1], bbox_2d[2], bbox_2d[3])
+ hwl = '{:.2} {:.2f} {:.2f} '.format(box.wlh[2], box.wlh[0], box.wlh[1]) # height, width, length.
+ xyz = '{:.2f} {:.2f} {:.2f} '.format(box.center[0], box.center[1], box.center[2]) # x, y, z.
+ y = '{:.2f}'.format(yaw) # Yaw angle.
+ s = ' {:.4f}'.format(box.score) # Classification score.
+
+ output = name + trunc + occ + a + bb + hwl + xyz + y
+ if ~np.isnan(box.score):
+ output += s
+
+ return output
+
+ def project_pts_to_image(self, pointcloud: LidarPointCloud, token: str) -> np.ndarray:
+ """
+ Project lidar points into image.
+ :param pointcloud: The LidarPointCloud in nuScenes lidar frame.
+ :param token: Unique KITTI token.
+ :return: <np.float: N, 3.> X, Y are points in image pixel coordinates. Z is depth in image.
+ """
+
+ # Copy and convert pointcloud.
+ pc_image = LidarPointCloud(points=pointcloud.points.copy())
+ pc_image.rotate(self.kitti_to_nu_lidar_inv) # Rotate to KITTI lidar.
+
+ # Transform pointcloud to camera frame.
+ transforms = self.get_transforms(token, root=self.root)
+ pc_image.rotate(transforms['velo_to_cam']['R'])
+ pc_image.translate(transforms['velo_to_cam']['T'])
+
+ # Project to image.
+ depth = pc_image.points[2, :]
+ points_fov = view_points(pc_image.points[:3, :], transforms['p_combined'], normalize=True)
+ points_fov[2, :] = depth
+
+ return points_fov
+
+ def render_sample_data(self,
+ token: str,
+ sensor_modality: str = 'lidar',
+ with_anns: bool = True,
+ axes_limit: float = 30,
+ ax: Axes = None,
+ view_3d: np.ndarray = np.eye(4),
+ color_func: Any = None,
+ augment_previous: bool = False,
+ box_linewidth: int = 2,
+ filter_classes: List[str] = None,
+ max_dist: float = None,
+ out_path: str = None,
+ render_2d: bool = False) -> None:
+ """
+ Render sample data onto axis. Visualizes lidar in nuScenes lidar frame and camera in camera frame.
+ :param token: KITTI token.
+ :param sensor_modality: The modality to visualize, e.g. lidar or camera.
+ :param with_anns: Whether to draw annotations.
+ :param axes_limit: Axes limit for lidar data (measured in meters).
+ :param ax: Axes onto which to render.
+ :param view_3d: 4x4 view matrix for 3d views.
+ :param color_func: Optional function that defines the render color given the class name.
+ :param augment_previous: Whether to augment an existing plot (does not redraw pointcloud/image).
+ :param box_linewidth: Width of the box lines.
+ :param filter_classes: Optionally filter the classes to render.
+ :param max_dist: Maximum distance in m to still draw a box.
+ :param out_path: Optional path to save the rendered figure to disk.
+ :param render_2d: Whether to render 2d boxes (only works for camera data).
+ """
+ # Default settings.
+ if color_func is None:
+ color_func = NuScenesExplorer.get_color
+
+ boxes = self.get_boxes(token, filter_classes=filter_classes, max_dist=max_dist) # In nuScenes lidar frame.
+
+ if sensor_modality == 'lidar':
+ # Load pointcloud.
+ pc = self.get_pointcloud(token, self.root) # In KITTI lidar frame.
+ pc.rotate(self.kitti_to_nu_lidar.rotation_matrix) # In nuScenes lidar frame.
+ # Alternative options:
+ # depth = pc.points[1, :]
+ # height = pc.points[2, :]
+ intensity = pc.points[3, :]
+
+ # Project points to view.
+ points = view_points(pc.points[:3, :], view_3d, normalize=False)
+ coloring = intensity
+
+ if ax is None:
+ _, ax = plt.subplots(1, 1, figsize=(9, 9))
+
+ if not augment_previous:
+ ax.scatter(points[0, :], points[1, :], c=coloring, s=1)
+ ax.set_xlim(-axes_limit, axes_limit)
+ ax.set_ylim(-axes_limit, axes_limit)
+
+ if with_anns:
+ for box in boxes:
+ color = np.array(color_func(box.name)) / 255
+ box.render(ax, view=view_3d, colors=(color, color, 'k'), linewidth=box_linewidth)
+
+ elif sensor_modality == 'camera':
+ im_path = KittiDB.get_filepath(token, 'image_2', root=self.root)
+ im = Image.open(im_path)
+
+ if ax is None:
+ _, ax = plt.subplots(1, 1, figsize=(9, 16))
+
+ if not augment_previous:
+ ax.imshow(im)
+ ax.set_xlim(0, im.size[0])
+ ax.set_ylim(im.size[1], 0)
+
+ if with_anns:
+ if render_2d:
+ # Use KITTI's 2d boxes.
+ boxes_2d, names = self.get_boxes_2d(token, filter_classes=filter_classes)
+ for box, name in zip(boxes_2d, names):
+ color = np.array(color_func(name)) / 255
+ ax.plot([box[0], box[0]], [box[1], box[3]], color=color, linewidth=box_linewidth)
+ ax.plot([box[2], box[2]], [box[1], box[3]], color=color, linewidth=box_linewidth)
+ ax.plot([box[0], box[2]], [box[1], box[1]], color=color, linewidth=box_linewidth)
+ ax.plot([box[0], box[2]], [box[3], box[3]], color=color, linewidth=box_linewidth)
+ else:
+ # Project 3d boxes to 2d.
+ transforms = self.get_transforms(token, self.root)
+ for box in boxes:
+ # Undo the transformations in get_boxes() to get back to the camera frame.
+ box.rotate(self.kitti_to_nu_lidar_inv) # In KITTI lidar frame.
+ box.rotate(Quaternion(matrix=transforms['velo_to_cam']['R']))
+ box.translate(transforms['velo_to_cam']['T']) # In KITTI camera frame, un-rectified.
+ box.rotate(Quaternion(matrix=transforms['r0_rect'])) # In KITTI camera frame, rectified.
+
+ # Filter boxes outside the image (relevant when visualizing nuScenes data in KITTI format).
+ if not box_in_image(box, transforms['p_left'][:3, :3], im.size, vis_level=BoxVisibility.ANY):
+ continue
+
+ # Render.
+ color = np.array(color_func(box.name)) / 255
+ box.render(ax, view=transforms['p_left'][:3, :3], normalize=True, colors=(color, color, 'k'),
+ linewidth=box_linewidth)
+ else:
+ raise ValueError("Unrecognized modality {}.".format(sensor_modality))
+
+ ax.axis('off')
+ ax.set_title(token)
+ ax.set_aspect('equal')
+
+ # Render to disk.
+ plt.tight_layout()
+ if out_path is not None:
+ plt.savefig(out_path)
diff --git a/python-sdk/nuscenes/utils/map_mask.py b/python-sdk/nuscenes/utils/map_mask.py
new file mode 100644
index 0000000..0042e73
--- /dev/null
+++ b/python-sdk/nuscenes/utils/map_mask.py
@@ -0,0 +1,114 @@
+# nuScenes dev-kit.
+# Code written by Qiang Xu and Oscar Beijbom, 2018.
+
+import os.path as osp
+from typing import Tuple, Any
+
+import cv2
+import numpy as np
+from PIL import Image
+from cachetools import cached, LRUCache
+
+# Set the maximum loadable image size.
+Image.MAX_IMAGE_PIXELS = 400000 * 400000
+
+
+class MapMask:
+ def __init__(self, img_file: str, resolution: float = 0.1):
+ """
+ Init a map mask object that contains the semantic prior (driveable surface and sidewalks) mask.
+ :param img_file: File path to map png file.
+ :param resolution: Map resolution in meters.
+ """
+ assert osp.exists(img_file), 'map mask {} does not exist'.format(img_file)
+ assert resolution >= 0.1, "Only supports down to 0.1 meter resolution."
+ self.img_file = img_file
+ self.resolution = resolution
+ self.foreground = 255
+ self.background = 0
+
+ @cached(cache=LRUCache(maxsize=3))
+ def mask(self, dilation: float = 0.0) -> np.ndarray:
+ """
+ Returns the map mask, optionally dilated.
+ :param dilation: Dilation in meters.
+ :return: Dilated map mask.
+ """
+ if dilation == 0:
+ return self._base_mask
+ else:
+ distance_mask = cv2.distanceTransform((self.foreground - self._base_mask).astype(np.uint8), cv2.DIST_L2, 5)
+ distance_mask = (distance_mask * self.resolution).astype(np.float32)
+ return (distance_mask <= dilation).astype(np.uint8) * self.foreground
+
+ @property
+ def transform_matrix(self) -> np.ndarray:
+ """
+ Generate transform matrix for this map mask.
+ :return: <np.array: 4, 4>. The transformation matrix.
+ """
+ return np.array([[1.0 / self.resolution, 0, 0, 0],
+ [0, -1.0 / self.resolution, 0, self._base_mask.shape[0]],
+ [0, 0, 1, 0], [0, 0, 0, 1]])
+
+ def is_on_mask(self, x: Any, y: Any, dilation: float = 0) -> np.array:
+ """
+ Determine whether the given coordinates are on the (optionally dilated) map mask.
+ :param x: Global x coordinates. Can be a scalar, list or a numpy array of x coordinates.
+ :param y: Global y coordinates. Can be a scalar, list or a numpy array of x coordinates.
+ :param dilation: Optional dilation of map mask.
+ :return: <np.bool: x.shape>. Whether the points are on the mask.
+ """
+ px, py = self.to_pixel_coords(x, y)
+
+ on_mask = np.ones(px.size, dtype=np.bool)
+ this_mask = self.mask(dilation)
+
+ on_mask[px < 0] = False
+ on_mask[px >= this_mask.shape[1]] = False
+ on_mask[py < 0] = False
+ on_mask[py >= this_mask.shape[0]] = False
+
+ on_mask[on_mask] = this_mask[py[on_mask], px[on_mask]] == self.foreground
+
+ return on_mask
+
+ def to_pixel_coords(self, x: Any, y: Any) -> Tuple[np.ndarray, np.ndarray]:
+ """
+ Maps x, y location in global map coordinates to the map image coordinates.
+ :param x: Global x coordinates. Can be a scalar, list or a numpy array of x coordinates.
+ :param y: Global y coordinates. Can be a scalar, list or a numpy array of x coordinates.
+ :return: (px <np.uint8: x.shape>, py <np.uint8: y.shape>). Pixel coordinates in map.
+ """
+ x = np.array(x)
+ y = np.array(y)
+ x = np.atleast_1d(x)
+ y = np.atleast_1d(y)
+
+ assert x.shape == y.shape
+ assert x.ndim == y.ndim == 1
+
+ pts = np.stack([x, y, np.zeros(x.shape), np.ones(x.shape)])
+ pixel_coords = np.round(np.dot(self.transform_matrix, pts)).astype(np.int32)
+
+ return pixel_coords[0, :], pixel_coords[1, :]
+
+ @property
+ @cached(cache=LRUCache(maxsize=1))
+ def _base_mask(self) -> np.ndarray:
+ """
+ Returns the original binary mask stored in map png file.
+ :return: <np.int8: image.height, image.width>. The binary mask.
+ """
+ # Pillow allows us to specify the maximum image size above, whereas this is more difficult in OpenCV.
+ img = Image.open(self.img_file)
+
+ # Resize map mask to desired resolution.
+ native_resolution = 0.1
+ size_x = int(img.size[0] / self.resolution * native_resolution)
+ size_y = int(img.size[1] / self.resolution * native_resolution)
+ img = img.resize((size_x, size_y), resample=Image.NEAREST)
+
+ # Convert to numpy.
+ raw_mask = np.array(img)
+ return raw_mask
diff --git a/python-sdk/nuscenes/utils/splits.py b/python-sdk/nuscenes/utils/splits.py
new file mode 100644
index 0000000..45aa5f2
--- /dev/null
+++ b/python-sdk/nuscenes/utils/splits.py
@@ -0,0 +1,218 @@
+# nuScenes dev-kit.
+# Code written by Holger Caesar, 2018.
+
+from typing import Dict, List
+
+from nuscenes import NuScenes
+
+train_detect = \
+ ['scene-0001', 'scene-0002', 'scene-0041', 'scene-0042', 'scene-0043', 'scene-0044', 'scene-0045', 'scene-0046',
+ 'scene-0047', 'scene-0048', 'scene-0049', 'scene-0050', 'scene-0051', 'scene-0052', 'scene-0053', 'scene-0054',
+ 'scene-0055', 'scene-0056', 'scene-0057', 'scene-0058', 'scene-0059', 'scene-0060', 'scene-0061', 'scene-0062',
+ 'scene-0063', 'scene-0064', 'scene-0065', 'scene-0066', 'scene-0067', 'scene-0068', 'scene-0069', 'scene-0070',
+ 'scene-0071', 'scene-0072', 'scene-0073', 'scene-0074', 'scene-0075', 'scene-0076', 'scene-0161', 'scene-0162',
+ 'scene-0163', 'scene-0164', 'scene-0165', 'scene-0166', 'scene-0167', 'scene-0168', 'scene-0170', 'scene-0171',
+ 'scene-0172', 'scene-0173', 'scene-0174', 'scene-0175', 'scene-0176', 'scene-0190', 'scene-0191', 'scene-0192',
+ 'scene-0193', 'scene-0194', 'scene-0195', 'scene-0196', 'scene-0199', 'scene-0200', 'scene-0202', 'scene-0203',
+ 'scene-0204', 'scene-0206', 'scene-0207', 'scene-0208', 'scene-0209', 'scene-0210', 'scene-0211', 'scene-0212',
+ 'scene-0213', 'scene-0214', 'scene-0254', 'scene-0255', 'scene-0256', 'scene-0257', 'scene-0258', 'scene-0259',
+ 'scene-0260', 'scene-0261', 'scene-0262', 'scene-0263', 'scene-0264', 'scene-0283', 'scene-0284', 'scene-0285',
+ 'scene-0286', 'scene-0287', 'scene-0288', 'scene-0289', 'scene-0290', 'scene-0291', 'scene-0292', 'scene-0293',
+ 'scene-0294', 'scene-0295', 'scene-0296', 'scene-0297', 'scene-0298', 'scene-0299', 'scene-0300', 'scene-0301',
+ 'scene-0302', 'scene-0303', 'scene-0304', 'scene-0305', 'scene-0306', 'scene-0315', 'scene-0316', 'scene-0317',
+ 'scene-0318', 'scene-0321', 'scene-0323', 'scene-0324', 'scene-0347', 'scene-0348', 'scene-0349', 'scene-0350',
+ 'scene-0351', 'scene-0352', 'scene-0353', 'scene-0354', 'scene-0355', 'scene-0356', 'scene-0357', 'scene-0358',
+ 'scene-0359', 'scene-0360', 'scene-0361', 'scene-0362', 'scene-0363', 'scene-0364', 'scene-0365', 'scene-0366',
+ 'scene-0367', 'scene-0368', 'scene-0369', 'scene-0370', 'scene-0371', 'scene-0372', 'scene-0373', 'scene-0374',
+ 'scene-0375', 'scene-0382', 'scene-0420', 'scene-0421', 'scene-0422', 'scene-0423', 'scene-0424', 'scene-0425',
+ 'scene-0426', 'scene-0427', 'scene-0428', 'scene-0429', 'scene-0430', 'scene-0431', 'scene-0432', 'scene-0433',
+ 'scene-0434', 'scene-0435', 'scene-0436', 'scene-0437', 'scene-0438', 'scene-0439', 'scene-0457', 'scene-0458',
+ 'scene-0459', 'scene-0461', 'scene-0462', 'scene-0463', 'scene-0464', 'scene-0465', 'scene-0467', 'scene-0468',
+ 'scene-0469', 'scene-0471', 'scene-0472', 'scene-0474', 'scene-0475', 'scene-0476', 'scene-0477', 'scene-0478',
+ 'scene-0479', 'scene-0480', 'scene-0566', 'scene-0568', 'scene-0570', 'scene-0571', 'scene-0572', 'scene-0573',
+ 'scene-0574', 'scene-0575', 'scene-0576', 'scene-0577', 'scene-0578', 'scene-0580', 'scene-0582', 'scene-0583',
+ 'scene-0665', 'scene-0666', 'scene-0667', 'scene-0668', 'scene-0669', 'scene-0670', 'scene-0671', 'scene-0672',
+ 'scene-0673', 'scene-0674', 'scene-0675', 'scene-0676', 'scene-0677', 'scene-0678', 'scene-0679', 'scene-0681',
+ 'scene-0683', 'scene-0684', 'scene-0685', 'scene-0686', 'scene-0687', 'scene-0688', 'scene-0689', 'scene-0739',
+ 'scene-0740', 'scene-0741', 'scene-0744', 'scene-0746', 'scene-0747', 'scene-0749', 'scene-0750', 'scene-0751',
+ 'scene-0752', 'scene-0757', 'scene-0758', 'scene-0759', 'scene-0760', 'scene-0761', 'scene-0762', 'scene-0763',
+ 'scene-0764', 'scene-0765', 'scene-0767', 'scene-0768', 'scene-0769', 'scene-0868', 'scene-0869', 'scene-0870',
+ 'scene-0871', 'scene-0872', 'scene-0873', 'scene-0875', 'scene-0876', 'scene-0877', 'scene-0878', 'scene-0880',
+ 'scene-0882', 'scene-0883', 'scene-0884', 'scene-0885', 'scene-0886', 'scene-0887', 'scene-0888', 'scene-0889',
+ 'scene-0890', 'scene-0891', 'scene-0892', 'scene-0893', 'scene-0894', 'scene-0895', 'scene-0896', 'scene-0897',
+ 'scene-0898', 'scene-0899', 'scene-0900', 'scene-0901', 'scene-0902', 'scene-0903', 'scene-0945', 'scene-0947',
+ 'scene-0949', 'scene-0952', 'scene-0953', 'scene-0955', 'scene-0956', 'scene-0957', 'scene-0958', 'scene-0959',
+ 'scene-0960', 'scene-0961', 'scene-0975', 'scene-0976', 'scene-0977', 'scene-0978', 'scene-0979', 'scene-0980',
+ 'scene-0981', 'scene-0982', 'scene-0983', 'scene-0984', 'scene-0988', 'scene-0989', 'scene-0990', 'scene-0991',
+ 'scene-1011', 'scene-1012', 'scene-1013', 'scene-1014', 'scene-1015', 'scene-1016', 'scene-1017', 'scene-1018',
+ 'scene-1019', 'scene-1020', 'scene-1021', 'scene-1022', 'scene-1023', 'scene-1024', 'scene-1025', 'scene-1074',
+ 'scene-1075', 'scene-1076', 'scene-1077', 'scene-1078', 'scene-1079', 'scene-1080', 'scene-1081', 'scene-1082',
+ 'scene-1083', 'scene-1084', 'scene-1085', 'scene-1086', 'scene-1087', 'scene-1088', 'scene-1089', 'scene-1090',
+ 'scene-1091', 'scene-1092', 'scene-1093', 'scene-1094', 'scene-1095', 'scene-1096', 'scene-1097', 'scene-1098',
+ 'scene-1099', 'scene-1100', 'scene-1101', 'scene-1102', 'scene-1104', 'scene-1105']
+
+train_track = \
+ ['scene-0004', 'scene-0005', 'scene-0006', 'scene-0007', 'scene-0008', 'scene-0009', 'scene-0010', 'scene-0011',
+ 'scene-0019', 'scene-0020', 'scene-0021', 'scene-0022', 'scene-0023', 'scene-0024', 'scene-0025', 'scene-0026',
+ 'scene-0027', 'scene-0028', 'scene-0029', 'scene-0030', 'scene-0031', 'scene-0032', 'scene-0033', 'scene-0034',
+ 'scene-0120', 'scene-0121', 'scene-0122', 'scene-0123', 'scene-0124', 'scene-0125', 'scene-0126', 'scene-0127',
+ 'scene-0128', 'scene-0129', 'scene-0130', 'scene-0131', 'scene-0132', 'scene-0133', 'scene-0134', 'scene-0135',
+ 'scene-0138', 'scene-0139', 'scene-0149', 'scene-0150', 'scene-0151', 'scene-0152', 'scene-0154', 'scene-0155',
+ 'scene-0157', 'scene-0158', 'scene-0159', 'scene-0160', 'scene-0177', 'scene-0178', 'scene-0179', 'scene-0180',
+ 'scene-0181', 'scene-0182', 'scene-0183', 'scene-0184', 'scene-0185', 'scene-0187', 'scene-0188', 'scene-0218',
+ 'scene-0219', 'scene-0220', 'scene-0222', 'scene-0224', 'scene-0225', 'scene-0226', 'scene-0227', 'scene-0228',
+ 'scene-0229', 'scene-0230', 'scene-0231', 'scene-0232', 'scene-0233', 'scene-0234', 'scene-0235', 'scene-0236',
+ 'scene-0237', 'scene-0238', 'scene-0239', 'scene-0240', 'scene-0241', 'scene-0242', 'scene-0243', 'scene-0244',
+ 'scene-0245', 'scene-0246', 'scene-0247', 'scene-0248', 'scene-0249', 'scene-0250', 'scene-0251', 'scene-0252',
+ 'scene-0253', 'scene-0328', 'scene-0376', 'scene-0377', 'scene-0378', 'scene-0379', 'scene-0380', 'scene-0381',
+ 'scene-0383', 'scene-0384', 'scene-0385', 'scene-0386', 'scene-0388', 'scene-0389', 'scene-0390', 'scene-0391',
+ 'scene-0392', 'scene-0393', 'scene-0394', 'scene-0395', 'scene-0396', 'scene-0397', 'scene-0398', 'scene-0399',
+ 'scene-0400', 'scene-0401', 'scene-0402', 'scene-0403', 'scene-0405', 'scene-0406', 'scene-0407', 'scene-0408',
+ 'scene-0410', 'scene-0411', 'scene-0412', 'scene-0413', 'scene-0414', 'scene-0415', 'scene-0416', 'scene-0417',
+ 'scene-0418', 'scene-0419', 'scene-0440', 'scene-0441', 'scene-0442', 'scene-0443', 'scene-0444', 'scene-0445',
+ 'scene-0446', 'scene-0447', 'scene-0448', 'scene-0449', 'scene-0450', 'scene-0451', 'scene-0452', 'scene-0453',
+ 'scene-0454', 'scene-0455', 'scene-0456', 'scene-0499', 'scene-0500', 'scene-0501', 'scene-0502', 'scene-0504',
+ 'scene-0505', 'scene-0506', 'scene-0507', 'scene-0508', 'scene-0509', 'scene-0510', 'scene-0511', 'scene-0512',
+ 'scene-0513', 'scene-0514', 'scene-0515', 'scene-0517', 'scene-0518', 'scene-0525', 'scene-0526', 'scene-0527',
+ 'scene-0528', 'scene-0529', 'scene-0530', 'scene-0531', 'scene-0532', 'scene-0533', 'scene-0534', 'scene-0535',
+ 'scene-0536', 'scene-0537', 'scene-0538', 'scene-0539', 'scene-0541', 'scene-0542', 'scene-0543', 'scene-0544',
+ 'scene-0545', 'scene-0546', 'scene-0584', 'scene-0585', 'scene-0586', 'scene-0587', 'scene-0588', 'scene-0589',
+ 'scene-0590', 'scene-0591', 'scene-0592', 'scene-0593', 'scene-0594', 'scene-0595', 'scene-0596', 'scene-0597',
+ 'scene-0598', 'scene-0599', 'scene-0600', 'scene-0639', 'scene-0640', 'scene-0641', 'scene-0642', 'scene-0643',
+ 'scene-0644', 'scene-0645', 'scene-0646', 'scene-0647', 'scene-0648', 'scene-0649', 'scene-0650', 'scene-0651',
+ 'scene-0652', 'scene-0653', 'scene-0654', 'scene-0655', 'scene-0656', 'scene-0657', 'scene-0658', 'scene-0659',
+ 'scene-0660', 'scene-0661', 'scene-0662', 'scene-0663', 'scene-0664', 'scene-0695', 'scene-0696', 'scene-0697',
+ 'scene-0698', 'scene-0700', 'scene-0701', 'scene-0703', 'scene-0704', 'scene-0705', 'scene-0706', 'scene-0707',
+ 'scene-0708', 'scene-0709', 'scene-0710', 'scene-0711', 'scene-0712', 'scene-0713', 'scene-0714', 'scene-0715',
+ 'scene-0716', 'scene-0717', 'scene-0718', 'scene-0719', 'scene-0726', 'scene-0727', 'scene-0728', 'scene-0730',
+ 'scene-0731', 'scene-0733', 'scene-0734', 'scene-0735', 'scene-0736', 'scene-0737', 'scene-0738', 'scene-0786',
+ 'scene-0787', 'scene-0789', 'scene-0790', 'scene-0791', 'scene-0792', 'scene-0803', 'scene-0804', 'scene-0805',
+ 'scene-0806', 'scene-0808', 'scene-0809', 'scene-0810', 'scene-0811', 'scene-0812', 'scene-0813', 'scene-0815',
+ 'scene-0816', 'scene-0817', 'scene-0819', 'scene-0820', 'scene-0821', 'scene-0822', 'scene-0847', 'scene-0848',
+ 'scene-0849', 'scene-0850', 'scene-0851', 'scene-0852', 'scene-0853', 'scene-0854', 'scene-0855', 'scene-0856',
+ 'scene-0858', 'scene-0860', 'scene-0861', 'scene-0862', 'scene-0863', 'scene-0864', 'scene-0865', 'scene-0866',
+ 'scene-0992', 'scene-0994', 'scene-0995', 'scene-0996', 'scene-0997', 'scene-0998', 'scene-0999', 'scene-1000',
+ 'scene-1001', 'scene-1002', 'scene-1003', 'scene-1004', 'scene-1005', 'scene-1006', 'scene-1007', 'scene-1008',
+ 'scene-1009', 'scene-1010', 'scene-1044', 'scene-1045', 'scene-1046', 'scene-1047', 'scene-1048', 'scene-1049',
+ 'scene-1050', 'scene-1051', 'scene-1052', 'scene-1053', 'scene-1054', 'scene-1055', 'scene-1056', 'scene-1057',
+ 'scene-1058', 'scene-1106', 'scene-1107', 'scene-1108', 'scene-1109', 'scene-1110']
+
+train = list(sorted(set(train_detect + train_track)))
+
+val = \
+ ['scene-0003', 'scene-0012', 'scene-0013', 'scene-0014', 'scene-0015', 'scene-0016', 'scene-0017', 'scene-0018',
+ 'scene-0035', 'scene-0036', 'scene-0038', 'scene-0039', 'scene-0092', 'scene-0093', 'scene-0094', 'scene-0095',
+ 'scene-0096', 'scene-0097', 'scene-0098', 'scene-0099', 'scene-0100', 'scene-0101', 'scene-0102', 'scene-0103',
+ 'scene-0104', 'scene-0105', 'scene-0106', 'scene-0107', 'scene-0108', 'scene-0109', 'scene-0110', 'scene-0221',
+ 'scene-0268', 'scene-0269', 'scene-0270', 'scene-0271', 'scene-0272', 'scene-0273', 'scene-0274', 'scene-0275',
+ 'scene-0276', 'scene-0277', 'scene-0278', 'scene-0329', 'scene-0330', 'scene-0331', 'scene-0332', 'scene-0344',
+ 'scene-0345', 'scene-0346', 'scene-0519', 'scene-0520', 'scene-0521', 'scene-0522', 'scene-0523', 'scene-0524',
+ 'scene-0552', 'scene-0553', 'scene-0554', 'scene-0555', 'scene-0556', 'scene-0557', 'scene-0558', 'scene-0559',
+ 'scene-0560', 'scene-0561', 'scene-0562', 'scene-0563', 'scene-0564', 'scene-0565', 'scene-0625', 'scene-0626',
+ 'scene-0627', 'scene-0629', 'scene-0630', 'scene-0632', 'scene-0633', 'scene-0634', 'scene-0635', 'scene-0636',
+ 'scene-0637', 'scene-0638', 'scene-0770', 'scene-0771', 'scene-0775', 'scene-0777', 'scene-0778', 'scene-0780',
+ 'scene-0781', 'scene-0782', 'scene-0783', 'scene-0784', 'scene-0794', 'scene-0795', 'scene-0796', 'scene-0797',
+ 'scene-0798', 'scene-0799', 'scene-0800', 'scene-0802', 'scene-0904', 'scene-0905', 'scene-0906', 'scene-0907',
+ 'scene-0908', 'scene-0909', 'scene-0910', 'scene-0911', 'scene-0912', 'scene-0913', 'scene-0914', 'scene-0915',
+ 'scene-0916', 'scene-0917', 'scene-0919', 'scene-0920', 'scene-0921', 'scene-0922', 'scene-0923', 'scene-0924',
+ 'scene-0925', 'scene-0926', 'scene-0927', 'scene-0928', 'scene-0929', 'scene-0930', 'scene-0931', 'scene-0962',
+ 'scene-0963', 'scene-0966', 'scene-0967', 'scene-0968', 'scene-0969', 'scene-0971', 'scene-0972', 'scene-1059',
+ 'scene-1060', 'scene-1061', 'scene-1062', 'scene-1063', 'scene-1064', 'scene-1065', 'scene-1066', 'scene-1067',
+ 'scene-1068', 'scene-1069', 'scene-1070', 'scene-1071', 'scene-1072', 'scene-1073']
+
+test = \
+ ['scene-0077', 'scene-0078', 'scene-0079', 'scene-0080', 'scene-0081', 'scene-0082', 'scene-0083', 'scene-0084',
+ 'scene-0085', 'scene-0086', 'scene-0087', 'scene-0088', 'scene-0089', 'scene-0090', 'scene-0091', 'scene-0111',
+ 'scene-0112', 'scene-0113', 'scene-0114', 'scene-0115', 'scene-0116', 'scene-0117', 'scene-0118', 'scene-0119',
+ 'scene-0140', 'scene-0142', 'scene-0143', 'scene-0144', 'scene-0145', 'scene-0146', 'scene-0147', 'scene-0148',
+ 'scene-0265', 'scene-0266', 'scene-0279', 'scene-0280', 'scene-0281', 'scene-0282', 'scene-0307', 'scene-0308',
+ 'scene-0309', 'scene-0310', 'scene-0311', 'scene-0312', 'scene-0313', 'scene-0314', 'scene-0333', 'scene-0334',
+ 'scene-0335', 'scene-0336', 'scene-0337', 'scene-0338', 'scene-0339', 'scene-0340', 'scene-0341', 'scene-0342',
+ 'scene-0343', 'scene-0481', 'scene-0482', 'scene-0483', 'scene-0484', 'scene-0485', 'scene-0486', 'scene-0487',
+ 'scene-0488', 'scene-0489', 'scene-0490', 'scene-0491', 'scene-0492', 'scene-0493', 'scene-0494', 'scene-0495',
+ 'scene-0496', 'scene-0497', 'scene-0498', 'scene-0547', 'scene-0548', 'scene-0549', 'scene-0550', 'scene-0551',
+ 'scene-0601', 'scene-0602', 'scene-0603', 'scene-0604', 'scene-0606', 'scene-0607', 'scene-0608', 'scene-0609',
+ 'scene-0610', 'scene-0611', 'scene-0612', 'scene-0613', 'scene-0614', 'scene-0615', 'scene-0616', 'scene-0617',
+ 'scene-0618', 'scene-0619', 'scene-0620', 'scene-0621', 'scene-0622', 'scene-0623', 'scene-0624', 'scene-0827',
+ 'scene-0828', 'scene-0829', 'scene-0830', 'scene-0831', 'scene-0833', 'scene-0834', 'scene-0835', 'scene-0836',
+ 'scene-0837', 'scene-0838', 'scene-0839', 'scene-0840', 'scene-0841', 'scene-0842', 'scene-0844', 'scene-0845',
+ 'scene-0846', 'scene-0932', 'scene-0933', 'scene-0935', 'scene-0936', 'scene-0937', 'scene-0938', 'scene-0939',
+ 'scene-0940', 'scene-0941', 'scene-0942', 'scene-0943', 'scene-1026', 'scene-1027', 'scene-1028', 'scene-1029',
+ 'scene-1030', 'scene-1031', 'scene-1032', 'scene-1033', 'scene-1034', 'scene-1035', 'scene-1036', 'scene-1037',
+ 'scene-1038', 'scene-1039', 'scene-1040', 'scene-1041', 'scene-1042', 'scene-1043']
+
+mini_train = \
+ ['scene-0061', 'scene-0553', 'scene-0655', 'scene-0757', 'scene-0796', 'scene-1077', 'scene-1094', 'scene-1100']
+
+mini_val = \
+ ['scene-0103', 'scene-0916']
+
+
+def create_splits_logs(split: str, nusc: 'NuScenes') -> List[str]:
+ """
+ Returns the logs in each dataset split of nuScenes.
+ Note: Previously this script included the teaser dataset splits. Since new scenes from those logs were added and
+ others removed in the full dataset, that code is incompatible and was removed.
+ :param split: NuScenes split.
+ :param nusc: NuScenes instance.
+ :return: A list of logs in that split.
+ """
+ # Load splits on a scene-level.
+ scene_splits = create_splits_scenes(verbose=False)
+
+ assert split in scene_splits.keys(), 'Requested split {} which is not a known nuScenes split.'.format(split)
+
+ # Check compatibility of split with nusc_version.
+ version = nusc.version
+ if split in {'train', 'val', 'train_detect', 'train_track'}:
+ assert version.endswith('trainval'), \
+ 'Requested split {} which is not compatible with NuScenes version {}'.format(split, version)
+ elif split in {'mini_train', 'mini_val'}:
+ assert version.endswith('mini'), \
+ 'Requested split {} which is not compatible with NuScenes version {}'.format(split, version)
+ elif split == 'test':
+ assert version.endswith('test'), \
+ 'Requested split {} which is not compatible with NuScenes version {}'.format(split, version)
+ else:
+ raise ValueError('Requested split {} which this function cannot map to logs.'.format(split))
+
+ # Get logs for this split.
+ scene_to_log = {scene['name']: nusc.get('log', scene['log_token'])['logfile'] for scene in nusc.scene}
+ logs = set()
+ scenes = scene_splits[split]
+ for scene in scenes:
+ logs.add(scene_to_log[scene])
+
+ return list(logs)
+
+
+def create_splits_scenes(verbose: bool = False) -> Dict[str, List[str]]:
+ """
+ Similar to create_splits_logs, but returns a mapping from split to scene names, rather than log names.
+ The splits are as follows:
+ - train/val/test: The standard splits of the nuScenes dataset (700/150/150 scenes).
+ - mini_train/mini_val: Train and val splits of the mini subset used for visualization and debugging (8/2 scenes).
+ - train_detect/train_track: Two halves of the train split used for separating the training sets of detector and
+ tracker if required.
+ :param verbose: Whether to print out statistics on a scene level.
+ :return: A mapping from split name to a list of scenes names in that split.
+ """
+ # Use hard-coded splits.
+ all_scenes = train + val + test
+ assert len(all_scenes) == 1000 and len(set(all_scenes)) == 1000, 'Error: Splits incomplete!'
+ scene_splits = {'train': train, 'val': val, 'test': test,
+ 'mini_train': mini_train, 'mini_val': mini_val,
+ 'train_detect': train_detect, 'train_track': train_track}
+
+ # Optional: Print scene-level stats.
+ if verbose:
+ for split, scenes in scene_splits.items():
+ print('%s: %d' % (split, len(scenes)))
+ print('%s' % scenes)
+
+ return scene_splits
+
+
+if __name__ == '__main__':
+ # Print the scene-level stats.
+ create_splits_scenes(verbose=True)
diff --git a/python-sdk/nuscenes/utils/tests/__init__.py b/python-sdk/nuscenes/utils/tests/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/python-sdk/nuscenes/utils/tests/test_geometry_utils.py b/python-sdk/nuscenes/utils/tests/test_geometry_utils.py
new file mode 100644
index 0000000..436146a
--- /dev/null
+++ b/python-sdk/nuscenes/utils/tests/test_geometry_utils.py
@@ -0,0 +1,115 @@
+# nuScenes dev-kit.
+# Code written by Holger Caesar and Alex Lang, 2018.
+
+import unittest
+
+import numpy as np
+from pyquaternion import Quaternion
+
+from nuscenes.eval.common.utils import quaternion_yaw
+from nuscenes.utils.data_classes import Box
+from nuscenes.utils.geometry_utils import points_in_box
+
+
+class TestGeometryUtils(unittest.TestCase):
+
+ def test_quaternion_yaw(self):
+ """Test valid and invalid inputs for quaternion_yaw()."""
+
+ # Misc yaws.
+ for yaw_in in np.linspace(-10, 10, 100):
+ q = Quaternion(axis=(0, 0, 1), angle=yaw_in)
+ yaw_true = yaw_in % (2 * np.pi)
+ if yaw_true > np.pi:
+ yaw_true -= 2 * np.pi
+ yaw_test = quaternion_yaw(q)
+ self.assertAlmostEqual(yaw_true, yaw_test)
+
+ # Non unit axis vector.
+ yaw_in = np.pi/4
+ q = Quaternion(axis=(0, 0, 0.5), angle=yaw_in)
+ yaw_test = quaternion_yaw(q)
+ self.assertAlmostEqual(yaw_in, yaw_test)
+
+ # Inverted axis vector.
+ yaw_in = np.pi/4
+ q = Quaternion(axis=(0, 0, -1), angle=yaw_in)
+ yaw_test = -quaternion_yaw(q)
+ self.assertAlmostEqual(yaw_in, yaw_test)
+
+ # Rotate around another axis.
+ yaw_in = np.pi/4
+ q = Quaternion(axis=(0, 1, 0), angle=yaw_in)
+ yaw_test = quaternion_yaw(q)
+ self.assertAlmostEqual(0, yaw_test)
+
+ # Rotate around two axes jointly.
+ yaw_in = np.pi/2
+ q = Quaternion(axis=(0, 1, 1), angle=yaw_in)
+ yaw_test = quaternion_yaw(q)
+ self.assertAlmostEqual(yaw_in, yaw_test)
+
+ # Rotate around two axes separately.
+ yaw_in = np.pi/2
+ q = Quaternion(axis=(0, 0, 1), angle=yaw_in) * Quaternion(axis=(0, 1, 0), angle=0.5821)
+ yaw_test = quaternion_yaw(q)
+ self.assertAlmostEqual(yaw_in, yaw_test)
+
+ def test_points_in_box(self):
+ """ Test the box.in_box method. """
+
+ vel = (np.nan, np.nan, np.nan)
+
+ def qyaw(yaw):
+ return Quaternion(axis=(0, 0, 1), angle=yaw)
+
+ # Check points inside box
+ box = Box([0.0, 0.0, 0.0], [2.0, 2.0, 0.0], qyaw(0.0), 1, 2.0, vel)
+ points = np.array([[0.0, 0.0, 0.0], [0.5, 0.5, 0.0]]).transpose()
+ mask = points_in_box(box, points, wlh_factor=1.0)
+ self.assertEqual(mask.all(), True)
+
+ # Check points outside box
+ box = Box([0.0, 0.0, 0.0], [2.0, 2.0, 0.0], qyaw(0.0), 1, 2.0, vel)
+ points = np.array([[0.1, 0.0, 0.0], [0.5, -1.1, 0.0]]).transpose()
+ mask = points_in_box(box, points, wlh_factor=1.0)
+ self.assertEqual(mask.all(), False)
+
+ # Check corner cases
+ box = Box([0.0, 0.0, 0.0], [2.0, 2.0, 0.0], qyaw(0.0), 1, 2.0, vel)
+ points = np.array([[-1.0, -1.0, 0.0], [1.0, 1.0, 0.0]]).transpose()
+ mask = points_in_box(box, points, wlh_factor=1.0)
+ self.assertEqual(mask.all(), True)
+
+ # Check rotation (45 degs) and translation (by [1,1])
+ rot = 45
+ trans = [1.0, 1.0]
+ box = Box([0.0+trans[0], 0.0+trans[1], 0.0], [2.0, 2.0, 0.0], qyaw(rot / 180.0 * np.pi), 1, 2.0, vel)
+ points = np.array([[0.70+trans[0], 0.70+trans[1], 0.0], [0.71+1.0, 0.71+1.0, 0.0]]).transpose()
+ mask = points_in_box(box, points, wlh_factor=1.0)
+ self.assertEqual(mask[0], True)
+ self.assertEqual(mask[1], False)
+
+ # Check 3d box
+ box = Box([0.0, 0.0, 0.0], [2.0, 2.0, 2.0], qyaw(0.0), 1, 2.0, vel)
+ points = np.array([[0.0, 0.0, 0.0], [0.5, 0.5, 0.5]]).transpose()
+ mask = points_in_box(box, points, wlh_factor=1.0)
+ self.assertEqual(mask.all(), True)
+
+ # Check wlh factor
+ for wlh_factor in [0.5, 1.0, 1.5, 10.0]:
+ box = Box([0.0, 0.0, 0.0], [2.0, 2.0, 0.0], qyaw(0.0), 1, 2.0, vel)
+ points = np.array([[0.0, 0.0, 0.0], [0.5, 0.5, 0.0]]).transpose()
+ mask = points_in_box(box, points, wlh_factor=wlh_factor)
+ self.assertEqual(mask.all(), True)
+
+ for wlh_factor in [0.1, 0.49]:
+ box = Box([0.0, 0.0, 0.0], [2.0, 2.0, 0.0], qyaw(0.0), 1, 2.0, vel)
+ points = np.array([[0.0, 0.0, 0.0], [0.5, 0.5, 0.0]]).transpose()
+ mask = points_in_box(box, points, wlh_factor=wlh_factor)
+ self.assertEqual(mask[0], True)
+ self.assertEqual(mask[1], False)
+
+
+if __name__ == '__main__':
+ unittest.main()
diff --git a/python-sdk/nuscenes/utils/tests/test_map_mask.py b/python-sdk/nuscenes/utils/tests/test_map_mask.py
new file mode 100644
index 0000000..0f80e14
--- /dev/null
+++ b/python-sdk/nuscenes/utils/tests/test_map_mask.py
@@ -0,0 +1,126 @@
+# nuScenes dev-kit.
+# Code written by Oscar Beijbom, 2019.
+
+import os
+import unittest
+
+import cv2
+import numpy as np
+
+from nuscenes.utils.map_mask import MapMask
+
+
+class TestLoad(unittest.TestCase):
+
+ fixture = 'testmap.png'
+ foreground = 255
+ native_res = 0.1 # Maps defined on a 0.1 meter resolution grid.
+ small_number = 0.00001 # Just a small numbers to avoid edge effects.
+ half_gt = native_res / 2 + small_number # Just larger than half a cell.
+ half_lt = native_res / 2 - small_number # Just smaller than half a cell.
+
+ def setUp(self):
+
+ # Build a test map. 5 x 4 meters. All background except one pixel.
+ mask = np.zeros((50, 40))
+
+ # Native resolution is 0.1
+ # Transformation in y is defined as y_pixel = nrows - y_meters / resolution
+ # Transformation in x is defined as x_pixel = x_meters / resolution
+ # The global map location x=2, y=2 becomes row 30, column 20 in image map coords.
+ mask[30, 20] = self.foreground
+ cv2.imwrite(filename=self.fixture, img=mask)
+
+ def tearDown(self):
+ os.remove(self.fixture)
+
+ def test_native_resolution(self):
+
+ # Load mask and assert that the
+ map_mask = MapMask(self.fixture, resolution=0.1)
+
+ # This is where we put the foreground in the fixture, so this should be true by design.
+ self.assertTrue(map_mask.is_on_mask(2, 2))
+
+ # Each pixel is 10 x 10 cm, so if we step less than 5 cm in either direction we are still on foreground.
+ # Note that we add / subtract a "small number" to break numerical ambiguities along the edges.
+ self.assertTrue(map_mask.is_on_mask(2 + self.half_lt, 2))
+ self.assertTrue(map_mask.is_on_mask(2 - self.half_lt, 2))
+ self.assertTrue(map_mask.is_on_mask(2, 2 + self.half_lt))
+ self.assertTrue(map_mask.is_on_mask(2, 2 - self.half_lt))
+
+ # But if we step outside this range, we should get false
+ self.assertFalse(map_mask.is_on_mask(2 + self.half_gt, 2))
+ self.assertFalse(map_mask.is_on_mask(2 + self.half_gt, 2))
+ self.assertFalse(map_mask.is_on_mask(2, 2 + self.half_gt))
+ self.assertFalse(map_mask.is_on_mask(2, 2 + self.half_gt))
+
+ def test_edges(self):
+
+ # Add foreground pixels in the corners for this test.
+ mask = np.ones((50, 40)) * self.foreground
+
+ # Just over-write the fixture
+ cv2.imwrite(filename=self.fixture, img=mask)
+
+ map_mask = MapMask(self.fixture, resolution=0.1)
+
+ # Asssert that corners are indeed drivable as encoded in map.
+ self.assertTrue(map_mask.is_on_mask(0, 0.1))
+ self.assertTrue(map_mask.is_on_mask(0, 5))
+ self.assertTrue(map_mask.is_on_mask(3.9, 0.1))
+ self.assertTrue(map_mask.is_on_mask(3.9, 5))
+
+ # Not go juuuust outside the map. This should no longer be drivable.
+ self.assertFalse(map_mask.is_on_mask(3.9 + self.half_gt, 0.1))
+ self.assertFalse(map_mask.is_on_mask(3.9 + self.half_gt, 5))
+ self.assertFalse(map_mask.is_on_mask(0 - self.half_gt, 0.1))
+ self.assertFalse(map_mask.is_on_mask(0 - self.half_gt, 5))
+
+ def test_dilation(self):
+
+ map_mask = MapMask(self.fixture, resolution=0.1)
+
+ # This is where we put the foreground in the fixture, so this should be true by design.
+ self.assertTrue(map_mask.is_on_mask(2, 2))
+
+ # Go 1 meter to the right. Obviously not on the mask.
+ self.assertFalse(map_mask.is_on_mask(2, 3))
+
+ # But if we dilate by 1 meters, we are on the dilated mask.
+ self.assertTrue(map_mask.is_on_mask(2, 3, dilation=1)) # x direction
+ self.assertTrue(map_mask.is_on_mask(3, 2, dilation=1)) # y direction
+ self.assertTrue(map_mask.is_on_mask(2 + np.sqrt(1/2), 2 + np.sqrt(1/2), dilation=1)) # diagonal
+
+ # If we dilate by 0.9 meter, it is not enough.
+ self.assertFalse(map_mask.is_on_mask(2, 3, dilation=0.9))
+
+ def test_coarse_resolution(self):
+
+ # Due to resize that happens on load we need to inflate the fixture.
+ mask = np.zeros((50, 40))
+ mask[30, 20] = self.foreground
+ mask[31, 20] = self.foreground
+ mask[30, 21] = self.foreground
+ mask[31, 21] = self.foreground
+
+ # Just over-write the fixture
+ cv2.imwrite(filename=self.fixture, img=mask)
+
+ map_mask = MapMask(self.fixture, resolution=0.2)
+
+ # This is where we put the foreground in the fixture, so this should be true by design.
+ self.assertTrue(map_mask.is_on_mask(2, 2))
+
+ # Go two meters to the right. Obviously not on the mask.
+ self.assertFalse(map_mask.is_on_mask(2, 4))
+
+ # But if we dilate by two meters, we are on the dilated mask.
+ self.assertTrue(map_mask.is_on_mask(2, 4, dilation=2))
+
+ # And if we dilate by 1.9 meter, we are off the dilated mask.
+ self.assertFalse(map_mask.is_on_mask(2, 4, dilation=1.9))
+
+
+if __name__ == '__main__':
+ unittest.main()
diff --git a/python-sdk/tutorials/README.md b/python-sdk/tutorials/README.md
new file mode 100644
index 0000000..3583fcc
--- /dev/null
+++ b/python-sdk/tutorials/README.md
@@ -0,0 +1,4 @@
+# Tutorials
+This folder contains all the tutorials for the devkit of the [nuScenes](https://www.nuscenes.org/nuscenes) and [nuImages](https://www.nuscenes.org/nuimages) datasets.
+
+All the tutorials are also [available on Google Colab](https://colab.research.google.com/github/nutonomy/nuscenes-devkit/).
diff --git a/python-sdk/tutorials/can_bus_tutorial.ipynb b/python-sdk/tutorials/can_bus_tutorial.ipynb
new file mode 100644
index 0000000..95686a3
--- /dev/null
+++ b/python-sdk/tutorials/can_bus_tutorial.ipynb
@@ -0,0 +1,225 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "collapsed": true
+ },
+ "source": [
+ "# nuScenes CAN bus tutorial\n",
+ "This page describes how to use the nuScenes CAN bus expansion data.\n",
+ "The CAN bus is a vehicle bus over which information such as position, velocity, acceleration, steering, lights, battery and many more are submitted.\n",
+ "We recommend you start by reading the [README](https://github.com/nutonomy/nuscenes-devkit/tree/master/python-sdk/nuscenes/can_bus/README.md)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Setup\n",
+ "To install the can bus expansion, please download the files from https://www.nuscenes.org/download and copy the files into your nuScenes can folder, e.g. `/data/sets/nuscenes/can_bus`. You will also need to update your `nuscenes-devkit`."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Initialization\n",
+ "To initialize the can bus API, run the following:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from nuscenes.can_bus.can_bus_api import NuScenesCanBus\n",
+ "nusc_can = NuScenesCanBus(dataroot='/data/sets/nuscenes')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Overview\n",
+ "Let us get an overview of all the CAN bus messages and some basic statistics (min, max, mean, stdev, etc.). We will pick an arbitrary scene for that."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "scene_name = 'scene-0001'\n",
+ "nusc_can.print_all_message_stats(scene_name)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Visualization\n",
+ "Next we plot the values in a CAN bus message over time. \n",
+ "\n",
+ "As an example let us pick the steering angle feedback message and the key called \"value\" as described in the [README](https://github.com/nutonomy/nuscenes-devkit/tree/master/python-sdk/nuscenes/can_bus/README.md). The plot below shows the steering angle. It seems like the scene starts with a strong left turn and then continues more or less straight."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "message_name = 'steeranglefeedback'\n",
+ "key_name = 'value'\n",
+ "nusc_can.plot_message_data(scene_name, message_name, key_name)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "If the data we want to plot is multi-dimensional, we need to provide an additional argument to select the dimension. Here we plot the acceleration along the lateral dimension (y-axis). We can see that initially this acceleration is higher."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "message_name = 'pose'\n",
+ "key_name = 'accel'\n",
+ "nusc_can.plot_message_data(scene_name, message_name, key_name, dimension=1)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can also retrieve the raw data and compare the wheel speeds to the vehicle speeds. Here we convert the wheel speed from rounds per minute to m/s and the vehicle speed from km/h to m/s. We can see that there is a small offset between the speeds."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import numpy as np\n",
+ "import matplotlib.pyplot as plt\n",
+ "\n",
+ "# Retrieve raw data.\n",
+ "wheel_speed = nusc_can.get_messages(scene_name, 'zoe_veh_info')\n",
+ "wheel_speed = np.array([(m['utime'], m['FL_wheel_speed']) for m in wheel_speed])\n",
+ "\n",
+ "veh_speed = nusc_can.get_messages(scene_name, 'vehicle_monitor')\n",
+ "veh_speed = np.array([(m['utime'], m['vehicle_speed']) for m in veh_speed])\n",
+ "\n",
+ "# Convert to m/s.\n",
+ "radius = 0.305 # Known Zoe wheel radius in meters.\n",
+ "circumference = 2 * np.pi * radius\n",
+ "wheel_speed[:, 1] *= circumference / 60\n",
+ "veh_speed[:, 1] *= 1 / 3.6\n",
+ "\n",
+ "# Normalize time.\n",
+ "wheel_speed[:, 0] = (wheel_speed[:, 0] - wheel_speed[0, 0]) / 1e6\n",
+ "veh_speed[:, 0] = (veh_speed[:, 0] - veh_speed[0, 0]) / 1e6"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "plt.plot(wheel_speed[:, 0], wheel_speed[:, 1])\n",
+ "plt.plot(veh_speed[:, 0], veh_speed[:, 1])\n",
+ "plt.xlabel('Time in s')\n",
+ "plt.ylabel('Speed in m/s')\n",
+ "plt.legend(['Wheel speed', 'Vehicle speed']);"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Now let us render the baseline route for this scene. The blue line below shows the baseline route extended by 50m beyond the start and end of the scene. The orange line indicates the ego vehicle pose. To differentiate the start and end point we highlight the start with a red cross. We can see that there is a slight deviation of the actual poses from the route."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc_can.plot_baseline_route(scene_name)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Error handling\n",
+ "Please note that some scenes are not well aligned with the baseline route. This can be due to diversions or because the human driver was not following a route. We compute all misaligned routes by checking if each ego pose has a baseline route within 5m."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(nusc_can.list_misaligned_routes())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Furthermore a small number of scenes have no CAN bus data at all. These can therefore not be used."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(nusc_can.can_blacklist)"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.7.7"
+ },
+ "pycharm": {
+ "stem_cell": {
+ "cell_type": "raw",
+ "metadata": {
+ "collapsed": false
+ },
+ "source": []
+ }
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 1
+}
diff --git a/python-sdk/tutorials/map_expansion_tutorial.ipynb b/python-sdk/tutorials/map_expansion_tutorial.ipynb
new file mode 100644
index 0000000..95d6a1f
--- /dev/null
+++ b/python-sdk/tutorials/map_expansion_tutorial.ipynb
@@ -0,0 +1,1137 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# nuScenes Map Expansion Tutorial"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "This is the tutorial for the nuScenes map expansion. In particular, the `NuScenesMap` data class. \n",
+ "\n",
+ "This tutorial will go through the description of each layers, how we retrieve and query a certain record within the map layers, render methods, and advanced data exploration\n",
+ "\n",
+ "In database terms, layers are basically tables of the map database in which we assign arbitrary parts of the maps with informative labels such as `traffic_light`, `stop_line`, `walkway`, etc. Refer to the discussion on layers for more details."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Setup\n",
+ "To install the map expansion, please download the files from https://www.nuscenes.org/download and copy the files into your nuScenes map folder, e.g. `/data/sets/nuscenes/maps`."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Initialization\n",
+ "\n",
+ "We will be working with the `singapore-onenorth` map. The `NuScenesMap` can be initialized as follows:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import matplotlib.pyplot as plt\n",
+ "import tqdm\n",
+ "import numpy as np\n",
+ "\n",
+ "from nuscenes.map_expansion.map_api import NuScenesMap\n",
+ "from nuscenes.map_expansion import arcline_path_utils\n",
+ "from nuscenes.map_expansion.bitmap import BitMap\n",
+ "\n",
+ "nusc_map = NuScenesMap(dataroot='/data/sets/nuscenes', map_name='singapore-onenorth')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Visualization"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Before we go into the details, let's visualize the map."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Rendering multiple layers\n",
+ "\n",
+ "The `NuScenesMap` class makes it possible to render multiple map layers on a matplotlib figure."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "scrolled": false
+ },
+ "outputs": [],
+ "source": [
+ "fig, ax = nusc_map.render_layers(nusc_map.non_geometric_layers, figsize=1)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Rendering the lidar basemap\n",
+ "**New:** We can render the HD lidar basemap used for localization. The basemap is a bitmap image that can be underlaid for most functions (`render_centerlines`, `render_egoposes_on_fancy_map`, `render_layers`, `render_map_patch`, `render_next_roads`, `render_record`). The same `BitMap` class can also be used to render the semantic prior (drivable surface + sidewalk) from the original nuScenes release. Note that in this visualization we only show the `lane` annotations for better visibility."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "bitmap = BitMap(nusc_map.dataroot, nusc_map.map_name, 'basemap')\n",
+ "fig, ax = nusc_map.render_layers(['lane'], figsize=1, bitmap=bitmap)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Rendering a particular record of the map layer\n",
+ "\n",
+ "We can render a record, which will show its global and local view"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "scrolled": false
+ },
+ "outputs": [],
+ "source": [
+ "fig, ax = nusc_map.render_record('stop_line', nusc_map.stop_line[14]['token'], other_layers=[], bitmap=bitmap)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Rendering binary map mask layers\n",
+ "\n",
+ "The `NuScenesMap` class makes it possible to convert multiple map layers into binary mask and render on a Matplotlib figure. First let's call `get_map_mask` to look at the raw data of two layers:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "patch_box = (300, 1700, 100, 100)\n",
+ "patch_angle = 0 # Default orientation where North is up\n",
+ "layer_names = ['drivable_area', 'walkway']\n",
+ "canvas_size = (1000, 1000)\n",
+ "map_mask = nusc_map.get_map_mask(patch_box, patch_angle, layer_names, canvas_size)\n",
+ "map_mask[0]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Now we directly visualize the map mask retrieved above using `render_map_mask`:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "figsize = (12, 4)\n",
+ "fig, ax = nusc_map.render_map_mask(patch_box, patch_angle, layer_names, canvas_size, figsize=figsize, n_row=1)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can also render the same map rotated by 45 degrees clockwise:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig, ax = nusc_map.render_map_mask(patch_box, 45, layer_names, canvas_size, figsize=figsize, n_row=1)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Rendering map layers on top of camera images\n",
+ "Let us take a nuScenes camera image and overlay the relevant map layers.\n",
+ "Note that the projections are not perfect if the ground is uneven as the localization is 2d."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Init nuScenes. Requires the dataset to be stored on disk.\n",
+ "from nuscenes.nuscenes import NuScenes\n",
+ "nusc = NuScenes(version='v1.0-mini', verbose=False)\n",
+ "\n",
+ "# Pick a sample and render the front camera image.\n",
+ "sample_token = nusc.sample[9]['token']\n",
+ "layer_names = ['road_segment', 'lane', 'ped_crossing', 'walkway', 'stop_line', 'carpark_area']\n",
+ "camera_channel = 'CAM_FRONT'\n",
+ "nusc_map.render_map_in_image(nusc, sample_token, layer_names=layer_names, camera_channel=camera_channel)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Rendering ego poses on the map\n",
+ "We can also plot the ego poses onto the map. This requires us to load up the `NuScenes` class, which can take some time."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Init NuScenes. Requires the dataset to be stored on disk.\n",
+ "from nuscenes.nuscenes import NuScenes\n",
+ "nusc = NuScenes(version='v1.0-mini', verbose=False)\n",
+ "\n",
+ "# Render ego poses.\n",
+ "nusc_map_bos = NuScenesMap(dataroot='/data/sets/nuscenes', map_name='boston-seaport')\n",
+ "ego_poses = nusc_map_bos.render_egoposes_on_fancy_map(nusc, scene_tokens=[nusc.scene[1]['token']], verbose=False)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Navigation\n",
+ "We also provide functions for navigation around the road network. For this purpose, the road layers `lane`, `road_block` and `road_segment` are especially useful (see definitions below). The `get_next_roads(x, y)` function looks at the road layer at a particular point. It then retrieves the next road object in the direction of the `lane` or `road_block`. As `road_segments` do not have a direction (e.g. intersections), we return all possible next roads."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "x = 873\n",
+ "y = 1286\n",
+ "print('Road objects on selected point:', nusc_map.layers_on_point(x, y), '\\n')\n",
+ "print('Next road objects:', nusc_map.get_next_roads(x, y))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can also visualize the next roads using the `render_next_roads(x, y)` function. We see that there are 3 adjacent roads to the intersection specified by (x, y)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc_map.render_next_roads(x, y, figsize=1, bitmap=bitmap)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Working with Lanes\n",
+ "For the prediction challenge we added connectivity information to the map expansion (v1.2) to efficiently query which lane is connected to which other lanes. Below we render the lane and lane_connector objects. The lanes and lane_connectors are defined by parametric curves. The `resolution_meters` parameter specifies the discretization resolution of the curve. If we set it to a high value (e.g. 100), the curves will appear as straight lines. We recommend setting this value to 1m or less."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc_map.render_centerlines(resolution_meters=0.5, figsize=1, bitmap=bitmap)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "To get the closest lane to a location, use the `get_closest_lane` method. To see the internal data representation of the lane, use the `get_lane_record` method. \n",
+ "You can also explore the connectivity of the lanes, with the `get_outgoing_lanes` and `get_incoming_lane` methods."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "x, y, yaw = 395, 1095, 0\n",
+ "closest_lane = nusc_map.get_closest_lane(x, y, radius=2)\n",
+ "closest_lane"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "lane_record = nusc_map.get_arcline_path(closest_lane)\n",
+ "lane_record"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc_map.get_incoming_lane_ids(closest_lane)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc_map.get_outgoing_lane_ids(closest_lane)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "To help manipulate the lanes, we've added an `arcline_path_utils` module. For example, something you might want to do is discretize a lane into a sequence of poses."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "poses = arcline_path_utils.discretize_lane(lane_record, resolution_meters=1)\n",
+ "poses"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Given a query pose, you can also find the closest pose on a lane."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "closest_pose_on_lane, distance_along_lane = arcline_path_utils.project_pose_to_lane((x, y, yaw), lane_record)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(x, y, yaw)\n",
+ "closest_pose_on_lane"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Meters\n",
+ "distance_along_lane"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "To find the entire length of the lane, you can use the `length_of_lane` function."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "arcline_path_utils.length_of_lane(lane_record)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "You can also compute the curvature of a lane at a given length along the lane."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# 0 means it is a straight lane\n",
+ "arcline_path_utils.get_curvature_at_distance_along_lane(distance_along_lane, lane_record)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Data Exploration"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's render a particular patch on the map:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "my_patch = (300, 1000, 500, 1200)\n",
+ "fig, ax = nusc_map.render_map_patch(my_patch, nusc_map.non_geometric_layers, figsize=(10, 10), bitmap=bitmap)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "A lot of layers can be seen in this patch. Lets retrieve all map records that are in this patch.\n",
+ "\n",
+ "- The option `within` will return all non geometric records that ***are within*** the map patch\n",
+ "- The option `intersect` will return all non geometric records that ***intersect*** the map patch\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "records_within_patch = nusc_map.get_records_in_patch(my_patch, nusc_map.non_geometric_layers, mode='within')\n",
+ "records_intersect_patch = nusc_map.get_records_in_patch(my_patch, nusc_map.non_geometric_layers, mode='intersect')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Since there are a lot of records, we focus only on the layer `road_segment`:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "layer = 'road_segment'\n",
+ "print('Found %d records of %s (within).' % (len(records_within_patch[layer]), layer))\n",
+ "print('Found %d records of %s (intersect).' % (len(records_intersect_patch[layer]), layer))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We see that using the option `intersect` typically returns more records than `within`."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Looking at the above plot. Point `(390, 1100)` seems to be on a stop line. Lets verify that."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "my_point = (390, 1100)\n",
+ "layers = nusc_map.layers_on_point(my_point[0], my_point[1])\n",
+ "assert len(layers['stop_line']) > 0, 'Error: No stop line found!'"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Indeed, we see a `stop_line` record.\n",
+ "\n",
+ "To directly check for `stop_line` records, we run:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc_map.record_on_point(my_point[0], my_point[1], 'stop_line')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's look at the bounds/extremities of that record"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc_map.get_bounds('stop_line', 'ac0a935f-99af-4dd4-95e3-71c92a5e58b1')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Layers"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let us look more closely at the different map layers:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc_map.layer_names"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Our map database consists of multiple **layers**. Where each layer is made up of **records**. Each record will have a token identifier.\n",
+ "\n",
+ "We see how our map layers are divided into two types of layers. One set of layer belong to the `geometric_layers` group, another set of layers belongs to the `non_geometric_layers` group. \n",
+ "1. `geometric_layers` define geometric entities in the map:\n",
+ " - Nodes (2d points) are the basis for all geometric layers.\n",
+ " - Lines consist of two or more nodes. Formally, one `Line` record can consist of more than one line segment.\n",
+ " - Polygons consist of three or more nodes. A polygon can have holes, thus distorting its formal definition. Holes are defined as a sequence of nodes that forms the perimeter of the polygonal hole.\n",
+ " \n",
+ " \n",
+ "2. `non_geometric_layers` represent physical entities in the map. They can have more than one geometric representation (such as `drivable_areas`), but must be strictly of one type (e.g. `road_segment`, `lane_divider`)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### 1. Geometric layers"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc_map.geometric_layers"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### a. Node\n",
+ "The most primitive geometric record in our map database. This is the only layer that explicitly contains spatial coordinates."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sample_node = nusc_map.node[0]\n",
+ "sample_node"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### b. Line\n",
+ "\n",
+ "Defines a line sequence of one or more lines and therefore consists of two or more nodes."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sample_line = nusc_map.line[2]\n",
+ "sample_line"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### c. Polygon \n",
+ "Defines a polygon which may contain holes.\n",
+ "\n",
+ "Every polygon record comprises of a list of exterior nodes, and zero or more list(s) of nodes that constitute (zero or more) holes.\n",
+ "\n",
+ "Let's look at one polygon record:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sample_polygon = nusc_map.polygon[3]\n",
+ "sample_polygon.keys()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sample_polygon['exterior_node_tokens'][:10]"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sample_holes = sample_polygon['holes'][0]\n",
+ "sample_holes"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### 2. Non geometric layers\n",
+ "\n",
+ "Every non-geometric layer is associated with at least one geometric object."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc_map.non_geometric_layers"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### a. Drivable Area\n",
+ "Drivable area is defined as the area where the car can drive, without consideration for driving directions or legal restrictions. This is the only layer in which the record can be represented by more than one geometric entity.\n",
+ "*Note: On some machines this polygon renders incorrectly as a filled black rectangle.*"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sample_drivable_area = nusc_map.drivable_area[0]\n",
+ "sample_drivable_area"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig, ax = nusc_map.render_record('drivable_area', sample_drivable_area['token'], other_layers=[])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### b. Road Segment\n",
+ "\n",
+ "A segment of road on a drivable area. It has an `is_intersection` flag which denotes whether a particular road segment is an intersection.\n",
+ "\n",
+ "It may or may not have an association with a `drivable area` record from its `drivable_area_token` field."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ "sample_road_segment = nusc_map.road_segment[600]\n",
+ "sample_road_segment"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "As observed, for all non geometric objects except `drivable_area`, we provide a shortcut to its `nodes`."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's take a look at a `road_segment` record with `is_intersection == True`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sample_intersection_road_segment = nusc_map.road_segment[3]\n",
+ "sample_intersection_road_segment"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "If we render this road segment we can see that it is indeed an intersection:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig, ax = nusc_map.render_record('road_segment', sample_intersection_road_segment['token'], other_layers=[])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### c. Road Block\n",
+ "Road blocks are blocks of a road that have the same traffic direction. Multiple road blocks are grouped in a road segment.\n",
+ "\n",
+ "Within a road block, the number of lanes is consistent."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sample_road_block = nusc_map.road_block[0]\n",
+ "sample_road_block"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Every road block has a `from_edge_line_token` and `to_edge_line_token` that denotes its traffic direction."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig, ax = nusc_map.render_record('road_block', sample_road_block['token'], other_layers=[])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### d. Lanes"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Lanes are parts of the road where vehicles drive in a single direction."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ "sample_lane_record = nusc_map.lane[600]\n",
+ "sample_lane_record"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Aside from the token and the geometric representation, a lane has several fields:\n",
+ "- `lane_type` denotes whether cars or bikes are allowed to navigate through that lane.\n",
+ "- `from_edge_line_token` and `to_edge_line_token` denotes their traffic direction.\n",
+ "- `left_lane_divider_segments` and `right_lane_divider_segment` denotes their lane dividers.\n",
+ "- `left_lane_divider_segment_nodes` and `right_lane_divider_segment_nodes` denotes the nodes that makes up the lane dividers."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig, ax = nusc_map.render_record('lane', sample_lane_record['token'], other_layers=[])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### e. Pedestrian Crossing\n",
+ "Pedestrian crossings are regions where pedestrians can legally cross the road, typically highlighted by white markings. Each pedestrian crossing record has to be on a road segment. It has the `road_segment_token` field which denotes the `road_segment` record it is associated with."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sample_ped_crossing_record = nusc_map.ped_crossing[0]\n",
+ "sample_ped_crossing_record"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig, ax = nusc_map.render_record('ped_crossing', sample_ped_crossing_record['token'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### f. Walkway\n",
+ "A walkway or sidewalk is the typically elevated area next to a road where pedestrians are protected from vehicles on the road."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sample_walkway_record = nusc_map.walkway[0]\n",
+ "sample_walkway_record"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig, ax = nusc_map.render_record('walkway', sample_walkway_record['token'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### g. Stop Line\n",
+ "The physical world's stop line, even though the name implies that it should possess a `line` geometric representation, in reality its physical representation is an **area where the ego vehicle must stop.**"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sample_stop_line_record = nusc_map.stop_line[1]\n",
+ "sample_stop_line_record"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "It has several attributes:\n",
+ "- `stop_line_type`, the type of the stop line, this represents the reasons why the ego vehicle would stop \n",
+ "- `ped_crossing_tokens` denotes the association information if the `stop_line_type` is `PED_CROSSING`.\n",
+ "- `traffic_light_tokens` denotes the association information if the `stop_line_type` is `TRAFFIC_LIGHT`.\n",
+ "- `road_block_token` denotes the association information to a `road_block`, can be empty by default. \n",
+ "- `cues` field contains the reason on why this this record is a `stop_line`. An area can be a stop line due to multiple reasons:\n",
+ " - Cues for `stop_line_type` of \"PED_CROSSING\" or \"TURN_STOP\" are `ped_crossing` records.\n",
+ " - Cues for `stop_line_type` of TRAFFIC_LIGHT\" are `traffic_light` records.\n",
+ " - No cues for `stop_line_type` of \"STOP_SIGN\" or \"YIELD\"."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig, ax = nusc_map.render_record('stop_line', sample_stop_line_record['token'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### h. Carpark Area\n",
+ "A car park or parking lot area."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sample_carpark_area_record = nusc_map.carpark_area[1]\n",
+ "sample_carpark_area_record"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "It has several attributes:\n",
+ "- `orientation` denotes the direction of parked cars in radians.\n",
+ "- `road_block_token` denotes the association information to a `road_block`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig, ax = nusc_map.render_record('carpark_area', sample_carpark_area_record['token'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### i. Road Divider\n",
+ "A divider that separates one road block from another."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sample_road_divider_record = nusc_map.road_divider[0]\n",
+ "sample_road_divider_record"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "`road_segment_token` saves the association information to a `road_segment`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig, ax = nusc_map.render_record('road_divider', sample_road_divider_record['token'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### j. Lane Divider\n",
+ "A lane divider comes between lanes that point in the same traffic direction."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sample_lane_divider_record = nusc_map.lane_divider[0]\n",
+ "sample_lane_divider_record"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "The `lane_divider_segments` field consist of different `node`s and their respective `segment_type`s which denotes their physical appearance."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig, ax = nusc_map.render_record('lane_divider', sample_lane_divider_record['token'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### k. Traffic Light\n",
+ "A physical world's traffic light."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sample_traffic_light_record = nusc_map.traffic_light[0]\n",
+ "sample_traffic_light_record"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "It has several attributes:\n",
+ "1. `traffic_light_type` denotes whether the traffic light is oriented horizontally or vertically.\n",
+ "2. `from_road_block_tokens` denotes from which road block the traffic light guides.\n",
+ "3. `items` are the bulbs for that traffic light.\n",
+ "4. `pose` denotes the pose of the traffic light."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's examine the `items` field"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sample_traffic_light_record['items']"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "As mentioned, every entry in the `items` field is a traffic light bulb. It has the `color` information, the `shape` information, `rel_pos` which is the relative position, and the `to_road_block_tokens` that denotes to which road blocks the traffic light bulb is guiding."
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.7.7"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 2
+}
diff --git a/python-sdk/tutorials/nuimages_tutorial.ipynb b/python-sdk/tutorials/nuimages_tutorial.ipynb
new file mode 100644
index 0000000..f1d7f7e
--- /dev/null
+++ b/python-sdk/tutorials/nuimages_tutorial.ipynb
@@ -0,0 +1,526 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# nuImages devkit tutorial\n",
+ "\n",
+ "Welcome to the nuImages tutorial.\n",
+ "This demo assumes the database itself is available at `/data/sets/nuimages`, and loads a mini version of the dataset."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## A Gentle Introduction to nuImages\n",
+ "\n",
+ "In this part of the tutorial, let us go through a top-down introduction of our database. Our dataset is structured as a relational database with tables, tokens and foreign keys. The tables are the following:\n",
+ "\n",
+ "1. `log` - Log from which the sample was extracted.\n",
+ "2. `sample` - An annotated camera image with an associated timestamp and past and future images and pointclouds.\n",
+ "3. `sample_data` - An image or pointcloud associated with a sample.\n",
+ "4. `ego_pose` - The vehicle ego pose and timestamp associated with a sample_data.\n",
+ "5. `sensor` - General information about a sensor, e.g. `CAM_BACK_LEFT`.\n",
+ "6. `calibrated_sensor` - Calibration information of a sensor in a log.\n",
+ "7. `category` - Taxonomy of object and surface categories (e.g. `vehicle.car`, `flat.driveable_surface`). \n",
+ "8. `attribute` - Property of an object that can change while the category remains the same.\n",
+ "9. `object_ann` - Bounding box and mask annotation of an object (e.g. car, adult).\n",
+ "10. `surface_ann` - Mask annotation of a surface (e.g. `flat.driveable surface` and `vehicle.ego`).\n",
+ "\n",
+ "The database schema is visualized below. For more information see the [schema page](https://github.com/nutonomy/nuscenes-devkit/blob/master/docs/schema_nuimages.md).\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Google Colab (optional)\n",
+ "\n",
+ "<br>\n",
+ "<a href=\"https://colab.research.google.com/github/nutonomy/nuscenes-devkit/blob/master/python-sdk/tutorials/nuimages_tutorial.ipynb\">\n",
+ " <img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\" align=\"left\">\n",
+ "</a>\n",
+ "<br>\n",
+ " \n",
+ "If you are running this notebook in Google Colab, you can uncomment the cell below and run it; everything will be set up nicely for you. Otherwise, manually set up everything."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# !mkdir -p /data/sets/nuimages # Make the directory to store the nuImages dataset in.\n",
+ "\n",
+ "# !wget https://www.nuscenes.org/data/nuimages-v1.0-mini.tgz # Download the nuImages mini split.\n",
+ "\n",
+ "# !tar -xf nuimages-v1.0-mini.tgz -C /data/sets/nuimages # Uncompress the nuImages mini split.\n",
+ "\n",
+ "# !pip install nuscenes-devkit &> /dev/null # Install nuImages."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Initialization\n",
+ "To initialize the dataset class, we run the code below. We can change the dataroot parameter if the dataset is installed in a different folder. We can also omit it to use the default setup. These will be useful further below."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%matplotlib inline\n",
+ "%load_ext autoreload\n",
+ "%autoreload 2\n",
+ "from nuimages import NuImages\n",
+ "\n",
+ "nuim = NuImages(dataroot='/data/sets/nuimages', version='v1.0-mini', verbose=True, lazy=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Tables\n",
+ "\n",
+ "As described above, the NuImages class holds several tables. Each table is a list of records, and each record is a dictionary. For example the first record of the category table is stored at:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nuim.category[0]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "To see the list of all tables, simply refer to the `table_names` variable:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nuim.table_names"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Indexing\n",
+ "\n",
+ "Since all tables are lists of dictionaries, we can use standard Python operations on them. A very common operation is to retrieve a particular record by its token. Since this operation takes linear time, we precompute an index that helps to access a record in constant time.\n",
+ "\n",
+ "Let us select the first image in this dataset version and split:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sample_idx = 0\n",
+ "sample = nuim.sample[sample_idx]\n",
+ "sample"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can also get the sample record from a sample token:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sample = nuim.get('sample', sample['token'])\n",
+ "sample"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "What this does is actually to lookup the index. We see that this is the same index as we used in the first place."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sample_idx_check = nuim.getind('sample', sample['token'])\n",
+ "assert sample_idx == sample_idx_check"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "From the sample, we can directly access the corresponding keyframe sample data. This will be useful further below."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "key_camera_token = sample['key_camera_token']\n",
+ "print(key_camera_token)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Lazy loading\n",
+ "\n",
+ "Initializing the NuImages instance above was very fast, as we did not actually load the tables. Rather, the class implements lazy loading that overwrites the internal `__getattr__()` function to load a table if it is not already stored in memory. The moment we accessed `category`, we could see the table being loaded from disk. To disable such notifications, just set `verbose=False` when initializing the NuImages object. Furthermore lazy loading can be disabled with `lazy=False`."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Rendering\n",
+ "\n",
+ "To render an image we use the `render_image()` function. We can see the boxes and masks for each object category, as well as the surface masks for ego vehicle and driveable surface. We use the following colors:\n",
+ "- vehicles: orange\n",
+ "- bicycles and motorcycles: red\n",
+ "- pedestrians: blue\n",
+ "- cones and barriers: gray\n",
+ "- driveable surface: teal / green\n",
+ "\n",
+ "At the top left corner of each box, we see the name of the object category (if `with_category=True`). We can also set `with_attributes=True` to print the attributes of each object (note that we can only set `with_attributes=True` to print the attributes of each object when `with_category=True`). In addition, we can specify if we want to see surfaces and objects, or only surfaces, or only objects, or neither by setting `with_annotations` to `all`, `surfaces`, `objects` and `none` respectively.\n",
+ "\n",
+ "Let us make the image bigger for better visibility by setting `render_scale=2`. We can also change the line width of the boxes using `box_line_width`. By setting it to -1, the line width adapts to the `render_scale`. Finally, we can render the image to disk using `out_path`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nuim.render_image(key_camera_token, annotation_type='all',\n",
+ " with_category=True, with_attributes=True, box_line_width=-1, render_scale=5)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let us find out which annotations are in that image."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "object_tokens, surface_tokens = nuim.list_anns(sample['token'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can see the object_ann and surface_ann tokens. Let's again render the image, but only focus on the first object and the first surface annotation. We can use the `object_tokens` and `surface_tokens` arguments as shown below. We see that only one car and the driveable surface are rendered."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ "nuim.render_image(key_camera_token, with_category=True, object_tokens=[object_tokens[0]], surface_tokens=[surface_tokens[0]])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "To get the raw data (i.e. the segmentation masks, both semantic and instance) of the above, we can use `get_segmentation()`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import matplotlib.pyplot as plt\n",
+ "\n",
+ "semantic_mask, instance_mask = nuim.get_segmentation(key_camera_token)\n",
+ "\n",
+ "plt.figure(figsize=(32, 9))\n",
+ "\n",
+ "plt.subplot(1, 2, 1)\n",
+ "plt.imshow(semantic_mask)\n",
+ "plt.subplot(1, 2, 2)\n",
+ "plt.imshow(instance_mask)\n",
+ "\n",
+ "plt.show()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Every annotated image (keyframe) comes with up to 6 past and 6 future images, spaced evenly at 500ms +- 250ms. However, a small percentage of the samples has less sample_datas, either because they were at the beginning or end of a log, or due to delays or dropped data packages.\n",
+ "`list_sample_content()` shows for each sample all the associated sample_datas."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nuim.list_sample_content(sample['token'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Besides the annotated images, we can also render the 6 previous and 6 future images, which are not annotated. Let's select the next image, which is taken around 0.5s after the annotated image. We can either manually copy the token from the list above or use the `next` pointer of the `sample_data`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "next_camera_token = nuim.get('sample_data', key_camera_token)['next']\n",
+ "next_camera_token"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Now that we have the next token, let's render it. Note that we cannot render the annotations, as they don't exist.\n",
+ "\n",
+ "*Note: If you did not download the non-keyframes (sweeps), this will throw an error! We make sure to catch it here.*"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "try:\n",
+ " nuim.render_image(next_camera_token, annotation_type='none')\n",
+ "except Exception as e:\n",
+ " print('As expected, we encountered this error:', e)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "In this section we have presented a number of rendering functions. For convenience we also provide a script `render_images.py` that runs one or all of these rendering functions on a random subset of the 93k samples in nuImages. To run it, simply execute the following line in your command line. This will save image, depth, pointcloud and trajectory renderings of the front camera to the specified folder."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "`>> python nuimages/scripts/render_images.py --mode all --cam_name CAM_FRONT --out_dir ~/Downloads/nuImages --out_type image`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Instead of rendering the annotated keyframe, we can also render a video of the 13 individual images, spaced at 2 Hz."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "`>> python nuimages/scripts/render_images.py --mode all --cam_name CAM_FRONT --out_dir ~/Downloads/nuImages --out_type video`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Poses and CAN bus data"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "The `ego_pose` provides the translation, rotation, rotation_rate, acceleration and speed measurements closest to each sample_data. We can visualize the trajectories of the ego vehicle throughout the 6s clip of each annotated keyframe. Here the red **x** indicates the start of the trajectory and the green **o** the position at the annotated keyframe.\n",
+ "We can set `rotation_yaw` to have the driving direction at the time of the annotated keyframe point \"upwards\" in the plot. We can also set `rotation_yaw` to None to use the default orientation (upwards pointing North). To get the raw data of this plot, use `get_ego_pose_data()` or `get_trajectory()`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nuim.render_trajectory(sample['token'], rotation_yaw=0, center_key_pose=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Statistics\n",
+ "\n",
+ "The `list_*()` methods are useful to get an overview of the dataset dimensions. Note that these statistics are always *for the current split* that we initialized the `NuImages` instance with, rather than the entire dataset."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ "nuim.list_logs()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "`list_categories()` lists the category frequencies, as well as the category name and description. Each category is either an object or a surface, but not both."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ "nuim.list_categories(sort_by='object_freq')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can also specify a `sample_tokens` parameter for `list_categories()` to get the category statistics for a particular set of samples."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sample_tokens = [nuim.sample[9]['token']]\n",
+ "nuim.list_categories(sample_tokens=sample_tokens)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "`list_attributes()` shows the frequency, name and description of all attributes:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nuim.list_attributes(sort_by='freq')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "`list_cameras()` shows us how many camera entries and samples there are for each channel, such as the front camera.\n",
+ "Each camera uses slightly different intrinsic parameters, which will be provided in a future release."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nuim.list_cameras()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "`list_sample_data_histogram()` shows a histogram of the number of images per annotated keyframe. Note that there are at most 13 images per keyframe. For the mini split shown here, all keyframes have 13 images."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nuim.list_sample_data_histogram()"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.7.7"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
diff --git a/python-sdk/tutorials/nuscenes_lidarseg_tutorial.ipynb b/python-sdk/tutorials/nuscenes_lidarseg_tutorial.ipynb
new file mode 100644
index 0000000..9a4d480
--- /dev/null
+++ b/python-sdk/tutorials/nuscenes_lidarseg_tutorial.ipynb
@@ -0,0 +1,506 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# nuScenes-lidarseg tutorial\n",
+ "\n",
+ "Welcome to the nuScenes-lidarseg tutorial.\n",
+ "\n",
+ "This demo assumes that nuScenes is installed at `/data/sets/nuscenes`. The mini version (i.e. v1.0-mini) of the full dataset will be used for this demo."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Setup\n",
+ "To install the nuScenes-lidarseg expansion, download the dataset from https://www.nuscenes.org/download. Unpack the compressed file(s) into `/data/sets/nuscenes` and your folder structure should end up looking like this:\n",
+ "```\n",
+ "└── nuscenes \n",
+ " ├── Usual nuscenes folders (i.e. samples, sweep)\n",
+ " │\n",
+ " ├── lidarseg\n",
+ " │ └── v1.0-{mini, test, trainval} <- Contains the .bin files; a .bin file \n",
+ " │ contains the labels of the points in a \n",
+ " │ point cloud (note that v1.0-test does not \n",
+ " │ have any .bin files associated with it) \n",
+ " └── v1.0-{mini, test, trainval}\n",
+ " ├── Usual files (e.g. attribute.json, calibrated_sensor.json etc.)\n",
+ " ├── lidarseg.json <- contains the mapping of each .bin file to the token \n",
+ " └── category.json <- contains the categories of the labels (note that the \n",
+ " category.json from nuScenes v1.0 is overwritten)\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Google Colab (optional) \n",
+ "\n",
+ "<br>\n",
+ "<a href=\"https://colab.research.google.com/github/nutonomy/nuscenes-devkit/blob/master/python-sdk/tutorials/nuscenes_lidarseg_tutorial.ipynb\">\n",
+ " <img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/ align=\"left\">\n",
+ "</a>\n",
+ "<br>\n",
+ "\n",
+ "If you are running this notebook in Google Colab, you can uncomment the cell below and run it; everything will be set up nicely for you. Otherwise, go to [**Setup**](#Setup) to manually set up everything."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# !mkdir -p /data/sets/nuscenes # Make the directory to store the nuScenes dataset in.\n",
+ "\n",
+ "# !wget https://www.nuscenes.org/data/v1.0-mini.tgz # Download the nuScenes mini split.\n",
+ "# !wget https://www.nuscenes.org/data/nuScenes-lidarseg-mini-v1.0.tar.bz2 # Download the nuScenes-lidarseg mini split.\n",
+ "\n",
+ "# !tar -xf v1.0-mini.tgz -C /data/sets/nuscenes # Uncompress the nuScenes mini split.\n",
+ "# !tar -xf nuScenes-lidarseg-mini-v1.0.tar.bz2 -C /data/sets/nuscenes # Uncompress the nuScenes-lidarseg mini split.\n",
+ "\n",
+ "# !pip install nuscenes-devkit &> /dev/null # Install nuScenes."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Initialization\n",
+ "Let's start by importing the necessary libraries:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%matplotlib inline\n",
+ "\n",
+ "from nuscenes import NuScenes\n",
+ "\n",
+ "nusc = NuScenes(version='v1.0-mini', dataroot='/data/sets/nuscenes', verbose=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "As you can see, you do not need any extra libraries to use nuScenes-lidarseg. The original nuScenes devkit which you are familiar with has been extended so that you can use it seamlessly with nuScenes-lidarseg."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Statistics of lidarseg dataset for the v1.0-mini split\n",
+ "Let's get a quick feel of the lidarseg dataset by looking at what classes are in it and the number of points belonging to each class. The classes will be sorted in ascending order based on the number of points (since `sort_by='count'` below); you can also sort the classes by class name or class index by setting `sort_by='name'` or `sort_by='index'` respectively."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc.list_lidarseg_categories(sort_by='count')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "With `list_lidarseg_categories`, you can get the index which each class name belongs to by looking at the leftmost column. You can also get a mapping of the indices to the class names from the `lidarseg_idx2name_mapping` attribute of the NuScenes class."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc.lidarseg_idx2name_mapping"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Conversely, you can get the mapping of the class names to the indices from the `lidarseg_name2idx_mapping` attribute of the NuScenes class."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc.lidarseg_name2idx_mapping"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Pick a sample token\n",
+ "Let's pick a sample to use for this tutorial."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "my_sample = nusc.sample[87]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Get statistics of a lidarseg sample token\n",
+ "Now let's take a look at what classes are present in the pointcloud of this particular sample."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc.get_sample_lidarseg_stats(my_sample['token'], sort_by='count')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "By doing `sort_by='count'`, the classes and their respective frequency counts are printed in ascending order; you can also do `sort_by='name'` and `sort_by='index'` here as well."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Render the lidarseg labels in the bird's eye view of a pointcloud\n",
+ "In the original nuScenes devkit, you would pass a sample data token into ```render_sample_data``` to render a bird's eye view of the pointcloud. However, the points would be colored according to the distance from the ego vehicle. Now with the extended nuScenes devkit, all you need to do is set ```show_lidarseg=True``` to visualize the class labels of the pointcloud."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sample_data_token = my_sample['data']['LIDAR_TOP']\n",
+ "nusc.render_sample_data(sample_data_token,\n",
+ " with_anns=False,\n",
+ " show_lidarseg=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "But what if you wanted to focus on only certain classes? Given the statistics of the pointcloud printed out previously, let's say you are only interested in trucks and trailers. You could see the class indices belonging to those classes from the statistics and then pass an array of those indices into ```filter_lidarseg_labels``` like so:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc.render_sample_data(sample_data_token,\n",
+ " with_anns=False,\n",
+ " show_lidarseg=True,\n",
+ " filter_lidarseg_labels=[22, 23])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Now only points in the pointcloud belonging to trucks and trailers are filtered out for your viewing pleasure. "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "In addition, you can display a legend which indicates the color for each class by using `show_lidarseg_legend`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc.render_sample_data(sample_data_token,\n",
+ " with_anns=False,\n",
+ " show_lidarseg=True,\n",
+ " show_lidarseg_legend=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Render lidarseg labels in image\n",
+ "If you wanted to superimpose the pointcloud into the corresponding image from a camera, you can use ```render_pointcloud_in_image``` like what you would do with the original nuScenes devkit, but set ```show_lidarseg=True``` (remember to set ```render_intensity=False```). Similar to ```render_sample_data```, you can filter to see only certain classes using ```filter_lidarseg_labels```. And you can use ```show_lidarseg_legend``` to display a legend in the rendering."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc.render_pointcloud_in_image(my_sample['token'],\n",
+ " pointsensor_channel='LIDAR_TOP',\n",
+ " camera_channel='CAM_BACK',\n",
+ " render_intensity=False,\n",
+ " show_lidarseg=True,\n",
+ " filter_lidarseg_labels=[22, 23],\n",
+ " show_lidarseg_legend=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Render sample (i.e. lidar, radar and all cameras)\n",
+ "Of course, like in the original nuScenes devkit, you can render all the sensors at once with ```render_sample```. In this extended nuScenes devkit, you can set ```show_lidarseg=True``` to see the lidarseg labels. Similar to the above methods, you can use ```filter_lidarseg_labels``` to display only the classes you wish to see."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc.render_sample(my_sample['token'],\n",
+ " show_lidarseg=True,\n",
+ " filter_lidarseg_labels=[22, 23])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Render a scene for a given camera sensor with lidarseg labels\n",
+ "You can also render an entire scene with the lidarseg labels for a camera of your choosing (the ```filter_lidarseg_labels``` argument can be used here as well)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's pick a scene first:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "my_scene = nusc.scene[0]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We then pass the scene token into ```render_scene_channel_lidarseg``` indicating that we are only interested in construction vehicles and man-made objects (here, we set `verbose=True` to produce a window which will allows us to see the frames as they are being random). \n",
+ "\n",
+ "In addition, you can use `dpi` (to adjust the size of the lidar points) and `imsize` (to adjust the size of the rendered image) to tune the aesthetics of the renderings to your liking.\n",
+ "\n",
+ "(Note: the following code is commented out as it crashes in Jupyter notebooks.)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# import os\n",
+ "# nusc.render_scene_channel_lidarseg(my_scene['token'], \n",
+ "# 'CAM_BACK', \n",
+ "# filter_lidarseg_labels=[18, 28],\n",
+ "# verbose=True, \n",
+ "# dpi=100,\n",
+ "# imsize=(1280, 720))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "To save the renderings, you can pass a path to a folder you want to save the images to via the ```out_folder``` argument, and either `video` or `image` to `render_mode`.\n",
+ "\n",
+ "(Note: the following code is commented out as it crashes in Jupyter notebooks.)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# nusc.render_scene_channel_lidarseg(my_scene['token'],\n",
+ "# 'CAM_BACK',\n",
+ "# filter_lidarseg_labels=[18, 28],\n",
+ "# verbose=True,\n",
+ "# dpi=100,\n",
+ "# imsize=(1280, 720),\n",
+ "# render_mode='video',\n",
+ "# out_folder=os.path.expanduser('~/Desktop/my_folder'))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "When `render_mode='image'`, only frames which contain points (after the filter has been applied) will be saved as images."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Render a scene for all cameras with lidarseg labels\n",
+ "You can also render the entire scene for all cameras at once with the lidarseg labels as a video. Let's say in this case, we are interested in points belonging to driveable surfaces and cars.\n",
+ "\n",
+ "(Note: the following code is commented out as it crashes in Jupyter notebooks.)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ "# nusc.render_scene_lidarseg(my_scene['token'], \n",
+ "# filter_lidarseg_labels=[17, 24],\n",
+ "# verbose=True,\n",
+ "# dpi=100,\n",
+ "# out_path=os.path.expanduser('~/Desktop/my_rendered_scene.avi'))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Visualizing LIDAR segmentation predictions\n",
+ "In all the above functions, the labels of the LIDAR pointcloud which have been rendered are the ground truth. If you have trained a model to segment LIDAR pointclouds and have run it on the nuScenes-lidarseg dataset, you can visualize your model's predictions with nuScenes-lidarseg as well!\n",
+ "\n",
+ "Each of your .bin files should be a `numpy.uint8` array; as a tip, you can save your predictions as follows:\n",
+ "```\n",
+ "np.array(predictions).astype(np.uint8).tofile(bin_file_out)\n",
+ "```\n",
+ "- `predictions`: The predictions from your model (e.g. `[30, 5, 18, ..., 30]`)\n",
+ "- `bin_file_out`: The path to write your .bin file to (e.g. `/some/folder/<lidar_sample_data_token>_lidarseg.bin`)\n",
+ "\n",
+ "Then you simply need to pass the path to the .bin file where your predictions for the given sample are to `lidarseg_preds_bin_path` for these functions:\n",
+ "- `list_lidarseg_categories`\n",
+ "- `render_sample_data`\n",
+ "- `render_pointcloud_in_image`\n",
+ "- `render_sample` \n",
+ "\n",
+ "For example, let's assume the predictions for `my_sample` is stored at `/data/sets/nuscenes/lidarseg/v1.0-mini` with the format `<lidar_sample_data_token>_lidarseg.bin`:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "\n",
+ "my_sample = nusc.sample[87]\n",
+ "sample_data_token = my_sample['data']['LIDAR_TOP']\n",
+ "my_predictions_bin_file = os.path.join('/data/sets/nuscenes/lidarseg/v1.0-mini', sample_data_token + '_lidarseg.bin')\n",
+ "\n",
+ "nusc.render_pointcloud_in_image(my_sample['token'],\n",
+ " pointsensor_channel='LIDAR_TOP',\n",
+ " camera_channel='CAM_BACK',\n",
+ " render_intensity=False,\n",
+ " show_lidarseg=True,\n",
+ " filter_lidarseg_labels=[22, 23],\n",
+ " show_lidarseg_legend=True,\n",
+ " lidarseg_preds_bin_path=my_predictions_bin_file)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "For these functions that render an entire scene, you will need to pass the path to the folder which contains the .bin files for each sample in a scene to `lidarseg_preds_folder`:\n",
+ "- `render_scene_channel_lidarseg`\n",
+ "- `render_scene_lidarseg`\n",
+ "\n",
+ "Pay special attention that **each set of predictions in the folder _must_ be a `.bin` file and named as `<lidar_sample_data_token>_lidarseg.bin`**.\n",
+ "\n",
+ "(Note: the following code is commented out as it crashes in Jupyter notebooks.)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# my_scene = nusc.scene[0]\n",
+ "# my_folder_of_predictions = '/data/sets/nuscenes/lidarseg/v1.0-mini'\n",
+ "\n",
+ "# nusc.render_scene_channel_lidarseg(my_scene['token'], \n",
+ "# 'CAM_BACK', \n",
+ "# filter_lidarseg_labels=[17, 24],\n",
+ "# verbose=True, \n",
+ "# imsize=(1280, 720),\n",
+ "# lidarseg_preds_folder=my_folder_of_predictions)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Conclusion\n",
+ "And this brings us to the end of the tutorial for nuScenes-lidarseg, enjoy!"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.7.7"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
diff --git a/python-sdk/tutorials/nuscenes_tutorial.ipynb b/python-sdk/tutorials/nuscenes_tutorial.ipynb
new file mode 100644
index 0000000..e98f312
--- /dev/null
+++ b/python-sdk/tutorials/nuscenes_tutorial.ipynb
@@ -0,0 +1,1337 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# nuScenes devkit tutorial\n",
+ "\n",
+ "Welcome to the nuScenes tutorial. This demo assumes the database itself is available at `/data/sets/nuscenes`, and loads a mini version of the full dataset."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## A Gentle Introduction to nuScenes\n",
+ "\n",
+ "In this part of the tutorial, let us go through a top-down introduction of our database. Our dataset comprises of elemental building blocks that are the following:\n",
+ "\n",
+ "1. `log` - Log information from which the data was extracted.\n",
+ "2. `scene` - 20 second snippet of a car's journey.\n",
+ "3. `sample` - An annotated snapshot of a scene at a particular timestamp.\n",
+ "4. `sample_data` - Data collected from a particular sensor.\n",
+ "5. `ego_pose` - Ego vehicle poses at a particular timestamp.\n",
+ "6. `sensor` - A specific sensor type.\n",
+ "7. `calibrated sensor` - Definition of a particular sensor as calibrated on a particular vehicle.\n",
+ "8. `instance` - Enumeration of all object instance we observed.\n",
+ "9. `category` - Taxonomy of object categories (e.g. vehicle, human). \n",
+ "10. `attribute` - Property of an instance that can change while the category remains the same.\n",
+ "11. `visibility` - Fraction of pixels visible in all the images collected from 6 different cameras.\n",
+ "12. `sample_annotation` - An annotated instance of an object within our interest.\n",
+ "13. `map` - Map data that is stored as binary semantic masks from a top-down view.\n",
+ "\n",
+ "The database schema is visualized below. For more information see the [nuScenes schema](https://github.com/nutonomy/nuscenes-devkit/blob/master/docs/schema_nuscenes.md) page.\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Google Colab (optional)\n",
+ "\n",
+ "<br>\n",
+ "<a href=\"https://colab.research.google.com/github/nutonomy/nuscenes-devkit/blob/master/python-sdk/tutorials/nuscenes_tutorial.ipynb\">\n",
+ " <img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\" align=\"left\">\n",
+ "</a>\n",
+ "<br>\n",
+ "\n",
+ "If you are running this notebook in Google Colab, you can uncomment the cell below and run it; everything will be set up nicely for you. Otherwise, manually set up everything."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# !mkdir -p /data/sets/nuscenes # Make the directory to store the nuScenes dataset in.\n",
+ "\n",
+ "# !wget https://www.nuscenes.org/data/v1.0-mini.tgz # Download the nuScenes mini split.\n",
+ "\n",
+ "# !tar -xf v1.0-mini.tgz -C /data/sets/nuscenes # Uncompress the nuScenes mini split.\n",
+ "\n",
+ "# !pip install nuscenes-devkit &> /dev/null # Install nuScenes."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Initialization"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%matplotlib inline\n",
+ "from nuscenes.nuscenes import NuScenes\n",
+ "\n",
+ "nusc = NuScenes(version='v1.0-mini', dataroot='/data/sets/nuscenes', verbose=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## A look at the dataset"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### 1. `scene`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "nuScenes is a large scale database that features annotated samples across ***1000 scenes*** of approximately 20 seconds each. Let's take a look at the scenes that we have in the loaded database."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc.list_scenes()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's look at a scene metadata"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "my_scene = nusc.scene[0]\n",
+ "my_scene"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### 2. `sample`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "In scenes, we annotate our data every half a second (2 Hz).\n",
+ "\n",
+ "We define `sample` as an ***annotated keyframe of a scene at a given timestamp***. A keyframe is a frame where the time-stamps of data from all the sensors should be very close to the time-stamp of the sample it points to.\n",
+ "\n",
+ "Now, let us look at the first annotated sample in this scene."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ "first_sample_token = my_scene['first_sample_token']\n",
+ "\n",
+ "# The rendering command below is commented out because it tends to crash in notebooks\n",
+ "# nusc.render_sample(first_sample_token)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's examine its metadata"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ "my_sample = nusc.get('sample', first_sample_token)\n",
+ "my_sample"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "A useful method is `list_sample()` which lists all related `sample_data` keyframes and `sample_annotation` associated with a `sample` which we will discuss in detail in the subsequent parts."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ "nusc.list_sample(my_sample['token'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### 3. `sample_data`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "The nuScenes dataset contains data that is collected from a full sensor suite. Hence, for each snapshot of a scene, we provide references to a family of data that is collected from these sensors. \n",
+ "\n",
+ "We provide a `data` key to access these:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "my_sample['data']"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Notice that the keys are referring to the different sensors that form our sensor suite. Let's take a look at the metadata of a `sample_data` taken from `CAM_FRONT`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sensor = 'CAM_FRONT'\n",
+ "cam_front_data = nusc.get('sample_data', my_sample['data'][sensor])\n",
+ "cam_front_data"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can also render the `sample_data` at a particular sensor. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc.render_sample_data(cam_front_data['token'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### 4. `sample_annotation`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "`sample_annotation` refers to any ***bounding box defining the position of an object seen in a sample***. All location data is given with respect to the global coordinate system. Let's examine an example from our `sample` above."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "my_annotation_token = my_sample['anns'][18]\n",
+ "my_annotation_metadata = nusc.get('sample_annotation', my_annotation_token)\n",
+ "my_annotation_metadata"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can also render an annotation to have a closer look."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc.render_annotation(my_annotation_token)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### 5. `instance`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Object instance are instances that need to be detected or tracked by an AV (e.g a particular vehicle, pedestrian). Let us examine an instance metadata"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "my_instance = nusc.instance[599]\n",
+ "my_instance"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We generally track an instance across different frames in a particular scene. However, we do not track them across different scenes. In this example, we have 16 annotated samples for this instance across a particular scene."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "instance_token = my_instance['token']\n",
+ "nusc.render_instance(instance_token)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "An instance record takes note of its first and last annotation token. Let's render them"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(\"First annotated sample of this instance:\")\n",
+ "nusc.render_annotation(my_instance['first_annotation_token'])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(\"Last annotated sample of this instance\")\n",
+ "nusc.render_annotation(my_instance['last_annotation_token'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### 6. `category`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "A `category` is the object assignment of an annotation. Let's look at the category table we have in our database. The table contains the taxonomy of different object categories and also list the subcategories (delineated by a period). "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc.list_categories()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "A category record contains the name and the description of that particular category."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc.category[9]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Refer to `instructions_nuscenes.md` for the definitions of the different categories."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### 7. `attribute`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "An `attribute` is a property of an instance that may change throughout different parts of a scene while the category remains the same. Here we list the provided attributes and the number of annotations associated with a particular attribute."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc.list_attributes()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's take a look at an example how an attribute may change over one scene"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "my_instance = nusc.instance[27]\n",
+ "first_token = my_instance['first_annotation_token']\n",
+ "last_token = my_instance['last_annotation_token']\n",
+ "nbr_samples = my_instance['nbr_annotations']\n",
+ "current_token = first_token\n",
+ "\n",
+ "i = 0\n",
+ "found_change = False\n",
+ "while current_token != last_token:\n",
+ " current_ann = nusc.get('sample_annotation', current_token)\n",
+ " current_attr = nusc.get('attribute', current_ann['attribute_tokens'][0])['name']\n",
+ " \n",
+ " if i == 0:\n",
+ " pass\n",
+ " elif current_attr != last_attr:\n",
+ " print(\"Changed from `{}` to `{}` at timestamp {} out of {} annotated timestamps\".format(last_attr, current_attr, i, nbr_samples))\n",
+ " found_change = True\n",
+ "\n",
+ " next_token = current_ann['next']\n",
+ " current_token = next_token\n",
+ " last_attr = current_attr\n",
+ " i += 1"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### 8. `visibility`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "`visibility` is defined as the fraction of pixels of a particular annotation that are visible over the 6 camera feeds, grouped into 4 bins."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc.visibility"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's look at an example `sample_annotation` with 80-100% visibility"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "anntoken = 'a7d0722bce164f88adf03ada491ea0ba'\n",
+ "visibility_token = nusc.get('sample_annotation', anntoken)['visibility_token']\n",
+ "\n",
+ "print(\"Visibility: {}\".format(nusc.get('visibility', visibility_token)))\n",
+ "nusc.render_annotation(anntoken)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's look at an example `sample_annotation` with 0-40% visibility"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "anntoken = '9f450bf6b7454551bbbc9a4c6e74ef2e'\n",
+ "visibility_token = nusc.get('sample_annotation', anntoken)['visibility_token']\n",
+ "\n",
+ "print(\"Visibility: {}\".format(nusc.get('visibility', visibility_token)))\n",
+ "nusc.render_annotation(anntoken)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### 9. `sensor`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "The nuScenes dataset consists of data collected from our full sensor suite which consists of:\n",
+ "- 1 x LIDAR, \n",
+ "- 5 x RADAR, \n",
+ "- 6 x cameras, "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ "nusc.sensor"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Every `sample_data` has a record on which `sensor` the data is collected from (note the \"channel\" key)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ "nusc.sample_data[10]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### 10. `calibrated_sensor`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "`calibrated_sensor` consists of the definition of a particular sensor (lidar/radar/camera) as calibrated on a particular vehicle. Let us look at an example."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ "nusc.calibrated_sensor[0]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Note that the `translation` and the `rotation` parameters are given with respect to the ego vehicle body frame. "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### 11. `ego_pose`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "`ego_pose` contains information about the location (encoded in `translation`) and the orientation (encoded in `rotation`) of the ego vehicle, with respect to the global coordinate system."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc.ego_pose[0]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Note that the number of `ego_pose` records in our loaded database is the same as the number of `sample_data` records. These two records exhibit a one-to-one correspondence."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### 12. `log`\n",
+ "\n",
+ "The `log` table contains log information from which the data was extracted. A `log` record corresponds to one journey of our ego vehicle along a predefined route. Let's check the number of logs and the metadata of a log."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(\"Number of `logs` in our loaded database: {}\".format(len(nusc.log)))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc.log[0]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Notice that it contains a variety of information such as the date and location of the log collected. It also gives out information about the map from where the data was collected. Note that one log can contain multiple non-overlapping scenes."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### 13. `map`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Map information is stored as binary semantic masks from a top-down view. Let's check the number of maps and metadata of a map."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(\"There are {} maps masks in the loaded dataset\".format(len(nusc.map)))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ "nusc.map[0]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## nuScenes Basics"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's get a bit technical.\n",
+ "\n",
+ "The NuScenes class holds several tables. Each table is a list of records, and each record is a dictionary. For example the first record of the category table is stored at:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc.category[0]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "The category table is simple: it holds the fields `name` and `description`. It also has a `token` field, which is a unique record identifier. Since the record is a dictionary, the token can be accessed like so:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "cat_token = nusc.category[0]['token']\n",
+ "cat_token"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "If you know the `token` for any record in the DB you can retrieve the record by doing"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc.get('category', cat_token)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "_As you can notice, we have recovered the same record!_"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "OK, that was easy. Let's try something harder. Let's look at the `sample_annotation` table."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc.sample_annotation[0]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "This also has a `token` field (they all do). In addition, it has several fields of the format [a-z]*\\_token, _e.g._ instance_token. These are foreign keys in database terminology, meaning they point to another table. \n",
+ "Using `nusc.get()` we can grab any of these in constant time. For example, let's look at the visibility record."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc.get('visibility', nusc.sample_annotation[0]['visibility_token'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "The visibility records indicate how much of an object was visible when it was annotated.\n",
+ "\n",
+ "Let's also grab the `instance_token`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "one_instance = nusc.get('instance', nusc.sample_annotation[0]['instance_token'])\n",
+ "one_instance"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "This points to the `instance` table. This table enumerate the object _instances_ we have encountered in each \n",
+ "scene. This way we can connect all annotations of a particular object.\n",
+ "\n",
+ "If you look carefully at the README tables, you will see that the sample_annotation table points to the instance table, \n",
+ "but the instance table doesn't list all annotations that point to it. \n",
+ "\n",
+ "So how can we recover all sample_annotations for a particular object instance? There are two ways:\n",
+ "\n",
+ "1. `Use nusc.field2token()`. Let's try it:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ann_tokens = nusc.field2token('sample_annotation', 'instance_token', one_instance['token'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "This returns a list of all sample_annotation records with the `'instance_token'` == `one_instance['token']`. Let's store these in a set for now"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ "ann_tokens_field2token = set(ann_tokens)\n",
+ "\n",
+ "ann_tokens_field2token"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "The `nusc.field2token()` method is generic and can be used in any similar situation.\n",
+ "\n",
+ "2. For certain situation, we provide some reverse indices in the tables themselves. This is one such example. "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "The instance record has a field `first_annotation_token` which points to the first annotation in time of this instance. \n",
+ "Recovering this record is easy."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ann_record = nusc.get('sample_annotation', one_instance['first_annotation_token'])\n",
+ "ann_record"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Now we can traverse all annotations of this instance using the \"next\" field. Let's try it. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ann_tokens_traverse = set()\n",
+ "ann_tokens_traverse.add(ann_record['token'])\n",
+ "while not ann_record['next'] == \"\":\n",
+ " ann_record = nusc.get('sample_annotation', ann_record['next'])\n",
+ " ann_tokens_traverse.add(ann_record['token'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Finally, let's assert that we recovered the same ann_records as we did using nusc.field2token:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(ann_tokens_traverse == ann_tokens_field2token)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Reverse indexing and short-cuts\n",
+ "\n",
+ "The nuScenes tables are normalized, meaning that each piece of information is only given once.\n",
+ "For example, there is one `map` record for each `log` record. Looking at the schema you will notice that the `map` table has a `log_token` field, but that the `log` table does not have a corresponding `map_token` field. But there are plenty of situations where you have a `log`, and want to find the corresponding `map`! So what to do? You can always use the `nusc.field2token()` method, but that is slow and inconvenient. We therefore add reverse mappings for some common situations including this one.\n",
+ "\n",
+ "Further, there are situations where one needs to go through several tables to get a certain piece of information. \n",
+ "Consider, for example, the category name (e.g. `human.pedestrian`) of a `sample_annotation`. The `sample_annotation` table doesn't hold this information since the category is an instance level constant. Instead the `sample_annotation` table points to a record in the `instance` table. This, in turn, points to a record in the `category` table, where finally the `name` fields stores the required information.\n",
+ "\n",
+ "Since it is quite common to want to know the category name of an annotation, we add a `category_name` field to the `sample_annotation` table during initialization of the NuScenes class.\n",
+ "\n",
+ "In this section, we list the short-cuts and reverse indices that are added to the `NuScenes` class during initialization. These are all created in the `NuScenes.__make_reverse_index__()` method."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Reverse indices\n",
+ "We add two reverse indices by default.\n",
+ "* A `map_token` field is added to the `log` records.\n",
+ "* The `sample` records have shortcuts to all `sample_annotations` for that record as well as `sample_data` key-frames. Confer `nusc.list_sample()` method in the previous section for more details on this."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Shortcuts"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "The sample_annotation table has a \"category_name\" shortcut."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "_Using shortcut:_"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "catname = nusc.sample_annotation[0]['category_name']"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "_Not using shortcut:_"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ann_rec = nusc.sample_annotation[0]\n",
+ "inst_rec = nusc.get('instance', ann_rec['instance_token'])\n",
+ "cat_rec = nusc.get('category', inst_rec['category_token'])\n",
+ "\n",
+ "print(catname == cat_rec['name'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "The sample_data table has \"channel\" and \"sensor_modality\" shortcuts:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Shortcut\n",
+ "channel = nusc.sample_data[0]['channel']\n",
+ "\n",
+ "# No shortcut\n",
+ "sd_rec = nusc.sample_data[0]\n",
+ "cs_record = nusc.get('calibrated_sensor', sd_rec['calibrated_sensor_token'])\n",
+ "sensor_record = nusc.get('sensor', cs_record['sensor_token'])\n",
+ "\n",
+ "print(channel == sensor_record['channel'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Data Visualizations\n",
+ "\n",
+ "We provide list and rendering methods. These are meant both as convenience methods during development, and as tutorials for building your own visualization methods. They are implemented in the NuScenesExplorer class, with shortcuts through the NuScenes class itself."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### List methods\n",
+ "There are three list methods available."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "1. `list_categories()` lists all categories, counts and statistics of width/length/height in meters and aspect ratio."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc.list_categories()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "2. `list_attributes()` lists all attributes and counts."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc.list_attributes()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "3. `list_scenes()` lists all scenes in the loaded DB."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc.list_scenes()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Render"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "First, let's plot a lidar point cloud in an image. Lidar allows us to accurately map the surroundings in 3D."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "my_sample = nusc.sample[10]\n",
+ "nusc.render_pointcloud_in_image(my_sample['token'], pointsensor_channel='LIDAR_TOP')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "In the previous image the colors indicate the distance from the ego vehicle to each lidar point. We can also render the lidar intensity. In the following image the traffic sign ahead of us is highly reflective (yellow) and the dark vehicle on the right has low reflectivity (purple)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc.render_pointcloud_in_image(my_sample['token'], pointsensor_channel='LIDAR_TOP', render_intensity=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Second, let's plot the radar point cloud for the same image. Radar is less dense than lidar, but has a much larger range."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc.render_pointcloud_in_image(my_sample['token'], pointsensor_channel='RADAR_FRONT')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can also plot all annotations across all sample data for that sample. Note how for radar we also plot the velocity vectors of moving objects. Some velocity vectors are outliers, which can be filtered using the settings in RadarPointCloud.from_file()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "my_sample = nusc.sample[20]\n",
+ "\n",
+ "# The rendering command below is commented out because it may crash in notebooks\n",
+ "# nusc.render_sample(my_sample['token'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Or if we only want to render a particular sensor, we can specify that."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc.render_sample_data(my_sample['data']['CAM_FRONT'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Additionally we can aggregate the point clouds from multiple sweeps to get a denser point cloud."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc.render_sample_data(my_sample['data']['LIDAR_TOP'], nsweeps=5, underlay_map=True)\n",
+ "nusc.render_sample_data(my_sample['data']['RADAR_FRONT'], nsweeps=5, underlay_map=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "In the radar plot above we only see very confident radar returns from two vehicles. This is due to the filter settings defined in the file `nuscenes/utils/data_classes.py`. If instead we want to disable all filters and render all returns, we can use the `disable_filters()` function. This returns a denser point cloud, but with many returns from background objects. To return to the default settings, simply call `default_filters()`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from nuscenes.utils.data_classes import RadarPointCloud\n",
+ "RadarPointCloud.disable_filters()\n",
+ "nusc.render_sample_data(my_sample['data']['RADAR_FRONT'], nsweeps=5, underlay_map=True)\n",
+ "RadarPointCloud.default_filters()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can even render a specific annotation."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc.render_annotation(my_sample['anns'][22])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Finally, we can render a full scene as a video. There are two options here:\n",
+ "1. nusc.render_scene_channel() renders the video for a particular channel. (HIT ESC to exit)\n",
+ "2. nusc.render_scene() renders the video for all camera channels.\n",
+ "\n",
+ "NOTE: These methods use OpenCV for rendering, which doesn't always play nice with IPython Notebooks. If you experience any issues please run these lines from the command line. \n",
+ "\n",
+ "Let's grab scene 0061, it is nice and dense."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "my_scene_token = nusc.field2token('scene', 'name', 'scene-0061')[0]"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# The rendering command below is commented out because it may crash in notebooks\n",
+ "# nusc.render_scene_channel(my_scene_token, 'CAM_FRONT')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "There is also a method nusc.render_scene() which renders the video for all camera channels. \n",
+ "This requires a high-res monitor, and is also best run outside this notebook."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# The rendering command below is commented out because it may crash in notebooks\n",
+ "# nusc.render_scene(my_scene_token)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Finally, let us visualize all scenes on the map for a particular location."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc.render_egoposes_on_map(log_location='singapore-onenorth')"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.7.7"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 2
+}
diff --git a/python-sdk/tutorials/prediction_tutorial.ipynb b/python-sdk/tutorials/prediction_tutorial.ipynb
new file mode 100644
index 0000000..eb4475b
--- /dev/null
+++ b/python-sdk/tutorials/prediction_tutorial.ipynb
@@ -0,0 +1,698 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# nuScenes prediction tutorial\n",
+ "<img src=\"https://www.nuscenes.org/public/tutorials/trajectory.gif\" width=\"300\" align=\"left\">"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "This notebook serves as an introduction to the new functionality added to the nuScenes devkit for the prediction challenge.\n",
+ "\n",
+ "It is organized into the following sections:\n",
+ "\n",
+ "1. Data splits for the challenge\n",
+ "2. Getting past and future data for an agent \n",
+ "3. Changes to the Map API\n",
+ "4. Overview of input representation\n",
+ "5. Model implementations\n",
+ "6. Making a submission to the challenge"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from nuscenes import NuScenes\n",
+ "\n",
+ "# This is the path where you stored your copy of the nuScenes dataset.\n",
+ "DATAROOT = '/data/sets/nuscenes'\n",
+ "\n",
+ "nuscenes = NuScenes('v1.0-mini', dataroot=DATAROOT)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 1. Data Splits for the Prediction Challenge\n",
+ "\n",
+ "This section assumes basic familiarity with the nuScenes [schema](https://www.nuscenes.org/nuscenes#data-format).\n",
+ "\n",
+ "The goal of the nuScenes prediction challenge is to predict the future location of agents in the nuScenes dataset. Agents are indexed by an instance token and a sample token. To get a list of agents in the train and val split of the challenge, we provide a function called `get_prediction_challenge_split`.\n",
+ "\n",
+ "The get_prediction_challenge_split function returns a list of strings of the form {instance_token}_{sample_token}. In the next section, we show how to use an instance token and sample token to query data for the prediction challenge."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from nuscenes.eval.prediction.splits import get_prediction_challenge_split\n",
+ "mini_train = get_prediction_challenge_split(\"mini_train\", dataroot=DATAROOT)\n",
+ "mini_train[:5]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 2. Getting past and future data for an agent\n",
+ "\n",
+ "We provide a class called `PredictHelper` that provides methods for querying past and future data for an agent. This class is instantiated by wrapping an instance of the `NuScenes` class. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from nuscenes.prediction import PredictHelper\n",
+ "helper = PredictHelper(nuscenes)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "To get the data for an agent at a particular point in time, use the `get_sample_annotation` method."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "instance_token, sample_token = mini_train[0].split(\"_\")\n",
+ "annotation = helper.get_sample_annotation(instance_token, sample_token)\n",
+ "annotation"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "To get the future/past of an agent, use the `get_past_for_agent`/`get_future_for_agent` methods. If the `in_agent_frame` parameter is set to true, the coordinates will be in the agent's local coordinate frame. Otherwise, they will be in the global frame."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "future_xy_local = helper.get_future_for_agent(instance_token, sample_token, seconds=3, in_agent_frame=True)\n",
+ "future_xy_local"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "The agent's coordinate frame is centered on the agent's current location and the agent's heading is aligned with the positive y axis. For example, the last coordinate in `future_xy_local` corresponds to a location 0.31 meters to the left and 9.67 meters in front of the agents starting location."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "future_xy_global = helper.get_future_for_agent(instance_token, sample_token, seconds=3, in_agent_frame=False)\n",
+ "future_xy_global"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Note that you can also return the entire annotation record by passing `just_xy=False`. However in this case, `in_agent_frame` is not taken into account."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "helper.get_future_for_agent(instance_token, sample_token, seconds=3, in_agent_frame=True, just_xy=False)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "If you would like to return the data for the entire sample, as opposed to one agent in the sample, you can use the `get_annotations_for_sample` method. This will return a list of records for each annotated agent in the sample."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sample = helper.get_annotations_for_sample(sample_token)\n",
+ "len(sample)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Note that there are `get_future_for_sample` and `get_past_for_sample` methods that are analogous to the `get_future_for_agent` and `get_past_for_agent` methods.\n",
+ "\n",
+ "We also provide methods to compute the velocity, acceleration, and heading change rate of an agent at a given point in time"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# We get new instance and sample tokens because these methods require computing the difference between records.\n",
+ "instance_token_2, sample_token_2 = mini_train[5].split(\"_\")\n",
+ "\n",
+ "# Meters / second.\n",
+ "print(f\"Velocity: {helper.get_velocity_for_agent(instance_token_2, sample_token_2)}\\n\")\n",
+ "\n",
+ "# Meters / second^2.\n",
+ "print(f\"Acceleration: {helper.get_acceleration_for_agent(instance_token_2, sample_token_2)}\\n\")\n",
+ "\n",
+ "# Radians / second.\n",
+ "print(f\"Heading Change Rate: {helper.get_heading_change_rate_for_agent(instance_token_2, sample_token_2)}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Changes to the Map API\n",
+ "\n",
+ "We've added a couple of methods to the Map API to help query lane center line information."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from nuscenes.map_expansion.map_api import NuScenesMap\n",
+ "nusc_map = NuScenesMap(map_name='singapore-onenorth', dataroot=DATAROOT)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "To get the closest lane to a location, use the `get_closest_lane` method. To see the internal data representation of the lane, use the `get_lane_record` method. \n",
+ "You can also explore the connectivity of the lanes, with the `get_outgoing_lanes` and `get_incoming_lane` methods."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "x, y, yaw = 395, 1095, 0\n",
+ "closest_lane = nusc_map.get_closest_lane(x, y, radius=2)\n",
+ "closest_lane"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "lane_record = nusc_map.get_arcline_path(closest_lane)\n",
+ "lane_record"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc_map.get_incoming_lane_ids(closest_lane)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nusc_map.get_outgoing_lane_ids(closest_lane)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "To help manipulate the lanes, we've added an `arcline_path_utils` module. For example, something you might want to do is discretize a lane into a sequence of poses."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from nuscenes.map_expansion import arcline_path_utils\n",
+ "poses = arcline_path_utils.discretize_lane(lane_record, resolution_meters=1)\n",
+ "poses"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Given a query pose, you can also find the closest pose on a lane."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "closest_pose_on_lane, distance_along_lane = arcline_path_utils.project_pose_to_lane((x, y, yaw), lane_record)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(x, y, yaw)\n",
+ "closest_pose_on_lane"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Meters.\n",
+ "distance_along_lane"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "To find the entire length of the lane, you can use the `length_of_lane` function."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "arcline_path_utils.length_of_lane(lane_record)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "You can also compute the curvature of a lane at a given distance along the lane."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# 0 means it is a straight lane.\n",
+ "arcline_path_utils.get_curvature_at_distance_along_lane(distance_along_lane, lane_record)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 4. Input Representation\n",
+ "\n",
+ "It is common in the prediction literature to represent the state of an agent as a tensor containing information about the semantic map (such as the drivable area and walkways), as well the past locations of surrounding agents.\n",
+ "\n",
+ "Each paper in the field chooses to represent the input in a slightly different way. For example, [CoverNet](https://arxiv.org/pdf/1911.10298.pdf) and [MTP](https://arxiv.org/pdf/1808.05819.pdf) choose to rasterize the map information and agent locations into a three channel RGB image. But [Rules of the Road](http://openaccess.thecvf.com/content_CVPR_2019/papers/Hong_Rules_of_the_Road_Predicting_Driving_Behavior_With_a_Convolutional_CVPR_2019_paper.pdf) decides to use a \"taller\" tensor with information represented in different channels.\n",
+ "\n",
+ "We provide a module called `input_representation` that is meant to make it easy for you to define your own input representation. In short, you need to define your own `StaticLayerRepresentation`, `AgentRepresentation`, and `Combinator`.\n",
+ "\n",
+ "The `StaticLayerRepresentation` controls how the static map information is represented. The `AgentRepresentation` controls how the locations of the agents in the scene are represented. The `Combinator` controls how these two sources of information are combined into a single tensor.\n",
+ "\n",
+ "For more information, consult `input_representation/interface.py`.\n",
+ "\n",
+ "To help get you started, we've provided implementations of input representation used in CoverNet and MTP."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import matplotlib.pyplot as plt\n",
+ "%matplotlib inline\n",
+ "\n",
+ "from nuscenes.prediction.input_representation.static_layers import StaticLayerRasterizer\n",
+ "from nuscenes.prediction.input_representation.agents import AgentBoxesWithFadedHistory\n",
+ "from nuscenes.prediction.input_representation.interface import InputRepresentation\n",
+ "from nuscenes.prediction.input_representation.combinators import Rasterizer\n",
+ "\n",
+ "static_layer_rasterizer = StaticLayerRasterizer(helper)\n",
+ "agent_rasterizer = AgentBoxesWithFadedHistory(helper, seconds_of_history=1)\n",
+ "mtp_input_representation = InputRepresentation(static_layer_rasterizer, agent_rasterizer, Rasterizer())\n",
+ "\n",
+ "instance_token_img, sample_token_img = 'bc38961ca0ac4b14ab90e547ba79fbb6', '7626dde27d604ac28a0240bdd54eba7a'\n",
+ "anns = [ann for ann in nuscenes.sample_annotation if ann['instance_token'] == instance_token_img]\n",
+ "img = mtp_input_representation.make_input_representation(instance_token_img, sample_token_img)\n",
+ "\n",
+ "plt.imshow(img)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Model Implementations\n",
+ "\n",
+ "We've provided PyTorch implementations for CoverNet and MTP. Below we show, how to make predictions on the previously created input representation."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from nuscenes.prediction.models.backbone import ResNetBackbone\n",
+ "from nuscenes.prediction.models.mtp import MTP\n",
+ "from nuscenes.prediction.models.covernet import CoverNet\n",
+ "import torch"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Both models take a CNN backbone as a parameter. We've provided wrappers for ResNet and MobileNet v2. In this example, we'll use ResNet50."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "backbone = ResNetBackbone('resnet50')\n",
+ "mtp = MTP(backbone, num_modes=2)\n",
+ "\n",
+ "# Note that the value of num_modes depends on the size of the lattice used for CoverNet.\n",
+ "covernet = CoverNet(backbone, num_modes=64)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "The second input is a tensor containing the velocity, acceleration, and heading change rate for the agent."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "agent_state_vector = torch.Tensor([[helper.get_velocity_for_agent(instance_token_img, sample_token_img),\n",
+ " helper.get_acceleration_for_agent(instance_token_img, sample_token_img),\n",
+ " helper.get_heading_change_rate_for_agent(instance_token_img, sample_token_img)]])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "image_tensor = torch.Tensor(img).permute(2, 0, 1).unsqueeze(0)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Output has 50 entries.\n",
+ "# The first 24 are x,y coordinates (in the agent frame) over the next 6 seconds at 2 Hz for the first mode.\n",
+ "# The second 24 are the x,y coordinates for the second mode.\n",
+ "# The last 2 are the logits of the mode probabilities\n",
+ "mtp(image_tensor, agent_state_vector)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# CoverNet outputs a probability distribution over the trajectory set.\n",
+ "# These are the logits of the probabilities\n",
+ "logits = covernet(image_tensor, agent_state_vector)\n",
+ "print(logits)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "The CoverNet model outputs a probability distribution over a set of trajectories. To be able to interpret the predictions, and perform inference with CoverNet, you need to download the trajectory sets from the nuscenes website. Download them from this [link](https://www.nuscenes.org/public/nuscenes-prediction-challenge-trajectory-sets.zip) and unzip them in a directory of your choice.\n",
+ "\n",
+ "Uncomment the following code when you do so:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "#import pickle\n",
+ "\n",
+ "# Epsilon is the amount of coverage in the set, \n",
+ "# i.e. a real world trajectory is at most 8 meters from a trajectory in this set\n",
+ "# We released the set for epsilon = 2, 4, 8. Consult the paper for more information\n",
+ "# on how this set was created\n",
+ "\n",
+ "#PATH_TO_EPSILON_8_SET = \"\"\n",
+ "#trajectories = pickle.load(open(PATH_TO_EPSILON_8_SET, 'rb'))\n",
+ "\n",
+ "# Saved them as a list of lists\n",
+ "#trajectories = torch.Tensor(trajectories)\n",
+ "\n",
+ "# Print 5 most likely predictions\n",
+ "#trajectories[logits.argsort(descending=True)[:5]]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We also provide two physics-based models - A constant velocity and heading model and a physics oracle. The physics oracle estimates the future trajectory of the agent with several physics based models and chooses the one that is closest to the ground truth. It represents the best performance a purely physics based model could achieve on the dataset."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from nuscenes.prediction.models.physics import ConstantVelocityHeading, PhysicsOracle\n",
+ "\n",
+ "cv_model = ConstantVelocityHeading(sec_from_now=6, helper=helper)\n",
+ "physics_oracle = PhysicsOracle(sec_from_now=6, helper=helper)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "The physics models can be called as functions. They take as input a string of the instance and sample token of the agent concatenated with an underscore (\"_\").\n",
+ "\n",
+ "The output is a `Prediction` data type. The `Prediction` data type stores the predicted trajectories and their associated probabilities for the agent. We'll go over the `Prediction` type in greater detail in the next section."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "cv_model(f\"{instance_token_img}_{sample_token_img}\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "physics_oracle(f\"{instance_token_img}_{sample_token_img}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 6. Making a submission to the challenge\n",
+ "\n",
+ "Participants must submit a zipped json file containing serialized `Predictions` for each agent in the validation set.\n",
+ "\n",
+ "The previous section introduced the `Prediction` data type. In this section, we explain the format in greater detail. \n",
+ "\n",
+ "A `Prediction` consists of four fields:\n",
+ "\n",
+ "1. instance: The instance token for the agent.\n",
+ "2. sample: The sample token for the agent.\n",
+ "3. prediction: Prediction from model. A prediction can consist of up to 25 proposed trajectories. This field must be a numpy array with three dimensions (number of trajectories (also called modes), number of timesteps, 2).\n",
+ "4. probabilities: The probability corresponding to each predicted mode. This is a numpy array with shape `(number_of_modes,)`.\n",
+ "\n",
+ "You will get an error if any of these conditions are violated."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from nuscenes.eval.prediction.data_classes import Prediction\n",
+ "import numpy as np"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# This would raise an error because instance is not a string.\n",
+ "\n",
+ "#Prediction(instance=1, sample=sample_token_img,\n",
+ "# prediction=np.ones((1, 12, 2)), probabilities=np.array([1]))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# This would raise an error because sample is not a string.\n",
+ "\n",
+ "#Prediction(instance=instance_token_img, sample=2,\n",
+ "# prediction=np.ones((1, 12, 2)), probabilities=np.array([1]))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# This would raise an error because prediction is not a numpy array.\n",
+ "\n",
+ "#Prediction(instance=instance_token_img, sample=sample_token_img,\n",
+ "# prediction=np.ones((1, 12, 2)).tolist(), probabilities=np.array([1]))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# This would throw an error because probabilities is not a numpy array. Uncomment to see.\n",
+ "\n",
+ "#Prediction(instance=instance_token_img, sample=sample_token_img,\n",
+ "# prediction=np.ones((1, 12, 2)), probabilities=[0.3])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# This would throw an error because there are more than 25 predicted modes. Uncomment to see.\n",
+ "\n",
+ "#Prediction(instance=instance_token_img, sample=sample_token_img,\n",
+ "# prediction=np.ones((30, 12, 2)), probabilities=np.array([1/30]*30))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# This would throw an error because the number of predictions and probabilities don't match. Uncomment to see.\n",
+ "\n",
+ "#Prediction(instance=instance_token_img, sample=sample_token_img,\n",
+ " #prediction=np.ones((13, 12, 2)), probabilities=np.array([1/12]*12))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "To make a submission to the challenge, store your model predictions in a python list and save it to json. Then, upload a zipped version of your file to the eval server. \n",
+ "\n",
+ "For an example, see `eval/prediction/baseline_model_inference.py`"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.7.7"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
diff --git a/python-sdk/tutorials/trajectory.gif b/python-sdk/tutorials/trajectory.gif
new file mode 100644
index 0000000000000000000000000000000000000000..65d9a2daacd9407b64c58a71b5012d95bf3edc1b
GIT binary patch
literal 365639
zcmX6^2T;?^)BYtP9Z2XMLhlfIhfoxdVkjaYYA7Ndq=^Wcgc7O*qzQ<j2uL$D1wjo(
znjk?zLD4rVC@N}DP(;Mf|9m$)b2EE4H#>LpJhQXUt)ufnQ?tNbU>Eoa{QuzPMWX;f
z5C9|u1qH>$#YK=<WpTw&07w!L@G=lQWhv+*DssdJ5$`Ax8VZDmffEw=f{tqffEx&O
z00Q;^fK)MbvbKCsJR%_g7i@XJOD7`a(4j+~M`HZK&zwn04huZ0=c`<dLiGSZ7gnTI
zMQsTRe}obG0D<lU;C+C13k3cP2!0hp{lbIy0G(NR>7pZ&y-`XxBb2WN;eH(k?Zki{
zo>QA4q3dKqz9Nrwxw^Hdrj|zdKRSL=?z+^G4&KwZFek67K=z=BpS(J|Akc4ZVYZkj
z8xi{$?)L|9`vD|<0G-|k()WO~KY@sMpy1~QN;M}^+YXT`{ee9q=y#Ollar(c|B}nd
zo*rOe0NUBfS6e5uTLk)j6Zl(g@Uv9^Te0Sw3dPL7K+a#_%6EXd12oJCFD>y*&+zWf
zfgbOG*4IIQ{{q`T0PZ(1d(NEJbGV@~xN3&<aK?Xu9t;2!9!Q=rrWge3gTp#i<*)kj
zcZLb{o>Zt(@Vge}S{#*@AD2QW`CdaKW&q$b2=opBwgBKS48G5c-opdCAl+ZW%5xFO
zc~4+364(d_t;T~tMFHDMz}|V_ZvwCtEwdRYxd<Zeff9Zz`aC-3^{SY+WB}ZM1J+Wb
zT>A^?ek{~j6VO5j_HF`uRoF+f!0ZEHY#x}O1I_&gJz|4?{se8Ws(iTYKg|yB7VPQN
z>taflm&Iq4CS_Ni&AD<euR0~SJf2pZn$Jk4cewU2LvPdpd&S_LZh@KBfXNP^a1Ye+
zOR$EGe9DG=Uxa*I1MPeO{%isJd%*S{{KI$T{6@f|hoN;G3WbuJn|rCG;ATN?+0D$3
zE*iPGF0blF6{Vj}YwMsf3vPDy-|p}1>VBA!HPhF(P*vJImC--hojcB$espV&U35KT
zy1#p(EbrOGtw&>}vv(dm?3tU(Vb4yCPt48DEj@qp`Sa)Z@85m<H*Icw-uU+I%lECV
ztsg&r{r&rQXJ_Z@H|~F&|Kxx10K)%JApaNbe!$zy-j;YkUk48X{c~yk4;=r434quK
z#E{ZXOvZ2qLP#TEl1Y-|xfkzT<K!WRupQ46c}vJC?<u;4@{smxd8!{eZ60ztCvtV{
zgo1xNDUe$6uzCQM8+09&Q+X}q0;k(7UQGA+fR@j?kebJ6GqFL?yV0q2vCUV&+A_~8
zsE+@tAxgmku{;qfpU^iH{%N)Qq{8tpRV|t-Xi=p%$ya^DN?Uy_#(_Tq9y+?DOk-ZK
zNW|i`c6x_`0v^}B_7M3S!O0V<=)}|-CJSbwGyP77Az%9++w?gW`p_Kvzz@-scSW6m
zd#SnkUBjn-a!>gCn*FWgSurw4V#4TZM_N<NJM#v1htWWLWYG$oMSGbLyDumxe5(?7
zVhCYt5$R&|DG#^uT)*%3QC*D2mnK|q_3c=ncEk@MtYjM2PF{{on#Nh=bRW{Rw4FfV
z7NVPv%P#x1$a|;p0Mzv5t&&;d(2Cup_HAK1r?9Juk8O<xTP9A(-)ZlA9x=H7n4&*}
z7xFazGr;48)?w1ACtfEVK&Z91d!n${OCL{bwB-oqsrl?LPM048i|4^aaU%#tDV+tl
zLLvPMQK78tgNj`mKxS!w*$Qs9{<3<b+2T3E(>0&EQBr7Z(S24SPq{uPNT+G|VAhF<
z!p!{Wvt<NDm!UQNNti{S;KOpkTY@r)0mkZwa8jAfhj0<x2wh=62RGs<E4CV_Dc3cw
zQKmp6e{)obP%!lC921S)sHW=)s)7gDQ*%A+gAa>Lv~M9ESucShZU!xj^^a;ftq|U#
znT3+s0fis+Ve<Ve`bua`2IECx+a_$p9g{3^wM8HmIStQZH0SHwC6g##Fm?S;&{95t
zHHwAcSz{1yI$Taf!C_IZ-gVh~9JXe=IjK|;)z#7WCZfG_QgDn0Ab2<0d*|=Gb<Tgc
zHhS3R*WNdQh<UcwXUj>}k9@18=L4Ajb5&I8h4os^zVum*JO!QHX#6ycK@K{lMmnaB
zdItJrSLiUfy7UkZ+tQ=A^Ezt%T!|MVMk);G6zK26=4_kuU<k!b`InhuC-fhvK8t9R
zP3Z|ZE(c1ZC%b<^{E4!m#ywV0O|pLReeThcXVKc+JugFp-W7ZEUibg9z^2JRE^k@y
zZWv&mq^35wJeMjR8RfSKBTnK#3E7v8Wx2zSD_JHsKPMAoxi2(YO-1`{X{I;-{78V4
z`#Z!YQ2O4vDW=>2gC{E(`KsG3ZZ_--7ksq$+jS1>TRqm_{kXSKd=jmJh5yZj*;s7a
zOE=)Mz%GG&=L*!EO+RFrSmJ;$e#~>AFkqYUUHPc|Diy~o|3HV;zp3mXAi6`;QK_&F
zr@Rd%Q%~+if$oGY6eWHkj5}v<7J_!a>g;PHCIEN}zpNTv`1;Ox&ce6aYBEGxgttyu
zPQ~iJ*?2VkO1-GIH~?N9&V<_5AyNfo8+)<--zEe4xbmY9hu=zk@0s}cQIGdD9wPBd
zoMH5Blqyykl(YAVrhe$mm`vKFftz%$4obc#HieWg-yW2BsF-5yo#UEEZdB=W1mRH*
z0wTmfI?BT={PifdhApki+l8q*0J%hnRQ|xV&6kybD+3XR%Vi)Y374pJ)Cx#`p=`3)
z)J0BsMd_z8Ht*w+!w~U)04dcx6Y;p?vSb4bo+@8q;I3JABSd-j$LpS7Q;*}f8C31_
zlQze@Sx`;DPU`#(>+>^ql+JzJ1Ac2x{xPmfI<dFuyD{hXdS*Qcp0YH?GtH(2CTOI!
zkP*qxW<Bjb$y{4^(13Q?gnwwLX%Tq&k?Vmz_9&Qaogz7u8fTyCA0x+_X_n8(6w3cL
zTFj?h18Z3|@yS%cA|}J#<utIfX<_l>t66TpUn7sCQm+~|!1-pU?uTgwOH8p&S$v1g
z$*zxHZ?mAObDi@p+Om}!YnrX?h(O)6HbfH0${gyYWZqe<S_*N1V&h7CUn@9%b-rdr
zymH8iYnNpA!qM=;Q(k{|aMGWh2S+wdS!cM#Q2iYZU+3FJ$($!5*LQ%_ybrV0*55j@
z7G&5D5t(cCqBql*_CM)N`i}qXZ7co5eW2+13t_(!Ts!~VQCqytX7Z3|oB#2vrrr^a
z6EWq9`%Vna01(=<0L+u%hdgj-u;<A=Q2@>nCNsVtk5s@pYBqjI)_jHuCkqK?GvRR!
zM=;0Y&|%tr(t0UMyd-X{+?TXwWX<mYaA%(IldCc6u;M~HT%VtDnUBrAz%0gvqkVN`
z;yIHKplHBZTlfL;>h3U~(?+>aZ4Q1mY|6K|#9fZ%lwClnTdvq=Lv`@B7tqoxCo1dD
zB5OOt>|F;yZ$^b-YOyH?x?XFeNRs>PgL?VhX!DM@0)y#1O4E8L!{;+Ze@1Ir@4V*=
zB$bK7l&<cp$27=+zWJtW+CEZiLZgo|gW&5|5NE@EFcB$YeaX@B2rKsJg{`1z5xryY
zn0p8t!s3N#)BMU`aNdx~9WkR@E10he8JF%!`2X>BmT$4mv1NiqTavTXU}w;c9J>ef
z2R9g}KU>;8WV78YHFc8(s8;wYp<}Q{3x&d}@l^k?MQnCKxctPT-&?3Id#=l-@KbKc
zTgd&!n5&MqId=5;p8pWGCE;#gXcB<5ptWIa!JEi~zinmSXSVA+O%U}T%eeScJiCBa
z9A35705>>y8ujJRhp?<FqxX-qwuprh9yy{<$&ED3`0+1%QY_)WKxZ91`|@$(TSz)-
zOL2dffliHZc|2+Q;p4h3R00ioGuH}7lDO_-JWS5;@gNUt1}eKjQh0^1k?_H`5SzjR
zqB~OD(Hv03#^JXi-m#u3@;S-D1DI#^&AK^-lBXEwljM#hU;HhjeQ}Zm)n)0S(#Q!!
zx!v~JU9wtl;YS}bRmQTs&T4(LFx=IC1?qI?adQ|MOU#fxo;(<sIGoShh<sSc9ewrz
zi3u`kkeE(!d{cKF-PLd<@joXJZ~bSgsBgpPiYH$jo|YJ63*IbP$7ZQ7o!OYhc*t$7
zCm@<$Q&^Z+=b&nPCX+E{_ScM}v)3VtvR!)z5q475G8K&#pd!#c`;Aeo`E2dJRVr?m
z^@H@1_9#DI{KPuXkCqDuG!F)%TE+)CTb#lFI!LJdzwh#AatGDhxi0}802n@<vP~e7
zy`zN!g{ds~LlYHxoGg#yVLZ&GWs`RdPx#doHB5IbH{i#!DPPCHC$dsuDP+ZY^biTf
z;G%AF5^mB_Jvg+}TMy1e@K>5Y$QS+}2{ZQ0<rPa(`3*csUq#U*;!vO8O{MT@2Bq-{
zW|zY^jN_FEGuw&-%Q&TK#epq;gu<VRn0ZFXaY6nN)D5ySzaS!52)u#ge@Q|`P4XM;
z1Q;z@dhqBa?BEl`Qz%DMtO<z!I2b=)(kAC{!FxE3t`c02*uOx6p6)r__Lgre`JA&U
z;SZ626vsP4q}U~3yq74ZFsk{J<YP-BsAuBdp2}^2aiF4c3&OaKgo^czOA*hfya!!;
ze|Cri=`-cKU77DLc5#bKGkwp0@c`m{93mgDQox2&iHH@PK!KAv3vj9UDLVTj=r1vs
zSQ#)M&#z0&3Md0#%Sq^molVq3{2EcdIPcZYQr-jO&i*{sqMCJ2{NhjS#Z9$KA4!M{
zfYxLVBAsEUwOPO;TzDEJWotmdhvp6w(chG{->@lo0$80K49QOY&2l?_20e(g`h<{w
zdxR(}A&==s1tCz~BoqgW*~LfyTq=n^is|O;!^4AeXdHMp`zTzEZU_l}kbG{Ak-6u^
ze^`yzkC8t227-@+;MoxMI58yxc>%`Xb4I8QjG|zVHsDdmA*cpI_HjkjF(l$B6?K!0
zYN4ZU;LuWd^ahLXBNwwx552iwlK4w&2ZzpDLZq6h&~ONz3}en_w2p}1>IiQoEf?_%
zJ&ffY<zi&ZAlO{FuZiH`?9?wTbWS;Xg)Ey1@c$rTAmSId0sf6R%un`dRU|6Jul!Va
zc}pBBG`E~g)@Wk#W#RaLF);^`PTM%ldw~BvnLmllhw-hTmle@Dh(boqwBKcusWXXs
zVmC$8n}aKhO&$IKnEZVS-gh|dA2^7N8e|a%IZy&FTTcE;4tuSqaKM+mfkkxFQ6V3y
zI+4{O=TJLWP{s6e3jX{{7XL>)`4=6tiDm4NF`EECC>5T-gz@jf;&JduB7FRp=XWe-
zgNvkb5Ynv`g>i^%hO`;=gtJ~f_Lko(VrAt|^lxtVJLc8Gb7p^V7!yXRIT520C#J&8
zfU02ZyU>eF$srE<;Bd<NFdE0;-y~zUv6ycReozGFIg#;~#s7DT?<I#ngATfgySDY~
z`pxk2oh#RxiOAm)$Z7yl%xsD}ge+si&H(Uu^X51le2G}cNXC3*@@FxT($DK=!Y{v4
zxw;=NBpYt;alSm1@k47YPSA>aZc)|cRz>WKb9{RY%ufd94Y2`_<^N4@(4m9>V`KK&
z7>Mun!x5+zCf^4p-wKQW0}kEIZT&#!kDBD`i$EdXz$th{1_>dBMT|rsMkEmzx$tTN
zGRhn|eW$6E(H?UMITL{_BX-2(A%o4Eg7U82L{=|Xbu5`TRpL9}9%_E40T(_*xZ8Wq
zbse)nLS5s)OIUT^cblbmk(*46brpIrIqb4N{(S>Fq>jJ!31*9gxxa|{$;Dh#KiMo%
z@rT2AG)a)If!SvAHIWb<l5HJ#__A^6E`LORE_95EyU0bdyigXnHa+5gEms0jjYW`|
z$YLULMx*00tNjWCX>5VKf=8C)kyYd#GYez|vA2TW`?j^WlGW>K(b*h_Tz%f_mEUnh
zv#*)Z`QM$sV^W<*@{#WjHOG_r?SwGz$$U$3{7G^Ar_bMt)T{}Usu>-)waqSHVIs3R
z&80ZxcmJE|pAh0Kr#IY2AQ&OXki^CH%aQs=rrXBvAiKHU^vL#$Sj06PnjF{OjqRBx
zAIV<kHEctgokv>bBkLo3uMm;tamYS=_e31hFTcb2JhGe#`6>))rX#P=`wm<5dA{iF
zI^TEl#o$SozHZIF$-&;9YGegtu+61oMyi)k-CIgRKHabGnQd+AW;Q)XBVJkbL{$w0
zS~SOVAu-EcD<o7R7Z%HeZAjI9d3X=2abG~=z6}#u!n~a}ct8E&?Mpah+l%&MZhQD{
zdz3k=nA0=!dvLXC=&r?}OXMA)-z`-v)`Me1ePn3<4P@7gA-D5L%Q!I|Itm*#)N{Vq
zZ19e{<z0g2-Nh<oC9dP~!*-)c7D5_%5j)TmKF}jEkb!HHvp`5_w%N^eb>qg`Q^#VK
z`Tiqfe&SAUVyjS}@_C+*HJjawmxL>Dnrwczm*T)@@*V_fHQTU9en%qr2JegVjvj66
zo&3~0BQ+$p!s1IqR<U^Xf3#fVu&jRfXl_jGmvNAapODje<;|RS1~FmRc{I|0K=lg0
z(@d+(ARi9h<~-CowhPK&Ol6b$vn?$1e`jSe_@h=a_m5z%UAYlIU@-4#0fQF^8ao8<
zK}0P(GqB^q1rLq^tfy$!(9j(@>7hfBy>d0ZGBv$zE`u;F*6c3)QQqjB^gZ)ZUg7ft
zW-D#oOuiQ^{>}*02L}H)Cf`d2{{mxpm<&}UHkfcA-x-b81SQ)>z70I)KP+aT*}TKB
zVom`APO#oLJT};1%wuqJ*R>*83v8V~GGmVFuXz|a2sJ$44k;M8!9|Xv5Z#3K33F68
z7x_#JJ+TW9h-iPX+jhSSmx<rUSb8zU?qGmjOydB?BLK68{RjA{g%#d8fOm(SavkO5
z9S8L#L;Z*i`f;gq;JCB%kap>UX<IS-d8s}Bmb=^wDJZ8PX}D0_SQEYt_X))JnVt9%
znsf}a!@)#_R5i6e)x7aEx#Y%A4u2*y($W8!S+~XDWj^REW}gwOpL~R{?6OIKN)|v*
z#zD*(@p~lHJdA32$L|a0u;<G&m%E=GwHi-gw9I+JV{uR4eu57ArSS+aE9S|X1qr>s
zEIhz?MoPlmr}Iw3r1ty#zTp>q<DkZ5_<JROT_)HJRu(I|Tq&q-LP58uFY1&nCgD&1
zWWs7?Zbg!ojrJ9nuLP}>^I=TW1>s1aeFE>TtI*36n5Sg0@VQ#3*m9d5{^Fv<UEE8N
zs>QSTlkeHfb8gL1q(vPg%-F0{*<HV9@D~fbyyY)3&+yROZVNJ}FmB6W0{K6v%F5v7
zD}M@CwlbHsHMHNeV391?=TD3;ZLj6{-$-@7KF;BMYE9jH`Knq3GYoJZV)@GNVyqYt
zyYv@eew%G<v?i7sO?ze1E%wyywTRC6Nz$tdMgHhxnE%+f{*qVk`C+#4{T^wU_uO!?
zU!<!7tE2;t<zb<fxBUL%A*NiYT{_e+j*mOa@8>nhmb_aC0wx#m?H{>%)7PkBlVl
zQo=oheKnoD%Rz7U?0Jvh<K61<dm0BZB}4q;UW9(B+-1HKS$<nNm2$OMSjfFXQtaXP
zEWWci%$a<?zpPtY1Mgw9;{7^wJU@knU!P~ZKh*}wy#!I9^Bg69vSna4NnqjScNpsr
z#*||AjaM!1(G{c9U0#G;z-E`ZasL2jlQ8FgXnLD_?IXJ+Vfi4LUt28KX%M#f=_R^P
z{-xdWS}$q!pbtFf62$ypQb_!Cl+5FU#|VWhowqvteQYj?5BvcHPAHUB7sR^<6kTt{
z>=Q8`@sD1#&)!PC*D=j!v(e=!y(##2v<ZulLk~neZ<>whDa97;FfmcRm~DFt*s*=g
zKsYmpW{CT{xf~OAn<GJ+mm-Xuxkp6Ya6kNqz?<(}N`7^)*%_0B{bWLf|KMV5IbWPf
z(8yZw8{+NHHM71|voBX#Tkqg{s_tblxgXflBa)9#e7$=@cfOc&x4L?>l-qL!H(LK`
zLVab(!)4Gd5_w1J=ghGgUf$8W`KjNyP~KE{66<FI5q_2nO}hxsnEOe!**S*aIdaeZ
zhpnsf2-=6CP^|lFh=4h{_Ov;?YLm<NYNK@p=ziYLH_EIWW$^dqb(I8EOAKxo|AxP^
zK;591mF16KBOz+J$ZD2eJ>y!~^Pb0tdi4wLiWJ<9FS>i@*iWLx(CYMf(*Dd|g7lw+
znxQ1#nYR3^j9b%Hi<s})PXpbWV{zb^aMVW@|8oZa>Ky+D8CRv%-ZRxU;on}R*=8l(
z!?a<QGLZ)~JHjraCh(=e=G5ax=PE6k1w(Zq6_*O>pgWn)K@PcC`4iol>RwIR6{0>o
z5}vD0#r#&(MyL2y`^%Sg1ZqNZ1+P1osYJIrBs`vR;yLFzErDcTBUFdTK$RkiM#)XB
zXWowMXxxteaEq_x)DiWk(cP{RC5uPKq)boE)*h(7wNXtd4t-kVY|uPcDD34v7Wwnb
z*j*7DBwD5Ysd|~1=D`A|rTR&)X2IsIN@V9q1@ic`(qu7bc(z9Uz&`koW1`Z03BSL7
zI`-|sg=&Rp!RRoedFO}6S03MTt2Ou9SnYb-@klDp>*GpNu!(N1P3q6}%}>w1p0G(j
zekW@AP4fHew{`TwTNl11&SX<oTMiWM&&o|?$%{Sued3KBtxW0cxVPrgzS~du$I=49
zhx*RSWgectLWBr*zk`R}c=T3<>`9SqwRYwqn#S{?)@iJlq4er#^c{`W3|rW17S;|W
z&%<MPVuplq3~lThmoNdLrIYps-q)t@QZC8K(}V?`6pFM2ot1y-<ri}C9tDl}w7{!F
zTb+iV_y|ho%9mZFUrf4`E41<S&dpdRH0j$0_Y6CMi=pl9hKBoVl_5XS<K@W*duN5M
zZ@(TF_LH0h!R<fMzsR2dcIHy;#e4H$q;oN1Bro;Hu&SJ5Zb8hHTUP05vEvSFr@W8H
z$tz)Pq{GL?rOtTMs#C3xcl#WRRes#AvmZ94T&cFa`s_<`J(6z39Mk7FbD(Qu?H?B>
zV3}a#DkS2%3=faJHBje(g~{{OTwEx2tc_*;8kar0Uq`F;3(vY#9-29<Ag=Z5weZyW
zX#m12&0T7Kn*L*c1mRqWA3?djey}}xHbo$*!t*T1mToT@-gnT(T4Mg1yA;eUL^<iW
z<BfLLTiV2!$FJR_V(9scrHP&L=w;3SS`<0tI*6cCy3&5~JOo2nKjj^e_jGL`>e7nD
zYI=R(yGMU==9`~hh*%fnm0=Dq(j-bM7jl%Q!~H`PUcO!{KdxjvR%Gvcy{p)M4-x3o
z^L4y>s{1LOc1K>~R$py!wEJQH#Hi1XQdm)6G6ibMI#3Z1S0`OD)dLy|OkF(=o723v
z*?Xydc<1%Nv0;xoSf+r^2!eEBrdsYS;&oQVEumr4p9gpGjo658b&DU$)hZVz-xL`}
z7N%yte=lW>IQ+HHBI>28)CtMcWDq8K>iYSwx;M>Z&##_>;kB5|H_|C{^YWi0$|sK0
ziUp+D<}4n&{pQ-zX_H3G0r5bGHp$`~YqCrH03iE)KPR)OTc${kpV!xVV_qj!NjI(Q
z@&t!bA!-&k8*vBc@K%-!z)C-!f8|1YwY7;3#Rp6HnaYXgP#RNb0Ny}$l__ETk}#76
zRbfyC{GXX?)A?dKTsff3)I{V8^SnB*pS7Clfz-4H{;bMu_4c>}+9&2wO`JEP=*<V3
z*(?A`2nJR0+#lM0D;G<*mtIwKG^<hNk4>?c=HTF_Pv?u`eC=hh&(L;w63mD(%!?{E
ze3(=ee|J*4^P_E6s3Amht$*ZKH@T>2(>~FZ$6n?es5`Zh1=RxVtUCoV6?(f7&P=fB
zQi^8!g1saS;3$Z9<qS{=-l{`TrHXxr!f@i-{3nDai6{LtU<3fnWriAFH*<>s6N=)v
z;Ps$pO!`6{e{##H*cWo4`AT3-5@S?mfitVS0FwDSWN*GkF^%KAfg2JU6*SKhrUGNC
z`@&!b^fQ>CF+BRoYe$na^gc<pVu^#sb&NBiC~aXB<s7%B*%!wj@Of02PR!JisLQcN
z*hRxF<-rmvmrla~;8A<1>nZamVcA|aBax1=2lY_If)Qcs?Hi2HIuPHEA=XCR!Q@V0
zUdpOs%At5ic@^@U<P47IZdl0Arz)<Si}hKP+-$R;6ewwZw9t?hC?3YRPtS!wn+=E6
zew``GzatoE%LW^n-q>$U5eEwn@{pX*ZCaFGh!u0pIBH``@ESKZZnC4ke7Re9$*(;~
z#QM~MP``Q9Z0kr*J9k6FJ8+qpX(udI`9P~|q3A3J%ws%hD-q8DwM+Vl-A##@^qDLO
z#o0^kGVD~k=upzaC@hfB$#1HmFWXIqs<Yt5EL$G=&Mye(N~*}Z!12k}QK7#OoWd>_
z<gs0kRo|A?**n*mVEXj#S16hL1H{kQUN6$2_Bqtx)AH}udXZYb&*{*iyvH!AOmQMy
z$BqcoGxX)@`y(54d&(|U4RZ3^<cNs=l`IL|?UPCUxXG>g(f8eNomv;b2L+OO6a&uk
zyywDg(u)6SeAZL}x*CrzJO9M?$U`{}o&`d&J+J6LnRGnyPNL!i1&cFC{)Nv{<7v+$
zk`;u@AH;{>bmeFt^I`qnZdY>^c%!IXi8TvjiaQVngnsNy0fkk%jD$ko$P|>U=<3TK
zfnc$I0`w`d#JZhC!$}XbY1Uu?%fPpemSBNvaTBBcx8EWXM4V@CD9C>#ySks<mGb6E
zYH2ndR@Y#v*Rx~QLgx!3qJl+xc5Zl{j7E7S28-SXwW_B|qV_w3;2curmH8Et6t-UM
zKMRo<)s2EsEr_fY<e<uD>FM*FLRr<gPE?|ATLM`T;fzldy2L>qG~6AR!Bv|ph?yPQ
zKR@>vm3f=HHOx<pdwRbOf8dGv_P>{<$uz9r)F9}+!|_eY(Eiv~CB)?m#gxs2W=!Y@
zi1R5f2BReJfdz9I{>7j`=!GAk&W*r%TnI?8@K%>9>m`r8_cTP)PV)LQsn{y`4M&ro
zG^^AtOfsjz%<?e&CP)jFG-EHbL4unu1y&1Clx1G_AM&Y^RcK?YV1H~!sima~x13yq
zNLAYMhjBBI-1@Nk#|Pw7&*Y~dFyexz$8~G`i*z#sk>ZY2kslGp=|CM+C(PE=Nga`3
zQiXaQL+vkO@F;s9;!#j@kWV|)d!q8Tn87oHxg84T(eD-6-z|<tchWB<koGfbzK<<>
z>;sYnQztcas@o@!e4<7M7$Svm$cT@Zqt<}sUrjkEZwT#CQq+aW0Q6#lZrbZ>b~_Vr
zp1zg`9nY_%fBu4%wXB`D3)&c!O~Tkq>2$tU3Q&wq+4+s)(RH>r1h3K8$=Fiz&RD+1
z<}(qnKn|W7bLBSHWwbiI9};^f!>m6;cL}V!4%Q`QzydOiNEs%+5KC0!ig^hQk^94!
zS1mVl)eGtY@El@-mRl+CoJ=({-W}6|aYp7Y7|MspB7_x4)Yy8PLcN*8-T;qGdpQQj
zb2dfo*cn<#T;0hQxFzDgF#;kr309gkRbo{P>On=~I%QM#P2GRNZ3qL7rab>PrK!;(
z`(eKt?vDk7RZOY7Uevv|QgbdXJx=3l7fWH7rcKU>e2z2Sp_)mTsCS`DS((mQD3Mck
zXdR>{4$*4?U5?A4;6wv&<T|$VxJ)7$VYVJbs1E{4z!gX~+DeTL6Sc4eMqg@N%OD6A
z5+;Alw9`25fK&@D6_9e4s2=QsiI`p&!e3SX1s^$Ylf<S?KDSI`f&~y@<rW*2Fsgy~
zc&PWm@!%o#7HVWmMgoJDA})Saz9gMXwKU8(t(0xjt0iwDpPuLQ6ECbII6ek4ZI{S(
zh|EAC2yF81VQwC?zi_1`4^x*HjV*57=kW1)&{DtO^zdyprQG%Iw<YpEAf`d3wXl91
zSTy*`S)ASJNvaZWhPkio#hq+F2Wr=AdnEyQz@GdU&yrMML-#Pl!<97u+*WBRN^r=~
zsgUvNG^)XjvkIO1&x}eBYW8Pq;AoLdNW>o4a%NN;J8Isaoq!`Gva&%#kSk^tDeD3~
z&pT7&E~SU@ry|B5wL$cq9Q1c67n$%Ll$~>l{@io&#U<J@2o$gb2-TI#MDfxbvS?{p
zN1dR07R>Bo_>mBpMcf1BkcJCDwo=N7l3Hi6bjd}$vKSpSU|upt;VF;mJ<RFv8Gs)A
z2*m=FIwTc`1OMuA-d9PX)&#gM2FyN71FPrEE|r4SiI7-Bv=N=E9QV%yR`<;?pKh=y
zy?JI5r2nrZI(en)EiDGCz4sBe>@gVNB$<2Tp6w3VV`<o%HGFT&-P;N3=hWf!4K`vp
zW6Y#nWRyh$QW*kLn!uHm${FEx*OR6LjwEOM7GwF|n#mhO(+{&JHF@SYfIkh+)gf+6
z-fXoTs%pR6N@j+33e|u?G{9%Pw?)6ZK}%7yibTv*4Z?|7?IWaCo+qu7e$^g+QX~cp
zy90P3GG#U%9VKVobIp3ige!N!<5RN9cQQ<Nz=O6W<_xe>++61J1OH99bpl9u$ylN5
zuseI-)t*~<Y?&6^P}BH9w$bcn)MVDA7yP^$EkX@$&IHSggU2t=*0#GX7r0quvbA%-
zs&P~`JVbS!+Dm$5wMM%ro;5piyJb4d+5RRL0TO#Kol4L1<G6p_a=*6APAAcH=^3)o
zFpDMdEq}ptPI`(5#C-)1D%HVN4p44s3Z}0^_evi-a<imAx17K&B>(o@_$}pnquzWe
zD_rYPb30W7M>S&##_mxySg?3Th6WSDYlVJCafRNYc_6Z8P+3uvt)=?9k~rHq(~=bN
z$-7&RB>CoIc4+3L3}bpmNK4~Mr^m1LXuoa6HSt}_1GlU%Qx2b_&5Rv(;$+kJ2OdYf
z)O$Dp_1_k5lBhhl14d+JSmfxfvr1!Th?+02Py(wi5T@h>`qbZ8YJN0yZ^%w%!WGZZ
zJbbe}0sf1BYEK|Q-NG5t3?~H-;p34|$?G1zq%7}A(9!k<(cP@R4O%>_MLzYqM$3}?
z6is&WR?27iNiL828jlmbhyDQ`QF!DKdI_k3baNUksSWTnh%uQ3+X6$iSZlq$x(otp
zXepMUa)JvAX@%GknsoAp%y;Usq+=L@z9Jf^s8=!kM!sqW_eya-M>0JG0ZE22^}?1P
z?!jZiXh-ONzVsD8Y=#leF0=*u&_SBr1D5Y@Q)+=NK8HsIQ}#vKPk&9jswesP+^D^A
z-JfD4)uN>uuVEF%tWV&ueT8YCzf}^m_|I|J=4urQlgD=SPmF&96hX`1pX(jRf?!e^
z`atio5AZlH*)In=wfM@1oGn^!TI?}{<F5GVQxBbKU0;GXM0>J-(XJmkp42au&Xo1r
zu5F!_a`h1W??Lt3wUav<<fJ6p$N}B=R_^+fln9ncGM8$clVMy5{ahB%5||z6`!ISB
zZcb7@dZ)86m5~O3<#r7&VtJaj{}DFH-OPCRbFCfuWmSX7O-tIJv9kT^ug6g!B_s#&
zFl*XE65B#ad;HXY03N>%wk(BMI{iB~`=;I9LG^vO#lOT$s9uSgakdgJR4FII1=-^Q
z1595>Z+VK;)`<Er(tS0&c1n{0sNS)MlF7m0&yN9kG8TVit^hw>+$xs>NHHi5kFys`
zXcnXlQX#~+B_o9e_oA;TUx0<tp*;Kqcc_Vj1r-+uNSG>nt@AXAWNMVP<9z~uUpKpm
z%{l^PtqBTx_3Kls11sX2j(&MDbV>!ofogJkRbDKGv)0_vprER3^Yta=slbjB>EoO%
zN#A7&CP*rU9E+$;$I{H=AZ8k9V*<@ZT`(D&l@wNYnw;f>hvH_c<NI4gT}JJXQMDP=
zU|)ZmlqutSA3f2vlm^-=B+GCAWA@d&N7;JN;K%hBAFUmR7`<l?BzMt@(s9-zCDI26
zy@s=n5ke(#@)IC9ER~UNN(;HFcxscnR#$dn<K0G5){*sWU1Qla#tS=(-rteqS_rC!
z8az&o7M}x;5!53#^&YG`o$`X_7e*_2C!Fr&LjRytWe{GBBza*$8`3<}Adq1jXyXb+
zp9umFK}>QK&Ehk3S=mW{q)_LxH_8G$!{8F{o+)(E62vLao%c^gxrJmNRIa2pSWf%$
zz|SHo-99|~vY90l`s&L-*7S0Ct<O5)#dJyw&BSs&*+ck!3;ax&#?e!c0G-TLbQT|>
z3>k*c4V9J>&saYW**9T*G_8E6V@j(#P;!#qe+t2aNY3&|c{~KNzcWi!$B*)y8owF>
z4vC_wlPu-2U<=$+y+80=0rvFwEaCCislhBc;fayZM;C}JT_Q_|lwnp0VSc9Gj3zLn
zeR^!A0+`*z9Uww2Q%(({&xjC+1IlJ8+N_B76B%ZNHUD|q?S#6hb(lvSbSmi|n?$@;
z=W$=pbT`f3c^mz7VQMAW4f=jcWha^=3f9C*YT`2A!9at@i|s0Dhv!W`YH#!v!1?S%
zEkhu)g|{<aK<!#w`Yvmv9a1t`qB;cl?f7JvF)|X^CzUDiQ!V%u4*U#0>j*h(KQt?O
z-IWg7huf-g-SL^{*aML`ng%^C%z<qXMddj{T-tJ0r`s4oWBv#o(o35*uMBtSq$Mru
zr1h6Z)zBy(;B53kSJ2&b#5lE+7MlYff5lESg?A3Y<{`A*&N6`sH(kQ#C6M4nBCQb_
zWtU>9P)V__rD!`rLfpsnIUnaD8I+gs#ZG1z_8<Re`>4hH;-GxwYfgDfaszN3ow&oM
zl(p$`mtpuh0Db}w*SHxUvg*7P#nnE|Rt;kZ9;GgBxhaQvAy0ylVpI(V#GDC{uLOr*
zOAc$!kY_*?xQp_>RAp{*oY>FUpUJA6*@Pl$wi#TICacRNM7xGjMFidU=V|9#;CxHu
zs1HYs2pNV%$f-_^olvs=&W7|-_WCzk$_|Y{n@+%v#<z^8;J!yP!MO=A4K-Q<j%Hp-
z_ApI43S`ADEk>%r|B0J9x`!+nka%oN%vZ9?&rBI7P`&UM+lF%?ZmJec>WRhs0zl08
zi}*m=EbRDfP%Kdmmki6IUZ;U!M|Q89WEc>3)kvvo_>Akfy-<t09q)HLZ8BOxg2q41
zKAMJ|Z-FGMO6wvh1rxAymEjRJ2g6lqdd&ybZG0?na0Sz+(eI5s#KDHZ-UUYpd{P#Q
zr4D}$mSj>i#K9J7KVLRJ`EPaB+~}-2<B2+_Ba}_GxbC%Yz70AG{P}wj@_b|Ozk)Pa
z61c5`8XWe`HVh=rN^OqaZN9kMdYj#JoBiVSZqT*eK-JV{)gP*a-6pa9<>r4&f7<5K
z+vfhX{M>!tOoTl+XMv;2GcTA|g5zvvtENVEh}78TCoi{V&7xCPO*0;Son6qqXu$MR
z!%>frpdP-|H5-UBs}?E_Ht;121cj=S{=S1F48U+f!-RL7(o-{)P{kCk>s8-Qm2%Hu
zZavEYT30jw_(MapxK;>*qE8IA%~12GHN5hT^iT2+LL~}9r-jss42N8W>!;_gStal<
zs;{*OsXAU)I`uIGxuATw!MzNXgecZ<SXX+v@62wTQI6u!wIhGDFYCa)f&!|~tl3lT
zlQ)(~>@^8_v^d_Eo(SSV`I7~8q#wL<XQ*7|y51t9Uyp_+x2hY>FKSt2Uj7kvCo^2w
zUoJm4?ln03O5>rUa-lE1kzS3SWjY=TN2cg4cd`&uhiLo*8b>yOzgNqoH(#$#&foBA
zp6**;oj!2W;O?WoglFrEzmxf^@29T4IsV({=Bt78TU(#oZqI2S%W!$h=qM`Bzf3Vv
zv~cT?42x{F5_up*v{GhZ`AwN*tn2IXYV5V+r)aUsI7eFi%zPkCB-wO)M)wH*EFbOu
za-f?!lW0g0VJ!#36PFy$y2(%zJze$osWl{jlu*IZmnq)@3}j60g1p>io(Cqln=RG|
z9X69E19pf^tiCcLlN+zBo0am5-)3*4=Wu1vm&=E3PL)W!tBNfDrD794Vs^SFG5dr6
z5f|R#7ueXPpQ?T*LJsf<=*IX$laoVee8~_07*j!q9%ZbWt)?ha;W%Ht>u?`m`RgKA
z@)+SVZaxh~Hd{4jp;!L&Pkpq0j(g&2Fv(F=sqW04x^zmYxSL|tac{ZEqL#Cst8T^Q
zfKf>sitlUK&wqs)53D{$>-2ARcj(;V)Vt`seD&s0?^@n+k=2j>aGk-p68qrfC-e42
zRy&-_b0%A$i2uaCZw1Fz{y_wM*|(Hmz{8A#x<}owd|B`Qto`4|H!kw8b|1SK50X}5
z2DWfLM8i)b%SEOQ^fxH=>y?5VH9wbpT~#0NHMFC(XGXdPcD*CD=U)4xV|4mgJrM(@
z_XjW*44(L&dAEx5m#+POI+1PT_Vs%PUr>%mwt7RR!Xc}`JKv*kojN<Ht#do&H?!CM
zSw?}~{q^7&tMaR^)0n`~8~m3Zq<nL?A!xmzV%(oB&poozd}W|>Kx*Gjtz#y>?RDAh
z)|(5byW~4qKi79RYTmB`JlN|FozogGb7amezu5gYicy%nkY9GU_vMy}oI!B@t7KHv
zoZ7v8^RrjB5!B$BGucn<X05QX`vaBBA%mvdZ~b+Oo=LJHcL#nJm^IlzE*G5hJ2SbN
zEge550QcK?sOQMnlxXl*ORBOvL%nJ8TgKkExw%W~c6E6^E%oFU^w^IT4@BK|yO@m{
zL_#5_Phz3&Z1&}e_A1-_&t0G7uH&Ex=ej%kptlFjG$dt-9I$8&BVy$RZENTO;iKQf
z)G|dsOSK8imZh`of4+jot7k4<OnWc=e&@AOd8tyA(uUg?;J|*UUY<u{hs<X-faNkC
zXn_NHd(<ANdHdvf(mNB|hzHajR~}sGup_sn1WPTd5y1RRkv8!MS_@s~vD@uf8!SYk
zS7ma@c22IBu?REsxsA=+$Gh$0MKAHntID;IvaGOIUXv<2V&>_mjaN@pu5V@;F)4hp
zz7UQ7;-*b1J<B3Z*EFBphUw(kyS<EiD}{Dq9br<*?dzvBFMN1-;)kb5J0VNQFOX$k
zf949rkfd3kd(eZkDeFFTK&}Twl|*z`+r$N~S-#`ti>Dvo#ZJI&Cn4D{>tinlUpDog
z1PhfuiT~~Ug4bdSZAI00-R6RS>z|f0-s+U=L1gJ8)n)@FFIV1AY%#nl;d=aOmq?vy
zu#V#HL61tR%<ezE_WTb#c9lR6#;)>mLFS|L!Q!(dn11bPcdy3F!d)%nn{hn6X503%
z>Kp+l?Pr)cE$n{SRo<h<F-OhPQfwJNaz`b#D*1^yc7^pV5t29Z7TZp2*T=gmO5gWi
z?4(ljBpC{7k6S@}s~&QP)@T+?b<dJ_II60ZI^VblO|E7%ZkzGIjxLXB*lv*ekoW*s
z;K3V=u%qp<Ck`K{gVFvvotBs7w^Qo0UCp)KephBl*Z5yE+B)L4iJh=nk}pb03zmID
zr&%rq$`(!kt8@c!i+8H`{Z@4^zL|_Rxi>$*)M_ssvpr#D-6}iR^{_h+P2me8LL^ri
zcTSN>JexSLOaK0DJ|e4g5Rtyv3wB)(Dp@kEwgYLEBtP92Wwon=&T;b<mxoe(uU4tx
z^|wdQ@Bi($Cme_@H&OZ^xslrTl_#6TlQ1)2`7j$^ulZ7vSP3)4hVXry>PmMAmY)U=
zo_6!eyO+e`i(em+W)5Hdq5n`4^zi1BHy%01R_d{t+>){(?;Nd7s@SsHgw1$EQ34Sn
zeXw*QdJgm=ej(%Fs04r3I=dP`S8BzIj|A@CI8|e2Dt4O#Lx^(8@EH<J_);gX?^ACY
z+fII(dvNeXS<%G}#?bhBCJ$^T+kA@v)lH!wrt4M{yzSX*rk*lG_LmaK4bl(K7$$cH
zW|?F25a-_%*5VqQ<sEV~e2S@*62XYS_;*V1WpG*B5KKNS<YA|Ag=JiqK~!qEZrXkz
zt5Sk)q*p+Jb?(0E`KH&jy)k-XTP-p9!t21GN&AC_=350JTQzGegsFn*co0-iw6`}9
z9YM^9Xn!pHoNR8>GgU-pa5DRt$5b%qOwzo;75S5yufAQPirF1o>z)imcZ^>-^lR|H
zuh5|*+eC~Nx31`1UGviSZxfXtH;ZD&>}6e>9FyKCfAH|L<*BU#1SHwyWBGp1%*YJB
zPKx|%=~h&tIJn?P2(HOBP=2OzM8e^7>Gh=$8)N5Lp<ae>FjhVy>|6%+)wh^}NedmW
zPwGLHCtJ<ehLyuAXIv2tC0C_0RpBLA9#3tKDR!D)^jdKe^R2YznCA58@;-a|c&*4<
zR1Tv0QDJRjk80%;Ta%t&1ztQ#R~Xzz6T3<RNtz3wpO9cKcwWa;h3#|K0#UtpemT3|
zO`Lr;B0kPIAXYmKQ*Rts%GHCo4GI2Ib8RwW{F)2w?B;p3ar}vAlYLzi?x&pq{AZT_
zqqwjw{`|ig{H@;qZO&KhnM(gHBU-K1zR%um+H+864CIEmj-)>6Ie{Yt794&0MsUF*
z^OIN6;X|zW>^6Ilp^NWO)@eLX^TeRG+Kpd!P3+x0=DqhIg}W_ol=l+$@F*$&v0>45
zmS`H~p@3swG_+t+CceKWUP&M^aiz)C8IhP<_);9P?yK8~x<fu}vp<u6`tzvON?zNl
zy)}EvW&vcp0^)rNGG~mQ9b@q6PxDF6^Gzd9v}f9f)Y>y0p4=T9nt!o#<G-C{9-(@v
zkI<~c(oP$9|KnXE^I4LyJDJ{l4g={|HwJ1%v_@S7GIHq|BK^{RwiAQWxiVoiT*@mw
zEM=+qf#lu-Ds!|l?NMu`bJsc1g4c)IkGtvuvs(fAeIys-I8n7+-i&#q5Pn$567<O#
z7R;*M)`NPNz8C=2wyeDr<j7t_48QsS`?7iP<*CWRw1Acrl)&Vri9iN?Okqmd+04*6
zS$z3y8bsi=z2!oNRb#G+n!SM<L~k7>*NVK_KdP5fi!&_SPmi)y?jx9PT?UIN%&k7j
zFnZJW+Epm=t$-m&h&zs8<rLr?1<D{sy#ALhbL(!%6i-5|m5yGVAGKN?9b#vkW6)YT
zqeIdalauyiQ7*bml?47q-8jgDCI6FZ^#eeLK7O>?tWchpgAkYT#}m*@GRieLZEDfu
z)LY{pUM8t;1xiB%T`3|d8G7z6FTxbJ)aZQ(x8)fn9br4&9qNWF8Q~4FFGpJ<f*mCJ
ztP*SWQm8yL^8bhj<NX*V?Cz-XNGGx6bEc9Slp<KV>U1I4S=LsN=U;yJOwRMvfa#LX
z%(FKfsxdQfZ7;+?D`Q2x&{#_mlwF&?LQ!woXQA2&7_!%?z$aS{YdRZt#&IP&yiLXn
zqgE>Kte)Ek={E&wGzIIcoHXaNI`mwa$5t@vdZ>!6;F7J;UcK)vw5z|1Uvj?3@nD7c
zBKup)Ij>!<_eKCukY_i@)E9zc0%*6U`Hj(`G>H7lNIBcRf(*cgo8fV+Gx21QFpyx}
zoM5e*cu+L~1%Ssg%D3&U7APX5rqJ>b0VR+CU{B0axjOcIbfto@YiGP;7Z~G0(pbD-
z;LNf@tK1#6*ML|e*7OJvQ2g+<6p+QLJ&MUf0k&u#eqGmQ0ANv3<O~!6a8Lsr!T^Ar
zbwVvWv?V)6EnAd;Ao|$s|3O<XfX<3i&Pv)IEr*1~yISr6y8Y{hW9x=PYK4#0j4}xY
z*{nkMe=_R`ya0$-Iemuz13i_DOB+#bA2r9_C{YMkv{Wxu_+U9Rb=Xd+=8UV&%&0z!
zdht0;x(2{5WH`-S&Xy>|_=Z6P$W<o@vMuUzIB?BKxPqabY+TFLS2wa!Ste0Oo$BHE
zC0jvZihwkQAxSw}HF4<qlnpOXYaEdUW>wt@S8#3pXV*1G6hb1JjHyk@5zWT`VsNo(
zSJ8Xp+Aa<;BvL^2P^k?7Q#nHJCZM?Lk9;YBFVK|Q+NlFp+ycRXagd=#tth$n&T3NL
zlu?-NzMwd$N0ic|LJ<wHKb-AsmO=m_G_!TciOVcrfB+4P=={>!uMbwtiEJv-tZYHz
zbL0(x(cbc@$kbX9-$uVNTYfHp*&?(zu~NFHdiwLIr*2sAwp;wugEHF&LR;l(q;cB7
zt(X>2n%cQ4bn<gstT?47v|S(!bhz8aN|*|=+yEy&0j=7O)M`zKepF@U>H?=O#25VQ
z7&A-+TCEn5bTDRvfUL|$?XfIcAj5Ycrlc8MjEixIy>7}fcpD5?vYRfCgjFs;EVZ&F
zS%#(IHg`3zuG*XV+A=~n&PEJVsvcVI5GIX3f_X}w;sCkE_7{1d%z0h##`~iN*imby
zqYbBnH3MM_wwt7!fVYD@Qz>n4B6%xes1(9;Hh&?~&HJ65pIwZ#UdNMqtpQm(=kP*4
zqBgLu-eEWAc-3BpO(D)_h>+UH{VC_ef~_{FaLx@Nq*L4y7`fN+`GTD#Hp&vP*B>g?
z7JfG$G&3K{TR88l69=@q19z*S0#U%dH=1wwsX9ENs~1*J8GU}CVaHFll~`ph1Vwh8
zP)+rvNos*4Yjl6|mUWwJjz`#<nU)WbM?XCePdxGrzR>ykPKPRS6s%3h<<!B>g|KHr
z`lCv;Q)C79rX(|2I>I^_?gpH<K0GK`^%UesUYmlqMzfBc;{J{;jxZvx71r=Ee79-J
ziajaAJN&CQR<ai_nf4{dpCXFa98X@e42!Nz8{Lav@9>G)zo)IJMpX@)*}_us#u?fz
ze9+5Hx3N^*jMlG(HZkuRjOEvV4F(7$?QrYPZGG*19je04Fl>pyx1uY4HUi2~N1{b+
zcI++5qcSbFk_?Jeqpi$sCc43P%oCC$_|zn&LjXr%z--OLBP+?H%MoD!ZUpl_78?sT
zaw^av6JYbyQ0+~inNPb>L#*=gZe^Bq$QfPX7+&d4R3`A&_iM%(K=FLU^+#l!8$t7|
zhMZ+<c4wE>tUYf%Mf%02%v(K4Es7*|B1=$nUry@VWZG!=W2S&F$W%PuY6G8rD_Zd{
zS5<iAl!v~7DMTAfH5w0rY*O_sAp$8Nv6}CaEg0!BTQM@>7Ix%&o&!3hOGB4`EwoiZ
zdPJ6Y1fFIqLGo27ZEHTk(!L1MFPbr1v6cSaEoEpZd+|j!DdSvDZnk8Cm2_g|-l%><
zj9@8*KR?&-{3o%a->3M`%yI3M&nH-?yUc~y!wI8$O9ZhR1F=d2siDVWJW9G71YYqN
zbQD>)v0LL9^NGd?oKf<NMUmz{f4W5>oNZO`Wo5mISGfxLceD1V`|R5&yw8WnZV1;b
z-Ovk;9#|hWQPUJ;#|aWCMu8s;bN1r^X|VHO?*6!v4t7L-5hY)vvZ~=OZ>c8|1#-hA
zyXCVUgt;KL3^CGQFx+jA*CRTvH;pq{P_mv3aoIE9R%(VE@F@cOPx~bUygm6=N{Nz_
z6rX2Zl5E@Lmg`pyTWMcD#FUR7G|-fn>NXBgGn(6eaRID5ru2CUtPuFkIksD*(jf4f
zfk41F3#l01Au@O`+3N7k5U*s|MV9Kd2a<6tCrvwO8rj(O#*=l3F)2wp#3<t83z-1J
z3CpOlA8l9ZQ#JwZj3%RAecr(td*d_~m7k^c-FW(`(HzI912-C5KKo`%{DeJ3K*_}I
zFpKy4EVA?)<Qn<;!gr&6_a9JtB&;8!9t{$ZZua`rs=&2{aqYtMOdhfAW%`GAYi>)&
zZJQ|tJc;XEy!WY!1Htpy`or}Fc|b<^B}?`*xUX6#*mPQBMAg+^4*3%=+y8%D-Gy6I
zZ}<oPvkh1W-7r#+kWRr70t&(?MG&M^P}B*iv>V-w6p<LAfC3H!DRqRjNJ$AeKxuV^
zNXh5N_xHVidH#T%UFX`a^E~%+-|ttQV!tx0l^Yr9uD`=aCi6kho$w>bKYSVEwWAr*
zhP_0VQ~^uJGuVOvjy1}Yyc^<pMmU<TToKfe+$~C{B>dDB9%#{Z56mUqDvXG#>~Djq
zC~!&dIhVo<P`ci6NSLC}6{&`&8P99n0>pzKa!?3wsAz|cR@HH1Hk6is(I%g1pXPQe
zRPG)s7kHMW>ugu|R5FtAaMeEaxD*Qn4osToIHx?WTd>x4s7W{SsZA3m{aJBNrP*i}
zzp`w<S)L|k#N`A!*oZ0(SeLe0x&_&J^xyrbc^aR2A~U5RuyIXsih4G5+e*Kl&3#jI
zv<wxt3lCG*xo=lxqX!Ko;loroTnG)=k~vt4Hfhu_URk(VN2K0Jl&X0@yiG%KKL)|j
z*jk^>f~cD6b2+t)JMTAW<6r>!L8gx6_ke3&E02C(7r4#fU^C{}X~~b!*VNEeM|nX}
zvgl>-iSbt0C0&pEEqp<Yoc~Y~)T7gSy*rmjuS|#59B++DFcRo`StA?C?p^B@%B6EK
zFS^vbS5M)0Z}YK9x@Z&i#<=<D?V$eFat7S?^7vsRZ<a}JUmI}3`mO0+i}76!Jj3ni
zkY<a4i6@J@vpAxS*wR4)I~0P~9{Fo)pF&%Tu9o{Ruv#EFDuD9&#_q+9K>5dH?XRJA
zY_i@qyWSTFkKfB{``-Gw(wH;cG>2=Q*n}9;+C*MsMXFjv@=e}|I~iD+NM;%wo#?kA
zk*Bgu_;!N0yp3)+8tANo!N5_g*WGTV8D<;>HWgBiiJVLY39=d2M20#fhEk#konuXw
zQYKM0hn4${uJ?BzW-@MXkArznoS2FvNLCMSM`}BPVz~&T`B~^KqbHrZgsq|MB=;6q
z_5jhTyGRj3Kew6o1jw=eJl*x3D<k!X>7`~NBPV$Pl??AQna6BPG=Lhf-sFwf`1Ay6
zSUd%Wo*R0@4I&#Rk&inw$So)#@1wshD9hI#btNNFaMNT^@^n$f^x3ZG#OkY`sGO~L
zlh&$@uiXC0<$Z&L|LyH>iCsC>V^e;==HBfWOPZm$SEktcP6k~*)fR_+td`*3GQbYV
zNqYu@T58-HNV6mPH;xtSamt)83%K>o@S*Z@j0!d5?u{`igC+e>s$$vF7i#clHYofx
zQIB=!jd4uk0LoN+KrSlqy8U9De{#C=g1O{s;j=GKntBzSZbr307h;lOm+D>SvX!e|
z6q((S-|L|o>~FmuV>=$ie6p&2NQ!(1D3&E@8D~bN+_oxBD-Bt}<H=+AWRf)K<c?WO
z@}8=>>=bp0pzvR$2`%y&--H*4ZMzE}h1MdfrXe@tIXeV4bpQ|>#)&}&f;4D_t*Ga5
zIWMT|vG4EekqMDXb>!zsN?d-+MFN*tNrgz4m%ra&LndNQ;ov<TIL>iuTc6H&{e0mr
zy(*6SMLJpC7_`DzY>m*f0K+l*T_{u6AkOtj<Z%EGfN?)KZFSA{@I@(myH_4v%}S4Z
zADj_Q7>4C;MIzyAf%1hsmq;zq3bo%YEJxWYWQD&qv%PwVd+#oV0e@SXi<3KHg|;@M
z+*AUvK{qSKZzB#t9&HL4OMq4XJwXYlF$_#oDl|f3s6a}eL>RvPp*l*Oq`1~4ZdYyP
z_+=E~?kna>O5m3`g=}PxR=OoaN5c`zABDB9m0rucT&^@;1~u^c{3L?W@bRJXMtjPH
z;hhG*S3xoA0#CriPjW@SvMS>Y@0;ytfk~ori((+QB`2v+Z#hSfhhJQIW!yCKuJH#W
zpE<c*G8JHr>NMkKO$rv^LGCG!%o4_Pwn62WFV}ZJjWW1n366F{fH3@SBfDngr)TDZ
zq{2%ihMXT($O}&07Ogi|eWlyl8U5alZa$r2>|PC|2gKf=2@0M45vQ_ob3O^DC<|N8
z36pWz$T;L$SaLcwFB*@))K+vq3|4K5;lDizx#r)fUQ*s9x%|Atg(MZv0CBEdtR{Qz
z);5jsh)wHDJ+|Z`%cKU5R#A;*eN1+BT4|*>^6$;a_(mXvA2Pd-rJa+CJ=JbSve)XY
z4#2%!)}3(~vCS37N}CsmhezCrwX?hiS-d+g!FZYn@0}Ja;y!y9oOj1mWEN+hV`tZp
z+6PfjouA|%rJq!eW(K(ppB~z#r0FH2Lq(%g{7UX23wcfXFO?eeNt?wOuSN2+%SWec
z8K<rC_Jxmoay*$SexJJ52Kj4pQM1A*0~Z)ACMTB-A2nm}yvDObzgysJhd!|XQsjTN
zcW5k-HO6s51!E<7U~X`dD2Me-1H!t}P6@@T<~t<gqG6HkH3W8h9inLcs>|@yU#v^m
zX~B27XhTzGb!PFJ2$7AUp;wY7_S&6YzP{5pYyf;_k1TaEaPkTB^mE1IskoF)=c5MD
zRMbIxvR8f%fFS`HrX9z5D`HOs4k1H=ZQNqUMfhr{G5?rzG4-M1`?=?VcQ;SCWJPxR
zZQDW*3KYQ`D$<g=#%bJDv~<Xbg^t4jn3t#)E25FW<Eoa13-ZWJ%KV{tXO14U=7~*k
zPn49S)k0N&f;8j%Apn7Vk{Zt$E=SOOUHj_dimBVXC5G^wGchx$&obX|35Ok157RDB
zu>{)*3v60f)F#%w90!t%;T7_b2LwBIg`;M<l3ikte1-TT%UFOu9;<|!%U{y4(E9EX
zKS!05TUT_F+&bE6@mK*G@rmdSruE{M5g<_ykB1F{bnY>P7ncew$^43c*C7HuKC$W%
z#ce)&xGN$u3FZc1J3bm9rCe!p#)WY%ts+aBIW?=>gBw;0Yr)yDTT3u%Q*CsvRhppr
z>~Sq|Ct+VSA*3}gD1j_!Dg*r}u_k$xy`oI<<&TDa<BcRLFp4>HHOd4}Hcuvd6`F~A
z|I2}G4-Te|M6oG2DVXScBFyR-Lh_mkP#%Z4+&T#qw*@l(u#qkGzQ)|k{xhaxD24J~
z*&MSIC4=lcWZ2JJ{G18yWPvUMhv-3BLyTn6gRo4b8_@&dMvXEZFcOaw@_YU}*Fl{;
z+dJ~{*G(LWTz_8EG*vDm@3=sxFTDZG8*LJ|MN<IQdN`Z89@gK@HE%nxhg}ZxqJMg~
z7EmfIflb?anb<{!nNmTg@U3l$6#$gsVc+SP%+Ku(5h0<VT228{7qf@YhZZLbo0(Jz
z-*H`|9yq^BjTTZ8G^Z4dbKPOQfj0ZI&Rz?^s4_HAR~WGc#ub7!yPjgAvZ@}OAXj+7
zqffuTFUPyCfq?a6=h-IMVN1lPBJ(@waoXqX^20Zd_sh2Vf%*7V5vtGWqBRjq!|xdW
z1~AXosLWIHbF7fnnA}@avEYxMf>p(azwVyke>)KCE;zV=U8DdnD#_10K3z2g0MLM1
zymFUDy1`;Svh;4kGT6W>#RnpIS$@k`AQt6JEQZ{*(D*5mGMc<5m4TSiFrT?@hgY<C
z!f+LEYq%7vcd=i1x+z9~v}MZap;IkyZuuEG*23M-P4chI$OM?Aj$4(-SZGcgf6Yq9
zklM;Ukzi;s`dqW8zLZcyTU@L6S57>g%>MOcissqINU@W((wzNWr~Gig^mbl~uXLgI
z#s}jahMO7)@5o-}T(@&RH_uc@UNMIKJ&cL?y^BsM{G@FS?~l@s68tc5+ia?q<qX@u
zZyc?0H2jq(Z@<X~G)VzG<6MCxLDXG~db90Wv}^smutIro5^u3na8bbwzYlN0I}L0w
zD|At(5R#^;M$&~lNts;h7)qMD|042>m|lLzNwf-sMBFSZuZ1EiCLrYX$OlO7PD_uy
zm^#UQaWVXfuSVi~d>04+etd#m-9N5zJ_zl?3N|T^8I8z_8UX!{*XFZEKHV(EY)&0N
zrP3c+U-(o^o+b;={S}qo^+u|I17hXN!0c^Bi52qy`&0XkCy0+AT=BU}cZMFKQ`NHC
zHQE$iRuJg*wNPqB?w-2e?2SY7|HK{>A2wUIgMw4krx6eqLn?(GTlk{4J;snx3@GFG
zd2st&9!^iqrTUF9=WQ@`1kng(r?OAN9KXl;7KCR`2%&B|M%akBk@JXW9kxER<)-3}
z7H=*km<<Gq0bs{}`vn;R#|f2uB<RGg(LysRRtvH{4gH?Ex`8?RoZshHH4bP0MYL?2
zlK$>^tO$LUS!>xj&tSVm6*mUn!sMW>%w2!?O=n|qasm)Yg?^#_*dZHhd5ZrcfLDK^
z>ww=!v04H$@FI_YSLd0rR#m1dvtd9@-6xs;m^?BeZV2+9AAzF{fSTRX@{`4m(z!1F
zI{Jcde|ccq57Us(Jhb*^58O;984_=<x4_gr#iFYO13$BRu9BZx&x6y%SB(A(aWCUx
z6MxU(Y`Vp#J_lHO0*bv{3ALYiTENlQq<#^`?xh}lSHPnC;o<4xb0ER*<-EHKy!x#|
z_!sOU?tGhRD@0C{j5APg`s(5Aq8Li8uSQ^cuuTnlcboESr3SWa!sB8x8DA}!17f?@
z_V0bGxVEvM+1%gpVzvta3}MqlB&R>KGFm9+yfVPyhP`fT3mh=8+cd00jcDy}fw7xE
zjnl9T3BNPW9L$g-tRdLJG$~S=_`?C2JeES>ZHCx&w#qZ}TS>y_RwR~7G5wsVs@bJA
zkoX}S4{d$^G6+`)0He%G@D?6zlqTIP+cQTIyMGJQp~^Ea4c8`#WLig1JzTU}#cuhN
z84~l>A7z4ugv;+B?l3s70sOA52nV=~A|9Gif-*d@pZiiiWw0E@e*8(sk3HtJJ7i7g
z4)`=p@~FE@imke2;osbCt*zOA)LD@IqN2W}*w%^LENqQ6$>SG=qu&-fw64LJ1#kh<
zV0QpVIMLFJ<zt-yZT9)Sk_OYj8)U5M%TG9oc8kd3exn1XJJOWF|HmWNNea%N3UT!m
zAL57$Ljn;t;&c`E?>15#wmY}(XhkqZBvjo;Yo&33e3_@fixb)tirV&(hX8$5d)7(^
z$>q2)i~LSnoB_Zmm8EKK@#uPrU$jN^`U}Lf#V$NE)SnY0JWH3X60cyfE%`H6@XA+M
z&|kHhFg%2sf%1399@wdvgSAg@8PbuX6<jj3O7VqaWczI-V|K}DLz8q>>b1lhpBBtt
zia@)Xm|8WSJ5|hzoNnjN_gP~8y{)XUs`6bjK@&Xg>;>|paa?DDzGwcJ+SGciU@74Z
zAcosiRAs_UrRWl;f@}U9^c_e>@9wmSs{|O|_qoe}53n(6qO<by;+2|I&$xhvNqFTu
z4AtkEnlN{e50fZP{%D$JIa_5qZ;EwL!aBF{prXW=W;?bI{m|n~C24p46h$>CO5O3L
z%vv$uHc@bfBDG=kL}kSPX=VCJ-krvEhO?wt7eHKRE{%3RCQ1Uz?x3r9Cj;hLlObF4
zK+6<IV=nq9=`Xj<ZU_dfq5Dk0dC5CLnlgFE^J3W)yZk+*WAr|oJ-MDGMJ8JmWFbPy
z1cfb|yEKuNMZ+DkTs+v+B+b%15}Rj<Ma2R<fBITAWWY4Q_YV5Fr~M}{qzH4Vo{OL@
zDgKmO&{I=tU?G+&;ka8Y-dHT$J`2Pi2b|w{oC8(}!`)jp#`<9K4uHtc=if6dt;}dw
zqp5C@og6>8xpH5I_g<Bd2Hx|0a!zpt7R3%%7$^H6;4Zq<cAUrMt1js+nAt^wdWo0@
zp69#-PY4+3aFjYIHcE1EIGe~G<{#Q&1RZ~KYHU#x3|!_dKE6Xx8@Il8yRJP$(-{A!
zFVf!k^DMHF?9)I)N;CXcXPq6hq}C{W?OaA@?%uU~BfjRr<7~w100MP%AQFFAm)6Kk
zzFg6n6Yk=J2D)F-2cLEE0(|bxFzcjAqq^1)HFL7txhRG<lIthUz&oQ#i5>j>TH*@6
zCG~f;{3--9Jou$YdGHr_)!cXEE9yiXY@}@BGL~)bkU27Zq*jWrobxm_^uHCVdH0P?
zs7n;rXRFH+(rl9u@w~EoO?Yr0-=W&$0LJ-Fu#HK{EepY^VuQUFp7S7oBcr3T5|5P!
z@?SBOrE&g0kc2Is$!g&^+~QynxR$j-1!Zpj;B#U;Y(M;>iDJ%XbldNYA|-)9XtJ(l
z<nN~`_a*pvj`au<?*^HG{7)P4IvMerwOl!vb+l)|+G^9al*9v>94G(!cv(bapI)mS
z3B4$F^Yn(wkFrRYwQHT)cl-aIj3wBM;XNA$G@soK6&uCuO9;uGmuV`Fah$#5=)r3R
za$hs^PGPNAz}d}ih)1|n<Uh$A+M8Iuy_(|WRR2~!OUJl*t51k%i~{(@TkpLkfH}H9
z)Ocv2<S9W<9Ex*DKRq&54~zM-JOt0{NL`iS5xc;%aUu2*M%<g0LJ=@wt4|*<6AKv+
zc&m~ZJ$~iIi;GCJ$P)^uFGmHoX<M&oTz|_zVg$iEt1dct&*yJ7ojL3heHGz<+3aYK
z&XL(Hm~3MBq;r%^N26p%557@ZvLKwj=983P?zt+D><0j^34vr^ayOK&85NTQ@69oP
zd$}d>_tSHa_HNjl0Rm2|+0)m=&v&|N&xz4hj-5NpUV;+QY2Y<AN<Qsz)8~1L{ie71
z#g@ru;@1J_EhY!s7b&-k+JA!<m=o?(6S~GiG8}}$Q+)|i?Z86m8#Tl|5%+YP($sUU
z;VT|#4CBKMj|5m_$|2U7$BDw*<-|(>xx?1{xtFsx0}&S{IQlLclY$G5T`ODtX-LeY
zdtWrZ_b3FsT&T%jXI+|Z(;B|zao1--Wa~w_ExGtTh{t%gI_UyW*iCV_yDgXIig{6_
z6-L}`V3=51Y8iR?iBM>mqqJqC^tNxi8^6=eFOgrtR1w;#Bwd*)^Se70F6wi_LwPiN
zhNpU@=z>JHvs3XCA923QxrJO(b|Y(LmMzSQV{f?A=|0`SVqxY{fjJm`M)CQ4^po;W
zZ<uC5)x`MeV|JJeafvU=zd8vkc0xGt#iwU|dcTyJ1w4Z8M09U+_!B<ls9Wcb2Vz70
z{T`RyaVfCZJ9Mhc`zwOar36#;7~)scpT4n`>e+jqCFq^q#7-oi`-G@)k>D|VBQ9Bu
zu&FaTmU8s4In?ytX!93b6E3^c6xGo*Grn6|5cPIhm)AAvg9zU9W23a6P<c9tcKIqT
z!0yATbSXI-9_QH)FVOQ9UvccY3FAiD>Wv(pUoxblpLr=Y-}p*Dz4e7h_#S((A<Kh}
zYuB5n8lt#T<D%7`V5<JDvps-|-7ZWj;^>GjkJs4fuyJ?}Zysz*7Oj#fy-kBYeHa4P
zwk`>o2@6Y>J=!3Wr4^gyRW4Z%eJ%Xg3z7u{VkHEkDFRn(o3vw>%K{<{_V=|OuM+__
z;HkLWA(qF}iKm_-RYghH__exZ6l_lryGm#|sxyY2i2|6lja$#Yu6;Tu-yezqqNm!p
zjGjcr{C+<>u>u%vc?d*%jByu8egCTG`ZP&Cr$Kv8JO?%`D0)ZTSXKI8UK53EIxLf_
z$G*_=<~G2gwHJO*nzPXo3;USM*&=o2Qx-n@i%aD#gSCFa)Avr)3FTUsWO$7Id300m
z>y<*jOPZeL*)BsnUl9NS5~;^?6*O6y@Ik#*Tvm^Lg%;=G&M|a=0Wq(1yU1L3hk$2~
zjr{C$D46oHmL9v;6(#Rkds<*lRP5@Vmp3M_7%n`|G7=87plyEb0j+=Y(%~r#m*S{p
z9zGF;v9^YJFNuIZXDBvjS<N+V`$P5^+GqUcb>GjAotvh}B)QCq0<HqF#o3oR3T{;J
z<x>Q+Kmvg<{lB8@FN>x2IGDXV$=Z@Tv1tyMdD*S-r5@xKO-T}*sqNY)Evs<6gLbqo
zfP4?AeQaplH{FIa8bz8-V$O|adI+pYES;{c|8Q3@o^rw8soIDpwPpgr-{);Kiu0cl
z{(yPm$eg?l)GhyODliE<W~x;xDeuF55qioRaq8Npld(mRQJlm~jL`&zjzJVi5m%oV
zQbQ`6Q-s}-e_OuEg!7&^;!_N_IdiM=0-?o&MoD>cJ3fe0*$L3w`qN8xyZPX7`$yUK
zb7y}P<IL`?7@6`trg*HyT9obn^VkndK&;W<aCQs#n|m$aIB7v3&rX8~w%r8#+LF`t
zk*M8e$dKnpgaFU#)(wk+A_^jrFZf`Ga}WTe&-BxbN>PHUo<3WkU0cqW42>I;%?aw|
z){lAgTB9HNeD5#TL@u>;QFH0u-4Q=cdOlwUJ!W6h3@fjiPzyr;d_skt_e64?7t8~b
z-FcroK27D@q7WrUA`B(1%esC^c7%Ypb`BaW(uo-`;!uT=lzA%QfmgpYLieRNU;uj1
zr~b%?5^@x6Biu1EN+{bqNmO!SO~1U_7ct>g@%x5TtwEvMYh(P)=ZB7^2am$jaW;#M
zT=G4vlq?~#X^z1LoDk5064t_u4a_c<_w`LRja8wXI6=SlD(~Kd=}pi>LsVmR!g(*g
zy7tD6pC?XIVmw}nhbHTD7Jx+$omF^Je;Rk^xDzD%l)?Dvbj*LMTVg?zjzoJ1N<~HV
ztX4DI(7o>|xsPI0{us@j8_s`=Rkeb9S%;#-r3kj%o?nvHKXh5xU}b24_fbWKe934S
zATf?t(}(y>W=+3G>ID1&Mv*Fjhl`0&x+zF<(%^gsfb{EPK(Kvuf>+W~y65BcN3fxQ
zTNym9!H2{a2Q@|)?5l%@ph~gU#+z8Y(Fm1jTq1*STsn+4U+E}IMkupoYvNi5Owv(b
z=8pl8ON_XOly#3xKrp#s7J^z^w<iX?&*RP)?_QRrEjD!VC~bR;r1@$%exYh#ycuIF
zntVJ@?jrh&1oQYa`j;6)Yz@QsCeh%c2+GjAo9eH{NorxApU8@nj9a4s&jczOy4dOO
zd%2rRjmKo^1>tqcAu(E8GcUAjo=O!NiX{1A_pP}BP;o^oLN1?kBu(=;odL#$@kRec
zoakbq9sZf|0Rdw2p0~uqqM@?QtezE-chZx{FQ=B_o7UGf_P$c}qs*exv0Z%0HYVrs
z%T>oI$!1g?Mm4E58po||i<#o{P6K5+4jkrRk*w^~>`kKOO7>a&+(g=U0mF|BHDiOl
z&g)q#VOkRMXjK;>BDkL8C2I_f3D+xnB;06I@29D>k29`3^GEudD`BV(%_=vqotMMt
zmds<Hi9hER&WKt4ObOGQl=9L%rSObkh!%wda-Uyj|ImI3s=aNLBfHhALkw0BoKJx)
z-1@H2YkB?0;`*j_;VRlZGZ_6xO;KeZ6BYtTpxlTbX!MfA<23v~n+PkZX<VIBGd`{J
z(e9zXl_cUsL$iG7V%X&J;D(CbxB6yJ6GpsPO1S8=kg><<0GQeM>nHxfT<&yD&ozEQ
zs}%emeR6IRnp@p+B4SdIKX@hZurLDUCD?<D)z-^QYuQSZ(7R!#zS2ew->C{g<>nba
zl}!9q*~)WqGS1JMMTjLxORCZH=al1HipV#kUS#lIHG6Gbu>=w5?z-?vtCNz!1D4Ve
zay6MdZ@_g>DzU}zpahjRmUTb9g<kG_?Mwo1@J8RyXdsJW2IEYqiU~=%;@tLuYBWNs
zzOCumQzf>i4GPLJGL;biS0$)r&GtZ#lTg8Oa3c6kE03>+1wwM@^;rpNQqI1U=mP@B
zN4Cf`O7WEV*FX^C<e+|xDPm#cBk$wtn@KGhpVcB%4H{%_T)*NseLRZ|F%l+qN=YSG
zLj5YZcTiQ0e+OjQP8B^glLK=~XI{v^wB5tWNpQfQVbf8!w^Ww33m~?1I)Is7?hQ&p
zY9&c3{6A7H>r#2yhk)xV5|4SDQpFdNWMAkVdxZE-mhomVBzIU4;R7ag!uQg8t8NL^
zHU8u>>OAkm+U8HY&vO2dzNQKpzZ*_>7u(}u|4TcqIRX3SeD4fJWY;L|%{enb7vCn(
zr4nW2=Pu(3nBeOlz4@EcmCYK4xGSISnqMy!>2l&w54>9#@nuN#q6dfm?@WM;im&pN
zp@28csh+o9gqC*M`AK_5KIUSRB;9pZRSzJqRC%L3mzFgZCUsh<6~`WYhq>qK3E~PD
z#T{Ka)MUG;j}O-~By_HGoEIEQ<B)cLm4A)^DQl;CK8>kH`O-}7$mc(#WZV;ISoOvb
zql9pdC@<!7fiA!)31g=QswbEqRty&Psj1iL*_`xgL0!d{iY(d+19ROtj|SFD_5|~5
z`d<N0>njkw?;dl8-C!PvsHdcN%bb_>3nnrs74_#lS!g7RGU8l;<aOiHV40Md|p
z<<>PFDB$K^7W0W<b_~9evg%(467`CA7%1U8pX_;IONC<UfKN^098u=D*`*;BKt^X5
z*M&P;2^waZJ~4g@-YEDj?zNlw_p0m%fkCKhMpClEy#<TJbNOKi5p3U~2?#NxsI#Rz
z8C!f9D<(~aA;R1(=3WzMzm~1zb)z#xoXR=W-5t3!VS+mE{PRy0e@TYs>9{bRI>orj
z<ZcTjzhr64-@&R#VU>;n>(c<z{<K^PJKJ>+f#ak~1v96IkDysby>dp$9#;qEwhdC{
zKyqU?Zo0rdc#gitEeiubk1yWzt&=?zHNl$_iz6#-{fMUl&gGHX=QR|&1d_UF>5<|l
zFKYDF-Ou<5-;{Mc-59RcaVAV@v&XBAt#9YFdV5JNN<l2`#O>H~8sC!*BDUs*tKR>D
z|4Ej9SZB;rI(m<GfsU_e_sZ&@(!9?{_$rvyZRPFEkZ=;rJ(-^=%O<dG-U|1ks<<4g
z6<m!si12Xqb`U=P7stS=%%$n@>x82~=5P7ezD4q=19O<u-)6YdkFtlAU+VT3H*Erw
z&l0VCoC%O$DZk@FsIojb!I#VXnH2M<0QI9{Yj)`Oc?zwQZNgk5Uv)i}T-pWKVZ7Be
z<c;Ze=6P*Rtq!Mo3}<Y7pL*0{a}Bp9lq>;}P1-f*G6Io8etvtQ;TL}oDF~_;lHVq(
zt7oil^^>EPFqJX+uG82g{sz$Gz%@XN4k0FkjrM|w$Xo9olJ!1iWq1%ud57)Q7*lJi
zXQIX0fBd#Q=5j86{J!_j3{^f>=w|1z`Iq7Rm66N&uaJvz270{Ukb`pZ!$8NDPSv^W
z_`qC=_`*IgD(XN`Cwp_Y#a$;#n7jS#(^3>DRxQ^^u~PEKu)m?osSTs=`usD@f=FeP
ziZa#dL07GxvJv+cZ;Q5#GkW{9_01mMzU+K9J8}F}<+gAnmdhO3#E*UT_M%^`eSsZ}
zn~jY;3>GvKlDVM&@t7bKxTmfHsda?Noqw<mCAB_z&^eFpCWotRJz%fJa%#KoXShf4
z2NKIq^V{>!Ub!y7iJemqoAA2gopBsR2eig0RnfM8esF%26|A_=J2oa{aR20{3d%p0
z{AU2LmjmZ%#z0vlrr9w82_?>T@7SyxE@QZ6deoKHC>X)|C{*__jA_m?iB2M29zNzM
z)rIO;LA@yr|AoKP#flU%$8OWH{}GWrG*lN2vuDcnW+X_70Y1(`^K%F3ENL_ih=R$0
zAQ|`*8+$$8D3NwsfE~Ck5SMNg&R(p3p4aY}1#TOEr-w{-rCk3+Lj^x1%h*~TlE8Hx
z`1+1pZ#E$_vn~nlYM~5h0t1%6qaTJ3e;}PG5hV6U1*MZ?^UNu5Og8EDIBpj}Jy%VN
zhXHR)`MHO|P4S#i3C<HleeZG6+vBj#_~abQJ(>kK=>AcaDw<BYL@-ZbOUIfYOKKPq
zWYL8_6Yi+w##>O7sAD*;0O!ml(c3$zpIV^m$F|Zwjf+09z!k-Yce4`zJ4Ssuo{r)~
z_u-R<eW>5!c>-nl>$iE8s8MX|Nvi_s8COG0V3GXtj(bF8_Y)LQnHcw4sEdh|*g{GR
zo|$p790H3d5u?r?OAshdoia*OuN37cW@^E?OJRZnzM<E1PK;NC@3D}|Bbl8L?8T#8
zTV_hdL)D+1xKj+P6Wv(b215s5!Q--NG9Kx+GLFjr_uVVQhrXmNdW2VbAY<m7KR$7$
zdFy)Qf+sjKvAz$<9@fFZ-1hLe{vfey-KZYcQ3`*~W^vA<glpeX*y)74#sXx{1YF6k
zYUyQ9lz)`@C|jQs2mD`l!T${v!~y?vA^%tN0D}dNG!H>R0bV3pMnvZ7k>-Jb+NvFC
z9^4mrx$Pa{|3i6P1NoC+*B!(G!0L$d0E6w0C=V{Azk;CmZ4UnnLYFkoyI5LU+F$g$
zc>T_uz<bv(T~xY^e+d9DP?$1FnL!kG>HiTtAcp|gPfql{D(C=oqF+{=>L~oiPwK^W
zxe|AgJsZ&O9Z+|$LcceLCU$urWIK;_De-h2bn}p`;6MKybM+O@txyL1j}5+!R6YQJ
z10}9Oe)~c8TSHKbL*Pj8ATERc--5@DA0YSn6IY8ILHpK6b_agYh0yGrM*SbVqrQRT
z#S2t^F@BE<-md}uuie3-Dll^-{@3ov-U7Y&3l#P7k5905cf)u4Aw%1s#l`=%J3t#7
z;E`Uf*f%ysH1FI#x87d&!J?Z-b_WEK$cIY=fLCB}Bb2>b=2$)vmwgdUzsB?0=Xim%
z^JBlTL{f0ty|d3;oHLQoPyb)R;{b_1PzH`@lRXiUL0`y(54`sX@wg5w`2pMi%Xjz#
ze*z$@ULt*f&HfSJA%0=N#eO;ym07`7Sr4wS;H-L#FWdvY8ssd^cP&o?_G^IsJkHNY
zf=B!RDR@jkMm~WC_CN!lf!%G;pJ~-E*&cmEu7#YnRpLd3|3ATl6q6p3TpXJA^hofy
zQb_~tW`K?akKPKm&lLdm093P!E*ON5^n*7?z{7vomX8pR72w|=;LqXzI3C;UY|A@Z
zV|_0Dy)I?lM~+8gLSlMa@{5#&Y<kp-mvLk&?SCAP$hR3Wl~r-I|KoVn|F7c_-TUTM
z@3Yv7Zc1b4%cSo7j;_W}1FyS!W1mF!zJ1l1n?BR|w!b&Mz3F4`n}LDE&wZVp9iImV
z#wO?ghw@lh{9npree>7PwatxR8$UNT{vXg|cjp^(`Y6N)1p8m8g99?9+fMf|G2y|T
zWpi&S{+PrEwS^Ih&L7h7`-5MvR6SC=(zF$GX%}@-&HM8~b^gTdnRuRKR>V?4e^;c4
zj>W)yr@gbWzCh-2*Phq21qsB`vjqZxubm0+Q?9DXKwk+YgiVNM{_3lW*RjVxC3`Ym
zYP~z_*DvX&wI}2=7b433a+{|%pIp47;`8SDY#Ro7ZlI@r-S$Z=pT3wo?2er=9}q_C
z#(uk)*;6?Ccz;dclAGF}?P2XXHUzhx!|!3x>zLHAfF?NJg7)&qH`iJ{v6}2v$L>@J
z4jhr53S9bG(mTKSVpGw>CtE4=blp!E@8<2p%3qzIPa}90-lzP1)OOq8-3$Vi-_~qs
zuP>6Yddf${%ljYC_!v$CL~=ix8wBinHOH1BdpX7n%90hAO|MCu5?Clr^6l!{D7=2K
zM!JCTr)yq_C(P0c-Na!$1PO3Q5NE{xmnBaR{(t4-;i`6IK)G(j*iy+Du^T7e;jKL@
z{z_V>SFu4wE=BPpJ}Oy#nc+2?Gwfl3h0A?sL&iR<&h*4gueX18=iZT>e;ha9BX#HB
zkK8X2yl|h+fCk+1q9QUx#VYz(cZs`_(Vp&i@pkFVWJN1OT_oOS&KMchH~?ON%adtI
zN>hFfPxOD41we?pVVT(2eRm(vQ-}K`96tZ`4Ci2e$`{}C)cskQhy+g{38`eV7u>5f
zwxjBE@2jYDRZ(5gfSg*pj-_|)>v3@W6X`OXEc_MQuJn_P{tc*7Lq1{zja2KxYw?;v
zKP!QE&fZAA7ajB5p;1rzQc4!w2Lz7bTRWy~!PQs*eJfDqQ`&t1woq=@v-+NSZ~AVO
zGM}&_LV0D5)k1IQO0sOI3&b--<EN0<Bm%y_Jz@OMF#6Jq5I(YHXS|qvvI^~HTrZt(
zo-3)ew$IML^L1ZI)D605Pk<6Rkku_qW0FkjE?w|b0rTL7UiRLeZ2SWFl;8CFgr0Vu
zX9G)e`L&6DeQBg}DoU&PQ0^qeKTxd}@U*P6I%=}BE;##XQ#_yM-&3gz^Xz51@rU8Z
zZ)GUWi}LjunM*`RD~F``sRv$5;qk_Zh>0v2zioSqPrk2WBs{sU6rq1M8Jc<O21_ya
zG1<6W#KyH(sfZTYBdhzJ{)gGnd`m?c%q-sh!}s%oo=MEOY8*QsPK5yMS)XR$w<YYl
z(h{7*l4vb#>L^uNCGK8LZkK~N#ni(&(8tf$i>ODBaJGQV7X8?{M~{+7{0{KwE)kxF
zU884Jqe2C&9&>2t*7e`Lh56<J^F(p#<x)r(o&n~0ITfe?JRb93=FHXsK6&RRo{vk-
zp-7Pfc2QAE@UVRc0w6CiW>slH_9ip(R)Y!KOae5gg!UtFkTT-I3MuI=;WH_3481ZK
zS{UFlwKhPx1RHQ48V6)qISHrQJq0JzKOPNh$Z0o9$G=l>I=s#)gQ*~RT?-UfKIwt5
z_mkw&uBTw!0J$X5CB8bw6z{P!-DfdiP+(?p?E&tCyB~o_n(7x<G*i@nAALV{iyLp~
z9?4w=T<S0xQ3BsVI0UwGxGjPCuhZ4NjF1_1_3Yz0_T8RB+|~^6Q0>Z5qD%X2fk^6k
z%yNbKVGBF|P(^;59|$}~19DE6PSvu_!hifEBbUBMV&uBs%%8&`IO-W<@xguHqH7AX
z4x=rgk-EBnrz11hHzCSpg61uPikSzmG8FOhr+q|!xr|5;ea8#FbD5%1wOL@jcR-Bj
z@#_{XTLgT~y+r#ZP|=4<20%<SipS$^QM`84*uWG_m8!s_ae@-bHsh*adHTt$7)z=|
z{0)uQ?sy^yK_r4LHvCA$pC(GDiY)^>2)M{5v#eX|&`U5$NVG%Y{MNwfoZ~X;SHI*>
zsZ6{dlR4{hAGxG>BqDgpl?wLJT{~-LL6~mIoG~Vum3w{Q>m4P2QFpvt|3r-P8k0k)
z!Wqg2iaZxq!d+=`TH+if(Q&B-<7K&O_X`IMHlnZqi>&P5;tV~LXjk8L_>n`c*32r9
zmUT~QM7(UF39@_FCvVGMS%<{WlZ-D(J!q44xRXd^Nb(e0eB{zMa<v{A;^}iOkw3eV
zVCe8!tt509-(JB3ew1@Q)R>_-X;iS{bH<^*%S1(m0zdV-7t-NwW^~!5M&c$@UwHf?
z4_d4263_Zku2_|R(FzD1B+1)jA9Ea$kof7=`PTBK_G4<ecoK!#^h1eF^!-EQ*S5^4
z`}K<+IFEQEk|gB&pU-S{7G6q)+Vac1cKTa$Sf2rY?nkWH=QHUp`yVYG2G7JPT5VQv
zG$eWc$aCU+v_g>-z3l_Zs;E6luvmEpZslF5a=KADdrG9YG9FDn{B!S09GCgW_5ixc
zMbSu@u{WV9OwQCt)fkG|3yxAe5QCi>Z{Yb_pRwbi5V#eIo*d#As$A|=CuAn)F2#u9
zzOow}*osCRZQg(4KDt{DC|9qP7&YwhM0RP`pvVMV(NdeNRttRPo+tNPz8DUHdkbFc
zuORGls6H4?92|%VEN*I}eYg+e;M?F)DcqD;Qc<UnR0hNkri$0u0gr?mohJw5(v}~?
zNp08pxtz_;Zp~rhbxlq_D~^R{T?dl_^Yli1vrkf+Q<s9IzPtrMfdM!KnoPrf1#^A&
zp`bC$mh)<m+{vT42IoRa-r{kS<bRGoE2%b7<L{$hAHFjt3vl=jYOKfMl_~I?MaiK9
z!rwC)wZ9s==9Rihv1c7hA+yDc;`6rLch~Mfhyn&Y%K}hh(OKjz5`Iop8wSo1xN6|n
zEMW`HWjDQ*t9OC<Akq1R&Cu+U<<6{$cuSn(&^u(%CYu;;|8(9081v-))ni6uy?SCk
zTO#q2^=x&gm78Z%roI2+g-G`#)aeUJA~R-exout8mbnJrD&GYT_^G8?XbxmT*yq2l
zG8@ki!I$><8{0a9n5s_PRdT-r294yBF^R%qK!TMNAAW8yrRC&%d;)e;UV{t`@%;Dq
zcBWR60uZ_6>b9m}tJ{0xPQt0?vs-VF|EzWnDIxeesiBj_=J1@n$g#G<V<oxo22ZVn
z(hMEfZWtRHab50$Ujrb_SHR03MF+iXtM>1sf(OfyBj(`|B<$B?0X;<DTjt#RbY$Z&
zdcGDr&o8S-3SZ>s+GJg#(GfH{yg2}kV1qFiuruz!0TkekbA7~q6Uvlq&xzc#1-Xt~
z-4DF_Av5?N3wxL4^+*LH{}<(VEhIn{3qOt8P!X%Db%2hL1?#!?0i@X?MVshwQY!K_
zH8|2EsH+@g_4;DnYd8!ar8Ojrp+Lc;C`MM4gc0@;k(@+AGyifvetWO%7*hYC{~spm
zydCP73Pp<UAV-H-??g-3Vh=@@C`ABx7OamjjvO2dJ%|H@=y1;`Ckv<`FN@f{LD_iv
zc|@niz#?{w3S|$1uMp!yJ>n)gk@c$lhXY)Mtmv1v6gehXz$YGGjI|r592p)&9vMDJ
zxIzn7j}h~M9}paXkDvA^XC&;~f`XV*@Id{6YgmN~<Vcmcn@cA5E5a4-V4DWw9#jai
z=-@~luxUk-MlrU8ne?2DSmVFcF2E%qnQ(9)$gVgU!<Moy0i5_^bN(K2^#}GZ9+pH1
zPr}1~@<!;GhV)aD@UvJ3lj}V#<QWJv6A3=90xoSymG3<FTqQ&5D2Ll2O}!W^PLABo
z1?3N<9qJs4h>+1>UCrEb|0F8)Asz;+;6JJ!lwCW;btbNvh%#$H8VH6OmV>3~sdz!I
zLlXLk5GWvIRMQb91Myt!3D1nMLkv*YP7sI;<l{0^Jb-$4>^S+#Lv0<lQS>-9^C2A;
zOpOb$#bO&!y#y4CCiLq_pb$iEGg2fZuGbWUWtdquXX3_4isCHzQ&M&{34vd_@s^ws
zGKf}?e*j`dUWN05@Bjx6?Olsa3D*A*1%e-KW64+(IM)WzJM>IaKrQxzdzOE>kpIA0
zk&EDa4Y~iA*aj73Ekv!Hlr1#@7p1$rAwPPiihaEMsK^&M%Kzq;kL-xTuODV->OO+L
zUVhm3@}WTR!?zbv@A3R0MrZ{(`0NjG05soLS6XHm^w=Hod;oEw0WM0$>*e0x9|+x$
zDDd79`7NJc%cCF6C`h8hm#Oy;=@RNt)A??0tWVZ^Vk%D~M7Y~w70BQAap;UvZUorz
z1Mr=MqKYG3W1wi!96RU^fR58Xbb`3*!|~4Abu4HyjrNFDFyDd>d4=j^ln~*l_oT9B
zAn6YgtjI`T;>6}J6u0;~m`d5cW`OcZB|8)F688f9Bkbk?`ZfzBLOi<1Q5SraTBA5S
zp_Fc+iZRh4Goev5+RP(LGp?|cT6QuPNnS=)v~VBAn;$BZQ;*ZYf6Q{%d}#Ex3q_=S
z=M{L#K(S3X-=;fui-gppXIyQ3n(P6H<I#^hytJRmLAfr+P+_`{V8KA3U>EvjFiJp=
zzmZh-9zfA6APNj{EJE0>C)bAkfBcI|+LJ0gVv<!TD3`vkg7pwW4-%hV)vGQL$~klb
zXp?BBTm{dj-dlGwVHMc3Mpyz77QsX(hDiP<_!{qF=GPzASLWjHVD;(G6-gC8{yzV1
z`|RsTK85<kIS*0DLM&5j#8#?ct5t5hpxXd!;B4%;(6cRibw~^Lk)6sI9u}+ui>Jck
z>98O?tiMv|FCJ+mRkjoyVm^tK7d}kYWPnwYUMxV1Bw<02XygOpok|9xn(^ux5m7@&
zmm;z`p1<hguN|aSKZAu%Q3-EpwQ*FKT@&o?fTL8eR}<-F=rf`G4z$A8mlEq(Dd5$)
zMh9v7>qdd>4lm>@8b~+?^m^O#&gxNey2n>KW(h!+;1OSGFG3`EM?-KUh-U+n=uL8+
z%{Yc&tSY>ppyX9^HbBkvnGjtltCNPDpT*9zkmd+fv@TkP{#=117PXTo)`K0R2eRcL
z#Tam0jw@H4>$4*=^9Q_uX!kZ0Q9^ueceeU{FNn<I7-WG4oSQq4)m%yRr>k!_=NyCa
zT17#yU_1=<MFV}f7yTPo*o~_=c@>+#ihOs3Er2lI`r!Go^d3Y;^6}H{#;0@SJXlGt
zEaZnu+=r(O_$sq1LZ7?;I`$8hzR~z0b_pF!g{JP;2dkWA4|qebuTei%mZK%c7(iO+
z<tnVBe+V~5#n;=!Hxf@PUMo`?&2~-A^yrI6JY(wAHo3mGM1(P*nT?nuYz3sq(5gy$
zT#lIwVMM9C`?7y56PfgK$3*V&eHNqP-2n0j5V1#tcs~c`AA+NIp8wAXp`A*P=|w^M
z+e^)FFL2)|ro&%8h2|4G${2_;0^$k1BOH%dqoF5Bm46v2&BEc#zj@k<6{|Q{GX72C
zfZCywtl|*f1e{C3F3F|ZwHqyBo2c#Y$j^zpFVz`fJtp|9BY3%~q5*gMr-@ONI&z&L
z+S2V?R)LKQ#xm*X5(e~Ien%Cn$5*7cl!!=WK#Op&P<`|kv&vQ|f1VRN?~Yj@VHS_T
z6C8AwhzUMPS*F27l3))GI+Ljk#_2B9Nq%}_7YS5HU&5pwAg$pTWd>NC3EsfPcVu__
z-f+k)C1q~*8%YK=UF$U6=RCw=LtPNH&7Tjf5Tz=;DMZ8xMFfS6Sz;airqCrSm~lF0
zncn-AikYNxTw!qdk_LV09DYQOQF<TI_wyDVGeLzWQelb2AyMJOmsdwsvbf1(eca6q
z?`}G(4=0AvYdMo#D6qkytkSK_!nzNoCn6#O<hadlj)<$4(4Q2z#=H{4ofBn(njT{Q
zqhm;G16_IOB`P}T#=saJ5l#bzGGYJvKL5A&`M><pY!yT{5uS47Br!)*aAVm3{5okY
zC}qr-h!*?D`Im@YWg)`ChN8oVVrX#j;Tt&{{my1cxrdbBOs<4{)Buoe>Ol<%8#!bk
z?Wpbccr14k_BNqkk;TC?{<s8>T_$5N{}2;|0hfP>$e)w!O5;mMvXUt5h0@nZ8Z?{+
z&0&2Fqd~*y&>SZ0romVi0e<r*j5;t%1>h-%xao8}Je@H8`O{P;9`0*^@cB7C^Yin!
z>FMtVh)mMVf&o1E-Hb1bV}AX3gIxNd3YP01B9sA3BaH954ka>R6e4{cr@Rx8XEi-?
zq!G;!+BRv}Be!Xr#YDbmvIy8M8hUvEy-bwJm_|*xe}Sg-LZ_kOI9R>wTnHX{Mv*;|
z4*mEKuFZrO(V;JhU?qlwm+M%c=rk1vzbOh&XH1>ypTDUD?>z^n622b^Ka17hzr6dt
z`0x8t^>?D-4@>1AL_@?`<sawWW-b+uW-@;)htI4QjNKq%wngeb`k_0*FxPMOjk=@n
z;GlkD(Ay-;9oE7!eX@iGKMYnGOQe2F!!7Mi!}zI~89IhVtrZ&pWopiScn3WS>CC_^
zd$~@vyY^E1p}D_c`7_HoB$U~*+$S3RE*gHu8g8fzH+6$Qdp}i5gBMIA+o&^B)!&^8
zAtDptg@PXr5kJnqpZ+Sk&|>)GS?Z5>Gb_*DPglCZE3Bsph0|l<(|Y~$L*Y|7jJY>{
z@F(Q2;S8wst#9eKrgB)V6qSXbPaJww^aS~9?LQ8Ig2CT4gT6<xp0@^X&<6bga4HK%
z#Vr|PmM9q3Gv(<3^mKseG(imh?mes1daaX;a?C*W&{)>}t0-|~YV+u`ThraCt8xS2
zC#>%x|4r$=Kb#+WH~&OzdO&nKFnk00-)KGtu6PUnz8WfXh>$!)tWdv}(7sev|Kd;@
znqVQ8fKJ%WB^HCZL#3CmVX+a|zjQ3(SJi(vu>0=6g3#bJ##*227@qvcy=Y92KA(<b
zUH$$0%fD6B<sVb;wi&;^lP<6K(`MDH;a{s)?ix%>pPIf~@Hc`w7jYE4)7()I0cq%m
zrZDCj-u>!&hQ5UEoMa(Z$!LQj^fC^+QivX-Vj^+pM97X0@URECFC{Mu2$AIcoQdsA
zom!~vrCUEPV!(d5ZIAyTY0UX6Y5O7{rn4CPB1J#W6mFXy&Ig|wO~o%4r2fpUS?>I=
zwe!$sDzX~d2CUz%MdjhgrBgAXO}ppOom*7QDjm(DV(f9N5-O0T7Z9F8jL<XikB8W!
zD4O(+J$24(7Rs)Up~|w7_Lr*&H{b_~&6o^|Z=h+U1Kdu^f@)YTAz<riDj2Hxv!(vn
zfPy6jybPD_DJ{IP<Q6<7P?08P5WWYCoB&bdFb@uaydRW8gRnj3;IOvMx5fvX(UY$(
zq!oR5@G{ZhTu1W5ccF)St{?LpZx|l8Yql;{ZR60X(zC13DUK>SUw3nQZ~lJusFKTT
zpD(SC-|{KBgubZ0E9}H_Z*@L~@ZRKb)e4+6_3eEcg>G-l{^GtHce~J_^zY8{;pSqR
zo6m!Nv%kpj7uWSKRl5wo;nlye*7UmOqEf!*x0>?zRMF6fE;pKL++OwJJ+KOj+;YS<
zoSROK>$@+1COJf0_wQ9@Pqh2qP)fPddm$^JvnTJ@)cdd-pq?jxx3@!Ih8djh=o1aO
zZx<3=ZJfHsxHzlGwP5t3db!Gr^x_i9Ql+&;G1N=Eu2DX!xu=J&Vmx})m-xcvdbf=J
z>_PCN;kVpi4uf#=`q@PJ=I+G21)_y@Yt=!eLi>te6wzGb)dr>+**Q#-RNqP`in);1
zIZrel4k>Hg{}qbR`E@X89(SxH-q?)o#mZAQ9_#TIQ}}L+Y|rX~uv-7~<1UA#DfkzO
zohbDlITIU$Vb(B8v4#~uG+Ip`D7vxsY_$eAJ5nRIAGR*@h_9ivlS8-+rk;2m*zdFw
z(HF^hV^&)B#8mgkYsFOk7bVcb@V?!}qFZwf=0%|kAanI$W(!pONnn1>;Cq2)c8e{)
z;*qzm7Ae0{1bw<BJLG~Iu8VRz1Yw*-zpM_LuboeMm8{ugQEFrOseUfyLU*;lt(S?F
z<GI-`-@07a{-k~}VINo$LZvi!t|(%MGn*~c;Pq+_=W+qNT@d$Hr%*s2rBjG>D1S{X
z2vwLncY3#^rsdAtgC`fS{hF|j^Yx{I66HA-Kt(}knfKUC=e^M<##x7nKb>6sZO^Mr
z*&)$y!q?z8eV^`D9$yLG?p_odKD!Ss3>sROee5^7K3PjJF3c5o5qTfu({wf`gU^+(
zA1!b;beFwoiUe7_Os<@W%cqo*jfL|a<&4fvIdxnYhs}af%Jr->Q0im0bl;puCy!F*
zF3J7Z#uv<_lnaL(UOZM5I5c4<9cZ^QUv|OGV>x^D!p72FDtOT1-V~%Z8f(sT-L&{D
z&viL2-QD8y$Nnpijs?4yTfg@T%KKd}60#(Jtf=K+kX@_kszSqyOMwjwx2h~wI}6-K
z?=LJpw<s;&4NP{96AP9Ga%1_M2Rntu7$U|z#wuW5oVCyf;Bw~BY6D?QYokoCx;(9i
z7=BhP=}=O%)DAt)%o`__y2OO4SG3@+(xXsDFc~~2{4CL!>qJ?*wCt?$8B=4f%=%g6
zom`VM^~9qIP6^xt0TbO>DP)8s57*yzW#d1~hzm|*+$keD15+iM4;buxuW}n64S;c?
zOJr>_FE%*PE8^5doEH8SXJ))9?nPIu;^<%Gmz&;^;uBH7HDJb;S##V^<YHhF#c*Ti
zR<6_~HoT}u!mMT_S9W|fS_<ARX66}`eaQoRxxz%^-cV){+Z_5qZkuQiiKhf5gR$A|
z7HcHNq(`&y-p_g+ftT?;q)(n?8Knh!OPu+h0O0Y5n~8S`9XEuR+r*qQ`cAI2a0<xJ
z!p`ZmGBqP5vT1CJ*K$8u5WK?Q4X|OvFT&3uY_rP0f0y%ywc%^*vnn*M=^Maph#~&j
ze?(-^9=gpjPQyiCwib;ET~zLStVi<la4&Frim%T+??_jN7np*vt!TS@uT0eJ&b3zU
zgCR9NlBqGixHUF;ByQDI-q2q6tiyZz*gV$h6JealyRDg-+S%>L@8-5yB>VF$`7I+X
zkK0A7lu2Z{$0HKP{tt@IJQ~XP{o~IpW`<cY7>qG?$ujnx8N0|56<HcvsU%xPsb;ez
zG?t2%PeYqZHH0YD%-E$Gk|@<!5~Z>gmFD}K-`~$U&$-XJ&vQT5^}gQs`}MNexWa%i
z(Gh03ROsu~c&n`L7V^$RzmoYH{kMKSPAv_X1BJC(e;M#MLqcqJJ$v8R(YH?hquY)o
zUpJvO7AfCnNJS}zSM%<!#G&>eIyXfKubgr8b8%Pi*m5`PKl3xtMU63TXy@dG^OD`3
ztOwjp*<37t%_})-wFvEVrYQ%{F<mDkHYYOlbF*W}#9Q453w1T$wst2xfmO$=hT%v3
z;C3zyr1>U{+5@i7421#rwt3T5#Ji<Ss6lK_(LcT{8H)OFkPk(7qRtSmB|NVV@=s)<
z3oiMokQRF<pX18U691F8oTU}J95gt>xML7oR#vjW#5QN5oQ7(ALQxR)k5@f*Xk9@|
zigdLW$qKIVREU{a0DC_QcP}1tIgyr63P*V0@+nYV4&7!OEj=#wHKxg6<JMMLTHF%l
zz4WuwImM&m&W)XgZjJJ?yDG_0WI)ko$;si%qc*o}S3~6bdFRNHby^AA;Jy{mS_o@x
zQaicKd%*vNVXN4CJ-ZSAVt}o^PTk}htD+IFKXu{p=xKU)9K>um67%k{f_pEGqlnc(
zgcAz5L+Q~QXC|>)^iHxu8N!=#ez17fν<8$0=04K>g#_{CCr#Z+_~~Oa#H2P}
zPdN7^E5qw81Dh;2r-41S+3b(fzQ`%>__t#P)@MVDfBJ(6e<C6Zl0tTyjq)@&paRsI
z3zQ5n5g}`;=J9$(7)cGTFgYtzy#!7hX6-pU^Mcxs!w!e<pse?LRD>N<e<W>7(!O`7
zV&{Na)lu2VA~p6S9{m2Sx#Bxmt{%!cPy*JWICq}7-t)J$BR)kU!m=H_G8M~YA8IWo
zqDAhE;IY<^LkXMbVpmVU+uXJNWqk4*hiwPTfAXNOJ3jO+<ej)m%{$ce37vH}4b^Q^
zb)kkX=L(2~OaVK66q3qj`pUKd;YpmtDQkO?=o!&DzBh(6yN`@CKZ$!T_S854c-hoW
zyyy59YNsQ9QyVE6E%TmgO>1m8RRF?Xb+PChayb0G;nY#>1O-cQcU~f2&MXB4n>G)0
z^V-Tn<7l%q3Ddq*s+uAZ;tHvqI;eEGskRy}$Nx;*a@lG0GwBri&LGIVlT?CD;{o>y
zj?E{zA034VezmNAf1#9h$n6>vJ@@6`k5^ptNoDPrxxF2ODsqK#HkUz2p!2N^(GoM@
zOj+S}Syj?d#+}Iufuc<=@gdpH!EPIuacAUPgh-OjyMHguo#WQaN(&N5%lW(x_&nxM
zRKlmPCn&(!qsJh90oX<WF%{T`P)$eMzWHfnF2MFJz%sMhsSEiEHt@Yw`SubZ%@}^5
zm6};7BNi0c8^f<m<VQ*X7+ok=mDe1Hf4XpXHd*1D9xR7Z_P;8Y<ye6|+0HB*Wc>`C
zO9p*52BozYoIrqd)1Km{n0v`*4lly@x7rOjOF15rmKW)j+H+5jFTkMC4hp^loXfT^
zWM@{<=IY>~xV-c=XfVSw6mdtKAs0N$aprgiuW>db%t9mJEy&_SJUJYlrn&;eh~*Y;
zmVDXQHXoIrkOt4-tH$z+POO1NGG7xHzWhw#_$WvZS|F|}NKbysLptfMG54;)cl0Y9
z7IVD#Pd&L#1vgLqTUI~&s^|ocVL9CuYf61t$bIXS7dGk{PR$Fa$c2UECAr8YMf+^^
z^9iH+giE04Ud9Q(j(VIIE*qrIV5;#RHP0zNXmEQl`Y161Cc_QqAefX1d`4Y?@EyyH
z3p#xY6P#750#x5lgBwejWGRlt)&r9mtn|?{x5Wi1y-=?R=)gwk&4A7w<DxIU&h-p9
zW}&Ni-g{e<)6s~6&3<y>l)NAr4<$sdtk`Eypig38Uox>fY!n(=<#M=64p#^wFhJ_r
zOhO?jI<0cUM5kc1U^hKK(E*lmrJ#DEa>If!XB~X_W_hp|NVy8u!h;*9xiIjoJNhhL
z2~z>jIT^t5CPQT<!YB_}-hg>B>v25I^)35ZYvr>sX9h&VaK}A@{w_czcPF~!g^WUj
z$bG_g&+=*6mIMl?p+bHC-78S7Lian8f<txw2V~be7Qp7S;D5{2wG*XBM)MN=^5eyM
zw<U7didj;lDqk~zX=aHO)xhNTz)zrh?=)@Jm4&IM^wPu}#a!Vi*AAwm9-V@WdHZn6
z>&5hd)20gU{!z{oue>0fT(%gtm#{IEUa()BzhClVKLE!?!y9Vzzu@zNB7DLaeFrIu
z<8(B2p<9;3H!#gotLil$C^^QJ8yqfYPvkw#0h?t*j-M<&Hp;|TZE8fIjuGJX<NbP7
ztiT9Pz85EO6fia}=<RE*sqTH8toe7`!Ep>8I?74J`v>9jzUiXzkFMdD3sSR#o~}Sc
zDOLDy@DZLIVU}esVQKvXYgPG0_4=qFH}7)D-z`8NSz|t(U>+OB95WW-DWC|lwD{N>
z+!z5eDHJzEa{_TJJsenf7DQTLp!p{wt4bo3HD0cZ$9oGR<S)e>p=2+>w!DM4f(w@P
zL#xK~Uoi_BSUi(VEx40>N&J<HUPchLPi7E*qbNU?bCMtqHD3U0i9tAA-h+zr^8wu5
z4zR&-Iom4*rlVl1HBDndL59my@Kz>X4Ek2)PAe2gTw|Gk8`5(C>pQUYB_I+4WL#)@
zK~US|sQ%r-I@fqxZtwXc4EWcE{5?EsrbB@PAJ(Z^jJgG7YZ$W|uPY9*gQ(r%vrsoN
zfJ!rT#aXQ`)sR?M_k%6c!4{lRwxX?Ec$%48@6AnXH!lw{wWOa|8lyn}9Pp+Nx!GGL
zqvY3RpS5r8%vo2W<k)pKI5|2XmHm`OJox6q*WLtZjG$jPIV7riYxMKi`hF~m$}7SY
zaz#>L-^+5KupN@wGNIRfqT;-Y+k|t0X!h#SC4Dr@CrASE<1#b~nQ9RXAFk0hrF-go
zIiAlMD2iNA8YlPpn_%us4dc9AvphEm`#jfW7_sS2T0xL^{%$_Zw5rE?l!aKkY)rO{
zMZBxW<?Ww4E94cp^hUV&!H4+;sSJqyEJzoKj5dhYr-F^BEPZ1ZX^n|vu+yvZQ*k2M
z;!Q)?ebjrl+3cUWXBIMUg!I>hCPO<f?vVNwf}T%<)fv#NNuvp!4KFq!SpBA~A%>!@
zPf#*+P)jcNCr6`>sg=##Le85oh^2mE2m8V4W0=DZqlpZbg#&xm6(ZmIU(zYCZdHEk
z<Dvt+C?&xC0S}HS+3G`%7^aq-SYx0OAd)dlpD-R}J1#O9>pBLuXMi0-y3!d1cCOZl
ziGqz04{WPyR~O;d`$$*F^8ZAaT%1mh=3F`zB7a(pK+6{J4XhO*5Bqbz%i&T`0DKR(
zX}{k_xF`I<(48z?Xo8DesPV?VSBR)yAXiIn(jaylJ#X?K$8Nk#m<*4P$WLNGnzu&n
zqgEc9h3Te6DJ=se&z2cKscim@%fWp_Jck;-F3Qes9#{mrlXkA=eT<4>8BoENstFyN
zSw_YzT?$Kkjrmul;O{ZWvzP}af{%N%*?So*hf=mF0dGn_p95??(pr#fOxHo7k4WHM
zgOua^e1-2|3qI_Y1EIA{lo3VTKg&s6;p|_4ALb*?Mi`hh`Ln=P^}BJJFnv2Hx-{`r
zgLe;^G&#Re5E)_TzOnb3adC*H$YvN$qjLgUIS3Wbt2E?K0kXDQ&Qv4Jc#TO)+u30@
zML9dO=lTpKh-HGHTcv?1A*|HzAV))ld`-TFcu=G8`POQ9j%{8rAFgSj5hczu63Q9(
zp1ffCR$baMk-IBzOPX9LPD?0(X~W{}M!}i<b5Rm&MLkR7!T~`9{34C1#P6x+!*{-j
zpfN_{|H~`Tseag-cRIg8A?70~`J+B#W-n$+#*Z?H*kcu8Z%1HLxO=J(fm2Em@_XQp
zJlKCJ0tZk*u%FM|JnZrS@-1I3Zi#U_slyG>-_pDL#)r2D1?DY0K|Ix$-U`mlK9wQk
z94cGt0yZK6Tuq{?%qy#Jg-6KE(7!VdC>I}|N`A`_hMz=JDYl0f^3$`YNI<l9NP=F-
zlztl6C<1H*>|Tk7m=aP9LiXtK=h9S_t{|%SC;M!j<zV>Um)r8Nb&}&h^TB7sq@fGY
z8zZ~76^4e^6|pzKH~K+t$L2?f_g)#ZzIVtjdFt+@sfVa~_IMq<8Me!(HNO~B+zOOs
zE9W_MC>*D3yTX@=sRii-_&x&MfdMv7W^-?|_KLsTABPw|nzMC%An1kjN_T`-J=yWd
zITYZ$xXZlXt#BHjw}qa!jUV^NEpIy=exMLC_qsWe44cLjA7wxcQ(DNt*Yw_kyy^l)
zDoDgE=p4-3Dg8DyP|{jx-(DpL+*=6QY+KmNnh*Jo;1-HT;h$WBo*P@=I|>=8$bTL6
z*xk4zN=7NeJvu3c2TPz2GVoOXqlb5y1NF@Pyjt6N$kw_azjx&YjY^r;j6&(5{QN`6
z<K!-Kn)~j33FGEGmF%=(ah^9Y<1L2z)Tg!aF{B5jk;XeG1O+C9Clks~+-k;*L@blu
z|7Yn~+mz)LGK_Tb)hcqvYwY2UykRyt6!!>=5VVD_fB^=8@bo>9^-h^_e+KS856@m}
z-_Z)Igq$B)V5sq#7n@)vUnoZ+;D=^qcY%LwqaWPPWm~W19o2&wpU%h;^qbhH8IOLu
zJqk*76y0vk4_sRc<ifx4(_jtWHon+Qetu>)<P@kNo1c%Jhvl{w&<6`*Oh#II;n@WE
z0q%IJxHtW&tKX_OXm;+uoN`&t=$^Vf+W)}n{DFVc4XC|b#(^}sZEse?8L&ZpSZb^9
zuPaNde>WvORsio`P@+_2;SSMXaBPgytxnq~sg-wyax<QxGh|x*G+?`@An*quoM)Te
zmRN8BnSc9M{q%9;0y~F$wv4=R@#?m0xf35VCMYEv?7J9Hn@5WU!Qmj~wfyW}cAUkp
zZ{+XD8`+L=legE1(S2(r=l)pM_fJq9qk9?L&iSZ1x`lD4+(Q0QoOrc5@SH)RO*SOB
z>c_Sa_@HS%+;?j|uV8OB_|EhuQdNF7fw@2Kb^cRM!S=Cz#;Nv^e{`5|yUM;!#r?|7
zPi`JwhfFh4`D*=5a(n9DyA`^<_|CFe`y;jILbQ^p$0_i0*NSa{%1j1QhLbz5_B<(D
zF39I}wqO$j3Vt^Yg7cZya{#@Y6ClWcUy*GOf)<{`9g%RtBpeuCZUvu5eqQ8V5CE1i
zRCc@aFQiBFkJBu&sM%~RVI{|IC7H44emQ;esY3rW@=YreyT<Y@WzMj}&DX%}8}NOF
zkjzl3Z3M)WpTD+ma5GT2y|>(U-<hKK505LTS*6VKi7F%-C!{{P6MiPH+8nfF_N7j5
z{`%e5CVQ6jH|_Z5(U@|R^6`4u<zJTLEpuTW=M+9K&X3*y?<H?}LGks5Mg#Z!^>S8<
z{j-s<sHRPm<)K$#D2&C!v<WHL^JBY1qL?3f-v@o(CViH9^|Mi=)$Thp*WdmcOzt@S
ziMQalCA3#j-xsVl0lK!MdCye0Q1cddPj8vA(dCQHN*1xl-+6tC&b}AxI#8?iL2Lip
znpgWYpnGORPO08iv!u66cvHx8=C&W2bfQL5svTxFeLe<zP<^}Y&bEekzPUC}(sNG&
zszgGclD>bD{#@);U#!D4uWET_f4b|W{=Tusyrq#l{pW&T-NRb#bUZ?Re(;K~MXbxe
z!Gs`}PX`k)E;eIo<zWv}%KJBHNVYtKTMhgIlby1<ywM5VpEc^Kl@N8mb$~r!)w9x2
zlyOrqq<(B&9EQe+xs-X)rT*jwy+fl(4-%AuvR7lU1;Wr0dxivzsA!p<BprRz^ya@L
z<c>YsE)i96Fx8}#Jw6&c&xhupODsPr=eFH$7-N1vQ7mty6<vWuSoD%15OS~BTP;?=
z=qgCOXpKFo^S(o7_9WhC8sEKY^~U7jSi)s@Ml?&_u$lwJ9(FM=)2gfazP5quUA1W%
z8<GNu%t)<YK<4|w<w5RJ{jJ8kUY1?o<+)f{1LF%7oa_0!uJ+ybNErba!nH>;o|zI&
z1powD%=AV@JPwi5h={Pp?)p0~3bg8Kp9*&5bHH;Zwd-NG10MdW2r{gSep_I_Hq0gv
zbAP7oJsiaOv*G`ZfTsFNK55&bN+17mZ^^n&P*2%`z*iWzUjl24tJ`nLh|7v;9yVC_
za|JedRcsyP@~b#AmSu4c672G+I3eA3COo0i@u||^WqxwE^IMlGi7xtnD;31TDuz50
zK$621A+If37qNGBT^~H7_AWGX?e5l#CQa<KJjb^*8-9A}DsBCSb^Wtm0l!{d9&(zs
zE~z-}vQ!T#wJ%&0cVH#yYFC9PEe1O$FI&A>Qvy3%ws9+VhI14Z{z^Qtsf?aB&9rE*
zR?Q1)|2cl~F)nlZLN}h^C^gvEKws_wjydxqr<Eh`v|NA8{jffe@Unj-e7W23STdQ3
zjptfQ^9#0`QvP9+y%t!PEZWl(Z70dUd{%q3v3ZLJ+Cg2Kg@zr)rU$C@N*xa5TK&rS
zFC-z+HZ_pwMEvt;@#*JrKJ#H53u-lc8GBrkue}n?M4{ey6s@o~|9d8XdLv<)GTYj1
z#+2tKfR)`o(QtMkj-HJUA*9N~kO4x)CC3rsjXTsu{5<ofID)hRb9B}-=|e=1t7PKx
z!FJ*9*1wS|JW9!GWCC%W<uPjr^InU*vJ*2f{zV{W2k}_SZUi<#gz%vhfl%=XPpk&T
z3|5z#asR?ar4NWlV~@>C1G7ccvzB>X&+p1_&W4O_10k)vg5*i2HSp~YB8rPNj&SfR
zTcw}hreZS0F@e^gt@}iq{>TKKlxQQ*QK3@)Q2BM6B*S#S4)w;yGiF|wuo3V8ZNg$<
z$3vDPUCr5Wz%q~GlBjxNK@|6pf(mi)HgSl9?u;+5-VCs@BrzLq%H!N@mwEdbzOBI2
z`S>*UXg5s3D#GdlCD-Hq`U2}drw<+^*kygJx_|Teurl*`{i#Hwp51oBk~CA6+|F|W
z&m3t7@3CWM;vJvm#U?V9*bvv9g`4$;ht3KcS(GsU4$UXrJk#6>>)o>uEtxiLS-cx*
z@Bh-k7=${W=%M9&GvLhz=IP_n9+qdziZ`q@oX*$xH12LG3gHT+r|<3aF#mhf+W;>t
zt3trw1LS(E=o<LLl!O`jc5!sK;wk<-&D6c8t$+zA=tvly;}X~OK-1$>j;N=dHwc*#
z9lH(?d}Dfa(CwuiyFM@qTnpczvw6j&_k=+=s%Ks9RrH09@vBNHy9epja>yV`95I04
zY@e!HnrFiz#GiY8IQA+p%G>xWsaqiRMq&0PZCtAtjuZ)7j=o?#Gk<7Qx_S_cQAOSg
zp^-~3oarH2J*#$HUl^v>Et`sVu+?wTF-I$}5D)(AahTnKS+3M0Y5w(fS+Xp3Ul&5|
zlYf*;aT}w>EY-Gbi#wzaT-2P`_9dsy9>N_DU*?%Jr72Y@;tvw{H!sfKb#xZ5K3s*t
z{TQV8B|Xm?zoNI-Y{fla0^s`GIGia1a<}}Rr(dOQDh^`a(0krv1T?;tA&N=WD{(%1
zdqbZTg<NoWela6d$++3y<l6>$@_6Xw?BoPZ%H(UCKOM>~XaiTNpvN&8MYm0iJD|I*
z_t<Y8xLe*8?cbx_cB+$=yPH3&e*4W(TN}P%k*x!h+zPhebP*NF$v0S8gBnMmicq7T
z+kb_853^Q;kH<01u9OWVzP&wrb68hx(G~6NG$<cojEFRA3$QnFinJbvbm@#0VA{oJ
zEZRlNmlis&{+XzhKLd4ZS_8J*b;?<^)3kp{fBT*+TSNtKoYvl$+TcR0J#}N3g2I;L
zsp<pi=gR=y!Ebp=+|LObp=qJ`gDp)#lA1lIV&nEpN8zsP!j1#ZpB-lkL8gar3Ss=e
z_(P#T!vevVBN>d1xnGLZveN2btzFT|_|Vl%n{07r*Gg(yg%?zYN&=x*CXOd}d>h5V
zWA8%;H|)V)3D{!rr#?aX0?zwdLku?RM}l_1Oo7|=hW&OIb<n#*Ae!;9XYJBx@Y>OV
zT{a6R-Nvc-%WE8CFJb9^fv)DeH7}#^nw4vp<CP_QeY?jJkkNi*`(tmpm=)UM+14pS
zUqrY0p&Jz^ByAG2yP2-pi{WvJVCXxTbVQ}{@%%ooOIC(s4#&2^)H4IGJRG6)X!fU<
zK0OT~vj6vpSicC{cX5h%>HxweRcYn&39#yAvA}TXUy0T{pn9Re+sI?^WH3h;&u?Wu
z4Ahwm<A1>4a>)A<7FTrez7&6n|L<${hm)IAI>g_STm1V`V2kV;SZDBkR9#%jf!<>_
ziwl3O;uX`*3e50w+P5&tLzsLxL|Kdb<=cm}kAH^Vf3FZeIx{nP&8AWZJ%8YY#;8R4
zyCO-tgjG(jD^UoWzx=;>A2}1_7!xSZ1Vx@Vdp~rIHQ%5KX}n;<j~a5NLmrY|<%oKI
zk~|%{{KcYSe*l$BMu@0t{IOJN$|X-hhlOc}l~{e3nEg|oXu1M1vx%lq*$wZ58ehwZ
z#=PI}FEyDV+~~r}e*-GxqaOT@4J+CJj0~8(S8}U?=t_n*lOawM-<nDDiyyz_h)zwj
z?<Uh_iAM+y85M#?WqGS5Ufv^?K{6_>ITr&Y5QlcM@i@cIRLyW2+zCQ!7VbQ@2C)zH
zejf@mi)PDf$hk!eaZ0Du+n;%ia*Vumjj}K5r?TXHY7J8Vp9*_b*r)O~)@ajP!wi;D
zimq5L1}0#={7DlFMNe$IOjF2a17HaKG-|ZZ?7z6noQ|~yj$38K%I2Nzg<!26EQ-Up
z=DM1=iY6L_OE0XC`cvg|ss84~+8~Liis>Z3lBsCkxiAcIWw6~C>=QOVuJsVtX-IOt
zr~RzhDa5nv4qLn*;@o<rEXUIxs_6I&;w~eBWb2FzP6aR~N<WEA$%0q<)9N$bnh{s*
zyIBfKp7xV@?japWjAsX$4PktI$rn00B!=<Tn*3w@XGIlF1?EIucZzEN0OXKjQR|?m
zro%bATS9dn7Eg~lW>y%6s6G8pxKcm(N+4LgIZ@-tw$g`KLf<8?u`vwRMw^S26hM9a
zg+>$8)5?2GRkUj$!9167<mNee7Nb0SG;abd*}C14csgFt@o_Vxiz<YiJcBKK;k_;e
zHk(h%_<dh&m_gEORb92=F7J+7o@xqz25zUSix|++^Lq#dTQWLAvm>`qw!N)Sbmv1%
zlRYT>OAz7({#B;txQa_QcCDDbO2qEfg_WcP&sGL`YzX(bR=Q^}RIBR+tt)&!8E<FH
zRGI#SyGzqBRVDy4*ZQ8F+8XU%-(fZ@DhEWi6nXMA*o@*2r&q;qK|?t2TzWhD7CI_&
z)ISV(I<7<FJF%2Hi6s%XPWFical!wvQU8LUW?iQsSSpfI^))JS;`)iAkrUsC4E^!G
zePZ-Ph@oO#f<K<!jbpJu>Q&yGMbXQJw89N}xr?1!W=l>?cYMHk%Z_5t6YCI{!nzZc
z9d7mP9DblP1G`2zXFof@EO}YxRaS7VsMDo5Iw)kqW#A_r3*lhqDqn#A31&t=?KcrB
z*O9GUnERJ1yj;UJdE-@xS14;hGAux24LGoLoh=fdW8FkuQna)LF`Z_u_YYY&SAM;E
z^TdlSra~dsMZf_EX!IJa7P1eVWbc^UP*S(`ge4Adzy%+~eC{<gHB<RgkGb;e^B2_c
zuB5X%6R#8^l`ph}s56-mm(8|X#;z(ARsX$uV|$aOn!M36*);3AX}E#7o~eQt%D3Tl
z2gA?*!KZ3~wA6*4y>JnWUrPIv@Su>VRK>29Q#*9>*`L@_+@jazK~L4rkN=)u{@eWV
zUjwtc{qng8&-3%Uw6%tka=1FLD;)D~w#L4qGz?k9g<aoOu9RZZY|2o=RruJ}p*PIE
zG3ZcUyFs+PMN=RC;=-g5r?BmpG%AJ2Q9-f?=<@lO__?{<ZJsJ^G~2Xb$1G15Iwa>G
zGb^>ed(-EmgPln%qx8b}>D?VlmZXo79Unm-KB^QtGT2e)JKTwdEhZd9(yJRIud2^(
zaP6w_6^0WyUwsb_YtG%?uQ7C|Xxj`y0Co_7Il$hWGs9o@#+cxU<bD}Bo6@QpA0GPV
z?d$k7NU`BLO9b2JIw&o+QofG5JNa56&1Xd5X$q5SH~p?UijTL@xDf#DKFAMG?kd|8
zbH=n!>2q$-{}@|ij=YEnE#9#?kVqZuAl!B!yzKmP241NG&js)y1bi;zcC=B%kq-B4
zPsb|H<3xmg+JH+FgnmcAZ;d?)V!zR1C&tevntQpR*c1X=yO*KDkZ-6IBI>9LjE*xn
zeI12(9oE$k=AES>opgN=mLuql=&&Kfo(YoelLI-gJ#hz7uDHCUd<!>I?;cdworS4{
z+2^ix_dHu6W>wV{fxF|LY&RG9%8tx4?H!g^d*2jxyY;e;9bu^87k+FSL)PDs59wHZ
zu^)Th%hvA49-x~}6z;_P+jc_keKKp2wn5BYo+VaIXN`!=@Vb3NaEpP|Z!J7+XuY-r
z1EiUzUYV!f2`J!xU~Cp3mpg6K_)urBry(@Ob#HGdNO3`+*#uesk{CP^Bmdx>c_rtl
zS;OuHuyx|M|HZ@Xq4VL}geskU&<&yHJXN6%P?#0Szw&i)pd1|+RkUt57h9OkdaQkc
z^sRARxq)=~yx`)C!K0S0f|@<`iT3S6vlT!wjH4JP)GQppS|c<+zV|Qks8)|ZiB~AP
z#<$8Y!ES`Q&5OPV84!BXR5~HH^=1lOM#6tEmqIW;dH%??H>Ozte0T{qoMEQMF#lm?
zvD#?yzYGup00;mg@T&A!G0JtpTNh5lk<))~Nq3h(-WqfI7A=EE)13g8S)m7hC)+03
zv!2Qv0$2{8S!ebeht{*5l37mm%TDdOo@wkib32SyJzaY}1gTVL?xJxN2vTKb@<U*9
zp&Je`Xh;S{&&ESd06-a@?oBk`Ca+){@9j-qnN%B&W+SDm!XKrG6M7+NI6$aq-)Jj>
zM0hZb+i5mUO&Cg_W-bE++&9-`fXD*abXL$R%`nk}Bmrqb4~AgDy85h8ZCT=)N2oSy
zi?&E7860NCnKy@6&$Da~vA?GR&=qS{I!K)hn2I|Tcz{A7qvn#24Z%h(0*Jc*lNcdo
zXyI7VYBKCPOGnJ~{@ff30pM93*kw=0t60BNHZpR(;>JOD{Tr9ksorowEQCP`SRv!V
zNw1p2cD97+fp;CSlO;DA;`^O#Akp(0yB0j${sP;hnAmA5rjUiKV<=QoHBR~L2xjPH
z+3nW!(4qs)L_xyWW>BtR%%zd~gyt34>8JL~cY8-lK@|osI1nIvk(^Ag2LgfA-46~O
zw$rWi^vt@XsgU6}4Y8^G2BXv5)hO~305dMw*JI~$@5h$b=lT7f&f^dM9}P7A>yUFZ
zi9c4aPR$By0(p5_E7>m$Ah0-EoV|l$2*_e3ev24lj>yiEfuE(>GKdlN#NpOM`#e0e
zJpbpj^H$6i(}nNbZX8yrKde>6P`|*i8GlgxfNei3vK?Q$D9JW!>N6FC;W$=-wg)L0
zq+u>#_}akzIwGTXxE_^}E4(u{+7qu91P!nQ|Mv^rd0x#_papF^xBJjxdyY#}+{($~
z9~awPuCj|eAoeJ>Wv?vhaTPlb9G#*fxd#=}1g0;*mmwafEp{B8@W^fNCLRE|M;%BK
zpY0Su*{W^J&jhz{MdGNh6}yQYMsv*e3J|kxC@rx_Mr|e&n(KJez1exd!JeA90%Dnu
zww8Q#xct)NzC0`E#sd{PZDyqH(rt!312~vLKiYg=>W_-Ql1|l0vDaN#CF4G+4a)}P
zEmxKm`r1!xa%qITLDmA>p31zY_6r{liCRmu&wl9rt}i8-vFqFs?rv~X=O1luj_Eq>
z=$QrO-Q(foqLWC^qSZ_lfx@Nx_9-_6=mju;S%R^bIRKCD)&%R~MPz+en6d|HJxd2C
zh(%I&+UImdsu8)uWtsg~HXh#an|a#DjS5ns-0xpz*bgta{`g5GK74qz)ez;xy?Mlx
zuXd%&A_-t=FPQJWu?h+N{B(+;euIH=x$rok;rAz2!+}E&_W_8+Q?T(vVb0BR5lx<&
z4Etz#*SeG*cKawhmjI%Ipoi^k>|;Bn5JyH+zcR?8^Kd{mJ1;Ctu6KQ4^?^>Zhs{MO
zS<>FFd~_j)aiM?;^`ffq4x<u;@W30GY2fGsszMbYk6#zw_cf1(z>L?E^uT&_Dry?0
z#sE$v*y)5&z10{P)8Ay|X@^`F8H%WYdU~F%s6KqnHqhqnzI6{V+p8`Y7b0{hgt>B$
zdMN`RJ|8==n`JZlO&d6l6~QgC1>emDkm&zG)~PClG?nE0W&jI0+BSHj@dfh9`%fMs
zZI(_JfM^$1@h_f#O<i*Sspas?`>*XWeu<-irdjMg|37ysPhHOtsqPRmFxT<so;FZ`
z1tBEl{Upy*YL@X=eWm(-J*8gVbI%;gb=)yH(12r8c~ZbRi@5H@YJUxxOLQ+tw<V>z
z-o0h7oXU=`s)JDv)(M(3fQSvpo%dN_dW-6Lj8uvEmWLeVLR+%RoxIHCG2TN5yj3FN
zl*WV9v8*}KH6LA1$~Tv3aY^FNl99<OnswDem1W|1;eDS2aXyvC=v>Lymj}9Y!X1w2
zi>5w4?pOWiZ7rctb*gWKc6f1mhwfZxO3oplO^K{`-&H{R$IW7g-3U46JWI7ZguG)G
zKF&XRp)Dju+mxs~{Oitn+vpcn6AV8?Ie@fw?ECFt;#pw|0&A$38vS75xOUIwh)|b~
z+^Otrq7nx#z4r&zKois`Y}rU@er?qzXE!P>%rkm--dcehS3btu@R3pps5S0Y)Q1yy
zB<sj2rJdxreXe!xWPcfn&?~Xx*LfN`E6hsHpOAL=5rsSS>roDq{OhEA<J+cB^w5I5
z|Ne;n7Qjn?A>$FoLld7}%hwlSc2F=Nz(9nR{>ppm6>iaz_Wp&m%%muCs&;t*-#tD$
z00G9)et=@ZU0~4QTy!9Dqw$WAXe7sGh+nIKbLfR&n_Dyca7dis)Ab$GeU{p3lY|uX
zinvu&l5uzaM{gK%jp4R9(`NAW-><L1SD&;tn5acTQIb+h&i)O`)cm~*G+RfTjcSp_
z(vx{N9ZzHm*im_nava>MK24390kRX*LZi`G-yf}Cxv%4`IACZ>8~#S1`&19nVZe`F
zk~2u2x|p-+`Qq>~G?3`OxLyOd-cUebAxzdbEa@I^9c)pJN>c;?h0brb1A%uHzo=d!
zHC39vVVRh`izsg3j!En|&sAfxs_i;e{nqb~B2=b*;7Hw)VO+*D*HzURD(RW(A^+N*
z^LFCo#aA}H*$J<SX6JW*JO&{P=3cHZ-XO(ZCp#3f-}LorMrWy;oWtn<$9U6BkN<0)
zj@I!~=5dq`smI%0{X0<ufS{4rDV=GcfSu1&xk^+{&RMw!pHv@Sw3R(UOP307;uKu`
zR*fICCk=Pz*9&z^Z0o;<Ud-i{KD?0ZU`+q=23<I_d<vfrFJd9x9JKR3RaYCwh<|Ol
z?!3^Nfb&_J^@Pit#P;D(4gx9!O)=IVasgBnaPWP~(<2vBHWYbA$2)d|;NS!OV{cNv
zEMt{oNwnwV-6osrxy)Mca~C2tuENY)`Eod$0|tk1R5&m1Lgau*^V<0y$9|s8*Ge7C
zOjS(M`e4b(<5D(m?AeK1G!Dxfl!7XQccx{Yy6-q0V4(vAt1htA1XScsi3duzOUW~t
zj*OlasXYm4JCi(lyqT~0p%i@K3e+ICNg!vLsOW%lq^r{XrRU6~oHJ|xKp`6fCRqeo
zqI)hwHsNJx!4x6D2QDL<$|wQL6~e4Ir0sOixlww)eX(bp;}EaYiQrd&5NQ6-AFhJ1
zgPIhxN#{1jnPp6XWc3Zs!m<;rPlgcIv5Z(c=jxw@ytXtUl0fgPS~EoM8aK;Sa4On(
zDFTVD3@j4<hLBYqPCbc3LN`(|@~ypA?!V_Wx@>k?W~P@!&&C(y)CI`gUODyAINJ{%
zRB>PyGWzNjt<Mz5+_(qrNVM2uncM9Ttqyw3tvIy61Aj-gFsX5h`|%ZcFoEZ<nO#$H
zJw;yEoZb=og>Kk7Y+xoOBa`$Y2Sm~8(r0&TPQ|;WgPL<0kh)<^NoteUcQI|fT?e}{
z$!y;?jX5`;9Ye>xAXe}Q0T^ln@~FDKCF$8rXxaqR{^CT~Wh=JrsDF7*F5Tvf%`Hzi
zW72W@E<|Xdk$LPGQ6f+FHl;yflnrdcumI@<2+6UN?iR((NOH(2oh324v}H=YNvGR=
zy^K<EK3rQW&TAB}R$ixefpT@^Z37t>iSv2~QNpgT2r39unH*(T;|(7W<o|bF2kCV?
zSm2cz{v6ZD-E=2E?22R<ZEES!<{(d+^g+B<t;J=hnZdr$eVnQWW!w2p&X@{7iHrvz
zf&f5KBTg-_k9JD(cS_fpC5ijV(9cKv!-(YZvUP}~37MHy^9zJI1SG$^rAyWif%TQY
zP?#Xx(6(=l{JH7s>0@O*FfYUo>?|uYsX^Wx>c#l@{V)JsxOc)4(OZC*?D;#|WpZ+&
zv|rpoXp))nAA(rRm+o2WMf%FOZULv^TeKNf=Yi|#=#Q30YTAXM;Fp4YYg3atwdw-c
zYs~~KY%9reQGh>h@^;4IPyqOBgD0Y$AG0t`_(n~2F04T%^|JWuJh<z15axK+mHUJ~
zxO}*nr6j529~j*ZQiz;VJeQ=Z%@?(A$<4Q~>(i{eJ>X*XH^DJevWK8}U+Th5P)Y@G
zSGDkKs#1NjBjop<m5@(Xr4yyU;ybl^LK;oSa}|#esldVSJ#L2tXH-&J`KGQacvIaO
zU5};Ugh5*3OYWp8mD%%<U++`slpLwa>sK2qFi)%PL{DcUTzWlJixA01*E=-b&Zct<
z{uXc5ozm*<@+m*laLO-gn&11R_e@(ncyHS1tEK9es%PbQ_5txXOtz(~^3Uuu!tB@o
zV0^1SX|rF0rK%Bi>>&O+6{f~yc+xxbKL43OM@C)Hf&0jc`D2QyL|N=)VHekY2>nI{
zc!ZKEyNzZFn6DB)xwO-lzFttK_L5)Uw1Xf39fcP$MbEq@84VL=yK~NQG&MECLmK6z
za@v&>W=U(ndwK;D77M-PZkX+!Elk@r&$=j$=n1M^EH2t-uY3Gj%=N8wmi=0uhBG(A
z2cvm8nd?Ow(+F>A49T~-OuY51;fL9%_vzXm;s+UP)qQQE#40Z^k0cOj-M*4<%1EMR
zWbwWp&t()nWvlnmeeVC$#rj$#sHv#Qk!dAmr)~gp2K*-P>!B=sCH*U5?w2PtgmIz-
zI^Hr%RoQeLwlR&oBPU9{+4LIrKsbO^;XNuo<^u8@od8zEM;l7P;4jcv^sXukvqoFr
zV*I;V+ylQW=Y*(OzVhE^)Ydue+VtWDPq>i-O}_qenbuXZoFUFzd)0DPy0CqQQ^q-V
z>j6U!i|T6F2uUz+6>5HA;Bawk52sg${NphK0K>4Ep++0>wv6cSz~ue@5RYELhP3NU
z{Gmy0ZUaNuIfD5Y2d>V;18QID-|@)%Qtqt3__0iw)Z7NhHKFxpK#OD%u<hkzDgcZB
zA?GIe#>wxgG$ujgw(k&OFd_HPhCC)PZnw&sJ36qVH^+px1@Ja)l1B>qz;7gIfT_8O
zPfAO>UyAu#UbD0wKam};b|~$d=-%TQ8dP>^*@rio{}mlbmfJ>$r|?m?cgeX=p<8&<
zEdun+Gt<J56Vo(hlR1NVfwRqR+$;kOqdw-z%g$s>ptQpPM{5W{oJgBcFkLVU`i}ly
z1C=xHMwqu9VyRz!VZlvNFV|7E04rc{YE~ZF(L9W8y~WA`bc+BRQxD2qKwD3erUj^l
z14y30r?J2>Sx0M_rX19Pn_&Q@MFxlo%#1+kM*h>aQ=pMqq~MDI4ur)RYrK-fjq{Mz
z2hamN1(yyBmyk=P7)|20Mb#7|<Cjao9K?#H9Zi*cac_hIRt=Ou_b%wp*P!I6>+6%l
zFL=180P1<EV;V@UJx)uhhN=*UF}J)#XW`}r#VOBP_U^;Xlbgc>nlT{AS|5@Q$S=lg
z{V<9e;Nd?`D%4Lr?-$p-2$>__vykpmRJ8^xG${ff$U9e<(18Q592PXUFmw(AdL$)X
zD4-r7+Ef>Z6m0n=0%^B{qRvmLwhA>m^!0rk*`|huuo}o801IO>qD9~*o(EDuI4a|F
zwiWso05fC#aic&h%>Q0}Zt?J*v03dqFP)uhasLSAuYABnRV%qC6Ij<ek}pg91Ar7Q
zA?rW~mtMr>vr;q`&BlhzJ~rB7h0##KmfAek;{XYA09`LJ+Bijm^a1nC!BVDONE%xG
zuF;kSo$jDz{rk|#8jCEt&StW8Og*Zn#=>P8X_A3_A|T=o15|rbT5B|7mT|_RN~iUK
z1-eVrE1YiHffphvWW5nT##1m3tNVb~KC!I(pPBkl+FL7;R$<(k#0m5xGe^sK_^-5A
zf53cBI{Z%|DUA!Mzps%3m@XfHSc<gwdK>RzYGnGk{t$rQF6n@I3a{^P$1!D~8qhA#
zY_bj#xQBnnQ`mLQqH?KDf#;*nLZ8E6Ekv5JgQ{j8cy6Zt$Z6QUa(zLZ+(0mVC|D!p
z<rga!i7xPXaNnXmF61Fi%WcUkilwygnbJ*hK#a8oj_yc@;2If5uNmli0nr4a{XL9}
zAZszK{}M9wA5N&eUQpHcAlv?MG|Hr@EkXULzBe&|0|WANLe4ZCDH(QZqp3Xv;go6u
z`lQ3<^HyOUUh?-goXikv#t(y^Nzm=IP1Y>Gl1)JQu<i$tI?fvU1F!n-_B+<T^=O>+
z-&)cp!8&n8*X8+?(sw7b74#;t?j#ekAn|l;j(nVjfs!*v^0Y@PH$RuuW`*m`G_eun
zWz$-%%2c()pSt>|jS_XBkI+zAK0ojN)*F@nXq87U&#BhBq$dK8IC}Jrm%va(<fWfG
z-@ICNV!Z!TL-Z>%`n(L%J)@r*erdK@M#1^=r&1pnj{dj+0p@1^fM}r-Xchw^tl5s<
z>Kj=ES<h^prXpLY$R-KVL{AFvZUKjO#oPxrP=WKWbnA7{qbmx!0JJ+TO6oWp_fygG
zv`QZ_Mf;C&j9H1sk*(X$G=&@l9#OVY?l6<Kw`}+a?lzVv?)kMZDiep_`fw)BC?^Ab
zO91K@T7=tP($DZ^FB6t*^t$7WhPc-1lW2_C-Wp7FvU5@kPrUI<*A39I5D}kHlbQjT
zByJz*ByhfGr|?k5ZhgRks{H}N8f`+60cdVzDXW|fFb6fTs$+ecMazH9C$Shlu(YfT
zJxGw>N_bjxS~8J2QRA^y6;|AAu^#uGbJ|5+xNpOQ?A=fxOXB)#g6Q)T{7kUhKoU_y
zy|n3`{;t8lrOkt4FF$qG6ynZ--Qt9eD7~|lhrT9|8W~CZ{G|K-iXe_;SfT{EBFLWG
zZfGL;K5Ojuk%jITDB!)pv4{1SXvwReuoPXA=x2o9NHnBXTZ92@&T2?(bNoHvPO5Up
ze_Gek4mXowtr?UlPuNHy#I8AVf8+5*Fl#PB`vcD@w(~^X8vOc1#Jd(YX`5P+Fk0@u
zHusSFMbIOwx`Srl9G%Y+Hiqq8JgYBZ=0|LUjkH)i1kC_|Ea#@+$u{|%F3gUloo8@2
zO>2p_UZd#Q#diR3(6%AOnjh&by2M)V%S6c!re>jRnlUk9nyT4C!ygLBvyRtLcr9n%
zyC*L_?O!diDgv3pbF&8Tno0nT)WL#ABOkSfJ(6;O7lmPu)^yhUwFiW#P6D!b^u%q+
z$^A|8H?JR22m8IhHTj(h-6T2VOFrvQ1v~5~+0`gJP2jB<r~4j+_yVwlbk@(;lOF`I
zVKtR+i{UsPvYm&dlU+e}6+-<AZ5DWzr`%(05h6-dpCo-CSN60j98oK}w&o}6jMvKu
z#q+w^uh%&ZA)6Vm=7q{zXewLc&e^JxyzVX2xwK%3rkmQ2tHP?t5!gIUB{=T^UH0#k
zRA0%FM{~}H>H_uZ7mnuPe46~!MZ{YY1;N;foeXEkH0_}^%h5NJL%-2KXo>H~)+eh=
zU4-~Rkjlc?&>Af<K$0mGu5XbfNCOto$&93@)G|xiC;bPok%uJ$=PzunMS9hqP6Ui4
zn8G(yl+G3Az`eB^4eIYJ4M1`LC3NR!)lGTY7ePV~N@CR8O98y}zj0a)wCkZXNcPx>
z4=*8ro@*hpI(8<sL#M8p0TWF`<h;^B01yH-KUPAt9IFh2T$x)b7fxdWBQ5d+U~W4?
zNsP*$He6B*sc0kg5%XHqLumfS>q+PDZb()06|8@!?7gs(IVY^z!+<3+NVp?A5wf%#
z-UBsi`9@9K(N}daL2W3+BDm{|TSajLPvN+vw!2ziLDPUVq8$&~TnN&%VKu$~eeG`z
z$ql5k>&Us?FYX5Oq|4(@dh6BDl`|T9HOoTBtUS~VW_g$+7eJ~!PL%R3tw{|d>U|lw
zbB4ZCzfxyK2Ptv{gKsb`<29USRqF>N!|Hk~HO+6{nyA;3947GH?{t9IU8e0&x6#X>
z9Q}S~%N{bUQAO|i(Q<_e3<ZGTct@<xJpJozh?sb48?Y-hL9puG_D>C&3plVKqQ5Ls
zzq-MAvo@;4s1UUEGxO2&d(ibFk_)YU&s!bRuSYSse}0qNlAj@PE7*s3u%Soq%g1%*
zPoCQNS4X$n;5+p(`2lqxX|F=N_Ph=<mVU3Q3*<qiY@R#_mRvLwiTQugtDx97f7Jfg
zXxh0nH%rG$V(9(bFY5GzZaBW<B=Tg-eR3z|$=u(Xo84X&{O8VfHVV+j8{J=|I`<04
z?L7dAA9&LZLtyf#_KO|rg%fCtf1;NbDStquyTl<7{n?yQv@?p4{s-N6`c)FWASzd(
z<U-*7+*<!j2DdJ;!*y-%{yF&lqBd1fYp$TsE8n;CbKIg(o&UGhd{X;rZpdP;ayU&T
zka_piF>=|z%+(sTZ~Vy-A#AU6S?1BbGwnAw|Fhg=W7v3XZ;O_#!h}S}qiy-tSr4kv
zPglI^4Y-X93g%Ns#&k`_-)tuPf7XF)VUD`<9xu=m4@+48W%O4N>h@{Ez<*$lg*}h6
zCZvkew@Acf@U@9xHpXf8#WUKt#a;;U@Ltl0;39GB_8rrAFj@}dcsm_PDjDJhdX)OM
z+48V{c6z_#1(Mw**e<~<W;6RkwCmOwt`f;2*Uc@BWXQe1Uf-lG{+#$?x59PF6uj~3
zkC>rEVV~l^_czCNN8`RsX{ZEEC=Uf+j`_>}4KjIo&+VW9wu=E%YO|OT{_yvF`Z1%`
z*$-TtUY;$*Wqo+7eRPB4Y{v~yTCOM9j;EG8p|&GczjMdD%}aHtw%(C{qIYj~TWXXO
zkE{jjd|lm<c%m)Yi{2lFAtg$dcGES=tJ%hkFtl(Ld=g2gue>8EeU$3J1k2ker4vWP
zTE7T?(s)EEO*L1jb_7INXN?5sK{j0@<rk}$>g-1Td%v0dI1aQ3nylOqcKORs=g|YP
zCzXwS20RfB+E2Am0kh7tSYnB~O^Qo#AzzbGrXO(rVy5x6{xhag4{dCOR|BhKT8D8|
zD~8s&f_Z3_V<w>U-^MvW&V;8avd2)1JtOXHx7gV@%k=WQCkO@P+(_dO_ElTOFY3O~
z6jIDO@J?%5_}6>r<ILJ6+OR#iOI|5f?}J|GV!TMr#;(7uh}*HPBCF78Mm}>f&^$V}
zYPj#!jYPmhTf33pHVr=k|9ma;)X#GkH^*^CHvHy|ow+a0n(2+0$3K?l?R`^D{kGry
zMr)mex>w!l!zZ8MezeJAJY(EX{7f0Bio0@gUs(+tzl4&8Op6WL1cIEL8v)KxeK_Gu
zYsk?h05zZa4O?~Z_3MzG|8P+|S9%*!)}6+$i3c86^C5fwWq0&Z>rhww4SS9?vtkV*
z4xVvy3Wt`u|D6>KqW0^|oQ|(~to9*cYS6x1jsKie9gx@Aq$2m<bC4e3-!}5n{nqcs
zQzyv&%4DzQ-tvL{OJ2|y9ve*kO4#pHbk9+5Ws4?g>%4<3`33T!ZQk1kJx31)>vYE?
zD-(uvL-WJMdj6;s6#+4=#pd(2!!Cw9FI{PaoyPzDH&n_dCmpPmrXXG`pR(#BPL-Ce
z$mku{&!3mYLlt>s7r_*38|7Kom~9@i9KT4B>%Wi=(LuX)Ho@H_e<b3f#YDu73r8DQ
zYW<zux)UzJDDX1(NAsVNl)JC3rvgjkn~>HIZYq>vbW@&vYjGMqD0aGZkwrC9&ag7v
zhR?eR@mpVDt9j~0s05ufiuJ}Gsfpxmyxjil%h!Oc{>qJ^%wJAu?sv*xneu6@pva(Z
z-Z*GIqEwOE^8V0Yup8oz-X<74%_`1l^w$+E-KbLh{g#TbBN+XrjastLZ)khk(+w&}
z%CQ6A_bP!tI(BDXA`;}wk3U(DKkbgw%evom?0wj~{nwA&lz!`eCyJkT1Ikm1j3izw
zItm8G?<XD_biOJ<zUiZ%-uEEY5Fq7`m-szB{}VO!G8f~b^mGv|z7NE(re8V_EG^k=
z+u@HMWV9$QPsc>=`v)6p1?YD-Tq2fY<u_jCdOY90xIEtfzFqMv$}&55>xCN25H^N5
zZJBlI=<@s3dmA6ukwSTkmncQ!Yg<rT@5VL<HyNq`ch9{rzK^=5IQNP%@<Ab=ivd!$
zG}<YCqk|Q$T_*kLU+fh>B>L$=CBRaEAp=!;FwRr!iF=Fl56U+F(@L*h5wHuvFH2|6
z=b-x3zNeLRCR&*(M$Ydb4+;@YH`qCZJ(-f_i*vXoY01(ZU_W`oEBR<D_Q7+3oPIIF
z9VNNsfse;z@&w!HRCV(#A<{A%r04R={eM4$=)x)gLBJ4@)$OJOd(rW=zuKS7Ca^{V
zMl{Xqnvd!vW~v*H*>!I(J9`EfsOQjgFhT%)_r9tL#*J_KPWP-f<rzBFC#X>bPcI`B
z>BnDf)j{+;0u#-31HC?&Pv+n2@mAFRo91JEYd2C&<Z)D2JV|Rm%q~9()?Hr{%lj1S
zQp%|ChIpYS?mo5)A8L?a#U}Y@00fy^EVj2sZHfC}pgrUCV=(<`>8SM{U=Oi(V>cf5
z+xT-CC;lfQ;O7UBWo|p8e3<%H8xVU-!!LT^Q`0qEjpLtSm9{vV8(%xLV88%DLkv1J
zPXZVmgdmV0v+8L&8Dr(-rN*FRP^=Cx_cR$esp<L0+g0N*7k-u#-`_Z5`5&kuXzu~&
z>tY0%U#;+Rzmo39s&e@!%&Pa)&rYMv_ho>@=N#dhK8kz8WnT!yEE%|LI{4Y`cU#bZ
zz>5>wfRbx?SaB@n`^llA|Gcu}%yunIx*-<fw#GLB+g}icQJXxIpoWtj2UnmQl55HZ
zSzy(|pPD}cjDd`v8xG}(Ad74!Dp~{LBMvt>Jo;(#(UIWV(YVV!;PT@|p{U4cW8LB%
ziD5bE#o%wOn~0oSziRvaL!~mxxz;r2=6VBr!!_XQ_6B%F*WUid4_9O@$jKPlR36s4
z^*>bAZQ%8h?H_&*S^jU_sEZnZdM9v54e`x)ncPcEC3>n4Wc$i(sAfD_m_qB_OzHNq
zxuzVUq^InEDk3ssB==LjL0<MJ=P=|4H3}I^J@t*W++Tj^`(n$RSNoU7Cz}2T*y|Q<
zHSPRG1DmGSCn%QH1A+pDir;WmLwYYJx*{?^`b`~<rnDofaZ5Q)W?-k9Wn1u{x>cV$
zH@jJ02i5z3gxz~Qlm8z-{%Z%@%w}^wGiM2n5aoO(hY@nBCWpKoM??;_gV`L?C`C$h
zNQjzB5o!)GA|p!Yr4&*vsZ?6OeZIfnKi|K8f9=2BuG_BbdR@D{uIJ-%-yMC&L+b(9
zWSiy@1*7tJw?28TTGYK6e30S`H?T*9Kv;eOIgPD?Fp%p8wYsCIN@BArje!Z=dn!!C
z#nRbix(a8Um=eakF?o3(1le@#W{l%~ve7|gukZU|@kk`Wm^Ls?hPH%HA_-2A#1|M1
z0hD`w-rS?*&D(x21>HLJ4Al7VNWfPxu!Zs|Hk*oYeNiu+<-`@~*u_bIm~FQIxP`R<
zn&;}s>hUd1Tncwbz4CBVO)|>@ze=8d-_T$)GvIZ)`wnEpU^j0oap1PBcO{6x1!v<5
zul-cDv{_7<&yE?>(k*yo{A7LH{^QpA7h6mHXm0gU(f$P$AiwK1xsz$uL6#nslm7WK
z+W&alC1WS2m#z~f4ys!b-og2mY(2Xb_gmPLzRNp1m2_Od$wSHSmuZM>k;+(3QQ$A<
zl@voK@RG>d1M*^p^wr?8bLefUtBU5z5@deH@3Z}X8ENq!Ba0C|j6C!As`$OTbe6r^
zEshKjHJXk-S7)`wUdcuJb7&QP+8_%|rGWF8>^pwi_rJd?Urs(aGUM{%XXa))CLDOI
z)JO7T@10Q3*85TK^>Jjv?<Me_@ICMRyc^7kJD;&0Rjljt0BO@}<X#m2Dt-L+OkUG!
zmGYgv{{P0!EK;Jx_ZcKW&1U-%^RVN-u5T_EeS0su;zu=FnM1kkKv+GXVlQ=jDmoQ@
zcnh8A{g!?qTX+$7W3~Jsu2H#DxxLpLj9>|=%EOBihaH69gLXKb5M4;VYP>XPpXN0t
zamJC!+D()$49eTCz<1TelOG7Z!q*$K$NWJC3x}>bC^|YKssmJHQuXE@U}fAt_w+Zj
zHk)Y8-4yQwC%}y0^V()W=CnSIye(%y%39g2wA`<tkG8)n#OBPIj5~DHU4h$#oM|^8
z`;ryLI20@r!pax`tqBw1Y_V4#SyqLS+nfIvo2e_vePx(kuMKp?${lam1zK`c5XjcU
zb-@yP#QNO(d?)G-SxbbB>0TWEjER6NE^<?Z;{X{KC8g^adr!=XN8Z!=U>{3#78TgV
zcD2GI#LLse%kbZCl{G(5vj(YKL1bWvX0(Rd5tbzaZqsmYq<MsR3S6f2GRdt)F9PHM
zej_;z!6Y%1-^CE`-_Eb40Op+I*5(0G9Etrnh!CWbr&P3F5oD}QdzW6s{3@L|ANiMS
z1m>rLl_<LvWV%Vm5+4IJOH7W9b~D!x;e2!#=g^4KK0R!y@vUvLSV)nVr>!1D{ilbH
zQgLOy{|kw-+VtYR=6O64ipwdcyeGd=qD+x3E%q{6a)8raiO=8RL{6AK?c+GmzBQ`J
ztsp~rAsCN^^v+A{T9?QI+y=r7)jr6w5{kngV_vXxdHh@_9rMw7>0u{Qsk=3r72k6k
z@H!>d60DzX7|A^;*u^@ei%YpwFWR=Q4P0^e{OF}(MFw4+lYIimuPaABuadoVsOZPW
zNgn&8{yg!N#4#+0atl<56_=slkTYyZ8W~U%=kv%c38!#KI`SgN?yr#Y{w)}urLdDg
zL{m&8pX!3i5!*P&KYH!H@vgisu&BS%u!x;0&+*sUq5`YV7zP-_SgL_Ca9mJiW^kfQ
zN2Zgg)=5s4Yy~yrwX?pOk53l}_^0I$DH<xP!dVd?HiEuFAr=Jq#j~Ekc3`DGb8TL>
z%1Gtmd)1%BGh+ml$|La*d@=3~nuk9dM^^`WP!9<%5ftDGLdsz7#5S7pSK-+&jT!Hv
z0elFAM6b5sA__&UJtodIk%6F|!`XUA5d$@PP6sj90mi7))~f>;V677IhW3DS(#Zwo
z=Yk5V5^pJDTZEFep_o=VjlFL$1zyL47BRP!RS(C?rRYOa^g*)x2vduK%KGH&9mQJ$
z)7Gc6;m%fviqmnOww+2c|A^;|;1{~0aW7iWz3!3R|3*D34t!Br_7&4)#}i#RVYdaa
zUtH1G+6CO@$w9kStgg#udjjPxvPaII-!iJlBjLhfI5i2Gx45&nqYoW8(>P2niAV>)
zGS<^?wfS#C!rq*aTgJpZ(M36_Xd?Hoj{#EL2Em&K-LKVV>DfaF6K_w=f)ADtYEb8T
z$jP$66oKFZ%}{%pjs4AU>;cJa0H>Wx&gL=I6Aw3~80&vqP*O$eq68BA1oaEw!Ci+z
zF^Jra<<e|MgK=~Ne(fUsE6O+=^_5e6R|1G#F0dbOmaJ$TB{WNdnl7-Bku!z+D~Sd;
zf2?+pAqT=6uB+_?n6?4<?-Hu)?ci9DjuNojL%!km#gi)+_4a1;lFpEj7u4CUe}OHh
zXzhDD^==KIY?)ZeqlNcANXi&eC15^#12IS6gTDzaY27NORn=zt0pT@Q7-aa~$1P_6
zzXA&cq9PVpl$Dj`(Nad5y72&z004(!uss$s@piJ|ib^3NFw$<>|2ZrPpo~n($jB}K
zufqa?1OmWOI5f>n=U}?z;Yjr;d>C=JuTRk4wD80XvBPp`f4E7U@(loV6)jVzraps`
zUI9Zz09XW|)<I&2MeeH%a?>364Z=_BYjF|{&hJ<M698<afhTge@DEBh;P(9i0$<8S
zH6J{{KS<QMq8QdDlhB1da9&T6F9{JNEE`hWeu2QhObi}rgib?KrxAqTfS6xN5CQpr
zf$X0^(g#TRlkH-D1^n9|^fyI)IwE@NfNo1nWu@fx>%g5muxnSP>gu(`0?V)eBe48B
zZSk#g>*i&P*$OQ&!om=Ns=tCczkv%6l}35+`FZHXL+Rgq@bq`khb8d8f549)pfBG*
zk0-WwaCX-;ML({NDVy+am^{SeMT;pG7_3xIx=c*5K)}6l_%#E)3t`gN4#{?<SX|w!
zR*55CNXai1Q!Lru?NR$Gr6m7Hv4H=#pScbI|KRXHDD>twU=y_Mm!|q`0%ZO_)OaB9
zH|c*A%l9ncZyxY36ZoDX@$rxW9|+h4AO532oQc~rRe`MN0rj-Oubjix{s!H6glewa
z*Kz{*!vTKRC{6v(VF3-#05cB(F~ahY5Bl{JwEo>}^7Q@(k76#!aIWf||GyBHY-ZK}
z5SG&VyvmmSEtf#QPf3q;fqrq69@Xp{ZwH<H4eI!<(D+b_KLPnM1Ag=awDJM;a~Tl*
ze+Ua`{Tp~?V<&%p?>H~MWr|EDmy{HrWU;Q76<1xOb2v;2i(P!KrK<4S)glh##`W&*
z+gGn$pP<nn-0FH%eWrDs+C6%cG175=^v=YiuJH-l{{)tsqvfTqM{iAzQFw*pqrJlq
zx*knkd-HOXH_Cs=pMU;FjIg|a|Ng7^<Lm0$|3O&3ef##~$FG0?{%!pF`9=6m@P7#`
z2szn4mRH3P1M>}a6VkchibBd22}V10cf?Mx(m#4tUUWzpJFU>`xhCoSpWeNC0!8QH
z-SQ8QyVD;vqiZiZJ!+4jm&o7y53C}Dj>|9A*ei+!7S)gda#`4o#Fr&qF0QRduOgeg
zLIT6C0#M(rW7|}{Vn5AiykJz;bSCS0_pf%RjUp8c%Z{Ahds$lDCM0$i*dy^k!M26a
zu@-x+4xogdON`fDNP0STajHSX@6OF9tqr5c{Pm6`QF4<V%_2vxT#PE{3sM|<KE3Ev
zt^R2_tO86|@A>m%a_d*ByJXsTmrFsH5+QewX^J--U&xmp;tK{ux6J(RZVo(Jkc!yQ
zw5pJ}30vxXDRKR&NkPUpiKJ$fN?#w;K3&dpj!lR%$@qFo9c981QtdXAzl|Bsb-GPD
z#gpKtRhTBSuNZ-s;$Jb})hjLJfYBu0p(E_Bz+|4uTVKmtom~NV-ujLp&u*-qvgb}^
z=Ag9Xxtp#?lk<SI<C1UKY5UFDJ!B`@gpECFS{%3zQ>Sw2Qm8@1>?J2q!haQ-2_5%C
zt<7~@{i%Q6J=WT`k*>Gs6fhhsK)#W$nL<zYbD9cWj}BJa!w{KVmC)-I5;~C{sxl=9
zLUZeCq)*f=l*H+~kdru_?*3&DSB;*S-8VXgvV^Q14giS`F3RqaGHz!>PV+tqT@Jrq
zm3v@VQ9;FcYNLYP8&iea%h%6EB>q>eU?oK^VMjMrfkeE;$H`s#h?C}Ru<a(E*N}Q-
zX+4Qn7o@@L9^FWZ&v#rMo0?>6>eaJik{b`nUpKjNdgmYgn^^B%rp?o--w%3!&&1bm
z@0<T-=Dqf=rOf2*n(NeQaO;?i4Xl|!&6f<l@lncPY0oxeg^byN2Eb@>Pj)(iy?PIj
zS~VFs6)*3k$v)avHLCY(&%_X4KK$giaied(7p@K_JGDUTSm55^8*vzv;R9En*el}v
zLnk=e{98bnJb25)WVQC~5q5`EInK)DCpw|m#uP9j^BdZ7CuUlWx9@%&yDj<h-0Jny
zM8`XySI}G7`D@-r1l>y-YKMZ&DKO3JpL)U%-<u41!A^32oTxygcSOBXH*IW9zAx9k
zEj&Ah40?Gw7PGJ`wwCQc9?!#AeQZCK=Xs{)4_7?ZB>eTEI0|>?Xj88rf0?b4Y~$UF
zdQ?`HuAgwyWFo3P$MZMKcjmLW3jA)AppQHxWg8nMdj$4()9zt$lS4r<;>N4*-RrG1
zs37NO>4^DVcxQ1%p{8#P>{H1)S2n5x`iqTo%%nq<y-b|XY(@O|aa+H5bIKBgdg%<~
z+`?!NN=xW5L2M7%7wT`Lf6BaGU8r|17eHVlrQp{oHXGm|8|+baU0$x2@)l4XA2+wB
z9%S2fNjxTDzomq>0Zt!!qA;fE`w>%^TP;0YgQLmo(Kq*#Ab+Zc)nM9yLJgu$WS?#s
zs6HwC?-E=J>I8)AdOI+u-D8CfUh6D(i^^zJ_B!6D?+<$>gG}?eN~1p2_IkO5(Ao7$
z#&?U}Btm~t6SEYf^*5o4`ofv_)C8hx8Kq?z99Q;lomHT7>fOS@z%eCUi`Rx4Q`4sB
zlH0s<$;AoX|EzmVF!hqqd2W#z=S_KH=qaTk(#X)l%*oVd*@6MDVlU03CuLilBy>N%
zvCF_YYN%J}z3fH-KfHX+w7(UOi`4yqqF>kCaf4t4SHhGOEft|W%chFwLd7#6@tJ_y
z?Rg2e?7+#)OjrN=-R>Db-eA&>o!Z9SMKP8;Ev+1E0pHz#QwNb4xjy5?X%8+t$S7)}
z5ICh<yjK6i=SrinLA4fOXEQ{JRMhMOn_BJus0`#+d@x4o(F=F$ndnIi(IRx2ooF1m
z>{pPvM{8G$o^<XdXAG20H(Q(m9Kx|R<sRiWyPzNkQt5@2n~FU~g?L5d#&G#L#jck7
z{+G;4-F0FV$)<@!g(QC6F<g@-U&1U^+wZ@fR&CnYB<YsK$;5}cwlCWma1&OjcfYW1
z3K@5_y2ph4c<!ogzvw;=Y+e?fS)p<RN8blYDvgxa@#F!{`ygAx=2u*>iYDa<PIT!#
z<e6@F(-pM;IH*tawBjwMf!hrb7zA|OtXPS$2#M4@R%wCRQDB;!_7!w+R<Y#=rNh57
za9%V)?OA*IpP5P6RvDDey<Pnha3}MZY6vjL_L4+;QgraX*blt|(>D?SK7`H$1BaN(
zWRm2aJp+m%^<DNw))&mhuGQ_UH-NnsJ}AMw^x%18A_Wnl{v1O-sK92&YKx=<k$f-+
zWaIWhXVqmFO2AX(&??P2?_@$wy3PJpf`O5Ox{QO$gSeuP=K~R&&$6)d0OfwXIpVvH
z4VT7I75TZ4A1S^DL*;zjr87v7edl|IDE;oHSOP^`?w4z^&9J(*i+$nI72bOar)k}3
zaq}^?e~_68FRAzY<Cfh|1)ki`K|No%tCGGIOG*9Dj;YpiP@$3QENxAG>Hpeg>K2a<
zEd4q(m9og|cCc7h*I80}27*A9fyB#JK3LO1@ZcwNGjQkLXy07xZiV3k(Y2)qg^Y=7
zre?&sKMV4FH|UYOA9K?|h?N|jIa|bl+2h(nR4M?JT(x?5#`jC^zX%NV;cd3ALc)Qq
z;bV%t??B~w_&KT}Msr?*v8!JS8+BBf0#H7lagGOQTqSgs`}N2dpVGExzgfFK0v9!Z
zD_))nZz+GcZ03LiT6ljJGiQIY&sH(*Z~`tcvNc6lgL!CMqe_p^A{nkN6^D0Kj63q}
z*i;P|j(B-heWVCy7yVhys2Qe>$Uc_dS-Pq|D8OU#=3hd<9S`;@Nx$A|SeT27H*qD|
zd?7hY)O*EkxM1U7wVEZ?ms;lKN$g;!`wwh_R>~U0`Px3z&3$puC@wZHtnlJ}|D)As
zGrpKUl(=#9)g$G8d#v`7C2cu%{a|v`x~IfJsR$x9^pUbs4|}Ka5mt`b5_#k{b{KBM
z1&u8`uT@<xF)!7~zvXAUytDs)?6>o!H>G0aaBO!Rxg^pbv#)i+2$r^8lm>3TUDw_H
z@7d}-R!+N8$S+#;h-G?xUO@if{x&cAgVJqPu2FQ+)Ri89E%|-#$6ty)d{Bh}ioFAU
zL*O%aHhZUg=B4ahT=rfAL5eW|$=^#!y#=cHihMUJv7ZZ~vZTfh!|6g$J%BWkQ>myx
z7Lbqcp~#r<tV@XqKmeM@Bc9AfmC*OnxsnyPj&QQcd~2zzm-j$JXzrI~FB=}n&xZUD
z{Um~^ob2atA{{Vk<v_xerFL*YYED!-7Fh`~F;YI>DwI?Mj+oJl%r>b1G7!h~5HI-Q
zateXH9H}lWqL#&=;1M)dFv3O(-b|FB)4K79?{O%Rct<byvJ{#FMqdX45yvbQk!qyW
zHZIcSaAGT`xYAkPs2a%@NY>*K+HBBvC52zj@O$y_jUQQ?M-T-ZstFiKHri4uC<26_
zE`eA6*N|2>OfOfm7Kb`7KnGVzi~r*C3E{Gf!PBu!zf-7S;Q{Leg689>n{25aIEp?t
z+qL?@WOhu<QnAr|@mD2ep^)M#L008!pSp~=t4LycV7t%6DwER$(FihtYy}WS1VxpR
z*nhW5z8kQ7iVzl_$4hbcgH=*})wu7tvRvlYA3z~WU+VK<$o@IMKLpJ8tgv7Oj6xOq
zQEYfG4t)G;A(gbRheYTBj?IUNf^mXlUq*{7(i1B{$kQ7jn;pRv`Vl2;S}u^Bc0V@Z
z5~3KJKs^H|<2AnC2K}>9VBn*pWB~Bl*dNWY5{8GbdU<}P05~G!rjT{HLGmb1GI&o#
z>L}p`d8_20l;9xhjjL?S&A^wI>L1qCzwpCDs?c(m_F=6MI5vpR0qr0`>aZnsT)K-w
zX5+0rH%U@Y1t7v#7ttO~5V`7}0SO>ej5Z|6WPFB|J(!UM9*g~1on{Fq;HrtS;j*7`
zW#_n(6u{~atBeoZEx#_abIt3uP-zPQ`SQ*psw+e-1oMRz(uqel;*gmm=wAMwYmei5
zt<X<dQYubW|3pKe%IIxul{9Snj^r*EuXy-nqkLd4a;Mc9(sil$9!UyI8lxvQZgXCJ
z0KIV9QvN1pu%gnC<b5(&PsD;W5ZDb^skg$)GQ$Ji;u?Ekd%!U0$IJzF4&3`cnFZTA
zq`5d4R~M9?jNnH;9jQy6#?0d?&a<U{o+^7*7@4|7=?hDD41e}O6XZh^*i?uC`8ZEU
zvm2a{xNi1^Gg8YW%v0@ve>XtyHYC-#SjBX>>K%pNqSL_lgd^?^nJQ)Rwzb!mD-g_z
z-Yt!m5qfh@TgidwUE__=2zDb0a?K#;<OpV++VniU{GtF*WWlNLRRWDK6@^|xGB0VE
zBSh!flJP1R^`|Qoiz6w)vM<;N`NWGFosjJndP|kfyiUwZ{(13RdfW!NmyU+apldQ+
z>c%WCa;l-kD)7_G$5a*m$rCt_qp9PVH9||#xa8WHV)4y0-TH3HGALt36xUek-g2QK
zxw#r?*u-sZ$0O<dO4A~#dBAEQw#^k(@?${~;dJ>b(g)j#IO+skKX-ttilGo&ZuDG9
zuE4C<)OH5T&Js{tw57hWoy*=bO~~LaUG0)H?d?Q%-MPbEWVG}<^sC?2Y5)=eAlpb(
zHW&07x#K`5!unF`$M~z5|1cB*qG$y{!=L{y*on51N)49%;&koE-gf<Z5oRY@?~nMM
zp0Uyf7G8%#wqrR>PEsnhd!B`IzWTHU=mB63$iKC?4%aDnMFB-A&AgOf?jf~$4y~Eg
zLTB&Rr=ay7pr-h)=d7Jo_2keq;J-U>v_Cp;dj+|JRhX^c#tUpS90t|lH5R*XMn;36
z0#I`A{vM(9CK)p?M69SHVou{;aJo{wokfI9@z&h2E6y2&)~!Nx{BCD$fuwEije0DY
zCL~Mj3ex+^mi%K4<A7#mRF3p2Xo{hlguTF$S1+!+=r`ipnBo^wWZ9jIZ(>m+q-)Wo
zV1JvQs^@jvYkJxNq!vD0<Nd7zmY8&)zTvO}LU62wb*D{SNc#%caqX<sTLPk-&~@jT
z>-7P`1b{Y-lpQ>Wx<}~!c>{8D5WK~yXDCVc4oNBii@e4~UKJo4#f7*D9Mw#@Urue_
z>(*xjfjVM8@(qZfLuVtidbn`SKmFw#sguL#?oxC4Lbbj~)BxN0uS(2T{I+j-j`R3%
z90yeM5!o&t?ibvcMc%Pf1@o_PlNUjwH!$&@g;&)EUSE+EGYb<}oZmhtOyOELouvDc
zP`|gZ4fx<!BVYsW^{QU+FPJcW6k^+Z&!i93@802MqVye)CM6C1qYZV;V31D^N=Sk8
zxd^#c#4>h79fY1e+bh2=y&Hx4>LdG=1Qx}ws0SzCGEfb}*-$UC??s`I7j_Llc!su2
z9%+aHda%1g+xt)}k+Qx6dBSdxDmvTFMpYhjm)pzbx9EYS4FzC-gmOz%&tFdVwRj#5
zi!ABm%?rnO?Hth-fFuaq$|y}34&Bm+nU-uDKfAZcX`q|~U;XX%mn)UsUTcR$-6Nvz
z0lShx(pR1odJnqlzmTD$$hq;CSce~6Wh3kP=*$<c>jKOdHl%;^0atxOG7!*YL%xtb
zGNv&drBd2tcsU0lKOqU6YwpEQ(q706mQ2P($bSBFR~)Jos6Rwz+-Lhp(Flk}?)^Wt
z$R-kB(GRoEePFry;D?<E3nl{Ecy#b7_0kx|)sK;4JcTrYDB{9jaoQ8N=&D?Pfch)-
zWOG0q=Y9DCx0yI?cKH6Us$+EiY0Xc_i`bbjjk5-UDvxmJi2k{qf(PqmGjEHhsC;w*
z%D4LR0Se&}RD+f;VA-XN@<+NpNY!$Q<8N6w5fN-A0Q(`7cXiBmnlyo|(KMV!;LDR@
z;UVOcMd+l`AEz0XA0{9eFfm2Hbi#Z}9t0_ZRk(;!E`rntAL}iB@EbFQ9p71UZ2&jh
zFXX>#c#>b>Z^$<!|IOrt1oz+&bOEP>|NJT++3JHl+b{i%CB4RxZX$GtqVGJ+;NDvW
zneM~Hi7qr7L=<)t5JkeLm4^^?0-`_U%E@=qUwrNsKX?6to4qGA$Ox3ibDqSPfX5T3
zLrvz#_9Auwh{$eE9p_}lTR5|(x<c2MO>{eP0cY%I@bK>(@~)uD6g}-X6RPoGoPo~g
z=v3ZD<YEzSS;4DUoPP?ArtQ6Z_)|+iZuYW?Qrw*<hUE6I8V~8K@pQrIr#{-4TBN0e
z{9>5=>ba+)J9FCHIkN&xh5b7>hnJxj&~z^R>8Gca40sN_MnkjNDK7Im>zQgW=JBRf
zKYJ3{0Ll9#ZY5RsM$hN{<n~udX|alpyyWF}%BPyC7%oZHIU%28F+VtbiMkI%c^J_$
z`<=`Cr%Vo<0#H}(zj?4CeO2zn6lY%l8RiA|*#L3OTmarq0!s-BO@+E<4`=O<K&<}T
z7S~<;>X#&&uu`H@a*U5`CL%8j;AAJ{GXZ*${b9lPV|9to4?rqy0&#+k(4-=!eJ*56
zyjqdB@i<%H;V=6gClTQ<kvxt5^a*T0f*jZG^Ra*3^q$_t`P4*~?!+Rs`_UhTHf$2|
zG7;H!b!F-9$|d6G%Yf9vF-*uyV+#`{{g>!p1nCmfkBi*55_d7b0I8FLrze1C$rqS8
zU3;K$OV!WN(X*DG@L4?yW`Hl%51`%?WcS~Fk|C_^a?$hYz})KJKej2FIQ~HKx7aJ<
zf<E8<ymEJCbwBc$5dQowT8w19sFVKXgn9DSY=fk+d}=;Spd3$v9U{Y$NU(U;*IRYC
zpM1<R0U@qT4W4>utI;u(b;x1&YGd;1rOPkmGckSa#eTe0hYQBSY1xc`mRKm<MfkF7
zXOPuKBGxMWpT6JtXcmq1M86I91NUV^?AzlpPq`p1f#fj~avSE`CGO|T1SIRg|3a}9
z{FNp^s*v=J14tbw|El1_$!zT;{71hj{4+kh2LC<efbgUfV)?^y+tKgxmJWW0S9!n>
z?z*(%KdB(L!*3#ZJ060^V%`9K0XcFn^&Wny+{}39w=QB~{$VkrC;FeU(SeQ#Eg|UT
ziN8-BsV~t8T?B$d`1{NW@r?6}!<RfJfENhh6<Ep7|3s$%Nf!23Gk*hr{NL}ie-&wx
zmxz)8r8W3c&>7=!m#~samm<`Y*|$o83vMMcf4*O-HjmjE#IdkXl(%@-;E_*!dg|<h
z$3BtWsZZNNqzuf&a!SvY7L3-tV;g1>WeEX_+vCPgo4cOb{rYa+`s%OY>@WNKbALCz
zl6rh)ul)YyoB!#?L11NSD_&iM`a!5kW+9?;4)zh#evR{LaBw$*pm(?0z!_|}d`)n#
z8mCgEw=r|@UNt`O-1^4XOFnR!{UiB3Yl}e_cGZf0uZFKDOx38>IUF{9+n@S%v*yo}
zNp**#FZ-%`<FCGOBt03gI`w<o1-rCm{(pNs5luXgN*C3Y)2XlS=D*BXl+CnP>TsrB
zkGUt(-e>>z<HDVSS_k``Ve~qE+EiK14TrS9>&uTMAOCeA+bx{bJ7sk1oPH<I=i5gK
zg&^L*H6Pqi;dP(QhS<*CxW)<ggvk~}{iNmY1XpP*`A)apX67vx3L)y9II34~lj|t<
z+sA8<loQ{g5}Vf&FT829fuJoP;(~Zq5AiWP-HNEUJS#Wumu=q7O&LBF%}si;VZVjC
zm47w`Cm(nTKc@KtzkF6JdB&w2*%710!b%^ev&cXtrhF&NO~&*a;SA{b7}V{7@mREk
z0*S|Rle2pJ?Yh+7d?6bda{90=4<|R_H)PQIZkyMJ>W$qNA1X^(j;p60-1{ALzci$G
zb!NmarEhJ;gOQ1q!*km>T~E|N6{mcB+T_p3Vlcl6)97ETq`(Q)Ps9F=?}iG8JhrRd
zJnesTCGL!z+&S!ZmynzRF`@8x_aqN2xB4jH%dYRidqBS$u}+`=zI~M^rQL+hll+Bj
zcUf^U)JPL6FIu@*6WiJfemrfx+>+aN`C?&K+o)FE@7A1{GK;l2w3FNHzzOSo_i*TL
zhJL85ZTN)mVA2J9^FW_XpH;lo7H>H@e}Sm?@LgX%)T+|EWTa`yf&3I%eJqU^%}^tL
zZ7aO#k8@Yc<Y-H%b=YQje$47FpA%$8)voAV{5+t4_EuNkpF5H7@6yj?8~hH_?f?0{
z_Y2GQDN9yk-bQ6{zjyKWufxyn@0fG@%Am6N-oirPyS&xLHHV4esjEE;;H?+3CZ3NF
zzg;&U@sD9G#B1a~ZvAkP_V(B1y40C5hGzasIQ)vyv9m5kDhVX#a^?^7H!F9~j;hsG
zy&s`BFMWt_H8@{A>X3K0VBg!5yoshArGx0(Rz?0Io34;dFUh>nH}Af7*5z%6f6&UE
zk%`6rg}*V|<?O_!XLEHOix*SUUTo0KML~?yALFJpf;aZbzZXzd=Gkg8W24eDGt{hv
zlWBjsMZR^Tm67~d{qC0ges<k1ia*-WDa;|#Lg2~#;6?Q$+<|KX(#cX{tl_i6aMPt9
zc6a)l^bZdefoeQ4L_MKD566K2tdQOUOu@F}ogK>0+9|TRY9_M?g!_EuN)1VWOEOM*
zuDgGKhqIMJ4@~-SPNT_c%n4`pnD4|v*>kHd#Sezy+vKZv#;hKs|E+d`ULw+Ly!5no
zdQp)6K)F>=lh$osqvk~=Ifc-fQ@EtJYFlJSZC@dzB7$`_t&V!wuPmG_7#cM>pMWyD
zF4PFwe2Fk)I-51HRWIK3LhKcV_eV^0oZ`AQUwa0?gZ-PN4<!Vhdd4cUdY6DsWyV|A
zt{25$CsYm1zBOB28pxioQ29jEcF4p@7~R~iEL$%Q-F@{@{GqE>GpmbCsxOVv`F6@I
z(^bPl7IQf2t!fs>!x^p0D6Dhck&aKW8<&9}4xZ8I;a)aqyexI%C|=Xg7iZCs&dZo5
zO5dYV<wvwD(v%Y=UT=&UKB|``Jp-RgSU+UZ`4pCHUF-#(T-HdTdizpuD0;_gTOR8S
zjv>X+|1gJybpYL{DN|kfzyFl7odVL3)6H{-HO=7_BkVRA>2MoQ4FQRt6#Q28t5K3M
zJ#4~W`ddrXOEm}TfG9Y|E$00EM^CF{Cy44i`NF5ugN_@4Clok1i5(kn4DW^aJ1@Dk
z$DX+I17CSEfBx&WoXO<Z)P&)4gV0vZRnO2fzoqssx#peJGeIB0GIVZkzw{G;Bh`CD
zChr{4IbH=fJyKs9Nrb2!R)dO*<w|c$F0>_n935)-7?CS1H2ldNcU*8*Piv1+YpiAL
zy(x1tH4~lr(aAIS-k>JGbw^T~WQsq{t288jt>yS!oxRgDsm#OxPGJ`%F~_;^h^#Ym
zCqD)0BgAMf=o+Jsr0iJ;RG+?2lUFdCw{*LGA~|0Gp>N=s_UZ?7K`xM`2T+sEQx5%0
z`UN$@0E11|4H4Igmq6Q6cEGIZD$lM6e<l&7&nm_oCO2ySV0+q?m7UCI-PT-h@w7Xy
zzIbec)0nH4vaj{fo`oQc+E0$xtApd1{QNUob`vF`-GQ}+uZPBh!aaAqQ(BaK!iLeS
zoITeqq#T|<khA4cv_9*fHSMsuA5#+5n=>NbLxmlxA(dS=NH4aoZ;7vUeq0h%_+Rp;
z|KcqlJyQLeRIVqvjP!D$sZ5Ypg5|b&U-76^xk@b0Ymd>qeZ?wdp+XvqYEYyBAm%U6
zQWr66E&5H4oE=r{W$E-!#@~v3Kgig>*`P$(kZ;MPHz#|3-g6nq-lF%Wnr4~wh;}eA
z4z~86oXDyKrz>00^K;!K`&xoIE5es<@ae5h_=-!ZoNv>v+LKwsu3GVj(b-c5nB}Io
zy$w>zCN8+qpjQcKb@usN+UAyN2R^5}l@^x2v|K(Ox#C=WWnyywnKgqSgGyguR*k2#
zIx;?P**>{aR$>G(%-f9&+F}t}hNrYwUCeW@UI;g^NH6Kx(6+y1p%D41q3e5xlE$kO
z57Jk_co;y1sFKcJ%~0%NX^kW(SKibz+W)nvJvvq|D7(Z?zM<yPs_Vt8zLsq-Oa0sP
zKGSl~ywGx6R-J5-^O<tH1v+KfnXT@4L3nas)OjU^%RUD-EWY-M`RVszW44o&VcoSo
zT3KXKoQ60?=V78~-n<U&eLQF4_>AAQ)ve)C>7B<~FStia|JA#u?tFaPD|WeO=)z2i
z0ZMPJe~VS?GM+VmCNw{~@=vVJfj^xNIH6pL21`eN2Xk}ZUD;RC*lL6u);Yaz`eniD
z9UEv`&i(xB=B+KS4l2!+``m<3F~R|Ck(lG;o&5SyqZHJ^K8UcaF7(^Aqh_~lRV~XQ
zY}cz8h!|ek<Y3JH+qnrqo!@dDHXzcocSS8{+oy|?!x-&jMc0d~6f93>@?b$Y39Jn)
zMxbcSV&rk)Ct6FMoYG3;fK0J2DuVhG^~}5+u(pk(82PBGG&z@1+%raZnTL2FL|j%5
z^e^|q#-L_VH&ukQ{3JCbt#@-h-8xQ}{<6`D(OuNs&AgK1n#Plk;5q)i;(EK-1cQXd
z5@D&u;H3H5V|<V*)<uov(%-|-3Ukp0sOj8o_&Y}DjI^-;)HMvcHMZPS010ZThP)dr
zCL*@8;4OScZdmOxHiO>D{B^_e819l)6w|83sJ{lTd#*0OvTk9`?L-dT;pPCSp6YoX
zK|;8gvOyYHj}k6inFZ3<qv8OnA(^>roE};2@-GIuRj=3`4|P}~yL8h7R@I_?osNbz
zrsE-DQB3l)+5&>vjB4|eZHK}+xI-|kV?$#<zgB$ArYy>eXrVU82c*12!C}GL2(V@~
zcp`(H<OX%0A8{9qxbU^~p1B{-t$y9cgcfeK`VF@vj3VVPmCeKV@r<_X=<WqK<`}^m
z@G$o~Y9;fGB!Fg$_wZR!E9j=kCx8@{DKtGQEt6`v<c0BJ*ynf^pZ4;Yr@3GYWe*k~
zjnbui-*3A)-nI(+k0+tQq(!lcuFX=g8{?g*``dza4_7<AilpuI8hP8<KBJ@S2yV<x
z@Q!EEiA?sErRIVb7@iNVEd$}zJkdcEMLxw4pwdv_g!5EGq3Qcpc=9~NlTbMR&clJ^
zlgMv8*kE|Pdpvkzyi<M>izkEelaJgcMUPMbK%AV5^?NK&eiA!LIPZb4Waw#E8U)H-
zOsuS<HtXBUS}Ko~kUUSfw?=mJN?PCtSeS5Ok@1Se7B;od9InFgHU((qDx>WYAdMC{
z)@$N^)I>u5RZI}v)eCybw=mVD@Zg}t0bPUE)67(($ypQN>G0I%?9|_P0RYorD~Hiz
zXD^K-fE7UCIgqpsA2J6@OCZQ#DM`X2YFm+=p8w+Y)`b;|ocy|5QJUFA|2UyUwwInD
zeK1Q1)_wt2V;8NC87m4pa@n+DH!pF|R>FCB?g}GQ{CYC1a6A}lkAU7j`d~%dID%KS
zca1EHoiWG?dOVD#<%)bi)i4MMi69{~#EBl_MGp*<2nmx2_L4CF3nh5b1B~_%06HP8
zBt6)SC<Ve`DG@v^zsjjq8Dv}->;P$d6qULK&nO_%?nMROn$Xm+0VxtFYRZ=jlo?w9
zFijm?_>N+z%y@Q_>CAESWbs_*X&A(n-^R_g*pbwnnLX|yPvyH(0Eu8Hi2y*tbRQl6
zGH7qtTx8bVwkl`q`&$ca%w&jUSONeO0#G*jBeA#_tedNh?47O7Y-wvl!ffZMiE-0g
zW9nY`l*-QUP9o3Zl))qgs!oDSQa3K&2)cX1!-G$AVbcj6+k96Hi-kq=69IVzeoy+I
z{1x5Yn>V-jskr2@ff2?F+WRTUd@;zpf6lxkB$yR~_oIgZ5<v-`i)&<}!eba2fB}@V
z?BYM*#=L~kaDH_`HT6gdcnhAE_>#JF$>4o4T%G_@w4t0`WaQ_7HN7UZ1>tq3R2>|{
z$qDL7f_jh&J(Z!$omUPTH%Ae91vzjH;rR5XPZXcx%!EvrL83N%#207h`m>JVh>l5m
zDwh%5e%bgh)HH-1EQG48JACP#LFYss>7G#&Lc@g6trGMA<vnKl^aDC$Z^584g-{so
z@jkq6Rc!rY@<U(|F56*jWJDFO9X2h7%GFQh$S+E`jC9^p@5OLEWw6K}|7>?=p%V*^
zeb!XXGm0cd5Z4IrYhE6)tINgFL$g9cHVRXg+)6>nR>XFV!s=2!BLzW!nH3piG+xYu
zMF;^E7Dc=uAz1rm#IjNUo>dT|9y<*ihk=tWTd-*FCpGgqs)`Aq!?U$PH(}!YQ`?Bz
zaOt&^5m>in){u8`e1@(w*EIjP>6wP->Qne}KI0e<euW1w7Z&1Eo^M^OK1#y3bt~r!
z86}<YJg@339^+ayK4_jC%nu6QfU5WoOxMGLjI5DNiYoh+ssOwVD?UTls;c35S>!Jv
z{n=^AR*tDrj-lcm_@wECbVOY$8{A+T;a@E=<1PXlz6WV;fUrXHUn}pK>mEh3b&N3{
zxVikHk9!`|;;0e)(>paSQ0aATjXqq}UjZ4NFdx7^E9R&0r~zk)oPutlFHhlovE|rT
zC}S>2?h1AUQie{5-u02{ekLNqsQJ$H!reE@Urb@lCHP_SKradWTnC(l6_oMECg(s-
zE6_&M2v;^(cj>8NeB8|a*M>P@ERSBIXBNeLhlyyhX@PW6A^S(DCOKlB47}%X*PB^{
zW@%YLt!3toLa(sMz26HR=E-ROUGK2l6sGObZ<T?{j{<~HN8E{^7K#{Q$}l^mA*A`T
zd7rx%$)_da2t@~3jG7lz%a+G}q9W=ysiJ_;5w+^4XIIpYE<yE=Kpngod16$A4bjAd
z4O15lHNm>v*IGGLX#j+^NjO%=%*8|g%Yd9x(K;PY^H`~Uo^<=Jp9Ep4Qn7izG}AWM
z^$eo3(0hp%IyXaLLZ|T(j^t=F+@Wpk{d+bXG*}?aJdAFumq0!go5MKV5}H>|F|;w!
zVUBE((9=jTk>7yb9fSGfmh8RYn{5ow$#CYe1byOSku_CwiDJlxBzd)bS7SU(e2{8G
zv&w8-tXQ@xmdn_4)~^_9$A0d>g-S0iZ(~s=0{c!rx3*lS1=&{JB3LIf=kREW%xZPg
zV@k$ns;Uirs+%G*6;jQ*DM2>$tyyj--oq2TU`=cw&!1+=rP|ChjvG<Mk6A-b_}y06
zOBYHQU;LbhT{DRAKooKe#xfBgYz|e6xWtH$(`S7S4NWRe{b<OfW#FHrR>Sk=85w{#
zvatTRG9zarDs2g7tHy|gz<;pr+|IeyT3VIE>ALY09+?E-H<n@h;E6ot=fw=D0j97=
zki}-yv6Mgl)(#4be5G+emrIXH0>pZY!$xwwi26U$3Qw2bLEl4!2Zh0p+i(j65{-nS
z9n4Rb04<5fOBGP^A0E;qn5@3>uY8EeuJ+Y8gZ`L9WP4rxjK3vA`W)(!q*tA~94cDV
z_oNymfOT!CU7snoIpD40M$jdSt`}8Tu%_2SJ#dw}6&ugSZJ&p9<gq{*@2RTTs8}6|
z5PlE=!C&o=kZA$oafvbCl%&OhfcL^sJUtXxmp=YHALuy3@!ZKw!82)FF2FUpDVp8U
z@83M^IO8oA?i>gQ{g$A*BNo3irtV0xrE|bC8x$?pQqi#my#pEgVPJhCc==dX*gdLM
zCe0X2i<<hb+nuBy4WV2D@Ivsm7K-Bc%PG8|SN4gExl<SfMI5jGj|Y>%eK2EE9Bt^*
zO6w_U^k8=BzTDwlCT%Xd$d>puHD|b>nqg?;sQ(U>c|eo2<gFm$tiR5HJMathv!Pkl
z_xmMv&Jc=wo*IhgE|!+lY^ufQ_M@g(mfqP^gX-_%V=`FEdUY70#s3}^K+Uu}VYLQ7
zihyg_z_0vhIz}YfT%1p44RfxWEHu!u*dy#Ca4DJu0g;)SCQ%#*hrCX}J3-_x(suBa
z7y80ANgfG(ZFimVieVHDf`9(hPfvUkCM)(JRr1uV#D3+%s_Neb?2`OyMxhyer!vS;
z2-4!M8J$fi|Ilx}LD9AOV_QwrBIXq#1l@y-cUfTp^S?t>3$ZK;j7b?_kTW@m-(xTL
zaDRmo=!9y9_+mVar-=<0`418UvxuyKL3XUK$aj+YA}Cm+ddBz3&w|mqF<I?Xn_Z$4
zlIc6^%D9LXAskZ9NEgCP!iKC{AhfOFq?SK)L`T^yqHWXn%6^8^-5}Jy;>3JOXBNdu
zD}UuXY}4g_>O3sWiylgn`1IvSfDL1Nb+dI&Q3JUs;1*01J5_idtaXj~DjuYW2Tgo|
zwPZv62yl4Y?>i-)$%K?*KI1hUu_NVKd-&mI+~D>@;?nHH<yvmcKO9bLg89N-rp$8s
zyQOQoJeK-Lzf<u+qo<+_yzQs!Eea`Mi$mj<SeJ;~%;$C;ZyD&b9qikQFK4X0M$W2Y
zRe3~~zix2;GnWe)bK?q+!w$?~Ek(`kPuueeqb{>MPQqEZM7qt<wanyxIg_wzHvFrG
zmftybTjSZ2Cd6Z(6U3h72FWy81p;qAD<K`r`|xnCC$#5TSMH+d{>RX%SN-=?e-4ag
z+@Gj2NedfM(eu0Hjj=o=9(fh~_yp=slbZkZ=QjEL=I^JUem;6^8bQri4AP`YRl`uK
zIXR=%ulrLt5$U7PR_4lW_E$Ma=3jVy_h>*NLUKlvc`EX~_A}am%YDh?n|+_AuiPH8
z`rvF8X39`e4nEi*i3oA{v(z}{@XZu4=O7C63MjnyU$-`co3)`0XgkeKnRT<MlW?`d
zHD@#GEY}^4_8JA^Wy>YX)kU3s)T->uHjSw5cjuMEJi3ADx(H|Pp-Gz~UtI$v4_^TM
z?I}xL#Ril<N|CKNCp}Mr8#GT9#+{Q?X8zaK)13CGEGNpWzJ=<eZ8VN!1Yw=9u1e-M
z-e(+1=K}*(JB7?SF=VaVRP$$6ZnPo^tqsN6<-|`(8*%t9Hlh1f{4`QH(J=MF3p<nv
z(W;@PX8Y?@Djc7aZ<HVXOFs3`+Fp`paIIeyPqzF~)*@wgn=Ftts^cGQN159^;Fj{|
zTtn>_W;=`AllwYPoM#$GlwCb^X1hd$Gb;UakDXn#i`3zCw&a;}nHkcz6uKzxJFa>_
zo7=7&Y!qCHO@WMy44bN-Ou|~pgAb{_-(lob%xgvRaPQm^^ARP;u1{fqPV<ZrIFyAS
zVRGklC)9z=X}a`p_tPhB_O@sntEHR=jXKVE9QN5djUSrW-ddO!zvGcjAT)2OF3C;7
z94ecJ6R@3c^fyrtYux(_qn928!EZ?$wIy@SkEpTNB!|Ew+Dz}BCA^pV%nLpAi`3f8
z9sU{x(3w}-Z{AMX>lC{gIGQCjO{KdpAKYz9E5y;pH0_?yl`LM+G;Oljluu5{=PTT8
zzb!&arykh7MQ&Z<Lr68{4(8OE4?5;~GX4{5Q1#$Ld53Mw;tImr==#lHu6$?7j$0Qx
zjt#(?P?Mst!u`831@>=-ajOaQOD<A~9+vE^nU*Cd7@~#ix{mr@ww<Aph_Ga-B@BPH
zE4X2lyK|+LNjl0cFL(8nA>#|5%3vjZmIm0@yL!`K4DF^(yPN8Sl?q-iC>H&Cvd(ik
z-$^RWQrQ#~uF1gh;waZEHrASx-X1Gspr%<}o|#ZjQ{}V3)C`C;yaBfTe52<6>kJe5
zMO288snFDY?uiAs+-70`5rkvQmJwkR@mJ6eco$3^uH3Nft%k4asN;+|Vjrv1h^I1c
znh{+cnS(7%jV-em)?;#KA?l0W3|moPd5%E$<V&Mbs|6X%!@fkVH$w1Y8)eX0UZj&;
zr|cHEp9jElh*)`2C@Pj9p^kJzhhyPSfg6~F{8D+hVdPe)PIP`OOErIf*d$(CqB+n!
zG7e9b&9Ln?P_924_HF=ChrP~vL$yt87noj8ml9u!H6NBe)fH!0bhfkhp#(4It2KU>
zv)aT(Ay}yo2M;}{N2g&2;7Dir2-F}%lkEgO2K4y4kWn_`DAz=^&B&52bKJ<oZhin6
zD)dr#j(e5$IgsgxKP}hAj5kd>0*g|`pH=Knkj-4)Z6XrDmwdh9c35iqtS$-df^j*;
zlv!tAc6P{TkssFgGJ~ekFHJNhV@PQ7(N)DJug14d{AuIU&LS}yO)hJ4g;{d7Gv(SC
zf2r&8ocauQQ?(~oSTE&|&lKw&Bl5b>iX=C=h`v6fi0SddD2oBI9|63rR*aG>M_=_2
z4#+JDp{6qfs_7gL!OHZBoOdy-x618y-1!qp)s1TZZWP(JgTn7c#7Jji;c{<<P=nt@
zX~!HYCLhOsF@3r@HOGrPsD1L+s;-s*ABw0GLbOg(P>DE5YRc{+IF|+bz$EyDBSYdh
z<*v+E$T`DvX<4(bEWIv<)p&ZCy+x~9?rDY{X&|I%%^BWwB0-@Jf5MPJgz5^MG5Nn9
z-@Jad<G(m?eii4jfh9<C{leCLAD$KJt*;?O-d@zGpS4f}^?FHPfF!%Qi)e0=BPlIC
zq&$p^mfXWMd2MQ{@B~NAB{gmT&M$L-)ttmUf|TX?uG%c5pBSFemd-`f4Xp(<^D^z*
z){j$Euy}8n*JClD?0Mj=FeYi;>YCdt9gX*VsRh*->Dmi4j1jh!(vT`ICv>LD<-hJR
zP`>AjrG2`i%7hcODP5Md<Fy><hUf_weguF1iRyu$*Rv(ps=h_MY5!n9WQ&Rp8@vel
zbjUHl1|{cU*?>t|vMC!<U&F(#lnYMiJ_1QAD<)yyuh4Xp&pkLNor1Bx5C>?z;WlZ~
zFb?%40UJcVtTd#y1~}BMx^Zu}2oN57*&es2_bGqRMveIy94tB@M|zj)(pG^}vMVN+
zPyX>uxrHC%Pv9a`@f{duN5bCHH&auet#ACAIJ8mue4uCchU|~kPw<~d=gG&q>h*n7
zVK;u=Ly6KTU;S48Nh@<5x-(6m^J#j?y-#6|IenPFwBVLOIZxmx`w9T##nmGfe}abZ
zr3ll8p7Xhc)8-@G6vwmC<B&KB^=kX%T!yyfp!H2T=5z=;cwnNd-R0h#Z|cTOHg`As
zT5ApGK=`-($-fS{)Dzq^K&s$g=67dIE*{?c54RHZGkNv{`TLcr$Jd`=8FAl@rIYYS
z)XQ!a(d7QFMDGO&f|EtADrfqWowf4kkDd8*t`-lHA>brAcMmHc6Hi9BB**RN4$jau
zGxuP+mu;13^72(ELtfSE-}cn8aBZZ`CNS>*IscI3Ynl^+R!<>w72?mCS}uj~&T9Oz
zTHASKA~EpBb%g;rQUK^Am3R$@1tIM4<w@N`tE_^|9Sg+r9Iq#8?}fZm>lK*1*+%D%
zzrKa50~N5RZ<}Ptm}g(*Cs{L`xqb<~&u=Wko)!H-guPy$bv<#QE$QzK4ZrLAzn%N@
z{9j$4oU)w~6sMF)K|obl#WdR}TKtK9EPGI#HtrPE)xyZtf(5a1dhA%{YU}mbF%x2R
zUVZBer|<O)jOZz3BWvhUvdi*Ou0c(xhFidBLZKt}p;<D<lqCaw!#2b1u`n$vY&uQF
z29Vqf_lKW}v!@)|cgEHZ^!w5Q_jYIXo1qTfv+}=P9fL3an1dV+K{%QOLfTy&S7|%e
z-8}jr(J1hh7lUT<R1_2k6rEx+E6F5r>XNt%@Nisr-BAcej8M-u(U4~}U(Bm3^gEM^
zJsh2|Z*hpXUIfZK_z5aHI2p3V2D95rZX?c3xy0RVmLeB1tP17Tw7a6k5^OtUi#+Ph
zroWlq=r07(CM66a;cJb9q<^KZvF<w-QjHSoWS&Ak3Lwj^L>$3Y?y;=ux_={aNVjNA
zq-(%@(sa<61-7+)lvOxxc%7og9jIA%MQ093XAT&(oHHg<uWmlvIR>ET0Oj@=gJrV1
zQDY6s)!b;@gcv~F91?%KQ5kp_fO1#`8zNknKMg{oBHf&|4R1+Xn;g7{60>5{)Z`&U
z`7*0SH?;~6YgwrJyP=(#Lw4;nyY3<D;X&(nKKc(!a4AFR;lcA0-p1$so^AR|P`GtO
zSpyIeJv?xw%+(yLWcjWEmPIpUQUgoCyMi0>vQ2oXi+U_YWwsRDHJ~;;bOq<Xz0HS0
zBycBu*3|vKoA3Sp-PJC?T49CehzPaaaNUtJr0LDu$#K;WYKS_gw`EDhRm*qYKTg?y
zjH15EmF7{1YnS$q3>p=Jjr0r#@&^w#4;mVk9kehoY9BOa51waJ2g4eOSdZv;gJxv%
zm>?EK9sqJdvNhiJv-K7{Dgg|$DH{wdAGBtA?8NIE_R&yLAjPNwm5Esug6ltg<70V`
zCuEjmEJ#uB!+%Q#u56DQtIICIr>x=zTvlk7JKq};-`gAm$2Cy1k9{!8{E&U@kZ;>y
z-2V4D$1dkw9Xwixj@fyVih>=oC^tiZAv^#&vB!Y2$ELWUrf(>~cxXHH$xd!_V7ZG4
zdlZj!wH$WNhyWEf*SV8Uxz&w2AU=@ZySUv6bi^LCR@G@2v8dUh2F96}kG4^B%9n~O
z59Qu!i92Id(qI%9YEWF~XHphz<UITZ?{Bsm7IY%u<}6t!E5_bp$mE?-OfZd7GKg-X
z?ZQHwWobLO6a^xv&|`@$wiXOzigw0Uzo4cU5Nvan4F4aN?me8z|BoN|eQ#s4^Kw4T
zNQUH0$YIXMLP<z9hsrs}98&GzoWmS)PIE{^S`Lv^b3PQIlA;<q_!LD6N&4;k`~9w6
zyRPm2XZ!0uyx-5)^Kk}z&9hW?t0^_DEmi;Ir=)b==#1*q`UKxk<s&M7?*5s{5MP^5
zm^jAIrRTJ#H(k(-oSj9ZH-K}6y|KuDCWq2u)B~|EEJ*rwS5K<cR&<LNGuONWRst~l
zI+)TgEj><GTYJ;z7A^ILpsE#$4MDx$O;A09XZit5V;5ihW=mxm=RJ@w_RY`(<%%k9
z&^=APCgBn$9&<ZJHND0)mdRg~D+R6969Ggb7w(h?*A!4n=eAt3H_5XNK51*97Dz_)
zYQh*F+*E2$28zzQ?NX^)@xS4dbW3`<SG4%cm%mW-8GKS>cJ+rj>rSYY1Ixt?4|~g2
zPorJZ2J$LW_b2Yv<t;GQpa&$B3$RSM6SuQzugpr$nm==&8Wt-ippWh$O*4i|LyR(u
zaTC2vH#^ffo904^)Q?b;0_Oe~jeH2n*ah~;JxS7vHg!UABJ7NSHETt!YQBqAL7^d%
zzQ)w_IxF?k92EGDhDw?R8Etta@Abe*6|toPE4S;T3B}0;%(K9uvmZjD=ukuwWyqKg
z@7f7%`*t-X#?3a~{j<I7&9+nT&v?BLE9D{8_x%l#W|uHUL%F*IE>;m1Jn-r)0)p!T
zP2=uy=nJq*Go7}ijWHhC;7q)a876u}(<gqYko3Z7_pz4nfTdR!i|^Ws^MCKV6yde}
zPQCDB(Z_w)p8V(8Vm|v_$-CWLW<^^<tgb@13G7a%&u6D7TO*RJ5Y3%#No$tOwA^8-
zeu<LC$Z-pG;C-7zDpZrk%DQ$+(o?37D7*GDN7N@50^K!#D&S+&%?Qb+bWpUoK{Jzk
z<5H;T8kauoRry!Fir}>>R{91!w=(tiO-y+==C~y3+}3ULo7T>zo0i6Ly#_TBraS1v
z8^4&Q9ld6{;-)fRS4w&p9mM>zpr`k+mrCyB(BGcC+AX8$T9;gSR=)D{+&<jT@SCI8
zVQ#X8@+Y3idepDZlxl&ElD*GhmIHbmh;+Dw2=l%m<7?QGs7E(WO+%!2rs3l2Bzi;@
zL56*?WZY2VvEke0!fsLe8;s?(ZP{+=2d8j$i*AQUDQON^f|Y(e^Z0pUK}@OCOxU+c
z^-I5`nJUGF7}@)6uP5)%l$sP*b{BQKHt!N%8Br;HBlKNKXGTM_WJOA|kMOqiZ;5dD
zvZf2=U(;7nH}i&)(#sc1ac(C_k58RFdg9eV*>~?kVM|ACg@jjJd#eMf_HTQ4O!#38
z`hZy@bN%34+QCX@YoURajjYR0e~OLXb*Rh>bJ;#n#zXM*5Y#Gq=82YOJ3*r-P`m5l
zaghVzY{DI*2VPx&OS;m*XL`iP7d=g{nBVUHK>(l}f$7P>(ibuAGSMexoIshUJ(_5!
zmNEBhPZOq(_SMtUBszU`G8Z?>t~PF|*8OQ(!z9%-x^j-dFpLy2)I)t_u3MTJP!w;4
z+pK)SswvwgvU1>n^h%*lqM^tAJ$EO57mfdxxueot`!-BXuKDmOVqJ{LbX&1lJ?A7r
zGB<Rp#+?0nwC5R#Def6<7{WfAC=otENLaMgZw!N5aba%se}!CR;|^Cpk;S#a<MId%
zAzAwxqkoRbQ$<|V^~`azr?$J_O9#K*_xbA7@=?O%yDjbErM7o^oRw4kmc)Mk2HJH&
zn^$H$i=i|iDti5_nYn!Cn#2i(uN*NdD^EMTjeq&nE#9k@NrPF@yjt{XN4OVTxq%MP
zvTtRa{2o*C6x&Ja#;*XlZNT2z&QurQ3^~U9(0huq-?2Zsz3D|v7u03e;(S@|J{jSC
zyq=Y4RbAa)v-GHvOsJObTJflUs3RBV9VDvEy~yV7AJX#~`bz)6sDreZNOS{){SkXH
zI1kH5-s-3JHXW#Q^>M?iC#o{SPjjbx<8+|fTxQ7&h}Vu85Zb;GawkS+k%r`Ok&CoG
z!A!2IFWtZ0M=kr(_h2+O{bi|;i3d}dPtm|Sme3&Iq=D+IUH*QBfwE>E$NP$$<*q?>
z6??TMdesZkO*GfE!Wk*;u`oN}!XVu^u@^Zzi0v~-9)e=0*y=Ax4jO}zn(+NBi&<Wl
zE+=W`Lys`a0>RBHdyq8Kkz$`jt2n|e(n%9Eqel#m)gZbf?kwe;^0n#f#dzVh&3z?B
zpSWn|uWdp#bfG#Tz55D;OlmgnANrlrz5%t8H<(RDE&(r0pX;^`z&nH+T8sb$<s7%O
z@y|$Vn%mfmy}#_Igc0~oj_r-K-b-dzcX&xw`)9M>cBNqZ%+<LEM=IjglPFh;LmaFg
zs2jBWIw)_<wIJ6qjY1CG&P+C4VN`L}lfo@6g)O}<Z{0NGVm?^vv1!OU$_bd0iJcQL
zd*BhACP1ahQfZI<D1tEH_PL<}w~e($%l*dY!2MJ_nts3TN=|HMh`$pUoyJ`d1pO01
zJXc^AB+i0EsoSy=klh7c!)09xHC-b&yLN9=HTgBr;k`*q(1IsDP|p6Vj$CLlfNiui
z4sfW~s43aB?1xi`q#k+2hm&`<71S(7PI3Ej+o2&(D;IhVfGzePBV4AX!)?p{pCjOs
z1XKp-BmI?E?BQGCBR6*v6<QxE7??c2WAePW$D@_GZ(#d~K#vwD>}tb>t7a4|kD~Sh
zitdUL+D@l&qaPlp5r-ZwNJHR>++n+i@M!3~Txaz-UAPsV2Y{lPOd2Z*&KU+*&Wh{u
zcaCWbcTB&wo9;%Kn6+AJyL2RL*y*Et-|5iax5q+xH02Mp{ai}db=t3wK4zQD1B#D-
z90>fuPqNPS2-IEt+OSQuLWvJi?%*k)+fJoUiZRPEuTB8xL=RtlVjA7McrzXFFoOYr
zf|J>H`;J1Fsaq@a#_nEODFdqyKEK{THDsU^nfzZQMiN2*NBlrz&S8XA-O9ObU&Zd7
zm=2q$(%Z4~v(0Lwyh(_(b+ykYyDDUKC!a=xd{w)^P?$z1|JwZc;(q>F=j(qqmuF&e
za;Dd9<FhY76z!hZQYxN8Gu+PZ#|Z>X7OdX5k!+>hogylIo=~0mXRY#WJE}z6ziYPt
zs`P$Y>l5M;0!I2zY28Ve<!D26OE>H;yd%0Z`HB0!<C&rVb)LQw={I;4o-1=9(p7=r
z-5Cx>k%HZ!HQ|Skjz*n&l=ySLuX3UKY4J<jKg-gC%=#lF<AK-wzRn6==nW9Y0!tmy
zCT0AX+3=#e{@3X<dyW*Mt<=5VnM_7Ll@Lex4yI|bc>62632kATecg~%_Q*!)+s@4E
zKX!D@FVr0ICs<k4RSHV_lQ4$GXqHmjT-_})F^X4Qo%v>nUz#&RTC1<{j>A`}$lHCG
zyLM^o{%r&3$*N&M5KpBr#~_V_8`gr7InAC0K1wB&&0buM_Zh=a#aP7F-b%Rf^q!>d
z@Hq2ikwc_Cc2AmWoLHzw3c&<Ryl0J~r8ai~j~3(4Ji`wxskA39-cQX&4GxWu9q4D(
zN+;9?>D-KKRH;%?D4*XWi}))4(cnYH*U16fn28(B$0?MQk~4KKYER@3Xf{g-@?`{$
zdGzoe(-aT8$|RiP$2*0?O<kv15Ih)6FtHl%=Gr=_Hq=<DQO1~I+e<>%Bh_})m}tG?
zQO;}3el=(<#5irY?B$G)sTDUEcvpl%hQ#OYmtR)dtw`d*_G2g1qZ$v(#oxWt{P&x%
zmB#J^0G$EP(;b4^pEJ~R5Ie*wYW};3(Jq2KQvHgzT3IAPG`e^_D4=_CHz59SSii3P
z%l%rcZt*@(%z;6UOL;_BdTK=pBp`ftZhdvIj9|C6oE}M9vXyG|m*U}Lp7#@`vf=_$
zBu}5wGI*SHj_|>FEmB2K9JiiD(mY=+R!k*$^*cXSt5%{0SX$NfWa_-3E}%3z7cF46
z&LfseB_>$a>xM=9UXN)n)>TW#dwtEnJ_(bUlB+ao94y6Khd5*y>_|KwEwlC+VJ=pk
zdU&qzUTH~kfp_HnT}Av+wmb=Q<p-z5y(lX*@L;vR`6CgpP0C|dv&aQJB<LkAYcBnt
z!Z&qOiLa1iV>bER+b_zNnEl&CXm(Uz{oqQ)q%I}3<ecN#jG=TA1Ys0M%qHUW?@@nN
z+207kheS?fm(+@1xq5haPT<xfFNLdD{uVo!YIxAGVU=<ozrLBauTXApYIfbjXkbKP
z&^vw2aFE3Id;JBT+@xuee-*@jw3`T>)V=L<jdiAr>hQbMIysJ#CXE2NK*i5TQd&J!
zQI#aE;%>C(2VeU3eSzHUxlBKp1&w4+vRl+c5W08*Kh1Z#G3O^F1oc<MUQ56fcF_?!
zoJ!1Tt6s_I6_{z-X+k`L5*sj=wVdnd|D>uyx-K?(X*5?=rC^w2R3jZmpj#a-t_)hA
z!;DOi?=?c>aeI3u@FKg@ESKIAz9(l|%rZ{6%)Y%CO<*Xy5(E^K=f&in_iLy!2p)A7
zGRR8MN<x7UeL#o<tkBhhlBDrfsRo>ILF4&c&(j?PCK(?GOB(SOTg8G$9$CXwIxO|x
zv90|B=rq8MTbQkQrPhm#a6sn9Jd{pSE3fRMxa_90?oX0J#BUt_W<jefKc+uV1FfHG
zJ5BuOB!CAPYQDA1TUv0bDVG7CJP`Y7JauQVz%akh5NGkN7=j-m!$=+r%71t%amq(-
z6|o&p_$K&&R?SCwx-~~XY!UxwL@GId(q5dQ35tGxPCHW7EcO~fHx)=qGocOR{S1=?
z@GQAln=|;?Vq4q)w6wJgUHMhdmd2X~<(InDs&uqyq$Hj4L}NPZ<L(}jr`=M)7FuQn
zZ;C&$e~MQA0P!@grGnE|gV(owoz({PzKpx*Ga}F$&z^p@Ny94^ifVS*6QF2)0ON_;
zuggt8R9u9+K@ACIL2Cg=BJ0f*Y4m%&aV1`AmSUsd0b)LnpS-s;k<|d+ZqQMoAUx_y
zFR1l5P9`!A?JC*L;(U#6-=swDXcn3qFVR6Q0NU?Mdv!|ELePl9LQAkLWs*n5T33>(
z`vMR38TpAZI+UQ`COFg#gcMXZHhhz0p!v(06>~`OAX;~)044UOOxcA{*Ej5f1>`R8
zP_ZWP(cB9^sblq_Nbr7X>FT}q2Z)UQcGen0OY=~ERl;~r9s;Jz2DR%z$47YPr9yw4
zsGoh5<~@XRbHjtZqE#2)&2(C@^Sci9PUh@Bk|ylpDxknYtFzF%yk9676D5<Jp?DhT
zL4%&+{OEV7N`-K4-E~%cwy(xFdp{>DGwvzFZM!BXED4Ch9pcYV-;zqC)wNqm*veS2
z<^&afN0R_xzvWINxXY5)=e-Ic9;(_ko>VIsd-{f7%5l_H_q>=6<!gCGiJgb`6l&E#
zo%4fzu9+9mhCF8btzAwKLi~5jMwMJKhRF*H4v_@glmNj;c?dL#mUcDtTHG#!lDd9*
z%;}IB$uCrF#`!d2NLX&!gD>>i!+T^!lzMQp)D*J!WCsLT%YwZH5Pe+KDZsM&XDLFq
zV>47Lz$07N_oVrBT$*_Iz=`OHYe&UZuJzTWHGto;TQ>dRZvNf-ld5ncA8qz|j;8BQ
zy3tL5)>jWNh~|Y77^)&O)5kOiThFz8(zkqYk6`0(8YiEukQoto4BvO??G;prjCfu7
zFaXiz?ts_;0DoZ`s<7yI$|`^Y)20Cobt?S8tPlP>>&byhtufyhesf2^r<$($;KFL2
zOOD&2MsIaP?v?>1{S1Soy<w|fBu|)!=6UJHPOO<{@`spIp>p$Y`H4<!ZeMUOEI_{G
zojetYXWt=evZK-d05t0{03tMjVds-ST*n+_;(T*FVRt2P))}9!-9?{WQE2R~7ep@l
zK?L4^S{foyF3%l!V^Ca)3A9@jReq(^Idg3TVBIrc2p60uJj28vA|2%Su?}yXRAOp+
zn=EGCerC3NZ4A#TOPtISt_gx;j~)El0{NUUeZ=fO*FxaRwG=gkh4`yuqu)xN{n>f{
z=YvP9+|J4<iE(0c)AT`IGG;+TsfJG8roSs3C2z}f3PH)bdh&cXRFFfCrvCBZ3D!Jw
z<~mmy1rT={?%LVHo|68);SX7nRuuYWyK>}s8o;tTU`**A>E8KvZgYeJd*kR6M3)ZO
zyQAPj{^C>aU%8gZAi4)hX3#x6dc7^UWG)>N%Y)1)LjMJj4On-*$l}o?*mE3;Lg|P$
z-`yqueceaEle2*)jYUJSQ&hp!JD8_bNVy<QhAEaXEPbA{Q5a6{>>fy*b73(MhTr89
zs)(E_cx;s%mAW)C=4`>%MN-dv>K6MFcrx4vKhHx3-C-z`#2a^DX7d3ThB)XF+*q71
zF<Krqy|U9pg^UO}ny$`yjN^Zs%Y}q|se|C*PjIomQd9+8ysxY>Yl-D6cMFse$rNva
zV4~*bOp*NDB`obW!^Q;`Ft@q6TfD<Zb*)>v;-H8pOC(BRR}2U{k{dS#pu+HqC$-4i
z-QIC5a=5FQ@poliXHG^X7+XaMo(H0;g#KF)I)Ie1<4658gj#%e5_?KDv9M+;Y8;2I
z%cYy<5=}`SU3bxYNjN0i&wwKpY7U!Z%cOorUt*t_x~mFt5kqnEHgm~qpp?P6?6D@m
ztC@JuS-^oxh@U6&m72qV0GCci<SM}cp`BcYw1Mlwxbt5No>pV{;byuN63o=3`l&a6
zYy9!-5d?}Q5f|Y)oP&z5N&gO!#Xk&@XYX!Ank&;?5b(QVm3T3b4b0}rEzQB)r~-%B
zdtOJtU1$y;K;rlD4MjCs3Kv<ZjiS&VG%03t=CDCG6lWJzgTDe;lFdm4fagHS9)Wg%
z3sQb~4n=K-jjRB~3tY+DKAM%I;!!=aK@-ZU9I<Y=WMDISv6B3&Sv|%V?#?4KBgu<C
znx}<TI?V;g&!L(r*mh-Uq<rd^6kur#B1qf7k^~PmqWBiE{?B7-e7o_pX$9@$NCZZi
zgsx{uztsL2kgvKnw<BqA$KX%5>^WhgBbV$$(}?QXUvC9RtY8VdR6c;%dtCW;5>~KM
z_~7U0@|H3O2tk$oZG9N4NduajwNE%5*e$#V>%(lks})UUjA;F{;{KUz{<a-OX6O8L
z$NB4@<6!Oi|J(XY6nVQ6R$BvGdoCBv+fP5N{GDTPQGv+i%0H)~cq{4&aPc}&oY-xC
zP=T;SF?zeCNKCQVo%2KW`&2=;g(wah#Czlq7`gU@;b{uQYPVaYwvoGhlLq9<f2XAA
z1v`o@SBgP}Rlb>vCBP(S&l%jjv1h{vewd{2DHn*PI=Jwp;~<iL3Y1?>@+ddd7^qU2
zb~1X0?pEO>YrNM8-;GskZs=1WFq+)H2CLocL2)U9Y&XJ^5=_Z&ILI8o)g<$ljkKa1
zit3S$bKY}NK8*zu6MKkhzvL?TqHU$b8*|N@A6=pp<fvS-Gs)({y!54?v^WbnKVPY6
zM|dmGZWO?B`lU<L9sqXY<<AL|);Kku#q+*05qZL52JRBpNWqOwvJ|J#jE}6Mi4?o|
zd8^=HKmS!CFN&j<N#5#)9b)@9vSCgnU#1Qjh*1xogkAax`|*Mt%@#P!qoD^~gR886
zgL3n1yLJj{o~Oo`mo@s2%1)C;f_*PO9;p{G)D=D{P;;ybS`=Nc9W9UDu`0kg>R_Xf
z3jDV=ir}@M?;*y49z`)^XD<2Tr0p@%nCd;7i!7I;JlmZ4wM%)fv5;+lS0Cqlly(4H
z-iG`aBtBUw?A2zoi+<v*o>J$Lvrt%(m`;sEWWeiiNS(P}WaT&i2)U|C=L_lN6`!E`
z!XRg=Z<|0st3EldS-=Aj=mAx@l>+YE;FzjkXo^`BL(1hm>K)B1Mqw8}{Z=<e_%Tvu
z8uNpyaCY_l2`B&_O4U9O!jhi3-{paJ_lP!44c^by<K-n26@6l>grtjtT=`2&Q=S_w
zF2{k$_#Tb=zJxYC>t9XM4&rG2dt@VR)eT-uOre|EOYBhV&iT+jr&#mD4%V<K7UmTX
z*+_wC=BP%~K3Eiy8Qq8T<RgBuBFfqYA{%_KOp-UBM>YJ?kUM6OV+o*Xr!OjCLrACF
zxq>do5+8O;cO+dj_c%KmefX0(=Il7Sk(7L!2C>tZOF34e)GiB1ND1cBq&MiN3+`nU
z$;IjV-QWLHtV1eEIKYA(nWrE)E{2{&<{EP$0s2Xmn->*YA6I-K@~E552a|8}kp860
z2ZF-iHUi~WrPcZ+8I}CgXNv4b>RvHms+oMN+ctTcye98;l%0?|y|LCJ9m3~#s3<N^
z%H2|~)F7;SlXYSJq+Fj&Li?pQgXFtBp|0;l^bR}hNI+zK_hFVfEyg#Z?3mZ-maNMi
z`;W1MZ9Vlav_{2}azK4DkC)R<6P%|c#52C7W#HCOxiOwbSb2b(E4MW#H3cNgc_yDG
zU1ZG*sTm&h^~g6gB(Irg-4KnO+02UX@wyzDeZf~QnjO?%C@V~E=-S9>1F&|5aviRK
zHVwx)g7Szdnlm(-T`XGVSB$ZX+orGN^d!qU1^<x`EcVI2P$g4S;=nGt*BDRk>9)Nc
zOXlnsaDNTArjTQ*<oKY%&}$S&)kLQSFaY|aNfp)!I<s|v*o5>Z_WB8X$gVf!nw7lY
z1a_``Q0%<iA>RJ7BD!^aHb+umN8t_GcTVF71)gcq<Il}G;$D{Ht9LqUPbYw0=dx_Q
ziYEG?TOXuu0oNONBpa%X!iQvW|HxqjcAyveM<v^tmKErT7unQsrPRkOU~A92=IE2R
z=KTM9oVG7yot+1Gg1VdB#G45<5yQ94l~CV2lN)&aQe|<s-LOtVZM<(|S@+!=>-qIo
z`paNcaUpqrlkEK4Z=R=dj0(>vRsA$q_jg*5+dcOwUkS?=<kur@(g@M<7cb~%{GvHz
zX=873FE!9i3KiqJ-w=Mgra-q!&Ju2u#jIPeiX`@UJrHY(vQXxl*PY|F=2Q{gj-x_=
zlFJrUKi}D)ENIP}o!r^Fi{}pF#{Re}<;T;mU~iE+uEOLEGE`4W8E$*lUOh&h2XDWU
zx89<QOq+iWNfT*3K&~mH$NNT^orizfk_sT*nIp;7DPV8u>@98R+OL~LZn1eM4IsE!
zBkxoT86~4Sy}X)7C`jC6qbjA1%S9>T<u7Zsqy>JwAR5by#w9`lo)F~_*6z>E3lN#Z
zrv>n1CJ&AaT8UrFKR?xXu&`?LA@oC^kMD?`cdBlR5>ZQe-5mC1MnjPY*3AX99c_+f
z>`Sa^R9QDQlT2L(Mcm~@-MR-WACP^0n(B{}x$88mjV7`;Du5>yU`XziZ~jx-Ck24D
z#(Qt{j-1``1yo5-UJ4v+u7W@D>G$;J)41b4#d3pEl4Axxkx~M%l2mhfQ5SPj1Kwcu
z%<adL*~wBpx$|;`vpqSCI}!S`{;&*ZW21YsIf4LmjhB9-ck)EdTBlDx#=>o&>*{i6
zM=0vWRU5Ww`wM0Zk#9)5_=tKv47q>b#Zg+Niyjd}+aFaW6+rFrqu_JrpSJh{_&Mx1
zDsGL!c{n_>pz5|e1Ne4c2RnBrut)r{jQktRU>kNz4y5_7UGOjS+I<(|Z;IWN-C)g|
zj~#pXGPYPQ;RX31Nj*kECPhYNpfX3mL@-*9m?x$blzlc>d~*M8g2IbY1p6UQzW1PC
z?#@;Jr?!9uA0FwFQuzW-v_SIr-Dtjfn<#P5$C(B@1PJIB%37L>y1yO7P!gQaIh?1M
zz3TSMmEngIdIEXHxfZX)VeO~h<qcYV`ugpC|NJNM8u*61+dw&Fr~C7TN^u+6{e2G>
z%}?aNE;n$Z!4QvE?Ab8JbD{-(=IgBQg(~T!PMG`mmSYs`W}Q?B_3h~rRi4S-*_#uN
zer{(gK6qWy!GoWpPLk(or-o!oKFEK+Y>o{7t8C@|ctQKcun!*oeg$PFJsmOA@NQMQ
zJi>?65DiTIIt1?{qV+pe-HA%Ny}d<}!1%kPH{a(3oith^B`0u*7BnfMzg!(@=lcbD
z>Ew#V&?{A^WhA%Cd}FU~9Aq<FugyHXsIDSaEGbU9SS4k=4)d*KfIWg3DgCb118Mk5
zQyd^=lsK&kC|HZ^_3BE~TIe?hNfv09?QYu~MMuVqxQRo<se)hRmx@-{Z6_ZmfKie^
z_w-)HpvJEV-ImljyBzsO$6TTQ@Gd28w>LcKsH&R`AktAJJS!xsLjCY0o?p!%q8$C<
z1=)|3C3UL%NB+R`O8#Q%*Ecr|w7(5!#xE51g&)gxcsw~v+=e%v(FjZVeema39i{&j
zs|x6JQtKyoy~NJ{OhO*Lbqlicu`yP`8Yvtq{B33<R4rpn=;u*kJAC=vPME;9;JC2C
z=0Nr(PzEtv6c>?p9^$7Q#=Geg`S2E8XZc<Qy(3rn(3z=B@ux|)dgOhTW!Fs)-?BQ#
z<I-Pr7VjLssVr~u$yD~%*}>MLDT+4r<J6%D0;MRt=a;BBRF6cHu|ccD0qS{K3vQ&m
z?s;clz5eGOh*?6~c<j@aDrcu(q|+5bf~!%^%FC6LCso-T%lGaLA3sZ7R%zrggLzLi
zS(sm$MMw5O@vNg#g`4_l;wNZ6l%!tQMSQ;U9&K)<;Pi73&6j^6=sbHQ_Xs#GFM>J!
z^eIFsUM=Vz5W30wVIPoC+niOhH67bqs&#btaXq_FyP>(di_|ka7Jnrqjzt}O_v?eh
z$?%DOaV-S(hV|8^wV4xX(VpeNTis9DsoV}f53`xuZonbL!-Y>eDkFi!BaOtQn-x_z
zda_Gar{U0at^W0DY{ZX+EQ$_#TG_%uY(Lj3f9ghRWPe0=C<YGTxkQCP=~sZzlwNU4
z*7EK%2a6<?<{cojyM>s!yhw)<nK%Q|m9w5w}OR78xbK3fNvk14^yENHf877rl%x
z;d?z;KSa3qU-=fK33x!pmq9pNh;mc(;+F{^b@rD`vLK@L`2pQrp(u--ReyJj)ee;>
zJsWEck_m{={Ida&)WdfZ5bw#sPQ2EY6;t@~5ooUdip0+I*8b792%B`b6)iw3?oaM;
zT<-C_5%Ijv^7^d*gr92Y<@$M;JiM)&meH@-o2lk;r#Se?!Y?CD71cL4ImhQRV@_rK
zb@7Ad>e-zjCFh+Fop|K~9p|<amy>ge#IJ4Ioj&KLB@Bt$pTtb=6pEz2OYD_=ZXBh4
zw8zX+e0lGrP)xoQ%br}r|NgqV7d>*MMY=GST46X{rUTr1oe?l5{7N}X>K@p8cG*X>
zfGK*;K6%fFv3D1lcH7Gi_YF>(RMhxZSJY%a!<o9o-q7&)N2<tqW%bSTKkoHI%5M7>
z`2pLqpN;~$?gYU+m_aS7Z01X?YTQzazoMa>#S*{n@sVhC;Fky*M1(^VDFu@MGfdl0
z(URg{**v$01}7cHrEU@&gFccb(H~s)W48ne>B?^h6sNfz#^b@0Khp%37-{HGY)nde
z*(`%_o4IM3h7+Q^+ZCCEU&jQmY5G9M(gt9fIQf4-KN(NbbXi$+#`fkM->H$3*zA>4
za;d<073Y_^+6l_=pv25NlA@ApI^LTqEcc@e88&vI?(oYE?2o#ued_XCh)QjL^B(P5
zLKYUNF}CXl4N?R}bgi<G?%@na)qMi0%H5_TS`^{6XTBarH1S6~0gW^&E`?HaLgc=k
zjW$6+$Vw<BFRuH*k9qL{AVp2KW!DalSVQc0v3Vabgu7rsEjSy^y&|GOgE(1>KC&D#
zT8e^D7!iSu_V3W%fK_|IsN)HqyLcCnA{EEOU+F+;=hr)BoBW8BvOfm3Wc4#=cZUsZ
z_CMhI?$1NeGT;%Z8if<>(S25OAFLLPee-f4GVB0$F@It8uC7RV%lUP!Zew4zvG{mO
zq8yWE_F&vueTeH7W2kH)oIqG2(CQ@T-YH=4u9w!BMlZV3k8iIUr3L7e`^wB+b|?j+
zzB%4tyY#D4Di0(t(F%7!)QX!QM3&3VQFKcK)%Z(R9#kM?Z#r6C)ah~tw^-%@*Hya1
zD%pKV9UDs3{R_{`*nup_u4v0$>|1QVnAK7fY=tmMSP*Kt)N^A-*ZlJNTfN2u=J7h?
zbnu1%fK;8wr&3DLzMA(OBf3$E2A_80{@m?TYJ*Hwrya>xNgLSQ-7IQSe;g*1tC1kq
z(kr~j(9v)Tpeg8HXW2SQt?!P11oPReY>xKk7{{Gfi>|(qHWYSc=I%?9pwm&c@O))&
z0X_Y6Vw$R1V?gFt|Ic9)vh`aTK9sL{QMKDc0Rh&QZ<vX_KFatzXNMdayV$Q_G5sGv
zZ8pK0$X_$1X@nV$+g;gSf8_Jz9CdB{760fNq1OU>m$j~>`Ce5lb3^D_bv)?}IbVP^
zIBH>vqQNikRJCkR=LEUquQc=sKh&A-4#rJl4jJkUpaW<{b9<rt?9=)YF%hmaSH=fF
z`OCa${M57S@S{|oh4qO&a|YZ}S``c4y8Jt7ZkM)C^V(+kE%Q656`?!#YvS%*G@%qd
zTsn==rFbtWM3sok8i_@TsCCyZYAFAi#b%30y;B=#!sq44=R`{Vu@HuDb!8D<CEEI0
zoKe`ngHw{UN(n<4zfl&z7<YmQ58V;9tUWqW=uz9Z(M~H`C_lTh7>PX`%X>jNp0pP)
z)?D?Za9saOq~9;=Hmw>Z??FV_q@E_vH@8plmFROVz^{Wrr-Z`O(j_dQJp-0Eaxc1_
zKJLHs7?E|zuVdm2l_vahD$GvZP4~*-7H9cAC%7QT{5k|ih3XmYx8Tk|P`yKMH*~=%
zyf$Vz@Iwaxtlr-R{`>&QbU=>5p5Tttf`2T?hKjwH)exkW%hwQntx^Pq594%dT|ptr
zM6TX9pn47=|HnSobC!YoQ^OlqxLh!zGwJdA&Btk-bE{P?)@Sq@((XT6X*wQFX}bLb
zDn+suWOmOj!!)mn`w0LLw@M^c)={5ns*QGQiIEsjSPW>UO`E(t7G)?DdfK^`JN(G7
zl4&hB(X?oQ*1@WWiH0fYHd}O>XNAQ<#T6F0YDVm{&(>3*4T!G6Jx+6GpOc6?!TVZs
zEo2D?UKBav2|5lxT;jD)Rs6WJL~;8w5g2IMtN9yGyJz!nVZ>!--z+{uTRnjl@v4sM
z_Nu$_PQs?ecS>P|AeVpRoM^T9a(90}q9y<Gf0yO-00?Wp1<w^dDTZ!t#fdXRTlfJC
zZmf@m<PhiL{FF3;s#`-+et66$>@MzM5o8|+>iNM)iQtD>wd$dt-?WVy7)UIO63tr0
zKBA(BsYk;=aopXbn_Sep&(SFp*a8CajCPo=h2|LrvAy9jh7-7<1x@LWICv!v^I1HW
zgDBQNqZG&3DstMJW<KeT78bYjx+-kmjebHRX5B>%07S#}=u2d&oeDfMEEa#42KjO?
z$#!w~zHx}-5Y97Y4~)a#!iVS3_=9qUy*A04Z2_>G4Dx5?aZ>025cJZ9Y1oY!=AuVf
z%&=TcK`#1v`&obl%$(j`gD3yR2Pm&#!X|LMwitz1moAwDQh?w;5oiitLiR{n>Wz@p
z@XM-oQBfO=$C_tj3ywzG?&Wo-r>x3iH{~8i0H^neR^rKrY{c+>BBmB%zh5MaC;*9Z
zDkmtXx?LIV0r4t=et~Bas1vxZ6$U7#kn5pgF@YW&x`^4N$#ooVAW0G1<<z*MGV5Mj
zY`T1EHYJusBkg&IK+t%pQe1cnHDo@{O`PSsFW=5-OicJ%A$owaKShg)k&jh^kpGe#
zyLsrV1}Wk9vaSQcZe%g<yO$)aPo8kaP8`O0f5_lSIQ^{=;41FX<G?f7ga>IZAPC6+
zh5;e~0I2cbz!v|N`o9kV8jV5$z%CG!_<#6?C=RKlqP&M7?<pW~1^~jbNIrgXOh@X7
z8~lIrMIa<58XoK}4*>R1$YDNvAufJanRw>(uCuy_PdYd_xVS`k1V%-~#0H%7(DuhR
z13;I6K&>FMnV?)EDLn-j{>T4uLD+u~@f|>B9TfkD6xh-Po?%t~0jhri#TA(Pi+y-b
zFuCkFamyL}6A3<vSDo;~u;or|0f+to=SF2t)cANm^Y)jolZb4_pDYuD{e@sR1l6|y
z@VB<i1U}{o!u2<h@DB*t06brc%a(+lDLV%F?E?Oe5Ss`*{^B?*2i4L7-0y_nzJn^R
zCI8NbY~KO@mFaB!U-RO9p+d?uEd3eo%4aa`FL3Q2P_PN)EkP>(0k^gxZR-&BsOqa}
z=+mdjjd95MI<UA1{?EVo1^iqAo<G&Q!Z~=S$?00z*~wB*_Ne!hC*FMj0t(F##j*ac
zf6<8$yt7xX;t>9>mt2`Fwenb4a!6vvxp-EjQ}c-<SB3sBegXauzxc_=FAxHM(YWn>
zz+XUpTT*fS2x9yw_@6hha|~E>g8uLY{sjSlVu0U)isRs+Eg)o@<o!I<WikiFs)N>b
zKsuVRjb%jkBI-KZkNq+zods;&0k^Ip{y%;(0ZhCG-aG{-e}j{g;GYd(eO_m{FzDIP
z*>2puTe6kKk<5aal#<xAl7uT|@#+8HzqpuJb+E18xBeRNCmS`^3fXAc^Saz)_!h|8
z0`G2#T;~^n4M7)&fSp-j^Cjfx7&!VH__qLTe*ylj0$V%4=PlD`J!d9|sMXII3`TlJ
z1}i)JPI`KNLsCOa5<Ryvy`(NbnbVlm#JYXAqod<abIa3|tS4>vo>diaMw0)hV2sp{
zjNTg_NhzieceD<dW=s#YKN-s(?(BckHa^CDJ~B8kI5sx+YIgqP$B%sbVsUYCdG+fu
zU%*&fTmQB7|L}{ImG8Xwvxpu3ewK_KhuzIY2#fVq*Hv0trz<O~c~ImYU)f&6M15K+
zHq0c&3pl2Pc$u+?2zRLc2rN@%no{fcyta0<EMR`IC6-!c4yF>3vRmOedNK}&(X=yn
zR;Ut7bhzfwcIzcwgn_;7auhINZ6!n)3*r=Q;-2KG{5(yl)?-Xj#v+C-Wb8uEg?$O_
z9WXb!C|J7=qfquv^kND2A`*b><PErx$F!dZp`xK!C%D3nyXs<c%!D>8p0m*0eCBsI
zwDw++32Ot1o*gfIuPmnNzR7Zox-+_;pjK<83~=f2qtk1xw2u3|R^FgXoL97#1tivZ
zH>2zRgN<9@+7AAuFz<^4>wSTt<@!Fo$Cnz*MsL9<D?;c3Cr>Tq&Rb{h+Mw1PJoo6O
zVzTizI(8g9+%cCz2Q)vIN2Sja<Xs5|MF4>~iJrHyq!bUAIICsXiuf}(HqhFSI*OjD
z4J+z6hHlRuk-4<B3e86Ct)oCpCEn)S(Dm(CMGX+vw3L%!2BddM!e8zV`bcg?7o>Uk
z#=}#lJY$G9j}(7qYOi+0;`RjzFyB~jg=o51OUzj^kfxKdxn@W4fg~gG`$CimoSkOP
zxua^3kCmgjMIWm&#oWLc+|hJTZ&Cy^Q^&tkyii;5cKpO~NPKdxNz^TBkDkPT(A0`h
zm&(zbI}lmc&5FRdl*QW?|3#dx?n*I`bu9|CIc_%??pAx@b4}aRyAnq&Spgwi6f&xY
z<_~WONDQAeq03T8xiUP}u)`<TgVfJJ-PXs?mkP0Vo6Q10owT2Kym}U-g^k)}gM_S{
zHZxsIW1Nt<kuRPbV8DJKj_16wk;<VMeY>4k5xnZANIXB3Ui=Y0d0@!+xs!&juP#n=
zbZ8T2$D2g}H^kHPA=eZ?1PpcyG_6u-Mp&!lUO7$e)xM0AA<-6+M?Axh68&1Snq#`V
zvo3tM7xvS9zf?AH5eQ-bGEf>XU!Wy4uTruvnesHHFQO0X4%!ax8!sI5EcSdZPKUPb
z=y0D}#ux`)h2@!fKe*y*a--8l`nA;~dHS{O)~FYtfv`&Q?XdTqgOich|1?A?z5Dyk
zWHR#?_GLhX1M1oKw6H|Bxf1rb@%t^Mek1W;)y@#e!MSkhWPj7J{%d7_43ook{)U<P
z`n;*Su-Vsc<N%fBIhXI@u1p%#V}pLfn}@WKW(N`el#c@Ll}#%y?!}3#S86XT%0KW*
z-mvaU>T<eJitJU<WG$q&JRLN;G~^_pLh`V=R7*ChnHRn;VQm(oh!-+IV~YLcsxky0
zTkpX*xc)cI_dhbvs#Tv{|I+`@v`3?ZmSm>tVeX`!m*Z);hzaw6@<$U>bk}I2JB^fN
z*q^zZP_^`<a;#!O+>Hk8ng5tB$f={>Y<ueN3M4$@iD(<YY^Eos%Pp{<BNM_OW)8{o
z$0mDal*VbhI_^rnV)c_5(?TS9ds0xZm|UT<x|P*nI;m>r_OxC<p=Y=M7^&o8ZKc|o
z(9tWTlEJ5LnvkjG1>*1NRMT~H<i9TJ{&$-&)x)lX`J48@Bfq0E1w(^E$ynAqLt>S_
zl0{2bwMV*|WU)<iV|N6`D>f1w9a*f1=;J>xE`nwj^+>n4o<p%P3Ni3>n!7?q9H;MT
zb;_XObr)A+M?s3Z#x9LEgGr*g4kg>pnk*ik6Z9jTj*X^3E-pev>UJpo<Tv!(BU4RE
zVN|Hpr*XKuSH9!xrR?n#zRf7HCV#%=J>r-AowMV<NfKJ{V1KtV{f8>HTSMSAr<FtE
zxzvhpAK<3H(n%gdR!FBHOHpKZYASI}N9ZkDL^=|I9Evpl{__)JSql|l43*e-5M$a{
zh^BJJZvfomW(nifA_cm7TPxkhe)xPBj)f?DWnk{4tzmg0NjatSza%{2MY+T2o0z*U
zz!bT_DltGc1$xD!A|mtoYe%UO7aPqubCYctOGd}Bdy`))Cb38oG-cb8A4!?B(0D*B
zktssrrncS^bx2vPJx=~n^Q_=3p#L%OZ>_f4LnA-y3hkXInve%*>mPn{CgJinkXney
z8dWay?S#860qIsZFYJq%{0bu_bJf;bmZRPW)E}nzc0~e`Nh3$8g}2n2$oELA)?NiZ
z$7S!Mi>c_cuz`5O?AQ^w$s!D9HivETE+nDp-)@&0yiMP3l^1<-E~>`vs)ny3aUw27
z$7PWimuY26ijj<+An1#&&>o7*_g{#|W6#A^%l_7MH1XEQLu%X~qeb_n33B8Ke~%GN
z_N672_PRH)H@IohHJ%^9Ozs%OPCP>P5^@?#yiJM7yiLHpEAu}1yPkB!V)fFo2PGhy
z1`+Fko@VT-0<7Yd39>_(1m?lyG*!JW55XPVno7NvY3RWbK#--O&4oNQ+}&fvexKJk
z7w^8eL$RW)AR;;KfXiz#C_(f8rdeV+E@~Bi6b5&6I##(v5A1xAs$mfM0>a=kG-(7)
z<Nn*2#2cnJyg<Xer~EQGD%^+%nn_Ayn?SY}^ILVLsP9MXvt$A}43Xv#{2$x2-B4BC
z?&PR;7EDeww)C)%cHwH5Yg@@dLkf5;k~Zfa90NbF*xhEEKeG#d;FXoi+SOgl!Bz$d
z-tX(xEpQAk<rAfCorx{3zrP&YNMsgm`?Z<YA)%t1q(1vFIF5Up={fVH8X~FFDReRQ
z)b$G%cXb0wBrQYyos%D!S0%UXyzZUe?oShvI5_Hdp@y+**7FD|^%uIn_JEmC+`NIf
zL+r`MG)+0H`82HzH_D~l1d(5o$fol_ky?5F;|yYBcFB6;hrkV*-<*+wLAd1CiKS06
zpN;-THoY;zn>Xpb7C^9{XVcfT{@e6xO#gW#-#A-Dq#PC$n`7+zh-vox1YrDc>#Q(;
z%4b$uC->3~3y7J>e+qrTLSm}c`f_IbO$Uj<5w92jX^|yZx?i?Q0v*=fOsB9&xxeGG
zChxkpVnY^yO!4h;#P>xL&C&_j;;%DCJLUd5wUg#IDK6(SbI)lqe;muaCkCzfkm&C$
zpe2!Ndib&Z+yAP6HR9kns~zy0%o0QV{pWuDI3LuB7xUY*aTk|PJ6BpR&aI0LJ-pgt
z1@>)6C=A-TRWAHfyY-tPIWdlw(b}E4=j3yJ%*&ex>f3Q^9PI6O>>f5mV-;K&M2QWd
zI=HCMH&LBbR67gQ8idM)qwcvd_Qau-iy5=w7&!OBQmV4WXG5HT)RElF9eMnY=*wpd
zrB(r&9URjVj;nu#D^0rCNkeN{pzd)nqH%P-lX=et#iT&qv_RxID8=Gr<p73?2f~ow
z5l=!IhNC)IC~`6X2x^v!fpBa!l-1M213Z117_Gofc;c%X__t<UU3)@fJGM1EF%*t&
z*Syrh!R$DDpkx+7>3$f4!mmhS@Ou<GR=~Y%6BAlWKpKje#^_vuH*oo(jxZtzbx$+B
zv?KW*hXLoMoQvCQ`k62K`1#wOi;Ghx(1FwddOP(}8;Sqm#=H}QW{jt+crauTyASR`
z+~*`KPiGEvpb8Ptf0d~EG)A3WiX02s$U;^ZLuFW5^>K_DZc58$Myjh{mNwAR5n&f~
zWnB=E4M(-n7;W72j&ZPs$9x80xSBby;!q3<DsVODl_mm=M?D~Aoxce&WTWomb5$gA
zuSw)~;*qylNFTcdewh8iIQ<?ixpW96iw`t_hhXMBe-0>9KI1p`i+;7;kr!cK*{DnJ
zV1ol(^waV4Ei@Kr$a;eJXyqme86qBV!1Hh@|B+$_&l>ee=^Pij74AJlPLaju)yAa+
zc%UAPgP|Spmx^(zJoq&pJe8eiMY!_laG-90=$ZXmMN{CsL9VO|+DHh~J52}cQBGWy
zCji2<gw?K@yej|_sZ#t*8Bt~BP*VimKMqwW$snYo@;g9Do=`C_=I}klC7w{jiqK_t
z3Dzf-)Du;sB6?0JRmZSMr32GlmyaAc*2yics6z$jqMh)?LY^qa@N{>(veIJI)C#<g
zi@dH0<vXm$HK93+1)W^*8c*nYxVLXna4Hp1G43R}BUw6{i)bsBJZZD%eF?rkeQ$y?
zA}XH2#Ao)qpv~gY$0S)DctpfTjzlr5b{bG!fvB)R!s|>%I;!tzc@0~@lO?d9LKlul
z-Cw!Lz$2f(cB)PSS0q%D-6K3xDn*Y)d~=s<8w}_v0<N);zYCnNvEWxfW%FKVKeDYT
zu>_?xi#%UnG4w>k(xV5t^w!@=E#v5j^TpQpQHCzbCe*C7bX2D%BAJ_2MP+-k1%$^z
zKq^<33rdn4ev4TBE&yj<T)RL8SNB&uEUfH_JqF1I>q(WjctYYXfkF2rKfcCm1d8qx
zVge+@ue$U-#V9%zeO?GLHiedT$=M+WWcqucTDdCSe9tC6i^;*5gga@vKx{IK{TIRK
z=}1#vjR6akW!1>KAn^X)o?Db_D_}Jj6rmvmZ-jL*YJ*CVLR7HPAE7=__%<S2co#uB
z{Ca6XMi(Bj9Eg@$@$$1kF*()D@uCqLnm%4v-+^JSfPYsZ1wr-cDpzk&kj`JAH9Vn;
zaiL0{P@rn%?+-%Ncm#u*aUva%EkbOcRTtt3{jNb?AHI=7Lu_ThGe7OsF{nUJ+*qiB
z3sO>kyuNwfzH#gmdZ@Fgn!+08pj)XJ+bvLwZK6mmNJ+>j4?vws%SgsI@lBB`m-173
zS0z2~Tz@S@<n5sJJy8f=Mwy>3gnj$>hpY+~2$E7u2>|Yf$Wix72WU;bM~V~$y)1;F
zv(a{+(f5VQXYdHSI&^kijVurH#t(8MpsqYED|suE-*>gHTG_}!{@OZPQvfEfTu0wZ
z{}=}*j8{1qKqY?*eJIT}ECc%q0co$Yqk=>`9pn>ez<OL(2avgJkET=0LTyoWUZ%bz
zVs|CF)urBgc=wxL(951tUW_{3akY~LHn4K*S;(6%oj8%EWD?>jf(;I%W>@?pEP<jD
z&~O}C(}@f$1AqqnXXW-+gqx{V60%&B;DxL-M|9sUR12Frriro&&X>i@wXkk_?G$G)
zX>Iqx5^3pl?;$#qdP7F@(Y-S0<&|W^aqyK(3b#Ie4!|~F(B+SJ3$4IEdR3j75t3v9
zLfm#!`EyyX3XjoctKyZ#Xu#BkteNmu`@IMz1;reyE4z~Qd~Z;TeaW@OhYyQQB%aVe
z??*TqTuM{!nc>l<i!SmhnyPW+ZBok5@q%fG6iHXiPOz>J3p{Mt`KF|$su=p`!tS=A
zsB{|K(*|@u-)CoBD;)&Jxo}gP;R4kAuj)`VT5BI0Wa1I{%;>Q<cdw<@OerHO^+W9w
zE*&;NY;;^%ARm_agIS?nd>)&CG6*9@VD>)kxs6BC#~%d*pt{Dzc2-b!LM-TYmnKOT
zNQw4-*YWu86}*;^U$XdcZla5(L;B!M=KYm&yW{9G8VefOI1+yK(GYzqfR2;)C_rIv
zlW~o<I4irPElv3O4TvHqhHV>rjW&22K$Zm54c29}vD}PyJ&tT?`MD+ZGw5EmzxQYX
zQj&^4aQxbxG$v%c{Fg_Lvt5piN537ac!q^KuBQEvgFTmdvB~)2XFPhu<#@EQly$9%
zx=T!ZxzqxHitTz5kXh_HeNMtPn5GE8C=Wg)JpSE^d}h2~CLzLL&|S+5b?Ir6Xc}sk
zgPr3D^|QO)lW>U$9O}s#`*m!@O%2zZxHrKNo&C=;_w3-RX@hrYNSyuM?)Z$gp=ah*
zs5?+QFuZqS_-P&Y0EC`B<UabIo3LI(6B-)r0}%29sby2GgX5vUIIb-eCqBXL@#H!=
zYtpR+r;<5%Yg~w#k#W;tifR8`VgmPj94bf+W@PqOgac&A3yG>!Sxv;5zgn|hLY=^_
z=hQ}9fs@p`t^h2dhI3to?c_BY^k*E)8Ask(nZE9V&^(ypbsw{wNZz1gh*Ur?QTHPO
zP*i$l>C+(1#W+rnZBa0#6m%a2qx%CRzgv4K{8hd7@d%rlGxFG72&gIbN%}I8D~i3p
zjm*9_n3I+>(1CgMHj&49eeHyC)iVCd4(m!%C+f+y1D`lTeQcppE{6FWMej7T7ZX#l
zjC8d{?&YJ|H2=qcCm5Wp?1Qsx4%i7?s^%omjE8=k!~LRSq*rD?9|j;Nfe8#%$FNMX
zZg!mcf`+H;P*4M3(8H`m?lP*Yk7}QS`Fr=B%By$vJt(Fog1s`WNJPr8YBn#v{W<%-
z%!C*6_JQEsJmeAhl3xbO13O(XJSuLThud-C-H+=QIyAV#eLM5;70DGhr#AQT<GC+g
z=w9~wZ3_G)QkXdA@rQEh0S`2!%;!8rUS0urrK4P8KT38l7-O+7!xyGB;V(&uC{3g^
zX+a13x!MJDP!o9|`_qnb#evMDJm#O#CdW^zgF+1l(Pf&k-*eB5m7xz-NJ)u$*onqe
zQz1hl(D^f;>T^GONFu7fe&pjfN@Mhn+y7NZ5H@L_>a)XDvnRuqhdIQr7Ju+;*RE#)
zIcFYX%Q$b|zNL;)-CQkE@$g;$D6B~Fm}%awFK?lTn_m9qVB)uOW$?%b;7j8QJlW+-
z?W1K^I5ju1QWAN2wW#mI$#2VodqPfsE%iX@9>meOZ%YBhf)y_0bJx#_#HShPoI}q#
zT*H?}m$z3iQ;sDaJn$Ou<qrQ=iiBDYe+~RwA%V3&V*9=-bN+J&4;y7KU7GT&5NdcR
z)Irhv?eg6fx`V!H6D3xG?k1r(c`MYG>tFXho!P;54&P_sn-#wy@9>aKTx9h)W_=}6
zV&V(_{kzELA`UI!4DX4e2WpP`q?)%ndl2JxLT>a*^eBKHAMn76p`Wbysmtkqxj2pg
zhZQPkw5TASH~kEG_VXrCTFpKm5Q<yIW3^AMjlDBG@bU-(&E{wL|IB|Y<*m|OKB-6k
za@Cn>6qI|y`Eg;uV}T3#FYD#$%j;zZ#g}<UL!YhR#3QQ#-(?=Qnm4uhWhL&q>N*R@
zS1jJ*QOPdGa;=64AoqB21u_ixee7)s2Wxd5H#y!q%CT-dk8{GK2XHv-d#ExEGUWde
zw{vcN%lncn1+fr>ytV@8eG$4mF2p8Xt1)t@B(34!<2GGzym8F!JJ`EC_$3<OybxM3
z6Iu}lVpl}ibgpk`O8pS3Qy6jhx)9KP<^BJm=v@4n`u{k-n{DoMABMT#nfoP|&D_bo
zlF(cuk|KAt8zy2T328$mB)5d5&D@d-sZ^?w3L%w5Y2V*|f5AEDbIy63bKd9mdOopa
zf!+0s+mo-mVjnNcQ<v`?YL8*(|Dpu*{})Ib+ii~{12mj--zL6ux)PviB!12*PvH{#
zxpwunfR2DX&jUU|t;uN$G70aR(tdBgZn=3f+BN6T#!8pfop<+{)IBU&T31rj^P=8?
za*dU*hX658>Rf6Lu7~u*>MsL{EZMe--p|bgF-4aLovxVgj`*Ei84Q0WV&!FdBHl5D
zjS}Wqot7?=!r1-r>ksN;=W2a_&l@@*ta(S25%4SY?!`+_YnoD<J%2rVp6GkS^O9}e
zU-27`xEE)>_ME7=m;CNcURRG;@4es-xXr`nGcAoCm4o?8!m?|Pt0x|ugPlvm7ld8=
z{^reHeLt=3E0%)c&385zVjt`oUeccYZhTaIqyvk~lOv!P>Yj+9npB<z^tZH$IV^bG
ze3f?o$weR2<t1^)(`F+*Vkf)SEhUT#m&(1`Z9kQ_80bz*dKsPiKGHGV99`a?DB`8>
zzPCf6pLru_?5;ZU_lDiiAWvhu+ncu<wNLiG$EY5w_K&TabXE8)H<r^UsitBrxtWK=
zI3;&I^$8H%Uy;1Rk_tLrZdl=CTgDrysekibtI6*)N5cx?VxZ}a1zLQ!loG#SGOD0E
zZ6fK;<1Y0jt+8+3BIOTn?E|th-JYoXzj2{xz7@XtxNPy1){EHMve>SZ-6F2Y9aBkI
zp6pO@M4joAc~^7jif7?vG1GAd-M?LRLOEvtr<>Pue>_U5@ONS_mE-Q*wR{`U>C!DJ
ztCU+oPjY=7OHY1NSnN$RjX88%l(pcd>{~kQLf=Ncj=pMov#j$<EHTrqE1NnUP(?Ib
z{qh)Ke;(KvW|2L1sN(c@X}O}zzPy^UKg^(OIlT*7vOaq>>b|vbJM$Q+qutSxt?g=5
zMB1#x>eU<r!>+KaKm?&;(vw%dV|N6yKnQYECf)QN3OJ*6<(#;(hl<u&=AT;n7IOho
zVwc6F<|v2jEn4^vY07myxgjhU-gB#4rD;w6kkT3JX@vf5EvANn!rlA+wyl`LK6-HR
z5$)QnS%LeEtFPa&YRR^Lr5|7|9}Smz^M^dIGU^YHAC0b^Emkx<M{=qw-cV(~EP-l}
z>V{n;_Zb(xc<Lhe_ROv8m107=8lPJ_-{^f?+j*HSsq~LUy%@X{uC1Fp@4EMkE~^qi
z)T%oq_v2aOl@^NKhUk*RlNzRYRcM{`XTcezf^lWJkT@Jv4w@Q)S~1HSOT$4|7+|rC
zZybI##?(EzVBc%q_h)#6pu#q5y;#=a0{cCQ2Y*#*S-3aYecQP56FISR^HR>rC=(|)
z0!x<gH{Wzws(8{+%PZ)sfWS9Zifk(us?qK(((ccW-EB}_M?;{ivG-Q^p$!hWNCSDs
z&JogX^R>#2KhVS}JFJmEWXj3FW^P?f7B}zHQ4my`hE4S*9on>pnj@XAhhy~BH;JGZ
zb#!wI0T1m_!-+w<K>-!FRHnYV+4n?<E=LQvah|^oZoTNdvgw-1>KnDMh^f#!SdKmv
z>IHl+(1Bx6vp=n{)R8zRY%1E^509`eiKq(F<v7%=zzmnhsfU%K#Q;t~rS>v1@E7s$
zxmh>+4W4SL%IyZ5D#Yt=Y9{Kj;ck*F&V<Sj1lFlLO6m9bm_4T6#p|Ht#W)kJ#c`YR
zxlb-~xfqC`yuWAvEa(y}3x-(^RLMq-qx}3nNc{;!sI)T#bP#UV8G>Myr3RHTd8$Rf
zgjtKTo2};ax9`j2>~3$7+(3Ir(Y6R04qh)v!Gu}4^jDm${1lc%RjOv`cuMjMgZ=K0
z(C_=?a{-*AJ_%4m9*L2%BqdZPKkkqPcqltbQZ^z2MNV(lwgQaH+>4jf`X!$@B@@6T
z#PIsl{37wsi?W~ojJl85KG0WSfj6_N95R?a*tLj?5&~7#Td?)Wtkco^{bL3dOrA*X
z%whtp-wkzbld9t_q4GP9D4a1>*s_VfWrv9jk{DOg`ok9Qs5-oFl~j6m;A2sIm+*sL
zo0qTt`B(ktC-w`HJTtSXhRC&ss7LP`#V(WEGGDufWOs-R+O8v0r9B)szn3=5r?mSK
z#>P7%1r-htNqM{grWD;9zPzg%YhL7H{qnn*=fWM?l<%uI{W>p*mRp`Ww^pF>1?L?v
zfU({8mS{10#aav*DbX1NQ2{Nym@=iwH9Vo^RF;W=tUlfo$gJ!90YrTW6Oiggu1Nuy
zS2f-*_Zd$C4;sBieSXAI*=-+Fk&y1lysj}&HxDH~sbS=zwB=^hoEulQlz5(gy^>e-
zh=->`*g0!Mi1VyFs-W-eBefa(d$B9-IVOZb%V?#qbl8)~d_ix!S^ZZ`=ReRQ!H(q%
z{`7H@8-Ytqp2Cl8Qg3A(iX4^sNeTG1<8Rg2I&i~OuU_&@Z19jeV1E`%!S`0Z!%KFd
zv(C^|{xapn_n8A5|KuwFZMyAy!zUyfQ63!_JfhZceAqKlZKykLSjA4_JgQhtWp|m4
zO_|!C)g*7+U!^Pl{D^om;HF{+0=;?TqVq|mj#pCGmp{NeWF7AGD4c7%srkwu?t|uU
zVgr9-zn#h3_am~2mg7HZeSSUz#gZ}|-Onu-ZXZ25mLYvNvDl5|tIe}sfSD(<Md33g
z$P6k3d%K?OnWJ&#ho6dDN9<`sFVowz)&@oa(P^76v7$!~g;IoJw%vyT=WFgNj8#T=
z8ph8B?*&T~0ZyL<<6dnpf^OVLQb$rFN<5Vg+BEpN6<@7(_d;@Jz-OV_$EDYlaL1(`
z&)3`Em=ixL&3xxe=T}eYiJ6n%1dQPEgP9%Q*894=-KGly-+Zru%1yZzb(^F;6>U>G
zMOJ$J6<YCcK|DKJD{JET-}AprgnTw5B+?%mtBJ4+`zDj*270fqTVpcBw%qYzhF2~~
z1Pj&#YREssjHb-7#S+>m%C#@*9X9yhO=}>`aPt#(3kND~<PlKE9Q+*rw8S0>euv)1
z2(6829t%B^)_26iPIAo2|MK<wHt{ewd#6_U+4Mk_^|&;3S>~S0TCUu;WjCX3IU07)
zmpG2!Q<XXC+_vQqtAKTNsrY_pcgR#|J<UlX86!kqZh%!DCRrQY`eWYWEZ5gQSC+yq
z^7M#FE+`diTRtBfz_2r`b6WwQGAVf?)UlY*MPDw+K~tTu)K6V37cTV-vfvD@kMsQQ
zK%bd&zu0_=w4<Lgv#OxyYr&yY#WBfHSx=O;(?gXi3K^XzgG8t#V`&|R{j7(beOFhy
z29vUNQc|=)jXEptR;O$(pPRY?+p-F|e>W+L>e|k8(l@8tjZ=dCv@YV%tG#AzQ)NmW
zt!!WkH@l9aL(7^HA9IIB&)p1T(-JYDtrXDqLcyt~dvZu%VhcKRN@Z1Xz=?i?WTvr-
z#vbK#O72k{Xn7|9wsUWBI?{!?RrR^SJuSUM`@4sZ^+Uij5AI+Xt3#0YyOd^Ii*rpC
zU^YxExtM@%M`j@x%7LhMygH^p^tf$lGD)ds1Pg+F3f937)Wn>YxWnqQ6BY(GQeEBa
z*zquJbA+b>yw}U#Yx2e^Y{7|cN-7;}vwSsn>AY*)s6K=ZvQzVz5_)Xw@_vCRHr1@+
z-O+t|MAke1FzcRaM}q>LyyfMn&RZ_cML&?kkP_S<oKx4DEVoe$x$zF)*d8ozpy>9g
z%gKRuB|XDQ2i0Hm2$tO2dwdRXUY`g^Q9RdMaH5vNk6P=wQ_Qhoa{|RG4s5wYiK%r5
zI*%^KODpSAaXOGN1f*-%=swzWPw|3=qF@H`(ouIP0dXyiov%Rm6x1O%w@zqbEgriA
zw<+*@s#;6QVl7oRr-er<J)F|kD0W=1e(R9_{JxJE9i1G-(lsDm`q5ns{6stDB$ZO>
zO{q$ySRy9b8k3egfY?dJkGD*ecEM$tB?<2LpRBfq^gfgdy!f^=FZgY7IHQ{22PI%9
z=;JUHeL?}5m)JhRQ^SyTmVqU~K$R(2GR<^N4Fa-t9;uO74Ib0_0e-Iw5#<7Kn?wgL
z_;3GxR|3R219CcZBB|5)Y(`C1dw$VR0GMH|>R-Yx6wuG0unZ=@L7s`D$K2anA<}Xl
z33WX`VOI69^ERb#Cxnj>E!tOL)<XG5gP}Kbs+zj_#D0=4xnPzG65-2@HzD2`SISM$
zUzbe_CnS;!1z7U6btuT&zPt+Xz#mV@K;YoL;>WvzvMVU6P1Do+vsVi0smg$7GXH#Z
zF_+T_`%aw3=9-yioqAC4NW7W-ti8WqUgwE&MrSY!fQ3`_9-9eyjVZ3wNamCfDheDy
zdKc$-0tDTfSGLqr&OYb+EkYr($(zLEI@2I)VmSz)AW`JB=_4C6ZC>R}nX-cJN{0e&
zy|O8oUMS`MY5x`49;`zZ*(6=|y8(S+{~*3XiFw0GM=KR~r)^6ltZD|g3_ixW@3KsB
zf<s8|Er{D!mEn)RY6Ny69)W@@ZjTeq4+L&HgHwC2l_%e=XcABss9}{i6u_rL8tgkX
z)Gi9L=es37;-(&-zY^@%lm>ul4-ZICbl*zI(4!zO?hw2VHDnnbu5+i%y4Al590q?5
z+6e-{Ux+e%c5Q{S-C69{c{W%|V2r<I6Z@~O_Mx}=QzAx3$F;-IRMpPTaE_T7FKk9~
z7NDa8QpJ!}07^n{*n7G)P8e$JnS;(<N_U#`9v}qI!3*fp#3UJyqJ5SN7a7MbXvM{s
z&HY}<#DGsUG1Bv%so|yEjtCvtf@SK6>8eBEe+43tEI(-%nq3(m+$0s<)J^Hk=2PbX
zFPE89Y0tm&J-EHF>Q(h^7c4dIr(W2yTIeQz`Yiz5tLD(sYkWK3#{F4u_SGCZ=*$_g
zCH9D=J6OL7WaD=r{hyJqo=I1qKp1N_cgHG*UC`^#C#DX!E)RNO@{jsm+mCs!kg1bK
zt&l`NQDEiYK-$u#^3ghP>XqiS=4Oz?M7Ll_uVh~+M$)*sCHQ#(ujqta8RS(L`Tpl1
zyz)ixH@hR286M{Cln3456I1yo24IOHZ-z4qRGbwX%qKc;DTUDs5|DZMoi!|%`pWN>
z9%$r{i=R79+Dt<$qFFkX1ytm|kC!eyl?+rslU1AMRf9p5QXOHpV0k0Pt{GH@x6~0v
zl}#RB=2Lo7hUy;&+U=LWP(jfnQXb6aCsu(|r)19V=y$Bb!m)}MrKqh6)K&FiC-i8o
z0c(EtiR+Y*w{<=|3UsonU@H%v!vJsGB`Gh5QTSfr3|j^ChY6+N6rG3MkOBvUy0cf`
z?}4I|bmnnP*h!an$(I@vCur~A!D8Z{k8s~fS1J!Y;8i0Y2z=0RE;_9P_8eVfK%g@i
zAMRo>y;7wtKN>y%v`e8Z`QiFqAgUJ%cnec$7m?Wk)XR`nksn^vg5}>K&(7t!5nCj(
zsA7z_{Z*I42$7|&&}8Di3(t#l=iZ%ghVj?2=Pp>wQp(c@<&{&J%dkk*;X7#_pIj=)
zX22p6#on4V&Z|G34{8K&J#a(iB_%6MY!rmY<r8S_*T_odJ^Z3K>PauV@dq$#hop**
zjno3E2k$R@UY|vPIVh`^ajJfId;eHusyno1PC;$x0KSjsaw^3<5A1ao<?UdQNuy}Z
zT{=E8+Vd8c>i+0bBe|0LXhV8ZulJQ6?`-oL;J!<}fvY$6Ot01?7?X>Hf)t~)<H*t*
z1@i4AefN*@`Lt8WrtB_QDh*VxbX09>`SDfoSch|Q73|pdN4~>ok0X5kN|8~uTRR)Z
zH&8vOpk(+^tY{t<w?W^OXn|6nXn2?}&()?0Y`jc1LQ*hum)tf+FI604?ZwvQQ=tzQ
zJ#|KZ3^(DZZi~kQ!?F3%!TInMa>O|86pN(a3qs8?!B=26DgCh>Fk5qw?aR0eu4K|x
z%IR@vPH@3~M8p0JSXPrjgS0|@=*1R$dTO!<3-y}q3{GetKJQwfMJJE9kuN*HWwnxx
z`KoU;#S{&`UP!5G{K6YH^44p@oM~<K{HNk2I&dUdzwM3V3QnE!c_59$iDkp`KZo10
zR<5%ONX5Xvs_-04f$a`ZotB`1O;W>>`Jx8wT*C7!uyBCg79f0zTlcl6Wmp$>Mf${$
zGX+MYSZ|Vz5fro^Sk{GN#9hN6C{M+Vw*C~PA@c;6H)LGEMihvkfSAXhf@B2bL3{pQ
zOV2a<9Fpo1!w}HII%=^vXO~I&MhQ=y5V_;P+ZqCtO9fgq^2dWo8U)Z|n`#vr#Ws$t
zwL=t(BY$7MCe}NJYnlpi=SR3<r7{a;Rj|PIBufCu1Oa}c1vYj+RQ?Nu-Xw3j9&^8_
zk%{F!Tl%zEHhn(e_P1}*;QH|b!RAw$5@8lmhucXo0vbb@8%Q%F-=7KZ93`c>Aeciq
zvS()|a-+yKDFn^*rhzoE8~fZq`;LN^!pUej2%&Qdu>+7gNw&eHru60~V_=yKi<I_!
zEn06Dt+&VZm5!XZB^_ismAYSrq8ofDbvZb9u3$+MQuGI_sOsgR1KH?FWjDTSGAWd7
zdDxFmJXk9*jD=?GKpPUQw5kfuaY3CuBt>@ugbkG%$7QaMivy?=nN&%)q<x1#@y~w7
z-`h^OmZo7%{uG;}X-!rSCZCi`Kj{cU@1&(Tg33;uVJfexl~VNl0{3BPDZJ1D^;QXY
zzuyPtyluEQ%uGrvu09(s69*lE9^EWR+#FM*fo#!VJ6}#-2Ndj*fXdcg*;8L9UIQMB
zfz*3b5`XW+`;s;M$aJ~gGG7n|o{90>y>u)S0|#Rmpxn#gWGpN*?tD(hJ9a9#`mBeZ
zJB%`Azp>Mqf21zwRl4rn`k0`hxyS1Y_|EY6yzhZf%9nzlX8mdaa{e{&DcL6^1H_Z@
zgzaPqcKo+FktkY4v87Q|Hh-!RHj>8D%Cs}f-F7cJW>$>-y(9<LB&JXEK3ipY=*Riw
z(kYdVWW6fzK1OCLpy1sNv4dhSKLo>GuNj@i{5k0Mr)(#`_i6yI*}nYdmmjyE-pZ;j
zi0J*J7EIP>P&9gAC^h#)?v1nb0{=b~T4&OVNJ(BU$eg>@+NmVItit~TDT?5scSwsz
zLHu)`?D%`hIQ^9IZ*&|;pLJ@e_?>wZNN;&G6$_K!@H}8=ajM5iC%{D_{7r5<<=}sx
zuihg^7QiLJJn<@^xV!kyY+f=qtE>rT><bO48qERFR9v94CXqfW52-?Orit!CqeapU
z3P!c}bfsL~6z95EmODhNt>31-Zod9i)-$v}RrL7E=_$LMosDU;L(fn?IsXkkxNify
z`Y`*?TJOqozNn&kGIzYA!BDY3_peUC?Fql5jxC2i<rwh(OfT11c}zEYM7jB(Zo*pz
zqiiTel?LXPIh({EZMVY$?;gBsrGL2d@NemfvVh@7ES15|A5oKsnAS9t9KZFO-_%CE
z^Ja3^ZJ93(LmA)lM-M2(+)gjmz0ndda=!N3pFNLD{eLVs^3&}4C2CUlSEJi+5A%cE
zAMBIAuCBj$bMTOOubF~*a(jea{E>m`FQ3y(Ww|k%J1aFQpM+%8AO+_B>pR~a0(8TN
zmpitPGm5HBBN&T!yA+ehDPeJqG3kd4zouTEa@d`}D4u@sHKo*Q+aM#tDMh3}HcVv+
z<Eg_Omh{wS5<wH%*D_3nigpHGA?)vAFXx4d`F$axc|G*e$GO5jUEZdw<cs2#hX|w*
z840AxFc!au@F~stMcFT6%)*lML~s9ek0nCBA3YW~$rd-ZRiKrZ^emC9k0TFW_uaQ{
z{>n$2k+FE8rf-+?Oh-O7K<)f3M)`zx6Qh2D*{stnq<<@#`$+q0#?M8kf1CA1FspfN
z7+BnT3TSkHO^s&s*7?d2JFMDIQOg6U!aUSR7B~;#Bogf`bu;8lsW2a{=42lNDlgQk
zPMiU|U6t2_IqcC>V?BGgk+Fsg&Q;pim^r4NDgUK*dg@6<=zp?c603CT^A+^s`ty5=
zCbWz4^}X!-lTsc-YXjUkq4#nyV<P4m7-in|mVZ@zYF6@hJ+WmC4PR;eTu6e{$J>?S
zf`g+NA3O=s@<{!IMoXe%&^TV%xB*u)6V@xe7HfU2U2-CK$L@{CzK=g#Zt7i&rhDEm
zYAzRI>NYQX(9Xqf3Qpm(%Sl$et*BDR_0%pOm{KxJSJW)y9|>)iST-W7QoCn*^aJ{$
zx7n$Ii9C+buaA$#?+QgwadF1ozJdovv10gnLiY!B0C87F@zgh|k_r8q%*U2l#yY-*
zom<x8*6h{91N#^nwmQ?!6sP(=gK#sS+8<jVOCA2qf+Ghu{_MfDs+=PWHR++JJ-}hv
z>%Smpx3CSe_L~8|UBdNXk+=S+Ox{S9$U4~fU0N6HY1EGg?PT#?o$jYvBeACAs5tsO
zRPnUI?8}K`ZzOj=3q8`<JrURd7PCEd=tZePUGLW>D_4n|Y2zFf#G;R5XMJh*c!OdG
zO+bq`RhXf>Ds^`1ou)y@eXoj0@IwyiMy%g?pJGE{vmLNd)U=q~!VTrggi#E=@xo=2
zx{zyo4dN_a^vMAM#h-;h!GW>T96){WXb24T^cB=5T32-~;TkC!SGsdx)#)$R&AO9$
z!FE^`9=1FrH%hpaQ>>QOyh$~Ha_9`5n@X=T2&!<lpf?sISyn~W&@(A?$1X~H{|(gM
zYsZOIE{YE}uw}cGDFFnYTG`=Vwyvk@qrh4<S<qgAL)!@b9DpPL1Ob)(Odn{Dj`F};
z$B5MsF4|i_Q2!q>h9-CBLWXEH8N}VERstorPa>WNT<m^xSwU}6OJ#S{&3=k`;q)w1
zEF2Jp<Y4pTeSYqb@s`tZB@LvvMk#ghC&B0pwr#*-NoKdR=8SHk-9b<~ee=1l$frWb
z9a5d#7XB61+R~6ZByKeal1oCI52&hV+^Evfa$UHPV_v5Ei-D7_CSm-4d^$gf(bPM)
zNwI;SQvJ;Z8U(UB(sR6}6spLQcuCc)D%TJrnb;cIYx-Hf1>{W?hwp`jpfe&w2qF~o
zTe`ER6(pXB^fb)6Ewd?8vcBX@@vxG%Nnz>@sjIzSUo;HL+&um2OQ>kbzL);4XYv+R
z%;cS6P!p121x7fe3MZIj1%?rv%Atl$`a)Sk5@$Xtm*8MZvwpBbqXxOHKzIAI1Wz?Y
z1l)NCr_^?;G#4`pLwK+)-b9Fe4`T_P^s7fj>fJlhv?AMsdH!*uvj|6fxxZq4%%Mq3
zJcZF9Hdzctlx*f<N+POVWSUQs6!J}IOyPZ^po4o6;@Jab2*;>ACTKUPE#U6eps+8t
zzsKF&31q3GN+T9k9Ar+hOnAfignQxwspmZx9ExFnQ)bmm{8KHzG5$68+vD?|6ZJ~G
z-*mFVEC3dxftP<k_;h@AnyP8i!!G`Zlj5Vya_Er)TPrw;A^|vfsXRJ<>gaX%$DI-l
zE8RUiqvXb+et~**F{9CSGq!uE37y%56-c`92$OHJwhcc<!`n=dN~-2QDxVr27WlRd
z^KGy9ucJ{_!LAe$@4K~Wtqti9AC;uFf>FQeAt2pymjAezZ%n`)*~Q2q>?B}t7RR!>
z(aAcKsxJNO!5#e{#YY2KL$JesU<ESUGNehu>JO$M@&cEjh9*sW0Z1Y_mw@WW)er%G
zYKos3kIpt}$n|cfHl;;WUnCs6`?l<@gGg0rbv<4=1rD<%hZew9*uvqwx%J|c2J?zv
zkWG>3Ho4a1d0RV8MQ(e6)~)kTQ(Yq;HCg8=nQewE{NlDymq&GmI>cT?#G%gl$>|Jy
zzc3(D|0KEwT+_wM^ZAtoO<A6HSUq*YfA+U@)}WPvJC1VL953IEyk0joO;xc*3PK%w
zC0nN;QB!2u{qUh<m(ED*^YNNN&&LwKeiy~jk0X?qi7@OYsXv1V-oJ^Ja-cut^K1q8
z&#g#AwjI$N&bdbbaN0)N6T*F^nxX(4x&CA-+#IO)tEs?5__oZ~`jo4FBUq^E<^jk&
z(e(%#R;Ad`b&jeQR)-vpXL4RDZV|yJ-h*CsVqsz5!79Jzc=-lAfN=2qUzr;iD1m5F
zYWG@Q@spoHgW`!~O*Bq0-*-r|d1~P)<O|%3-uF>eg*paXfak*~lI8Tw>JOoU_n+7y
zhZ#R>zUFL2ARau;Yx(&;t!~V1E*?d*hc#KdUu=0DrSu>DlYcR%_1`#5baCh)LM6?j
zVH2e{86zCll)glsb1~Fn=$?&VErZLZ*fz294d`T<%(El<bJHiIQ^8#11k5&MkgADf
zZsw<-gEV9E%u!+*Ztfu7&pZEV%%lDzaL@fmVn2I_0!lKFROJ;_#&X_!U_SdvE-C2@
zNe+UOnq>P<g7L4xZzJHB-*Ko^dHftFWJExYN8o(!E}8EJ&&-4EFxR@*K*p(H&qS<4
zq3DHq0L|kWstI=zf>f#~(;sj$(7~HobHXEhzsI{c&VwC@c)=|vX#>(<54N;7Y43u!
z;s6kl_@1}&;lJIZ09gi7fdKxaup;mdnE{j=30I27kK$<FVQ||mfRZ;>yoy6MxNJ|v
zTV!BW6tKWVRxTXjIF7I8f<jJU(Q8Any{95USNnlJ_|P(?CbnX5y}~#UdR|698AQV2
z4F*8^<7BH%L=P8?Mo_d6V6-zyX8fqk#8Cz3T4^Hd>!*XCfn1~l17wPRdiDK^JsJYS
zA$o(AmP&2>L=)FtBu6872bMS%Tl_qyAAY`IMEA1A4ilD$1*WP4a@4KQeuNIt9OzUF
zks*~PIBatWwka&?2g8;rDH~Dk$APlc5zT{aYxA+@T@YOZtWCV8-|D1;f%R-rED}K`
zd_w|}BF&1Fag7e}W5~_UBLN?uuGji`Jm;^750EWCu3%e5vGcAx5#+LuIIfc_ePB+R
zLMS=4L`a|HIBH5Nt>q~XitT0q(0rx}RoxG&$wyk_EuhBKQFN-4e#X$xOyUJ=A{fp3
zHbn%({p}k$28&TzdRLuT;GY^`3*xoldMA7mH;PfOcO0ZmXF;&h&ZG6xp^bN9qMsJl
z`3myhogxt*=VD)`vMhTW4`xubTglo~%E8%D`*sD}Mv77+1?2~nX=F>sg(MNtj(Z%@
zCV9CnmStLlm5^p!er&}SIDWwi<{Sp)@-H0XpfyX?2CK!y%e3Q84v-WXB-C8pA<(Ev
zDml31x)ngnF|;UXo@3iuuUC%!=Epwb8Z86Cxz@i=%9U8_3!SjQg*>1(5enk>KIKh$
zG}ekxq_wR>!H*vSvj!s%Gk^|fhZToO$ul3RRUDll4l0faZaOS$jg8wrc1{6nQG6qw
z;q0|MZj?$q6AVkp5*76ZShIk#v5`SRBkAta7;~KbKdqe$Lyol9_IBg;yh)19<a^l{
zIK&j_w4{?D1ejuZOvV$3ps|w<ES2^J+i-{7CpZo{cq0U@G)cR<sxsYZ+_ByLsRqQB
zaZ`zfJKP97@$y<{6G<i!ZTUylil6WUTn86Fk)6bXcC@RY06=O3aM{V<blhs*$tW0a
zI1BPv9`_U>S0}L`^YCLC!-_#9Z%c^76o@21G46e*lR?hUC-2t?<i&9~E7Az;^Q37c
z(m=x`5hREu77bp943qRmASY(?=XI!dJCfa1bJg&8GgAob69wg5E2&$i=+6En`bCCB
z@g?g5{KkOMw{D+pI3`O3?l5yhIFyWM6~o6>UxIAYoOsYwKw8xt-#uZO1Gs6;Qpj*o
zXasw0lsa1CBjf|^$2mHzp_61M@nzXl>%sDk;jWc9Y4>Jh3>Lv>&p!p&PL7@!z#ED*
z{dJy}4ja#2rl7F#EoWU6ysJ!O@Jh8Lvoq{A%U0lCvx;(!a;FkufoN&&d_?0@K)72t
z&C_dX2!j0taVILG1iFGMMm}-&!K+O%Y|i>DvI3~I7pp&olb^btoC}=7aSaR_O{`hq
z-s>{1jgV;lqg;Jyd74qTZ2lSt1z%%jIV)gU5}R`+f^zcaiGEq1p#XjB9ZE-tfMw8C
z*;XYyH^ESvd^HnWDmFwqi$$~o6|uZnf1MG#&>~84v}Igb5jzxPjW>l;o=V7ICP=+K
zpq;WIc}BQG7SP1<qNQD)5rS`^p_n9M2PRsiC)JaN-Dk>2XOet&oo`EC2O{V=<h;S^
zX^ko&z^km=%AX(EV;4oM)Eo!!;qy*XiD15V7M+Tf@&+nYk>vbvcLPY$lR*1ru*2Gk
z!k26}+vCfEmob2R%v$YoE?b@s+EFz!=nl2r1Amp4cf7Iabe4k}Z;^5JjZyyerQUgY
zwb*W6cSY~9Vg}oMJs9~QTnV80>a&wL9ArICoi2H7-+e`GJ&cyQhR(rC1(D>ZSfa@|
ztpBFSKw{DXjkcB0XS@Xid1uluC$8Z{h|)O4pw;Pj56EDT5@R%M<=$*Ur9hgDMQO*9
z*6>#b?i4eSNwcGgvlTXw*Qg-ezw*hJ4e5^f>C;;rC>)gUnK<_}Xri8*7snBuB9RTK
zc2k@&3lhJKAm2(t`YK+Sg3AGbFS9n6?VEkqD=_AGGXMt_%-LrkhhM^r=Q!!FbqL+V
zv;FX&B*A}16N(07WZJ)pK3w_xS)ZUq_oFq*eLQ&EJ`kA;l#n}hY=DHC<y?86ZxYXN
zbZ*P<g+}Wor!R5d-$FWc&pnv}`2VXct_zc|nUVv@JY{Yq{hIr#+j`;&@Wc~*q!^fh
z=GX*5c`+9#2IvjtmLZ+04^~LLNl+Wq4gi?~$XMQ#UR#OU!dutMO8+wQOynp%s}vXv
zZb)PIL1ioiUm>w44$%Y@=mLS`INLZgmpO2Yi&0enXqH;ui7bf1TnavCx&1xII?*3B
z_on0%i*F5rP0h7kAoWR<3a-3#bJ*CwzFv@Z9KWMJwAp@Oi?Xi?q*CBjpha~6IDL}E
z8)mS;&iu?O5fa)Z<A4R;feu!C7`1wgZIF$tT)pOp97PV>%mIDvo0pkw0VkuKz0g%$
z^}~&%1jdN(tbXU~QIF#z_QAO5r)r9ODJ{^gn|jnB%s0Enqlm^|J~kUk>mhQfJkWqQ
zD*${zE(mzJ^OD*$5wiK%8X1_>Bs%2HvCIY=Y@X6zVtKrxcploY@=Ng^>*n96dmg}T
zg1b)v)Od;fR%{5G3KzI>w=X~Z*_rmX!n!FB#!x@fCmyfB0`d(cQ8y@-^Uo;B-8D-b
z%_viaI1cD8*tR{C{-CPw<qzA0Mr30`h%W$vC4@MJ?t{*%^LzwPkOb2TjNu`s@a-s;
zpbj!k4Dwjm&CDW{<K?&=<%a$7hI4D8`BeFNm~}h&TSf77aEals)j#v82bYSTm?*!5
znwj2F+V?Se1FCh8q-fpl!~A*Y9}4#TQ?B?cIqM`7UJtDOgxBnlJ8z1io+bJ^{2h67
z=n#k^`qRapN{*lmSp!agI?aJO1H5a}y&bWZaqp0?DRxxO+U*6mRavm4jC1L>?SF50
zdWrNaoP9fBhv<MDp`G{1E~I-T=^WgtpQzP|WjX1~A3->|5jLuVGtG`Tveh>DhMW&8
zuDJ46)-N_`7W`0?W0JfPwTBm@4Jj9a46rFCNU)W)C1hYH%8|Hk^s#v)#K!rg(NUY^
zTPYXbwT1=U{5TrER1HR%_Q`k%I3O}e*}&XGyG-FQ6IUZ!E(Hjz6vx2qb!Nl6IUY3E
z$L=kIeq+wh+53;=Ie2q0f1Q%%!3I;i%5Euj$H3P();vfK3wZm7`}T<!;Tk2kyG}CO
zcnWfeVC|#j6LbTc>j?tZlcXDq2W5JH?go**<O1DCfsa+AJY2`^rr2}ytY8vIe+4i0
zZ5%o`-r}_>%4MNitsEPL?v3KpiC>k+K%Z7K#o>RiIbzqY;)>UUPcF=zWU7`b9SSL(
z=Rb7#*Kitdh8}*uX1I3wdXilGaS82j@5vmG)%~`KB=H@hPLuFqHR|=ogK?Alg5J{-
zcqO?8a67;w(;f0*pZcI;vYxY<S)!9Q{QfmOF|@5M_xF5>{GpJ03-l)x`(z4Qglx2D
zZcMWwo&NGS`2GQ%LuD~hDkauEcGmK#K-rhPlQP6yC;FksR<D_jL+8=M4z#(F-~l7J
z)2p*Ys5dL9`onP+=Z&=Np`InlSdK+78YazGj^L#s_uFB>z-x7vej0Z$!KYCU8zqqV
zjOxFvXUDxo@iEyJd(2~J8vq%sh5LnfzE_<x4F6Y8(lutnj4s=WOj%@rbtgbNjZPOW
zw$7vCqr8hqYvxTc+t-sPz)Lyl2#2?D=#&}V#yoJyC>>ddlSbq&d7brkV}XM@r<B-d
zOEqR<EDj7%-flP<*_8|~=1J!<l;4AmwunZA<x8?y0PU7v685W=A$CnzQrpKS_2(Kh
zzKb4#FA#lA{rP46O_PYcZ4BTOZza&J^p;;<&@bKDrnJ91*O%^nJ7O4mk1xLvOre8o
zM75R!|1ZBd`!Cia!7|~4L-ulK%yZc<-gKj*qtr6JOCnb=Gv{UY$wHhC-3eEjVwsH9
z+GOr-$+)asG<=xepZNN`?(c)4_wOga4oQDj-F93NB8@NrU?VsM5_0bWZAXuc+5cL=
zPndrg%+dSjpV`}|iVCnfow!#aq|xlF>VGr#y550D=Mvw(sJ8hl+g2^AFgLJg9pis)
zck^F^ru1PYG<G0|q^IS5p!q3>CJ)X(d{9e#F!mf~Q9$tOfXef1`9p_Jg!ZPrUcBz*
zcUw#mA?<E=Z7>47z;d+gH!tB`GKredX=u9oqhnFkYL=*8WU$QOz*O8-U8E1{1Zir_
z1VxNU`33}z;DZ8ohp%R%vI~sfL^sEPaV+3X<!gI=UsRGOr(;V_SJS|KOZ6Eyt`Jx{
z4b7^B8h8<te(Oc+eG}7+{>Y(~1>jmIg+W3R(4^r#)W=ViVKdKNym6K~7coPtUS=l1
z=GWz3bsHUHCAKpdzION}%Zzntv%^g}`6ZLWHb7JJDuM_S9+wX2G-4WGDE~^<D8b$`
z=O<HjJ(S<Smxqj8IsH0D@sh#gW6G(kI%C$xCH#ph|8UfW_#s!QNK4}%UmN2R^>KyN
zAAO0}!mA=it1?G<kI*n!)7mOYGJHAdo>hA1&AP#H11aDT9F7J6;O*E@i$?+kljE7I
zFeUu~)^m~c4|h|F{f!<}s5|3A4e>Ai5-MbZP%(MkzIJ`x7ad3AZz`QT+x4aHTgJt)
z$}PJ*-OHhakQ90tR9*ws1qUtOG9jE1JES&(RxgY`ZjUcETcsVYNt{}FUe}#bK2{YO
zk6TgjcUC1GUenS6dP#;mTWMzZ2w(vqDB{rkJ_K%wj+gY;_$nl3&6pp4dLT<P^>b6y
zg{}`Se|?Of($y7buzLtXuI7H10OBE_iL<Y*{K&VYwp*}k*_-jLCf9$z&R;BnO<xC#
zJJ9TCBpx~W(o#i@qG?LYC~>vODC2h2%joh5(A-@X<!04t>aLG0!(~C01am;E=F3GQ
z-4f5PsTPA;B>bIs7787gO2w1r>PdIje*z+pUpP-W-*xNR#dYhME61>BZ718+OLm^p
z!o5>^-4Bbo_CZy0>pncN%H6<y`L0D~IKt5-%k{#Ts)mXGKG#zkpY7+DZKj~MQ^1mQ
zL0TwQ(<O7UG0o%BEyxdkkL)u5`}~WYR2qB3MBXe6ib4qD!)B`AcUXA>F(l}u6cIM>
zY?w2tDi+`L{`HI>pJ4w{St7{8&DI~|yYoa*3rDk`Dlg532&?ShDiFVPQ2sGWQ!zz{
zS5vZe6Lo9LS1+b&;xniTg>F19_OZ&XxRTa?mB=AY07mz{cNPzkevBNLE8J%aH&@xj
zqjWRaLc^rC?x~MTD(x&miCb{|Bq8s}rb6G)4fE8wg~X&_isln^o-H>j+d+5HA~afD
zXCt~|N?10zli6%NTztTHcc^R-j^#J~MBK`K%1gjhYjf4?ZNI2ta=A!!Fx`tgci23(
zL#(b?y|f+))7@(V1uPfjerx}1)zfhybj}IP_F5ABuieQA1=znO0f1@Vx?sy-i&iFn
zQCKCGWbe)7F6*6lSp6<`#*%a>++9rWKRK_^LZ%2KN(Qm|imJtr1}Gt@JVSTqXM0->
za*apwjo(L?M4C`!ceoxfQV+#%i&biz3>-c`Bc9dzQRxHA#qxxI(fN0gh_`b@tA{oN
z&RY>svt=-J!seQ26{qgEJ4|72)5oiBK_sQ!&7RG1$lamj{=hP9T9I95=r5NhNl)dj
zK7VL}S`hZEo`+SVwZg_zqfFQ%BR#6qR{Nvm@2<N1Mg6?+LWZK?@W>6Cjy{j-MTZyx
z#_ZmAl$_Wc@`|i}k{Q`qB*s-OD;j^JD$9gFR#Qtj&*j{EISc8t)lzw5jSu+Hmv26&
z8tkXJzHi7MMqVC2@aMVAfA!#(!D&Vwp5)hh$MVItZ{rc4Ze1AR4M3!h)M^K1<OVtp
zl8R$BqL5Ex9-E(+xDb_0F>HjdiDj^^$~6+ey@-pUYp07s2bKc&GYr&3rwf$liO_sR
zcx>KfxIIx6rJwoSVG0Pd>}FoAte~K#NNowfG=g6`aVNW(dV3cpTROVigLZD#8llbM
zDg4CZ>VntZ&0*(mQmgl*@YuEXPZjE)J?v3)A|ZA%cH31h=JjlmNZCC4%UKt(G(@zL
zbJ4*4o!PPzKf|T8K;XqCyqYedDkbEV$u^zhgdBoeGorc^`BQ5<0szn?z&cYkf2yJZ
zh1t95PMEJxWpplR%0rYs!#f;%gCgHdc3a+^$~zC^rFy0fla-1w-OSh1QaO<8@+^0S
zliR1fqgwIGALjBdE5I&0K@Lmr%K(ZTq*FdA?*@|nPOBlxU?SdFA^lkp%=Z40khQ4e
zZ0DH&I~KyKk%<c0esr0WgM3}5YI77J*%m2}esTeK4rk3t6t(V3hNp)_K8G16cDyet
zY`$@in{RPmvE)o^g;FhHOiS#lyK7L5$_@bfm^gj3XRV>R-2z$??;qMbK5T^D*t!|v
zN0utfvV1j#eYvwq6!caV753)?GZ6_=KNbMJm;$$-4dSUm5iH@?cTth!HQAH6$-*lW
zhi;y3G(X2aFcwcf{M6~Q(YF%C`{Q}&^N)EX(|9bHtOHTrq{HyXE=Uw%Y|lzvS-!g5
zAU6>QHRVn#W*w30>E*hFpI&H0J&QziUh&A%XaTEo&|dunWA?Eh>)caZQL)Tkh1kt#
z=T#=)Rj@dps!^BQh!;)Dz`uP>fDumJQlaPo;-v76w~7}S-g<5_U$ACbL8Eu=Uf0>9
zVnxNbh+p7nED)Xy6ZX4(T=H4GnoXI}Q5}5MK-{gSp6QN|##fdKtW)M$b(gyyM<eXu
zoj3Q}(%v;ZFnY_yZVGi=N%H}$48Q$m(Mx(CHqcPPds2X!-TZCUP7(?|D`joT(86di
zTj3Wtc6yXA6I}v7tBw}PwBT;=K=kJrJ_l2|z4GqoYjyv9-6*hYEmSne%GXB7KP{T=
zA;~5gBR+#%h~DGmlRLChIZLd#o$zB>HPI#_SO_Sw?JKb@3~b-umxz-aWL9kB6lc(X
zc}Ai$s!Pfrm4`}0=?p&j9KL!?tc`hb_0~TYQ=yp+<~d;?6o>vB7z5VU4!@FJAYpV{
zHd;?Ej@ed0k{w9Wa=mQ?#Q~YB3LqTlSpDxbEG&OgAPXQOSOOA{muTjSP7#<ptU*a#
z$de??#0bS7N!ox!A)z%<F81G#2IXevQrr|Yfexp!;Fa7@OA&Pyt}3k&U>ZGBi~vnS
zXI74Zt|UwC=QZ6XfaGkk{pC3Dj(6V=kQQtGJ!1h00!Ec2$~j=yMlk}WtZ|yL%b==w
zHy^RhLfC!<=Y2td0Kh@2<swM#eT3n5gxD-m-~~(UGs$Zs0&xWf5SvC6a-k=u;Aa_v
zpNS?-nyBXQ7-T#yjtHorOYNSNfU*_P!qQR2f)J)ri8mt2U@Vm_<LJ_vQz~+l3!eEX
z`$Y|vdMZPfB)*6d-xhzN0|16b_7xXFOm4^yvUO%61pf08&0-|~P)EVbGEYZ{Egus+
zOAthShe}9D^qC0pfFD^6Dy)+zAQ3uz3ozra<a<&I^I4PYuM@W*e1~ocVIvt4GQ52N
z(JzsR(?pSiR>*3y7P;K=xGKts(IpuHDnBM1%i5A;s-}?Sluz%Z8lzhn@--5|GfdOw
zliJaKTEY!hts@bgOfhd$&A`)e8W+~7D*h8ZDS~dAfdCZ*!O4=^XJ&5O5~t%-)%+pS
z$Cx^$IB*Y%ODGc=ONJ<~b`*CQ^?1mMFuD*C;M(Gheo0^_!o~H1oE=MOGC*_&px8UC
z{_cli?vQD_p3qsAQ6T}|+ab7Q__57J^2HJ$jtEsCLY0}A7ZOri5^|sjS$7x`NuPx-
zAkWVrZLuo9O%S0(-7p3iD)y*S->8=jZqx#xu)+t&fg9)qPcxp~euEoY0O637$1hJ`
zh)uQx5)IYHbvhSd#Q<Xo3F8agPdcSuZJKklOJWs)N>&lSQzNXa7m&8-zT#<FTcSMr
zr|?48+s~1@k1$XNqVn#3qwvV>$mXxJ9~JGm7`+bbcvgZAR$SqSx#M++Bhlg64{$Qc
z_^p$Q9RTyr^y6}b7(m*%0PT^-u*#%`?5S$4PylxAIIB|<K3%fa8!I5Ttp9W6`<qCr
z_<C9dIFh9TJRP~}WW+!Sb?MeLZ76LqRa}{&-WR=&ab&b_@R0=uw+LeIh2-6YJ%2sN
zB(AGGWy8|~;Zy=#_7}g3_s;f*y68uGQ@3XVP9=qhlUqG5AGdIOwM_PWxvZyz1+HUX
zfdMQHcOyx)CV4>-fbjWPQP)ZeMa}qp>$XhgGs0K~*BRiFud?1#eM30+Ul&9EFil=E
z1xtebuiVA5zwh6Spo&pIV$6V+RBmIky!)7t$9@D>M#1^g>>@}AMuIqX!-7|pmQ@X7
zeKc2b4y$+oOBEF<<PZary#)|n?h?vkjT>ocZI)=~pYfB5O5a{ko&;jA9Plq-C|=S<
zEnK3u-t`oYco4282g3D77n`U&K2lWv)jC$1OAbvSb!0>+&RD=A8Qu@@iEF@cDRqDt
z_WiQzwx6?i7C~rPO1Oy&Mw$tqicsQ-!BDg_e#{AF9#gQGcv$`byk7#U(x8lBVDz|J
z+LjMDzGBi%5k&TiPSCzUXE|%4Y;1&VTm)FnP0nX~|8+gG-Ex{cadhfa%!)donxMVB
zpg0l5oz!=GCMm2%u-jdiO2Ea{us}QL3HUZf&sb#=7cbZ2|3p<`-)ThSB~a^jjgh{D
zx46U>QG6RM{(}*cS0FWiYIfko3LR)P=ViILC~HZ8IAI~)EJ!dnZ9f`S^2=mkA<erv
z?6r8T1RkJlsL4p!p7nZgI>O=C0nv6Y7z#|h{PlKag0dx1eEz2xqLgrkt*{D2yn`vD
z(<2mRQ3iO$^OyO%%0uoWVwx+Z0&k1QF>aQdJw!2X8hnSY9+FUwsPQpzx|wk13_I}6
zmSXU#LNFI1ok8*?3ZxcT{UEh_3kCe7Bz=jJo?BE({if+a6t0!quw%$39(YjsSaX>P
z(o7PUPWO}f4G>|0TY<-KX+~VGjKBX~?K(^I`?hpKLoN`Ia%BpEB0}2;e07cR9w9?4
z0@TT()%1$zf039`zhQI$OykG}pI2TsB#*KoengVY94Ql&bHGVO!y2lSo|N~>A-YOs
z8EBBer2LW*Ze|^NX7qOBj2xGVa8G}<K?H1Fq)IjbEYbOocJ{BaQT2>`84Gy%s_19#
z<!zt=hnIZ(T)}^mB=M3I;n|CM?&&wJGxOqzDHaKGgQ^{~7Rqox`7B%;iw$8}7e@qY
zvVg#|UB%g~^lYxfrwCLyMcV*r(!5}@rHZm83RnLYvLsNyL`E)?q<q9B_|3GQd!bMk
z=xYNY9Er+VH)&mfm8S|~Hbs{RfyKWSxn{-)G@$Lue+VEjjte~)2X&AaFF#h-G79=Z
ze7A{<x`Iu*ELa(3lb&AhV$a~qUzBpJU`-+@SC)V$dWn2^;!UvT=LqQM9ig1<@yf4P
zto*BQ?Is|DBqm~NMzr|1eVO8rXt#klCqj9@h%^ulF!xU}LD!umK!t$k?|w$`oSs{s
zPy<4_M<CpY1NAB;%!6^b{4rHh)Zya5dgbB7s%*Z}NvD3d3l@wOILIX(h^&`ss9BE?
z`@EBRe<ScXP@E~Rjq9(LpoHYzR1of~PY6`BeX2Ug5?YPOUB7Gev;iF3e?uZ(LIeoJ
zun;1^WoPl@`TY)JS=xI*WL%8w%puKw>q>tXB=(9*tPDUoyEumX+^5+viy%Ni3s`2y
zzeEDsNLHV@LR$wKzVj7R%w#KOfJ8)xR21M(uonMo9MEsLjT76*GHWG(?1)!9G9qmW
z#|4f^w8e@$pR5K0j*m_&j9QN_UND@(G1yfCSy;^wX@Cfq{)@zedB24W^lQ6EwD>Dl
zy{gJk!7C>NdOEOTlem-YgIa?Tx3v#Gbp9p=8KCC7If^p&D}$93O3aWT(MF=%g|Y{%
z(^r3??|mbJpag*ItI!<U%D~Io>_z2)8WOWw<umt)5W1Hy&dOnR2cidFN1}p=E#O-r
zfE4h?MU^E$&mAIEGEv1G`JlS*;hi)kDH1`vc47)AcKQNaZipT6M(o{$?2UsQt33<^
zz_?Oky{J0s7E1DG46|_@VZiYYRe>P1!0~zQ(FlS00a%@zipBvsRD;U+g3xBI@XH$I
zBvqX=B*ne^;}7E{v<MvaTiR<(p<27g8VqpH!f+(78hk#@PncMo3zV+~%J<J}huc&t
zA{Adcsc>cPXOkO!YQ&oFJmG^)$1?_m@!?8frA?G@R*p)J&Pn@EnzYa<-*1Rm?!=Q%
zm4eh>xd)=NXt*u5?+aNGpg1SoFqx^=FO;k>=cGJnR~%8B&b4@(?xZ}0g61&(3|wu=
zWaKt4U?%PxvPjU#BVsSJwTEyI2ASZ@2d~a4%?T337zdS?7;|p{q8bFE=H?lgs{Bu>
zxg*)yT%2?+yU!Wb<z=U$>>=m+sQ6edtl3w^oiO^bQv2yUjKf>)EWoon1peZ_UuG&=
z0>qP>-^1?b)m|M)*f0JIC-mm&qjvyNo)#B~QWB2xOh2^8wX$1!r*=zmoxZ!!dF@S0
z_DzfkAmCrb#{-O*+(l(i!e|V(V0Yo8Fn%t5@vaANDeo`Xl65nbS0jd7zEiv3wNQD9
z`}t}u-|+b5xmO=eSCjVg^{qEy$Ji^exRHyzH;xaAkF^83>(U$F3t;yeG5`WWEP?k|
zzlyT@r<jBBxzPSZm1T5AHsjN?!Hh^A#u9KxsIk`uEK24AKbINJe!L9bo+#wAc1Q<_
z?7k@+#7=1-y}pZiReMtv=6%2ALF>o??1Rjq7r)P5Stc%>#EuLkf>B&rY44!Jf7DpR
zEzu~jQ;9Mt0#rT!2*~q}8sfPfa6;Xg=fiWAs~G(AkCZ*C$zvD6vL5VH1h`+V@ci5T
zn`Zdb?nz(nS0D&L1pVHTw;MNB5mh|Y#+`a8&U8M<e>JFLY8F)*W=d!7!A%>-%QWm)
zC1|GCCoUNr0bvju=m%i~8JUFVS~s6wwR!D4NBH{EC`(e}U}|A%3@{u1ZTk4jHDqu7
zpR9K5DYce^vL6vy*u%GV98+}(tYxOJfn%Zpp%tOsQO&A~oL-2FYk)c2g`Q!iGGf$A
zL<>C?91H?{iH*gIU<9J=sAG7~@psKKFzshg;*?XHew7$I=DI1}H=v6%2g4_7Rco|f
zHXppL<4wTFiC%~CIzCQx_TKJsdo7*(05r$CEXL6{pDN^!8e%AlX0hJE-SCd>@@&}}
zURx(wdHieYJKNF(y7ZHpGdFITF4V+P8rfY2e&P|1857lp&o5Ov&s8OZ4*rj>dk<&w
zf8fV|@4#jooAa4DACl&L)|@AYMkVQBL=iDjIi$83b2ds2Nps4vnnO8@oJB^Iq#CK{
zI7JEV{qy-=-|Kh%{`vj0|L^PGwR_j=em<X%=0>i=Apv+0a7b+SJq<CiHY<<P-o&u%
zUchnrzAqOpCJWDf?U#1awIIGh2}?XWnSs@?rzRTuFbS&fkM(;HS0wX}C7f@|9g;Xi
zV0t+IqN-6cb&siuT0h0lK0O64?zPX?E2IR&PbvmY(jdXHOk2^O!2)Z|8rBmyAG?0g
zH*mF?DQr5<RQA768v_Un8*?ctdL3<wnFkCn;bXvFylN$wZ$FZ+-#VA)wl~SWx6~7l
z(5aM&9zRPocNIb4(av(~B8C&%&z}~HZQ$(T_dDj#2?<24egIumRX>Ob$-`<KQU6+}
zoA|RP`Pl{Y@Ua3L!G@UL(uAL&nhZ(Gyf+~1-a9BI1SR#|(G;Kn`q`ze$TJ~dV|4D?
zo4PFR%7pb9j=u`$-ETN`8`<|fcyge?ZmfKu((!#Ekc3cQ(4Df;V6EDpD=F_!E-_ue
z>G@aPUfIoXd=>q6Nz3c?wD7Ua1&WHg&Z9mvOGL1n_*a2i{ku^+{W|-lU$@@6I=tJC
zYpBa-|EO1siRByxf5^npLyFnKUYj?FY^3e4*@I}Y_gub$|Bpv8fO1;UOM}34>bMxl
zION8laLVl)Ke3kIccYz=mGaHZBLv(-zYU#GO242*zPnK`Wpy9Nj)Aj(F8D?W-wS``
zKszR$Ud5a4P5V80^1^S<eczKEK~z-|<Gk<XAaNW3l3EC$Dltg7CMmPR6JoCyS3)MR
ziUd0+$&2-S20u&+cicGF4b4VbJH6`fT}(wzqTkD7p5>r}bB`U~zq!n&As$a0eK=sW
zuKQv__l=!pAgyV@QUKERV0ydmIH^yGp|EsMHHU+DP`;`(^eA$9$@-Hl9a_ij?AXu;
zqv1D0#y=H;&B@BcVS<LszgQm?BcL|S-PSpcUtFH*aC8q=z@I&31D&W=G-ry7u(U+U
z>H>+Ydq%f>f97s0+M^pf`<29^_J89(aJs_6kLf$;qX~<b4>M`ITTWEX!|uj>-<yfy
z$r!|ME!l4Df{pJ7YdK1-(y2U>*M%yYn0F0HR~z(Ky*$T)kSPe?gMfO80gf|lb%P6|
zO8q`+Y8OsRe`*}mhc*rr9#H`kgGl0UwWTUv4Mz$79WpG*MTO2p?Y(EI;FtGXXGbD<
zH<ejw7Y}I=8yppkCX-Ot?I}C|yhN3Mz1Oo6RD+yIl7EO(x8bP3xOP#6#IL=Y8i6@h
znu8vKs|*WDU-MN(Xr`UKok-=32>&u&6(UOz(-8K~@vrR_xVy}l9$Gy>XH^L5hr4`I
zpGF5G)MHwAQdgPY2Tyo&ftPbb*c)b2Z$0b~nd+KQRW8M%>yRF&5p5)_iVm@a$T(WT
zO)X_x4*u*{yhBLVCFTM^EJ;ah)I}%|=lOX`%RZD|X7@V^a_I%W0u_u>`dOPQKQC6T
zPn#-#5m1>JRDpn+Xd5WAMLZ3j856?J>|=p5IdD|Pww&GI{F=~Vmc8Wd6}pzQK^-0M
zA)r~Ps*u33k!XuiE{ZN&`dWCy`s1N$s}G?WB&cj!(0i7E$!7@D=uSfHsIhR~i1Ai*
zUpXbI&c4FU%DZg#9>30BvJ77T#0P-fz0IT#=8o7loJo@7uu68ADtf`k9FXQi_opnO
z0#E>}Z^H$N)|~fO0l?bkAXfRS;?Q&kGuAp(_7ml-IZC=kEQYE44H$G$>74a6AHnkR
zdyaX?lo*u(okIN}t6+*=<G^);^{y%<LAKuu@ByN{%n=(~((3?QY^!Iiy~NI$#vi~R
z>^ppl(M^M_<QGYeY`^=~)}pUQQl8{5<8^*p2hk)OC`T(AKvq$BiHC)zI%eG;RNy4J
z4d*?g&x_yMar%yG+v4RvQl5yP`ik^C-)2zm2)Ev;NBO(AlAp=<nbf>agNAL0t2+^_
z2!!Xbc0T@zgmbFB{qZEU-i&r;?ian)VhPb4bLYi3!>|w}RVaK_Vc%7-M0Txm-2LTS
zRhCEgJsCrPJYwRn29MOHXQm%+aUccTQES$RAQJ9#`R{oV!esosY-bR_X#3gHQxS|`
z1r0!%9~G2%RGp>%!F?&T!+*<HDvk4%C&Qf$Db#oL_1(F<GY`R1EQ*(Lw1i*scb8xl
zQKR-`nC=Ic{Z}|P(m~&_(IM32NKV*Qf|yQbY4BbLh0vV1v)I0$!zSDvVb9mn&&U_u
zyYfttXW`l8t<B#0fH$9gU6z$@Z?5=+3H$tG&j_qmqS>Rm6O(>zg3H{eHVuV0KrB<f
z-yeER%b@9b01B`VCowXvtwG<OE36&4lFt1(l%rJAIm_lp+svQ*;@1y$-=fSTPH@5!
z7j6kWwW&g#<A5!HYM5oI;48vXKMX1C-~<k)84o_COaB)rv+x4ldp!_<eLgKitqAdQ
zZd{8wh~4{7Mj+_eqR>IMs$?m?&~~7R)~ZUE=qN6+yTbmVe%5P3TW8-Yp`kMSO;>4M
zun^;;5!%yAWvKj^uD1xTuiE*;^MUO64#nlHgYGZH?~nxc;1`8wHvtbFa;@D*vSxFC
z=)0R{pQ>dXsJ2`xI#p&f;In?khByA=W$k}@Ke&0qUw!rZW5EMu%yU6XZ#4K6m(=~b
zZJDuphm}(N0f+>bby3@P^4O6<E!Atxx{HwlwuL`+au@E$%lHXap1kCZVJFKItI=0*
z11lI?ZG4|n4usXKc%r~|rg^z6aBaB%4j1`F`ksMrX3swND%2Xwcd!~jv2=d{h#K}q
z&W2D^3T6&(-{q_~cNQ~83O6uI2xv;URv@a@EO3Gh5yxFlS=+6vsGfc<2E~J<D6mu<
zZC>Tto~X;^eMnDo!bhy!1}~1V=J9g(KiDRA5Ehp3F|4T<p`3rj&jdj-6#3<B)D@+<
zrx)UF4;#{iyrW|XfpQcB!;>`vHl%pv+-SjSMQz_;C>a(YBgQ{7BBnVcy@^FV`U8DJ
zj9Kry1n|zo`h<Hau51HQ`!*n^3|+>Jtzpt@0EGImw<gi6%}~>ph}pzLd{WO${Zc&p
zJh|}~=v)mv=L~IrDmr`d5+fJBk}Of-BO&q!iD4wMUdXKf5xFwrwEXCt!l!e4wU8+I
zNfyRu6Bqa1IGo%Pq}8gq!Mk8kkT4O$xTbRTIEQ+S2|BkKzFKXY2vvfzT<n9=^}T$r
z*x5b$gCyepO#5Xj1VzLIP-i}b$(_w$|2{348#_5j*_=gJa%}Rer8dc$V$+h#9PnN&
zWbaW4%h)s>L&(x)h)i#^kV{sIK}wdLLuwTKwG2PuS0ftz2Psn-U^OBph`0TN74~?U
zjwVp94WWN>Ps9yTIF~U?z2MM+ljH%2j<Ko@DVeS%YWztC%mH>zGmXd~k<hFe`}9(6
zwYi$CthHz-yEFA8(9yeS`5Lip6S--MujDLx3%K~L4G_WYQGV%F3S5}f!s=ikI!x?R
z@X3%gv>`9YkQx4VSVn}cwR5^a!9ffisw^U#WGI#^;+k7+hu#`S{{aN*wNaZ`*>h`l
zgxr`dmDs1O+~<`*{;?wVT|fwT@;^?*Z6;_^G7{#cqRWBsNr@1erY%n7KR7dFx0}PJ
zUB=#$!rjpAyZ&rRPlOcz#l;lhGgIP1Zyfkpu+YcU7d;jE1X{m|jJzwgjYlh3<j0Al
z|50_xrXun@(C*rs4IbHyL%MT~w#jE@nSj#Z5y#jA+clTUWs_|&A`!2^UqUei!;*A1
z>|vUi1O)`A+=BCH%6%z84r)rd`_ss<!M}<d7GjB`Su$r&bKwF`no`@WGw%kF2d7cf
zc$?eJ=w2Rb5|4adh5mv?3SoitYD6i~i;Kq%)R^ggfcUKC%vMWzV1ZXMVre80RS1Y>
z!V`M$B$PAN405|`#Uy$SGAM99MC`h$HbPgd>u-Ab6uO&LGF}@1uaoz%-`7iwgi+DW
zy+(0KXfPJwms02}p`MSykoB86qF{&t4%FZZi*E*jkBTM6!7>2HR1!Rnx8Fjp#90@U
z(7WqB3)tYTlotIC7^bV073>KB{ty{EJdvZHSu+~>Brk7{x_Q2(oD>Xoaed!yHX>yt
zFG|qld~xlODI3jR;J*>@#m^RC&Rz|bDgXzV$IEQG)_}=?5yr}h8xM_V{SJs`M8W+&
zi@A+RZ!t?S1;XWv()tGH>Zg>4v1Lmd!bFoI!8J))a$OCkxFRZYvqq|t0>&}H8oZk#
z=1ds5UOl(I@o)-#OiT!C*ysSsK(NN=#U{?kr1n<0dYxYSfUK865qVX~?X~;t_!ka-
zkQ39AdQNstt5Uv@3%vI`7VtA;W>|WO0v0m_N4DRP0|T+H4|LaR)I?dE2;l5>(GzTt
zgSyzCzlz|DdP7>Ws~YMt2IZh7cOgv-%s#!%Mc!*f_2ZOpE-UZGbnXZMLaZYvOiZ3o
zHA}AFe?AOus>|M%PBDO2sr0d&bpdS}M1Bzfv0xC`<?OO%CL-{6A9-m*c+3JdDs>JU
z)3Sg;Mck|vTtxP7+}mNw3$U-;!T8h^d7m?|*CnY$7G;j5Xlqd6(R(mHkC?a&u{du<
zl~geZqITa?v8aS*AVVUnMwyQlPPNGU@LcThD7p*qsF`N(aQyi?AUaC|2sxK}<|3N>
z860SKXFC<F%>g$pSqS1Ds8L}qV`&y2>Vw2F|9`TL@Gfn$E8Bp<|5vt=5<;uVtDXUX
zXf*ne0cMxA@e>m}bQp5x3=k3ux_D9O++j5UaDjlmc3B%3G*VanR5U!sS257Y_mrEP
zTV%vRuY-}kA<^WROCdfd_Ic<v13-g-Koi>dmV(qQTxeIe+5H*#Aq3qr0zDTp<^v{t
zz;YdA`UQfUF%n~kX%wDP+VleLL;&OA@)gR*{{!s*fe!oz9o_~-PADF!I(3S3C`7GN
z@=`rIxKIJ{7rt*B0RP>mF@+)i1tPXUK^$S}TQNbUzMySS(BDY(^P|4cPvz#J(poT0
zO+Z^atiB#u!P>K(3;xRny-L>opJ|hCu$HU$u}Zo4C6qaes+$!m;se<{plTIVw*|ED
zfsX%xrr!XYCsH<P`SK-nbQHch1)lu-e_5N2^<CBmJo(h@Mx*<K2cGrK7mIEM&XjrA
zj0KL4`2zqA0#27iT?YYeLNK<ONaJ4BVizg4zw#Yr|I+Y;baDbS#I4cKHy<uEVFjKu
zgO32fxBnNn5kTx9(L0vFsx`2o3;hci{t?|b<AQ$X1n>#Ke-6O98;BPH>;z*c0Pk%O
zc}voN>WmjB7m-&3{U2^qFIr!$Sh@}5`~x*`#41xRHQzm5GJP&56ZE$Uv~?HBnE)mR
zK?A$W%^Y}c63m$fHh%*fpHa`QM?D*i7{fGWYqD<te~6os*wp-}<XpE0H{&wOuH@bg
zXt*OhS_In3LCn@dS04g@J0aidET2~ej@<+0Y=Q3o#gsk=`2E0tW1x*;;J+Dw{|d4?
z0GikVzHgz%XV11i`=4)<mY&CCveUD#*D~%kGm@@XFc}Z>@39{~eAv;^e!sE#Uh0Ff
zhwWqe*IS2M?~L3Y9B!N7G>(toXl)rS$ebB}_;jZ9Y5Ty~!|92-`RU=|;fYDkt2gg=
zWt*>Gzpnlt+2-q)wO_w>Wt;8)Bin59e*EArF8zOG8!$}UZ-A*%4!~hoxh{>WPSLIF
z$0}<k3!2Xi=ACcRB4JH4e*3hM8tvZ>rEgto327|9?Q~60_4EJy83zXDvMLIPubHYK
zT-QBmd3bWtDP8lcF>CE(Yv52%_rlrlg+`})>b$?U25?iZ;u6@Twep3hjn*exV*4E4
zb)R3|OeE=&pFFwa_16a<Q*ECNO8u*QYCJY7xjN(fR|#_DX~RI}+;0gwIle}xM>&4R
zCPd2P^ndXUL46J}gNfTeL-&9joHNZro|#Wc-&cQb#gtxLM0S;_I?|EigoU>D=ucPg
zd=`!WxpCy|v+#cjwUaMg0`BYZX}|UYC4-mty||A(YoMrL<=s(otpD!SMB{(!e@~@r
zZK~Qh=^QD!HllH~?}D98HJ4_ovwlNWNYyykX#@UC)Zj-~3|eeX5i;q#C4tR#T4(ms
zko!`9`6)!qeJW2pJMJKL2&BIBPBoQ~JOh}%g};iTua0n;4uV_>lD(>9zSH*R&rG9%
zkPUCcL5ljchlNm#kDnfgp6+y^WwSgZVmVp(kjUGb5k*ncmFqcXpQki)V@yp+4tcBU
zc$=HDzm6FG?OONDCv~?J;000#b4*v;iASBHOAPL2oFC|$wAubPSCJF1F6&iH7OW;v
zF5VpTjoClie(0j)#S}$D{$f;6fYCr(&{Ppv2$Su!+`yI+`h9ptMDBWrcCxLJ{>AFz
z@b5F?q%yfrwY4*v8+xQ@DPtA)w-#!d<)>9nqX=vCqdBSI^9i+ndPjzG#RumZ&cWR~
zQhObM&yKyfP;U(S6ytdbr%Pw08dj5@OSJ?!@ztNBZpij5KW!r=yW}0a|E<5@Z(qpi
zT*W}C1ZUHo%+{IHfAsU<0-|M^pYV_!dG@tBx$tJ<KN}|=@#C=@nFf;zY9E~6DLi*K
zdNOC}bF5uAeGC~Lcf!k3<>2QOg`Jh?UT@ahdf4u`*YQ3(1Bf1uZdU!qFvtXLGVJ^&
zR&x6I#@q#CgOA}c+I-+c)-1XrYy*4KI&bJ{iufP(TQdOo-K`3{z#kIP0-!xln&u0|
z9ee$Ug55aB?iVG!G75+?i!vI9Hs_9lHv)4ldYW1komM22A|+n0F>Adtt5LoJqWZ5_
zy&yy;`J?H}RGy~*_kFRo)R|BEQ_g1vR6BrhS5aH5n&G#;Q7r-Haw|9VdcWK6{j$vi
z*FM&)9U0Cs3OfBoC_9WFv;FNjkCb9;D>dbEb5lyMZRCSMH6Wh2^dZG!y+Rq{n7(zT
z8qPh5G~9Fjj^M?mrj!<8mAhmQ7xtmd*sc#sOSI{A?WR^RFH|qHIODjkDnnpsj|hKd
z7-rpS`cB|e7(eT}$c`yt;B7#d)_euQTKiH}mho!H@XC-gSp(y<mZY#6K;`O+i3G}i
z7ru*0*0#+Bm6_WizWpk@W`4P1SadC`#_-t(RaL-gvHuzYklz10DmzNCB1Y2UWhzm;
zQ?iSx{I`&{IENLGZ&{Lj(2I9OaOv7JT3}#>B{w_LV>b4KaIi?te#=MnN(?eGGVOI6
z6W94om;+ST!gV`Zz_nfjB1;)B<vc+M-!}U^SQO>k95+RPa^d=|6XIx_V|x)hL~Zb#
zR5)`n^Q;6!X5XsIo9{2Ocr85Uj<!p@<r&e4IkvADAh3tDnD$1fSExNkR1QHMk6-!{
zJI*(r?V%-2PNoGbkH(4_Gl}?&^?vCiV)GJ0fle11mIeIlMogbs)WWZTrP#pW3yc8B
z&9hE8kpxxydTjE_hv%f?ftOxTBJpZ(g$#${e9zROdlJY~{nK085nrX$IOBlGh<T!n
z8$&?h1E5ox1rito?>tp;(Q@n1+nSgGhJuEdww<7Hi5DuGGo$)%8)euVXF!z!C=$7h
zG~aUL#DRd^kltR)V_wc6d_eBTA|7+Q*wCr)a9xb$$EQB?&FSiDcc*2Forvc8hs#q!
z0dkp>>Cnv|Du!25!jjYi?2a~juU8~;>urRZ-FtP<fcGmbdFJts6db51?hE1Xbt(=*
zomM!lBwt(Ls%iBs)q9{M<A&WH-$jJ{<`5`0xL@`+)-U1Gbj!2RSBJLZFc;TOD-KYG
zjF@G^iRxvKSVHJ80PFstf%^*g+ZitJKR_=w1xh9)NuMg1U&y;@8eL~|1XEoh0fE-3
z{)cgPKW~?F?@E%)dwXZM4I^gqnwmngM278KHbLjg6Um0n0iC90N~~NqB)lPVtmf9E
zCINRl2u9C=5Y7Y-h*c9(bqo+;x!2|<WR(oHgEXGzKD@u%^Ur!IYrTf>Z3$H95a>O*
zmY(8~HWwy`0zkT?M|ZTftNsf}2i~sDYTCHUwV9l>mwcKNhMQ46cpAw^pE6?9d8EVY
zc>~JxRPo8Bhr;yOrXRlU>H{dsSQ<Rap;UZ0rOitR?Ats^DxPcQRfIg;aEh&gQ^I_q
zWIw%6I4zAN6scFddWBJx^La6_jM^SAB6&?%GZ?RC&tXPo=hB*us(ddK=g%)Wf2NWu
zslSxx+*GArHYMSHy;sJYlt|84AP;gO%FO)8GX?WAhck5RV$N+Sp8DqS$sHs5cX!a%
z&k`Nz2$6f_tKvS8Y&rO%J(L<Gy^9tQoctz)JE9`BH)n30&@ef5o=bU{cmr<xJY?+k
z+b`Y4hgSN2IsuDo3`#`+(&o&BwDWd_ncE@XL>@NdcvsaXpO+}8J+oUI=Jr|do<uIC
z(1La-4WJjq&s)phh%!a<YSgpNYbuNfSw$O0k`4#b=iW;h`pi2wEy}XH3YBj>igChu
zfLnf^R*Gap%-Ys+l$HUQnQ!!dM`{33o!7UV`#WO+Cx9_O_9-m<W}tfmFMfX1#o8>j
z!}2F8L_#faUoGcsIOtjYSFN-SUSsf|6}j_m0L*;O&XTtV^YMKv-l$*#SX$pT!Yq9w
zzianiIrZ-SN}vDM#uQmXZKDy|FLU+io8uyWuN4X|Q103Z2aB$RIDQ9U79k+rtv<J-
zZBN7>bqoWu&r)=jt=GR;5!*l*plH^nD6O|Y;4c5Mx#WHg(LY%Pu_w{_C;r&V&LXp%
ze*3IDWr=rp?;k{7U?nN8ILJ$1bkYvD&sA3dRKa+?^IWI`5YM^1FP#bJi(%)_P&Q%|
zlKT`U4eXe?m!Sa&HP9iV>T$_6@4$!l#nK)b`A&OCQ9B&;A{%1CroCsQr3Vo#wuodD
z+K?eA0syz7DeC!&Lc>ReWN@M*i5XL5eq+4*RD5$XD)A_4=#l6q1xkd*eoQi`>C@jY
zb!|@}#D<Hm<{@ygmn5bl+YK?#DwEE@Wm8!c7+BO^Cg!cQ0(V&2wZ+8~EIiE$0~s4U
z%t!f4s#d8;{lj{O2e?I2MfR{Dd`l)|o{T7&MSN$ShOecZEj)MkC`cSjouvhv1yb9m
zy?1(JrZB<;GFo9X1bzlJ!V65V*i-OAJ7+0G&f%J6FC;T0u8czu^u;)ur)?xF%rnwV
zn={M;=?A=k(pdEFeCqsSh@|)NY$s7F9%Ch7q6g@852L?fGc36xrKGqst)j&)80UeE
ziDY;@Nd}6!T9p@QE5UFJ$dum|V961KSf|J-(T7J+%HE>y^BsR<#f?Fpau*P(H4sxQ
z;^wDRPxvuNS=w@&Yce@4(vfN_Ci7z@4R$eN0)IwI6gA9dsJ1BIC`&*;jMZv^q!Pdv
zg5zW;x$;aMiNAd2w-whXaIJw<3Erk0pAs`Kc|2PXt(=yAzs%fq1|6m1@RA_9Ok`%q
z#Kq5`m)Ob%I@fy+g^l!Q--1T`fb0KbqNZ6V7e0jWdsSM>wYfM9VFdm2vZ@U+T}lOQ
zg+o-3AS_Bi8P9*8Xg+|;K5XH4-WOL)0KFW>Y+RSH2o+t!99l^!z+SL?aaz><`puL%
zjTePCs`1w<$N~3xLbyLtToNEXQ}8<||D3~-{pv9#7jkJo^QW-FnXWbu1@?gGfHF62
zlL+3+(RYobL2DtUlz=-#<V*PZyE?@c0;VHL#rw<h4+%+LbHy-T>COVeQ$*A|%pS$f
z+_!uh`d)AppKY+03tqpJ^<QC;P#i*`4gFUI{e!*xEl4{&3S;zQW<M%RVfIVJTGUAD
zCdVBqC5ZOmZ%<=TbFQLdM-voQLkudNB1Y9~NX(nVh;mlx-!&1bdEqx~WE&R#4g($w
zEs5s}-P;}U2f}L0vmKi<>ZJh9V%@>bm=q1+dvS*jflom@ZXIm_x3_~oe+>CXV&35(
zg49Lc>;{WC$TkYHon6_%uI!`;gMmBOec^9H;_fhEX~a9|pCwL9iD|%o?~cHf)iky!
zI#F7<6{t}6w&@{Ve7S<wq}|B=jo*c*zK{{7JRwu|Zo&cC&Ovsuk#1v^{0?GGH%C}$
zH%9%UAdQ{Zz(F(vh^y?HzNtH=6=@GYGHahyO<5f8!K6=7RJva(KGZ-(#AhA6e#-_c
z$M&lJ!4sCLE9=0*O-Ya{9HI&UclIKwel_iEWRG7>2M?))1td7-Wd(_hC_si-a1&N?
zg-b~$7PEgJ1vefnvoD5E)dGmRmoo`}NJw~k#ZkvBQ&QPGHu4P%=~`FmHim58g0Xl)
z7jzKRj{0QXnkO9(Ix%oK4kSYG#{Z0d8W%6-ih*&m?&D72QbDmKHPvK=PpRdT)cmK1
zFk|AnexVY2gNnO5y#^bo*fvomA+aX2gx$kHsbXQ`b3Ry|2l`%&+_tRgEC$`<B3ML3
zB@Q9O1?}iIZ|gR6a**;kAb|*9Uq5`+DR^b&Y_LNxOkQ+CuFNMLbhQ`eZP$pjr{1*0
zObck$r#Q~N5}m=MbGXQJexfI%j0qUGZ5CR0yRH-0dO#PhjuYR<s<-=6|9GqZ4JXUq
z5>bgqm~xPhds`EZ*K|?J<Vek>yN>USPVb0}klRDqn*pU1kj(CkxbMBiyS2}QB|<Hv
zdWer^LXiRoL_e77KVgeJ*h2QQklh@l2co5ejWoqd>yaRR<hHau4ebD!%|lpNwb8dh
z?cD0bTS#jBgHA3ea0Vfp57UXxKEdyh0Fjy>a1b7@Cmv9mi*A8Ro{BsEEJFq4!g7;N
zIh=ekC^}B+D65P4$12tB6p0T(DPfz(-D)0LHDGyQGY%Mmf%j~8K9++^3nK5ZA@rvZ
zlU~SZ=i}(7_0fCaN5+mdP(U{h7?q4jz?tph#DXD4fLd2k>2IOp3;>SndHYd$eoUOX
z?I6zF+fe9Hl@M`H2(?8j`@s=rKSjEx6CVa6Tedr&Y$5-X?^VaZx3)T?JCTYUH`x~u
zKeE74l7KR+%h;-OB0WG9fiPu*B)AlY4^ATr*oCp~usmhP5xMI^@7$i)7q>gl$_)OM
zke3(rzhx-cq>vgI#or_&XMm<DE~<wk{H+ezg>P2EqFfvX(!&NG^FWrC(u$mcv@ez2
z#JHS!h)?*S;qJY%Y@Nfx=@jN+s|R!rvX={jv-|#|mK2EtAq_)0Pz0RYAo>}>Tt@^C
z$b5W?nLC4F$?N8?1Zr(Q`oZmZgB`(Ik-AwA9(O$G29j&ugQCL*dd@+Nrog5YWbe5F
z!_Im~pA#m$Q6Dyl#zDH05Om(HQ@d&a2Sg=yKJG>Sw<SIK&~Ch=orOCw<Z?L2Z#ct_
z8nCUCv}z*H6X9|DA9L<^1Mnn;LlV;P@`lITTSz&g4T0P_U($ueN}CbEG}gp+y08+F
zU%={x+_@rP$_u^56RN^LyiY`2>m8V0=u+Z<5;zaXV|Fj8y_7eZGxj9rFd)b_O9X|*
zebu}Y48oEtd58z2^6+Pw{exVPfI`b;Li!^te9^i&y0h~7iBWa(sPeaZWpcm+BEn|@
zV)SkBaA)@&4#)}B)mhvnvz5m=g2872x9Y_Oh`{by{2~c0XNT$Qf?pXb7+J3>Kt1TS
z>Kw-j^Y#eKQILP<A7A}EGK58yceOt4th{6;zK1gLME6y!O#_W1>}CC+hKOL}kT>Pa
z%9$V~W|`gV*4C%U$5;_=FEerPoNJcw2J0>~fMb=%DWk#Q#Od-k$RGT$j^h`RR4n{Q
z$Lm&Nf>Liiy`#003024RzEyZucfPlqxtk^&{$kv9Y5{SN*-q`4UD`p0fJBrrcKwRS
zz-*8;AToI=3lcR<Xj<?z0m-xPa~0u_@WMC$p*}eeB*njt{sQ7AL#M`Hr#(f=a=~Ui
zuqke$T=;D#50r2A;KCWmxvxT|OwbZm<X`>7V-9kA1pS-&Zsolz;UB1*w9q%rlIjzW
zTzP(n)-bhu3eY={(Ag%(Mm@&~`^R;(Sk)NSBdNUH3DWN8o8CRI2q+VMHW=Eq9H2Pb
ziG?dNKN=<=Wbue*EV7A+sOAaxVwW`EAPr^keYfB9O^pCM6~OAMFqexyhgg=(b*>HG
z8*uKr3J)24zpazA{G5$?gugvo^qMyR`0;0uhs!Qgwvr|f@39xh;@{<#jMy#+f5D;+
zn`F0m=xRKoiTAOYC!~byyu|Nhq~HEWM!#gen-K#rUI2^@a^=3)B;03sa;GmC{+5vR
zOMJ@|fge02EJs=$BqQhWA9}Z|33vkn7Czncx{U-m`2;MB``}hw*~vq`;R#C}K>xbc
zu}wra@II0~5#<1wa&Ec<K-DJbyd(?nOS3^P$y?dNmPzQ)`mfCeXsK-p#~$$sS2CQt
zvZ&X5Xad>FTOP;54dsL<G2id@@V|GH7dd-JKfKilcs9_>M)G<@)&Y5ucj#pzvYGOu
zxo3>^Y*ygWt=}Xx7sr#w&0R5=BlyqVCC`n1=SAkCTR1{j*~3aP-4L%eejofYWj<}Y
zE8j-Al?xiA^!wjl^ZZ;%rI22!d}p1SuAG3FVS0DpU#_#zDcKd9y>8^5KjoY^^O?v4
z)nDzDMPBkiPC4sz8yMt25X67;C3((Hc|Bwezb^p2^J%^L2>M&E$ZecZHeM*7okm-u
zK*=w;dsm+W@X(z8CzScb*8}5w?hoNn?Gvr-#AzACj~`57%dJIv>fZ%Bk!toI@>|5E
z+Y<?|kwWQz`Ix_aKKaj@jM9J>qLlo%v)1D+39)M~UE#ss9u(pp6f&-m8C1~vtk5a%
z34h8)&9b&0QD)~BezpGh?P2m_2Xp%yPsHel+y)yA`U(c9>Hm{$gq0i#>^FMHgyrKu
zbL=<|PISh8n;!h~vWKo{BeJ}?cKY$5`}o^G=g{vgBfko+87!}eY82nlo4T?bGUZvC
zfe{8UhgXQ@P8;iv#S*ou2-hy5X~`q!W=^%<^*AmFFGx8%Rc_Nc7*==qMB9Zp^B3cV
z4=%3%Ui}iA<B06A;-(LTk#B1=MEva}X57Mu{4f7fa?T_#R3H3?`u#;K@^-D=)xfca
zqE}N@u2)0u@ef&+t%OXA-zfF0JKMkSg_psB4<D$nnnK6H-+p2z_86;E4SznV3VZn=
z;>X)W@iPrY>^Rkpwb&@gFd{DP*L|ep%Jcf3rc?LCBvT8_PPV^2=5lB5UB}0r!=6er
zp?MnPH*}BGt&ZfX*j{zN_k8#c)m!ZzzC7E0Z=aLq3Z?wSSOT#w!kTqn_Kfvhm2_ZN
z`jFI#j@2`Y@7Jl}*u-$JdKvPTtn00nh}g1{b=z{7{3-A&F4{LJP2*-tAm~97KHeg7
zi2glvn7zI=I((}@BsWxZ+t?^b%vNwsvm~Bp0k6G-f<8AE@OloRo~lg8Jvj*l1<9J3
zU@N6h(9`&Wav}7;L*4YRc28vXCyMea;y-qjB`e)9Zem@f)P@w`E#ZSMN{L^+ZtS-m
z(VC*I%fcWB6&&0($n$F{Qu{S)f7tHu5|){Jx{sZ8ld`fuV2neSu$Tr1-GXSd(@>uR
z{F!EE!9{MFR_R$*nsYJ9d;WvW{@kKjwZw388AlO6JHv|99jj73f!|b{c1?gb-Sq4F
zTkS{RnyOZeKzH2C_c<5!2b;ZB%b2k<TzjAAcE)?wc4x(^Qr!2OU4xcQ#NKb(PM40<
zfq`es8Vls7s@Wc9&2=z!|CpqYvi=y8mD|gi7J^E-zZc5{6e32-O0IO~4>!P+QR7J{
zYyL5TlSdAxIprVWn^)b8@Ep~uj6G<fAwe{R&#)4I|NVHKNHiqeN%%Tit$0(gC`gRD
zr`>UOJ7hX1$2KJ3Q|WrF_rQze5E&9h=sTVnSS2P)N;)~VBv2U9BipDPpL+7+F&b^^
zp6Bs8=MiP~8B5KgTb<c|Q{+!@LBSsH48n8|#V%GAeC3A-yirP1vdnk4{R^QVa{LRu
z;d3HtP@Mb~WP2z6Md;a*D?_jF;gRzOgBq6{*VMM$pA9+Aetvmr8M9x|U{Hd*{MLG3
zsh%bxvTLKK0&Fd27Zmtdya7+aW3DljV!Jh@FtPSapA<t2yRWYxcH3mK{Zfm2;4ysb
zPc(;%^<fgSZgH0k`c7@?iI-AtPw{y|2gBKt_ef4~hmgGeJ1XLu<50~Yvu=sI81d`9
zj;LVYZW$l2cxXLcL(l7x=MGF6-tx>-g33TF^rbpGI*MK2?D?aj3MlnD<zmXwB<<6(
zV*s=O{xj=8gL;{@%~V^TOPRl8D;4&IP(OWL!aH45Ge7<6Rg$3u{La5V@zN1R_(>Ie
zo2$&EB7zeZQfn`HH!y|KQYKulg`-|PgBfUcNt-jrYWjHFN#J|;ksGtKcOaNC;*cgK
zw<+-JU75Hog5k~$i(KY=0X@Qd#K%GB>9SDVhf!aB@S;#Hl}K-(2<TDxuMos5PXvob
z26UmJ1UoUqloab_lze-)%iH%1C}=5Duic|+#SW19BKV(#04mVHAwuAoi_VvIR8T6N
za@GFHes5ZiWUm-(A7(@y=KU0YAebf#IN`48jAIN1&)rya3})84zjBIBNt+2cYdMv6
zDYfF{s}glHlaA}B0^n+I;CD>$?I=%N1NJ|*0C3w5wfB-^W_?W2!vnxm`we`FNTthu
zHSN@cUk&I3sAMhH3z4{S#HoL6E;h>`ny342===2S)%ye4SLXVaWoEVPOzWl)g+eDf
zcQYmCpaa3IChT9H)6vf{2XbqsW%@Y_F06i9(LKtA@C7G&Ob1_6zJ-=_t;WfU7d3It
z&RKbzEToKUuB-7YKS0MNn|-FvHi*z&-|~ihT8mO6PpO}vF_(bRv9z0FLCSqA>9>oc
zcAufAWrpz1p`zZ|671gSeH>?>?X@f;Cyr{3I8<e2E@RYoNNLH}<;o^bh_<M;|HzWk
z8sYG(F6_g@w}}m&#>YnyB<+GYlQ6r6Mj@i0!=vp5jB&{#DgchTH5zr^-O4_DULSX7
z>xxU{aA2;`$0g~S*U8pzqH{(uOBx02f%&`33$E)#1*a<gQ_KThX@*A+Y`)SLf4VN$
z^i|dW7dBG6|2Q*#F3{|mcFL7MboxsXH5t4FLnyr7ng8e6isIrD@36kALdLqP{OK<a
z?r^~)2bLYn2P*U~Za0>0DuDY;qVzRdZY`diy(itvyO;NI&6NlSE4Xwx-JVGp3y*M+
zx$l(X`p!v2c5+Uj`Rh&Ft82w4QU_Jv%n6vn7pWqcCx%;bj?v;Lf?PHi&*ycYq4&q;
zXbuizgt84^$A%zu4~3(ZHj_OawzE8#1>z-N35Ek-QP*b+l{fHD3{o2D9HnI?O+3is
zB-!8ecYl`js`F>vIjZftO6SBy{i~+Ysdl7VrOQXw?G9f+Yjs196dil5w)q@(i2lBA
zhg7bbR|r>?YXrypmea;=tX_@C!!F8%Rp0YEt<Rqi?S6zIyKMCZzU+zZVLO9P`m&vO
z5GmR8m84)jYCq|n%l;kN-MLSd>;(0=JmxWU@D3pEcEZ=FfQK#@rWOBIu}8nXkAM5q
z=SG(YE7El_d>{Yy<Vni<3}t0q6Nq}2z4^fNi$;ot<IgOOHYuXw8Vu!$37Z`CzVo}+
z`9bxk)LRl?Z7mE2RBCQlEooY*Y_`EH-0k3hPdpJNo+9U-{BY-DO}m?|9klhi87SAG
zL0bav=>7R4_4w~*+|Fi-W}xj@PJ>$a7mr2)zYqFSUqv=b1%yZyQS+M|>DXrg^$<LH
zJ+&hplPE$rZ_xjdy1j+Tt#+I@6yIv{;2&}OWHX{TXG;Ov6ayjV7OI*|*V}o)O24>{
z;~>!=#kc0(49To@URj(Ez?E6T%RX_u*u8?~urF_MPFk!O@!ckW-?jx*r9~NT=Z?Af
z26xdXcR9<`*ZF{>{)PPe>m%3HE%)7LJSMvLT;Hti`u$|o$@Idz)r0Q^lr?)SE<Mq<
zJ@!z8(>`WE6*mWoVyTmhW<tl)&QzG!SQfgG^KDlE^h%Eq4e?`-Lj4!UHLRo`v!|q{
zhY+pT+9wv4r~W1Nu{4TeH3tFrGHYw#*T!V*+9-wZq4q4jFrv<HglsN>rm<q7>C3qF
zmmx;Pi_cMgX+}<qu*S0FF@SH(?oSI9zkg~aS!m4QT3sr8tS)~=aLgQf_^;)|T<d4N
zBu`)1QmDDd6hpew0n{r<s<AR3OOD_G-CvCHGWNMEFn_lAhF`6ZTk0het@Joeb3`JE
zWF(*mQX+#C3Lhr*GOop@Z{qV+4&f9Hq4ZyZ39+!5v~=s1J`)RDn4i$0m88jL^9kmo
z)?=`1n<|Xg*Av=O&^W*{b3X{fh~Vtmc?!Sw6L94~yCDPpG6OU5DQ8G~x+pN`!?gZ{
zOsF+g%sg3gQ{h&i=$UAz{T#IRarq=8dRo8O-Xh6sm?5|v%A~fL>z1i;+SCtj=s>(>
zm()S0O7?x0y2fY2$eR@5UEGm3C@ley3mMaP*BeJ<@Ej`-Ce(2!H6m4^w|S^Q$6hUn
z22qEbx>3a`AToDI9t(<Efi?wL>PbARadY*pWtd;dywvr$rl#4yckqudL)Tiei0E*O
zO?Mc9>a7YExl1J0z{0tMU<@T`eUQEkiyx`)F2<&25|rID!!d&Ai1*GEmUPuHoR&xK
z3Z*4rI>Oge^2VvIEc|CH^VYNm{MSyiy3v|8E4vohW?|bF3qN|R=F+B;+A4#|X2j1q
zL2!iXm;;ba!>e<!0LQ@^AVmZ}<iVlqHHqBttKJYxIkKKwZvblyA8=WQCE}>kY!Lq`
z4?5XSJ&2QeaJv6LUsxR8CWl+yF_WwvFa4(mCX^|3i+C#}THP$OGGdf*u@FLYcON`F
zF1$NwQERh+ckcd@bgE6KivydvU>34Y=z^y>9R_R62_}S?Hb?2Z7ZyqJpm&p=UX;<(
zam*~4t_|49@{unMyq@#Gs8GBC8XBEX-<CV!*ptvJXon?ybR?F|0gmkxwZ7u`RC>@2
zx_Q~iBi*Wv_>@3$NmnmJ6Mj&G1Rg}Rh_|FEj)00)pnn=XzO2A9dM7ehQrzjbBlYHD
z7xhD<Z%yK16(yqA2xC>&BVZf_-IfAXOcy5FD|EtvUlbd{5PX)>RKw@w#4=8kQ_h5>
z><QkRgU`FjwcL*f@2U+NZOK#eZF^R!;q3#A?VIUs8dmQc{V{YGs`Z^pyw9kR?Fht<
zJQ*Q0VgYzt>Wv7)p=9<T73U2AL-aYA^OVfYYO*b1DClbvo_Q!vLMRR^s5j_+mMt);
z4!_1k9h!5a710fZ4|>8|kWHXNg$+?7H|2e)Jh#ltD?Q{<_>V)1c06EzQkv><HZ5*<
zYK?ABc9^$5kN{^;^(a7y4P9Y6Y*UVo^B%g<8fiY55i+fnMYqM!Gext%NI13{3YP2<
zyBZ+mR|wU5K3UY3=EkL?gK0=@ssxcL)|Qc=Ju1m3z!LMuGDey+S7#}=dad?01)PLB
z<9s5q6YIRG{u9sq^(exdKzJK0=(PmY1PHD2uE8tf@k4}Es4GC%AFme@>mMNO-W<UX
z_{Lp-Yo%VSXFSuTjn0>$Ys!E%WN0d6aKc_{^gKg}DJ#t__Uli%rZ(pgdz5gfKOh<U
zKPrhZnt*xPg+EZ`I9{Fk;+<&Pl@XXlA!N`PP-0o+Y#v>hOM*)t!>{bin)3LvnbN|$
zekNAXlZDn(Z&8$^Px>-a5@5>QW2MPd304wKn{i+OB<4FsRKZ=s88=U<7(GNI)nAn2
z>9)L-Fb8x$YDQXOI{hAl_nN`KHX>+2rfHienZmt8yZsVZQ%+%_t|8FeEU5j8txyM?
zV~@I02-~NTa+)cn7c3Z%2puk_uh7`EImQ*vE1m)kKC+j_IjT@7a)E$O+=T7RLjU^W
zc8i^c?4nq6AkN%f#t!;Ng45;x?5^WTT6YSW4fDH*j!1=Q`JOc8_?xmEAXt57&3!^X
z^z|EvJx2yUB~!4S>T^P0F;H-EFY6o&z4G(*2Pb$o8>Tt;s?-C#yS!JPoLliPHL;9A
z);6^z`Gq`nIoh6Q^F;u!4Xritcb<bRA3#-h3DU0kY$D&Fnf~i546~4=e;P}h^3%-|
z8Hv3xdlH>c!$0ZDp>$2l@Sil+KV*3QGkUlPy(xPtbfv6(U@#g>D^;XnLuh#S6O$^S
z=7fTe6N2`>`lO7e_a7jwQ?_WCJpHdpj?4gO0^M#`P==38UbF&H-i67$aa?7XW0zDf
zb%MFR>mx9Ga$xRlV&BM%uKC7OzJnu$s9hEPf!gr;9>JTkDK{qwUqWCqn;=6aurdxN
zrNWS8pAu{HOC$+FZb2Pn43q2%70xr{L31a0g0B=wvieXwmLAcI+$EP3vgeNL5H>gb
zU}Lc8La<p#(7)tDVfLKHF@`5|-Z=ys>7>}`JMFyIVD>ddcOkflWjhg@e~BQt6!z*k
zAHLkh5frCT)v%|HO7#*$@NUrj5jf+ZzI<_(p##D75}ff{9v=R$PJLIWA}`IqfvjmO
zK>c1o5|`690=PP!uxZ#XriSIxwD3viKl(#nQOM-3<@A8u^K={Bu@fI2$gdvxcKm*n
zx=TRkE6I}lSgh>_cJh_0MHWP=ED?l-(@KTG%BhU2goPrz<Z52Ci<{&TA!8T9TbHE;
z8dlNDYG_{L(}nN0fZMSoIP6dUN0o<jlIP!&xw|7CZ`gK>7_Oidm!=OS84w}3RPasB
zES2-)Up45C1YhS6x+9bR8YnoyeUb_{zpFUqW!hwVxb2cfs!_tdGgv{syRe$f?vgKs
z8V*mX7NN~X(8A}aiktMyO5MdHX)Fb(Jtd!Qo7y7DJ)jS@pEH;-Fr#k*t@`P9-GUB-
zzR#Or+ldfk-z06{h~ahEb<a0O<`8{&k^wj3yHt{v%#yPb0yIZizWYwCFU6BcxAlbD
z$HEq6^0=QLzAHI@fI{a@v^{phUX!tXxpn=QCOi&%{<)^;?Zk7tI{UAdsr1)5&sfPH
zL}8}iQ-?FNY*V3FN|G%T+L18a<xO&WMR}k7BJ?&d9?pni?pi`L6YP?a`SD6aSOgPd
zwL&u?t^G@;eN#%p0T3JxqQ&{>ECu{@4)R!KT%3d0+VcH>Zx)}LND|aE511%*t>OOq
z*#2Zs%3d2(VG-!AJ}5p!%$~rz(9ommaO!)2uh4LY^X)f;If{xiL}bOju`rNr4<};@
z=~?go{u{5n5V3M5)YKPp5hr@x6oNHR!oK@x6id^O1zT_hV|a`!D`3?Kh}mX<Q%b?W
z&H39Ty62{#w}s@X?4J+q-rBZVqcPud@byO$_6FiVXR{b$g}bkKK>oLK{#o}mtwNG-
zd4OzE!)3U(zM=nYAR?QT2n^J0R^V--w8^mM=Qk-9Wblf}5B$q_=1hn=E@`(8U=mA{
zKf7we1+EeEu8_f|<RlY(k~vop*1@>z7g@{q*qy6}9AbXE^Gsz=AKv<-ZNP#6urD<M
z+f@p&wOeMe4U$o~vX-=;JLXVf5^YwKW{KI%-c`;#F1y{KsRM$rG#3)u&LS1^wdYc}
zR-n$@{|q4$?)SYE@Qs|LThj~+HpGf6*xr&|ANuyTH9bn{ti-d|Q%K|1zmNq<^gadD
zsg;yf5w-X)7XEVzS4P~%Ryr>2jkb@je6B*9{k@ew3~P%$8MY?qfjOpS{`a2~1k*PA
zbCW#K2GhY@zHv6x<#OD2L5Tj`rgP7_2@@=&JRWgO$etortKs8Jp`Y?$yRh?~9=|l>
z^+^FKO?1kP^Bp+iKvVe&W9vxrPkeehdM~Z!3j|0;Ni{OmSK=R_!KzrW1<Cji!SI08
zF_FTA-GNb|3klVibyV&qg!@AtzXj{pBv}9q3*!34{Yg5#f3Hr|wfe$rwV{DFR|XDV
z;Scn9vg+bjQY`vYGm8$GFC9{QCFmRkUcQiK%Vu-+T--;XUTl!<KSlyZQ92i-ilJ>w
z)36w@GLNbr0(%34U)@;;J+IUeV;O}@8HQ^+5%o`sUF;SQSyOe+++J!4U0JIbHuY?K
z^{e$Dw!`Qwhmd>S^Hg`H;n`;kTIiFO7Ro#3@z7PRO6UE`Ughf}c`Ex8-Ge(XugTv}
z?YQt^N#jW1{ga0~r@r#fHTqxI2m~pr`qgSz9XPjF<w(5UV5Y1FKd!q~6(%BMOM{9o
z9fgZ3yN<uH(jngopl-pP3}r$Qgp{*+#M`N1w~r2Jd@F;%L_Eceb6t$We`z)bMy!5b
z{q@<h!uHC-@_=3RkcYgi16AbWa)_Anp)d2V`n7&34xAJ(Fq)hd-uQC$&x_I1FI~Ti
zY2KWvGqDWKyJNSM`uw`+Wx<>mC$~33sP6@H)E#%EM7@>S+?aZgw?^$~-_tNBj#p3^
zfito1@$yf%!!)dOj>RT7THO3~FNh(#e}@c}_P-)JBvqdKF;_mUWYJM!q2`ZVhRnw4
zgO&?(2FVB7Ok#%A`Am#JnhJNS>6!IknNN~7hfbR0UKn4spA6$KT+h-;;(6UvySYHS
zz4wOi5+QcxRrJCAQn`@+xC>pE#*k($?0(x<#s=^Fokny%iP{2QFpNjZd#at_dG=7q
zdG|&tOd*yzAn2+drKNxmi5(DCI`BDJIv`fXS*9puYA_Yq-si1wfpy3?qY5D*VirBH
zHY69;W-u?8Xnuj9Ob@!Av;Xez=M%XH^cikWhKr|jtiKd44XdZD(|x>d;#6*mwZcCg
zER<U_8s6okzRX*yFOd5Yzu+?mEhFd6s!N<J!v;ht>p}#HO4lf8r?br3V0YeCJDsYV
zKfgS<yK{9B%BQM4+;UckX7v}>3L|4u>TkzeGR!uZpUL})e?N!mzdNy<W4)wc<$5q%
zVo=d9$2<^j<fgs$)57@M^&FJ(fC(&PD>fquxqQO-VBJqqFMrX`a&PE%x5%mjp&^{k
z2R&ZDtW2u%BKlOMr7t8stFI~pB`Y3({Tv<hkNf;ty2x|&Mi;M|tSPHD?a`<DKB0ri
zw~sd~4q6Q>HHG^v+^%X;xs9?<)#;Hi8h`q#%t8E-X+QR0Ms*vdA6Y#zbI|5vc(aGN
zypk7mS`Y+we2KlcNEba78}i`G-=(LE(##8MNwTivDh!L2aEAsPt+J${zNi6FPaDq3
zm`NQO`ZWL9YuRtVCT$kji4|>AzZ?!e=-}Q{c+<VUWCx?GyB+49m3?TaoWy=VVM+S^
zeA0Bl`2EkPwy3n+{ni}bHPj6k@$(Jb<LYzo+&>oNM4q6CU$uAmY^y3}1uCPtY}yIz
zsi`?X9w5KWgIVqbh$U7EtNkW2&XsuI%L!0dkRdzmIoD{<cvE36wFQ#yCEKJlQ03>}
z58q!l%|AJlCEW&xs=%ihI>(lRsK=G>g#@IhPjFNhu_;EG)cqR9Af+QSL#S|{q?j9Z
zN^d(rLI()qks*QN#Q?OgSTof^5G?&3IiMgQn(vQWWyplO>~);Vmi(QBxwAQ7KC>bh
zSj2Y_*&k~!{Ro?4K)k>}712~ZW`$2;8l|b){>nSO47YF>GWB?ovinpP8B5mWvz?5J
zqfi<s>P>f6hSPU1qgw*(!&@O}5i(%&GNwN(Vxd<S@jG`E{zU#U@9m$|nhdCrs_#|n
zaUJ|3!s~0K^76<K&i^_(uFye|91E6yL=-&GbVxY=hOhh!-oxCWCZ~S@Ol3^#fP-<P
z)wy;@jk!R$E%dD7y%-O}(kaww>}mKz1$*)F0MQ6~uAoV5N$uDoO}-6~ykErVT!6#x
zW(^5@u9QBAr51(xRVp&9ooqVu&=*E_tCw?NnYmZb3{pWTQY=`3@I1xH5yTJp3?JVA
zbM4Vpo(IO;azJBT)%>A#pcsRjqzng%#3|fxdZ+CybzKz2n4X6HC_E<2XDBg3)jZ7R
z?A$j*y{nS3H04|xthBwcmOz(&Q?rErXCQLu|6%Li!<qi$|M9<euragE`7~_K=ksBX
zZHAB}Nl2PQl8{plrP|DyGKWM_bBs_<390vH&Qv2xr5Z^pl}eIWzkNQx>-t{bKfc$s
zzjp1q_Pn-T+iQ>K{dvC)nydX09<hwfJ5bfpd2^QqIj?(vIU@}bjQE=koG|r_Z+sWG
zBV3_l6X(#>P$-er6RE-{3V;6<B5RVWXm?3`Psnzyh)1lp(-U#}zbPWjJ$lam@h14j
zR2}ZxT!yJ3=FU_l{?6qWdcJ-8{mR_;shA8Lu;CEhOg)OL!d3<(msl6iE<r4!Vj=sh
zsE%os>YWOtf?d-lYTAuqsLygv9Uf&eU5&?%@w+~e;dZ#3Aa1nkgSG}vP=#}7Wvxo+
z&=*XSKcvz+O2vLIV)uzfv?n%MGBt-4t(uUPxTdSe9db9sc)Y$kLq;XA82dO(Sh8t1
z@(3?o-u1`fiVTF(M%(WEjs1mZm};n`6v+2dc@TN+&^cYQ0p1RiL*z!6K!ZGu>|`E<
zNrhHF<nG>8jDgO>7DOJL&U-mr)L`*tQ}u6;v*P7pkQNb?uHsL|Zi!o!Zn<Ohj(m6i
zK|;qe>53nq^rU2Ww;M4FB1D0b(LFSswylQ!ltY({s`V&z1)X!QxU6zsy)YKj6LY#5
z`KBC#{QVH7ypaHtSXtzmplL>h{7cu5%ygy41}!OJ9bybCF+$ozJOXjTRjO1M9jN|s
z@W7wXc^|B*WospoVK|Ol#H6RO`4+q;FY#KfmDvRz`QZVk5mP-Y%gt**JZ*)J^ZO%B
zvHRWoD9BS~wgDY%&XFIaW;=J2paF%wB4Zps^qZgH!jM5MmH1V&1rN88yf&8<&XHHQ
z!8|bi@WyXS$QWquPG;5?op!x>SALJ%2>77ShVVU=rzY7}t_xyG58l9F!HCrRIfwe?
z77w21>q%Sb%MZs6n{-VU#?MeiLznkp(r_qWG`ICczboE$GWUm1|L2ID<2Ey$g?n|I
z&WgWqeyG?j5V+`yZaw^_eW|)xy`M{whes8xRPA4{G^xEVi*i+5WawROA!BZyzkP>V
zZ=aI*LT(H&vuPm;>AEg_O#4of+_)qjFNFy#?HsiMstewA&=tK`&OEQhz-MsB@AypR
zImLeeBeTOvjwgKB%P~&wo3KZ|J(n);mGk0cM^%rXk&NXwKRJsTyfKoS=i69=yF~gM
z{j=?;nV=D0+2cCG!gU~s>6yV^B`=vxy|@<ypz=50EsO|3ZLR~EPivJCp2G0?*rG^{
z6G9t(qaBkxM97dZw(hBnPu|xrZ@&JKTB8kHQp)}`iP?D2+C?&UWzca>xhm>I?FKi(
zC^H^hdOT*oAs?C!pMUk)8a|uqylZY?N(5pbLH<2OwOpkWGHz^&vn@;W-p>=4{h-F$
zbW98w>_pr-SShszB(8AGs+mPT&Q9Cl*UVx2d2$FFgo*}vo)c~e%L8YD<mOS>8IYAa
zIs~{%oZ+;mLJT(9c)0<!@=Oi=D{#X>1%~+Eb&i?H0L+yIj$#!pfeq8B@D%D#3y)o!
z=_cl66Lpf9hq9OlEl&8wHKNjtvs8Z9<*Vx~w>b_+WI>3)68D`)N6b4LS99^XuU8$@
zR|c@(!S)$sn@UI$jr3oHyX+ak;ReOEF%p5A`_g!J7nQs*BjjeVC)s>LEsfQ%bA+#0
z?skYc1k(o~KA||Tq4YE=a*!&$Mzo7SUm5b2NPO!Y40V_Rp*Aux<|K(3f#&nVqkQTt
zOL~{o(-nUX%xhlU9RwG~_$)aZ@f?kTIvjLhGnQE6!_7*}F^J3~JE-Txg1mlRS{@s8
zKn4^A2S~Zn?3{SPgKS5_{`)(_>PRqr9{Z{>LvVjyVy4~pfVr<41XwiR8Gwher2|RG
zG!7yuv)P(%W=@h$Q85pP+Cw3zEoTfg>nm0&WSu2O@wDa9S1u~!U0K=^hoR*)&Xt2U
za&?<h2spvLE{!ddmP1yhG&E{72rAoVL0G{Rd+8NtAN5_Ue7b!G2RjL>(x^~M=Pl3B
z2?TbtT{^z<8E(_x)+^sGk(V?0)ZK%Gje>}rmUiKCj8Xs#Qz~+lg*`{brBS7q>ZDTy
zjBB0Vi*z${h$&J7?bkq@=U_Kktftzd7?AiV+cE`K-Y$!FdM{c^##~Z1i=`sN>Lp`=
zlRS=PVis1NonSMbRaqYZo}95;GTicc){|jZ`W6W))@IQE;9=J5m-5{}3YfxAQpXOx
z<b0?+P^$yAEl($47l~ZFD{@x8pQbcPBjj*&$_I2ZI0WY2^75m*C=eqm5y=Y^%V2@^
z0bu}wUaFH>1NJ?<Xpf_rBsR)$K@R+srQmXU8h50(GM}P9j$LDk_QOSD(=oan8y09s
zX#wK;VK!w{yyx*lpy0pliT_fn8%o(S<shv2O^2RCyTT6WZIeX4kdLp{x4nS5gWpJ1
zW;ihEDQud|@=VRpo<l1TSIZ2=G<PXGkmDr|0a~n0O~01z2+MKQ&KV#~a(H8dR#IVN
zOLfR7&1zSoX9x`m9cY`O=OFe-YWtX}gOt04a~GG-Rp$3eU95DilOALl;OIsfm&BD9
zT=>9jhG07~kNh=AuDrhJmJ0!j&hMGgV)-bHvr`*x{%E>}ouh$1DTn@=k?bOs50IK$
z*e;Jj!fRA*3QH@)k*`N})N4x@V8MEAVEq)Zw!n(&8qld6@Ch1ho1|NnqOFFh9;Q@?
zA4_Eh=o_c1v^Z*p4d}Q|rS!b(8LUNCf=maCjWMrJ&Tyi(SS!puQ*-$&#OlLs*2QNL
z&v%HQb985Ui(kK&)^AH;)Io5;5j2|uhZ#pp<Qs=cTJ+2(R4W@zrFFMrYvn&mwa^Z6
zOEa#gYkQsSbUfMR(md(dd`*C@IGq%%N-JeRXFXk~3*Qk4o(do6iC?z-K}71eBDYDp
zb_O#cj+)zSm6>#_6taU~!I|>C0)9n$zFA+0^J)q5;yPrLgy@?SeaOp~m7_uIfO!{|
zy9EER6an-g*0s*Z{dCgvaT@*}2n3G>@QzM~IgrzFkkNo*#Y7r7^5!!p-MgATuIaU_
zg{*C?_t^6D<n-#}^Z|S@OGm2Fw(DbOklvGUz^6$_(+8|c8BiZx0!M|?gGge7#N#2r
zjAN_r>TO-SFS>ODTH7?8Mjb-zjpxru`WjU#kB~)i+$wdplsQSV(E!?SFh9^LSs5f1
z%fbRQ2q8~hhc|u^Bo_n1I1we%h`4RAQ*5!$oLJ;Tn01b;Qa4B{A~>Z9M&Q;vk3ys-
z2kj~y4JyHpm-Y3rYj^uTYEffo#SqRK$36vuUt_DJIqG1I^(g=>Y(RtG6{C^3rXI%X
ziFtQDfClw>2i_)W)`2y*zdqeC{5Bjb$PnvhfORP#X%E_t9Nh>T$<dy*52IoXIR=w#
zaG;R{nJU<w`|5W%`TO;^SJ{IK<5(T|NX48}UDd`sM{x%KGmdIK|8aSh;<5<=b*5{j
zIX>20)5=K)ZVcFFtn_R{N?k=tjtrdI2Hk~y)1wZkq>ZSolUf6btA^3^5YU%#070ih
z3&=xAnb|x?(f?wRBWrrwpbZiFxu6mUV~(kCFq}b$_!&v;qC&QT?p!1JjNn^YM;0Cg
z731E-`$(RCM7kXGBu6OJAZ=hW-BCNku{%=FE@043ZbHzIMe8V?_D{^lQ>a=}#@dyR
zaXAngjk-F_x(>UAbOo$JNMaG39#?p3E5wrPXs}JwZUKKAcGO>u(f1?&Cr!6vEx!s>
zHxtI2&9PvNcpY1!EQ6-7S|b-vmeU%x^?+J#99{f)lCuf1o+L>SG+&hpD=>3xxCzSL
zWbM(_=9lDCmnLjmAc}cq8YuxM{0H#J0UV{(<%z!WXO5k*qG7C=Wns9dLdV{tpv)<#
zLk{_Q5J<PNQ@1TaH*CtRWk7cZ{IbhsJ1Ns5?T2aQ0D=HOOHJpmn;N}woBMvpB{s0r
z&Dp7LF~O(&^m{0#?kU=dWOnOPu3)4&$_H5&JbG0LHnMHjVnE8?knK~*r3|F0=fV3&
z9Ni_;Nv+&nIbaywQB}t^JSl-0PQ#A?s-Yky<_nJ{x|9z|A*x%tJY72nET*Sx(3T)}
zha(SDyB$W?x)6^l1r8oMEwPIjIL?{qb=d`wkG|g+)^~MYrrQfFvDZ@aE4LJ=AUB#*
z#cij?ey0OZoosU)y9U78!s&@lZYoPT=bN4c;DlmZ)@`=we@?7FcK@vtk-2x6=(((p
z<|ZBw@06B1>M{>eir5IZ1rdyA9gxpZ$za>x$p$m&g#KqIV_np$4#=9*O!YaYiD1Ec
z<_9+Dy8t+=@=(|H&R`)jUj^1qrK_=z)O?hZ1C!W9O@%p{&C2d%@8`QRz>m&5a>EDy
z81K<(noLd{klHCnKNp~Hae84yBkdd{uH($el1Oc`j7PcLVJ90`cKA(_^dRln&1&PY
z{T6MV`lF5)I@7hc{nOq$c`{36KIxjOZ<?-AMg2}6JY+<;Hr{dh^>Cnz%R0nfN<l_}
zIc^Y8`@S4Y#O%);PkC{yiAvXwxUF(3_x_QA^CxmC*$S2|WCx&+*k!J8ZJ_X#y62lj
zT$Con73dqLLV44NVj<^jQ*D4}4mggg106vBx;!#)S<3?NADsQp$MeyVnp}{nHo<I_
zg&5rUWkW3eP{99pWYbSHBZ{RZw-)_66YmxM=;TLEt`SlpC`0fos^aunuPa@}4h&mk
zS&joL+b&uykkjhDFXzbGX#=fmmvPK{RzHb`9-$dA#N%ZEB#eV7B4eYv6$z<W?w}Qx
zE?{6xSIM@O1G;{x&CkKyQTEt5QpZG9a@;H0K6*MNU5wCk@Y)a0zr`b8EdL@L9qQ;d
z<sjKoQ1_Qlx_i{IM1@29&K?Q`tE4!7<kR-MQW?*QaQ*Ov;~Dl;fi$yWHwg)095I{&
zbW6d)+hF4q7EDgvFazi{1%$g`y-ZSxt+ka`4{?yrvZWhTIypesw0gEKho+)iBsEU(
zue2V&o6<ywX>XbW5cryz#BP96Hf{y2a>9t~Ejp465m}`qxfaRSxoll41?<Xl;D#OZ
z3xw$JD0Ft<pcojkWM{S6=CMMy59C+~Bt!rJ<XBt5udQOeaoe=SWY%lOYa=Qv+>n_1
z<?Mf_HWbZ2dCWmfTbBQOR8Y-kOGR*A+^|<FAjy}4?hUaQ_sCp*#ECS67^|~~Ij!-R
zDsk)f;wGb58WC#eJ-BQ2Wp=eq6xpWVZt}n3m+}Ebd$0;-K*tC9h(g<bN~3n>>`LUr
z<%lc!4*wv6#mE!aBuBqh;g0m$W&T(SmNm+TpB4%*{!Z?;Iyv3rmcZA1{E((X`t<XC
zOGUf-z8<QGS$ILY)!ne6f?RhPCgJBsD)di`|Gw~_SVD?%=?Vm{xK8uw^PxOAy6<f2
z8VfX9XrMdWCJ5|JmKpB*RQGeFw8i_}##ar4`@Xz~=Qn#Q+?s};;F5lAiA`!Pj7#fV
zc(%X)@J+cJ4MPB4{pBVAXoEQY>X+UX9J(jz<9M3!p>T}i!#LY_F13p0AAguWI*zWw
z5_Vm(NO<OSvAir`h*~l29zN;+bu=K<GP=Uz{I3*!Oh75!n!V>|>t7artgw{QUDj@&
zHCd*$Zz-zNYNOZx?1BSUhDr=dt>0NKx)$0XDrfO~WNFV%+zo!Wj$If7Qnf>LoG>0#
z*u!WS6JEM`BL?~rcI#+jlUHZp`3eM7gh{ErXgSTKV;NgxAC+U4fW=&cehe8IcJ;(^
zxoN<sJW(9aYXlqTlv;o9?T@Jw%=6{`;R@kA@kS*HR|-zMmJrd_a*q4b1@-xMzzMyw
zQDI1d3e|N0LRyJK*PZ=jZEOMpjCu4klQR=o>y`UP&9)=BlQ&MTFz|}?+n^70F@&oJ
zoBXQZWgLF`I}?I29d({Q0{+f}U_wS!MfF>724bgY7I)t`(_H~U^|H9PHDpI3R9!-Q
zjMY$t$)=mvz5dDXF7-cer!jNxrB3|S!-;)2vlRpRI8v|BK=4VG3)}_RC9S@m$cZnb
z0O!7XF@VRApnsehsn;jQSV6+aI@`s*<{n^5z9n!Tr;cnQPz~JNYM6c-gQUF4-6Ol-
zNoWpGB<vK$S2a4M4wVp-*cx)mk!>Ld{<|$WTWvL+YN>SMQHrC6uYboQXX8G?fLw9$
zSd;#RVOqV_A<q;0W)3&tQH-R7MRum5AK_S)^|KDGDw|0Ff;8=(asQ~L?3zwDi4(bE
z8l`(S+u*|B0*OZ!0!EIUUoH)KlltX-gED^Cr|e7lcXEQg$Z*d#!0H2_b%VB4L{o%6
zQD|lo9sUf$9My+}p!!>p+j#^+dF`bW{L3iv#4Eq)vV4_z^PAT~Lb{yC>t9+ANmqnd
zWCmUU@RuqA9mc~m6=UXTO~<ERXrj!zUd7xu9Vfm(q8h%|%Ob5hxdVZH@;f~zXPWO*
z+TX2eRT)0(xg%!P@ohkafC_)59~&8g%@_I<?m@l3i$Ku1@`rsBtG5_*yz+pZxbyXM
zNllaVpcGnu5DO%{&ha}M254$IF_R7Bi>~xTpw<~`t~TG{rUg^T5Tc9mjvV|Bk&vHM
z9!l6f{gU{}<i27HpakjNO>juMRmv#X^Ky%(v=m!%PR_`z_?DMp>An7=8IeBe<s8_|
zWd{JK;mPN@2;_%q%lVt4yUO_-OFsT#;hfsuY#rd}wkjP`cLz}9v2E8#*Xv_z(+)M#
zEbZ6`zl<8C?YW^a5Ahr{079H(kYu((g!Ft`LS&jja)SU{t6V?~G-lgxG?boG4?Q-r
z>5{sIFFa6Zs9A^05EPt<egDN28g+C&Sqx-<jykTlkIu2=ijUFyA!fzk5X|M@rO9*e
zh+tu=gsd76*CVPF&Uh|$GbIcAhECrjE>*qqtU<w*1wiydjRx4H&DWPu=h*2`C;W&n
zup9eelPFQg&9n^r2LC&rE**k-B4_>>L1fHYPJS=+y8K>I-W+CHIZ}Fl2At8s%q%Js
zN8-P{Q);BJ`6xl8sNUkD-qjMajc$)rK+<qFsnTN*+zx{JNS1$&EUQ>5LYa5b#FPWb
zvNI$@8nmm9o%qy(H8uHTB^2d13RW73%kynZm$qaM>6orTZLQZtOdCmdHxwZ9#$OS>
z<z(X6kBgx#9&)j!Pjwve`TmKj$0t%o9M);51Fb8_-2SpFUB94&K%cU(DfqFNKb)hh
zHL`f;kiF7_II{(^(s4g}_FP+*)g;^c2}tvATO8Wrl9-CG_U@qm?;<s4R4*~h9aWX)
zB;-dA!0M|ak9K&Wl6N>Vk7Hpbh9?@%XVgk{w7EP!zi{<)%V09vM?scn43C*{&ksxW
zI?hiN%zf8SLlgm)5rjxZcmQpA;tdrWq)Yj2UG*mgo5^_-rLmY63gPaE!^rTB&3ZEG
zMr@{@!$R(%7FBS-n2cNxi#qL21??Q8HoR#POU_lNKX!%rYV;PSF*uSgH7=6n-O{fZ
zw1J2ej&)BFDz58f)Q?diLq`QLNbqAT-AGlIsLpX#2ZKaiL$)l54}R3Cp(0`-$xpbM
zi9G_rJ{lQTF;;qZ9-?BYx6fgTc1bRty~mC!wErIkqHI@<JOVhD3)=m}^jZJ$XAjwF
zFrWU2n7!-Di=FyZ{p@*SwdhPa%wm!|ZW;yZv4{nU#^av0e|)F>e2pk9%qLPo<$mZK
z;-D(#L5@ox74F{%atkh?FqY_wCwaHC>xd||&iWCy{yTWQ&5Oc$HI=FObg9Rf%)QMG
zGlv3-rn@C!%3UFicE%7)&IcNivZAA0E__8xB7G{|f96SVwt?e^+4|LYDlZtE<ZdGD
zRU;c|T?@N7vj!u~u(2zQ5qnpnt!#nzgXdn)bH%D6POJ5yebzJ~L226Tvd_v%uAFR%
z`&opU(*{-H9)vstjCyUYg*TBNeE6!L{7-nYP6r~XBfeFK3YNLO26dPe&!Nn>XWy6e
zNg%~m5RHkqOc}(`M|EhV0;jlGefDI{-YLzVUIot;kdEtqe%^sqxU?aQChAobbUuT=
zH`(v^l=y>e%VC2z7kgt;H>#%<-}+T3oxSv*BBZfvd|@WSj}t6;ea&L~qKc0x-0Heq
zNBNb>hjA8Ur4Dg~Z%)XEt(BueTEC=3zF5dAu6+Zi@NT=waO8*AGKnsksMC!*@zECs
z(DP|^simr?J8{kiFvm;MJRDquckk>vo(jS$eBAvOhz#YfQ&0&v;~LYYUgI)lf?kgx
zB!s)X%!TgI?N=Whrz<Wqmj8t1UhWwakiiV7bu1O6R<m2%(FC2gQmZ09@fm$CV&W*3
zI)U_K-Iy0bbLAge_zgTR8{jILv1p15!cG?RY5DxL9{LZ0k+YKX-BfG~W!APH4%TI^
zGj5|Ji7*rh?eoM$=90nEg1{M3BdVhwM;Q!MZ=mW|BcsITS-%MabC!jyxtQgynbJ@9
z<!7q!tJ6Y=ic7bpovLN*NGcCOvawCDduWj0Uswm8_pD~-F-gv}QKX-@o%du<NM?Jw
z6Yk-{qeix@-J*&+=z}X81`btm6@drw>c%sb-z+FzuYn*)fcRc<InWfQnv2<sz8VAR
z;`-Mas!j9E$01k=h6&UWB{-V=iy`)yDr|OKv_CXnK}SRgtkfqWdWO0fSiQ(=R$6A`
zB4bl^oiN~FCF3TQZ8o+$IG~45K{9CS1vD4;;XN`<C@u}F>4l5YJHCkjS;OUjYQ&yj
z7D|sX*q|vtTTnEG$VPpHtPzotc)|Asn&F9VJZZAL*Z3<QHO-VKEs2E}8hmAg;VwAc
zX!Nf&<ar)CE=;jpq`yp6sf7v88kf#NNd5RA#bWE6Z@gexdx4-PNLI>vj`pn3u$NrE
zJTBA-tY1rqBbV}aR`LCt3(7Gxg~n=yz6G`61?dEopj|^KA{*-Pgw*3DtCj_$MR=dV
z1BI8w5ugKUx6nSTD^d$`C2<B@3(5@wgr*&_Ou07hh{YM4LwrZJwL@OBM3ncTIu=xP
zCDdQyE3Z#t`Mau>KH)E7GaPy1sy4dHr}5pyMVWh~fS|odRixE0Pt>$g{wmJySr!fs
zRzaEKOTuug3sUaEQn4uM!Qi9~^!xcmrDxTGk&vtai`Ne`Gj_rt1##|+;u68vw^U&R
zZR?GCm?hAIa<IxW6Jf3@R>S%<SEJH6rTHgVnTyl1ZWF7dDyRS0SglrKEl7ESq;m44
z0~RDbLH}SODt*CfYWro^5ah%f6&L4#7D$n{ZV`(Tzl5`_WXlZ3>;7abU^)~&#o^{@
z25!Mpp4IU1sY7oTl=?t&4j!^NlbqY9WG!*x5*Gy@AMp(eqy`A>pvvV>0k|yL^VNKh
zaaE-imPRuUwYFfb+t#<ZD8l4T6U-Lg5N}FFX><l-BNwEc*pkFx(t%ECPtq>)JXi_*
zN<TaDO{elC+o#4rFYet5b#0~5dX*m_5!ZA%?>K`MwoI|4+?#h&*Udh-3LuImXiAZ+
zR%UAWQ^&qwNC9dJQH>6xn7sh*hEdRruj(Y6rIM=bLz;;YSf!4o@f3%uT(@^%qTpFp
zH*n~GW($vbN4ZPqS?*GfAgS>wY;I(u16#>GL+8yx*``EJ8!3?GtlJpktnehP>)6f!
zM4Kd-83iAsOxUkh>o+erTn4K|@vL{VVLmxf=z@!Ft<Fg=BfTYvHlHGnp<yO9S4|g@
zhJf*GG#JB_E#2+ix1gi|RSNv3@satjtVY?ev#x7VB(`IZq^DR41rx=Sob<UwS&+W2
zZ;?GKDd^7siukKZ4%E*)>=jaTRrByto+6htS*j{8{A4X9RtITn{V!PeBOB`xY_L06
zN)SbBTZ0hB%Wj{t6qre1qWC&flwiEE!9+ffMmzHG8>Vp&K@NpvSY09lbN6jzM_*rv
z=y{&+eIHS;YN^RYzXJy@O}0x<cEuX=q`FVL_K}Qsjzey}n^ia^6}@u#*|If{Cg(aZ
zIsQ(WXM`uOtHihCjp>;2*}yo!KME(e<}G1x+VVm$guhM{uVen^Qc#9W^`Fv!9Wzv|
zNcO*Am9lokEu5G@&!Sv*nr!V;fTRu3l=CdL-cnI3ykMHN%=H%RL9>UZN!XWoY;gyD
zBUlMcvr#tOIg_yO#VJM4XZAm;?*>f-WFi&KsR}tHh$q|F5*OIEPw?7>CooHKcaJAX
zT}he&%T%NNbT^1hOli_<3?8s!m8llVQe837?nrVSp)l09d5_jQ9<|+B?^qYLr&=oK
zlXOsU$W#(ZdQmD8gnbE8QExRUHz4nG4kIKYolI`GAr*z=SjBjkJd*CO43#c6)SCtE
zIdryH7OEX)BoqvnlZFRSguvDD(QABJDqchwP_Lyzws1pGj6lGEgh=-49u$;PM>ah}
zBu!F!pKZV#v8X+2D@?dou*{p2$*ER*596f-o5D8>PYa<8h%k)-=B7*BV=56$pu~x#
z%dYD`(AIGQZt1Vnlox4mZyuCF$P(}+4!AT6y6l;SxYLyEL&9mZ$wouYfzLo7me~-r
z6TJmM3ld-J0w8q@iDWh;gs0I=K>%g?w-c$+cT{{$ZB)9Yxt0Y}Wg)@ABobaKGFWLT
zIP_+`a;d)a^@GqoE(vv-6K6nX8@Dc;VV}8Tpdy&&+0c{%#MLKha$y`9M3U=Pwdfab
z3=t3tAr$WgF5Kgr8QBxz;|JlYR*+4L-50tYlNJ;a%-ynhbR;iii)beqjmA)6dROjv
zUy0NJWT`ae0X>z#L-~6<r36KjLw*GYGE$5Ah!IjsA#!YnblE2)?CyZD%Be_W`a5$q
z<-c$_yYy%&BtsE&bf{Bu@PkqY`|hoK2J6)}_t{%pT4WDgaj=}=0DBr<{R)wi{pc6W
z9SGS-woI;8B(T(Et1(FJ7?$Le1SyfWP!cCXPGMbWE{Ey7JF1~0(zWTO%R40NQ;_*W
zk`F*4+0p-PDCgZ<?e=uexuc;vX?b3BcMnMA8Q%K>$Sjg^B(>V(cB&Fkajo!@lB>Fx
zsF6H>iEU$6oTwM}7gtfWj|H7RlzK)x`_aJ?H{iyFO`rP<3SgZ0IuE5!gsr#%x;&Hw
z4J@a+TQVEc$hvS0kkx*N;|3hu<%n(T>eIxDXCY*K%^o`8Lx)I$QtuRU-|8AjX^?ce
zk0(kX6agl_>G_IT9$Ie}bc~_Z=ycP9n~Klag|^k=gT_<ppa%~@iIpS>n0>kFg=6|g
z=0zJJON!$ub4XH3_E7+;X<mK#jM4jQ07fy9A;S9aXmSEt%mxwL$p|~Z_LQ49bm6G|
zK&t^&(28OL7PNDa%B8_jPd0W#;r<5x(T15uUG%{ya#4D7K!T(DDoPj9$j5K=%4*-2
zG*s*~JN#OLE%6s5JA}so&t)!s&=E`;pI21v#|a?W4y`Fzz<nW8K+&c*eizbg5PuaV
z1o|40sy-BI`%d;u^@XM~1cBH^7nY3;R?2zoD!za!zu$XyCi*j|?h!P=(j@iHVqNIo
zgk^*hYrjTl$-C*Zg;o^I%fnM|{;o){A%hE-Zn<E9-vTYIwOS6k_3A$o%jd3H4mJ4t
z;cHOgYJB?2@wc<pv;`%Z11j<UCJ3Tz@EPx-2_*;#)`jC}Q0~khRJNq#K57HUoTX|p
z)!&6FJHSo=`(K{<OzQ*NWu3g>^+^W`QnX}2gz;zrMYtwC<-`9oGP_rz4MwI4i}()9
zF>u|#uZ>;Yf&%kWx`T!ZV~`}~-J`g>dP~Rc`(?kb2;QqQkviE=;pGCmOLaE!+ha#4
zt;KA+#rn0Q06-HCMms!5exp9V(A2<GoPu%;mhlyL95vLVE{!qsmUWeGtsh$j8FWQK
zgmLKpt4NKVk)Nztv}57OJ_rGOC5eQ&8kqIgdUq`WzPbZT;mO)P<IwO2L+zO>nEl1=
zhFX>0=c*8m#GYtE^$-o?^vhKeg#Jnae@dfh;-;iX%x#kL@{-RdPMDwDiM7x0NgQXH
zt-N){cpHzs6mjku9MH#!D?gmS5Qr%rG4**S$B$v-)~|Kh<KBd(6uUiu*~h?FmEch<
zp9>3$w@S94WEE_s3F{OtjH`3HTG0XMnFxU48a~h>3STTtY3v~PMgf!8O<+{O;a)T!
zAK-K1rNKy;`>@_5QOOjET?u|w5#lqm)LV8$@R((x3rJha%6&E@U=Mv-b|UV?U+Tju
z62(#pEE~molOWh6xu1(lGC>kwI4nL>v&aht7MgG{0zi#w6MX3?&7WNx;c~y?HblQH
z+$dH2M7gY;r{~U9R8sd`1!0+RlH5C>XR=8K2ZX=*CFCUzRF??RoT{qj?1*oL>{ONi
z{bxm-u_m_)(PX!Fq|9HuIbz25>>!XFSUsOQWYw81;^!eU55GSTzIOR2QYZnv#R8i$
zQJ*NHSnaMJ@(CbBRMsrEd-m0cQT0G3QgW*~`OC{JFrXXIrOl&W*28KbiCx<NBirn`
zYF=^kx#1E0)2YVGEpo+2`%~`r_fF7rCGF1ExZ*jQdjiw@&Yk^zN9Dg%+jt(Uy0v<y
zNyRV(X?1YnA=<n#<^9^p_m8gi&YiZ&wKQ;ZKGzZ!x5uSm-Xw8?`r-%V5;oz->KAhP
z-RcLi&mH8L5f<&v^4L3mCJfisu(6zYkw>$8$tK4i#Z=s~?yhgDvOgDt@#%VHn@W}5
zQd?LTq(y1<>5>dT>O=m^KVd2L5|HP&1FQWvww~oqExp(H8MWk^Tp(w9`1+`um63|$
z%e%6RWG111R_NlLD6c`g2d*v`g<F@L`(;f8wWlKBy_U~!2dTRMU21=M)W7=2zyaI&
zr&Zo!AL(<>irR!(hXdQb9C)uFdm7gZa8PRFP4}>BXTzra<bruZ8P>m-I8TnwpB`Zl
zU^%<h024oPI`SM7UUR0Hk|1f+%{^2Ae=Y1?Y50J#d=z2Fa(#^2*GfI;`(-UQ&o12}
zV#?xf^#S@J^VrxYR`+pk*gblupYBz&Z@9Nx%zyGkhWKu&I4EW>fX~MM<|RDIH`Yu<
zTV}=is{t@9j>re{(l(dFF0SKC4J}?zdzcMHu)^zQ7t<%;9%WgM)}kLn3w^d2v77@9
zp0jAQ;LH{zL*#{7?ZG*y%;!_4j1r9fTb|>*VNVJ(pOEG>j#WLk+P+)mv;g9+at_Sb
z5_eGF54U`QBWRNw)1Qi>vkyuUFG?F<3sSQXxh(1N2uFK)vj>1o+I|Z&yR~n>PR2zL
z&(sNrvRcP!@7h>pfkpMyhrABTN_*|2{K)ut@UqCS&P!H}Lm0AUM%$}*T{8iP4Z59$
z@fqEx>pBnjAivO`?CPI15x;nb(T`RA%Kpp_|0Se4YIN&C?Y_w$>#royCO;3%-WDs8
zJdD=A^^#8()$d=s<7?-qLA>QZ#FZAaL$=IXNd(d|k!RN`m6aWUqKxar&DalBx<~b#
zFfTPhp7tRVlU$0Twk4?0UN<{u5pSU!4J$Gb6rT}46^k0ugntT}XV+B=9lC9N(nU1u
zC|e&j2~`XSGlw}Z2lXC7?Dk985M5NP^P!i7Z}eIsnc_{NOaF77eS%f*cnzPQ_-I0O
z;I9kf!<#cD7p)W2i=g7Wh1=sd_3y3HNf~>jA1}xVc?oysc&L(*UyN!-g>X+QoPR2N
zU+p#gFYR4^IDsQKHi~eF!ljGn;Am<QIJ8uvA|T9C5nW`91`?Z__eKkesj+zy9emV$
zqK<Kx+I1zDo0vqq4+xW#Yd@!Jazp@}qrr6cuCH+@l}$>T-Ri6ENxV(w9NoeclD!3P
zGs9>II#qH&xj$qjT*8=kems!tidIf7H&kV7Et4B1Zuf1JNfXtt6?Tuc$Q1#w-cvBR
zKjm&yi~C7EKR9`ttzooR$irM)Stxjju1{ejEEv>xL9P<^J{eh})o*N<z2K_rZKuwk
zbhKG3!q~c!P(K;+_IAK^V19v7tTPA>@luvwYsC1n977}9;LZX+F`Y7Mn?X_up?Dv(
z!-dLA`=uYrB4<2cjN7}i(q*8M46(zYHko3yIG71U92T~Z^y=mx+AE|26AW%6fes`?
zqA17pIa1^vI<;R-#6j2*P4^nJuA~V(V$K)XFENd#Q{Y3$DR5Yuqh3#}xE*WYaJ&x{
z<g)}p_U;Bke_RwkR!c*e*Me^kGxLBu_)Q$`nQPmgrqXvpVxMV(&<Pu@xnvZ-q9zu}
zoOV(61im+u#KMfNoi1g7Wvt&i^6}YUd!JV6|71(fQGKi`Nhs-NF?-)1q7<qG0C8Q6
z*XL0c2w8C3nxm?iHUJ__yee%%T-y>ymdkNuwLM&o^dg5P%x6`4ZCENI4fmxZPU!yR
zF-3{v3_-DGl9&k`8R(wPYBW+aWze8<jO;l6z}_PJUrouAY|oSpG2xTMTgRW{gyN&f
zp=O_5t|rFSadN#oG^RLUbsUYX?kJwp2!JN#uY)tbEB#D`nO=Q~iS?1XEz%F8%#03a
z35+kJlm?%mr)*<)BtY}Jj11I;@GRA_zQNRF`B>1i4pDJLYl|SDRCtd14q~G|U}rCS
z)ZCRV@{!^0Fjgbll%5S<l+M-v?L|W%fqNDKYGl5N`jZEtx<A(H<#%%}qWtR0$2FQn
zEA`4>M2m5@N3)!ZCor*rS762~SADz!iXg@mkf>av=dqNcpPoZ1KN;Y(Qw2WUc)Ic~
zXYYu0PCjQZYe=1xq5RdD_DYlQZqjLe*(gV9|G~>VwrED1<0qQjfZ<@eMs)Mxiu|_B
zdAh11Q5hW=K#w%cxbJJt655~~tn#)THZ9A;&Qn9N_d#Ofb0>E_jC;AwOu7|kX<9sS
zKkR!N)%GnR%k26>zOjTmD17^UNsNXg2x~NmjiLp0N}&GB^3RdNM<d$Z=<=iNiNC~l
zXHDkQqCsPmjkfGvQAduSpNEL0e*LA;Kt-Jw#4BYLJd4jy<%>Zn;M^X1v}9ETWZnY5
zraf$iYds=Z<n+Pr#<_KxcT?3kY^=ZSvhUjdmva!{Sd42+ICr;Pqdz{%(*xLQdTOiP
z0BjplK@PEEu`@6EH$SDEy7LPwWF3XWaO6Gf)4TGIQj1w!PpKitf<4EDA%ho}Nc9tq
zRJKS`wRby3G~%-KN=)lR(HB%g-4ArsW8$p;$LwZ<A4Psf;4|Fi-!N702c$otirx_%
z_Rln!7J&uX5=o3>JOFk0_PZ>4y4ouT2#WKrsl3F+$fu5=MXns2Uc%{!DicDL&0Bhr
zV=mo?&9f^?2y+KO*(ve2pZf26t;&a`*f-c;KHFH^x%<C3#hSLn9raud*_W7<jqBQ3
zHvX;qW5Vo-ykF2V-ihC%>#q*YwkfU7zMgokpc}3!eP$GRW1d615`F$R|6voDai{>`
zU%YtM^$earpF(Gg7S5OvDUhB`=XbJ3sJQw54OtUCGBvIs+)hnd8@U^7dV?jTrLNKo
zCR*zDB*m`RwjMhrr*Pjao71rM_dq+m#!!M<X;augDZB5j^+U$Fj8IfR%pt8F2YNun
zdXA+0*QUtxz3{gzy5Cu46nBEp1u8xeMNN(<IvX3s#%pRCjt+v=+fMjTDVkY9OxBVR
zCP(sUPBudaMEukgsTUNVqCaBb86Pgh@SqB7qVhjNds(51ooT;r?iM8>!A?k%S#<et
zir5Swr<o+7eqy5Df}&+;&k9tKvo*n`=W6VJot@rsQ#oNc-JtyJC`T-UlE})2dGVlp
zP$NBbf2xCAmf9d@jDma;i#*kcv10-VW3UDTxKIv=QS^Q>P8hkOR-Vx`=2U%pEPO{X
ze*nmu<|(G8psRpjR4SY!lWp<i6g62dj(g$3GuTN$$O|Lni2=KSRSNEjYD3S)H69ZY
zM_${HWaFf70y({MISX8c+iKYelD$3G1KW-HLP@$SA@`n<De^OKF%F(ncj}sOG|U(t
zxr|N#gi^|m$6$o&Bk}~Q7>%N1$)>kSoDL?Cy1V2b@kG6g&|=JdS~*~}n?|>=;WLvC
z*Y0Kia<Okat4Pl@`;g;%DA)IU!DCLsv~V<t0<6!uE&y<Ixub7f`9<Q)yk2THatgiZ
z#W--BB5H#ESshmkFF;}nFQl9R=;HfwXtC>s|BS(X?`TY!Tr&W&swJ($Es|+BjIB*Z
zSf5s8hW})NoZ(07T#KYXg3<wGP&Y=rl$yXSs;t#{`P>y3TP)^vdYgJo`g@UR9KxU%
zoHvIaD5v=siK%KIY8%MZmOH-cc$O%VDzp}l_;LI{obZoQpCgP?sis81|K_`(%aiv&
z3WMk)P{|?6Wme8*ttNn7f)=89k{U7pc>Av>o#`J8j5tK{FPEmvD?@mhC8P`SBB@|p
zsmOQKV1sCnS7~%C%$s|qVFii-Kq!XTzc~!n{{oaxDc@m<ULz5`i^SIC3dLA)e=%VC
zkkVg<ZJ%1EXpz|YyO3z1Tr)UC|3l2K6!DbZrg{-q&)$m?V!6D=N%iC6JSlmdAE9X8
zbu<rf<CWsOOLA3#2H)r>fLN4;*>6ha_wwSOUZR#f5jh;`B^y)!9IS49DzF!vD((FS
z1kt6Gi1%SK%C+B&=~LvcOW!k-#tGVfV#}YVq_aSuDoVfnx&HMdfMs68`(Btmt*feo
zRDYq$ueiK=6I}x!1Z9*rVgdPB#P7sof+S&R?_TUC_-`X7o>;BRg2>z|mbbZjV!x+S
zU$PWV;w%6NbH&PQHN}%_q;!NZZ8iLFFKWIS-$1adiVhL(0g@vWls8T6UqwESNZO1=
zw6YNA5Qr84aT8}~%LN~|mWB?14XFih_Jil#3N(AdAZ_rA4B;<7wF`@tr*i5y{Kc>I
z)Ju8+E(0kSKM1-wu0^Ia=zRiklyZL>m2n)9xr)5xo3D{vO!G6@iA7v^dGj_4(Z&-w
ze%Urxp$f78JgOx6HzrpXfFyp1iI!Ieu>c&z^ZPr?$!fUNy(S6=@WnxVewD40L0~Ru
zU@B2uOPFYUwCUEZR~-!^CLReD(HC7*x_P+^l$*WU77G}}xleZleYcjn=#_>>u}HN0
zc<`KYwdJ3}?^mnsh<xWm3?Zj1nH(VW)h#(urVw^NM3#E$Gffzm2Ovj8#kAr?S+~E9
z0S-(k+4!chD(ddN%g7b$Ds!_xh#c=)^v?Lrb1xB0Vx0&Ly|Y=k*=QTc!PpsBdu<hJ
z&85F*i+h>N$K|%?#R0cx#24#b@qMD3v?z%+pu4x`o;;Y$gu1h!%WJo{xea;Gyhd@v
zVGLSyy8OE^7~w5y-+b>b3nS>@wTi7XsmIjs*4t#_wpb8dW)GpMDEhv`NyuG4u3ae!
zIM^%)F$Q5K#7)=QTQ$fk05T*FPg(}T`)ceMP!CGCL36jrVo&ZunrM-4;WAZ>4Y{Wa
zLhz?i_Mh*xU=ZvCVrE}mTYQeGy!U2XmoYPE%j?E#5%60lS9+LGNwbXX$=>p_@H1S(
z1*%$_moOt;#zY+u#>7#^Mc=YO_4y4=A*fqtyFJ#@y%)|a_fm&&=LWd9wpkD{)_=4d
z0M7)aU&VZ3H9t^9Sl&0${0*-76Nv2rL&&Hxy`F90sztmzj?T8gc}B9U{qi2XJREk`
zco*-Q%!@ognSn2_mg4b%uVWyi33SuhZg(z}<fFK_cHSqM(#^FVTub5s;DlJQB@FWC
zexy(-=Ea)GgU_8`S(xgL{e8KJu`uvUCN6;j&N~d2Y$@SdwpypNO=3a($hi8uzoX=B
zKrdePs+Y6^Jdni{eTN~2;sK8Z%eCdWQCYNwu3X0oLB;k%uJsV32>D%XAa`&ZgW7{^
zyxxXr14L^uc3a#NhFoUgNFaC;oyZV84Jzo_h<OL_cGmCWF;HZ66Jz(T-OEwg0-U#U
z7}t_e$T=WP&0e5H8WcmDo1u3PEApQ8qa<A30+I~N8_T$2SB#nMr#siVwME$KElQa_
zt4=horJs(_Wq^$-J-5KE=IOv2i}6K|cD1SD$z+Kf=Hrug6ZyuVMxA=^cJvqvYBmoQ
zQ44>IRqoqQ7_(#hUZD(9c8jz(w{dSWRuPs=?<FqZ*l>)pljFAG1rD%d{}hcD<^q&o
zM??Ygv*z(HNYxH0AkkWT%$VcRR_<>Szh~oehN(Iihs^8o9;F~3#UfubG0@4uRt#cx
z233_+ck73X9+9-s)}_H^$_quOP=zlt;IgqG8B9<F>Fx@0+P=6IyaxJq3%!>K-9znm
z!#oKo<1CmcKG^gcWK4_2jY5`0FVvy0vj(X)sKUlNNNQVZrt~l4YR_V0=|D9};(+h1
z+`GxMr;3G5rScDmqke7AdQkGMu#*bM^!~1SJ;5N26wseHpSdrf&-OjNiE#;jkpro*
zJve##W(hc;yySBzNSXpt7Q65RPUb=VFMvS*Z?Q>O7zqH9Ah4Xgyu5^jgp4p+QwcBN
znj)dlc%;}dJ4s)4DW3!X!!^YxiAL_n{g2fI5fqoCU_>GfwJCA%1b?MKGyh<BclW)X
zu>z<mIXO8ZIyUOCuiZfvfz@;$1ZssstEIG`!r}h}kTMwdRaj)x1jH4x{Q_7|TgWhc
z6gp07TtABY>k0gg15Kvtas$!r60X;jgQrB@`M}-{K#=J7`3D57Lk_G!-Tr`1Jv9oy
zvnTTEvA~%_(dsuPBCpE8{)(9V1_6JKm7a<V+@@2Tpui_6OmnhA`N@!~K+qpA;BPF7
z8y-A!_)>{zQHR+7PdByPMlqQ>TZN!M?I3~M^yh!vCcU?pab;t|Ei>?v-=N+VP}2_3
zyA9m>3~hR1GdCwRJ}$EL82soTFt`a!{R8Itz{Cpp<44fHf55L_z_)c^`Z1yKvgef+
zkLFH~*3RS`6(^>v1DeNz#vX+T=q3;-UsCLnfn+HNB+#4g7@|9j^lpSGGI9PjUhYNF
zXD$Y~wuOf>#bA#F5{HS{1OTl5AG!%9!bc<jY6C0!z>W^EZVLRf25p%kK7!2tNE$r$
z1h%6=e-5j1LHquIVzyvmQ$gNSg$PCyq_GFo(}rlhro#LSD%b|yevGQAqTF~AR>A=N
zxdZ%Z6nXN0(59ErxhIe(Pk^nTf*ayVZsPcO(4geqZ0&0`{}<YHEjj0MY*x{p+l6N?
z)`ZktLrfKcKU9FXN&tQf@Vf!{*9q+0hkm-L{j{1g)&N}k3u^z1shtM?4FLZp0RA)3
z<4s^~Lt^sL-qKk*onBB-P{b&?Q&3oZE5D^ZGo!S&AoEUZ&h66HJ3T!;ciKB9x_Tx{
zu62)Pb`N(Ij@1m0+<P*0XX;7Sz21?I*2h;Fv*Y(hXPc+`hQ>OlCvMNr3=a>FO-{Xd
zz4-q9vOsKF5r|D|pZ`~E`uXeE_Wz1azrU}2<1O<3S8S3Zu#4FAd>AsYr;TWT9;4=7
z>Dpdn4~AH~uELkH#H3%~-sCSf)Qy#B?=90|wbkzd6`+*o-*q%Rx<*L&G(XmPa~}Xv
z7&9l}Kiti8)hXlbF5(cuJL=)Dg5SXy=e9Ra=#_MQb|WCqgSloi;%cCfr?-wwbboQ&
zb!=y85@T^<I@vvaKU9`T0b(WCvu(j@&V(YLe%&NV=O}LVMb(}vk6zRF=?v*N$Te=v
zP|85w>syNLDlRm^G1Y6N&8))4zl-`C;|+KAfnu|#yC(17`*y7`TV^PA=BLxS@d9Z{
z-`gJ#oRb(z?b=UP9*hn=UYjPlaU5E0`h?F{-gn*VYfplkVs?*5ugL?+KU;$9f;YTd
zi%wUku20ka${B9HZ>Z2)nH3%vBf=$*e|CdDF&@%??(ei!2_r_<|6w{FbRgbDD{WVs
zI|qb)^yTGhe}Xb&T`XLKBSw%vFD8J+0VSuMj1q9LSz;Lqi+?zkCBJ`e`9LhpLNzGQ
z!_u0oyt3eQCEtH%@r~)H?`kT*g=i==7)Q$ROv)FN&xX736P44!HXoOB-yX}7q`ST*
z6j^e#t&j&K4wg^3IHV+!bulj_M-+n|i0@W@Ra%QCL=EXYjXC8T@Fvgn<J98u0anR-
zdw1-CN#ixQC7+8)Kh!)C%8$IRVEM%BGcNK5Eo%^8%%3Ki2AIK#k9QuDtV{1$?A4jF
zf2*D_Y2^Ror&z|2vEq&BBQERclbP>Fo>;%QYa*nyt1Xg)+$bOS&4oL|R{Q$huEt!m
z5Q=@`^ld&JX?o8?Zpyye;P>M=nMn2hy1MgBaP{`+0U_zcInZMVep-dW3C8WrI#Ovz
zv&rH9kp2@+eC@bz#{WFS_6f$EX78MCf{D~!-d|EU$e)^l=-b=twF|o&JxW1`dzGA4
zhn@bZN2Nr(4vTV{P^WvC>g}5m%^0Rww;s)QhN8N4DocE9eO|0xb$afE2r6FNl43*8
zIN?~Y++@Gh-H&+Ebf=SpOPJ&v7?1oOG#S<|slP27V}5D3?s|dGuHUmv1E*hYU7uAo
zi*vZD<$tTQm813<1M_hcUk;C43JW|C_ZN|H$5>-u*!%eRjnDT@Si0APQMWA)uL#?u
zNqL{x^-V!?y6nn9U$t_hfl=kkeB~&A^1ZIa$Nv%b>N@ZA#}stY_V2mjdhu|!l&(*&
z<^C5X@bYK0;d>XnUOv9>d{6CDOww=qnSb6>baCCMR+*rZ9D5hRF&1?pmAR{+8@S{6
zZ<SwgIn*1T-1iQ@D-6#^<6jFMPPfS!C7<5xQ{1)Po*^uzrfeSXe`|36!}j1ODm2r%
zcR$#LWjh(^ALBDr)Kes}zL+!oY7XV_CCx6J`@W?A2*XbYt%{CeYUN%vS3K+25>H)?
z2vnV%MaO7ao~fi`F@$WJ=^05C)DRjmo-2Q0(-7~i2_AX3KwQaC(^FEDpJ2VQq72$l
zcXY@ZZXnCzj$2X%ETMzi5bPu+`<!`OK~z}A2hALu{U#_OO20}`N3yFT4XHX0EEsto
zY+NEvMJ_uYblMPaEKD2?Tjau&YA9KjJ)r$D5oD#!;EP?8cg_`X>EiMO4_$<pqQ&Rt
zHFV&Ed;2oaJy2M7Y#6z7R)?HdFOqc@nrvZsu27J(^GERSwd$5vBYQmDq`n5DO}{z;
z=<Nm6+0lk8!j$MTexQ?DhAQZI_xq6blG>wfO@&8W9%E(1v*I(@gMt2y5Q(M{q+JIj
zj-jd49atdW%`W7<ZYZg!ytyZqfUU%JM)RXYT`k-ybIUn$BYrYEfA)L5$JF|WS0A}0
z>>?+tIf?wZ>aMuTLa)CzE@4cO6+}!+g&WqLxaRrhaMK5AjbG&kn0V(mCdmEYTd&Qg
zk6J7I?wNz$)k|C%v7c`$IT~(Se!{%g^~Tk*CQ~T$*I~xPA4P*V-xsN>6ky0ZIaeJn
zvS0)+Hae!R(5BKt<AC7G)9$6@G=5fpCoJ;svil)vX9~K2H|B0N%0S7O%a6;8Ij^&!
z<(i=){?mM&7nbIRI%T1|@^#2IU4y<BLC;bymLK<dqRo8_J_hC_K=;)s*k^g5mB;%+
zKdTRjM!c>Ge0{CZX>AHJm?a_@R1ZYG!DObDyXbRvT1ne&)9-X<dy=cDDvM*1{W4cB
z9h`pEaWxYwsoJ#<RL4LE<TRgOT4>j<9_Wwqdz*6WH#^qiE3ovLLSGBpTe79TYrI-N
zOc-*FFdd%3*DXTX-Q4%vjs2Tjw123SRx5p9%uK~2wEDsG3d!r=&}Rqc1t?bDy__av
zSg&lbu=UA+YwxVYUCWiWsgAk+f(=MOe0(tjbWVg-aB}jPOPJ+(>o@U2XTe^(OU;9l
zPb%=GdXrl;w6y|0;VW6H0|VDz=3<2%+@uGB3z305uyq_uK|!!7mC!p}IqP>x&u;m8
zi;tnfWmoOct9SAyIeqQ+ap(Lp=?Wggww*c<h$|l9N3FRBM6je{<ue^swr1gOiS;r^
zLhlZlk-WVN?MwF~TO?9dcl^>DJ%yiXgf_#z%*n<`|IC7A2rx5DCMfa;mHBW1G?w|R
z`B;@|z;i;+y)n!EtKH(71hGPb-rkcJ+aLH;-D`uq^7@MFKwB@pP)B2&^a7{yAazYf
z>TYiGeCC(*&)olyqI3Ue`u+d-PPW;`Hs`ZVa>`-OXEvL2GNqE_kV7if98;v7*qld{
zLd_v5>Wx&AY9lO3Bb7=urHoV*h2-<y_Yb&UKU}xh?RC9w*W>ZL-)}rP-?mw^_OWE!
zSYk-GKWr8FuF8^8v$V_iVFeL=_Mn!*L|1*whC%Pg*HsMY^~C-y<~$=11^-MZx=UzP
z$W?y#tDKY3Rhnhv8L=hk6=}fC&8!2x<G1y__Z5B~hG&_BwXv`BnSh5;$%h_N>iYMc
zV8P-%e(8Tncl$HW>Uwbx?&($&8|!&9a3QNyX@L7w<>WiU#@-8@ZS3g$fBQzHv>)XZ
zyo%X5hjSp0YKKJrSFYtVz@r>#boWymN`zIf@yHANE3O953V4Th%-SrE?@5~Y#?f8-
z4mIPueOATzf!l6WIY2;*=v`UyJwdU9n<6aSKdjol_*BaOP+#}btj?M}W#7oLkJ+7c
zk}{8t?-vMRJMIXGS{MUc0O<F*c=q>K8%n?14?H|_$8qnTxM!I4gy4KbazK`k_kPX>
z*4HEPsgprDdU0d`QO}h#_rf~^+;Egg+Np^_pTtnjOP^2q#b-grBKze4%CGEl(obMQ
zPShtmcBo>f9^svKz}m}ALKl+SC5ZPlEg&F$_zMucvdgha&3Pcc5RgOL@5VcOSP83m
zf`tm8C+|;38mZW0+BXlLL(7l5Om5G#!yy0WA*KizMe3>33vg2n|1DurD!XFik7pQn
zY>zsw{Gn0t_s19)kzVllQKc!gkIjK~9-6a^{RP9W5;F^?z%n06JrSX6kNMxAekhR^
zVv_sz4(1Oe+`fq(1oFk6Q{G4nqyG7+*Uds}-yu4G3c00>y(+=F5I__C=xH${G6t%)
za6nzGxF$YL>(WR8$e*h6kB6~Pqo?fDB3h+JD3P+&ChQl9orsS*--Ue$@O~uD@xC0V
zl&omrh@TOhG#!Q75fC?U2=|+8u(jO!B9zT5czCPeXe!+<Blk4d;GrGMWeS5`&g~N@
zsE(qAJmY>oWG)1Kplct54R#e!mZO>bfRI!v;x;uN90K@VrKAUtFBPP}3{%T%VwMhC
z-keZwir@T<?&}wV?)hS+jnBVoqZrx_hJ&%`^djSSs3#%4aRKvNd>TSDdW(mtwgpqe
zcoVQf`Kue&3u#<eM&3F<`A<FMo(cBr6`Q%3P{2aaBhjY*I~FE;lxS3Fhy;|*Q=tDr
z)Zsj)#HWL*iuCAo%d1BwrEW^J!wM5hx8OEIZ7!~w*v~}!hxDNDD>>^lbi}8$u`s20
zs+<J@?9v8yPes$uu^q<(WqM!V*HBF&Z_jFUF{ZHI7LW%mal>1k8rw}}sVp0WJq5by
z52D>FLE3lGX##?jfc{NTbQ6G`1>o;ubTbaI4n<^tM3+xMk1arHM7jTVS8?yar)0Bl
zOO=+Rq<=hfw0zNR(NVKhk6yn6#jK!Jy6q1F`0`b-hd^e^LYO)teqpe4e4N4tuR;L>
z;6_)s`Q}h;0kMNs?lEV6;80?^Rk$~HJr)(fGdnDQ%y|=fq8@aFtMZWwZa8>B+IH@S
ztN|4RLyiJqILuMGi_U}9l{OJ5#M$Xkbku|?_A0eu`+2ARWtT^>?mN$78E8B4CEEq`
z+Q2znY&=+o7=Dxf<*qdW8*K5WYNEn@fR5UE(`oAh<q_bxPkQz@fwwD9X0ueZ6<>NU
zQMds(!slCUh)<(NBex92NA0rvcG>iBjDq%}VprI~OV(w>*pMG9b?$VhlN^<+;!Ey?
z+Ei)L9I)7;EHb3K_}z+89^5_kq_V>an-*}k+f`#H`#t)v(4KAJ4LLiI?d3FED&n#L
zY)40|zeL>TZ8kvwXj)g=jUB0T@Ld<wAZ>-&xhV83OQ{_lq`V`TZ{@xg^qUHH;e$(J
z)z>88f+6sgHsttg+1t^mvR~mKGiL4u{4}wuSOzAeS575g*}DD8K*Om+ApnhY<~ix=
z0b*A4&{-F9$W^}U<>aQq05HF;sab436^*xDjV{E&>v(XmGyOCM(GU&%)t~-x)#$+?
zw_g{O<z$68fY%-IMZrtG`GJIuX#5#C_7g$lSAzOvce5ISbDfTenK+O*b!g6Bp2=%$
zkUfVBUvuEp;o$w@B#%3mhtpaQg}{|Zvz|#}KG<zw7XcPSyrUMW*}FoC7r$t(@(=~#
z2s=sJrai_P7(jT&p1*83pO<nY`p}0H)pWoS(?5tC0E9XLC=Bql3CTda;HJ;}SFb5k
zcIH7<ue~WiM;6re^q*Z92bfZu{OT0l_{~=c=?(lARqGpA-qm;pJnL%84KZxs(2WE~
z0F(%>m$Yp|BA~q3qUa1IUiEz};Eao!Jh#;%=FB<()x`~HscbmxqqVl+44OhJTPyzj
z0#<Uu{^8#&Si7Fq>@?Gbp5p<51R&%*{FwviKVEz9kWYY3E+87f=QWzXLbTx!YBYd4
zjUNF5kl2UL!~is-70`=Hr?)8o**K|O>w?{7Z-X<!TD6>*rts^sJRbYrNw4o#BlJvl
zWB)EF&IuG`K9fl?5=guA{U)4FYcV}{;~p}i>ZY6Zo*Z>dkD_+wUnqjVkPmGWfZ7F6
zT<3EiO*zc{wU0`fhj|rmF&gLG`4>=5-q<IyPoo;PY!fExu*Ko9kSng(Z$z+LU~M}Q
zvDSwEx1jh#<|pIH<YfPEpn4!s(5CT&Gu@apgknqQ!(2CEr?axenRZhd)^?|Up+XEj
za)Z_{uhUac=&u7Hn9;yXqN_RpMZGslLj|F)_R3s9XEAVvsLMIAD@dM(B8-lR_xI3W
z1iu;Ty+T9ONe~-#M1%zJ@PP#BHjKRAhIE_k6G)Jr%D|5q?NsC~W?QGhJ-48B=Mrrz
zU^K7}hX6<PZ*%P#9q4XE9cjazawh>|b@H&IO6umU{p|za&!e761{^n?f9{fPk=6WG
z$-x7V@86F8C>}hu6`b2D8tNGyMxjV<fYbDX65d0_uL!0fop$T7I~Jgh0f-6(mrzJ*
zOA6e4sGZI>yE2s8J0y_|DGM<NibD5llx)nA<}|PQkD>v4?X!CJO{9QJS?=HdDo)ZB
zas}Wfp16^Z9G(;xOd@*($dPQo@oM;KG0fi#!CW9?&l*4%4yXYT179CsYQ0c;VW?WT
zF`{=tB{)3RenxpU0J};<KBGQgW2yXI=$Ib}8o;*vge8H4M0fefTpm)5fVjdFi*!a6
z--(r;A~k4$2HI2U8yM{MmN3~7IH``z21NclFtj&ElQ8gLUK3eYKlq%cX^weGJJHzP
z@r;kkXg~aDRmkoH-?s&qzj*MYy3eH**^L?Pp#d8(NWWUKI&LE9{xCNiZpZ7qA^87v
zrC3~^-2QUw*k0u%g?C>KRtacuUDZIWf5g{Y=dL{ax{B(h)fOtFk|%M$31GQS@N2+B
z7q@YRr(!MM>FWT5{3%2;=3&sgKFl|yI{$(U=BS1No<(UY^PfKKcwM{k4!0&&xW$K`
zC14WL)Z`C!xHCFbuqgX~yo~$%dK|J_-G`U>iXK#=1AQ3tbUf&rY(0`%J>E$`c#1(f
z5;1oe`G5%T%^JBuM3CHo`(MI$XnD%<$3i=>e*_A*7Uc6W@)bmRQ2VV<gFP<}CwPp$
zR1qqSQ=cD=cqxk6LH5PU%yBa3-6TMwhjB0!0A&`vyVOrXPm#F<gjfx6g^I9jlMBay
zb#Rjft;knYQ6oRaFAKqxAi3F+zEANQDuC*J=<oBI{{V_#qu~YAsdAjWddXD9AvbwE
zCX2{BFrr-Cx$`kV;Z6<exm?l$W^m#%`s+UhfdIL2mkQ5*fP8>^o1YHM>zODRMt0LC
z^|Zlzcyi%9ISgRp9%fY5)@9N<U!V|LfY15EGn#~$(=xKpM+thPZjK1g1Hj90@|A=y
z6$JTwJ{%y~6{Ys<+nE6*zFP%fHwu_3JFmj9&;B4*oWeZJrA-e-eCm+^pOe6@s0p9%
zVxQW{t9-eaH{@g{6OII_O@pfw5v2h=^=-2Pz-ZAvxF+WAL(tuq#DU8tn||{ZZ;4^~
z1o{2n=gvgS(~0mo2^t`dlqBwfKIWf&f?koJMgiBJ5d!?D&~I)+yssnkdnR%PT24Gr
zj^%8g$E><GvR({&by3cP2);PH@wPD=!ImH&xi1b)A_W2kS(;NiZ3Gkyz2bQ*jG>ps
zidPlC#Oi%1i<Zw5D|{v3k5)RA&3NSSs)K#7D+|cyfNQcy;P`X&hUCGdB!Oy(GCwBG
zC4#x}U{4GxS0H{exy-qUY>fVJMJx^HA^hM+q%|qB;4<g^Pp1uW!90?ajDCr`w+(bR
z7oZq_MCV^L`kmx+KIY2}OZj{NT&A3y6PrKPJ)E$$O46j<?QyNqML`~|fO(Bxqc2bL
zkY*o%|7=hiygzsEBb{_U<(`BKqJQTpj_U9l+W-(Ep{M6zQv)55OPeqHCPp1GUS9aK
z%|%aP1o(=EW^H^@1RYwLlNqm$%2&{Syz-PU1Hezwe*NQL{|5F1dA><4xNP<S^&GQo
zUyPiJe(O>*pUYn!04y?fCpsSvtCoUmZvz$H^*xG$14w4Ons>E_-}jPUt85NYvsC%`
zqUDukfvQFL@N&rqpOW8#WE_Av?N`1z=pu^BCqfVF2xgxTh8R7}Xr$zJJEk^0OwTh9
zDmTm@qxzRA9dYU0rt4AbqU)YJCwk@&$f}R*pW}|QfuY`Nhq|racOHCp(fi&`(Qd0q
z_2aWYHxGwdZ_a(ct48`#T|wI^O`Moz-4-4Bz%qiS`edg`2;a-O$$n1DJ^e0dCVj7U
z?DOIk!L5zXv!u%b{{cYUP=7kh{_vmm*PmK{>0RAb*JHnY<%TvckdzC()hOLzadc&^
zKcm1N^a8%8mK@)BfKES?@%!<l?~mI5662pD-txED_Im|>QT%ml%l@~KALX*T7~sJo
zFTudQN@)v5fy8!56H8RW6Yv<dz0&+d^<k5tev5rw&Wd+S=Ibyzu88&~9tuS@WxWv8
ziS^}UpTku5QnASmIZFqxoDEh2&N&7cVQ*At8|Wk(wKn}6DxJwmio<#?RS`?!+sL_>
z=HIUx5m2InFPd=$Lb>{3=As;Uf01=UzE@gusro)>1NWT5A?a5rdj8%sVFY3}xBB>(
z#~WAl_CgJLYGHN~Bca2OdSl<(8=v6%+0n{&zNavseJ{~aK*KT$(;%Qc0C4rQo{n;*
z|J^a8#A)A<hHy4hp%>Vs9`&-Ei#gbo57oLkrqpU+n`@e98TCj<dFyR+nY&0cNm`h<
zv@yT=9Q1Sc0ezi62M5){;EiW1$QjG2JrUzmoqLa^_g<+Ej$A4pt5>m(s||YiPHLui
zUkf)L;(H{Hu8{F=Cn=xC7;8OH{`l2>sQta%!2J%=o9@<c@4+=zrUUUG3V&WJtv)th
z#}PNJk>r98#mIZJvQFTgZKJwk96w|K3a`|r8`Q>`1Y|cXo;g~yW6xmo*)2f;{h1Bb
z$}(WKX4mlTi|iLsu>_HtRpij8v8ry7;mu*&bP+xmH4h#bTFYGhQd=aqZ?yX0)mk~V
zT@dVR^*@scyP4vDdv<$ebu&60&mZu(gU*<{y7znY`+q8lA;uGHVTH`sk{69ne|F5>
zNt=yl#S~aW-3s1ke4WM8M0gH%zT?UMqS*a+bVDhmd&J$uyDzUF`TSm9Rr!2*n?9}k
z>gKTkGfl+GgI8sotAf<;uxsAUTY?(pQKxT|!5uV)UqxHfA~g0i0MS+4pS`V^&Go;>
z{yO|AM{~3??q(*vN%!rq+!J^H;l@rPz7c#Y8)&3nad3v~L~O50YWDNqSm3yA^oA6Y
zlf1BJn<+*)Ft-2-Xy3bL*mr=*nVfO(G3t5ZFCQDaH_>WKk%>U?=q6zw0G#!l4~6n#
z&c+dr5UQr~!t<=vt^PeeqCEkWX5dN`_7Cdm;wa`)N6$TWA!@B~xwqr>$l}j_$DOB8
zgBoLsrzXLwQ_;Q_kUBUq&I^mJ;6oVdH8RAN?w|~L4F_`l{63m`DcAWys9wt5hY#28
zc!n2^p-_pz0f8oO_FDE8DoU<t^tFw7r-g7M0OW0R8YIPOTjoiXvQ7WszLqjoC$g<K
z|4K!_*~<*ZvEfg8BZwzH-$zSA;U68K^F^Ku41^b^7n4Wh8`*4FZ{4q?TpZV$TfBYx
zG59wHYpp%BV~OYMKGaf59c4iceX)lZ0=34)0*koiqP^7rwkoy5$GgVK(4FOb*1EQN
zX4CDLRe9&vGY6|K?&6a9OqHgsmz8(d1?+75NV&D(WASpT_+;lM{jUo^6AHF4jAx+p
zE0JSAj`blW^)_6<Bp7*xZ;icx#mMmW4c}jvp6&r}C%mcFUGxjOv`^Wrm<MRFtZ(&_
zeB3!=^2lPnvS@Q#u0`}4ohk>3sJkt9Pg{+@15>K5ADYZsi&pkN$+#Q=XR3mad?fZ?
zLv&p8Qoc69#zCeuLVCRLZ5p{aqRVbxL1<N~?w5V}nj1CY;~<^?b<G&>g_?R(3ry^6
z*qfUCgJxcjV~e9HP_c8nV+hN9L?hm2I0Y4961a8$8y!NogGVfClg649rn8DK(GnTM
zYy}3k4;hytqrpTq3_Gl^8`06hROPqPDXL7~ZgYrAnzv<&x64+^PSCzbp9XEt&uaE8
z4z!WaQw-J<N^^!Q+E3D2HyO1tTDKnok5uK^UF!_Ji6d*!yyh$s)={H5n>6;?4A_LW
z)Snpgg<XZuyD448E%RD2TgCKn)t+60s5@QPokU-Wc=%0bXK$v0sodtWcfmR!8soFC
z=TBfsxP}2Xy<#*^nQ`?p&5&Jmq&0Sx*1D0eQXHq9IM4#Mj!Mqq1Xt`(bL_?6{@MfH
zeSXVe&gvpqHE}!4mRM`t{>HiCXTA2dIU<y)jo97wQHaUOHPK21k~HcYm~AhO*TkF{
zrQBmP9p?kwA9rN8HJ}UVWz@K{`x?_W-PU0&!ml6f^@)zYqIR{$PNkS}YyG2Uhs}T$
zuGf6_Crd9t5YgD6qn+Hyw{p_>7;sm3cUa0)QF4c~(d9g95lHnL&)1`<Z;aN;!eqYu
z6=P9ldBVgw{%4y#4x#<rKMaFmQ(rBDuKRlY9z|zsJ$nwVOFW43(ry`>ub=@-a>AC+
zEcijsv8_vWfK$(%7KBZXVVe3I2oU~i#^G4%ltR+_dHp}qfm%k#oq)JI=sbZ;BfDJs
z?u8e&jGk~g<J$p+frQrpu7Iy#eE(L_pt{b&RXg}y<Ub81&Ayd9_80s)-`-ft+5#!t
zYc~s>Rjzkjvy|c{`Mmp)mr7&R9k*-J^IjSsC3i2L4+$IIm(Zl9FHmzRh*zsneN~T<
zNXBIdpCHdTx;C<dYdP|^D8Y%Pu5phuc&1%8;UUx*G=VBtw4&{<PhL#bTRvr&0;d9w
zzyDwJe$Ve2GyWk2X@1*z7ni%+v2X9Ty{g4(0^cuCEcOD5cur!Ywx*S9#_HXP7<@|W
z`|PAg`tCkZn+n{4TEPZuIzYoMWzCwkA`w7m)ts)}-f@C*(>tzWoLlgQ#0_50o}CF$
zze_4A&C=<ek^k>eUhadE6PR~<m)iz9KBWiM#T-r<>S%QNf<+y=bas=ls;+`fT01{a
z)`TMO&V9ZLdNo2{1Z3Zx6s8qNFEX`PGDd?_bXAZ8&c8pTXr2OhD}W*NGxiy)9I*+V
zlXcPKB*a}r@5N~ao`jvC8*dio>Kx7^g&ENf{};C+C%?#vpHSM5yN8Xj(T3Nm_?6ce
zy2hQidjI5R)tg)7%uSfU>n>n6dsBg*iQvj#&+}azu~RWe89=>jG<#P)I+K&I=iG4`
z^hRpl<XdjpnT>Ms-`sy@oaZbTc_Bw7`k_u2P%G2(O$e<2agn1l8$o1ijJBzQyE5Rt
zNAGe@5*{4rw$z6>&3simMfZ^L46$pP*N}8C2{iq$VYH-M;gMzufwMr)+spSFS%Hn&
zT>sa>!NU7=nt=xUn^wSQxh4<=IGgoJ=uf+mcJPs)7k0Ec*R`dgD!iTkSMAga9Awf<
zRH4Jgtb}__a3{brSG!isITS{TXtqOFl*dTa<nv+s=>wZh$ma#Hp!q_b2_RsLi+Jps
zqddgrr|WzGWM@qur5$$eAdX#q{_@*f>BL7mi*TOEd+?LD=Yn_j1;pIzqNXm6$$a<H
z#+m$+)V$v=dCC;U6BuY>8fc1K5=vkMr9G@i!b-IJ_g1T%_kS=CViQeD1OeAi6LXJI
ztQ86&?(=!t^L=~cS}Qf=ffL^DZG#Klh*@XAUy&TWMm{<kY6_7#Jz;g-UNLQswNjW7
z-Df}5RbG?Bf#@b>-&2_5q~p9@ygXFF5Cu9s3eKtA&T$PLyxaikZ^=FTNkt0IuN(%1
z0(1=82eT^tn-^GKovM^24oTvYfMXwzfIbcPshKWH$pj^4Gc$QSeLtXb7ehP>#EC2Z
z%nrQ|WZyquHjjXKi2--yQIVO0$6_>-L=QFgxCFMbK@eDnVKp8?**LVl_@%Vsj!Gqb
zLW>dOS3>2O#O0YzqmD`f<HVhlA<*17(6KY}C!Bz)1V+;&BSWNlk?=sbv*P}!-~ZYk
z-p;I!s0zvua&Anrm6Z#oKY0ccAlfxP@>e;B{erLvz>Ca$Qu0&jD$8rDDs&avGUk7y
zCGXR!KQn@Pk)oIh-)c-_HWn54g)&|~XI%Sv)^a<HRZR-;d!XshCN|So5oZe|HPxZ#
z<-V~rQ3cc5L1Y}nc}eZ`N)f7Ra4byzT(jL~O>5`G;2CPK+`+n_zp#68&;;DpkqMaZ
zz22A={TF+ofOMIIDWoKk^D%Bn%;=!Z^1rOh!`@X>h#Tq(I0#oF7k{@DhTS&Z1$(v*
z30xVfBNWVZbDmNZ_qqih3YS0ZcmKRbyEB(*LuaW!MR+>V9~%&&s)90Ud9`U!r#GBv
zk;8jCKg*pUV_Y8KTTjyp478b{8Ri^JQ9Qk{_0mnq<5s@vP0gT#<wsI5`!sy4#z)-1
z-RSFgoGH(F)E#FNpP#3~T=`(LOt2$=r_22U->Qo%ovKj+|BSAX1SiM~rSUCp&={%L
z3l<1}im6{KpIrr1CIFTAz}CkD6QXU&BsQV;yuV~i5+9~>g7c)W(EQ!tg!o=MhL~#V
zK$No5C4CglUc09aFOqhaOmI%Nft?8~n+^VpoOJNs+ydXW9m_ZZQZ5g^$nl7W2J=Ek
zGC6TP)i@{U^N#u`fY^u*YW|2*r@vHQ0O(49+p;g$5_f+`T|8nz^rCW(XWzZEIR2Eu
zyDNnH<$Jrgu+ckVSsKqKR{E4J6qe1$ikmq}JeFA^YtQnl9Jz@rVeHx0Mg;kaoaVf3
zT_F(@|7ByYiCv+in>=d)9Akjk7(-P&xl7rJp-&IpmhJj(78-HJdrGA8;tlMm2I214
zT<SN@jitK}_ICT55QWu!o)H4KfZ%h4=hzmOnF+WtDEzeC1#kMKsJN$vSkqdrd-Mc{
z)D;q3MHvxuqUd?tQ-%+V6gG||f{YWH#)P})r5t@}Sejq1u80A?-uDF(q)I-wL$!kT
zPx;jA+@}jN!u}pU(#3nB1=s0q5V~X8?s>5j$7F%oaAb1!9~N(|bna0kP=hWX&2CL(
zcXbvzm@0ZnA=j?weVr~kHt{r;YZukW*-YGLY{HEF497_)LgBF2rz{Zsh7Xd5@STCj
zfc?o9VW;+}=D0W!MYq0`Lnted<6Hetcn9zL7G8^i<<!1MU3@I<djCZe;4Y2aj-|ub
zl>>i55~Pq3)ru?)KU34Z{qOdah+%>xrj{bKHf%_V0K~yLT4F<O5&PdwoMS;u>V20h
zWn3rIA}<{K7-VCIKY?u~26*ETeqj)AK%T)x`O1hFhnrtj=Ce>E5+Ay`!TAzmi)oYG
zK!L0N)BB^Om5)s;5vR{9>EEi)G2v+4h)JuGPd3@6H9;bYfv=Eq^B_pIur_59p5c0h
zyCC;ueLysR)1MCtFJ}5@np1FWr!PgGlt730bJ;7fEtpTU#dKRmN*NcRFOQ!)v1hdx
za4l#mq0?abh*hkH>$W{0_oK{|3AmE2ZIJlpRtd0m3Yby6cjabf?*!c_?`l99B#;Ll
zsALfd?14}fn$xo}lZcn=YFR{%3kGDx1EDNG=LCH|!vz501Me-^B;M!0(<<p<QGd!g
zl#RM6EeB9E!J54V0eeTF3NC;@PghJq<wgMt+={Su-Fg7TkH#3V0DFvJE!FVLt<lpH
zoGd3;imZ1E0NcwXNzI^vrxHgKmXqJi84=y+pfZ^~^K+T46I5{;a6h(cVx*FnVghov
zWRk=((zay=1}4J@FI864Cg{hCG(VWU_h<%q2mq<SU)kU|{QGyr)Sz?X{q=4fS&CxI
zXIc}%c2w|9ADMD!w($tdsS2Dd<y2bAgC%($t7p6x*gwCq$rIakpK_wA@cHo{q7vU1
zI}Kh0u#Kg&7Y87)eJz@_-531!YSUnV{hH}j4TW*O-f&3kIDjIcZ#ZCLokXnkMYyte
z@R!X)#ZA(-E?5e8=V%7Yp&3+`08VLQ9pN7ezkI}n2+Jbs-qp(om^>ZobIIq<s^|^r
z<ilcl6Y3s$=EL=;#R@Ui?5eAfh_HDhI0WhhR3<Xw19D%ouGfrmlx}`cVNg8;0Z*JD
zTUS^CYM&grV4b_(mn`x@0=hl`o6`ex<$`V7nBJB7|22UdjzmZ+LCz+eRGONL^pyjj
zIe7!tqIC56#86JAa9Em4l0eQIK^pbS%E+!#HE8Y2+V{@wAI`8TVN3)1A|3<M)dPam
zIhuglZR-i|2#}Q557l<FBYV$AII#l-kX5x<Gx~-?mU!-qJm75Dcgz`1S{ulg4i2|x
zrMA6FX=9o2zRlXR(pES@Ei4-omRU16d1CvN5&ilk_Zz=MW_1f*p>5NEpqACL1)UMX
z+4VKUELxKvZ>!VSyc7aRgOiLWFfiPX9KT$K9?a+#EIZIeJTJsO+#1=H7b(4j5J0w8
zF;g!}i@Wl^?0N3=9+o|k=fr1P&3tod=A_WSmHuYl`n}u94^}^!mnurk;eAD|*q+4M
zpE6~;-1!9^-Fj@6bF53p!#8j90_UW3$ZvKe(D!!aTh1vuOlHcXI5OoDpJ#}paH6v8
ziTfUzW9c=TGcLCe3t;6}JB~kqY};6%Z&Ckb(=~&60;mv3CwQ<l_}BiY5?QC(%1`Fu
z0^3Kk-u-@c+cJq0ID-mPR|qDfXCT`aAU^}tYDdZ}hAZzn<;78xiwp~p-PrwXriMOf
zQ#3PMl#$a6)Bo})Pqml%srVG~V!C%h7VW_?4GnWmc3>9--Ijj(6xc<|Jz*X}s~S*!
z4NW0{XDvS4M1#w2pCrK3Z#%G@Ch}hXKFdYx_}o@4e7HhxhDS+Ouy<iwZK3-`s&QSR
z8B3%L?$2VGHIL3b`YOvLY&?4b*q<aUfx~*Ny-hw><Dt-_&*gzTN);sFP5Ka7uIIpK
z1wH=)lF$#EJfDyxZn$v4S3PH5pJm$nfvpxmcp}W1cf@I8Elp!jrT=G;^bN47hTOGM
zs1NC1yfhJbJ*Ns5tpQCOuH3)C)_bHPV-w5%?bHb}A>l^lpU<bFEjAbDE51>1V>LOh
zv)$cxfcqfZaBLF-E47Jf@NGF&1l|JpC;suugvWFdL$joA*#t1~KX97gMsrpdfcC5S
zgfIdCSEzxeXiXnh_hR=*7Y|DprpVcnLz>&;Of{|d50t1jG&Q5^j{d=w8}32(Bk<$`
zl;(cO(1R29Dbr%>@9*%$GQ-72ivM;4Z#pXX>+bS6&u9)IxmV?Ladq?dE8TS|-%VcT
ztxb2<ZOkpVgxbFG8)<R0+480w@Ur8`*V{*+w8SahrJdYaVle0AVnElHb1t15<Em?o
ziN==$Mr@R}WSH;yFU#k7xr%Q+qyTN<Xlw0A_ASw(s{~z}ex7FNed*BDbI0>Go|zY&
z_Wh(nTSLusqtDg6Qgx&`(!`6F8-z=4X~)jpQHTzT3P0JCc?3?mH;a#Ya1uZLpz!Ts
z&cC(KE%q*>hL^5bYsN;jPW-pff3vRn8EELsSsyd_P=$YaFko9b9G448h#>#VwxP-;
zKnC+*4|-V9<W(wma`&-{kba%rA>7K4e-o*S&LL@K(A436xwjsZ80O>6oiQDxDEY-o
z40%KG@y!u@H4n-^S<(1%&?Pu-`jJn-I=RlnqKe)t|9WAEFNSPx4L9=i-=2T4vN1vA
zvXL!%=8AMs^`^y7lm%KU|2+H5SvpJ_*rDMg=c}14W|VmTEjkhE`IEj0rWxH>2dy{l
z{#=v2XZe>xQRhA;so3G<t0wn9X*-_8oB_-}H!L&!>F>BIdH&35n^RecbzgR0BYL?G
zv&}INx8I+4WhV$O*G&9l?8(9`36FKTQ{jYe+NT4%{z_TFy4%yN^E49S$=bAIoiRRo
zZ|D2W+tA;3lscsO#h7Rv;+NgfD(JXnP`EOlB7Z+<Cq2olM_P}xnpD{i$Dc~mGTaC*
zL&f7L|4hik*NXcOM0jrS?Z76SQ`a^dvCLyAN>;B)rEw~6QbkEM5Cb{YiIdAv-M3Tl
zqn>L;VT#V_l2LE<7;gKok=Tf;80~l&XVA?khV|^y8lUW|9^F>htaXq+DyRG1<<FL+
ze>z@P_p5Z2wstuD+{=Y#ODkG<*EGkTUft||?b@||lTAj)es`wAO{zmd{DX3(;Uo+N
zh3}H+z=RZc_%&Oqag7^6ZrUt(r?=(3g%{^s{#NXOIcE-+vDIVQ)-KO3m*Tx^cL-yA
zbl#txE_LP8KL#}%{FXZ65ZSo6q?Jeq=BcFBq(1W~=zUV{af#4->s9v78yin7dnUZO
z+tdSX@;B4RLEFBems!tjXv(%I$F|i}F5Y!<{ET5)*nU5YIkzpr&OVrJkc|~sd(h#w
ztG0f|S{$G$Q86WfUJyDYU?`~cs%uWrVO7LD%j_v+!*k8qM|@lBqB>-1w3qJt7+BJg
z7R1{&SeM^+MP%nk)kdOL;XFyPshzZM){Cswe7iW6FUFgdBab~$EeUpGp3ss$No%?Z
zRDgW+1$MuuQa+Y03chFu(W|Y`(r=Z|b9Zn@m8kVqr9Qwqn7=4$qlCydgaFa$Vjt(9
zq@L^raKti3&De#JKd6e4&7qS+hj9>m8eU$dF<Q>|07;>I!x9y{!c_UvR-8S*iSnDz
z)VxN8(Zr)!zxdT;Dz<>SVrKD==&L(?%QYR3P>2-uY2T5O@96yJ^mV0gbHNHXSj^Hs
z^;qt8^A(R}z-EjV+!t|zg*M?H)A+og=eZDqPH!U{N3HuCL4XD6HL*6uS{%hRF&GXJ
z=1`nKE-$zvhK3|K6$8?%B9<IWWW@oO*qF8EXEr?~gjy%xz=|s*gtj5Qs`_-q!iRAV
zae6a;I{t4Mh}{)qc*z3MRm1G!NuD%f8|zKCK#~iqXvk7vATh<8N{`{{xp&to<ngjX
zgx%r=&&TiYuh^7Y-~S|kt$TmA*LX=fe0W3YqCu0P3a~(xPlOO26}TlRU7$_i;Z(Se
z%d>n)nn7Jl<UcPZkcNO1O1gBah>6)SrF!QG`Cg(vXT3K;X4{)}>*#VO^JRqAng*Q|
zr&o3SrW;pBV>p<nL*a+^=wz<PV7ucU;pavbmdcEXbD9_&JcJuL&2;@hFb)5{Sh&Td
zPCl?|u*oC&Hf|^AW}b!+8A)gAi^>iEE&vr}e;>&UoAg%!Fl9cEo!0ccC9*#^EV(TB
zrcArx*BmYP*4YnF5Q0DOeU1BGU}Ps?h1Rm(-TKR}LLY_9G#qR(vmxw#g}icU=8sJT
z63{CfggvW(Nw9ANJ|O<E+8Av)A_F9{w>SX7`5Hz!@}2jyWS7_-`xv?=XNq;j5P161
z^FIqQB_sEDz~|Qq${>+E%8uVUT-ytVY6?+td<<&+oMko;{mp1tcX{Qg?s9U;!;?VN
zp)m0Hm>|z`yiR9EU|pQvsYr2Bd%(l&4DNcQ9B5*IVNcMlnpnJ3vtO-_dhzUDwL?Iz
zz}?|m+a1S&qd7%jIdoH8_;>sZE$*j#e?_4l^L4Q(Zsns8r$v=(62|Gxh3W#o`lz#&
zaT7JMijfOm3XiLyrsGp}`fF;;_2ehsPQBQL`(bo=+~*OaQP;Ddysh}gcy3T5n%>4X
zJZdd5auX`O-e6sFxj4sj?b4JxF0c!qUp%iP5y1GTL~b$)IeJ}FJUHh4IU@xAa3xnA
z5Sd1H3MlcC`+e}>0_ZY%mrg=_fnqXYo6`!NyY1#*Eb*g!f_$CgX&TG*KEeLhz4hAI
zW9Kg90VoC@@%hH6E_iU4kGm96mgTe}w}qz^zlK*teBwjB0}DOqSYkr707!50QgIO!
zMo2*#_nho*Vap3^_wRLEaq{gH2=d4$v{7*rP$$cyHOC%r(%mJwqTK;i^y*x~eoN5*
z{W7EY^j4py=fdN+?msWoVI=Baa$2}|TFLByN{>8Y^=NhMJ!W5%x6z~93|Es_bTDBP
z9hSJ^ka`~g%=y;x&~*3ef%a1~N2*!|ud}rl*u;`l=^LltggcrAs%gUJPs*q1kZDi%
z&vl}EA!E+V@9wnz1mnGRIc=gfz_<r-iJ?1%fm&anvR{z#_ul^{B}IurIi7~9Dwlw-
z-|do((lbkqOL{wPPai-0yi5OcTc6HIdSCk0uWv*A23;fmhffZj+Om07ZJ5K=6Zu{=
zCIQd5Z+(L{^x2DVx>#a)5~%m%A4^yDb-DDvKV|76^42wKul4pQnvt8bfh4gDh4D@1
z_SKMd_`~40w{(Gm+CAPvXBv4`KFX_gvTCW%V;%gRN0QEubf-ypPZ>JV;1{`t9vfoD
z@{17N<WL!OOtX`uLI4F5-!Eghcp9tA{)r=nKQZsMHoDKs+~2dAY|*T?e@TIw<P|r2
z!DF3it-?}neLtruEOLK@?s|>n(nsQp(Ncio1RY%?w|$;$-?`6t<$V76N}UDP*4MR=
zjs6y#$YYY+;7=+|#{D`~t==^nAs6!KF%T5wjcD4g>bFfB!o1?PN9A+m>sh{+31uzF
z7oSGHZsH|4RbWWnqaOh_$q#gf_gUjubJru4H5j_$V$U{#teAjY2bAmfvqvGdy1Ab7
zdbR|Xu?`(9<0@cy9^Q;9F<ATd)Z-)j!)2NvL;YKg44Vwe4{Gs-gOt3*3j!VC85AIE
zM2u;Q+=rbc?e(e9OyVI-uS*ZB7ax3i`pNy(Ui(BCo?05R=NYfH?`B-ChY2gzgyl@c
z2NHnp^L_sl0#G8l6P4?^1PGc3m~{oYwe2$|fbn)j%P$6Ck0>Tl;vB#)s>_vQvK*#K
zQm*hjjn8B3)#a1X{g~m)sEbLgw^Fk6!n=k#`JE>3cZUjH3?u9k`W+#k(%NEifC$4H
zA9~y~<F-Ec&SD>%DQk^BM*$1ldNB~fa27-+J=M!y>Qj5kMpr;QiefBIf|Mz7mNIym
zowjb9&iN#@&e~W!4SZ|0SG%0;Za7%8HSm`C#wNc4k~&YQlL*$>KHwqla~2D6YEQJM
zfs~>r4&u5xT!BhvLv1H8Fz<<*Tj}FvkYGKIs)X81)vRg;e{+B2h?4CB!;>IPXpO|U
z(aj#vfd*WUVa;$C_P~q%#)3XH_i|W=09=$y9wy_r`dUU9-g;MEzf)9O#_FU#*=HH6
zMWd>SfKJoX$>vXS%v?>Bq30yoxvH@AwYb}l!J2qH?Wcdn5bKyk7i13gM+YZdC$F61
zy2DwqPG>w;yec~(fp7+@iynCj?lBAqlF~C=9(kg?ENuF4bTDNuf$~Op+ToE00Q|Tv
z{7cYaou){pB-0HOLS~0kH_SHqt&K!xz-yNK+^UQz0(qxtA<oNaX9cM&|D5heOw4Pb
zt|0M3+*DOI3ySf=K_(9h-uiaNTI$SHnUj?j$pkx!^Ylyt2KbTPbR?)|mrtT+4;kb_
zcFv@;eB!{ohClO$=#wx)*Ji@{6KEPSU7jH`b4e?<aXn@<=-SQ|<ju~HT)5>H<0YQM
zWEU~%<7{G32C1=q?2bRlMZ~(qlfnIj&mg|qjbynueQvERJfCy0X239X56%u#9sMO~
zJKPZk_MPnABL*vLkaAEYOvN~dqKanw1myQ=IIx%-edl}{VRixW;UlD)NqkorB&bm8
zHZzh$-I(Q87*2s}NNm?hRTJ8KkLf+SJtlP@^E4r6wYb8D$3T~^NQbS!uSrTYNxteZ
ziJ=DbXzqK6*WjhiRqp94-WnZ|<L5jH^6d&>a#<)pQp<x!e$*@Ec`}-wr`XsV*Tb^S
zj&~voZnzM^t%rqcg@vkKkf7bON%JET49uUQGcNSk>vs<mnDBc~|7Ph@NXYU7d6_Dg
zYcb?0mV*R*vvv6PBZjV|Po(FqQ%`p3f;uH31Xl-}K;C6X1;;1%4gtZHdUDEYU~BWf
zObH7KFjOaA%^4?os=;=p)H&t*drq3!Li$|oq~~lH=AZYtw_UB?j!8{vt=YDr5S6zj
z{WiHb-&e28oJJ-2|1=5r%e`GCl$quhJ3oFKC+QhRYGw-VH4Q4~B5)edA10oUlDtKO
zo+Lit5OBr10)Z;P(18eSQ7p-!Q=b<2?xK?sVm89i&?(c)){bR6&(h^zKk5Lu_>t^P
zCqG4vb=qz3IK->@UUFx<)<q@rU3_rR&m&=gqv2g7ZE3#4_@3}-u){P^mrB}Al+#Hh
zp2Y1lSRz@pvRu02lf87kTHjn6?^Eg-B)EM-0}N4NpFMd;10|(7on>W=v+hZFMJYf*
zLM9j{+DpLSzubTg14rD()EBlwV|X<-4H%*TI?Vc6-|tp*<=2LfxAs=y32&2QD!VS(
zJ*llL*X(TFy$+bpID{K#`Z-Y)uO0JB^j%u%T`SJ_AP9Xl`mEx>#7G8;-A8siI9rd!
zYA~>(9nLj~Ja>vKwd!ac(^g_;EA`SfBvc_7(g<qDN$W-Cw9Spe$Z!(7@y)r>Fuk}f
zVHFHbv9LaYCNy~6B@+I=M#uo^;9AM9TpHQB{&FG*mMItq26~9EOp1X2#&%`aB<K=_
z|C&dgYj-FSf$)FeKZbAxF$5h!RJCQ<hOy3lKLiGhhsTS#FQq(rA-J+8_Y19Sp5-<{
zY6SUecal`$!6$D;kOeh-2dgld-mST>Tqk$KV;mj@AWyXZKz9n%Xh2w_b?!7v2}icp
zV5!n?pfb5{HLN%MY?80<*!)W9FwTIr0x%-FjtN+$^Cl*7F$^J;3wnz4FVuCp@^t4b
z=rr?jh&G`Jm+MsMAQCp5Al>dt_Wzw!zO%)8fb`M%N6ebFe|BGn$uDS}fL5Y_jAN)J
z3DFC^&kei@Rfnv_Bxy%|gC9k=b<R2WW^(!qY?^A?PRu5M#v_+RupvVw?Ek}!o9Xl2
z+(vac0|q!_6=Ugz8|Lty)Yutm`2lfH8#Q?h-8izn(d)6sVePhd3nXq=s8M<x04!sX
z>adqG1!{35HJWU#9h1J%XVC*wfm^qNzAPRDD?@~|{-wa(yshMO#9J?18!RAkbjS;Q
zW<5g#P^v>9!2l^krh$G>Qd}rPjaH@lR)%^rO6L(tCseD=B0Sp#;zCJ>A-`+$z~S?(
zrJ`k-Bo9m@7EgoJo0rux0W-z<?piFH2$HS<@5vkVq?ssZYbY5CcazkW(ikclN>Sxx
z*OfHz*5j(J+hNxje*UC8Ro)#-soK9mgox@RpIN$?&eHZLT5*4dyv$^NK3Q#OOhi)2
zWRN9&_B!H&JG@o=I=iyLggC)rD*%K5co+e;TBoZel4M5%w6pJ$=y8@tpN)#%F*b+W
zHSM{P)b}NkrR&79v+KjLS#DBrTIg2?9;^Cd;19_1;t<I>+SC!U=~jCTzUbPK*L_6r
zF4!9r(M7Os9rzOaw^t!cS3ISqv+AB$AP~jn`1Wgu0v+}H-R66tMfMOG^dSjAAc}Qq
zBxJTTq#~I1qmr#B=OF^9@e-`7jI0jJSq>ky)dA_|a~%vXsdIsTxfSYuV`S@bEkvwW
zHke%O`|Kcp$IT~q-c5RnteM%tKih?6zH5oir7)WP(H`Jem6uVGm+DRcklA;UaRA3K
zp<3F~xjS^Z29Q}Z*|C%5I4;{z*0I%>nI<(JlQQ!oP-VVlukmZwp4Iu^^bJ_!SVMlC
z){<hE49c7!=f1!v*c{2+J)@Ipe6KAqqi<*R8Menlt>$`I<9|SHKL#}bgrgBoyzfxu
zvEW~(8>GF^>~3Ty0GTL2S9Gh1{vO^TFiK(?E!{I(`1=6K6lgQAz4Ee<`SZqws?kE#
zFh;BnSUIWtKU=b`U!U<bK)py>a^Mbz+jsNOw9S*1&p##GR>7PRM;J3S;|UNQ|F__$
zZsTcJZ8}3WiR^Bufe&R|Mh;$lMRMYUWEY0lvcL|0Zj_!r5J_-ukcfi!%5@P@aU@ia
z1DHU^E!{JVbAS1t*URIlUfyJy!9k{tUS<Fx+63$iC;u;I<E<y8Z$1EQHbF#-Yko}V
zJbBA1Na%MZX55;6f~NuMh+122$*$-z?rz^aqse~8q7sse4#h>gXUy0hqHs3Aa~w!;
zUCk2#!F-Tu5!2)m$h-?=%4Ke0_s(~MpWm%<=l4F0M~@!{s<#1>?h$<-I-E@fnyk3K
z%)0+7^}ZSHpBemr#*|FLIxDkuuWX}LGFLc%=n7JzW}5hf0=nTB`DT>K+I3T9{<^}g
z?HxaOKj+BqVPvQd0K19nCSqu|3biRN8Wdye+u-d#!A@0Kp{=Bg!weV?WKskob{%>#
zx0AHH9r57M=0g>7q2GR9w;dlWzZ`JhX6IVj#^%5xIeqm`u5iCl&0<f4#<iU-)py9u
z=-$ak0hLBOTWB}BO#^pYU+RL?dF6i7^K9@fGxF~K5vl94uZNE%U*BVUz%6B(7UKKC
z<8qYHK<;*7((8S>imG!03ZlyHkeD9=eieAm`Sbh<g_cl#Cq)PdAfg_#nrMoD*_8}F
zprGpVc5e3F;b#RO`xB%Sq|Z;8&CGVFQrc!Sm8;YnDrW3k3n0Fqrd8yyVPc>!4;j&!
zIK@N`T6iw$e&hW3a6fzS#jRgJh@aU7yX0NJ@{=mfceVP}fnNRB7Sc2=?JO=#2+}$@
zbNYoSykXz*KRz!$n<33#L5;kwb?vh~=eeO_nldsw=iczW{fiX<qtdGX9XbuuwVI%P
zDt44aZ&IXbO&gcmToWbPZl^4wI+<!paw>IigoE10h*&v$B?~?YL$vIGV~C)bIyqk2
z_;op5=b`%CZ@;}bNON9Aj7ca&{<Csy_8R4^Y5bneDxrtkIl{)@rh_F{CbiHv>=vAY
zwIWW6@i5)(LgT(R=~V7HFGP%2$?f0OTW;75@OleU47912K(;10A;cDbgOv6$k=*X6
z*7EU!ob96-m;x0aufhn=m+Q>kw$xNxU!+x{>#@=%U_SS%t5e<W_1cgZ{<7{S53K<(
zz4MNE?MR_U&ct@p>}y0Ne`k%2N4~l=_F}$PO>^tEvtew5qD!YoUMG~?9@DV0By@A@
zOQJ>&LobGo%ZN&jA0UU%DYAJ?g}W;|HYr#&F7R0j+2?2OKiELbQy~gO@6kVBUW+^W
zn<oY?Ixa8z=*!xgCY`&Y^K<c`bFWh_rYpXtVEs+%DCK@Cbwtdzs5+qP_m9=KujEb^
z2^&hoBnEl!rh$R_E<86DGHqr1$Ey8#c*7mL8Y|<~zWOa1>6-RP)ov_4l7i4FbIv1Y
zQXU?>0<}LbYI@hW=6ppFkBiuJ<L-pi3x4Vp5UQ~+JLC%C^twT`gaL+g#{P&+!DGJG
z&+oa?Z2X3_^N34J&x<$odk;8ebzk)^^D{Di{VTvIWctie7o>&Cv6VWGd8C^(#IVHA
z1;^6chnZ<f{Vw>3GQZ&mYfULP9ndgZs57n(_p94}V()ii!`{1sVx|tTcx~YPFIxMI
zo_?A%Cy!-2KBKkJ4Il^q6fbzeja(Kkt4C%$_Ez7QGUYST0JmQ{Cg?ML;eP8Gp-#S%
zq4=4%HB5tpYwX;l0!|Jwk4`r@E@io{CHmq4bzDl?4W)}`C<cHS_&1HqdK`^@V&oL!
z7@eiv1Mq=HwB1x&YTBeJ?YG47wbkq-F@AM0<Vc&VxfpN$GjW%7#T5EJyASNy)?ab)
zx80ZiAjB+h!`GwYXGuczGkwK3!jmUo^0VR!QIP=f{gpnbDI5>Zt-7@5eRJVH@g`Hb
zpKmud)Vlu6$LdQ7WNnBDpQa-wyu@e#N<N~g%}^CZO@!Jiqx86}(Wf;Z{n#ud-_P))
za-KBrZ25k4D1AS!q21d_)B)7(CnAj>Gu7Op?<iy&?w+?PaG$0%zI!*7<2TB&DM&`e
zuGj0m6_8iQczLdky$5g7zL@XFb5CH#OjdB}>Z_xrnsK>7-)A}Q9sRd$>q8U{sd&K<
zA)XzgWRLmbeph&0F-k|Nlr#1zOGX9-Y-?6XAo{A`Q!a5e5}7C~=Ym5P(a^`Sy6g$|
z#%34aj&gr5rLzDEeta~rafz&>paVB~AT0I*^nqKm<JG!k^tZ_%bxkKaOmd>)((KXW
zDRjfIHEdCw&Numl&I=LU-mvX$_2)+#U%GyuDLqtW+O$sWS5Kybx1WmFpE2R+42kl7
zy?)~9MI3aM+Ns?Xl+_AM*j8Wm1iK{w$lo6iI<&Su`+sQZ?Y$Au-v?AeYZi7k({^|Y
z>h4mg<Eci~6u76n`1?|WE}yRI^joM9J^Wa17|2x1k@#ec1*<Qa1juN!9Nf#LrYNDW
z?(_n?L30yocOY0}p%RuYQ>8X?`)zCG3pu#YdjDS-tywH?pvOX;M5Nan6&<A~6Jz%#
z7#eG>vtVf&#?{B~O@%!kL*8564?ei_Yq<TI>S>V>rHn98g}$!MlBkxhCl1Q*n=06`
zLDszlpv)iw^C>317!8GEF>^8yGIQBn&k2s{SYSmid8u1Y5|#H!fZ1XOvca9DI#M>7
zBLeHDFPN%iZ%5foK0&4u2UW}Vmu5_W)Vy<>903T_q39p_y^Ew>Gy?eWw^%(XJUDcz
z@rrdOLvfc|wC4l7Z^n18Z7Cmb9Dj&>?+!Y0BlWu1-ajd5R}}I3GOnMvKY26Rq@ERT
zsR>sotN-7H+j=jhQ6$x6MduV22KJtbOqoJPrSa2^-g!k>Y-Dq;YHijJHv-=g`xP}f
z<I!(TI2LEVD(>w8-MOjZo%H};{NbZl`?{EOQr2h)6_NMuY&aKDqy8>+I`_hQ)nNH!
z5XwEv5tJ3phSa;Yp<12$liO&jbK<`Ha1{WEy2Z?CGlFPnpyYUM`tiy=MXF-+)6>?W
z0HsQmQ<F#3Ieegcmzbd_?FHLT_TF_?0-N>JDIAbu<W_~gN5&b49xth--3R0zP}!uJ
zmKOZTC*)w*#Qv)@@;+Bqfe>v;wA?P*(fc(sa>;d@^soQk?708bSrotspuEs$pf$zy
zju6P1i|lU;)z6-yHz0th{W|mE8Z`0Eix)MyI1}Iocjr+ch~Aw0vH2a+M1M#t5$TIR
znXC{+lbl-kEA$W7Y%Gfw${ojT^_(j!cCJ`F@o7r=!EJoWW*u_XL%-F?FN}h>9%s~E
ztXSB0VTbe|;S>*xl<y0?Va|ztAAYR*SR$szWbouq_~YzNT3D`H6&ne@K6B&4nG!^)
z16u8a2`n)(n9=2hsr^buHb%xCdSd&FvU|uaWmKV~D_Q;5C*qOF*`d^Gw%lI{O=SQF
zwNBoNNTsEr&!^jMUV2ykKb)NT#o3I5)J;t*3+*c19(q>IKOT+$y%Xi&L5HhsEWGpW
zfiWv&JUZ2%-%SUnkNa}|kF9$TXZrsGKK|Kxw%NgP%wcmTa!5jG&c~QzQfW@1R3qo`
z-JH)xC{l(9sYVh~ZOAE!jw;niNGBvYl<xiR>;Ch;uKlq;cWs~R+UI(IUa#ll){c6`
zua9>FMg-J$h+;W-C(;9r_aCxq+6`#TKdKU*OHe@)vq+&L0KYPJ%#Xb2$H9(-x~*N=
zImf|*RUhUz5Yubq-uEl2oRoSqCev7hU#O99=R>-I7dJ9RO`!(q*DbjeOEo3|`(&vH
zw=BWROi%w4uT#ua%jWVLv~PM%{rF33z+qVOi!~5mrgA$O{_>{R%KYqzo96u*X;Z2M
z9VB7I`Go?ljy<-QVk>u2QDnX3?K-&@x3?DrVI|Yju}eEP`BGMNr~?Q4jScPLo#f<+
zc2E(~Un3ke^prSokw~~M8QsBy0H9ZE>Tjp&6ru(ZIdeDO|Dc7{%M+n;WKLPiwrXFg
z66(x#04YG2>Es7DE6&wOCkbz5roqu5q7e^O3t*D_Rs5PzGgg=@Ozap-A(fk$$@*GK
z{?{WS>A-=yaG-2=88;q!WEj1~L9~IpfY!eN4~J^SgZM%VWmaJt*ZGxZAdoJak!xW#
zaG7#b%5qM+Bk*~RwrPZ~05Kadj;xmlT?GtyvWpbsk!froRZa@37{P-7$sjE?;8SZL
zLytsjnX$fPr7po#Cl5BjLAQh2;Ij&)JoQXV2%>+-A|0#1gqFC=xUWDDGcjK|8kbRs
zXdVL4f8Rm@D^N)HiiDuK+KHu?_)j9|cF3o~(ZZ#TZRdJCh9ics)BMB7w(wNcCKMcg
z%p#eP-Wu4$0MKn7b~E7S;Q$GLIK_Jc(#$is0)UlPlx4{(N$Ie!z*Bgz3@7-)P-}BL
z3p*sp@25g(ZMtqu(EEJFv498$2a(;Xx5-kt&yr4};2A4R<Qkj-ozT`wSmjNsJv9Gr
ziOnp*3QGQF(ljN9&VL2g#9S_~&fn!e#=c|`AJ!Q8X@1kn6oy6Qj5v^H080$o`ILSv
zO!GieKP-hQ_W-O==pgf+FT6iex%B1axPZ7-A`>o<c%xi$jB|D*)A(b7!gJ8asVr$d
zCj6`iK823H!NDo)0vqs7m7LMtq-=}D%_A(tPg;2z62j|7b~&_@H8*Z*U7uFy>0Mdm
z9T?}6toWWbEJ;fcc&!do2dEIqLfSktHVsCmk3;K~i!()>zLd9T97-Kcs0B>xenMSY
zQdE%jChKezfUx6OKS<q6@JP9VCK>`HG=YF;EBgV2wq+caCp~vH<$b{4HP)^IRTLL<
zb@7?Smuw*eUlzz)hBs*Or}a+ThZ^LQVZELnLy)<LhobeZcF`fh;UF@gLS5NkK22m#
z6H7T7>qxnF3QpnsN&jnTUjsRZc3nq-&HiZ#ntcR=+#Fb_J4YE_Y0<usr@z6$|K)&N
z$ZH({zW?VEahn2+wrfYR9Ex04q7i8N4ZW9-EPm!HexH_onhSI=(NfHP*GeHgzDAx#
z-<qY|PNpZmS8}Hy-~U8`86C24B_r1It^r{6xZ%hOg;=ac?61L&4CyS^S9McSU#ZHs
zYTVpQpiV5Qo);2R0k$!KnkP$Fh_EeKTX6F{aa4Hd5>8718u?NdNF^jZ-FoiXGN2{R
z6na~YMTJnu+%~=J$6g3Eurd7~HUs3b%d$nn`CXm!kUbKMN~N-3wY+_^z@@M76dSF(
zi2;x(*a5TFBPk%KT$V_4<~}B>qn0Vct7-pkd8mGuL>ONJT&B<iYQEC!)w%1)E6Kat
z{th@S&i~U3gVaV8<N1~>ABQDN3)I76Sfn{i(hUKMosOOp*PNW7{~N$XJ$4Get+yrw
z-Z571!5D{W$v~E*FB3Bv3X#npCQ7DAwUADILX3c{5&a778N?(o%GXGAl80`gl8#+F
zzsNeaUjR+v$OC0kuG5I;)`(ahDWzQhvr*XN-ei;|Se8YQ<@89|={E{+$Vh^r_feBO
z=z@?iq?DrV8T=Pbpuha@KzaH|0Eq{EG0+Et&PZxgON`=L;-|YuYVnoLmMb9nq3J$$
z4Kdpi<DZ9d!947(m3LWD@iZV2zeq5oY$bs~J6-{bb!HHi5XagksfiOtInf`;*jWIN
zY$dGxiXS{a99#g)|Acaq(mpnJ;=xP8+Mv^+ag8yMTn7dFmABG7g6)7|u1LE5RYrA8
zb8cKw6o6ii2J)ZYA;|_SF0kH{)AtRL6N^A7S<(01)^e_7)3Rddn-O`2RA@LIfr^2n
zD926Crycl_vBn{cthm1+qrlVt_izqz@kfppYbWs`Tq(!HoTJs_ij~jlh+?L^j}HO+
z#i0N-0<dT3e{(fclh6CN!ExC$#)dG-UXbJp=;Qc#_u<s_-rD@Pf!Cg@6Q@g0|F)6~
z>wr2iB?<!Nc+#QHAhkHU`K=R$1$U%{IuN7=GqueTHRkCnPJ7s%0*uOXmf=!G&=bqr
zDV;Uu=Vo$6rR-0h&+D>L9J9po))^9gn3dkWE7Q$*(SjAP!~LMRLWrbmpP@EY|HX^q
zkD&==seMDN<2@le{{&(Cr@<L~iF-M^0h7?tOojJ+X>Fc_6DYJ*31P>Rj-R}6AT)Uw
z6<$Zh8ZrrDHQ=4LX5Zq>ljASVT}9uNLI=|8U*<UA8cx90X>F5)8>P;Re9ciF!|8zj
z8#-ydQLfS%GiI-)QYfc^&1(x#x<i(f)u2!<6=+YYKF*WA4;s&jZocm|33%kU+hb?(
zfSjz2B6tI8CLqnIr-bn?-V=_}ap2pgGItkWYj@T_)ObR-&A@pP9n-eOd@h}8bUc9~
zy)J#?CLR6r&M86o+#eoJjVuR?4?nMTXn}*03#oD5gX-9+^<77_w;nrI)4n#1ZR42u
z!X?`36jxc&sfjHEU}9&Q=4`<6q{ZX$o--Gya!x|AiIRAJTJ)MG+mQ@e?bc3WN#H9G
z3_8LTkTm|Cx%j%}J`3nMtsM9RY;o$`f2PTwG^ELb<2N}<AHt3#3%x`jCUhL9#G7=9
z;mGr!^|RvoCR;MzVy<v3mD#F~_=UGLZ?LEoIiy4{D`Vot1^Z@vZvbhQd9pos-`Yq2
z#GBGhpN0Py#6O?R0h#SgSQliZOWKShF?Cmh8(3B6lPrHwI*de;4j^c7_O$c7^K`%~
zW%s8SwEf7{2L<@?^CT=8Y*-<5|G?dTfQs3x@|T3w0Ib7-&fPtj+`Ti~eb}co<AnhE
z2$rYI=Uat=3S)QD3eLN}R6_MoYtz2oUV50TwNv}gbZ~~c0z6pGpP1=JzqPls?ZNAN
zXDf?syS4o%upOrXm8xSzzz0Nj_%L|xS0(K5A@~L6+thLh^}x9bqX!p#aB5WCD*2A;
zVL*wBTjOm>u@pN%Si_{T4^-3@ULqo=l6pd6DxlQ0t~7#AN(_I?y(WE}<+?VCih6yB
zz5_P|qP^dSC}dj3r?BLHffQ26Y-e&g_Zlfoa4&(12%|n(IUwC^mP|S*e?_jyh~9=y
z=Et)jhqq8{v#?fBwBoK;wyvW%9ARAmHsgSaOvTyh<oUyW*U8<G=jT`WBpM6un&xQ(
zk<`ASI2&*Ae8ytLzV?Uc(K#v!`^!AvVg1kK-mw>_45-gkNq6G|Ajg5{Cj>2}J^VST
z#+ZOB_gM-w8A}76;(Hb;w@bV5cl;6F?IXOV`f`$y0LS)yrFe!AHE<<5O>r?GyXalZ
zBf)<n>9(^)l2v;R?fU3zR`RGC()S}e67Q0}pR7-qkbcsjSPF6~0X0m_g?`S`Hlsqf
zzmH=rg+**!qa*14yR*dy<5FCbFZmUv#8c#4He~N#yS_RtzYsM19zjeYKibQTX}yL|
zdOm&cGS20e$RVD_3bkA}CEz^|)dT**<x5dnH<92Bf4+@T(20*aF$?J;9U+*?*ZxbY
zzI({XUxA8+L5kn)6{EE-OpWgiUTuJ-Kx_c04ShxPDAbgh^JM1P^j<_5{obekON;ZQ
z+*RgxkRmBmbNfh2Y|SZSD*Of@e1X?0rMY~3&-NM#w8}XZYU+X-+5GB!M;IcJw+r{&
zIp=MqBH;=prQ+MiSaM4r^O0{8x&@%gtfSxTx{6YZ7N*6?(_55j@zUOHg>*}zC{jUh
zr(oV1qM-<#`taA52T6Tnm%v0!-G%QwD)=UK{6T=iW$s_V3ShFJ2&tJYJ<7i1AIwiP
zpB_Cd%P~j-J<EtZZ&%RWDIYld|HP)~_Qs6zvO|YEfpd1F5_=3!yy*$Q^;n)(bNKe=
z#?P`w+7;UEb6IXR9_cG1!xV@erm`vQIfwAkHaiQOfdbuae009Merxkn(C^`iI(y|;
zn!m2j5)Fcg@t@vgOP{_$P_kjJqc2$2^pIGRweHOlMRL;d-=d}@C-)?5mG8Xm$rV;l
z%L!{I7C-|wL<OE$W+(R9@QW6Et0kbut$JU6V`4(ut~-ynwObG0+x#rvso_<%SAFU{
z?y$V3KaX~)JF`H-#HDi%TrRE5t^a9Z=~u9D*(&)#uH@c^V7=)cp2R8)Q+pFkFBJJ=
za5yb1MK&YK9P``NVn7Gx3RH+nF!w=LJl)W>N2XH`#J{+cxAVi57k-)QyL+b{!kE*x
zLQnG8Gg9bO@rY(?KUjiM$D9$>LSZjFF>!O8uJZOy*2utHMU0o(-3!ht)?Hn?^~Cgj
z>+Ltn1&lNm^F_ujmfoP;u6$jI8*#<pWxn(W<mC0N;+=*IgVv(mJwIJT&^zmkScqfe
zPncUnAnVHpbipILfRkLpp0C=q0X5etR)a>Lghw9RIi{fE+#RidUe@lYlX&6k5nJvl
zoJljk3MbJWSc4|h5>eGVzkGY@tlN_$K4$in+IuB4)3DvS`o4B#euA?^ud|)(yHBBT
z3UlKC_<m#e;!e`+)epFs`{4&IWaN;{-H<iqLQFz0V{q@(dZ;vdXXB!?akI?G4M##}
z0#3fOEZ$B_ySFWnvF~0O+US|=9XIng;}bBF>35`^v~Uj4E#&8HZwvdn&(MC|sil>i
zxNoL2gXKIrd$jEH^2}oMyI|(mqe>iEefu;}T_G;4VMgt?)3>zOEIEt=4*j89@1@1e
z+6-Un;2(jdah73Q<TE)42XD%FUiwh}s^HP~%;}9ngIsdOoA4(lZ^!wEWsm!Yc*}aI
zXuXf82kZ&f#U7~xQO+jKuPVvrZ}?K2s?LwXr9~YZ5I<O&sRF{667-(ManE_<%};vP
zdyNkH(2rddo&0uZ-}5P)kxsB>B1V3Eadm(|eeAaHS2W&UidwaT(!So}@R`P$EO~5R
z>2vnUq(}brRH1i)R=?4M9WS2j30d)oq!7J$2xXUD-=dXSt6lCp$w#}=%XPk#@u!zm
zu|CyPJ#|G^zed^C*uB}eI2QkyKTlgl9`m7Y4ZK^{k!shW{M3{E+`&uT_gpJRcBPLx
z%R(Ju21?ZW5@`MbP0lsF@+;h|OJnZaSqO}-=#vVRPdXc$fDEJl?8NDrvRSAFK5jCI
z<M4-PUa+J@?A064Kh?^jduQwMCYc+6aw<j}eT=P~w>JX+z)M?$r0l@Lt=wT_km+RD
z5<PT$T8B8qOmVi%n&`l%NpX2NBkkux!2spH-e7y30duFZPzkG$JSV=rNryf{&fV5N
zoG2+j%PdHwT~oNHVFSmKL2ry}Gf&#&z}05&?2xS6d1%CWXCYCM@CQ&>ZLA2Hb5C1;
z!OJV>XW=5~X|fnSiixrV;5*!-IQtnECs4LZ;lXycb6`8^K#f+HECM?#`5>TSht0B*
zS7V*R=2E@Y3Jbe!nsl6f93aRHMPd^c`bsY~W$iYg0f5lP$@e82*tVJXBt;PKZN9+2
z`j|&({OY{C0lNJM^g!-8nFRdgi$<`)samRMpf#SMW7F5AhXDD3&-O;X)KQo=2TV>-
zca&<i1=_)t8~~=(L%}Bb{xseKD1{EjW$nTt*_iQx6?m{~w3H1{x*F!7z_Ly_C6J1e
zIe05+S~WQ5>3@H?Sr4?&iOMfg5f=1CkG2}H@O%rp=bfTudq_pf9|0^OkmX$wrz6Fs
z)?w&%Zng%jR6(o!-_AiNagVyzVm=z4rzv|yJR`d2W5YnxpfJv*4&bSEaMQU%wkt@h
zZFWT4UDRtmXq;?8=@Z={4`9c25OYSuR<3E3kMs$vI6DfIYqGOER%;&KjBQZVCw~!w
zUt{U3X(Dg~079g(_L&)}<P)iu5goX*3qhn&8Ee_mSUo*<0QT9RP*?F2Ojti1?I%bD
zK?Rf37QOiEQIf+cgtkC!manXS{(<}YxZfHv(3Vvg5ZfV<2sMPw>lIq~ho@~EX&|p3
z88Pqe1V4&_D?-_xK>AzHqD9KC=TEcbE_n7>N<}riS+YNMeg?;2FoDlzc&Ni2F)3zT
zr&2gnN$sWi4tZ;tw9l}QouH$jUwsINq#~q*o^r|`YU?eVY>O}kL~d%Enme$;xAYc3
zq70(XlsBcFJi_qF;3(}9%U;?m9WeD#7I86QsrO9vtpJ0e8o8g;>ycJwff17Z0DQDp
z3W<L|ZDiFJuL*T8rsP`<eItQ9vTeoLOhsi`5R%T@hYu_Q6NjXoKils;4m^@E>)tiv
zdr~{^>x=DTRmC0gtfn7=4`SjrfP8Wb6dS$ke=*<$4U+fey>Q*x0MhUEC66UaAb3dT
z5ZaiI(Gq+zG7VSBT=MkQ6Z8fDNj11+39GwVaFXE#?|@LKY;iE{x>__9Zrf-Tb5<v2
z#(?sR&1yQzI0aTMC!ZzWFwo4ul4M-pb?hwGXY$ys6yvAcz)yu(OC<Lt1mL{Dv{0V?
zSwf(YdsHrTx^a`H^Q<rsnTMSZovyRKv4fN;a#VJhq(NcYd-BKtzghGY0M$;F0<ia*
zPlnKfqk~R>`;vo>Ewzf8*zia7RcDDU)WXE|#Ew@eDql2(eEBV&zyxd@r1)7VZ5~XY
z4hqKA$gihb5A@QwA&Z2lh%IpnMu%(FUkvsgd1}lE)sYb|={n&%r>GtO+ZeSK4PeMm
z%6j6CRYIO!NCnw=H1-+2OzuiyrinDt!KSM6@ewd)W|OrI%#WL)s8@jFyaIpjWFm`+
zGo)quqJdR;eu&p|NO-6rWa>(hm^68Q`!CRIIry&P>^k|H7QJn|>c-GT*2i~2?P^A|
zqtEVan(g8^^%1X7v9_Q7L|tml`ppjz#a4Mf9e0b(<c@(M1H8q8Y|!WTPr!CxDPS*G
z<etoc%SVCywcBpgm964a04MH1nYZ(R)xi+qj+)sT^~^yvpN34ZHbdnSfmuNTPW^Jt
zv`<zvfLW0d^PFghw&<zfYHJMKM+88T1kDY~7V!{oG6MYoQ2Gq$hrOu|m7W}|I>bPK
z8V^RYf!peSs(bLe<Mv;WauznSFZ)0qL73Bw*!p9~_pw7FLKz;vU7wwo3DkpI;h~C5
zgbNjJ#YE7k*f~1l69c=w#mg+?+b=NUREAE)a*m5p<1^Y2hX!HV)1U|zQlA6Ur@8dn
z;h}WzHQtUvHij=aA)uYjH;Rgwrw@mQeNv;}@;*gtkeK8qzaeMrz-Kv4fZ$gV3iYfC
z7WC*6%z>ACeJIzS0d>UZSqc3VA-_b&x{MzKN8!8$uxKVWLL&>wk`r(knnMZSR*(qJ
zk;6+6Nr6fV8H8cvBgBBxZ2U6Y{}Fxv1`oJB2%NZs&)Lm%VxeHZ-up8Pjnc5XOt3Bw
zoE{RKt`X`xX;;9>sHn-k)|uP1kb84Im#e`Retb(RHkJlIwFEzjN4(|OUsul3X$K8z
zY=bZdG*Wm#D<7Gn2MU14d|Hq(Fv9#?3fNvM5Oi7rle8oozo_3QPftK}_kh*+9MWGZ
z)LnwC4B;@Uq4n7=SF>}EvY`%or8bVGtr~2QCfnH&YQ+#gO@&3%5m98Ua{R8N%aSBI
z8N$xbTtUd002Elv?|O;fT<ClN#$_ph`zss6#yyJ??MN@^UpNaYFARV|_tGI+Oq6OT
z_(wK)xk19lIKtwf<HiM<7#j8s9T5ZIK5;MXmc-8LAzbiK|1hW{9coX7+K|~1Y!ccL
z=1xYiU&;L7nfCyM&pyQ&y~spCaZmyy^q1%W4P(}s{D*$>_Ei9~?S;#c%yD9Q8w;B&
zv<&2Q)WhFuuW83MxZpEQ`&K8<?K3IAM9IHAja#P+t7N#}9MKpiqEaUBXD#V89qz-%
z{$w2Z%OHq**r4KA!)wSDX;7f%#mdO27*)&=Cwq?Os$LQMsj<ZNLdcIZ5YutLTi$UZ
z$V*O<2<C>#CH}d|-s3~*7uJpPk?y$t`r;~q;vo!&X#vPE2mga1?Wg3{qgM>VgQPYp
ze<f7YUV-*_Dh$#wo1rpm9H59;gCv|smYn$qb3Pv?vndGwvzxp|&R~V_Pd}KFp?*=O
zSt3SHNg+`@1P{ZG1Jmq%n>^8?no65ebao7j0xI9u*SeV5DDj4y=EO;Nnl31c2O57}
zgn~*$C|GVVWHm&tiJFwES*1a4eDYdmlYB|y4f1<`s(NG%QLBDi_=u^QbW#t7)vFZ=
zsFf|YwwXnvq(L_`8-5@BPqrEQ#{^>$CbN$nix7ZbE$Kp>&LpYe9DE_C)T;VJlf2;<
zwCR<5D-x~^AmjUx*-Ydu{!VI+jz=Yaeq5u(@3Q9-uzm|SrDt(1RbE`CIczZ&Nx)b{
zV;;~lUM&?oZ-n;hVT_yc`<h+HyMnX^qfDHxo$i*Pk{dMu=)m-q@dF@P21pwZ`KOhZ
zXDU{(*eH{Wi=o4gQ7@1ADS3@I%eZg*Kd!B8?gG6|tcEgem#DG7c=l`Kd$+lm0bb-n
zCH^<Hu&i7(F&tt(e(irbL}IQ;&6Tt_M{N@uCH&Hi98CAoHHIo%Mn+Br1;IW0xQc!-
z+&GAS-2ZVK;Rjvx!SPnL-%>dmm?bXx7hZahj9JN50fnW<%f=Z4N#zu5Vpr7t=eYkq
zSLqI)qB-NGIk)y`2p<q}Vd(ZP25y!Hvw6g&nZW8c0DnS*%Lzh^7<Lcown?MJoWOcu
zNfbSUdmymxqu+L_x$!ED4#3acSHnf#xq8va@AzHtJ<~I^JwP%Wwj&^I`4u&6F`0T-
zVvQ^6O{*{QgL^XXc5ahk3S7{|Zml1*HpvT}i1V$h&m#vb@NdHE1i~xF6d#w1|HuaS
zS8xJeKoH)LV^{I946p_r97~t0N5>#|M-Jg#{-Hop!;N8n0E`WqK|FXVjD6CuzZtmq
zaSw*Pac}X65Z;~c0C?BMyY^o|&dx+(gVYCh=u}=q-3a*(6Ej5ZLL1<M<2<>Ww`CW@
zZAQ%CF_0Z`K7W@u!e)Ztt;~jL1VRAr>+e0D&KfrCK_~$*YT!3#;3Y%!Fj{Y(jX>>f
z0&DZU#{tqfC_PR3h5_p%AB2&sd)th2A-ClryCNxknich%03_stgbCMa&OIarYsx)O
z=}Nq&y9e?m6Q@jWR0kT_nVpkSfX-;IHX}=!Ra7I3|NnzN2m~4cBtRe;Nl8f}QHCfg
zq9v~)1bxB*APy;d%uL){Ny6I;$#4=s76OEagQCx%LVb0GtPfb&Xa*%<kdfM|0d8O#
z0~r;p9c<v^Z*On!?(Xj9<{m+dJs2Jx869^lz-PC!L7Ncwfg)Sr@JgcOKLA)4HpxZ7
z>pGx!cv-fOOzR2NT7RXD{h+N=;KzxY&qBp+Vtm`hLN8K+o{L2M1CrN(m_=~pyvTv;
zb_o}b`ah$4$v0>pyC{v=L}+gSpbdS}xFl^8U~GVbo}w@}4vMvhDxCMXyB>GsLICi`
z4f*sWu$=__js<@^tu!9yJsw(Ig1vPM=<J4Fzk#i;qihs`|6B*&r0WP}pY<{Wq3rXj
zj&NrbQMe9pS0T02Duct&SCf#j3H;_b`1Lk0wgjGE0Day9ey#%B|A4hEV0{5PI<~u{
z#OWs2xvf2+`h3Wf3%)I*{*OkT#wKC`fCYu-NQjkyK)0cgZUXM6mfYn4+$H6M)z14%
zJ;U=)oXw4lFLZY1MjWk$LkFRdNh!i(5HJe>Ur>lS09XZpe<<)DJZe)H*a8`>YpRaB
z0vl(*>xV_20PeqmlfU8NkDZ-|147;xBhEE~8#}?BH__KGD_q_N(*FTDtDv;sK-nOq
z<1cXYsccb+b7@o1rN<t^(A_2%v{^6uKh|de=zj`4ehN&y1>TGT&o+UvG2qWS=*NKJ
zlLntbVpZLl^s<=Din#2G#Jr0MndOn0#Yx<<v)OeiIX65Ti-GM_;9oxQD+Bmf0{ppz
zn9n49;CPLefY@808=JVx6QIW%!0HBM_QkR0M=TaAFDK_*N$!ozlI$BLcREv>n$pus
z>#{OhZ)V-BXuNg%_U*gf-8Wj>A9mb%oL|*Gc&A{rW^62VaIo|Fvv$GM?ToZX9UYH2
zjXxfD3_YtIyZdnD&dcF0!Nkze(8RMBuit%~nx0+!@@0N*{>zt@pR22X{;aL7{a?^$
zePe0q`^T9NLeS>{44|^D_oX1kwGKBjj>_#hspM2eEJpG3h`WwgEj88++83&Y$vL+D
z5A^YDK0Mr3|LDB*R%9m;kn6jMnJB9n+NE?6p|_E=I%yA#);XNhIx<qKx{pCLS?F{8
zC0B9TcNi0G!k-u~l&s8^ckXC8n6ha~hsLoNdsE`LBPW4dy$9Gzj~CxPx^vnteI0&S
zj`HNX)!C@Yp~omsYV}>)zfPB3x+1MiiA^%DjVI@4E}vrFpN-!W@#$Hkr*Ow7)ZOYV
zY^NCaPDS;LC%%t}lW#m04%pdwqZM6!0GOS;_~MSzt~Co2eB{sk@%V`Y_DQMYAI2{2
zP`o)TzCCx*k<EPk_)fj&^CQ2%D_gw#_(*qHwr4PdrYqai^uy00eRH(tLZbK)KFPW8
zo#fLb%vjvi5%gzk1<QGz=VPK~Duy^YsB8ZKNUwNJGD)=DcnW&oGW)0(Cg)6=hGBLZ
zZC_;1M2(FU?32I0+M4mf<nI}G*a%|st#M;x0ULtzG>>^$U@`Hl1Q;q<_*j<gPCvr7
zQm|u2{MLvLC^2nMV_P4m3QO>Co(=1)1YL99S0ieJ;QHL~Jk8u_mNP55O^(J%9`B}n
za@I_NPF3YA!LD5T{Vw>)`A-uAPb{`p8P+8xEl+(ykNZWEosYaLv#)FHSS4SP*QrH#
zZ&T>Ame$wSbNWOxmd`wqgv72tb3eV^aHP4v&`bTAd<X*YUUNZGGycqao+vSEhmCpD
znkO0xk6!ZodPiE6ot4a9;ny7!EOi{U3VMHhu0E$pgzsLDy{*yt@Wx1U*MIJ+&;0D8
zx}DB_emCTQ)@LS9D|a?(*a6lj7EClQ1@kO9BGb2;N`9<CE>#|ov;B0$Oe^VA9oy7{
zMOQvqE?k7uiww7VwZNIx3V7pV8!g{WxOg$HIIOK`v;0t--NpT=GoUrYrW2x7K4-(_
z!mTQTXrlX~R>xQ5FB&{hf3ap@+5E@;C)PL{tYJ0pRij3F>w55$z110c#gSM8vCwU&
z+wVME6Hvc)oxHlakk(M?oj>BC5clomo;cgRRrdXAF9zI<-ETj1+xPAL(sy%TiNr={
zkvGm8AFt|<HY=aI(@)!1xnnjWV-xv(zN9K4wocOF#a8j1#yYiAFTb<CB?_FOXFOA2
zI>Ao{OdF%v=5AISU)*zIqfalD+A3UG-l+q1lW_FyX5X^YGAz7q_&jY~t~)NCJ9V^T
z;NDUH`ESN9sN#?P;_keGmF;5|DQ3DS_Yw!amX`H39;1C<y{-&~GED8JbsX};j(CVY
zEfW3nL&QmgZZ!Z0ytS_!bCe}oMc1ksQB=?V_>6|Z^jK!IHQ)~c>Co2x%C6Ur2e+L;
zY>OdQx;nrRX|>LNs`b$FEL9X?${74_m4euP+tQFS@&@Z@&j)$&G82UDhyi4USHjKs
zLrIPTDjue+1oBhvcR)zhqAtG6mGd;ol6-z8vzn5B%CRZngd86^0}KD}z=+~`-k`)E
ziDeO*Z|W7THSLV4k2xkZ!Sm+Wx@-4>0gJB=vhIP>!S6!Onu`ILcR#tPQw+*HGnF8G
zbeOpSIkR~%JI^L^$F0xBMR!>On$k0(wbHdyqKlMkQZ@WGl?g>>Jtc`MvQ_$MVOoc{
zt=bcbEdQ7V*5sG+q5PZ{ca%LKiTw2Y@UR4ECzR-_0awYHZck?`p9$Q4GbuV(JZLU9
zB<f8(5@eO*1ifw$5)=$IxLfD&+qf1tcQ{vUyA}VRUQNM6hLw&?ZFycgnUNMGX4TFg
ze%M)qIkOH|E$Z#80iLMVuR2&sq6TzdMrTS?xmiyb%c%cR%2{HAC2|Qc6@%a$;6lNL
zXr8nDP`2WF<NLrND$G>yG0K@h?L&2!Tu4m^@3JY=DlW5(ErH264OLjpObn<SgB13-
zXIuuncKE+!*8Ul?bJVPbYi0A2MIwD-`ZpXE7b)H&>0Srj&gE<9QF8v0GYQp9=<Q=)
zPmhlb4n%QKZ}jkn-W)#GrV^j4SzoWn9~<$j^|q~uu~_ihzM8tiYkNjimKnW(u)e=+
zsor^p;zBRpjJTb4qD3#|G&dCz#@R1l6+}@<7dif4U)GC;;FjoXC$)Z(-*RldbO(f|
zr>VvLN%XqwWg$q58x?Hls9bnJVxi3lURch7obxzwdTN`f^5Xb;75^9hG5_A)PQ$|X
zet7ptKi?g5Y<8r?F&^yxsMTy*t>4zMn-#fHTxf8irrFag!=kzpe^>!lI@If`phn{Z
zSIcobQglLM6P;|D;UdF&nFgr=Mj54b*Ik$F&96J2TYVfRX*y(i^}Vg|IjfYO8CO~K
zD`79ct-R`cq-5SM13-J9)gy!VdD8d(WIv2jC%PhkY#(~@2y@VmC1ag}vcu31CYiY-
z%onnzPo)NERMIG;7fV=_hod?-Ge@uIE{BU<ymKsSUcnLhBmSgF(fi)AI>X|M&4}_e
z;==^HN)Ll1($fj;%964~`f{A>-%nmy2Q>{9Ca(Pz1F%U!ie*M{gU0YjMkIX^w-nKO
zFwYSCJ`L{ll#fUpWi#}C`;ZFDK?ia<I<1?gdDQ;fA*S?u{fQd+Duvf2d-Gw|mI;dm
z>MG}X5$Qv}l+Jh!?KUzxUbXNMVx(-F-_Oe0A)yA%Jv1DBXFmhu6ZcZXQoW+@x@;Yu
z45jYBrC-JTo>3aqDC7>$YKmMBQWrs(HO^&hhtp8WgM7?Mnzh`TzCv-#9f96&2PM3#
znBCsdfxiD4bT@FvB$Rucco$TQ$<Fu=(zPxx2l-tQ!H3=mpah<eO*8!*^{x$0|H<YN
zEc%P(qvzdIO}phDsxR-}b>-=;{4AZ<ce|371hHoLZmT6r1li$;lGX=%zlHi=_s{mH
zP*%Fv<nGC1xexU=e0x)iTGNwz3W+DnQcp=ox&75Uq_Bs!B3g;{K1rvfe6h>|{ap~_
zZzab-{fA+p&S&mR05j!Vc30H53tzpqM%{WIEvWkCj=gX0Xf%{HHyZi-GS?D|_zZG(
ztB$$he`oiW6E_&lJ@e?2<MPaIE$h^6%A-IsMGiwjoJP@K$CeF;Z&NoyhnA+2^Eton
z2W@wBy)QX^HhsFUb$7#5DlUd*@mR+DEG81?1US<0R_J2f4?BEijobr!V^je4eQ;8w
z04J0nbS8jkeS;Ny2F@FlnJFeA2uWg|*%(aNGx1+84|$rETpS(!hk2}PKE8a`p7~RD
zb9HBgXOejU{3R1_Q!6IQgC7S#_0L#(_MX~OK19}$l4ps>2mpu*T(V6wp2kgakb-48
zav2*E7mi-W71<mFH{zo?@?TQ%U+VUojbjZj;68H?m|McW2jRB7#qgZHUUZPdLfkG`
z5Iy*03siq40C1s_wi7eOw`j-|`pH6eCX%op0}tJ^j4hII^wH3eiz8kvflSolH}TTd
zHSl>o$qV8PX%NWF5~lkq>&ALW`hobMLHrl4h(#$fljevjJ~4=g9UsJRaiQ*HH&<Gw
z$g=2qDgMhjmEBa_2qCL80Os~dSc3zp=%<@a!<Cp}Hz(r?>8ZT|@fVAQGzXGR_Dtbo
zH|hG0(UA`sm{B0@H#Pc;TCga~qTCC@IFH-kM(M1H`o>08lhKzs#&94}oPbCfFTgaJ
z3w&kz?L-}eoo_E>m+E0mtnv5G>mSV)pB_IXn}uiD0mon9G*nP~mqO3i9_WmOQ3N7w
zOWUYcdcheuygC5>-#8nyQP984P`WC&$;D=lBNYiE7a86nd>acmY`P3u{?O8y7XA4)
zz8((n1cu+sR1BBsE4y=**eEU@eN!M3`3yk577rN*O*NiVSZ62epUR|^CesxsYfu$K
zIOz$dTmr_%I}%O7dC)L2k|od7NKvmsO~xUveOA@(uonPIe*^WB2p}BE5qN~naCvek
z`6{I_GZNRwM9wb|QiRpIJNPz`{l`AKYl8S+rl{>zs6!K8#c;=rzK$^!G9HBxzfcg#
zM%`RO2~Q>A^mFoU1(mO}`c-5YpQS86BfO&u3+TwzrSSMBMW1X<i|to=={finCN%Xk
zwCI!B#dyt4fsMOz^j}U&UI4sEvz)6}0jFv}YvIQ$s^qif+h10lqLk*06WDl>XI<E+
zLA(q|XN%!~d<`2ZmA|k%wzVYMu+Gh#tl+&Wb6!UHy;NOd67b}#JOZMKRlPD_URdI#
zv2H4$BmZq6pE`=90cnjglA}gA)<I0MVX@n?gYE9%e^G>S58P0>iYyIxa#{4Nru1<#
zxSCwvzy$SJRxeJ&ee`No7UQZMr65#<n`3b*6B+#)k;QX+*@Ty!fcUIey5s#FxbAOX
z9XjRbH=Hf?LGQ{QGIoCyPI^-&3XckOL|?*#OAV^G<;4)!!<-5Qh%;T~hf9!oJS1DM
za-WS9lq$L}ftU$2D1bzg=#_DwrDWZKTRBqwJUWevG1baEmjQjze|BU7_aF;m{LH_$
zlX#jgT8*!&W}~KgBpe5BmL?g&fMrz%GU=$x<04D|nL>3a#5cW~LtYYyFqaV79M_Uc
z%YXI8r8&7W?oH<_^{0SKiu#wPX${8uVmvN>a=duY#En}v7>s@i42rdGhD;0u+#42;
zVxwCDG?$I~vm_caoF-mV;N!<&Gm-!4vD@%y{hXGOO++r^WbXKtR%VL~LnKisEc1}X
z_@-n)zfLIw$^c$m09_gvsUF|1QJ(-!=i+A<5EZWp5I;`&F0nn?QvWzm+j-~_l(&1h
zjqF4GSnc^uL97WGrB~~-!lP6#!^PMwL^kLh!=xtwIDl^v8E*Uz5@F)Y`68|Dcy!<f
zs$pE@VWr<CJ#-N1f9rvl=@6nGAhm>$q5*Iw2*GR<ir1I9HSJ{dEiyXu5L<;3Yl_Of
zy<lA+KnR$(UfPR!)Zl;N-E3Z5`U70J)ef~bDjAQWIAz|H>o2K}gdx}<775j@iYF34
zhu^||xa@=T$N*<_2pY}gwN(S?OlRSng2@RHE)|{Oj6S`EsuqYeEQvJGdVsy1?E(=Z
zzI<q#RCQCYlgr40>E{tV@^){9lyXH^m^a3{u&S1UNPUac3aBtZzO@u|3z`YcXv;CI
zs*XW^J*PT#1D($3Y7Qzx9J}?&NIU>u%84oDARF*^B1t_3<A@Y)%d<q0tL5?_W?TQ+
zp2@xC1{+u9UDz*9bUxTZak)KL4xG?5WmZ)Bm2$D4P9(Pv)v8A7qxl%I@;YNn%)UdM
zFSN_4QK3)I;TM2f2@pbtdG{t8ZC`oY!xpA2xcv%*yv*pRUPAcmR~8D8*@D)=_T3s6
zLBNU5OKecDCVJ>@P0&{n1h*%o3Y2v1jz^>72m1Ysx3K@|?P1d@4{P)}c@=K^3xnKb
zi#{Ur05L%36@H5;GuajHcaXA0t{*_aT{tL`7P?x19gHV)AE^yc9x4Rf4J1`DxgEsW
z^0Rxd|A!v@?@)mTTIszL9>xy6NGR3$N_ch<7waPVo1L*1Am&t0anGsyI#>D8x_xzT
zq9G{7IDT(?k|w8DcoYt^Si)`V;c5gOH}R-jj$Gmd5V<Q=VG`kJ*1<o-xZW;yCSL*y
zV16$(iPqpgkdfD35`;CPk`pGD8wi~@TIx0Dk<<I8Ki~Vq?E7MrAVR2d`h042PE<x*
z_h$^uh>EJ$(-Vp{UCliQ?hdO`#$IJ2hu?^_(NRqN{e~+v`uw&ulzYY#^h9JCyZSXd
zn~q%UeAE$*yAyHiBJ;kQd&JVU_#X~##;jO&x@ZNGL~JeYeyZ*y7A2h-r5=NLy(DT%
zL#c+I-{he9j_4Y?#md*~{*RFTCwkjxPp>wl)8Zv=hT^v7rG9fz$&5V1lh5`<;vP_M
z%nvn9=}D>+0H?>eu49<{+2T3s&VyuFvWu0)5#yJ1ds7-EI{+TX#ulm@*U?|>rmMUI
z&P84;K~8tePNxUMkfB?s<0qWvN?v}AXu4gD>lGmW{z2w&5pQ`#DJ^nexQI7%ggiRv
z15;mvFp8YUIdS7hfhY6Bb&<_Gwj@u}j_ue@FY4a5dR-Ov;wlXy^l6M3_l_Jft`7+T
z1c9+D2vO~-%iOoIsq`k$joSf_TIEGDX-NGqRVxf+DR7<4LQc^SYJ$eQm0;77uqDCM
zB@`8QTsV4xpJChtW5|0Zu#JrWaXd|2+!T9)%SI!w+ceVvgaP9)SVa2T<7y7F#5B9<
z>eJ`=_71}*m0I-mq_>?q$Yi`oO+GS}i^VMaSzN;N@h}sq;B@&i8sn5>@B<DpgeQID
zFI)J-PS<l#zd1DlGQ8GZ<}NgS1yRlHagqAuF``6X3IF|V5O&pU&*U;FM*Cx*`3*s2
zVGjFa^|9KNd-!z@W;&)h&-wYbg!EpPk9ZbncP%qCGXQ6_G%KDW`kRR+bw4J(#~Fs<
zo-gfs899TpdNbGa5DT-pYB}fFmpyCn><hW>b^xvqc&pfoJWIx0*%>s8$X#O2w`Ym}
z#qV!Rhmyu{V{M=c-(4=wkSCv{*0`v88u}^|)jW>f?}X-X(n`d@FoErLWQV9(=OyO*
z2LZLmT3-g%7REdlJ&S+atbolsMEb`;6*OwJ7aZ`a5i@;-|4TddI`q=YlI6UQo6muo
z1eCcE`-w;^maubr=sqe?2JI3-{2>4-lfQlE^IoHQl84NilO-;vXubnbmzGMOY*hPC
zBb)Dkh)~dZi~pWGvyGS<H@w&?rgG42yY852q4>%c)Pp;>YesuVHU1?#;f{xBW-AWA
zbNVVBCBtm37JNlp;@%6;_qn1x2C$%#T?9PUuV^)CBENBMYB@={4Dd(=c&nUmzs){)
z)!>eeEgPL!(Y}xWO%v5_y)kqv{>>hy#SXV{SeVT88j^CwDHAezPiCDfyiCxynW)R;
zb21ji4o}c`0gR9qyFZR5^FaQ=CzF_;yH7ai+MbYfv%gF;Qrf5w&_WvOe*8^+Qd7Og
zA!47$ikZL92#>|sK2kJ5QuzYIzqGQwk8m%UMl>&-xvih6PkN4_QI%DAhY#yL<LHqG
zf1Gd_xorlpyB~3B2_gDcB(wi>@-n0N(84zc{`95qJ?5_>Zs6`=w&y3C-rtuILPxEK
z#kS=SGH%w*o3zuIldfrAQfG+nbLy8pN#F4(AhNmqs%tBq@A2aFhrOqJVwY!LIM3MR
z+)onu2@ABz^lex*bXs+obtuk<0@MnRPfq1JN5EuWO{ICt?vwBPhjl-6m{aU`uJq{~
zb*;7i@pnaBtYpaMZ13l12Uh3yV0EuIXj6Zxb!iObQx2;Ck}pwrtJPlK6QkOB@mts|
zuQ<)#tI25jdb9VV0d>E2(~P(9hy%JuB}CoYeKjOnd~ce4`+O^VR#^B^JNz);<k;=A
zF=wo{kEkOFj`rD|F>8mtKHNKg*6!cxPxS53v+@Q(SeAIT*v*j(3vUld94c*dPn~Y5
zEV15qantKv_Sw24i<Rp%(XXqTX_<U+Wrc<?f{nW0&A<upFMc1)JV_-F`dlQ9_4Zf5
zNY(y(4fkU*@g_>)1nZYI&JQlGf5~Yp`9nh}E`F`a1h!g~sMjjjng&FI?}M{UYQH<y
zwy0MvU8OQqTyk_S{+R~tlnWcWc_Y?Jrm@t|#Suo7Pte4e^)p32Nm4>KW+8b=0jUr?
z#@&YCCWIr;iQH78mJxqFn<q_>4<2u_F%r2(h5Y(#@4U~!+J=3$-%u+Z>}RUkCDO#-
z{;cqx%>qMl`;-TBW=8m$(6Xo#Xj8f9PP+$*y*0}NhXRKQ#Ox%MQE9p%Gi1osP@`X3
zLHEtTd4`9K0R)Uh(w#22>X4yPUu8ykf7_#roQvg_)2Ig{QP*+6>2KC-ZsQjGVL6J^
zpy-Xx)+eg>Sk1`4_!E%YNsw>XR5aPq)1>Gf#e9_c-(-Kz<;>_mLfGn5lWHjr^|}68
zA9HvC?>ll1R%#hf$h243dS|D9FmU4v>Fn149q94K$e&(WBDDB`Op{xK)$OtGaB`NL
zbQLiNGk7iut>2MFI_l_TgJ%q>qU5k1=H<c}mDl#(Ky#D0$j$tNsh=u`whw}H)j4##
zQE~T~HMIo4{%N>(l2P1wR~^&-(n6Q6j3b9F;w_<c%rpH`H-F7163XVkB$Ton3A1Hs
zrd@4n|6wnaeDZ&*<UY_*oi1^<b?uvMIQxA0<2`%1aHld~^SVV<2&$EVy=a2`t`@o{
zdgjtdPU@gY%_XwE%W<|sh2ne^UNuX$Vej~q|NR@t3trUlujhQ*jOr0Pdlsg@D5voa
zrKSTw={ZMJKsbj1m(Oa9#TA*dn2T!@>ebs4IsHLJ6p`3T-d1ra&Q2of3c;Fubu8qX
zF|D;BWtN)&Br@7UbAs3=$8sL;3u@5TDEF;$wGyz_Gz;Lh_zdiJqM#;8?~3$0%lvrM
zO0HWxSkhn#EZxb?!29On$w2zIv7lTU5JY+l6zM|w7ks0IgY7?EED||4UN3x<Z=Qs%
zsT7;vuW&msc6X4hVJT(@Rb_f~*;5vtl>poyyMA(IfCcusF&T)ABiUZKC<Lpq1d)Ok
zSy%=cCCjc;{4qH|zki1498QloWt{>4)CnVmks+7yCG6bimQKro`tS+no;5^YRZE|E
z+mg*sU*&A`rTt<>qYBFK*<DY*_LVd{j5|D)xN{MTuo?&y0o`{$uOTJK-XIU?_td6G
zHmQX@GzmP?AIY<RO(&hWQfkADMABAaQjL?Ta$VcZT$i$W$u>P0`F>`PL?Tl+Th4}Z
z#nz$eO0RhHI%3Z@JKKR;a+<ACYZ@5NNfubkTWAg|r1(lFje|;egiETQ6nh9rj7MLx
zh8t9IMSG@I<Wgj1clkF~OHr2KiVLuvn!ob$qm?|X1uS?nH}^g=M~b_Y4o{t6XDG}R
zs6sRK;3C$}b}+@6aX?*T*`fUVcu<4prIu9+PVMg^BbR3HlJnH~Jf10QdQZe+mS78{
zGxu-MdNcF+PEE7Q#FqxH`*NQ0j*ge)b04YNM$gjx`U5487~38lf#kU*)rvDa2VI$b
zmp+~|q-F_<)K<kL&|MV2U3k6!d(C#PHE{-~18Y%HC|3IcJEbtiN#E~$&NFbhNmZUb
zpD`AhWq^NCYRsoe7+uNNc6z92nb!L+FnfR>Mn}{dm%<ZEz5AI!(VR(<t~p=&(DM$-
zE*gvy>t1lQWkMQLR!P3F1hSL}Bz-K+HE*dvWt4i#|3|Z-ACk@Cqw-3cS_e&yY9?(k
z8oRfA2Os&*^ml)S$ep2ClipCDC(iY|`t;PAM?N*Fu?3MnM$l!G<20Xt;=xw~uLle~
z%W)k7*S+0H*J<;4duXy&@&?dPvEnHACM`<8MOv!6Oo-rDdr6zGPiVM+(4KNu@>QMb
zDq8L$k~cf+*$f+Ho}tG!<X4({4!4Pk%Cj-$<*V+O3sKK8$kO6k-aFX{xQk?*qiZP3
z3}vTYUi2u`NS6}PANjFU;b~p|6u>eOj4gu?6Rhw`M`YM1j9=EE4v*J%obJ%k5k};H
z0cm(sFr1t@s2MOTdF%U6gs}lVH!pTKq$s#G?_j05Zo+x?oL8=cY(Rgv%|nHZ_^VFH
zrBc^gYwYLFoPFQf@0HK-3Fli6g19l~{!^JA9->+qFGk^>RMg8^f6nSkYDMdNswf%p
z_{7t^!F2e#r{b!ex!IMXuXDAJ8678g`0-H(!T@~gIuqXVveyzHNLr`ITFkvHJlm2+
zn&MGe!*d<CwmXa`lEjBS)b4#e@+(Mwk=B1xX(HQ#*sJjBg(Kzt^JmpFHqS#Cee$X2
ziXtvd51rKLlONNcJlB{DMD7^8R$%?{FC!$(oosL3vrNqp&R&gMazrg|zd39dEIsT~
zU_Lt?alqm2+@5Nq9Xs9GKk4+b^Ft3+jX~MYhXcp{6D;ZnO^ejtT^CDPA99cbN$ena
zC}a)Yc`nY+ISo`PE}ju-3#`QMB6f)$cgVWx_zu3u7bMR&kyES<6Ro9N%WT-dcM06X
zkEKhY92U55l5B1|e+F2l#-vC5k9hz1pp+PQ2aDkMq9?j*=Zr!#9v=xnwZ-&`wE*{2
zZFCds9&DFKyaA;vZIh9f(P@la?{vMd{K&;2NNd5k=>?BE9QW=ONc~%TQ@g)QM!q#D
z+@3T!A9FF3i)-`Rc*cQ}8qD7p^=`l30Vi}qnlR8q61xG$ivMr?AYx2GMkXC@Hk~`_
zOj^A><Yi#JZ}VxWlLN^$Lo0K+FlphV;v(-}y@qH&7n>(i+n;-fFN=RuSCQOU@ar?a
z${1my0h!rrpyi;ur!)1=-JD`Q5pNM@r$}Zn+d_qXvoef)iUyuxg4NmA4!33BoB$Tc
zFpqUzr;W;$w3;{pflf@f%;uUvpgsU}tPbX;Vd|`BN{tsAdsgSQ&<&qLoLYh`if!lE
z0_VU1JRBkOGPlegKqV^Y#*P@40&P`v<6R8M9xnBl7DUhC{@@p0F?+8!Uq;I>^T4C(
zx<o_(5o1LK*Cc>dcv>$PLC+}}q<B8^4J^PHVWQH+Ym_*Ogq!V1#{n=33nmJ{u?~AY
zi5FsirpHdoExk!EBv7lYZp`ylss&;kV&+hDj`I#{01vE~;-iW8jgpKFxS8G;`woTQ
z*F0!&aUm;d942Oy8JvCl^XERkMt(jSt&yE7N;6Z`%$Fr9yRYBejcSTxH_N9B_pg!J
zOBr7HYx^TL4lXnoE~R_16}I)Da$6$rAhjov&}h>ti%IxF!%KnN2_j%lnzDf|%5bm0
zS=*i=xa`Gz&x<ACPNJG~X3i8_m7A4F*2!4O5M5A`?irA9g6WH8kQ`ucBAW5Ow)4YT
zN9szg*3%C%VKi=KUev`n6?``@Yd>eOcnR__@^bPd9KDW%X)2Y4w=lJhtJV=F+|)Fi
zp{%>9-6J`}@lcD#&P@l|s>w{Vq}?G4dVB{8{(_yxB+!v+i3f~4cpwEJ^Y2?LVlBcc
zT)AP3S)p?6a99>tU;S&bsjXgmV*I0?uI>rn+&)WajPJSU3>n3soDbH0CcM-=@lNPq
z$PRW|XU&McgTWS=8Ci)q!iKLq!ByGkB^EOXT&e9M!w#HYk9AijPetW4(Y{{*vm&Nn
zPlVBsuu~drzB}|OPm}SpyJ{ipEFNm1;nEjv_=W=?@XApu(M`I*yM1v~c?ZPA7g6}g
z#hy6u7Re;nRjaV!J<qP%1}h&$f>al3RpOD~tRJ210sVKSA(6=sb2-0vE2E+dacceX
z6vQsSE9+!iQ_5Y(xfWYMz&uUVWMrr9V2mt!L3TJ~G1_xR&8ohS<_Gq$;{bSg{Ou%g
zkCjGO?j)dY48KJO@B3PJWC?Z}iO?k}lK`#b-6F4puOH={|F{g_ma9HwneON$nn}`3
zre|#jqhkIKMdu#Q<p2Nid*_+ihGA^joJq|2ki+Ioaz2$qBS}R$RVvj^7|FR(NgEPU
zsZ=WYYzUP!B}vkTN<|?R9rpe0cU}AUzIN@p-|yFb@BMnd9*^aFN9S0q-3nla+)0Zt
z=gWpaCqry%IJ|0<;)(m0yHL)LP8}GxW5mF*`Ig&}EpcXCU7VN3yoQcd3D3m+SUU)+
z^+<=g>7(Eo(T<|~m!q@2*gQ`M)df+MKG-C5WmG)qM*$zb&bC&eTyn*i0=u)xsFvqp
z6%r0;uw;WvgHQs~-dvE1e41xnV6dA1x|Vkf3}PMvKM!nvS&7%SJ->_Q6iUly)rYpU
zkHjUJP@WHz`}^0@EPvbs2RtY|*wOOUnO-}nvXrDZu!24&N4>h--{4nR(Td0jfyG@Z
z+UQF18RVdFfW@tcnGd`V=k`ay;Nt3nrJ+kE<@mJG3MF!B65|E;_h>&P@S?0X9NNQr
zH5Azb1P~@+bg{4RIJBbTWHvv@PF&D-{7&4G^WjCnC$iL}@x+F9w&^XJjSzB5xg(gy
zd-xi$*YJe5n1ez_yE3?^HgQ3Yk-dxg9*kGXow`GxsP>h}M1Y0U)H2LK_LN8dTDFEx
zgEBi`2oEA67U&}(ZMH10&x?pc{cdX<2ryMT)_WDHd2M*P<gmEl#yU6q#y}e(_#n72
zs0Ox02*ch*I8k4B?&E^U(1+(X8>YV6?g#EV%vPdBju-K^0?j65_`u;OnS-D(+Iph!
zIrBl$`Nb>o8-jZ2wbRSg&7TT4&;}hBA+#&UgOln36X2mBM7GVPa9uO)2beQ@#L=F~
z$>z1m6&#Q+g-2-!#EICd?OX_9pyLxvjDM-bw2WzJcROTgQp0|J@xqo9!2|1yFJ7tM
zO5nOnuDTPrI<H~wmkpdG<An|E|4p_))&oY114kSS9c#w)!#NwuIh>rgPLimW)IxMK
zJTLdn=+pSU?>R~|$~PJjR}K%=1}Qzdv~BRUn;G=N2{27idc?#el$@_s9!z+QV4j&e
zpU2hHf~tG#6t1?v-H5Owzp*!m<lthCN=)CK3w?1CVr^pmBZ;$)2RSG#To+<#R}RVO
zd?B+z*ty*J`(PABV3iH=fKvsuab{9`eV8FP>AS4IJiy-UPiL+en@PJHDhBEJZ7EqR
z^q|H(ALl4F$MzuI6L=G~RLj=)-gY&dd&p})K*8(lY4#-{ymOqx&9!M{h`AWPct!CT
zuDbx1wEhZ!!4<UICdJ1@hOLJ`FYzfF&ri=qr0ul(-)3;j3i^mib0{HS3y1i)eQe(%
zWZVY2_lt7D^1H~%LimvYIbyK?mcn5^Br8%OuJ)FWj?}(9@!DJYD+dEV3OCi3@-`OI
zZ;M@Utlc?Cs}lvO;(QNWLf8*K9xqw;Mg8|7wh_Q$Tq)W=4k8g?p#&Ilb^GQ|Wv>=1
z-5DciT$2~a^LJ)hrq4|k-sfb@BX-Fc&qD&#U$iJ5Vh;I5$~7WM@*?*s&(V$v!PtHn
z8s&IYBX=1=<8d!{z(G%!i{-MecvblB4;L(U^^eXKBKoH@f%lb~k8?e_H#(3#)Q!E4
zS0N*apjF7anm`+>wAL^2$nEl@K%pZ%#nju+dUaO#8WF6|;m8Zy!{l>YQY*v|BME$Q
z6?Qf~B_4p|%E869aN{{xsRioTVy$=!yKkjr_c&-&dB-PY%)7j@obH=ehxt1v3gtbR
zg<{Slb7}3I>nRi9%-y2zw}vX@b~|3gk1OnKLeTFsGy2&O$H9W<Bb+891y{nhVn)-}
z^3+g6Xu>#io7gjjUn-NXc8Wz;wO3PujPfHTAFjQH^G@1&A`yEt=GuOrJtRi-B|-gg
ztVeker|}DiQ-jzIMUO#mnq2M+x(f@oLCpAU`v}guIZ(nF_SjtFuZPmrD+(yau5J6d
zkkp-59?z$mJgIy6*@Qox8qYRDUNK;9pPpsi^dXxE;Xf`R5=}@gvGToB&@qmvs{Z_a
z1@4&&^<{7sP3HBtaW)|Ndk1%%%&o0xDcnViZ$=~1g+gK}@Hq!!T@Hc0Jt<Lrqi+Mr
zUPP3t0==74eI@U{ok9-n`H%{LW_DS3>1(~eQk0F{ZM=G7bTMW1!>m?}w7&gL&zgs3
zY+(mqaqgw8`<)gy^eB|h1IG4!jlNw}o1hSDztzm|9cK@7z59J+>Yg9di`ng&_0-fK
zSsdQ(Z|4A}OZhxHAv5B{=^d#la$Dg1s9Y>~?aI`KXLE&y%{TtjUvO^%z0lD&-=kxG
z-Qj;ooSS5m?fkogYwHV^VHD>GFFqUcU*h|lwr?^NVm}}bQW0`_*E+v<k4qqj`0@=5
zF|XmgY?7-cckMp15vXB09Drh0{d#zF&Zh&2+3aY2EqBZ_@h-4o`NKR3NS&IVsgqBP
z`Ci+ONd7@{cjWHnhZyd-`|buF*U79p%2ixkwr|^Ul>e~3>K3?59$OMe?Fo<<hybO1
z3Nmp)R(JWE^l_*5%qkBBxAJ*60Hl5ziDMQxUr^d`&~6(Q^BGxSl(A|gmo!p$zwkL9
z>bEeuxanMLiKpMsSTp;oKb)%lP~TNf;IRN}9ty7UmH!)VUcSt40;l~~L^dw2Z;}@x
z&N{I)a2Vm73RE`(kM^W4RV@Ie1v`NLC$Gzs%E6mg+zms%83E@5{vcBJ?hhIR&8w64
zj6<4!ZnQEeK1dxXZm+iV(R7~!){T$b)fGNSP{0z-9LbHfD+po9Y_iUpoBGZ<#*791
zhARtc)dc3k@YcsEcjJMA<=z7Jfe(M%Rl989mi3q{iJnO+*g%|69|F7V`$aZt<ahWF
z<nhBE{nKi%ZGAm(+&|qXz1o?sNT^ved)(J?I-HXhgE;OTa-j~9-pPrp3$*VHit*ic
zkoIou7Tc-3aDAMTFnDV<4mjqJ;=_-f|3P)XiEu82$Mcla$c$@#;IkhQM!Bm-tDsyX
zR3>!+znYRc#=3O3DBDQy@Z`xutJQQ#O|Mg}SNjxA$c6L%{SSe(-ZOzq*59G44WKl@
z5};Jqi}z<(l<2vr*IxpCIZ3}`sW(`zN2#mw?4Ry8%N#yJQdq9Lg^Z$Fv@OmV4c9tn
zTRW56UR{l!n#=Eluh;6>x#lsou@bFmy)ESNUG&{+ljTO63d}{a=zZ^$)Xn#c$#wzN
zrTcKNG(BdKm-OA)vyoSxT)S|GevGixXp4*?2eO(YOw(#gwAcq$mJ~%e8VmQ&<7ZWP
z3cr5{dM!D2*Q<*U(u}QI&p`I*&fHr;c{j6{lb)WxabS5#a`~0G;!U0R@unwrgNz`)
zmQB;pmydZHJNBH<y0)uK`?;E!u>C=S!@lCFshn!wxd)>cJU_n}NPkgZdt8QAiAu*A
z1?r(+Tubskp?U9b>w0sV(yCuZYSS6b4=x&^?o}roMvgQ-5<TDXkNW~pE85u+qH}X+
zZa7RI=^4CH??E=+_TFFp=Wcy8wU-eyOPpueAtezsOE2Cg3MI4UH9#=+vjEayFMXM(
zSHRV;JFfhxH%iaRi9JYuusZ#Oe3o&8e&k0e3&WO#gg<3jT>L)4Os~!?+!4@PS?qq{
zWCYwNEl%0@gvG+mGDj6JMq&y|LHMfRW~7isUE~tNs9lCIhTnS=&swXXj<wfrvwfW}
zOZNHXJc~(w-|LClapw7;ez|SZpmUYcS|z2(aeA=)_#y>K>GIp`$EfKzbuls1q_fp6
ztGuN`D<c<Q>3X+oxyWqaYtI3-yt8W(fyIbE7?)iAy5Is6-dd#(8NIjZmhvWu(!Cee
zPs&__T=E00f~nsx$Nw_7f_8g48dtj7Hnu|)TmMS^WtjSsX@C85&9}@Belf8&2r4Fl
zhpM|)J^aXL;vVfzjPk;zRLW{Nu-Y?s6Z=WOS&d~bnqA=IW-C72XQYT4R)uEFkZ8_N
zSL#^^jZE7Za_8OG(QwPI#pPkYpL6VLoAC&>A*(*M8K}$5N#AGKHOvykDe4C`%D6Eg
zYs{p%nQhQJzvp@Kfg*nEGkgDFg{?-M%(xiR&ZGOw>~m{a{aVqCf>6z@TBP!Wf3pn%
zaIMtG&%BHt?##C*#}b1`(dZ3i0KAyE5_AxE=$xhXf2-(w&!`J3F1^Z#hbpbn-oyAc
zxPaS=`$6k9bczov7TKrPHM&k@{zB@XYp;?`Y`DL&tk};=qxMW?PxbEiqI}JMMlw+C
zE+8^e4_9bKGgUvhwsdgPHk^%ioA8cmvz>Cl2W+qf8mhh;z;?Y<<ad2FyqEfR+J{|c
z(AMl2WFpC}R)yxl5>Y=_2P=QJyXa}xJ2!|y*s;jdhckMy#0aSI+%4?h`DqQ7xDT#J
zt1*ukpdtVe^vbec&L9ZAlkiS!j0Sfaq*$dfIrb6#*o<U}>Uqg)zqt`7YeS633}`^D
zph@|E|FFi#9fj%e)a!@1$qsYRy}z}ol=ymkn+-AR<Nu1d3K$B~i#*^A6?uR7M~QS5
zvqZZVaT@O%xSxvN=-w8&9{MY*4>-feDJiM4;#b)vdZI%64?uwkl&Qoh=lK3jg#CHc
zu;mLf-`r(HX~WB2tq7CXK36l^41VZiF04}}-fLEM#qDB3@F>4Ux;(YcA>4*2*p$#~
zjlC!Y^o9Za9Dz$t4ax22@ElV^ibH4RC<)a^mFUdDuO{Xv$V)!`;3cM3)_g(0cOU9I
zI>KzVJY&YQ*Z9gHHizfQZAE%J7!8!=rOuqpoE}>0=ahcmnaR61R0OM8RNaaZSI(oj
zHvFZMgLy_eX|_IA#T8uc*hSrqH6LsXamX;cdiVxE*5imw$d@_E5sO50Rjrr8o{SEQ
zsX;FrAF5}<!9W=yv2DQZv;2S1sH##>JVfg`P~ceZ$+h@Y=wym0bre>TJq<qP&MAY|
zp8_dL1_wO%_V5(vd!q1a0UISE=MyO>UHU>&B8o@qBmL*V`@BAVbtz}#+xdu=mO`cB
zuwpHtvfj_!b3u5cvTeiW+s?*(oZ6E*dOTg97`-Y8_goigCYEYP#lQR;G7Y!S=+nRS
z@3B)e4K7gf3(9c}*`g~#-~y}bX_R8Ori#!VCa_~^+-R$M99AR$MP!v9n86`K$@2hg
zh7st#vQ(xOgFswfJm)49DFisS_?=MmmtR&Ch}^d~5+|}p(Rmm^ib_IW34cK=SV!>V
z%hDT2ALs5=ly?1G7ke?CW8F}h%`~{94ixM?Vp^TI>Zvi@xoF${=-PdcR>H<XisOG2
zWanE06(VmBjwxhE(&RF5NTbOfG3MEL!+MW<MS7zwtkUsh!k3p`5GD<_f7ec2U^x)J
z^d&+*?2Dai{&MWs(h0{1`j%boY^Sdg8pkB`B4sCEQrqHL>kx|m9&#^fEc8mp)qTYO
zR=v50LFj{BGnyJl`+G|6*O%MhG?Tt;xKqb9Gx|%u=L>i^$tunsZ0m7u=oC49wL+`z
zAJ}ki@!G~^K~c)=0;q0E?Z{OC>co?Fubud8{E;#8ztUNq!~_T(u6HS|)<G{$X5UMk
z4yogD;pk**Pm&k#q;GTYUS<E?x-`l0tz4@fc^^1`U*i0|*=;A%(JiV`PaTgD>aj#G
zE_sX<e@rZpBPwD|e@M%Sgf#ql{>mmY#UaziT!*G)26g!dAibD_5jamR+WlFpl`BI3
z-$?p8{3XhmmLBuICcSM@i6`m3ndfYy)+X3vCeKILvX(uy=^%!1bHGy_$ql>A#2si(
z;yYSTIIT50iHX*2UF>z#t>C%ld8YgsM7Z$C&`$x;NH2zm)9lCzQuVY-MaZ+siQA={
z9A-3?#CN*4=fXk}U0)agSam`R6ZOVlCvG1k#pP~g8R@2OHcuAiGb;~|8RY6`b*6iX
z1vc#-vw}Pc?dB0sVsY4`;o%JJ-rpkbHaur3Pbb;k=&80JO;4r31RC=z6s%5S&3UZ4
zD3=0gnxCGr!ZzRF&@W{)+lC(+Lg%q-3Hi*^htPp@fNF%mHX-%g%Rl7<Bs2C;`<yt8
zq^87eQh>7j2GKq+u1lZ7feOwR*{n9JHxb*OpqPM3=BY5tn0LQvfq!gfX+5fSxaZ|Y
z0_`+^Y@fQcFyi$^9b>XNu2^=ELZ&MR4;1M(bKJ>AzjA`_c0gWk)}9yX5O`;i@-!Kq
zO`Wf^1XN!yaol(i)i}@^x=+g>$hm{-*2p%N2|dgj{hcR8+tIuuX;AfK%<BbC6&0*I
z3)0O!eh5#a^u3m>fh`FMHmhvWW|%6C{<~%C%$4d-Ya&G8<PHf3+X$e_0c|QvtV}1T
zg^<lf$|MoCap*_BAUf{dugOPl<8n_7$8JcZ(ottK*Yk3{1Y!$(1@&5>IiZ_N2(M9=
zIN0Tv5XVUb5q&``<jLbsPX#bLdXD2%Em~jUlOI9f5y!v0-a}_r1eO0Fb1o3bRI&&z
zT#2e(li1kyO6}s}864F{T|9SGbq*XiKl-zi=iUyW_<$m{z#&d(kh@Xegsu#2pzf!r
z0wMv3r47(YeIT5eCDS&TQI<1*cp$5egpfyqOLoi~h9{l}K6><e)7s19>#mR|6h=tZ
zTiqMke|RODF7-aubkYjx_4{6z7Lkz~+zms6&C&JH0J8JtuSm$3_!#nP;+sjxZ&wh$
zLl18PF>>_K9fI{rdKD&<P<fpFIRoX;9xSqfDyQ1vL4I0vLP?|TDfws1g65Qs7p*(-
z?Z#5zVMYViY!i0@%yUw7>QY(DVNk5ck=r?1q*C>}EK(f*^+^#iL($Fty$2L9JaVC$
z3B241M&@!(-P%O86?xc$R6euGd62S5n0Gx5l`K^1@z#r>+3_JxJQ}tSq|P;nXD9nl
z$lm)0ZEM*ygLmYZ?h$rBNS<Fh72*75_ov=p$q;oUm$*8s-3WQl3vo;Ke7jS5$#6I(
zD&IXBLh2GNI$aEh0~F@FU!g^Ia4`4B)DH6^aw<65BH3?b`0A~vAL2dAC4DX2UYJ#Z
z`zX_d2R0>d*3c3uGm~vAlWlb-l*d8ZT;};(Q%G~kMtdPfy=kvBIey5~KTmzaE@hkg
zVA!1J2J;J%j=C#KCp4MQacnPl9^_F6YsWph8Z#w4i{{3w->WbMkJ(loL(aa^`^M43
zz?>6BqpP;-zPsD!ibS_eei+X5)Y?wIf27>358{;E>r~zAAQm|#SK8HbTx8>(Zj+B}
zYwB%)GYr%RNDdPl^b9yT`Rl}p-wMQ8NY~0?;Ov^zBp~Ljrx}y2P|ruHTvWgK%-kx_
zZHN_iPekluX@#&H#UHofgq~i(J25>Ec7mxi!nd7IUFSxYO+4@flW4PKr{t}@tDqLi
z2ctAkk59eqvky&1nUUJ4y5_i-CxkCsQtglS+5?SyMRT#DaO!!Eb~zpQe(u0yRx}r>
zcNR<r{I=shiHEkZqw)`8-Vw{`_AZ6h)=)c|m)qZ++%<4yT}njH$#~%>-C2?zfvrOI
zJ>x?kFYyg}`#~Q7J5c)_tor4SfxRDuj=0MFGxbJ(fE<A<LoRY$%A59$CF_P^-10oJ
zKN=4lswAzbI<_=yqC=f?Ufyn}v-nAo;~a^t>5`h>X<FYUGbn-@umXIJxEgH}^FDnX
zwSQ`K1Cp(`*r&twbnoiTq82L4LB$^;4%mXp?M#KZUG8xZQ$k6}i2+waoekg#X>7hk
zr$JI7?>kcYKI31P*bb6jSGl9WptWAs7-`6hoMdg7E^*@OU+f#x#OYR@W!bN8x*ulh
z*Cv(-CR?&5$lTCPzuDJM7P@3W49%ZaAw6nVdoSXfRY{Nh<{)kv9(uGPeHR6#W*Vv*
zxVzjdXR%>Qz@}{;Da#y(nmL<VPtw=e`4QPeH!;Lpq195sQ%Bu{B7UXaoK{-rkG$IC
zw+iXo*?)$ma#>`mJ=90*1o;NW-Y?kYHwuyF>ps{8rmT`XEH?QuIpmO@7fMAJM~Hs4
z7ow73cwDa^Ud7Nh^;H;~lE*}~F;VSIyAogb91bSN7t`!<zG?9B_8PaY_oO{(5cxXv
zFN;8VQs%)_s(wA#Vs<}tyXok`peGg9=sKZxUbjeXh_#SshDcUZe64f}eA39P$TGC#
zdHM0)NXYO*;&-pNet8gOMu4gx-6^o(Nw;oLO>ya`UWaBT=rptb?x0z@N8c3fYn1o-
zE0bCNTt_iIC(As<gZuvR<+rj$Fp>&VXVQ(|r(RF){W0O~HqLRX5lQRI%&!<1hZt4)
zTp;Di{e3$Dbfw?;m4}NS{cX`?<mZv3kM{Gd%efW0q@Eu?A@<4MQS;wi`2Fq~oI6sZ
zR<Az0(W|IcVcO9G*T7~IG4r&kKUBBwbKqs9AM^Tk9POSZl?SL#nn->ccswL8UQ8o4
zgUlcKe-Kh{42m?Vrd6$8KmA)&?{OUlU&Gs?jZ$0oexigh0b?@zKTPjM4=>eAUvbc0
zwpJ$aEy7RC0$m1_Xs`V`AY{S9#LAE}`df6(3%Ah|)oG?k;S!d9^6}NN=+{;|mWyiJ
zS)FHl$B)9C<LI&~`%l5GK^w<C5#mdTlI`wkkg3!ma)f-eCjp5B>rugd$O-D{LU(hJ
z@~onANlZ}N#ZNwcW~rIl)DpM0p4V<$?%eozmo#NR`q05U7zXA*^P*DUTN9adD3eLg
zvUIEQ^d^^*a@ETc$Z|)Sw#j>|W1``SM{X+s$kFDhkC$U=&!I&2sk&OrG>H5ghcgFW
zuzM%e_fSi0y2*5ohXMD-Q@2$iYWylTZN>B*bF&1%j+dU_8BwQQOJxF;C+YQWYHeqV
zQYzYXkCm<4{8|xP?fISK7$VXnWvjh}Ic6}c4>5znhn@QnetR1%KV8yE6L($d*tp6e
z&&e>#sXc9t*}p=P7p^iL+wJ_~JiiTpqWF59r*mweY}2ikE{z;g1j|*Lg*fX^qJk{Z
z5Qo+e(fEkygCum6-FqI#>OXqaF;McZ7`I&Er9(o6cloX{{`y#tx4HV%G#bp--{Fsl
z9P%@Fyti?^2RZjC4#!gIZ1d~zRG7?Bz~9~|@ig-?$Havn|HN@XM^n*>t|7a_UDc%M
z3$<KYEU2+H4CN$|Ye_(w$+s_P9+)~J(ro;t8Ak`-ve<cSU(9!odj@zj!h<qd5DJ30
zp9(mzDuUy|k7TD^t8tUm9)rJX0Sm|d#G*}mGxy&*kvkkwVyAdb;WR^aSG>&j-J7EJ
z%J^S1l`JIC3pF}nx#ZD(G~cnNZ+AQE-&{sy9tY9sm?k(7b%Fjk=A~=b9iOrRcOhc)
zULn<-h>QaazyH!-5$SgBecqVB&9R;=zgn}$JK*&QzT`Z6&J#Pig34|CwnW?didOfs
zH;yv3=@SGCs&(Cbpj1Uy6QCm{m-dRjm4J1B+@&A?FDe>BLxu#%Wq_pSU%2!Yhh*El
zGKAY~aX*ReQ1e;06V^us>&f-j)wQwdo_S@h#`;#lrmO@zdd}MlM_wyBb#3dNrw+L|
z<VCnkazs%~MASs@20lkSqqFkLnonmqCBrkZ&QV^!w1pz6!Bv@W$$N)fJ0O>Nuz{oA
zd`CU)njhB_sNSFV24WoOkrxOyp6#{RGvM?;5OT=C+jLXV)j*w!m{-3+4kTVi<AqDd
zoSo48P49B-;w0Wrc5b5gWh>fS<p!_IFFT@88|JWoAd#ibPD^||w~;XFjjnLJ>s5FE
z%g*n;PI;mm7epF;qMh{n9lkvGRY#*hHo2VRU-qJ^9r17yKDFFqPg32z%z80w=QrM~
zLTyy3AqFUmMy?At-4s&a_;1K~wRuz+R{JDBy!6@=ks6cLviS}n4y2XLy@%m!@`(}G
z?V~Up-5Wg>Prr1U%eijjg$bY6j`*vQ`sFwgz`UU6y_0b$<#tA-9{1!!U1$DQ&pY!z
zd7ii{XLlCI6c3suJas6CDCgGYXp7Kk*At@i1J8R;RC4NFdNsFrR_@Ey%+n^t!BZNa
z8FYJMvloA*LwGz6N@Xh%YI|@)*LC;pE%%|$;!btj4ck9)`Zu<m^$xjp%*7}Jydez{
z@J$4-&3n7ikQ#Gn=rZSQoz1f!t#0O`8V`_)#MAMwP|`5^QCrKA{1P?+Y5w~`sTq8)
znrF2B$Webab)@Ep!(?^w7Oz>3gnnb+PY+5Or+BN^^kAo7o~zqcnP1@FFR?EDy9u<F
zF94H4=fKwtBRVq#-SjG>#Gb~%;09j}T|;ZAY(Dy0LN{}5*|D;5ApV=m?{$rXdi`F9
zkG_2|P)>0%?k{$_-oN)kr>PegsunO?sGarg@B0@HRVm?h|7NeK*zLmeQ-_*L{5b{d
zqOGDAQ*Wvx0*N=%$73q8%Zwf*bmbNqm_FC=WAq@cT6#X16RC5xX3znOkj~cr4f}9s
zrH-_|?7x^N8l4vqy{8q-qB{4+H}I<PhFRR}BTWZ>&w;+jMBf@HHH>}}Yiy$2UvjMb
z-;3Jzca<i=b>y9w#JW}b9{G4vl@(;U>1^fKAl|ct|8_g%<+5yi&{__=@3BSoC+fN!
zQ&!JLh8to!k8JvN@USA$U@)PzCN6Z_n3C+Ab=Kd|d7URz&oqaeIPo-keYam>OVe*D
zU^BG;<^YaI?Lt=i5<<PsKT=sv(HQrOJ5f&mOIXnJ{cFNq|49XmC`u|WN>aeBEhWOt
zN;d}GeSg$t8o8lez#*lJ*NjLxv!KGFv>_0fXVn9Eme^kH%UWkE<g;CjuVpk`vz{h@
zd?1`O8_`J2m1}$)eusIMW)E|zT(HqB+3M-=T9RmBy1A+;4_PawKAjImc=D)O2FiO9
zBAV-zqr+dE_MnY7+*YztN!BK4JRZ1Xyvtz6Jq?DR9meP=?dw2vnaMO#KSj;DWL*zc
z4{epZV5hYHVYxnW_hO52shLD(yIaY676^3Sn`>%nfU6PKm)x8vufiO}6Nkir@bwj4
zryI;b4Cx$76oNWGJzwTWErIHLq1RUE`CU6tG?x2-Qy`ntv%QoP#jukX4p#$Tiwx$a
zJI+Uh|JZTiaGPKoik!5*2YJHIzGsG-1=~EE;IFd{-PZPL$Au$8frpaS)8A!5AzzkY
zSMP8^aHx4@Bv#Srwy6Q>QkPvdQ(*VTxHRk5AXuBe6IICEr=%)uIXV`a9Qyq8gVTbu
zpSCGM6>%&tZ}pcu#~B4H3J3+0Iv%^`=v)jXQuk-xHQmF5qJl`uwtq3v72a;(<NDJk
zg_uZwk<r;5e?y(lt&_D!LXJBvZa#P6KyFL_>3Evsw>DWDuR$Xb^%_n%M7URYwr5Of
z;7gM@(OJ>?XU=CLq}jfN-8BC?xzdk!VYdFc+uH^00N>W*I67XzvBJHbwdMOm_S%Ai
zY0nwa9zy@-;`BP1@_<g-htAvp(*+aXa~Z?e5f}1?SDKav2K+yk+D&Bi9-~g<T5i3E
z?Bntvn(glk)=>qxp7GNTc#k_Rp-&-aH$Qf&Y07u@vY<+s@!wE-fSWj3TaBgB;M`X<
zxwA?4P3n|AEd%7;Jf~bb*Q-lgR33{jqkLz;@ukZ7y5s3En~*oFa^ykMCi868QXvv9
zI8Gm@f!24**owI3f(<Sw3KiDis%_;o>pm8)r`g9pEed-S?E^fRp@~xK%MN#v72jux
zobaj?oQ@YzIzHs&Au04lKg-n&Ed(xpFD?7a#t|hDCEXDuY3!oL{c$+S?h^Kx3B)n9
zM)Wpn-1}@?1JpExjtblvpgshkKcr6oh&qL_ZX7t440s?{?M_$ZHiSG-Je{%_T9~z6
zsyLig?0V>~FAyj!Ge6EzvtL9`KRTZ9DE5t8XDCl;HBq_tF;CaNd}9^gt6E_MVZ|>W
zHthrQ-lIz#BbaPFpH{aL$WkmtZcLw)Zr>5=N%Ckv{!H{Ch3v?*R%$%sgtmcaBMoJq
z&4MA$oK*QoIY(_Z2_8`5qyMEwyW}ef>^=(DFA?{`k<z;r$=@}g*~ad372G5j5Xx$i
z)tB%XchFo?y|QA8iV$-wzRr-cOgs-wEb1CjEz^XK&DKig&m5N<_U{`d>uD~ZPzaFw
zT^N1(?d=zCQb7m*t<LTF8mh#++lOVR^5X(~xQ<;++^qQ}x5rDwWB|0+>2091BqKjp
z7ExzPKwuXr2y3BvEMpLE*}0@;`<sp9Dl>If7e(WnLr6Bw+te2iMjajBb~$eQ2mN-n
zo4Z}`KIySvyj4cVJcRoUx^hM8of4P=viH!LzlC^yNJG}@zK&(N{aV&djp>0$X8#;4
zP$PUPuuj&`78ggQznWFV<=g^q-Pb3Nm2B|Lq&X{InbGK@Y&nYNUWT;@y~B2^ThFDW
z{{{-lzxe{KDI8(i;E}~4G0Y-E1S8YVn*14&#~$#gAYtQ&7$by@umtt^UkfUTvFQ`P
z7oFs-cyqC){7Bl&y~`tC>86V>eOFkJ_&GMj_Am}yg9^27-iGcIoXO~L;N~&+=Dj5s
zP8nHIeo?)2Q|FLw$R47F`ADn>nFGoez_`Lzk<l2NKn3lwPg-9R^<mPQdP<3H*ya)`
zWJlzkq0E+Z3UAsOH?O~TP)Htv%Ej*LxhzF+f{@!RyMFEn@@A<kPIn~9d<4{N(w%b9
zlZn4swzp48`ft^9BV!#hW3E9rCn}ucMV43$(x5ofE^P)5qUi^64B{cMhW`Sw_gU!u
zbFBP@7Pj^r!x8+v-+ZmX8)0XtYXN<9{z%$6-@kOl@S}91k|)rDF~e9j&!9U5gu{Nk
z0qDVRWiyxI+0gzoks+SY<v%>7^-0+L!T9TE0#p+C!?1?^bVVB9C%^f?yOo=Tib=v@
zQ<D<S80{>m@ql{`t5bK3Av(hffRIKR6Cb<^kNQNzvzrebgsahD<RWFiRH0(RDpQvb
z$^wxZweE`$+Fv@=vup%!U;>lQKRvQK+>2SAXUUwJ$G8Vtdf+hIC0jb33_5&Y2vZp^
zu*0SYZJKD%c^gw`hDqebk$T{l7wJkC{0Am-No(s|zxx;kdxmzFvMPRelo16tA1cwk
zQ_y+Um&J*srR&ax%+HNyAks;3&vi_Mz&+x!&kre#&8O%uw`Tz)hE7@#&%W(^zGnLa
zc~wk53~T3US?k?O{_V5(n^j?ZQxufc8hxK{r_l+_!17LkUTkd#a9oDYx;KUH6Ljnz
z#(8;OyKiY-Mczj93u~tsFk>bpe|ucg+SN`d8K_XCHBW1=%?-HL9?rMpDa^(2d)KWA
zit8*+!y5??l{zotWdCiweC!{qm-L~+_h%4o<?)_TdGlx)3P3;i5NBCOQ^C3klK#&U
z$zRr+U0*wd3+~;5>18^x?c&IU5Q33P7{x6g(x(pbF~0-hTNog9At;%T*iTop2dx><
zRVuHkn6u#LzQH$()^Y?@j&cWvK#ke1c9e>Ur~e6)Vk$4X57CIDej#(ft2uvIDh=<&
z!sn7H^B}BITFxK?Gb@6qddNq9-u~U|jSqf}lLA||Y3!#HZcDYN1VLhoBuNOn8c1OZ
zK1@EbuiO<Rwq$<@hCH1{>7-Hk-WDCZp)P#f=M##z0hopac2B5CCBt`Qz<0O9tG=nE
z$*73z^55oCm0I%oY7t`75`sfjiv?*!2{7Gc%-p(N{E)gJ3A}k4-Yp`Dx8)4cFlM+$
zB){x&hPMeFYAZoo)`J~^t6pHjxL5-%CZ-4{lK2?ZlFp(R*1Nf2*Bqu<(G47md&*Yg
z2HF_GEKH8ej~76WOkBJ0Vb(Jkd`K~Ysge?+;#i?l`VEYsYZuVfvZSyi20Vq2$YK#E
z1jJ6zc_xQY@=PsA85wG&mJUK@i?pZrQm!VdbBYm@SVTMX*s#Y;1}fqwOTmB&{13R3
zOe=q!p^RkQ7Mob)CVF`>F%H32hsYz<3QIUa!CxWRf*&swHOmMaNpG0w{T9^OUJVZ>
zhy=hi84wE^JcaownfVMp1X-+5!La^J33TSAyk!B#dN2I>Zpu9CWoog4oFqRXBHA*b
z-x#DQkVeFHJ(gH)GEqmT@9S_NY>uzp-mv3u??z#}>E}e^o~!8pF`q$)VAQAfD-0+J
zd4IYmg$sf<Ws*IG#4(nRWKPGN_MU&`0F(w8k+C>|^7vD%@G^`<F6xsq%TcBSRv7a#
z<J<K6<Pi{wui^y!+QR=CFbs1B{tgG|I)CY(X6(Q5QK1B+P#~Y95Tg6BDOZ`8EV;H-
zq%O2^S+}hBZ<(m`btp^%EkVVCvD&f_ne(y~=gR-zUrXi2Hs~+m|41w_O=2Alu@En5
z02Y!2rV@){(IxmZ+^DsSqg-u{4YaWfzX@IjJiarr1krsHDP#*nanD|O*0p{3FD9Aa
z&D$8J=RD+nf*f<2cB~MVAi?4Vj=>qAIEG?I8D}CNb3-`MrkpzkN7a)FMmxqHGf~5$
zwpn8}K%};X?jovE&l15S08}IcUV1~ZgB7ciP5CL+jwsalec39Vqii8T{Z3Q#p*>97
zri>v^i8JlI$S>u0(`EYJhjiksRCn11(5855=MZ!gu_=tl8P%UsR27eRcoCnX7n$F~
zR<vb+vVjzv!2I-8wt(G&SJ9MsCw3sl(=dC{-Wp(Hy@bHERa$LO8e*d6Xz#qtbz3de
zx>N(w1*$<i>nuu8t25|4$-jH7cLcUhmjE~AVdF%8O=UmqnL`gtlnj`gtUNS#epw%o
zrqN+8QKxPFil;r0YWM|&Jlq#@>$$SkNl<Q5sOCx6r;HgbJ*(m5?Gn103H_`AMa32f
zcdZWBU_uNeummB9AR&fDkh&!|Z}X>Bl5`q{1m-sM=nQID>Pno}xhnAg@4I@MRFyBT
z?k2}hGvUo1-<Gj%?;HAjrZp^R-eDLp4jJ1_+p;?qK(aJvR`ihq8^z^Ec~a8voVbU#
zlx1IUK4U~c{xWrMh|psvU7tuWa{^-Pu-1fB=dVb&@1sr}Rk^7sR}0kjIbE?n%#03%
zGgVa*BPp_ln{mRcglTXKpw!4{DweLJUb-a%ks_oU(nau`eRsD=vVM!S_t5YeWJCl#
z(E$=TlWuTZs*yK;Uk@0b02F1y|NWK#_4x<WjJAx;Lc+F_LvJ5EB#8N>np!xbJUgP8
zu>y{}k>1Sos(9}HRYJN4!n=SVE+SPo5Z;-B_n@dnNWnOkG8v?z2U2MoxZ)y#!P|Vo
zL!i)NNLYsUJJ3J&r<*sJ5kFYX(@a@E;8@H$oNJ;xK~ba9U;zq8Ufz*G5Ak(YQq(de
z>amzjUbBzfl8BCE&x5zJrfDfvq0qlKx6an%pw=%BkuByRgdXXRO}}ysB@lB4mh6u+
zk%A4PN$=(R;<S3QRLxDQmMT?CNK{XvsLLM$&QdIph$SZ~%b3J5iUIA4=kArTtz<qb
z5vnc$y!e;|iTCeB!C52t4S{Jf3cczP_?)>u9U4aW))fn2flO#~P4Om4akzkJeMuKt
zW#+}2mUw!pAGqN`!{R`SKE6t5O5BqU09x$zxktl=w!@RZCAuMV;~mx$vGVZZWv#?x
z6=6#96JHDnA4uWuWT`Wxstl=GvVglyRIx#%%8-HZfIv%@XnLDYAf-ZUUxja_L4$^1
zU3|sc<Tt+s!38ZC8BVuu-My=1OcNQEn(WsQ<h&x)%~?WS%`LuMBUib>(<mB0XPuip
z5Mj~;=XBzJN{&C&V(|{vJQrsvQN{@%GT}KL3ieb*tUq{Ph~djE3|v66MpvThisSio
zPPn;byPa4Gu6ZDMRV|6G&Y<9jhP6FFf3i+j*zhYh5j3&{iPIE|{VdRECdg%<Viyf+
z&qojr=^Un!W|^gD;TP2Fb>@JXzlCGXl9k`Am&G7dHMwe2B`K;*DF~=JrdhLFqP_=&
zFM#N}WZ}J}@GNr*@8!7#jU6%%23SYLZlNjT=@7y_1n@)8grBl7u8*QX=kV~DcCXta
zqEYzy9|RSg0H+7+AE`&NRq-lLmD{AM9s;6PlkO<XkN{FvrzqQ!@qw(m4XbL4XGqK5
z_xa0VXM%(guO2?$r%0Gkbort<$TI!O!Zb4!xA|b&C}FK4g)L7tQa_yW*>N%UY_S#4
zw3n_v$<mz_z?(eqsS=&;2trN3jYEfsK7c2Tl}o(-j6ef$*T5Kwe#-KCB&Bwn1h%KZ
z>o!Yu7Iyi?W@QW|ZWx4_zKk*;L)=&#@6NUj0^+!b?pUI#S6Mh-gqw^eWr^^gCpeex
zTW|%Cv<?|Ommha2?ScM;@(w`zRFdwX;P4~M*!~8_*Te`uGcnGB81>D(odIeZKYe8t
z8pyi2gRb^7k(9$kWzy7oI$91Nsz3rSp!9WHhsekbx7jNeZVat(@9Oh+D|@85MX_bt
zAm5*fnDS!u774D7$W?vahIOE%%osa8RCY|%ZnLK>3lM-*)wxDJd4d?jfzascA&C!O
z#qQgSy_5AsTvKIUNmw875wm@kFbyYyJ#{}ziBss<A>e;kDL1dgKpg+5?*eIb)73H<
zX1i!c#$B}!DA1|P$}0@;&o)?HF&Qk;xXn5P>bRXt2fH1pJsdt|U8P;{r*Bg<_K?i)
z?jtgo%2#D1UR7PIyC(IXXA#SX>{pq@J!g#P>1s5PdMf3Ns7ZrH8{7c0o&g@89)>lh
zjV455$_cUKy{=%-hz?_gtLD0Gau<YU(nm6_O<HX826{D72SaMw4Z<IyCHqnkhiE+m
z1pECI5{mX7*#lrCwhHyYSAp&_U8kf=qjqV1DmF=-p^<W#wQG0I$m@|!uau3L6cr*k
z<5k7RRkc8A+nvrAz5#C;yRqE@96k2JTl)61Dg<jGJdYu~$43~9cv`73tfoM51&S@g
zK(SdOxBAJ0oad9TAAc0;3^(fFnHP_}hTgcMogq+ne1o@^z$d@KWpH}W$1aWA^!PDD
z=*oGWDau=cb7Tqt-K9b}M1$5=*o}&&h`GvbO_XH{gnzDXt4Ot@#<-36KCMCdv!S{j
z#OtR(=PMrSMbpWC0`p*A+e))%RbBhGV194*I^FPas)2%p-Y1mCls~ro(3l>3^!2q2
ztB6GPU5QJ<0(^4_K8?|LShl{KLNrc3TC|{j2uKPd8*nMmfUhtECN5V*bfkZlr#lJt
z#4G{A1$57qqIO7Ww>_)TzEOE1K)NO+cC&7Iag7Wm&Dnlns+x+LR(Py%@+$D{K3=hk
z8Ii`-T@-z6znC*uDsQ<7FONfmggVQDxo{CawNCaSSgM|lw2!!7n@_=f7l&{ItU{FF
zQ2_H`;vLwKviAQA9TP&2#jT_L0I@I74)YnTW$5Mb*8Trhf5hG~9cd^k(^`1FxaorM
z1Zj;m0{{Txp!V9rn|{S{1g-fH02y27bzEb;`gpQLn15UYqm_C;+B!8PEtF5nwniL3
zYajTgS&+5oLdelqf#sdWFXa%WH~SZgHCs=OZ@J`CbR)F+^u(>SH?41PEu8l`@)HF`
z7HRBd9tdB%br=NcFW&oSHh;Y5qN0YS#TMS2r`3(wN7d_sb8O`(;m8ZABg-8b^4S-j
zkw?}na)eTF<UiKX6G7s@f%~+a;vb)SZ_7M{)1w`C`Jj{Pn4^~MuN>A~4MXbi#G6f~
znr36npGpV7m-nlZ^8S5(uSgKICk3BZIXT0z+`8w@;UA~2=~vx9xTL~!kDM$PT9$wR
z?u$r@A8daCMz4U1wxcZklyxcTqroN}T^<|FWQz^YoD0a)e(W;Go<j1sL8DRMANjW6
zBI1HRnyQtP<wxnkvma`1orHokgESdc5Ohq{WW?{u7j*nXm&74LP&~bG-;p2Ng7;5U
zgs>H~+Fw1f{BPA`kaDTqd(6b4@ug1e)`OnGA+oOhdZ5)6?*UZSb4skcjDHih&BBpU
zrHhvB+zi8_Mu&~Bbxr%{{mSSS$abn}>qT!hszcI%+0?#~{BMmbDpYbrW<PP4i<qev
z$Pz&jXu=@iM2Fvc<`hwF<&zy8Xw^>&f}eS&7{0}u4S)F;j6Nmz-Cm5jC=o&|_ar`2
zv`h^MFa@Bi8WC=;^LN;ehUXiUGVQe`Nd5<(e!rBnOZv~!3tO|woQtW`srm(NoR*NE
zTn6nH&|F{U9+ub~05?d7l$Z(qLLL&+s22-}>E+5GWEVaQfNbjiolc6hwad2(b`g~n
z)4w(V3c_8N0Lqu^Y6&JE&Nu`pQE$Chw7f45^md0|KlAEV_zx`tdb!5D+%czZm*{Sg
z`wbqzxwma@N4`mzY)@guIB_^X{I#bNNCuYB-Q??~bnD%kN}~HWK>vm2CjZF-&CFaH
zGWP+KI_N^m=9bw<yA0up(Oy<r`0>B#VOZhSHfv;0$Hyd7o3f<d+1>woj$3|{Xc#zF
zqqM8tJ`O7MDvY0sPy#l&AGxZNd;Lw(jvLA33jL$0iwHwb?)nJ#cf9y?fW({$(T?xT
z2sXRWr=n=F&=t;uZ@fi6ph*MtOQ^%GYE$xu{lQ@S=<1OO;`TmzkQ2|n0=h_lyiGXs
zX5XT9?3Pl8@21<1zC0eEyC?4&c#EH3bmh^sjZ{~%#OJFVsU5<^w%eSRzvL-}lOC(a
z{P9#wmdNs*%Ny-TeC$QXMJ4nP4kp1bP<u?Ouz3)yu8D-1yRq_{s#z$#T>mrsMW@N~
zVCT*HbHAIbut#P&njus;{*=T<Anql0OPEntQ`xEp0O+li`j9ij>FjI17N}Nz1`5Wg
z>MU-ee=5Yzc7VwW7x(3!0buKz`8iTUU4i51I)HUnJtMK)+V5PqGxhe&_Q$aGvpwpw
zQWtl(GIh7qUafXAo1S~!wY%AO>oUD?^TlAL=)nSG2Ni4|U8L}3b#_BahXXWq`*CEm
zA(#-t+tg}kSV((lYVLqis#z)le<}oh)2}|#36x&`;)ndK4;+$Sx6Uiy;@1p!l?9WV
zm331a(XCe0Qs#-=YBPXJB9v-mB*G^o2sdYne|U}un1KUPY@?fQ&G!%=L48T$S9tpv
z3i18~QuX+fSEJLccKl{VOAKve>{um;L#{e(%eWg>4OZhSRJ!(A^^}T3EltsnT~o-H
zR9E$j!AriNpz6Y%QAXH<*O|tF%8E3D9_#{AOuj2&zWkw|Ces7#=0#zJD>Qh{xUbs>
zGAL${t==xCk-Tthd5=l(z%Sf)SZdXCi_XuaCWlN(p<HLsLG3fs7TuTB6M3}yoCTr%
z<IxAZ7!eJZn(2P|dZk)(eE2dE>Es!P6vTPLvgGF&%OjSlvVia=d}beXd79_53c|@J
zHJ7^u!xm|Dl0TleyBJl%KGjHFUEHBL8gk$BwS46WKSn+6dv*dkj7m!PRGS7$Gj3-p
z470#iE0lA2xt=?oX+h%+9|Lc0Z{IQ1%<_3!kIF}R>9&r8Fj+zlUo1LH5pY6o+g)nO
z^E{DTWV+o{<yKc9RGBS&wg0e$sgXv}UdmKDyc7mFlYb<CEQjnp<54gyu2+4VK?L@`
zQU7lNLdxpY3Ew|HLKgKZ3>SI0sDE~i@6HE3yLIu&<g!liR0F&r)e0-yQn`PQjBpgQ
z?l>ov^%~taSj%mw-9y6fir5XjKlDvM_3UY{d0C=1)Wug3e=~n?j^sazDUI^=I#$}#
zDombRkYg-R@C}W+O8JXhZi|!-CPOeuc5(Y;x4lg8GlZd<LI?9LO=hP$PrWTV<yQFV
zG_fNF@zrnF#&p^Y33uDzS)ZaEn_Z?sJq3G(tOI?|8u*ofvwRbB#Wim61<3oh8x%(!
zn5Pt46GluU$i5q#D?k~|(~y7s6K7_&AdMI-B_9J0X?*n#(_cz>$OEem%`4)_<a!lX
z+Q%&TY2|&%x-D|EZoqZa!r7m2N1+H45vnrcG|^~YuBsTZJLXuVaImH&`1Tx`b0Lck
zZ|Facm=|mpO!jJVi0{>=Gs^NDpULpdMK9yo%*q7e$*LYQ7wPpHA6Bpb?%wvoha8m>
z6WkjGGEx%N+Y6+;sRRkduYvsMn25Mo#8Kke4LRa;E!!70xryvt=^SKXYNq{1rsejT
zbMj0ldFuPsJAT3uTyb`z?kv-heT`bElP18pb}Fs7jVSCLNs*e!<n!7nEAt^~H9Zkw
ztfO31l%ZGqrzT0I81&1aHutiS${bAp1WE*)Su^DP%~4WeX`9~2Wu!xbFupRA8U=F;
z`R!-=KKsn$;kVi&1HR}*a6gG`aDYPduc~@~xK9+36An=qhL+`#ec(r2@a7Sq($y8u
zduh^q>KssDe-4C|C2y^WSj_zSD9wZXhp%VJOEloJ0p`1drz|bnKgJ%ibNY!}G0CA~
z7>JA7Qx8Q-XCIZlifAxc&22zMgcP>e-rIsVS+-q&SdXM{Z2->@He-d{`0WRuWI1l7
z{qG1ipwGiiqEP6e*u+Qmcw<qo)Rm0E(KxF>DLh#S<%$E!`!PFxHIK^)U6JP9WORUp
z^spRC=5Kt8P<?!R2bvuBP8d~m2~r=j?LxG(3vHWo$WHAF9}xf8AKXsUcCcAFhi-2_
z;<dSymT*%a_e%`1j9jnHB>g6<{h?tp$%rilm@M)3?3-?yDb5yRP4RcsT?y9cX52e{
z^eq-lHd5i5i39H*ISfwRuegkGfVh#%qaOO8DW`(((~=DP0Zl6$oC=<}qr67VeRm55
za#ULoraRFfnKf7#lSY(cEpc2kAh{%pTT*UU+K$X?M;wzJMNgBL2C(lK8WCe4zdP}3
z!tJW6Va+LUmGDCh8UosZ`KqGWjzdkUcq`7iVhUlcWBA<}u)q-H(>uXT)jY);$g_Rw
zbx8&T<O3tq-q_npW-&>;U%CgRC*+fyw)-Iqj8sAr$0-Bi*{Mvy0g{hc<M!NzMx&sZ
z^<aLoh8S!ihFFxtEJKPFZ|pp%j5!Tw*gDEnGcay1Jd2P0%{;u98UV?cVWoKLJF!B$
z<WLK94_K<i0l+~HQ8mehzi0jb@G&~e#>e;$5(wIlmKNN%&*W#}GegiLm<kAoF~5j)
zrRA<K%$odgB!3?k0UZ4$1Xsb2u78*<&H=^p3Cp)(N0*Hk?Cl%jmIh(iOn~*t#wrJg
zNGW%dqxvQoykG5@))1VQQ$aq=af$|Gl)LR_IB=;|+xsx*B(@`|<_~W`59XeT{h?^*
zAB_fFa=d`;1UX2XGjR+1lLmQr5#oaLo|T-M&Nyl&1kaK2GI8|}D-e&emt%lrf^(uZ
zRkS4rZiE2!Q*LRJoW>PZ?IrA3IfyUuC5~eL86a-Sc&_8&r+X!N-4dnh5c)oX4r<5Y
z0N}u5K6J}-^`ZAlf5ea{J{!?|(5npWjqBJ}nyxk(-wI?)VB1K7_0*3??w=w3W@7wX
zz{ZQ%-^*w04E>6fPsZ^<pv{_92Tu0S6oV_U6CouDpH4RBB+kE3{*|F5M|G+uG20~y
zpPkabQxO^MyS`)x55a7@spwihtGyR_wnOK(F*>k3FQ^@K;9+D+2L_(8QJ)DV(rCX!
zu;(;XEC-d>jipQ8pCXQ6Y-!sZ$=Q!auxlZE)(OF^0qh#}!oC%7Jb6oOJItC2(cxdH
zwkkK)vxDL=B;|E2K78nBcr;Zz<<mu3t5~7aDe}f5>H>iJ%Gj!KFQqHWF_{T_oO<}^
zn4+b!4tr6M>!qMS;j~Kt?awfHwx$lYJwixQ3gn{)ndl%IhbV&Pia;y}4AmIrAch>t
zRN9ciks@Qx90Uj4OK83eK<ia6n}N)BYDPIF6Fu|dd@dz!;p>Hjl#lW;&Ypa+l1$nA
z7a#xMCwx{0rnmgk$h7$v5SlGUME|xeXCNig9a1T@pMfR~=wu2){t40JD42*5_LBhK
zmBe{_3bj#z|FJby`>yhIh`bhnjrdo;IM~D6Th~4V<=4rV{7gYW{<>u)otwLEe?A$*
z+`e%FQ!6@kRRi_kuGjxZ*S&```Tv0*zjr=hoAa4D%b^^?9GmkT8%YSwF*!AdN>c5F
zIS-{NX*rWLB8N_62vHQGR8uPH@X?u+e!kc5uiqcP{l9D1eQno$z4yM~ujj*GM8QO^
zUubBQ_|ksl;`P=$CR@SN;Qz9b4xMt@0+o9J%yUxg@w~ip&Q)Ljnb&(`yw+>2dh&Eq
zuuU9@wJqk|2==D{yp02Pn5_MSk8U~ym`{N{Hk9S4N@zy(8BO-k;91Ey{*4y+Tfug9
zU^nJB8g&_Me;z9n3unECCsW|*#G~sb)(<NZ<@rcAT}6gKEvPK<_%c*r(y6>vsEil)
z<Lp=U!>)h<Roc!C0c838J_WGh6Hc5JFDXFd+BTkzlV4}kn4Ta)`ZR!2H&iSpf;Of8
zKNJlBh;6+9KpG5D+R|v`FsN-RYFmMWSO7Q#0v$mjW9+2&nJWA5fyKrGhYo^|9z`bm
zssn%r2;?UN4F-VY;u1+l2GJ>q^ibt+Tld`-;qfFA>3<rH_nu_0)Zn=Eq?Dsk2ZA*Z
zSZ--FePD0{7*ee&^B4}@0%?9hL8~b6@9m%^Ij!~t?F*60>$^d}4+CSFhL0j7+p(z?
z%CQsh%<qs0URd~(_-NUB!?=qIuuZ7Mx`fFF0Bo45PRs7z0I0u#*eM*g!&{>=$nzRC
z;CvL~ksq)b2K)*HZ>{hDMFM{kfPd-0zf8!x81>0mztPyTV$2n;*p^1q+XHXEB7V8X
z@OLqIybHO(2W@FIzs{Jha*XCK8F79C*M5WQA4!jlK<DNl)Avv-)8MtIz{fGrqcza-
zGHCM+@NWh9@dotoAF%clc)t#sx^Gd=@oqWi!*BI!Z_7M$DQUDmd}8e6#F%^CT;i5V
z0|6IG%9H}YbqKT%EqP5|mv5kcAyVR^erSyk`OKC{bNFb9m*2IR$nzlNQ>fe%6lPS~
zU;+R>f)MW@a_|2yO9K{L2W0;OO8-DI-{qmdjX^&_JJw9prgnqY4}*S&V`gkz#{u$R
z5cL-_YBC^Xyckj12x;sAbzebVt5&->jmrH8T=)e#`vFw^52*VKYWfM>c&J+65L!7B
z&MN`d+koE}#3%l*PcsFKZ}~KHpr`jCkNyA;egoeg0pFTp?kimQe{h;(?6WD^Wtjyv
zr`R2bnz@j#wLsZAsAFBMYBHm692nnv-%rT5$;`1P8l9F`kXOPfYRxOjZZG3sWiiTY
z7}+;+^O~>aT;VoduesXO(caP5*LSU*KXl{9==qYa(cY2~&b{I8nMYmYV}&=m?_Iy~
zsPydE#EsF}t1~x;MsH4!RZL6`4-e1GKYQ@t;r#Pg3yW_)eE9J8?b~nPK7IVSh0%Qf
z@#FWufB)9kfBpC0f3Fw+N6~<gDkQ#00G!s{7D_;ox9U<_o>ipwnxX$uGz%l`T0_7|
zZBvzA&TD|E>Arb<xqXYGF^L+hLZyK5Wdyw=RjbH%p67{7w5sQ{X7(9t`OV9sQl|%(
zTx&fqdd|F}u{;!=ez4CjU235S^JP6R9}LVc<KA)M?)fy=O?~ZuD>Lvtv=WqD=55%0
z?Lbe=2j8;6-1>18Nzp-RwYxp4CK0wP)$3c+ZefXe!i(na&+5ZCTfx$|^y}{*%R*K?
zs?M0aW&A|9ezGYuTY1*_-t$Hh=cN^B2ZF0QD&L(lL5H1g8!36YlUw1j-NE<ywfI@<
z0`qqVcYpV4Ja=WYKwWwM+w+2nbvk6T?8fYu)#j%%c89JEeZLd2^^EN9zsco;hjJxP
z{msC0Aba`Ul92?|@=K;Mi~>4J0Hs#Dt$lg@5EL-@1r9~WpIIP1c8sg>_#AVvKLOHk
z3~L#4OXIZ?Ji{d<L+@?eG&R^~R?1eiT8@=99ove3S)>NMAZ0Bt*SP?(U7=o9)3{<4
zszS4ltlFn;`NO;4_CzOS-|qCp?2m4)FHInbB$+3|6k>~|>w+#<8Q&Hyo=+&7lFHDw
z-g&UtPdDb0SNzxB23d{x=z}MXFb35unKERoSAOho;<=I#{GroP4zQ=*l?I-*?gJJX
z?;D#Y<VE?Lj%Qo+%Y6LwQPr(Af%?7<Xq_uHp_$Q+zKpl|Ax#cNN*}Hz3@paF_Z^pQ
zZa?k%>}iXc>3u!LqSz%J4<G*v^K6e`{j)c+{HKiFs38W)QBQ8$7?YR3_8!_ZAF;80
z??|85-rETkrP1!E$&c`D8-aTp4~|uf@hkR;-}1XVq$@t#HrS62EXCeeFzU3sbI|mz
zbahN}5NxU4?Vh>AGs)rdW!qHmSqF<9ergNXcdO<(6fX72gFGXJ=KJJ2(#;S$0;~6x
zQLy`FW=|j0=E_}t8Gq0R6^L+b=q^#U-<7pv#5y~{VxnZbcHS`MIB$2(pK+o2G#HX3
zlU;((`nl=0^!5BsGMEK9midzc`k{>4^!PY&;xw!4jEmRM57Eb+6Djx9r9(qrE6@C?
z4+49C`zf+qcpSRxNb7jVb;+ZF%I_3^s5ZTDl@)v!O|)y?UtS-dNF6lpx)QX+mzTMA
zrcmq+-M+`_U5P<6r(Df?pGtDJmqJ3=Eyrr<UsgVsONvj}oNB5WllZc;`=Lt9b-SbP
z!dFZ0f5Jx{9*t7wU)b$hix!e}u8@ZeBIzY>2ZhH}_X|NGk8bZD)d2=KyzX|E-QpP?
zKK-2p)iR1e1-3@YTCrU-|3na)rdqt(_LGJLW;9fg2zz^Me4yhMuh}T+^xw%GErWhX
zuO&Qfv!w~-@Ow%nE%b9l<!kopnSpCtlVMmBl@~n*G4k!+ZO4C6hyM{WP>xHra8T&b
z=jn4cO<Oe;_kv)*kT?*r&QD`6^FH*fzay{b>hZt4VZ3I)(9=Xy@~bG<!au?xaEYQm
z(TkAf!4Za}Lai@am`~&%gZk*<#MG3TE}~w~+eL`v{w2Ithad6tAee1Ma?iXI0sqij
zcfznvTYZ6~K9qG>|DNF!?c7w?h4(@nXE{Q9E5)wa@J_u0h<sm|SNzjn9P{5Ef3&RG
zU8HeMh4r?npuWa3n@3B<6Xv-Zno~koZN_ov3c@xSPYm4ZmaR`Z&#mn37DY7XC~v-p
zSRR*kZ=NgBSSuWp_|;gv8@lIAj{X}_Pe1xweNF0WYc=YV+|F><RZTDPNiDU0ghLPw
zkk>(vw<uJEW7^bLkWj2~3W}I0<mz?hN(^K`*k4~`q6wi=){%|ZT$YQ_^ZIxr(G*Br
zaKWikOQqC6n)=FDRcYz6uBK^zx}fv;zb5*60I1;j&U<RetRNLR1r6KhQkuV^`gj`~
zP_2zy`8qhv^w+N<Vkm=oHfV51+xg3F^#?g`g><8jjxK4W@5f3$E=;McHI#nu->H@T
zdV6-Hf6osg?(!`ce9mIYUs*vq%eH<!FoK!66QOdI74mA6rAlO_Yl3K-EE)CM08+Lq
zFob(4>LB@Iwh!P=C8+^+lk<<?YgN9zNw=7OGA`^DKcL;Lt6lj$M6MypM24G4Mo*5u
zO%h6;5ov05Uf#b5rYI>!B8+Z?Fi&fniRId!_441T*nnXHd8JVI0wrMM0ZT8q|G+b3
zfol@$kradcW^+}GL$Cg<ViA|U9#4C4LM5<uD&WzSnj@{)n|$~5sy^xOhsApq?4-RY
z^{~H_`*-OMbc)6DiD=q`?|cX%d&w=6@_pRcu3P7j&J=mw1cZ##E>n7bc)v$tsr9hQ
z>29H_!)$xMnoXqgn<7)ks<Dz&gEg1m-3<E=falt9q9CTD`kQ%bQwXunA2kqOWXaEs
zsg=m|^C9imRUHd#k88h@I>}<;YgAr;r`6(@haTD|^7kr3%hZ33Y`ZQZ!)@vg+y5@T
zp03tDTk`W9zU!(O+i$$I)WLeFedO!=KVP2T45^VSo`hc#Gp>t*YN|jbiPRaP@7^Bi
zi_@I+W)UwpP4Hd$cW;|p?#kO*&EuB{Q`a5eHr;NKA!bfoch{7ga`q%d&UQY~=w6TD
z(bI|Df7dPpd)h-!eXQ-RWC+Dmf$r3sOY@U~;ukE!?w<;b&XF)E4@zyo-l^WM%Aj_s
zU-XL#xtAo9)d@WoZH~i6>#G;a;j^WKog6M|Ag(sieKs%DV*fM2HLd#|_pMX5HQ02#
z=_&pEy{KZyAdQTBM$O11|IS;z(`S8GgLF)~c`xWK?~L5%U=_ZAHZ@kGzHg}0E4l7#
z%OzO3{AhjWu>ZXHbFD?Xnv1>o9ZD8ucBXXAC9~Qb7j{rz?zV4s@de>)#hHG!Ps=}m
z_56?fY8F-u4jQ@XW~{VOt)17_lCj2%$mpF_v%lsn!<$#a%bqC%?}kfu-T6pPpN%R#
zY~rl;;%y8*-_H5(n&24lFjI<tCM+YTw)0@k-M8z#-4*OXyg*{zvFE8&5fOeM%9(?W
zCaJJwD2Emg!405RY8{mS+PpT)=DHo;D1TyZwOSGbYWw)L8XoxqVQT+djjVcsmCKtW
zFR+ow$S;LN7tnfs0t0tmedJi&&Gjv7=Gt|RwP4>8(NFGj?2~($zq|aDXAbkUz|qHS
zU|s%a@mpy?+6EIlLXJ5LB#0>VbMKC7X^T-BLJ5Q9mPvH;BxZXm<`4O_G5s(?fjRjz
zb??*>XpO`c{>52Et?<&`mtyj$WWhOPVArncgUJ#Hv99tiCApc_ljN&Z$na4_5EV8<
zOg^Q@4B@7NV%%FSo$@9l&vB69Z<xPn;zg?`3i%S~u3i3mxV#Fr^=@>lK!QDOw_*{}
zM8m{zboLU1be~8DbZ4_j>R}4fn_W-rR!q?7U+x<edXMyRCj}HL$M!!H!pSF;Uk4>_
zyD>I|5>~{Jy?njHIK&)J4N8#z6Uc65hdKM5>XF87i7gK9C_7{xvpj=AJ5j_z-a4n|
zwp!3)h1;2<Ze|f;#Xr>(1=&G$IZTE(Dx|B$p1c}V)P{6O%eMUsU@p;42$wJpb1~0u
z(9iOM=h?R2WK0QHW6%nxP7cj;A*s6%d&;qMCh+=H*x~X#g%m)NtObuNn&HZM$Koux
zYInB=nTP%9_=H6+rWVgST}PSF!gy{O$`tA%F=cE2@EAv9frD1>JVs5!91#_|fe|qk
z*dVUt?mch}ZWB1I$H~rMs~!TBIH04okrS`6O00cRq*Ba5>{Cuoh7NKC$oox2f_YF+
zGIXv&V~CT$YQQc4E~$tk?@hJ8bs8VzV>e6+Wg`F+Vt$|qafMVKlA#a60|-ueJyooi
zA{HHk%VTFwI6B;Yg3O`j+T>E5dYC>V#cvv*K78mNj)USW?74k~Ea`lZjMKio68fWh
zu@uZ7Dodsxl4XXV^KkIm3i`Q<ok2M2wsSocu^x_CHxKj}UQlra`;3xSVS;=wI)~Xu
zM&CQf_1LFU3H6zTdQ+jRB!Y@{Xx|a+Z8?`$z@EPxMA)caFvaG>mqU^%z=LS*m`xFg
zgF9bSdANj#q?;gr*B=Pi&;#>8hlA0*9I@s@Vyn$!y+kA|0(jT6{}dl-2tzS>g`Ke&
zzahs`BFocSLW2SI!c}?EphKv1_R%b_AjtKj*i@cz0!`vDWNTjrAb#6f&wwqhUtFI>
zHc-VHsAv|a=G0`Y+$2Jl0uT;CSVVLKxu$`LPOB8_qlk5r(TY6Ky?M|pn)9>>xtc3}
zm+kz1GOhd^vd5Yr!m+`ASXa>*PXY9a2|=9{_jhXwS4M1T)blC0XkD;%uu81$5Dp_S
zN)T0EWupLCQW+81O%pqs+1NlvTXH}<Lu#(fSFh%YHE=+it?z4B=Jmlq!|wRP2a`zU
z5q}0%d~pst0wAByA_lrCkAiT2wybtO)RPY-qpZ%OfZ}EcYr$4a!%h1jV!m0QN`>JC
z)x8w-JrsZ;S7!Oc)$z;{KC*;&fCIFaky|HkAX(JL=HAv%d1Cbxu~yX8`{=9nJP;AR
zQ+?6`OAtrp?&FBWJ@VZ@(t-!hAVsU$74nj*lPXIbsBbUS9Y}trpefgQe3y1a^W=p*
zXy#q8&qvf%#jU@<DL@^eL4i|I*59}#Kh$w*6gf4_N#w?NWR}vo9-i1&>vMMbwKgqc
z7GwO`vCC2s0EyqU_62)S)RgfC`N3qfd7eVHpGM}d#!X1q<0J{go!C*JYT!83XQTw6
zp8iBmubZJZ)f-3iK;6KlZYscAybQdCr{R%TyHVYIG252f9=_O3N+XNL-|-6vTCGsz
zfa)pe$@nWV7eELypb>cyrU4+{YchG4z`rAVNG&-Wrg$@E`Fy1&fBV@PEJ*<Mt%U9i
zI^26B;U_2S2v_6CFT-dGB<+3c$3<WOZn8C6NT8#b6!h3i_34!^^WFf-_RF*98xRqa
zU_AKreXI>@-`PoIVq6Y!B<Y$Z&&itblX^VKN`k$FNu#MRQJ{e#P@kZd%3O8b42KOp
z?TEbwCRDVNG9SDd0Z6X4jGKW=$w##N#3nPvww<r3+d@pp=nI0wmZQ;W7f268MWr^)
zPXVNqLYC=IiEf)H@9WsNG*|*h;~xjg8-tQ2b6nG_h8yF|Eh4gJvEQk%sb-yc0DL4~
ztN{SW>EaMnI1mND)SOyCME{p3#=^Ch^ZkkdWak+RlWs}7<Nkm75)6E4EvLH)fe~nX
zqkeY(7Tx@e44D&Mrk0C)<ElJ3;!G_t%rt$i@mL4#!V;&qJ`&!<Yv-?G-{=C|g6;c=
zU3(99{pW#{x^Q^&t<<r~g6s3n=R`=?W#%&+@>U#jF*C&fDW&&pWsJ5K^)=R=!}G$!
zHg7!<_FC4h_2+@kpl5jd=XkfX!0<+Dqatkx5&_uJ;CDOV;Z>>C8zarZ=xzJX%kAVU
zz7jv0fZ|Zv7LhkEyP)WtGh%WW#xskbJj8>YgwN#q++e7LO$xOA)&s2&yi43K;6Ql=
z<cL9&&5dTnWJ-P+B+$L)Sf&`$q}?TuBb_o_0prDUk?_#C4GLu=Z*1f7P01AZzcdN?
zhI>qB3A+zlcgL6uHlgh9s(R;J%|8rd$>{z2(fL&DU)o)0`%s1Ta3~kl$3L$ve#14#
z%lg~i7e7!Xxa*ZG%%^XQ9?%MaBpm&*%0CK1zqjcx73)qOw6`TBTH!)hHtX;Fy!Bf&
z^;8qVYys5)4S$Ib%Ezynfe|W{BPD`%?JS?M_DSbb_Ad@d%RSYm)BpUNZp&L~E0b5j
zHdA+^d6!dcg`t&sUTJOuD6elTWV>$@$Hq4~?5hlwRsu=3>g?cvQjeo|oUIHn=EKRb
z_(!@6F6z}(u_Ga9sIktL+ruYe>iA-HqJ0|x>vH<o&HZt|D9DO2*VCM|<e+<C!?ZuS
zFoVi%9=NlLnpiiWMcxCG^&^M-g!&6`Q+kr~lL$X_@iBk0tA~iTsF*^O?U6LWm7bL;
zqO?CiH-dgXQSA>qX))Ib_*uK$%@{)3uW^ii##gMmizX**H{~A=X4w9vV#ZtbeJIdP
zYx_NvdRxKZx+5-SPURIYAG{OOa|rXxE|DVW>Y<7?yAjSE1h9Bhr#)WjE$4gqsJq6p
z{B5~SI5BozlI0WE`N?VDlcKC`&ynvzrQm|B5hGs#l$4macjZifQ_qYKzEOr)QlLIZ
z=4XKssZ<2>c30!7ueSUX$;*k_pota_B!|2$MnzhUdZ}PuW%u6`cP;MqKro<qQ~`M}
zC+@mZ()<CPq5M}+A3W@4tHTq)%s^$mqJK-{Q|uZobTUf9<Op{DFFf8Kz5`E~S#3R%
zk1lb41~+9NnR>i>sQ=`1AJ-|+uP1hj>{IPO`!?&&V~%!pEXA<4`{L%tPro16>z{{?
zJhRhE;(7qZCta_t&SC#?vaV1w-}_1Uiz5<<Fw4~~w{B}gTOuw&>?Q{!ihT^1<Y<>Y
zN!jeObe8#aB`&0HngJ~J>}mG=i+akZw1ne8chb^u{V_Ng`u9v}+^x$>*Qk)rHxpQK
zSvNi&JDmRfoHN`+@IN`Ojf39gW83+iH~6pWY$Vo|fkVB|(wfB@DX(YkB#(y2krCXC
z8Kn3-=F0bj_JhbA{+wb*sg>c2wJ#Q`HTp4B#3SM(Z=!_7hqhb~uuo4t<mIg^qBm=%
zRtY@BM-H|_gnqV(?wG`UBoBoaY@%=e-1`<2KRtrmn5cbRs6{mWkbeVHN<<mD-dya#
zj!YJ*xS)O}upEqVpH5)YIPm=xnEiElu)yvgf2Ke0R<wH$<{|W0p?c5@>IN?vKaDYY
zgWX4gr3uPXw8Z!Vv1<Y`{uWzLL5sZR^meDd#DirHN}qm$l=U8%-+4k_<6HP1?5S0x
z<!%&*=)D+sRPrF|#&UOg*n{PG><kTdPykP&et#N_Fp+!YKMD1vadj_Lo>Xb^pnk2B
zDA=H2N54B-5l1FcFruxMPa@<N<>xg(tbOZS5#y(Q#7<9wEHpJLTvQ10jSVL6;!*<n
zI^R{7slQgm+?3W5Huc9gm~%cY+zIFBzi(2G@?nYi^+YnP4ULE<A|g-Q*d`1<nzUQT
z3v#bqyYij4@)-M;xA&VuRKw|??U&HjI5E-wD{0-k{&6G#$w(mx1U33Y-|4Za?alIj
zKH!Rc?38~R2p#15y>=@GY_eX<`!A8oH14i@1RZ)*OI-21qiv0q<at&Y`TeeIQy=I2
zv`ha^Dbd@NcH{xyQ5fr`n)YY%y>)j<^xe~L75c%NZ`2+pc$}fwzq+=xyAUQQEj;3U
z)*x`<DCVsE2iYBcJ!ZU)n1m<IS4}p0wJZzgOe2P!(g~E+hgu#*fJMt*Pbt^zqD|;B
z*E)?};(Xx6X4-6=l#XY)+*Rq7-lf|v=Mn?^wDqgs9flFm+=ktC)1|-p5gua=6LN{`
zPAjkfemzjC<8xjn;@v)_@+%(2XQrQML?NDQZoHw)c*?dmRBw!C&J=vUBHnoP%>?;B
zo!iO%ED7Om?|<!)xt59gG{zp!V3#siee)uYk{J##pRh5YnM>Z0^y(^YG1ca5h4oqI
zyN$$~)sH|^CdxdOOb4s6?b41wF&glwJH0}6uS<VR@a!>P66jjbG<npZ^ePCE)w0f=
z2$b%5vSwaF))GQR-t;R?J0&_e;jEIs@|b!u<#Iure{#Fdxjn5K9_oh~DEKa`0!gF0
ziTS3R!#QC`HHNT6{PAcFZ(tkjT&Sn1$gvPAN>qyf+|1EC{c4?m>C|Vxx>5)E5be@*
zqRO^v7lr20GB3BOL;BSJW&3%zgu{gv%c6sq(w0a}iMktHt?HA-DxR0#R{@ra;m0}}
z+1JkKGpfq&jOx=AT;t#6><x_2LFh+BB4qnAO|#F0es;<BI^NO#&?haIE`2u=H!7<5
zmD=9F3xnYau)E+I((?YHGQ3H7SMFQo?RyIlvi`ARs4DRtLpw`96F%u(+`S!T@i;f)
zx9&_K<<F#g`fSGQBD0UYD6##eEdwgy#?$YR8W%}U^XGnR+zaBrRW#HBJ^1P?7dX4=
zsbeEHG!<yC>^*w_OwgL&9`442>=1sW41KvG)Z5R6pTsb2I8P;xe5eq2A!^ELH&ixo
zBUANbm8jd{DVKu0`=!-SbRL3AdFZ|}xp?-3MV+Ll_bqKslE}BbwJ1<_wAzM<SuZlY
z5ht8A=e|0l&N_DC)f;|B%esLsE6nufCsA?C*{=Ax1@jX<{q^!;A6X-3l1GYcjzu~l
zr{zMEH3k*Z5U-#A@~?PMwTDWw9)i0<-<SV4r8~Oq_^Aa&nA8O$x_0To2%8@_oE@g`
zRT;iw+ohU4Al9O7H{Uih-JDY!*?N>aIgO{vdgD>LFRaVXn7yLQw%5Xg^I?BBJqIws
ztFPo5`PtjdR_THzO#Gk;eB0N^g8f-M1=;k+rVfDPeol?@?Da|Cr==R+ot(p5o=Zc>
zL5-}fbG(=Ppjw^uo)?{LEmct^=_4ikyKE^s9k|yO0HGNa)v1$!S?Mx-=ehCMNbj}$
z@``N9@vTYfS*~2y(^Bi2AFt%<^s~1gl`L>38HbTKc&0LoYM~;q>@W~<ia|%4&1*u;
zT_QYwr*!*m={Vw-U33)a;#t}|RP%Z+`zVwm&xsG|b&vWqs_h%pY}3H%Pv3JLa4b6^
z0}ApXFj7ozFs~W)d${|n07os$j?)f?Sden1A|gwAe>jnEFT=JGH)(82>jwq0xtl4G
zoFDe*febsN_5wQvd3bR^Mrk<*Y_8XQLSX=#lfEc2(m+OXqA3bugCYaJJXZxqu2%Cz
z!JT{96U(5~D(?e|pLt$)DX%rJFGyI|0j>IY$8#HA15$1NtYh5AmI{jxlIJ3rT>%A`
z_N2I5I??j|xsl$21(*TO6zrn1C+zoP*mmlax08!GE8irWM{1`>1w6|9N4dBE>*ZpX
z#DVNeWMdxQ6uDkFs20o@+O9iFkZ-%;o^jQWMp_Hfs$Zkm2Hz>I@TSYyOiV0oxwK9a
zrbqINHQAQCkFS}nRHUual6l{Et`xo3+Ys?|32~Bfc~c$7)s)wnhMAlMF?P`Cb&N_~
zB&l?VZQr!d06?GdRA5Bmm};{(-QlE&qN9W;TqR&Y7AhLJ<7;<l=DDl7%+{8zK@@#t
z&*FW>96lx10ktZl_Ft*HTix2kj|hU%5B;+1qM_YI*Dpy|n?GyjIA8T9G7MbJX7FEY
z)h#I5EAjZ^%O4>oNt!ukU&_w;pBa#|%%IEPT7{LVX+jlOKinkISxHL|6z;2(!#PB5
zBDG6fG$Qcy`{LtG3+yz`lF(7<UkG{+I;nX@_$Ru9{V68DUwf46W+Egg##|P^ZLF#I
zQP7+*r{SI`iUd6fHfK~s>HqD4%l*w|Z9ba$sj10E8O_$@2ZVCfzY=mzR?EGJ#0|vX
z<lq(h_)FWfG!Tj=hqrHL7WmWfw|e(nFeUIn5_l(t#INx1tIsg8mXEjdk`{HrQ*5bV
zO{oV2y~hvw_Y=sMcYIqL{ApzB0Siyng7iQZTIeub;||O|c7AqrJ>sVZtX0u;Ils*@
zkgF=M>)wOz7-`p}+Q|Sg+67QpdtZ~~RiEAEZ{6Mpx(8*@N5dvTE(1AY5;TGGXOo=A
zU(4P5x2SYYQHN>a)NI+uDD|H`2#ZKizm40VG*6YKxn02iwATsOn}xD*2z4P4T~#k3
zX9!+H<rz<pR<8?&Z;1Vc6E-Q^v*%1IuTJ7~)8guY0CA7Kv^P+#HG=jRu2Vz#Dz?n~
zHF^B6ufgDTbg*5aTF-Tn>F0uco6j{f-Z?|?s~%{lbS<@?t2rj$Yt`eSx+dvL!)^~V
zkd3lGj7N%xcEC-M`X6-U1sl!{H#D%+!zGeT{F;~Ga<Xq^zvQz5mme85C5Pe)J;$Ht
z-gu(gVa9tMSq9D}h#E?+Rf|gq-rRGuG2x#AP(jzGFQt|2WzpAb-^(|<dAwRQ-`iOe
zVvFi+GhXf-zzx{noXp1b0R^$g3UHmPuEsL|#GLd8a2n+OrZ+SaqXq{QK;eg0F{Kij
zbxhS6${$^`c9fIC=DP1qeVB&Z7qO#%oRy2?u4{EJMqQD!5o-%(X)Z+=D1S(-{zJ%B
z6Pf(5;$BuF=Od6vzx?Z8U#lHyI(zj7C0CRRy{9#Q?^+#K{O_k7kG;8!bZ1QrmW_Y#
zXVqOIa4LV_0#9jv@+R!d>z#SOj>zBXff)s$#r&rS<nQpZ0jL0|f`v3?Khk2k=-+ms
z+DWWlxiSSf2>_>6sPF%V4Fqqr%55)q1T|@&P=Jzx^yWyc`;5F3_?@`@5DX70%rnqK
zBN}fa@tLSZ(bX3Wrg7Yz*Fg<7n%P&E5h)`K5taG=b(y?%qyN)x?Ku5ve$9Vr?c?jY
z0c6#^{7sM~2_9a)tDne<(S+T#sl_7c2iVymNFvD28C;hQuFAGd6#B-=e|^RB<vELY
z64##c!f+RY=44M1a%#;>r9D_~uk!2^?z}L7h-W~3+UuHsH+pBH?peFIv@%s?P?<c!
z$;F(k9*B8U)mWuN8IWHFlx?Iiw3^z=Ob{1RbiBTcQ^`GjV>H6NQ<|i8B#~8Q0COd<
zk^!fq?A`-pJ98r<I9(W3=PWgrEzT9%ggS&yieYTBgMfi7Dts;<>d1pTW#yfm)5a;&
zkM=dCUhjUXg-UD!<FuI8xVz1w9DgD#nTt?Zb=kiSqCgtre_#hp=SGsY@{}3iWq;mj
zQqwh(obP4CVSs*V(Nq~%9g@`=(NhwIqhkp0V}!CTpz+}z#PA-w=qlLmCYVh+@-_j6
z)@F${S>Gmh1c`Fc9tcO0wsanAo~eG4d)-MH<lj5m{TK-n@sq{x7~}g!=#b2tO{N>U
zc5@67k@@~6e|(u%CO~Mj8G2-R=W7&x9j&V`HM1rr-coLGi(cl`WvmS^mClJGLJ#Y=
z$UEOno})PeAZLKy_lI_G57cP{sOa2!az+~(6J{(Goh0TEk!L+Q_DKV9O>nz4kyU`c
zRD=U0MFvzZ#GJ~sY+@*fLhO;-XI2%=36<soh9om@a~x=TK>*Xz!P|hk7kGrxKz=IW
zu2*Zx#+>SpgzUf`5RQE-Eyc)c-muWSI$2O#`WS2V>Y_~_EP&noi=TZc8u4Nh;XJ8!
zVdTs+6;zrD1jl3=Ho@D*Oxo|ef4q=uKw$3P$&{(HNylBU_kUP!3P~6Fp8UveHp)9j
zVsvPh&8eWgH_&(zT*qJ9(o{aC=1Q0TeJq2N_Yp4bU7eXB-CU|0ISH`WF20-+zV1ad
z&moQ|!17Hc-Atg#3-vWzmn<{pHyPAP>R`bt(6)j|<S=(9swXxf43LUu1jN6N?I-w<
za*zDRow;>coNwMaSJD~!qC20_Jw|<-aGAfRn*^^vP10YMeI(*)L&S5U=57;zn+DwM
zz&+JJ>BsW#Q3@Ez>B%%sF;KbtMf@}meDC8`0uk}zri7QFW!fZjeG9W8YBuw73`ZEY
z?A;A^l{=|c4>LFzku2T7P>*s`{z_$=H#lD4lh?_MCgAr{vjf%um&t*3X|=;7PqAR>
z=l!luIQrH_M)+UIoXd63ht}0<&&=go_ZZ05F}uB`)y*D;S3=Av-Npo_@d%S-oy*fw
zupu(XP}4SX?$sF_fbg&#JfhFO`PmcR<s^4vwGCgetI0aYxd~+Kla14#iCBANBK!Ec
z0KaaiTZE=t_G`Hk$DeE>p-F&b8Xrsu@=LCr4f_fx4obA8B5ZmZ&A7}o++&d!Q-m*G
z8{FNzboPV^Lyrd5Zwh!wWH7#uUG4QJ7>G**-R+{1!qb!v1CPcp=N>()>wiQ#3RxvZ
zXI1h1xvRN0878d^h>?CtGZL};nL=8YUz&hHH-;n<HPQ>Z_j~O0HI)GfyHnX<{T_AZ
z`Nvvph7lSRuOGZ&!+Q}5%iSp-#h%P~gE|&h9%7V}Xp-Z|v%J7&xd4;rdYA@13}x?2
zhMdV4s{q1J_VdRrr9-o|45GCtb9&WathC#$KE#<G;P^F!<_$iU;piW!(@FxnjKJ9e
z7jUE}n|)p|+(_3e?-}A##8T@}B5}*^g8Fc@o#z(9#=wSru-RI0tr3L%_u30vnL61#
z(YO6AS0JYiQG+ndq34XW$%f<Ht0z|VoF!@BPUK!041G0WxCDKo$!kTZ!d)mMfrPLw
ziO?I_D0I>Jy!7)DY;EaaD5mFmauwwH(94>{rwMue>gXB=?Yym@m6f28XI$K~4c)lY
zCy~rM#g#Q0$-T%!7-Z~p?qyb5GddnUJ#``v0t>@rY}X<{EA8bYc}*`8vz3TyKlVx-
z*Pri-_Hu68?}vh7;_lDr<l77#Fzf*z+0V4|sVZKh<<95Y0=A_%gb@j1TU2E+vdQ@V
zqfq0>m@$ueg3Qa{F|oqOr<&le7|a$J04Cgx*9XVU&FZP<rEEJFL4aOa_SE9dhb&B-
z*$WFs`pBuF53_X<Z)n7xy&eY8N!6T)J)H~BBmP*-su#D68r^$AM3@CZZ0BTGin`5B
zW_52cH_|nYbbS_ykfxrdljNxpQ;6+yv<xK5g*~Wc@_J(`-^c!bBo1`J53IWi;8G`>
zP;eJAH2Z^3AO}`Z^yDPc?2ru<Lo@cGLY>*q(ly|eu9pUcB~@LBJ+16(q8yg{;;=R(
z%_P?-X!refHy14}Yl5jc<?3h8h3}|`DjpD%&CZFF2=nb%^eDFfZEEIp+n-B9f}###
zR{!F=4n5geg|CwLWeKCWJcO@t4sMl6LY^flu%gkv$0l^|;t|^1x2g_4>hvl5A%}0l
zeug|oIVvE1HP;T$w3&?l$m|x8(Y8&2AJcNJ^~Xl~8Rq&i8QW=MLWEY_n+*?ms$-X7
z((->pwY1q7lcF-|WZ1qYki1V^DfJlzSrs1z#o($(PSjFXbIu76&OLy^9HVG9%s_#A
zg6*dylb6+Vz&9RZ$UnQ22d?hVg}^0Gjxcv}W*cu&9`dK?K9?+bV0QLFV0pHg1CJr+
z=!)jF=V+as_%2h%J573M#Yp2e-E*?2qm%6~0<t%iXs?>p@{$F>Tpx6o2`ip<z9#1h
zhnwq1fns~W*KaTkXyK(u#A&~?1(mta2U;wez^}N*DzQq-*JZ8Z)ITes)6F6M+iT3?
z@`c4sWj*j=%!=k}$EaFP(AL5CXfTFwUqEDa4c$rU0m&r8l;aNFu<(|euXfXCNxpE3
zSl&^J^UJG<y*|t^$|yMHGWTD<hxKxpZ-~38&lX9|yd{xWefvGQjd6mI2oh-&4JFgE
zz*5WpVgs&PgbHmD5Kr+6y+yh^LJ!EuK2Qvk)krGsK_ro49ci}^#yN@k2<IT^++@V{
z2FBM_^CC(@Y20}8W9B)Z^0YY5<9jv(VNVgMJn%B+^9t<s%!0&W5l!sfoQ?=6e>J`6
zxGm6|@i)Zl+gns{5Nuz@N&p`op=)}kiSLM{M~G6_Z(<|7pq@CW_%iV94%ooNF?A40
zyvcoM8=fq-8-6-3gUf94fz%~_w#it1p}AH1%@x9FAH*b&HML4mKE}nxl*m@MA1RMU
zg6iHT&hT>~PH9cWqGq|$yyFt?G+n<Pi`cOo@f33ejrR9NoIwu-u(H}(EE(vhGmZo<
z*2r2?A@y9Qk7B+e{VN#$rr>G_Sqyc1%)<CvdQ8(nJv^Q8Ks91D`Dp-S+elR>F=8Jl
zyAq>)lBQkv4RVeh9I|=3Jf|YeBNb5NCmHe}C)bvT6uDVVIbPx2Em6NJ-y_mZAdRhz
z^q&Rs8Og6sKn9K;J+;O}(cWD|-M6T2@U?nfTm;sd%ZclIbV!rFsi>-Ai7>xrd-JB@
zk533HiM6YZb<^Is+x328MzvHgRGdva*$CE38DvddwZUhsYBRN^P{}>J{bF~*<Z}!9
za@{L3O4}ini%<_9Fz}oWD9}J#Y2Q_#Momo;$Vu7_zIwKX@N(d5vA++b^b`frwLC!%
zOS|zrXBU3TYYlRG$l=M1s&T=~>7z8&OR+|AM;HI@1R-*b^pCzw3JBMP`74B!Q4>Uj
z%ADO}rv;47dpl|f0>+?RUiKQq0l9HaorV%Y9D)i*`7{jvc-}&e78|}>57hO}%F#i-
zas83fam2ReOPZXO<`IwzA#EQm{;iva-A2^sDVgx*+~dZJ&oA$<yPt;0pdm#+R2#s@
zO+pmy8#4%*Dn<|++}(IQ%znwaYz}dh$CTcPP9tQLauL>?HT63t(BM3Gib6ggI1gq=
zfOAo{y5fGwn5mi+($}TSQW!QIBO}+UY=27WrH)?*3ng_@$-T^Iv<;5g*A~*-^5v@b
zIQQ@L$(ra<DIK?*S3}dJhYCXxgN511^!E+*t|}&+4AFOxtf7CsfB%hZ0Id~3vkEqk
zmyBKDN8Zano0fcF^wff9<?or2=v|4a|J!KQExLHzKI(y?^UuR`W=AK7tD@ITUJd3L
zC*tJ-MC9x#nqtb=RSzl5)>&08Hk*61TWiC^tHT9Vo}l@wtTQKSuVF=7Vsv!aqpHiU
zXOo?N*FCV@b$Gy1+AubetmSn+8UBjAJn(qgul`Z{z1=Q>Ahpk*ERMnWbA-(A!{6^+
zy%<;Yd$}&+wc3Q7?fN6gJ1YbxqkUh`e|tZwx5HEkH+;wggWy7^F)9TrgS9Rl)aXZ=
zS6OxS&pecD+y)x7`0*vJMB-Yr<^_o#8QceYr3(Qb+Bw`kmmKDy!b;Oqaj9o?HcKg#
zLS&7MR9L!QfTOG3;mR};Ml=^FA$tmRBS+QlkjsJH@201!!&W0+Yj_+8rmIt8mP$*K
z{{7YSpn-i{Bu&}Cb&i<^i{rAjxQ&2n_D5@B6P7;mp*(NS>&0DGtsVJ>S{+hi)W5W-
z>HJG^&N>O-an9a;q~J$vjbWKRBz+994nT2sB7y36zo#*3`+DdwZd61{h1&*STI{&#
zrzl_9&%Nj1vO7|nB`sq++p}e9VSW<SHSYQWTCu&QxTc$tjE}}(K;XgH_ngs?U87uh
zoaBFVv)H~4(P~Iy8-HM;Wl!wmkz^}Wjqj}!y-}o8Lv-XgIhQrizu8phBm%Ch{oLat
zo4|VG))9G?KIFA$*nez$Q)>uTb^lssqS~L7<Ga-kb@t~d?<FYCDjlhcy5O)x`_g*)
zbRuQ4bDoNm*f|#~?Id|FBG8mdD!e}^!vrHRo`j|je?u$&<Hz<Nj2P28OfJD_*Tzy#
zmwL65o~OPx+p}d)y_!*L(#9OKSTSPpn479(!8Ws9zp2h+#vQGePj{J|SqxVW8CKpw
z*jts-p}e1Geov7;^W{_c->T~{rJaWGQTV*KZK3IKXhEZiic8A;#edW8N;n$WbjV?S
z_PnsqxBF|l#GZ2j5AlS+ff0NQ_6nAeC*r=wS4)-qXxwL~ZXWH|3OcyoZZ1^v!<D%;
zrjJT=BI>b2J5TdXoOfS}neu+`JNxXPp6fJ}yVGzQv1@5W@?LAvQ~L3@=e35{O&#>a
zryL<l0s^$FklL4P;;5uH;BL(oY$d`#C{~1o)od5K(eWyL|NRS=D(y9%1hC@3YyVvw
z&^E8oSJ<4M=~$=9!j4LG(o~8-V>`0^)W@yTA9YSy1R%`k`c+=`2~qv>wq?r@RW;|}
z-z|$Jsw-OR(`<p<*VXP*b09H2!%(@k>)6CeM~@q$h!c}Mw|{^Ci@jtEM`))Jqxo9u
z?)<`wb+qoW2sXnj<N3?<vsl$>UkKaZL!vdR<XZ41!<8`?b@FX#ja$dE^fbUFI&>A1
z(|I{W8wJfi$&u2+c8uW(XT>He_V+T5@RL$<ZITSTQU6Ar#CK95Z^IM~Mq&07)s;H<
zUS*wTx<3WZN((%<?ffq$CCdxS(*DF4nW%)%)Dh?NJa_C+6#8ndNK*evdC>HBge76=
z=9~udrRjj;V`Vv?#789GFDwOV^mDU{FSQKo7^o1LV=EfKo>;mp-kvX%<$rN(`=X^j
zHwO+owHFamv80T_3xk%Z*tF^X?TK-a@HN)JsRb>u_<+}P52n0@q=BNxHb@gRvhdhv
z2+A*xBYmEXnJ*nwa|H&VC;7}{!_ZBY?Lp_nQgLE)onSe7(>@(=#Bjt(A+E4#-{I9a
z<!>|`WiF)C^yn<-6H-DK?W=C8<G3qUTsnrMQoZBuT#i9dz1}7tB1<F48ITvVj`TCK
z6bvvXRWcHkjCoJJFW%9}Ngr6Dn<YuHBwF+Z<wpeXc26x)U86CsX}O!a*R&mZLsMxE
z$}>!ES0-s|s)jz!wJGdSmeXNmDS6y8Ie%{Va#0I}s6n#&>W5Y1Xq;P|f?QRwDGT5J
zx%QxmSYN&kW9yVAW-rlMdD(J&F|3Ur#0`(UwC(C*Ks4d-N+ra@zxYC|IqJzstJ{ca
zHa^1=>0y+YFdGBOYK6#cc6@<q$<VPf!@kP9lj^j!U7Jrv3$NUt19oj}<3v&7G10)D
z?RpjRZ;FR=C+ufc@}o-*@D6Hk^59UD^OwwmBE-@aVov^C94v1DiT}j;L|W?^=X;MR
z|6p&+^hzz!oE}B_au~gK(Iu)Gvj|68nD-refP9dJ^ffZdC{pt2SZ|b!L7#_qyz;f^
zr8LD`urg?Isf0@g4H3(RoH8qfrB6rQS2IJX7S80@L*$HqO#<6I`;F2~4_y_t4^Vn$
zOERbFr{hQv)ws&2xIk@%L7w}rub}8S6^QN($EoxJnbiz_r$$<KJeciS+&zg<?;y13
zY4<zr=DWx?Z*sCPzWh}{9Jwx4#GMZRvsjoV_iFsm2^zwQ2Hi6d%sw0>lzqE88}X^7
zmO5vy#HSSNbZ9|t2w>a(fG}e3-tEX7IpVznV(zR;7kf?f$S@W4dZUHPar3zjWq!oC
zbcpUx!T`8PTq?yMiz2Q%Vll<6y+T(Nt5vAKrX<^c@U3j`>-P?iB4*edx(EIehRwL`
z;@1^7D3bcgDk7tI*0c&??fX~mzgitW)aj|#;bFFJlXa=(+2TiNrU`exFb0MX=Ie}p
zLA+HhjAC~ttaFC%l$R!xZAVZNE>@<EoOsr*%3Z%nx#zU1kw=2GWIwflnveAqdAwjr
zvPU-0hS5uR#{$m27|~UTCNJmAw=jul;($izhtyMCAtsh8?Al%NX!4F0;_;jHpw)d6
zjO)W{b3Ms75fcBMHG`+~6zlCRFBVSbdns0!rb@8`)lZ+%LfU8i{cwzkIid1eU^UM&
ze<9@%$gh*N=-J`Hnc7hWb-Hpe(QV|yqJ)bIL{e*2Ft0*{5ms-D+hv?OxP4;rWKWbB
z`(>K)0x>(DbwhoLE!cKE9B%J@Q!jMMDWVx)oS|bGqOk2@!(*|nX*HD+pGn<@%ac}d
zsvmz4aUX%(3xhhi0SPuFLL~Gr8cD>R&1@B(YbPfRaTiP><}w5JbwbBNfeLwRXxW7Z
zX#)Ky?f<cjVF|@Ksz9<n`KmR|RQEf+o_2hE*2Q+gQC4BAN$OW~e54J(=jK%Z(X%Z3
z4C3D-MAIdFC{cB%o%81(P-{|u%u;}~3TU!@*kKJd&>t?z9{7*PLKiaQzC)mDj|>LE
zepAkxE>1eF6&i_`@5+J^+l4lBLaRam+tmMJh_3z$i)9H+dho7LrWJL<ULa7^4nOK6
zb0?VTP?zhF1;LW#m+UX7k@3_y(A&!asYURREJ)z=OL+RQQz^^b<>JM?TcNNK3rbkX
zf-p;#hn1n5_6Ypm11ATC{=EZ+b>P~CS(~d!Ej-gG*~OenF{eN_p+WsG{%WW+IVz5W
zr10P<6i52=kUd419d<$DJS=1lg5(VB5Z`)ck{9k6t~d!=03npDLzH^PTh^S7ki<Z4
zO<}sT=_g@BztADE(t+eG_<KN#>}=Mubq51$0Ydqjr&wsen97WPyYSGEo55Dv2&q0x
z7_g-Jm{IZO+7LyTsFz`vkWk^f)u3RIyFJ-)Ayj#P_8jTs#CEQeQESez=*S?7<9!LQ
z+Nn8}WsLVS6A=dkv;)=IG$J6gMqD%(Fq0OTlA(+LWF0p?ap;R|Eovb4k6`Px%T~)w
z67Oi?{fbm4JfxFv^xb#R8uF&y&4Dd6OXVp*H*3^4pCeTmQ6J|#H}_bLV1%8HuP!?}
zz2`XmaoTnU?Dtcs(yEowDeel&b(jPFX@4dcG}J<KM&M)oEv0qHv_@i1b|KWx&ROOt
zJBb6aoX?XsqQ_6W+a;>_XF1t)hU3<NpwF>5T)#{e(_ZAf>rB|57)HZRCr!Z<`z@k~
z2a&_kNe)c)-xt-koSdxT*!1B8fgzg1EQh83Y)M@e9$hU_*;@p$!s+aY0Y#T(%Tk=h
z%b+#_b<YThUi_eysP<r+jE)NJ=;mY7W%9B;g#NT*Lq}-nz+U+Q%_na4RtKIPf^J=K
z*88`~n>3sXUaAUW8AmjxI1O$}FhoBF9i}1H6lb+U5Vnx6{uzXD5UR2J6~;jpw}ksA
zopsmi0n{MtOze|C5V;;l9I8~2=j`-VD#&isWoj{;0+FwCRHA|u#xEUHt3UWQ%G`Kh
z;$x6$dSm8JXOM++U@_F)&XM`&lI8PvXX2c-L`WSO^|Raq&{Y~PH0~mrj{8VcC(h_n
z0Lww4#R6yxA11Jw_H3c*0tg%3ufXmPdr`0M2{A{n>@H?e6W@8kmPs_{+PrsNdmSkf
zSQ{5uumGeuxy0w)e`9y3NO75@@aAkh?A`N1jbyjSLlCY5#H6q}b3t;2K$jvp$1O6=
zO~A9!l-;+^Z;IUlBq{pU=zbYCSu2>KkL$;Y)4M_pZ+r!Ur5tPX9Tf;GwKgl}CPH&|
z^TxdN@h@`+W}meMm0X|jk*!lL90%R(r{$wcgQ?t@)c*2@>2QjBYveZNbvjbyO-_^`
z(6;TAVVoa;5^$AFg}Qh%KTU%E;c<<G0HI$q4H_zxnLeZum#?ML-xZ#qAnrKUV$_p!
zr6(srfz_`-2H7YudskM3A!B`Cmk&q@O;rX|deGcZWl8&1@9#pp>Hb&I^0Lu$8T$Kn
zE%eK~94g8a%9XtmNVUEtG2))?A%{XkILuxr2tpyr11EgH)f~$Yk*a5Y!4H|fed;i|
z$=u!tpg%$!LTR0^SXwwbuF7bvC2@S<qeu#5GY7H>U~c_H9az!52H^5O;o*puhc@cE
z!yn|lbz@QkT<Ukrg95Y6O05&=cN_Y}=K8~z4$j6KPuLBBR3HQXEK}&2I;mxuOyu5>
z;eT(=NGX6$56&k3ec(P2^}J7DrOmL@an<Z$S}%a4mI2jikZN?lTGO)HR+x5GpmGM{
zKn`Ed)3zIV;E=)eOm2LbBX}@ms8R(IUo}`0R9(ZLbJ#-E%LccS)^}4K--cg3)s|dg
zne)V9xc;IpU3Y$j)GxJ@F2&m>eMXpwIiS6klRNGF`~`4rra&uB__B)Sx!L1n@Q1NW
zA<V&~ZKK!O92aM<uo`X>w2tPO;_3N$u!w4q4RFb@{hs{jBimy5E`^IpS<bR&+T`XO
zZ_PmhTep935L4ed>^UGqH*+S^quupQ&b#&N**U3fKJcZEIxGv&oB`OK_iCSnR;~4h
z3q)Ieal3^?^FbZ&5ogEcCbBpa$(;_;ejzvR`1h;OI)HwlzNGV0wmq47Wnj=+bnR|D
z$mS!gRWk+n<7gf%K#rKY;s;QduAq0}q)g~i>0iNybcGHw9#B5F<cz_AXP2S3YqDKi
z1`S3SnPwfPxaF<;YkAq=SNma0mH?U9ulk>&GNm86rXM3Gwz(+CJ^m9)NTeZmq7{~Q
z$j{NwTbfBp)3o_hS~$UygPSQ1f(ZTUz3mC-h#4=vLz?Zxtrr^K#olcl(OGk}$p|&#
zh8gmmFw?mWQyl>Y-d0UZ^(sQKD95Fd)#^%+xC+B`HA-CV@s8fy-@Mv3JRR7gu5MmZ
zjRVQY(d8x`Z;{QV_7lzDE9e}{dBD~-X*HMKoQCS~rCb~vw}$_3B|Xz&%wuG%OlAxP
z_XEHXwEGvRGRs6|0NErS3|v<%q?w3kn`Su2e#-Z_D4xY?F+E8GWN7oBoiWf9H*AbR
z)71Z~qxly{1UV>5)~VM_c$hk8r{E-G0^(I|<}`gWNtlGHd>+=FreUagMultxfs>JN
z(6%tid^+7@(%FPf3_rVaBASk*=8(TPB~1&(!F%K;OEw~mfw;<~Du`QDx~!d1><J6t
zJ4o5j31;%<fZBkLmGfQGY41=|eeHfL9lqu05$`%7dM{X`hlXAvnmvFR+4*=y>wun^
zx!hB*T_yg8O}QuahsQFH`jQ;y=J#>O-9ZHs2`*CcuAsvA4m7%(SM%F=DB=6HeOQ5(
z_OMo6cch&YX#Cl`KjUU+3{9XyOK|SYN4O4~0lnJkt^(>?WNL~Z&{^w8H*I~Q#kmoo
z>kWoP>!TJR*ce-2zd%<Rk#O9U_mvIR%93V9867b_@>+VEnq}vKI0$jy9Ncn*=$7E9
zQQ~qi|7akuJHigE?kxatG}tOgz4e#HKRS(^synZNkQ>m5c6MqJD*qpv?meFA|NkHV
zbLZLE$!X4;Q%KG^MB1Fsr{r91NJ5Mfl{9lc&mkez9CAv95K^xVp+ZQKPICz9gd{rX
zxA*6J`CYbMF8lL&xopqp^YM7z@AunvR6<D^EEMncsb>-2Y_or;O@-1+S^!u-Hw&&E
zMBF8BEl|h?mil7gy~D}IO&%Y7^P@9UmCC8m6lVD?p<pMZuCa>!ABcF{pzSgL-zVdM
zP-{ddAwGQL=Z2N>P^TA;a?X{)Ir<T>+NXeHB2V`jelOM43^JFq&?U{S@HbVK@3H<u
zil}Erm8q&XZILgsRg8Oe-y~}`F`Jes%fA%&i3D9P1<*CXojUIAItqqcx>FrLFD-l$
z_xO;68^jll^F8To?g^2I_x!a03RP(FA_5N{V&y{HBzm}g(k)fTVRo)8Zv+>_{^lT^
ztT?HnWA*bwQUAjYN0k5;DaGd9katmZ%mnh4T0kz?oY1|%O}fiuRkMvJnGrQCm;4mt
z8fH_J3F{7^{S{+Kquv$5Cvvbvxrkd2i>;xH`xksQk5TuY-Y_VQ^KybP7>4)$8$RM>
z*_nNxp3#AP(>I#9M<*iyVe?a`CeZZ)c;HAE*^O@&`j&TA!pk94S8U#_>v^#c1YOTX
zLGRPbqBZL4_SOLXQ6}gii_<?W&ED|DjdSik9+A8;j5Ic^b=jE)tWAHFQsvAvj}J5+
za#bM?F>R8Qu3m~8h5$ZArUW#zkaHhUV5#XS9mQB#NEVrsl9ecjNF>M@6?fr=AI|RW
zer1a*qa`FUNWd~>@+N@lTq`V%{+iQo6#93{@j=vg%YdPzqck(wV&3cpyv!ukm@#m%
zBit>YDL&*H(%oV%26+<xX#d?bb1rc28DM()bWXZyE@Wrr3~)2HZv>qpw|G!Lg@XQ9
z<oe!Aae2Vm4&3_HTCelkhxERArALZTS3jf~>pJt<ol&#<F`5}RX7xK$jtS=MWOX4t
zrT^^rG-2`Gk<-csmURjT;&@piMaBiw{h7TOck1(<w0Y@$Keq&&%fvMVu*<#bO>@+H
zyUTx<hsLU`)8sB|S=UT<=^ta-7OAdH3b_P7p!cTuYI<e7YCV>kq0(-bbHwgKANX)<
za08(__E+S)Nn4k!eEH+aVsl~kV;$%JN@snR%udY`H{qteFrB!r>3z|+J^aL;R8(L3
zq2{5Mr7X(eF&d?_uz5tvWNB{mlf-b972UmvU}{i>lF5tg7<+v0r$4B2*W0yhnN3-d
za=*_DA~&D?`1Deg3IFkycf%~(-ZH~)$^fbxbTwP<`EhOcY6pL9p(h=2ab2Y2&m{20
zL)QW>pZ2aF8!t5d+0_)#;2@rTG*9d!{tgY)x3(i=e5{pHm8U;rw=8VB82wnSLCXTw
zK(m=<=^4}$$sKQ<q$4|;KZ7h)rHFG{mhV&Ml#B_PF^{ig<muJ2KU~wRts2e9bim!}
z^y_Een>l5FJqT(KHd9C_WyyYDXsy-~UtNj5len1l=#rOT15ZBsYu~qK@kZiuu5qi*
zQpFy_Fi7s67<9Hge81%i5#P$FrWke%f${Xbh9@eFeIz_n?C1J`;hs?A^!toI2_r1g
zqn~Jf>`fD!M$6(;E9}7OKf^>z=~rR9ZQFQ*j|-OVQ}B)ky1kmKEVU(t1S>iF5^+B_
zQ0ltPi|}inJ28*o;U!j@Es_s=0x@UDcF1fcgB6{0(<tLBYNbJeRB(2#)9XNJkn)F;
z2keJ<uB+{9nWety&bxK@tYT3B&L$Py)+vQOG0<QU+_PL7WYI|?xJudww+C1@4&r6^
zWTps_xSx3Gq%)-B*I#|5k@uS+-#wK+@~@Tb)9=&C%GtN5n~pm6nv{%ryD_0TLoYP3
zV(met^yO;WsKE_tdQR9~$Gb;pD@X^c&5S*$rC+WCDT5peZMw1tiFl2}X~_{jnl_(A
zT;4VoTH`YJzD%5q?my@#J4?z`W$I)PDafjVg--D&l2RqS*ede{A)mr82@17NKKGB<
z2}Bs>h5Fn*%V%1z)u&Mx*qS@dC;NnjENBN6trlmC4$pPIKAu)}i~~}Bz{PuiJaZAe
zviEG%%+eLfs{|G3ts=bvB1U4(Q}lqbolcNd(`yX^^<8(G(5_-&4$*mWb#_~!wp1~_
z--{a(RWSX@_Igy<SY`GebMu_k==Fv^;pa1UO6bf}7nX?=Vo}vu_|?x&iiw9@#Wt_Z
zQ4Ol2>s)U>e+(^O+;@$cXZqF6Ma=>vo)z4Od!YXghH<Yxx1b?k>zA!GBwBc$NELE+
z1B>QRQkI>+AuLE>@lYl!YAcAQO(p#N8jXz^n#cGOlZlfYxJL0at=|R7C!B)d5tH-o
zUtXmfvAL-xT}dc1Wv4$!GbV=?L5mfB<9ITwHd!?bDhq#OufS50y^7>t)V7C0gT(N+
z$a6N=0{cn9$~m;tK{?v?gS!}>nRYoA@rs%(0#2$$9ZE(%6J;q~)PYK_140X(>H9wy
zU}MJm<kva}%^pUlo052#Q+yD%ezlKudqR-y?1c&??b4_7Fc+M><&nYV`c{10U_CxJ
zB^rQq6hu|;o{`&}%LkX^RkB&$4z=S-u@oJ#DmN=#7BweO%>wsw)<H?QQojM(C-bEY
zp$H@?*(C(Zzb8E2I~CHa)R`>%vJ|YG%67egp(Cw~Rj?U2H^m$>hc0MH>?OfdwN76O
zB=+r~GfIilT=KEy=5$lrWBK7KDIzCI`^0}32?wT70z|hgVMHcCD9AQFLy{Abjw?!(
zWtHvUwgkV(AYl1n+CSsn)vgf=3NTgS<;F*hO^d|Neik$ku9mB46=cM>eMUM`76^Hy
zD=o!A2rKr2`F|SF#C6e1OUkmvBeq-G4jXlbmadsme_fKx6OQB77ky1K&buZg6gP1+
z*MdPn+s)zSSHZ-T?R~pYZt&#^^!}+s2f<Er_@vdo=N@yQl8?vaI6$LXYqW4s3g4z&
zM;>mq>iAb~{&p}r#b`GOX&KRBY(ujUDq78Bb03-S5sVN1P@ifkf6+wO3HRH1o;9YM
zGg}--8noU9Y3?bzgYx97^S)A3f3)*Nh8qhOGb*j=F8srVY_4$kYN|GoqIP65+c*@L
zJaJV^Gp_!lJ(8PlTTu)WVOlw$7>6Giv&%=92M-7rh<`@*;vP==+2zjWMty|H)~+v-
zv?t{mcAx?WokBb0bC$$1SN@ybzyS!#EeSJueWV>?$c;{yjYRq+J33)X%3Ch@1l<?1
zA2F9Vy0n_c2OvaEH&W6&Elnx7MT5=xUj@lkk0`R|$87^ehyZGXj?d)+!bIF6nqvjL
zUv@uWLmjbLR#K4fA0<VmKVoD0h>|OVhG44D?F11i=#_M_@}03172@ok-$O|m{xp$-
z1xV3v+Q#e<2*dE1kdOH4uGy-rDbe3sa<0WzUb*I}h9|^(oi@e>=`at}tPxVSdJB1+
zB<oc=7(%*hG*_9Q`3NJoo(ppN>0xsQMgl~e0g^;Z29?Q&>4cssZIQ+7YOoZ;iKXtF
zbRWDG?|b}|i-zvIK%@;ngOD_xb^tkr{ZPghvRi#8Y*oS1h<dhPr#`!6q7Q6#`j_h5
zbZCd>6Qj_~Nn$_+S4pkF#$HWE_$bjzT7mirkmb7!4#9Q1XEC|Y`^HT&c!Nh7-US&n
zKn2TnaWDs&%l_U~I7Y#QtirStDqqpQezP~@@6=rMG!^5h^&1jF{_vYquN7ZN-LqM{
zb4#Ze*Z+AOA9+*I+_?{?8=8b(bdJJQDuH*|@m@N!S<P2S2ylm<VKdi!AH6#B?<)Li
zcF&5z=wV1Q_XI<Yo`jKAQMaQ)74r&3!g?qV4Vu$_hMxamZN^%=!0&sq4Il@eU2WCz
zSucFB3Leqt1Bn1L<orgS1(UT=wQ4zbkI*dj`0VIjJvdytaw)3O@>6S4H=%@`V@leG
z_%k}apUa19R&bz?j1t#mD6iiRlSN>y0dm7yg^>w@XJDPCA6gVDY;hbDgZ1G*<~!l|
z;Q6_CW1XfO<M~k>-QTY+rzo2<ws%yX^I?QeKv@-ZPHh)!qvj<vLJ}mkO4T>8Rcy0Y
zY^x<&Fzd}=1VYkg*fVk=r_YW9Yr+I6x+$+e5jLI^cHu)DnOiwgpyA>Dqf~56ri*9a
zb1M!2rhIL6#ToDkx3!HWsKB+L(bfKWb1g(6kIEt=>u$(c(C{<gkcinAB{_>a0Q_o=
zLPh02%Iv?}$pk2!*lFvr6ZRv6%<Fkf0LakdsHk5cL4^_(O6eEd1NjY-ZRKnmvxFu1
zTY2B05zL22suXYt5kjv>BUjc+OW6YffI0BwAY7meL^ztDNrRAf)!1k}O#E^tPf49M
zE2Bfh=Q9Z4og{b&A4Z|!04hO;Y&<F~Wx%^zI~Go)%B->#1hoMlC`gGVokPVHNA3ob
zp<8MYOGWv}J3_Ujv?}eObsi?vCVH5Jm1bgczd=2C4*e`yc>neU$Cop#j8prKTU)o`
z<HOv(<?&v3%tADE;BI^z%B=>&!y2w3|B`UTJMf>+@HJ!MvShi9UYQt%B4G^oheU9?
zxf>3`vp{$~O~~U}HX|SD#{D@nudvL7h@_ynbOjt&D*GA6pDHotto(<JXk=p1DJ7%{
z1z{#u*quP3ptYjl@{wOVw2xY>5OE-QuQtNKR-?5N`F?HJ$MGi<Jo&%cwma}y@$Fif
z=^A2AQvL0|Hs~ylO+wJP#KNTcgcgM%a6vf@Q88+dLy(OvGM~&paiS=FSruPY(pn^A
zCzyJg^Ri&~+D4w--8=Xrz;|;FUJXmY&}98xp}pF0D?q1GN#^tVE^+<bPD`1LiGLbA
ze8;T9Ob}JIO8q{(@ei%dhO!vL$92=S^cQ81FonP(H&H_Oo0A}}5a;P2g|B?*Xd&jy
zYLpLEVsjSyzEET|7*iYODIh~yLHHcp?_U6Tf{*5sz<#@Ow`dUIQ|&gSKW@OPMOK9&
zUAJ9SZ6i=2O;6nZ8G%H_84mqiNK&`%!#-qxw4xDXxH~HMx#$>XMS{Bm@*B(n`LhtD
z6$3MLO;ehtN!@W2geO3+;$faV@yQrPydqgE=w(HUd`6OfHxE~?Z@j}qO>y-8^x@R<
zu{NZA+N@DG?n)p9%vP*P`)+aXyIfzD!kZ+uy}UNR7UIt}oH4)M>;~SLOH82~e<w^?
zQHUEgn_p*PnmXtv2cbfyEZoiTGp{5@U&<s9eeJVq4jmLygpp)=dr}cwY@=t);DG_T
ziawx#i*?X729v>4Tt}oLZqbE+<R}!OlpH2kW=@TE)5ZKeP5T06%*o=%CkcNj3i`DQ
z8lk%lW(j9>r8MVoV^0N7IN{}%25)x+PYz~fPjDI?>XC$5$waysl8R3hAP!`S&Lp{M
za{3BKc#c^$%0%VWDCjgwFOEsM(m>N7L^ofA02XOve)(0TP*=5!u7e{9lmRg`c=neB
z5C0(d=)~APJ++z?vTWeG>&10d*;6*h4Fp#Zz2_rx1hS-Hlqw^V*h+^6x_npW<DQ&2
z|9MuvmW&AFz}=E?W*}k-X$(b|*hi<q&d@~8NSJ}dPg4-96igdTc7ysd%+By3)p0KY
zw#*mi1DN<z@CndC`(qZbYHS+mkVHisjp_TK1_cHE-r_*4CKYpL$INf<BS#Y_W(l2#
zbmJTqhRH-CC}3wV)wDmvbAu|AWh>cdKiXD%n9dh9x?>Vi9JM+tUr&~R(?!jaL_15u
zO=m@oorJ2mqR0+W=oyJI!;>#cB*H2s%*ga0>LK22;pVJ-IeyPg?)Df3;YF43C^B83
zTl{mVvEm584{#IUa)*PL06|utnH&t4uy)YMp@N%k!(vDwkSH;O=;KmF3X41p3LKD+
zP(QCMFAO4>eTWw$%iO*T3E`qS9j~MT_yAqF(m>8;Z@4}${QeZ}zp2I&LHE<olh`vS
z$4exNz0V$}o_$?{YyJ}XQ84idz)`_yuUYW`y122(lOD45rCx=*JP7<L?g@?5%)!FR
zJBWt>oRqXCPxe!Jsc+UtbOXjaKIj))5GUwzX7~JE-AM09V1p!l1@H9R>IP5AMy`--
z>+CT#Md*5=$8i8o;|R1M7?&xdrzE%n9kQk4jLD+s?uB2B3*Vn~R2($sG=vPK%7~FA
zTFDYtB*70T5jZOr#*4Ue@9gEcvln=0^|_Q!Y@ZI2tOr%xk0%~RktKO*!f!9*nju~y
z5MTi;O?lkI0cD&7z%)oJT`t@T>d*%Bph0OAsIZ4el_D{1{o?yIS;9-lCjg`kq_}M(
zBf-0(H7hz<NnYl?wgH57u)|@O;oSgyoi{EJ)ChE(U1ywqXSn_jIrS6;5dgq@D&^Oy
z3V%S?oI-`z9F<>G`6HLAIvp{+RJl&Fgwu<Y;k@*V(~=IekW6DJ9YCu+m-k3=@FPp8
zmUy<=Wu4WNK>`2FNjM2IVgV~W{YhDGkZQB(tl11ZLW9oTeT6#ck;jvp63cu2O_+b0
zG|Ue@?IOQ8D>}9p?;+}k!r`Z1qPsaPIz{LK6Vq&1_@gXbpDqd~<2x#4=5B_@@H4kT
zLaM7Nw|NSqmC~^dn8bsIoAiC$B)QI6NjGxIWr3NzEp?#zvlUA&jF!1%>6`{)EqPx|
zsbpMHoduKajsj1i+&@FlVpDmfyB~=d=YARqv9n-uMTJDHuaxPSy}~P7m!?-dSU~L<
zYOYsG-{uMnliA?PXGa3{H;&8T=<EaIuM)e_p#Wr~EJc@hU6d?w?IwAE`p}^+^j09M
zq*zE+5YzHlFXK?HjiSN|`H*{(MA~$TB&k^(08xOq(t!$rAag&mxX1G^EV|qcV;Ky$
z44{LB`7k1X!HpHrb6jD0_D?tc=vVLl)~$8DJ3IThayI1IyqRN{W*j$YVSg(zLo|{i
ziJ(!L|AKc5ZNoUB46ShfuIY2_1O|=-iRytwZDyN9mfTmlFWYu$4wHqN9EdNOBJTjo
z94L6Zws=1vC}sADQb7GOps?8;$+=#6n{o#lHGX6EJlQ`hlUMqW3pTj2tDby%f!^lJ
zNeha*W|R+7Ch7X0|N4vHjtCT~^6$PwIrg3=B1~tOpHt4MR!t@+pNxcuNW!&fxWrle
z8~)4?u1ygc<y0?}#uT|tLMZNgyI6_g`u7Z)_Taga3A2)&<d=r3=AIylO{%=SPgbf~
zvt5dLr==_|7v5nizf9?aB($O{)|HdMI5W%!x59RgF~sE|s)TKT;A$UrF*>fdX&6iD
z)ZUW*m7!v01rMYk2Ha#<Xu=g-p>nR!CV;z#5G)fyXaH!)e*kes>>O_(c2;tMEU{B1
z-uV+><S_JlXMx!4q{ik1d=2TJ3shL7%0}dY_HoOq0)B(}?RNlbZ<Vxx81FHVWE-f!
z3aC*;K(qiHPzmYPl;6u`^*Mnly`N(aGMRhMjL!PKAqj&=glZ@w`f0t5cuWUr0Ja}w
zz?D2#Idh&a8AwJH`<MsvY{_pG^5==~c=9EgyHG&fHV7M<3OmhL`CKV2&CJf$pG=y=
z!)X=sTmd$w<o{PTOosPY3GH)OS=k_tAS@8Ganc}=1^~hEh&G&I8IE)l2%dOXo-6os
zRfUG|Z(CdrnFcVUOys^MWL|K@XPUA}BZ_l)KokJ!(IlH5jJa3B=c>hhDqrt>*?66=
z=nB<sof@+F4zl+q!6Xt~o9V5~hkt*)n%A<X`g!&c=$+#fAh&fvdy(GuhlbY#l7ENe
zbV$$ygPxupAcixGnvthb#y6<_-&UZPR4CuL5JI_79#hWdn7kWXWFf`(ArBJpu;&{`
zE-`85)>X;)B!>X9IE8OA=YQjI=CK$Hwb2XOn^Z)o3ar9fyAcHZVp^jsumIOlOG$GR
zBqN=$GTSEnuux%xDhKBwLA*~=T-E`OO<2lNGd{p-6D)hM!5HCX>XR%uRwvA98X?le
z#rUygSLB6QzO|!NOmCY}-4kiQhduwvDkOp=LLN%SQ!~qqcc5*!H%ppV-pslurmaU`
zmJ6WtM;^=BsAR&qHOp_oHVT+l;OSllX4Lx!XfBs)6uz=NpRPmijY=dspW9l-Lf|?_
zxJ-O+DH7YCml;2PBl~i}(Vo-Wib-h_d-R%qICf&MNEt@VbdCo_D)c7WmKdDqg+8XH
zqUJ|l^}<E27@Qkb8Qw)snr!gEzj^)go4m&12i==<FB)HH$PA>2m}VP(@ul;+$Isgr
zA3cBtR%T!%zW<w)MUSRXUCX5-=fPj$&8s>sbB}Ulb}d5qPb$uzA35f$uXA^CICydR
z_3LLxn<zzUW!E;;#^7*mKmU|*4le_*Z!xpuvA!U@L(~gqKEAwqL|*@7=(PrjQRTyH
z4&};Ssy?&kjM!1JsN^&kv(#T^%5Ic)4Wq=3JgI{zS>E19dXBU^+^8&_+3rm_>uBD|
zJ$zqrQ&DWN7p1X)lXKr(K0d9Gw`Yj2T<8Q)T%tb~*-BkGY&<3%Gj!0^Y<oEfYq~iM
z$=g3<U}1lvm_k4z$fOBSxc0D4GE`J|HTC4Z2kdG|{d%k9gE4Q5VA3yd6b!mqjp$pS
z8YNRF&ChsNdV0jrk`*jokboocLUv;#e*HuU%ll~8<tOC9A*1&?Je*SgMJu`1qlYJl
z&f22(G%?dFc1ZCrfqVnI`oMfBz&$caPn+FI4L9RZHKmJLPt@y*W3tpQV=RV9xpssh
z!=Lf`!@9jWB<e|>H$&z2<O{l%;riTP(n)_NlSMpEeh!20gAsnX;2jLSQ}(-#x4>lg
zUM;XT`%m#S7JS6(m{Y?Kxnw)d&ibF?+P5ch0<WUoI={l|!*l9YIW_xYP0(#la?AM-
zL6oZi$t$$7P?%kB(Rl=9TYZH`wuRL2El}!R3xSS(9iLmD?vX0Bh=$8Wc;`0^mR?>#
z8+jQd+qZRi6@)AGoW_dxi^svmi_2cS>e>IP>Bl3kR;S1AJ*hi*X6MH#Zrl+?T(8cL
z!`T_gk1d1OG^B-<BK<axozOb4IH|tF?1_H0b{oU}5{u=;;dMeEitHrSTkzfJmE7`6
zAS(RcLhIAsE`E%W*17pW2RPcON!{o(GZ}d$!$1d*A`GoOl2q>F7z-P;4Nwj&MYQa`
z6FYfuuf?x`qJDydazT!q-FV7?#FCk#r(QrB;t1l^<Yfun^kA;R`CCi|@(NG(VB}Kt
zjq~21ql0@#QBU$M_gYL&`+F;d7==;~qpm*hcnv8agVb>^FF5wLuq}{esbW{8dfo8b
zRV}eWmYrefql_$(TS;qSO*h|#7C;fxx<$thQ7wAs2lwZY_NmyBnJ4Wm<%Y>UVX_>@
zSt^&DL6>Ndv+(Z<f+4fWJHkQn$%kQ9NMlrxB&0`EE8Z<>{q&ewq7&pCP|8%Uy+<0_
zK$CwDS#aC#!8N8iks?nYsT;5{37vho>`p6XEpn!7gpx#y&Z9jK>(B=?lw^21jz|m~
z{jzfft<#K$1fHsfb7|fY#*lqpKD`&kW_LLgEu%Y_x$}p<$WyO)fz25?hE!)k*};{}
zixrM*b|G(Nq#Bp+V*Pz{!eXD>J5&r4`>&ss2I{N~R0d_VmfbpM>SU`3E`WV006}js
zOZUV?qdoh375>-_?jpGhIeID*GFM-j&*0IXZ{{SrNh#*b(FTI8zhpzGb7apdSl=V%
zkT8Q8t9*B8r}0M+RR0u9w4Vu!D8`XZ*i&O>I6JDM1-?P2X1Bp=S>vNVxKSrnbN$q1
z`+*yUPm4qe#zM#p14W!pDUVe96AAXYqwpRHRngEz>iuERf&|VUgO2XGswnY~olTZ5
zc<NvkEt5PupzW5Fl^m}`Jno(XN0nEz<D1IE7Qn(79elrgC1zo$w&EAP%OC@UdRJ^=
zJYat<(16K8Qn;X;ace53niw2*oP3m=J(@HRZ*;R3`AThPyt#4Uyp-+B1p`az%~^c5
zPk_^@G34F-tfPQWpps^iw?hO?L{!dBY7t=hFYl48C0XzNJf43xL6Oki)~`Y+$RqBQ
zj~)NJoaUS5o`YXqKC}}Apc*+at%yog#!axqXG$+&pn9Ky6w9^Tt%>lYT1kN|;3Wj3
z<g%6lQW2sd1#3y3J%OFgxIy{wu|s!Objke?3aG6XC%5&Xu)*5SuhK}cC2&<%9cL*l
zIK1?qdqH5^r5J7C5F<l$XpIg`Gs->7XDD3e3i6{0kd$GZTO>cH0oN5I8pyq|$vwme
zOXf_%kz5XHiQUw-nRHj9k|*pD$|97KM6Q4BmkA-mk#@}xb+ta?s|>#@d0q-ur{`t*
zVpDf}fCeA*D~caJ_Q==+jk%BHbYJpJLb>4PQvxIf0&jtx0V6Zv;|>m(zhy;gqdraW
zq?4c!p1O|Tz1*p4h1%dI6}9M0cPlTK_oeXDqH~xaoF!B=IrXGwAm3mtMTDVa32g;=
z)~xr*+eSm2OJnlFb?83N8p_SRo=nh5y~rn_ZFn4gPW0s<F=#O@`{>#&((W3CDSo3y
zB#_rRd_(J5?o;y^5(l)$d&r;(op&0#o5-$ps|jvZi7&&XmiAeAcUr=4e{RlgtyUP?
z>Qh<u6S8Siy7H5Q1~9mV3v3N&eKSlwW-L`oY>T_MQb@vvArVE2Rrt>Fh@PpJgGeXk
z*^|;Mp7hn;?Po!9y==s67)Y@@)?o|}J58_IK=1zE`@Y#d=_1|TS)P0)M?}omGJK$j
z#FjDQ*O0z@TErd5Muv^@eLxk}zTkheZ!&fWj1)`D_BV5q_%fYthT~-ftgMT!_|%x!
zlMOG#9Cs#-QIJ*)JS6VEsxL7~r%Iv+9B7F-71Ag1RR`Od5)|U>(~D2&_!uv%G#+X)
zKrVEPQd+ow&&~4bcu^iZVQ6lmX^7V-9)p#>6DZzdcTyQmd3wR&PvO~o^gv5VvQO85
zqR9USfT*DRP$)p&h5}*$0B8z6z%Rio{eNHnj~qZDpa4LCK&8Y91Pxim|MLcbSP>y#
z63)x(|FD4*pxDzQQC=zl;0yrP5U3jf#N(lns+uRG;S4{iqh>a?MzlZ|7Z+=5YY%rf
z?=XQh5PQs*rtfAZkOuw(fICR!bvcPi6jC4!{DDK(P{?1}phdwA_q14R*shAh@>_2I
z!v;n|Br1qeU!g%2blS6!0QB9xvR5?1nxx^sk-ERY@MrqKzy07X6Ue%b^b0Y!UqIwG
z;6ElJf8EFPDouFQ4)|vY{BZ*Q9Rlt6f|u>kAEIcZ0fqU(EqNlXtw47-tm!7Iwb<xt
z)t<+th+k~bbRFdBP2|T8@b-ORtr5IauD?;Vd!*5LsYH{#3BL0is2M{K4MC=-p<_cL
zI|IPKC%}(>u%OWYaRmHq3-}*7umlLOfz1ujr{AElF_Xevr(2gCnr{i-=dPB=K53#4
z4hGjeJ}Qs~5U?}}LXm`a5dgG;LEUIfGeW&nO#jv%nTkLxXOI7N7vG{o;n|UAbL@O>
zxdz>d@hnHfN1*CMV2x>!z0U-Bi(t@)|K|;Wg#N<Be(M0g0gYu~_fNoZ2QdBzG57(~
z|EMiK;sV-?0{uOL9X0YC2N=ImUhfZuK4l9Pwqvq8L7fedn^%=9N0FDuV0U(a?ross
zGq`byTye=Uui;4b<KP=?;P(yG?EkO<Q2zwzsQ?>z1xyY@$Nm9*e?db(K`$nNpFe>g
zGyBGF1V582=A25o6qiwUF6+vfw9C;ch39js5_4K2>o0@;G$EJDfr4M4mS3ofiMYb2
zpsi8R*fy~7UFh|rGmk2hlUV|FprIf$<xWmZQ*vriO>)-lmeiZY4Xu?;ovp2{U0t0m
zcbbRp-5a`EboWU|#vps}QTy{}?ITaqlJf@JItN-h#;R+^hdUlW$sXz+7%m(h9vmE)
zm>8d*fAjLq?Bi$uBL_Zw_^`45^~;z4M-FTY$bqe`pWjwj`S0fbe{z7sOGb)n1PnD-
z_ND(HIWW$L+6%~mexkj_qkNKOmaKhi&Epij;>iFh_1?$-M-JGZqCL4J<3IK0@!dMt
zYevx_8}n;*<JERWdctG2H{5bAfYq)#v}?H5y6W4sKWV?|&GxzLF!QUu>D66$Ux-R}
z$1VSxVb@zPINrPctkXDl=Izrs)gvWZzftmL>rtcJ6w%#j#L9f12iZ!F=EM#4g~z2T
z-V!s2=*4H5M)MWuZiA!ayX~(W`77~bz#QuHwDyx<^-2-AcjVpS7Q?~Us<4Fl!TZKR
zbr#x#Vx#$;YfGpLjvknzv!|A)MI7pOCVu_+%)hsD{)l<ccHHXNqn8_z@)yo6oE_{l
zaC?_<ivN}BxXbTu-~Qj5xhjVeo9xq%+RH3MXiP96v^)tiTFhq&8!ppAa8qqOb1|>b
z+0=q#cF$Af%76N$kO-<(DY7M@bD8Rm$fIFu16EbpBe`BdIc+1z`HVdt^{xlxXF8Pf
zL$?RsIvQzp<|<`01zl69kjq@~c6fq#o+h{Q-ASpO)+(eZE4WKvI(Dq<$X+U#h*d11
zDeh7lWFVPkh^n&Ua)TBG$DHxxtdQDDTU=exzLi(v*Y&qgD41vZ6bh-9kO=t~AhRcK
zR2|UOD5_qhO7Bulo`R65A?t%5ubGFm1v7Sj>{)gt=hF1l)qdavN1FleSaE;YFcaDY
zEQ&T%lmdY(tP?-ZP2Vx!E?KhU7)oMqbzn49QW0g_8f~if_fOcrSckZ9YW(~ZE#8F*
zMcU8Zwr#qw0<E%FE%O0Cx$&v>Q<Kg6hriu>E{uj>+s7fj&gj<Cn7qxM?LfWgRE`E*
zGN*u;Ox1Fq^&FP5)`m{MB7Qh9{V(a@r<z>ls_-Gjf1eufD<24MbqY9xbX3|3oIvVr
z@k2w0ACCuow`hksc@%AKC+8?_g@7{*ExvUZ56enjFgQloz29RLeZ>Fft-J{T*aK5$
z2J2H+k`F|uFT%?Oy$xc1v8Ubv;PIWAh`8+7si<UO+JP@zlZJ<9-v1RLm0I=3y)WC@
ze|5_7-if1T9J}(brg28zcPa?`-`y)K`tM}d*`>$|?Y_9Wyl+-DuIN1<kEAP8<X8|S
zhV(OJBIc`wcA|ZU*dv#<J8cKGJi3slDxwsraf$g4V)A?o*8FWLH(tXo`+QpsG#CB*
zc8aq9qv}WgclXaN1)tT=zSFN_C|)(HYrR!mYpLv0c%aHG|J%(xUU{|10Np|~7k6}N
zHClN4RhZ~&;>-_aZ&REzCGf^4`P5%6A~peY3{QU=*-UL0r8HN;nF##TJSZ5TZ#IQ2
zq#F*@3L&SyIS1W`Dp`bHGc+J8@6>$nTay)Q`j=D_knU6V%tfs&J||GLXkzMV`SUbG
z9U!ByNbX!Ii@JxEVy@yR+o~Cz^Xn=)Yg-!jAK+<iWCmo%NClp;i&K^Pdp!9O?M;mV
zo;Ug+2>U>0@?-t<!0y}44rW!=k_W&>Z%x1#uf*H@olMGrcx1(*8w15((uRH<Yq@Yp
z9e^z?OFn)P?Z`#H&>c<}vfWsVT;caUz?9}u4H2^C5y>*f4HmBEDp*e;N|0yk&}Fs4
z;vA=Ar&e_>Qg!jR|A0q`3xnxvdzNLuLmyN{fWa+NDnJ<OQ%Vdj4hpj?`@=;j4op4q
zMu{l!?WVV{Mcbn2qQJ~fQx&oEtld#-$BJmpI`wROe63tWO5by@zhBqv5>9~6(Z!gQ
zbzf_>)#sPrHD#(fH;4yk^;b|<#*BpPGO4%RL;uG&oI_Ck*XOT^-UyY^oN>O`8(dB7
z&r}fLb|k`SMLEinY4BODN34s&&%Vnl*G?#u4tUlcX!>X)&wJi0d{EQ)Y)W&81yl1}
zvEqlAw<@k#O6O^gF1Js+8!J2D%EI(e5Bk*v+iIp61$@&a$x2???NFH&ts-NRl)7GT
z;%wG;Lu`d6Mx7l!aFTQz5`9y(dd4*-Ef^pFDC3B_8}s4lLdfc;F+<_4o?m4Ue5k>R
z%*_^1@`6okdBhIa_TT37WIMiYB8LKfxQ{S~YPNd8Al+amxuED;E@e7lm;L<NZ&o24
zCljhYa}5f=fIj2Ta+t@@&%OSd0y#FseqS>&(^W9q>Ji+YZ@!N|vraMUxcgz)F7jr9
z?dcK?`=^j76^~nqIXYp-ZoW6#TBZ75h-e>H$%uP*|FO%HSS6c)jM%#87GBZ$sx&cz
zo?()v=+rZLkr7FSS|n+z<E6Rq?KvU_cl1i46?pYkgGZsnZ2nfA<?w=Uj8OX+W#~lY
z$7Tdeq)<@#=@bb!<^m+NY11JcG6;yUS*I{H{LAhiz8P&T+&%p7YrJpVcUw|biO^+{
zE|N@r-A+NiSz5Mvd<eOc;v!F7+IQRt8#ka2+lV*@hSKhfRJMHFw^8d(4?K#NOTDGn
zk{MP=jFr`~QxZD6U}(kz9B*q@9Pj|tkC&*#=0TO?cQ2nhV<%rtycF}z5W6z62lqXr
zzUFsJzR6gn^QEZ;^RhP!P2d^w*)4-3N^9XMlLJ^kt@=IB;*A~mcUwKrE?3#&ga9V7
zB$>iN*{Ri(2&nqYs1LDsmi+MGH;1NuE5od4n(wIxk+RT%mz<`|>coW6%GCNZ2VXg`
zMFfM7k@fW^TP^vgnEpkAh7!+TW(BnB-|8z~uTxIm6$SJ2#wPk-mQH+9Oj8UOmB6*y
z?QG|s^ougR>^20Kt7ohl)~;4xJ9FsjZ}!suZ!ex*fFA=!|1wI%u8?3`{>t^5)3Ekr
z9BiszZ8=vdw#m~acj#UdnlKq3Vao4H0Ha68Vx0F;-Vma<`jp&{@3UnszIqh#%zHh<
zdD{dWADQLz=Vt@4@!*T3=E1wB&_I83bIX)!7iHfV_CiHPRbZ!uSodv5gm(>Ka`^s&
zFYEYz|99BaiSfs2oim=M#aP_{ocR>p{Jl8q<6>6_#c&LJGU#w^VCSG1Q5)WD8$4I^
z?7`Oqe;3k<KgnkzpWoD;>N>4cbsYERxA}B98}oVoeFRhMz*kUei7j<iyz<-Edppnm
zHYGgWM5s&d2kUA$yWKzam-L`wxkKdiiV_ck2k@KjpZ50LGg+)pygkePvvNkT!nHg6
zRu2bZ0Fq1)(mnVh!L=xcl7I_;RA&`iov^wK*E@bLhIX;}1KfQ~_O~Fzlo2dT#Qt?l
z(v~<2DrGIhWgu#RBn2f%La$@sPIxK)b32EHB^|29^3o45f%wI>#9f<F(nx=I-0meD
z>sveg6a_QVazq&q(lAcF?@gD82Wn`jHX6E%fxgELgyKEl9XyxEIA?na$xjwaS`}Fi
z4jkDl>*bwN_yY=A!YsC6Uy;)FKEO}uFsMF=X<NLkb!tkfdsz%<M-aW()|_#~4vow>
z*-@NGo<a^b$BE5hT{q7D3X%UwV-2rGMXsKU6o<u*$=<@DS*H*|B;W8caI;(BZ_c?#
z`WdM{*}aMYf(athQ1_ZMvV8=(@*qLpI6EWgBT2oe7a0<7^jzQUPHi$8jEM|M>LX+0
zIO%#YSmHFcX$*A-xBs^QGw`vF8Ur_RQO(@bt;Uh<(|HXb073(NLQ(AubPWU4$xm&k
zpopaSQE$bMz+M#?YKE4H1_!!74;>@MTN=aWOI_V52_w;Yb@Az^NLd=2z>Q|~TOvBY
zBac7@beHm8A3sw-Im2E>s=q>rH6yy>QSEL!`G-UE5pL)@QqGt5xVlI5qakb{CMriY
zRw*uUDx*N}2bAzi_GWW&UH$HDfYH?kUtSey8AC0VqTZ|)B&p#isD)UBkfaVW&;-fi
zWFtr*I0LldgYKZ9A1s&LW1!aKl|RG;ykhNMu1j>gCsLx8O*@T|+&(hXNz!XBzA5Nd
zo0i=egO(e>W4PpXCTeLq_YKX}UkV?%bg6p@QO87IdsR|9R?^5xjr2t`y7EJ$fTXSS
z8H^(dT$8wY6$i1{9i3SEmclpS(wI1GYPH}7t@M^#*+?`tdl&pP8(Xgg>E;%Hp^(GH
z35pG6_XmZ33}xJ-mA8$hM(%tp<7I#l6kQ3($xS`=V;yX*UMkH(Bj-i}b2<SPn2T+2
zPJTuH=~n7kh8lS#JEsGCh0AT=q8xou+g;c=5_V**f<!((QFfl?man_TnXyOzjAw#5
z7GmG?Evh^w1`vwgd)dA87y>f$F3Do~+8<iHjlH`wyI5=jqo-5WK*Dsh&T0R+a+8a?
zO~K9>3QSgQQWp-w1>Q`aKx>>Wa05xQYqaf9H4M}SF$b@EVo{KpA7}iLfi*v&@Qj&L
zx{5Hfs!~M)$}zd><≪DHci??Q?lx4TEOd^(GvefnzvjRA|SR3DJSbRk$+)K>5`y
zZ)$*Pzz&${MASGZou$1HYxJ9q3@sMo*jB4#g|I}i?ryc^R`5ihy>qKqfO6ELiE%R<
z)y+q_uAXzM-+kbm;1El-22UN_LaO;57ibI@n~`cmcu|Vhds^nez0h1BMMW@oudkl8
zid6xp7KWJc`Hgzwuq)lkZ)leQKa|`Id4~egYtEYKPa!39MAm>Pj<dTPGH$O>5st~$
zDRDZ7`nqzvmW1q+0P!X9A9}GhFPS-f(90~PTt6R9T!^QU-5d@!-{>5vbNxpjw)#nN
z%h(;j0(*+lylnt~cZL)1z??5_PF+PPb)CP+LFtB~mBZ0T;;$w%4?Vbt``NgYxHW-H
zcRRq=b1nzMRlt~nseswlh+hnh<`|SHgcx5@lykchX9w}>Lfs-kaOWK<yL~0ldN)z|
z7{EUW0I$znU{g>h?a`f-R$X6o^<$y@f(Rk}wLfE+I}~i*q<(Sfjm2@Sf7XGd=FAat
z_KWo-7aH7iwe1k}R@^B};Ed|lD(V)u_)aHjsX2b^SW82C9fXt8+zwY*MSg5NU!a3j
zc0@OlO0H8%DoBF!>x`r-!Q?rn-VI$(<BU+xJqQwd8gKX!s0t%m#+y>&Lt!B_cqkWq
zxxCrZUvY^Kz4=mglLVQRu24RcD{Kf~TJ8KBj}vAGM(V&=JEWUk_mGuc8FkE?&kKD0
z#R)Vetj<}~P!@K@?Z!6Y{<npCbK@%E?X<&%BHjLi)-LF23dVV?`cM&e!yi7aYW!CR
zJM_Du1t4wVN?9h1XK^4x7*3efB|MOny4rHRw#z>hb)FP4D?<njRro?dO*La>YaW)c
zk&oI*G5(42hQ;fz$*-F4Z92kEQ<V9uJ!&clA2&D<kh4g|hBvnPO5I!6sS{R(uQR(J
z#)F``z-3fq6uUiWuuSDjYgzl*o~)pe0?fXShXxL0?qJbg^nbt41X?I!Jh^?xXs}o8
zUUVV$G#eJ?)ZqM~A^l^)rhC8GZr?}%!Dpg&y4=uR{0xZh1B4N*StBB!f_ioKYRwh#
zp){HIhZO&^F}>cFsZ1Y0Z-4J)p|dZ^zuiQp(>u_tbWa9+^9t;*`rQ~BENmED2q$Ts
z%S$gSU3BkPha>(0L&*VXS}1_!-iq)-7XB1^^(r-)$!foWs}UX;)Z5kTaDDzPC5hW1
zHkTGEp}ffuIn#}e<wMPe@4W)<Q9}_i!+kC|3||A+zb=w$U(mws{xgPMA`KUvN01n(
z<O;$4#T_yR5QGoQvv2ywq8^0iSI~GwYMd$^c){-7#39?lEl`1&Ws<>o$nITl+IC6T
z8pU9pNpLF);}r!KLK^gD>|n|RH1|co%`{<rit-E2-OX{V2>RK<Vv$Wv-zXBSnKl+_
zkCNd!YZw5of(is@%;yJUx&h@eEOlTP-e^%Vw><5@w5)w6JdQj5(I~{>(ZiJw<5Weg
zTP957GVH!T+_U+~kLtcVJq<+;xj?Uo;knW;W7uwsXF<#c_p^vB&a-4;bTe>Kc(uRq
z1IWe!l^l^zG&ueHQr!bTuMCQiO01A#BgyNfjcut<Z)~rP{}cH=#+x|A9V56i6L#Mb
zw%9zeB0g9j0C%BiPHVo5J}=S$RD9L3UdCOY>4#&Ps78KCEj#Z$^8_RsNW9`2zKSTk
zhn)6B2mcle*|~|6<Bo5(V5Cn8&0I+QL&K)mIpR+!{N{I`ngbckWE!X$6K=low}qYg
zq!>BU=gF;d^-22Ng4OD-IJ4*7{SjI?4v}>g{iovfPnxhYV%YSH4K!CYnThs~M`b!i
zE9(Ly0g9i-kj0$0B^PXGiDTT?igJ_m*EGjR&dD=xp!1<KvT@hqn){BiVVby}xX}0g
zRkdklsIU&~-@iwK#z1hnAxXx|#a<Bm7(n=ANnoCjZ$~PgM|ZG?liJPFS0CN`Bh2Q^
zJ|CDp-TeHdGJF|GNZU*{=*}~0eHYmdmppH@Ch)X510JOLe2e+LBO<pM^I;`e(WkUv
z_OqQ@CMcuyy5+lmVE|S+<QkwHQTDq1?QSs(Pu-2bkr|w~QkeTcPGf_Cb_txSN)6`x
zu51XSeuHx*QUz|TX|O&9TdIH^Zl1e1aj|Xxvp*#4<|_dkFwbZnEVPEBnV^9C`OMqc
z7hG5C5unu?SC)B*%|IPSf6%0-3UH#>=83<n*o!(sQi(!rzRO>o^Mx>Qplq{N6RqH_
z>^A#N_2`rq0b4)X=R-m?C9<EZ0h;HY-=y6-`v%r&o<(%K+P;d~6^pHE!i|^tPIje^
z?GbzK9Q(~#yRC3mN<Q|?%-d76l&UdPLz%B@lDof?5Zl*W-58k2VeArfr9NT@7L8j&
zgRiWa;$#7{I~)||{H--w|F;)VNj|61(aSje{2(Tpl8dex(@4Y-;BK=cYoSw2q_>NZ
z)D9xyY`W>S+|b~}Zx`-6_w_Viim?cK5*7iAVXmVCA=9+7S4~F@R<B1ihAeR|%GkkY
zDJWLL)jN!R#@RTltV67^k`4}PI9GJ^E6y<l7+~Izfug@sF8*=DrZ*#tX<ueWkgs*j
z_Z>;GF@dMB_hh>Lm|l`g{rR>!G29{ub9=bYi-L$8hM2O2>#ENQ2$eL)f{&pJO8`P<
z8XEB$qoe-j4zT$#nBTKmhqFatBGEP6WidLS0AL=qV_Rsb+8tUt5+daEY@<kLZ~RI5
zMaIX-z3^17ZtlSNyPoZ$9;Z0&OYuvKBXq1qq{6@5?_av@wV^>x-7vxLqq>r@)PyX1
zb?nS_*GM)Tpjy7zeg4l(LAUj%DfP%-Tl-Unux}6$!9^TO0X&rL<@P5QZ#*vE<6l8J
zlb}rI0y%pQgJ~z2mhI>9CoSF}o)&BPeB7}rw^CPAu^C*ou0h-w@u+ov8$VtA*rT%C
zX#30SRRWV4g`XeseeS9GeAlaW>k0&`_<ka8oUSf<Im`H_SMHm)Nw;o|M1cb$8C%Wo
z_xm(?-3n9b3+d1edL7Wf%YJ#=<I9$>Y3xmjJ!$8oR(9@t-;zdT17NqIBE&?st%4-=
zmwtwrGP?jS(#@dU^nwgDPCe-QcByJVTUF#njS##0f?Zu_bkC#+#>PWbu089}?w1+A
z`IP)ov8=8|+!y*#1Zv81pWj?bw8x<SYPxCsoA=bnoxX<`pB|{OP4n`h-?-$nz!SRK
zT&_4TeMtFrs^p>RxkWMm(8@=}-r#E2>rr~sBuEKrC<83|m$)ECl`yd{w726~>kIp^
zK2~K3Z&3^wsH$fg2~!{Ejmg?wP#hyduTIE_d&)_eqI05#{g?4%MMaQ$Vt3u7R2Z8T
zVSfHmv40Hp*!A$H_<WS+`4qJ>xg0)Eph~suH2zm&xRrk$!1`NX@-cpso(FqhT2*_-
zlWwhdgb}@T&D-;_HThuY<L4UZdQ4QGTjuDhLR?LdJm#<qkAf9-{v1?29NO>!fI#_N
z;`rB=bW6iM;wgq?^)6@;WwIsnnrd%&U#{*}XK>NU+624n8h^i|Gy^Xa`ZRA235i}h
z-%35GwH<ju?OI}U3)w~fjE}yesV-PpT?!eXBL0++(3fixzc488qx{`k@6hD9`b2>0
zjePmQ94XaVdIousc(RRbLllmwoEF0x4*~PS23$^woimRqf06s(#Wf3wvYP67t;fNl
z=8G*KuOTFIzWO*3skI&&?Y;Vnd%AXVTyjpGPOHD_{k1YVt8=({PP%YA(-xKZEBd>Z
ze8iUX;s5+rxT=hI`-d-`G2S?iF&SmmUr*FnxGd>M15ur_?8|<tCTF`Ff1_j62Z+|5
z_DD$&%;Pp<#yt@IuD@N9^_M!O@@MjltofnpBYW(jM>B{@n<BVk|MXWkuRVA^mA--t
z^3#6xd1?4Y184rk+3q2*V$8Ss%8Vwm-_I&W&zV$;m&YtThR;<`l{{Lq1iOSbd@U>v
zCI7S`_WbbbEPaUY9TUuabnNiaIyI@qa|)85uY2QUHN81zRmw#r+uY;--KkXxETT-b
z+uy%@?xFpGm9f(09K^}0PYAi4vEVfQ{-qOZ%NA0@?2h0qz-7N0_-f>YDd>-u;yO}3
z$s-y&{z~ASa$(;SlCqbq8zq{z^38kbIiKj-^hcyLMZ-P~VOfi)ej;2$$1@upTAi{{
zhR_&-qOCMpN|%}|{uod%0Ryu_LGhNSYxzjZ<QM&#pvxa8Y!DJPk(%Dd2&?6_toS#|
z@-fXUDP?2HSN5~Qgf=1k=b#k%Y04>_5F%Hr_i9_Tl6bFU>fQ{AiZg!#&py>pRW~cC
z^v=nVpP`hBeD8RG-t!eVv^7h%o9#u%^W~O*Bh<}8vZ<V5rR-*?YE3CpchgeVJ-%18
zA80ciCgXCZ4_k3}cuAL$9O=M>q5X5rRDC!4W#=RoT*U$<a%@B)hUpkkL6I!97D0#T
zKqMmOu>0RVLU!MEKm=IWWdzK#6;oh(w-obz)S}LQP<me@93o7bX-@0glCcl1L^{jQ
ziM{<q)?Hp}JI@K!mkj%$tk{Cw|A#8-vCyZWpoo!O(7XIB_=&VE4@rA*BQE)~!{Hqs
zxRd!@2pR#An%H6|sNp4rlZIse^Mz~LC0*fX`N=+Ir)nj@WujOI;s14x7Ng+MTl|9>
zfh|M)&SZ)Fn#Dbl^eiflDl_xErZ<B=CU=c>ecIHD5)RUn)({K$NrG)l*vi;_=1C`Y
zhN>FicaWv9!7TX^6*2BzxP?xj9M|NdS9zGxt~b&3F5JPrXS%vGJToNfjo*K6WejTC
zRp!1e2J4^ING+SGQLt(zRh+>&{iCN`{lgus=3he9CGA%D!nD>Zi9@~1BZy~l>Al3X
z2gyRw>5|5~H|K27{_H@=AF(w5B>mEpX4>S&&<~2ZmfUkVi^Qq%Wy{5JDEFKgD)$7K
z)R8oOt9_x}(D#JI91CVTZF%xl2Ft{$4jUK1zgvEZB(bpS%P6Zx?`iL4CKcsZue-bO
zPD>nAVqv9)hjbbM#GwPHuyG3(jJjp(jHoq#McF>00;!@muRs`E%91!`YNglPh};oo
zgCTMxI1&TuPu=_`KSfC)!9fjnB30N_!1lo0EYjEE25!15bALJW={meaNWyJ!Xl3%q
zORWym#Zn8g(lVIIpW_N{hI?juq-g3x`T^ktS`aTY)r50PD=eIWEp|(J_)9qF&KFx#
z&N-q~Q+n|4>GX#*D-<rhQ?kwtiVUPAW0gM>dzZOX-P0)SMp5T(!xjWa7kQA~3laL%
zvVR?<<044xN}i@~qd?hr>mhf_xc#aG_udFksb=>f?ty84C++zZjB6-Frks<0E%
zi@TVx-%&wlDX!X~h{k#=Y=ZsFK_tlbnr%Lxp|0PNYw$^>JFFdK?2OM7PaINF519@1
zpwQ3)>H~_J1z9&`Ni>ok^={eZ@FNT91IVJBLZ14W`aUp=58b7~%Un8KFHwVw^PgH%
z-rgJN%k4s(y>Rs@B0gwZtIOl?I<M<S(=2B8M!w5aM%t*$GYxP=uk;%rJuVpX`WW--
z)$K}2{uV^WJmWdOxnr_~!SP5FyCz)os`^5_61~?AY9A4eI=B%ip;gb5=pRj$V1pS8
zGAZiXnU?<_UHAUT)c*i}{OmsWF_*b-Zn=kC=DwM0AtXtv4av1eLX!7pGjqQSNgFDO
zLW-o?%suxg6*ZD5l}e?XzCPdY&)@w6+d11gXRmW!ug8;hrb?(Tl!cqL&%B`4qRTpe
z&s&4uiyba!{+Y<M0X`o-R^~ITIerYCenu`$OP<CbV)<3a@0=J;YB=0-cR!C?U%r<w
z5^u<mdk}_Jmff-~c(pySO!SF~hX_CKLz~lsK8x-IA7@$lKXQ-p&DmF|u@<8K``N+M
z*+ia`>dTdWT<OhJ7u{D7HB=iGO5q-gIgGl<bNFt6L;7u8+|^T~WCq{q=$iUx`F8`P
z?7Db{Zm+Rz{?R3eHsY--xs;6<uv^4iTk?^&b9#F@U~`oHb)T+lVpxq8I^Hy0S@#ao
zK=p!<1tN+cFyWC`S)MY+p@ag=5Ny9shSEA%n3IuelX0*x16`eQaFh80!<75ORM=o*
za`}5#9E$O<dyj2D?m=dlT)MN885_a;^rh3KEi<tJqCx}rMuW`-SvJD9oCt;MgPC|N
zWB{|pz;6~LHrTUG5IYKQQi~xvYxy=pyVgL44jFW+Ax9IRuHg<B7$C%U-=7NYGD)uv
z#Iy%&&#}36fr5f7o54{8m`4|CUm>XVIz6}{<F*nMZO3<GIxCjK6m$9B>rf&_WLXJH
z<k6g30L7Ji($SgAoBVeZ1_T02rVS2{NY_%itFv<JBcQ2UdbN$~__={$xMZ}ofH=jw
zL(PVO?`5U7u*_6)EGp7Ra@d*#@a5NiAMsuIRn7PY*|WM5i9;plc!K@2FnigqYiAJY
zV%PU5TZr*9f?HsAy%~PW%meO3H)gNf2GgUyS0R|_+1}~bL-XuK1qzGKY`HVN3bj20
zC9NJI;8dXZY`QL+p%-Z%)FgJU6CS3V6ZKQ-KcCA%$r=A5RCnfzZTq}dFEa6L@R6u&
z3pQi@Impt#tB=7>#e%g9U6rxm#|xbK&)dCBo<9eax|*r@YscD8lB2&^wlz!&q8L(`
z$)8{)0`Ncr%)iA=UWMt@GVFw6O3u=}teN?WwPJ<JE?O|7TL=e~doYA4s4cLG0KR>_
zO>QDRHDleMmCBOcHH0qUE{OSU!oZI*>(3Ni(c_lY4Mr+Le%unVitN|w1XY|xo@EP8
z?n>`&D1F%qA6(5$Wy8SFV2hFYjdi#+k==3-kP87OPJnIsNyDGm+&UA1NbSsA+V>zd
z8J2DfPY<=t3}Wy1?G@t{pLJ*E^gxfEalJ&LA$;7U-(Nbolz*qtvDdt0d>6xjw`aI3
z>uh1>mstcJY+qPkpqHC&SXCZU2?_ULX%N6#KIv8U1#uqDLt0(z2G*5Z*~y!*G0%)|
zKO0-7v?zEMg@7T=(oU?j9=dx!gXnYLnn~=XrQOqW*`#IsLO2W>cnKlrJujRhxXUN^
zeQ6g#B;34G)nkhH<kis)3bDJWU>hvN3L|wKVrMgWW#T&H(;r%o`G_^D|08=SJa}Af
zHFMCD*S$G$Tya}vL7>dU54*#}g**0sy}G8j1#juXm7J|g>m+R1vD{xM-xewhR#}8i
zW3j%8b`Tv-*r$TB=2bx)QrVfQMmAWiDTje~hrq!$HnW+hbW0CqW#U)LCrBf|av27g
z@$!3&SOG$ZJf!LlH)U4C1qCM?O0)1ZDe6$7ZiZkYqt~7FZ)to>i<N}0?c!wm9Ijwl
zvqCljmL7{F>@4?Sn#qZ8Z>qV=V~ca?I-L*0Dc({kY&`9nC5mAH?AXOge^h_%&@;r}
z95JJnnG4C8W;WB7fedRPe^oITM|RcX2)^4j{$8i6`aF^PP;}~bNdOP<zs+?t^x3f9
zpLo%aB@HKG9(q!lPP3NmEneoXzWwH>X$b62*0c)#aMRE0?)pByL8|=`B|D8e85KE@
z?&@-jmhxYvO6<-|4YKQHh@)^85l?80Os(GI$Ml=X5JbRGnB8aO;3tz0Y)qE0iw=ZN
z0InEs&lYGHw(=~&9kF>JI5r(Ip@RC*#_nVs3KKP@rUyb5K9=4DLGu%_>E;aq=OOv0
z3c*G#BJnMt@@^2twl=~%Jx)9GoSgV|!37ebL*N4wrdat~z)$MVBz`6N8?l^Fg9~9y
zr$S@weK;JL{qHmYZ(!`}5jh<%0^t>(3$(tRp~L#7ctT`kYN}fg&=cf7k*dA;d{r{a
z2ORF7j@v|RNeB>D{EOWUhfc2J?$|<055si+s`-4|@uAhP^0ut*sPf#%3#^?B$%M6%
z{Y==vI3y8devH<nc;(;Eywt+-$V%{l%8rjJ`jd6~)MOe(yWF%TcyO}Ga6Nc1%VRQj
z<ok4He2bJC=0J>Y#R<0YoC+&+ljdcg>kojQ%Z*YnN9J5ay{6PcvCM`-b;63dqb%zL
zr;)eo<?Ca#=P7JzveVPw1!oC}l7ws>-LY|Cx)a;@@xDm>c4C3^IA%U*eI{L!x{nu{
zKCyqV1{odibpI5$f3A=40oU0Yl~I~^{u4<1{^#+(Z(gzS6JGjosr7kJ07^m)=$$(#
zBy6!nHlMwA*=NfT{xiK*St)PD2Co~;B=K~{-leNHi!m)crHrd&#=u5}>7Y%T5SyNV
zT5wVvyWwR&6Z(q$nbaY`DW^4-e(+SSn}6^b-u~v*rI=@wSr(}U*f+u?%$joRUt9=8
zxJ>{Y`<Fe<zFTaeF4Qgov)778W((os8Q4df`p2qoyfwn^x}q0jM$t1t04B7MTbVfb
zam`tf0^HAvc>j;P^6i<L_Y3p?W`;_SO-XjP>lv}!B||JhUJDv<2`clGhOotk`QjXs
zF9zk8EyA};F6j^1K5y15($(H0MhF>yEf9L{z94j{kd2V<1P{hS@Z@7@TZ0Je3Gll8
zv9uQHysFHbF6mmj+vmOmCk0Y}fl;#L4ds`w|Lte0Jb?}4Es|oFuTtjqZa@7L0@Yp~
zKW|iU64*`<)AqO?IU#zS-yr<V?5kB&&ufxBMW*juGjuv}%#fE}ESqx?ZB+*GPwVf_
z<gss<8pRX#h8w1fdn-q~zdD6WcUBv1(Pv#<oc7xUVu8h+2e+tr=7qlh#j#y=$y<gj
z9eKOd!$J;>eg}UIXn;umtTZ%!yL}{za+PoXv^MfF;ee;D&w_t3ApYLUN*r)nV)|5+
z2ssZ~<Tb8UfyT~fQsoXv%(Ap!&QJc?d(kfUa3Lsm;@tp0b1Sd^_5&~DEjtVa_1Loo
z*i*h}ZgWlYOJ!VQ?yf(x><Gk`G-5}xlub#f(4^&L2v!fsG}4nldt{HH2}R$B#HQXn
zUJnoV1fR6HzeS0<{u!i!G1j<)>yf@ZI|Do1kUI`PKXHP&Fv84VzDj<gbzp|(Sg7vn
z9{nVdvi-xJ?a#7pAzz^~?mm#Cl0g$_6O5cVweS{IG_--vFs*>_(;i3rD6QX4|LAg8
zmQ`hSVoiDQo#ABNZ{0%@yrV{WN2Lg`EVY_e>65?KGo9I&Z+<+K`DA|H0xq_G*i*<j
zae@ZF^69kS+GCN0q3c-$1Kh@MYtXI8G!#PKeG>Y6t6+O&V&gjmRW}CtLwLRce!T^*
z>^>f@1zs(~U5I@b?7$>FSnJL*P6?Vyw!VaZIOf#C?2d;DZ&M!UF9#OaqTHi{j{&Iw
zg6P+Dq2%!jo}^}t3{rkg7zNuFUbShs#cqJCE?vtx_QZxAzpm=Pd?YxpR!N)vaYF@M
zamp&R1s*a;+xdeg^{QU){-G2fvjgn;S&5StSEFzJxk2d6Jfj<}FE@JNHcjp+(~G?Q
z%$$ZIldn!@e&2m}t&pLEq?9&gGcXuZ4m-7hL6D&8c|NpArm5}YXcf#}mCp3&04p_!
zH8;dtX{2khKWYW;wNC6%ey1#@d;T|P=*8Bbl~7%uGwvCmp1=Y&VTrbJR3Ss>tDKtk
z%%p6%i#%CN5*kis`ItcC0T5gmj?hJ(TcI6TrMdWB*+pPHbnu9o2~5(xt$I5XkBN8h
z5HT38wII_|DiW!p_eU?@NW&uxOxB{YN>pK9-`PyuY(n~zH&)Fx+-Wt+1Y9B+ZD|PB
zK%FxC!P-6PAK-p4Ko=J0`}IF0Q%7@OJ^NjTDU)`xjUa@u{(TF<;^G@1NRzqtNyP6I
z%SvyEIRRq0{?Ia+fiDaVob|m3rdkuOJT$MnoD4Cy3)m5Og1VX+*K%h4a(Xo3N^ciC
z{*(HIOH#tl2sU|s5?brK_wbg+I!>eJMHk^|KoSgo{@J-rcy|vota9c8Fs%M7rF_!B
z0Sj$YfRWg*?r*jVPL9V=!FSJ}-LZ~<wVr?ZK;$&CIkXR4I({wdO|kYFz#u~B<-@YL
ziiDkm@LKwx|H^y90@H^N{0J+|d?#X%PD+{kOh-*9t7z;OvI(D-e;C>Q4F#A-CZ8Qg
zUBn&1NC9UrzG096q|*p|dzO!9g;koUf>}%h^=P$u%tVVv=zyBzxl=3nwLz(BS%Yv_
z8|$~euVhVQ1KNUDuXvnKRy$sEtN4vhS<G*nG&CUGF|iG`oJs8n6Dii(9h;0<-q4#4
z5wKOeS{aA{b)|YqgDuzGmm`@UgID$MHTvIciIQ7<v5Z7t@w_0jaN*hb1^zV_z%Sdw
zt}s15Qk7*^KC;SXM$5gtPy&}&GLQdbG<Wr6oZXItu2roeW1-!6{X@lxU$L(iGnO0X
zMnbfeqcZI?rr=~@ja$^7a=raQy#mvQo{K$7R~DiQ)GY6K!|o*>ZSwC5@H#N_G5#Iv
z?;X%^sRz0)_V4t^uR2W?nI9`n4laf^DRILg7MMq8M=Cl#M}6|(B7cgyJu{LmkUgHu
zbWzax_BcOHbZA!}rru+=Un!2<@x-cWJ`AR6JG8tnwq1Ir$nnwolNZuf=BGz+0+-V&
z0d{K~zLms{V^R`Z&87Rx^;?p4ISv{4MOB^rhEv?2ml3=J!Fdq`aZ@$?W6xb<7&Dc$
zsEZJo^5NRJ3~To*-}7YyRc15nL~oNsO(H*|$7Q2EbrhEK-r{UhQ^<jsA)Q`ol^
zX+@;p+lv%r?&Bz=9KMT1HR1qeKhzTZ1#&Upwo4|bB04rSE2$FS=AHOgWoj^`!rYH-
z>Lco0nA0cxp-IZKfAR(sKP^{&OtSKEUwC-+BrGv{Dn!)qPsJ`b=BYbct}3n9z7?<z
zMo1$ZEcML~ac(Q_({=n5K@K^&d!Fi^W9+0Yo@=LjK9?reRUCP+xs$XKL_8rAg?$(H
zG(hv5bx-4#KV71Kq^vc3Xu{zwe)8D)11t3bb~ih}UUd@U<KSU};rc@R){2nbhR@7#
zS8o|+`DV6LCN*86g9eH3o#qnvyoi<fKpHo3Hst1--Phwnr8B9QPaMc}es@C3R_k$O
z;FpmJ(bHXPJ)(x2W6ZrcPRiRsM{qnsK_^!>#LLuA(JXKm40o>Z)F1XPgyIQ8YM-^a
zZM~G??TQ|+QE#ecOqKXINUrUY-Gb||{`UO@vF2k7=}#;e$){qUm~Tj$3RKLX6K{05
zy{I0-nGNc|94WuvOs4gH$nT|DQG@ILMx;3{oka^By0ARxjAvsN+v1|ssa(RBGvw~B
zBa^qb_F722m_H`_tUggn?@DK#kE%Z>PN<S{N*(q(uY<^1&RNwQsIj_@x<e8M=Ud0B
z7$zL(>Jg{Znz@vo?JenAtUaj5JZ&$eOQ#Z`u^BKGvk2ISn55f&ym8!Dq2NI`Bzx{!
zpL*z_ah)l?R0>Lv(1V1RRTrJ_P!&Mpg;N`Yy!8Lr<C?F8{mCn2*kA=t%qv2X)V9s0
zS>%g<b<cBH@yU3CUr4ff4gBqTv-6zrjh^qXN;4Lj5g(}?+f%eZ4bx+zi6Odr@+yLU
z71dpvykXcx=(AFZmlE%HK|e4kvzXp@Ct)S?c&|xsX=ADJ=~i9Iy#$7`%n(aAc&je{
z-6J>E#AK{B)d%OnO#k^@2-huyM5%HaHSHXjKE4RIIZKd*$N`drB;|&>-6pg<xgs&X
zdTtey{xyENq1~iIe|c`wDFj#8lL_2rg_81Uo9LV=R3#OAVf&WU?%UK+>8il-h8Sn5
z(B915Ov1c^Ju1^ew^$;q5Q4Y6CV#GXLG;xwi2OvHVr=WFxXNk<zKv8M&yFvRTXVPY
z^H2u+@T6ohG*hN@Sx7`^FhMyT5tRki5*D8+3m&wO5i*w6Xi9zN+7h#Ph~jLBLKoRZ
zFYT)2!fm&UXAOFFZiv*xCe$m_6W~<8By|)USCpk9knQ<A+0skek__BbQ)<B?rrSx<
zCx(&pW<QI^fpOU1`g9LbZAbc6JpjvNYH3X(Kur_b2cSVFl3b9s7Nyorw+E4r%MA@~
zue5c~mrA8cU=!=re<s7sj&o=MYqc$A6$86}o1Kqjy-_=?In_WOK%K>FDvcspPM3<G
zg<>?k9b!pJi&SJ+&~Dr!8!|9b=s&w&r+U+*Pp>8gQF=K>;uMfcd&kMpU;7>>aTg(b
zPYw`WqIaGdB&qY1p0v281CP+0eKv055`dRtKOQPQTUDw_*l^DoT5&yB2+`;)Rev2h
zAU<U~bpZ9fzCoCi)T7Bc8_0`J3|n*RB3{0ux~#Xww}wJl4MUdQI8kijaIiszQe3IX
zwZN7VCo(ZR_)qNi_X&yJ(ay4!HMV$5qw8MB!WwPrC9T8=>gCrL<@PK}g9d@G)je_~
z!`EDv&-KJ2DpXl$X|XgBabzIpXeQ5Tdp?fK*(6i3Pv+?b&wj$yZ~VNC`}$gKUt1Gy
z;>tlOJA!vs3<E<b+}E4HpzktuL;H&<>Zj6hTP<)savV3U_qC+6)~M2i=`^b;yd#JW
z%2KYCge2qudf}$E+C&iM-bw+7(QjtQk&qI{>BU;~NXV*`r;%SHtOx1INrYoF(}eps
zIuV9}t#t>15aqM|5!f49S-)LBTzS4#5pB^8rtfI)mGE8R1!ph{4;+0h8s*B6d*`G3
zpUJxVj*>#mM{;;oFRkMso8D$yTOfpIgR{IhYH#C0UwgPT57Xf0=2W(>#|CnDC%-|t
zr>mP)C8GM>z39+FwjvXvSZ@+}(7R~d_6$SnT2NEayUE-L=huoGcvf(h3ClJI1P(p&
zl-PqWNuJ<ev`gr*7`}%(+shZ(n=H5$7|@tD$QA9*qgzDHf=1pfykKA1UaJW5zKSJb
z9?@84Q_roXHg7i98Dwf6{}Sr+pAEvZVX~cD_c9O)M&ANDjs5s}+>a#X|2mho4L|3;
z^<gZG(gqy5J_BFA*@&t|Y?T?e)?+d^UaK6Yc@A`;bcDwkqQ`Uvay~lnS1*TDW)go|
zgv&_&nweWRU_lRtuDu%P+D>H+A*6Mp9%-ULc~O-E5)MW$RsPVB9tQ?(ryq%U^}azj
z8pr5`n10ArVMxan?a|n5ym$`ESa@s#SDhV`If`D8JIN4D!vw~3*Wn~ghsGRM$XCoN
zxMHWM5Jj1jdZ*fH9U3)R_DHW&12;FNVYGWWlG1w;r1;9VLkM&}M^@E<>-X%go2uRX
z#^*$tSGzW$!4c`2c97!AY2*5yeUSsRJeTAVHPVux$5cgf?it3MkHC<q?tNnt11<Ym
zlBTZ|XNduqT`jlR&Qhm|mV*Knm7>I^3{@WOQ6CR!(>pR*&{6a%-lYfHJ`BGzahFIk
zSsQlfg`jn_rFB8p$Uz4(NqXhzV^fgjgr{Q!WJi6rCXaEZ4}8BK9J+rW5dJu5lVKkL
z!9htT5j?q;c_mEXx!(ED_ApTMc&JcSzJ<4X+S%7jePNAxXH9_Uy<ndV67L~!EP5AR
zd|xk+1APIciU2OjKzKsByckb<NzxHD`Og4LJlU-fg2v-k7wG735YPD|C8kg-Q~(8s
zC9McP7LGO;y4se~M5aTGt`I~kco;U(a*kmKu$Jy~_X*t`@Nne!ki-V8{Ga)j7VOr1
zh5#}0GC3C_9za(Z>9uF8FQc}Bx5ap)syZsi6e`g2Baz6EL!+;ZE*H>7Akwr&sXqkk
zIY#I~Cm`KPzZB@-fLPT#Q9d~BHg$bk==HF^->!luqE+uyyZs?R`@ae7IG0R%a3(0C
z!U!%*cjmgDv%?@!-sh-%3jt@=yZEibZG*9JS4BLqz-=1)ms)4VlG6$!;6*Q36l!)+
zxC@-u&Z`yDvi$qUGIwmzB-f7GN%9|%)3NnWMJwvh$dM1$r{hO_{lcBFbChE=h^jeV
zq@L!aqeareI#vug+w}cM-%b+@{2+s(4;O@+)X7fII7|}(49{(Ti}YhZNZcpijm9AG
z!#rKn;e_hBd5E_Y$t>cLqd0w1n=ic%pku<gD5B&F!8hoN<R2ai1x9#YBvBdqfuo@Q
z=P9$khYx4l&yp-hh!`4OsR9s9J?2zJ`@SE3@B!sHQh@LT$$LUyQf5+5(-r?5Rvlwh
zu0r%dggc|X7TaiGKkbSswBvr5RsWKv3XhuHXB*~h#!)u+fk2)?ES4(nnG)^Xmm$lq
zu2QZX1Jfmi1hHvAB9#$m20i<sN8hkADY!=$m~@zBSZ|OlQAD&e5!20AZlEg_(qeSN
zM8#DEb2?M?60|caUww(O#&E{p!-{sZg&#=qTgxM!Ya|8y4)IyO=jNNE0avZ6UUfx2
zIbhgp>&Y;87nlprJD}))te2%X0O{UC)1?b2ly-R64irE~X+>I3fULJo`Z<9?XL?%7
z!2SnAc4Ua^1W3)3h-tqPt>2)e6(NfaV^q<0Su&a7SKn?MTm<o#e}nA9+*C0yUPXfT
zBtqHXzK&U#MZZwhd&lYidM)R4P<O<E-W8`phSu{4nMI29i6c_t!~|ow{W@Qp*QbLb
z7Pq}EO4Ki21kgf2I*_JQ+NeWIFJA;nGKr{E5T^Ux_4I4eiF&F`foSiQm@0r7<tAsJ
zy)PLMBd|`^@)bS#h}<WUFZXW!5I>&z@*0T^>Bwqut0sw8=t@i%X5VPwR2>aJjU|mV
zm=gr%F~@z|FG$x9Iv&fk!KefWJ89UhT9rc3$x&C~AQTkzK!&cH>Slh9{&33x)2ZLo
zwS1k$R|zD|u0diJ8=c-o1=g<`uPzH3v|D$B;KMT}TG3@9lHcz4d(MvdG`NUWM2O`s
zIRR0e{v|DU8bX#7Vp8Y`CFOaOe3bI@ZLWkC7fG1E3u!VaiU4b@F(&k#9Sa#^?F0;x
ze*fkBA~VqY(IAt}=<A|Q*8^hDF9NC?iv=r?%H?+!viqJNd-53x2}%)>`Z*E7$JHkG
z+GAeOH?t&0$2rWc47|UAcsK8cB@{0X8~_32ek~Z2X1OVrH5k)beBEtUfLd$FSLNqN
zHl1mP=(-=&v?FaFE8Bl8Qzi+jCd6VH{^O7yl<tRzEWQGgC@bX2_7W|pi6!6V7{fZE
z^#oR8ucHbyga9aZt_Ed4!CLnPXBFV_pl|$=j0(j;Ft28esoG6DH8$eOi5Ui;fQt*}
z{+2H|K^9Y-T}Rbrs;^70&t8ekY|5Buzbz20KPj?7a%7U4U|98O(DoY{b~;IPrW??J
z?W508ybNy`bED>(+XTY`BS6^EoHqyPG{SXgT}OWPD_?c_YIseTme0rskLQf}9-jEt
z@S#^*y{}R<VTE!|5r@9_<OHP(<iBZc_Pp>oLDC#l+TL2zHw^KHr&iqpwZc&ytW#IK
zVCSDY{b0!N8-4azEx}m$%M@pO8V^kvan5yCn&7QML;KGRIyCjaI_;|B8C8?b4$5VG
z{doE9e8I-lUQkN|@;D8CMAmMi!5k|%WkT`moVoj)&}HmgIQz1RzVM`!wtNGC)0~1E
zhG#9D?FM-XVXBh$Zco!L3mRP<difu{on@2Y$abV@az<AI`IX$KXqDsfq8aUNvEuko
zV$&y@M+yk@9FB3&TXz@j)1<uJ4C@;%j$sG(su9J`PuXL@jV9Oy)@Shu<1I~;2Xa-y
zajQpPwp_p4NzuyL!7g6VXm-g3<Wlj$Js2b%!{|KIrx`wHJ#kGj7$mWx7S9@Fo9xgZ
z0MbO7v(A|SS{lN5o{q8<!k1)JH(&Fn;m=*UomY|extaE4p9Xx-cUGT8#EnvVW(l2@
z5a^}fogQZG?9hAT>6o)am_Uy3*|zKy!d)xj?w~1+=I(O|ZFu!%jVb(WuY)^Czd+Ew
z%CP)yWPj5XuipFo3&d=?&Fy{_H$q|OrT6##3LLRL{CVFfDns0V;b{}e<-hRa+v(M#
zOgo>iA|ofJK9DSVbmz`hYNBg!Y}@n1F9>%TB_E>dMD7F&Vu09kxsc&v+YKDPcPjhA
zY5luq-@0Vp^^V$3$D6GjS$xTpPTi?!eWSqjAdn9(H136IUj{6{JG7G`f+Y6mym4ZZ
z4p>Hrnv^@bt1EksYhR+H6M)iQOevLPGC>omrK8!5mn$Sy;kUg=+P*|*v59ZnN36s*
zfud$D$5<mbu1${K=fD#<91^t`2Z4(wDF$@imKxQp>WoS0;8d^#RfE({a(?e*(A_g&
z4wc}AS1!levRM&dC){~-YoSZjZ~ZSW(Bq|vPDh7zGuc3=EPmy?7_&oVGEsJwNZs25
zP37sFaye11=$Jq<cPE+iNYcj<_*vSiP}t6$blt7a=um@RJ1uY#xd%H!5b^op)J{Sj
z8dWy>oNTosVy8<A7PvgmoA-Pr!h-y+a>MV<FeUJOC9a~o=e>V0V3|lnsy}`uQDUUV
zVsID0!Du&_{`3NCRli!TkaOA~J)2qC#=Y!k0q|Wh#m@wpbvikTx$7{vsL<)x4W7)&
zD!blvP+HQPV2I4lrM0M|8{bNE9f{}_N_z6(VRrLPHSo!?r015I+Ve@AmO8g!hUmoY
zp_(-WnxIBV-%cQaH;H6FYdo&PN{hsBOpZJ@a(ME>sZYRoW8ZF%N^Kfgq{&*MG{CmA
z=e_Uku!9hh=|yBN4Y}5Z%w@Dqcx|2U1SusDRoX49)*CrVE_Yjj%o>nbaJADU!$I6S
zt>C$R^%t=Qn#FO?SMmfk=N`>K9@qqc_!G!VG<OngKguc36(V{*!1y0<|0f`|Zl+c;
zV8v7T_(o85lVF(JW!LT0Oga^Qo`%%w?%81{!6CUlN>&=-xBj~rZTtQ&p{WV~+dYgA
z$$iom4M9$f0~p$#!;BLzZo5JKWnnz%CSP-dj@{NoJ9%IN53H*oS#|VWy~M%2H48nz
z8w{K^*y%FU_oPZE$Da3Drp~9BEB>D1RqgoMFaXhSs50I_a{oYjc6Rri=k@lXY$o__
z#m<8l!>rgwhRMKy=$06iv*%qhLBH>t=LEm*A+Vr0b`s(OI1|+DoU{mFcsoJ7oj3C0
z5BLu;r$!xrR{G13p<pIy%?|QD%c+oFbwBjE%k92HCI@Y%`y8eT({(#YgQUh8F+(4g
zeT@Cn93Hrdc)lK_QVp@GPEf?tty8BRRW?mg^dBm0Nbp)$yN~{}?^kAk!`ErMt(f+}
z=F1=F0{?>Goq$3NUmo>9tP_A3^3;-Fd%oNir=IuAI(b(DDY6fuk?f^|O23+=@cSwf
zwS9J2k1J{-F$@z#>vv`)F|AEb-S17eTZ0gEQKp4Lo=o&?F41j#OmUagh1AzpMIkQP
z8*J5IgsnF?B?DBhqJd@1>>%YiK^#e-)9C-Z{*~$xF1h6V+})kb?Wy+4{sHY3C(t68
zc7<BnWwIhr1>-}Ult^htAKkI2G<>Gfd@nqtH=Azck-KCPI#%m)L1+B<i>zOS$l=mR
zv^sS*W@+O3Q#UD%ANnbf3_bJ}*Hy#pL-de7(f>~1_Qf37ec(+%!^=tCz?R-J>t|~o
z{4W!^B{fAmzSkkrUz2uV^NWo3e5pVHpkMCKg|MDIm1b5OjMS5Fb7Xp61l1L0{?vS1
za7SnUHSC?d@sVJ13(Y(w$wSsG;(~omMQh|_y|sa>lto`M+j#Ug6FJxWpH<r0o3pRg
zw;a#CCuB*LcuifqrjeqwhXUh0KeeaYFOcG*5a7e5Fh}7Up!C#@R))D@Ai3p!>Jo1;
z*KCAS%eXmQoQIKuW3e5poG5<BE1)6#Qd;uTq=t<@vJJiz^X@I`WA`J`V)@3`wHc1Z
z8y}^?-AX6#JfFzcsUWc_Qn!=9S}_ig9c`J_${UXs5E^UG;HbN1kxPnZdc#*+`?aDb
zniJC^kDWi9Py`Z)H$OWrnmNLAl03Vy^j6YnSXVRWX-`#NMQFZ<2Y5w3i|c{<Qb+?T
z;dti@dkQ9(E0O}wxv47n&t|a#zO5d2JM{UP=5RCgT9260ciM@kD;gjyBQ$(#*EK_@
zsVTn-N>{F@s+-BRJJQaJxMGd?3io}ZWKjXL$f@`9keZDAA?`)j`C^1zKw?}UOa`t^
zXBjwz(I??Q^h~FARjmsT9^=|C1Aqo^w~RZX0j#g|$6deJ!AXJ)god9DsL0DO)wvpY
zSctdu428HorIZCZ7m5}-A2e_T<DU#~mx6Vg!*g-hD?-1=MXM4T<vLKQ*ia3}`w4?Y
zgf=p6sW3J5Ibw&bkI8~k;=Cw=VKkS_VWu1=$mZako%4Dphw%cDl$FXe6%6#)b_k#$
zf{xC(1>Sq-bGFEPhFpT#Lg8n)j;r$S;PSxFx_`+htnJmZmZaUcbOG{u*m2w5<%nui
z=Q|<Ykz$oz%frl~5O#j<3-#icdotB4ux>B1qX-L3*|Ey|ld0cLGxPO&l3(XpJm{xF
z;Zp=gc67=K6ZHhwU7BL@?_Lim=Zd8r+O9#5?Jm4`?`SqyvR7lLAu8Sc<Co9m)#brn
z-x@qvMFgV{g!Y{}i;<}Ec%-=I5sy4MVys$TkwdvNsT+o>MK(X?Lr(LUHne_?*Bm9$
zUasxnhCuy$A;MbCB-139nB1fJlH=@?zAF%?JQ_Xj&_>U2uOy28tsHc?foSfKz=BIw
zyf;g~AVmg8cAwLP|4R1<Q?Su?{VV;t!pydx3oBL-U@OzI#$s0prdILq3z-EcE9q3M
zfHnhWTAHtvoV5!@S4=Q<Qvu>-`*nmP4<bE=%Rf6UgzCD344EbUSxXGHx0|l2>n1Rh
z26|DHE?0>Ifav0lP%m;#4LJfPTgDf$tVc?E#J9{j4@lMJj%h-LAo<UEm>~|a&>v9l
zppa0$D)Mr1VYG8(CRuBewcLe~aB8|~2;SJMVJL0xuyoCSQOE%8;)=LoxQIBW5JKlb
zumBNhl}r#1A*b6cF_LT-Gn+RT3eE;YRGoQ5Oi#<8i)C?<FAWmWW9lJZ#*s939^Ecp
z6}4M)Q{<nySvfybbxh#F&H=SsT57(u>JQC^=WLxt$j?AJGAC5ow~m!ke_oLCglZlf
z2{h@N72oeys?|5qugkeBLNNJy2~;el-en3^TjwF;WWmr5MSm=m-azEhQR_5_U1_MK
zv%9|CLjZoQk<u82f$Xm%AfgGe8dcmd_)j^~F3zCH+lWV2;sCHO>W%cF5>a&;#uo@V
zf!S{J%H*|9=AIGMseki!4-M(dX))IvTT$O-H{chWj73efLv=;7t9}&b8*i)*IA%{k
zG%*x}Ge;oNrZ>%nQ`(*Xrbj+33^H-v-?$G3v5P|?;_Ui0j`X2KdZYsk?3`o6zlq?F
zIMFh9JE5kpO%839`U8}fc9%@rF_GmU-&joTv9x(nGNtxWc6aEFAz`h8ho3`)q6UiE
z=8Rk9UQL-bN0(z@ht_sMN52q6X4eO-hlx<!pM>^0uMd&`e!rSY!-*fQ=uufgNyg6#
zE?r{6?jxPjWlFIi)rc0QH-#Ck<vMNhcL(4AHaH|!LO+;FTxzei`YQqf>mg+%YF|v9
z00dngJ;s1*khDtGG=}MZ?d@(q`DhF{B19j0(X#X9rvG<y$7l3#>zuslS%F#t6@))X
zo&GDcA4znNMfK1aiM5()o5IFJ-+d7(x&)92fp$R}^%fR9%P}165r3pqd5#JIJ<o?V
zBDR1sGd5i+O<w(HK(4P`Jr6cwG=z@+b6_o~&iy4OaJ0)ENh%ybO*hJG8m@zOa<3>;
zhPPvMuhH>qG=v*F-sKl1{Y9lv`3HLd@!o`gsxVY-iB=`H8eDYB2P7uO{@Pk_pLRfe
zhd`>*|JmG>1mJIVOvPQGI5z>;HPq<C4Za%5jXNOQAcUky?0MBrpL36f-2>ASqi%G#
zgeRC{tfN0(XmVj^<v%yt{eVfCDzdqh8j85^LC-=wp`fpx2X*hS${%fgVUATE8|Wt(
zuA~;|%~{9hL>1V{Kf1pXMwW;*`Ke4mJ@{;$f*IPRiS&D=Kl;#ovd70w^NH$~>RLRZ
zu>5=6l^=KVywBf|mM2f%vRf@l!Y{r;$|fHQ7=2tLL&QHtB?;8kZpQ?JTq4N)3kGR1
ziVcf$?hct~OYz!WB-VMiY8qFY0@AIRTZ#i})tqY`QFAj;ZG11z<aS3GlA(HT^sb+d
zYGo+qjw06tiq7GJTv5x@N-b6%%*nhv8>As-q%#hBP&$5=Cv?Dq9eaz?<IdCW9K4C%
zQ1gQusPF)ao25YzNK86QAfmgwbih}zCn8dyq_KCmdKKY^r8`}E&ro*o*=HIXmwEgA
zs352V&9n_O2ALkSCeN!@9v``<_{-SCRD6=nIkz=uWaNP{n)<o5r~1dLa<41j>IEZy
zV*4KcPP#zdSUK^L_!vj54W}ZH1<9hGEs7rrAi}qZ>Z}jW!!*&hg$$Dr!-?iiU5d<>
z5L9|nLYNKd^wQJe0-e3FW^ZoTUGBYc6Cw$c_g*|Fxzhm1d5hIlucj*|qXu)isON*Z
zhMx>PoeXpN%766KdZ6g#x~&Jy4a@7uMP8o|4Gy&UeqWHB&=Kn*sC{2hmBfz4NP%{P
zd=fx%;3!rLR@v#3M)4bi2aA9fS!M(KbHy7a&xdu=;9ETFFEp?u$1fbN9oz(K4%Nrf
zK$c`oAsrrVq6b_T#Dx4wrtaZ^rHe(-#&l`BE#M1JV(ZDHRwQ>w>DWdtXC@m94~|g@
z-f1yG0rm(wHWmO`s`wt7LIUo{9qjjNnq>N@26O!HSTkm6U0R1DGR2WlBcLjv`oSFF
z<3J#r5(;<2z~7>_)08%xs9;`a_0lhSG6*^-t!`S6$C`aycw528v@am^#Lxf{;;H{@
z_agE)QFS)jVankBM?SpX8!6um50X|_N;lW2)hGt7Z5IQ?IpT+j0=0C}kp)qDQ7!cI
zTo)a(TnJVI5YOM~ReyFhBdET_slBAA2KDVXBYnf<!CPJr%Sc1nAo2Sr=cz-0mhV6f
zPBz&`cAcVT&XcLiN9U}Z+L|lS0=TOV<08-cWb=ebDi0cH`hJ5biE@c`FH(QW{oYRn
zJ;zO0j)0Zx>q{^H?YWNWqCm6&8F`S522Lh|r-vofV?))~giwEu=vSgjBThLOt8$a8
z{*e!`45p|<7>zph{++T;#IN}{WS<M<T_d{+DUak1iibu76>0E5qIm?Qkgom#n=*!V
z4u7jALlu{%f!fJ}JJ=u3>*_b&{$Y&+S_Fy)9gHP|s8G|%TzG>H3|g$Q#aF^`9M%^A
z(OdluY)D1?z2rj0YQFju@vr%$j5+!E#?@5G?dtmiO$DS_^K~I$bS9SvAHE{-lcLUB
z5JhQkiCv++((O@qB7+o)Vc`*C!4w65zN&7qdf2|4+MU`m%hFfa*^OM|J)8nRvc5t3
zb@(kE3A9`Ml!gq><}p$E!9KJi5yHO4&TSaj1fUok8sMWWAM1?qVX5R>`D8>zWa2ib
z|B|o%d_g^2_Gq;PxO+l<ovR*|u`S_`%A1Xav0-5}g#gMnxvn}_8|(Q_myv6izW{*}
zz@k8lOv2YM^a5`lG=gWeZ4!&pz`uZxI{rE~SkoM$Y)UaoiHII?S6-qhZ^!WjIhgI9
zZV*k3K$G(KaIm^1>5qj6#$Jt~sf=YYrg5q?x+;7Dt@RD9aT-Mi$&t4f{IumT4j?%i
zaeI$rIv3RJIN!5nLEBZrj|=L<EoOl@`Ji!$)wtdBuFCB=UBCc8=cL|k4jaB~<Ur67
z#Y&Z<)6xXM_dcURzSkK)Su<(03Q^TPN;#pSHW!(*iA7b#i3M}!SVW&&H`JrZFwq%A
zayBB7-0w<3*>Dfr^3gA6(8B#kR%g&*MESLEN50M+Ilh245zelmLGoB<omy2tkWVsQ
zj?BLVPOzNszubgtcG?XT&*-di6CcPvNDcA)Pg6>=z&~ExEV0;>MD(6VqBP#CmKz+L
z7=>(-(JHu!Mh4vGGiLgh{U0tYJq+f=K_q5xuOF7#dVc!I>)S^@>_76!BC^af@;FgG
zg@V%kI4e%x^Mk0~$=!dND;GjJnm$RHUq=4qV*s&(lT8QyI~^JawR*5q$42P*lcG9T
zs_29ZUak{R*%fVZt;2haRrs(*O?b;mOyRo1i#qi+E;In^X8@8d<+z+7Bj@Cfy!eK;
z;rp3>lf&=#L*Pz%ETHYUk!6V}{S%;I9xRM}YJNLlaNJBkR3U&X`;i+PG7|j=9P<;T
zPFT}<^<jtn#-6v7uSe+FU~I^2lyr94eB1SqQ5RWvOWCatGDyndn2>?&$gY=R#^yMb
z9YN}HEv)4eQsk)-^eal1BCFdW!@PsWoZq^dPe$Sw&`^;7T`ndNn=--?8{?~gp%4GU
zsju_Z7I7-mbY&U^<-?6sz(QFx<QPFLgsYIkk30^Nr*T#P5Y=?+%o4b={#l8aOSO3C
zH8yZb*Vt3f7pcDoqvq0)R1a`Fc%r5^(?{oC#PE(UIO(bmlMUb0`xL5pX1A!Ow;=~D
z!G{G2*@rlXq_~oEPc)W^sxox+L{fIfoopf(X_<qF!Ky@MxVe^ed=WqXgF?$9D3($b
zyLfWdPa<*2@^cuuPOkE9id^u1xJ_JmxE%9%8-Ggtz<&_Lj5`!#?)gF^IW8;t9{>#z
z>IDNbVaW%`8evv9l`FQAPSj;>E1`A^UKov=&Tm7|qVzq(5O4^P^{=?}4Ou;{^~{3>
z6rPxUt@E$}9ZkbY&vI3Z7kmmh$iapG-U`JhXuvgu*axoI7+G;78R-tf%q7cXH!E?N
zeaAR*D;09az@S|+rUn+gV^O(5_fKm2fmpYU7hsh?n^u-CQg>!-q9R#VyjVWBSaFy4
z9b$>gtg`5W?c3TF7U*F9ieCNVP6Ytm%@eyp=chWEP;jbvkW2&SoFfq)20-E;xov`!
zN50A0UWcLj#FvCg$}p8Gp>qW<_dE~tD@j>*Ht#H7A?W$#<3u^&m_i^CZfSI(4rXS<
zVZH#XZ$;3Ene|2+#E>{=AcBY5lMBzc(i=?NPMM&Wt-bx4iGvLZHnQuTOOV`Xv8Iz8
zk0h}c(wS>bsP8=P)np2OLCS=%;|R8a@?op~1Y%H#YvG8Xg7z+hK4=^hFX!I8MtA>(
zQ+vQytyWAwx6pEya^)Z$4va?&(l4CO9pA#wl5wzK?(mv@>SLAug-T5YofnfXJ2?)a
zDij*`#%|YG)Ei5_0654m>-9SdS{(rOp^bh7=gcB^d)SUH2A|XBZeN3B6AIMgLw2kX
zl78_aLFWJZd3CsZMvL4ZK4CGxQWVQ+dY?cT?}f`ps}z8YwT}tmHTN`V@2zz2V2o}M
zzxmLhY16@MB{zBU^?M4`Npl-8`2R<nif_NfU~m9HLm-N>va$-|61s|7`(e;<0EhsC
zPDw}{F;@r(K!%3{k&)2Tr^TWU==@*c)ENMLFrq#Ha7F|YXP_MtA|GPoy4NT;(!;~U
z*Vos7pLg7eJ%LdPC*n_s_=IVlu-G<EZ;JreA&_bX`7HqW0Ry%NuRl$<&-^>5q|v2O
zsFpa1))U%AN7Od=Li)}?#}Y+0Pk_cx;%YUIet-oPBzay83Y-WH7HOAL;_5<1WuSjx
zz&|C>A35X)ag$$QV0*Ct&lL0*4_(nmPw4pm0iXN@4w;a~UOeJ=IZ*n|(WB$R$Lp1f
zibQX1&lI=|zkXfxN*Q)43;8x1{H_$bbrJYk4*HP;{Z|Y8yAEt{L0cWbYBPAM*m|2h
z{a&U&*QAuU3AFqKUl~Qs&Vq-AVcXd0uj&73ohvKgZT{)ochIK|(37V&#ra-0vv)V&
z*xhzL^<q{0XjAg&`F)qhsgE8V+cr+&uxwe$ylvnV1iB}VY*E$bkYz3^x|Ha6<x6?A
znM7UN8&!1jY@SE#jWGW*G03BB)D#3-27s>s@J|H#Lqz5~u=9_C>Pv6n_X%LrPjVFQ
z-jCcn19-lL?q3Ct`~wAihj{!3$p3)IfAE-3RxwWlPCqL|7Hzwx&G7B~9p@3O;}58L
zNvWp9v+!C_-DqHa3sU$$%M|E+{C_ReSzu-yHvS9r;vHn{AMpAg@cuhwX%qN8BfByg
zHGDZ>LXmrUTQoh*s`wvjnp2&`E~he!Q}VcHi|&Lpmw+})K)-KFP1b;J{)QEPNGX4G
ztYUV1PXT|v!5+<>n5?GL>Dk$tMFsiS%UG<Y%(ljijMB@@qMI$uW^VH~YTDY}-QC&I
zaigWB;%Zy}-P?UNxp#)|6b`fdd+$yT-+De(d;4C0%iZzp>Y?E~LjyU3-Gbq+p{ds1
zrT)IYiRqcQORu(R)0aytYin!E%gdiXzF+(B`Rmt>Z{PnPZMwPsdHs#>_5X)9&BXwy
z`W(!zt;*R6hC|x_Xw#wA`k@lteT~6Cchv21qlq?Y&GKIkUeG%J?tirDI9)EdE6kaG
z6*!46N&hp{e(mv9xPhHa_UB1v&3vhT#x`yGv;?Z+dw*rcX|GgJN7~^>cVhW~(SXxC
z676_qL1bLl{G;>H!Hs!aP?K!)n=c=*(eK6e&+7&VJmmJ&jKuX!w-)GEXQ))Ry&V@3
zF)tQd)!$oCEyXw@p=7+8XD2c1d9LJk?D&7zL@lez5<k4)N$*m7(O|rn`d~le=z}M1
z!PhU8{0sNKczxyVm86$t4)?o$T)OdQ>&vR%_UQKGtH<w0j5Z45E`n1oDO`K7HL~Cj
zl32Embx8RQ>|Rm{ce%(q{~r$4z;Tuhc9lzL9kncW_)F~&W=QOJt_ttgF3Zz+KV4FA
z5>w7bf!6LqU&MJlV|eVSiRl43v{y!G5>vbHyz-7%SSrxCNbT{^SuISi%R}c{mTP`m
zZJ+o0i>=Kntcoa^E7CcVshDZ2TIO$8fxMfgVZQuk%>LLHhBj-#zGB{caG^9`*C{@P
z?Z}!59n@i&?^~);Sk^s%aB@CO3P(&#&$407lh}oq$X|AFK#~oIN_KHsXboa~n}?;`
z@@;P&f2CWpm%m3=zRI^5VwE^-z4IK((itUum(;mLoyyX1Y0PR&i530kPCq<s<!4EG
zH+-G)3m6*OQQ2K0ytyi3BY)oZTPC{Vw33Wem|xnLES>igZp}&Mcixs<(fkI{(!CfK
zFBP`x`Ey8zxy_#39l54onr3frU2LBn^QB4W86mL%cQJJ;OE<D+_#~CzWo~#T!wcV7
z5vH^(fxFxPJJuTwNdhH0C>r=#*6W|;1pLM;Un~1p_UB-iao&Ly_YI6j*bb(9MY(C!
zQdgF#^rz@u5nGLe?>xad?c;S$G9u4R;0D*9OkLvY9*D!7JVc!_zYxjpOceDpds=$X
zVC}*#Mbuj_XU7X!raKKT7i{TfDNVii+Dzr$Iqor>@xc?qF7&rC`c#$Rx2dZUt&^*x
zy(uiQXrAnfVr=A%-&LBrn`u;__|9vd?0qmB15)8uJBaCJx992Hi++haqe**Lyl~vK
zb^V&SpW|3U6!Js(+hGx%k6M@aBDxKpa26aQ&!ROhFmpR7MQ1g%bVMG$BW`3x;-6$c
zU%0V%UQ!`GCFpr!%1*mZhPlMgtk$&26NxjQq*g9sG9FA#6~u()p)-<I+`C$B|9tLC
zQUobes7@`c(cB||d9Phi7%iPJPCrsvbHT5?H1ABK;<xPwFL+#bu2)2=`6L2)FT|k{
z_0IfgZAmARQq%1`mcBKzPgESScv<n6i}6S6J%4}kJ3j3<-szX}MCZw8hobs??B}8i
z=}I&DO-hvZjdYo-z5bTX8zkj}yAJz3nB>s|Pv&?@FT5Dkv`Z7#VJcDQbv%z%B=mkv
z9NPvkW?^pYfnkQ!LmrF8wRyMB?3NvUw8yS$R^*}eNj6xdPG0P;n%0f$X(i%QJH(}j
z+LuCO9+6&peav(zi!0uNikW}R!`q~}--!A~4!|ib>&5z;Y6&Ci2+SY5FAjcAO6c_f
zow+OGTu;?{7g4E$;>w;)D8$+a9WvePN6OKT*FL@EW)pLjeLUM)b?5MY>z%9oU$OhN
ze=(S2ROCJHtdOwCt<SG-5#sD{^1XY8&m2Eih~HD@?4{L*F2>bFxMCG!X;z>C$F~8y
z=nl@O6pF~_yFc$q%bncUN6WPlUp8?`C{-6XWPfvQlZp;3)s(wFY_;ES;4FqwU*p5<
z3DE7TpL<=!XnJE!UZ2Y9G&=r%_ilV~*}hXOXZ4JR$5&@PP+s|3stM~(zM2|kU**iT
z*JOsY-aE7XqF@1EG!KX#^ysC2VMrdFco(25Q{LKnVn=|)kbU*-?qDSy<^TMhjrQ$E
zW$%_yKD?eD{I;vG;>c2nYL|ySp67Wq#Z!9T?7Dlxfx?(JS=9qRYYLc0g>~U!SM&~E
zbFcDkkMl*Fb*OAjz0%Qgr>mH2J?R8vWDVd``q1MT;w5i8ldj~jT1u!)Cgs;;Zd0Vw
z)y3ae#Yj_9QOtl=lflfBd+Y1Jr^;z}$Q?(2fciG)mh4s)h#W$M%obL^hGl&Ni;vto
z%)rabC}oT%5WhV1J~(O;Dkp<0%_%tn?8nx~c{sFX&)dedJ-BktFv{0&ApECQ>Y2NU
zSMj%XFR5Vwikyg=lNigO8nW}7_Mqvmc#_)vVa!ku)AT!cPkU@no7E&j2UPfUVHJBL
zyNu6P^L&0HYAFZatlsv{TomRMS-;qI!ST@QV*@Qqu>@K~HmvsHpD}0P)=c#4lwSwp
zZ4TDzdx>sYAK}azFM%#O*F+oQKwRTEQl)Qmkd1fBOjw@ZEgUY!C$3G(E{51@&U1Ci
z=?ckJIiZup`OIwNKl1Lj-1#?<+l`+ct0!x=A4Wnfhu<5#QnK!Ruk^+J%jW@KcN?S4
z2)J%dMpl%Twz@4m;$CA>hOw3<{HCQsq#kwfzjHsd?3WR?CWkD<1x<>PE)>5fwj=cu
z5O^$$4~GQ#gYn49qKl~LhaL7{7Pdg!i_4K-+oza}Yc<E3bQq<)vJniCh8BBmqO6Nk
z%=1xtOEKbQSqSV=zGM(Cmbr6kap70{vBY@&?L`Z><l%l@59bC{7N5fmzuud6ft_&O
zDylACfBrg#`<@cCxZo2}=Bs66$sTqyD>!l%^vL_oB^T3_B9RNuPeqLbOBEZ-sKh<b
z-&wE`BlP^(%wCn*@3%3+YFT#xoZQ#FQ;TU^Lhaw1{l+ZUHtdavGycpxut~FT60-C;
zke$mMfxNJJrQ5DtY5=~_(^2!ISPQT9s^u`wJ+I_!;jUSY)^MUYp}@X-L4xW7>3J1J
zO~5{Q*DUxYuWTQ$Eq~;(x7AI}573ChUX`3x9!p8>-zI(<q<l0vNj`ykX5>+6$<=b|
z-r^4pHh-;lj;{D;mb8TeJ|s1Nvi*BaDTZML{rjVfg3H1N$Fu+4?Rnm!pmSuard0P>
zGa8@YF!ck6!0R6U8HE%~OWcx*3!~!;@{cGCn2pDnniUMkf7!46_CY;o9{6d3h@+;x
zRY3Ty$L&Qxg4UJzzChJm+3JqdTA4E26GjXl8znE2#On;ey^-4<oscFGNua$&Ap8iY
z@i@tl7MPg3(t!abC=Zdhj!YhqyL<ffxdG{gzNmh5O3LH-N@0x2fz*RVsag%G(gcY!
z6sesiNkJ3)$9);h$A?o9ax*_@dZ2{8+PfYi94ThT|A(S`k7x4z{{VjPJYy%vInN>I
z!w5OsoX_SgDI-dfCMuP*vk@9fNSgDxMk<y1%=wTCsZ^>Zl}d$9l6-%D|L>1I_PFnR
z*ZaC(*YkB>z}yy`r6Ix|re%ArW`+UaH6>Y>hD~`329Q(g;toeGC}zxP$YpAly-C-b
z+_f&jdY+e>y<rPLeKvfUd#v7Iwaa+zzk$EjvKw@awGbA~fNj2m0f`Z>ZM^uwz%o>-
zP?AHVaFv5kVUEiE-K^rC;!U5U-qXSQXwlv0F%r@7!UZ^<hB?MWlO|x%B3L{T0}Ten
zSL>X>vxmJ^1cP$F>(c{6Tz(T>?6&asaGbPuhg=ES0R~}y6A^{0nc)C93og4zMwHIL
zNMsBV0qkPu@9)UHx4@DUu+=)~N9$unq58kw&DXct|046&X)wqFKUo4GN3cg2u+lQv
z40-pj!Q3kyInG5nhgT6tn`E`0=C_A<ndtjUAj<!?=&F}xz&b!{3^eQ*hc1Dq<8rkp
zH?VVb7`+K5R@|%Tqfm%DrLaB4%p3G8N|um#a%;7%Eq+IZ5F<N`)l^P&B_#Dh0q~Nk
z=K>#3L;KBe#F;RNyh_7DKp>ud(ZIxfM*f?DeBB6MgI3V5BXiL*KtLgRTy=bBBimKx
z^BRZUODNpGkoT8(^ezuJ-(&?ZD(TbaI#%Z&UO;9M<$^lsF<ySQ%)q2tWJ<IAGotau
z2^rK6M>s_W^%4H242}Uxv^uaKXo)+ikP@%5UkZ8QBXaVhvMh4ZkX32Nb`#q-7~|<P
zCv{zJPX&Ya;WWkAqa;>g66*(<{AB5LZyBORaW5<`|4LDj-elr6A2;WXT>LH@ImW8n
z>ssGvJXW|{KTc70dT9459XnFa(?f!<>C65mmy{wQJxu}CpbPty@d4kFO0)|o3IHVI
z)*c~zxN=GETlmyMExhmR^eSojbITpr2nKJTEsQ7$Tg5?2n_$Z}2a)(q2l&F7!yw8Z
z+}-{nkdY8Z2W2hQWJ!=4qu~#kMO!QYB!1UdhVh*19;$AZyOL~PB+i$QuKCDMBO!io
z4@hUg?nXeOq-vxn7opeW7K8VKjfC=&8uPWyo2Wk4FbEe6#C?)Y{DXrCL3NDU|5>H)
zm@&K{5NxuDi(3QK4<DbI#x79LnH)POlZUnj^0$*P8_R}x;cAI}aHKMYodqCc*N}-u
zO8$K~C>dlKl@rb^la2#5kfb|>Ab7CX*Qx0H1H$yYKsC8bgE!QVOjLQ<7G~GWe?{a+
z6Cvvn%DTRL|9-@s$Z39<mIA}o-d!_SRtAt{R0mP|3Q@YA0nBvS#(J9xIudTpU1-{k
z1Ky$2#f={t;hS{X#uE6WH-z({0vlI$x}|xx>tesJN`a&dswGrfLfo`(^GU!VgrFv(
z^w_Po21y$-!sU`%#5;Sfw;sM5O6LHY$=@Y(IIX(v0~~{Eec1>}f0|ZQO5f6vdlOZl
zk7s@{lHXHZZ*EkpwIj!<1ynD-a)q=ZeVK|<p#y*M@x%_&OK`QFqQ_O%RkyV^JPdSs
z4IUz)?MuTxP|D8`C>c=dA2rI}Io_!RLhe#&rnYJywjd0lr2iR7ix?2#f=}%uY_LM2
z);sLG?!0Gj4bT5_^=)*1ONNk0u(n1xk-_+YgNSEfn~h7S;rP9V^0iH}+oG;<R68%T
z0TmjmP6)a((Ot&?+KN3G>7jGlyZ_>_;Z($=o$NQpq1}hdiNRT;dk{}ykPrcU-{!-@
zSaySWl#YZ1S11~TxK(^v;*RcaW2GYC>>reL6-pYpN!S4`|C0~&iwId2VD};sVbr5K
zc-oOeduE>RGWEE$a{~vFkPsMAoiC_~bsV#tdr6OZx%Y4l0uO*D5I1k%z55)gKyRxT
zwcWFqR$%~3_Bc2$@GFqUSu!nH%}f;`CjaQXy6R}F>JP7uCdOeOG{Z<sSRw`Uej58k
zl66-P;%Df#wfgWW`hUO9)k7z0NYR~JNABvGm=xiVY;m`Vv2+KiM{oisl-lw`9LXb@
zzo*x=orfR7VSi0vgSCyf=~ZgN<1gI9t^sAA78;_pFjheR4ghj*AHnRJoE+(lvPItZ
zv3k-cByFu;Uu`IS5*cs7&KDyT#m#?jwRMuD`!_!=Zh$R=E{=j89x|8Ojm7%0!Wfu;
z0CuBuB_=F9{Nhzw;B#0M2~*iCRyTsrz8Hw40f%~Ib9~jdm<*LUD&~ukY`T;RU5YL2
z?vs{o5D#4ubt8m0t9#hLIAcVp@j8)VqKqKoqFOIh6|0um(?_Dnh(mb;^q;rRw8^_Y
zhS71L2evikJ>y^OkxhW~Jr(KeIO(dEwmLvsB<enPV{Dy_u6=5;fb0684^t-XuRAY-
zgZQ4G_ea5RjZN3F@(_Zefl}nL5CAAy>>BTRcsNt4X`&nWhnj9{Q>6aa+=JUReLA-K
zdc<R9pSP>hhsy!%)h5w1T^{wr{%9h+{=EF0q|RGf`LF06edKs3b-=)4qkFw){0s@%
zLHv(&K)TMqM@9=^j9}Z|pO_Y6$D})8BcS%g#urJrphH+$I_95XKuH?%;IrF<o3Kdw
z0A~;4j$;0peusm_1>-x9329P&ekfWyNQDMMGJrpoxa~ju0_@DPe*EV}06DJ3pyX|5
zp1b{HAoh`9fpi2jZ$x4|)jONkaY6Ar`O<bG{6o&;ivy2$oCG0u%Knj-T@j&IyRdEb
zUZ2nQ!#{3a(ncA&%OJEgJyFN@ErG3;QY~?Jw^4Ez^ARoWk!s1gku(f6iE-wltmE*E
z{$humMgMORs$Ps*1Y}Kg%r23U-qqL>S)6?$kYX2gVRn1aMkH)Z2@wiFNL10bqRG<k
zY@P+CCk643&IzNx@Y`|aR>AF;hImbq_CFE2LEP4V5?c$ne=o*n3Mz?We<4dQW%{~S
zFv57>6o&rDj#qeh&m{pK+o+zi*=%QWOt3X=@T2LFyCHu6pRh$Ts#T25iKkRjWfW?T
z7aG7iN<x)xWXi@P>?>zNNP{FdM9c&%Rsegv^qh#t8kb2vY<}<N8RO*}3V{km6PKH8
z@m43W%R=n=ljai&*d&@jP3Xu2N(Rs0d(AlQML<LlAG_wE6)RyDVr9j@bxvR3>Jkt*
z+FfPvg_wXLCJuQXhg>*$MR5P1pMvGT8SKUh$)m_Spx47*Pb(gvjbOFUDylpoXdlGN
z9?vlKGJ85v7l}9oU}g=vQ>#W37LobFzUmZI6AAg#zIk&LoTH1z9%Iud=AZ^J=B$i5
z_XyE*=Shu1uw#{RQm#3zf;9YG-3#%}jg`zemwAh@U^;Y;gk+OZn{VCB?_aq}Mn&~B
z-9C=HnRWJ8r<DAC?0e#avGeeZ8e=u!?aKCnMa$=3_rY3DVvmUh(c*K0ICRkB{)0BM
zP=jNLc$%ZdsU0sj&lE~u#VwhsN!JUzJ*qUHY=4xhupc%q#bN0GqrnQx;78Q#ah1DU
zj}tMfg{k5@n=~=xEY?!YI^VPbX&A%)6d=@5kn`IaGoqWnsab|a9~VC(>u0;~r=rF*
zklCBU-Zv}#Ns#|~*k^`Rl|<^?eB=k=JLqPMCXGUw3689?kRMx4C(5ppz%)~gLUBbY
zKR3+~qL>dW(2#xGgFgQO+bR^*cTW`vK@;QGvT?}#rSH2A%g)Nk4v~$#%~5x1K82ED
zZ5x?-&ih|{I5lIWxj{o@XJ?<F+y51#RLIgI5^|A<K`)L>BBr9A1dn;au2VOiQp~qd
zt=IIAa&G{P$l=DlyJzU%JIJW8))Sfk^WOx@%NalJ$zkLW;BXR5d<l+gh361GyxDR`
z4ROXEbA?eb`bGn`m4@mfOV<l9nWVSJUra|^U|PyYd^`GW>C)Gz((R<#7K86e$AQgQ
z(LO2+OSk;1hMZX6boY^E70U8Sfo(^ATqH?-OvD0OiDP1B@?6g`IYh92pb+`<tx~YI
z%Sm-0W?+GGY2aWuE*qLlEx4JxzV>BDc+0d=O4O~4XRi9OJ{9=;xsxj)Lw73h_=akT
z@zeGl*QnQC*rw^(LI@X~xp|Y65hE?AT^`iubHwGHcd}m|H+<3>*`UFExt8P_cKv|$
zFRRhOBE6u)3I`T*9{MP-AgxrN?|NXjz_QG#=?|dfoVxXOAEsQ0r9I#3Uwic9FJt%2
zEEan=E@onf6iuU()V}750-cVurzqUvCZBUDj2KzI-PmpV0)znj@!S$0)R6a1YW#1F
zKiwAD2~YHBJ@Wg<X|R}C$WNN8yH)P&wLW~~Tc%s3t#ZwiP-qzFmG0LIa@#FOjJi(z
zs{O6qs7UxJ@*4Nznfc!9t2jwM!Okl;PywBbPQE#)81X7?T*t_JE~gCCbm9~9k8|EQ
z+Q^v>wUg62mVk>IaovJjC~jr+zl1KlciG+DDqWJI`^k&7yw=hOq1sNmUx4iU<jH7E
zs!XbS?d-p#I`OrL*=2TF^!`8o#AuC`$>Qq4y5boNm}^YRKCXh@d}x1R=IWmzZDo*P
z13V^>G-(&f=pI{kzkIf&-Y$fYo7!$y8!u~hGJg{46;R=me90ku(U=uLe&&w<>)YAb
z+}Kb)qGr69rGrip^+QfiT^7IfUL0q}iA@LSh}$Ov>!ma!QkWBp%JXg`1@_L5atK?R
zRV6+l6#rU*^FI!!C?qNaZ}Jh7c*S#KZ4%=ZB%c<pX*i&ICeO%rb>1;6dBtm6qvK52
zC40ujpqX!X<8m4tZcT%w%e%UA3Qc#_yir?R>m7PrJg|LGafhz(H`-PrniJVJyV0Kg
znG-^vUpAxE-wetBn}<zNDv`B1l=`Do0Q+<E+^nYh45!3@Gw*vTTxcn|&HuIWtRL;r
zYMZYfa(pzh=EP;9pm6B=<G8D4okF)a6*J7Z9lPkbH8-QLeD6#93KNaN1zT!a31_sF
zIc-ti`=BOdu<f6hjRChBEz9sl9J3(3XS(nB3wZvNVG9W=uYN*1XYo_lMdV#8ZBOsQ
z!++u$&qva<-UVdO=2mwZ4>FCbk_+XBw_MEn`ccE8Tl@f%$n=Apf!(&C0ce|yG0@og
z!#a>_PI_FED6@`I)-7`tNqh0HNgA|j{&}iHP+q<oxF4}5kqaWWH>WjSZk19cIHE?;
zA|2Vr%&6#cLv?0)jn=)Yp2=#I!wUY(7Sk2l&Ibu%t|_BIC3SVD_r??{=i7R1riuY0
z^izfnE<El)Ox!@;uF0Cc`vw#4eP&4XYOoO#eex>89PPH@i~fut?GFO5f{YT=pHYLm
zpi*7AnPy1aTr)&cA^cBEohJze@;-jyftShURg!*CSSDMAjAMd!j%IJVBi7wQuIWO%
z?gz%)vpFg(eSoddDHt^IP6P7EJeDS?7j|t0DJUA0Py3D{BB?iU$J4Zb5j}*SWd5hL
zM!CH1821r8NLi&2@_`cIGkdP+HagIyzM8pNLW8p#*{%I=VR)OjezRFX03xD<??T26
zh1_AlcM3r^M%!g4>1oof-gWNt=g0=ln`NMU4`IRv1qCHxLC-%|4575Vylvxg<HrVx
zcV(sC#oYrQm2ElGl9m?=tr1i$aI~WKVsRrWjzkj2fF2=7Uov6DwT1+WgzRjA8zziI
z2q2H1NgqfilQQ?tG{xBn#1xddc<5fV7Xq9Ll9tWW_4rDL?aKB>rxTzm7k1~xgBeHR
zWni$+Ik*q$(Prqz!=&)H0-5FqJmM!kSS{K-M|Mb-8|>xNvN^8=RO2e5yn>3mbVmx7
z)Gkc+DbN#(ji1z=g2+O6$suUu`qvr@(^1=Gv4@$YTJgG=;?#BoVK`7-Q=H}owOT?&
zL$AssalkjTLjb~?f|fel2lLI?=p}Pf*qoIy*n2AmE?H{ZkZ@pI+FFm@4|!-g85;5J
zjbWo8DAs(0rPM`6s2L@zK|Z^pOMOdDjK>`z`n0<G$zm;1m{#TsL+t#Jg5vpp)x*d+
z)z?HAS{$#K#2GXaTlnOwNkAdgQWcvpz<E(2Ivy{t@jrPAM&XI*e>jeA%35v!q5sS;
z2Ez{F3Nys9aG(I0Fh^pT5q|+i5_~!(TJ|lQ&=RhX<Ul46TjHu^_hb@<ipez5Q%7%C
zP#41HkRQeIrwz4>!G*8AL9090U*2cSm#^%Laq;NGe?9#^a)V(4iTdU8PkcGRVL3NQ
zzAyPN&<i1wE^m0sav(KJK>_Z>r>98`daE-B6`nM1c~Z)ASuRjR&L-*GPRErV6|?r=
zq*`aUffYO~#*DO4yCbU5n0*3<A^5RcMB8aKZDAW%M*=hfbM8g_fi4?<kBbEh3z1lO
z!f60LOXq@9@8u({AEW{^T;(mU<v@r_jLqmS9RdPr9SM`0H63-b8XeYHc*nDgQE|wi
z`-Dt_&ZoLd+WIQqIi*UTn*vta8%a4v8fT?<RBE3mvEwWszK1K9^(k~^a^Y5F`)r9$
zVBrfijE5*CpY2n;Y5=3%kd+E4>yu{-T0!<i@WJ()y18LqN2G7geV=a8{kIC#K6cu@
zypaNEZ2W|G%KdaqskA|d1R#v<@11cFG{o97r0vw`(W4{1=?_nXT05u(jiYbnuZ;|{
z1FOFkXZ3g8;`U4XQ>4+3CGwy1N1U1_K?z=5tX>{e2mJpmYy7i@)pkRS@IW$6!RjLs
zX1r024kpLT7EhR+c4124eRU^4d9LNxlhH1`_C6($LI5r0AjzXnRmA{in5u(Mn-E&<
znCNZaQjEo!bf2$1hjd;Pe^Rju*Z!WFIq=`DygH9M&E+!ovxlBAwKnVeh8dnqPv)6@
zb;?H2sOynxc)m;4AYLCmZ5WaEn!Ow!-6&=pVQTQHqHekSN%k&nZ-6?Tjh7%ILplv4
z=_$qqS~gT5jltVd5u34oPer!=skZsNzFzdg(iQ7uviS0YPR;L0IqZacrw@n%L;M<O
zDuI)g9rNoK*H+;b&s>?(OK-qRt85(=i;ZQ6tqKiDsOFj^=ckf3UKMxMBoK6{-#0<E
zf#_!l2mSE*QSEriw(f5?dur>QniBqz<0ws?_TZxYymI8BC~oC<wNu@9DjCeImRtwY
zwZsna|MGH-Y1Yb1U6s$^@7TDo8QzCKaKj1ff?$Xm9o9Lc7P6W%aTSs5&2jLCsxNI0
zF${=!tD_tPOzhJ#VW6Wh+sQCA9UM=D>*IJS-q3a9)ADT_E`@@tabSB-65O?^{Ltsz
zNgc8>8;~liKPb3?pDz+pR6C^W*%vO=-C|F?MI2->*tAZgk&fbtoTq8+DttrhMTDiH
z2x)k=n3!Wv?8aIc9H((Z2v;L*VUYaFOC5-le1!h=K)^cJoxoHG?(?9*c9VGS0587G
z)k>S|zI44}CTC9TbSMq#N#&$Y@B(Q3fC+dvzr!M|>v+<wJYq`~>C$bm;x@6kN`!Eb
zD4CIO=kjwpcPQGCEpI<!8l;;#km~_b2Y=$6@n?mwCb;=nPR}C(drjt)1QxPt-Dz7B
zp{5pxgvSepX#{wjcsL&5k)IpT1jFtd20Vs8XI~L4l)#J^=E$*;hYYlC^a5m3@kxU-
zuIX@l`EHNzgD0;d=2QUuf>ip_Et4kJ<u_LLXOa7t?9Jxds%CPqGv)?9?BLeiV@)8#
z641$|+Dw1}bh8_o$RoB~a4Rg7meY9b?$u&es04P<Rw}|4M!TvLA^fj$((8m8k0$cX
zlIM9$2$9A-8hKDO53H*;;042+0ZbMZA(J_V-jrcSnlq@-J`(4au~fLWQ><ENZW;Wi
zFX{x9U_W!lc*G&BzYsgGZJG&+zeis9iwo>;IqBVPDq*RR$XOFwSbp<~ByLouV1@?c
zjv`X1?gq`^unE{k3~>x{6A_hC7)gZrb~&W3!rHn5PRR3G<>AJs2i=>z+NOsMyL7IO
zZ&n5Q99d$MC0>8-@lFYmo)%bt61;l?;i1}(paT#!qsE1Dz9<Jt@8pZ%6X4q?ZFB5r
zwnZnmpBJ+d*6UIk48=-p&8RYvZfYWCSJ1&WeMpFb(YJY++&D~)>ei!UYi$eLN!{c=
zVY_HK+4P*V0*X%pccS)wYfnI{3_K3Uyq-Jwyyt$X8pwiuABTe<SA(ZE>8252zI=`!
z17@Y|d;1>G-&-j#3EuIy+(A5Yc()Z|=AK}y<7aA}9hvxIp|Ns?r6j`sPen^va=uKs
z(Vs2w3<-v)zeA)E&`;OS2WcaSYC}O|Q<lA*5hA}?0dVI6i(}7?iK6agaCapk=rg=s
z6U3RUiIF#(Hr<5tW~wx-*+V@1LgqmzRVrkO5l>)x5O|^Pey8X;?(`z>C5YXQ+%fMQ
ze+ehUf@3&(Z&Ph+f3)SXj;4=Pt@#Nia}sPp8~>ke4)rsbAfDoHp6(I5ojyJkx!-h(
z0lJZ%k6y6&Z@!41ghn!LL+KADMC_t<sT5-A0R!%~$J~&l%^^Eyj#A5t;SSA&(iTEr
z^!Uavv`6w`VYq1-7|-2c5Wh5lLxMsKVCe4Q_*Hns62wy?=lj$6&&Ccx1_{a|bv2tv
zC5r;V(2xr1ou4e_Eyhh&-7FJ>vb9G!sGj0Sy@gqP;EznH(~|kg2_v&kW<+&vxNT`R
zfJnG{Iah$#B~gG}C@^n<Y?E~1S9rVl+-)zpI~QOPgs1B}xLGrZ;{Y%8$8hz(Crn-G
zXd?Id53jhT;TPk>@pRIIkHB0L)b?JUU(|yTk!v;`?kcU1VxB&+I&I<JnTm_ZCRXnF
z$G2)?g<7^TI%G{O+8i=Lcl`KEZBqNio@N3DS@!~e72dDPNad8P^I;}ex#8qa4;Af`
z;IW<JXFKVzBWEekPa{sMJ#V}g@ZdiD^7w!FRam2S^v1z!0gdk_-f_5;vT5(`XflD*
zA>f`{#kkLKGM;f#NIuz3JeH{wg3f5nz0pXoIw4?q_zN89Q^n-b^9wC6&mq%CSekt#
zfspmL51~SIwjg(*LRIEuf%xtVl(4(VecYa4)PyMKlr6V%Cv}V)*=aC>^X8;1dA&Z{
zNBKD%pBdR%#trp`(*ND30p4+|uy_Jb#+JLCa60MMb6+9UMQndPTB@geP~kJjHOV6#
zc%>13V{yE?aUpQHDa12tGr`aT3La0+XnFCSWhP+Si`}-71Qq-oqc^NEN87tud3fKM
zvgCqN^|8wZFS3$yc8xsKy?*^!;!R4_2FIN=n1Tdh8FT;8aP(3uO^4Sq?VGjeesm|4
z(#`Sh=FFUX9l8W@#YK827)N-kWQw8RXE<(;WK%}~Nx&`1MdZ>oljJg@K?is&RON~)
zjtnJ$;)2ou6>G+w3Q-OrsYwMn#pfduPE?gB#6c3gcL*GINMJqPeOaHmA>Q#JG_SGx
zn8<F9M-&ImXA%S;{3;i>@T{{f=eVHH9mzyTg;59`zi#N$c1~O&)T9AM)8TqV!DQ7N
z>hK6x(wV@`lUMChC+WOEq`qW}6M}CJZEIUNJpS|o;<jJVY*VqhK>_Cv_N0()k|`Ad
z!Z`qUt0s&LKTo-A9JdFWa!;qBKoiVmG<EO*_W;A|WGCXVgu9Cli*1dGq%VX$0W1j+
zOFl?_1{96c`?rI$D~b~fe;)_`D9D!h(l`{`Jy9aq{=e<dcEYI7b8h-8`IBa=$j~5K
zhyO<&C<BP>omWTM;mEH-%Go;4ct^9U(&!(|#6kVZxksNcy~i5Tm--_@+xb!0CfX?H
zj_P3(xo7rytglk1R%6=SxS5BOA_*J<fqiY)=Lo@TWGmE9u>WS^em~qkK?CPT4Ak8l
z+E&8dDbdR}<Fd05C#X<YW2*y<T_py*intCpTbcBwu0X9<bxS$=oh7z2klc~VD4?f!
zV$<-dI;YN)PHSSCt+L91{p$Sr^d$Q<QqSpbUJFlIo&2mubs$2}e#P?9V5xm7z>AII
zyr;vWXbW&b(sd0;m|&7Z=icO{-oCz{wvib7is4S=rQmoBwaMN<Xb36txIYv#!O56}
zx|2)}myHCxbgL&`#`8*Cs<5^Tx)0z7L#Ry}Mrd;eb6alCL6T3@v0P1~y%pZ-bGLm4
zMn0Tg1sRBPCO+@WFWa`W)6yjL{`1>?52YmTQJWNqdsybBYo$pVw(s}1az0$%?<Y(x
zG=m-q;KUN($DzS5bT|J^8Kz(NAD4%_myP)E3-4Zv{0?w~sGNz<evP)kh{Z+@no}%Y
zU4KO6hYEXa9Hn$3>V3GaY|6}8?GsXjvV=qqXs#91wXXZPpHBq9nz+Y#_x3)y>X4Rc
zi?nc0TRL#9eYpB@VrIc4*)TF(!hBctvheM~kr{ZVV2s|4hz~{>Y>c7r_&yr+H9wLO
zAOi}p#=03SoVPi{vxTa^49q9OcY;9$FnkJQSK0_<vKRdK=6~Bs+^i^1Yobnxm|bU9
z_Rds_cPmKo*ZU?UEA|_6_d@Ou?N?<}Ilwtnt3MB`gowsLU+@3H@C)=%TIzL6Sh$cI
z62+ls>bszxGoYJv@beS$M`>h<`|8txL8v<&u`q~mpWp;wx$ztHg#PcqB@ok))@c{D
z*8ypLssnqZ`w)ksX(xu@s29ydJo{}2#^%AtYox|fPiw9o)*`SDiCf|+HvgN}Pg_XN
zb&Ks5=FmtlJryK`|8Zr+E@2BmDF11k_~(;WUl(;=#kX0)Lx$G>IQ}yXLS*nKE4beW
z4wYV=D@M$PkV{UE{?V1H<VdI3eyPM!>SuT-n|MZm;`Z11TMCZVKbwkZ9Xe8u(O(5=
zky%6n*!ohv@8`YvB>N*0*t0xz%%|Mr^j`<B4L|rf;IZJ2-dqbbeHT^VuU0sk_H8zn
zar8T*tu<vjh4{S~iBLU&q|)J2g?yd!^dLx1{x!J`>+Y@tLI?H(NO(OnP0v)hG~b8;
zim+}wNjoss#f%wTzb?ty&Div>4-;3Jhmdz>y<ZeJ(IK_A=AUxtt1$23zc0q&f6+%D
zJzP2oq|QIQFLNJ`;qU%VguWgai)*?+tP~SGlR+gO_w~Da>>fgj_;XKz^nJUU=Pkvc
zZ=-y#|6zUD_6uvK%|2rT>;}J_;{N1p0C~chhcq-8kh0sPO;;X$009Gh^}7~fGY2m;
zM_)@Fj6WRox-WY+8zjAFMR)A1o*Y`*^NRL(naoGf{^qHK>$o!8WnFn!!dRS`k+wVO
zj6lCiSoS9#@x6-42jG0#%(tquwg;~tdbxqp2Rn0Lc;B}_d?wD>e*3MAQEf=V;K}r<
zjP}1n0T;6^m4|AtCQ2(2=H}jiCjKN10H+jRrLWY|a9U26M;G-ZB7jc%a=@)VxVAZ2
z(d(5-`^vjl(_62e3)^lITpd_xABPI|e>V~PX4kJ!-3yOG_I!>HbXWwL^`A&@nmOtA
zuFdu2|GYaM-JZadnnic=tC5dl&b>cePdwj@J%cveArhWGhOn4(5wsPjgLRP`TJILV
zT)m5n3ClStJaY<_`}Ucs%3x=K%Pj6uGznL+N0#)Te7y>9GOfg$GzjR7Q^oR~qxzMb
z;nMxqFQNVxKg1<Ixs{~;{H=e))AvCeA?iwxoGp9AF_FnK5k*c4x#?WR=nN3s4rY{4
zs1}|38?JV!j9qPQy*|j5v5A<!pSa`^2Gac=9`+hXM&bu>&g*iIoHU8o^Geod)ALMk
zEaak$wPq4z`EpeWaXjwIqcaYDx^vZ}$3&J-?gh2t0-yf%W5rZ)J{cJ#zE61I{5Q-!
zKTQ4XjS1(OOwf=*xVR%+<p?bkE0c0K&Ev%1)sjm2)E@hKm1SDf8A41`Wd8+{vYwv1
zoMXry|24G|4h||+1hqT7mhM%CLr(<wzv|k3+Ec2y6J?>#HK_Jg%u7zH{?T*YK)ZbD
zM=mj!o>@XQO-vs-=x5sRzflwfGhl49tWJj!Xq+@J=st0<S6}ln2wN#7uA1%ICYXA#
z{m;1dmbRIMq=4f?uYx~p8+Ual>m*i4g}Qu~NtnPP)yF2BUqg|T@J6#PH<Rw^;(Mk|
z`6L;t1|~e3`(|3|VDb;nca_F1Ds%ev>zH$B1ZibpT+BzdQ`6uK)e=msl?;!tJkKsr
zh^s&HD*C`j+S_d^6Y*n4e`Y|sqld{ykD`a3lfC@^nHcMVRz@qMcb|EKaK{eMv<sSk
zJ3@<^Pjnm_^YngE(_3R*BtKp+4-dsY?nv)vrd&$s>&;ngfchhUWv@sX+>^<FIK4g-
zdjCz*b~#T1dh5-NiOVf<=^jHnC$vml<^(KX!ycNP#;BZ9EMDCPi0Bu@-jV?{E!{3e
zyUhO}L9<=gg<Jh!>&`KcT1>jhSOhXrPMbr%uMUso*rk1bpfGujk)xM=BiA)S2hX$&
z&_)J3_#+Q0-zDx^B#TA7oz<uMJ3U{OW?*=tcwCz|R3UqdhHcXu-<C-)>ySN=?URdX
zOV#45v*)#}-smIC{vtP}7#XPSZYc8kBW>AU?OBqDxr7=Hbe@#D1iW)=Q1(o*jdO6#
zSi-%`JYT&y;V8R;)B8FD_g@KaHOthJK1!~2y<1d>>}Dn$EMtw5rm=(>qLT%Gmq+yb
z&R;h-u(D5=WY;Un?b>?1Qm}hempls@D7ZEkqDwTQ3;3}TxOId{n4|lop&Kb+XLs;4
zKeHxRX4N%w97)mcit~Mp{EFHS^s98zF^)BP3JsFMH&c`x^ND2?Gv7~r!L`$trgQ9l
z2V4my1vxe{kh64?tfN(Qb9u`!qO`SCuDiS%U5}*ZPLQjTgUR(f^9V}ziPaU9nxK?9
z_4OISKIZ{Yz|w#mzo~u+M=^xnVppQe`&HD3EXr5e@*)E+{6P(NF|)cblc?tsQV)0O
z>qQX@q@0tf-l`Ic-m5500Eu%ihk>L5=}oSSX$2ay!~CFbIP;gbY<$=J#y<VgA*4Tr
z98-y5_KI+U%gwmMi&y2ifK-iHS@BZ>OMizy)b-%A!N5bi&nqk=)GKcAtZl!iNXH?J
zt%RUcKi*=j7Mhf3)Q-Ga3QG4J+xqvRoO5}-JcTqh|F|b3+VUW&cgU2tpKA4VUYTn-
zf|JNfO#PTyRA0I3@v-u$W`_ur^{r@Xegg1R-da!yJQhtJ2Xv6|#%hs-%~5fADQ
zx3~2T`Lq{f(TvX;)1Uj4Xri0tQ54=>IrtYT;f$*MA^2Ot=r%a;2pAYYNuim@W&yXg
z?0bpHpL#Qm=Y&#DrqI?^-MwyGqqEj(aTa47`^vgAMFeZ;MuUQm9+ksSLVm*qqTzfa
z-F%+q{N`?LzxlIdwA+_Y8nU!K>X9>NvSOw*Lg=aKO|&SJ`$7TtK;<^AZI3J|%#Qq@
zOgq+zC<DhKqEEM*^SYZH<)S+wFT`kX8s&7jNo30;YgmuLmO3!vuG`w`sa4#U`$B5B
z!d)WW3KuM+dBu-#q345B8}R1Zt~Y9_2P`!@Cnil7$YGC(Fhk+h$)dnf^nxJG<3Z@l
z(joVv+{5lVU*2%ENH$0+5m6QFQOI<MU;IinrDiVL$LWSwUA#YNSQ$S*w6A~H)nNA`
z<C=k3I&oBQN{l%|Vqu72JQrXdC|yYO19@!wxv?}P{p41JA)l8#GXf?=C~V8laD#|4
z2aU|O7Z`arn`PQ<^%n)ls|v4NAQd2W^c%6m-Q9?3(zMf9oSlxgd+x2bX%?>HJjah8
z6|X0GHPyGANy)5`<B{igZ7eqhCW>LkR3<6}M^|VggDZYmJc@q%HhuzB_Fq?@qfosh
zz3FD{gE0QK{A2#SRX01%TVHigng6nuX!Z7G6_>7D{PO$fTY@(|O}0>LS+E!uuzw9C
zrMP9^(~;c@*ClOL_TXos&o{50tG_3VWwEsnhj1EnkT{fhnAu1^d-Ja#AWsV{m46H!
zfg8?J)h<-Zke7)fcpbamk@v%BKvTARqfh>pD|atyN`qt4vBQIYAZ1&z*3(rcK7S%g
zzl>`Ab9-n4Zvq1BF><Y!I$OgzToiQViDIL8oAb{%sxyjJHF;56w4Il}H3#j4$<nwv
z^86CqeDu>0@Am2@5Sw=5&1Rf9!JBrd&^YA{EPSC>Wjv)Rn_oMymEXHXx#rBJ=ALiT
zlR4{z{ZK9b(bYK{Z(K2%6>Docbw$QgdwSXIq^Mus`*WKawU^lZt5z9bxk9((AXya)
zO8q#dw0G>9y4voYdXsgSHjrxDIRy@|m^flb^Y5PzU-{wzPWDn7U_k47)#Uk3iwb8X
z%;jZe|4jCgFY16l<GaN`&Bo0#{3>8KK3hG{mYem@UKQ6s$8IXHoz8i=5JGRt3rs~U
z`|ZItVdu1IyZmR^7Px8sB$oCP#3^5lTDUabEJo&s`ykzrQB0t?9I5MSv-o7!4CtpM
zTq=?8u*y9mW|YTOxg`zll8@E8Nxt%KdtN*Cs8q0;UGF{Sc{$0hl4kZ@D+*Q~kJAO2
z9lP|ojgvGv?wAq*Qoe82#m4O!aiXzOGFaN180oRcTC|5QR@HJX0ERAm8ek)%-T;@G
z@_ccr&!kohZyPm8!~~(+CPWM5BVB{)y&UHZ20*?5e;}5TP#{JFP8s)J89td`8hH(?
z!p{axai=$U@@^IamD)F6SOGa;qC&}oPZ}w+Tj~SSN*xDXjYVvf8Pu8Z@>@b*ZQO`M
zQ%F#fic3`g!beScy(sWWvI3H*Dq<?|f#A5E=mxkm&Hq^<h#u$NGGDNxa@sA-qhu2Y
zT%D5{(e|f8ke(d>n-2?9hPvdLcr{AqmYwz{WBYXlNPnFRtKy){XZsz`r8W=EzayH>
zvkX(*da9?_|6%kJAi74Zvx%-NDK&DwFEK=d0*kD?_}2NZxJEaoLB{R$2*+ufqSP~|
z)Z@V$hoD6siW8uO!~J0y8ZGN=_g7^4$Cn;pG5}PJ17goUsGTlFqR@-i1yOr9piUWR
zDyiVi0dj!{{J}r4Pc~9%2<n+Kp#5OpP)+Ec)E_wRx!%lkp)<}NU_B!Z*wVF~vdK1?
ze5k=Y;MZ=}N&fG11F1jRN>i^C`IN0@P`d#}yUdG%m?5*TTo?B`^C9swlh|n2fiVgP
zv7q%~=8cyI6F)O;-%|SaXOuD84fz9@tFOD8<ff3wcNt+D3H;(;^%>Tk@vmbyr-8Mg
zyZw70|Mt0Vwe{JSwC5wG`pI@sQUnvapvJO(CB%6!qagilzPoZO{ioT4gdC-5@`(&u
z8K-cw$;15?;1MxE`lSajLU*_hSe50dtL&9LJL~iV;lzmj-65^8QBybf&pobzXDxI!
zO4<v0>ALx=FVDI?$zW-9HMq{ZMgA)^(EZ>V<t9EHkI2_fie_TwpWLi==h7iDW&KE)
zDw@B=|HnvlN{%%n%*>PHW>aV_VwkUx>ERGg=b69m9H0$tX5TBP#`Ho}VPo8KFtFML
z9p5k<g1k2Y=*7yoLEf>qH5kMz3MQNe_m_LyC-9xy-1HX`YzH{DqP-t2#PVWhh@wOu
z#@$Dcb&{DkKF(B(QF497bhX5oWn%y&qeNp<Xf~9d*y$lmJh-vPogkjL!<JJ6@%AJ=
zC`!<J<sLXYUNJ8NSM+sRWEj<fFPX)gCRCjI!QQCO3)Zu8tImk7GXNi3S)g79WV)Fl
zW58+mw+}q{>F+7-hZAcI2O!D4igaNx-v}Ux%Rly`MU2u{buI)kqM@Esnw!=g?n3S@
zH+m~E9lPt#ug5{8CJYmU;XNrcMl!}7V~?~SxON(HY|1M1h%EZA?RS*>2KQiVeJ@`7
zx|?9jJizh3F(r{UArg{6>QSZ1Wo&{$u40*1nl~)G&U3kUzf8&^+cgQ4p`=Un<c<wE
zIQEuLwWRTsECjN(XW_AWeb!`3P)DxSIOOpv#29D%#B9!VV&107O^@N48y3$~8>}8n
zn!4tC=F@9b51@J$gq-CCFPGKNZd_7m^X)guMLqAAHt<oJU>r5$B&rSFIIPvP5x*QY
zfBu2i-FSHUkcShleX^z*|AUMS69iu?tjFa!j6bXh^TQ@c_bl}H#UJQ+@QBC&8~7_9
zOXVG0FVtI_S2>b`>K03nfSd>VLlq3`J0F<yfoFFLlwx9d3t~mlpaO&J54{|QBu{;T
zV8zDLQEtnk<b(G2I2t@q+t=%q%a*8JvYF&hr1n%2Pu&&%-WK#&;$}>1H%ems+0tN~
z$<h*kMYp>_)#HvgcxsG%MOiV>+tH)%lk3N$N%?axpgR;Z$YCvT`)O^(8Ibog$am(0
z)gNr>q>nOfUwd4WfQ_Zzyxd$wo0$_G_-(X%XP-prj;`BG{xzZ8J(R4o1bFfuFkb3=
zXgX*1qt8(?ja?bgW2mezim44^6a%7><_5G5wBg;f$2FGXK}gPs(GbUOd{S|q;<#}B
zmZ$r~*npkT2(_>Xja3B!uC^A^7OO$GtU;5`6v<=@9tx6q@ch!eqEbZR{bwJo$CVt~
z4r1zDjmO=P-LCOZT$6qbpLWet#P<c%ps;nOAKS&RjkHd1<1d2_LK`q7U2w4tMnnEv
zvEYN^3BTqQHx1z@uK@HMO9J?dHP@N2C~{ez&#$~_ZpM@x5n|~Gk`<>(niFg?%Riqr
z__2k#Q2~H(GQHJtAueJ4nvE<Y6YwSwyk)U3&r-p-`<!!z!qseuU2Z;xyfW?6sd7p6
zH<uyf9_H064*EeLrNnhTuA#8xZTUV2LgZ28Z?qq77pdm{3SvzwSE3bTvucJIW1f{M
z_ILO8S$CCNT#*xyWoZT#zW~I1Nd4Ib*Aez^;#SMwfV_Bj@=U)G?aLOSnL)m*r%Ak-
zh~;g}amdnOOq!n|`)qooQe_P3MXR6-V%`1Tw`jf`-M-O{5Yf*A4z2g7CImNrzuG>g
z%(PS)-v===<3zq9-Tk=dN$b4~kq(pv9U()k7*SW>tz`~7H|@&dkj-@5<m5L}DzfMQ
zMd7MxQ^I3bmVd>T(%~*m2Ql4X-@UH38M`Otsb*BKV+6MTS#Lctd&f_It2=qBLb6mP
zSt{&T;w5p=4)+=|QeoH1i>|>JvNbY?IuB2PUhe`u?$f%Ok>(%O54#FryA{G>RAK8N
zoeYM|03eh9GitYZ&eAXZ8$`CzU0c*)Rw7RSWy#}3BIlnjz3g9?SmVePJFC&vfqp|i
z_|qZQRgE#5#Xhtu&V12V?~9y1(e>hDzZ0!rLrA$=4@!)+IT>kVEC|gp`a+Wb3BJyi
z!Lg%nNN*eIw<U!t(Rw-RPYnD9C1cR-onq8H<$Rw!tgJ(G08rkTCCkh*qFl(3Rf_KV
z;+kzQPXzW|C0IEAFv}q$SIO;)pr2YMJrcIuk~|*hEx=M92;6#pLL3bGzA;!t-EP-`
zexvz5?dM=a0o!4=Dc?ru<iACsj-n=}oV(3bDC@^e-$;!8g>jto=Ri)=F9x$gJ9+?y
zOTcHEFLE|~#{?61SN^KFC3nc?{20eY)0684)=6Rz@_PwMnKA=p2vJNyY>Sr%G-DVb
zs_$n5l+@=#aw3lV-~ITkR6E{);{*XeYg;JSi`8Xn^ek0(Um_e}8A-^HR5wH7vCS2P
zF+E*>-aw^%vv&}r(nUEJYo{>YyItgZ{?YFZsme`#Gu0yrf+R;Jy+#?;sDAF?DvmU)
z48Cb)-E?&{@41fmUjVXj;;Qd<GFc!Y#6Cy$2SSGz>BiFOuGhOcl=gW=PB=oMGh)_0
z{~HK&S?G7P9l~YY`p=kxUFfx*>F3>#ZIs!M5#t~Juqb}ZG9Ezc^|-B%yIIdrE`L6*
z+67YE<W&g|ZZD8U(hewsgIi`Cr~KHCEHN87rq{2xV<6st-fj=!wzGJ1Z~m&kU<|+k
zpqS0tdDg?0zsP(CVF`$TsiW#bTDc<_Mr71W;3O-GrMEpp33BJ?!QEdDFV6NqTD$#J
z4kSkg$*+pFIADDwxc@p><KqU`u?yU$nVg$NR-Xo`O#f3(aC~)xqA=6D6Z}=Q<A~@?
z7VJa6?O6&Z(O><e_`pazl(C|aB~A^4+TwJw!mb?{Iuh}1(1=DRTJ_~whY)AQ-Th=Z
z=h58C`i<LIB9d{y&_dg>cUs2{8Rl&<;C4rP7oMQ9U_*6@VQZ|C8;yJaGX^co_0B|6
zWR}R7MTXNn+oi1Ek;b;0rNH@<`kX%XO6IS<>n}f?RHs3XMf8iF{!XlA6wcMCT<mEd
zAcq8bYct5psX0(+o}mxP|0N}P6*ApHCVU$tS%JykEGq%6m#H%}y8svzQ&?H6w#oB!
zNiA552Yb}L5xiR)Ga}fcQ-mbk$$lyz1UGkjW0Ti6X;Zrrz45I1O59{KXYa!;E~jeZ
zEHj$QtNk!1=cYf-C^znX-gPV*_TuJA>$q2LX*KSVSM-n2-Zh>HEVtg<oAGhwod-W&
zY<q~K+E#{CiS9}%hxijjv3;{&Hg|5xas4@Hec5|KmC}kvG4pZ`_wgP%1uD?wr1JD$
zFM^HCJ;Js!kvoyXqbij|pE>8b8D~A@zY_mq{a4X#2zOM@z?X0EXEZ&xd~Wc*?zZ&B
zM~#8w<BsP_yaLrTKHPoz>IS>@>1Eo_#|hi?$5lx0A0N3XYfiABrTctGQ);Dm5mN1B
z)Ahk=8>jls2Rl8v!%KpFmrkx#533)`Zf?7Z(8^fAg7{hiI*%%lQsuiZvwSqutH^W6
zQWl|4>QJg*u)3S=8+UpA8cBiF8^)TCoq_wlv=W1fCN^S6a_^S&AuT@mZC`u-rsgc|
z(QfVeE?%mUHW!I_n#cRn&eYzO9G8Y)>+1g2PLqHe%pmKZgMbsFPs5kgBd8Rv`c&Gm
zdManMp)7v0Y)8Qdnn#^Ln95QJ(tdBr<q5^XdJg5UnA-K{@(6v1<M}CD)fLZM&Q~4#
zHTt3IP}Y2P-j*_)5h~VZ`&jw@k!Lv<Lk~^Dlw$nfysOGiz1nbFSGmcwA#21z+Uc5T
zL&y#&>;40~``g#gon<<G3(QHG8`I<T!M(qeK$l&Y$gnRmhzFpfOZT4rp1Hs0EalBf
zTvt3!L6756LU|ut{&hJnq%>~{H0Zy1HFyNd;CXrxhmr_62Oks-3j(99=GC*ecf5<(
znPTUmrZ+hCCh{8<P~PS+w$(iU$6aA<f7!xEzuFt)P|#_^n?T&dZqBpK$KpnkkeT|(
zUHl+r#l({k&sXLV<mX~2Ecf{u>9PZrxsm(xHfDeq1)h)i9|grlaLtNOhWb*zr*Yui
zL;g00F72_}hnG7%r?E+6q|a1qdKkP<D2dNJ=X2=*_2$oru;<HrEs{MqzCzPBcrdMZ
z)-9`@ca=&n=2pdLYh8VBJpJ4iexvCwNfioo6J=cnh&nv@)GR>w&1061|4I;~2k!Rv
zt1F|wdigw)WkP42yD>C9GEQF#-|Q!r&S}=v-!QHDqFK4xc<IxD&xoRciqGz<9oI*-
z&hg}y>pTLU;7_ZE(mTROLhpiN_0*}}AwFfFf^+Wed;^;fd3ZOe2AkU5NYEl)jNT=%
zFPu&U<TBlLaF#ravsw@WV+2NYWuhmfgT;)BN@w6wK~GNRaC)4kt9VNi<+R3zz|*p-
zNJbxNtcS24dJa6X(OmEM{x`zYvtP~)z-b?}C`Vw_cvAIrSNz4+ja=Jky!7B3ZN=84
zIU@p<^|g|bub(7#9@k>u3x5NPZc?=A`+#x27HmoqR-jao0Ll?8%aZgFMo4fC66*}?
zCgUkiAwRB?4s)QFey>F2(|`1Fhtu7Ycv^0E%Q%|fXwzHIzQI&1`Dz*%y5bVII{llR
zS2sCSXn^yU%UTr1)lkRukwt|sRv~FOs4-@ll$+(#Y*2zb2&E`wKutms;kMGMPv|h^
z1d6G(xc{D_8&)}m86C9>NLd$;R-u8-31a|bMc`3V8i<4i@{GKcP5h$xs1DE=6CE|$
zZl?_?AHPT{)f;PDWd)Dmk^+7)i=PfOAYB;X4F|>Dg=%SYay-7*>P!)vl38O{H74&6
zWg#82YN^zKL)iQVv0x_YpwTdfWh||Yv`7KheP``bJF0q;_IA&wNsw;%@GTddu51x*
z0DVM^%<Gn`O8WzIde_B1ahY^!ZTdM(=CHwkbV$}PEzHuEj_p{eRdXTW#Vmj$cg+Xi
zE?XIO)Q->Qx}Jx=-C}g8x;y4RM@1^>V{B{%Ly4S@wnPpq^bqR_QE3*Bh0L?piJ-gu
zK&w8<Lzsaq(lumWP_ysT_(C~LUMO^39`$_E)^hDw;=EGK#au_{W*Lnq?u7jgt-n|}
z=-2yCG(HPw^sShDy$5xg_eVG(8}^jEt9TRR){)Qc$-Q}}`|7Tk{%rM&RJotdc<UFt
zw0R6at}ZL4w_qoO=|~<v@Be<1wS0?=;ApA17m#6wWskxx-YA%>SKPJJA#8tSGd9r?
za(1P=z^PJ1<!vS`hQtGZTgtR|C)9XcwDpi~8;B`eWh>N+VtsBDDZqhW^{AwM%AyXe
zBLN5hAW&78@rI0@Ox-z1<N;t3J_qVbT(p{p&l$(wTn8h522dbj-jDaJmi>pza|g|q
z6zDzgSAqr(If!!4owR*}Kw(%oA;~Gb8zLu+%F}Mxf8ijZZ@ki$+b?N(lP#)MP`Uls
zBoh>@9&=+rFOY#*-Kb`h$WJh>ZMjYv<ojkcP@zUNk<9%h@P=x`9dMjN^vbS>Lr1wc
z*exhJ)%B>w&C!c#?jTvM{NqW_TJ0Q%=ofU+x|Omv9iv~cBg^PuYMUI7W)iVt(V>{g
zI%vme;_a3_lW%xgu^}nPdNpRQ)JB5Y?%np0=2Vh4(I~xL=oZ-ip)h4Nr3rIvK-<cj
zhd=v>c-~RIrYhpK!ptN8Ws?94QABd){d?-XSHs(CD709@Exmt29yX5--SJjYO07v%
z-%{({3y~Y%bj@8)7Br~XMN=EGnKfEmycZ?Ver~=KfXD)nk@s(&Mp@(#rgYe)dv^m0
zqI}I%;YKe9>N=(4KX0x=V<`w}h+OZ1*rtvm_ptESxLabN@aywn%&PKT+oZg;#Lu&-
zFOg$7HSLft?C$9=a%Ci*bEarnO+ve=ku&Pz8@G4od<`i3%hkiN60SMpsrPT{&9h0k
zz2!6g0EjMdGfRVAYz0AcG)J~DZ}b&xz6e5hQyvTw+3+k0MBDqCXIBw&c-zITo1rW7
zzK-O%ke$k9+A~g-Bu@K>Cr^Tip7-|E6d*z~)KgaAucL|nH}-NBL=zsyLrdV>ekbbD
zt9=UbhNUM)h)&x@o(vZN0L!mfW{dg=;w9d;EXH2}9h!wt{DEC?)Uue!g4oj<HtJ7T
z{lIm4%dqkGPlw$#CmC>qeoFsLuT(J^c~=I>B5!7yPCUmLPibv>eB(0J^c4`o<}$1_
zVKpIMA(MfYNKmB@=i5G`P`Zl|{=Ug#%m7$zg7eZq8`1<|Bog$L5cmB42NTW;j`1&5
z{Ezeg!YiF0nU^>0Yw-YpxPi*5V~VTZ#0v`4jswU#Dr(=E6ZA8hGM<Jqaj|RF3T7gO
zPMK$)K&mZb^qd4eLxcv5-vaJ?w=rLcXc!fN-q&gf>9n?r7I+|Noy-_DYbH1w6F3OO
zaT0t$h=>z|IPVvD`gjrp>F^eBAcS<rnO*-xroSbWEj@PJC{#nyQS}o5mnhW~cW$YA
z?krgDlaXFqFYJ(T^AP`wE;qG0F(grd9$<jJe!U_~>`!%5(`b@b{A|;$1@XknYR5sQ
z$m<d^8rq9h=^eHqtA5%-P@%yhgwP{oaDwEYyF^{orkNqZYfV~eyb&bmRgQBsvKEv#
z9x5Zh+DvQ7WyK-McqE5tbDW_z2gi@3%0=|2@9KcjY1b_iH)TZ3v;>_%!i-5UD<F`6
z{-5YikUoLl|FL!N?@a%X|G=L+*oLu#L(aC5bBvsib3PwK5}9L?G*Xcc8^g?Lj-k>V
zlT=93c@8;~Q%I_jM5$D&C9n0}`<L%epFd!`c0I5C@VM^J`{Q>1j)!${MLW47P?UDW
z>MmpUA_9yikYUfBLtwVAOPetYG?Y0t=FPiZ=a<&nZRMTFLc!#<`6cDPZlxw$-Ys=t
z__hN7!p2ckLdlw~GNW6urhC`wgiG*sN4st%8WmBG);{@3hTE*%K|6c74*gwC$%ieJ
zB%l{DH5=jL6Tt2zoY+T>!Y!}@mi@eb59s?6A&ns}Ikugk5@Tq0a2uF5=OUlo7BR<t
z=qJO8Q~<$6l*M=pxZI5u#jP6U<!+&5tk8F?_80a^9)Ko};pFh>tkxkOFlarZHxn*g
zv!pp)thO9J*TIrM%h9^yr%or4Z>@Bb!X+fbl|;tDV}88&ccej({70PF0vYv=Eiztn
zW(5Q)9%>M*i7#W+#+PWF0II!2c^j`_=bY?-gJij34al-@apH$a`k);CDG>;0szwQ2
zpJTXJi13c^8;?Oo0thy^AQ5e#CwFP|^>TVBmjJ!&Cl_%-O|tu(xvfMXMESvz@$K(g
zC({u<Eof7ar0%$|^AWi5xKPj%=TVLL3RPqQCmtjzzDO0BSehf@TCo6}LY7VfNiQs^
z{1Ji)j=+7mvA%SH8)?WT$Y+5-x_}SV7QRRlF(&B`3A`x|5sG`Y(G5LiV9*yK1*OJ{
zWB|j*rkqGfLyhYql0}!DFB^j~J6|>HlJvLnib}U6Oo7GCZiNUvd;L;GF<ba7UNR4_
zbf8<vxB$NO-F_S|(#+8eG}KzgiTxtEL@q0#$&e~OTbKk$C3l}UUsd|9rp!y)bBp~h
zK10dB$%6+50ftza8Z;D-HNe3J1<MwIhZxma3=U6j7b>`^=D-car~p~aDX`{ibFNIG
zGZxL&oB3u1G|QNBjjnzdIhw9S#OI*1oZW>*7-WQjVMq>Dm`y^B;=MoP{WrrcbXjoY
zc!7Yc)MATTrS7RAXyNXP&9FsajcOZQkwGWfo+Zf+mqZ_$RQssh87<LG4leu1>5XG5
z^ctBaTYyjftJDo{>abxt=xl?$PPIdiF3UqXHV8H(g8JVe6`8;WmA**X=J@D3Jf6*!
zdE+n3`E2}!2GJ46?RqDdqGHcai-;{FI}I8+Z2{m2E-Zv9-fD}gC5xx1npcCv>cC<X
zWYn#0`MzZZe{qrTLbA+m<(T*P>Ge`mNSWyj@dOpifoZ#1BPfhqh+D#FaSoc}ls?42
z3k2Xvvy_Q?8yGG+z!<jp9L2kVVl2I$(S8DGLEjk4^@RV6k5p9B?ebGqMlYeyE(xbc
z#$F_u#`Za}dQFRaHJfIA8^B^KBveaxcr-z&kCQ*lX4iKo_R*xU&MrwcQprOKhR#;x
z{c4L#Md;ls2AWWF!7+}T@K^|_^;T=C*?*dQJTiULt<wh0u@ar6$g?#H)njDmuBMO1
zgzc4U%1UYzpjF8Zn3j8LtCJGO-4fMo#Hk*2YLBVgelwrnnu3=@6C{x@IAWdyyp!bC
z3WTw`g+J4FrQmOWAC{cQqk>u@?`SGYTsJh(R0#TzDrygvhA1QN3YqTH;q}_U$naO*
zumk|6$_D8GXYVzlN}bhC9zJq*>8vY3{#Jq7RQQ~hn%893KJ#u_HUN5>hd2ww9j<rs
z*lz~Nh}E*ix7b=c;VDNVlsBkVk8q;NTp7a^8UI4%<#4G}wu%0>ldW8ZC|~8OY(wz3
zQ<gZ&<7WWblkV)V_lG7|y&s00`|pi+>>=YrlBXlaREHS&>>ALyd|gZzXdZ#j(bdJh
zh|fcd!z7p>^_bi6<|U=gnv&Z~@*7m~7_LYH0N!HD4|Xd}NvUngXphrgb>L82AZ2MG
z*=m4f359nwNh4iERe{{f-9rX4@iQO=&WsI|dbG_>nQ=#G*;el>KFzlaRBp`Ln^AaH
z2M7G$U?xmR6ab__AQ>qsDH$1AX<>1VUHAYvT%cth0fSE=;72X6`-zI`F}wZt3IET`
zj0K-OB_8jm3;+%Q;D&(tgFvSd&_vzcQNCb53L<$wE=tYsu%naHJ|DlteQrKJ@d1ZV
zBqk;wi3}2enGXS=1qLfIM^wv5`~!e3F!;L&;*SCN4|va%D7wU5qSXu87K>>+y1OVu
zb;ut!9|#@sL97LXw?YAaD8TaveRBs*#fhy&L;2Cbzc^qk3c^nY{+$K3P6F%4#V1m9
zugFC60H2T0Fs8q2QLOXrB&Vua%5aL)o1@31+e8$v?83}I;e0^xA0YJ$5L<^5e?z6-
z6OR4@`+pbOe|bOf%ROqE>{+eLDipob4m^AS6}XxWmt_8B0RQCz{BqzEQ}pk3fPZQ4
zj}qO*YMJ6~p!K(qz|R~W78c-{YwI9^oVm3H`te<8d`%`l-{tmAmlEdb){DodGo9a7
z#LUhFm%TnLU^Bs>Txqca!6N~II>ZsJ8uCqX$WqjSLc#4+`RFRwL{>s-o>OW=yid7^
z&<Fs0{QqXADDW30!qW%-$SJ)J1-}tGIS4*8hdT8P6!-@?@k=q{O-R_ALU>6T;^uwO
z{p+xsCCcS*;H`OX#SLLia|bWp6CP^^{V5V({-2Nu>YD;arhv(pz<j^Z>^6AfHNY3V
zBp!o&eh2VB0{_;4pFHs9kmZY(1LG5suaX2vX7>M(%+%b=DcR+TnMKZ7cT#d|PG4+|
zX=s4`D#g&}z?thn?iMI_8z|!gmH%MHKc!1P;jVsgDjSQw{>u8=eJYj8%wZN6<lipN
zynQQ^URIx3+15h8Rd%iO;lqdbIy+l#x8=9d$BO8ajoJMV@2y|UzBYAbsPDnt@cs3%
zuKD?r%(jWU5BjPa7Dw)l&R$%6*f(;2c<#aMr-H!`!y{w!ua{phufBi3`tjq(4<A1K
z_`ELAGB>{e{IMkfGkO31{rkh?egF1lb$Rjs1T!W0ISy?R&qOi1yxtA8)eRI1z|57d
zJ=AX0e@@KN!S;rci^Nb7O4MYn3P>N0W$*F}v%c`hU*x~}=e@2M>}^*=h6P|I{d`>T
z*0g`{;Hm7qXgf*&Sc~{x`dx_w?Ks*Q*D`AXn7OA9WZ2;JU}#Hc@O(E*f1h;xRi89Q
z0sbLfH_G?UYybX{ePSr1r;4xLsy$>mLiZ)F8{8F{Qf!PK(ao1K-;i1Jh_y}FJ9uE_
z$!;qKk41YP`TkYciSa&<)7L|5yGu3gJ2e`H&t{kETV#3G`=$%|<*v-udB_sdtXJQR
zD@OQ_R$b(G{*rmV)ox!G5V7~>1}nMnhA>Q~ro9?zz)LHge)IV0zx0PgFAjP=JqPtP
z7*Q=@B&w`O<{6BTlk#0uBqd+F{I@n~e?GP8=iBVpp|C>%_@(JQ%0&;28H)i#Ho_Y>
zX-~3!M@xR5#oI%Zyny?a@(L&<!-T!uLlIN79@+2DeV&t2M$_?2;Y(>antdNSs*mL5
zVtvZ><>@4$h$+7<T4~|lk&fRZK3{Q=8vHA|zc)yzOmiyVzSOr5%lfwV{;HP{S~W(}
z@R_H}CTY-v_#1K8yQD{~m+h>Qr|Cn(=VXM*8gka~Z1$=HD5eNHRSL&9l;luGlN+WC
z`Fpf}<hlGDHT3~<?gx5ecvsq@Tvq8?@g6i*u*SZ`^U2<XgzrX2T>i-r7WFq7s-Ct@
z1s$G99tJOdKp&~C>s}WTqqXnlnVIK?+4VU&7WQI4Dh>K)V174+cBjo9by%6xaJl`S
z_=SU#a*y4&eQKq!qgUuhd>(^($|D>f>hALZUnG%n(t)ZnWl7v2Z4Qc*$**3&-gyJ5
zww_<_+43dRu<$0NA!7;qU-@Ll4dsAH2wD|>jMbf__|U&c;b)0U3u9|N_|UK+B;UpF
zPz%;fUVO<uJE<RlPS|B1Yxge*l9T9H41a%%sg+vZ7;80|sy(Ijxo)7$ff%mGcX`3v
zJUJgOu_qu!Ux;+iI@d6F@D1VT4-bQ0+v`;?l`I#1%}i%oqrHuQZy6{mJQQ>t((g~T
z*1sjU;B+VyEO%yHD!IvJd(jh$5nPDzHZwh|n6L(g<5E0j^fR4Z8us*#;-5xTq!e46
zmwZc#of~s_dLSX8PQq*lEm*~qumn^eVO-f(xTVO^L!)8=&ogR5e{6<BCtpt*8?p2q
z(D!p!?tGmVecS4wx~u0|y_141JWYJ*dQs`B=U4{ny?>IGPB&G)d^#I>9)K!nge!w3
zcZCcONUB`_B%5ZNwc_Mg7@+x12ERGbTfG<kHxYU?hyX?;I~TkG;bHtlk)>9SVOQh)
zkjfu2EH<yZvxr@HAgkiFa~Ew7a@`hTj{_s)yHM&-5W<#B@}bK#14YMxtOp}MN<m`R
z8a~P%iO3qWv$F?eZY8d4cB2JtBulog>Z8BGVlmE6KA1MO3#7_8|3+jgqCuHZaZ!KK
z1v|W+AWxhK8weVNit}+63Ysfdol=NVGzVq(edBvI%p9}y-zomMp#sFuqtI)<2*C!q
zOVg4OZiQ@9BN=^B{7BJ>Jq>4ec+N?Ocm*|EgupTKZYwnnY*Lg#?kWe3NZPzByHljx
zvsEP95YchD^^3|Jhfc}ESQY7bm=0A0m#*|WqM_jkJN`t5+Zrh2_Iol4DRQ_Fp&=EC
zWw`ACqa7NJ*t`0BRkv7|NLuRHGn8DU<KU{xCMDzcYn(zSX6-`%fs&-2C~N#=|KW04
zm7tF%@pjAQ1vJU|-%oO(g}ke^-Kte#rhol^_*hS5oH>2j(R5Iz-)Ez3G-t@Q77)x6
z{HbZv{=>QUVq+1Nuz7nBxNFmUhv6EY^k}?kui+kvp^-z`)~r!~9AahAI)*A(o?+j_
zzl2LXxCT+{`gY^B>_JcHWGP_Ssxm?9H(=CR6s|<Kxd{!8BGNU#FD74j(N#5fo(v)L
zC0o0MKRJ3iy23Sm?d%ifgYCgcIimvMAW6O*QpQ<QZH;sB{C|?MntQF^uqR8M&9ks#
ziSrLF6WX*l7*_1Kp2AZ5!l+izoI?akeusQx;qOL*y8Y;6?Fey<8p529s<xlMEqqIA
z=yj{WSIdGbSa<0nQ&wMm_R1=a+8ef1zlKTOaFlhE6EQ4p>ZwRlt^Ka4>pWUBfbYZY
zKm8E|Kjstodg0<8yDM({L^fN`nW|(KW8JL0I`U%b%T%U0<zH@f*;rq9P<Z_pB$7PT
zAnNYaabof-$i7EsY1B<)(obpciZJ%T!g1wP&Ij}sDJ)v5Ce0dHcZ*+??haNhI+>{F
z>VFEEA{;GuH9SkdY7~{=BcZy;=;kY(WBbnO)TI6M7cP61{>~-u=WeNA4C4Hcy#Ay<
zWd=#h-X>z@(Xt2P&(@F5C(?A|xs-9Q_0L0YL5pWP+*328T`fX>+bsl6#i0Z4pqbp4
z)sJ4D*e=~$e`P9^x%hIov&X_z>1o8C8@_Er6d6U)r19!MRD|6cjb;-u`Dq!rvG34N
zKWOx=p6?e`7P}192(KpG*@Gkd40F>zL*kW#>@}<}QTCVI+^7h;Pq>|s1J|gujKTHH
z;$)rfB!{kSrLV|alai6>=38EeOzt)7nzU7ol~$dB60xF*=L|q{9<eH_ASlPnt{5eY
zTYy*I^!{L8@r^3Fxcft+%Qt?3EH=Jn3w^>r2OL^YKCt>y<@vJ+q~u1?@hx4%U!~!J
za03izT}JJ(HRWM>Nl209m&_hSPGwE+*98y_v2&?8Bn>S9-4*ODF1m&=U5>Cc(1sMk
zZHkXlu?R+WR&gjptR3M{Qvrd`<%9AAzy&S$>R%M_KKpHQod(P_p?+Tx3KtWR7$0mH
zG}YMo3m$?)bi*zDU9(IXkX<+Gb5A`-+<9;C{m02h$5=5-n+4F`zX$Tp@JH^UeQ@uK
zDpdMgl!vXDtUnC;qhx)M({}Y_ORfC91B$Wg&gd|Ev!C2$)y)$&Gn9i04u>?B(FZ<@
z8WS32*j-O6_U|3!?_j2G@9VyHwaJBpf#QK~;a)X2jA_@i`Ze3_>BEC-D`4TrALzA8
z-Og~X>q=2_FPhzrtn9~Z0|5X!*~A~hh=IIxO#J%6{Vh@Q4+}mgbwO<Mgiy4xzOBh*
zzt)(l<U>l5NT4)iG9)S5d-Y<RN*f9{VPP`?sa8AiAM}DW1I-KYV{Ty{p|wj?CATI(
z(Af)0OG%}4SB4X`Ky9zaremV9WXk4V^1cj2QMjaSkkH(j;b+7_A{7UUVJ8Y}s@qP4
zAHD5+p2SXnIOD50L&b-q^f|V+xJ*P_>dK5Hl;o;*&q03;vxVD}>v;Sl!98|=j6NmN
zHN}nZ4xF|@Luv<5sa*S~D%nDqBnK%8y#Z7T4L3kKrmN!Gb1y|M)}~McYRiV#9`>!i
z1DU>?eth0G6_;bb&+UnC$faMI^RuS8RNOEpr_|3;9}9V%70-uc>Qgfb7?e*6<QI?&
z#UvH7X~Y`D>2E>zR}a@6KBj#lS5aR*Cer2w6|%Y?va^cW=Ik?@u+gHS7Bddw`trau
zTHl>;L_;v;L~1t`_hK;k2@mt@n~^Ey<cp}#+*o@hU$MBLJnl+?sw1WgE|HOf8+>oQ
z`Hq6R6Y}WSA+83LNK8n*yT8jwa(jZQREqr)EBj(Vl6eu;KSA+S#cIzfi8%4aV)Rcd
zPNKYk>>C=`_vBC#1rm?Iu8{Ih_!p<+aKBC)<7wh<eaI}}xH3pnsPiZ^G3R03nPb<m
z+pPuW)B^3bB7<MfUu2SC9W;C*VVEL(lpy(M0_kRWsH8Xf_Y@?r6S_Eu`Hc><iOR#%
z@~R~uQvG>7_7|LmC0<OUdN;$KbBgf#<mSHP=@ptb?Bmdv7%rRf!$>mC=cEk)IWdq2
zCRxh{Q53p71~+M1ZDLx}TIj=Q=75+Z`Mj-9-05!AR_pnzbr;uF!rx?Mj?Txe_hbEp
zun*DN=T;B%iAUQb%wn?7D1!{bPGl9d@2iHoUA*TRHVyHD<bwG`4g2?!2s$PAS!SQK
zKI)_%%*Dhyl3`yIGxs9a9%P_U4|!V~D(#YaDkd9oQf#$IIBgBH-r?0Ec^>ew8b5O0
zgPgxZg+H!?II+$v>x(J=ggA1FT7yc3-e0*k<3ILoS2l?p;&K*DtL7r0L{mvVXP-Ig
zig|Rw57(>HyON$(V#=POzHlhREMc#8j8>W2o}ZY%)I;oF7>`XyTUH4HBW^+rZ<oa`
zZDw8mnNzG0{5;lSnt|(EVjKMla+NX>!k}<%B}=>#>j(S)#pHudgnDfflQhb`Y)!uS
z98!-7)WBX-P0^esqDl<v$;oW@7fh4ZdK|4jZ2ADdFost9f~DtcwT+I|TS>!pr}g?O
z_?e+GTv&u4GVzh;O_;UsZd48zW6D5+wDv1iLe9p8SDIW1frltfimRJcDtv2<+;z?0
z;Xncoo<xL`aiAGi<tiLf_aMcH7!GKv_YNPRR<WcJg;KO8UD|~MB4!@4Ejv_It(ow4
zD5&ef%_J@?oC~q_f%pq!)5w*E`%ma1Ao~I`L}i78I^&byH6KYr9LXt*SuY<uVhlyY
z7Kd-1*n}B!T?*_@2CApYABH@uGBlcxlWGlzo$~LQ1Q}{#H(AKENs!2|K!5~Jp1A#=
z91KM)Pz)FU1czQWljNc!KkvpallipI!8t@4>BnYRB@nLNwX4SWwvxVj=}(x_r`us9
zaCbA@TyP5>0N2i;9vp$pOqiY_)1Ks9?d!bIi>GISH2osYz~*4ZzjwN}VW%dpik=F!
zf!^35i&qIl3{RuLd(VB2%e*w1=_z$hc~Wd-2D#IJ2Z{$BdU!Kz^VmRQ38@v*({<5g
z-70$?v)l^#cKGU*T@qzwDF2aN_TMsk@Y?GaBkuVDi4*sd(C{#{E&iJgwz<N(8Om&e
zUzCKHqc2DYON=jIV=sz_#8l<iA?61S+V-L$n?j*~?>uk=(@r<qaG|xoQ5wNrijz=F
zPS@RmMg#<#*6B6N^Ah8ioX4C7BDnWY;6T;Gm>(1F1ICi|pCFARD2oQj&4X##+b43)
zxaBdCfe&58J~W*6bq0~ZS6<yajs{%~GP(B4-ps9eQ4-ppR&T<7@;q0z(7pWi2Xp$h
z{L{3{*_%%>A3!?`_g=s1_=ztT9x3!Pe?lmNTe2bJM^D!VTrdkN$tl56n~rE@1ee4)
zr%-O3`vk*KZYgy8Do8>gqnNicr@ds0E!dn>*P4wc5t)uAJPt)?ceiy_t}FQXuCwrJ
zZFmIkkybbg|IXbV-Lg$-nR;RRi46I86jC|RvKEuQ5hFLEa%Rs~CW4W}dnNYw)7?Zg
z=<NvVU&%%Lwi15g>04<&J%XU}lr!kyeh;t2oUhZAM+{5i-t^KF;wQNG!*Lz?QpNlx
zDB>gZ-pPV}4JhFjh$T>OksYZohk=rh>ir=QI<4t*#jY7oUvc2o?(i^9w+b!KD!%jh
z2dn+UI;QL=&nixiBl1&Lo&FMwo)9H(B9H$h8^bqIPygOIz6qEwq7DrKGj1J<TW9fY
zaK}dw4Hn8`SA|eVcyK4`EA>tm4s~(}!%7!^VB&qxPOP(~JB-L6en>YW-*FbnfxbjJ
z`t(^+EG^WJw0?S`OCx;)G#?JaB__nu*2Kq_k-yyI4J88J`HU%jf}x3(#zVGjozw$E
zo;EnX)2)k;kGbIN_7gXa%k_K@{KbLWz+yApJK<zF^JR7mp%ph7d`}R^E#4yoT`J+I
zsv}TYE9?^YIdcy4mpE*RPF0?})i#3tIhqYLDSRP87Tw@yCjvgD=Z}+O5XNZu1eDCZ
z&(`kTB7#1@6eJ{9=Nf8ha?p=yoZ;s9Uz*dpzCfp%-jN98;>0XpYj$-4^&f}$O%>ay
zgH~x3O7<B#BoA}i#(1J@9I5O_D`vLTOA1Be8tf;Q)Bxq*51#c+?CCzO42tyvqf#jY
z{Ex5?Y-9T2hp!L;KiVFj6NQIuKAsYWYMM*xFs9zD$l*wXX1hFwVRe3gIqrN(R3!PO
za;W%F2C|=Z9=r`oCHEfs3p<ET@%(5O|Ev1a3pzRzY(pB>(xT+!c2TsI@HGwHWHIjN
zw$p5s;)9@xP2w5%eXk}^XE$L=`8Q5%-m|M=JLO&}bP#i0D5)JAF!AX#ZWY%(6E3nR
zFf$-zYfU_G<8J3?adgYW(58qBPGVu)JBw8V5`QuH)X<MsSRT0mfD_$)`ph{D*@Q5E
z#GRaNB8rae-bBgn+zH2_e)H_QTOWc89M-9D3=USd2To=QoP?zdZcpNZAVD9q8n3`h
zYU4?MhR5PmQ0)c_6!8wl*;7Q6c0l1&B;FGyZtMdg;$Yzbi2wG+m`6&pj%qO%chcH^
z)TJ)|wb07*ZDQVaBx4h$!@m=OM%}!8zI_IIdTGp*3ZEs5(GH{HQXrn6ZECdI&jj=}
zGMisHW-BN?K6$4+%oMpgvAVb|^qsX@!Afop$9MiZb?!*#j!$JZq@^IK#gz3@(H7;e
zNIM@9`Jr*`BaFBSoc+Op&%VB$NQFyXQu8$H1zKMiU5AGm7PqU1Tm9)?0p*w@#Ygu%
zICm_vwrm(3PEjmEO#t|cR?)u{?)g_@@%PPdm}ME)R(7{w)7b6ic{$k!r*16`sg0KX
zjE-~(!MHu@QT%ptgp61r4IQ$8yHAWC2OlpK#!kZdPK)uiovDy_A2G<;UYRd5<^`-~
z@!+_#S8sj6ye8L$#)vz9Zadj3J`UgqfoB*K_f)GUU=KD{J50~(*1hQVlP^)r<c0FN
zjaLDy8Sf=uyhD)?a^jKj9bI@bAin4F<>>6?vj~Vs(<9uZxYxG3eVcgFknM*wa?B3I
zl=u<z^<B*QABy4ku<yiwa9=683qHjg5%dHO*x+o%nDY>uQPf{HR6i?gIDe|y0=q?m
ze0&H=dHs&`?4u;;vj_%&{m-zjFy5n3$wBcx-;KCpIW%!t>Q3R%I1pg+?&RYGgcj`5
zC-3Cfyt+I{{`=j7kEB1SeT63iY(NCgpUBTuRhaHaou+&aKPG;0)&F<<q|po1uO8nF
z^CcnSOk<zlis7ue7m$-Sf6S}@q`llNwTU>-S@6IF)?Y=#DIz!7B5dmR@~-1RqQ}d2
z`#-~vi%NXLd(6(JD;{*3P_ki4{V5UwNGgKuL*7r7Z{#XVm>qS8JoS8enEAJ2h4-y@
z$hutnM>it}5;DfzirATGi&XbU$>%FMR{5__HAvwcnJa^ZKx4qoKx&l{R#hahBo27t
zR@NLKXPgkZjw&*U9+Lic=U2?QUFL}m1!hWokY}2ZK|-H>kwOI#qeLXpRGdt!wLd=t
zz<vD_{X2s%Opm-f^ghm*y1;K5IB{wJRKumX%#Ul}fa&^w>;g%~-6LYxg4^N(PSwH7
zv|oiXV@I#N*E_yE8p?B$G3aEhzVMgi>J3c%w=vrAV^x$6bGHm^M2I`Hl=amDzx>9!
z6qM$NenEU(u^6en`8iFD`$2Q#X6RQvDGp{Hm)eK2(Ul>0HgK>vq<luFG=PpEIaqD9
z!M6c(qA{{JKeLY*#rFIaF{A`8D9$3J^{}-I^q$~om*1o;!1oR{g9@)EB``K%Nm_TV
z!4#7#JUadr_-g^Syb(9FP|@NbO6@LTqEMu9uNGB|Bs*e@F#67JJYz5<Dt~?l6KQW`
zaXCXA4ka)yRc)H`nbZlM*?|3nl?q56qUpMhf;=IYrnDKd4MHd^9QAmFAG>k=>NdMR
zc}P>6EqNVKsw{pA*7n(?w)%hj-Xy%=ZlK2=c~{NT=*3w`p7^}E6SOLD>Ke7qi5+{@
zg7s=&f!@l>&^3n>K?LQ^FS3#hx%2TlR=i~L@@$#Yh@|W8Yst{*`21S-wAX(SE>*>l
z{7lM6+*He>d^<IU9ZCPQR<QqTCQ!l<H+xZgtQAV`N!mghi(AA*X`&P&>}tZQIka`S
z%+B?^mlg4xwno>d$BrFTyRtIhMCyw+U?EI`qNT+Q5$^%2V&kA<z^j)ZuBL@aMb1W-
zu2Unn7x*_BDDrQ~NV(kY>(`Xa;&$)|g;G*iW7?UuqN=9-;A}XXOe}3ku<Lvt$%le0
zdPH4frfj@}Qya?mi4y_M(+8NRWuvg)7^wZn%K^P;@%8=%W~))0-Pw<bK)mpSMvY5i
zP6$gS<-uG~OnKi+5Ci8!e$;r5IkA*24@6(DmKag<jGw`MGyW+u7|l#Cn#>xD5}Q?W
zFY{S;5?MW;74BYnczIp@>f_^Tc-hWs-|fS7tJa5OA1vao)Shujq-6MQ;q(x&Qpej2
zhvP171}7RFm(0qYNLM;QIyWExYz8-RP+kxauL-nOr)cC#sG-6FyP0jJyDtD0mmK+g
z3?Z8MPI0FxTQQ-rQBNjg&lq}<d&apaWfPw$yach<sx3s*myNqP8K{UPNJOQcfd(c#
zdaE@<d4nu0OXsdH43vsc;^N^B!+dC|lnaurX}@tbP=N+2Z6ky>^QL@N{Y#Dl&ayHa
za3fV>x7e}p!-G_~FZCD35*_cI(3<7A<I5DIgC#ep-LA>4*$T&coy>^N(Z7n|>@||L
zQBlA6jb%wbsRu<`90YW6jQ`lHVArBhZ1@iZvZB?!ntai3_#XC*41q9Ag4_JEO@H_J
zqi9OoL2HUj*Bu|aQW)!v9glMNf=`AZ3m8RFfSbcQ_z17AD#sN*4b0x88c6G3!Cjhi
z(HhcY<VMAO&Z`}K>1v=|$b*a^7?;F|4Z!JOVdJg4$VdiD>EO!puBx^>hq)|ed3&<s
z@^@SFO?<H1V7F@&QMsA|5h|J#PBE7-SJ=EmQ1)r`>oGE(_mrrL&7cEo11?9gZJ6?T
zs=7Z&L?XTRlE=#)>upRgQwJ=2N)+a~xhbT}#A8xr#odFh7YToUXRds<H#N=<b=fe#
zfZN^MbDk}0WkAa^tH|+?XfFNz?L(1Y3*cBHgHR4EC6#M9Xu#G)z;R?qWyr9}pQWyo
zTdO9i!VT6FX5D%usO)pD@ZakFn55RVjMJMhFT;NFGnC@{Pt@FZt!;Wg&a{ki>7SYR
zD}mbFMD#GgY>sks@Fde147qChOsmUWTK&OtT|jrQ^)FkIKq^6AQnue!FRJNSYiX`H
z!pmcS@n}AjotesLuv=s~SFdHj)P*&?TfSvlCiglSyVRwXQ!|`t`!blJIu{i12ZjT8
zX%*x8G(rUT&+jf9U*psVh!8Pn$$FC46!$r>Fi7V6?z<8WeNVo}6_Liv2)x##%l&8%
zW=n=Msf*@y*aBwOWeX-Y(fXjH*sC0Pq|OlBvgXq6{@}Tu;3E3&09%eviXDV}Q$#bk
zUEI$Su6Rji5Wmn}cp?dd#Ii0{x?Qv9=gZ_1Qn$$p#jhUKJzjxtEZsIjNN1b$;fOo0
zosANJQai!KxQFlSOg&_dcUMGR^*r#^CGuL;T5tNWsT09}s=53WIZU+C<(x@RG!yYT
zBZ63JJ)d}pQvB|zi3U9X`@xGQbfTZ7;*@wPtNYAaoMt+u(V&eG?R1bJDL2u6q#iSR
z8nJSG9o_KwOIagvYb+tR;`Yy2B-OJRg3q~=+x`W^oMI9T|5CuI^Y-(!-MSXDU2>-J
zn;I3Kby_~c4z;IUT$~Q_FpL(FOY8l}Xk2gL&cs04SE(%cWl4!SAnMAO`oc?Uy2yzL
zxW<eWxRCfs)r9O(znJ$?kI%ci+e4;UoD4i+PMp%rmoomy2#p`MHi|#U&9N-KhO|fD
zP{OjP9VS~sd-ZzJ|0?vETFWStm2z(^W68>i`abz9{wlWax7!y?HfnfDjFvch>m&zK
zIz6Y=YP;q4d+e*Kc@N{a8TH|wTGU}x71>MZy^by400apK4x<Ff;D91xnCF<Budxk}
zl-+l~=Dpi1C(Y8vLZz10GdgDQ7ruKyKM$xLwYRf1QP}&jzBJxwxSnKq#H-y#!S%Dz
zA0cK*k?>|>uQ*2I%%lp7q8}BJYT9wn$=G#Hk4_Um0Z1zkyJ6^`?G-TZ<h-|SzoUX5
zt9hAji0xngbnyiLs8*8%>AzLop{(*%h-Dj`aP~=#k6)B13OLIZQU=ASyrb!)ngg}t
zwvrs2pn|ibkaAEWE@c(&NIG%*i%*i-rtODY$R3v9&VuWK_wmcc!()4e4*b1&s95dc
z^G(fK6ehmsLuJ>rM&j+ioHRDAfAeyUNjvY*9y~&z<^E2}IG`mhgF`8rHXg-f6xU@~
z-Vuf|Ow`FasU%}S22cgtKy8a>v~7OeQM+(7|6wH2zQQV2247qEl#_cql4x7mgZ=sA
zwjc(xyaYcQWL@slUa|)I(2lr-eb{$B<A!Ut45CB69$|i6L^DTgp@^y8Ci1;k(AqKk
zwl{w+k}o`orMXjVyn@;axiHC5tL`*_VG1p7N2Dy5mCeJ^JX2X*i_%uZPu}$_!5jtm
zTV=6eC7EI+Mpejlrf42Czv-$*6!rz%uJHktgmcgwWjZ>D*|^v!)jvu$rF*va*>6^!
z=RhRupCTwgj4A9`S5>8m4D7FPXjSj<rZ6{&Q#A<LOOP|X1ec_ul+f^UZk9-CF=-J2
z3R3Mj(o@e?yC2!7_7V`II5eT@BK{&6$@>ni4(_U$*xtti%3$vZef&Bi#f{CZ$f|Cq
zB|}i(7{aoMyFJbJ2Orw!$~56{&1EcYK(@A?p%vkfPwwDkYxUcS(Cs$q0enD+R8buL
z2&LU396r%=)dK2qq9Jah4~{5uBx;<;Iaai3nvfvMY+8p)m6Cs<;$TL9D{Ne}e1p3?
zHz+;W<JqA}n}&JELy}H5F8xkhkn0Q1^DMg4=0HG~m`1RJGsW(<z$9Ti{Jzu2mU!?d
z&Beo~t*`y|(eNTcliZ^931+wn6O`T4lUFnBR$cJ~6(`tK&z6_LTJ}0diLzRFy<v}B
zk0wE{tYH1ZGXr=6FwJ8259;tnw<DuJin}X!zE4u;fq2&?-$h)=pR!DLhJIJc$xUb=
zBGa!4k)%_YQ;#@7eYSq&8IuE7o9I;}OXf118+g`DxP06A5k5cBFfb*v6C~t~qdWGE
zq{rtabLmeE>5r!1+4VMzN6`2a)vvj^`}QHsTQk0D2<3mL-&%R_?K-R{_#U}3!-9iP
z!;O@U$V5dvtRw48qk&2f&%`0(>|&E04w{w+b;)xO6nQ*b9iApTCCyuHAEnw8p@ugG
zt7L{UD<Jw6tn&=GF(LB}F*_5Ku69HC0!iVr`Owgey&|=A@&+^0Z)6rt6%qADS_r9Y
z<vR1O7Kiu8%se7fyxkqL97z?HT!-xwfCm7(Ch1k)1z(OrSPZiNOl3rZKs_Q4i{&#|
zpQO~ODEVRbmq=!u!C0&96mm?&RfatkM|a`zCqPH6rig=>kJ;x~*|84#k-+$&Hb}Q&
zp14NW9Yd-AREOw@jN6gICvb(zB${-vFjL#iuvl(&iY7lee#YKd<fhMGhK1S-rt>@i
zo>ENo_5RCva9%)Je#|<o;rpHj@4gQ2HZ+HuLSHr`RPuex8RPVz%fl`i4&5L@712{6
z!!VSgr(u!HQRp}tz{EXn2=c4wD6AZraMqw7Yo~j4UwsrJoUjSqkH|!7OnQ>Dq6f2O
zC*j!E8AK5DaF^T}PO+w+{ZW>Z`9yyi0$wu(;Wsl<gVLAhB`B?<vLZ}dQ7@Nel<IYA
zWt2ncm63o}ceN$vzb?N6$Lj3(tqz_O(Dz5wqvEJ=ocYl_s(sVrGEz_e8X|-a1U!a}
zsJcaLw?SKSPBnoPs32hkWTjQT?Q%K6)Y;FH8GQG}Uo=7O9Q|(P$f0N~x}_&)5uSzs
z+0E0jp;?hUtK15B+<afU(E~UG)+cYo&oJKIN>f5ZtP(TE{O!@`W;vEaNKUWv1mtOn
zs7gKKEc+Qd$d$<=Qo@VBL7vZq91w)8j%VrY%gT@a>l{pHVG&AW58(-joL&m`%E|i+
zeos?5!j3}_>n6y@_`GAhYs!Cv_my^Aeu5{N!bgyBf}r#^5nL=)*)~@G^|FqWD%1yu
z^T9#Yu0Jd&+Q%<P!!G=s^K89DKb9vFo+XZh>DTB(08@qJCrXsvjH7vK#0ko1(KsVd
zj(hFK%Q|TUQ;AbE>A-Y6y1(F?<JO9a`{rUG59&-ma03C{yNfu@h5k<V?xfmmHf7%p
z%8DYtW+JTHs%}0V1LaDUJl%t$+*KMxgB9kd-=x!ew-@^CnRA>)RvWMuZD=RM4%~!B
z=n$qisjz@vM^dOHWbd&-OyWYN2hrYl1dEY)Z~~DZ$Dt`z2A6X(9uL!4P*f(qRP>hc
zKRK-Y+VJB5X2;H37G4!}OLt>g7jnoUy<^H`1%7r7I`iL~r@~7;=5(1G!g)j{c=JXQ
zz|Yv=LVhCB<AyM4yjKvZ0dQU(b{unlFynb1C}SbJ+<|#9{!M$4qWmpgcNtv3Cf(7)
z{{|1p3AIT^FT1lY9+`RMAKq!t>a*)DUih4Cfwmx&(Bw3*n``jUSIfIuZv|iVFE~$O
zGF!gMQR3GwhvFsK@lr5u9<Bj^$*M8Mbj`cE#{FX6^NTkJ@71wG&A-4eP!G-+K}`<~
zD&*`UPQPQ$gV%%Z{AkTizMN||A#TaecFwxzkV7K`Vt$=mQP6}7F6{1VeAJqcO%$#~
zP#@7J3U(a<JIc^7WT<@#)Hy{Y<?eoW96L~h9&iduEh>OeDiPs>r`NON`P{7VCg_Y1
z6!zefLL%IQoZA>8d=~dk<x}<vpMcC1NZt)((q`UI_VUYi>2D0A<Y2_us|<K1D5D+j
znKj2M0zSGkOc5DGnGF3Dz$i=X<f&RQ$_EgUT6SO2o9FB!D3fnej}7`&2W9)1?y}q5
zZx6s$84@8exjj+Bag_JBYO<~Ba@V0#b>F%wQl!t5;i23k=ex4?S|JI7D4&ssqsqB`
zp#{gAZAFXhU5#>cbuJD>Sdfp*_<Yz;$vjnEzXxB|MiKhzmkAlndc)NV<qqwi06d%M
zXli!7H0aNJcxr3M(~$kpkNK%?3jZV<;yH)AC*dj#;iz>u{~Whij96t!6xU|~mJAg<
z17!R@=LfCOHBiOCnCV$v{CNijX*E6L2fd*M)s7Up=qP4)E^`rIwiuM@$BvW|779oa
z@|i!}>J^yuv1gbHd++=4C`d+r8V-&$!8F5tHZ|ny7)iK7h@)uegx1s>_&_A$Gbt}>
zec6gys6YlXYG)fX#$HS^&v0QV#ALGu(A6kvjtD(U@ZX=3$vve7F%@bL$`qH#^qUY$
z^@$Qkiw3#~d6Kd(F!UZC=^mbkF}et@i|~|)y-9-}nT!nOaR29GnfunWttMzC6(;8q
z6DkPWIZoR;2J&^V=s69gppl8J3aCc|&`v&8RE9A8E(^mxHmyN@4eN1j(y)6h2Ag9#
z0npoLIsj8Dikp>2iDx3<i>aAzDeR-@*k~dwW;I*L?IYS*jjE}fz@on9&z~b_`ynzx
zHxY5%q7T#e>vOVi>r@mPT~(x_)J>h=k6}yl=?{K5+E(m2!brNE0%)PiO<I%g?Hmh~
z5n9R;At5q5zd@nPSq92A=*^Ho9^GpmewSVLqk(Yle(m+u?99vu7Tu7hLk!a{+Y1$0
zyQ&?#w}V;i$-Tv4sSKJT7j!U6*k<OqnptN)Nv&`q`=2-^Yxm{~FWEJTK9F1sd3wt!
zHsN*AsBXeZF&|2RhEVh$u};2*`sPHo16e$#;-HsS@O~yWGZ5kUAxB}RVK}ovp?8J$
zlotB|<Z6g%L{kH@M3R<9^;py+riJPQpX;gA<A>KM-UJt!Ky|`N*Pxee2%)*zItSv(
zHXyTQBb!Vv`1w6t+P)#O_2hZeq@{;~)AA>2Gq~0Fh6-LF2KH;kbU^7SDArp`_@>Ce
z%=}3q>hLcXu>wfwl1i(99kmuAZl+j+GDK6LE~LY|r+^Feu^GW!AA)8#-x@Fvw0vDY
z=K}B2`9iqn^0XW3`Cj-K=ch@wZ+^;T;XK%sbDi)ddr(Lt*Xr8q1cu3C_TX!pbQkD%
zW^(=Jv~6_0Ul5#s#>Ls3l3{^^ADv9eXLKMAoa)K~00aPHH>$?bomv0g{R*Jw!SOPn
zFMgR~KJ@U|?Dw<Tjwy7v35|Bd##<WMfwED7sxCFym-V=0R_p%Bv%7xsXmVZFU8ZNU
zVz_nJv!r7|N{H5u!7ZI4o=b|>LDNh%pMVJIbH!6<P&}x&={Y%E9+4%=FCB-o2*_w`
zGMwR^DNYAg-Ggo)$|JQ!yw{}P4xL+Ae|PwsU~A}#))B1^x3b<eS&ZhvQ}IDId0Kn=
z_jY>7svXn*oeGerV@h&U7YEnZr$1au($-(d1wj!7aoYc#tNig}{qhNW{g3;mmbFTl
zTI-lD{`yaCs!dUUv7-E7%*_KwFI$)G9T<~|+tT@^-O&7^Sq#R30h>5Gs4(^knvXqP
zFl~zBiD-SAFH*5RFJg4|z3}{Px-cy>PDX^FcL+N@)Z2A@vd*>4{D!%sR`f&nk#fa2
z6DbwLs5_{!*9*VZXlJC?jgGxKF@ELTy+5>G(2BFzlGad;zWCPLr1L)$Ho22_>%&LL
z0}wX1LZ==C#8=ivDz06$d^MXH*B}yg2=erI@x23F5EZraD*(uM1Xrq@521DgkQ5wP
z^Y;OmN9^OxsS&-}j-FvnIePzy5fcH)Gybvm&P!deiZgkxIi<b8vA48756_RfSg6k*
z*68&hY}eB<#4u3gr1k8hZ`Ja%Q6C%x;B$AM_1`G_e3!qAn1Qq;)r(iG7Qaz4T(t8i
zl!IuOO=g7v7S^fU=KeQFh&*woR;z}%Y%6h4lEk4#72jtALXupNu#!f5uHF+yQkb^9
zM(qK+rw;SO+HxApqI!77rl=rAn(kI9imhGN{6+gNXS1bX@JhcYY5-+ExE7n|VH3RN
z4LT&`yrTF;)?{GUFP;4bC+z0grPkH-9-7TJYEiV$?Z6*B0h;qo#Wwf1Q>TRvI}u!f
zv%G~y?*x|#s`|B7yTcmwefzwvw>&Zi5XxxESI=|lCvU@5SQBGLxI@#qd_4hu`&LUq
z26~-{d2^Z$pCe+K>Iw`N0$0$~l!KG)SaUU%t~oIppOsvqXg#pzaw%EH_lK0y@Hcz$
zOS8|428wMg;k_X*smn}_-ywgLk_^1>dfTLhyhz77h4sDYG!X-aD%U6Vb?;k)M0+%E
z%wHSUzL8?bOg5O?S7@`SVRswO0}Dh5p**6e)$hTKF{1JznRUHui|}E1g<5ir-cw2|
z2wru_-pxKWn%u~wMftovC(rHmws~HfoQLT267n|CKFxaWX7t*h+A1x(UY-~cf9JB9
zwZch=k@U^FT#bgU6RO2-x^sor`Z{9OZp)76N-7T@Vi`?FXkhqEty`__;rQC9NN>05
zNV>7fRD6c9)4~Q=vmSG<UND8CDuVpOiN}u;@pjKOG~@vTR~5YJj+@5aAMXl=%ZqZ7
zqdq8AR*V@`=&P1d>b$2oE;hs6*(R;;)m14AZoep!I1X9Ke`r84<$JY$3en=fO)t>|
zwD{+5k<jh$`|gd;AXe{cBA=&aYFpNT0;q)3|0afS5Df}PS>Ah}AiBFJoLe)?Zto&I
z$U+!$a{^k9o?&ay8;iR{{5tBCKO?dV3TOrUk7URq@?d8EQ>f{eQTw&7JEO*_yV<<s
zTK{Q)(R3;VO(rV7u*E8+%M>&;aFeu)`oAR*0Ou6GHgbPm&B-+)On@vwendKI6tMDf
z%?@WBX7X&2-$6d}A0!>Ng#Hd+Y(k@JG5H#O>T5G1J}I?QoybfAH8Eej$wPLWjECM|
z!a{o@cW+U+Zkydu0<i=YP7zTic3D{|yoY-+2Hbc!yHATX(Ic2_kz46t`(|iSPDf7A
zcwfH7qwoTj;kbM`%R%@qc-JQ$hNw>{4BM$C7ZHMNXx*T{qXv6(+)8aPR?wV$_F!2l
z?{_$jy*}~!cqXyWz0|krJ+}^m2+7*}=m^Gg&8>ciV~-ppLJ1WriYS@hyIF$m@_7=%
zZj<KYKb5cFp?OtnGFu{;lP<jo;a99$UP~SCD?B&fD;G}rU~$19+lZ0QEZsh+JL^01
ze#8E(^pr;oGJQBW-9fTKQ^Af_6X=9q#uT&qR8=PtcB*!mT3myc3n&jw;rdRmQR7Q(
zZ{&M5C}s!Ay6AVIj=fx=9i$1WzBs5=&`SKsBpgYnNLs}{S3=D<Ci1xZ@^~sj_Q!0k
z3#$eJ;&)3s%K`aT=>RhZUg2feC+*-45g%%;<Zr>Y851$l7FdM2ysWO}I05SPO2;Oa
z^{K$R5u;mRnNvUM2;({iI^17&D5y{ORE=2AAyp+$9tn=bfSvL<;%_%YOkgWc7hmAo
z9f<>O+eP{DeWl9$#U@%zB2ZA~^G@^tGsDa&4U<q$K62gagXh$GMP)?>O6u%2`3=_N
zlPf((lY<=}o_8;!7JV&!A_LR3q$xXjI0%v?5Dc~y;^vaxUx<U^kv-l7CJuU4H3;F-
znCHHcz6-PdEG2)IzN>{jq?OVxatN)K+xJ_o;2FY-OoADp!#Qyw+3FvEo1Y)e0HsQ%
zBRw97>xb|(&#rw<+9di*Z!8%%dq(*w3Q}%vuXq@+=f@KtMto_y!fzhD!u7uHPTn#3
z&NydEW}1&``pVufLD__0*BsC33Tz?ZfRGIL@d(wZVS%&o$@DyjpxEP#2Tta!@@y&6
z{aHVLps*{57<Ofgjf`6BF4gnf<=t9a+*1Ri7S)!X<GIZ9xb}(*I@zW!nI)+*%_2|2
z4<p|8k)prt5&f-S7`IcImB8ib2uMttBtdB%K~wkNG1{`C%l|h&VAOw&5w4NGtA}@w
zcngojFd{;4ZbI?%!|R#OCJ>LEYZQs3e1|AI=ZkFJERGiDbVbk5-2#Kl|1E(~l*rvH
ztnTu2fH?U}q+-3`ze~M%V62}M^ioFNSU(A6vk$GYvIrM;GcAp4Wv?~P8{Y$=d)xbJ
zLtn1tyH#mrRo`<3*RX_U4;Ll)j}ms>$7M>|6d&Br5Q8po59{5+*o3p#pOw*kTbQxW
zvwiU#tmxIm-R4Cg?2hU3$|V>f>KW3(;Q`~_zMg@rkJ1m`@NFDfOscvtkbiRH-BaV6
zG{2AOPyAX`74)ezB!`%NDV#3<Fwj-0XDI!+%U%^_7jpnM5!^meE8WRX(_|N5&X%gs
zr*!8)Ufm~e9X<Eyqt`P*f2t^}qZZ9fc|w%IpL61n#NvoxB-!Wceuc|u(R=jW=56BV
zc=k$%pL@LBD}H@c6)bV*K7D%%H4Ibb52+!3B@Iqy?AZl6Y})}xUY127oUP)4XB-67
ztQ)lhi0gDKo&}lRoj~XeC?Q{nY}kHU>J?Qiyf=Ah&&-?8$2f)#I48b;km6vVw*$$<
zMc85`{ejq9Q6=T?`VMVUc3O)#-g}%_JqY!kt3i3I9uMrE4^<(8jafLGimS1_*V}kI
zuzm)9Fw9Q!B>~qXI`dW(jdEV^E*GOAaZCRG87M?IdWNL<r`J5b*ljUGOu-S!>a}K#
zPeVD-H~l6pRG%YDzmkRS1#l`?dbH<z;0tfGxptOY5aOSVE=xz5vjB7*V$qtRTMyP+
zBqIZt)fxG_xnwPBn3iNZW{Zt_0@jWN3NUt>rVB|G$_qbVzu5#6R}jaVP<=(ubrtLk
zLY4-MWIt3+C|$OdEwx4Q-riWuK+cz<iPSG*&#Z|w{x}7V4uujldy*>bCffl02vKE1
zfW4X1owXkAnL~T>-f8n@lP=qL+<ykitCSm)G$Pw;a;DT%2<o*x+SDGk@j7)&5K7us
z&eAp^wFeX{CF7Nel~($rW4ET0fv+!qtJ$NE%h3H2p`<Zy)#pq6j#NL_D<fhnM)x?y
zvKJc_SBmwvN_ND(b`lbpUTaH^msROPr0-qjj$C`q%ju@Ybyj~M#Ag|bRGLibW#J?6
zM=KC(mk3>=UA7TayCr?!tsafMbj^w$3Bk|Eq#EPI)YnUl{dd*V`*m5P2ITa@qUUdd
z2KA_zy{)AGZgSvxbH`LYi6W7TQa&g&pXS+3Re0mHSC@;@c!z%pHCk9IX(M?dGi~C@
z7Y6I^Ie?+ZGIY7=xPrRRSJHL!-ny+pjCkXLRsF;rI|Lo9(UPt`kKK36E+OA;A2XeR
z2t9m=Zrx%3<Q#%1NEUECbuQt08|m&X(aT0J;bcU}ExMUt8y*WnNUpe1?a?f}c+@-p
znT(Acj+jTU8%GtWU-75zo4g<8neeXDpM*oE3nfP$KxSI8>@-%Q_6&mmMP;}?ZglIi
z*ZL^~?~_08H<OSE9M2bo3WsAl1;N7sMAusbncf3VmkGFZSw-+cH6_syks$GFj*AfD
zww%Pu;tifX#-$t`8+D3LS@GonsR!tyMzbc@Nt24JepL0!AX1c}U_5#)l~d`s)@vxk
z*6~?29k=_^M4(o|>{R<~yPp40WFm+HDlMJh^47>9lGW1~e~Ox*VNXOC?fgkcv<w?0
z12=6owu=_@IMG%URN2exvhz)fMF84G8qM8*iqb2lkcpzMD7|q|^m-;C86zhqbZXl*
zHHMmJ06?NRsc1l{eq27W7ZIXZINPIr7OdHH<Zx$(eRHwRABk>WdY03=TYYb{Mz6kV
zdZUwqUfJly*#!}Y*jkyFJo-groo?9*TiLC*fk}|4m;RVXZq`JSxFuYol@)j3gFn|^
zL^8&DcO(BQl%tFQ!v{G?v{sFHdL(ZEfoPC>X0OTU(caLA9!}S7wJ#mFzb@^Y9+yQV
zUBC8bjo`1jRP%a&x?gjd1FSyoW*aF6$1K8(>YgQ`CgNl%((3EISg38(f21qX1I98!
z=oOMzk#r=6^Z)3&^LMEJ_;2867PFXPW*GZ6V=vo~E$fVZZ%9JYSSn>{?0cUX`xax(
zR*j`X5|JcnY*ADcl1gJqk_xGi&wOs*`@XLGr~5wt!8zxLbDj6=`FcEczR$Hasq#)j
z&AL>X`!b3y(D4F5lQ<Av;9l9#ah6Y8#LR&%a6z|<@!;8*I1yp~<Jm1=>GUt!9hN3R
z5Uo9n^pXOEkA-+V`CsdbtgI|9S{hy5C@}))sm@r(`38Q#S8pmIbf04O3kX9g_8)9a
z-PKXlCi9?>Ub?zKLm#?cV?>_}&)=_G_Myx{jJdp&`?GWE)fW0($fWlm_IdOC)3oO;
zgClDr#1W!ee{j8cO0yzFUYBFl)FcG>yxdKZcj7cx_DQgSJ?h}CB_^ip9H!$cR$E=r
z{hOmsS&M5^Of`8zdoH>tG#+Z9utt+)e?#xj^E+<83!{PTQfv98mYX4(WBWIm5}f7f
zbAI6ZZm31q8SWYA3;$Gy)`jh@VtINaQJsS{3A=6m{qZm1cmIB^=m-AN`J1QKtXY<5
zr`yl$N2|e<l@{oMt*2l7tjv1IU)`Eu`I&M;;BT93$^VIco%PBigH+G_=x;V>f$w)V
z2PeG@9fSOwmFJrMu<jZl$@Ks59i;GfE#$LK!}kHi8MTtz3?cHh$Jv}$R~ykmEoai+
zl-K^yaSjy-S$6=~FP1pZ9!-D}t$~IxQ?3@OhcQ#D31ppBw6lO@`AdrT0m3A&K&U}0
z&J)iOby{<K4$;$Hzn@`2Ea^ATayM7~F?QqHPgvOU%9DniFrgR-DQ&eOhlIREF18Lc
z4}S(Fh2r8k4_y4v0ak`v<UoPGV%2iJ4kFfS*kP%%1!y~G?d1x3T|Q&Q7sVxvkugRf
zqVBRMZBRdsgW_X=u)wq3a|e<v2yV+7)fPmmrS5*yZb~VA!-DSw$-F1kQx**R*CniH
zpBT4*<k3&0Fh~TkeKQawSq_r4;#{|SFVz3Zy2vkZihS*flCZA5Ao*;Qcw0+fv$f}9
z)A^s)x)i{Dv%)7ra*U%Kc{f0Z1^Q!qK#MOkUE%a>iUzm;^zMjW)-iS4_r<e1C!v-r
zc}*!_21te1Nem9MoP*NcLX|L(C1gkzSv$B9O$x;%adfx8Z3m^wl8y%Q^$DqZ9`3my
zKp@zt_Q&n5N4zJ><hEM_5Ey-v;KU)=fsOC~j4lEjd`yEor3$<gG;~>pcb`457HO`O
zv%B*_b5DhQAENB}Ua#kwvF<<!A;n~H0FgyUmH@{SqaoM>Bp+Q=0q5n#(nF8|o^vRg
zy%lQ6V+!hqwA!3J@<z)hN?L2~i8%l^UW{`28nyTqBFoVP@PO=6s_sUG=16}azr03u
zzvYsfdDSO#NQW6?!Z8XEy_L3{)r3&BHBE{>9(xa|&d6Hp7h*HdU+aUT4+#6(1*ua4
z8}abAHtQ0I{9`{_J{;7bX0ygz_>%AR)-s+K?eaLs%&E;^h%C$rF>f6>fYmCnIS6-p
zGp4UcK4E1>vb3l5YxO)cSwURN^E#9tb3B)RE|)`6XX*rehniH=lZ%4z6bUO)><kA^
zZ*kx?*#(SW6G9jZS|9FWplEf!w^DcR4S>>e!Xxh*<fW$kf*AD3#$!39$r3%h`6YtK
zvSq#7$6v*v@N?!JU-L~;4L&v;DuL>-2d$G*gRcESrjdom&g&c@A38$P;(~A?71+Jg
zkFWfozE8!ipuer@$1i=Mu2?eL$;6XZW+TgC-P)-JUH9FY_z<SScxtHQwsFDm)0qkL
zBu4&4g2trp&vf#9GGcdD-5^R#C(kuz+d|7U)j_u}H}Mxzmm}HGDUsKA{px8s;W30b
z)1eTw_q(dlls{dw6m~dUn0w6(s}K0Zoe?rDR_NTZ9-K=XS##Zqr-DS>nIhyq(Wrq(
z8n&h@$Wuu>)UkoAJOG}SqEWI#cmdXAf&2EPicZHmJ-kNa({p8|@f!Mf3~vI*bJvlI
ziRg|$64Wd%`<I(kp?uKW{~<U@ltKv!PyPYAi=`BgjB5xsRlVU%i2p3og)(6p`&iCn
zC(_BTPZM_I-9ZhhyA2nZrfG4etdv|);Cj(URu-Aqyk=MyuRf9zOiC%d63(5qgqK+9
zKnH?;4ZvU8C}+7F)HC7>ek0kO^9AIC-@ZmC0ys3NV3C7B2L%N-HJr0Ffzk$YQd@VC
zZ7zHU<v{nJ6T2WwgY|no*M>#y`tXwv8&35ZmJFB@oXy^*>aIO~S8fcyTtH&K8l3d4
zIA!`DD<vXfRS#OGZFui_>>F*nI}Y3daEQrpU7y4ZuP>`wPgu6FY-1ZU&dHRX^xADk
zkeV?o-=yq~fF#DsGfSg#QRe8MUDpBNzn-h1mSS;C{P<rHYTtMOMJ#S0`zyrMZUCXY
z(=IiE*Gb7Zm0a<%U!|m<=uH|@fgB=0bbB1Mwq6l^LXN$EaD0>_!yTYpjb^KXAt4f>
z@5s*ra$YL0FkCo?UT}OJ7CWH~yP-43l`Z(OT_|0OcJYxuA4?TgUfMZ>!%-BGapQ>-
z6#Q17zV5qVi`g+3h(c1ox?zlZUhiwag6ERcj?$^dfpF8Yul7#X2gWZVNdS3!arn-)
zo~So5zudZ5HLV!a5i2}64W^a;IO)JrDX;CambEqmXwzQsewYN=nNkB7ryVb=BPT7-
ztxIZE^&57LH!gWUIfYI<DYc>M=2~Z4sH~S0L3^B(T<=+<Q|eH9(5*AB?*1LQqj!A&
zAR$K6mpyUP7SC%%a;Lq$+g;-M+r9;#d<YdI9=)ON`R3tX%YH_GjcWXG-mTiuH6=U%
z`?qH`IFm%Ao|30om1L!+&E%Jc9>l}I@cob|eq;8So1D3|mfyhSO|7f?Q;io=#=k6N
z$-jJb5&ZFbOOe~+@VBscLP`gxn%rvRcA__baAHb_bq0g<(;AM4et6ZycUh))HTK=f
z+1#fmqmwg#>zr8nbE_ABNzA}yqMOHCIysXJI+H@wJtUAZ`DAuPtSV?5lqFrZzIJ)4
zi%8I)0k34-y_7b8-O|q{j&f71_3L%3&>Ulzp}Oy@pRdNO(^~kOn)`F4cUND1u3U@T
zTB!_Pd8%A;JP?F2>5B4#5C7a{!YWR)zTE2GDsx>f3jW@77PPmiMog!FuXV0MCQ97S
z)KLV3GciU^bc!FokytNjwe3vAX%13x`606_=7!c$^XaDXlQ)V*aF>>PN_xIn@PBS7
z@6XZfDQs-{8n;w<`4oB)el0rc@F(N@Gew_D+#(v`cYm%vO_Mm2-?wZMROx3^VaYq^
zn*GGV)2R)=Zg@mCG{MyhrZdiymRE$~k@>cMCF{g`h=wr%0PzQL7?)c_xL|&h)^;%(
zo}ZNd!9q2CI9R+w(N#oDDXUYnwaee8sX41QH~PDu!?2UyuXOX0twQ)^`8PS%^PVoq
z^pcRyT~uWN%yLln4>#2<jrq7gGkXtjOk_f_+q9|GrM3aM?$dHrI5sU@pW=IlzJB_p
zVgFHvZ3#8tl7u9in_@1@94xfstuquxjoiS<E3{>tc<B4&H(hZRn<`h$TIemoE8Sd}
zjuU7)i0HfYz)|)@SmSk#^mjT_!Zr;RXYDWk*0!lQorhaCiOqlewJ7TQGnE28swWx5
zXA>sP3=@4moR!6UMgSv-G_2p3HS!p-UVL>+Nnyei;1t;9*;z(Q0QReeAjaDy;zZSq
zM!FEwVq*1HoASt=q=j?&O=|TF|J*n$Evbf+9Xq$KU8IM9DmyXfTQ2HlhP#e;bWIrc
zIE{WfwR85jg>vCT_^aW3J+5Kh#vl8zg`VUsLT#Q-$+33OTjnMU2~Qmds#v!aI9+85
zh#J_`^%{`Xe%B0b*qjSM#EmHZC~;y-I?WQtnmOrqaLV{jNGg=t+K;b3Y68!qiAlQ-
z>Ls;f^S1isg945numa_LVGbu;IBXsN8)voo?X<W`yQ7(}wRnH>b-CRxh$I()>#7P~
zR0!rV$UJ|+zaK8hlSia0?*7bm7V&c-wic5dVvTH6Ndo5$ITJ+@pzEh^9<iMffTtDO
zhM%;ATAwIXko1#Qvm>U-OOKd!Q@|3gHNi)j7WfgRJii_)4viG}*}8A4#rY@PZ%x+_
z6@BK#wU8a8J<%xwUHbW6K|C=4X0m#>fc~DC<F;fei=_@hRk^Y&QX{5YG+5v#EyVnc
zZD@|tq4_a_BDtKb#Ebwy(#}}vat=Ch9lp57bgp*1B%?LMz_9kcz1ESp-P#DNa2hOi
zo#1wZ(5M<`DeI%XWVSMYNrOD^dZ{@_tdndX;u%4CSZ@1cx9<|JxwiPKQ#tR~nTc$d
zYN4{J3Y#aD6q$cCDCm1u5V>8-B_9tQ==!>nnKDCNSMQL3lSJA1AUn%b``=LtU?G6G
zhxOZU3A}menF5T-jP3po9D?TT7Xg7K#VG=$a*%*5he5v*s>jEubCWFO=)dAzvCTef
zQq#^iBC*N(?fIgvA;qFOWM1s?ffY~dhW$zzu;~4UuNoFO{<KHVqKzw7M!Mc&`$1i^
zrY#4vvUOO&X3eSJ;^#!92xhJ7^G-f!d+gXosh=}KA&15|mxQf(o9$A0+_^+S-cZzf
zoW?v?-WM#vVZ2aPB)-WSMnG%uc7Q*u@dV*(zJGt52gS`p9B#@R$+;f|SVDbQKD(b$
z<YUO|6=><!A_iP@T%9nYb*k3F{NXuXX+?guBR0mX;rD|ZY$cv_X&%1nIjUC@aO`hT
zf568~U?=&slup+*i3HkfxfMz%oKjb9wNNGMtw;vC05?S(f^6vDVE2F%B2}A(?D&25
z5Q7=wyoCy#ES8I7Gh9`D@DvXFUT9L2QEt%@RrH@*#odL7*Yi~-VSXsLF0o$O9Z>y~
zfy*1Kwg<?r$2~b<vH#dG1vko^XU~GL6hY_cZd=x)`l16nfUWofDf2Lgi2k(BZ?OKi
z7v}Ru&XIZ!L*7i45B#mQy8?qqZ>8qY0yFk=qvsTOpltLO1111irRU1q3gl;8I$sWg
zD03K)B(l^7XMwzeW1zNcz+iEP9IS1guZbdH!%>FN-isv0K~O4+VJ5d*)5B@bwhs-@
z+E{UcW%BAlDxGWqu6iG>82{91+E%x`FWWuuPfeS+lJVX|X^gZ#X*dXD{>oL*JI70q
zj!muT1A|W%p`DzbTH?OP!uET+6s=Wt92&w?S?_63)ZJJHVx3#xIz8kNZ`C#U2_+;>
z#5j6#aGDK>u=?9(YRpS$o0I1yOe#SF)U(qglsk7)qETYTn785!IO`-1h`PPuzWGTY
zzi`U>x~jf<gx@~Et{`>IFkO8ln0N5xcmVEZp3q$PM*88Ans))cmWRg;1fZmroC1pd
z;l1Dt9S*=}fwjPH(q)r5+`EqB8Mps-yf#-kjXmVa71!aC@fZT}a}R<qy)cW9!2JGp
zdlca>%s{G+Pw28K^=cP4?u-wB+-Bl>I~fJ?KOn@js0W_-nqal+>cYA0;b)8IbNoO1
zkLGf1&B)P_ot#k7#-JxOor!#U2nB7aVkFI>WyZZ9k`)-g4#sjW-B_7Np8-hcmIog_
zWYxh0yFrJywVVHoS^{=$9AGo$FvGz<!Hc^5gig+5^K*4EQ5P)CTXKueEoFle%DXZ_
zAC0W1_~ib+-^Q~K3GfoxKa9d&x_G65@-z$$u8!a97g4p|sI*Aiq=?yoL=7qQmTxTb
zY0=4A4L3hh83?xqpjQ|xS>FYE8B%kX<i6huFW0;XtCfCXwOYnNDuch42O>>A!)Y{H
zMtT8^i)&g|g)t#zWM)<v8mn=xC{s+;Zg7Dp_uEg#jq%-wY`>NwtG;9*$bcz_fhEbW
z=Dui^1U%6fG%{momix;Z1ya`T*fRXYpVXkT)Y4nQ7+wt|pb;5S<50rHm5r#qV&eMM
zM2-ANmGk>n;k#ur#GbR*1bI%ThwqOLTN>o{&+zMAVC!tS=I8AfsoT<nuzo-LmKvb?
z$N_*iFQ7>kwBST9H*~&Y&L`bOvc~Z_Xv`)QkmUaG{|bQnRJ+DCfBQ)%tfiet^LH}M
zLh6o`oFxk8$aTVQx3CMF2>f>!<i;SuYZOu$Q`l!75p_p%xdtyjUs7I!8gv?a#YWn2
z@M6~QZJuBqb7Xh>q+c*_iEK$uUt|gcY1ArL&bbl6K=v-kcJ9C4Z>r)T$RYy^P_X$=
zaC<ah#zovleQ&!)azzlCPu}jaQ1YGt{BuDht}4KVK()&@?Ztxg+&24AKUH=6?I^su
zcxtWO4Zk<t%i;wah0*}#Rj@0U0*<VCn9r8t+>u*nB3`!%28Kyg*9h{K8G@@c4B1{Z
z!cV5vrXCLm39|8nnbHZIKVuBo0!YZZR`SJw?98_tXI`o`FqNLT-0uV+Lp1Ez9T15I
zj76YQMlP>_=2-;f-S3*~E%H(vuoFtTX+!G?2sNj5H7~Q9w#wTLqzr}=)<BrwPY=>I
z`8&Ac_t>cY82wt!sqZ)BT+T^oGG}c3RBrc4_0rI*Y{6MJMzIw$%NBI1v9tIh5<!$Q
zdZoEk1FC-o+IJP)Qjok`@CJ%>{ZMXLyC$bbx2Hj(!e6ed4+19KFYy<84?vUvs3-#F
zvjB)kC_SFnBnmw!suOu$M9_PsZVUYENs+B(lRll}p<;*y3H3+t6s2$eQ@a4ada=$u
zw)wwDQJoyg<{Hc<faw8YI_8g6_hFspkymM$?_AUjTR^qLBD-c*k?l4^5j#T>J>M7V
zPZ4cs#&<FgKlYc)BJ$_dh+DBwZTCs$aQ-}FfR_6Z7X7dW=CK4W{2~X|R5Q{+gmkZ}
zDl@SQjFn{$Bx&@LZ>{LJTG=%nWW#*?T5Z(GA)}YC)y>KBkL6`L86?ze{yY`jQu{w7
zi>Qn?qgBc^+FkRVLnz*B^LCm`J42wG?V=K8q1GX=z!q3$=-pb901IDOVp^V#)Hnme
z^Mm}yhh;oE#Jgyc+kFSGhpl$?Nq6%Qu)&{NgEf45zqE9r;zEAdNlhUe0P>Lmnz1uJ
z)ekWm$A8yB=Cidc{G~?PmFf=((dqzL>A$@tsP{*mj<2MP`}dKM!PP0!PiindWS4sk
zml}~HZwW`<k&paw*Bc^8mVi9wYBVi!@UQyqs=o=#o{@!}k=q2}WJP2)iRJYz@DZYH
z9>X>jcwcRcS-JOq&0p3E(rCiPaD%X(T7tc7J4-UAa$HHL-sn3KDXovRtFdn0@=#-_
zZVF;1g_V92Wm*|1#*}HY22N-}g@09YW?XH>@~|`q#b%q=l?v2Hd!H^7Smg?Cagg8H
za{V<BpDz+QV{$i`IGzc}Pt+zXqUON(6iBudWe0p1<DxlCInQxjM6=OvKcqtdr`lEu
z(V)=7#G3$+2uC4#CKf>vQk=(txfcHY@x6zTEH<*cST5w3hnEEaB_1&&1h_7U)v^Q3
zV-~YU-{1$ul<SWc1rye5WJidYo*Il!q!*}3yqkkkH^4X?!sOHNhJO(K^QKn^XUo&1
z#QT=%f?+}X2N!)|uv)1uuIn4_<3K>J6Qs!Cz}J3hE`#_qb6>1k$OWntq**|9I3~H^
zd)}^+)i?37zmX}=)s&~hPE0@&L`GMM&{|G_sVJ(}f3blu&8V?#VO|gxQ(6F-75NEg
z^zr00HEN0&k+zZI;Ik4s%%n$Pxw|#^!Q7rR^CD66D$M!lzwAF_WPx2ijDrGViy?4}
z`C%z9>0M3my+zw@3a+w1b&u;XzpA!Jl+Ne+9ox`coeq;Cr%o*D+&!LH2cSM;P@QDx
ztY6sZWkMR$zi1xoGpW{3#M{g#|D;R!e+q0Hlbs=oWi8ck<;5IoAl-n#I0rpVXkR75
zl)>=YPNNkNOnNZq%30f$tc*C2RJR|LAAqcNhJLG+E8!;p*fgwIfYir^-if;K*k9I0
z<qdEdrTEhHI$7~rY{t&KEY|Nrk)QZ?|H#AlC4TpdzmIeMO_5uthzVx&_#R^7=Q!EV
z30k*6aAkRzWW@o=IG2bn%_U08Zl+j=U*4y36X#{kyYqg<<gj){zo&=(f9@p!p!Y8n
zoDTpbKmcAsLPA(rSQL)c1ZgVE%X;wfo!JL4q0kr@{G2h)TT|-TQNDfsGUzNMCR!lm
zs1g9!?CY0ch${d@0iXmZf__lJ&json&L8Qc=&#}tY-3|%XK(N7;u>Nfb?i)3baeFj
zbK$3tdFqnY+5w;&1ZqS;iwy8x2Jl<@0#$<2FX8Zg5AzQcx`BWV8}iK@hCJ8c`(gy*
z=>h+l09!_&bv5uVSmU{XR^btRo1HMrRjvKpfm?wxGuH4IPPorDe7`I~|5^e6IRd{N
zA^#l(cs{@{5AYW^f&T&k-g)5PIN<9!_(X`xU%+J-L?6Q(EAX}{J?qqR)~+rvU^L8b
z@%-^>c~8R~(1F*0b)#nyOYrVppu3yzcC$cTx%9soAYSF6^`Zl7*Mx>gpffX&m(Q^)
zU%>yzy8QN4@ZGdzQIXx9JGPf|5?az@JMKnLuwuTHL~)B;rlx#bpPB$brU-u#0CWJr
z0~EXy1#8oU-%%x0M!|9e#Hw+jC76Upm9v-aqw|83a_F)7{?sA_<OKjM1He~)<SGFC
z1c3jLe0zeZT@k5O8iWgq-i01rJnk}C054=An;XH6U7-875x0sJD~CYcs|T_wy=s~f
z<9VRp?V!z4_~`%PE+>HJuYgyx!0a>ru`%GkL11qj%4-gOG3q~w&FIp|YPV0R`oGF$
zLT*)Tc4<Uri4E&cTwy)^W*d0B3YPl>dU*y@{2Y8`5mfjWTK5&y^b5GX3%;=h-1`sc
z`j5YDN4V+h!K>qT4X<cT<Kd$-+1c481^G8~Q|=aLwcJimE2}RoxOqFHwXosdg9i_~
z?svAewdJ>^j#Ok$6s13T*!AK;+d^Hz%a<8%2D`_ec6}ax@cDCX`n{*^4~Oq$zZt#%
zeB$!dK6-h7Z0hRx(&)3N%Wo(5(aZM>`{w2H*R{2km6e}sUsk_ueBIpo-{|GeK6<&m
z{paWU_fJdjYM(y%f4P@@NRuL~HhF6StcWE0{++sE-{BHs-O$TA`+~g~2}_%`_x1(K
zf*Gni5!Xx!u581Km<U;xqJ7@ht#~0hmXbvA!IRHA4)mi%HEiU$QS9u?TY*GJShI|4
z!P-Tlr6~H;^CTEraO8JszOX8_e#ZE~a~mPW6PwAu5HAp~nivpN*sjX?A#>)N-a)>Q
zkoHG17jTwm)+8oEAZUxfvlm8$yUa5x2O)U4=p)t-=^f*)dtcu`HN;!WiLIbX*>4g$
zWz9-~34}ak>`u`sM5@%|vc$~_#FgT$93Xl_V6*q)E3bjM7mp5Hds}pa2kT9EHCGcj
zQWpC9eyne6+g<&~)t4V|BWour3~>I_fd<m{s)c-sEa!G_p$|$8TuYFX?mIaUpwH0P
zx_8J+CnE&nrBy5uFk+%-9WV~sOwxOPf{LfSaP%S+LIpo~4j&P9P-k*e43|Awe1&78
z*?gVz)2?P6dC^Yty11#AM0wDFqw`)C`|a_iJwQx29=lSguQjuh7L@qt^(P^#m7p{E
zAD{oWOJfwCbu;xQDxi!XXQz*8Nk3O1Q{ap^QGRFgMjHN4kFEg2KCp1<ICrw#3U$_I
zRtA*M7`F8fxsoQJ{Z#xly4-4GKYjWf@n!!fM`KgO%sOd$P==TLec+|2<^uhrZ@V((
zhG^06T}gK{U+j|o-uPW1?eFBWBZmTTM+IEngaXN??hbuExG9S5U{rkP@j)R+ymrBz
zC73AL@BCe_(kj&<B-&_N<Ips*;%faR%G%YEBcj(#akGxmGuH=2+os*$2tmFc{oe14
z8($2$>|i%<|4sT(8Iebxe$g-@?SI}@TSRxmi|li2-u_PqTTRe}qFnF{RMw6e&{g4U
z_A?g@7BYX{tT@)5_@#YR=h3eS4{vCCtC-<!Gwq?_iAkWOYx<lew9C50{pYk`P4G<R
z;&ZXHUaaQ|s07Z|*$c_w12&VU<}0zb&U0(5!Tqt`o*U257Kol5^MU8H2Fm<*-Sjx@
zH+gf)l-J@qFR&t;WQTvO3+^2;JT5GoyvR<E{@c+76^xEj-2TG%Aw+yX6z*}AIHFqT
zbT{!+T~UB{LYgQgOt{omcnsuv$9BfqRwZz@3($<dQJ25_fXn=_?6?Eep^wjy%oN+z
z-?|B(d3AA243{G0XY2fWCfQ1q{l?FVv1ah2hnr>@VmMT-9GP|P)Q6w4UcT{9m!L&j
z#p3CQon|a*wtf{q975=91hH{X<_mYOxJ0}8ojm3fE5u?sB+B&J1mxlJ3clqN6cV%b
z9ezVqM%I+x(LvN|lGsSk0Fn$!nN?Rcykl*h!24P|N31-p>!akaG~AlU{}#r0hPy7v
z84z;iOx#xlK<-utGKCngQcN0CGktDd^ON@|or_nL`b>e5^8b{Eh=Wc0X?6B61S4pT
z57Tn+r1SQZp|IrBs1u4OZMR+Fq%eV0k*8i?&0v>Y<N4G6vNG+qj$0OQLC%43z<<6L
zf};Mnly_$=K6`gw4xi!JklEAGgwuAFJLB^C)XPWtyD);6_;96)IU0q2Sw1movWd0Q
zi(BD*+#SbI<(-VlA}Z9}0*OjCPBAcXD-i1_^7GH*m$;%+b9u{B?di6)CSjm}*n|sG
zp-hq2;v__SSF?dxkZiMXf%e3>!YdxPPfskvZgyo%@lRZ}y1rL&jG~K6)BCsKuv+`t
zB?#)t-jd_@4S=mUpPon@)~Wh}yRZ^@Z7Jcje51~z%OU&{Lo<AcUw-O=(y4}~ezgek
zvjsOEwJZN*xd@$S-F_4opl8>WQr1%lVeKBQ5@oUmmy2!uq2m!3oQ`Dsf-j}CMix9t
z>RaCnFaS~R$_gm<=VZ92)=D08`?uaMRCK2(*2%_Y;SjrLOJ$g1b1M|8_f)iOJx!TL
zj8(3g$hA8s|IpJll-tGhdU;-XWhbkil4NgU)$e$!cS$<nfQ>x;;L#_Ab;q2jIM=Qv
z`Kt%N@+Tkde{WLDC#zo8cG!Zq>L*leQ9ue%;*eEbxw>U~84ZNZ1A_Pp`q5MnLW?yx
zjH<-q>2ZoBhvPIt#7aEuo1;_Zf`_%nh0$j#Ckvkg&CQ|*Sxb|F=}!h5dhcSNpR>53
zMUH3AZuO<FxE!~Yzn&H6a9&7W1ah4e9VE{?fu8-PSPtFG`FoWEl@Usp^8p+LT6RUI
zpr81=YT&rF#E*PW%jB~P$36bc7c?A%ROo5H^jz3}$1I;HIza=c{=@x{U$U57&=mg9
z<5H;nR+QXp`t2y=o-3=qZw^T7B8}#RUDQ47d}T((+eT0f#cP3*R;)H$wId$&gIsXk
z<hn?4T7f#EVub(M1zsG%c(k%QKuIC{D=UUFnDQLb2e3bx^=?3vw|C&-zmU`r&Zj#|
zkb9I3o1&GClodgV=eKuS6-&II%zhsT3D`*w3-A75-1k*!6`yt8SYAM3q#U7g3n?==
z#%I@SnPK0hvJry)AVaP+w&C5hwaU8sFC{}PrYIfR81m_}MG4YzCZ*<tuIE?Xrh<Qm
zD1uR(loJC_+6)6CkMfrnfa*H3${@@_aPvb5*6QWNMkEe#OH2A-A77mr@^gw?rgd~G
z+=xpNZT?qsfAg2r_scGOV$uEdzdytj=HT12W$Rz<=3lzCAd^bD+(+YeOno-{`(5lw
z*|^k?El>4mJjn#1n4Vu)7tLpi+8)IqNpg?O154p@0=sKf0cB*DA}HH+nZXx?dQb&N
z*E(9VFtB&7Z!a7>vnv$aY}Fp|9dX9B60vcW)Tal!b!}+3bm_woqRjN^XbA(V#0hYn
zpoR#Zr(^0+Pd?raap1sr9v?n1dh&=~w*HJh!~M0=DDpi@CjZ@esj%D%PiQ9V1WEHg
z#AfLj@qzsealGM&f_ebb=GjS2v##e!$n+akA6P7<k-UIhTOj4okJjx@<KBbkFQ#=?
z=m`7YD-nMQ_}xc_aC!bZFCRvyTw|{1-$}dc5zRR4P_ALe&^LmcjHmSber(N5*7)vJ
zL${se`Mo&J7FSyiY~!DrdR`f2i5wJ3ss0)sCuIkTZ`J=+^{g^g3V&_ax$(Pxm3(}G
zdx%;FJ3uxZ6B&)b8Q9JjN0VElhtA3yaIE8_g`yd%WULxR^rRlaeETx~{0%#)rNEbT
z_5FGg(E#*An#JRrXFc_kB4Q#n??Tpo3!R=eup=G$cglO>p0`v3z6fR&3X_S0ODt39
z@v$~Zm+6DLkxlo+{;Y%T7*J<y49rTc?&n428cf`HxH!zv7=hchJ)zZyQrHsj>KDIa
zkpV7Y=xl>WmZ4mBl0MVYejN-pv~vM84cN(hgwS7abWWDzWEv=TXAXAzDLQP4@P0E8
z71m*vMJZMk!Tw>W_dT)s^^_A`Vg{lFGMUOH2Os8wQCpdqiPV|<c)ogn&11)hCeTkg
zB8weXn$z@Hs)7xjZ}#ZX>%Ri1{UJ8M8Ch3&%Mc{KhFRNyJ=Nu|3OW6lovcNPza50A
z(<g%oX1i4Appv(83gn2m`8QB74KAZG9zIW{40U1cR7CpwJygO4#Uc>vRO1dZO_5^y
z_;{igNbvY;+Ux-4IL*MAl+SV%BU4Db3t$-oolime(|;_lH{jok7O3hKlnJZ!GXxCN
z&yI=Pn**ATt=?8d<=73SX+J+(TCPeB#u$52lXV{1h&6FDWNPzbFURP|x}`neHXmG1
z{);{T@8|uQRK~_M&K-a1=#;sU(m%@cuCHUPmu8CKh02BsS$mg{PjR$!Arf7*QaNEI
zdq`yBJ!p}5$zM8rwV1E$kDOzxnO1n@Ytdxo`4Tt|C@s=t_C<Xiky1w3yTm${MW2Nh
z7H+ScedK9OrmC6z5n200{^`dWzv)Xqhb`*-$GNa@Y$1nLgE6hMQ7CumDL(!$9j{-j
znpopRra)0!BHA6+Ry413wo$p8<&6+o*%9aXd)jT02&6S0#wYjSEpC^7+*#50El_F0
z_SLK5%W{iLBnlX|LgR?O9PyJUSdOiSv7bG0W;1vqkKp@)ihkOPE^H@4VPVP?xqlv%
ziBJ{l;hBHg7*DReExnv=rKaVdt`ZLSR#lujfCaU(M2Qt|huziA6sx%U2l%0(&x+&k
zY0=I>e}ADGMMHGFWUaXJTHIL6O|TK`!W+8KUnC&Ly(YrMDSSRTv2GZ&EmCq{<SxP2
z=P)*ANBLtvR2U}lkshaoWh!e6#4w>+>)Idb5UKN!-mMyHMO6EJJd7Kt!gshVR#4s#
zoxQGo@qx=qz<I}Yh|zBD>d)gWqNjQQ$zmDo*>NobDf^$Om&(K;A0`TRU!;$nWBj&4
zuZ^$U0@_<1ZM~kR&(1yA;pD<Sc_`%q?=aW*g4Y!xkgV-A{*ysG_*mxUH|P3jUQZ}k
zd4jJ2zh)C$LfDY?qSHDuu2M?u<kg=-e=9s346?K)P<2ICOG}|c^sG<Wg-y$1j<nP#
z!%6Yowwkq24MLNQA0}xVT;_4*4bnfwl?;0(B>F(?9rjqS^)cu~u?$7hk(#^q7URN|
zU$=4DdYhzz6HLqD)AMVVZ}Rx_+AwAlWo?gtH=bX0S(h&W6FUOc9H+}p2-q;7#w3D8
zTuF_A-I-2^3E|q{Op#VaXeZHEHVsVxnw5Wf5XP(i(xU-V&1<e0xK=%VM;`W9Xe?fg
z{6~nA!_@P*Vq57hP=V*0<YD><LXSx`%7r42?wylqqXXkA!4DXLwc)2Im8Qz+kOrN-
z-F%gJK8uW7vb*I1wGAo6;w=L8#I7UUw(T!BV(yo~Ght1ZZd`0lb@hg@9StfFm+pl~
zzTDM8-|=gF)_@<)SH12g<zMRYIcqS5ud}Jc3MW|i2ZBu$T4V%hVKI8H(AO~#?YP!Y
z<sRo&@xNDaKWQ!}K@yIy)Yqt_#Lxa^WomDB*;ETPI~wHSGkLA@t}9(Ndh7tFTW4~O
zDl$`R*WO-@JRN(^5IfX~S)}VZwr1-e)U)Hb`rUQ)c;{`zf+(D5p})OWAR<1wD)^r@
zx`P(~4LIFpRq&bTA>340Cfi8kbv?3TR<HlmKG0tC-?m6WMXT#P!oCS#@D*2qL_hBq
zd$@k8pM3R1M4Hxy4%Y&jed4Od_+dE|6|<fqmx$41KzBr2GgnIvoWKFy__4042ymlc
z-$|pV@oW!>6UWKp-TpG&!=n!|zt~6Je+vDkK@UolJpD?rS1EOxC?2w)<uzzQZlJZI
zb>BSnwPTR#5{3Q?7sIUI=Ya^lyZ8Ti^k@<G%lTMxWmh`jp0g~QIh8c!>6SmY9t>@i
z>gA~UaOJ;$zMZPy9a3>&?p7zV!UNNcAIlQFFom{whvT)2JZ9(Yu~6rOgtnU04(F)-
zZq=~kf_WZ!BBSmQ4>gQr<%NH5b)AfBZhwn6dYJ#;Y4pTHqKy3gL2z|Py`(euST#T4
zE5x2?Oj-~Y$lJNJ{I2L(VshuaQ+bSvexguMw2PQTuIGlZ=?Q(IrS=Q2!AIhtPqL3#
zlno}%m#qA~_Vm0PT#w2kTKp7Zn(Syt(e>i|WF}~yF0}YvLZ&{eFyL^g5q5CkeUX3@
zPO}Gp$w+Z716{U8RU*^w<_NhfgXN0(x+9?3Yq(Ez=#lMPtitR_@sT&-BViIRKFxGw
z;2gV^`(2|4MB&Cy)(^FZT-TZya$Fy3ER2i`h!2c6;2j*1N`S0VjWu@s&W+ujOfA0F
z$va4mLCjJ~HTpojwczmpYnf(a8I*$bLu(r>htgSNjg78R&iQw8#3}rR3=_kbRdd;z
zX6GjDt`F9uynN&RBvi@rF{<$`ozo^7v&Y~wVL%VF?_aKF4X+M5>}tQHrZ|Tt{U>}A
zr-3Ds;Y$oDuiI+YtcZU_pfPn2;BDlr>Jdy?IyCX+G4H&_X6NB%t^MUz<(iWfHx1<7
z<RC2Yc{VJBAozP-(3=LWQlFlLbla|Hu$b_B3lCK1p>m<Kmr`3l&vq}H_^*vmcYh9j
zLK@g5pN5m*VXf~jaA5&tm?afzNNXr-ziF&g_Lq(^vJSGU5!}83(QLh5%By58zVCE$
z4S6VL{3up5sw}748moeZKQx_t_yKmF0E+<ZzeI}FKByj^0*CYE(LPLE(8z(wh?Ly8
zF=<tNavrnqN&e#2Qk7B2<Hyj}@L=*B|94m<Hu@)UNT2?)a1zX{pZ&`TT6*_J&yV|Q
z+ppyjUMCx~vzVVS4hzA;BB&=ik;gSY`|o!$A$z$GAHgQEEKHC!i(kNC-yIn5TcwW}
zu0M&|%CvmcYfrhYayn&+4O{#G3n0N4#xc@<j>ELamsb2$sjx>Hi(yze%K^??c^d^H
z7!jb);DW}jH539vR4r#`s>>NyXX)?aq6a_WGIs%h2a+(n*8LoJ<pW4K;Pm2CSS#E$
zHpvcXIi-EUmH`g8cHjAZICRkJpOyKPzPz_sl~F9lkGztA9SUee7b$2UTvo!cFoz_W
zcTLd2-8--6Z_3OITQ+eJ<t#};?err&sTv`(AUHvS`S4&1)YAG*?OldFgaGb#UJ0hF
zS-Be6w?dR3h<%_Lc;Jt}VtX2~Lo$9R)*8Op`G$|sRQsTT?jZ=qws6mr1&J$eRp*2Z
zr2u6PER6>XpuWEQs?CbpDOg%=Or8>(14})FNb-aXgFmW=;N)8HIug{McLfs3D}exJ
z8IQiR7I9s6EfTOG|9y>JN{jtD`nbLZs>b_Lca=5Ne9Go3Zqi{*7A%<B%e_E=cN5U^
z^TE5Di7+ZiTXT_4*nBc=@L!mWK~v=(PuYeIu_M%c(0qZB7hjyiJY=H#>4GuiFrQx7
zEIUh6<Z;5V)q(LZX@c;z3e3mVH7gK?Jqu3DH9K`1l4#;x(mR6u!MQw_S1^G7L55xJ
z4Wvsl_w(^ngt;_X*wMuP2XPfASdlpwh2|KLp{mY%C-M)-$$o0ao4yUT+d}_f{L<mU
zA_?|@U7P6N1yilX2+mdWq;D)&j2^qvZKNz)mLvB4+dqac5Fd;PUH&~>%$T4+V!WbU
z<hlwKcB2;-V2w9;^Ju#5ygct#5|5i^M0+Nc|7_>jD+yQf7U|(E8=mG1+n}F_mA@H<
z2PeH;i<9|E_%TW-(OLHr%=;-gi}+(<@<HZe%jIi$n@1S>t)-g<pMjd;3R1vO<;J_q
zR6jEaAPqL8SzMCJ5z(kTTCT0oA!*N|QyN?sd*tnlCgW7xh$b>dF&*ri5g+$AT0-Xr
zD~^74xoVosTdJVEqShA4@&T)_$-RY{EG6OT7cNq{q96AkNuH;1=`3spP0Tz$l|vs%
zFZm*1UnJvI{>*7cz_v)iYpd^3u_e5~h+e0}C+)dTWB-#Q^vTljCbDpfVH&Eeg?^ip
z(0lr1%<=l{ss~$CUQ2_r)cfS!yUjzyOHuu=?deXbRd+Jx-stS4Q>#z>3A+N7mnp+P
z1z!LlHo=3+=nCz#TxGWmg_|<kfg{+V$&v9JKwJp<sA6itmVub^N$Jd6-_mz3&>w#w
zrwnG8R_JDb9G3G`U9TIwoD*`xh!&^)SzvsceM4gZK<b8M>D`^x8eD_d;zNU_IL8}C
zF>JNmso#x|%<WFXB|%y5S+K?>-m^Q_Vv+nD5?4qeU;EN*JX*r*d&Q!$e&^2hZrXR(
z>_b)f1B=E6(}c{9cwZ_Qsqn<>n=D~rpik;m|65S@<t)6t9L`s<cnr8`>}0qA8&@{=
z&Y_%<I6ET2gLD`Sen~e9xaw;EFcY1XfmT`^ce)Xq=lPXy!)`GXHMzpLHBlDFaK9ce
zuYTzDUv+Z3sx52b+vB|Dr~KkkOC+pO9J(>TJW_TL&%oVn9CtbFjz`KWt)!gOORV<%
zYSP7N10iL6IWCH#dZ%Ly%oxRKHgh3ks+FgTC>a%T{dT45dYwq+iole@n<G`VxU=fd
zW*a6uHS+EHVN)K(qY4Bad}F?FY}bJP`%1p@RzMcy;ygElZxk~utvUTpdpfA@guxt}
zeL0{B0vgNPi?U<H745lPQqI))U7uh!2KJTiW(Hpsjat83z3VT~wS3J`LwxcBloNX`
zF@=X~l|0{%tqam7=u-uZ0+HRfJgqsyg8U<%mj3Gr(?OQqZh`Jqn?<TAW)*Da5jZQ*
zd-}}1_#E7<dDOH<nuT!F*^1SRezwv&dCQ3cI&&b&ic>CgYsx_@y_wR+zdhavzFIlw
zcUz`^2V1RK*oxA;5a+3exTLom8#)oWDKLxvo@-Md+3>newsuFq5`B2n>PGoV`iIN_
z09tOV5ammsXOc#;>f~PSJ}A<lo1s4=6!Q__;PktUc(_L3vy7YbHg~)rK?+2M;hf&;
z*~|V#2bQa2eKSv@bvi5f-kt6evahPLDo>O%T5bxKeXqA$8sFJgnSci&9UDNUyw#(S
z@(+Oi@@#fT*PG_EpwE~;NKngaI3hgMT5v7$+C)Df@KDK8)c<u>p=^=SB`(v_cx5zm
zNk|TJ`;6q?X#amgI+vsrDR4c4PmE-3F<|JQ0;tt~i7E!1_a}?$V+gYnCi=9r{Dp6a
zW}z?q3<AZ$=_rX>OW63sOG<ZOn7~QYw0~L&OIc2Xl#L67iD|5GGEeO98TQ;2{wUq%
zWoVqI(0{WWh$D+!S?2(H5&5|?siNBe@nhgkLc<o=Lmvlf>76K4>|*3C?nvVDY$bn{
z4<hT_pPHr+4r@@TDi#|G?FZw;k%BiMO@`?Qsq@UhZ>e(6%WFw5c$9p*9IQ|5-)al?
zgoKZMfTrC{%9egc%GvJIdM~!@P@>m`?1@abWPSygS<z7^fo58&A{uO1ljAPEDJkhU
ze2<08iyr~yTB})VGMKkhv(n@O5)l15wHS3yFkJnFvsovtXp%h^Z<tl%wC0zl`G9Tu
ztFFS?!S;m?jzP<Oz~%s4rhAF5NG<vFcOj5UKv$hCUK}F&lm_>h%D<?PUD}|Nl4+Z~
zB4tH-ikh{OjF=%bSeDuwbVsRwX(XxqomZ{+9a;VwcLrG1J)q{+T@V|1U3`1QMmtyk
zs3x!Wl3F+N9$tu}*aMixRg4O@u!fr@m>PO%j-uTiJRSO`m5pn(>$_L`(iW5~+!e^D
zN@J?Um#kxV#^0F^&{2lOMeK=RO5~yK=`K1VGHS~1nNRAtUH0#N2$$K`AM<pMjcnC8
zC}S5{%s4vfAyUa*GYdMKcal4B)l+%^Bjks^?dhiYdq;TMYV^%i(m;cqss&bH=&Agc
zo5F6ZbWUd@>)rZbqGf#O#a_o_LyBzSE)zZ#JI1Yel7Iw<lVLjOtxF30B(_4ep9R>{
zX@QHu)||EIHcpKK7u3OjAk&sL4*rsp=BW7qJk7dQ?3E#A-mb{MjgNGEm%w=Zmt(_H
z55}AuJC4qwzA$OKQ7|q7Z?uwcplqzy@RHZ@NJCCPQ+UCm+e%!MFNAA7(Os;V@}|E>
z`)0`K!x!)P$%Uu`pz55Byo*-ctNz;{L{qzp<CNk9q_!<~1t>VsZ0#%e3f{VqZd0*T
zrx>jK934%Cez_;EBBuJRFdi~e>mJ>CWrYLkbii2BP~wlq;e0L9OfUD(;!2##i;dU!
z*#tkd9}A52#ui{M4K!TYtFLjefqo5J<3G7@{CGl&pQ-WJ>Ynh0%wOTXfzlRId#VGb
zPpQmg<wY^US9Y-wBln1gT>0~eROuHMlDB0*`wex4wq44_2@M<Z>vW|&v-3+HsE~J7
z@$bU+%?ak2dKs~={^r~^19e^oQ*4woO|-beLPE&yF|Cr;b8J{Rhc6<$TEXW#$hI5W
zbHtiaAy}qj^)1>#=!1t-$X^rjh=J#Grhk>f=SK?;`&5A25z6|TRnuwjA%R~dy)Gth
z<75uj%Uy`+^Ey^5XeARo_m_b^LfWHeVa_yJ;g)D7T#(A_(!j=`2Wi)}0GV|xMmq0x
zjIjLLb7iPpG}t*#ryt{<5^&reu+XvA5q#KrYz<X2x4$#CoYq<%ns4az5~WsGJGrR>
z>iQI#`yE?<&`NBOl%ca-l8dlofX!+5CwROP%aZQ7+7#PfHK7dO8<xVYSvKb0kcp{v
zh0_Mgx3BvE?UD$d7xD5!_TU4JSayS%;X8;Em|B?QbADm;gn^t+zMs9Z9p_K)O@J@U
zhI!J^2v?{aZ=otssc+~){IxxJfLxOuN`J+7${lIw)0(Eps??oeV4@1;@Z45elDVA2
zKmPyB`NYVBFo&yc*88lz_5$Q0wv%}(B#`gNOESDkbumXo0=5KV{~#Hg?o8zyI@lmM
zp`FB5E*PoSf30?5Rjjb}P&M1Qmh`xO=0Ok=4K-|@wMhT-wY;iM=3QTAqH53H&qqiW
zqqHgi<jUP|aVY*BLDTZ8*m1D)dRiQiV(7+}Q!rE#xA><BFVo75am`w@H_bfpNKo<a
zg~Uf3abDl-D$vRiNuq1fxH&;V6tQZ+W<d0~#9^myR1ydLw5t3fN<TCUR^*8?Iw4SG
z2ZpA|mzJv<M}YPmYOazWtCsXvbK7f3@*GnAtPvl^P^^#!|Kkn2$jKx{QIHLQ7weiy
zgmD#(m^1^?4@otdL|k7eZGQ((>dKXRb|Zp`x~@|uwj%KXcT-@ALzz6x4T1`AAt(X^
zSQ)yq0$BU-VMZF`M>ADV2%1qc5sW^E5&%MgT`X$#lu$_cncw{IL1$!%Viz+Wmz|)R
zYD&n|Xk{vqz!%nv`JMDGjT|;hv7mGeW!l~S5ucWj1U2JA1h%a+$$+vO-y@!5Z(eJr
zg(J+L&Wa0qvZvOwj~|8OGENu{WU{K#>@NQ(hsbPpYy&AF@8QM`EPZS$5l9gWYAuXo
zmT{QrN3)#YXOq!__u34_4p;@v7c}|Tx~>2iZrUTYd{C?Tr7rkxdqy%~dA5Xs=U53p
z(<qBVh%Uh0+k_3=k+;2U3ui>L&!uXQLn2q;-IW>s6Cl_A#$&0X4_}v{=xIsshedbD
zmFhXR2szxIt&1ISRXrcVkqjBZd6j1-v8}|Mn7$927dLe>4FR2|OmKak9-?*Ma2&A*
zE0MbL;xdC3a~%e-g(EEi_R9YXsT@S-qZ%quD<yVzqiBLUFC5~0-zsmxP~Dw#U40Pg
zip{>r=37|MxHyvWc+WIrjZk>BtcnDXvS9(Ya!gq_uH6+ostDJwE+3oBGA8Q<duIWP
zgR$<9&m1oPv5{Kto>vk0d<zBOIyA_mNRX<1BA1<#Bx0o6leYG}J`mOx@a$hVL^$0=
z9ViZ_!Y_{J(LHk&gP853nX)^A${Q*KM#a6+{Qi2<{f!r5ICbvIi@)XL>xwz{BMcBX
z?HGX~JeZw5iQw3G&&|W?OdO)B_>hrQ=0fI6K;XJPBAN?z*-ndnm8rq1&Uz-;3=uG;
zX8&0clINI((#NaWLpAG%oF9zWHc%H@8Hz(ZYS$zbGo|!)4C(5Gh%Mi@zo7~1j`%5^
z55{JNp2}5Nk;Dd(XX2@IeVIqfAGuI7lN&N8i;5KL#|&Gsgy;EchBz6v^d-Ziu}OMo
zkbpV+smdpTSA*jN<!R<KfXj%|v2`eR2nor`-e>LpL1Y6H{Jt~r1jZ3$kWEI9R7I81
z*Lu<Oq!&4HsfS6j3G2WSYWfj!)}5^^`R!{-tW?TjPG_C076>l#6#jJ(c^Q4+jKrM*
z>f{FwBX)3{EY83UUWaB;|1M=7S%+e1{L=CKUfbs9X*Oq_K)7PQv8MYGRS^9&NQh%r
zQWgvor*e^#a<;O~Jt4nY*f^0#?o#Mt_Ksdrc$BRykgud6Y;%1)_))g1^K><N(k9sv
zO$IPPdXYuCV3$XlE8P26+C^^W`$dgY79j2P;s9<j*Xs5C5ty73N`L!U!am_<ArSRm
z+>k27uliIfA{*(RWhy_Z+sBxUDm<HBcIHF2suKUq>xRtqnVKM|;5x%awed^)Wc7AI
z+^@9gakyK!Zp%1qPVpF$GiZ3=-fn%_#r^GO1jOaFCHuTuzE3Zt239zdS^PeC+%d}s
zu&T^UvkRILC3^EelJMR;0Ul>eExof_hfv0$RPr6Z=GkiY^Y@LJE$`vMBZa4FIibJ_
z<off#b@~1d<f6C;@B9cvn+gdihKx6*M&PN9!Nx=N=-aOmcg`WDNT#QrajICaOp3>+
zbiJ#|-a$-LG}-5VRGLMQkM-E~V-1s6#esjQ*<Tt2<KMx<|25rq0{Pj&0@&#r4<D5d
zrbv^(1o5lMe~+azsw?zLk{&skO(8V8Kr$mt`H^c$SkFr-9v?#sEj7H;Wqd1p*g%-K
z9f@zoeei*z(KQ4piF4(QY6jn1zQr9FzBN@l@X5c$jEt>&RSTNNe@O|{y10pqSgQ16
z&j%}R$d3^(Zc($txY9Bs;KoC4o2Zu@e{Ypb)PZjwYO~U8W=>64Ln#e2M}t(3anl4_
zN3V>(N+$C%34W}qSMX#`CVxI~CXZ3ScC#?ZmBEL@F>jPXJU$;zLE(`J<#|5{sav<T
zAI&fc<x<JxDOXqKy$3P>IeUuFL%M=z&0bLLX3}CT(iMFdu8<fZYkVn&8E0m?^RhBy
z$6<o7jN_EI>!A<RyR|DzktPfYsjSDd9dCcALfRJLX_jDkw`Rc9DfH>l6yzMhO<nvI
zK)jk}M@W0;w!qnLO<sp%4PgP|uvl72lHIe@tT`IQuW-B6YQz6DOjME1JkvYpaXV|d
z>abK0l2G&*(q--Oq=1t=I;rd9b@h|YH%OjL-uwOsrwlU!fD9i`fz@xd?;Vb7eTOOV
zs3{6v;EUA4i|aFatQUgk+KcP*3|X=oo=s;*vtrV4X1#uUBlGu{QrC$LPtDJ{F>d|;
zi?93sYI2ME1pcIv1Oh3v&=Ux~g^tuDgpLxbfQShlL<9sxL~jy$l`bl3P*9o(QbeyM
z^dcf4Dp+Ys5fu~_6?2DoW`3Ks<}Y~KS?f7#pS?d{1n8W3HY;-3F2ykRC2T=Ci_Ta0
zJJkRpr5oe9Qi#>plh2b7$TURnWUu0^s>t?Zgimzt(<#J#>z9NN@BRSGl$Rj|4$-Qr
zsHC?%m`v7$WH({6^FI+&A4#NqV!Am#eGflJV9~rUMdaotLY;4u$$a*uHT<6iuJfHs
zg|lz6BV8j)MlAM47i2x^nTf1eS%I~6KI02n-%*%UFfHtMX)1Q{*r4tu$Uj1Af!{z>
zv7*-fpsKcdAyvcd(<_4akeZf{{(|yEU!)+}JR=03#p3lWo+x`64}UG=olR!nP=-IM
zMVw8#6G;H!Qu03-<br&1Pv=0ENsv{}yq<?d;Y?ORDncakWxDF}cx*s>DD#|O#*|Pv
zD_I3AB4qp8;^P=BkON-~e8sfO&rA?iR8@*k!8e_NEdSf0GYr~YP!=m693D%6b0U{7
zg{6Z~Aja}n%_GOJMR!MLYl7c|C`!T=E*Bb1M28=(Ai($C0$JT}A#8*CPo}pq(qGq^
z{X4)JslEFoFm~^3%+7-qCx+j}?WK<aLQ|)syE5}5m<?ZUgk}%(N|>{%tdPtJ?wtt`
zjwpJ<?~Doo{0}e7kdbaZr*<n!klQ|6wUdO{NPJ{#h#FUmFSgipeeaYEWKBs4E#`^-
zG_(ti?U#%{v^&*Z*#|cd$fsoH$HX15sD)cld@^U`^+(!X+Q(++96nE1w&i`*QWE~V
zPdLRFNz?ws+J<>~=cF`>vDj}?T{o7mvKvz%$L1o=@!-mSBC3p$T0;$;;%fyn;QP#p
z%MaFV9IjyDiKy?89&^A~0vX7MO1%s2o`Ah)2sxNO{nJx%y7-f7RB$H2zBN6mqCWfl
z0}k^^&d=cwLVvDb{T>qDu<}7~(<Tyn``$-BlQwFc;kteFV^Lwrb8G!&y^n624XzNA
zdfAP+;nyIp#=O-O-=|e@_~-Ha+>vq6rBnOW;cV;WZ$%bsK4!wyxeVIOAynM=QXSF6
zjUQ8{P0uFa;oWkn4jUJ=;qnZyGX9c5WL(J%sZ7H<(n!Nd&?Y^+i*Is#M-i7{n>Jl+
zZKZ;Escp`S3~xUeqx*+(R8mjMYNthpo!JqCw{Ur^v_Ehtd$>03oQPs~dg^YO=}y++
zlqL)ntje?NF3vuGsT3V=RGt=f8d&?d6?5ty`rM)K0kIjhIcOOehUWFgzzgpA9$Jsg
z&Qi(}TD>=|CY0d*%-~5*h*>V;=9|I48Mo_AM~J`Hwf~i7BxVBHBMw~Y?ccXQ9|!$_
z`2RR?>%Vcf^tON)6qNiDN(J_c0!Kc71@>ZKNi&&QwnF|BvF9d)>LFQx?R}~HcOtht
zG%>j`6HxC7XxltoeIrNK{5U*a`jl9b#TnKSFhTv@zWqV~c$jUAiGFDRnBNWDZTYD5
z7CN)zNI9^#+dWVAi$B^A=DiIZ{h1t6pLA|GQ{wP{858<n-)VyX{Z_)rKAe)Duzgor
zBe?>|(RC`Fsp|Sd=*@tCKQdCI;;4}MXIlYaZeAGx{vpM$&rJ5(gJrkPzeajaUA2`(
zFk?<^_70XAMod|0<~-H(xo&}76OSr&6V=PUJ9dqH{@T7vWYNPGZZmswaVHh*vQSX#
z%pF=sfgri~vZDCx2TAAB+Cj4h+?REyTPpcBxqojBz#{r|FejtMpC7BS%NC8pbs`DE
zeDGsiJqV#C_v@KVz)rV6G3M7T5|!s!C##CUG0vUwlU1{z1wS~whCe9#T=pC}@Fe<!
z$Tifg{;cq_<O2=n+n$8OFAIneD6&X8KH^IgykAEweP=rA<BNOS^3h3g-S_);cpY+k
z63qQCP0*u&3U_W|u8ivCVJXdrHxIR=>%A^gvu#Gy|1wmTu2x!)2Tr{t56g4Kj{O2c
zDs=b?&vti|t47&!GIuw#WJ8CkMJJ-2kL}0VZ#_K&uaCSnZj;#2#*&M!C&Dmu8TGzq
z0;__vFdH1T?9y(>X>HZXAA5R-Qh#W!mJq7zt~jfhbi(KC!Jh|2)DXT&!|ZmJ9m;TU
zz4wf7AZzKF&9~wj;)SCH#POJ)9pnkIly$o^YK`^E!nXKZ=U8%zrG0_si<@!wXOX&K
zW~t)d6Ii7*tKiGUt^qGgRI6{$hHLFSb0<Om4RuAtmd@}3@(kJRjE*nzX%YP%YwHzt
zvU&4*){&VWc`Rg>@YqHp`fIMnpMFkLRy40c%J#rSF+^187lK)QNo)XLdNJtkjj+8R
zYMtxU?Z0ZUAu;XJwyN^m0fzls<_Appq;xkUv(Mt9nFrT4g>J<b)I5$^#IvLX0UeWN
zXxsPqX7pvg7dJ>*FT7`@2MNDd0ke0pD`ZqwE**E9_^8%@Uv<V|Pg3bAE&iRc@G@2I
zFzHxM{mIT_a)vp6XD56Q5^EhF#+Glk1o(H<*-4?*jo}Z6d)q$7e7i@!Bx<QncRxy*
z+ES{R5yambKD#jFug*Nal|A~t>)w8&k3qpc2Dzk0U!y?{6_kEkxF~SrPw`cUhj+)X
z6^Vq)7!=W$a<GYVKQweJj15+X?FaVnr-xmYFZ{7;kB^l5QF<n2j?`_0v{!vJ)(J6E
z%l3m6G`4qs<8e(?wp1LHtzw3HySrE>(UKjR8JJ^A^v5^;u7U1(|Dd=E>_omh(Vx7Z
zo=UV>1~7B*m9qi2X0NH{y0)+;tcozU&ubvxR0%u5KIEw{neNIylHUrvS1z7lSh0)?
zn-s^-7N>=>2u|#L`ufI0+xt|pAD%g8DSU`*Xiv(YVaM-yld{KQXaF=9^s}6V*c-Rt
zeEFl(Xnm+^1HBJ&h0=dFnS=OaA7;7{r(jq~HO|=T1Mo8JjJG9L?|P#2w=`UFaXeV=
zbh;=tq>op1EIVS7C+9gi2$;X9;w82oQ%BW=ILzdF$MnXO#?fD*+Iv^)5E9kH{i@{n
zBD>cPGM44SmKh}lq0qi$_&G-*yWPA~J~3{(>alTmS%x$qa3fByD6|Z2@Im36ytl)L
z;6~Y{MM=eg%yyr2Ph{ES+TKvZd07WcF|ap<kWXwS&^G#oeb`{}Dt?v)mxT(2rl0t=
zl4bUppQ%&5+swwyP_8<Dvyu`*JWZ35A=Oq|POJ*om)K3bW%SQZK!n7XsPA!HOWmNG
z`MN}4n7*g1E$N!A;;$!w_bg~%B3QD40t1UN%kR&GNT?b?)!xPzH4@UL1|K=1LU|K1
z6BMD{DO0*mmccuxNJaL?7xHR%&}mlL1g=Mp)pH5+Fc-R#K@|rI>pl~ou&+$sc-g*H
z(uHgamiPg+FK1M8pealVi^&m9?iweB93fEnwI>rU<WYFKL)h$DF=96}bfUqqT%>;X
zKxWZ#k9P_Q`fK$)I2U8yak`y?|B29vQNqL7B|Gl!K(iA1%ER>|n<N?bDnl5cB_)L7
zt~w29QYPWY6G#vRzX2_v>H5W#1@ZX3IW}~TaDW&XyTcdyBsP!E<t^5FU5rN6R$z33
zYtKoC20WZ@^=)|FgK*vL_*tltK(9a|saN^d4?@lyy~VE8InvO%u~sTlg-tBcU};f^
zIXnVzr+y^^ZWUK}a?7p`(EwNX_86t!OIOO(5Hif0M>Ry&)Liz_5Um<QSISaoe`o9_
zdI@_Q;(Bx(yJ>+f1`g=ytHpx90e!bH&gn8^Oc5<usPxCRl6d3`RS3_$jzC1VOTI8T
zGXsq%*A}-02$~8`0GQtD|6!v~iNqh#wCX9clnD;%_iLj+V7>h|MNtr*9HQ$6gB5?j
zIPTXSLK~!JkaUO^a1Tcvn|RR_`FvK>8&?Hci*#3)Iwcusi<|7^Tt12kz!_{X7=&~}
z1!IP+K*HvHPKY75_3Q~Ku{so4{=EisVgU*WwIcjn>SQy`wJw|H8QIm^YZ(c2L@Ukt
z&7#c9e=tMf+1f0Pecuo%{x__@asom-Ynt9+2iRdu^#;b1>Sv`Rm2e(l(mXGElprQI
zH<1PVQ6-8Kn0i+43CVTJ(8gu1KpB>;q94D;D1Ch7tz|*X>+Xi!i}%u`J;@KUSIOv*
zGN4?!B;#B-dKE^u;U1SLEi{0Nik+ztHW#u=x1^jrI{P%VQ4-UU@b0cn$#A*#p0HAf
zNU-GZ$^No)J|b=?W!t(A16wYu;t;>8-LtMO@_k;3g3{8_zf;#7R+;IoS~c>xTp`kb
z)2(0R`{j({BHNr!y?4h_($r@S0Wr+#i3lgr!g})F;`<Fx?0d0_!)R^uc+p@Ls6qul
zL#^~eUf7qAWXwXlv6$$~XK(wmrDP~7U+l9E*vpEkROZ>-Vpgh3^l<;&?Uqk){TjzJ
zyYlpaU{A$1<F&UV`@^s>WIVzUNu4<+d49WEiM#=lxJr}QB>eu3*yrNioUXLP%WOaF
z6x5*I0iUODbc$D;NnwPDMMZXI^-sjrOR<oy-8VN^=KH5Te_IBa?-9MX$@e^-aIKVm
z2fALQZMbww?R;C5jJkXZb|n~ke&R`4qK9a5YhTKbIT(TLkxQ%Yeb<&FVku^DGpzog
zmSJU=T^&oY(o_BxC6X)A+xp#XjPv9VCc!V4ZSE+B-5)bUoTT1hXg$22FI$fsdv@`2
zTkZ{AXB7ljXshS(Uyx7^TX_SlSI&PDKd7O>)t%lYy1=Hp+vN>A6Zwm}N4Td8dQAlK
zbW66hA-?y{Ug-Nh5}lv=0!_}-%hScHf<z-hdvf|L2^lu#ioXLnxO={{s^juGJ<WfS
z@+(x@upQgq4O9KPoQir~G1%~!4rEooX#=V1jF60J>KhsGIJVv#ZP!ecF$CukE0kZ;
zbTw#tufckL5apSvNl-7|8hPFdl7h8+yFOrM^*SO`inf&g3<Pv(LLCiy#Em(a*CjT^
z08-+mO=O=))g_#FaX_e@@eCDTPkqV<ZBY7<^_eyq3aQRl2Hc1qktiVc9C%FraZis>
zB%m?-*4c`yaIII1-HVvx>dw&g%8AIW1B@uH@*EhM0wCp8l)bqEBbP()?N?>Mko6pf
z%pVO}x!f_p4+yi9TJ<ZC>=7q(#0&Zg)9gGWxrLnwv8qehv}u$2bi=)UqQ*TKR1dzK
z`gq9>ks&;@3Q-&e?C#G!lTfZ$m)yG*k}e8JO;yV#$^a4+P)bqA4pj)l2B*-nN&uN~
zrpy{GZw0De%+|$lwGw;P$h`#lgQ@@+E`Nx53Vg2LwaOSWxfi=VNg3E0dlsf}gh>_G
zS&$0EwkCm*#YjcWEUtr{Gy~CKb3-(tiheJ#Jiy#sj5gK>Ao#+m>69tTC~N9^O3{UL
zP}_-gQynfXxn$Rn&C2LO+mmR~MM{CS;0ytK7tmC1r6m}E^_OTuf-8DyY_$|H5$}au
za^6>qCqlsl5*R68q3*X^qfRGw=Pl(T-dlSQO!S$3EriW;lx0B*?28u7=^`c0r*t_u
z!l+GPx<e}a(-H(HSwP##v2C<3$NF_U4;+;d5`uEU0L?$SpPo2kMM+2EN$jOd2f~N(
zY2j{B>|%N6P<e`QIiR-z)~8>)l+vpVe9&J2%Yzs33Cp>&UW~9Abut&;%(Xt%i@!w4
ze~&4qN?B#RjKJbs11AuH{o0!S<`N(YD=L<EC9rtJe0mNi(O=TTP1J<$c@4t>oXxE<
zP`6V3cXs`!fxwEaWq}4CV#Oy|^|}xD+b|$7MxRYI#5jZh77Bp7>Co<%a?RAQ_g>1@
zbMW<t<eGc%IUpE*5Ee)Q>I0AkH8Pd+i0!BQbQ<&p3%ajqGD3^xMHFHTSObuZu#$!?
zgz1sMRT@sm4f4&*f%lIosIBFT-gLw|j}{6Nmx!E7gWHDo;K)6@clK$bZ}GLJPrziX
z#2{$wERBASvd}|15t53Lh8L_r=xp#<nB!RbfAv(EjLfTbxe2oT-SJ@c6bd-h1CWn`
z%2UoNP@r_m+0M0R)X=CDe?&9!#6C^=g<fQ0FCzN-jUQTiD>R`6uJRVg2n;61aUY%%
z5vZha)ynz06o~Rzz5$!B><zK#?<<^!pa5l`0e;$%K3Sg&=6b>Am^ak4bdm0mqm2WW
z68mr%s<{HxxVSOO#2p={fqEU$TCWTQ@=0-g%nk)wpaBJX-RO`zQNywsJ=tS>ZSL7!
zYVOsHq`}8l%v>U*71#)hopnD%pU=AamL~MJSAh$5%vvwki_$e#QDtzAVkyWRnrA&1
zzS65)%$L)n<*TNX%PA&-bGqJrLJwTc;+rUqn$DU~Yb(CE@e#$UkJJeccBMg_q)TI`
z<ErdM65s7#^7|D9v)yK+wg43AlXbV81CvbxdaZ@lAruN>B13*m5Lj@}*?8LSOnrLl
zhkob0Xha4Zl(Ggw>CH>U&I|MBVw+8;QKn47=*wPR9U2lQg-naNDF`;v0V4p~BhOxv
zHyBO=>#uP2NGi_fiDWhKryZKEn<n`=cs+W~ax5KEPeJwbg`4@G1}Rc*>3@iHV~mD`
zF^6}0NC7&Jy9c~*fhl&t#L7SLg6Q{MGOYV4=rK0BU;B5}NSrfG1<@mc;$Wc7?i2kB
zV;6ScW?oRb+8B;;5uBFF)d=h}-GW%p=v%)&D){{6?}t9YzJ8!2;zp33zEjJ-f?lLm
zi*7kz$h?=7_?bZJ#pgBau5gt*KI^}vnXvhW0*ceem(fCpc)QQ`sSyyV2ZXQ2NjERX
zWV{iVSV0d%M!wsv8gOtsGcj9sj<CTFzYG9FQhm(-{`C<0HdKfXCLlnvI-AxBz_<yi
zB@Q9u4G5=D9)g~ys>%HWB9F{Z!vED<%F{7ii_Xgh!{DC~M!k=}OOir+q3LZhKce+k
zz{-C1<IqJpt`7biSh%)T=>i$!byI@Uvk}C3ptv?|$k{O%%BdP)R3djt$e5TFRKfY9
zm&AXX(=gQ_^~+RQ3j5LH{$sIDza1!W66|XoSUas3p2M|DZu8w~zL{kpZyLoY>{Tv^
z(9;3KjcNDoX#_T3?t=m1=~uxG!*m}E1X0XVd}>IZ;u86MrK@C-?l(cNdkA(Q452>Y
zH3YK~g~Q{`P8`6=Q_WXI9Vj;g*nRhZ0BSCozNwQLH5Bz@2^hwjbHS}Fr+Ap(X6Ow=
zbv9SMpKB4AUSsHJ<+Qpew5Se!rWx0ZsD@aS18^vJIm<z%+23S$G&!PG|L$k`r$svD
z?Dtn<$ci)rr*FnhY$;|F76c-ifu_@jOuKhYQK~o}G8sQT)6+L(@HA$_Za33<c31d`
zeiCF47UogaMX0X>vTSZ6vok=#i5#_Jik7-u8?Wz+GJWxi4s4O8o5N(B;w$qYI^Mky
zckqESf8`8;x?(zc&7xg5ZGRPktH=Ic{(-AJ%r!9PyEFm9am$^T(6&sfsXOO~i@gn?
z`m8JHn>nb5zxtyq1JQlRW}AQiH~(v18LXN?N~6eDQx&aDyd68g=)_Fb_5Qg;QqQ3o
z=WtC)ql-&@z`uI(Wk4(JIXunbQ2_XWB~6LkEB&$4ps!~9u8T4yJ*ba}!1V22TDW;j
z(wi*w6>QnP<<OJ3yAUjmhOmVy;sD6wv4dG09CweeFf!WQOt6kjMu&b0+O|^~rjz2>
z7#-<wUh*9zm8GZl&PKZZuHiW=G0U{p@^KS=k{aU(IMR={{8>S7%+C5A#55-<UXZWj
z=g9QZ?HgYEt~}jln8r_ZKL%lL=y$brj`o?;Ir-uo3!@=pe2=*-$HXWZRMAd!cXE|y
zKYMT+^N0OswGWYz;7Fk<#mt}nW_IgdkK#n1iC^2^J;uy8;_Cfioyc@_D(?nZ%~%J#
z{(*)}1S$@IGmgiq)uzAHb+l>i%WSWyxTd3P2SM=Wh*fPt|26iiLX`U{!k5XyW^5SO
zV5y6UNxXgB?$bqyp1npKk+^TM_b50G5SC(EbcY`6GGNW8ST?06jo6vs@6_>?|GCML
zT9UFZPPfRRQS^NoHDHZIu3Gn3o8ffDGL~)z1w)RPildHH?;#+-g7oq$0UdixLu37(
zepMdh<|Dto7b6?zG>jEcn0<Um&}V&LcD^GOOSiL3{B9FU6@R^j3+*{hu@kKtz^Ku!
zewv4$eQ`gQbHBeYGs5mvc7gl~NN!r`pJk3_3|NQXYd!Yaw3x4+2G%YBA6m=SvXa)x
z;VM_LVG%SnL@$AyWPLOW?#(6C+L`+4M*D3)(F0d6a@RhW=&aDlr4h`1QF5}qdNS$Y
zR!Z(415`oWu)|!<zvfaqTKddB%atapd+ZeLo;^m{W_~Zlnh)PVWuiXY@8O%F#-#5r
zgV)3D)T%UYmoHewU6GY%c|YW6l!Ir>?yH7sszC2)_z4VJ@9V3_QHTgGp=!^YvsCNL
z)Cm?_V=mpn#L0@+=kS6%BHee705&c+u9!+d`h^HjSn>Y*h1>w^9{3BPaPnPyl*!-p
zL_S&K(R<9PS6{K+8)1s5{%--OpI!YgJoP1CA4ZkW*?8Yyd=57CORv{P{_ALGyh4@l
zeyPz!C6-%jmiKOm+iDhbRSEwPF<f=LJaNK$>$3IWF+*uyFMNfI>NC9C53$tf4O4~~
zkZAJhoqAS3?~U~$tOScql%$_)+%IVoR(u1s(=`u?6HN!r3;w;-MfvfqOdJKJbPso(
zA@rny0g^X@$<F1XMZTs_rn{hzerug=OcLZT>K^Exp_Uq#hB}w2JJSlBj*M5C#xe)X
z_mpw#J!)O%bt=lr$1hon_%GCIuBg$@>!@1G=7~JD3N*hsSLYt)(}el8`AAhn#?U`6
zVRg;?M<vp3q#O$&3Uh^TAAMswGlM;kG4i<5p}~3NJ9OsMk@t;0qH_Q0?5!djcrHix
z#5$D9kI=rex<De*vb-05-smR>V;`#?5ILY$e%-_D`PstriYEFI<AEXYLpDjR!jgve
z(Po;i)@6cyvK<%=pX-zwmkJjjt@qbG+kV&P9}M~E^Xt3ebIE?wpqi1ly*?uNTcKGJ
zlsG`TB|V@!@%sSREUz4UFQM?Dx9$tU=>z{Arh;<RaqTSmk6%H`xul#FM^$n1ffe@S
z7SEyVyn4Tk=4e5Cova^2WRjHBd~WD&>N>)%&@4DTsvuSQO19$Zn05z=!?CXF7v)}X
zGO-Tkl=tOc-u`ua-dEYZFLQU|t6u)d)6uxhy!%`A?5V9>_{Hd0kBqDQNdIfvc2bc*
z)@?twh>(3;l-F6}mF^~R+gFh<m4Uz4zGka$yD8@+|BiB#la@;4D&?#g5O$B6$&*^A
zUQTkaC^`(6sfb$AvT@iwx?vJDX0GGq=H~P2vI!qj_Ntlp=iX|JZuDOg_rOom#nJR%
zwZ3Q@54!Zh)_9ZAlU$EMZAYYF!O>Ok*a)noCC7Q!*njTD$uzzh#^U_!ZKUM=TTABX
zTRvQGI*-jE6z7s|ZD8aQ!9G#4@}(5ze08Ps%WQi|?zP6WnfYSq?t3bGZSRtw@f33?
zYNo=&CD*?E@P|DejnCEzA@;i+w~jN}GybH9hYtHM?LWBj&F5_RvE1dwkK;r&nULf*
z{1u&9=cThP?1s7w7=E}C2A5?rL9Gcrbx^|RJaGP(;rBT=|7(flK2eS7zG>GxJu>t`
zx7Y~`xA4x(dUu)#?ml07WKRz~uX$r?Utn{51S{)c)VAdQfcQEIFS^IFVw%gTA$jZG
z;^i=%J*Y1)9=^Qibv9ZM6BJl?LTuHgD!F+vv#KR@76BH@3+E?3l{T-@5Bgx#ha&v=
zjh0UMPvkHKd^VDZ4YK*_q!QFfbySSY@xvg5MW!4x+Qo4_!JP(@H>I@e>jlE~BfY9;
zleNw*#g?1q4piLx9y{~Y!%CyAE#*+<&^|ru^VaT#jqR_sVn*$*og4L;8oKzYn3Z$H
zdl5>pe6uRs%C_HFfX3x{VM2c@z3hR*d{ri}EiY;k=2xvX%xR&Y<L*2ny92)_;Fc*K
zB9m#mqfzyWk{#^(ZF9lc74qYs`#jrT#RN+%9rn{^o9FH2FDU$&yZrYDr_f?m-3GVi
zYO;|@&*|v%8>R>{tY!PogjYG@@6Et%-?I3S(pZoxgANOf5Ynt>>mMnQ6+OVeuCCLA
zFxVNMu8tJ3?;ylD6gya5=|;C3oFTU23J)14fVuv}<k^4iH|RKJmn|Yr*vR?8m7W~G
zlq=b`>#w#=dvaP%VRL`xJbV4xSc<8D%?()c*KfAd`L=WA^q+1ne#jgwk>*;cxpGlx
zBr{)Jg5&-X*Q;zn`Zr-d7;5TQEHWcu<*^xZA_K|>_lqkcKX6l@$x$!pR6Gud48bTb
z@G&-IgzGh^_8)$>Mf9_g`+Ew+ulZ%aSpQkHVt*s>HltdCm~iHz>Y_9`8YQ@UD?dB3
z#x2BHRshW^9we*;2j-xzr^I-GMD(ag|Ef1~H!)o#ZzeXMN7QR<E5sV=1CR~el3rt`
zbaGAdJh2cd&pGcHI**Fj)sAHikYAi>Cf|9E7QrBcubsh{a9;0*413*grQ}pNHD{4a
zYivjT>XfopMh(pO7aw6fs;PAi>0Y}2cwIMGcp$JB%h;G~+p62!nbO0Jjk|1m$}viN
zzzskYgKW%|0cHGI@rV5)IPaUnHq5fXq2Bz+jd|lU+kk9ps*o|11KCqSHw8yYzTz*4
z*Ueq%+fnO3{JKxcC)3G_pzZS;B%v(W*exDmpEso~V*GsuA2TM{Q-z!G@6J6V0=;PU
z=bK33kE61o6`GfD68cDea+K-Oo_q|z-rc>k!D7XLC@T4)EMLu55|l1IxN&uU+TIj3
zmz`8vi>~^#8=*$dR7&*40c19^1N*YEe^Kru*<PI!`M@KRR{pb9%tB1_Sr5W5?~4YS
zs<~5~oF*odO;M!sIgg&|GC>}AnkAzi+mO7Pe60C%lBJ<Z!-+Vmq&Z0xMq%6R5ZY-P
z*PRuqY}|01u@bXc(#7S)FVG{XRMi(JA=aVC!Yl+jhYeONkr59~KefLNZgpbVj9~ao
z@>=V%MKfoh1N%$rkNn=&$fkKMS=wXY`60b7JCr`HR!LcL6U`TtG>2uX^~%rN!}9O&
z2-7s~KT%uChyg-_pNk4GK~c&oo;5<y>eWUl!uz7s4{G!Z+pK_51Rh|&QKZs23^QGz
zo&jywkV+ym$|pC{i92(<=sx`)l|(j%5~6ruVBD16CZ=d;(sL8Bpw=>pUb=sEVngNZ
zqlN0`gA|d<Le|i@g%zfm$A9ARl=fex$tAl=raObcz!i{J_3yMvWnbHmW5+p_>)yo5
zSJA>J`Kx6+^S~buReg<AE`h;BNTyJ3&ejI|iPM#ct$Y;$Z?}7Z06O>JC?@4EAXbo(
zq0G**ZSg|Oox37gH*<h{z(&}MuPlq7MTB0k7wC<KT_CK_xfqHOKR2c5)ij4j`pW<u
zR0L9ChVirJ!rW(doqE_85Q^O11S4rsk)~>{dJ+u485NB9Z(pCp>B3Txa{gmAKKImh
za)y>80DhNd(j^ky1u(+_N&dP7m-!yS@WrW-*@q+zfdLT$^a`c&;xmskNgADLVn)I$
zZVn#wmkm;#1;=c0@u<*=vCco;aKxBb!7;x~1yO~oaUatpPu+va<>SE;aS!!KR)mH2
z{7=dmY$$1N&c?{QA21}B+Qu<41&rmWZ6Mm`fx;XO)7wX6b90+&74rhhL5Y7i;A#BQ
zKf~FkD0e58U5L?dvMGHnUR2<L0SD_{j(F#=nM*6CVE;sY2|U4xOKDLY2g?-oP-R10
zN;$lYeX98A?u<u?48jlDt76rZwMyVE1NgW@tE$#S2Jj!JP@&*Cblfmjj2ZS7D$M{y
z$&X<F%)tq4;bs7IgC;Q^4iEsaVhdV%l{o%n1G5l=cNe)u1wM@_ZBZ5IEOECQ33lYJ
zu6~pjg^i|uv)~%16cK)NT#7;Xn2q3t9>0Pf3}aktxW+9{4J-q|I(Uy-xQcAx=lR3b
zpt-u>M=H@ogbgA+2PI7-0GCj>OJk&MUP-?lmdl5I14I}+kwyZpbM9~HkkSuTIFS!n
z<=1-)l$Ad0#yl_)Pd+@PJhIrTQKa{%Ej1jyvf(A%15F$FDac(OjB^{`@aS3*`RS&5
zOIc}}%#k9%I;ehkslstj28wuMT{U}O7pO?gx8O-pgEX=bd&6k~D?zvjt-+}FU}=<-
z50<1_dEk8n>69Aj-QynRN#O@Q<3Ct(h$sNee(um~VPhbHTz!~jkiQL*I~^(>__?fh
zgXKou?=T0|!1Ag%5y_KU8^nJ?dw7jklv)8W7Yj}6k)G3WS(=Bh#2qZ<Bf&5wp}p9z
z8PX0sA*otKuU!<FDeefyarxIxwLe9RLS{nW#!#i#ZYXT^C^j<{?0YO6_~!)xTk-0W
zqJ7CBIuGR2d#b}x+KGp8sLA$=CmdHUe@j(z%judS{$n*}(bA~>V@T^WNMwp2dYXqa
zoRSt${f2w+H56e&2(oCISXJaY0~JXmAQO4u)4464e6Sm>K7;a9jSX>YCGGHAZ^e;k
zK!>)dBFb&M)t{b)i9ddMXyy67mPK*9Ih=GD&^52s%2Fv+(+RdWbIU&}Wca~>DESP8
zlvcO2S;k-Lv55KDl<2C;V<DytMb~+{r--N<D)N_rpLrCd@}jVzn_?FUAr%T|0MV(}
zrJ#ISXBtM#sQo2Vlr}daG;ck4RaRMC`3g}(#X|vii{J(bHn#`ByL_t)TW+bwS|2W9
ze~bv_8;M>i+~`-48kTZlL-F(CV{T)urNSXZ#kWL7mz!Ga^Ids0W=&v))=}-b;)P+N
z`BNTvg<~F1bQz@T)v*zV#RxGvBbop?Oo`nI#zFx#NAS~iZBZsoR5^;I3{pSBkskL_
zUEvto)d+V3MmM;MU5_;G^F<!aIe%g+Zg@Gh_iXrTK{W~#@S-2n(9#b=ur7QEfD=C0
zZgQNKLnkVPhx+x`_7!-kzOKRF(!y#KC{7T}|KS<`SEC!%WBW&4q`*KphmWWPkX^f(
zf^%<!c&meb6LkKFun~^H!l)5M=K!@O0gog<4;CUo-*QZSzzTWBxEI9yw=B&k*PMMi
zoqH%^-7E*?X+j4`)(wz-yOrO3WMB{?Jxy!~IF`n)I65vN6-!sXu^<m1u!cJR=UJ8+
zEET0Ic29YtQ%poan9@s*`6_{Sy9U7{2w&pCs=gua5-Sx6F~x+8v75Us=C%?POZVX2
zC<oCcCPoN^+hGHGc7WBO#q%2BylLT$ajgW7^Zq2C%Mz#^kfP~U81wMJ*45JsXRxM3
zzvE!P;|oWH=VfD`?R4qN6xF<H>0Q37j4z%h)Uy!J3Fad`;e59HpPtT@c~G3b@HGl`
zMPovCQIUs**K(dnu>jS`j^_-v{p&f=(@f#<&v1u&uj}PXJ46jTqQqUky9mwshUWj@
zIz%Ca06=_~J4B&ySS)r|Jd~D}krENr25BqGt9ZlV;Q$Z`0;P(G1Q|*D`oP1(f#_)P
zE_WE~tFdbx0w8+`c$Yg&27r^I$QWJa1D;T?I9Obuda#~fgtN1=gM+=tUQhq9W68<M
zsi`LqM<0#!IYe?J-`eF4k-G=Guu4OTZf(R(BWx93aa<g>27&I1hd-duHCfOvIba)t
zAJ&Au(1gA)L5!PYKI(uzXg~z2z&Bk$paX2F04t_KTZW*&#=w6Tz?LO!*&MSCHh3bY
z+v$Y8v6p-+O5@xCnI}%z|Lk^~0e~$>@UDTl;}2SP78XPRf8&7hFymh!uN7!ug|Bmq
zzhi6I-W#dM%AyVp?{^rBc71d7P_y)*(h}4zdU)p!thotwrAm2MJp59u^YVh?&>-~1
z3}kXr^8bj3-?l)jpAgeeb#L5oE-O4ypLz0jR!U3DiPAH!lX=M>3X^|wou{Tk0e}Ml
zdE$sN0O$mR?xNr=no_(FkxSyq6?#d9lEIC!Cky;oXOQ5L|E(OZqu}fRS2=|4KqY=)
zNt<z?Z(fjhfa@P{^o*<f`Yv=>52?Qc>TW^atispqDu=V`b(feI^FTivK+pfjHw5}8
zfw3uIa@RK;1E%_|`Uist$D$fB`EAA}ttMwnU9-*|&pEft8YX5|CghYmm$#&p)kf6q
z#wT|Qof{UrFb2CeD^dRpsM__#e?yv=!0qeEj#bdz@4$oK;I1F=mha|Glg=%Vle)+4
zo8JKg{{bWaA;)%r{|4iR7f<k;I2=x1US36U$@RR<?tIRz^8A+Oyxj7-=G>b__3d3<
zU3c$vx3=CIs>qru%^tdYd$Rl1!u9hbBN;;jcb^X5em~ik**)BTzyDVGyU{zNBl#oU
z{i9uvpPe0lH#9IXIsRnj<@1&Iv(MiwzFk~;|Ni~@`lr>^)vq7_$2wf!+@%h;zW@C7
z{n!6+hrfP&|GN44{fl@1uXSjb`47RlTB8KZ$rg6scr{#ds6BM#H0z^NLdgBV(eh8D
z`%9HNGA07PKDwPDT%mdJ_mQy|bvanlQfO)QbI2$*_RZ;??zXT)js=XXE*D*rn1F+X
zrl7$hj?z{7$FFYM#8bmI<^jd@@T@zu7y4}`?_}_ROGUi=#~yNUsFP*8d>@{3t52kW
zU>g&sGSb<$ID{9m8ny694*}^oNB6->eXRK(xt!XHJ0Uh8#NOd)>F~VA<b7r@n-;{g
ztoS<}_u0Wqxt4gBl6xVjJKgb%vKp>2-uyPiMbhEFE^1>K>-N6|s$LFVVO=0Zr(mS^
zXK0?JX0pZGRaOQ<`c(HP36m+90<Lb4z{Yy~;eXRPqXsy3NNz`BLFB_3u%BtLW|?cC
z>IfGDo=EC=Vw3F6dWu^(l7SXa`_A7R6TS+9N!X>#7olA@+30w|fJO*yzb1Udw-C7@
z>HGr^#*se)zWMs2q+^H-h0e?gBg6Sc?q07ImaLS`uQ^!m-n--(%;yxA9mZ_kW2zvu
zQnNVJG@$aTt?K)B*OKN|O>f(wn6pgR>k1^Gl=S#p#$F$%rykaOHU@SxiSD#R4*6|}
zXL*_>8eKbA{`)qk@Qm?`nPXC)#h;MvOT&H7yaKH%qzDzV!yKn0%?EIT%kiYWH4Yn$
z^Ne?>WV-audb}ORv=$yx*H057gh^p%)O0mr;<f&N?lqwF5=ysFwBHre?$W+9TcXZW
ztq~a_KY^}KSjGya(1!n)2f5NGrLFH{qLr<(-=fmkJ)PeT2_V~dc@iC6WXt(CNG#S<
z@!8l8IOf!wwrJ=7`1}KsKjxn5;UGtizYKZTIM1p`2WF9Nf3B3`w9~lukIrn)<({X?
zju;nZ`F3w8JN{hvf#QD5eGo;b_wdeG>j*G?Nt@htW4jT}pTq16$*<9-4>M8|9JjXd
zo_+FRMn+U{f8$M&7H1CJc^h+3`>CoJ$R2xO#qRN0+qg*sfvx+`Hxq6CNSeuhx6<jP
zhBYAhiC(Wp-{=vnVr`?_+Z|_n$#=>0aqOq0Hj@_tG!E2aXNA@08N6@p=bF$n*IA*n
zpJuQ&cVdQI7Ivp$D#;z|2ji#)ogMDdEgo%jQ_0VLuzqVs`T-mFY6QeJb!Su}ZEyR7
z->|a6z=R_8CY2-A;lGX{oE};|GHrwsnWoO)r|Fpzp2->GB3TdIe~C>kKW+ESi^}~W
zq=B(zM#uTgdne{d6ogbY;a{!pb6$%F((A9O{@(808}!UDMQ3z3jqw8G`LQdpTZ{kL
zVu}Fd@Ld4W>%gH9d_p~N|3qe6J_ic+n3tiRbS$X~gjO+rt#ju!5<w^BX0wgcCKUD3
zid33qP`HhSGk<mn@QqPL5nCztXOBU2(WZ+ir|n{3POGY&XTF<Tu~tpNRV%L)?l+4B
zwDk58;+*y&$?agd)6*(ZPY=vX{TZ}wIE6l>-gjOW<W;mvT9kaYkYkI%(9dlx?xsID
zi*LO^-@XsT=++FTRS%!}SJxh8C{z1RPt`<bpFKyxBa}SKkqf0`j-N85Q0av7Q%s_;
zS8=bjg=rBHUxQ%H$T=JOK{YT`&z-8l)r>egwXrmx!>-Y;^Xw+cTy?rTT(cW&KU@lw
z5NJBi@2_DT<C{lC)<Iz7wshEoC4#J+pdl#uTFK~PZgYN=@YQwmD`J5Xt5l1`P=oT_
z2I2y~j*M_P{-uPF@>W<;IMq=s1)^=+<qEHDzh;~7Gh7lST%wwrIa*20cj~H@M_6RI
z{^For#OS~(X~ZVLD3h{x18H-D`p9LsIxUfj`2J`}r2G~n?CX)*Z-z{EmyD!eY{ou+
zkwId0G|rbzm+oF4w$e&@s{R8~q@ap4Nn=2jN#f++bG^(|Li5qq6(NHOB}bmtO(67X
z&>5uSi+kq_4%WM?O)&h?>EYuCEh^N{)gE%q3C=hepQP?O_eg9GCM@@wFZ5kp^UxzG
z<2`@efLlRgaSRMfjXh<0*@944S&QQ7(j`S#KrOXHQt0vu#V=e&_NZE(p)`Q$Zj`%m
z&gH!1hrsaq-$2zOUb`%90?d5K3%d}bRcwtMkn@QXMMIyd@5r#=5!E{VImLI=HUQf_
zZ_Xq<?sp0Gkkmq$`|qK^3K9al4%>qr?rhonatO?bBdIvcf5~2v6T(7>uF#`}JjmCV
zKAKi@YiW;{_RGD=*Or!FKO>|gkyadk*H*_V$JJ0e`7>};;ha!^9z~Bo7NURjRgS{G
z;}CD*u)Z*yOxW}^{?*q$CDGnY^GvW;7|QNn)f!!(U!%+#5EtIZmUrG_dJr;vH6|xO
zM`_(9v9Fn$m;M+CiX$XU$}Bzrb_cUZ%UOt&0vDYT4Ea*G2p~KXdfgN8;q0DLwAyQf
zGb+Yv*e-tQY4-dW$ot#*5U6=x|AYa;Jj5ml)Ea8un&#X!`1XT=DUet;V8vV(-x@u0
zn$d8J9Gg36ETVrx$0W0_WUKbq;@#%zE(7hi&e{{#3GK}x(ideKT@i*r*ion=qj3{z
zJ+fBRv6z1J{g8PgPonsI*b4#H(B4VP?+8&YJAAf-Tx#HYu9{6yj?}fylAgWW*)Qf+
zi^he06}=<FK^E8#9Xy1YU*i62eq?-f`mL4s5guI?rtWMLP*Q67toX@xd2TF_Dc!o&
zkFf5B#0oz1?@gp4-I&F<hr~`-ySOh+6^<l2hZ{ur)}AE=z2E2m+nZ@Fa#Sg3hI9C{
zW*M?cg#48sFIgqE-zkau-aTwjXzE@p*+Okb&SQxj6h9k-?`S1`9^L~gX6KxYL~<%=
z(y=Xa51M7kFZ9mOj#cCJ0f)5#>`(e|VZf0n^(Wa!kUEL1e_Pcjbs;^exQE!cmxSKG
zb<?4lJT?>~Z4AKN>}o_m%(~yRRGVLXpzn|-_V5|)uMU0T&B#~pS2}x%!k%o=OE&xV
zcgJ${>3(AlsmT!HHX;AwPpkcbdf2LCst;9bhH_77l&9gZ#$VIQorzsrzxY7W`i9S%
z!3hE7%^J5}-+v4)O*r!NsK{k)@5?#QI7bLVqrMtj!+Q=NNVu`PSg*;+I5yU`Lgx<r
z>De~ZaOX?w7u#<YLn1yvh;@gT)g@Eav1$85e+MHp=S5hmhnK^Tz2v5VYf|Jq;C8^t
zhNrl9{5=j7mvEwJa5z-+tTaC!LOFI^)Jc+e`}mcgm@qHgCrXMn)P=+`Y5gwTv_IOR
zl75f?YaNO-?14!oC9Xb)RjVjFCn(Vf5J5zoQ4Y2rjvU-C3HQQ%=BF>INc<>1_Arhk
zXK)HkO;xQCwZgzWHlPYa!5zJj@#ol+6ewd3veb!v7iVG1)HbZjWKaRW8hOD-c<{>v
zMCf$vj0Z}yM8x$u_Im{LatPdUBh`J*`%A0iqURBLDmwNX^v!X&)rXJ|jyWas_KV3*
zfvixV3&m$=k!r-y*EtpgoL$4f7?kbFJX$8{uAw2JmExx27aoxeDH~!pB23_0fpi#3
z`&hP|0jc$S)Tv$@fRVAoPl@Y>97{QnJS{!1As+Z#dWTLvQ;AnL%Xz$Q_A(<Xx1Vyj
zB)0k*DxlLWWci@U5||%K|LTjTdqKHXvFE~|e$&{lYZ5lCqTQQCVkM_>B{@DGM$QRm
zM4|X!eBs?7J{yg&;r(`ZBw=>!z~}+`=S{lYq*xN3^=WSR;|Y#@MwB2o*~J)6Age?H
zl>4+ao>n7f6^T0OfKfCTvjnoqm_zc^1P1^*$Cmq>e1fGO=R%D`JC})gq)W!9i<Rh;
z=EZI!^5km7u9Tn#$<eT`LPJijM;tW0lEea__H0Ml5tz-S6=`186(saWD$VZ%=D;?~
zha*FpL}wS9^sx(Ro7mAgkxsHf$WWHTJQ~Z+u$w5-HITEX6bGn@n|(-rGbFz6c&f+G
zvp0_A*!{q7`r;l>m={HbWMqnTAWFl}qRD`pC9hnr&38z`sXW4MI8pmgYmq7Av{BS~
z2&-)TJ>KFD_D_N<n<YxUV<spD=ut*Kz{y*JZ0Z4WNFXy=VN<Ny3+fi9{VndW1v_#q
zryAf@6c_94F=WVrM6E(m*KZ$MA58j9%fKgQ9649y6Yh~ObV&}o|M-%=0#?+JCt*03
z?l*ji^9!G`8t@d0`n^YeY^sW(mJB7HlW#+xWI{>)@cU56ahbzwp+Sy}qPNAy`V;3q
zMxD>XGsY(k{xDrfcp{wZUau&e6O}=K$>2}v|9r<-dlW<Nj-WqnfG>=kVuR3?`?Y_o
z>^(VqR(Dct-5&#+KzJVW%($vAdQ0Sbgji9i!V%Bt$C}!Xny|f?K)cp+dKk8R&jo@6
z>-Pj~WcUQlAlZNI64*1A)Fu{1jSvKnpx4<1%NN*a4b1C$xKj#rFHs_uuSnadeAEGx
z`hFCqE;JHZO{+oQt*XP0#;JOUtsFyW-O;zdg$m!FyPF|*s`P*tAF{v*cAN2Co5iKZ
zopnLjf02aR6gNejuk+=c_os#q?T_0ulR^mpqv7F){b_ls%Va99oY8tQr4(}EoRX;!
z#E}8DU^M03<!Mf%&kmqxDa|7zc_)|ad^ky;CJ1-uc=EfMHsz>rt@yeRoK&`+Bm0~#
zRV?pEBHN?Do(*f7x{|XA&T{-`O$&2+v_gy(O1Yzu1zffGF1%7!&+5B8vLD94z$^(Z
z_<ks65ps9=T3Qb@Ye*o<);Mwu*NEA*jxD^Wu(-Tg+)D~aELco;Gj>|qg@}N;Qh3`F
z;<m>!RpX1S0iNP5m@S~DR$EdxcnOC@4hKjQW%9C%agSQBl89)N?6yC=`~z}%0u5Mf
zL&6Wh+kON5wL#zIxWo2FB!8hJrmfz;vHG)%WK`-^$>BCtj;NM6YB0|58?P{G&C#8m
zVL6el>rp^q-}s|a@o1~b5V&JVB%(iFm+q+^F^jk}(dtYSDKtVcA6>V{>v;e$GLV<F
zBwiX(M*@j$*20^v$VGHP-V906ez#tgy{yU-rI(_Hfh6|Fl6HGjJ0C|+0Oqq%emVNA
z{RCvcpfvWj1ys}WC<UIQA9w7UN9XW~PJdTPA!gkS;ouG6fgCZSHSF@MXEy3~io{1Z
z9!CVt)t9K{74LVdvjy4>Yi_Scm7TkCUi=tglo?MWDr^sn=^FUH@W+`QQ-*3wtZY!_
zA^3sB6XciZr^VO1=NnH&tNgQuKh&!AWJICEDYBy#HL`KO&>rI;wSPq!c1B&|+r|xh
zO8Da!7eBS#|M!I+W#V7C?N$JDZyR^}Q(XS~t7x?Pg-4bcMHeqA2&_XG|E4vFVnq!A
zC&V|QeYftjsptjmtAj4s_m+}iOg#6c486Hts1tRk)ohC&@$<TuxID}vL~5(`p;mdU
z;Lim}{J%$B=D}JcXiReph+h}$dv!PcrCJInx27;~0F{$}jR|sB4{m60f4G0=!VvwA
zQ5&pS&4Ar=eSIWQ!lM^AtdarqEhv{daNIEM{531$m9q^!PQZ07nf>6#>pK%eK;r#y
zVwk^{PdTy5hZVZbj<McCzrWf>oacKum~Q&iG6*pJ;@YdP!wv-EPBK)1!?-<cC6~jp
zY2lsvwenFql0szfnYrHFhLS!h+*+$v8QoOfPE^||kX9qzajnFC<A$U!PB@RX>=KQ3
z1=fW*rz|Cp$H?lJp$;9^>nuZcV{Yf_V0=xEGIEqt4&Z+9As2pKVb_Reeiaze(-Ld}
zq3nXu;X8F+-|>F8(ZyA$J3yDhyjT>gQquu*tJUm8j`H~fxPcYl>&v42kv^s9a4G@X
zw-W0Rc*wtI%$pVZF>bOsZWt9)sjd>{t;SZT<%P#zKWIA6G-&uV*<=+G=xI5)I(EtX
zhUA&~nqP4U-dB-5uW*mq2RkPWeg*ofQbl({phFr~H@p1V9_Ym!=wp{iCQpL4A<DQu
zk+-v7I2&{ZI|=<}SSTZse=*eN(Xov#vw!oH)%<bENp2@&q}rcL_ogaQi;KfSPYqvA
zm}$0&mR$Q@9I8ErotiBHi}yiFu5Dwi8SGj%QON-V&3=P>yFooApzm%-j&M?12Ceu7
z)shGOO8P7#Xh_}l33I8tW}Y7^6l&z|Z9<{v-PPr$RNE9kfyQ<SqU@Ea_u?;x_q<s9
ziDx~=UduZps6e;1Y5if|E!6BzdR?RLb>kk0FCKcup7KgHE5wf1@eTvc*}NFuHrYS=
z&TKW$CmukQ-Md>X8cBwqV2Exp(0;uHcty~!;z}eh>L7W4gQ%WG>#6K@G-S`46UeA{
zV>RekES0OTP?MAQFXH$N_z?gekAWXy3(Zr+w&N5!d45@x{?z;=Nh7>F;ksNK{p^eW
z9l|?GE9|6~qla8GyX4Jc{;N0Ec73j-(Fx&50G|3_S>W+mXde@OLlf0Mhq4v1Vs77a
zzzAhGKmQ!>zi&a@j?nyfLxW0y*v#TMH(DC4un#Ny>$GJ1FyO@2<=U3zV+8b*#)!;@
z{4asH3n3DyaH+OezEgjmSYo_wQrPZCvfr0g4#lWkw5dWoeMR7iyqXiL8(;PnG~Xe6
zHAm#C_P|yaAR5B9g{Q`k$({(D2$&*3a!McxFVXK<{r&s-Me?ps@=%Ke_(;og%$(R}
z+|4ZB{+F#cExP6IQww*P==@uKzfZ#tI=tIy4avbmY9C>%n_7&b51omR{$#08^c4O{
z?0xJUTKtm;_Ys=%Ds@`d%#nS9O%=@>9Ep4+kcQo8qHRoj++TCJH_V3BL%#_ZeiP|r
z3W+Phmv~}rdtN$U$%pgyA19bO!IEU420=pjoqg=l!4J70F|D8L{dZS!lj9zsCOINH
zMF{nQ`R$V)JcWV&IVwC6V_v5QM9|SS;;SFHFsTZN{SDuB4`?vYE%FSW#{RStFnG=X
zGg?=&+PX5d1J#TXTYvj`m-QUtr|X(fqZ*dz5ZGlX{%z}`Wnlela>$iH-mSg!Vy>T!
zP9>@Ki1imobWz~(<jq(BO$2b`U!OweH|o4+UIjh3De&&zBome!6bydll=M`R+80j_
z;#kkTSO=bG9_)$}5=X-m<IuMSPWf{GHGaK=CIm~ouX;{p?*6V9ueCj#eo%P`2W1kj
zZ}Wcs6ICYREUB1>7A+Nd#$NyQR_Gb?=5&1JruIxbMCgF$r}SG7zkrVepuQZe;`eO@
zdP?i7LISOO&J}NP0RSX*gZisH79ENdtWQHn;vu9`RigD>%vTj~4)P1g>so=&MYFh=
zw;ik34&693%5BR}iF?b*SN?6k^)qxX{{&Tq_J~D7RG!)=e)^k7ZH`Df^-nx2GW~+j
z=|5|6D4yr1fUYA(MaIrwJpyjy_d*A*x%wLhBreSLM}=Q9V2z|bOAr=aZ0Aj7QHWD@
zTK=bBXW)swwW_n0)_GfkiI57#0s^%-&2r8AGNMR!?Ln4;C56{bf=w2R>IOfgKP*LF
zHBle`Uu4~TJd^+XIPiN1+c0bl!>~C{PIH!1JDEdhA*obzOj1!2l6GQq9!ZjFD1-{B
zbl#kk3aOS(NJXhPrQVeG{_XSl{`tG_$9+HU|Mti3d%Nz}bzRSErzCZD@YRW+1lL9j
zI~CH6+l6SN&pgwo3ob<CceFh{Na-CE?T`4exQwR5Tsl^W`<Aq}$+J&@jGpCTcFH*o
zXl3g^AGFs3w*%BOzE3=?%I1EDa|&Tiw3_spwTZ?T#2FNW`EMLbi|L^B+Z~glj9SB%
zJEOIoIAZ6T(;!zBHu`tMd53!Nw?fqmE2u~k;aH^A@JWo&l&OBKZ7%=HxMuYy??N+D
zJ<@RjYgw&({YXqe%fj4<(Db$R@fiXM65Ao3ZzBkeyGTw=boX2BjJ3PR<-q-$A8%Wm
zq(;7csOy2aGgp*cv@t|?k7iFI;3z!uUd?qVvM1m6mdV4jYdW*0jEBBQbA={C>_GF;
zB~)Fl?L<(Mf>9iAdc1b$360BLV5yqx8?&+X4eLNIAx1vOM?V<RZ5{DSu0XD7iR++P
z;J7<m(yD698-o|253!zD*{y#HI`gY$cvi!oW&YyQ%Y|1gAJFghvsGs66Cp3%2HRn}
zA0l_ByFItjlyGCqa(U`U2X77JqK}F`-nJxNaIVWdKvc`;Y=iz=haIqWi#>smI9yKq
z@ZO;=I}zP)sV#)I7AFlY+Me3n@L}L?Ay$On5%&QoYdzZPLKX0><X0gRCf#Ih!hR7`
ztH|h#2k7x1=e*zbVEv0<%fJh9q7!lK3-uP{C(8n6&-2uzx<UrNXAgN(!|-X{0{1%n
z(62cYM3?#1q}seYT8G|61Qd8I6n}0lF59~EwoC1y?3WXwy@Ra!Vpn02X-!U!QbS_S
z*_*R$%ww`1$&LS^75?p)<nlQZV_vHI=!O~?L3-4(Y?A7r<MnUBzS1wHE6cRcCs^ex
z7iy9o6Cs&SGFJUYuN}8u7+qO~iQhQ^d9fvrYCb1;8aGJyoz;a+)Ot0pPEmr*?p(k!
z7{Ckf!{E199=WVQ2XzU@w!ZwLd+;}ThaMD5b_$p1^fL2E@*VBY{K2A~E|5svcalS+
zP>3I^4|1*xg_=p`@xRE_tSYL`<GnMCg~FYaVDhyt=jo*H4uSOf_Cn}%H!cyyQa>bw
z(`<MdABYBBflLnQfi-ULE4+?Zm8f2=S81gX;WCDSVwZc?G$#cIgc7?{(^}2)PHV)P
zgsR>}^kCoOdFqEU^7gI<>b9o@DqEWX=x}_RdnyFN8#|S_+m4VWQ%CjJRokBb1V18X
z(HAy)7B1{7<QzW{kbQXFN3-)r1ZK!$Nn<~*Tx#eX&akVydKw*N20Da?{CZ6GXlznP
zoC6uh&q|>hcWL2Sq!}H}Q>d%EXJUxiaW@~!H=PdXX8>8f@N*TM!sHRo@dw8>_5STp
zty+OZnMr7RZGNx_n6J@x6OHs`j?$$W3B8#RjLH^Wdb0q*q{I-uaRcoBgxi{vYIM90
zI6OKQK6&av3(OUJ5*ZumU@`%0Hd(`RB0s3rsMtNAUc}@Z)*QEaCrU(hlXVt-hbt*B
z;XZ*k%lscZ#cpq%nEGs@dS^Mt{t?qp|6D*`qO&P>$h|1+ZLhr+lf2ir02bfRfnJi3
z!@j=cW@M548#8*~YhrdXaZP3A)fG`?HV^jBII#n-x5V|S4y?O?(U61o9Dz&geAU@Q
zo^N}R)8ZmszE0kDMx679peSZjncQTJzBBReus;Be)@<ocs!AO#b@&;namn_efqZqB
z(Kx5Ds;&Eq8uTRMvpAT2DmvfcRk!rp!WlzW!FI|b^<oZ6zh%&&ZHLW#i+jS8m0l9z
zIkDbh7W8u0$7sWcLS@^fK@ABQP?C4Qr9I$k7$MEz`eUaI(?}cZ^4B2Aq)ppb$|8!z
z;f3udjvo#_V7Vf6Ab{UIBut{oA>|ZYKNi;3h93Bo%mX9MM+_For?M8v)*D9lL1=$Y
zjc#@G{&L>XZxyAxFr?gKR{JdCc7Z6O0*SpYfgE{8BwjK%)m5We|I}QNnOxqR9+6oY
z&h*nes^B-*F2MW<3HoxR{6rbxZbLG#Ifpwr6I)O`=!$d*&UB}=rU~JsidY0{V7|Jk
z_bd)vV`ze_h0lA9Mp>DbG{U4xZ-V@vvSxfUzeT#nSv)9>j@`zuf>;cZ80%(H<{@W6
z8Xs7=6jsD*P5NXO;7L1<KA`cR4hQbSaOf1G@}8vIBV1+ODG#aMMZ(Pk2|2|VK78+%
znVAsh2hTgbCOrM6lDX%8q~B<iHG3}^wI!8#dDE}v6C{5R!h{u9Bg(Im`my?=$!!Nf
zXP6cAaF;9<6r0?2%b?sU7W<`*op;C|wx3<Dt>ZiB(_{%84xemfkJ`uIONCzQnrua1
z^b;V}wl~T<>y>;F-RjWb*Q_7kZujK`mj;9e$%y3Augs5j3uW;32#H}}<%5()6+n}2
zx)+G0?cjAQEk?pU#}z%Y$h~`VGGYrzfD<*UuxzKM&bt+cli9qkfva&`YH=a_BHUfV
zz7>uow=epN9X?;5m_atGeScNJRHA#vzt%cxvc)Eh@3Q;kZCC1#2TsKaEx8-x9{uuN
zi<3WblJsC7Mlwi)Iu)CC^+0QUBa9yxi}oTZ)?SEAI`F{Ib$h$&9GdE;>E*uaf7ebU
zkKPe|HF>@I7ClLmU*udX!!Z$}H}s&dcInyL%<*}(y)KU{ZW5faWCx;>0UEUwQt6G8
zSM6W>PI&j9uZOSA8fdQOJOb(5-f*hb6sL{nbw0#z85)AlhS&wJo1H368JSY3-sL%e
z2TMJn<=3DGrQ|eJ_>c1&&U`fW^!xbY@bfDd&i-uq+KK8tnW+F5KMnlV1N*B_ef^+)
z(py+)7qcU0*3@VlTdH|rKg@0TwoQu@ctoPUKhe%~)~kaoz_HzIy6VctgcqmoeG5|#
z=0SC<H7WyzWj8OLYl10Pu{EGl<tDaDQ(gkGXeYZ~EXw^<MaluZ)ei^~iMPZk9{MFH
zEz&0kQT=qwJ<m3d35shsayhpLA=w614lj%~um_7s=ZSe$3rc%Xa1A5{RUros&yuz?
z1#_9|-X5hF*w*vQd2?&H=9BKZDLzAz3sKgj@%lBZY;Uu9p|rUe0qH<OFKidW6G`{i
z)F|?2yhw3t95JtMOIPK4!TuCah*u8}p`URCF%L)#5wylCxNh6&eeEir*yxGDvLofR
zQVFm+Sh`S%I3#O~BYXX*2iDcFy;5}lHLzQ`D%2v|KDFX%pEe+`0pr`)PV};TF6Rjq
zox$T=`yzmnRh{=hPpI^zv}-Z>YQL>j4>29N9q=_vG-VPfPNuruy`3NFlHP&>%((Vd
z9X$UV2MU@aCb(Zw<c?XRjDw(n`o3>eC(mrgzwKJP;#5KML`n`zFr_R?7I#Oqb|*0#
zhNq}Gqo&WI&+MeNn+-`fuC4k)Dm@RTdXL~j_!?<12TI&)Cq|k*lkr>e{^>&4-d3uz
z3|18hvpC*7T&=TsifC3P6;I}oe{-Kq3l3$sW3LwIVz`ltOw2reLM5Qw#Mk9WF}kWU
zc~;T33iDz;Ky|WXyR2C5d~b;Ewj#uSQPZUbuf`F`h4Ml1h&Vrn+#wd|PF9{<+f=fA
zZ}I!U1*n%{nMVG5cxD$PB1Pbn=8It|O^#6;BPlt`gZtdU!|o>*&<Il*r)IVOtE}MK
zAN-f&Zoj#W9(NudP4ku(-hF3Uf2lTih&Cu+bDr%ns2zd5+~{dhR@(&xJrpOJKy23E
z)Y8Cb_%uq~T{fDC>YR)4xY8{{4v+v5=YEzu^aGH02n&}cKS(6I)7a}KuOjHf0=t)>
z+Ve&Gn9WZOh6cUB^G+TnZ3d4J1r~FNX9}y=^Kl{e!Q!;DY*5R1cWabT5V8Ids)GFy
zio*Z4j<|?On(t~)1L<tBJM`u8_?%|)MjAmj7(F$ByZB_eRXFXeJW8(-iv>|=cU4hH
zE3P9>mTNog(>Hvb=f0jO90=Ak<}L)}0JWS*@PF1-V{M$bt)i)l4bJbG$U{$Fgq^gY
z*~cg59mQ_6ZiP$+!XlQvW%F|MVKKyu4c8?ZT8W2S$Y9HY+k6=XKhmf2S%l93eU2?>
zK>#(|eD|U!<<`n~i;6}02(8|WTP1>)8g@hlpiL}dx#y{v6wKEky%H;2Nf5^rFxDS5
z>?O?3@cTBoQKZ5vIR3C<0(5(-K+G)q)vK}G%fuBny8jKj*0q5@(l`_<P@jLIaUM`k
zQQ~5l`GBs&XMqnM74HCfs5dnG(52o?6<9jeRX*}e^KpsHM^)`vp_qKM^MqJ(DGrh6
zPUD#WB`ari$4{@%S?0nonq`o9kGq4GPBleeK<<@^%?BUxM&NdB2F8greiI!0^TI~+
ze0=c+bDR8LIk)(bv~VgQkG3H2O6k*xV?STLdlb+4l$f6?v6nQl^KRxPk`+kW6?B=w
zP#2^&pWZSeaLjcG`5UB?_VoR@+uGb>DEoenIQNnRCa3MWMmQ&0Rv6P2l1*YydLj-J
z+oxsre6k=&#t-rrB%w-85RZQW<igv;^U7Sy41f6Q;6zFw^3wXyzG@*!u=8bZ_6STG
z6s#-)f+nhI3wMqJtsp=t{SohMpK?tAf+>TB$)L;(K|UCKXUhm@FtSkw-@Powv%vP@
zVbW$b)u`tMY)KdK!D~dp))cFIlkmMwkoLblKRoZZe>L7l4%)9>5Kh%O;cz@nF}XE#
z5W2r9+|*rdUP!#|)w8edG=4UcKLX1-da2v$*)FITQ%zYT5-3`DA;b<U8nipQ1c`$%
z^tC9}$iWo4^~Do+{nR$cDR=T^f^;BP5i4*e#ZPVta_|BU0!&EOAQ6l2sH&8{MwAD?
zW;9o;{uKg|K&T9=K~xE!6a1GE(kRQ@8ySEZDYU%%m{x;4kn-v@+oc21Zvw2n{}tlg
z1S7F42`O)d%MD{#ZrwvTd@+1s&%3xcBd_}qN+bMGtWxMQP)K4PVp>GCU8}ExAH))~
zQ)vLn-pieJTEsK$C^$3UXY20PdDqB~z_W<t?ynL6_3-o2tS1lUuu@>k{So_@_NJJa
zLMl-yba49JCB%WWo2NtbP|IT~?Mf$q=RdxN=zcFqnZ4=SL|1jKGQo10sVZI>k!wW|
zr>0Q*%SEk`TCfShKJ9?!<NeG&!1?|5(gk)XDSAWOy8<$Mcl1kYdoJ!ge6vvbzeSac
zE^MPw!CIhdZDd_C(H0VQJ9|NOcn`#gfjBAy6YyYy|N5VQPd7(*|2p)fSyg%E4U}P*
z8^i<(-8a=n`v2F0+8++vjx{${PADV;ys^AFCCt~k=%*mC#mMDM;LYh%mAFkB&fbVD
za$pHIbeGzue|ujPW7$C@CB{d-l0@y^I4nLU*DYP;kUa5`-W@-nYeVX?E3^R;@JjHk
z?7fN)B5~O%jsQU!(4JBYC~t(sx0}lgH{@H4ZI=V#*xcfe(`&)Ej=JaVNme>HEZ8i5
zxf3ytxhCvY7U1%DZcTYwFU15!;ZIYZpif!3TF2R{_;ZJuFo%4^JD(a7w>B#3I5DX>
zl6}+ne*jvRFZ~Gql~aF70#kjbKjq7t>+&YJGk}GxMWg|_iL(WV@oQiaBSKO*I};MY
z5bh&JFbajc+TNIS9tSs_XjbckAK|ZCfGAv5$u9^J&)#+qp|Jo2yXOYAZHL6S-bKJL
z=BoV@`UYD!WF7s;>k{xSM2-uUIsUow;1PZhN@t(M_on=gFQ+T9s&ed=f%cM+aEZ)V
z*rQfey$tmVP3HR{_-g)zpatORCU($lVj*HM+rK2fJh`Rm<fVM4kUm7)3_Mk``}CmK
z^ccSwrg(q_b_*580KBCQ?j|vkqE4l0a#b4Q%j=Cpi=H~F`o1{0-(Sf0^;gw!R|+R7
zv3zhI!HDd$7O86lr}gtr2J9^IuSr_o^(DgYAZlxHSKd6!un1XjI>heSh~~knc7nt;
zM+{eYt*tQadtY;D<+A>Zs-0n2r7-`gBJ4*V6V5)m?@Z>MxE<g8lu`lU?C&3iBgMOG
z$$~u#m4|G&pPI#9kttu~@<l%B%h(`>^+ovFXz@Z6LCYQojs$|4sXABou%TAWAIjSn
z9%Lfi*F$wHS(~GLbzH05c2`~YeTvJHC6J?e)gSXpJzKJYq{Pne&yFxuoKx2^70>p8
z{^vp&y<q2J?n+(JA##`A24RSH0>28*47qI{*nUaqnKhXVPKAVz3hbGe9E$I=cwyEr
zs#IlcFlk<YbhC9SA34Ymi(EYX7SYrz$X*Z_MNi#bCe360dx&p^;t$aObjfqPFR$(X
zaRoQ16?lje$jXWOUOQRd2nQ!Z?b&~d2tactpMij`Yuk%{8^2-xU^$i_gwNf${9*b!
z_Du>rWD?4hvk`k<t47E|bMQYdJy1GSRjKw3mtHGKnuR!#c#NCMf4}1wSFY5|3%q7;
z#;v?WnyKO2KsKJUC9JUUM$3cmn8+%PmGpneRX;b9l|obgWq*Pnu6h;J1V5UQTRv6j
z)OvDg&H7(yAFoabY%@SsBln$Hyc-=VzBNSB0zP{o>H3ZX;@tI5-J6qtZ2Z^z-}MI%
zh0eTqfd@)&d}m157v9cp%$O-2OlA&3g8`*1F+85?G9OuUm&EU=SSrX^Oh?@^6biCX
zf(xaH6!)!m3;4|0Gzn?HAaz1_;c<%V&tE==4}j7RrWYca+19(D>dU|e($w#tLa*KM
zM8$h3NeX8Hm!oDE-Xz}N$x4gyOL>Jm{;;>?sJJVtCxb7{i-lwMjkPrX=EP!7dH*+h
zu`%m6kv%9N9rzbPzHyup$yaFB>2G677ru)V^OiMPTS6_iySuSBTZ_L4t|G~M_BS_S
zOM5m5Q~VFOi+K4Pgq}ogLe=<m$DVhB{l8PZdw&YS%RKU=5Q$oxNP#k%`13H~#(Mu#
zjvqikH(v#WkPQ4o=snh2Zf@`#X~HP_&EDudV{dvt6O1t#JXvOhG-Wj3d01ut?p_YM
z3}Xe3HS*6{neFAg|MBUG+k5i!gNvp@_1*XlHc`uP&GDwtM#kQxpKG4;bDF4G@-%{V
zH;{v+JQ@j~H@zHXj2;S4!mQz3a5aQ_QWN^qZ<Q<mh_|)uKXAW7&9hQ#f~tjIyh{o-
z^SfR2!iQY|OWmq55VepH?gt|#y2qRBn!jP{FVb~)_@%{h0k&N0kdF0d5x$0B>9j|b
zPc*Tq$h-0Di#wY{jW<$)%YL_sT{~;O2$c=;z8FsmRuYxMbdn7Rb4+y@16}`|(X!mo
z)%yG_cf27@WAP?22I}u7nSRTMW%b7~-p;bOV*j*#eB!@Zn{AL9{_K~S3U#JFGtFU}
z<2D=cPk?x8R3)KBgF@u7Iz?QV1bwB9Z?GLl$0B#FUFj)s9Ga<9_m{7j37G|YZ+gOT
zd#gAMcjLJVmFyO;P7Um@6&9S8AsS_DsO_VK6ltW!(oocylN((<T`zD1QIw1Xe3TLu
zh)_x%sSPh>p~(1@tYv@mq4>}jJj4j3+@}-iM6}(K(5X%uGJB8qk1mJe>GCR2wO*z7
zQt6spWM8S<TG<Vr+v@6;t*(c{$$5JF7d{=wold~?Z*<K7mD_Cb-t;kimrn+#8Wd$7
zk=$XcX>*zBOGQ{#FDTc>;NKj7Na~)|T%Yc7ckGOP-ie47>Z6#M5}f$V=v$vZMMI^!
zr}U(>bxX{=lG>={kshr~@kD<Y{ccKydTqzYi7UN2E!OhASlLU&>0OHvHa(#Z)6#>`
zJ;%drZy~E6-gF!beQ*D929ZMj5X~QG_US{HWVYr;??l_pyx(9^pL`&gz1F>-=Kb$@
zSg;E$0aJ|hg-RjkHAYQ8QdM1%+R`mbq^Oz%mt4x3_1i8Hq^5(|ZgKBOsI&jCnNU-^
zmu$Y63T_(Q;H}Np5xBqndG-6ztKaJbEl<S_mm2!GH^AvWyd^ahWfkao`%{4}z#?d4
z&Jnvm{@OH_Bb!@3Q}M;a!T%4QhIF_y9%{QzHe1)^z@?opt}<zQTzX#Ij&@^xcaG>q
z&ybxrIB!vu6rs1V)y52|(A1s;Jwo2IOY3R-<l2Jp=rgFcs%?M$yLS};GLJh*T9Msk
z{EaiDp;d11r$aVNL9%^pS3xc68Z8VxUv8vG*>$O4y%~CPbH>?4eGbJJRn!%=>8vi!
z)4LA1M@8hd?sB1cEd-hL`1@cM??&U_AHwfutfVcT9Ag&|5+3@y2Yx*6Gj8hn4NDD<
zYI7sK97e1kfzK_0VB<2f)qhD(KPb8*-2QUVT0<wmJ>Y8>olQ_!p%{9F(FW~AG0&NX
zui~ktQD!u~+g$@Oy=j0T?!3mP7;Pi3E;9?16hW(k&E0c=4v;{CXG4DK%zEDb8t85n
z!qcrJvNt%21>w5KXlfncG+&Y{aW)R)q_UG*2Pe6@y|YTcn{(B65<i<1PizGIMHg~{
zRESp}hWt10#NR6_G1v>`F8EvG$5CI+3d2w!)krBq+p%o?A=%D2|EAx3hiiC68Q~7x
zClhEecHH7ex|M-2jqZi2u7Ld~2^>pz4syQ;Vz^LVnuWP!<kj>*H3U(WC7BHS11WOL
zW>=q<Ia(Ko73OAdISuv?soHp6eEH6avP|;BBY6wDuTnBJa;JN+qrY=)$y5y}F%I}#
z@lL&f4Ao8K;hwd<k5iOo2$?-_{dn-4c*@FD!Y+CS7A)pSl-fq$S9XP~nzHMkOpr&<
zl{{tl0=(iKk>zsTOOl6fF%l(jcC>0xJQcA#t%_3{ZvfmS3p-}9y38<3D;d<vJzDc<
zT5Yl4WbCyi(!k`))a)Rk6<`{_Y4(A|InN8hfGaBKoGY>M*4WmN&#C!!zp2@)qJCr&
z6QV!DYImsu6{nO16xrAlOa?W5uA`unsrAl8h4<w%(w!rWzA7S|F=Dg$M!njk6@b=y
ze(_fISVF$~!?)X|RCdmH?ak@ABfguL3ZfRe%kQPY>G#?r`yEfhoZNdIBimhbBEtwB
zqD0R^pt)wL-tg{wfw$u=J7D8g!=p_w@0lsE38q%%7v6B)Z>a*UBg1@p5qs^=SNcKg
zs^mBOR7giumEQwY*PLf(_5X|(OlNJlg<7N@JZ%k$u`xYlSDQ$MO4er6>vP}AII%2A
z(AdwfK1XB&E)k2IJ@f|sy%{`%$7Go0JOEo{UvY~|;Tg<|3$Ri@a8l2!i-_;{uPIB6
zahZ30XZE6(&16ci2xB>{_nNh)jA)V~Ur+C97n%3R9k#RpRmB+}W%cO&7727Q6a?FJ
z`?@aHIio=x%qfzu1zD=$ap#g+GMQ#P-eqPln}oZuL0IXGUkeIfr5JS-@j8us%!do9
zCg)mtNKZg$vsEZiu7!JhL7dKE=EN<G`mI(ODoESxgzw;XmLTukAV+PF98c5gb?|!b
zCG`n-Ab>lj7M#kjuZVEutv}ddPP>gCea0X0wlZ_^ce?<@PJJ;Ig%xzg)k(ruXlCYD
z^FuQLG*Sm<$5<BaQ*`7z4))pQZGOX#I%)hTWoP0HD=#U0y@AVXj`uH+8j4+~B}e&n
z{f59D-H$j#HA&TyCY3a}V5*Y4$)+6I-rUF|S4s+@_}2$i!ZPYmh3w<|9?$F+M$xoS
z%>umqG9-Lm*PBO2ZLEtx*Rxqzg3i%F_X+WW>xeojeXuBaaJDr2j$5wEG06R^?@O`s
z%do^pLV!>KdKpwY0qRdDxJRpmS5UQbh0x7VN}CqYZ}`zpe#kN8FKWN6=4PpybQZRT
zaeT&9V;APdWkQ|6^?K{nFW36+4?w9Wm(%VfW`uO86J9ZLpWalHbY~eT&xq@OoQkBI
z+HH<Q6yp~*`TR@5)ZW@><JRp+;ty2Z5Jmn&pHg*OE&X!v+~bdZvRVh)=)o8b!*_Ui
z*C)Y@aUAIyw0kf-tm7x5U6~{5h8)@S=alpCx~-U#O+zC}oA$ho*B@l-7}dB@hr%@8
zK|ZJvABK23HgD%sp+?F#G!3D9|2ZOI!`#}Wi{|fmbc0PrZ($f<A9~nCxhfphy{+QR
z0O;ANHceJ!k2y-)zT%0UnL*?EttTHz5O-db{>0Jbtqf<x_G5#Jm-Bu%9LS?Ma?*YK
zv0mx)n=&LBr#fOxM@;&x-AW}>O-bFxiEPN3{A-kVrf9AuqSwM*FJx|<Cn8_NK{lc{
z>FRMyLEFE$yg<s-7{k0xHy_i&c`Bzu7dZ4J&<1Q=fcNm$>A4a$y9o7p{V>#UM3ZmX
zhdh)K3mj20uo7-=GewN+7AaJ`QJ6B+Xk9DK-r2;S9_EM%WMoj@IJ`iz1oKvWvqi}C
zPd{;OsOMT3t^=m>OQ0vg|JTNjv7)GP9{{KzpeAZ!r63tPWsIA&JA{KA=xetjtVsk<
zq~`Y54k9VN-gv5g6yBamC$;s+CzET<-|EuE=YSfKPYvhmUE}{oo~RdvGrDM2_k!J}
zdb-Y)$XRjv@QLpPQEtTpQ-lJ)cxBhzhgWp7Lu31YPHjQ}N(WAwAR`=gdK}Gq?D;#-
zXR!E>B!+SPb<iz&Ab-!coy<wfwbc@I7oaEQJFUEV>bw2gB<;UZK(+VDC|Ugj#W%zS
zsp&Xr8uX5g<Zi_e^OoM55xSLjP!aQB-w_-G|9tt8<k^LKYSeR@sORrSl}|JD|C*qv
zdCuMKG)s23%WBUq<Qcz&0q-^-){3&)37fGo-t7Fu%O}*7KS->2oii63mb@WEOmiOL
z*+#MK@m!Zxu&=+oj*(4?xv0OJ%&#|tzIwUM9cRw$qUhuY2DUz@euoe<xK@~MPk#M8
zCYCXaihV|AhCbhHGGgis?k~RZlkFenO!%>~Ijq8n#n!is16!EA_lR2W2&JuM^PS0L
zbC0vSK6FD9{;$Oz@9+<=dO?OMct!?9gUnHcBTX|s@Z@d_HrNRDaYGF<`;x&vaR0uu
z%H?RdLJ)v0Q_x2(5_KM$u%B(|j>{Wi>`zxG)=;f7z>X$dZ!E-Di1L?7Rf^6Xj88}}
ze@R<{+{^7ZIKR>94Ml@YLGwB3bO`Z$&pLk3yKC<@MHK4VJV)L+zSB-WQUXi0p#!Kf
zm>e^jp;Ne}&U`a2hH4`@xQb)V)7BJqAJObKCxSgDyF(JDX#O-+a{YTH^CxQNJA}MA
zm{J~<?jr<+ec!<t=6r1jm4Fq0ChXi_7uGk$N{OeQ#=R9jpFVSUmwA)#3nd8{`iht>
z0gagXck(O{e2XZs?J~_o7XLbTz_62zd~J1h2v8M*{^s*7e0sfSD0*^eNBn>fpJMP6
zn2G0$Cf?$RF$^I{ZIZ0}y)^G$e?Xwp4(;hmhVON67GWmTr+5x70#mBE7LkGJ?CvG+
zkLFE1J~*20U+UX-7_pPA+A2|*Y`)yjZn^MCc?xpQ3a9U7MXx#@*rhA?AD4>dbR*ok
zj%R@SIC;+{f8}TWhUtlW=^GkDeespxv)fBxHsp(y;I5eJ;U@506WB`3C1$ftUiTCs
z<CbUmx-&_aKQ~{#PIhey`M&arwnUl!NxA0FQzwHk3*^m8t!cmM20@8ZiwHF~W%BOC
zK0JYM!@A)rj;-tVo{kMqk-&>;$VG1~=pS5g4eQv{+vQ-y>mHw~o*ib8q8Yy1Li4?E
zd-i2rh*z2uRS&Ct<Qw5Y+yj(t-o0L3(Z@O|Bex)_45&J@`E0Z$AIi>X&b=JPHb!&@
zet%{n0xNFML26&ut+@R25*Oyj0uh-|)Nmii+pYrHQ7LC2XIk%FXFFHMQIqT3MmV@T
z6#jKeS<--J6JNt-4I><4AbYFF4D%7OCpzACMp)A$=l7&EpK=ZcC6e(`U+oxNSuNKR
z#jQrMEt0#zL^fiwCtAKs@dMM6Kz%*Wb3o7>XSlcGdtGN*-t+?&KK$vpDvzH%4`-yB
zRUm_GEu2{T)Q9fr48w#|tS|e!*H8=wrSJMEMr0K(bn}MC<naPZI(w=?y$GDStKs`5
z(>U<U6Wu36eDN8Q>T>R9Y7(6V?hp#4i#$4U$PR1WxUlc>^rZx!IL2g;CYhsfKMlis
z^q6t!gJt0R61{IBo<%&ZaNs-m8&Uq9<_eHmDmyjldyzm&PJFI0y<7G;&wgVt&!5}4
zRm~K`JyJ;}2zPB0BF@^{u$Ft)ae<!~t=Bd6%njq>L(aVUJb(3PGGh>eq*D~16eppl
zPeOE2w&)b8&kXJ1cF2LBaq7!zT9X{tiEVw`nG6|ElYU7P`j*b=Q=)g{QzU`k!gs8t
z?sM<PqqwH-U;>eA(wcHA+xjfJFf~JBQAJfCf&WCP+C*{9)3`zrn5baE)BH#{t^tj#
z`A@U%q>{J08Fk!%!Q^3rC>R@QaaoC$>HL=b0=UG_5~JqUq=RN@(Qd&uu8Bv|_i94-
zGU9fHCBMPb$#Q5K*%Z;y@cAh~WUC;%@o8+68L3{E)Xn_L1M#jNVl*WYTtn&xx7kOf
zfxU5icguLeA>B)V>((yuyhntNK#%T0UEQ<;s>vMpmzYBRdR4Lm=8oQ+um^>oR}D(N
z=wo?)o>!yC(I8sUCwu%6K>WQ3&7wBv1pe=+T&WEe>d$sK3>fX%qgh7LLu?lTm%py?
zO(NCs?hRH72MJ1r6_F3>&@IfkE>%4qv%Iw}H0wyNIR-2%r>^np^?V_;WA5Ia!U6uV
z#(DSd1Owo>eD?(jCP=D|-*+tyGD=n4W%PAXH0dL!b?)u4co6Bxf<KNtGc7@^lOGC6
zdAMbX0e6-{u|FJQcWbJVuQqhzMBm2fRFnIiH`aE;n#c+UZ&jz4NCevqQcZfPAuTkY
z*&bH_%!L2kCgNrzQ_)w!YtGW&Sfr|EM5n8a(`G@KsGpj^g02PWfX9b|Wm-{24{rMm
za?=YC&VtzGqCS`>f7&kywr5YB^K1+&NHZiSh4Hz4J?Bc3@=73>-r>2f9t@R6L2S
zETP&AQ{ma<2MJV_UT)^P>o$=*8=%`PF5U7@-$5U!D^igMKSM80*Q80B;w<%#^=L)?
zR3|HE=l7`7L6}*xp(w<yvrNOr0=72Jg^}WGNkNiZ-mVF)mLsWJEYJZrj#8qNs`Ut9
zW0!V681DYql<Z_?LxopJG9Q9%%($y1Tp^omD*-Fh(`|@glep{VX%dSxBTEtNaBo92
zsQ+&I0c4TNmxaLz8AUtlr&gCMBgN%F!&5(tkLh!Utf6Af@J>x~O9rubFPV#Xr|6%T
z>N_iN+jO3p=FXEDiLIT_=-qQkT#NH$+i`GF5BJ<*^6*Fo!3>N@q@FDU5+Fa#unP1w
z#Uc*kvkY-0s@M^)WiHdo|7p2rmzie)RDb6gF+tjN3Unc*B+B7HI%tlR7dX$Zy|dM@
zqA)ZkQ$Z9)C-qpz?AS^NBbq4HEo%|01o_kXYxK%4<uuz>6@!CBFwyJ!xgM&mhz(Dn
z=CiwP?i{v~_*sPiFZqD4keqRVBh09_cc^HC?&z&FNXh}r{gjT~J!v0$H2v3le1!Vz
zccIfb^2Hu^yfgxB`8#(ZhAri9PC1VU&P>7xEa{a-#aCS`Sk_D#y179lg)K|_bj!*e
zx?ynuq&J9?#&z+!eQp3;djvp;B{osFZ<Y)mNuUzg64pVg$spB+513u&u4P__KZ8KY
zY~V+8PS0l7;oI6?oQpiZdpHO~2XQwSu1luWc`O|(7oY1)bn7~#8Dz^619;FB!r4ow
z#{Keg`77q?1`%b9Bp(Y`fZ$l*a1YgTq|2(v^TF}ep%>kUbv-OQy^5;$<i~YCc-$Rp
z4E9~6A_lpSw(&feu9=rSFDt5N=yDx@-e2x5jPMpxx_RAeDVZkKYP!_a#STP*Jd%2-
zZHLlZ!IuukJH_+H=t_iEN_8pF@uwUr{=0!G*^**ymf{6NND#wZoAGX&M6fK2Yhu>@
zX5H<@0q){Kwi${_h@&3pvdo{!P_a1{)8k~<)pgEVKHbveF-U{BOCav--z~==$)L`A
z1x@QYyv?fKW+@n~G=I}WFMiztE+2@|CNF5Yr{KLwTguHA86v_u%_1X8Ibt{SxGmZ;
zVccDgCi|5dQ}R~bK_Lq3aAUQXsis7U!X;s`6ce<~>8lCxjxI@<rbt%~xKFPIS{I;L
zgR7<^=oTUMu2uyu+LhN(w<^qI&8-ueHP^h{QJxXW5T=^mw;vI?f!huzj^=SRKPdX*
zQ<OrVM)Uova*%)WflQXsj+{5;ane+s%U+2&uCT40We57vaA?~&vOK7!!rZ$j|A$3L
zjcdF`atM2xe=YJVduZt9({Vxd_WjSRUHr?>*YniP1D#cs5E@ar*8>}DsuX^D^rO&G
z_Ph)>_Dk>Mi}SW8NH4Gb_!D6sh%tNL`EE|C`+6sL#gWH{8GY^K2UK)fVl__7ucaH3
znuEy2zZM&f63^bWVLzgm1D&oiY_Xc-pa=jdsf)-QkgFC*UoKJ&tc=uL<Tr-w>)BhW
ziCEmLxgKT}T}f{}^`UVKm9JD0QL(ZABu$+8xFM3t%Dwfu_cz%1xBh`o%GRwJ-6adl
zWdpf4#ZA<8UBB?%LZgN_;^}1{Za-;v#UQvg9Wmi|CNeG{?lj%PU?e18|GVGmT|wkY
zwn%4Hu_ABL#srj5lOl=;MIsn*UO(8_r0r&<bRu})Q#IGfm^t>1w`O|uH3Uvp@re)V
zWzMc4+dv6?xT0(Ww54_9C%e3FFTsJ<m105Q-V7mFg&4J<eI@&>oYajlySIA~T1J<Z
z*Jh(=Le+oeQj6Y5@#y4Z&p-JVxMSa<2aS()WPXG~k^Xos4IO4UQxS|>u^|h6hxy6h
z3I4A>#VC5>Lm6w$k89?D&C6b3DA4h@9^|TUaqDmMQ}K}jWnr%~oS^}5qeQXA7O|9Z
zCPO{}uhwm9;}+Oe^?oTa9rBDR%vq#b!tZs~=zz+g68M#zhyWW^+uu^ZSGf3>u;cr`
z7BzC+Cdl;~2YPQ>dj4H)-=!TI^wR9O#<bxi8~Q!?4}kv6++69=Q9EFqHM@^^Zfp35
zw8{{sUSCB}*Yr>|-96GwlWDoJw?9Aji212F?pm|`V!38?{3%oke^aYS_j-WN<(QX@
zGxl2>VwCqbwGQN34H<yFdnU`eg(fUXrZ_oLb8_RIj(o}^GxE!D-((ZcR`T8<Qb38j
zjBJYA-*NNAxl9j-TugXS`@Q2Kp|X#!vmgJ2pEH-P-*P+MLU5rH6LiNJojeg>#-~_(
zRugF^t>mXhiZ8A%4)V;*T9&DL460_Uzxcik^(i2t3G5OBJDKCfIkZs*I*sfp{)v$)
zQB4P(oMXXXF~PwOk+^+vwIz*urH&biJ-gm6z??>E^`9*axH?i))-OV}FJP6doXZOK
zh<l8~yC2@?hZkz1klNK`j^}R*!Y_`G=8NPqIZJwC3)aN?ev10Vm_?Onvsi4$#Osgx
zBFW|9X>GeMa786kd%2I6rA827hG?zblkvve7D6?;%5<b{P>}D;8|?UbzC9v9XVhI_
z7TJYX$%dKNr_zi=Mckmo>8!>{<qd&SWsNkd_GlA)ok=40SmgVI)M_PSRaL$^u^V01
zW^SfK5pKQt@!;GK6}!s%LTi-=sP2W05a-Q?E?Mz9YUjbq$tJk9XIo4D%u+LF$JD+m
z=EDq4NT~=%4aeLWpppL2XBwpX&QJ|{{CJ;71olC`S!p>bji*OMaT<i+BROAs;Y<)c
zlnXXIP_OwrJXb4muntv8^_5###6I+Q25WsG>aO`wtA2375zWy;H)1#^z}4)sz&PL1
z6f`HUM4{q}3*Op{IPOq$Dom{&!u=qW=(ee=_yd+ZKDYB;O36k@4vaTEF3PB&Mek&W
z>GY4ReccN-_=I9E8np|7-7{)Gm)78BMidK_(a2LW=$h*<+`=mAFy|-f7GyvrOB`F8
zNQq%K)SXsO><&Fo<kL;tg{U?w?(Y!+<C1g;H5!;BRa7CX6YhL6<Fbdyy$ByzM|_SQ
zdcEwK&achKw~m8KySbF@QzpfCF;aUZs5Svi;@TRfuW=59nmn5cW%q&4o@h5GJO{wP
z_nJBH{M(F_kB;Qpr+|~|7YG~DyOrk>ruDy)ZPzW--lvbp+-@gRRPHH8OJ`4GE{yOo
zhG>Lu6>V$Es2}6mRCP)J161h`Uqq`zyXLZqUN?!ZELw5UoH^{jQ}#?Vg{#$X9&@PG
z39L0;RvNBy-hjM3<_tLbKY|A1XM48^HPH~;rrpSE_>|3w*VI94>y&r<Lv*~f^8vk+
z{T6zU^slp?2czbXcdigDJyMJJ3Qavf18>6p`CywS&VwWrWSi=gFp$-)|8L^{j9+CM
zhm$cnje&V~HKs3RW_49V%f7+kSrSCrH<#eHZi6!^)GL#DP|qe7I+PUb;YvsPlE4}{
z@-?VslK<h=!2ws%@p^g@wz-~4u$e(WDe|g=B&DS4Kc9qBNiilaznpPz+3;-fdwsFL
zlI7n7mGGrU`%j|`C@<REwh*c4T-K1b-I+Yg<6KlhR})&TUgIFkT<_BCg-_3gg+}e*
zXe<0fi1^V>LhWS0<_xOJOi=SrO0-HCo2ov(eDn0#dHeSZ()sQYk%R3J^h;BjNV67d
zn{A@HlZh{AN0(0TK99D&m!?%c$w$PA(W2$F;+Jh|;p)AH;*<i5sz0wcvi56Liw|AW
z-Kbm)aeJ}B2isPhfgFIn$9|UeZ`gV>vMga(zbf~{$2b>mvAGF&{~fMso~iuf#cr;$
zwpnF=Uik6IDpMtcRdrfO8xbf1LbM>#umRD%$X*^~TQ2>+{UsRNlLAHqe5r=~nR{BT
z)+c}8mzz?H4<^%C;$?}2^!oF#Z1VdPLVmyL6ap3Lp_V;z&63<!tjw#yKO!~QClOFb
zd+QBl<dsi>sG@;u+%PlXRBJdM{4zN(e*?3}z;yDV&4if}CT=^L?CG#2S^9+RPw}d%
zSn^e4xwE2{!opIfFPnAa^0Alc#Je!vJ>HXOl24<eeLbt6pk14C?}rs7pGn{Od(@s!
z^pHk{j@(665PScnDGJ<*{?m$C=38PGb-E22j2c53cH^Tcd0I7X+YWVxiI`%dDP(Kk
z=;|X>KekAUR=q3+(DQHoeRXQ^D!0^Bgm|z{>**pq9F^BRPBHpS0Acxn9RR5+N$qF7
z?F67{8dqXKhMHuQ#WZ^LQQu|pvI#)O*Q$SKt3RI1t@y|6wOFfW1Lmy8@3W=9TmSiU
zr&P;p3gKOgd9HG#qfy|)(kV##TY{+S>^4F|jME8KRKPE}S9>2vuS%*7PSo+Z0$gFK
zE+icLy-OKOQjsH-P^c@REPEpxUk|?>pOpX=iH3VH3JS~yDN<o9)Cuw?rk&1AtvZSQ
zRG)+P5G&ghFWcb3SiqFI+qi=R8x<q{<)-t~Y-A1z)3^a)&Cv`T#hmKa3Yo%m?6UNi
zYDp5b$YMqARtL60<pl_9G=OSF*^g6RmPhNprWpS2S#xheCyL;)qh9Bp1bGfP*4Cus
z&-Mx_Rp!$<%t=Ir(x)8ogFyBUloANb29d}RXze8X3FLi>e}f4$mZcaFoEt+i<TH%a
z0f;Lb0J8uX8w9?*j1`CAIfSJtqX`ObmW><|s}-!D|1QB@CK!^ZaO2-_;kBs8Q#gxI
z)5R&HR*+$qJ=%kyr9#niBxpe`E@KEv7(&P}MMaROgZrY}M)8c{+*fJR{X;OiE>-=j
z5uMDR7#2a3K!xKh&c|DiUI|&MDP|yB@|HaOlZ7NGm<7?1C|9>CtANTKsVF4t03V`M
zv;j;XhVuP%+6XF2V9fV6Q*}J}R)~@%l{;c((98krbhO-QR_m4C{S5K~jvFsU8yA$*
z`LT>)P0KEmW635)EKR%4+Itlg-Ohee$&_wZFKUuQsFD6BT69T}f-g`0s1#eIeOsHr
ziN95BABtB~b3kvEoZe^3-f9Qn(3<vY(5?eY4nVYs$GG!Qf%r|{vIBRDwF3KapPK^v
zmCayeU?$WA3<d}*Pyhn}fQ{k+ek*pt|1JR4|7~Cu06+r(7NM%I(CM&PtTtH75pX0J
z8gGRo{zucn;d@k7cRFIWY=MS{p%psa?%nXTG>zn)W&jWX0CWIgDrh<okY<6~76b$z
zP)dukh&N>YkEZiwFqom?Sy@>Mnl35+(5~q1uA#=|DhLHlcN+}3f>y4u!E{-wUbND_
zu}15Li(ZR8`m(FJ*xX8{uk=V0KBo*;NOk`zgJujsUkpH>w4rhg@B;^u<A5bCU<HgF
zv`~>*C=Xa`Jzs;CxoACdQ=hefEt!H9eBFO*fFITnxf3Aw1eV-^PcF*;f=MH~4mUP<
z)w6WubU+>e%u<yfg?Wu`GFSnJ%)z!)hOKYk9M~DhyquMOcHh3?NXBqN$Y@sT>up<4
zX@&V$#g&(<Tx^0|y$amE1-aCUu4^)vpLUooH5nX)%4E=?N9fsE@PGdSOFx0n-@#9x
znwFFVR2F4i<YnK;&2BuMu8``QFRy=+cld)a<MHFzJAFt1;6Xrz>agPflj@Ygmn^i;
z?Lt)RrJPL7DvsDurVJVafKLGMRT-f;F9E=RD!?KJ^IOGgGDLY02wO(%o(u~g6)7EW
z0{;)FYgKM9Bh>T*x6Z~_DO|b%(Eqt~V=`d;2{0mEC+VX$YY8e*mF>1CS~Y6#xi{Q0
zJzg1HSf$YE4hyRe6`fdL)tq_y!up1;td>qh(-8dngy!YPo^6A`$yLZ5MNB0Jy5!2&
zrj^T{1YCV^;OYRVXI{B?4m7j`daw*UlLIgR1C9RD?3+{hK7DB5Mf9U7;N@*TpRdsA
zj*Chz7UW$o;9adKz0@iYRy7p1UcGVS#_gM3*W0gL;$P}7;Ejp|12=CxyLJ6xTkD6~
z6T^dDV^2i6xBC?|U4L7@uz#$p??L;+kqfe!!T!F-j~;z`t%yly6(Zf&uirk;&3>Q%
z@?-IzFW(lwE`I;?<EMh9TmJd;=db1eqv?LH{JZdNVe;+NZOQHbPp6Bfsg;`q77+)h
zsG5HqlZH<!g#M^m=YsK!e@-~W^;|9<Uj9a=LVrXgET#7roUoo;p3|z2%P+Ba+#Et1
zo5@!*UdK*(pc`)LbyDYlI^DHq36N_MSd=FHECI<P#=Zz`UfgZ?v#jj7cD^PkQDwdJ
zBS_!JvO^x3c6!rlml*2;&f=pvOa0FG|D4U*KHSyb1C(_#iZJX&&Q;Tw=0BR&7;VkG
z=&Gf9GqjSLNcoxBzS}p5kzrpszg>{=rp!E;-?_Z_o?+Dcuh_#V<j!L5V7c0+9X7z*
zz(YeK^V8Z_=R70Ew%py8zkyB#y^5DlT+h7lk54AOf=JLb`s!v8te6=-`W{}oU)Zip
zROoc!lycwmlvu*7)0p?wn%=^|#4QI4{jRYrLcRVFFkm0YMaW}q*FMy9pD&17Bjn@S
z6B@dK&SiY#=<!C#-kh?@cSX(?{7r0ymmqU`?Qjqoh;%g{CXL;VndEfq^}Y{Wm6$>@
zci>*CW7ZSVwESS{Q>xZ_yhAbi=d+O=VNb>rKb{gPE&GFtqn$%NFX9g(9eypF2RRVS
zOpoUvlozG~7vm^zjr0S;c$xvLW#>>`+iTTSy_d))F^*?<Up%JdrHPL(TDhs|DkIdZ
zR60(DJuK~t?0FJ+!pMxxmzxIk)M`f#)^Bw4u_@yl2|2WJP3N{S`gyuYKm625i}g4<
zNT;J_^T|tbYIb8A1rc61SF2RL9SKK9aw&&;qP2Il-g@Fq{N3BK^NrakRCAmeOVc0|
z3#x7mef*-$27Ml^Y5zmweIi|9$;La4=D>Rx%X|?k$?=UTL)&d*{YLM|r8r1$@TgOd
z)<2hfg4MleBx*5#CR_d)3SG3`;#<V=ESF^d-lTr*0rYB0jJCcRdza%}*l}%Y3a%9W
zxerJSTj3L4p}rKA(e{&9o{=6#`uVa=Pp4lqJuJ<DmhZfd+ER4(wRr%OL&<l#jJ=*<
zrlz?mJvt@qOBc#mj{L<3^=i2K^RQmtyY_Y!R|ozYyt?D&TEdoA8^iIn>%PZ4Je#XE
zv+VynMLMOGBXoYGzJ6IOxEZ{%^@8p{$X7k6a=1(Bgy4nGNGiyKN^U%sl%{rVu#=nB
zdo4L{y@%tqt)fQsmGtB82AO5Onx3tNl}2<cw7RF)>Ie_@toB0H*BOnOjtG*y&R73A
zl<9Wc!+xy=eyt+c@*xPJ?I2^{VQh|1*sStSRFB%>IkLul7f3PPx>P!PIXf@*`9uAu
zHD$v*be(c2a}0Ec)ms{^?kSAoeph=wC=Rhfmua%v)|ENi`qEGWXG|53MC!AD&trYv
zH*OC$%r}!a2EyzUr*zX$%6gZDr~MJ1n&0O0jdqA-+Vc(Q{dmwuTR`Ujoul*`$<cq)
zMG0-1Jvli$k`5)8M3_h$t`tL!rKBBeR}ZL}sL`+&vcz((MM*7%pl`B!^Bh$`GflCA
z{i=eg^>7@0&L}WZ|C$J$7Z%@M$2c{!H!`Pd5$zAa2ThPe`EPaZ9ZfOa{ESvq+clGW
zl-Lm$OFs48DBtCE0ORnTZ2^DIYZVy}oj3YHgIRZ!dGS+{%|hxTwQmv1&md6ia;9K!
z(ywV;{5c5|W8bzXW_JAujzbl1Ip?1!Rb88jvYiLc+I5~nuYv%t(>2-{Xk*!(i++fo
z@`b{r*S^6HqIuY+LbRLOr{MhaPpq|Z0WU?-NVTC}!%<5Ann2}lo=|d9e+ur>{|tOs
zNH=g9Iib5xhB*>6wfk+N{(~fz(fzK2;*%3wUm%vG8NItheyI*o{~>Bw=+9J{F7mXS
znYnh7H5#7e3ar0A=Gg3BWrq<#;E@#Lio2MGT_$WZOKN~y!HiMunEKX_scYhFh^0P-
zXBce+NL>U4*Yh4WmyH@}h%8%g+XVNC8VK#3g=j=>-_qdP=iZWRXNvRccSw?spSWXM
z^$HwMiMy`pg_qh@zxI3D&<IiFk44rK0=JLPc=~abL7ZnNq1UEcqYC)Ovnld-4&}ni
zL%{y<zVOhnr3L7J`Ef>eqGHtp`W3soRF!Lg_^Ew<4?ebhsPdxs(<IAj`^2Lu#xulz
zhl~Q9H0Bp<GqcWrVc^b*SyNREk7|_nshB{Vg2zajGVhLPnJwk&JDc?!+B~KKrMqqM
zst7uCsho+g8`94q>?$MP(m2W&;g3{2$P-p8?MFV@{2ASob6@|p1&(7iISFdl7xuvA
zFV^jT9d4jYds)=W(>|S_9JVAadW3v`z<SY&!l-($BjZP54OQx@=1%?^YEV)ehp5HQ
zNwl`DDNmX>v)P5)7E46hE+yvH6magGs4ByMcoT!!KP{LVtylU?;mUXYEr;K-svT}H
z(?i`Fk)5rUJ?Lw{5P{n$YsRG;zx@z@W;^zJ>|}SXUTU0t>v9Pe^%K!w2S++HHgsbD
z-M;>!#e)>`jOP27K}y94_wCl@XKpFk$`uA+#ni?KJ^q08V!yU<0=)09YgZtf>bdkX
z*ZIAlvF)vo`>R)X>j!T(fm|+dcbPVgLqP^Ijxe_fUp@Y?)}cN-gQ_i_gcnUiR6eIt
z*7HJ3)o%lgW6PhSh1=)l&`9eC4S^gdlTz0Ax`)Ba&W>DZ2;BZk?!PHZ*R3y=?MK!I
z(i5Y#H7@g)zwwNm0q~|5^K<F{TJ{xeYu_yU^@?feA*DO^UzC@fT8mDuvcN>Ne6C>b
zx!)Rv+%@Ni^-tiX?wWh7^Y0MLTua%?J|Vy)Q_z_@71dcoyWJ<LKY82?5Et<6Hl=ij
z=9Z6}rQNckjcOC7Ko@bC=pNI2_~U~+PN+>bT`OAo;gPXu8c~yOwn{vEHGlbH_up2l
zV<WErkFPs_hqC?S$3Odwbr$;)W9)18$Tl;^zGUCkShB0Jl_d9U7)y3Ssv$&CvJ_JH
z*eSV%P^s)uvXqL*{c(TZ$LFW-aeV)SnK`cOoa=g>&-3wI)x29StwiGz6gkTid>d>W
zyd-tMh1TeAd*P6I(n_%F!bzcbcCB0HB4(ZaX0cCJ**oTQPMQZ2{do|1EU-LmZ2{wl
zAGs37Xth8ckB~T3L6}=*dwBme-P-1E(PG@d1q?EBocD_Bc&7ra&I<*O{g&@!E0RQ8
zt-H`J^2~0(x2PDT*CBSFjlcHOg9|X7xY71kBU7w*Mx)AVf&Z(mAlXyGy40!w{!}1V
z?i=72rg>E)dMuhtC-2mKl6e5&!Xh*!=ZGts2zBd@5eHfglf!N?g&%P)3~+c&&R$fn
zM*3?;p2AbaE8%eoe|ep7`1K3QJqgyq2WF>JvnxXdXm+k8=mQjQ^a(2m8nOjNJCWuA
zeievwM(W_*EXS_wVNGnCz`X;y{v7Y(DL%PEu)U?S#*k=k`sK7X3@zj=#|qQ3C95ps
z4VsS^mqB{YK^(E*Ew;lh*2Eu^s7*j>VI?d9x_e_#=NUf#L^Jnx(Lqae{$q@h9uF+c
zRVtt7aPkrIc^n`jLG|ql<TRFgiWy1Vx*#jV&-)8x7vyk)qTM{1J|BuOz?^rjyu9zE
zKS<{NJSVb4<r&W7y{oApPCJgkW(-YwybCdz7^F;p5^=>zXp<xVXoB-WPT%^^96~eQ
zXfcJ=F^~|oUrru=mR1{uyy%`|NEl#9B;IN(O#d3%+Wn-bh~Oj}>|=!qpn|6%bV9!Q
zb5S9uS_9L^G13r^%wnGAT}hJmG2YrB06r~N2NJeQQGLZ{hBvv%5>CleJxSJ511g)a
z!B5ge|7c#=Ohjoap|yA8RF7D%eD15(7zG+{e^X|Tyd*p?H%BzVS^G?f3)pVvFek1K
zlHhgf#cQxWIpg4LzKA!<b5-=OTK+x???feKUlSSg4V}R{{s1F*psD3fhI}j)7Hc`0
zb`_sV)xD>faa%~)f?OomU1(y6dL)ANQaV5V$f;j5mH<?#2*_$_*B?wQ%2|PEamZEf
zSG+W@x%VmAQlS?G0(W{qK5iF-_CyySTQ0-Z6Q-g<-F-J0yqS5q+lnasW6Z*Tk`^S8
zdhPIz6mTeHr4%AtgWh%54&YqFZC^>hgyJ@^;WZHY{s@^Xf2_SJkpMil*`jl}8_L@Y
zwQq`++l{|%SfTwe&wn9Lj7HBV!tU0i$*Aj%HYhPeu~9D}d^`X6;gnby4SS(A<;+jV
z=@Q{hEI14Sb-l!#XaTPqV5DRvB7T}XA?%b2wI`0InCTZJ4KcJ5-k0q1JvL8zDJwH1
zQw)975&&_hK=$L(KflWJa4q(<!6YU+EY1j0Vs3G7r{{Uv$X1dkD$7?<9+WclbDirl
zq7{yLp4w>S@w||?b0RXJY_+=ZX*W;9(yQV=s7*_MngQk$M|f<?Er0mN{hy5ee&lIt
znms$q+gqLpNLSs?vcrPyWRaREWkYO@So>{6ceY=`4YwG8wBW@7^NSAKM&mS^VM%t0
z&AF8|i22yfeJnq&8Da@28P_cTS%AJ+mve$$u^?M=7}OD0sGIu_;vy)M_i-LeEP=l_
zkGEg5T3pKr5>qx23UTC=C3Yac&V^_=l|H81eknm0tP~4)TQc7kN_OV&7+{vM(Vb+y
zfbZyK>=|_}RJN#K5&(Mr?HyI;9CuJ@7!B#CX%eS``7;N~cZs`NWO!NyC3!MJryV)t
z<cM*v`n&B$Nogf02H+FVJT(W|q9;_hfYr+wz$F1PD!#gya!a()xLhcNtB7)uZ@Gv!
z%EyHhB>Wx};3J5PNrJq5Y~eq5@s6jZ4qFNwTv(@kC0XeKWV>9TTgXhM0Bt}@p=nOF
z>m2H%o?VhEFHdWHg!zHO+X5=v`jzaq4na)|d~dBFdg6k`$`1kLIzRav&V*Vx$UEmQ
z`cab@-|HGMtzKM<?-}<=2Q=lgGekuhqiSU-2ILN$1ncV>jGaV@Qf^7UjS~!3dpj(4
z<8xr<mTWvupu?wiz6atsR-Jg8SiUNPQ_7L8gkz?`%2eX}OQF?u*|~Qlb@ecZ6yNtE
z%)2E#i5bV0l?5&u+&{&s5!;sfoFA@}R$=6HS4>NLr%c*g6(vErl{@{|C7^Y;^Lp4e
zf8K42%zGA_6i8U2NYy0NG>=&-k$${9viZa<+oLCj?s5QCXhPZ5WKz`8O2=fz|23kZ
z0)DhbZZV0?bL6n=wP5giaQvYy#%B-IehH~FEy0x`>{)C%A(s16)Ui3tH6*gYfxy2}
z7{3ldp5q4mHGupv2E|T5)Y*?^w=ePfw&S+>Ja@pSQD!?-sNvB-F;!I07v-yS<FztZ
zF17Bte#@V{qQ0gS9D!fPQ}eWk!80!8{dbSF#4cE{r4*N9?b%Xm5qC*=ZTD338$5tP
ztsA+Y?s~lH+Luu2b7~gr;f?ApiF~c|eVXh?g@lFGc!{`}0vhI<Z#uq3l2FRV9DYtr
zD1g}eIP`(6Gcs69-$4d>ACQ*O&YG@4rl6!x;X@s0sy3_D2dN>op>d7oai>%<nIS0D
ztMVQrf>bA|eM|Q69_Ps)GDDhn{vKBdATGoL2o+Jm{H6KC2wSIa3vtJQo0X2|;~+Xu
zx{Osa8*Lt%+IEc>qzvL&(^cF9=KVv0f8!I2ti~X(UiA7VKjC{P_>Zr=YaLp~Qd|4-
zajyKp#yw6X#xWuxp4X!Ow6Mxu?2CP;{A-zy9;^p&iy-BriW4f(cMBon`k0Y7;Gm{-
zvF(R&Ew9GC#M6;t162$n_vk9;!r&P9H~9<YvI1pd(ls_Y=~a;5%OYp+cPWE>%GTiP
z_OV>uYK_B{zt@BeX6^M$c~8#@uCaMZYuvmmjSI>Gvz$lvTTfLV#%fWot8NobwR#Sy
zbesGa1oYv}L`ih|o7+RR{TCV{{vEy+QR&}H)kp6)cD(^PjzOHLN!l{>%^xp=5+MJ?
zV*{PC+f>tF&L!zwwE{6EZm;gk%J6)If@avrx1E<`n65L3CPQKHb_`@X+13urxqAs&
zG%J6n|LMPzL$dQvdM=k5JQ2!T6B6)>AjR^AvSAlEFe-{~p^5)15E-1$6S188Ze~PA
z5)5uc2WdVz*)$n&r<jP%a=2ZScbSSn=cW%=`q!B5iB=Cf@y2Mv>m1;eE!cSqY_UmY
zY7Fgh!GAYTt}6X6CzQ0hqOEZyL}F27(&<WNr-ie<JN{++N!uGk+iwg4d);LKI=+nS
zhx6RA)VEX7@6V$IzK+;UCk$G?Kz6-`oO{x0-6AF9O__*q!{zg#!hJL=P#QWV8hk9%
zzFRW^ydjkLzn{WJAG#VGnMrp&_OLKJ?44;IoQm$OeO$w2%j6*yQkMMkQ_o|J%*P0(
zX-+`v!+xi|#*b6);g8072N-0l-;MHb!?v9Z>jgNL%OZa{J(cZ3md=8`0HafHJAfW_
zzCzE#A7fhcQu;YCshqd59C)jZ@Z-FhZ61M#`jBlx9$|vXik&^Z0&OvZxNx`hfyU*}
zp+*c!*y^>-m!iehj@>a?N&uLw^@&B)j6ZwBN22*%_Cf}5n#OcIE<OiMmcS2{4WPgG
zAKXy42?`&@7}xRyv8>(Rn@hpRdI?gMI%!<Z--V?0DDTvNC+l*Rz^(;+gO26n#=>Mq
zVU?kblnW;#(cdlqt|Y!UH-%r|AP<@l7a)BKJ}Ad@q!&tBptE(Y5^@}SSF93V*Y`?H
zMo;n22SkjiNyp&UiYT7dDHQ;VANw3NhWypUUDuqFc|CWNePVoF$}{*%*Apa9c#?>U
z*5?(G@XM&P!{Z`0&qP0nil4qpG+m0<<ljdjyZgAOJzA9Bp58`hbK9JJ+fW{=Z}Ri(
z>0l@68#8ox_qxd*NBG^Kc)-YT6Rh#{65mgriu~NeRjPPCJW9f+*y!*{yt`%LBdI+v
zq%yYux_|VUPIr^=(K{Qc@17WI5k%wYD%DcBlj8ra;Zemz<Yw&LR#Q{7U+}*tpa~a{
z-abBVQqx?tmWH>pdLL1p>BvU5SECcWkssb#SyEdu0oo4zft_+-FDUzeYE^ygJ_w!G
z^ZBs&!5i~8RLg(U@j(Hhapm!cZn>|G&tRKmm8yUt-JzoC6*<2^NYHiB$2`!(eUV-b
zfm`CrYLu5MSAO}#<U2(>jUEzypq#0j^YH+Ll{Zi9w^Ek}_l#tbX_FA`vEA*wIlm2}
z%W3deWj_5m6KG<mf-s=U0A2C-;&Js&A8YmJ6qs1<=I<1i-{FU&Bd!?pO5A{$>gziL
z4rrtnTPot;c;($Mb4EWzG`K{(r_ov?17?^v%TXuImSUaw_UEut`P_iTk%DKKzW~z9
znZkF9cEZrJfQKZm{FHrOsoBA=mPoAYHyLL8rWhboNEJqrv$<`V^`A~B=CWj6AP)?i
zDRmjYebj3tl?dNH-55ON*IicV8ait5>SsW2!g{I7CG_I4CYB=3Sj?^*A1;EHd8TPo
zgxymRl4+N*E#j0aw)y5r<9%i(I+15sc_O&_crninzfJ(8es-0Gf1d-NBV-S9dpEnq
zUfA#xIDbn$aIoNMk4Q{azZd$;aM(DB)!w?lfj->kUOfHj%9(gXRHea!D3*6{)sE*B
ze&`8h@56wDi2P|AMyxAoOGKv2kMVNSu%a;M#;cKRnO+OK&%v3RdxQ~7Ih~R(;ZJ3p
z3*<(6M<*^MM$1UbJQZs^zqD3?R30KE{`GP2UoE`MhXUPMMIbJvq5Eu;=_*^+@Z|3y
zxRiSi!BXsEwMsYcZ`^b9bcNC_x^bhnTMt~zc+xiaSjiRvS--<|J6$Sbt5zo}WS>RN
zj(Tx?a37JF_4wbE%L-MIX=2&`B^Yj(Us-a7iUpq|C|0GQnv~jE2i8?wa-A|S`{Xa|
z(p!@|w`}3z)jpw65&yb7Iv65u4!s{=eJJqQ;L_!4>OQ?frL;WF5O`I0G|`+NvPNa-
z#Ag~=ip*d?hni-Bm_s+kDu~4EqYL5Ps&X8eM(MF4QQTeDTf#!R)afG&>I6Xr?<o1D
z+WkHt*nKVkX{-@mk6B({FRC+zzwM<vY7pc!8a98n$p^<+J!S)B3(BPQcm;CF1lngw
zi57YFz#^=lD5gdE&k5tgBa|YuN9QUr)$c<Z+fEnEE;u~+s6n!p>dx7Nrs~3^yv71m
zIq7AAdGpKS_3Ve%fGEh0B}<_sukvN<2Vist?m*_{_4`GLMQ7H)ZyETxlTXqIa#tLN
zPnX%;<vac{r6ty&n|&L9mCkkOXwGN4;@xi(sF1Vz`ZL?YI#;cDmEOmi5_^-HV0}Fe
zF4&R1dQ)?#GoXC58X9i)A;i-6!yyEyiA%~fPb=o8!o>M%=(H{2Y8e-C0B}+VaZ|Y2
zg1A2V40s+}Thp0tFCSsh5~-H7I}dZ}yev8@wdP>-wcIsxiEbiGyn_$M*I`keaMPe;
z7tX~L)Uj4Fu2rFgf334dBB*J)6wHzN$SVC7fpC!Rxr2Bf5U*41yPa7bw+3uN|5HNE
zW=RI-8N!&sp3+6f5;AE{LL9!kp+2T)qVYS?<ky+k<(&M=S~WRm1I{xK1Lo7EBihUF
zy>0HeIvbS~wunA|h^tgQ-5;#-VCJ;8C01$c#?g)^)<wIV*1^bY#C<VBoX8u4)Y<Ui
zcG$E#_}60RC-K<Dd|RV54hm=Bq_S1Tcb+#9UuJ?lp4u*T?ogqyO3R)+XWn~kT`TL8
zXpnFZ!^<KGiWa6tB2?||Olq-tsu$LbO;_o|C?cO!-E-(C^C6Sk*XYt{X0&mI*t4x~
zw`ZAD#{QO7;Z0rOYjid}YzAx=f^LYjt~n1Mn;~?~)3c7r<ojGo=jkFcUsa#AH*L4|
zs0QU|{{+CojIH(krqC_*eP~|h?Wd;K3QnxRm@wrVg<bGxx@>~v@4D2&!~i~XkG15l
zn#4!Jhxpt)c?}b_>%_7F`Qq?dyn9f)Eb;eLK4c}rv%bMoLJ!mVh!AW|EL;9ONr7Eh
z4H7~<w<yB89GwJXL(tyW@Fz*)=g8U?OPMrJCcuozZh-r<RtR;A`CjuDXJ#5auN<8-
z{Ag`&P5LYaU8{vL8^ITb^4@PvisXl51GsFq7^Piv4Ea@n>5a;A&(nbCNfaPLd9mDW
z3WJHZttv(|y8d8aeECk2T>u}3J7g<4cREw0HfBCJWr9k>f1FeK6-nQ=c13C>+7^Zb
z)7^_S!A>i;Es9<9J%Y_$rRQ5cpnn2T=XFTTF7w<57C?Q1lAi2$+k3dQ{}eRhP)0&L
zSSs6({<>DhMjk<U;G*T6Si5D-PAP`JD9VJJRXG)py=pl5E#T~C+!F!VvS?<h1m;&0
z@)I^l^iio}AHPH{Sz{iNew8)U1?nA*Uxd%kgQ9*Bau5ID;a=I+f|2pJi<Z`!6AEtI
zo=dv!xv_YC(5wGf%0OpAm#oliFH}p`r80AA9s8=TyT6D1u67$s(t2&X*Z_j;{LDfe
zwh%hyz>0p+au{P1jTDa#hgW}Uec;aN+8i4<cK-JS$H0D<^a)1{%USx;mJ+7N=iR$+
zbJZpGwU~IooB0mBJ3tWI@cAAZyW(l3cQ)*tWJIGkC0E3%Va{kQ=G9>~f2a=`C2InE
z%#@+h{DOUY?pQD8CaZKK4vek89SqW+X_Pj^=|0T)shYu97`THfOIIm~$@cXEWQ5K2
znvUlaEV>qR3ZNX-eIO(5EJJq-+kgU<mJ}7(C&ISV_}qljj4p>19V`15dpk;Tp*A=@
z(&UUGd0L5QC;uGz!=T||{M9gS5rAuyD!SPMB0wZP0?RzWSv_*8-!hk2|J=>%Ba|<;
z>?A)cxszkrfPV2o0TMV1KUq+o$-Ntu5LO2>%^c!MAO^Feg!H(4+5VfW_!{dp>og}p
zm&Uw@{xVV<#Mk0q-pz77pZOlrk{tlkHR$A+zOrzj(D?lhHyKYJ`AV8q{B(}Em?ok4
zn<n}@InRvj0#7Tnm8#fdXhxi6PgeW@b^MWN6&5LO-+K_se4d4#tpp7ftQvd@a8@*o
zQ2v@+W7-AKkn=M*y0$K0`o=cqlkK=HsE-H-TjPTfXKQheUwYygfd^A(`{5nw8dzpl
zd=VC8l?#9>QMQdHWu>kXELD4Oh2a){(t)MY9@Z_$cPat!6!N8lEP#fH{rhMgwj`2j
zRAJ^@UE4Ng=wIu%d{e5##_>5+UrrPF?EA4bOx=JUcRX(h$-~9$gthU^`dcRnrgR`D
zn6Iag_}}o|3%l8-6bk;+mT*;=D}FY{b;A7nA@t3v&JC5Rhrgcv`m_4VU@*?{x{tEd
z1*yhAa^Xi5<%4$i_bubA$Q5OwnAJUa!+2(mN%I-6teYA&ZW|#np;w=1-xf!QUHPbt
z0!Bl6ZAf=aEFAwv#w5mb4X$UKA?$`nTPIab!!|vV=ggMUKgx=}di4E^i$ie~IeuO$
zo4f^Ee_{H}h<0f#bu$RQ6p)qKuE*MiDGZf}kQ-*i+uVK8ANDbY41@`#R*E807Qqph
zVMl*9{G-ZsKCb;7=%m8Qw6qQ|NDa?JfwvDs^TcjCN8CS-RhFkJH0)LF3ZS&x8~N<A
z&Lt{iS>+NDPcp;WuPSK?7G)_;BK*S->qfKEzbt5b8_+=OMy4oZ#d_#WPx@U3D_OKd
zo($4J7%{>mACT$yF!w|dNSQ)qjV<Y)%^m;TWAQ1eDi`sX>DCEUWT~37lE_7VWcZXS
z2f<;)VGG^_>0KjqT@e+a*wBC5WTgx#=7u-l*8)+{^fqv(2D{?dSf&R!V+`EaPPPy-
zlFqS%xo^S6Moc$+Q`PNYt=8f^hHA;ywFQ|KGn5XTrcq;^&PJ*Ezx5rbleEXy9(d?x
zlw(>u=hT?i=>yhjK3lNkJ5QoG6037HryE$?S@5`R(l}ZDK`D)!$!g$6A4fb%Oa%VB
zr`}kqkVSoV)mkfDE(36=$ux_XXK~UA81AF0Zr>;qo;ic;-+h<E?nD|RBARGXgue^-
ztNK6lrtE^S1`k?G({a?}dnXZ+Ag;rf2kGCfUV1APFJ-Y7(?d|)r<<UrTLWAMz<4K^
zqB8`lI(#*0PzKKzqS|&2TQ4`%xH|`;yrBhDh+o(P8U{(4R<lOvJ<+~4e@gXK-5!p9
zfqSC3gRJ3}T^7dJ^i*Y7Y+mN=Cf3Sxh5%4`oRhB6lqrqsnJ)!CPy*dzBHSv?B(sI@
zLa0k`5$!K*bFubU*+$Pa`xryS4H=kE9)Np`ctjcEaB1;PX7=VRvr_3HnQOf7fc&JJ
zPHuD&tnDFdNL(I3PtwuPPwemYv-nVF*(v(>rFNyWiLli8rwLmEt79X3Ducb>()$@5
zPRh-4*rU+qi#fxdYn?Q%%P&J)AA}XXyjJ=0<;jN2R0;QX)AL1usIl9A29}Jm^rO1c
zO>I_@4~SciFNxjTQ{IAnRW6rj)hJqc?Hg^m%kU54=xP7?mj>Iz-A6PgE8eR#+J5MH
z5ml3v<~H}@is-$}L`4=V{k}CwZRUirM44Dv*Oe`B!CT;(<V}%MvwFWwg=$2RE&(V{
zSdAI(WEp&lC<&^A^0eD%)TLUJ8t(&bnR)vA>$=Q5Sm-`Y8BoKZo;syf+$IV7SD9{9
zc!>N|)}|EioaIDF;T`L!BaJ8J1hS!$KZsU>X=eF3Hc>Bhs$Uc=Xg0DqD4XZ4?dh^(
zcB6Irb;-am*Zy2<`+wVA=;dwwI~~3B^e>sHi`W-aS%C9HH3*yZ3r5unx2<R>`p4T<
z`P@juBJSuqV_BZI^9H%nLng5m4qbH)K>4TpcmPp7CwR!{!;VqRjF?C1KTivAocZ+2
znhqknB$XceJL0R>v7=9)Dfd3zII&)8%-W@Y)U##O%!G@^Y-eHfy2)u8I|GRJv@@J1
zVW0omF>Xkp$jFa5jSr<cF6%VZ10S$}K^DZRC6EB!`qSP&3vXS3H4R0Y_ML~N&LQ(s
z7VTgzeCN6m(3^$zN8P+6S|fH9FWB+VC;%Q9Z8g4|wx=x9SeLF*Y9>AA#z=$<)!f7s
zG50?scqz^|d<YbCL;$uRustow3m(k@n;HOVCY=K9X%Ifxe87uLR(mq1*Z%Fvh+W+D
zWahc1%wwf#)Pk`O;&dN9#IkIS_mP6}&NICAd35J=``id)%XHQ0&c+!0@)3Z^0mmdl
zZ=^Od;_foWaHqmuA0EBvPH_Kps%)jeZGO{mV~rOVUGr0)+>7o9p}YxgFTZENCDvbG
zNfZp3(Y9$7_HII@ERddN8?t#AxN6_B1rwJToyH;9qPfG1uses#FC5hpAR;xEYu{_T
z@1=e#;wm>t8_7nb7*v1HhfhepZe?2)7)fnXXd)5j5fpv-BG0@wp4CfJ1~IQ@g7342
zEC)r+OVBEQl+yWd#UFl{2}y-mu_ryaVHSsxAmnl|IU|iS6?i)_{M;;yCG@&@>K)4<
zIT8Bi$%m`Msa=<>b=<B^w0jkam&weGT@ht`-+eqP%6JE&4__ZGRBIJZFtVXIgB-kN
zJ{u>8rB+G|wvyqesd;Yr+duljemu?(WM8_{=wloXtNrA?F(B+wwpe>(Qvg1H$OZH6
z(G!$YkG~SJhzDrUaB)V=-D{R%o!-p@6DY6syqn(TcL=JRIT`*Pc>5|VxlYA}>kNC}
zU49ODhgWi`hG+)W<$C5w(3O|Y$#OSwssqoDvOkun%gs0Nr*sOdexA{htUvx{_P#QR
zMxi-<fg|^Ua$zomf+Jyi?h(%s$tLe->ztUY<UvH*z;!sIFO|=f^}RLkyP@X;C(Dvo
zUivj&bK&OlS+;e>KKd@FnX-$$ByW#SWKAMFRSecPD`?)I`tiEcoY(wuip+duFK4Z2
zaL@1hBE93Rj6_qH();`QL(?j=`cltEC2HIDSy29-IrYWVxuOa0ewd%Rj%_zQDG_1T
z-l+bjGjaEWsM5lfxpdU)#a2zdV{EgOKt+kel)3!=2k+ZQ0Vwa(NGxkNUBNKzNc8a{
zrundH8HLMXbyQOh7!d{(Ap@hsK3&O!eaE$vr?e<EI^x)E?UT>2mZ$$3H5^++yjgd(
zn(?`2V3I;fXP5TB&_nPNVTzcWjK#u;MDWQxuwf$O1iplOj`8BkG*sc5vkWN6WJ){Y
z<(zniX4;dt?T(+8v*08|q*trQ%ox2PBl^OC;m>R%&FrO8upyaozsF6!J?JMeSANF7
zzSL0T!y@B5>$S!EB2)WlZH;0RL~NM%5Lv7;sB~X__(Esi<#zCrX5>i##2S_wrj(vM
z#<}z3*mt|D4n+YUfBQ3br*g^94ws9Iza+2ZM~7cywU>>BoSVwzaGp%=w5TW}k_;FS
ztuJywl~Z%fBg77g0?{<-zztZg3+OnaEmF*;Old87!zvT6`X>48)w;K;ea#Rie{V`@
z){$oJ`;q%=x{l_T3MyFM#`qK#>N3MbS<gS9Mn?h}d+2=q5uJaz7)Cy4`VK;iD@0ar
z>UA%_ecenbuYJ{>n95zD;H}B}3xBi@d<lF8f3E;_0Du+9(?a^E5=-GRTlC}OeN=&P
z<ns0W(&jbG@TaGT8`_lJO{62K68>Sv$*8-5<Y?bUg!cegkGyq4DI~?~sKPt-sJ!EW
z6J2>sJt>c>mj~86isHz!LB?C@39GuuWCg#LNOz5~%sR1Rjqa7+t5&8gFWWS^57uQQ
zSRm(I8~&7iFXIH6ViflH3j)4-y61i+pu#EVB#U8y2jk}$(DgfV6>;LzNbdWNE;x-h
zvkz8MPP3ZUqN9u-6BTveF5B&Ar8H5S^}m<`<gbi*X_(Gm8A{V>`aZA$*80tmi+YfZ
zKb1>%o~W&TN!TGAm@!!<M=AT*u-D??&Ts;iK9=6ke}3?hp;}X>%+SIW4nv0%59QL4
zFAg~M4<R4FJ^7WDmi1%xok$AzU9*R08|UCph-raJ#=1Y=^xXrzv&4Kmow>_<u5pH;
zLtcOP$o0fwAE-QX;*!CVX*7fn1xfk)s5@TFb2Ri{7#DPvnj>oVI;2#m&9G8DEs{E!
z!!Ftkq0F9skpPoV%%eg>w+yJ#iDcl5McODM-TY>ADvsT&8~(B&3pm4c8e>8z_*t2p
z&FkANrN(q*<lltysJY#D8X*bZp3=MEhgAUmP>LRhlV`u7dvdA#b8hMI^M<cq+PA1q
z2<T49p6-`&@6@*`%2mFI-yFia?KrIZM5JDm+kF9NjQcn@{xZ}MTm^xj{cwce+f%cD
zKQ$Zalk>hNN`=fp8jw&V>hF(63xK87$^E{9U-B1M!eM8?7ppVhY5$xOPJmsE(h~PL
z{B3kg<pIm%<Nj5Hkw3VYLQ#MNHq}Wp)j^c{nX2xid4o*$VKk`@ie9X3W^vb~+l6km
zo_?|08dY!o^Q;-~$#$^T^VMdh->5s|uQqd^KKoX%3g{7mLRU3-9)}OT&YUrVZI~gJ
z7X|urel7mB-nKp|UXYpG4%WqAl-rJD;LTU%9LDajOj8d%eh!W+BxYGt9RLW|O4~~S
zG76t@g<E96wTM?t!<$D@qw9p~n}>m)l~j^1jA3<Cw@1gyg1%MT7$zI26nU6uV2<y4
zEj%f#m9s56zv0k2y*!ANnlwl{2y@G;uC~3VeKul8`9Gb`r7@z2DqEY&?WK2kbnvtO
zC`KT^D_Rg}=0247@cBSNz}>cvnV3G2g+<y$?(N3zvWe>U$4SXb^V`enU5N9CRoOb{
zaVEm}==K^fU6t|L^6MAAuJ7r%gK}G8s||QJrO9Ka++%iH$L_av?ml&2)evb8YDjcp
zDpK`~Q{PN!>WhUQvrAG>Q6p4+jqc*k%K8ULI$za=!>6{N4)au*dbv<c*Es(nj{3^(
zSn<YPe4&y{IV_pPxs1~fjPxA7_w*lstwG7#FM<T$$8oG=Mp|?ABb-DAujI7>T=~o&
zLinJuPF8T~R&^2|691I)p7e}%=R@N48;@~WPW~t^R|X2tfzrd+w5x|ABQqZW+))bz
z_;n?+AeY)3ZC>qu#NtQOwbg4QYG@Va%kyxP7L@da)+1Pk;8Symy+*v1v#y-8Cmbty
zWw94&l073qcNU@sW>&N%DrS|b3k}Q0tGvD=3jyTe6|0lSfmcXV?k~*S{T8K7TLc*+
znz^wgde#1HTzXo6BU;kx0~YAY!;TFGil_X6TImU10g|o<t(rTV#1Lx;Hx}kQ?p<nM
z>72yE!Z9Ao*X5G(05g=G9G{~<Fln<9V>e~HQrx`;;_HgaG|7a?d{^mzVkiHLUSiXV
zxR--y;&)eeER6*d3VV_G`1t^fN2WEO9@uUFJ|7Ac96x{PlJ5t=!)r^4nR%zU^6u+B
z9+KbiJ?ty4Hj?aS03v^_ng3(vI)nuaMa@(WNL+5JMvB;|Z8PlEp1KkwC92Sy#6R(`
z%%8rekZRlxFlt;Ji*#7f-}we~O+`?K_L8g2NGI~ywo;3*D)d=fPT$Z-&BJGi(z_^Q
zE44}{dUL7ps)1{q?f}2-?%bg7f*Syy@OoM2m5Kk@Wpk-(^lPujmc*{?x~}o5TZ1Z4
zz9=`(`z?G*Y^8X<f}v{qci&a(WL}MP$9Hm`S-32XzwuxHddozI)5?%Ke>Uz{+TxBd
z_#dNW^T~`<i5!D1K$n3ojLcVU<DI_=&O8G40uM(`M??#kRR7rPs+t^(`0yW(tRKI1
zw#>2GYBo-%K3vpHNsD>n==-LZ^~YE{8y{c#kg^;5+lI2$&2uAAj(eWw%%lt6u>Ros
ztr_Xf>m;yDE}<sp=UkZ!;tdcr7a14>nZyT(w{lXcUchG=elWoB0^$Us1$>UuC;4g!
zcK%=<REiHE2$l_Ujpv;(oSRRxm@DJE8Ta%Fso(RNtk1vvA^>x_uc%|97Rp34cO9YM
zbf0XstTveAhhT~1CZ+RH^1xaJ+puZQkXDskJ42Eh$g>7R6>z}ePQk~@$Cz-+qa0`D
zZfKA%!dQ-yc4DYfZX?P3tZ;LVIN-1bp)coK%>HI}2+Re1ResC)oq&*zKDrjNGS@y2
z^#>g+oE%5U^1IaAN^}wNeNCwY25Aju&Dq@QRDfPzfXZKeRs#Pz4V|$3!O*C-lli_2
z7d^U%b=bhOsTJnZTQ#V^u$2xeq^xH-v3=Em2dEqh6Wh~415uV8#jswoC&yZ)FU@&5
z8S+>h#ZQ52bj7du8Wq=Yuth_v=yG0d?M@9gbBrMun`n-ma-!AK0tKq@{Y2Pprd%sI
z;d~{Gr+^AUgn^M4>+sS8GM!hbbq)cEOQzN$#amGVF`uHI%W}sIe-8$PcQli5L;~Kq
zAw&f}H%ls=&k7P<JQOmngqeQt0Hxp-g;xPeV-0=ze}xUpMR>hGITer-t3;9xbfS0E
zc2_6jfeq)!(@iY7?e%|<VN<dJo28fx0-^`KAD8)RrMk?T%(f713eS|xM-1A$Ds)40
zq<_iey2rl~=MGQj|JGqkZjcv^XqzI;b>x}Ef0hdsogg)L(_3T$E*{QXb`)S$6|T&~
zeu#su@G?SA^_NkAQs=7>XO<N}IKx5*=gL1&CBO0<#aayx;F@u~%UgsyK%{A9Z}ZsE
z7GMPq@;sgC**@%eX?ZuS#V-5qo_iERQw9`f_zf<tMu5jNCr9buK4cW(RXFcmVK<3X
zP!#_0;T7$-&<!8feKNULS{bk4y2I+Wbq=Tu^KuUcj;Vg2*R^xX3>z-{3)^S<2)=@&
z`EY;}M?py;r(#K;A0@6gJtMUlK(8!-TgfaKW~|zS5E@5%cUl|gq9&tg2getVqW-Wn
zZaR1s*P}cGhLRk-P|Krr6?w87yQx|^+fS9{-HT6<p*3=WY-<p^gQtE_EEbo}={hUE
z>_X(}>?=s%4dAj%Bm}<tMz>r^l$N+|OTVr?CzldjkX&O6(B%Zri$l6?%=>!moz+x4
zEC3p(5$Z_+yk|6n2p`6pg1xD7e(WIc-<=qXE<(k?&?Vd+g7JbpC>K-e$)$LB?B0dh
z$<V~$38mI(Te)v`VE{quuw6jBn+B)P<cA(0;h2w{t~0k|Jb>nbCS2Uy<~|dZB+OG_
zb<K6}Y;YaUe+>1Jc;MVJ;Ma+BrE(!bpKcki&Yd+4!sz+EV`y{<<rzCZ%1xd98?SnH
z%-JUXd|@Es?7jwOuqNKKs=MG)UEstsY&veReZCSV>tCuT^GKl?-c?zR{8qYU`WaaJ
zWB!4D3i$!Q+S0A_fJ!)ij&3nL_2mxAPubQn&><^%iJ_T%T^R!j^XWYrZ3j(sQEP}x
zz|YBV*`iXlLxV`He9EkhVtl)~*022BV$UJ7ACw!Iia67Vv3u~p0EfQrtOl_F@aDAX
zrfR|EbMY^+e{^t8Urd?Z(Q7`L)vl+`q70G~{+j-jyXh4ozTgBm<j`KK?O8Tv<b^&C
z05%Y<gQMSeGo^O0u*Q`(_ruOIY53-|0>lM3ZSwlltUH@G>a{JtRU*!89SUcxTk+k`
z0!wTW#l&=+)(m?1WhU`(Ka`aofFRPn1yBeC987jOf6)Zo#7(plkg)(?gM|JcQ25Qy
zWr16{e)!GS>1>!OgSxRHE5(_6dfe^Ru{h@C-N#N)PiK;w804-4WTl(QI|DA9G#8=1
zp3QbMbpuP282S|)lw3D*1pmvS@7E6i{}@O5Pnr9Wzw06PU7q?o7tu0j1K*yfw?d-&
zL**b=TVVBB>Bm~Vq!Duz;uasTxoZ6MAP^7KfIKbZd9TT3+{gK{3xvc1k3c7JcDLA(
zkK#quNWDQ!Ch$ki?*{mXLS{bmy}xmg+bwFb-!b=~>BHC5S<;-j=G-l<M2Xi_^T=>N
zQyZX07xCg1&!om_%#e8Dmbs|YP_jD7(2Y9nASKz*ZQGS<$^`N=KcZJodD^?UG<>`-
zc->FN_sE9gshU5{<>&5&wwjSX<m<I`;uEQ(9$Rs}5FlxhJgC->dn->1-%I~_!!s!y
zEMAeZ{MtgK+J%2sLf!`oWRqRT-rwJ;=mxwwgpNol<)qtRO5=^~(*u|v4-?nGrV}Y(
z)o)l0d#CexWs^z}BR8=AE?D>gFR)G>d2NaA@%~#KB4uD5BWV>q*2{yHGH8NGCBtB|
z#d38rH_6moA^N_>Vo2Xd@n)v+2=VyVO|7EqIVPMF=SmM>_t&dKu*UP^Y@m=Nfu|L0
zvNZb+HGs5VAi0^lFZYR)=S}QsrtcR>YM?N$Dmg*A(tT@1;%%a^qu2$QvI|p>EW61!
zgt$WEuH$g)o^^do<<>m%O{M_cGH)8*N{#`K4FQ*L5cJp;Ga10RU4YijH^=fMgGjDN
zb0{8`?+b@Mvy?Q>QEOJnLd&1SCA3&ik+X%~GfR@~l3LhR-D-}D@QO<<UL|T&T&(Yu
za-T`VyE9|m$5(EObUAu|7R5b3B|UbFxYaA2{fbW#W;G)h#v1rsHh057{IoFthXj~}
zcAwfhQD3}w!U19+S{qQyQAhNiorl)3z`-jdNqcF#Nu+&|hjOiLOda#DzF-ujn~%!y
zx#4>WawBB*?5m3Th~Kk{wse_fOGG<z;%v}yNpp>&w?u33IdKI9-aq5u`i#?6gJhl{
zymj=DxwkSfDF&ij{l+8->{aWhnVIiZR(?sY`YSN|!oo7$o1Vy4a1Zma(4<FME@|m9
zbbo*Y?tkK@;!kF~nH{d$>3t)FF87Iz%#fVG0W;zmU(HQi(vMMUJITN>A4j#abcJVF
z=0Zlxp4?YGdSL=cMsD_EQW}6A_D30X$?+eR_R<qkO6QuX>EdA_h9T2huwzjn(aB(Y
zrEcDeo6w><yA^K>JT88K-){2SC0=@>F7dsxxVR-zHlD}`C-y{BKLT$WlNX~D!2FJV
zh4(p0cL5@GuP@H?nl#Zu%BwHN(_W15;kUt9ma=U%S7COy=rVxEpLGdB&5d>4;w4_h
zjL1cC6i`k|VLdVcU&930syfM3jUKhp<HX0f{Mm~e@i{4$&{>oR=yEqE*OYG)es%Zq
zwt32^^c{}0zpxpjWiHF|8GquNS#8dHBa)-CC3x(sAzhwARL-L-MG<A~>Fg^52)3kg
z1M&D!NJ(nYM&kl|VK%Vj4SmO)QpJ?S);D8lFNR8Q^@B%)&5vt*YMB}koyDV;IPYG~
z{G9;1o-;U)!V`saWD_}xMLkN%M4WC<$Xs}+B>v_$Lyz3kS)xcnDZXjturYUSGO<7n
zlAhDu82c5{n0NNeUXw(+LNaxk#4wpsd>PxPYaEJ-2Zr9Q4_&IeAN=W#@Ti<zj}qyt
zB9@+LK)mPEAL+={TnA16?lEryh0TLSR__Mf=YW~yZ_0hi!s*B60&lE+GU@77$U6in
zhSAODfIf%);?*KnyI|xx`}3G|LK4jJ&{4s$Vbi`xft0T#N4yBL3(dy=Dh6v(qK}jN
zF4XXxz=sFi2k`888_(Dlzc-iGyl2w{yp0KX+AU@>gH}91=u@~8c7Vbuh*yWe&}WP`
zm(+0$_1vCtU2YG-t3({j%E<>h^bBg|q%<7}Dv&c*x3)3msGhrz=k|MhQHW&<pdWaB
z&V22Q8M>!O1&LDWM!^a}?BP8n4?ze)(3)_|oz&}MA(O3A_aWnvWsn@cQP6NBq{%82
zfwprx_nppZo&8KyT4vV*!uC|^IE*T7%gonlo*lfg8hs62jHV?2vBOxBSraGDmiBDJ
z9Oc*#J+O`7rvDLtFUOnZxOe=c#r?m6dm89e9AZe_z+;03{3Kr6=g>D;yl6UN{$U}q
zdjKaqBZlb;dUUXUmmL+oWG>Qv9wqmM#Ct9bE8Ex1T8|EO@d5#_(r=uzr2lrixo5tt
z1X5V<kyoRuAP^e6U@H<B+{9sz<8wM1+%4Zfy-AWh829aB@XUCltFIYAKnY!Puv@}H
z4@ySXXI)D_hKwL`rXGkWLUGA-ulOFtk{CB$D&P}Vi2_odXwv8cpUZo9Zv!l<%W*0A
z8t_vVTl3YF#TXf-iElMhcnJb(G~T?KT0t$_id7<saj3D$IMKej|2fiRWYd-Rl=y&~
z!5T|c+(P6`tcxyj!W#X$=azfLm%dB%9u{5v48trQx#L)R!T`_R8po~6F*4(bP(RT8
zUJ$bxYomnhDcA{YH%5+Tn+bs~IY>7+ny7KK{$U7`y7!+ejepL4WkQ$brNgo(95s~m
z?TE5bbUdY}eL&Mq((YR`$t;nslnqr-A{uoO)4K!jYT?0st@bAXV9Fwqmp!G-G+C#u
zg(yQW0|i=d3-y{G96;kv)&h7dX?Z|%E1-i5L|Bo3fp}e)hn`bMu{_={lMGT8wLNhn
zRS}s9DuQmjhTbSADgwZ=Bj&1{hXyW(OnuId{h%(GN)s7fFr8r>8_NCK1vQO7eOc?_
zj0IR4(DSGcD4F;|vf+&b7_an@bVBL-Sx1ub`UatnB1`Jw-p|3Gj&05VrevUG4dwtK
zco4)!DIV_~$*Z_pq(}yt4w<(cfCP<d{r*Yt7YT}c*(+v!(_<l0wi#mFg%{B6{`7jl
zWEU*bM793VEe4>!BR>xs^l&XCe2&P};W;HI34%~KcSG7jW$AFWbGThObACK15fGu4
zt$^=^ZS?9>K!TS5>S5fa51}6&H>3a2g~Sh=usBwNSTl~f$$B?BxEl)vNkV#jT_7oM
z%Xo)kj7f|mTChHOgn6h$<D2U?8j-E-Q;b*J*$<pImxcgIbQwG~)0`s{rJpEqLtb!7
zp_Ps0#pkgt15$~KQQ+!QaM2}tGrRZrlBIg9uic2AKLhxzbckSo(WDh0BTEn=gQa$U
z_$~o4x&(~c`pHDR;=xdXK=+$n)sK{s-bqWdF{-ep?oOA5o4`96`yP-J4T8r*@Bo=f
zuJccK(K5uyJFr3hRI)`QKE73f+G89`(od#(u|T<SsRBWU^Q%5C>?M11{NMA8)n_5b
zk~9GWprG}gnb&DE3IqWxt*Z>2Ttrt?Vh3ejlK$gt^5BBR1#?%Cu$TfdQ7Jmq9w>D5
z&XX5;m<hovei*_UfNr%XdYBOv4X(<|&C2pRO`gmJRRGG8(s6x>N)-C?thpu`Qvcdg
z)%PTr!tZD|tc&lyGl<VhYT{KR2xxYn7)#Tq5*5QhD(y+?I^86(Mu5j~{3(c8lzGCL
zi>82f!lauV3IuVI5lRFKEnT`HH+s}-<o~UMtw{9B1MzNV0K<9|6R99xDx%fMVwZsn
zqYGw$c19Q)y0-H#AJ$Ch8efqNbcUSJ?7s7u`fNJQWC$N4O>_9(Ytq1wyeK5n<cVP`
zqfT6k-eMRxbO=+)(ZOIq6I;$6B-Bn5jrt>&j1S%C*>p^>WW-EH(3>`gVbsGeLN@-Z
z%01j}M^8K`whw%+^i$j4y<h`Cfet6RIIk?@hDh>BLF0t?!IuR3@Kq8+Pt?0n#%*dx
z0;HNLw!T9+ig2I-F=OHtEP4>Fz||)}A=`sKU#MkJmmIdI^>Vzc<Tb^PKYLrfdVWL&
z-BLwk%f2C)@bli37rJ1?)}V5mDVZj4r0PxTTdjhferap%rN^iM1p$JEV0_TCev>?!
za6<<<U06UpS(uu#8b{57kMsv6%MD#rvXB1quc2Z?>^Gerc`^|f)~rPB36iuafH1OG
z%r__WloAnmW3VO)kZ}c$Ofqumw<)=Zkg=Rhudxx3o4|#1SsjvwF(TWz0V6z$(~^xM
zSiGuA<$YR+5Hq2ZY8+nbpHssZv=)Y*x+O=09TT0Srx9~;dv2XY;jT5gy7}CC&&OTt
zZWB|#0Zx5<!8oe%>#XKdRdj+6AC-1AOqo3RA*!2a^q2<bIp8nAW~f(5De?ABe$S-b
z$jY>C<@@l9Zx|!*`prVndc1l%%EiOd@Qcv(N=v_}M|*gs`iYxFXSlo*z87m%<1m<W
zOc_1plA*At))!Ey>{=o0t?D`IZ<@TjwV`@#4O44-!#e-7+s2$>@KE;C@=rgcuC>Q6
zYg0Oq@2mm1PU690wQaHRcEM#Ryx*o!=7Zq=_Cq<Y!)w`vT--8GueprlGR;np-;s>g
z&hN`d&W16#Zv-zYxA8Ezsd`rSS-}`<RCqP<7VhCvVZ+JcXhkbsFTAi*^SDZhg)psO
zJaR}m{n$km`U}Rw;D{(Yb?^p$%jdp?rD#8Am%j@>@Gku(isYq;ixIvH%Ip)IutLhI
z^aOGWzpW9u<kL`!xD+D57LW)N2+b;f4p7GZb>EvL92uX<%o9L}y(02*$=3r221Rnp
zR(M?*h^3>Gd5#fTpcU;%)UpsHT~ImN^dVQCWjfk(r3!dCIS7?l+zjX&v^%-wP~^JR
zbEo(V<za~CWjqDYwKYo&vuA#z_GGFA9yYl=Ozx|z%TS)%QMsjgl1TJs&Y=Ny;PvEi
zsgc$hoHpx#CNJz2+@Vl7u2A3FL!6gi9WxizqVXB5mdbuK+_jK(CJ4P>5^&TdEamh1
z*(ab+HEYY~i#U*jA>u+@c53`5u@<hU#=5PfJSghps#hF$^}5cTNwR{eHnjI3`}xa1
zu`-K9%^xPRjzX?DDf;TM@7DB?rprU6u36{kPZj@h3(816Mg1%DgdPyZn&Z_Q$D8L|
z+56i0#XySY<7`JXW}?8BPD1{cy2`}@mce2)0Z0AqIWS2j{2b(zwOFcvKtz#6@fWXd
zg<An=TR3w|H0*!|f7br9Ch9Q9;3ro&`Gevu+0T(xsY<6ZYhi;uq9QT?8|^U7q?Oq~
zo|K)KLBF;jXU}y)jj#&n{?m=8zjS)iPGa7Y-c$>m3Uiha_r?s{3L=98g6}$8DyI~Z
zOm_hj&iXbIC7u+5LYaG%{T<2p-&$90#Z$cT5FMA8Wys}qg7NK$>_$5GE?F3!sZhaz
zm@I|D55(BPOgi=EQ>N5e%6s7v+SRyvKKHR1SZZI1(WDyn;<N8$Nlk>Nbs}4E@;g&a
z36X^fBMK<wrK(wbJ#{Wx5V)Pktw_=`cbH@eW3g$w9_V&)Z?O2Z!L1{#Gdma?B<5gm
zwem9tdAzBC+u!N%4845|qG&*XUvlC-@w0_-&4P5CcvO<viPlgr3ZN@9Q#)t%aD3br
z0Ls?fu_pt{R0|>)w##v|e%LEG5D0mgIG<(A=AvDxVrqS3avA5d#JlO}e!QiY;Jl@`
z8csOVU?8D<H9HcoB^5}1Bh-axNw)9y{^dL({nM2ZMuJEo@D2#U7QX4!7m#y)udgaS
zEV5?uDaRD`Niuo}#tZrAfnZxX-WVFRbPimFu)v;u)v7<r@BT@<8>ZpRMe@R-uXEg#
z9NUNE)QRZn`BWa~(jJTI1<}ax1#NnaY0{Fcmtua}!-hQQ0moiSV<u35j1_&rk%b*o
zCe|2*aka9y`c>Bfy|z;bzB2=K$udOkDHH*!kvI>*A?6+P))WlYzULGbkYph;2((rW
zdK^-$SADJi*nq3MgR6V)x0MQX-%GF*)mPt8EXz+VUubJbUSq0?JCs>aIK@t-kc81@
zezddNN-oJ=38{?dfOxSoIIrX)ofc?Ug?D~$GfT)qwr>ddt}bIk-S};j;}wgnNnv$(
zC_*x@wg7<u{Qsdt0G|J$L;n+pL;<3z096rTMK8qv6^CH3^MZmQO2>S>!H$mn|A|AP
zu$Wj>gr5Z9Xs!8w;t&9E0RT9!2Dt1Dbc#TP%Lh=7#34&d%TsRlmoHyF5{E9uM~8<w
zX%Qp~_<36ZfOY`jJ`z@PBn~O@JXXQf>4>%KiQHA?uhfx$BMuoAfqsUAkGP>9FwmD{
zz!fpjA0fbh(2ywb04Oq~h?r4CygdOQQo#)A3Qy}|#x(f8$bwds;5)K_KeB*-RRKFH
z;5B{dzenPb@sT(LT-HQ?LMgS71lvxXtPT_yv&0;sL;u<XcFcimmWUA#<CzfEQV-jD
zFRKo3s|Ril*Umb(oIQ0dF`+pre$dBq)Ya-msKaCuW%*n{CLqPV$g!*xa`h^*?hdG>
z8PL%Id2k<nvt0VcZRp@2WO^F>@}<D)D)>kr`tbv>u?>7Ztz4RYv5t8}4_#*8O1ghP
zv9i+cdFsV!*2U$Fi?3b<-F$rnH!%T#EF_==0C;o+G9CRq#}U<M0M~^Ra-}0m9THdw
z!0`Xohc*y^um97BQ~}dU<}dSL1rI?FZ;IU-1awyU-adkc1^~U|fbns_$W(HJAoDs`
zW*yhH$3kU~1as<j%bL_G>K$1ncGv2YZqz!~v?ta!#g~`yln!#$JQuh#1Z$Xtx4aW*
zoxwDXnmiZ=TswqbT?an>4DDD1)cp%+|HJoa+4kY^g^pqC@-ayFS76_Fz{oyu=xDY2
z7x?C1fu6Pa{+Xi&5GIqEm6cJN$EwRpYtLl17qA+y72Lni%BZMHzxN+B)Y;kbsO@1x
zT4R4EeXuxVvfw{!XsWaAKWpgjt-=0|spsu8FR!O|4nBO=(|5Not$(tkf9TQZWc}Oa
zq5i&qMxL+DzI(U)>4+QpvT`I2eO>$fdHd`7x3y3ILx<M4zpefF^*?lI=l`KYyL&%3
zw>FmN-aqEF|9{Y-N^=HK&b{0^A45y$hIYLhd>CXH&`-ZIH~lbpFnlnR&n~3-wssnP
zqiuZ%o+YHJ<ReGGkyh*rX+@d@dazYlvYBBHXQ;J);*Jy0i%rVMRRNsg^sP7fw;lxc
zhupAxjy`4`cz3I<3r?5GsQx|T_pmwmd4ZfwC&l5nBdoB}BDcW5ysc@zmygH2rgXlk
zxn$)uP5yPRnwfhaF(-P@5zsqmwin*PwFEpZ88UQ1zBgDABNb?^kdWH`D7p`bQordn
z6!Rjk+pSjqU9O;)&t;<?ou)DTlj?WWS+!mZ8;ty{TU^7+?cvd5I*$(P`Qx5+?bQP7
zG-`vpo4%Jc#@4Idc{{7tRHgFR5B7ify4QcE|M-94J8u}98Rk6aLk@F3Yh%u2&V<Y%
zNfMzbYMVLcd@ht@B+98ms?9m6MwC#EC@De*I_>lG{ayNA`u+p&3$OR-c6+`aulqwk
z+0iOK2<RY@^shGm%%3kI5UP1E_nITKMs<k^7sXG77E`?|?Nqi)oFe+#>gP53TbPq>
zI$Dr<mwz-}aj}p+nlJJ@zQt7-$zS)*?W;6#sel;O5uhw4aktEIw-i*a`Ju%qFJ-uK
zSuQ|8W^2)HaxYdy^d*iiF0d7O42826zLO^IustGO7=88Fc%iSv-B9~a<Di#nJB5h_
zIz!k7=Mt@v_m{0tDgT%Z^dWcJ3%`onraJrg*kPkvA9P1lRVvsKm28YuKAyr0HaJ<F
zlk`QZf0~?m)&%FHxO(umXmKw@gT2PcLQnC%d8muRO*Uu3{jYrL$gnjCKb0<lzV6r#
zQAMVP*LW@y9*##~E=pMTKQ}h=2SN-O_#(1!U(^^p-|<U_jS$CcLZfp_&u}*8i-cH-
z<6g&fv-XQzwReOzi^@=I`)3I#oKcW_#z6wtmT8UvDa@R8Taoy3e>-BbF!cV>NWVJe
zI}PEwJ<;TsI&A2R9QH}|9%QilBGcCB-Cx=(0mD{1l)xbacPxfH`To`@S-*6laKFdV
z+If1;KUb?!Wi?-o`qcWVOU==QRhR9AKPQb%mEy>F#9Oe<Z89{Z>x%8YJj%J)C|nu9
zx9a<oM;`0`Pk1#ng=}3C-fsazGfoV7E^eX$%(~@V`vA;uI`sSAg6;GBRn7hq+~5Ov
zzHgVJ)*$c>u8h0Bnsxk@MmLG>3n2yA<!3CHVOs+r4izxhAbGcRR|qh6U%qM<cp^Tb
z;Ni%)LSED~@iG4=r=woGE?kOyx7qi#QZo8Ut4iDnb9@olXx?`1{sPO_`}VX}U-vHI
z4w)yShreY}@(cFHT;yOdUNYV4UD9C1dR<M;YwaM1T2kM*UdK04EkN~p<zju8L5YL2
z@~pxo3m0H{SO@rol@nt8@E}Tik{|h-laZL;VY1O<gUDALd|Avm2#;t3touK=?XtdC
zUaF|f8|(=7SZ1?VWFoanM8=<7=o0+w4-|OA857SZXj|c1Bo1~2xl3XVVe=g)C2$_f
z%fmw}fgd#2D1sJLpqQV<cmkg=ao3D&a-ak6?XOmt)FXl&>my!J`yDzpIH!JI^pxCg
z$4J~v9jePAEpLSN;vW_RT8ks^Yhcz!KST1wvYtTuUp(6dG=TLDJPZY~N}c&<G>5!8
zl)m6?uSE(^G|t&8*LUEUf#ujphmYCs<}zgmuS3KDr!PWw^7|7283xMfPOZ7(z|$=c
ze|9`q`a}y?7kZ7s+*paP=364YwXx<UUV=X7gEaVM;ghLLI(CS6g5%9sE>vq@8RB(G
zXQ=F9eeVp*_5hsK`}aiRAgWHB`}UaZU6G5!U$W10vy57@(z2qOB?LklsKE;GC5&qJ
zUL)oA%)OzO$Xm)U*3xw|;`mR>7rR|Bt9RsP6$)Qbl6n)xK4@ZHtAq|IXq~ddRCX{$
zTTZ|P!UG&Ke_Zbs&8So13({rkRv*)tcB^`=Z2i}?WcJN4KNbJ@mh^S8*|ju*i~bB$
zPAD@m(%#Q`1Pd9-GUb29jQ30z3kF5y`b~By8cJsYWXtk#<6k7C{l|ieISf-?qm1s}
zCDh?sZOQK&m+^Tgl4I5EmR^fGj=vb$kv`sBMk}PEmhFxEMbnR3rnx)fcxle2JGpX%
zIzBZ&lKTaUPZ!6lo2a1lpzU&*a=DV@nCbO5#NtaA+E=eabvL<a<#fsp5S~;-(y{?(
z)M?NK+$g^2(wp8~m~U<=x7l;tzc`^%LkzMaFgvK1fBElSJZSHP{pJ!`wKrc8BN8B>
z)sVhm6(Zn7sSsHHZ2OIuRdzp{d9F$U06QBly{m4gZD^8Xlz(>s#<%F!dasGP`Cdk|
z;~DaMtkc?DIiJ^_wcw2Rn;p|V_Doxjd~T_9s=)yz>%V-Kpu@QyCgqAZlpNO0>I<~?
zo~wRGfQ}p{JZLmgY|!Hl<(}d~>*{t!v0ap72h)|TBy5ro{jT6?{2eMNmuZ|(j$3O(
zKPftc2I>fTJY{D@F)fqma5FBj<NHbkp~}AZvwVzKd31pvP5DAA3FhDxL0A(aU(|XH
zJ|RC^bTUbuPm_Dykt^(vyQv6UcJ*%3Jh?WH@7IuhvRL#&{<5dA0p&WuPWRk4yS%OS
z`oTUp{^11UaBFN}m6zbbt6LS~J&K6sA3Gz5Ps$>6R4~fvIlx}N>JY$W6M4q4Bx2C~
z@56P~w(|;dhq6NlaKIMFUobRJFC*$NF-Q%4$C2xFa=|5j(#>+k(t|$w+vF*BTHCQ0
zsyBBn1q?IJ9(=he4;g@v9%;p8P)fI;F`6X;d>`E-cz-sqVRv?}DAP055-bHS^OUSc
zvOG@hN`aV6uKUdgj{4?$FO`N_gMXxK4$sPGNPVe=%@aAN9b%+XeO{D3H1gKc^e+w%
zw-Zx{;<NM<1bmWx^>|(Tv1|mVW#d`6l-8aAavcbhkq$y44x7Aa(3{S2sZ_TdzW&0F
z{ps3x1GfLeomO7?yD>9i#55EldZ{qFt1S$1F&k(xx*urnvrs>M?T_cWm2kA`lY?u3
z<tsl7^gIGzDjVHvw5ny#x3k|vh0=E2I_4w^EHHGPF<2|r_G>VjpF1RCav&!pmm2;<
z^&>*<PJb($nN;&wd%Ew=R@|}C&_yMUaBJaeUMEU?jR?2uwaPk=678+AIAE0esn|<K
zlHukpeUMM{yz6wq6tPFi^7&x&FA`qmFIQ@T2wo3`=-b<@_~H)v3g^H?onH!d)Sl?!
zgu>$aop(Z%rxfAz<H~iY^IOhdoU?y8NE43a5n`guw&1`ZM4RQP-vKt`f_|T&FDKBd
zRP8#;MV-$$&n$avQOJzlKzPvwX?a_3bX-w9DhRJ_2N0THLQRfB2(_r^9EKSHypl*)
zv`^z_Czo-PFE<3g;A(QeyPOws{1}0mr5;ayh1uGo_z{mu@1sLBaT^LvzYgzG3ke_M
zGvzY;W7B1(Q2s6H@a^*-jg5JamxS^thPP@Z#l4Wv^&NkGQ{!|%8r_eciHOsUv<PG!
z%MwMDHG}hae9|1UpdqK(Lt)>I^*R8@_81cKOMzO#e%8IHJqj$|9U4fm=in6`YA?1<
z3F&N!+i->c?i0CZz>du_{6}+Ki)bR9RwipF@_mq<T#vt70;w2emmlT_Ar1L4XQ58n
zZJ4Rd7EG#x1mNlVMao6?#0YAFAuCneE9aRSI<WFc#&$}<90H$pf;uG-F(&+1#Sc}F
zI>*uSqUMk4!<@zo9Xo|U!w?+`>IVQEQvrTM!>^tx5ZsRPi93tay(ld&RMX&lunt9r
z2@uDGoqf>?FL{_BTNGcSk@6I3{)NbVk)YH)ldl}mJ7e%hXqfCL^h+Pn#HN#(jak%f
zRahqJOIA31JEi6W*@|GUERV9GiCc4uwd4`jB<-y4;CH*=|8V=pH2Oau2REq0E+y}R
zp~8!L{_@iBbYl@ZO-+aE_mp_Xp;nxoWJD-e{Xq0LBOHmVC>NBEknsdiGBf6TvUh9w
zhp5Q<5j~hN=vhMGzc8rbYmBjikx!%Kr$YB|yvXN5@H==K0^^tCkH$;ny@rY2o)NxP
z7{YT9+bld0BA>qt2m;1t{E6^;t8jjoMs=itzdML60w77cu)G<h!B*-q8vajV@@;i=
zC(qPQ;TQVEoUlrt2kEEC!`c(KsY33*PC)AD>h{oh67=!5*>W-XT&?7<Eog|N)n68$
z{&nyXLcml>&8Y^d=*y-NkV}1ptA%lLGaeN%cId$+XKxCW+I6a<0&)<4{)9Z#<_EZM
z5JfA@ed4FiRjUPuT&M_h&>|hYFrBBrtwass?{AFVOAOza+7EFr2Nz0zC1m0zE)<lV
zap8cT$K}>#sWe8`i=LLpEmx|&62AYM^q?I3C{`>iDKH%dDElt*1r4?Bg&6r`_BzUP
z4Vw<u37us_MEg<OduI?Hg-)$CYqK?|&hQ<oMn~*96?s%WN3{=du{zETjL+xwKp`UY
zpuyM2XW_ZwK%vQU@w^!nP9jq3a$}qmdco1|MI>f}k~dBg+ujnrP+yy6kOrb=LLNhH
z{h%~z=BrsX_vFC49*~A?R5<sH^{?wcBXjH@<2LJp?|C5~ay>Sw8a`pcyFE=C4*7oj
zp^%28SGx6e`+L~^_M3zna{yG|jC|iI>%`@Hsb#rUe8x}zjE36gKeU5+dm?Y}GQLD;
zjO|5DZVdW(@O<|f={liSz6-P#={K$EEr=6`u82Zk2=8$(3<6plfzlen+1(E4cgHa)
z9s39rG{n}d@MzrfnD9%MT2#O0V#jT3&TWt68(?4_*}7S%GkllGqdyL#>&pwiSnkk6
zbk5fcx>BIdTz6$Q@&aFF`1avslbk<jSZWK{gIk6=(Y2>$ccnk_AuMTxB4BhFQ|yD3
z4<)qKx6wUdrk9}iUkN{BsY&0vtVC9szek*l-G3dfWk2qDWaImYU*f-I0r_JX9ybl#
zhuXC*lin7@20*t=ML35c(@}(Qf|nJ*>%@KVL}bm}jmiwfE!et^Ppjnn*w}kwwIEWl
za*^O6LY;euqRUIquVT5!D<C#3(RtQgW5C(T$|fht4y-&MSW1*KE85C2Z9I&5K~Wf{
z6)T5W!E1YN`!Wv^sLD%1;TjOB`=|wKfMZ9+=zHipo^ipciNx30U5+K9cODDx;aj_D
zw;uk{0d|Y&`(4`S#{4KuUsI7(bt6Wt%<~TXxjA7=$<mh;qyL=J0{41)Uhl)IC%{dr
zrJq#&$8NMO--E|Py*UtS?7cteEA~V;(j~>PZpj#Xuw+hK?1ERRxp8(s>fQ}Z-(~D~
z3faqCL~x~Vv;-R5Iv^8*3dC#M0y5bzq0lbk2BF4`qT9}QujD??@fTM0C`L}#`+@n8
zx;yfEN8hWys|6sG7opCN!`{fKlabcD@p&LY5B$y^Ow37+b-phWa{s4w|J~mET2~@e
z7?;6y4>9wQAnIM|B_T3in?Sv;UnFGoKA!icTacPk`3rqhMY!+y;|JZpu<!1pj)Wjb
z3!7U*C|@%TcW1_BrUdCyKKi<McW%mXw~lv}J+5<rVRDtaPSpQ*vrBMl{IYY(U0PmU
zVhT^gkC_uH(hqr(ooZj3+TbWQ$9dw^@udATBj$dToaVi7AB<9$hrz;_Ohg{aBgTFa
z^NljHuekl_6RSy*DdQLaw+l`yM+H!l9SD!g&)u-eE!~VO_trpm6EZp{gdPx6uE&<U
zryTzc6Y?wUw&t*Za2u=$qgwPcNq5DMQ4=iiLkeR(5rKS>1M*Rts5}C)aSIm9g<k*&
zZc$MY3kDif9!g%3l>?}MERg8}4-!aqT%e?q2>}>W#Wyx6J=)D`)+3iE585Wt&?my%
zfTR{0{0tSIM1Ut0?&sKqkiP^j%Oh_9EdBM-%Krq(h236TPgOeMA>gQgPUr1oC;#9x
zV|>9OH2iK;<IRCdnGm_5LYU3Jm#6aJv4#4YznjyJJvpe`i9&*#zaZzJQBDiOB8J-c
zQ&6N1c7VkNC;q`pOaAWLDb@N&Cg4@6j8KIa`Mq<D(I1g{bieBsAj*RIu}kCzN$j49
zmvQbzuknCWH=hZYMsCK1&$kG~5MQ4Pf`34uj{5QA>_MN^qyD~vxB?&n17=<ckO1nK
zvM|c(FyzmI@aKIxk9QA5cWqGl!}(pQnMs~{X#&4%Ig`+#`65<sI96eaj8@jl6yb-c
z*jXRNYrApY9;Bm0K7pUR2K;k`O}vr6G4R0jW%8vj*uKxj#YOyQx89t=!|T4^7p$VR
zc}!Q9cAx(%GFxkzY$vAWnt7fLkG=`kBX(`oKFE2To-e~vnKBscfFWYwCn$;~e3-w>
zY^3p^bSK=I1384guGJ}Y5ecs9MZMWNu0ye)Q4@?=oWoCglrG@%0-J`pFW=?C%O9XN
z(N8;w?>~4xmCEvYojas5g$#*@tRcl4o*t4Ry@)xxf+)^Vx&Lgcm-f$K(4}4AbS$?t
z6`n{~{lO97y^Yvkq=9-Eihy7A>S$L6wwr7{IT(V{qu>{!ErO_E`;V*JA36UCPMN=v
zj_|tLLV+W!_E)!Ii2C-AQJV4t<eMqT35}ADOo&A5G3g12e(Z~5n;`8h@OG=@tzTEv
zKBu#fVE{*wE!2;9Yv8It<%DeVTFootO$d1b^NEtGO9<c<_LBgNU$Jv$1n`e@hgI&^
zC_fulOGLUI`VyN8XW~VE(JcCiPo%d4gr5k1A*^|GAt3=6i-#gMw<NE=l+@&)UWN+J
zNkRbp&7k?414~k3SmXfV^}AHKCr@xHPyiKbCFsi`7Is_V->GaP=gQcv?2=b?*JRi{
zK@%>c?S|dIh4b%zCqz9JuD01XsJMw-_}8l;^|a?SE0GlL>!Vagt%-JN4CV)CEjerU
z4@=N?n=u>IRWVWd2fHAnm(s}n^v)7~9unWMxdEa--rfQXZa^}n^t3xfPz}*SH%3(4
z6Y>M*gMV&>u6&M<KQZQs%%g6`{)3t73)YkvSD$+f(_eGl0{fYYtZ$9!ZoP+X#7Fo}
z2Ht%aH1+OwUyb?ooF~qP6yBRyw95Hu)d$?oKa`ljqnN1>bAQSm&Yv+8eOZ0(*Z2g~
zOQ}e)+`;*(PyaHu%FvsKI>UcZ_>1$nX9<WngrnBjAf#^9pbqkO8>+I`D!@BAE(1i&
zmCY-Mp!{PWR8tv=<zy*Jsn%_p%Pq4HwE}}%FatTkxZdKFFXQP(T<N&ndv_pjj$jx>
z_ndqequlS<-Bi=quYc;$fKDKb$bbsUk}D}o))|5_VufCg%fn8^Ad_e{+Pqc1%u}d{
z(bzMGV#SZ+?@e4^b%Z|NOZ>8Th{zTun7@plYRoRYU=%W)R-}|&6k~OA$2?6byP%%%
zqMg$jW@px5RHnYabN}AwR?q{zNn%l`5-1qO-}}*XvBN9Lsk~9Y;C&x;B&Y1$N0F<*
zD|YvQ#|Il-=3D<U5dVPfQDX^K%;KqI@o!36tmd^ojH8%?pwh_;JebTp)vpsHm@S)x
z*Ks*ppV8F!tz4;kwtXFA6Y*VxlxGJtJ>I1x6>-*v35&~2mNQm%%%{mOc1q;6Xs@YP
zJod*#ZN8C;(9-He?_M$bI-=)u;Ayq#X{Wc_L!H+&%KLpjX-DGCTu!=N!Mz6SM@FDq
z(`Q?|>~lWkQ^r(vqvl9(?5&|TxrZ43C+332N?8D>!G>YbPD<+s(XcGXv^=A^SetyK
z4=oJ^6>rr?wEZWy9lIG2lMcny(Jd4rhVc2isZ#&k^XBtiXs2x0$w8R4%s>*KepJL@
z2S(`L7a;|-4#t%hm2SXi#(P@d7tz&KaK`qyJMl9%Ybbd9Pt_Gvu2c=4F5JSd+2
zJb&|by{Yt7_ggi!#kgg?%J18ZOayz}zE8Nrn(VA?49)AAMg#Q?{-yl3#f3Ter@4AB
zP;3fPf18eKyGy4Zzs)Gs<*!z*q}E^3$ZNIdZ#s>j5J4qWx^?AbZwOp=c<)ZDv&as`
z^U&>$3C~VFZoYlhqHYr|jO-rfZS)HF;%+GO*GS7z<lv7Mol?&6@sZ7BlDgbo_k7bj
zzqPn)X9Ke|;OE6Ze*|o_job~%U<nii%n-BA$fZUJ-zz%(%B$$<!Jq6*(Q-!Lb5+bv
zn(7$wZvbd&WcnAW1-I^gC>Q#)C5g)r9r|)rK$xfSG^9?v^{#;<KUe!mbGW}aDE|3_
zOu1k?tFh*@*biFV)b(V#FP?HZw@RUyOBW!eYTDdTeAv=kgHPZrWv;YMeygp`99_Wc
zI5#NGa7v$jsSe8(&R{hAGWBcRzvQI5T@#r1ye*$_CAsrlZ{(ruw443Sxr)VVp(a(+
zkL6qO%bi%y?45{I{7H3?s3F)R<CCm6LpP$_>skc3I(4pYMBAh1;f_zkRb2&wwt@}C
zkCS{P_bQI5#|W-k`32m>_uS>biIRv3T6?8h>}LQ5WgIKjw|_miXjoj5@hRjGd#w35
z-(eMd!WtB<Z(BkfL`UAkC80@bgsn_B9t<n5ul7;4%5nVdV5V_a+4Yn<_dHkaGuQ1B
zCR2|KXA*LRbG>GstL%blz({C`=H9X3$`F`fxDl(>;62=hXbn#75_J4gi!3|rVzF*?
zCEF!7(pKcjlwG(;;$%JUwtE?Tfe1Y3&~D}3{do3F<DHZHqkn&jkX$T)C9ZZe!xVr|
zke+Fiid1wz*c~98x7Gn5Gfy2Qxh7K?LZLWt&cNp(tCh~)(8*=TJ2$09Qo1r%)Pcy!
zoBT$jXCN}6F!VKj##(f}pyMn{Vj|hsTEoOX)1P}jG&`u$$iuuyG!2_^{_ssmMrY`7
zXu7nzED11Hbe<;9_g~!W&>mhV_+tv2>AfTwI=WIqB&Wk^lxO=jxnvKcHuTbsVJJyo
zqjDe(duBgx@p=Vjm=Y#;i!&lp5`x8ohy^lqxIofT$O&qOT$o>>%1s570v^bx)4OW5
zwhiiCt(BPI8yfWSeR?9#&Ek!9u$GD1AtQIL?5+dU`LwR!->rx;!VNewX_j&B?Iq+)
z_uJ4bx_6}|p>p9_6G)*PLK`qo0lDf0RmUi7l7&>JX(N|C5_%6VHpne$DCJLr+4NWu
zm5Y2XVj2-5NjNy4HKN6}TGviFcBxXvKU3gLN1Ak7!!aApth=%OH=d=aAGhkv(`6K8
zm`Dp9+9ssy=E(B|%oDp~Bxa(7D{CQlB?M?5CQ>>NYO#va7?t%(5;KM4+pw~OHw!vY
zv5u4N8W2_4L8tdp5>1RC#j@-J8S0>@1B`(Z#e+^Dk*i$u$-M)75koGP*Nw4bXP8n&
zvvf4(e!&?rB|tMIIO2ZT#8$5T8G{s2&Eb)UL+wj)e=6;?bLdt1cVDW0FH{vN=LCF<
zUWzx}Q;N$ifhdG0qV#D2Vv%<%-{8Yf33%Vixb=E5rfyTUWrLcy%0Px<ZN#O2IHm$Q
zQdRq-e8r>ih-G!GB*Dg%Qy79_a)Z?z`5Z4zxtGUW2^KUhZ5DAZHkfuq3QNc2>}HKs
zM+z_Tnm%N@?SGOmjR406ESyH5-Ew=m1i5@%OD>?WRA{lc@=KOqzS4*ML#m;|&j%qA
z3P>1qCS2QS_@nH*#uATz{kGQt)_iGiK<JyGJY5CSK8x^7-|8$=cPm@gBhp837$0IH
zY3!+(p%+!y>uHfQdgm*mUCxzAH*BK|YMxG$nggiDo9Ny-t&5UQoi9o$mA^}@Jvld%
z5im(jgNHlccKslq*7*$IWEYpdJB(RVTM#bWC;igQ6$)ZMc|*_uBZv|a$lnqoxWOG$
zTpujIz1$UZf6?CR@HkVB;^P>&SN%bH?UT}9{0t%6{^uDk<Cl+eop6ugh2w&fA9#lg
z%@3_+nTLi{gq0FOyAO>!lmS4IMMVkC%eK5P$I$ela9J;|D6&hk<c%cooOkkA%*~V7
zWQrYpWz;2(Pw!#krHDtHc7jxW#XR3RsF*72?8MiTAk)`J#SE-MF2vj@NY<6-V^9tO
z%M^@Pd*2frV@W<WMc`vlkpAI>of7jHu}lr!0xOBkCMjWH*?TF_!>W4++O;~aTqjWf
zQZXXA=t;w4l?Y4rq&}h%QY|%tbl(nt{@Vquu6p)Upe`hfUq<rPRnPl_4(S~?t$>J@
z_tKxFGjy&WMw!S0He_yOh?i^`t|ll(IA#HNsh}*+_qBd!bJ%`y9j4bPyf8pL`Bwke
zXQCjog2fH2D_j4C(~%S^$otV*=t>d4=Dk6+4O-Z{A9z2NVOFl)Ynv+J^WVksA7*9h
zGW{O^-l8|$H@NxVL<A}3VZcs9Ss&4KQyEQ9oEuyX&2UtEa6&{MRW7i4%gJbTJZ(_V
ze>tGQ6FoW+|660YZf-Z{Pkq)4q9Bk<I0EWE%mHtg07SOnKh!gha69uUgrJgwTf+BG
z>F1me)%^RX?FUG$fkk*>`fxs^)ui7Fu);4QB8=_Mj$eb`H-Wa^w=BCvi*(2=j#q9^
zu9b1bB;y!NsavT4^L2ThDhI1BU9(5{ewi#f{t{o0WLAH-xu_Q}tDpg)VIvqB0Ns#;
zh1b&fTG*v&fCw~PUmoTYX+-~ZljeVeJt(o7l_^i*7q66hw!{dLH?Ks4>tE2dO^B^m
z?$dDwP2JWRtikNHw&w0^A2q`M#x6nHCZ&p&TnO868Zu0&{*lIa46SL;(4UNifk=$I
z-PN`d409$%mI#t5q!XEZ&=*w+C5Y!H!x@p5JPlSsj`1tCj6ejCeX}3I$vmyrL5)nm
z(WMEPYdX(m%t@NB&cUBKgQU4&_-SAr4&=9jcotvo6sr24017l<TVH3J&AA@vTzq~D
zS|RYLHH~J)fqN&BHFHegf4Yw2ipo=L8<H|pc%SZmT&Q~z22^W=`z+9V1CV*~HF28u
z8E95E2e4^EQ!>@MkAt=jSt7DB&Qtf7xg%By0baAekOVsN*kZL%c6f`Gk51E_2gbI^
zR9Z8n=Z0d|%?`e=5=$9pasX(O<P08ojiP&h4-n$jr?--6`YD|<?5LNPeQLZ@6K5^=
zr#bz-GJ#U1gDyQAN$=DHbuU+wAhh>-R~~$JOmi4MJbdT*nt9lw_JYVG1Pz{AS#p@R
zA0O;d0y5p&9*rbr=$bK<2gFlaN0q<vrR>o=>*?izql~O^C%@qyGCN?w_FHX12mvNc
zWg#jv<2wx8X(LCOcYg}V97i&F&rPxL3D89k5Pb!4qLz-}V+@Bn0AkfX*1M$D4kj1~
zB#9_l7pIF<4wvc!FZe-+pX9B-XwnR&&m9I$cT3Vz7?AbLKYjz}7Bgd5K&4n~wUw-e
z$)|5DvaHGWSzUbb)GMLrbcEU=KKuX?1K&`Pw{q`zUDpZ^V~DYwj!cX;aSn}|Ae8_O
zdnc?V)JVU^9sB=u*DO2kR1d~CGHbDUuJ5yahyyH<gNQwNO68TtD=gVb$*K<d|NN{b
z=Q5t0rw@G3R&Z>%v5fFMVXI%sBFR6w>r{Vt@#&c-);)ibk!j8j;Viy2kxyo2?I-js
z9Wj=bz#~OKF<a}^c-}-STCt1da*dPG!l7%?rc#q!`r|D-D_sy!+MQAtnScDR!4kjs
zM!;*6&vVN{sL%##J6-LmB9)=wU>I_xTMK9XEDRL7RIN=Nkz{40dm&_N5O0(`7ZV&_
z_cdL>Lmx1pB3U%5qK(KLJhAA-4Ub3k*mnA9E4U=MiAA^BxcmXkX|09pMH&i}lpmNG
zv1_ung9@Ia^Kp6vf_pR1?!hfNX(BWlKaGZnE%T6&fA=jrUJ9Z6OH84|G(F7K^WQ)#
zP2#d6$3%kBi2*&eF=G-u-!-~?v*_f{D-XXf7}t?~ZVi5x3X5>aeA#j7x&c21A<B)0
zDYE1}c?06|xY_v$X%Ej@>8)oX-k7e*5v6*H-t0q7vgd8u-C(tjK+4MzwS8ON{?-9R
z(fh12Cy>45U_vCYj@3KD$*ky^?qJgqpFl1LEY%?ZP$4IC!_l@ZOBX8mijiptaQv>%
zUzVic6I;#IM@>F{Q5Eg32&hHrzt+a9NLQ*Wle(@fzBu1=JDzE&XXqL5)bPk+<~OwL
zwIA7E_zxd#tFl?plJirUoYVN&JN-@|2QcB6PlIE(nxzq7va8w7@tM3TZ+FMyq4Nqy
zyoEse9mSpV&~JzF*c`N1zOxgEWZ0(E^0c)w6Tj7*{cQ~TV`1aO46F$e_k%xwq=lDl
z+cB~QZ>)!^*~)V#VQg#AAQ?xSd^X{EcoOVZ`I@d6>GF*Jx<9_(Ze&U`aIRWeG|$6#
zlH!(o=gO@i?{{Y1xA^_Rg9FhUSxR1@*0!9-ThGKgo>erJ&)kGKZB4z2p3BC+(|C^<
z2+a<woWAxTZ`GiHJYSHq#?aRX2^#Q=+k)tMjk-<@)%Kh^sRMdz(+jziZRwP%b_kR=
zb*fHzfQ3xqKG@L6oH%DxwU$}*Z%(m?&&uSEVp2c@g6Vkx)VPW`R#+;7rWW<6KcAh?
zN;Y1*0&_k9jgiJ0)j*HOF3~BTX9;+fNS&FK`Ie)zAEo&>X5gn*fR}T5e9vUE+BX*H
z<M*ezhr5%G<U1U?-;ur)1-E9TLr%U4U}Q)ybdX859eouSoIt#AZy$4zEO9oi%)3*~
zSI^ZCzHvi|uTIq?eaR^kCk=C_yjRVb$X|n{wjWvT^|6x}90%8G`q>;=2gwjYrnho*
zY6c03bLv*X*&OSsIpwbhIzsjfhgK1BESZqPck{2GpfcWQQ@UH{G8PhnPwyWAB@6xe
z_DoeRyt4PHTlwTplM8J0^>fOL)V+H{8<+WoGR^?seOOcyx%z&@!8#o1c0}*?_-ym3
zZMqDRQTin$jmkan)>U8G-o3BsOs}(=OsUT_^gJYj5qAB9Nyu^DcQU|9Y|`&B&FhB5
z)-$t(MKdvh`0JCgsrSa-XQ>R1_x(T+4nRrAgVq?C9~$lgHV|l)D$6SFkJIn<B@YlP
zS6ov<EH@V{go1LAIJT>W7q14Vnc+S@cPglZH~=r$e12PNR;d!`mnyM7`?eJTakjfH
z`D6MWG>CHjb*6!HdQg3SEw>+?u@Zzl9;;xQDE<3Rwl*fG_6Ra%%U3WyaxGDafUiv<
zfzIX3ZfWI(y>;Jq4Yp&hdjd>kN0CFK886baqsFP25ukKE*6vKMkx!&@oUHJ}3e_!D
z$w>YW7FpviA91|Wrcs2zV&)k@x8Ha~J`t8T{W(8Um1meZ`k}+|xXVhx2B={ZaX#{C
z!O1T&^}ve?49Dxo6}pzyVKj}m<uQDV38BwB-@=oKtx}&tMC&z_d`?VqGEds+zz<^;
z3!lAm3cslL@SWlly|Sf;f`CKU5ow$J0&n1nM2nI4$7Vd*KUjwUhvk>sI($SSlhO-I
z%mOym(!=j&C+#N@A|FTN=Vb6;(yy5`zbD+0Fuqg@2e;~FGMdxQU;EFx0e>6-p!>hg
z#JVzMaNvdyaMy9B3lS`2C$!qq3t~^S_pb<l$SSE5+l+Xko<B+9Nqy^p(nJEP@ByAi
z0V!X|>=h9In6m30(`}1ZBzP?F10n)HqPxbMKEDNuEmv=F!1;GiGJ0um64dVf<p0ae
z*176C`wS_=`?A&easCr%eJVJ=1?IB0B}Bmd_d{^DEu!_xDWyGNXLQHs2yOy4NL2bc
z2ss>uXq}n=au%-?6nScSz9^vBs1A2~Br-Fh7Y0Z3%M#<N99%h{KFqTNl_G(E1!C_^
zZuZnq9)1%hWp82Fqgt7fe#bDJ(K3FD@5EPcq0}`{lNuw+kl+2s$5t*(5fRzov;Ckw
zYx(4ZIMH{}=hpLMW4(fNo%Y$nWO%*uR9MJ7o&g-qiFsLj<hWtZYQ%`lp1d-Bxyxle
zhv<B{X;NJ0h-S>!17Q)9IQT}+r(m8?%<;_ZSM8%FnOlE<Qa=$J<_!JysUycaH;-e2
zt2dAn2D+h}{M<(2`?XNTcbTXCj0QJk3-k(Vo&_HdUu+sbev(ky`j5}Y26XaUwp-?8
z{K`Di(OEx{dz<TbiPXN-sd`N4TWas~#PH&}$jAA_(-(_Da<^qBZ`fhQT1<6LmiT8`
zx!u%&5KBJ<)P3hWrUMJ!+PQ7`XrKH`{?H_n`|GTqPK=Hr`!C~WLGO=<AFw}8N?WU6
zCC}R5c@Ksc^pw7S1kDSNfw~M(CzDv(_pWsR;45%tL<J+qN9Zn(uKwWfAK8P+Z8fXX
zY`LB?=A(C_9G{F2ynoKwIs0;wC*zYJ1<?0EbeScp%6%I3{4D43#x(bBrX{+KJ)E0N
zi9Ym7vh-_V+L)n^<C6o;(V63+bfCW9T=bW&o`Y7uWc-`XX2D{qnJK0WRlsIafR6lJ
z^aajD)No=IRsZ7eQ)3U?;&Y>WPyM2x1h-yh`su<vYtL44;YPDiSTpNyrA`DT&8)D;
zq>`bwmL_Do>P|jc2hU0ceWjC%hY`kfe(}xs*CBiuiJ!QK<^Zn3Xs(!=_xf5VW%QDS
zS%&8E9i@p<4d1JpD^rS1AWeUbu->nWZK0!wmb&{2ueFDcgkSDXMv+IsUm-s)hmAd}
zF+a1;Eh<s1cB9WHDY1F-DmMquX%#C;=%F+Z>RS|U5yHA_=%w1hKK0@9;Q+GIv7L?2
zXO-y=2?uNywq7*?qKrnM2UIk@-8#NH@HLG*Z=vNXLIxY~Kh)Qn6L~I+_BwAYFI4oY
zeVTx`u}&Tw@2Z9WJW?U!5Mj{W=h9TiE(S4`Se?^LD-*vkg$B5l)48Bc-Ib3g{B(mp
zVq5R}7nE~6oFxWlH4A0aIqRQkB6DscDz4Qg{$Zr@QN6i8Ke-MJC3N&If<7!n?hV`T
z`-0+eL8Z8Ici=O5ahY_{BiN;QF^v(5S*e7Gv*n+)hUZolx;;+XBj~hTw~6r5O5#S_
z_T_V)H-`LGc-In&9pTCrBp>v~+L-+b`;;P--=`khu&~zf5XVxiZf231g|3)#IPc$k
z^tAuO@QU;*-QhzzBf~o^v53Y`NYzD)Z{gW()QU?6S`p!Z#6N1?c6qgr+4;ok$Z1E_
zD@ka(i;ly9f(tb1qG93Jte37rkTdiZ>(x5uQiV^(igHCA&+wJ=Q2Ozb1Kqf9bU~xV
zttdgmMIu<W;*H`l-ENmKtOrhpQ$U>To%-l`YUPHIY8~q%$+%s4n{m>A<b{v~%(95$
z^E<1vTxfo7CDiFi`ER^kW6rrvm&S8me(4151UHRg+&71tKVAlaO)7rq=je_Mc;vZ$
z4bKqf@qs=yWJ(XuciQ#vca|Ko2>qVP4Dc7U&Xn{dlhOr@BLXsn?6&~p_cXFU7s-$4
zn#lKSRbl-yHa^^-STwB-w?5eY@T9<MY`<%@5Xlx1w<|z|KNn9#pC7~fZ+oH}1E^*y
z(r$0)_A)WO!q4z8|LT9U+NI@^h2~0gJ&vS#*8`7Wy1wWwic5&=r{gPI3eB&tt&9tr
z-a8Cd1??9O=(f?c(7m|TWAnMgFPH3nLZuqX=dHX;Vy`7mcG?*Tutm~hO#Fr@Ru8UX
zS#eDhjqdAl_l1ann6r=%!F;7&A~wHi#<$;Hgj>3X4L6?dy?R!!A7zoZ>uA4f^y57b
zRCw$cHgDSb-qhHA8?=LsF;*}I(;QrUzNr89*aP99>%Y^9DwpT-g*OE*D_+vQ`E%o}
z;Db-`LAnp3;Z2_ac!0?r8$tf6p*Ohw4mR~D3!`nYEY=6UKNOT-sHMkbpe51=(jrw&
z{p~UCwC%FzDcYXC_H(lpz$C87wJkDSJCycbiz%tDm!Wv>Rhpy{M79Avp=oiq@Ind-
zfFBpppR4UK;uOk1t)yQZB^YKf6&b@<hU9Rec~0_dsGw99+!Zv~PgcOBt1)5x9bNY>
zQ@rplmxIlSYT~14z@sk51I#)R^i1tp<Fyb?rgctjvUYCo3wr~?t7eiCFIIj|&DyuR
zNHl4H6mn)xx*AfP=d?jXdM?5ZbF#!Aw6v2Fjw|+0+lk-(k)CSy8=^u`xSl@VAZ)D;
zlRNJV?sl{h8^OWco?Y*ySJs|0>>rZL@~w|jUV_i<98wnj02|jDmN@a6Bw=OBD4lFC
zeH*T*p*7=L;1HUavdxm#rvv=wnR0EMY;9SNxo>-z+&CwUAUid_91@;UO$X%7q`{-+
z$&TU2>3X|Bp=LD~!8y<Ulj-a<nJw-Cq+_+?;O<j4)6=W-1g9*b7$A;m%?EiQZCcqn
zVKd7Dsl)H|e=Z5sKssxH2CSqtw(6KSNA)uS<WJ?Y(pTQ|1d<Sukz1^c$U+DFS1McR
z3?XeZ$RJSaM})mi`ooH(D3x1ZAezCYj+wvOaMuY#&hfDH#NqdueZSvXL&~w#4MiFA
zjS}hUqOyp|2smIT+X@ykGTFXF<gc?w*Uy6<JUl>CmU!>YzC62H+kuhTZ>~sO$=(ej
zL!`XMb(kT!A*G5^$M5(GR@a%=lrjpF1m0`5*Nsa~$=A{5NWP)#B`f|OLfE}fa|RJF
zpW<<=S@CGNo2kD*O)jRwQq}KZ$n+&hzWiQqzAnREC}vUTm|>FLfrL5*F}`mKp=NW@
zv-(*&r?;Rm35JD&edb$?7k-gNZxVV%>S@yM<H`ERq<is|2xDqlFrnji=t3HV3K9V)
z3A3X0UIf;G(Qj-|8hgp>1howw!bt#}euaQCUPjjXUmin`W57R`wH~Y=xA`d6C3?5A
z?goFKJ<g`f`#+vIYf3`ZMNK|iUgUM|u>k=9nwEVifeNTDli!{s<y`n=EwgB{@nDd~
zj~9c|&Q6qA@u-uMAtS0gd%~C_1g}k6*d(ZlYrQ6)*0Mvqqb_>XPUCa1oc+fJi(8Ol
z-6d<;vXy+Ku6<4p(BNd?-VqKWT$jq8>lNDuOi7MGl>8#9EE*2l@7;78q|Y=y3~AfN
z+jzwT1goM&l-a-H3w~8s%cvS-hIvJbewPD_8B4lTZCto&$6w<^rQX<Et1h_Y2Pla<
zbPb1^p|unY;ue={XjNxFtK>kx%0DcpmDMV|?mzpYefxQrPySWobFU#ugXsi=$IBP$
z`M+Qrgm-(p-o;ST(C8uEM_Z3iO*WvDG>0JQ%0cWr0dC4A3I5k>gdF#Pw9YHZC9i2o
zU#}FBTg!lz_&D5jT|VaL{Bu#0-e#<>3-Dzui^vkPfy~l^IEtd%DoaTBaAyH^to7sX
zTWomCz|Echn^(-{NJ7ILRK%XV^q<8s^V$lC_p#N}<<T~L23Bb;Fw!FrJ-+s*Cr>{@
znDk}iXtnGs*(C_7`m1psL}eV9=sDvio_Gar(#wXZ#5z-{0{gH>;OrwowZ>I`b
z$91q2M;vh0BH}wJV^z^nB%h5?y=0o<*L%uJ1wZDFG0bG$mO;I5r%Los52rE}L~8cs
z5GLqS+!q_!*1iXpU-lE8L`gACqfJ{Q1F}Nl2>j+tltFDJ6VI7dnep@+k~{Kr@+%E`
zLiWndgSVSF-AZ5HX{N%7q?V`kkh8DQUhRW_oP)F01P<)aw58D(vC(yqKHMlFW!s;?
zpCZ4BXJFLm=;4YB31Esc>Ezz9<^I9ZS+?ZfkaeWMy&0ShWbsL9)m)PY49kF`iGW<U
zbSm*;>N_Q#9}S+w*z1#a>J_l!+E^?OwSQkAR1R8ffyEn%{A~cCRvLdJ4MZIyD5beE
zJ^qtG8gvk)scdXYni=k;W#EuuZHBdj3kFNSBQY`}!;y0+Ag+MNDWx+6@_5<scv1C}
zq{oHsAO-9ol*vV0@KlNgNYX%R(TpdSxCP+?^QCKq(zN3y03lc?{sN7Hw9)wT0>@8e
zYLSh5=#i5^85Y~0l?LxA2uZFZt<Yp$rsY;hGGwSnA6w2v*eaK_50&8RnY-J5PXbv|
zJ|LyalGFRgYA7Hj0z+n6UeUncsZBPscOOtavLDjM^DD>;*=Qq!G@QnkI>0<=uY?rA
z$pXo*LJ&Jx3MBt!8PU=$Szw%6i1avJI;CEwg}p5(?bSK5OnURGjNHHRx(`iMm<g4#
z%S8MZhp#xOHrATmApe~y)a1&ktHCU4iMq>pen`-nUTaoQ!<IV45J!o`i)0TBrOf0I
zqow_O0ph>O=6ghp8XMIDHb@zg`wNsNFXZu6c%2LjT=laXxbm~^32y4yX^ujW%b)^R
zp>9%GrSYoc-v;X*Yi%@Gw|X$ygou)Dw8o^nv&z4jE|ZN4tP(PbxY~;eB<rI}+sbql
zq1<ZN=3qj2PzXoJg3Vi+b7Z+_sl4jzt)I83aPk8vP+5*#-ioseNHLtDnq;lIr(Doh
z;)GyzmSyQ6h6r1O@|!jmwJZ;Q1^!-dbu>!2>&5-Qq;s>RT<=A(*mR7Ar%%dIv=T{x
ziHQE|<&`XK<E0`ok#A45hLIUc1Ix}?ITo#g3N*Y#1i;<_geZSw>^^uTC)ka*;)0uZ
z1EdkqY5ys$l9p?^ml+{iWQBSx`4=$T5-NkPb)8GY;>f~lVt!lp7y?j$eAU%rN@xwx
zLa)|%7^)P=f*)o{$PX6Ad9|$hE8uZ+^1jMy)($}|i{Ii(i1}LAS59hGe+vf*=%E8E
zk1f&f<Bb@)ZCP%)@>g>oOZHxt?3g3=`ug)+j`>(%M6hhJ=q4W*FCm9%y(`1!D%OtJ
zN@zGue*C%;a{}5M5rmi6!wyO*4B9R#7VtIiB?Bm}<N>W=lSz;c+D4uA*c`A-x&?Rx
zP18F~F~2L5*#h)n1J6aQM8+JUCD2JYy7OR$g!G%7dE9bzPX0M&P`xWXeS%ibUvLEi
zqvESI20x0bF}j9<*bi0?;Qc$SgQ)YASRvH|(%1PTTHY?D*ci|=vX4TIEhf4vBkqO+
z{r|E|BcPTn*3>^*7XL7=oC!@TId!G5@F6529D6P5o%iFT!D?%HH$XZotxE`Un3XF3
zjCG@bv$dCvFyE@xcXkJJlqVe>v6;YbpdhQ}Ar=UrKZ0E`JuRXpb}6LPaabefN`YM>
z*|!V=8@SOX1Z&?JQHYp0V4$v3YU63Bvj6yLWrHAh*K851pu2RbaklgfNrpqO<!9o#
zFNI@CJ!Vr#0uYl+8q{OzQ{*J1g{+u#C+278#T!qOZrXo2W+x9idG$chfJU%1O|QmA
z2e+=7fV*w>q5jz*p-}wcsI)DGCfNa$>LE$BuvH>#%~>>(H2oe6h9?<0|Sp0_fwk
z>--R_-a)6HsNdrX{Ztl}Vr{uzc{L|GkeA+>gCMME=nPm_kZS7rLs3Qy`ORS4f$^oq
zG;9x1fXpL7{{o>7*WAWo{%Y*Yn?B3`SZ2SOWOwZ2QgNp})gU#{VvBoPq$U6hSU%m}
z>apR3zV23?rkK^PHRpF*d;I_!9H>5Q!7S1_&GAzMqW5g9uty9@9vHs^(Ht8j_FeOD
zvSkNNXpJRUDR{FJQdV00{xsjRnfMXx;7g}lv1`|z=JMQn2DMi-bZf1Ldcpi_RNY$u
z^>NTqv74@3@SS3noGTef90Zd<dQqNb_MK$#7i^Itg<%oD9ksQpWDBkl1^s4v+sUov
z9x*-}h*72;S$pSt_0Dy2@oCD3oQ+4@t%&NA_*P>0dhpi>W+wwokq6?KIx#p1h}R{4
zFpDNRLznJlOAeE;G`1dPNOeSFbDib2A?9+G2{;RR9ODQasF#c&0=GT@{=Di1tyfGB
z9k9^RnX9q>&Ia{H>(<k>m23t>u}>d95i5kk4!*HYlJZZoWs!;J-p~=<B(cXj5;Lcw
zevv-{Gy0sYx9rBC(x-yH6AETy84>9wUl=mqKw1V!RRWRUA_8ysK`~|8eIN_0WqX*W
z%44LPX|huZX|5eZknrYn_`<*EfNfbHop;h_9+DNXTc@$K?ZM9RTe?n&o7RnKiWXnB
zkv3Y9QThbH-zFOASr?dPy=LYu{HxxKMKVdT!Qy}vLzJHh^CH5VM`~wNXA#n+t=21G
ziQWmp?^^JYt)+9G{qr3KIXfTOk-?R1Zn;BRi*dSH3~)LdL;#pI>zf%{Yvzh}xo;8w
z0@a?8q}qU@l`LbwPGaFPOfLJ^=8&<PTlQ>4VlwIGB2mFDKKSqEY(#qtr^#sOip>kM
zPY+0YuG3vRHoCgotoa*!540WodD(AK*L&ppuVEh|zqs@vt4bO<LWp!eU*NA`q((w;
z^y#rd!Jv$`6+4hpl1Smt^i|0b^ujg)GPI>OY!sVduftNqNAW<kgBxITrO(87Fma2C
zW0E71lfKuIItdF*i8&%_5wMS+8#WIk!G{-DZWwv;2IZ+BMa~EEZOFIzVbj1KnPc{A
z+F;MK-{Fx4XCZ~<n`yIJsC&s{Uo=Qb51|l>Y-BH+_uvw?*GbR|dH6r5joZmZT9?$t
ztIFZlGTMXpevbg-GZdNMw6++!rGv-%hJtT?g9G?&&_(N)9SoG>BUeQIqQMSUvS+PV
z^tGSj@mf~Zhi^_26Wz(?QC-IBw?0E?@>>Q4${_7&c{Ktfzj(({npH74bb$FyLwu;@
zFeSRV8}wKIC%eFU#i(-tc=FG%$c_E_sx)HB<qMqKf+@Z})f&OEnnAJm(jmm?(^|@Y
zyDI1j6~dsB*W=(x56G=S+stn|q{LhkqCKzS8>o`SABN51gB%?H=BqzVxMz2z)7RN~
z)mQ(f>-g(;keDi2Sb)myC&ZqW(ZnaI*83N7L%|Mgk9aLW2#cViZ`QgijAtXW$qnDc
z{&tW2^t?)$p3V(j2{&xSZn}M^U!spnGw=A7{P-6Ez4tTS#cZ#SxCzi<M1ECN@dGIj
z$OFEm16q`9TJ}HqzqAqQp3}vA;k_B%bGY&tv6l`q2zOSlEoN&}(UYc>nbA3Xi?mBb
zu}pRv?=Ylqy9y<#DW0O|$f;4S3*M_-Y=zj}^^AINdZI7hg4%m6lhkup>%73Qu|a<%
zuAh^joU&na@H_aR=Ey<h?)e5ao~6Y%q1ny6CI8)R1EtvPJk*v_mXTT#=y*VUFcV;5
z5p7=mJ1R5Nd|_yx;Q^J7hNQa>q^8CE;nSC@+YtsLM>F9GfP(~Zg@y|*4QfTT5&TXQ
z>^T-_xa(4ytnTjs1eomDfmEpXswzCLqdxTOLF(Qn*X38ZWwDEOXyzw!yyTu+cnNnZ
zd7dgzK`ss%tS7;Hz~asnmj$x1!#UK}W;zf0J_ehfbcSpXQl#z%R(L3J<((^c?lX6_
zxC}*vt=^g2h&|KZ+n1sIoFo<)j1iDdYRQV;4@<V;zoeP<pj4PF^Ga6v!4c`<Q$CS4
z4_^`0Xd{)kArrH_52t(g|7?Rw(kU{B8OD!wow8UjR);3v{L(UE1gyp-a&4~t`33HH
zrAXAsLiL|pBu${0SchucRj_H{zIFtLaL#oGo|ty(7gzF{Z-xXOnXTs8c0Wp0UQD?k
z0y;TwIoY{sIa#f^Wl2EiC-}fSw35Nn3nd?KTKf$(@_U5}xC#(Rn7~V}g<!n{lTsbp
zHp5`7!*Bk;&*!?yfSFHre6J<f39IE0HP2l@07z!g<IQvCa{;m%VnR7^P-_5WTAJ+-
zy=Pt7eNBh>x+~1C)I5BFE)Dt5y2a)M0Z9ByxmQ4CM@DVVx%X0*Y7Xx5+m-Ic*cQlA
z79BO`lHCA+0y$EKrdM{jV~MJpQw~#YC<7pGc_fQj9N}7Jd_Zd+vi?HF!BC%tm9$nQ
zrBs{!NML@RY7HDo`lr!<3I)FD+pf(K->#t-z~)82XJ*O|S$Og>^aq*QmpX*MUZ#4M
zFI8JbE){nonqJSGmuK=n!1Fafru|=<1`;6nzcmdpfS4{oS6EQX2Z@XT0FHx!iNeST
z9SuVdyuTmB-CH#5FfihOObyVPM0ixR-v2i>Y=8g{03c=G)G(8wdH@ccg2tZG3{pQH
z?BwW}l9F=v?Ah2T_cDx7GYGU#Y21Z@n<bGqq=kDWg!?1}$~17Ts<>Wdu`V4<nU>0J
zL#<W;&3Qh^V+nydalTQU@HAHF3lO*>0Qw>TTm^%^0RcP^;2RRiLjwK-2z(I%uZqLJ
ziGX;bfd8Zb-=)FJ(!vwU0xwngM-)X~DG5I{6kbz-@)Q9)&3$D9$TI-^X9D=H3;d`h
zIAW|fE3J9Q-l8WMFz#T%Ib>4h=G^P;*mu~g&BLiT+_U2RxqIi%+(<rC8Daa_!(k%K
zW9)q5^V27mseZ$J4k|@w+^+haEYqr}faK?)ZrlL>53bP*z1=QUU!(B&G3?bV=;-*q
ztO44WHNJlb?(6_&=VVKB&)s08_NM(mvhMsJs{fB0|Lil?8T*oDF!p^X+l;Y|b*x!y
ztWgqD3DqoyF~}a3yhkCC8bXK~Ye;1)L>gOBDx@OvxqQFZkJn#tZs*+2Ik$73uh--L
zxP0eMz$pFF{I!JFuftorqyPZwA*dk>xb^>o8l8urh6doCS~A@wiSmCP4Sv9vLtq2|
z_}^h}{Vbp`51h{iKPpBSR{B>SA{zaGzC%P~7BD*wc>Vlv*32vxDZ6KQqnfX_U97fE
zq@lsAzE!)l(CyY;kNTF&RrgaKx2H8c4lOC;eKI7{`U254j%*&VXdeJ{d~@#@Nb2lE
z^vwwOO@m)8!-tnalV5ozzW`^qfipV-uRa5o_W@u22VVFC*!rK<z&oeD@x-ACpUFi`
z|6?kZ%4BAh73SP$WIV~BHI)=LG%)DR?YVUgPwVRr9gU|Q?M<!C)y1^~8I*U7^r7o{
zFB<9x+n&5_ZykHo@S(1Hc(~=|%iOHao~GyBLoGw}q0#z*q4t3n%@gnLeOP)i&_B`N
z_xjztm6_@HpH}}rO=D&G+xPFEzkc2N{_W@IPd_()tbgD5^kd`O=H}<EpFg*^cYgi)
z^?Uc%?(YBo_rE{8e}4Sf__*}p|Isu;aiDw^LOCLf+)IbeZ_W<t%4-~do|L=fRJi=q
zlXK;R?Xkj-7GObWbnKdeL$R7e4!@Ay<CUip=DDk=i3#PAY^NfPkYS@xGDAe!xoJ9y
zOSy66XUihgRiggRk&gu+*t)O9e~wbj!Kuf$i`0lYGWR#(S}!hW<v@6vl!C@eeZhQk
zbE34WT452Wr0boC=V4vs1;vvRvJZ-zK2@G)JWy*@jX(E^5q0ry>yZ@NoYNmu?S(0J
zIG<&@|01mCHsQOH!#i;o_HtsiXmvZrdWr|?^fl{EcCngcj%dt6gVFOyi$qu`<x$J}
z4{rTIT&>mGZ?2H?Y?q>oM#Tr;4)W%yeiN(2bXdnk&b^4?;#CKu%Kt*BfC6bg|6L3=
zncrkOUtw9w*59C`GMq1<65}*swz=lT?>1zX<m++JDRxsxZ#rDo(6XuqWNH6RiApni
z=QNt!azmmFs8?9^I+8;k5BFS(uYPH0l*=WCTebguCu%OX&~N>YN7&BYCV2trKRCS_
zd5D^L9l=2PuX_@fgLhmse*Kz6YCi{ryO<lDpFyQqRfqSBj!FR`((k&Ks26a9tT4|D
zSMEp0LS!=h?W0cB^6IFMjjOo*+wglApsie&pBR@I-k)WmC!)rmBDIN^zHq5ywf=yD
zGg9%T$a3WfMZ?ElR%@3m@n%TJEo<0<HipNnkK1+M3$_G=eXw-1lYpR35VO=COb_t-
z`s9rUiWOmQ^!n<>QhzC>c5fN3;}rd83$1k2vWtW)w8C#&xS;~IOJ{yR^#RVhCn4gr
z6UxS&NG0b&^VbSTiE&2eYbSyo4)KKZ?=35DBV*cbRXs<aNLLCw3cF5ld9b?0r;Ct)
z3RHKdtxf=u5^qOD(m-uD&%fd?c#kw3?LF%ymA<c$ZZ7=J!R1Zgi>46RSCF6^SsTO2
zA5gYPaQ9$GO<6~aDtxPxyIAKl<S@%H3Ip>+0q(tc*CVFmBwm6nf4*)za}dQRt4AXI
z=;NOF57^=T-pZh_MFMql|3hIRAtAr@j*<t42No4aD73lPH}rDeYQ@`CuMmg-bs0vP
zE$s8wN&pK3rDuh$NrUGjuU{)|{%%|7@m={$p3bM%j9rHC=ZMH6QKVWI9WP>8D^Zm~
zm|Zug^J*`rlVX090s5yyqUR^R^HzSdpg}ARzLJy*mj!=vIClj7zp)_v>hVQ(2Uym4
zGt$IsBM%&#FCtOpV)~8LBXo^jDpz(YT7vL#_Y|hy@lw6|#FC@M04OIElZRQ|5z{l6
zEWFI1D8TYRIKYHB>PBRQ`I>)>`(3kV(RY0bz-dT~Pj{_rq}~B)$;mtpC+;~{r}_&W
z20!;C?;lUqW$pG%zWs1IJX#BJa?~;ACN5q2H%saQB^aX6h=&6onB<|3lc;S4ClQ||
zYKRLC!wcEYL$9*{gJ{Q33T^6U3rIZ()%ZbCu1<{#&lX3)3$(#7FsV%h-6B4^pkKbY
zy)0F{Pp^(%WYgINn6-H7)h29)q9jG9dIpZpV719}xr`+jUYN>)6Rbg7<5SS^ED>h-
zm)tK?oD*O(Z*NFnAHO<Q+ap><hDj|~!9+E3(M)3Ru?&6n=KGP!XmueTfj9d7dcv#G
ziv{hM>1TO1gFMzNTQmTQF!Pw6{&gzSP!h<SdcZ?9R#?s7j25xv;B!nb+F6<bm&AW+
zI$P$zb3#T5IKHtZhjk&a2C<Si9KaNcCCWZML}~d(KL6g?MF$=fd48#Xg{=qm=W@fX
z5>ui*K7}&PR_??NWX)qYMD<nuCwX2GZQcFQ)=w!ufqyO0jvM}{s}-UqR(;Ch&b8{t
zmLDl^BJ7<%*%e(_6$SjeOE9e4@IJ+1BccXFTt-7_Kh{>@TAaY!;_5Z`Y>i363L>Z}
zX+9FAT7H1xt;Ii8h`Q|DuwV8<YA_HQyX|^(3cW0Fjr^vobM>Z>WlqS6a|7IOEtpB7
zw@i1KR1;aTAn)suu-)h}4K45ynD9Z>`2#li39K6)<6DJ~XbI?vKPQ|oJfeE8pU-D7
zL4KJvsY|T%Q*|zu-`Y?YD<=!aZg3H=>V!3=B-7=~7ifR+yk}E2%YwX?sU5|dHm4Sv
zum4JyDPHeaC$&$~H=32-K91)94$MHyP!Lzt1q|~yy1I4%#Io~)QbU?$9}n_b+Q7_$
z_!L6PuRG#aYnaCC6C$VcOL(WIGkNTmjM=M8{1EpNA@`cu3@)Ra!lU+Na=O^C03&~&
zQKTIRY~k^4DC@J;>eSMJ#;${X9sC87%?pt_bB4x8B_pz>s78{e^n&G>pazC2UsKy+
zhW(`pUE3z+gnEQ_T;cZv;V*YG%DLRSH$gzr#Vs0ol@q|DbDz-gpxB{6wbXftYqajj
zYaUl6nIN2XLu89^ZLpWu<`*pJ+!m-haamT6rB(bbQlj^_w_@7yVQ<ClfI`la!E*+E
zlxdLHxcp7V$o!h^oq!&_w4JA4{d<Vow@Z{qq=vm}K2oKHRfw5KGm~3hkz_n=l{2W%
zl!qMMl+U^EVV29Z?>mZX{e@t+myDnfUKE;AA3<wih&i>~2S*k^TgmTDR0-w)%w%<(
zq4=l^MfT++-08yPzi5z}2BD@AlC6W2+9x?&Nahrc$A|OW{H}u>|2FnWIAZeq71NR-
zLmus^GBzeA@YsQ#tBv3@+pc|-($k2kyeQGMj*Q1J6ni%QX}l1xQ!Ngh8@&19sPmGd
z(wmhzhZ8b1h(rzerO{vB9DhWxKW~hY&0hruG8LC?U}}58<($AN+few2Z@{u{FXIf7
z`4ZNHk)v)KUNc>WSt#bGhYL)2R-L~3Pld-?!<ioEaT#??vBzXG1a|6EnyxYHiLJIZ
zs#ntD8!tir67{7Q<$0dgv-}v3@1Blsb-ul@?hAzG%Jl!-Y4X1S!&l*FOD`oYRJb_d
zropZk2Hr#|=AUr#d81jz{|sLbk9^T~LPh@1ap^%APqGJKb3w9pRaTqvTEGeK0k!Rh
z3D%wys69B5n)yKcPl1O?{8)Xl$NMGmy#qIo-;K=n5~<rTA&R(*8Db!6Ou6=Gj{qmS
z^i0wwA~+suvjH|H3e1J40`v^HrKsC<Nu;0He^qi_l~<OFc_S!%Z=-~duE4EuNbkvu
zGK0uXa>T?j>6cgt-!e#LG{jiX<HHmR*g{5Z1{JX+sR<{Jgen||oixqhO}Jy4eE~H&
zDzd@3=z_hxuOMNrci}4>2Dtz+Ac5XHQmi~L@FrY{R;2+*$3=kAgo2Cv#K6sSYHs5Q
zk!jztB3r9Q{%S|4{>G7?9EkZCC}L11V8hC318%5CHYSG6ccZMT=rA1Zc(Tx)7s!J>
zj^OL47*(8jBg^l9ekeHmly-O8fe^S}1-VQ0W1NrCWMfUx$S6JX*$d?LR&A<3>a?kl
z=E{ZhZ9=1LJzHU=zbw1Pd>su{tC7&t5@N94KIAJR*jyj%aZGq63KGQ?FxMk%V6(2a
zp(IP`d<;71mm7<Is)-c6%1Nr^(3WX58H(U|Bs9EKpjHU-AWULy1HxwnUS;RR_n&qc
zLtXome1AHwWg#I>LaQ!bYB?;rvP5_#%mnZvR9i?O|5FC+e!L?Q5~3Hk&lWI6NgPKD
z7!yyzBAEON;rGo@W2^YG$B{xc2Fv4FgVn)r-U<KHQ-T-BHx6Wb#~;9+Gms%9=U<?L
zFe2DY0`_tg3|7NiJxOSrDgca<J%K!Do`|Mkbha9KdoL<<lX*S<2=+#ywEGX!_Xsa6
z)Qfm-g9IAGL0ngDCLmBehkuF%w&8+L=v~!qLzUo*0UV%=<0ZFE!oPgps&KwKfU&#b
z#ZVzDVLI}p9@K{ok?lurvpns%nO6FUu!*v1F8D(vEJM6ZM_ep%h<?fb3SpBl-g*`v
zZECI}zm#4w2F^G#CYbga@{gqb3nSsep<xn`hG+>7w%`;OeA*mVYMwW$rh=a-C^x@i
zIxW1*I-6LSRB3orA>n3yKnWy)Aydg;Z3^9^mp~38Aex-hdu-^RNyxViXz?1D#J&Ee
z47H<{%YDKWE^wd%Gd4N6hvY=pDB?5yWAI9MqlM7BM(BG&vLs?oio|6{0QfH%*0}~Q
zs4iHzcSDwt>sgt%MlaWUE4O{F@?tvbO~0)-5t`d8)V!h^O0F={7cggIgV@Ls)^%%C
z?AbL@AintN6#d<*(r^pGUS9xPSO|$haT$zN&PCt+vV8zT+g7`D4SqBL63Rxt<KEHh
zNahbMHqy9KG|KD{)%wIW+Ic6^=p=sk*IkH^pE4!?Z)85tl%hTPBngPHh=(|Bggo5^
zA0?A;0oDv$vAnu3%1>C`Fbdp$>EJ24_Ak+7ms1E;05JM(#aBQPwa8GCGxa33#TTOR
z4vHn6L>AxU2|aEXkeBDBvL&viJ|R{|idOt%gc7^jRD`4tsnS?SxB+Gt6z)5r@6EE2
z;cV90>V3nud$Ma4oRVT^N|aS?_(+y|BL2)!II>ph{N|`5quqQa9O8;)$sERc+1QCE
zNYVz_mJ1Fc-NBWi^6iTI?;ksz?#sEz_j}C?2IWJTTKoyE!7K>eS#~TH&Wx*R2;Izb
zBp*H_$QU+DfcF8+GZuA|*}qG^I3v8xNpgpa|GXjmj3a2IATX|u(jkb<0Ai+hv+LC}
z9X3FZriBmkV~C>%kX<%%Ip&`6$wu)f73(~gjG}3jF<7TTqq=9~S5+kEGp|pZ5bLDa
zS`)JMle~ws@T+`T2QKt>n@~a<)|HIh(_?l?sTpS<6VfOrOr&Z9k*{HAQjT4Wda5H_
zjSS|>hpg$(0xYhA3fA&<ok*}uCJZbY8C;)wJT>py9WN^7(LSo?bQr<N6M0^gzj-tm
zUU_qmD}K-jd5>*s4liO(iOl8K+XK}0i1&_i!gzyFm!&KHohzL~0gR_Y8)ITWj)}ej
z7!JG;a^wR{whNh_%VJL=V@T*AxHwf0;uwGZNF~c)_6e^--ETFT@lhW96Q$Q}LiXcg
zQcfb=1C;!q-{F2UwOd{=%&gFHBIK}jRbSYo_p8>S9h3U?j35(LKV9H3biuSkD6d<r
zizG;DL@M6ndj>K4qu@zdlD~57mUPLj6W$hoPwMKuyk$j{_?C*An=CMjF5QznQ=P@f
z(=TH^EjG$i4ynAkkM+zTv>%cNDo+hbK;1t{VABY8=cRjtd-q##<>%LKI3<)w1c`sD
zv*bUIY0QuTVQ<Zk%6o5s{t$aq*UKIk#Z2=mF@E;k7)5?eeTcH`z3)W(pxCMmL@L_x
z0$!R&0MoU*8w-=MU)hiJv6j2k2Aye<dA)$aTKnJZ%nL`WeRq8MXW4;HwA!F6+CYJW
zS_eM$AmO_c#G8&!?|X~J4ysD=*v=01Txb;BO@!zkwzlo{+?Kuz3w>-_pK!_5pt@CP
z50%eB^QjP!cj75815ZGKJ$tN@G)2TA!_jWy<H#@m9)Ne`g7gYoY)SVbP`z-^yX2P%
zfgPgUTHaPP|CxB;{D#2%sNfG0a+`a-l80Za{y%WSQ${ju%j?eFOlb!$Xlz#4Y9c?J
z>y<R}1i6nIx{&7|$dCYLsDt?uIq<Z6_$3lN2@5}uLZllbhuisfW`!MJ{-<3ju-5^(
zcT70ASR_Di5Tozr$Oi8_9=;bLw&b{;PWBHi#;cbPeG?dFF#c*1JSG2NT;ulm#Zk{A
z%MANH!NF2TW*WG(w&qB;fVDT|^X{>eXbHe4FHrP7QPU2v(DU2-ahGo%8@MTYwp7gg
z0{<oUxTY1npCb6%kT*Vx4j7HzBO^mmSWi9WlCr8Bb0RU^6L#2yT~>=#e*47-_xv8v
zhfkZE#4@f;AX_&0?qT0*hQO_;Z`Xlm{3HSB5hM)&^&~>6`Ia$g6FhO!cLy}K&~yZc
z)Y^Dyp?5t&yZ4+nt&g|SRY7FTfsYf<o64P1mqpwxU^qwc*3Sw(>{hyUQpA%4tvw%Z
z<EFcRO!OQ3c8R#Sh93FE<d~bi+_8~_qc6R#(Zah%VRc>a{~mM~FAL8`biRtJ$6Xc$
zd)!0*_R*htB?RnvSr0>MVdt71A17)*2=p)C>coWe@pcjsV_oocj*zgpF!@Ge<eW&=
zMG+lz{2mcG^&Voe-kfj>g54GT>_#qk>xXvVxbO7fM~ETWkhg0CHg+2>OApWT>pD`9
z{icPVwb^P-iI9nu2+QZ5krMx`4Y6ePq1;j5)fvLl1ga1<MdI*q@FU;(iLb=c?!N*7
zd;YSF?Hxo8&_4D6aPyGRJ9H<WTeC?5FQ$Oclvf}Nyw<zO<?EdaGY^$3Y03HTuUv-9
zh$F=%Z8Bq<CkVF=&}L6wr6?B&67of&00n+qCl0c*kjFM&UXGpvd){S|mKHOMy{nHb
zv-qm@-qz*9pN}!zN-cKCX>csdJyFCRkcg?AxKar74i;{WadyIf-b9maiD0DQ)$dwu
zfo+om>SxVfA(uIPxpE(p^hCa4?QTYB`RxP`$Ae7^28_A|Y9b)o$3=JYp^2W<fXWv0
zjb-WDilKKeu*aruubH%i1v=t+uYI3NW(n=F1dEew(!WV(x-G^lv?%xS*VuJNsIn)!
zg*Ng*;4*NdoBPq0$#)ME`fm1*2I-B&e!Aj@_*<!`zFA${{>tNuz?)4-mz(fk04%I1
zS*}FF5sfa*0RO3&B_(`-drrO4q@~FmsA~(k#}PmN=@PmZ7(6g8=)2pfu?A)4&Suqn
zx<pItvaoRHEPlb&_<#DROjX<jlG4p2tK0_PxNT^@f@9}}<UNm8epe^_Pe+%vwtFqc
zyb?108o35|k$lL|a5nE(tTZmqI9{6i;Xr$l_Mmes^*IW0<Uqj3;!Hbnv;&VCJUZYU
zFQSpJ6ZqV7;r0aE8-i7*Zj^!THMbGnbW#3G|E=E(a~J-N;_JYEth){O&~1*W<dc#)
z4pun7zX4|fp>DIn&vQSQn%^1xem(q6rh$76jp1-g{uC6|=18b3dfsrC%d6J#Ui-FK
zjkfB%6UyseGcy<R*jePjF@|>V1{r}~8R6>e=I?~aFY<QN{~g4=(&Vwv6a5b(@Q}p!
z{OYH#Smhl~(p^$3>)z5pBb2BIwc~O=ts6S9q28(Ofu%$5;|px^!GO@bkB6EDk0Lmq
zSZNE&Q?W{K3tg~difJG3EAw1(007ZA2u~K^MUE2xmUm?Rq^y;8NNe-b8Irj_hkWDa
zMd6P?I?$<HW=H36hU#1lT={b{Q%K1WqPXICHlskv@&GmWMCV1Gy!j$dn=z_L$wRA3
zDc<n=7T5~lEjHGSiI}Aixm)uMWW0G<n*LY7l_%#|U7G4g9-<mn+UtySjp+GIQ53Q!
zphB_#Gkxt^6m;U-0cs1JX~Tx=78+Y*fkWOk%*HwW)AIyO!ML|&RM(4dTcmAmG~myo
zHG?@<giK<wmB2Koe{&4Q{%q@^;_QeR!CxQv>YUmxJ?s{HF*UyLP@b`e@&ZnM`*6}o
zG_|nr{SW?6r~6$>p$FpJPT*ky^mnOMsSpSlu9jBpG6>ishh;F-^Vu+ss0Uxe<k=fD
z)cXoe>d~@_=_o24?&9)EF>ge8%}U~gtJ<^a)zhzVv`_jgr9ty$N`mH#02GHe{iSLN
zi9FLU!>YnP=oS%>US_CW_lMoTJgU~iP-s=xme(okP>_9algEQ0T4CobFQk)_-QP}1
zf82s!#vjyM)8=`gWnO8;cRg%Av&j{g_x1Z#PD}%t>4z(}=g=v^<gnqGaZ4q{VLeq%
z^Mx`JZ^p}=A(c*fSFIoHY?9&E0@I}k-v)rp&BiY9pi=E^|CE?skB~k7bf>_a$53fj
zpR-eXkNaOZ><+2zTh--lb0rtWJL&?m%1197+>&eastjPyhq4u=a7U|r&%L$PZu#|o
zZwQ?f3#<{azL=|o`f{MqU*jomk>wA_$MN1)W-uvO*6)QLuOmBj4cQ}QUs_p_t^Y!^
z!=DS3D*E8=YzF7)J5Rm(4bX{}KOf8EFdwp)(|hBFL!<ij3mGAd<)YS0icF>PQIuMe
z*8zzMUEnZ3!D?zWoq`@d+!0m3YETg!%=oh3_J!%^bJ4dW(0oWHBsn4cn*7?YaCFjP
zK2bD~XZWNWJ=R3+mMV+9m{Z}wRDml|*$<j+)WCOosO$xWX3ZvW_E7dGqx$fAc{l(}
z2s=GytgkblS>Z>W@mMeUsCG;KLR{leaSQE~fkIJve+ENME&bFH#j?aYBdy$x*XTI%
z4vx|L(mP4Z-#nu;86fH5_O?J^%dz-GGNt#;r4=$><;uuHzuEG4{$u*Atxd&og`;@q
z-%3=;<v13rC5fTIr-+9?jM9^=OM8#av;UoQH7)${a6|4BY9TMi{%mAoGVRv^r=aUZ
z4p@yFD7eTgjEuyE^1LSxN9ZV<?OjrEF$H+y$`owmt12z`H>T`tYvdX>e*_;W9Y1qZ
z9O(%Fi=H(@|B4zwf`NDmo^e83Y?AOrBZ`{qbmik`0Ep5gmcRObCU5*naFS$1dRGzd
zu6rSmSoKNal5>?WK>3KHEhicNQW<*FdR8Ib-PZQQaymYZRg<?H(eq_NqG6*()c8R!
za}L^nv0GiKnQR1=q6tzrXzxp4SH%m;2YXiaL9RL`fCoZ1hZlH_2fEL7Fli@tD0wmp
zYf@PAH;K&%ggO?;LmRy&nv1F#Kb%vg8us?X!UT5z0r-W}&>mU`)WhUiWMT34A|68l
z22{o*UD{k8{_<Al((;<bQ#4#dB9ZK{2IhAp_w29|^ThP}VFWv8!|P#?r&16B>m3U6
zHDF{p*zQzQ<tzPHbYt<A$Hw0@28XT`XcC)7BKK=++}H#|I-nVSkPJNhDH;4>Oi|Yy
z4a2qRKUHKcV5Z0?dEWlP)@nmCevW-^e_!0PB9$)F3J4MmGReP!>Q(7L`8_{X!;&0*
z#j`s3VLgWf4Y5VU%U~F2+rQ8+h^8uDg-`g}>*Hp(i|N|h2xI0F?1np2{verN`Q?Sl
z6J<yogz!R`6%R4YF^aLJ<Gl63Fqch^w2~VQna(|+oi2vUc|fsvuO+j(XR8$`&x+H2
z$57GJJ!0ZJ7_}~GWOF~YqQ+}5%=oA&1_9Fg62av80u)b;P;jx_h{bJh((@I?)YXHX
z09rhS_r-tP``w191cgh`*tQatdfd--gUF<|9+gT4|DP`)(bH|$5M;nh2i==vlpQ=w
zE-VA*_mzg;;oPmJXyXeB{<9sbbwc_|#NBS@@nTRWJiT{x8u*BmznHYo&P2V<&O2+n
zz@uQtE0w|#mB<m-iZRnpa=8wBxWj4TZy4l#-u8T}!-?H^|4a~n{72tyMbX%8Z>bDe
z?oEJ_*q&sJMf!B@xC0Zhj31VV<-9)_U&jl$E_Cl9Y>`s&^nq$2@U2e70PoX#g<E6V
zA?t&AifcT5mzy|e{#G&<H|~gI2?ZJ+VMwQd{5#lon8>C45cYB}f50iK<#%v~JcI(j
z0hqTp<BTgl&-@P^P$M<AjP&B)9-1_qHoMlG?fu2)C9KiWqjJNWor4>RP<v$&$PrZm
zOvo8VKSmDnm)xE%dVN0b&20q`&()@kTd?lT1doLb^zPu>%3F>aSAaRe#rRvi<}FW)
z*?!px?`aNbP$_2-X=}2ORQkyonUo`n2wY|lK+dNs?#8@}zJT6g&=aOnKwcsXBwovT
z0$zZpp-#Q)rs@G?oKfuuW8X@Njqr;(qv>}l?Bu2ldiX}uk*@zEjTFGN0PaU`ML+r6
zdF=eFfL%}I`2B*}4;f}q#dt~@SIL7D5AEd@wtNhNqAU=fX?&nO!V!uO$<smL_a~^!
zbM(Z=?lSuUvuWxR_>-(N0#p2;+{JxGhzKLOZ<d{Raar@sm&=)Y7T3P$pu0=-9G!<1
zqDZy*q3ZKiS=O!G@LHvnN8vZLQ%=uI&#Bzd@h}?H5Nzf{_@Gxs%dn7rHZrnUQuNQ6
z)-Uekd0OOiJYiJl`LZUcwKQhLVY<5se&^TxFTlW~SN{bVSpIGvvGn`4a0Zt$$cO0c
znoax&H@~1z7S?uP{NsP)JR<MDsIw!&FJPnZ{d*k?(X5?8Z*y?b3{q-sl|j!?x#fy^
zVg&!aDfA{5s(Yo9k0<%r?BsOjR1Q8n<?{y<)uBw0cf;xBSbBWw9yN$>OEBQtXUql(
zckA@VPLfANwZ7;<AV%xA^sCWJJ(Bi6t>h^h55u-?AiQE0%~UM>2<u1=D7zO-{Xu1d
z(#tBPo^S6_<N$huj~PXQr8`B>BT^7sf!WI0ncihB#N@UoMdZtaaGx^c;6ZiTpn+=l
zts|^kTKSqMfnXI7b&|Jph6hyDUbHPjm1c?8u4XpfVe~2*3j}BX;p5>A7jS6L3uPaE
z40W@L4ghJa%76)IV!Y-@Fj?7!SCLFr1b{d1-ZvsCKGVp}3S}DZ@O>gYNBciNOSr96
zWuiQXm{T<9&=dDD)CpzTel7x}3}$-uKu<Y63GU_9N>C1cT&TwuMHAW6m#koEwKD!y
zGX9xmPdOHS_?`Sbt5`nzY53tfDk}aNPaEJeN90yKeZc^6wXyXi5BQ!E)wNMxZ?F)l
zE`Vd@T(!tb)dN1P1^Q#uZz$bui>~yr6x$`Yz9X95Wb^pUJr^F#yf|n=YNJcbFj{BS
zY15g8@g1u1cC1>s$PSv*n{#4`LeN5_k}31|f#-ctoWh1lv{}>~gLW%DEq$QqfNM@#
zrN5qieixv5`F>^rGxO+VJC%!i?xIu0Lf1HfQs$bpYU|xJ5xOytWr&Zc#PW}K%`Z<f
z_>K^!{7vPKqC%pd#+|b$%>k5NlDHL}&cHAx@K1BoDN1G_Ni$5X9@xc`nulSy^fuP(
z@$-yOQhIrHeH6G#Lxs!O;zWTTGfn|P);!5WtZaatQRWz5#<v@+oFPkUK1?c|s?Aab
zH3MBdfpy-fiE-iFIei%}Q)borGpea5XSlI!nCs049#t0A$~ZCT{HC6a@aNZ<s7QGU
z|96z<Ofsk<7E?6{ySs3!@o1J>7?T8MUShxW+#ULDcz^Nh%fTg=17&<s8ahLX0{xe2
zaS-$fyg>Jjug~A_*(;PiwgobjVLaCd8ALc!xg!Bh1nOvp^y)*+WIUf}=}QZ@0v`!g
zA2(WbW?F(7ZXbR{GE*$Jo4R4E7m=ZWxThcOe%AnmUadc?fcX!?j3&A}XmrLI^<;6d
zUvk{(q#n<pffjNPwG6fdf|<ly^S1S*?TC>!ps!>QR|A?ZBWQ|dRB5bpEj!~xpM9-l
z6>IEHB*R0GJFr=g-`non7i}Z1d$gb^KbJEHZVqVVnAxmmUc}xyre>+@(??O$j_;r-
z*fFo{fLs))ybxwGyEZMHcx5nMfuSlweL}X-^)xyd>$PpWYQ#vDv^tLMZ^$t-9fV(H
z&;!oVTZ;Q17=o3^)FUJtpFLsH*Q2ZrVomas!p$1jAde`pR?)JD$Xm%>j``uO80|lF
zJ?GV3R^~B1*S#KVB_Fe^3}A(fGh6L-pJpy!d$GR%f1ONK7t80CZZ#*DCnRwOe~4|q
zgL2m)9f;bVvboHN+N={S>)zVlm->iH{-8RNRV@oH4iHg%s}s^G>U8e9Ay)?u&X%Y`
zcz%81#pkP0?Ofc64AgTC@rNdDz-%^X!ufzRC1k=v`{(wi6fZ`G4C68YvSmk|$226`
zb{cClu3&q)X%mT&4c~>$sqw?p(vOG-%ATufwz=U34<@1T9^TYdcv^DiC$$Xk5PG-|
zqe(_t4@*^21Ib3195)6X+0fABaaO7wq=mB4qm<N@%*zM^Cti#Di&J#2Bgd7m+tT{;
zW@Sb{vq;ZZK8&6cEXeABOK^u|cfcQIlx=Ml*==x160fqqOX{kALBEeC&!coRv(j%a
zR&<+p{!JHaD_33y>~%XQS@6sS8>C_12W<J$Hee%jRFtgw-62y%+6yTJsG!<~Hh7HA
z@<Qgk-o2$~W%10bi5^R3rh_u@uElhJ1IhwHQqO_q4{r&1nRo^^VniF8(>Fwc3dH<a
zZSd-^6O+r{&q}=h7wmQrfSMTSDvE7}+FA1G?t5HN0x{{;<N3F@_o)jqj63&pdQuNh
zfETUixFTJ%7Ce)V`XK6-Z9V5SKIYKcMYs!|^$$j@C^ODA@D?f~qELqGEATi;(5#q^
z;ASJg*i?jUMOfIo(G|{^Z?=PRhbMWq$ZYTg8)|3Ha}94rW5al~LErl`b*A|*Y9mfF
z`Yi05uPjj>e;crLo6)tMuUp~RRP)hq5soZcvDk263v@CU{>Ha$R!Ehd&wRBp_AB7d
zcIUA)E_LJ^<&yDBA+bjmBLETKcXNtwi%?ceSm@`jR<`qz&X;A6>);YB=8+u(=qAWT
zKa4${Df0UOm@R8A7Ht?w<K4fFh=lr5498+l%lu)RTp?P>YcwZpL2og97u*=<X_;bX
zASEJo3F5dF&YJ?}OKzx7{qVNE0SI-d%;ttMHeRIr=k6~%cDeD@Ycayigf%sD$?0#u
ze3c`=%2bJ7l4N`=iiXP|w1EaWUpquE=3sxFh8gC(U)nr|s~Goe5J-{EJgzqP1HzlA
zwsZnT-}~DEQ?I)~q?%*^zepp_pfn^lA`ia2&GvmRY=Y3#aT_&`u&f%ld|Z_4N<2Y!
zVI^n$4-b8kNHiMDIKm}JIC%-($w9|^)tWh;YjUD8;7^P3XHd_pP7h4hHe@(Oo+q4W
zJ@7Y3uJxRgWdsgZV8){Q>_yJsnbzT+yyBlxjmFD;%DkvHdj$J|MWVDTQ<DUl<i~ZG
zR6dawjo(%gM(Rh8H5>0$(v@a<$nN|`oBefIaOFxSpD{?bHps4bS{yx`%;|fG9){uu
zCdpBoi_ycENY_~Nl;}+MU#J&)IIh?)@JP&>FXPUq%uRk(H5f0BgWG~Klj4KMdU8~v
zA4{}F+>PQchx#=Qdc5>@c%X=gKK$4!hF*D{8Cup7wBxk@j}()zaIyG_;`Hfhw>Rdw
zBeJUx6Rmk7E)QGGt#+N^Mn-<6NXjnd(+35Z*-xR?)Xz`!8CT4}b;*t69QZ-I7Bx;y
zK%l9fqZI2PeflT%m6i6Z{pHyxl`KC=*YkjvKCIX)JMd-&x`TPwV*|s(z?SNCpTJta
zix7#*hRL^y)~hhG)^unWUPt`%X~;rOf5O%&^XQX2uZk~?tHG0Zq01U40Bn=QFs3+T
zmCDN0B=M?h<n}I6mXCk`erj#4f?+doul5FH-Fl@JyBz0AzbY4A6~7!dI+Kowzp?>y
zvj#POFI=jq6}Zu*;8vtN*qr)nU?K9;!F-UQkwqFz#S8=sDpO*sWmZ@$QBl}n6NaL#
zw@TTYTayt*ODD}?t=xWQXVbALS}2{Z@#02%a~$`-f%liebN3t$c;o$t65=%@LJS_p
zg&Pi@xuQ4DY7C~4Gn<sDN-Bux7(-dWiY#ASr*GxZ(3^kzcTx{HR!`gXwR7p0SAuA`
zT;>Nw?hPIDak0bgNN9|LtB5Y*=Z)6HoM%;iuispg`;wa+GI-@}DEH(g0Q43a+D$(N
zJr*O!nx4Mfw_P6cjWccDM{>OzR297$;pSi&UPH&`?pJx`sqozQ%LD^q_HPB7+v(qo
zn#0WBT#h$l3OslIXa7Cqr1R3UZs{zV6{cm83v=(GM~fWG%hi(WFG8GM!p7q|+Wd)$
zH^Y45C;OEKag`t79R^gnT4L2;=I?Tk%Wc$lUz5$JK}!d2HCA>dc6qtj3KCiC8VL)%
zqGP{AP73(vKwZs5Kre{Wn3tWvE(<y18!)-PYeq951+zb|x{{b>&#j7uV&ET6eH>iI
z3rC~gCk{fF&@d;RovK2j92#6HyNKLMr1@tC@lu0(_$A9`Wr?K7?^$0yokiNX)sM$r
z^M9hHmEhvY3%(>r?aIpuc#;xN{^QqK7!w`PL0QaTMgnBOCX93Cvoh>ecYHuv#JkkI
z*R-ND4)AHeDr5fvf%i!%`L4I2nQ##jujXh<{DaICa;DNNU;=4Tf5+Z7k5{HFs4`)i
zNlayu%2(4$@F!NH8@`@;mgna`^w2G;52|vI4iw2gZsrOAx^k$UpHE&M%~1)28IELP
z%4VH|_TQ9Picw3Df7X28V0`Ky?A=7)=!aID<^m@@Rk(y{IB!B5#C<y57!{|&{dcSQ
z31&L=;t+7Y9dtQfv*JRlx4Xpb57p<|j8cPZ{u?XFWl1D5Gzq(QR26ZFwG2moj-7_A
z+ym-eI-s=ey~$+8`ZMLrcGyq^5C9X#9IB2z=|zHK5G+8rCqr1(>p}Ek1uYXPrkHMr
zR&oIT*eSpeUWx0G8Xd035(;JS7gsH|V+eP+z%-rGw`N|D!-7{#e`HTYR)&z09+g*l
zSI}X++HE&?ObEl^zioWhi~k^>v4kN=O2f!zJec>*r^e!zR};S33GD{k;&~p3zN}eY
zFB}fq`aq##P8lpEV4QAV@!oqY;(3=Lr2DsKt7r<NF8ExhVNGvKsgW2VtxTbdvJ_zB
zCl{LHZnu&H=!MoDa%J~F5pHa$-91+#EZTYV2fwJD-?<y1Xp)Ne@z!2MzR{kVX??*q
z{nPb#X%OI+eS+JV=&VLs&<3&R{g)|ION7Z-%&#+?QllrDk+mPZhgLwpT}0h<1df%v
z?6JCOLQb)GDZ*<Ud?48ESJ5j0LQ8%Kp<HaU_oDGHC8|TCazq7gt?^>mnGCY=5Ntit
zR-W)1*z2M{;nvU8IWTM$4t4p4avVkIEG*f3*;VzTeG%e~=*SsVLP)$@$P(=^xvDT}
z0XqK+;s4mUD$Gue$y1stBh@oc(rGBXtFxr%&#%i_54%PjGAhn-`8|?9Dezve3@M3|
z#6e8>{Yr~@J>NCIk?{G=&LQsZn+d@*d!{O~!cXyf-QaDhtpJRRA_R4N_PtyP|EB%D
ztef|@Ug~fW#<n<^nzNU66ehCQh`;A&&%-MwCvOXpqJ2fI4TJ6bj@lCLuGp<oeyQV*
zM|P;UiV;qKN`dWod+Xmd6Yc>=`_mj$PULiBY#LzT9Nm?4KTRvpd(_)TxBiKqhu?^;
zNc5Xc(yIfXow7}ukg<`H=rK{skWdR)i1q%|OyC>}80<dV5Vf5yOck_6EP#iO?h|`U
zFy9Paom=Mu3zNZ8tN=?FOg|_?`$KQfL-W!k0o16_T(Om2Fr8-c({Gz?ds5tPzTZ>C
zZk_>+Ul+D|Xto8O3ON_jcgCGwD6F-bj8McGJ}rI|=|FnHvN&_A`))Dr2X?^cFE@Vs
zNl?IKjIFze?5#;J?+-#}TC$2i>s-rUH=eTUbSkvGo8NFPeiW2n<T7h1)rWREWoYMR
zI2oi@;4p`J<ui*(5PNOhFXDgfL;}VS&khMPYmF?q-gY{%9g?RVgn!*4I8ton;mXMg
zJ7^^rf%2nV!qH}Wh0~CbKJi`Ndp!?F`C49o#YOlP*^Gy~ZZbAY+AMzDtogl{GSKdG
zO=m#<5!h6DCfr=_IL@??i%<D|nh?r5CxAHvHo)oi)};&QwKkB|Z3*zToc!9G9Q<Vu
z5uwFrRrxysu|ZA1<EI7v3r}v`5wbR$M<(eRUFlpBR}Ub#RruzkTO#DCWPW7v3-q$&
z0tFl#Bz$Ml@C|eU9&8piqLSD~$d5+fRt#+gWahiv&&<>g=-0JH8w~O+#3^q&YIzwj
z*NtM)$1wz}U{bmg2IpT)U<ozFBj<ev5$A3>o20~xN$TBG_AGV+7+tV+?LI(etA+*I
zDt?l-Y{AIgLuK&M<1H1E?qdG17jzlGev9@hIj$j9V85RQ0afy)mh+lA!67(eCj6K_
z&T8MUU^gK>8=_ySWLj-6e*SCZPgK9I3>+^n%EXLv=vQ-qN`-b~fI6)qi1za1LY6`_
zepNp5fsm0LfNC(O_L0~9kHmY=zVw2=GDS`C5s?5sE$X@4_kjk;00jQ(aS;%bGlWds
zS(GrksbcfK>`h@a7*1HA{>hJo;XZJkyk{I)u#(*DLR>y_d!Br~^-k(hJG-Bv6MYUT
zE!R0qVm&A&{?laBLQC+?&S*N6VDL0B#^K22a-2Io45@;lAMgmB$+Buft0`*5YLHiP
zLMORagnw?;9^oGeo<{xj2R@OhYxh+0roj3rlvqL!)JV|@zoy-cd!ueEaqa!x)-LRA
z+saHC-;<7&TKIh19ctit|ANp$qXMN7jno>3#joZP`K~ope)=dacdJ)6H#)$4QrZi^
z&jkRzW+YoBT0_MW%!}3EKP)sUse^<PIv#vrVuoJoDfn4+oXg$|R?3Je>=o}p1NpCx
z(rS8o6Q6USpE69<A<YZAJH$+WCJ_Ra9aAQ^$wk*JPE;9Hp0yo&AweF!9VI=ksNQlC
zKNm3ji~liG{Xv#SybwRCllY+c8~i01n0=x4t@{CFG1D4E$vi5mD0p_%7L8cokMt>(
zA4#r{xz}{<2)Y~LwiD~d*`uNPDIu8M{7X0nieQ`A^@S3Fc>DP7_2s1-We<MXq@wMT
z0D3mYm2a=E0pV7wp~zHjg4|AgrWvGGevzw7ussc#@=}o{_%PpWG}7xal>ts~%k63q
zJoRFbcop|C=G;r^FPD>LI(D>ky2Ob^tYwM&96e(`MKXIxNzn3{VZ~Z}N3=gk<i=pS
zQ75`qA^(Z`tT9L=?e{hD;A+?~<2Yk&D)L&|jB#%ogm*!>uBE;1Kb2YeNZ-or6WfYn
zLRMA(KH(6Sk8h$(hSOD!Hu50t!ubdXyPxdWgapF6(6uFVv&cl!%Jbw6TFCGjt0Mt1
z`E4Q!{GsbY*_+uP<Gh;OLW-^u^*L!Qx2U>ixSW6PNn6)XvSn=$Rh>;rO1y%)1-Y2W
z6+#?E+4AX++Ddf_37j3lH~gFqLM5WD?}<JQ++2483QGWf51pHd)?Xixba~te#Y2v6
z-~^K56XaJ}@V}QFt|d1zN8UPX{$<hHe#jthuhZ0S>;Mpx1yc&d>$J0NhVtoYnHD1y
z6h(5!GA_PE#=m%4{6<5pTmk|g%SG{D+zD*eAiOhbl?6cTRUS0vL_YW`{hpH%wpGBq
z`0BpOZ<3}<XF_K2&o)7N-vQiuej)GThE}NYMV_O?*B7k%x{+Es^5f`+1~H+EaiYgd
zQTgtb_cB<+)Lpmde-thy*M>_+6?N8=6S7NNTvD>@*WY`;&OBRNBEQFe!P_$>dTKiK
zM+zCNoLNXy`2=`<>o$VPcXp?jw%o~ksWoL#=57c=Nt|zx$|pmjuKdS=kOv)YqWAeo
z`8`jSh1RiVFOZSV$G1O5JL8KAU)StZ?x}yIK_3p~ogcC0f;+qHGVZ5F{=B02j3$}t
z<0PDjk{4HT0`fvwfC}t%EnfP5`mY%~JTcF3892K_F*LG2x-BGvAray~&R72TtGZW^
z^ZF(6E%%lD!rK!+4zi{v8y(KI_ZiMPYL$}#&$v7}l(1sF^gmm*2zXsdy6L|E@CxPB
zTf3vnSRowIJB<czlKs0&H<{#&O^ex(PF$BQM~ut!h}!}6WR5kwh%SMY1Ms?L96lI}
zZy4Y<NxxckNG}r!X<&IvF1y{%WUvrjEJuLYuKr>{rr$m^9^+f~a%uLwo;59M5-jGP
zF0Oq&WhX@WwypCjNV0<@IgBNiA7<@+^z}wS4;O@(L2}9XLx1E~v3C`uM<sC)+Gcki
zLP25~E;7Och(%HHMSE6ROwvnaVV`B0tuBD3lu;>p6D#$}NjLb8%ep8oHt;C~gk;{5
zWnVj(q2NYQ6s*9TYu`S|24kPGucOkta|8PR2`q*V-RX4-JY(diQv=bpB=gyZ0cyxR
zt9IJuzJWXyBX)z<s2+nRX;~J2O)7`Af%Q%x%C=R=6k`?4%h0=630IM8o{({hk^*yS
zuh_9B6aqqH@wK_ouHI=tZ`$r5QlVtIivP4g)j+`C7eFk1!iN{SJ%9B|5hsr;ynXd8
zL}uIBg+=jA@=x}+drY}&cTLIB(l(CL2d_N>>U#kk#2b^SW+V3XRed_e0E;`EqZL@g
z?cQlw3G-TCxKJNJ5=$QK#Wvlpu;-OPFokPR<gLoi_TwN;!`%>yAOthwe_;1rAdD!j
z=ns$&L<2gik2ts^ZPIKze8Dz-cvnQPHUsA?$THahtGWKC%`ZdPnZhRdktb<E%-LZc
z=ut$a5VsI=^Tco$(EZCKf2_YizOSaAm|e!w@dK~E>V9|<Ri$bcz@Kig-3yQHQD)HA
zx@?_0d*m%^Bn!K(jo!E>h2yHwHv7FY>ml+o5d<?r%utD`>*x7yT;jrTur>3XSNeYc
zVyv`GO0_*G_)z_zs$c*(GmuRc*b||8R7*wO2b@^J;lVO>ML*v+?u)MMm1WNU;jxzy
zFW~R=awBo)12}g}AeOaQk#C$2{Zg_0Dq`Y`qPvj}{vg$Z<r?L66#zQiWf`V7N)4w*
z@Ym7KR@FXQK@*Z`F^e;D`M1t*;SJFYBn#&a@mFt>{`-N~iVZk@T+ODrJ34wb!*5{$
z9p>=hWNI8J?VVEEjE}|x8V@^KV&g?UgZgI`|3m=tYacI<4n;5H*RqO)NN+9{EY7ds
z<eG{LDsn;!?NrhcMdR--$+>G&`vBxsmE;~qjoXDu+ris->)15_bHSJlzV*Q0B_gXl
zYd8m{{#thReP6^aW|-S(FSL099JW-|#A)iRT+5<Vd|$gHcrC~WV~^peL{n9XF*pP=
zySit46J)+j<0E5u%dkqWCuYQyf;Jh3bGQTRc_|2QzjYOb1;ACdq+1s&&xV9Q+W`y4
zyV<YsSP=To=*QGM^CPkX?9%|MRi~AW(hpi*PH%=ix&U;l!Gh5fx~tR&qe=j+VpB7)
zg3L5UtVd?OT=nLM3auNNEf8x6_3JBK@IikotXoi2mQenI^iBQ0*HLYX5Kk%ul+5vb
ze^@A#tK}-MMFd-uD|I`R)H|8FqeJhjFfC00;T<yXKG?dCX6jRFtyUsbRzTdRwbabX
zs43Qu9A`J+As_JFK<x1^D{ZF=GOgVJZEwzA0f2mBaDB%Ku3*3n$Y>di2C#H1u!#Iu
zHp}^+j4E8B@q#iG`JuN`YX{D^4shO1_>;__kL~GZ)0~VIa=iPg3G0SStr|>O5D*1`
zNrEQy;}o$}Od1o;uc7Kswe$COlO#FMfh;!gD&>F~K^9LsRd2O4QpHE5BVBSGFb5K&
zje^;joYU{p4f}vK^D{??G?!ZZ-Ukk#A3rfHkKxzVidsK@rwqe?b|Kdu0I5+)<E-@D
z2=A)ZEOS#)`;UJFAejXGa~<c{;p%a4td7(xDB3L;L9rGcU+b4O5h@W{=D3CxJ@?}r
z>BAjfbJ;muegHWVwve%aC02W6blCR@VS%w6nBI2<OVFlmPa6n(N%;7S6mn`}4?MrN
zJTmj>GD7dbM}@pVvzhBna+<fUrG?~BJ3FIrBXNXSJk*B_wZk56i0odZd8U#5`e=I>
zPS2BpNPe6kgJPIWlZQ~pzK{g>waa%0lSvEWVk=k(c2VU!SR}3t%2{sxtc(W0MA8w<
zY8G>jfcwJMt2C?f3ajPbb2Ik8GIVhWd7FKl%mz+w4k$N`lbL*J!J1Xx2#;)b)9{3?
z!(5PWA-nMc{ALPKu&{-KN$^i)J007fHK$dvKkVYa@#4JIe&MYd-QZvjh|B@yY=L}w
zuX@P`CEhCcqy+-0vdc<xqkWd;M^vh`ZMNT@*INyFds|?7%SR0?azK{gCsus-I#|H1
zDHYMbk(J;?wyMu}l5^jYl0J<M(EUnYYfCa%4`6!k99WA3+<u`u3UZ3M2DI~O`V!v7
z1s`S6PJN^O67`hs)bU{zLObkCrwfr)l=B+*?X}L8MqmwG3PiphhX;ci;u7ph2IMhY
z<wcOjHqAy0YkKh<*ochi<kOv`Mh!hkhf!<mg0J12m)Kw8r<|CL?{<0uF$HuZcQ_Ks
zdGgo<9E7YWTA?_)t)wes=1hgLg5m<V?53UF7$53KhOFa*>@WTVF|f{UGkcee2+d&V
z@=~q|)By)WX`v#cdy7Q7rA8G%365K}-|Qo>IFBAh{%uV`MGWbH3=i&6Nuny-{aiUU
zV9oAjAK1=}j)Jw$n_3v_TH`%kkh852D}VAyIWdbetQSOxMgm8O0!f~*WF8!9P_oHL
z8)sQ%8x05&=~E=%g}HuL@uw<Bf3u7JSXF4N>?d!t-760;G1VmNA;8l&e;v81;j%R?
zC;A}1Pe%w7>t=*XVp04>MkQj)k~`7?;e8W|Kf$LtXlIb3ziq1RPkWBO%_L2C+g6uL
zw21)OgMZI_IcC=R4%@7Gbh}k9=eYOsu*?TQT}QfgQn%TRHmwR6uvbea%>as)z^NC?
z^g*eoY~z@*_RX3$SiBC|R1NdWS_^;a*tY3sC#?gvvW?8R(NDb5v{c3UFmEm`dY-eU
z=qtX#Qz++%jL+ro<Yz>tyGhI|a!$3n>N|@)vc=dc2ZQ2N+TbL}#XsW7**%t3r|3b=
zh`uaM$m+WeI~yYS;{1)nfitnWx66OJzyoUe085|YWCa~V=I11}={vB_E4}bg)YHRY
zKugk8>{A#JkhE}^=Hfqf;RN-RcY0Q9y2c17`ScNj8klrq8?-#ACsSY>(`GP8$+Jq4
zNpGJOFWGKQw`n^oV&q?E`4)+weC@EqM?ubuR3wGFR3{BBHfD$^^__om@<R9-hw^it
zQ=sHOw$J?hz<^e;4B7au!n?HkC!=u(5Pve1(|v>kY&WLU{Qav-A=X?#L^FBrx}8ee
z`+HCN6i-5KzjP=Ma&5YN;S7m<P00>JR%>`yM-1-^eJrUBNYR<=Fwnw24B7$t8|wQN
z`rJA$Wrp1%aG*|{i|-(6i!Ppflq0A{zG<vb8P*tMN&wgn?r`*`AR;z%t*UnJCr0l7
z@p2I5D3VPAP&-UCXywbL!1yO&)F(PQ<!cT2!qjtJa2ks*4u-$<6h{%R#ar*(e0-Gx
zKL6&PJLmPnp+b!N_j=<xAG9w!M`~GZKh$nO^thtGE6_;+lay*74Jh47ayzlFf6R8}
zLV|;ykxem}^`=LwZHPFMX3_PPs)K5M#^e}v^{U@6qiutmRiL9!A;xOITdZT<SQKQm
zu+81&z-Vk>9<-HzVzLklCyx9F<3zuR!f;XoNpWufCprMd|F8m}gE!3b!$dQ{MO!oj
u3@gjiJVCVUQ{2q71DF|Tbxh-id*j(1^a>qr0}qIdu^9g07qnOe1OPh*kb?~X
literal 0
HcmV?d00001
diff --git a/setup/Dockerfile b/setup/Dockerfile
new file mode 100644
index 0000000..ced1d81
--- /dev/null
+++ b/setup/Dockerfile
@@ -0,0 +1,30 @@
+FROM continuumio/miniconda3:4.6.14
+ENV PATH /opt/conda/bin:$PATH
+
+RUN apt-get update && \
+ apt-get install -y --no-install-recommends \
+ libsm6 \
+ libxext6 \
+ libxrender-dev \
+ libgl1-mesa-glx \
+ libglib2.0-0 \
+ xvfb && \
+ rm -rf /var/lib/apt/lists/*
+
+WORKDIR /nuscenes-dev
+# create conda nuscenes env
+ARG PYTHON_VERSION
+RUN bash -c "conda create -y -n nuscenes python=${PYTHON_VERSION} \
+ && source activate nuscenes \
+ && conda clean --yes --all"
+
+COPY setup/requirements.txt .
+COPY setup/requirements/ requirements/
+# Install Python dependencies inside of the Docker image via pip & Conda.
+# pycocotools installed from conda-forge
+RUN bash -c "source activate nuscenes \
+ && find . -name "\\*.txt" -exec sed -i -e '/pycocotools/d' {} \; \
+ && pip install --no-cache -r /nuscenes-dev/requirements.txt \
+ && conda config --append channels conda-forge \
+ && conda install --yes pycocotools \
+ && conda clean --yes --all"
\ No newline at end of file
diff --git a/setup/Jenkinsfile b/setup/Jenkinsfile
new file mode 100644
index 0000000..58641c7
--- /dev/null
+++ b/setup/Jenkinsfile
@@ -0,0 +1,189 @@
+@Library('jenkins-shared-libraries') _
+
+// Aborts previous builds of the same PR-
+if( env.BRANCH_NAME != null && env.BRANCH_NAME != "master" ) {
+ def buildNumber = env.BUILD_NUMBER as int
+ if (buildNumber > 1) milestone(buildNumber - 1)
+ milestone(buildNumber)
+}
+
+def update_deps() {
+ sh '''#!/usr/bin/env bash
+ set -e
+ source activate nuscenes
+ find . -name "*.txt" -exec sed -i -e '/pycocotools/d' {} \\;
+ pip install --no-cache -r /nuscenes-dev/requirements.txt
+ conda install --yes pycocotools
+ '''
+}
+
+def kubeagent(name, image) {
+ return jnlp.docker(name: name,
+ docker_image: image,
+ cpu: 7, maxcpu: 8,
+ memory: "8G", maxmemory: "30G",
+ cloud: "boston",
+ yaml: """spec:
+ containers:
+ - name: docker
+ volumeMounts:
+ - mountPath: /data/
+ name: nudeep-ci
+ subPath: data
+ volumes:
+ - name: nudeep-ci
+ persistentVolumeClaim:
+ claimName: nudeep-ci""")
+}
+
+pipeline {
+
+ agent {
+ kubernetes (jnlp.docker(name: "nuscenes-builder",
+ cpu: 2, maxcpu: 2,
+ memory: "2G", maxmemory: "4G",
+ cloud: "boston"))
+ } // agent
+
+ environment {
+ PROD_IMAGE = "233885420847.dkr.ecr.us-east-1.amazonaws.com/nuscenes-test:production"
+ TEST_IMAGE = "233885420847.dkr.ecr.us-east-1.amazonaws.com/nuscenes-test:1.0"
+ TEST_IMAGE_3_6 = "${env.TEST_IMAGE}-3.6"
+ TEST_IMAGE_3_7 = "${env.TEST_IMAGE}-3.7"
+ NUSCENES = "/data/sets/nuscenes"
+ NUIMAGES = "/data/sets/nuimages"
+ PYTHONPATH = "${env.WORKSPACE}/python-sdk"
+ PYTHONUNBUFFERED = "1"
+ }
+
+ parameters {
+ booleanParam(name: 'REBUILD_TEST_IMAGE', defaultValue: false, description: 'rebuild docker test image')
+ }
+
+ stages {
+ stage('Build test docker image') {
+ when {
+ expression { return params.REBUILD_TEST_IMAGE }
+ }
+ failFast true
+ parallel {
+ stage('Build 3.6') {
+ steps {
+ withAWS(credentials: 'ecr-233') {
+ container('docker') {
+ // Build the Docker image, and then run python -m unittest inside
+ // an activated Conda environment inside of the container.
+ sh """#!/bin/bash
+ set -eux
+ docker build --build-arg PYTHON_VERSION=3.6 -t $TEST_IMAGE_3_6 -f setup/Dockerfile .
+ `aws ecr get-login --no-include-email --region us-east-1`
+ docker push $TEST_IMAGE_3_6
+ """
+ } // container
+ }
+ } // steps
+ } // stage
+ stage('Build 3.7') {
+ steps {
+ withAWS(credentials: 'ecr-233') {
+ container('docker') {
+ // Build the Docker image, and then run python -m unittest inside
+ // an activated Conda environment inside of the container.
+ sh """#!/bin/bash
+ set -eux
+ docker build --build-arg PYTHON_VERSION=3.7 -t $TEST_IMAGE_3_7 -f setup/Dockerfile .
+ `aws ecr get-login --no-include-email --region us-east-1`
+ docker push $TEST_IMAGE_3_7
+ """
+ } // container
+ }
+ } // steps
+ } // stage
+ }
+ }
+
+ stage('Tests') {
+ failFast true
+ parallel {
+ stage('Test 3.6') {
+ agent {
+ kubernetes(kubeagent("nuscenes-test3.6",
+ env.TEST_IMAGE_3_6))
+ } // agent
+
+ steps {
+ container('docker') {
+ update_deps()
+ sh """#!/bin/bash
+ set -e
+ source activate nuscenes && python -m unittest discover python-sdk
+ bash setup/test_tutorial.sh
+ """
+ } // container
+ } // steps
+ } // stage
+
+ stage('Test 3.7') {
+ agent {
+ kubernetes(kubeagent("nuscenes-test3.7",
+ env.TEST_IMAGE_3_7))
+ } // agent
+
+ steps {
+ container('docker') {
+ update_deps()
+ sh """#!/bin/bash
+ set -e
+ source activate nuscenes && python -m unittest discover python-sdk
+ bash setup/test_tutorial.sh
+ """
+ } // container
+ } // steps
+ } // stage
+ } // parallel
+ } // stage
+
+ stage('Deploy') {
+ when {
+ branch 'master'
+ }
+
+ steps {
+ // TODO: determine where to deploy Docker images.
+ container('docker'){
+ withCredentials([[
+ $class: 'AmazonWebServicesCredentialsBinding',
+ credentialsId: 'aws-ecr-staging',
+ ]]){
+ sh """#!/bin/bash
+ echo 'Tagging docker image as ready for production. For now, this stage of the pipeline does nothing.'
+ # docker build -t $PROD_IMAGE .
+ # docker push $PROD_IMAGE
+ """
+ }
+ } // container('docker')
+ } //steps
+ } // stage('Deploy')
+ } // stages
+
+ post {
+ // only clean up if the build was successful; this allows us to debug failed builds
+ success {
+ // sh """git clean -fdx"""
+ slackSend channel: "#nuscenes-ci", token: "bWyF0sJAVlMPOTs2lUTt5c2N", color: "#00cc00", message: """Success ${env.JOB_NAME} #${env.BUILD_NUMBER} [${env.CHANGE_AUTHOR}] (<${env.BUILD_URL}|Open>)
+${env.CHANGE_BRANCH}: ${env.CHANGE_TITLE}"""
+ }
+ aborted {
+ slackSend channel: "#nuscenes-ci", token: "bWyF0sJAVlMPOTs2lUTt5c2N", color: "#edb612", message: """Aborted ${env.JOB_NAME} #${env.BUILD_NUMBER} [${env.CHANGE_AUTHOR}] (<${env.BUILD_URL}|Open>)
+${env.CHANGE_BRANCH}: ${env.CHANGE_TITLE}"""
+ }
+ failure {
+ slackSend channel: "#nuscenes-ci", token: "bWyF0sJAVlMPOTs2lUTt5c2N", color: "#c61515", message: """Failed ${env.JOB_NAME} #${env.BUILD_NUMBER} [${env.CHANGE_AUTHOR}] (<${env.BUILD_URL}|Open>)
+${env.CHANGE_BRANCH}: ${env.CHANGE_TITLE}"""
+ }
+ //changed {
+ // only run if the current Pipeline run has a different status from previously completed Pipeline
+ //}
+ } // post
+
+} // Pipeline
diff --git a/setup/requirements.txt b/setup/requirements.txt
new file mode 100644
index 0000000..9e554c7
--- /dev/null
+++ b/setup/requirements.txt
@@ -0,0 +1,4 @@
+-r requirements/requirements_base.txt
+-r requirements/requirements_prediction.txt
+-r requirements/requirements_tracking.txt
+-r requirements/requirements_nuimages.txt
diff --git a/setup/requirements/requirements_base.txt b/setup/requirements/requirements_base.txt
new file mode 100644
index 0000000..4067e6e
--- /dev/null
+++ b/setup/requirements/requirements_base.txt
@@ -0,0 +1,13 @@
+cachetools
+descartes
+fire
+jupyter
+matplotlib
+numpy
+opencv-python
+Pillow
+pyquaternion>=0.9.5
+scikit-learn
+scipy
+Shapely
+tqdm
diff --git a/setup/requirements/requirements_nuimages.txt b/setup/requirements/requirements_nuimages.txt
new file mode 100644
index 0000000..60585d7
--- /dev/null
+++ b/setup/requirements/requirements_nuimages.txt
@@ -0,0 +1 @@
+pycocotools>=2.0.1
diff --git a/setup/requirements/requirements_prediction.txt b/setup/requirements/requirements_prediction.txt
new file mode 100644
index 0000000..a6b6243
--- /dev/null
+++ b/setup/requirements/requirements_prediction.txt
@@ -0,0 +1,2 @@
+torch>=1.3.1
+torchvision>=0.4.2
diff --git a/setup/requirements/requirements_tracking.txt b/setup/requirements/requirements_tracking.txt
new file mode 100644
index 0000000..abcc4d7
--- /dev/null
+++ b/setup/requirements/requirements_tracking.txt
@@ -0,0 +1,2 @@
+motmetrics<=1.1.3
+pandas>=0.24
diff --git a/setup/setup.py b/setup/setup.py
new file mode 100644
index 0000000..65c9afd
--- /dev/null
+++ b/setup/setup.py
@@ -0,0 +1,60 @@
+import os
+
+import setuptools
+
+with open('../README.md', 'r') as fh:
+ long_description = fh.read()
+
+# Since nuScenes 2.0 the requirements are stored in separate files.
+with open('requirements.txt') as f:
+ req_paths = f.read().splitlines()
+requirements = []
+for req_path in req_paths:
+ req_path = req_path.replace('-r ', '')
+ with open(req_path) as f:
+ requirements += f.read().splitlines()
+
+
+def get_dirlist(_rootdir):
+ dirlist = []
+
+ with os.scandir(_rootdir) as rit:
+ for entry in rit:
+ if not entry.name.startswith('.') and entry.is_dir():
+ dirlist.append(entry.path)
+ dirlist += get_dirlist(entry.path)
+
+ return dirlist
+
+
+# Get subfolders recursively
+os.chdir('..')
+rootdir = 'python-sdk'
+packages = [d.replace('/', '.').replace('{}.'.format(rootdir), '') for d in get_dirlist(rootdir)]
+
+# Filter out Python cache folders
+packages = [p for p in packages if not p.endswith('__pycache__')]
+
+setuptools.setup(
+ name='nuscenes-devkit',
+ version='1.1.1',
+ author='Holger Caesar, Oscar Beijbom, Qiang Xu, Varun Bankiti, Alex H. Lang, Sourabh Vora, Venice Erin Liong, '
+ 'Sergi Widjaja, Kiwoo Shin, Caglayan Dicle, Freddy Boulton, Whye Kit Fong, Asha Asvathaman et al.',
+ author_email='nuscenes@motional.com',
+ description='The official devkit of the nuScenes dataset (www.nuscenes.org).',
+ long_description=long_description,
+ long_description_content_type='text/markdown',
+ url='https://github.com/nutonomy/nuscenes-devkit',
+ python_requires='>=3.6',
+ install_requires=requirements,
+ packages=packages,
+ package_dir={'': 'python-sdk'},
+ package_data={'': ['*.json']},
+ include_package_data=True,
+ classifiers=[
+ 'Programming Language :: Python :: 3.6',
+ 'Operating System :: OS Independent',
+ 'License :: Free for non-commercial use'
+ ],
+ license='cc-by-nc-sa-4.0'
+)
diff --git a/setup/test_tutorial.sh b/setup/test_tutorial.sh
new file mode 100755
index 0000000..da236fc
--- /dev/null
+++ b/setup/test_tutorial.sh
@@ -0,0 +1,29 @@
+#!/bin/bash
+set -ex
+
+# This script is to be executed inside a Docker container
+source activate nuscenes
+
+# Generate python script from Jupyter notebook and then copy into Docker image.
+jupyter nbconvert --to python python-sdk/tutorials/nuscenes_tutorial.ipynb || { echo "Failed to convert nuscenes_tutorial notebook to python script"; exit 1; }
+jupyter nbconvert --to python python-sdk/tutorials/nuimages_tutorial.ipynb || { echo "Failed to convert nuimages_tutorial notebook to python script"; exit 1; }
+jupyter nbconvert --to python python-sdk/tutorials/can_bus_tutorial.ipynb || { echo "Failed to convert can_bus_tutorial notebook to python script"; exit 1; }
+jupyter nbconvert --to python python-sdk/tutorials/map_expansion_tutorial.ipynb || { echo "Failed to convert map_expansion_tutorial notebook to python script"; exit 1; }
+jupyter nbconvert --to python python-sdk/tutorials/prediction_tutorial.ipynb || { echo "Failed to convert prediction notebook to python script"; exit 1; }
+
+# Remove extraneous matplot inline command and comment out any render* methods.
+sed -i.bak "/get_ipython.*/d; s/\(nusc\.render.*\)/#\1/" python-sdk/tutorials/nuscenes_tutorial.py || { echo "error in sed command"; exit 1; }
+sed -i.bak "/get_ipython.*/d; s/\(nusc\.render.*\)/#\1/" python-sdk/tutorials/nuimages_tutorial.py || { echo "error in sed command"; exit 1; }
+sed -i.bak "/get_ipython.*/d; s/\(nusc_can.plot.*\)/#\1/" python-sdk/tutorials/can_bus_tutorial.py || { echo "error in sed command"; exit 1; }
+sed -i.bak "/get_ipython.*/d; s/\(^plt.*\)/#\1/" python-sdk/tutorials/can_bus_tutorial.py || { echo "error in sed command"; exit 1; }
+sed -i.bak "/get_ipython.*/d; s/\(fig, ax.*\)/#\1/" python-sdk/tutorials/map_expansion_tutorial.py || { echo "error in sed command"; exit 1; }
+sed -i.bak "/get_ipython.*/d; s/\(nusc_map.render.*\)/#\1/" python-sdk/tutorials/map_expansion_tutorial.py || { echo "error in sed command"; exit 1; }
+sed -i.bak "/get_ipython.*/d; s/\(ego_poses = .*\)/#\1/" python-sdk/tutorials/map_expansion_tutorial.py || { echo "error in sed command"; exit 1; }
+sed -i.bak "/get_ipython.*/d; s/\(plt.imshow.*\)/#\1/" python-sdk/tutorials/prediction_tutorial.py || { echo "error in sed command"; exit 1; }
+
+# Run tutorial
+xvfb-run python python-sdk/tutorials/nuscenes_tutorial.py
+# xvfb-run python python-sdk/tutorials/nuimages_tutorial.py # skip until PR-440 merged
+xvfb-run python python-sdk/tutorials/can_bus_tutorial.py
+xvfb-run python python-sdk/tutorials/map_expansion_tutorial.py
+xvfb-run python python-sdk/tutorials/prediction_tutorial.py
--
GitLab